
Identifying Probable Dementia in Undiagnosed Black and White Americans Using Machine Learning in Veterans Health Administration Electronic Health Records
 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Population
2.2. Variable Creation
2.2.1. Structured Data
2.2.2. Unstructured Data
2.3. Support Vector Machine (SVM) Model
2.4. Validation of the SVM Model
3. Results
3.1. Demographics
3.2. Variable Selection for the SVM Model
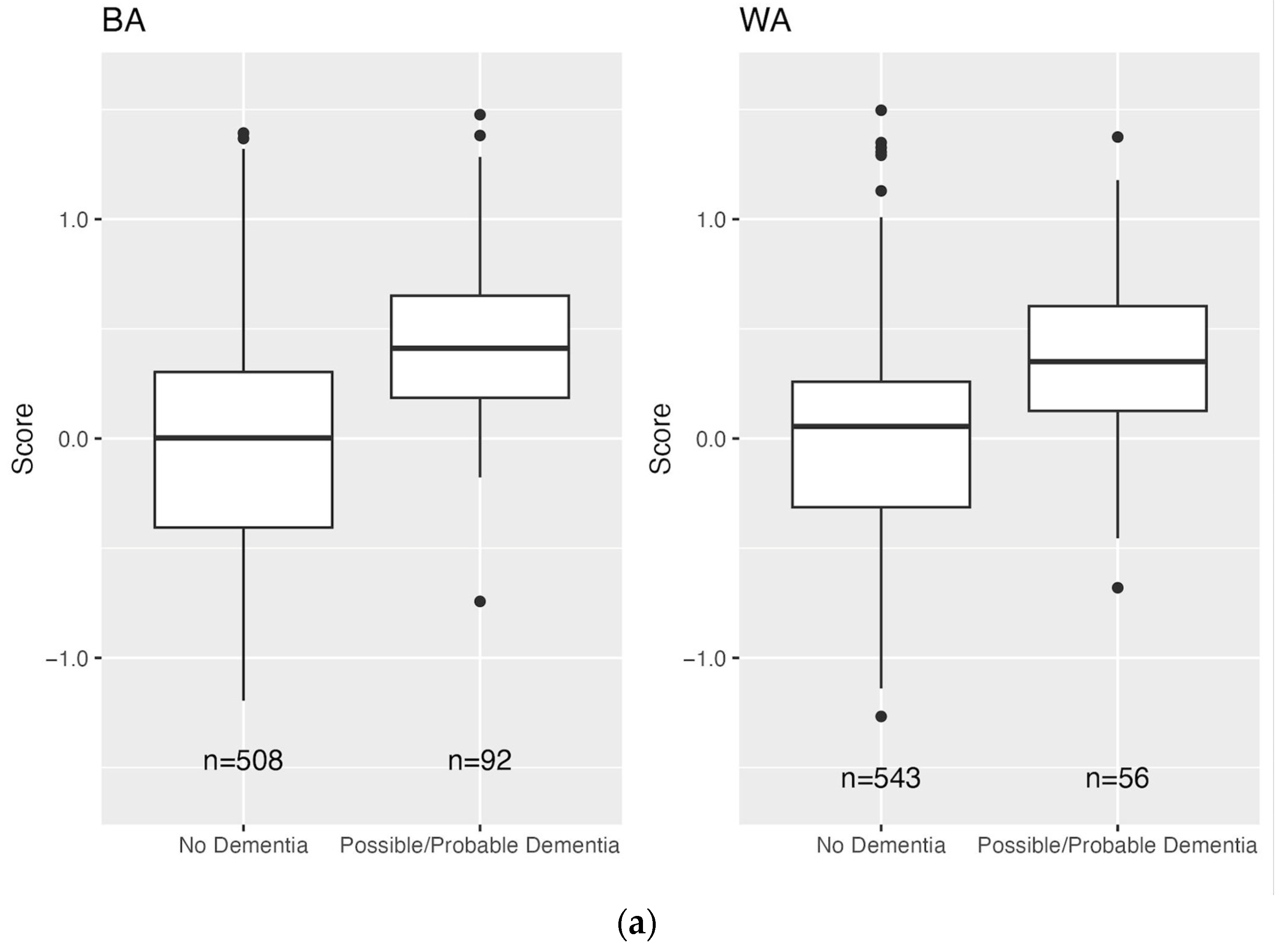
3.3. Distribution of Scores
3.4. Prevalence of Undiagnosed Dementia and Screening Test Characteristics
4. Discussion
4.1. Significance
4.2. Context
4.3. Implications
4.4. Limitations and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Barnes, D.E.; Zhou, J.; Walker, R.L.; Larson, E.B.; Lee, S.J.; Boscardin, W.J.; Marcum, Z.A.; Dublin, S. Development and validation of eRADAR: A tool using EHR data to detect unrecognized dementia. J. Am. Geriatr. Soc. 2020, 68, 103–111. [Google Scholar] [CrossRef] [PubMed]
- Amjad, H.; Roth, D.L.; Sheehan, O.C.; Lyketsos, C.G.; Wolff, J.L.; Samus, Q.M. Underdiagnosis of Dementia: An Observational Study of Patterns in Diagnosis and Awareness in US Older Adults. J. Gen. Intern. Med. 2018, 33, 1131–1138. [Google Scholar] [CrossRef] [PubMed]
- Gianattasio, K.Z.; Prather, C.; Glymour, M.M.; Ciarleglio, A.; Power, M.C. Racial disparities and temporal trends in dementia misdiagnosis risk in the US. Alzheimers Dement. 2019, 5, 891–898. [Google Scholar] [CrossRef] [PubMed]
- Sleath, B.; Thorpe, J.; Landerman, L.R.; Doyle, M.; Clipp, E. African-American and white caregivers of older adults with dementia. J. Am. Geriatr. Soc. 2005, 53, 397–404. [Google Scholar] [CrossRef]
- Kalkonde, Y.V.; Pinto-Patarroyo, G.P.; Goldman, T.; Strutt, A.M.; York, M.K.; Kunik, M.E.; Schulz, P.E. Ethnic disparities in the treatment of dementia in Veterans. Dement. Geriatr. Cogn. Disord. 2009, 28, 145–152. [Google Scholar] [CrossRef]
- Cummings, J.; Aisen, P.; Lemere, C.; Atri, A.; Sabbagh, M.; Salloway, S. Aducanumab produced a clinically meaningful benefit in association with amyloid lowering. Alzheimers Res. Ther. 2021, 13, 98. [Google Scholar] [CrossRef]
- Callahan, C.M.; Hendrie, H.C.; Tierney, W.M. Documentation and evaluation of cognitive impairment in elderly primary care patients. Ann. Intern. Med. 1995, 122, 422–429. [Google Scholar] [CrossRef]
- Fitten, L.J.; Perryman, K.M.; Wilkinson, C.J.; Little, R.J.; Burns, M.M.; Pachana, N.; Mervis, J.R.; Malmgren, R.; Siembieda, D.W.; Ganzell, S. Alzheimer and vascular dementias and driving. JAMA 1995, 273, 1360–1365. [Google Scholar] [CrossRef]
- Sayegh, P.; Knight, B.G. Cross-cultural differences in dementia. Int. Psychogeriatr. 2013, 25, 517–530. [Google Scholar] [CrossRef]
- Hinton, L.; Franz, C.; Friend, J. Pathways to dementia diagnosis: Evidence for cross-ethnic differences. Alzheimer Dis. Assoc. Disord. 2004, 18, 134–144. [Google Scholar] [CrossRef]
- Rasmussen, J.; Langerman, H. Alzheimer’s disease: Why we need early diagnosis. Degener. Neurol. Neuromuscul. Dis. 2019, 9, 123–130. [Google Scholar] [CrossRef] [PubMed]
- Black, C.M.; Fillit, H.; Xie, L.; Hu, X.; Kariburyo, M.F.; Ambegaonkar, B.M.; Baser, O.; Yuce, H.; Khandker, R.K. Economic burden, mortality, and institutionalization in patients newly diagnosed with AD. J. Alzheimers Dis. 2018, 61, 185–193. [Google Scholar] [CrossRef] [PubMed]
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural language processing. J. Am. Med. Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed]
- Gottesman, O.; Kuivaniemi, H.; Tromp, G.; Faucett, W.A.; Li, R.; Manolio, T.A.; Sanderson, S.C.; Kannry, J.; Zinberg, R.; Basford, M.A.; et al. The eMERGE Network. Genet. Med. 2013, 15, 761–771. [Google Scholar] [CrossRef] [PubMed]
- Shao, Y.; Zeng, Q.T.; Chen, K.K.; Shutes-David, A.; Thielke, S.M.; Tsuang, D.W. Detection of probable dementia cases in undiagnosed patients using structured and unstructured EHRs. BMC Med. Inform. Decis. Mak. 2019, 19, 128. [Google Scholar] [CrossRef]
- Banf, M. Learning theory and support vector machines: A primer. arXiv 2019, arXiv:1902.04622. [Google Scholar]
- Gamage, B. An embarrassingly simple comparison of machine learning algorithms for indoor scene classification. arXiv 2021, arXiv:2109.12261. [Google Scholar]
- Shao, Y.; Mohanty, A.F.; Ahmed, A.; Weir, C.R.; Bray, B.E.; Shah, R.U.; Redd, D.; Zeng-Treitler, Q. Identification and use of frailty indicators from text to examine associations with clinical outcomes among patients with heart failure. AMIA Annu. Symp. Proc. 2016, 2016, 1110–1118. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Sachdev, P.S.; Blacker, D.; Blazer, D.G.; Ganguli, M.; Jeste, D.V.; Paulsen, J.S.; Petersen, R.C. Classifying neurocognitive disorders: The DSM-5 approach. Nat. Rev. Neurol. 2014, 10, 634–642. [Google Scholar] [CrossRef]
- Katz, S. Assessing self-maintenance: Activities of daily living, mobility, and instrumental activities of daily living. J. Am. Geriatr. Soc. 1983, 31, 721–727. [Google Scholar] [CrossRef] [PubMed]
- Alonzo, T.; Pepe, M. Assessing accuracy of a continuous screening test in the presence of verification bias. J. R. Stat. Soc. Ser. C Appl. Stat. 2005, 54, 173–190. [Google Scholar] [CrossRef]
- R Core Team. The R Project for Statistical Computing. 2020. Available online: https://www.r-project.org/.
- Tenny, S.; Hoffman, M. StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2022. [Google Scholar]
- Tang, M.X.; Cross, P.; Andrews, H.; Jacobs, D.M.; Small, S.; Bell, K.; Merchant, C.; Lantigua, R.; Costa, R.; Stern, Y.; et al. Incidence of AD in African-Americans, Caribbean Hispanics, and Caucasians in northern Manhattan. Neurology 2001, 56, 49–56. [Google Scholar] [CrossRef] [PubMed]
- Langa, K.M.; Larson, E.B.; Crimmins, E.M.; Faul, J.D.; Levine, D.A.; Kabeto, M.U.; Weir, D.R. A comparison of the prevalence of dementia in the US in 2000 and 2012. JAMA Intern. Med. 2017, 177, 51–58. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Ahmed, A.; Zamrini, E.; Tsuang, D.; Sheriff, H.; Zeng-Treitler, Q. AD and ADRD in older African American and white Veterans. J. Alzheimers Dis. 2020, 75, 311–320. [Google Scholar] [CrossRef] [PubMed]
- Chang, C.H.; Lin, C.H.; Lane, H.Y. Machine Learning and Novel Biomarkers for the Diagnosis of Alzheimer’s Disease. Int. J. Mol. Sci. 2021, 22, 2761. [Google Scholar] [CrossRef]
- Popuri, K.; Ma, D.; Wang, L.; Beg, M.F. Using machine learning to quantify structural MRI neurodegeneration patterns of Alzheimer’s disease into dementia score: Independent validation on 8834 images from ADNI, AIBL, OASIS, and MIRIAD databases. Hum. Brain Mapp. 2020, 41, 4127–4147. [Google Scholar] [CrossRef]
- Qiu, S.; Joshi, P.S.; Miller, M.I.; Xue, C.; Zhou, X.; Karjadi, C.; Chang, G.H.; Joshi, A.S.; Dwyer, B.; Zhu, S.; et al. Development and validation of an interpretable deep learning framework for Alzheimer’s disease classification. Brain 2020, 143, 1920–1933. [Google Scholar] [CrossRef]
- Amra, S.; O’Horo, J.C.; Singh, T.D.; Wilson, G.A.; Kashyap, R.; Petersen, R.; Roberts, R.O.; Fryer, J.D.; Rabinstein, A.A.; Gajic, O. Derivation and validation of the automated search algorithms to identify cognitive impairment and dementia in electronic health records. J. Crit. Care 2017, 37, 202–205. [Google Scholar] [CrossRef]
- Wray, L.O.; Wade, M.; Beehler, G.P.; Hershey, L.A.; Vair, C.L. A program to improve detection of undiagnosed dementia in primary care and its association with healthcare utilization. Am. J. Geriatr. Psychiatry 2014, 22, 1282–1291. [Google Scholar] [CrossRef]
- Jammeh, E.A.; Carroll, C.B.; Pearson, S.W.; Escudero, J.; Anastasiou, A.; Zhao, P.; Chenore, T.; Zajicek, J.; Ifeachor, E. Machine-learning based identification of undiagnosed dementia in primary care: A feasibility study. BJGP Open 2018, 2, bjgpopen18X101589. [Google Scholar] [CrossRef] [PubMed]
- Coley, R.Y.; Smith, J.J.; Karliner, L.; Idu, A.E.; Lee, S.J.; Fuller, S.; Lam, R.; Barnes, D.E.; Dublin, S. External Validation of the eRADAR Risk Score for Detecting Undiagnosed Dementia in Two Real-World Healthcare Systems. J. Gen. Intern. Med. 2022, 38, 351–360. [Google Scholar] [CrossRef] [PubMed]
- Yadgir, S.R.; Engstrom, C.; Jacobsohn, G.C.; Green, R.K.; Jones, C.M.C.; Cushman, J.T.; Caprio, T.V.; Kind, A.J.H.; Lohmeier, M.; Shah, M.N.; et al. Machine learning-assisted screening for cognitive impairment in the emergency department. J. Am. Geriatr. Soc. 2022, 70, 831–837. [Google Scholar] [CrossRef] [PubMed]
- Boustani, M.; Perkins, A.J.; Khandker, R.K.; Duong, S.; Dexter, P.R.; Lipton, R.; Black, C.M.; Chandrasekaran, V.; Solid, C.A.; Monahan, P. Passive digital signature for early identification of Alzheimer’s disease and related dementia. J. Am. Geriatr. Soc. 2020, 68, 511–518. [Google Scholar] [CrossRef]
- Bracic, A.; Callier, S.L.; Price, W.N., 2nd. Exclusion cycles: Reinforcing disparities in medicine. Science 2022, 377, 1158–1160. [Google Scholar] [CrossRef]
- Trevethan, R. Sensitivity, Specificity, and Predictive Values: Foundations, Pliabilities, and Pitfalls in Research and Practice. Front. Public Health 2017, 5, 307. [Google Scholar] [CrossRef]
- Hyman, B.T.; Trojanowski, J.Q. Consensus recommendations for the postmortem diagnosis of Alzheimer disease from the National Institute on Aging and the Reagan Institute Working Group on diagnostic criteria for the neuropathological assessment of Alzheimer disease. J. Neuropathol. Exp. Neurol. 1997, 56, 1095–1097. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Sample | |||||||||
| Cases (n = 10 K) | Controls (n = 10 K) | ||||||||
| BA (n = 5 K) | WA (n = 5 K) | Combined (n = 10 K) | BA (n = 5 K) | WA (n = 5 K) | Combined (n = 10 K) | ||||
| Age, mean (SD) | 72.1 (4.8) | 72.8 (4.8) | 72.4 (4.8) | 68.6 (3.5) | 69.5 (3.8) | 69.1 (3.7) | |||
| Age category, (%) | |||||||||
| 65–69 | 35.7 | 29.8 | 32.8 | 70.5 | 60.0 | 65.2 | |||
| 70–74 | 34.1 | 34.4 | 34.3 | 22.1 | 28.4 | 25.3 | |||
| 75–79 | 20.9 | 24.2 | 22.6 | 5.8 | 9.2 | 7.5 | |||
| 80–84 | 9.4 | 11.5 | 10.4 | 1.6 | 2.5 | 2.0 | |||
| Gender, % male | 97.9 | 97.5 | 97.7 | 96.8 | 97.6 | 97.2 | |||
| Full Validation Sample (n = 20 K) | Chart Review Sample (n = 1200) * | ||||||||
| Unweighted | Weighted † | ||||||||
| BA (n = 10 K) | WA (n = 10 K) | Combined (n = 20 K) | BA (n = 600) | WA (n = 600) | Combined (n = 1200) | BA (n = 600) | WA (n = 600) | Combined (n = 1200) | |
| Age, mean (SD) | 68.5 (3.4) | 69.5 (3.8) | 69.0 (3.6) | 69.3 (4.2) | 70.2 (4.5) | 69.8 (4.3) | 68.5 (3.4) | 69.3 (3.7) | 68.9 (3.6) |
| Age category, (%) | |||||||||
| 65–69 | 70.9 | 60.3 | 65.6 | 64.8 | 52.8 | 58.8 | 70.4 | 60.9 | 65.7 |
| 70–74 | 22.3 | 28.6 | 25.5 | 22.3 | 28.5 | 25.4 | 23.2 | 28.4 | 25.8 |
| 75–79 | 5.5 | 8.7 | 7.1 | 9.3 | 13.7 | 11.5 | 5.4 | 8.2 | 6.7 |
| 80–84 | 1.3 | 2.4 | 1.9 | 3.5 | 5.0 | 4.3 | 1.0 | 2.5 | 1.7 |
| Gender, % male | 96.1 | 97.6 | 96.8 | 97.2 | 97.0 | 97.1 | 96.7 | 98.9 | 97.8 |
| Race † | Cutoff Percentile | Sensitivity | Specificity | PPV | NPV | Accuracy |
|---|---|---|---|---|---|---|
| BA | 50 | 0.89 [0.53, 1] | 0.54 [0.42, 0.54] | 0.08 [0.06, 0.10] | 0.99 [0.93, 1] | 0.55 [0.49, 0.60] |
| 75 | 0.89 [0.53, 1] | 0.79 [0.76, 0.77] | 0.15 [0.12, 0.19] | 0.99 [0.95, 1] | 0.79 [0.77, 0.80] | |
| 90 | 0.61 [0.40, 0.76] | 0.92 [0.91, 0.92] | 0.26 [0.21, 0.31] | 0.98 [0.96, 0.99] | 0.91 [0.89, 0.92] | |
| 95 | 0.37 [0.24, 0.48] | 0.97 [0.96, 0.97] | 0.31 [0.25, 0.39] | 0.97 [0.95, 0.98] | 0.94 [0.92, 0.95] | |
| WA | 50 | 0.86 [0.47, 1] | 0.51 [0.45, 0.57] | 0.06 [0.04, 0.11] | 0.99 [0.94, 1] | 0.52 [0.46, 0.58] |
| 75 | 0.58 [0.31, 0.85] | 0.76 [0.76, 0.77] | 0.09 [0.06, 0.12] | 0.98 [0.93, 0.99] | 0.75 [0.73, 0.77] | |
| 90 | 0.43 [0.24, 0.67] | 0.91 [0.91, 0.92] | 0.15 [0.12, 0.20] | 0.98 [0.94, 0.99] | 0.89 [0.87, 0.91] | |
| 95 | 0.30 [0.16, 0.48] | 0.96 [0.96, 0.96] | 0.22 [0.16, 0.29] | 0.97 [0.94, 0.99] | 0.94 [0.91, 0.95] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, Y.; Todd, K.; Shutes-David, A.; Millard, S.P.; Brown, K.; Thomas, A.; Chen, K.; Wilson, K.; Zeng, Q.T.; Tsuang, D.W. Identifying Probable Dementia in Undiagnosed Black and White Americans Using Machine Learning in Veterans Health Administration Electronic Health Records. Big Data Cogn. Comput. 2023, 7, 167. https://doi.org/10.3390/bdcc7040167
Shao Y, Todd K, Shutes-David A, Millard SP, Brown K, Thomas A, Chen K, Wilson K, Zeng QT, Tsuang DW. Identifying Probable Dementia in Undiagnosed Black and White Americans Using Machine Learning in Veterans Health Administration Electronic Health Records. Big Data and Cognitive Computing. 2023; 7(4):167. https://doi.org/10.3390/bdcc7040167
Chicago/Turabian StyleShao, Yijun, Kaitlin Todd, Andrew Shutes-David, Steven P. Millard, Karl Brown, Amy Thomas, Kathryn Chen, Katherine Wilson, Qing T. Zeng, and Debby W. Tsuang. 2023. "Identifying Probable Dementia in Undiagnosed Black and White Americans Using Machine Learning in Veterans Health Administration Electronic Health Records" Big Data and Cognitive Computing 7, no. 4: 167. https://doi.org/10.3390/bdcc7040167