

Advancing ESG and SDGs Goal 11: Enhanced YOLOv7-Based UAV Detection for Sustainable Transportation in Cities and Communities


Department of Electronic Engineering, National Taipei University of Technology, Taipei City 10608, Taiwan
*
Author to whom correspondence should be addressed.
Urban Sci. 2023, 7(4), 108; https://doi.org/10.3390/urbansci7040108
Submission received: 3 August 2023
/
Revised: 27 September 2023
/
Accepted: 12 October 2023
/
Published: 17 October 2023
Abstract
:Environmental, social, and governance issues have gained significant prominence recently, particularly with a growing emphasis on environmental protection. In the realm of heightened environmental concerns, unmanned aerial vehicles have emerged as pivotal assets in addressing transportation challenges with a sustainable perspective. This study focuses on enhancing unmanned aerial vehicles’ object detection proficiency within the realm of sustainable transportation. The proposed method refines the YOLOv7 E-ELAN model, tailored explicitly for traffic scenarios. Leveraging strides in deep learning and computer vision, the adapted model demonstrates enhancements in mean average precision, outperforming the original on the VisDrone2019 dataset. This approach, encompassing model component enhancements and refined loss functions, establishes an efficacious strategy for precise unmanned aerial vehicles object detection. This endeavor aligns seamlessly with environmental, social, and governance principles. Moreover, it contributes to the 11th Sustainable Development Goal by fostering secure urban spaces. As unmanned aerial vehicles have become integral to public safety and surveillance, enhancing detection algorithms cultivates safer environments for residents. Sustainable transport encompasses curbing traffic congestion and optimizing transportation systems, where unmanned aerial vehicle-based detection plays a pivotal role in managing traffic flow, thereby supporting extended Sustainable Development Goal 11 objectives. The efficient utilization of unmanned aerial vehicles in public transit significantly aids in reducing carbon footprints, corresponding to the “Environmental Sustainability” facet of Environmental, Social, and Governance principles.
1. Introduction
With the increasing prominence of environmental protection, energy conservation, and carbon reduction issues [1,2], ensuring sustainable transportation [3,4] has become a critical and challenging goal. This issue is gaining more and more social attention, as environmental, social, governance (ESG) [5,6] assessments of companies’ data and indicators are being given greater importance. Among the elements discussed, the significance of the “Environment” aligns closely with the United Nations’ 2030 Agenda for sustainable development, with its 17 sustainable development goals (SDGs) [7,8,9,10,11], which concentrate on fostering “Sustainable Cities and Communities”. One key aspiration within this overarching aim is to establish an accessible, affordable, and secure transportation system that can cater to the needs of all individuals by 2030, while simultaneously enhancing road safety measures. Special emphasis is dedicated to addressing the requirements of marginalized communities, including children, women, individuals facing mobility challenges, and the elderly. This will be achieved through the expansion of public transportation services, thoughtfully tailored to meet their specific demands.
Given these challenges, the research aims to address sustainable transport [12] objectives by utilizing unmanned aerial vehicles (UAVs) [13,14,15,16,17,18,19] in conjunction with Object Detection technology [20,21,22,23,24,25,26,27] to achieve real-time traffic monitoring. By leveraging the high maneuverability of UAVs and the precision of object detection, the goal is to effectively monitor traffic conditions and provide valuable traffic information to optimize traffic flow, improve road safety, and enhance the efficiency and accessibility of public transportation. Through this study, the aspiration is to contribute significantly to the realization of sustainable urban transport, while fostering advancements and innovations in future transportation systems. UAVs have demonstrated their extensive utilization in diverse fields, including digital cities [28], smart agriculture [13,29], public safety [30], forestry [31], and disaster inspection [32], highlighting the versatility and potential of UAV technology in addressing critical challenges. Furthermore, the application of UAVs extends to crucial areas such as road damage detection, which plays a pivotal role in ensuring transportation safety and contributing to the establishment of a sustainable transportation system [33]. Simultaneously, the rapid progress of artificial intelligence, particularly in object detection, has underscored the importance of leveraging these techniques in practical applications. With the advancement of drone technology, UAVs are increasingly deployed in challenging environments, where direct human involvement may be limited or risky. Consequently, there is a growing need for effective interpretation of the visual data collected by UAV platforms, and deep learning-based object detection methods have emerged as a promising approach to address this demand and meet the evolving requirements of UAV-based operations.
However, object detection in UAV operations poses significant challenges, including real-time processing, accurate detection of small objects, high-altitude flights, dense clusters of small objects, and complex background noise. Overcoming these hurdles requires advanced methodologies that can handle computational demands within strict time constraints. Enhancing small object detection accuracy and addressing scale challenges in aerial images are essential goals for optimizing the efficiency and effectiveness of UAV operations. In recent times, substantial strides have been achieved in the domain of deep learning, with specific focus on the advancements in convolutional neural networks (CNNs). The significant advancements in this field have been instrumental in addressing the unique obstacles associated with detecting objects in imagery obtained from UAVs. The algorithms pertaining to this area can be divided into two primary categories: single and two-stage detection models. These approaches represent the main methodologies employed for object detection in UAV applications, highlighting the diverse techniques used to overcome detection challenges in this field. Two-Stage Detection involves extracting candidate boxes from the image and refining detection results based on these regions. Although this approach achieves high detection accuracy, it suffers from slower processing speed. Some of the algorithms falling within this category are Faster R-CNN [34], R-CNN [35], Fast R-CNN [36], feature pyramid network (FPN) [37], and Mask RCNN [38]. Single-Stage Detection algorithms directly compute detection results on the entire image, offering faster processing, but potentially sacrificing some detection accuracy. The pioneering algorithm in this category is you only look once (YOLO) [39], which demonstrates all-around performance in detecting UAV images. However, despite its implementation, the prediction accuracy remains notably inferior in comparison to two-stage detection methods. Additional prominent algorithms falling within this category comprise YOLO, Retinanet [40], and CenterNet [41].
The objective of this study is to enhance the YOLOv7 [42] model and improve its detection performance in UAV applications to promote sustainable transport, as depicted in Figure 1. The expectation is that this research will contribute to the development of future urban transportation systems and environmental conservation through the integration of drone technology and object detection. Figure 2 illustrates the prominent enhancement of safety achieved through the integration of unmanned aerial vehicles (UAVs) in the domains of public safety and surveillance. This integration aligns aptly with the objectives outlined in SDG 11, which focuses specifically on the concept of “Safe Cities.” By refining the algorithms employed for UAV detection, the potential to establish a more secure urban environment for both residents and visitors is significantly heightened. Additionally, the optimization of traffic management and efficiency, integral components of sustainable transportation strategies, corresponds well with the aims of reducing traffic congestion and improving transportation systems. The strategic implementation of UAV detection plays a pivotal role in orchestrating traffic flow, thus providing substantial support in realizing the overarching objectives of SDG 11, particularly those related to expanding public transportation. Moreover, the ripple effect of efficient UAV utilization reverberates through its direct influence on reducing carbon footprints, harmonizing well with the “Environmental Sustainability” facet deeply embedded within ESG principles.
2. Related Work
The YOLO series, namely you only look once version 3 (YOLOv3) [43] and you only look once version 5 (YOLOv5). YOLOv3 represents a significant milestone in the development of the YOLO series of object detection algorithms. It was introduced in 2018 by Joseph Redmon and Ali Farhadi, building upon the success of you only look once version 1 (YOLOv1) [39] and you only look once version 2 (YOLOv2). YOLOv3 sought to address some of the limitations observed in its predecessors while further improving the detection accuracy and speed. One of the main innovations of YOLOv3 was the introduction of multiple detection scales. While YOLOv1 and YOLOv2 used a single scale to predict bounding boxes, YOLOv3 incorporated three different scales at different layers of its deep neural network. This multi-scale approach allowed the model to detect objects of various sizes more effectively. Additionally, YOLOv3 used a technique similar to a feature pyramid network, which helped capture more contextual information and improved the detection of small objects by adding more convolution layers. YOLOv3 also introduced various architectural changes. It adopted a Darknet-53 architecture, consisting of 53 convolutional layers, which contributed to its improved accuracy. The author stated that Darknet-53 operates faster than both ResNet-101 and ResNet-152 due to the fact that ResNet contains too many layers, resulting in slower speed. In addition to the standard YOLOv3 model, the authors proposed additional versions: YOLOv3-tiny and YOLOv3-SPP. YOLOv3-tiny was a simplified variant with fewer layers, optimized for faster inference on resource-constrained devices. On the other hand, YOLOv3-spatial pyramid pooling (YOLOv3-SPP) utilized spatial pyramid pooling to capture multi-scale features efficiently, leading to improved performance. While YOLOv3 demonstrated significant progress in object detection, another branch of the YOLO family emerged in the form of YOLOv5. In 2020, Glenn Jocher introduced YOLOv5 with the motivation to create a more accessible and easy-to-use framework for the object detection community. YOLOv5 adopted a single model size, focusing on simplicity, and relied on transfer learning. It provided multiple pre-trained models such as YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x with varying sizes and complexities to suit different deployment scenarios. Both YOLOv3 and YOLOv5 represent critical milestones in the evolution of object detection algorithms. YOLOv3 introduced multiple detection scales, FPN-like, and Darknet-53 architecture to enhance accuracy. Meanwhile, YOLOv5 brought simplicity, transfer learning, and PyTorch compatibility.
3. Materials and Methods
The experimental setup for this study was conducted on a configured system. The hardware configuration of this system includes an Intel(R) Xeon(R) Silver 4210 CPU @ 2.20 GHz as the CPU and an NVIDIA RTX A2000 12 GB as the GPU. The operating system used was Ubuntu 22.04.2 LTS, with Python version 3.9.16 and Pytorch version 2.0.1. The experiments were conducted within the conda 23.3.1 environment of Anaconda.
In the context of this research, significant attention is directed towards ESG principles, with a particular focus on the 11th sustainable development goal of the United Nations, which aims to create “Sustainable Cities and Communities.” To enhance the capabilities and accuracy of UAVs in ground target detection, the research specifically selected the Visdrone2019 dataset [44,45] as the training foundation. The Visdrone2019 dataset contains 6471 training images, 548 validation images, and 1610 test images, totaling 8629 images in all three sets. Compared to other common datasets, the Visdrone2019 dataset exhibits unique characteristics in several key aspects, making it an ideal training dataset. One significant difference is that each image in the Visdrone2019 dataset contains a large number of annotated bounding boxes for targets, and these bounding boxes often overlap. This feature simulates the challenges faced by actual UAVs during flight missions, where accurate identification and differentiation of densely distributed ground targets are necessary. Such complex and multi-target scenarios make the Visdrone2019 dataset highly challenging, contributing to the training of ground target detection models with improved robustness and high accuracy.
Regarding the Evaluation Metrics, the chosen metrics are precision, recall, and mean average precision (mAP). Precision measures the accuracy of positive predictions made by the object detection model. It calculates the ratio of correctly detected instances to the total instances predicted as positive. In the context of UAV object recognition, precision is crucial because it indicates how reliable the model is in identifying objects accurately. A high precision ensures that the model minimizes false positives [46], reducing the risk of misclassifying unrelated objects as the target ones. This is particularly important in UAV applications, where false positives could lead to unnecessary actions or resource allocation. Precision is calculated by dividing the number of true positive detections by the total number of positive detections (true positives + false positives). A higher precision score indicates better accuracy in detecting true positives while minimizing false positives, making it an essential metric when analyzing the performance of object detection models.
Recall, often referred to as sensitivity or true positive rate, evaluates the object detection model’s capacity to identify all occurrences of the specified target objects within the Visdrone2019 dataset. It calculates the ratio of correctly detected instances to the total actual instances of the target objects. In UAV object recognition, high recall is essential because it indicates the model’s ability to avoid false negatives [47]. Missing relevant objects during detection could have severe consequences in UAV scenarios, where identifying and tracking objects accurately is vital for decision-making and safety. Recall represents the fraction of true positive detections with respect to the total number of actual positive instances (true positives + false negatives). A higher recall score signifies that the model can effectively detect a higher proportion of the target objects present in the dataset, reducing the risk of overlooking important objects during UAV missions. The mAP is a fundamental and critical metric used to evaluate how well object detection models perform, particularly on challenging datasets like VisDrone2019, which encompasses 10 distinct object categories. This metric provides a comprehensive evaluation by calculating the average precision for each category and then computing their mean, giving us a holistic measure of the model’s effectiveness. In UAV applications, where drones navigate through diverse and complex environments, achieving a high mAP score becomes even more crucial. A higher mAP score signifies that the object detection model performs admirably across various object categories, showcasing its robustness and versatility. This capability is especially valuable for UAVs as they encounter a wide array of objects in real-world scenarios, ranging from pedestrians and vehicles to buildings and other obstacles. By optimizing the mAP score, we ensure that the object detection model can handle the challenges posed by different object types, varying sizes, occlusions, and environmental conditions commonly encountered during drone missions.
For the target detection model, YOLOv7 was chosen as the approach. In YOLOv7 object detection, key modules play specific roles in enhancing the efficiency and accuracy of the algorithm. The Convolution-Batchnorm-SiLU (CBS) [48] module combines convolutional layers with batch normalization and the SiLU activation function to improve feature extraction. The Max Pooling (MP) module downsamples feature maps while preserving essential details, helping maintain a balance between resolution and computational efficiency. The Concatenation (Concat) module merges feature maps from different scales, enabling the network to effectively capture objects of varying sizes by fusing information from different stages. The upsample module increases spatial resolution, facilitating better integration of feature maps. The SPPCSP module enhances feature information and detection performance. It is based on the SPP module, utilizing pyramid pooling and CSP structure to effectively capture target information at different scales. RepConv is another key structure in YOLOv7, used for auxiliary training. It resembles ResNet but incorporates a 1 × 1 filter and avoids identity connections to prevent their occurrence when replacing re-parameterized convolutions [49]. The use of RepConv contributes to enhanced model performance and training effectiveness.YOLOv7 is an evolved version of YOLOv5 [50] version 5.0, where the authors introduced extended and scaling methods to optimize model parameters and computational usage. This improvement aims to optimize the “bag-of-freebies” method in YOLOv4 [51,52], which increases training costs to improve accuracy without increasing inference costs. To improve the model’s efficacy, the authors employed advanced parameterization methods, replacing the original modules with more optimized alternatives in YOLOv7 and applied dynamic label assignment strategies to more effectively assign labels to different output layers. The application of these strategies significantly enhances the model’s learning performance, making YOLOv7 a more powerful and efficient target detection algorithm. YOLOv7 belongs to the single-stage target detection approach. Figure 3 presents the structure of YOLOv7. The model proposes the extended ELAN (E-ELAN) [42] method, which utilizes techniques like expand cardinality, shuffle cardinality, and merge cardinality to enhance the network’s learning capacity while preserving the original gradient pathway state to ensure functionality. YOLOv7 employs four ELAN1 modules for primary feature extraction. The neck section adopts the feature pyramid structure of YOLOv7, comprising one SPPCSPC module and four ELAN2 modules for feature extraction, with the three ELAN2 modules directly outputting to the head section [53]. The YOLOv7 Network mainly extracts image features through the backbone’s MP and E-ELAN structures and its architecture is depicted in Figure 3. The YOLOv7 authors assert that through the management of both the shortest and longest gradient pathways, deeper networks can significantly improve their learning and convergence performance, leading to the extension of E-ELAN. This insight is crucial in the YOLOv7 architecture, as optimizing the gradient pathway allows the model to better learn image features, improving target accuracy and detection performance. This control of the gradient pathway becomes one of the key features of YOLOv7 and is essential to its outstanding performance in target detection tasks. This study further optimized E-ELAN, making it deeper.
In this study, improvements have been conducted on YOLOv7, and a novel model has been proposed, as illustrated in Figure 4. The original E-ELAN1 and E-ELAN2 in the YOLOv7 architecture have been replaced with the proposed CBAM Ghost Convolution-extended ELAN (CGE-ELAN).
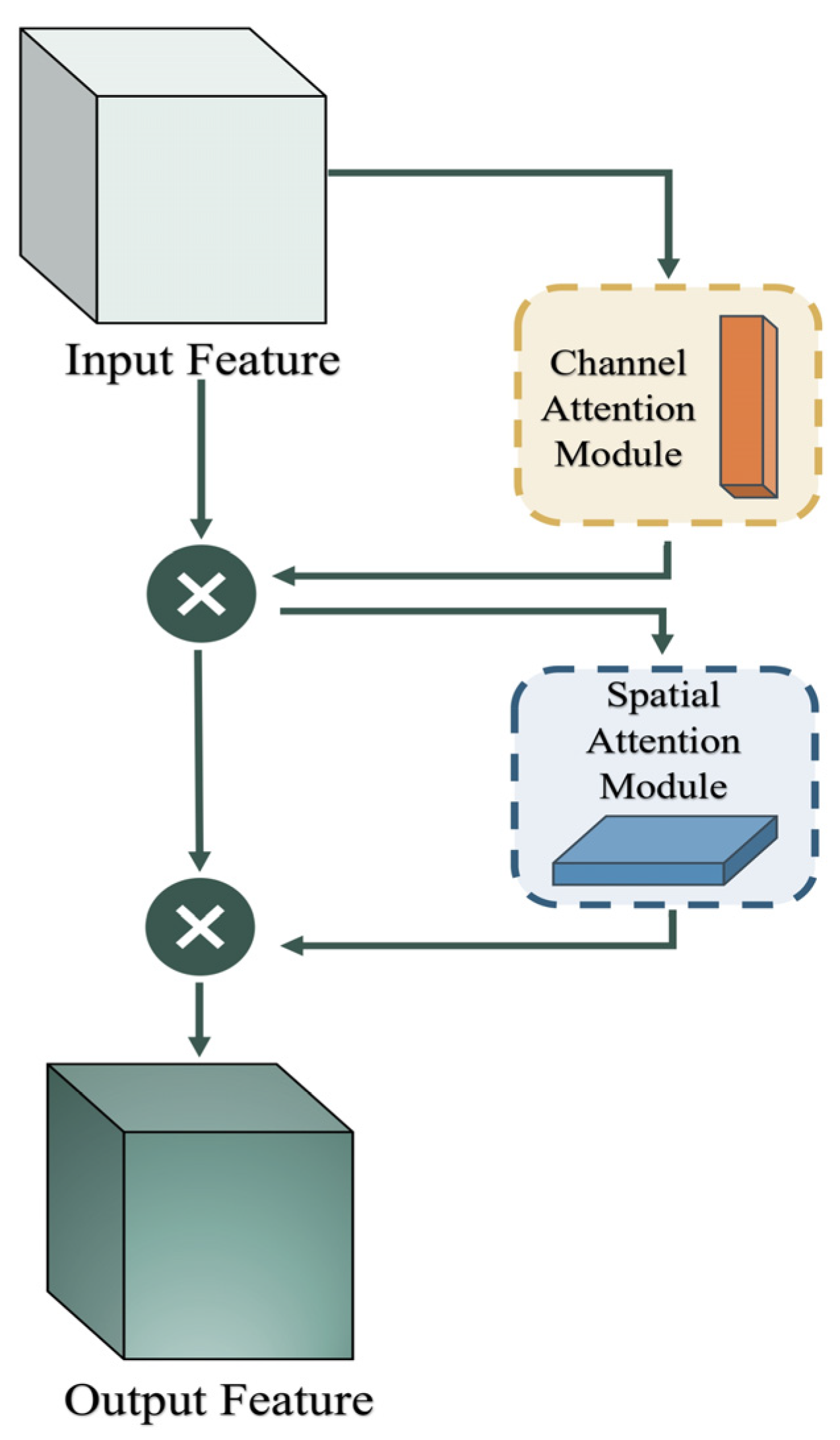
This model incorporates the convolutional block attention module (CBAM) [54,55,56], as depicted in Figure 5, which is a lightweight attention mechanism comprising spatial attention and channel attention modules [55], facilitating attention learning in both channel and spatial dimensions.
The main purpose of the channel attention mechanism [57] is to discern and handle vital characteristics crucial for particular tasks. It enhances these important features through weighted operations, thereby augmenting the model’s ability to process input images. This mechanism enables the model to learn more effectively, emphasizing task-relevant features while suppressing irrelevant ones, optimizing the overall feature extraction process.
The key function of the spatial focus mechanism is to generate attention maps by capturing the interactions between different spatial features. Unlike channel attention, spatial attention focuses on recognizing which locations contain valuable information and provides complementary information to channel attention. The process of computing spatial attention involves conducting initial pooling operations along the channel axis of the feature map, which includes both average pooling and max pooling operations. Subsequently, these results are combined to form an effective feature descriptor. This channel-wise pooling operation has been proven effective in highlighting regions with informative content. Subsequently, the concatenated feature descriptor undergoes convolutional operations to generate the spatial attention map. These improvements empower the proposed model to be more robust and efficient in handling image tasks.
After feature extraction with CBAM, a set of ghost convolution modules [58,59] was introduced. The ghost convolution module consists of two steps aimed at obtaining the same number of feature maps as regular convolutions. Firstly, a small number of convolution operations are performed, for instance, reducing the number of regular convolutions by half. Following that, a set of cost-effective operations, comprising a sequence of linear transformations, are employed to produce multiple feature maps that adeptly uncover the underlying information encoded within the features. This design allows the ghost module to reduce computational costs while efficiently extracting intrinsic features, maintaining the same number of features as regular convolutions, and enabling the model to possess rich feature representation capabilities with fewer parameters and computational overhead.
In comparison to the conventional CBS Module, the ghost convolution module differs significantly by excluding the batch normalization layer and SiLU activation function. This distinction sets the ghost convolution module apart in terms of its architecture and computation process. This design avoids the traditional convolution feature extraction approach and leverages a lighter burden to extract image features, as illustrated in Figure 6.
The effectiveness of deep learning models heavily relies on the selection of an appropriate loss function, as it serves as a critical metric to quantify the disparity between the model’s predicted values and the true ground truth. Regarding object detection algorithms, the significance of the loss function is amplified, as it directly influences the training process of model parameters, thus influencing the model’s capacity to precisely detect and locate objects in images. Therefore, the careful consideration and optimization of the loss function are essential to achieve optimal performance and robustness in object detection tasks.
In YOLOv7, traditional object detection loss functions, such as complete IoU (CIoU) [60], were introduced. These loss functions consider the aspect ratio of predicted bounding boxes, but do not account for the vector angle matching during the regression process, i.e., the potential mismatch in orientation between predicted and ground truth boxes. This mismatch may cause drifting of predicted boxes during training, leading to a decrease in the training speed and efficiency.
To address this concern, substantial improvements have been undertaken to the original bounding box loss function, known as CIoU in YOLOv7. As part of the efforts, the CIoU loss function has been replaced with the more advanced and refined SCYLLA-IoU (SIoU) [61,62]. These modifications are aimed at further refining the model’s capability to precisely identify the location of objects, optimize the bounding box regression, and enhance the overall object detection performance. By leveraging the strengths of the SIoU loss function, it is anticipated that superior results and robustness will be achieved in the object detection framework, which will be instrumental in advancing the capabilities of YOLOv7. The SIoU loss function comprises four distinct cost components: the Distance cost, Angle cost, Shape cost, and IoU cost. By incorporating vector angle considerations during regression, the penalty term has been redefined to enable more precise bounding box adjustments. The SIoU loss function represents a refined and comprehensive approach, offering a more sophisticated and effective means of handling bounding box regression, which, in turn, improves the model’s precision in object localization and significantly enhances the overall object detection performance in the framework. Through the introduction of directionality in the loss function, it was possible to enhance the detection algorithm’s performance in terms of precision and robustness during both training and inference. The adaptation to SIoU has proven to be instrumental in achieving more precise predictions of target box positions and orientations, leading to an overall enhancement in the object detection algorithm. The formulation of SIoU is as follows.
4. Results
This study is primarily focused on UAV detection tasks, where the VisDrone2019 dataset is employed as the benchmark to conduct a comprehensive analysis and comparison of various object detection methods, including YOLOv3, YOLOv5, the original YOLOv7, and the proposed method. The main objective of this comprehensive experimentation is to enhance both the precision and efficiency of object detection to fulfill the specific application demands of UAVs in critical tasks such as surveillance, search, and rescue missions.
Presented in Table 1 are the experimental findings, revealing significant advantages of the proposed method when assessed against multiple evaluation metrics. In comparison to the other methods, the proposed approach achieves an impressive Precision of 0.592, Recall of 0.481, and an outstanding mean average precision at IoU threshold 0.5 (mAP50) value of 0.490, surpassing the performance of YOLOv3, YOLOv5, and even the original YOLOv7. There is a marginal yet distinct 1% improvement in mAP50 when compared to the original YOLOv7, underscoring the incremental progress and enhanced object detection accuracy achieved by the proposed method. These results underscore the advancements the proposed method brings to the field of object detection, especially when it comes to the implementation of UAVs.
In this study, enhancements and optimizations have been undertaken by the YOLOv7 architecture. By integrating the ghost convolution module to enhance the depth of E-ELAN and incorporating the CBAM module to achieve lightweight attention concentration, the model’s capability to effectively recognize and discern objects in complex scenes has been successfully bolstered. The utilization of these advanced modules has proven to be instrumental in achieving higher accuracy, particularly in detecting small and overlapping objects in aerial scenarios, as illustrated in Figure 7. Such a capability is of utmost importance for drones, enabling them to precisely identify targets during high-altitude surveillance missions, where accuracy and precision are of critical significance. The improved object recognition performance, demonstrated by the proposed method, opens up new possibilities for utilizing UAVs in a wide array of scenarios, including surveillance and reconnaissance, as well as search and rescue missions. In such situations, the ability to accurately detect objects in complex environments is paramount. These findings highlight the contributions of the research in advancing the capabilities and applicability of object detection methods in UAV-based scenarios.
However, it must also be acknowledged that during aerial photography, certain similar objects can still be easily confused, such as motorcycles and bicycles, as evident in Figure 8′s confusion matrix. Recognizing this as a common challenge faced in target detection, efforts will continue to be made in future research to improve upon it.
Moreover, the incorporation of CBAM modules and GhostConv modules to enhance the model’s performance comes at a trade-off. While these improvements bring benefits, they also affect the Frames Per Second (FPS), leading to a reduction in overall performance. The attention mechanism within the CBAM module and the convolution operations within the GhostConv module introduce heightened complexity to the model, resulting in amplified computational demands during runtime. The ability to detect objects promptly while UAVs are airborne holds significant implications for mission success, situational awareness, and decision-making processes. Achieving this balance between performance gains and computational efficiency remains a pivotal goal for ongoing work in this field.
5. Conclusions
The suggested approach exhibits the capability to improve UAV detection tasks. Utilizing the VisDrone2019 dataset by successfully enhancing detection accuracy through the incorporation of CBAM attention modules and ghost convolution modules onto the E-ELAN module, contributes to the broader landscape of UAV technology. The proposed method has been extensively tested and analyzed, confirming its advantages in three key evaluation metrics: precision, recall, and mAP50. This enhancement in detection accuracy and efficiency holds practical significance in various UAV applications.
The conducted experiment illustrates the effective improvement in the detection accuracy of small objects achieved by the proposed method. Through an in-depth analysis, it overcomes the detection misjudgment issues faced by YOLO when dealing with such objects. Comparisons with the original versions of YOLOv3, YOLOv5, and YOLOv7 validate that the proposed method surpasses the performance of these existing methods. Notably, the mAP50 shows an increase compared to the original YOLOv7.
In the future, efforts will be continued to enhance the proposed method’s accuracy and speed in ground object detection, contributing further to ESG environment and SDG goal 11, “Sustainable Cities and Communities,” and facilitating UAVs’ greater assistance in environmental sustainability. This research achievement helps drive the progress of UAV technology across various application domains and provides robust support for future UAV applications in urban planning, resource monitoring, and other areas.
Author Contributions
Conceptualization, M.-A.C. and T.-H.W.; methodology, M.-A.C. and T.-H.W.; software, M.-A.C. and T.-H.W.; validation, M.-A.C., T.-H.W. and C.-W.L.; formal analysis, M.-A.C., T.-H.W. and C.-W.L.; investigation, T.-H.W. and C.-W.L.; resources, M.-A.C., T.-H.W. and C.-W.L.; writing—original draft preparation, T.-H.W. and C.-W.L.; writing—review and editing, M.-A.C.; visualization, M.-A.C. and T.-H.W.; supervision, M.-A.C.; project administration, M.-A.C.; funding acquisition, M.-A.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset utilized in this study is openly accessible in The Vision Meets Drone Object Detection in Video Challenge Results (VisDrone-VID2019) at https://github.com/VisDrone/VisDrone-Dataset, as of 29 May 2023.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Alandejani, M.; Al-Shaer, H. Macro Uncertainty Impacts on ESG Performance and Carbon Emission Reduction Targets. Sustainability 2023, 15, 4249. [Google Scholar] [CrossRef]
- Baratta, A.; Cimino, A.; Longo, F.; Solina, V.; Verteramo, S. The Impact of ESG Practices in Industry with a Focus on Carbon Emissions: Insights and Future Perspectives. Sustainability 2023, 15, 6685. [Google Scholar] [CrossRef]
- De La Torre, R.; Corlu, C.G.; Faulin, J.; Onggo, B.S.; Juan, A.A. Simulation, Optimization, and Machine Learning in Sustainable Transportation Systems: Models and Applications. Sustainability 2021, 13, 1551. [Google Scholar] [CrossRef]
- Bamwesigye, D.; Hlavackova, P. Analysis of Sustainable Transport for Smart Cities. Sustainability 2019, 11, 2140. [Google Scholar] [CrossRef]
- Kostrzewski, M.; Marczewska, M.; Uden, L. The Internet of Vehicles and Sustainability—Reflections on Environmental, Social, and Corporate Governance. Energies 2023, 16, 3208. [Google Scholar] [CrossRef]
- Barykin, S.; Strimovskaya, A.; Sergeev, S.; Borisoglebskaya, L.; Dedyukhina, N.; Sklyarov, I.; Sklyarova, J.; Saychenko, L. Smart City Logistics on the Basis of Digital Tools for ESG Goals Achievement. Sustainability 2023, 15, 5507. [Google Scholar] [CrossRef]
- Bartniczak, B.; Raszkowski, A. Implementation of the Sustainable Cities and Communities Sustainable Development Goal (SDG) in the European Union. Sustainability 2022, 14, 16808. [Google Scholar] [CrossRef]
- Kalfas, D.; Kalogiannidis, S.; Chatzitheodoridis, F.; Toska, E. Urbanization and Land Use Planning for Achieving the Sustainable Development Goals (SDGs): A Case Study of Greece. Urban Sci. 2023, 7, 43. [Google Scholar] [CrossRef]
- Terama, E.; Peltomaa, J.; Mattinen-Yuryev, M.; Nissinen, A. Urban Sustainability and the SDGs: A Nordic Perspective and Opportunity for Integration. Urban Sci. 2019, 3, 69. [Google Scholar] [CrossRef]
- Weymouth, R.; Hartz-Karp, J. Principles for Integrating the Implementation of the Sustainable Development Goals in Cities. Urban Sci. 2018, 2, 77. [Google Scholar] [CrossRef]
- Lobner, N.; Seixas, P.C.; Dias, R.C.; Vidal, D.G. Urban Compactivity Models: Screening City Trends for the Urgency of Social and Environmental Sustainability. Urban Sci. 2021, 5, 83. [Google Scholar] [CrossRef]
- Moslem, S.; Duleba, S. Sustainable Urban Transport Development by Applying a Fuzzy-AHP Model: A Case Study from Mersin, Turkey. Urban Sci. 2019, 3, 55. [Google Scholar] [CrossRef]
- Tsouros, D.C.; Bibi, S.; Sarigiannidis, P.G. A Review on UAV-Based Applications for Precision Agriculture. Information 2019, 10, 349. [Google Scholar] [CrossRef]
- Gupta, A.; Afrin, T.; Scully, E.; Yodo, N. Advances of UAVs toward Future Transportation: The State-of-the-Art, Challenges, and Opportunities. Future Transp. 2021, 1, 326–350. [Google Scholar] [CrossRef]
- Butilă, E.V.; Boboc, R.G. Urban Traffic Monitoring and Analysis Using Unmanned Aerial Vehicles (UAVs): A Systematic Literature Review. Remote Sens. 2022, 14, 620. [Google Scholar] [CrossRef]
- Liu, Z.; Gao, X.; Wan, Y.; Wang, J.; Lyu, H. An Improved YOLOv5 Method for Small Object Detection in UAV Capture Scenes. IEEE Access 2023, 11, 14365–14374. [Google Scholar] [CrossRef]
- Wang, Y.; Feng, W.; Jiang, K.; Li, Q.; Lv, R.; Tu, J. Real-Time Damaged Building Region Detection Based on Improved YOLOv5s and Embedded System From UAV Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4205–4217. [Google Scholar] [CrossRef]
- Robakowska, M.; Ślęzak, D.; Żuratyński, P.; Tyrańska-Fobke, A.; Robakowski, P.; Prędkiewicz, P.; Zorena, K. Possibilities of Using UAVs in Pre-Hospital Security for Medical Emergencies. Int. J. Environ. Res. Public Health 2022, 19, 10754. [Google Scholar] [CrossRef]
- Raheem, D.; Dayoub, M.; Birech, R.; Nakiyemba, A. The Contribution of Cereal Grains to Food Security and Sustainability in Africa: Potential Application of UAV in Ghana, Nigeria, Uganda, and Namibia. Urban Sci. 2021, 5, 8. [Google Scholar] [CrossRef]
- Jin, R.; Lv, J.; Li, B.; Ye, J.; Lin, D. Toward Efficient Object Detection in Aerial Images Using Extreme Scale Metric Learning. IEEE Access 2021, 9, 56214–56227. [Google Scholar] [CrossRef]
- Li, M.; Zhao, X.; Li, J.; Nan, L. ComNet: Combinational Neural Network for Object Detection in UAV-Borne Thermal Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 6662–6673. [Google Scholar] [CrossRef]
- Shao, Z.; Cheng, G.; Ma, J.; Wang, Z.; Wang, J.; Li, D. Real-Time and Accurate UAV Pedestrian Detection for Social Distancing Monitoring in COVID-19 Pandemic. IEEE Trans. Multimed. 2022, 24, 2069–2083. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.-Q.; Sun, P.; Li, D.; Piao, J.-C. A Novel Object Detection Method in City Aerial Image Based on Deformable Convolutional Networks. IEEE Access 2022, 10, 31455–31465. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, X.; Yu, B.; Hu, X.S.; Rowen, C.; Hu, J.; Shi, Y. DAC-SDC Low Power Object Detection Challenge for UAV Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 392–403. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Feng, Y.; Zhang, S.; Wang, N.; Mei, S. Finding Nonrigid Tiny Person With Densely Cropped and Local Attention Object Detector Networks in Low-Altitude Aerial Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4371–4385. [Google Scholar] [CrossRef]
- Karagulian, F.; Liberto, C.; Corazza, M.; Valenti, G.; Dumitru, A.; Nigro, M. Pedestrian Flows Characterization and Estimation with Computer Vision Techniques. Urban Sci. 2023, 7, 65. [Google Scholar] [CrossRef]
- Verma, D.; Jana, A.; Ramamritham, K. Quantifying Urban Surroundings Using Deep Learning Techniques: A New Proposal. Urban Sci. 2018, 2, 78. [Google Scholar] [CrossRef]
- Nguyen, D.D.; Rohacs, J.; Rohacs, D. Autonomous Flight Trajectory Control System for Drones in Smart City Traffic Management. ISPRS Int. J. Geo-Inf. 2021, 10, 338. [Google Scholar] [CrossRef]
- Veeranampalayam Sivakumar, A.N.; Li, J.; Scott, S.; Psota, E.; Jhala, A.J.; Luck, J.D.; Shi, Y. Comparison of Object Detection and Patch-Based Classification Deep Learning Models on Mid- to Late-Season Weed Detection in UAV Imagery. Remote Sens. 2020, 12, 2136. [Google Scholar] [CrossRef]
- Hildmann, H.; Kovacs, E. Review: Using Unmanned Aerial Vehicles (UAVs) as Mobile Sensing Platforms (MSPs) for Disaster Response, Civil Security and Public Safety. Drones 2019, 3, 59. [Google Scholar] [CrossRef]
- Mohan, M.; Silva, C.; Klauberg, C.; Jat, P.; Catts, G.; Cardil, A.; Hudak, A.; Dia, M. Individual Tree Detection from Unmanned Aerial Vehicle (UAV) Derived Canopy Height Model in an Open Canopy Mixed Conifer Forest. Forests 2017, 8, 340. [Google Scholar] [CrossRef]
- Alsamhi, S.H.; Shvetsov, A.V.; Kumar, S.; Shvetsova, S.V.; Alhartomi, M.A.; Hawbani, A.; Rajput, N.S.; Srivastava, S.; Saif, A.; Nyangaresi, V.O. UAV Computing-Assisted Search and Rescue Mission Framework for Disaster and Harsh Environment Mitigation. Drones 2022, 6, 154. [Google Scholar] [CrossRef]
- Silva, L.A.; Leithardt, V.R.Q.; Batista, V.F.L.; Villarrubia González, G.; De Paz Santana, J.F. Automated Road Damage Detection Using UAV Images and Deep Learning Techniques. IEEE Access 2023, 11, 62918–62931. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 8, 1–25. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26–27 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhu, P.; Wen, L.; Du, D.; Bian, X.; Fan, H.; Hu, Q.; Ling, H. Detection and Tracking Meet Drones Challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7380–7399. [Google Scholar] [CrossRef]
- Du, D.; Zhu, P.; Wen, L.; Bian, X.; Lin, H.; Hu, Q.; Peng, T.; Zheng, J.; Wang, X.; Zhang, Y. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 213–226. [Google Scholar]
- Character, L.; Ortiz Jr, A.; Beach, T.; Luzzadder-Beach, S. Archaeologic Machine Learning for Shipwreck Detection Using Lidar and Sonar. Remote Sens. 2021, 13, 1759. [Google Scholar] [CrossRef]
- Guth, S.; Sapsis, T.P. Machine Learning Predictors of Extreme Events Occurring in Complex Dynamical Systems. Entropy 2019, 21, 925. [Google Scholar] [CrossRef]
- Liu, K.; Sun, Q.; Sun, D.; Peng, L.; Yang, M.; Wang, N. Underwater Target Detection Based on Improved YOLOv7. J. Mar. Sci. Eng. 2023, 11, 677. [Google Scholar] [CrossRef]
- Gallo, I.; Rehman, A.U.; Dehkordi, R.H.; Landro, N.; La Grassa, R.; Boschetti, M. Deep Object Detection of Crop Weeds: Performance of YOLOv7 on a Real Case Dataset from UAV Images. Remote Sens. 2023, 15, 539. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D. Ultralytics/yolov5: v7. 0-YOLOv5 Sota Realtime Instance Segmentation. Zenodo 2022. Available online: https://ui.adsabs.harvard.edu/abs/2022zndo...7347926J/abstract, (accessed on 22 November 2022).
- Nepal, U.; Eslamiat, H. Comparing YOLOv3, YOLOv4 and YOLOv5 for autonomous landing spot detection in faulty UAVs. Sensors 2022, 22, 464. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Hong, Y. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Chen, J.; Bai, S.; Wan, G.; Li, Y. Research on YOLOv7-based defect detection method for automotive running lights. Syst. Sci. Control Eng. 2023, 11, 2185916. [Google Scholar] [CrossRef]
- Jiang, K.; Xie, T.; Yan, R.; Wen, X.; Li, D.; Jiang, H.; Jiang, N.; Feng, L.; Duan, X.; Wang, J. An attention mechanism-improved YOLOv7 object detection algorithm for hemp duck count estimation. Agriculture 2022, 12, 1659. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yan, Q.; Liu, H.; Zhang, J.; Sun, X.; Xiong, W.; Zou, M.; Xia, Y.; Xun, L. Cloud Detection of Remote Sensing Image Based on Multi-Scale Data and Dual-Channel Attention Mechanism. Remote Sens. 2022, 14, 3710. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Chen, J.; Liu, H.; Zhang, Y.; Zhang, D.; Ouyang, H.; Chen, X. A multiscale lightweight and efficient model based on YOLOv7: Applied to citrus orchard. Plants 2022, 11, 3260. [Google Scholar] [CrossRef]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J.; Li, X. A real-time detection algorithm for Kiwifruit defects based on YOLOv5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Xin, Z. Efficient detection model of steel strip surface defects based on YOLO-V7. IEEE Access 2022, 10, 133936–133944. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
Figure 1.
UAV aerial view of urban landscape aligned with ESG and SDG 11th goal-Sustainable Cities and Communities.
Figure 1.
UAV aerial view of urban landscape aligned with ESG and SDG 11th goal-Sustainable Cities and Communities.

Figure 2.
The benefits and contributions of optimizing drone detection align with ESG principles and SDGs, utilizing images from the VisDrone dataset.
Figure 2.
The benefits and contributions of optimizing drone detection align with ESG principles and SDGs, utilizing images from the VisDrone dataset.

Figure 3.
Schematic representation of the YOLOv7 network architecture.

Figure 4.
Schematic Representation of Enhanced YOLOv7 Network Architecture with CBAM Ghost Convolution extended ELAN (CGE-ELAN) replacing extended ELAN.
Figure 4.
Schematic Representation of Enhanced YOLOv7 Network Architecture with CBAM Ghost Convolution extended ELAN (CGE-ELAN) replacing extended ELAN.

Figure 5.
CBAM Module Structure.

Figure 6.
Ghost Convolution Module Structure.

Figure 7.
The detection outcomes of the proposed method on the VisDrone2019 dataset.

Figure 8.
Confusion matrix of the proposed method.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
The training results of various models.
| Method | Precision | Recall | mAP50 | mAP50-95 | FPS |
|---|---|---|---|---|---|
| YOLOv3 | 0.259 | 0.183 | 0.154 | 0.069 | 144.927 |
| YOLOv5 | 0.425 | 0.322 | 0.308 | 0.165 | 52.9 |
| YOLOv7 | 0.584 | 0.479 | 0.480 | 0.274 | 166 |
| Proposed Method | 0.592 | 0.481 | 0.490 | 0.28 | 45.04 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Chung, M.-A.; Wang, T.-H.; Lin, C.-W. Advancing ESG and SDGs Goal 11: Enhanced YOLOv7-Based UAV Detection for Sustainable Transportation in Cities and Communities. Urban Sci. 2023, 7, 108. https://doi.org/10.3390/urbansci7040108
AMA Style
Chung M-A, Wang T-H, Lin C-W. Advancing ESG and SDGs Goal 11: Enhanced YOLOv7-Based UAV Detection for Sustainable Transportation in Cities and Communities. Urban Science. 2023; 7(4):108. https://doi.org/10.3390/urbansci7040108
Chicago/Turabian StyleChung, Ming-An, Tze-Hsun Wang, and Chia-Wei Lin. 2023. "Advancing ESG and SDGs Goal 11: Enhanced YOLOv7-Based UAV Detection for Sustainable Transportation in Cities and Communities" Urban Science 7, no. 4: 108. https://doi.org/10.3390/urbansci7040108