1. Introduction
Techniques for embedding hidden data in to-be-printed content have been studied for the past few decades. Such embedded data may be used in different ways and applications, including: authentication of a document content, as additional layer of protection against document copy-attack, or simply as digital identifiers in applications where barcodes or Quick Response (QR) codes are actively used nowadays. The printing process normally introduces significant amount of distortion to data embedded in continuous-tone images, so techniques that do not account for the properties of the printing channel may not be optimal in rate/distortion terms. A typical printing workflow includes a step named halftoning, which is the process of converting a continuous-tone (contone), normally 8-bits per colorant channel input image, to a binary, 1-bit per colorant channel, halftone image [
1]. Binarized halftone images can be easily handled by most off-the-shelf printers as they are binary devices themselves—during the printing process, at any addressable location on the printing substrate, the printer either deposits a colorant dot or not. The halftoning step can be seen as a heavy quantization that could have severe impact on previously embedded data. In order to increase the robustness of embedded data in to-be-printed images, the data embedding can be done during or after the halftoning step.
Methods for data embedding in halftones have been proposed for different underlying halftoning algorithms. A selected overview include data hiding techniques based on ordered dither halftoning [
2,
3], error diffusion halftoning [
4,
5,
6], direct binary search (DBS) halftoning [
7,
8,
9], or clustered-dot halftoning [
10,
11,
12]. Most of these methods embed data by enforcing certain criteria on isolated printer dots (halftone pixels or halftone cells), which makes the extraction of embedded data sensitive to synchronization/focus—the data extraction from prints is effectively possible using scanners and very difficult using consumer cameras or smartphone cameras. Guo et al. [
13] proposed a data hiding method in dispersed-dot DBS halftones, which embeds oriented features in an arbitrary halftone block that may contain hundreds or few thousands halftone pixels. This method is named orientation modulation (OM), it offers flexibility regarding the printed size and the strength of the embedded oriented features, and hence, the capture device used for data detection/extraction. This OM method was later extended to color images by embedding oriented features in the chromatic channels only [
14], and it is based on the color direct binary search (CDBS) halftoning algorithm [
15]. The data capacity of such CDBS-OM embedded data, depending on the size and strength of the oriented embedded features, ranges from few dozens to few hundreds bits per square inch of printed image area [
14]. This opens the possibility of using CDBS-OM watermarked images in many camera-based applications where existing barcode or QR-codes are used, such as: marketing/advertising, ticketing, packaging, IDs and passports, documents and certificates, or supply chain management.
This work is focused on the detection of CDBS-OM embedded data in chrominance channels of color printed images. The originally proposed method [
14] uses PCA-based oriented feature extractors in a simple correlation-based detector that does not use any knowledge about the print-and-scan channel. Other relevant detection strategies are using reconstruction error from sparse dictionaries learned for each orientation [
16], least means squares (LMS) filters as oriented feature extractors [
13], or image moments as orientation descriptors [
10]. The last two detectors use a probabilistic model for the print-and-scan channel, the last three detectors have been proposed and evaluated for monochromatic printed images only, and all four detectors have been evaluated using only scanned images. The aim of this work is to propose an efficient and robust method for detection of CDBS-OM embedded data in color printed images captured using wider range of capture devices, and evaluate its performance on a large image dataset with respect to relevant state-of-the-art detection methods. The proposed method is using PCA-based oriented feature extractors, and maximum likelihood (ML) detection based on a probabilistic model for the print-and-scan communication channel. We show that PCA can be used to reduce the number of oriented feature extractors, which decreases the computational complexity of the detector. The comparison with the state-of-the-art detectors shows that the proposed PCA-based feature extractors, together with a probabilistic model for the data communication print-and-scan channel and ML detection, achieve the highest correct detection rate and they are significantly more robust to the scan/capture part of the print-and-scan channel.
3. Results
In this section, we evaluate the proposed detector and compare it to the previously published types of detectors. All of the presented results are in terms of correct detection rate (CDR) defined as percentage of correctly detected oriented features from CDBS-OM watermarked printed images. For training the feature extractors and estimating the distributions in the channel likelihood functions in Equations (2), (5), and (11), we used 11250 training halftone blocks obtained from 18 images (the first 18) from the CID:IQ image dataset [
20]. The feature extractors for the different detection methods, as well as the dictionaries, were obtained/trained from digital watermarked halftones. The feature distributions for the ML detectors were obtained from printed and 600 dpi-scanned watermarked halftone images. For testing the detectors performance, we used 54 natural images: the 24 images from the Kodak dataset [
21] and the 30 images from the CSIQ dataset [
22]. In all of the tests, we used random quaternary watermark data i.e., embedded features with four equally-probable different orientations (0°, 45°, 90°, 135°). The halftone block size per embedded oriented feature was
M ×
N = 32 × 32. The size of the Kodak images is 768 × 512 pixels, while the CSIQ images, originally 512 × 512 pixels, were scaled to 640 × 640 pixels so they can carry approximately the same number of embedded features as the images from the Kodak dataset. The watermark quality factor [
14] was set to
η = 2.5. All of the images were printed through the Caldera RIP software at 300 dpi on the HP Premium Matte Photo Paper using the HP Designjet Z3200 printer (HP Inc., Palo Alto, CA, USA). For the dictionary-based detection, Equations (6) and (7) were solved using the open-source implementation [
23].
For scanning/capturing the watermarked printed images, we used three different devices: Epson 10000XL scanner (Seiko Epson Co., Ltd., Tokyo, Japan), Canon Powershoot A700 compact 6 mega-pixels camera (Canon Co., Ltd., Tokyo, Japan), and Huawei Honor 7 smartphone 20 mega-pixels camera (Huawei Co., Ltd., Shenzhen, China). All of the scanned/captured images were manually rotated, aligned and scaled to their original halftone size. We calibrated the Epson scanner using the Color Engineering Toolbox [
24] that uses 3rd order polynomials for least squares fitting between the scanner RGB and the XYZ space (with D50 as white point). From the Epson scanner, we obtained two different scanned sets, at 300 dpi and 600 dpi resolution, which, including the Canon and Huawei captures, resulted in four different sets of the 54 testing images. The Canon and Huawei cameras were not color-calibrated—we assumed sRGB values of the captured images in order to convert them via XYZ to YyCxCz for watermark detection. Given that a real application scenario may include different and unknown scanning/capture devices as well as different lighting conditions, we tested the detectors robustness to those type of deviations in the following way: we estimated the probability densities in Equations (2), (5), and (11) only for the 600 dpi Epson scans of the training images and we used those estimated probability densities for the whole evaluation that included the other three scans/captures of the testing images—the 300 dpi Epson scans and the captures using Canon and Huawei camera. The reason for using only the color-calibrated 600 dpi scans for modelling the chrominance print-and-scan channels is that they are least affected of external geometric distortions in the scanning part of the print-and-scan channel such as rotation, scaling or lens barrel distortion. The Matlab code for features training and detectors comparison is available as
Supplementary Materials; the training and testing printed and scanned/captured images (including the Matlab code) are available for download [
25].
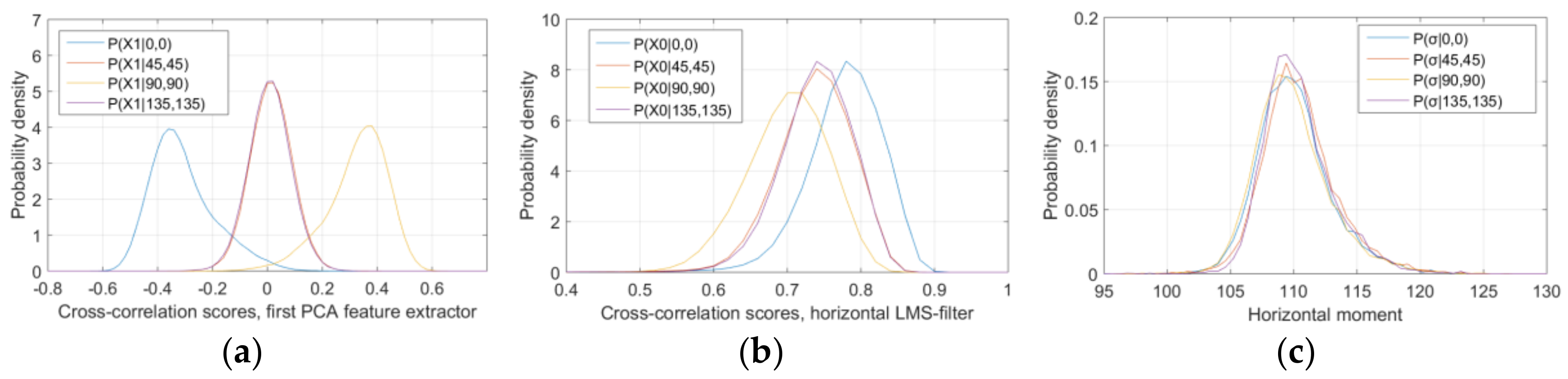
The moments-based detector (Equation (5)) performed considerably worst, with CDR below 45% in all of the tests and for both of the chrominance channels of all the 54 testing images. As it can be seen from
Figure 5c, the moment’s probability densities considerably overlap between each other for different orientations, which also yields to very low ability for discriminating the embedded oriented features. We conclude that image moments are not appropriate to use as orientation-description features for OM data embedded in dispersed-dot halftones. To avoid polluting our results, we have excluded the moments-based detector from further evaluation.
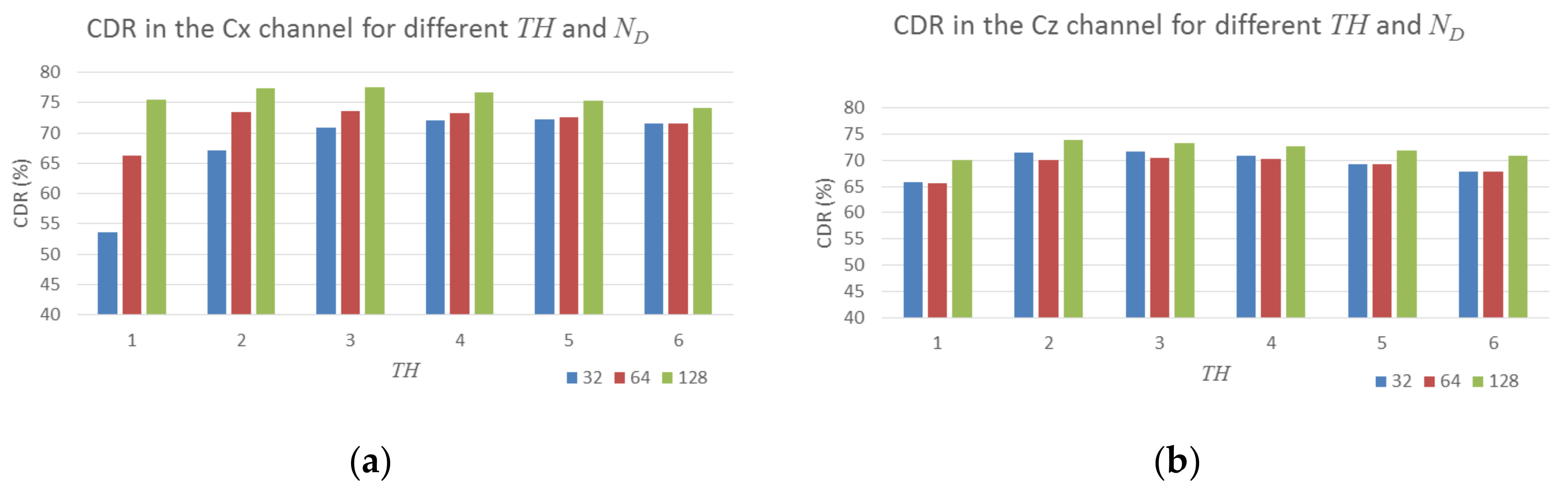
For the performance of the dictionary-based detector, two parameters are most important: the dictionary size,
, and the maximum number of atoms used for reconstruction of a testing watermarked block,
. In order to find nearly optimal values for these two parameters, we performed tests for three values of
—(32, 64, 128) and six values of
—(from 1 to 6). Regardless of the scanning/capture device, the CDR had very similar trends, so we show it aggregated for all four testing sets in
Figure 6. It can be seen that the CDR increases with the number of atoms in the dictionary for the red-green Cx channel. For both chrominance channels, the largest tested dictionary size
= 128 achieved highest CDR regardless of the number of atoms used in detection. Regarding the number of atoms,
, the results showed that different values of
may be best for different sizes
or chrominance channels. However, averaged for both chrominance channels when
= 128, using
= 2 atoms achieves highest CDR on average for all testing images from all four testing sets. We use these parameter values for the comparison with the other detectors that follows. While using dictionaries larger than
= 128 may potentially achieve even higher CDR, we decided not to test them because the training time and the actual detection time using dictionaries of size
= 128 is already excessively large to be useful in a practical application.
Regarding the LMS-filters training, there are few parameters such as convergence rate or stopping threshold [
13]. We trialed different values for these parameters, but we did not get any significant difference in the final detection results. That was mostly because after training the LMS-filters are normalized to unit energy, so those parameters hardly influence the shape of the learned LMS-filters, especially when the training set is relatively large—in our case, we used 11250 training watermarked halftone blocks. Therefore, in this work we train the LMS-filters using the exact parameter values as in the original work [
13].
The 54 testing images include a wide variety of content. Some of them have areas with extreme dark or light levels, or heavily saturated areas that include a dominant single colorant or dominant halftone pixel value. In those types of image areas, oriented features may not be embedded at all, or have very poor strength. That means that the highest CDR of 100% may not be possible regardless of the detector used, simply because some of the oriented features were not (or were poorly) embedded with the CDBS-OM method and therefore are not present in the printed images. To demonstrate this, we show an example in
Figure 7. The CDR from the 600 dpi scans using the proposed detector is shown in
Figure 7a. It can be seen that for some of the testing images, a CDR of 100% was achieved in the Cx or the Cz channel.
Figure 7b shows the scanned 20th testing image. The large sky area is very bright, and the OM data embedding resulted in covering the sky area with only yellow colorant dots. The data can be relatively correctly extracted from the blue-yellow Cz channel—the CDR is around 94%. However, the absence of magenta or cyan dots in the sky area (used for rendering red or green tones) means that the data were not actually embedded in the red-green channel of that sky area, resulting in low CDR of around 65%.
Figure 7c shows the scanned 45th testing image. There are large very dark areas where the OM embedded data cannot be extracted due to absence of oriented red-green or blue-yellow variations. That results in low CDR for both channels. However, the CDR in the Cx channel of the 45th image is significantly higher than the CDR in the Cz channel. That is mainly due to the darker tones present in the image, which are rendered using mostly darker (including red and green) colorant dots.
In order to eliminate this fluctuation of CDR among the testing images, we used one-sided paired t-test in the CDR analysis. Specifically, in the next tables along the CDR values, we show a column ‘Margin’. The value in this column is the maximum CDR percentage points added to the results of the competing detectors for which the t-test still rejects (at 95% confidence) the null-hypothesis that the proposed PCA-based detector on average does not achieve higher CDR. In this way, the ‘Margin’ value can be interpreted as a CDR margin of a statistically significant improvement of the proposed detector over each of the competing detectors.
In
Table 1, we show the average CDR values obtained using the proposed detector and its competitors, separately for the two chrominance channels, Cx and Cz. We used only the 600 dpi scanned images for these results. It can be seen that both PCA-based detectors achieve higher CDR than the rest, with the proposed one, in the Cz channel, achieving statistically significant 0.8 percentage points higher CDR than the old PCA-based detector. The CDR margins of improvement for the proposed detector over the rest two vary from 3.7 to 11.7%. The LMS-filter detectors performed third best, while the dictionary-based detector performed worst.
In real application scenarios, the detection of oriented features may be performed with various capture devices, and it is not practically viable to have channel likelihood functions tailored to each specific capture device. Therefore, it is important that the feature extractors are robust to non-calibrated devices in the scan/capture part of the print-and-scan channel. As previously mentioned, apart from the 600 dpi scans, we made three other captures using: the same calibrated Epson scanner but at 300 dpi resolution, a Canon compact camera, and a Huawei smartphone camera. The watermark detection from these sets was performed assuming the chrominance print-and-scan channel model obtained from the 600 dpi scanned images. We note that this is relevant only for the LMS-filters detector and the proposed PCA-based detector, as the old PCA-based detector as well as the dictionary-based detector are not using probabilistic model for the print-and-scan channel. The CDR from the 300 dpi scans are given in
Table 2. It can be seen that CDR values for all detectors remained roughly the same as for the 600 dpi scans, with few detectors even performing marginally better than the 600 dpi case. We argue that the slightly higher CDR may be result to the absence of down resizing when aligning the 300 dpi images—as they were printed at 300 dpi resolution as well. We can conclude that the 300 dpi scanning resolution is still high enough to allow non-degraded watermark detection from the 300 dpi-printed images.
Table 3 and
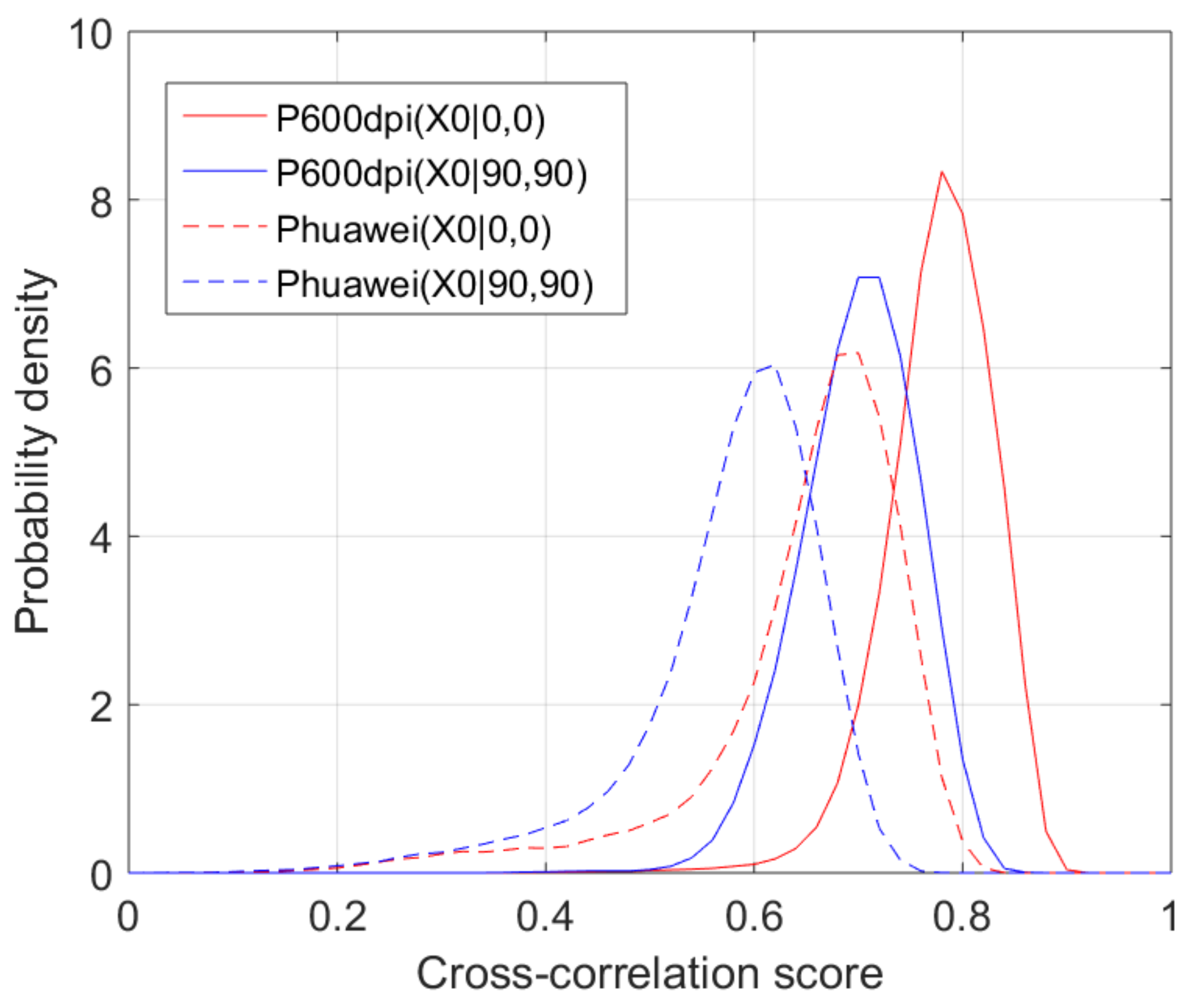
Table 4 show CDR obtained using the images from the Canon and the Huawei phone camera, respectively. Compared to the previous CDR values obtained from the scanned images, there is significant drop of CDR in both chrominance channels and for all detectors. This can mainly be attributed to the fact that these two cameras were not color-calibrated, and there was a visible geometrical barrel distortion. However, the drop in CDR was lower for the proposed detector, which further increased its improvement margin over the rest. An interesting issue occurred with the LMS-filter-based detector. The drop in CDR in the Cx channel was quite large, and it occurred for both camera-captured sets. The low CDR values of around 30–33% are very close to the theoretical value of 25% that a random guess would achieve as CDR (for this 4-orientations case). After inspecting the issue more closely, we noticed that the actual probability densities in the channel likelihood for these cameras are shifted from those obtained for the 600 dpi scans. This is shown on
Figure 8 where probability densities (for 600 dpi scans) used by the detector are shown with solid lines, while the actual estimated (for the Huawei captured images, similar happens for the Canon captured images) are shown with dotted lines. The main reason for the shifts is the capture with non-color-calibrated camera, and this impact is further increased by the lower orientation-discrimination ability of the LMS-filters (
Figure 5b).
Except for the specific LMS-filter case, in both
Table 3 and
Table 4 the CDR in the Cz channel is significantly lower than the CDR in the Cx channel. The main reason for this is the lower visibility of the distortion introduced from the data embedding in the Cz channel—due to the lower sensitivity of the human visual system along the blue-yellow axis. The lower visibility of the embedded data in the Cz channel is reflected in both of the Canon and Huawei captures, effectively reducing the strength of the embedded oriented features and leading to lower CDR. When compared between the two camera captures, the CDR was higher for the Huawei captures mainly due to the higher sensor resolution of the Huawei camera.
Regarding the computational complexity, the proposed PCA-based detector requires fewer calculations of cross-correlation scores when compared to the LMS-filter detector and the old PCA-based detector. While the ML detection adds extra calculations, they can be greatly reduced by using lookup tables and increasing the memory requirement instead. In that case, the computational overhead from ML detection is minor compared to calculating more cross-correlation scores for feature extraction. The dictionary-based detector requires significantly more computational power than the rest—for the case = 128, using = 2, the detector took around 300 times longer compared to the proposed detector.
4. Discussion
An interesting discussion point is that both PCA-based detectors had similar CDR performance, despite the proposed one using ML detection criterion. The main reason for that is the high similarity of their feature extractors. If we change the summation order in Equation (3), the detection metric of the old PCA-based detector can be re-written as:
In Equation (12),
is the equivalent feature extractor for embedded orientation
θ, and it is a linear combination of 2
K PCA templates obtained for embedded orientations
θ and
θ + 90°. In
Figure 9, we show these equivalent feature extractors
for four different orientations
θ {0°, 45°, 90°, 135°} in both Cx and Cz channels. It can be seen that they are quite visually similar to the feature extractors (2nd and 3rd PCA components in
Figure 4c) used by the proposed detector. Only two of the four equivalent feature extractors are linearly independent, the other two are their inverted versions. Their value is very close to zero for DFT coefficients that are practically not affected from the orientations embedding. This makes them robust to visual content variations, and they have similar orientation-discrimination abilities as the feature extractors of the proposed detector (as illustrated in
Figure 5a). However, as it can be seen from
Table 1,
Table 2,
Table 3 and
Table 4, using ML detection criterion achieves higher CDR, especially for the cases of detection from images captured with non-calibrated devices. If the old PCA-based detector is implemented as in Equation (12), then it requires same number of feature extraction calculations as for the proposed detector, but the overall computational requirements are lower from all detectors—due to not using ML detection.
Another discussion point is the comparison between detection using LMS-filters as feature extractors, and the proposed PCA learned feature extractor. The LMS-filters as feature extractors for detection have been used in other similar halftoning-and-watermarking methods [
5,
26]. However, in this work we show that they are inferior to the proposed feature extractors, which can be mainly attributed to the fact that they are responsive to not just the embedded data but to the visual content as well. That degrades their ability for discriminating orientations despite the ML detection criterion, and may render them impractical in scenarios where the detection is performed on images captured using unknown devices. Another way to illustrate the difference in orientation-discrimination ability between the LMS-filters and the proposed PCA-based feature extractors is by looking at the joint probability densities of the extracted features using the LMS-filters—we consider a two-orientations case (horizontal and vertical orientation) so that the joint probability densities are 2D and suitable for visualization. The joint probability densities of extracted features for those two orientations using LMS-filters,
and
, are shown in
Figure 10. They span smaller space and are very close to each other—making them more sensitive to variation/shifts in the cross-correlation scores due to changes in the print-and-scan channel. While
Figure 5a shows the relevant two probability densities of extracted features using the proposed PCA template,
shown with blue line and
shown with yellow line. They are 1D as only one PCA feature can discriminate the two orientations, the two curves are barely overlapping and are distant from each other, span larger range of the cross-correlation axis, and hence are more robust to variations in the feature distributions for different scan/capture devices.
The significance of this study can be sublimed in two main points. The first point is that an improved PCA-based detector for OM embedded data is proposed, which uses lower number of feature extractors and ML detection criterion. The second point is that relevant state-of-the-art detectors are compared to each other on a large set of testing images captured using three different devices, with the training/testing images as well as the code implementation provided as open-source.
As a main limitation of this study, we consider the parameters used in the CDBS-OM data embedding. It was stated previously that the whole evaluation used fixed values for parameters, such as the size of the watermarked blocks, the watermark quality factor, the number of embeddable orientations, or the printing resolution. These parameters values were selected based on our previous work [
14] as a good compromise between watermark perceptibility, watermark data capacity, and CDR, and hence, we believe that a real application would use those values (or very close to them). We have no reason to suspect that the conclusions from this study would be significantly different if different parameters were used—we argue that the CDR is strongly related to the features’ discrimination ability, and detectors’ relative performance is not depending on parameters such as the size or the strength of embedded orientations. However, this claim may be investigated further in a future work.
Another limitation of this study is the manual alignment of images prior to detection. Manual alignment was also used in the previous works [
13,
14,
16], but a real application would normally use a method for automatic image registration. Different strategies to achieve image alignment, including use of synchronization points/patterns or exploiting periodicity in the embedded data, will be investigated in future work.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}