1. Introduction
In the past few decades, there has been a noticeable increase in data dimensionality in real-world scenarios, resulting in a corresponding growth in the time and space complexity needed for their solution. The successful application of traditional mathematical optimization techniques frequently relies on the underlying symmetrical characteristics of the situation. While theoretical optimality guarantees exist for small-scale data-related issues, the practical application of these guarantees is challenging due to the significant time and space complexity involved [
1,
2]. Metaheuristic algorithms are commonly employed in the context of non-linear problems because of their advantageous characteristics, including straightforward principles, robustness against beginning values, and ease of implementation. In addition, it has been demonstrated that metaheuristic (MH) processes do not rely on the gradient of the fitness function, which has been shown to offer greater precision and practicality in terms of solution accuracy. Numerous MH algorithms have been presented since the onset of the 20th century. Moreover, MH techniques have been widely employed in diverse engineering domains, including but not limited to route planning, image processing, IoT task scheduling, software engineering job-shop scheduling, automatic control, mechanical engineering design, and power systems [
3,
4,
5,
6].
The increased pace of industrial expansion has led to a corresponding rise in the intricacy of optimization challenges that must be addressed. Numerous limited optimization problems exist that require urgent solution. These problems often exhibit numerous local optima within the feasible domain, rendering them inherently complex. Furthermore, the difficulty of addressing these problems is compounded when dealing with higher dimensions. The conventional approach to solving issues using classical derivatives is characterized by high processing costs, time requirements, and a tendency to converge towards local optima. These factors pose significant challenges in addressing the feasibility and economic considerations of actual situations. In contrast, heuristic algorithms encompass several approaches, such as greedy strategies and local search algorithms [
7,
8,
9]. These algorithms rely on the inherent laws of the problem to obtain improved workable solutions. However, their effectiveness is highly contingent upon the problem being addressed, limiting their applicability and lacking generality. The proliferation of software for computers has led to the implementation and utilization of an increasing number of optimization methods. The MH algorithm is currently the most widely used optimization algorithm in the field. The MH optimization algorithms offer a cost-effective, straightforward, and efficient approach to addressing such difficulties. Optimal or near-optimal solutions can be obtained within a relatively brief timeframe [
10,
11,
12]. The algorithm can identify the most effective approach for each problem instance and obtain the optimal solution. The MH algorithms are classified into two categories: non-nature-inspired and nature-inspired. The categorization of natural-inspired meta-heuristics encompasses four main groups: biologically inspired algorithms (BIA), physics-based algorithms (PBA), human-based algorithms (HBA), swarm intelligence (SI) algorithms, evolutionary algorithms (EA), and a miscellaneous category for those that do not fit into the groups mentioned above due to their diverse sources of inspiration, such as societal and emotional aspects [
13,
14]. Nature-based optimization approaches have experienced a process akin to the process of selection and elimination, resulting in their tendency to exhibit greater conciseness and superior performance compared to conventional techniques. The MH algorithms possess a straightforward structure, offer effortless operation, and exhibit a broad scope of applications, rendering them a highly favorable substitute for conventional methodologies [
1,
5]. The classification of MH algorithms is illustrated in
Figure 1.
The SI algorithms are derived from the collective behavior exhibited by social insects, which has been developed over millions of years of evolutionary processes. Particle swarm optimization (PSO) is derived from the inherent characteristics of natural swarm particles [
15]. The evolutionary algorithm is a probabilistic optimization technique that draws inspiration from the mechanisms of natural evolution. The genetic algorithm is derived from Darwinian theory [
16]. PBA is predominantly obtained through the use of physical principles and chemical reactions. One example of an algorithm that draws inspiration from the behavior of systems with numerous degrees of freedom in thermal equilibrium at a finite temperature is simulated annealing (SA) [
17]. A few other examples of PBAs are the gravitational search algorithm [
18], Henry gas solubility optimization [
19], equilibrium optimizer [
20,
21,
22], and charged system search [
23]. Human-based algorithms draw their inspiration mostly from human behavior. One illustrative instance is harmony search [
24], which emulates the improvisational tactics employed by musicians. Several other widely used swarm intelligence algorithms include the krill–herd [
25], artificial bee colony [
26], cuckoo search algorithm [
27], biogeography-based optimization [
28], grey wolf optimizer (GWO) [
29,
30,
31], whale optimization algorithm [
32,
33,
34], dragon-fly algorithm [
35], ant colony optimization [
36], dolphin echolocation algorithm [
37], firefly algorithm [
38], slime mould algorithm [
39,
40,
41], marine predator algorithm [
42,
43,
44], mountain gazelle optimizer [
45,
46], African vulture algorithm [
47], artificial rabbits optimizer [
48], etc. The authors of [
49] have used an improved sparrow search algorithm to estimate the parameters of the carbon fiber drawing process. The authors of [
50] proposed an enhanced version of the snake optimizer for engineering design problems. The authors of [
51] have proposed an improved whale optimization algorithm for cloud task scheduling problems. An improved version of the dragonfly algorithm with a neuro-fuzzy system has been proposed by [
52] for wind speed forecasting.
These MH algorithms possess distinct attributes and are frequently employed in diverse computer science domains, including intrusion detection, parameter identification, path planning, engineering optimization, feature selection, fault diagnosis, text clustering problems, image segmentation, etc. Nevertheless, they continue to struggle with efficiently achieving a balance between the convergence rate and the accuracy of the solution. In broad terms, the optimization procedure of a MH algorithm comprises two distinct phases. The initial stage of the process involves exploration, wherein the algorithm thoroughly searches the feasible domain to identify the prospective region where the best solution could be found. The subsequent stage is characterized as exploitation, during which the algorithm conducts a more thorough search in pursuit of the ideal solution within a region that exhibits greater promise. These two phases exhibit a contradiction in their approach to addressing a problem, thus necessitating the development of an algorithm that can effectively navigate between exploration and exploitation. The algorithm must strike a judicious equilibrium to identify the best global solution without being trapped in a locally optimal one [
53,
54,
55,
56].
The no-free-lunch theorem demonstrates that algorithms do not universally apply to optimization issues [
57]. Hence, it is crucial to enhance the efficiency of established algorithms. Numerous academics employ diverse methodologies to enhance pre-existing algorithms. For instance, the authors of [
58] proposed incorporating an autonomous foraging mechanism called the remora optimization algorithm (ROA), which enables independent food discovery and less reliance on external sources. This integration significantly broadens the algorithm’s exploration capabilities and enhances its optimization accuracy. According to the authors of [
59], incorporating roaming methods and lens opposition-based learning techniques enhanced the ability of the sand cat to conduct wide global searches. This integration also leads to accelerated convergence speed of the algorithm and successfully enhances its overall performance. Kahraman et al. (2020) introduced the fitness distance balance concept in their study [
60]. Their fitness and distance values determine candidates’ scoring in the selection procedure. The population with the maximum score is chosen as the secondary solution, replacing the random individuals. This mechanism aims to increase the likelihood of an effective auxiliary solution, thereby improving algorithm efficiency and the likelihood of escaping local optima. In their study, the authors of [
61] introduced the natural survivor method (NSM) as an alternative approach to solely relying on fitness values for evaluating and retaining individuals. To determine NSM scores, the researchers incorporated three parameters into their calculations. The factors mentioned above encompass the individual’s impact on the population, their influence on the mating pool, and their overall fitness worth. The scores of these three factors were dynamically weighted to decide the individual to retain by comparing their respective scores. According to the authors of [
60,
61,
62], the potential for enhancing algorithm performance through effective measures exists. The data mentioned above clearly indicates that the enhanced MH algorithms have garnered significant interest within the realm of optimization.
The present study examines a new methodology known as the Reptile Search Algorithm (RSA), introduced by Abualigah et al. in 2021 [
63]. The primary source of inspiration for this phenomenon is derived from the cooperative behavior exhibited by crocodiles during the act of predation. In their recent study, the authors of [
64] introduced a novel approach called the hybrid RSA and ROA algorithm (RSAROA), which combines the use to optimize tasks and perform data clustering. This results in improved algorithm performance compared to other recently developed algorithms in particular problem domains. The authors of [
65] introduced a modified version of the RSA specifically designed for numerical optimization problems. The utilization of the adaptive chaotic opposition-based learning strategy, shifting distribution estimation method, and elite alternative pooling technique effectively enhance the variety of the population, thereby achieving a balanced approach to exploration and exploitation. This ultimately leads to an improvement in the performance of the algorithm. The authors of [
66] have introduced a new approach called the enhanced reptile search optimization algorithm using a chaos random drift and SA for feature selection. The RSA algorithm can be enhanced by including chaotic maps and SA techniques. This improved algorithm increased diversity within the initial population and improved algorithm progress. The authors of [
67] have introduced a new approach called the improved RSA by the Salp swarm algorithm for medical image segmentation. This study aims to enhance the efficiency of the RSA by including the Salp swarm algorithm, with a specific focus on its application in the domain of image segmentation. This approach addresses the primary issues of early convergence and disparity in the search procedure as put forth by the original method.
One notable distinction between the RSA algorithm and other optimization algorithms is in the distinctive approach employed by the RSA to update the positions of search agents, which involves the utilization of four novel methodologies. For example, the behavior of surrounding prey is accomplished using two distinct locomotion methods: high-walking and belly-walking. Additionally, Crocodiles engage in communication and collaboration to effectively execute hunting strategies. The RSA aims to develop robust search algorithms that yield high-quality outcomes and generate novel solutions to address intricate real-world problems [
68,
69]. According to the authors, the RSA has effectively addressed artificial landscape functions and practical engineering challenges, surpassing other widely used optimization techniques [
63]. The benchmark functions are mathematical functions commonly employed to assess the efficacy and efficiency of optimization techniques. Moreover, despite being classified as a stochastic population-based optimization method, the RSA has vulnerabilities in terms of maintaining population variety and avoiding local optima in the context of high-dimensional features. The factors mentioned above, as well as the distinguishing features of the RSA served as the impetus for undertaking this study to enhance its efficacy [
70,
71].
Q-Learning (QL) is a type of reinforcement learning (RL) technique that operates without the need for an explicit model of the environment. The integration of the QL and MH algorithm has been employed to enhance the optimization algorithm’s search capability, facilitated by advancements in RL [
72,
73,
74,
75]. The authors of the study conducted by [
76] employed the RL technique to dynamically choose five strategies for enhancing the local search capabilities of the PSO. The authors of [
77] have developed the differential evolutionary-QL (DEQL) method to produce a population of trials by utilizing QL. The QL determines the optimal choice of mutation and crossover techniques from a pool of four distinct strategies. The authors in the study by [
78] employed a combination of PSO and RL techniques to develop individual Q-tables for each particle. Additionally, they implemented a dynamic selection mechanism for adjusting the particle characteristics. The authors of [
79] introduced the QL-embedded sine-cosine algorithm (Q-SCA) as a means of parameter control. Using the QL technique can potentially expedite the escape of the sine cosine algorithm from local optima. The authors of [
80] propose that the exploration ability of the QL algorithm can be improved by dynamically selecting the search strategy of the arithmetic optimization algorithm (AOA). In the literature previously mentioned, the QL algorithm was employed to optimize the approach for a certain algorithm. The presence of certain limits may impede the resolution of various optimization challenges. The QL algorithm employs a reward function assigned a constant value, hence creating a situation perceived as unjust for persons who have made more advancements. Furthermore, generating a Q-table for each individual results in a significant increase in spatial complexity. In order to tackle this issue, it is possible to devise a hybrid approach incorporating a RL algorithm. This approach aims to optimize the selection of a meta-heuristic algorithm, hence maximizing the benefits achieved at various phases [
77,
79]. It has been observed that the aforementioned literature shares a common objective, namely, to mitigate algorithmic precocity and achieve a harmonious equilibrium between exploration and progress. To address the concerns above, the following measures have been undertaken. A QL mechanism can enhance crocodiles’ spatial exploration and exploitation capabilities. In addition, competitive learning and adaptive learning mechanisms can be used to further improve the performance of the RSA. Hence, this study presents a new approach, namely the Multi-Learning-Based Reptile Search Algorithm (MLBRSA), for addressing the global optimization and software requirement prioritization (SRP) problems. The choice of appropriate methods for boosting and enhancement frameworks should be guided by the algorithm’s challenges and the characteristics of the optimization issues it aims to solve. QL, competitive learning, and adaptive learning were selected due to their direct relevance in addressing several inherent problems associated with RSA, including the convergence towards local optima, sensitivity to parameters, and the absence of a balanced exploration-exploitation trade-off. Alternative frameworks may potentially create superfluous intricacy or may not fit as well with RSA’s particular dynamics and objectives. The following are the major contributions of this study:
The multi-learning approach is proposed to improve the performance of the RSA;
Dynamic learning with more rewards in different situations increases the diversity of solutions in the population and the robustness of RSA;
Validated using 23 benchmark test functions with different dimensions and five constrained engineering design problems;
Validated using the software requirement prioritization optimization problem;
Compared with state-of-the-art algorithms, including the original RSA.
The paper is organized as follows:
Section 2 briefly discusses the concepts of the original RSA;
Section 3 comprehensively presents the proposed MLBRSA;
Section 4 details the SRP problem, and the objective function and constraints are also discussed;
Section 5 discusses the results of the 23 benchmark functions with different dimensions and five engineering optimization problems;
Section 5 also discusses the results obtained for the SRP problem; and
Section 6 concludes the paper.
3. Proposed Multi-Learning-Based Reptile Search Algorithm
The RSA is a nature-inspired metaheuristic algorithm that mimics the hunting behavior of reptiles. Like many metaheuristic algorithms, the RSA has its strengths but has certain limitations or defects. Some potential defects of the original RSA include: (i) the RSA, like many optimization algorithms, can sometimes get trapped in local optima, especially in complex search spaces with multiple peaks and valleys. This means the algorithm might converge to a sub-optimal solution rather than the global optimum, (ii) the performance of the RSA can be sensitive to its parameter settings, such as the values of
and
, (iii) when dealing with high-dimensional problems, the RSA might exhibit slow convergence rates, (iv) the original RSA might not always strike the right balance between exploration and exploitation, (v) there might be situations where the algorithm becomes stagnant, with solutions oscillating around certain values without significant improvements, (vi) the computational cost can increase significantly, and the algorithm might struggle to find good solutions within a reasonable time frame, and (vii) the original RSA does not have mechanisms to adapt its parameters or strategies based on the problem’s characteristics or its current performance [
68,
69,
70,
71]. This lack of adaptability can hinder its performance on diverse problems. Therefore, it is essential to note that while the RSA has these potential defects, it also has strengths, and its performance can be problem-dependent. The proposed enhancements, including the integration of Q-learning, competitive learning, and adaptive learning, aim to address some defects and improve the algorithm’s robustness and efficiency [
81,
82].
3.1. Reinforcement Learning
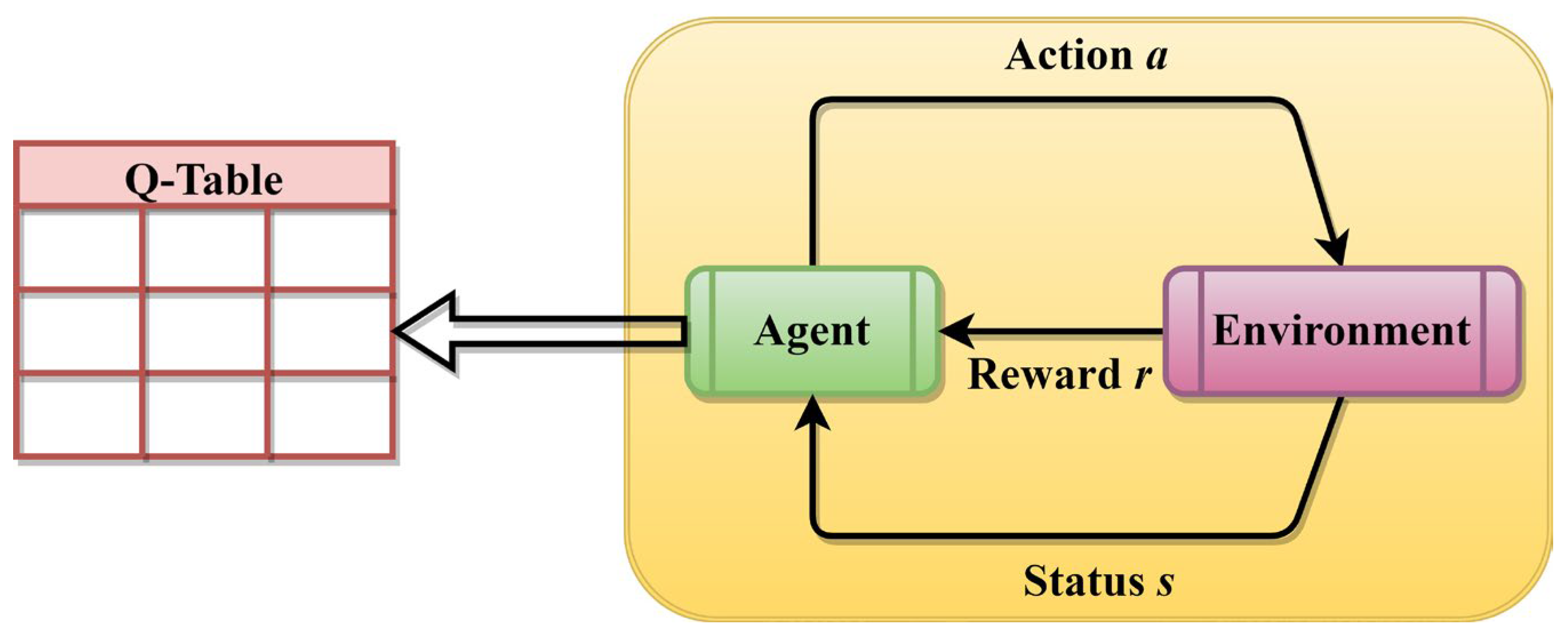
In history, numerous noteworthy advancements have emerged in the field of reinforcement learning. This area of study can be classified into two distinct categories: policy-based approaches and value-based methods. The Q-learning algorithm is commonly regarded as a representative example of value-based techniques. During the process of learning, the agent engages in actions that have the highest predicted Q-values in order to compute the optimum course of action. The objective is to establish a reciprocal relationship with the surrounding environment utilizing the agent, afterwards acquiring the highest possible reward to attain the most advantageous course of action, as seen in
Figure 2. The Q-learning comprises state-space
, action space
, an environment, the learning agent, and the reward function
. The Q-table undergoes dynamic updates dependent on the reward, and its computation is performed as follows [
78,
79,
82]:
where
denotes the current action,
denotes the next state,
denotes the current state,
denotes the instant reinforcement reward learned from the accomplishment of
at
,
denotes the learning rate,
denotes the discount factor, and
denotes the predicted Q-value when
performed at
.
The Q-table can be represented as a
matrix where
and
denote the number of actions and states correspondingly. The Q-table can be described as a mapping table that associates the current state of execution with certain actions and their corresponding future rewards. The pseudocode of the QL is presented in Algorithm 2.
| Algorithm 2: Pseudocode of the QL Algorithm |
| and the action . |
| For and |
| . |
| End For |
| randomly. |
| While the criteria not reached |
| Select the best action from the current state from the Q-table. |
| Execute the action and then get the immediate reward. |
| . |
| Obtain the respective maximum Q-value. |
| Update the Q-table using Equation (10) and update the state. |
| End While |
3.2. Competitive Learning
When applied to optimization algorithms like the RSA, competitive learning determines which solutions (or “reptiles” in the context of the RSA) perform best and should influence or guide the search process. In the proposed MLBRSA, solutions compete based on their fitness values. The solution with the best (e.g., lowest) fitness value “wins” the competition. The winning solution influences the position updates of other solutions. This is done to guide the search towards promising regions of the search space. Competitive learning introduces a form of guided exploration. While random exploration helps search the entire solution space, the influence of the best solution ensures that the search is also exploitative, focusing on areas that have yielded good solutions. As the search progresses and different solutions become winners in different iterations, the search direction and focus can dynamically change, allowing the algorithm to adapt to complex landscapes [
83,
84,
85]. In this study, competitive learning influences how solutions are updated. The winning solution (the one with the best fitness) provides a reference or guide for updating other solutions [
81]. This ensures that (i) the search is biased towards regions of the search space that have yielded good solutions, (ii) solutions can escape local optima by being influenced by the global best or other high-performing solutions, and (iii) the diversity of solutions is maintained, as not all solutions are pulled towards the best one, but are updated with a mix of exploration and exploitation.
In each successive iteration, reptiles are chosen randomly in pairs from the existing population to engage in competitive interactions. Following each competition, the participant with a lower fitness value, referred to as the loser, undergoes an update process by assimilating knowledge from the winner. Conversely, the winner is to be directly included in the population of the subsequent iteration. The framework of competitive learning is provided in
Figure 3. The first step in competitive learning is the winner selection. For the given set of solutions
with the fitness
, the winning solution
is the one with the best fitness:
The update of a solution
considering the winning solution
can be modeled as follows:
where
is a factor determining the extent of influence and
represent other update components (e.g., random exploration). In this study, the value of
is selected as 0.1, i.e., 10% of the solutions are moving towards the winning solution. In competitive learning, the influence factor, or learning rate, critically shapes the RSA’s behavior. A higher rate, exemplified by 50%, accelerates adaptation to input data, fostering quicker convergence. However, this swiftness can lead to overshooting and instability, potentially delaying generality. Conversely, a lower rate, like 1%, ensures a more stable learning process but may sacrifice speed, potentially causing delays in convergence and adaptation. In order to strike a balance, a 10% learning rate often proves optimal, offering a moderate convergence speed without compromising stability excessively. This choice is typically justified through empirical validation, where the learning rate’s impact determines the most effective compromise between convergence speed and stability. Tailoring the learning rate to the problem’s specific characteristics and considering computational resources ensures an informed and efficient choice in the competitive learning process. The pseudocode of competitive learning is provided in Algorithm 3.
| Algorithm 3: Pseudocode of the Competitive Learning |
randomly.
. |
| While not converged: |
| . |
| For each solution in : |
| . |
| . |
| . |
|
End For |
| End While |
In this study, competitive learning provides a mechanism to guide the search using the best-found solutions. This balance between exploration and exploitation can enhance the algorithm’s performance in finding optimal or near-optimal solutions.
3.3. Adaptive Learning
Adaptive learning refers to the ability of an algorithm to adjust its parameters or behavior based on its performance or the characteristics of the problem being solved. Adaptive learning can be crucial for balancing exploration and exploitation in optimization algorithms. Adaptive learning often involves dynamically adjusting algorithm parameters, such as learning rates, based on the algorithm’s performance. The algorithm uses feedback, typically in solution quality or convergence speed, to decide how to adjust its parameters. In order to adapt to the problem’s landscape, the algorithm can converge faster to high-quality solutions. Adaptive mechanisms can help the algorithm escape local optima by adjusting its search behavior [
86].
In the proposed MLBRSA, adaptive learning influences how the algorithm updates its solutions. Specifically, (i) parameters like
and
in the MLBRSA are adjusted based on the best solution performance. If the best solution improves, the parameters might be increased to intensify the search around it. If the best solution stagnates, the parameters might be decreased to diversify the search, and (ii) by adjusting parameters like
and
, the algorithm can dynamically shift between exploration and exploitation, ensuring a good balance throughout the search process. The feedback
can be calculated as the difference in the best solution’s fitness between two consecutive iterations as follows:
where
denotes the current best solution and
denotes the previous best solution. Equation (14) is used to update the parameters adaptively. The term
represents the parameters to be adapted during the iterative procedure, i.e.,
and
, in this study. The update of a parameter
based on the feedback can be modeled as follows:
where
and
denote small positive constants determining the magnitude of the parameter adjustment. The pseudocode of adaptive learning is provided in Algorithm 4.
| Algorithm 4: Pseudocode of the Adaptive Learning |
Initialize solutions X randomly.
and and infinity. |
| While not converged: |
| . |
| For : |
and ).
. |
| End For |
//Adaptive Learning//
Find the feedback value by . |
| If: |
| and ). |
|
Else:
|
| and ). |
|
End If |
|
| End While |
In the proposed MLBRSA, adaptive learning provides a mechanism to adjust the algorithm’s behavior based on performance. This dynamic adjustment can help the algorithm respond better to the challenges of the problem’s landscape, enhancing its ability to find optimal or near-optimal solutions.
3.4. Multi-Learning Reptile Search Algorithm
This subsection explains the step-by-step procedure of the proposed MLBRSA. The following steps describe the formulation of the proposed algorithm.
Step 1—Initialize MLBRSA: The algorithm initializes the MLBRSA. This involves setting up the initial population of solutions and defining the search space boundaries. Given a population size
, dimension
, and search space boundaries
and
, initialize the population
:
Step 2—QL Decision: At this step, the algorithm uses QL to decide the next action for each solution. This decision is based on past experiences and the expected reward of taking a particular action in the current state. For each solution
, decide the next action based on the Q-table
and an exploration rate
:
Step 3—Competitive Learning: Here, the solutions compete against each other based on their fitness values. Only the best solutions (winners) can update their positions, while the others remain unchanged. This introduces a survival-of-the-fittest dynamic. For the given set of solutions
with the fitness
, the winning solution
is the one with the best fitness:
The competition influence is calculated as follows:
where
is the influence factor and its value is 0.1, i.e., 10%.
Step 4—Adaptive Learning: The algorithm evaluates its performance and dynamically adjusts its parameters (
and
). This self-tuning mechanism ensures that the algorithm remains flexible and adaptable to the problem’s characteristics, dynamically adjusting the parameters
and
based on the performance difference
between two consecutive iterations:
The dynamic parameters are as follows:
where
and
are small positive constants, and their value is 0.01 and 0.001, respectively.
Step 5—Update & Iterate: Based on the decisions from the previous steps, the algorithm updates the positions of the solutions. It then checks for convergence criteria. If the criteria are not met, the algorithm returns to the QL step and iterates until the end conditions are satisfied. Update the position of each solution based on the selected action using Equation (22):
Step 6—Iterate until a stopping criterion is met and return the best solution.
The pseudocode of the suggested MLBRSA is presented in Algorithm 5.
| Algorithm 5: Pseudocode of the Proposed MLBRSA |
Initialize solutions X randomly.
and infinity.
and the action . |
| For and |
| . |
| End For |
| randomly. |
| While not converged: |
| Determine . |
| Determine . |
| For each solution in : |
| QL Action Selection (Random or greedy action). |
| . |
| Select the best action from the current state from the Q-table. |
| Execute the action and then get the immediate reward. |
| Decide action using QL. If , choose a random action; else, use Q-table. |
| considering the influence and other factors using Equation (22). |
| . |
| Obtain the respective maximum Q-value. |
| Update the Q-table using Equation (10) and update the state. |
| . |
| End For |
| For : |
and ).
. |
|
End For |
| Find the feedback value by . |
| If: |
| and ). |
| Else: |
| and ). |
|
End If |
| |
| End While |
| Return: Best solution. |
3.5. Computational Complexity
Analyzing the time and space complexity of the MLBRSA can be more nuanced than traditional algorithms due to their stochastic nature and dependence on parameters. The time complexity is provided as follows: (i) The initialization of solutions with dimensions takes ; (ii) QL Decision: for each of the solutions, deciding the next action based on the Q-table is , so in total, it is ; (iii) Competitive Learning: Finding the best solution based on fitness evaluation is ; (iv) Adaptive Learning: Adjusting parameters based on performance is for each solution, so in total; and (v) Update & Iterate: Updating the position of each solution and checking for convergence for each of the iterations is Therefore, the overall time complexity for the algorithm for iterations is: . The space complexity is provided as follows: (i) Population Matrix: Storing solutions, each with dimensions, requires space; (ii) Q-table: Assume a discrete state and action space for QL; the Q-table’s size would be . However, in the MLBRSA, this might be abstracted or approximated so that the exact space complexity can vary based on the implementation; and (iii) Auxiliary Variables: Variables like , , fitness values, etc., would take space. Therefore, the overall space complexity is: .
5. Results and Discussions
The performance potential of the proposed algorithm is rigorously evaluated through a comprehensive set of tests and analyses. These evaluations are conducted using various methods, including:
23 standard benchmark functions with different dimensions: The problems are predefined mathematical functions commonly used in optimization research to test the efficiency and accuracy of new algorithms;
Five engineering design problems: These are typical problems encountered in engineering disciplines, which provide a practical context for assessing the algorithm’s applicability and effectiveness;
Software requirement prioritization problem: These are intricate and multi-faceted problems sourced from real-life scenarios, offering a challenging problem for the algorithm.
All tests were conducted on a specific computer setup to ensure consistency and reliability in the evaluations. This setup was a PC running Microsoft Windows 11®. The hardware specification includes 16 Gigabytes of memory and an Intel(R)Core(TM)-i5 CPU with a clock speed of 2.50 GHz. For coding and executing the algorithms, MATLAB software (version 9.9 (R2020b); Massachusetts, USA) was chosen. This software is widely recognized in the research community for its versatility and robustness in handling complex mathematical computations and simulations.
When evaluating the proposed MLBRSA, it is benchmarked against several other algorithms. These include the RSA, improved RSA (IRSA) [
65], reinforcement learning-based GWO (RLBGWO) [
82], improved dwarf mongoose optimization algorithm (IDMOA) [
102], RL-based hybrid Aquila optimizer and AOA (RLAOA) [
80], adaptive gaining-sharing knowledge (AGSK) algorithm [
103], and ensemble sinusoidal differential covariance matrix adaptation with Euclidean neighborhood (LSHADE-cnEpSin) algorithm [
104]. The population size and the maximum number of iterations for the 23 test functions are 30 and 500, respectively, and for the real-world problems are 30 and 1000, respectively. The algorithm parameters can be found in
Table A1. Each algorithm is executed 30 times, and the results are recorded for a fair comparison. The performance factors include Min, Max, Mean, Median, standard deviations (STD), run-time (RT), and Friedman’s ranking test (FRT) values.
5.1. Numerical Test Functions
Various statistical metrics are employed to understand each algorithm’s performance comprehensively. These metrics offer insights into the distribution, central tendency, and variability of the results. Specifically, the following metrics are presented: Minimum (Min): This represents the lowest value or score the algorithm achieves. It provides a sense of the worst-case performance; Maximum (Max): In contrast to the minimum, this metric showcases the highest value or score the algorithm achieves, indicating the best-case performance; Mean: This is the average score of the algorithm across all runs or iterations. It provides a central value that represents the typical performance of the algorithm; Standard Deviation (STD): This metric measures the amount of variation or dispersion from the mean. A low standard deviation indicates that the results are close to the mean, while a high standard deviation suggests that the results can vary widely. A specialized statistical ranking test known as the FRT is employed further to validate the performance and superiority of the MLBRSA. The FRT is a non-parametric test to detect treatment differences across multiple test attempts. The detailed findings from this test, specifically pertaining to the MLBRSA, are elaborated upon to offer a clear understanding of its standing compared to other algorithms.
5.1.1. Capacity Analysis
The benchmark functions are categorized based on their characteristics and challenges. Unimodal Benchmarks (F1–F7): These are functions with a single peak or trough. They assess an algorithm’s ability to exploit or hone in on a single optimal solution. The results for these benchmarks are tabulated in
Table 1. Multi-modal Functions (F8–F13) with 30 Dimensions: Multi-modal functions have multiple peaks or troughs, making them more challenging as they test an algorithm’s exploration capability. Specifically, the ones with 30 dimensions are designed to evaluate how well an algorithm can navigate a complex search space with many variables. The results for these functions are presented in
Table 2. Multi-modal Functions (F14–F23) with Fixed Dimensions: These functions also have multiple peaks or troughs but have a set number of dimensions. They are used to gauge an algorithm’s proficiency in discovering solutions in low-dimensional search spaces. The outcomes for these benchmarks are detailed in
Table 3. The best results in each table are highlighted using boldface typography to make it easier for readers to identify superior performance at a glance. This visual cue ensures that standout performances are immediately recognizable.
Table 1,
Table 2 and
Table 3 provide a comprehensive overview of the performance of the proposed MLBRSA, and the results are quite impressive. Across most of the standard test functions, the MLBRSA consistently delivered optimal results. This superior performance is evident in the best results and the average and STD values, which offer insights into the central tendency and variability of the algorithm’s outcomes. Exploitation in optimization refers to an algorithm’s ability to refine its search and hone in on the best solutions in a local area. The test functions F1 through F7 serve as a measure of this capability. A closer look at
Table 1 reveals that the MLBRSA emerged as the top performer in six of these seven functions. This dominance underscores the MLBRSA’s exceptional ability to exploit and find optimal solutions, outshining all other algorithms under consideration. Exploration pertains to an algorithm’s capacity to search widely across the solution space, ensuring it does not miss out on potential optimal solutions in distant regions. The test functions F8 through F13 gauge this ability.
Table 2 shows that, out of these six functions, the MLBRSA surpassed other algorithms in all six, highlighting its robust exploration capabilities. The test functions F14 through F23 assess an algorithm’s proficiency in navigating low-dimensional search spaces. The MLBRSA’s prowess is also evident here, with the algorithm delivering superior results in ten functions. This demonstrates its versatility in handling both complex and simpler problem spaces. The standout performance of the MLBRSA across most test functions can be attributed to its integration of QL, competitive learning, and adaptive learning. These methodologies enhance both the exploitation and exploration abilities of the algorithm. In contrast, the RSA, which serves as a comparison, struggles due to an imbalance in its exploration and exploitation dynamics.
Figure 4 provides a visual representation of various metrics across 23 test functions. Some key observations include: (i) Trajectory curve: This curve tracks the progression of the baseline parameter of the initial population over iterations. It reveals that solutions in the MLBRSA undergo significant shifts in the early phases, which taper off as the algorithm progresses. By the end, the MLBRSA stabilizes, effectively utilizing the available solution space; (ii) Mean fitness curves: These curves depict the evolution of the average fitness of the population over time, offering insights into the algorithm’s performance trajectory; (iii) Search space coverage: The MLBRSA excels in thoroughly scanning the solution space, as evident from its focus on potential solution areas in the search history; (iv) Exploratory activity: The trajectories showcase the MLBRSA’s primary exploration activities, characterized by sudden, decisive movements. This indicates the algorithm’s agility in navigating the solution space; and (v) Convergence and global best search: The MLBRSA’s ability to converge rapidly and relentless pursuit of the global best solution are also evident.
5.1.2. Dimensionality Analysis
The performance of the MLBRSA is further scrutinized by examining its behavior in high-dimensional spaces. High dimensionality can pose significant challenges to optimization algorithms as the solution space grows exponentially, making it harder to find optimal solutions. The primary goal is understanding how the MLBRSA fares when confronted with large dimensions. This is crucial because the ability to handle high dimensionality is a testament to an algorithm’s robustness and versatility. Several statistical metrics are used to provide a comprehensive understanding of the performance across different algorithms. These include Min, Max, Mean, and STD. The outcomes based on these metrics for all the considered algorithms are tabulated in
Table A2 (for 100 dimensions) and
Table A3 (for 500 dimensions). The functions F1 through F13 are chosen for this analysis, with two distinct dimensional settings, 100 and 500. The population size for the algorithm is set at 30, and the algorithm is allowed to run for a maximum of 500 iterations. As seen in
Table A2, the MLBRSA exhibits remarkable prowess. Specifically, when dealing with the functions F1–F13 set at 100 dimensions, the MLBRSA consistently outshines other algorithms. This dominance is evident across almost all the tests conducted, underscoring its ability to handle moderately high-dimensional problems easily. Moving to a much higher dimensionality,
Table A3 presents the results for the 500-dimensional setting. Here, the challenge is significantly amplified due to the vastness of the solution space. Yet, the MLBRSA rises to the occasion, outperforming all other algorithms in 12 of 13 problems. This is a testament to its robust design and capabilities. The standout performance of the MLBRSA, especially in high-dimensional spaces, can be attributed to its integration of multi-learning techniques. These techniques enhance the algorithm’s ability to navigate vast solution spaces efficiently, ensuring that it does not get trapped in suboptimal solutions and continues its pursuit of the best possible outcomes. In summary, the MLBRSA’s performance in moderate (100 dimensions) and high (500 dimensions) dimensional spaces underscores its versatility and robustness. Its design, especially the incorporation of multi-learning, is pivotal in ensuring its dominance across a wide range of problems.
5.1.3. Complexity Analysis
The computation time, often referred to as the run time (RT), is a crucial metric when evaluating the efficiency of algorithms. It provides insights into how quickly an algorithm can produce results, which is especially important in real-time applications or scenarios with tight computational budgets. The primary objective is to understand the proposed MLBRSA’s computational efficiency compared to other algorithms. The RT values serve as a direct measure of this efficiency. All the RT values for the considered algorithms are systematically presented in
Table A4. This table offers a side-by-side comparison, enabling readers to gauge the relative computational speeds of the algorithms quickly. A closer examination of
Table A4 reveals that the mean RT for the suggested MLBRSA is 0.08 s. This is marginally higher than the basic RSA, which has an average RT of 0.18 s across all 23 test functions. This slight increase in RT for the MLBRSA might be attributed to additional features or complexities introduced in the algorithm to enhance its optimization capabilities. One reason could be the lower computational complexity inherent to the RSA. However, it is essential to note that while the RSA might be faster, its performance in terms of optimization is subpar for all the selected test functions. This highlights a trade-off between speed and optimization quality. In the grand scheme of things, the proposed MLBRSA ranks second in terms of RT. This places it behind only two other algorithms but ahead of several others. While the MLBRSA might not be the fastest in terms of computation time, it is essential to consider the balance between speed and optimization performance. An algorithm might be swift but not provide the best optimization results, making the slight increase in RT for better performance a worthy trade-off in many scenarios. In summary, while the proposed MLBRSA might take slightly longer to compute than others, its superior optimization capabilities make it a valuable choice. The detailed analysis of RT values underscores the importance of considering speed and quality when evaluating optimization algorithms.
5.1.4. Statistical Test Analysis
The evaluation of algorithms often necessitates a rigorous statistical approach to ensure that the observed results are valid and reliable. One of the primary tools in this regard is the statistical rank test. This test is essential to rank and compare algorithms based on their observed performance metrics. By doing so, researchers can determine which algorithm is superior in specific contexts or under certain conditions. The FRT is a prominent choice among the various statistical rank tests available. It is renowned and widely adopted in research circles for its efficacy in ranking algorithms. The FRT is a non-parametric test, which means it does not assume a specific distribution for the underlying data. This makes it versatile and applicable to a wide range of datasets. It is an alternative to the one-way ANOVA, which compares means across different groups. The FRT is particularly suitable when the parameter under evaluation is continuous. It is designed to detect differences or variations across multiple groups or sets. A critical aspect of any statistical test is the significance level, which is set at 0.05 in this context. This means that there is a 5% risk of concluding that a difference exists when, in reality, there is not. If the
p-value (a measure of the evidence against a null hypothesis) obtained from the test is less than or equal to this significance level, the null hypothesis is rejected. In simpler terms, if the
p-value is 0.05 or less, it suggests that not all group median values are the same. This study employs the FRT as the primary tool to rank the algorithms. This choice underscores the trust the research community places in the FRT for such evaluations.
Table A5 provides a comprehensive overview of the FRT values for all the algorithms across the 23 test functions under consideration. This table lists individual FRT values and presents the average FRT values, which are pivotal in the ranking process. In summary, the FRT is a robust and reliable tool for ranking algorithms in this research. By comparing the FRT values and using a stringent significance level, the study ensures that the rankings are valid and scientifically sound. The detailed presentation of these values in
Table A5 further aids in transparency and clarity, allowing readers to understand the relative performance of each algorithm.
5.1.5. Convergence Analysis
The performance of the MLBRSA, particularly its convergence activities, has been meticulously studied. Convergence in optimization refers to the algorithm’s ability to approach and find the optimal solution over iterations. The primary goal was to understand and evaluate the highest score metric of the MLBRSA, specifically its ability to converge to the optimal value. This optimal value is a benchmark to gauge how close the algorithm gets to the best possible solution. The speed at which the MLBRSA converges to the optimal solution was analyzed for every benchmark function used in the study. This speed is a testament to the algorithm’s efficiency and ability to find solutions quickly. In order to provide a comprehensive perspective on the MLBRSA’s performance, it was benchmarked against several other algorithms. The performance metrics were obtained over 30 runs to ensure reliability and consistency in the results.
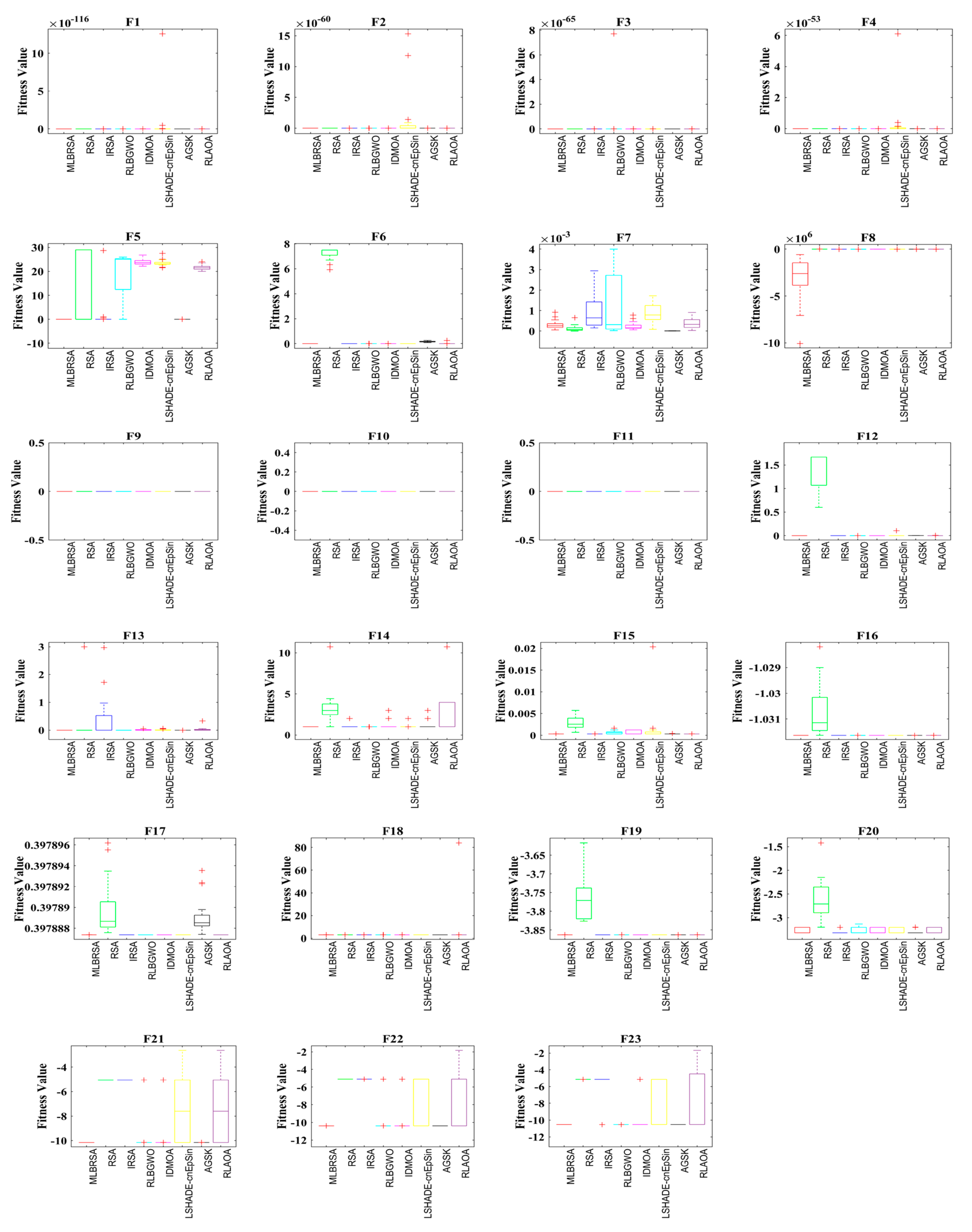
Figure 5 provides a visual representation of the convergence rates of the various algorithms. The MLBRSA, in most scenarios, showcases a commendable convergence rate, often outpacing other methods. This is indicative of its robust design and optimization capabilities. The results highlight the synergistic effect of integrating a multi-learning strategy with the RSA. This integration has led to a marked enhancement in the convergence efficiency of the optimization algorithm. Not only does the MLBRSA converge faster than other algorithms, but it also reaches the optimal value in fewer iterations. This rapid convergence rate sets it apart from other techniques, emphasizing its efficiency. Box plots are graphical tools that visually represent data distribution through quartiles, depicting five key statistical metrics: the minimum, first quartile (25th percentile), median (50th percentile), third quartile (75th percentile), and maximum. These plots provide insights into the data’s spread, symmetry, and central tendency. For all 23 benchmark functions, box plots were generated for each selected algorithm. These are visually presented in
Figure 6, offering a detailed view of the proposed algorithm’s data distribution characteristics. It showcases the symmetry, spread, and centrality of the MLBRSA’s performance metrics. A closer look at
Figure 6 reveals that the statistical attributes of the MLBRSA surpass those of all other algorithms under consideration.
Finally, the MLBRSA’s convergence capabilities have been thoroughly analyzed and benchmarked against other algorithms. Its rapid convergence rate and ability to achieve optimal values in fewer iterations underscore its superiority. The visual representations provided by the box plots further emphasize its standout performance across various benchmark functions.
5.2. Engineering Design Optimization Problems
In this sub-section, we delve into evaluating the performance of the newly introduced MLBRSA. This evaluation is done by applying it to five specific engineering design challenges. These challenges include (i) welded beam design, (ii) pressure vessel design, (iii) tension/compression spring design, (iv) three-bar truss design, and (v) tubular column design problems.
Each design problem has its constraints, making them particularly challenging. The primary reason for choosing these specific problems is to rigorously test the capability of the MLBRSA in effectively managing and solving constrained optimization challenges. To ensure a comprehensive assessment, each algorithm, including the proposed MLBRSA, is run individually a total of 30 times. For every run, a consistent population size of 30 is maintained. The maximum iteration count for all these algorithms is also capped at 1000. One of the significant challenges in optimization problems is managing constraints. This study has employed the static penalty constraint handling mechanism to address this [
105]. This mechanism aids in ensuring that the constraints are adhered to during the optimization process. It is essential to note that the objective functions chosen for all the design mentioned above problems are geared towards minimization. In other words, these optimization problems aim to find the smallest possible value that satisfies all the given constraints.
5.2.1. Welded Beam Design Problem
The main objective of the welded beam design problem is to identify the optimal cost while considering the constraints. The problem considers four design variables
, i.e.,
, in which
defines the length,
defines bar thickness,
defines the weld thickness, and
defines the height. The welded design problem has five equality constraints such as beam blending stress
, shear stress
, bar buckling load
, beam end deflection
, and side constraints. The upper bounds and lower bounds of all design variables are
,
,
, and
. In addition, other design variables are selected as
,
and
. The welded beam design is illustrated in
Figure 7. The fitness function and the constraints of the welded beam design problem are as follows [
106]:
subjected to:
The results obtained by the MLBRSA and other algorithms, such as the IRSA, RSA, RLBGWO, IDMOA, LSHADE-cnEpSin, AGSK, and RLAOA, are listed in
Table 4.
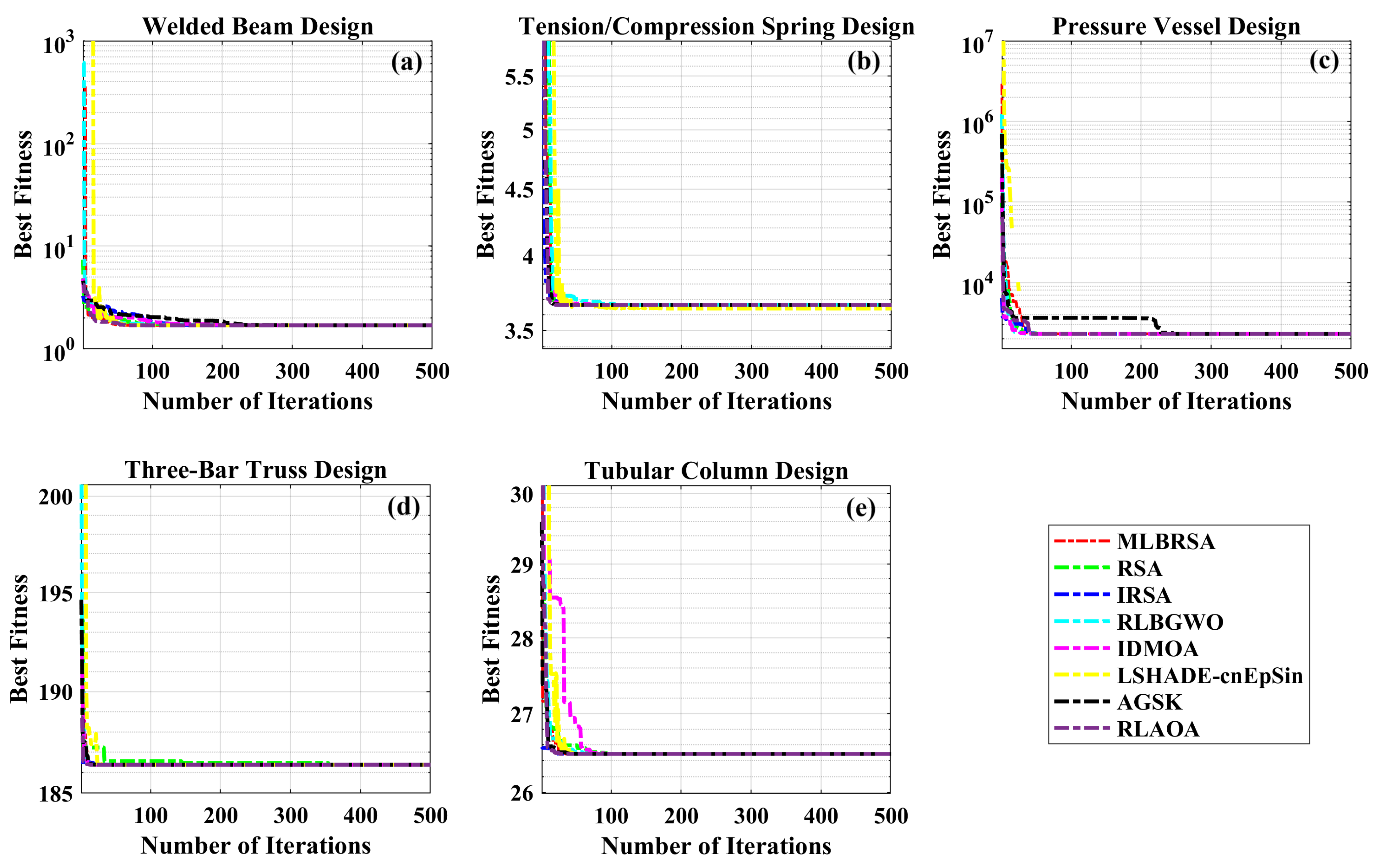
Table 4 shows that the MLBRSA outperformed all of the other approaches and cost the least.
Table 4 additionally includes statistical information such as the Min, Mean, STD, and RT. As a result, it is decided that the suggested MLBRSA is more reliable for the welded beam design optimization problem. The convergence curves and boxplot analysis of all algorithms are shown in Figure 12b and Figure 13b. Furthermore, all FRT values derived by all algorithms are presented. The proposed MLBRSA comes out on top when it comes to solving the welded beam design challenge.
5.2.2. Pressure Vessel Design Problem
Figure 8 depicts the schematic of the pressure vessel design optimization problem. The pressure vessel features capped ends and hemispherical heads. Minimization of construction costs is the primary objective of this problem. It considers four control vectors
, where
denotes the shell thickness,
denotes the head thickness,
denotes the inner radius, and
denotes the cylindrical section length. This problem also has four equality constraints, as listed in Equation (31). The bounds of variables are
and
. Equation (30) denotes the primary objective of the pressure vessel design problem [
106]:
subjected to:
The results obtained by the MLBRSA and other algorithms, such as the IRSA, RSA, RLBGWO, IDMOA, LSHADE-cnEpSin, AGSK, and RLAOA, are listed in
Table 5.
Table 5 shows that the MLBRSA outperformed all of the other approaches, and the obtained cost is minimal compared to other algorithms.
Table 5 includes statistics such as the Min, Mean, STD, and RT. As a result, it is decided that the suggested MLBRSA is a reliable tool for the pressure vessel design optimization problem. The convergence curves and boxplot analysis of all algorithms are shown in Figures 12b and 13b. Furthermore, all FRT values derived by all algorithms are presented. The proposed MLBRSA comes out on top when it comes to solving the welded beam design challenge.
5.2.3. Tension/Compression Spring Design Problem
Another classic mechanical engineering design that has been considered is the tension/compression spring design. The main objective of the spring design problem is to reduce the tension spring weight of the framework, and the structure is depicted in
Figure 9. It considers three control vectors
, where
denotes the mean coil dia,
denotes the wire dia, and
denotes active coils. This problem also has four equality constraints, as listed in Equation (33). The bounds of variables are
,
, and
. Equation (32) denotes the primary objective of the tension/compression spring design problem [
106]:
subjected to:
The results obtained by the MLBRSA and other algorithms, such as the IRSA, RSA, RLBGWO, IDMOA, LSHADE-cnEpSin, AGSK, and RLAOA, are listed in
Table 6.
Table 6 shows that the MLBRSA outperformed all of the other approaches, and the obtained weight is minimal compared to other algorithms.
Table 6 includes statistics such as the Min, Mean, STD, and RT. As a result, it is decided that the suggested MLBRSA is a reliable tool for the tension/compression design optimization problem. The convergence curves and boxplot analysis of all algorithms are shown in Figures 12b and 13b. Furthermore, all FRT values derived by all algorithms are presented. The proposed MLBRSA comes out on top when it comes to solving the tension/compression spring design challenge.
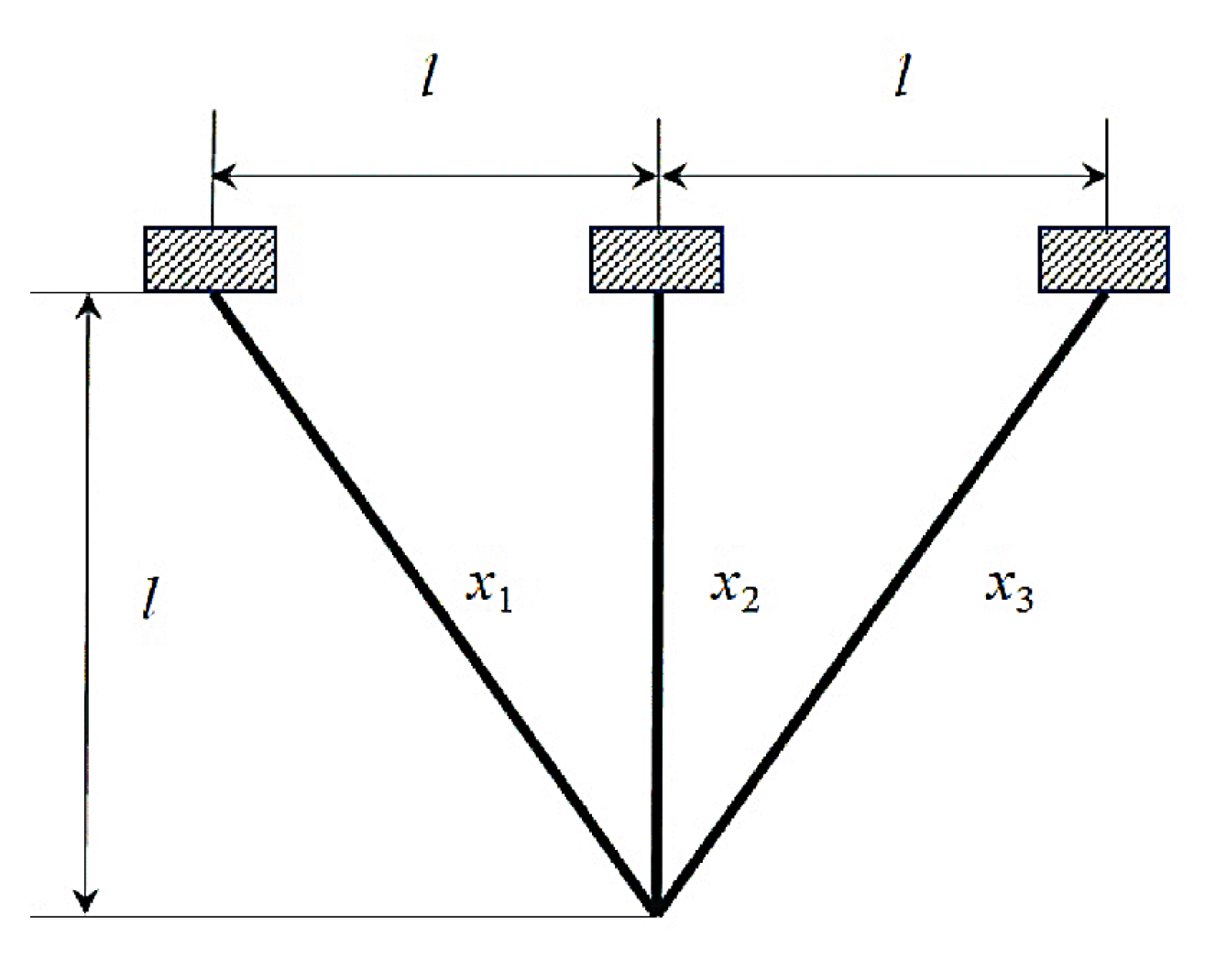
5.2.4. Three-Bar Truss Design Problem
The primary objective of the three-bar truss design is to reduce the weight of the bar constructions. The problem has three equality constraints, including each bar’s stress, buckling, and deflection. The problem has three control vectors:
. The bounds of variables are
and the values of a few other parameters are
cm,
kN/cm
2, and
kN/cm
2. The primary objective is presented in Equation (34), and the equality constraints are listed in Equation (35). The structure of the three-bar truss is shown in
Figure 10 [
106].
subject to:
The results obtained by the MLBRSA and other algorithms, such as the IRSA, RSA, RLBGWO, IDMOA, LSHADE-cnEpSin, AGSK, and RLAOA, are listed in
Table 7.
Table 7 shows that the MLBRSA outperformed all of the other approaches, and the obtained weight is minimal compared to other algorithms.
Table 7 includes statistics such as the Min, Mean, STD, and RT. As a result, it is decided that the suggested MLBRSA is a reliable tool for the three-bar truss design optimization problem. The convergence curves and boxplot analysis of all algorithms are shown in Figures 12b and 13b. Furthermore, FRT values derived by all algorithms are presented. The proposed MLBRSA comes out on top when it comes to solving the welded beam design challenge.
5.2.5. Tubular Column Design Problem
To handle a compressive load
of
kgf for the least cost, a uniform column of the tubular section should be built with hinge joints at both ends. The structure of the tubular column design is depicted in
Figure 11. The material used to make the column has a yield strength (
) of 500
, an elastic modulus (
) of
, and a weight density (
) of
. The column measures
in length (
). The column’s stress should be less than the yield stress (constraint
) and buckling stress, respectively (constraint
). The column’s average diameter is limited to being between 2 and 14 cm, and columns thicker than 0.2 to 0.8 cm are not readily accessible on the market. The cost of the column is expressed as
, where
is the weight in
of force and
is the average diameter of the column in centimetres. The objective function is presented in Equation (36), and six equality constraints are listed in Equation (37). It considers two control vectors
[
106]:
subject to:
The results obtained by the MLBRSA and other algorithms, such as the IRSA, RSA, RLBGWO, IDMOA, LSHADE-cnEpSin, AGSK, and RLAOA, are listed in
Table 8.
Table 8 shows that the MLBRSA outperformed all of the other approaches, and the obtained cost is minimal compared to other algorithms.
Table 8 includes statistics such as the Min, Mean, STD, and RT. As a result, it is decided that the suggested MLBRSA is a reliable tool for the tubular column design optimization problem. The convergence curves and boxplot analysis of all algorithms are shown in
Figure 12b and
Figure 13b. Furthermore, FRT values derived by all algorithms are presented. The proposed MLBRSA comes out on top when it comes to solving the tubular column design challenge.
5.3. Results Obtained for SRP Problem
The software requirement prioritization problem is a multifaceted challenge that demands a balance between various factors such as cost, value, and importance. In this section, we dissect the results obtained from the RSA and its enhanced version, i.e., the MLBRSA, to understand their efficacy in addressing this challenge. This study ignored the comparison among other peers, such as the RLBGWO, IDMOA, LSHADE-cnEpSin, AGSK, and RLAOA. The comparison is unfair because none of the selected algorithms are utilized for this objective. Therefore, this study considered the original RSA and the proposed MLBRSA to prove the superiority of the MLBRSA over the RSA, but not others. The RSA and MLBRSA are applied to the SRP problem directly. Each algorithm is executed 30 times individually for a fair comparison. The population size and the maximum number of iterations are selected as 30 and 100, respectively. All other parameters of the RSA and MLBRSA are selected as per the previous discussions. The data required for the SRP is available in [
105].
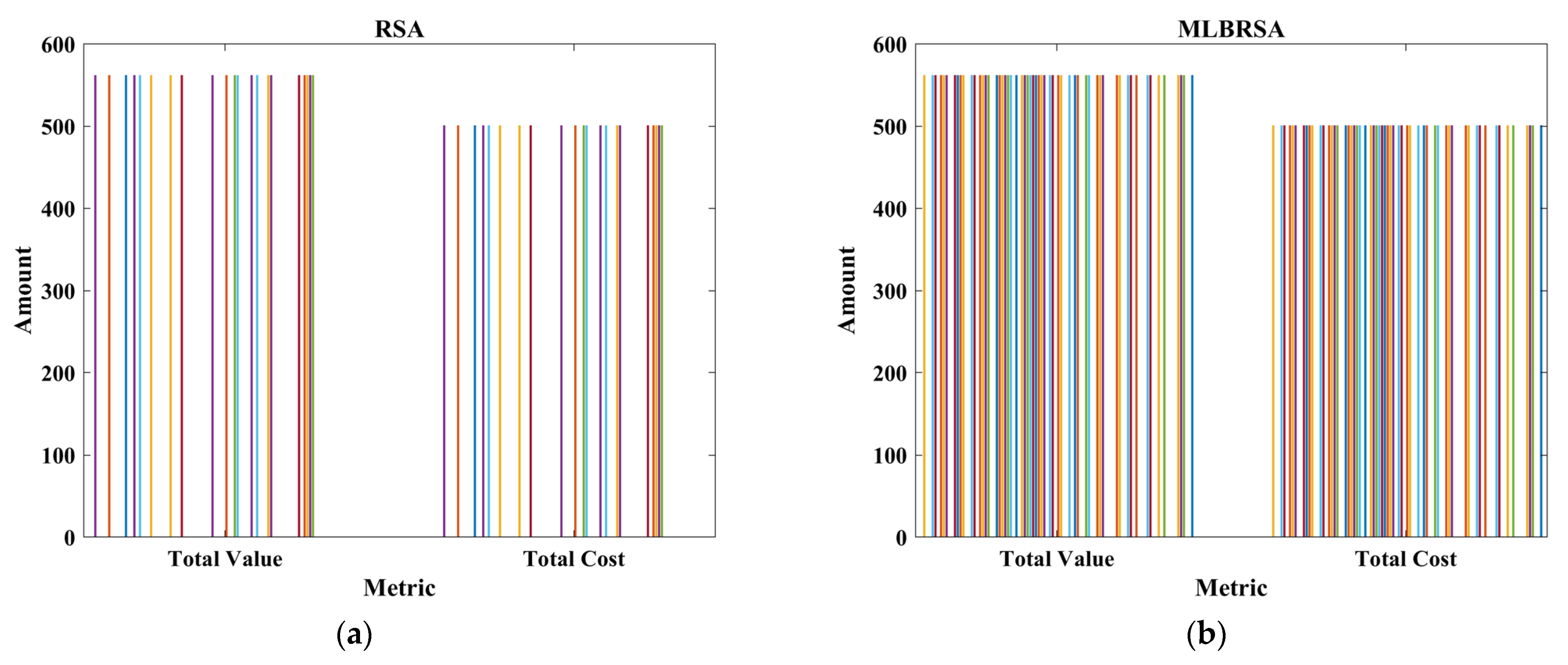
Firstly, the bar graph between the total value and cost is shown in
Figure 14. The bar graph offers a clear visual representation of the balance RSA strikes between value and cost. While the RSA does manage to select requirements that offer value, it occasionally overshoots the budget, suggesting potential inefficiencies or a lack of stringent adherence to budget constraints. The performance of the MLBRSA is notably superior. The algorithm consistently zeroes in on requirements that maximize value while ensuring costs are kept within the stipulated budget. This demonstrates the efficacy of the proposed strategy.
Figure 15 shows the pie chart between the proportion of selected and non-selected requirements obtained by both the RSA and MLBRSA. The pie chart reveals the RSA’s inclination to select a substantial portion of the available requirements. This might indicate a broader, less discriminating selection approach, which could include less critical requirements at the expense of more pivotal ones. The proposed MLBRSA showcases a more discerning selection process. The algorithm’s focus on high-value and high-importance requirements ensures that the selections are more attuned to project priorities.
Figure 16 shows the distribution of the costs for the selected requirements obtained by the RSA and MLBRSA. The histogram shows the diversity in the costs of the requirements chosen by the RSA. While diversity is commendable, the spread suggests that the algorithm might not always prioritize the most value-driven requirements. The proposed MLBRSA leans towards higher-value requirements, even if they are associated with a slightly elevated cost. This suggests a more value-centric selection approach, which is crucial for projects with tight budgets.
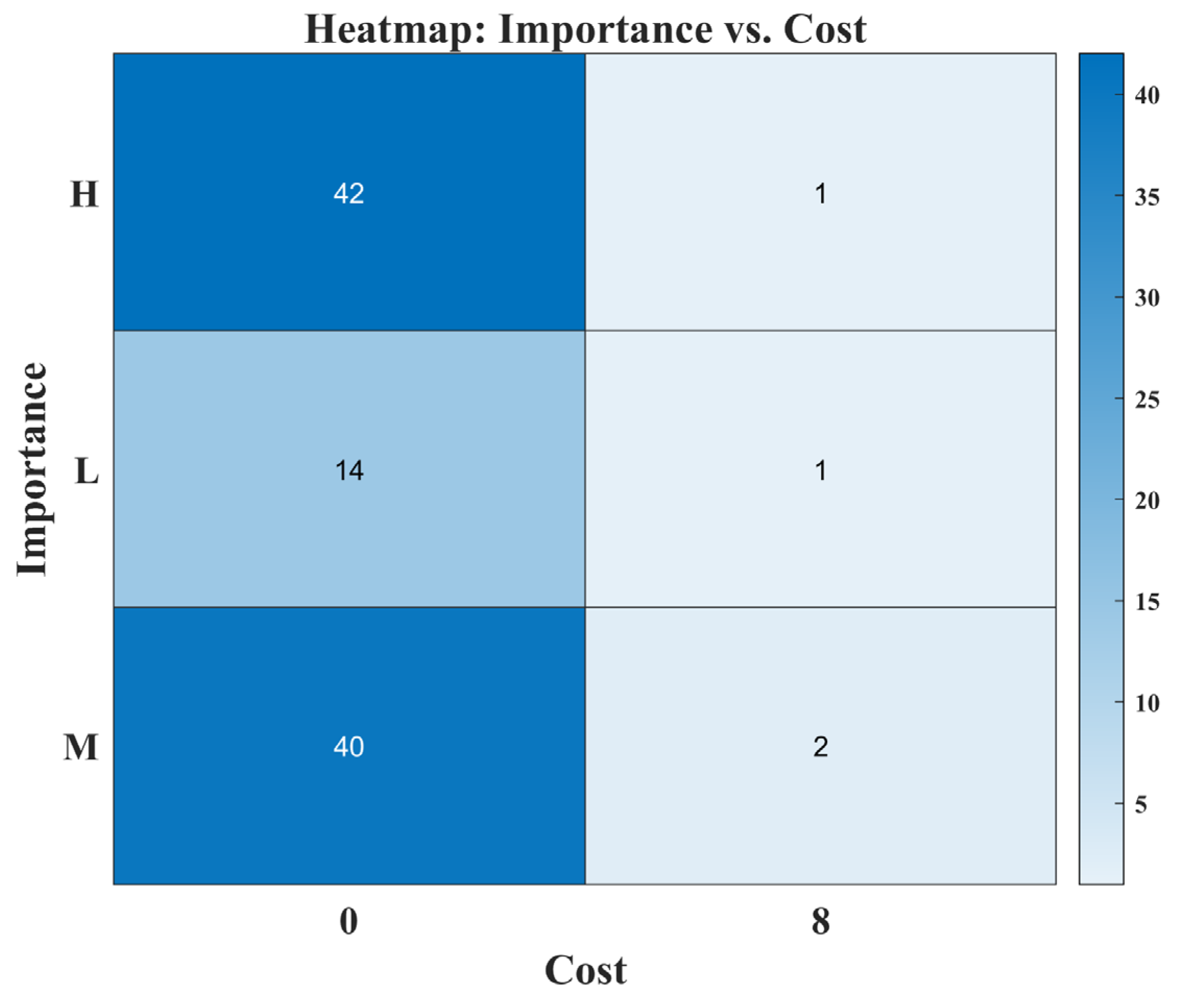
Figure 17 shows the heatmap of the importance and cost. The original RSA’s heatmap indicates a somewhat scattered approach. The algorithm sometimes leans towards medium and low-importance requirements, even with a higher price tag. This could lead to suboptimal selections when budget constraints are tight. The proposed MLBRSA’s heatmap is evidence of its refined selection process. The pronounced selection of high-importance requirements, even those with steeper costs, aligns perfectly with the proposed strategies’ focus on importance.
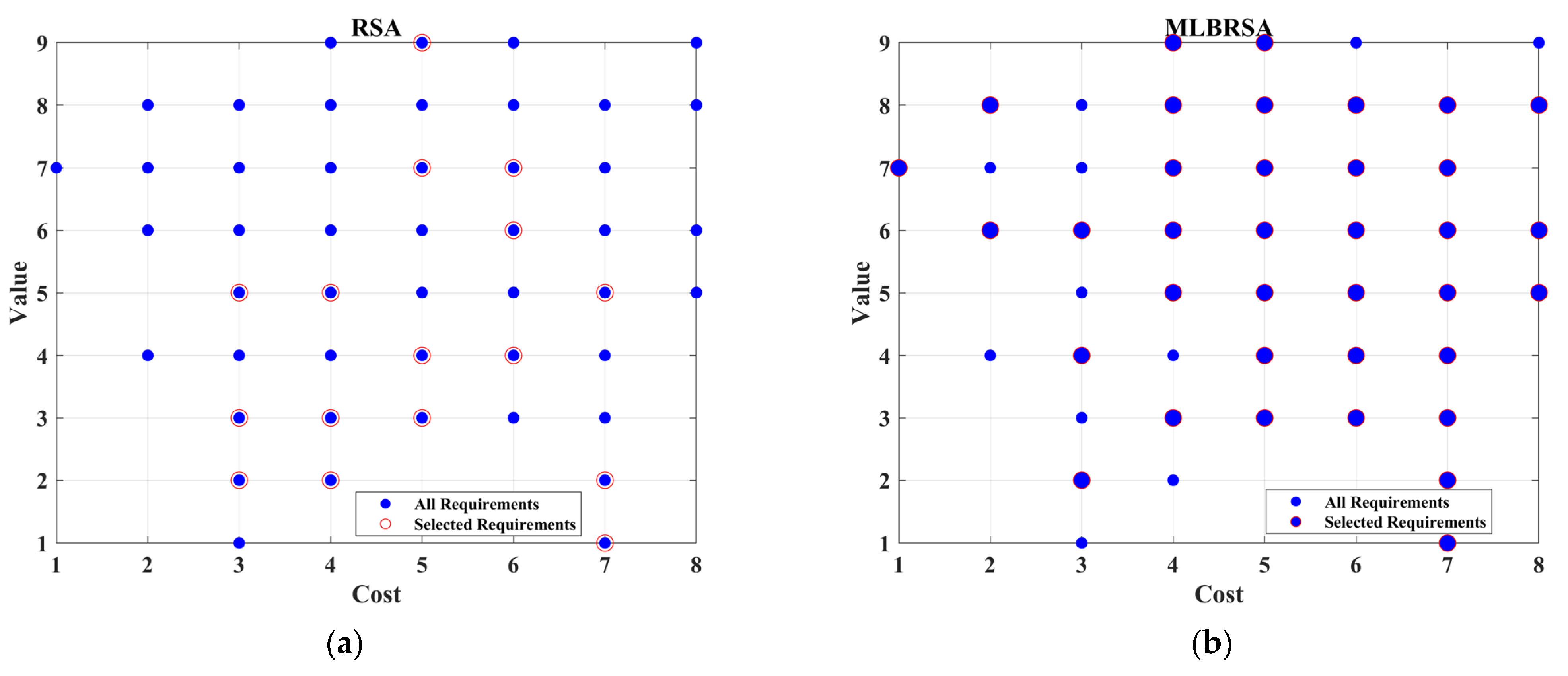
Figure 18 shows the scatter plot between the value and the cost. While the RSA’s selections are dispersed, the MLBRSA’s choices cluster around high-value requirements. This clustering indicates the MLBRSA’s capability to identify and prioritize high-value requirements consistently.
Figure 19 shows the distribution by importance, and
Figure 18 shows the ability of the proposed MLBRSA to prioritize ‘High’ importance requirements, further emphasizing its alignment with project priorities.
Figure 20 shows the line graph of cost and the accumulated value. The proposed algorithm obtained a steeper curve, and it is indicative of its efficiency. The algorithm accumulates value at a faster rate relative to cost, showcasing its prowess in maximizing value while being cost-effective.
Figure 21 shows the important distribution of selected requirements. The pie chart for RSA reveals a somewhat even distribution across the importance categories. While this might suggest a balanced approach, it also indicates that the RSA might not emphasize high-importance requirements, which are crucial for the project’s success. In contrast, the proposed MLBRSA significantly emphasizes high-importance requirements. This is a testament to the algorithm’s refined selection process, which prioritizes requirements deemed critical for the project.
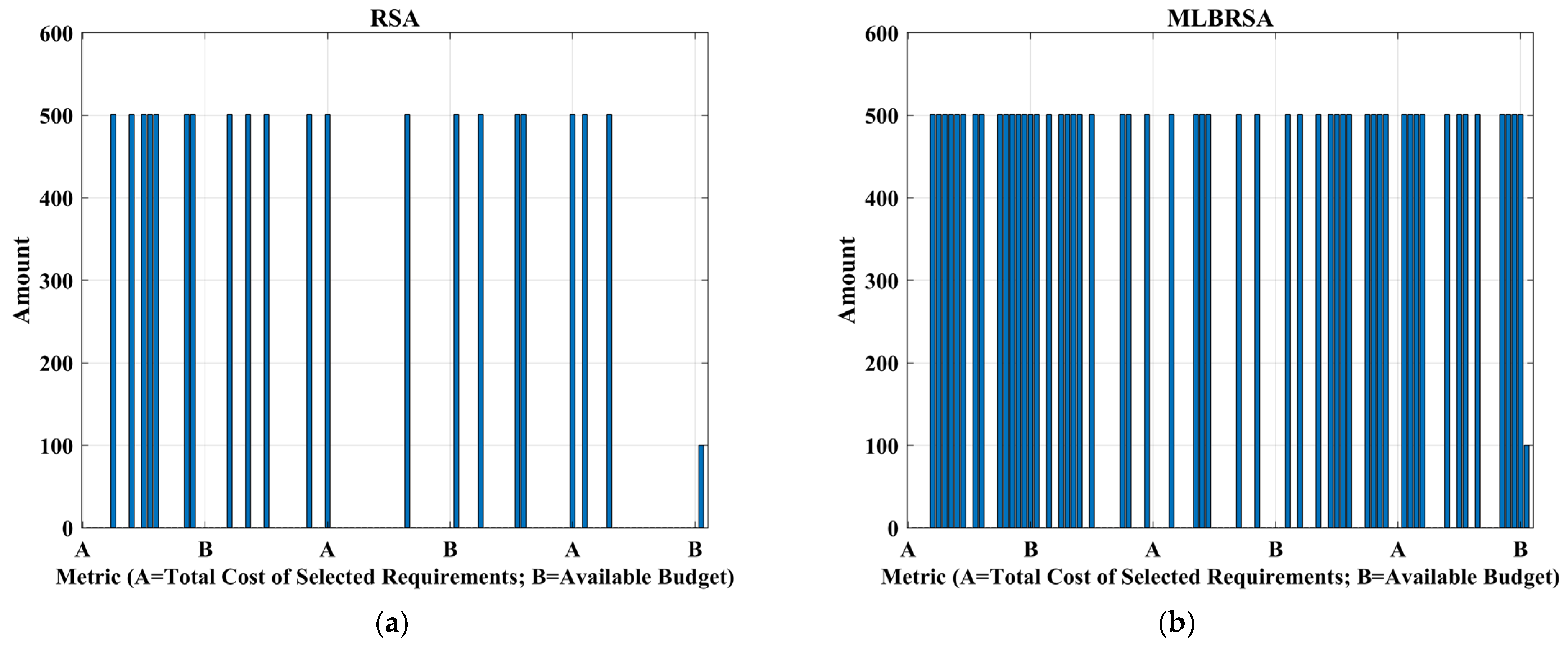
Figure 22 shows the budget utilization. It demonstrates the prowess of the proposed MLBRSA in budget management. Not only does it ensure that the selected requirements offer maximum value, but it also ensures that the total cost remains within the stipulated budget. This is crucial for projects where budget adherence is non-negotiable.
Figure 23 shows the histogram for weighted values of selected requirements. This histogram provides a deeper insight into the value-centric approach of the MLBRSA. The pronounced peaks in the higher weighted value regions indicate that the MLBRSA consistently selects requirements that offer the best value for money. This aligns with the objective function’s focus on maximizing weighted value.
In summary, the comparative analysis is discussed as follows: (i) Value Maximization: Across all visual representations, the MLBRSA consistently outshines RSA in terms of maximizing value. This is particularly evident in
Figure 14,
Figure 18 and
Figure 20; (ii) Budget Adherence: The MLBRSA’s stringent adherence to budget constraints, as seen in
Figure 14, sets it apart from the RSA.
Figure 20 underscores the MLBRSA’s unmatched ability to maximize value while ensuring strict adherence to the budget; (iii) Importance Consideration:
Figure 17 and
Figure 18 highlight the superior capability of the MLBRSA to prioritize and select high-importance requirements.
Figure 19 showcases the MLBRSA’s superior capability to prioritize and select high-importance requirements. While the RSA offers a balanced approach, the MLBRSA’s focus on high-importance requirements ensures that the project’s critical needs are addressed; (iv) Efficiency in Value Accumulation:
Figure 19 showcases the MLBRSA’s unmatched efficiency in rapidly accumulating value relative to cost; and (v) Value-Centric Approach:
Figure 23 provides compelling evidence of the MLBRSA’s value-driven selection process. The pronounced peaks in the higher weighted value regions indicate the MLBRSA’s ability to identify and prioritize high-value requirements consistently.
The visual representations prove the superiority of the proposed MLBRSA in addressing the software requirement prioritization problem. While the RSA offers a broad-based approach, the MLBRSA’s refined objective function and additional constraints ensure a more targeted, value-driven, and budget-conscious selection process. The RSA’s broader selection might suit projects with flexible budgets and less stringent requirement priorities. However, for projects where every dollar counts and priorities are non-negotiable, the MLBRSA’s discerning and value-centric approach is invaluable. The results offer a clear visual representation of how both algorithms prioritize importance. While the RSA’s balanced approach might seem commendable, the proposed MLBRSA’s emphasis on high-importance requirements aligns better with the project’s critical needs. Budget management is another area where the proposed MLBRSA shines.
Projects often grapple with budget constraints, making it imperative for the selection process to offer maximum value without overshooting the budget. In addition, the provided results also offer a deep dive into the value-centric approach of the algorithms. The RSA’s selections, while valuable, often do not offer the best value for money. The proposed MLBRSA, with its pronounced peaks in the higher weighted value regions, consistently zeroes in on requirements that offer the best bang for the buck. In conclusion, the visual representations provide compelling evidence of the proposed MLBRSA’s refined, value-driven, and budget-conscious selection process. For projects where importance prioritization, budget adherence, and value maximization are paramount, the proposed MLBRSA emerges as the clear winner.
6. Conclusions
The introduction of the Multi-Learning-Based Reptile Search Algorithm (MLBRSA) marks a pivotal moment in the landscape of computational problem-solving. By seamlessly intertwining the principles of QL, competitive learning, and adaptive learning, the MLBRSA emerges as an encouragement of modernization, setting a new benchmark for algorithmic efficiency and versatility. Its inherent design, which capitalizes on reinforcement, competition, and adaptability, equips it with a unique prowess to delve deep into complex problem terrains and extract optimal solutions. By amalgamating the principles of QL, competitive learning, and adaptive learning, the MLBRSA not only addresses the inherent challenges posed by complex engineering problems but also excels in the domain of software requirement prioritization. Its unique ability to combine reinforcement, competition, and adaptability ensures it can navigate intricate problem spaces, continually refining its solutions. The empirical validations, as evidenced by its applications to numerical benchmarks and real-world engineering problems, not only validate its theoretical soundness but also highlight its practical relevance. In the software development sphere, where the prioritization of requirements is often a daunting task fraught with uncertainties, the MLBRSA performed well. In the context of software development, the algorithm’s proficiency at ranking requirements ensures that pivotal software functionalities receive the attention they warrant, thereby optimizing the development process. It offers a systematic, experience-driven approach to ensure that pivotal software functionalities are not just recognized but also prioritized, optimizing the overall development trajectory.
Looking ahead, the potential applications of the MLBRSA are vast. Given its demonstrated proficiency, it can be extended to other domains, such as artificial intelligence, robotics, and bioinformatics. The adaptability of the algorithm suggests that it could be fine-tuned for specific industry challenges, paving the way for more specialized versions of the MLBRSA. Additionally, integrating the MLBRSA with other advanced computational techniques could further enhance its capabilities. There is also scope for exploring the algorithm’s performance in dynamic environments, where problem parameters change over time. Lastly, as the world of software development continues to evolve, understanding how the MLBRSA can be integrated into modern agile and DevOps practices will be crucial.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


























