Review of Deep Learning Methods in Robotic Grasp Detection


Abstract
1. Introduction
2. Background
- Grasp detection sub-system: To detect grasp poses from images of the objects in their image plane coordinates
- Grasp planning sub-system: To map the detected image plane coordinates to the world coordinates
- Control sub-system: To determine the inverse kinematics solution of the previous sub-system
- Create an application-specific CNN model
- Utilise a complete or part of a pre-existing CNN model through transfer learning
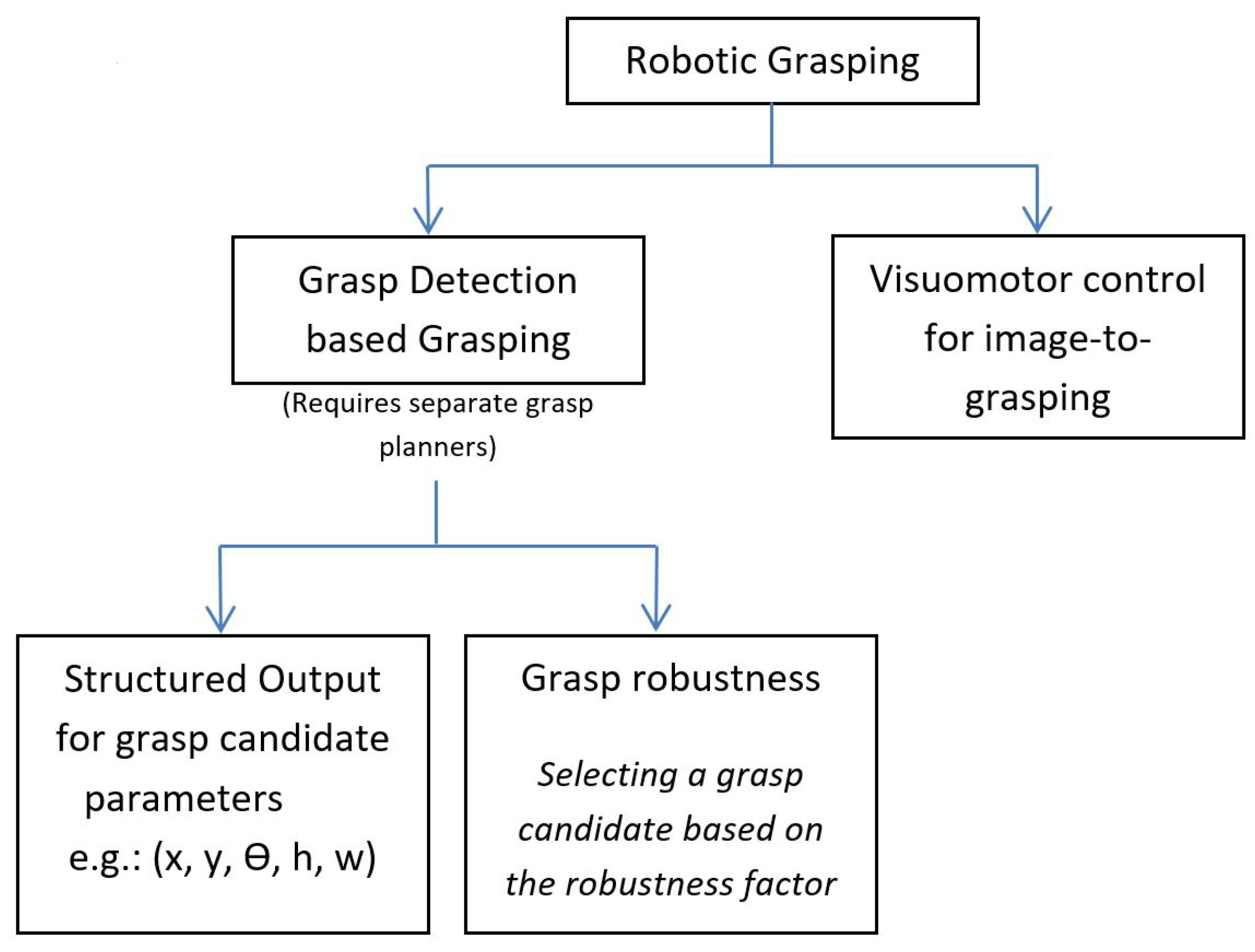
3. Robotic Grasp Detection
3.1. Grasp Representation
3.2. Grasp Detection
- Methods that use learning to detect grasps and use a separate planning system for grasp planning
- Methods that learn a visuomotor control policy in a direct image-to-action manner
4. Types and Availability of Training Data
4.1. Multi-Modal Data
4.2. Datasets
4.2.1. Pre-compiled datasets
4.2.2. Collected Datasets
4.2.3. Domain Adaptation and Simulated Data
4.2.4. Summary
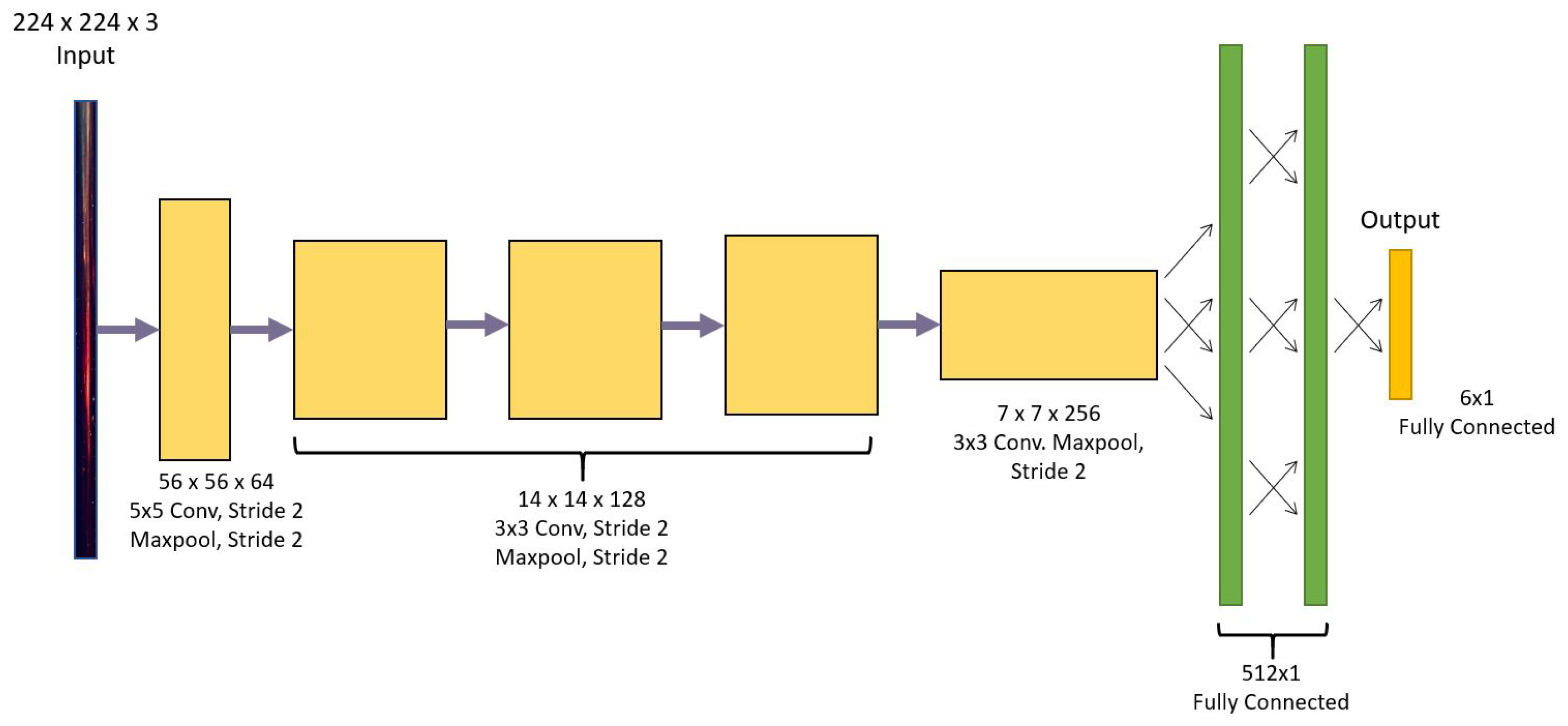
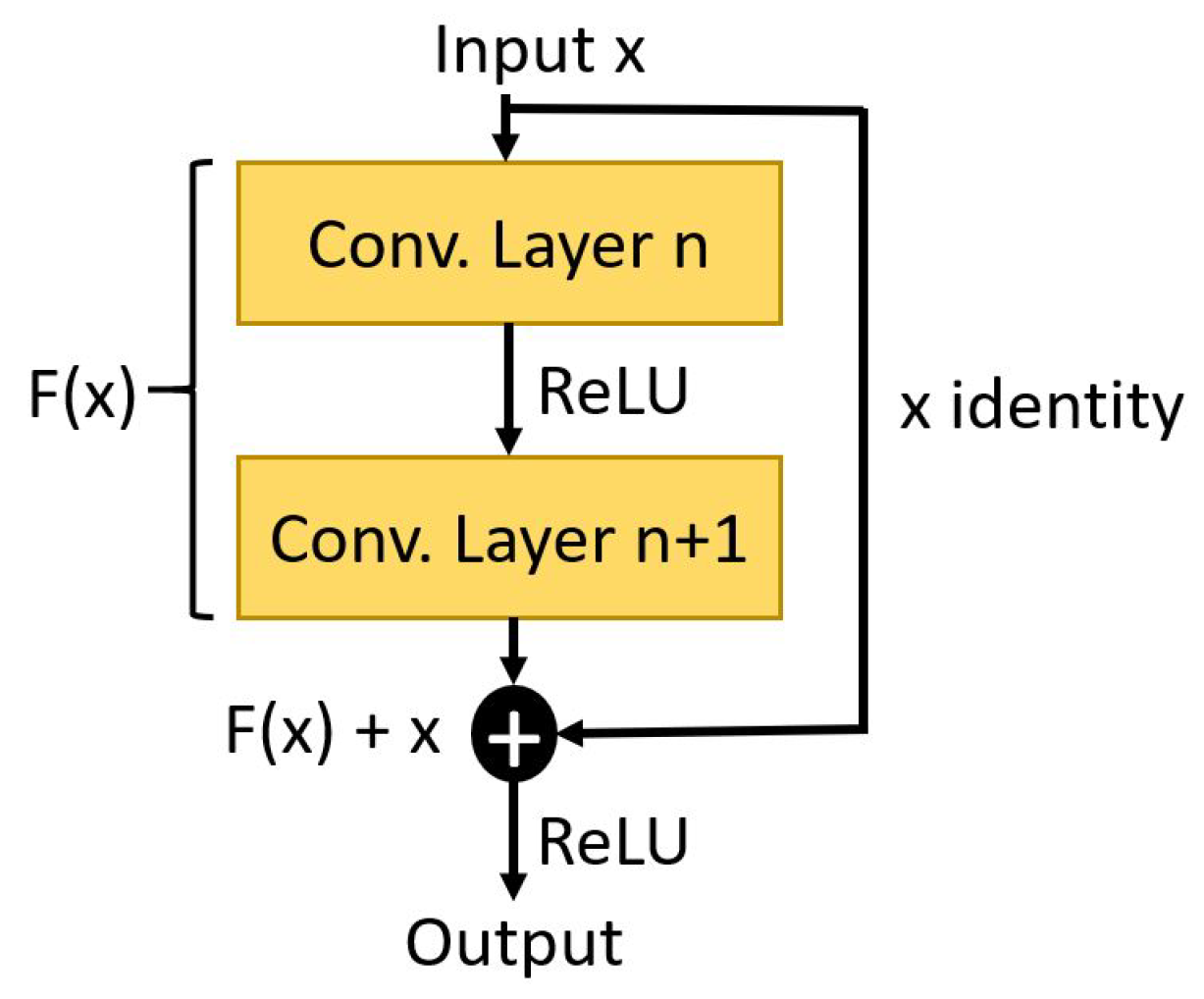
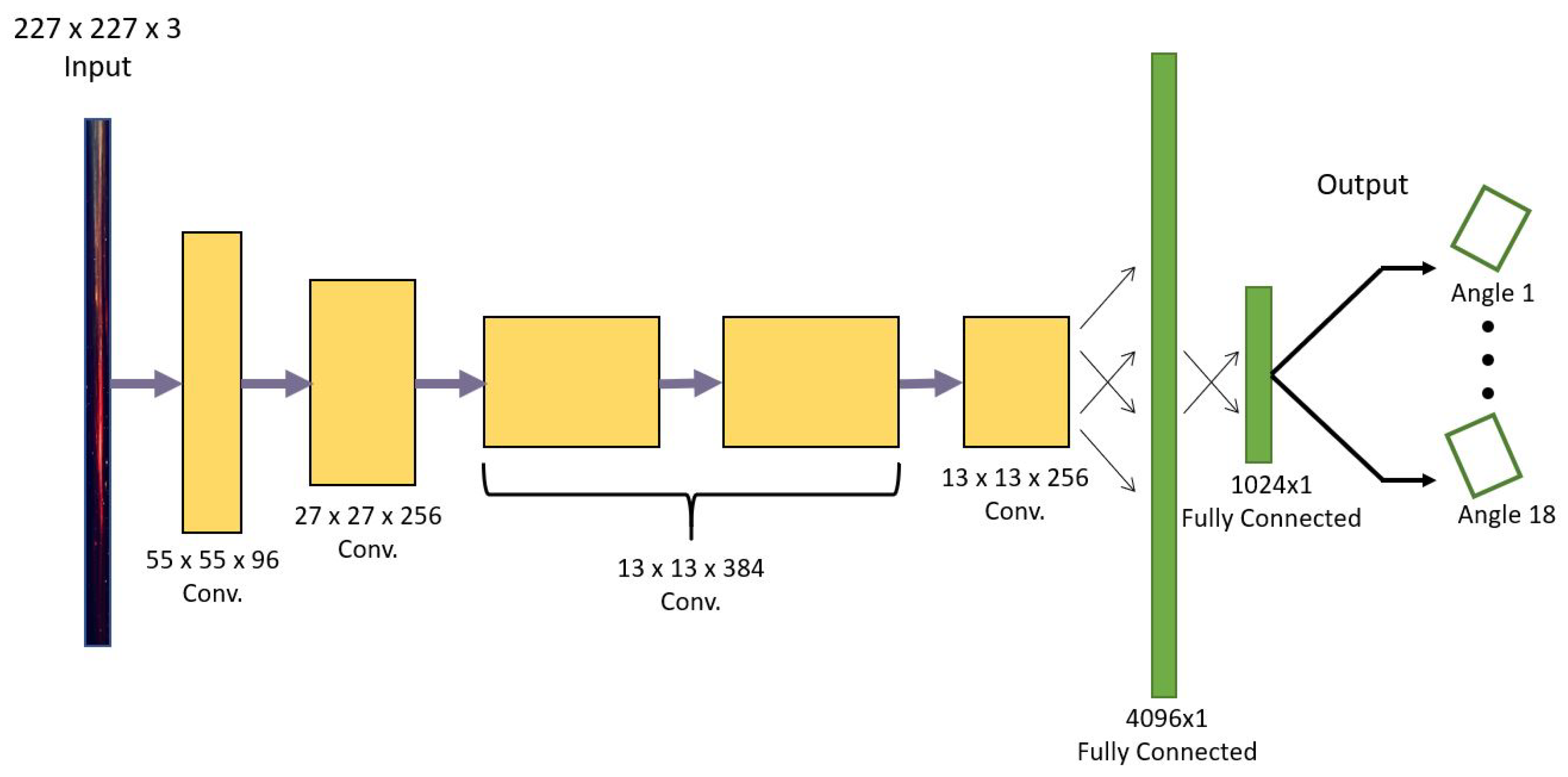
5. Convolutional Neural Networks for Grasp Detection
5.1. Architecture
- Larger datasets would result in increased features to be extracted while limited datasets would result in overfitting.
- Deeper networks would require increased computational resources during the training.
5.2. Transfer Learning Techniques
- Data pre-processing
- Pre-trained CNN model
5.3. Evaluation of Results
- Difference between the grasp angles to be less than 30
- Jacquard index between the two grasps to be less than 25%
6. Conclusions
Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| APC | Amazon Picking Challenge |
| CGD | Cornell Grasp Dataset |
| CNN | Convolutional Neural Networks |
| DCNN | Deep Convolutional Neural Networks |
| DDD | Depth in 3 Channels (Depth Depth Depth) Image |
| Dex-Net | Dexterity Network |
| DOF | Degrees of Freedom |
| GQ-CNN | Grasp Quality Convolutional Neural Networks |
| GWS | Grasp Wrench Space |
| MRI | Magnetic Resonance Imaging |
| RGB | Red Green Blue Image |
| RGB-D | Red Green Blue Depth Image |
| RG-D | Red Green Depth Image |
| SGD | Stochastic gradient decent |
References
- Lopes, M.; Santos-Victor, J. Visual Learning by Imitation with Motor Representations. IEEE Trans. Syst. Man Cybern. B 2005, 35, 438–449. [Google Scholar] [CrossRef]
- Ju, Z.; Yang, C.; Li, Z.; Cheng, L.; Ma, H. Teleoperation of Humanoid Baxter Robot Using Haptic Feedback. In Proceedings of the 2014 Multisensor Fusion and Information Integration for Intelligent Systems (MFI), Beijing, China, 28–29 September 2014. [Google Scholar]
- Konidaris, G.; Kuindersma, S.; Grupen, R.; Barto, A. Robot learning from demonstration by constructing skill trees. Int. J. Robot. Res. 2011, 31, 360–375. [Google Scholar] [CrossRef]
- Kober, J.; Peters, J. Imitation and reinforcement learning. IEEE Robot. Autom. Mag. 2010, 17, 55–62. [Google Scholar] [CrossRef]
- Peters, J.; Lee, D.D.; Kober, J.; Nguyen-Tuong, D.; Bagnell, A.; Schaal, S. Robot Learning. In Springer Handbook of Robotics, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 357–394. [Google Scholar]
- Mathworks. Deep Learning in Matlab. Available online: https://au.mathworks.com/help/nnet/ug/deep-learning-in-matlab.html (accessed on 28 April 2017).
- Chen, Z.; Zhang, T.; Ouyang, C. End-to-End Airplane Detection Using Transfer Learning in Remote Sensing Images. Remote Sens. 2018, 10, 139. [Google Scholar] [CrossRef]
- Rosenberg, I.; Sicard, G.; David, E.O. End-to-End Deep Neural Networks and Transfer Learning for Automatic Analysis of Nation-State Malware. Entropy 2018, 20, 390. [Google Scholar] [CrossRef]
- Bicchi, A.; Kumar, V. Robotic grasping and contact: A review. In Proceedings of the 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No.00CH37065), San Francisco, CA, USA, 24–28 April 2000; Volume 1, pp. 348–353. [Google Scholar] [CrossRef]
- Kumra, S.; Kanan, C. Robotic grasp detection using deep convolutional neural networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 769–776. [Google Scholar] [CrossRef]
- Ju, Z.; Yang, C.; Ma, H. Kinematics Modeling and Experimental Verification of Baxter Robot. In Proceedings of the Chinese Control Conference (CCC), Nanjing, China, 28–30 July 2014. [Google Scholar] [CrossRef]
- Billard, A.G.; Calinon, S.; Dillmann, R. Learning from Humans. In Springer Handbook of Robotics, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1995–2014. [Google Scholar]
- Jeon, M. Robotic Arts: Current Practices, Potentials, and Implications. Multimodal Technol. Interact. 2017, 1, 5. [Google Scholar] [CrossRef]
- Tobin, J.; Fong, R.; Ray, A.; Schneider, J.; Zaremba, W.; Abbeel, P. Domain randomization for transferring deep neural networks from simulation to the real world. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 23–30. [Google Scholar] [CrossRef]
- Saxena, A.; Driemeyer, J.; Kearns, J.; Ng, A.Y. Robotic Grasping of Novel Objects. In Advances in Neural Information Processing Systems 19; Schölkopf, B., Platt, J.C., Hoffman, T., Eds.; MIT Press: Cambridge, MA, USA, 2007; pp. 1209–1216. [Google Scholar]
- Saxena, A.; Driemeyer, J.; Ng, A.Y. Robotic Grasping of Novel Objects using Vision. Int. J. Robot. Res. 2008, 27, 157–173. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Lenz, I.; Lee, H.; Saxena, A. Deep Learning for Detecting Robotic Grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef]
- Redmon, J.; Angelova, A. Real-time grasp detection using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1316–1322. [Google Scholar] [CrossRef]
- Basalla, M.; Ebert, F.; Tebner, R.; Ke, W. Grasping for the Real World (Greifen mit Deep Learning). Available online: https://www.frederikebert.de/abgeschlossene-projekte/greifen-mit-deep-learning/ (accessed on 13 February 2017).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 23 February 2017).
- Bergstra, J.; Breuleux, O.; Bastien, F.; Lamblin, P.; Pascanu, R.; Desjardins, G.; Turian, J.; Warde-Farley, D.; Bengio, Y. Theano: A CPU and GPU Math Expression Compiler. In Proceedings of the Python for Scientific Computing Conference (SciPy), Austin, TX, USA, 28 June–3 July 2010. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 8 November 2017).
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv, 2014; arXiv:1408.5093. [Google Scholar]
- Redmon, J. Darknet: Open Source Neural Networks in C. 2013–2016. Available online: http://pjreddie.com/darknet/ (accessed on 12 April 2017).
- NVIDIA. NVIDIA ISAAC Platform for Robotics. Available online: https://www.nvidia.com/en-us/deep-learning-ai/industries/robotics/ (accessed on 23 December 2017).
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Aparicio, J.; Goldberg, K. Dex-Net 2.0: Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics. In Proceedings of the Robotics: Science and Systems, Cambridge, MA, USA, 12–16 July 2017. [Google Scholar] [CrossRef]
- Bohg, J.; Morales, A.; Asfour, T.; Kragic, D. Data-Driven Grasp Synthesis-A Survey. IEEE Trans. Robot. 2014, 30, 289–309. [Google Scholar] [CrossRef]
- Zhang, F.; Leitner, J.; Milford, M.; Upcroft, B.; Corke, P. Towards Vision-Based Deep Reinforcement Learning for Robotic Motion Control. In Proceedings of the Australasian Conference on Robotics and Automation, Canberra, Australia, 2–4 December 2015. [Google Scholar]
- Jiang, Y.; Moseson, S.; Saxena, A. Efficient grasping from RGBD images: Learning using a new rectangle representation. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3304–3311. [Google Scholar] [CrossRef]
- Watson, J.; Hughes, J.; Iida, F. Real-World, Real-Time Robotic Grasping with Convolutional Neural Networks. In Towards Autonomous Robotic Systems; Gao, Y., Fallah, S., Jin, Y., Lekakou, C., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 617–626. [Google Scholar]
- Trottier, L.; Giguère, P.; Chaib-draa, B. Sparse Dictionary Learning for Identifying Grasp Locations. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 871–879. [Google Scholar] [CrossRef]
- Park, D.; Chun, S.Y. Classification based Grasp Detection using Spatial Transformer Network. arXiv, 2018; arXiv:1803.01356. [Google Scholar]
- Zhou, X.; Lan, X.; Zhang, H.; Tian, Z.; Zhang, Y.; Zheng, N. Fully Convolutional Grasp Detection Network with Oriented Anchor Box. arXiv, 2018; arXiv:1803.02209. [Google Scholar]
- Guo, D.; Sun, F.; Liu, H.; Kong, T.; Fang, B.; Xi, N. A hybrid deep architecture for robotic grasp detection. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1609–1614. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Z.; Wang, B.; Liu, H. Robot grasp detection using multimodal deep convolutional neural networks. Adv. Mech. Eng. 2016, 8, 1687814016668077. [Google Scholar] [CrossRef]
- Pinto, L.; Gupta, A. Supersizing self-supervision: Learning to grasp from 50K tries and 700 robot hours. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3406–3413. [Google Scholar] [CrossRef]
- Viereck, U.; Pas, A.; Saenko, K.; Platt, R. Learning a visuomotor controller for real world robotic grasping using simulated depth images. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, California, USA, 13–15 November 2017; Volume 78, pp. 291–300. [Google Scholar]
- Mahler, J.; Goldberg, K.Y. Learning Deep Policies for Robot Bin Picking by Simulating Robust Grasping Sequences. In Proceedings of the 1st Annual Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017. [Google Scholar]
- Calandra, R.; Owens, A.; Upadhyaya, M.; Yuan, W.; Lin, J.; Adelson, E.H.; Levine, S. The Feeling of Success: Does Touch Sensing Help Predict Grasp Outcomes? arXiv, 2017; arXiv:1710.05512. [Google Scholar]
- Calandra, R.; Owens, A.; Jayaraman, D.; Lin, J.; Yuan, W.; Malik, J.; Adelson, E.H.; Levine, S. More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch. arXiv, 2018; arXiv:1805.11085. [Google Scholar]
- Murali, A.; Li, Y.; Gandhi, D.; Gupta, A. Learning to Grasp Without Seeing. arXiv, 2018; arXiv:1805.04201. [Google Scholar]
- Ku, L.Y.; Learned-Miller, E.; Grupen, R. Associating grasp configurations with hierarchical features in convolutional neural networks. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 2434–2441. [Google Scholar] [CrossRef]
- Amazon Robotics. Amazon Picking Challenge 2016. Available online: https://www.amazonrobotics.com/#/pickingchallenge (accessed on 6 July 2017).
- Schwarz, M.; Milan, A.; Lenz, C.; Muṅoz, A.; Periyasamy, A.S.; Schreiber, M.; Schüller, S.; Behnke, S. Nimbro Picking: Versatile Part Handling for Warehouse Automation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017. [Google Scholar] [CrossRef]
- Johnson, J.; Karpathy, A.; Fei-Fei, L. DenseCap: Fully Convolutional Localization Networks for Dense Captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Wei, J.; Liu, H.; Yan, G.; Sun, F. Robotic grasping recognition using multi-modal deep extreme learning machine. Multidimens. Syst. Signal Process. 2017, 28, 817–833. [Google Scholar] [CrossRef]
- Wang, J.; Hu, Q.; Jiang, D. A Lagrangian network for kinematic control of redundant robot manipulators. IEEE Trans. Neural Netw. 1999, 10, 1123–1132. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Chu, F.J.; Xu, R.; Vela, P. Real-world Multi-object, Multi-grasp Detection. IEEE Robot. Autom. Lett. 2018, 3, 3355–3362. [Google Scholar] [CrossRef]
- ten Pas, A.; Gualtieri, M.; Saenko, K.; Platt, R. Grasp Pose Detection in Point Clouds. Int. J. Robot. Res. 2017, 36, 1455–1473. [Google Scholar] [CrossRef]
- Lu, Q.; Chenna, K.; Sundaralingam, B.; Hermans, T. Planning Multi-Fingered Grasps as Probabilistic Inference in a Learned Deep Network. arXiv, 2017; arXiv:1804.03289. [Google Scholar]
- Johns, E.; Leutenegger, S.; Davison, A.J. Deep learning a grasp function for grasping under gripper pose uncertainty. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4461–4468. [Google Scholar] [CrossRef]
- Zeng, A.; Song, S.; Yu, K.; Donlon, E.; Hogan, F.R.; Bauzá, M.; Ma, D.; Taylor, O.; Liu, M.; Romo, E.; et al. Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching. In Proceedings of the IEEE International Conference on Robots and Automation (ICRA), Brisbane, Australia, 21–26 May 2018. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Brownlee, J. Deep Learning with Python: Develop Deep Learning Models on Theano and TensorFlow Using Keras; Machine Learning Mastery: Melbourne, Australia, 2017. [Google Scholar]
- Ruiz-del-Solar, J.; Loncomilla, P.; Soto, N. A Survey on Deep Learning Methods for Robot Vision. arXiv, 2018; arXiv:1803.10862. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view RGB-D object dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 817–1824. [Google Scholar] [CrossRef]
- Song, X.; Jiang, S.; Herranz, L. Combining Models from Multiple Sources for RGB-D Scene Recognition. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, Melbourne, Australia, 19–25 August 2017; pp. 4523–4529. [Google Scholar] [CrossRef]
- Cornell University. Robot Learning Lab: Learning to Grasp. Available online: http://pr.cs.cornell.edu/grasping/rect_data/data.php (accessed on 12 April 2017).
- Levine, S.; Pastor, P.; Krizhevsky, A.; Ibarz, J.; Quillen, D. Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection. Int. J. Robot. Res. 2018, 37, 421–436. [Google Scholar] [CrossRef]
- Bousmalis, K.; Irpan, A.; Wohlhart, P.; Bai, Y.; Kelcey, M.; Kalakrishnan, M.; Downs, L.; Ibarz, J.; Sampedro, P.P.; Konolige, K.; et al. Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping. arXiv, 2017; arXiv:1709.07857. [Google Scholar]
- Mahler, J. Releasing the Dexterity Network (Dex-Net) 2.0 Dataset for Deep Grasping. Available online: http://bair.berkeley.edu/blog/2017/06/27/dexnet-2.0/. (accessed on 6 July 2017).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Gandhi, D.; Pinto, L.; Gupta, A. Learning to Fly by Crashing. arXiv, 2017; arXiv:1704.05588. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning; Google Inc.: Mountain View, CA, USA, 2016. [Google Scholar]
- Goodfellow, I.; Lee, H.; Le, Q.V.; Saxe, A.; Ng, A.Y. Measuring Invariances in Deep Networks. In Advances in Neural Information Processing Systems 22; Bengio, Y., Schuurmans, D., Lafferty, J.D., Williams, C.K.I., Culotta, A., Eds.; Curran Associates, Inc.: New York, NY, USA, 2009; pp. 646–654. [Google Scholar]
- Xia, Y.; Wang, J. A dual neural network for kinematic control of redundant robot manipulators. IEEE Trans. Syst. Man Cybern. B 2001, 31, 147–154. [Google Scholar] [CrossRef]
- Polydoros, A.S.; Nalpantidis, L.; Krüger, V. Real-time deep learning of robotic manipulator inverse dynamics. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar] [CrossRef]
- Ding, H.; Wang, J. Recurrent neural networks for minimum infinity-norm kinematic control of redundant manipulators. IEEE Trans. Syst. Man Cybern. A 1999, 29, 269–276. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv, 2016; arXiv:1609.04747. [Google Scholar]
- Chollet, F. Deep Learning with Python; Manning Publications Company: Shelter Island, NY, USA, 2017. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Grasp Parameters | Depth | Pose | Physical Limitations |
|---|---|---|---|---|
| Point representation | No | No | No | |
| Yes | No | No | ||
| Location + Orientation representation | No | Yes | No | |
| Yes | Yes | No | ||
| Rectangle representation | No | Yes | Yes |
| Method | Architecture | Accuracy (%) (Image-Wise) | Accuracy (%) (Object-Wise) |
|---|---|---|---|
| Direct regression by Redmon et al. [19] | AlexNet [66] | 84.4% | 84.9% |
| Regression + Classification by Redmon et al. [19] | AlexNet [66] | 85.5% | 84.9% |
| MultiGrasp Detection by Redmon et al. [19] | AlexNet [66] | 88.0% | 87.1% |
| Uni-modal, SVM, RGB by Kumra et al. [10] | ResNet-50 [70] | 84.76% | 84.47% |
| Uni-modal RGB by Kumra et al. [10] | ResNet-50 [70] | 88.84% | 87.72% |
| Uni-modal RG-D by Kumra et al. [10] | ResNet-50 [70] | 88.53% | 88.40% |
| Multi-modal SVM, RGB-D by Kumra et al. [10] | ResNet-50 [70] | 86.44% | 84.47% |
| Multi-modal RGB-D by Kumra et al. [10] | ResNet-50 [70] | 89.21% | 88.96% |
| Direct Regression (RG-D) by Basalla et al. [20] | AlexNet [66] | 71% | NA |
| Direct Regression (RG-D) By Watson et al. [31] | AlexNet [66] | 78% | NA |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Caldera, S.; Rassau, A.; Chai, D. Review of Deep Learning Methods in Robotic Grasp Detection. Multimodal Technol. Interact. 2018, 2, 57. https://doi.org/10.3390/mti2030057
Caldera S, Rassau A, Chai D. Review of Deep Learning Methods in Robotic Grasp Detection. Multimodal Technologies and Interaction. 2018; 2(3):57. https://doi.org/10.3390/mti2030057
Chicago/Turabian StyleCaldera, Shehan, Alexander Rassau, and Douglas Chai. 2018. "Review of Deep Learning Methods in Robotic Grasp Detection" Multimodal Technologies and Interaction 2, no. 3: 57. https://doi.org/10.3390/mti2030057
APA StyleCaldera, S., Rassau, A., & Chai, D. (2018). Review of Deep Learning Methods in Robotic Grasp Detection. Multimodal Technologies and Interaction, 2(3), 57. https://doi.org/10.3390/mti2030057