
Augmenting Deep Neural Networks with Symbolic Educational Knowledge: Towards Trustworthy and Interpretable AI for Education


Abstract
:1. Introduction
- How effectively can we ground educational knowledge in a deep neural-network-based learner modeling approach in order to provide control over the network’s behavior?
- How is the performance of the NSAI approach, in terms of generalizability, in handling data biases, and how interpretable are the predictions compared to deep neural networks?
- What are the effects of the data augmentation methods of SMOTE and autoencoders on the prediction power of deep neural network models?
2. Related Works
2.1. Neural Networks in Education
2.2. Neural-Symbolic AI for Education
3. Neural-Symbolic AI for Modelling Learners’ Computational Thinking
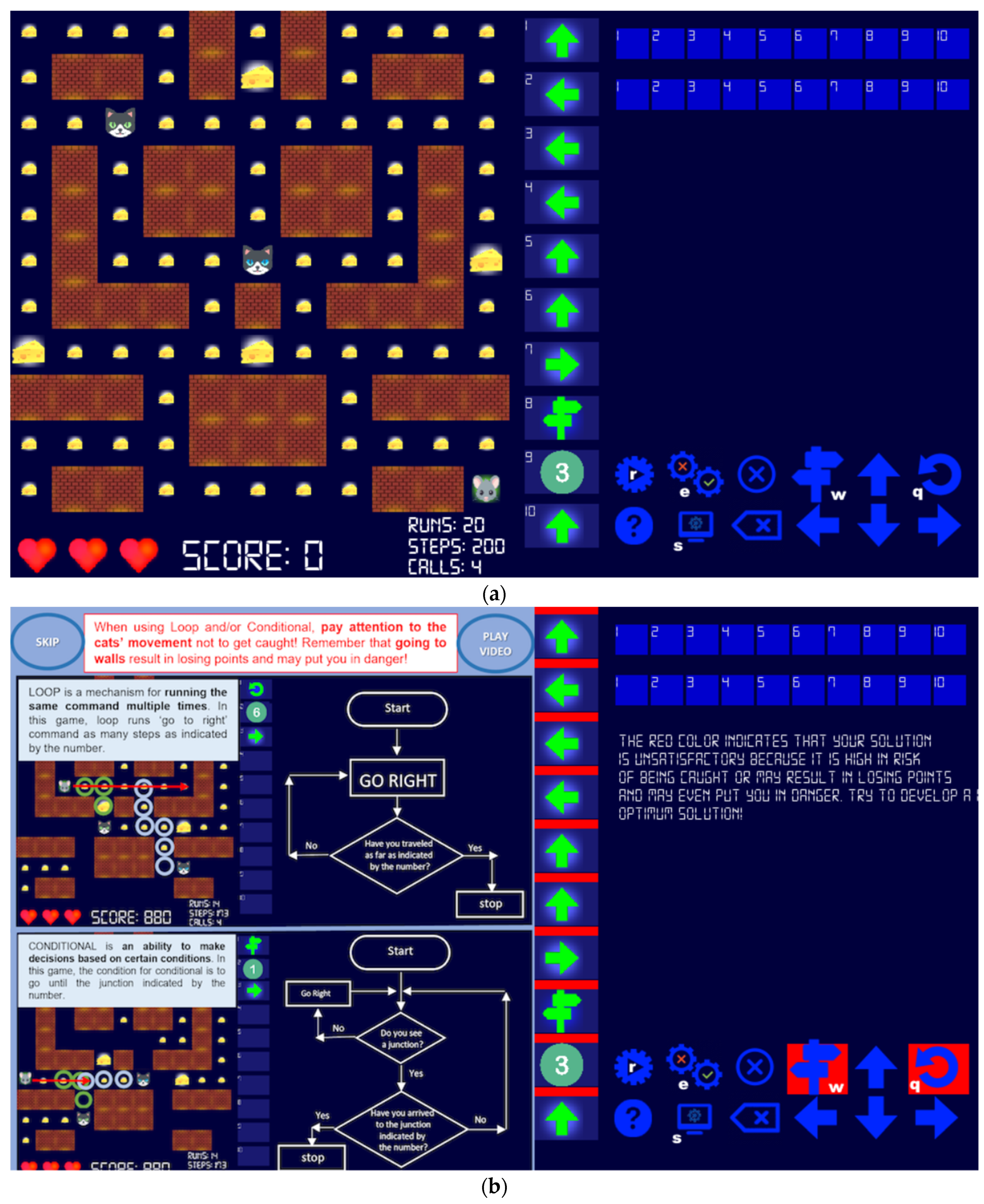
3.1. The AutoThinking Game
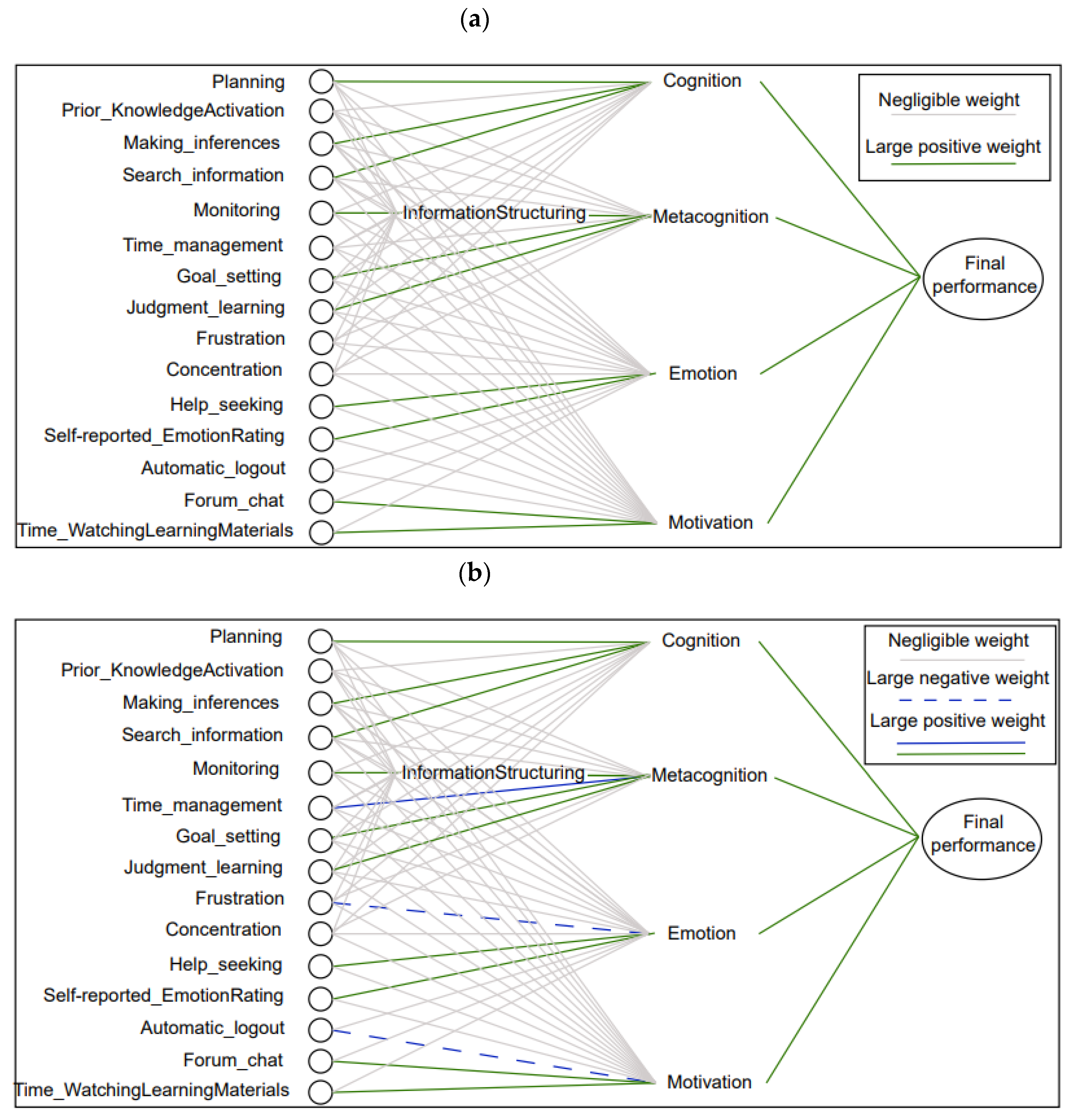
3.2. The Proposed NSAI Approach
- Final performance: cognition, metacognition, emotion, motivation.
- Cognition: planning, search for information, making inferences.
- Metacognition: goal setting, information structuring, judgement of learning.
- Information structuring: monitoring progress towards goals.
- Emotion: seeking help, self-reported emotion rating.
- Motivation: time spent watching learning materials, forum chat.
4. Results and Analysis
4.1. Datasets and Educational Knowledge
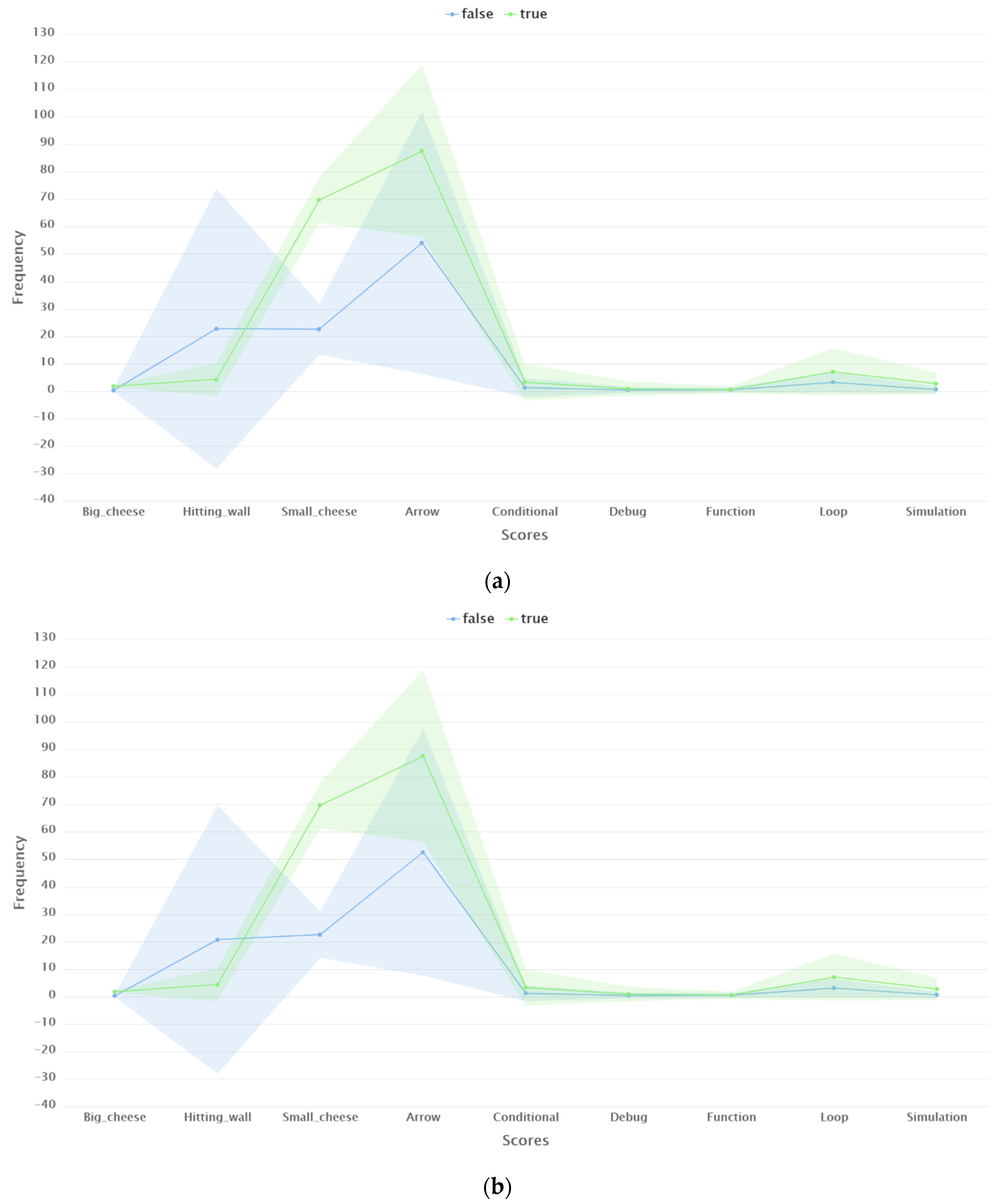
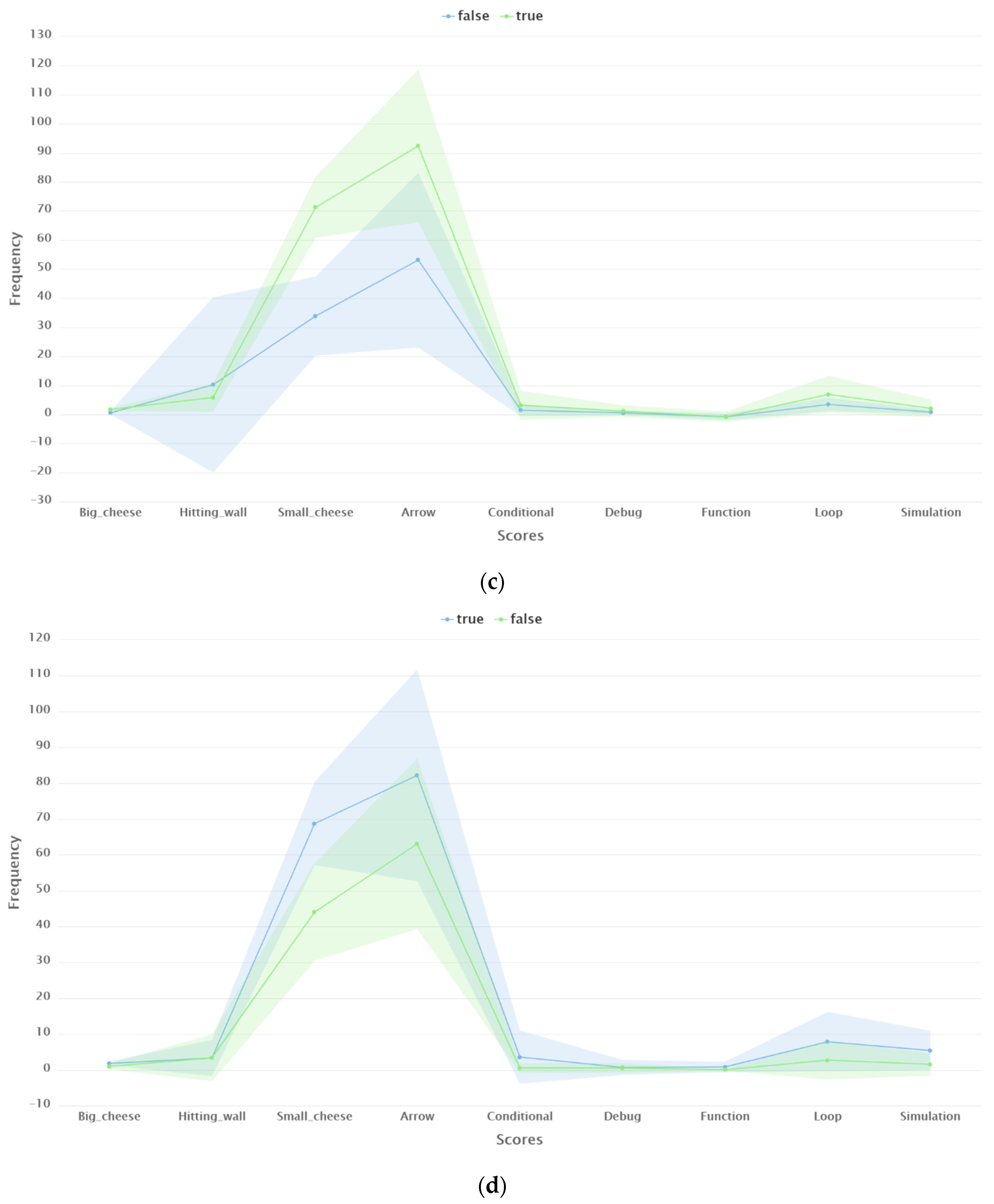
4.2. Data Biases
4.3. Experiment Setting and Evaluation
4.4. Performance of Models in Terms of Generalizability
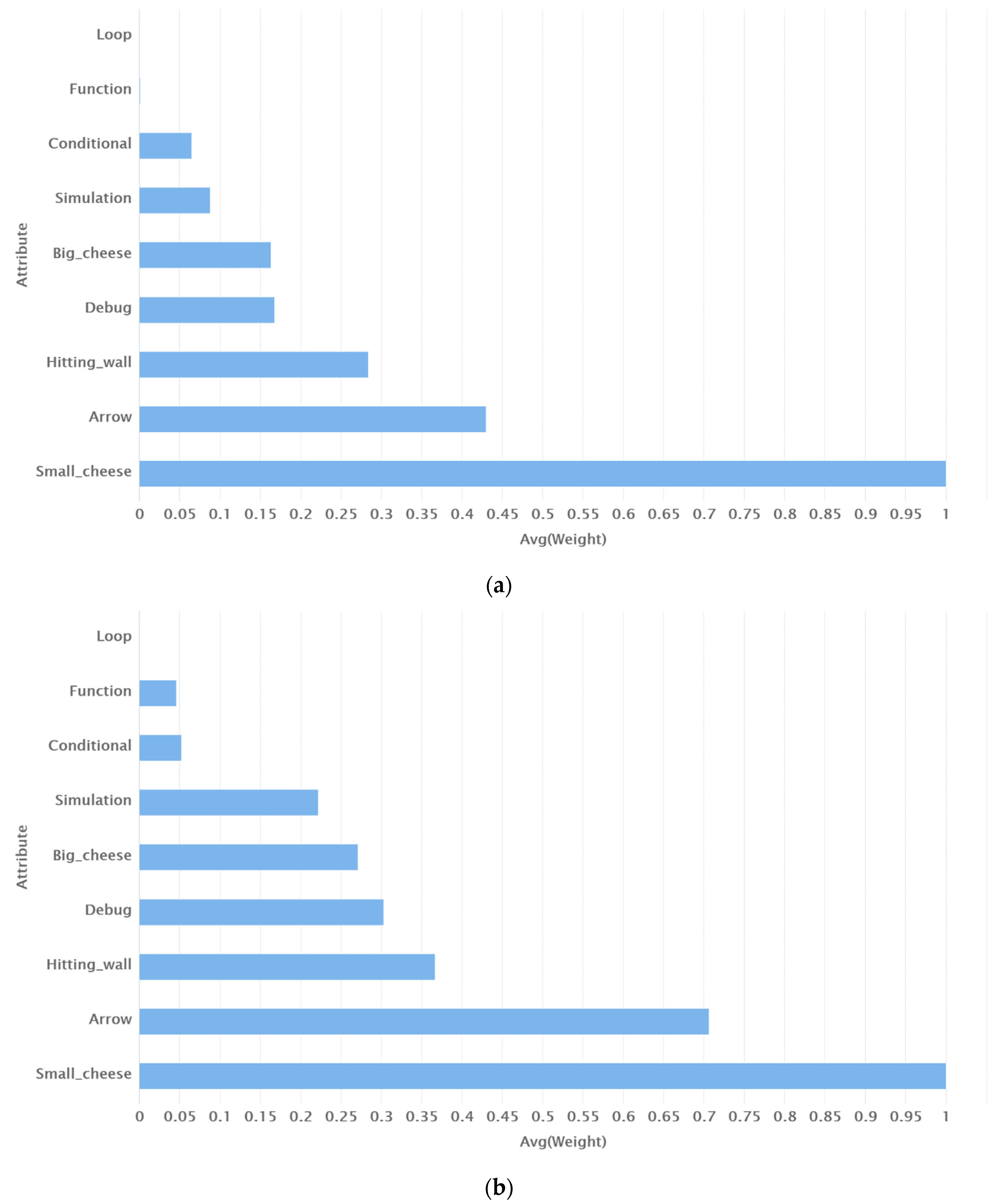
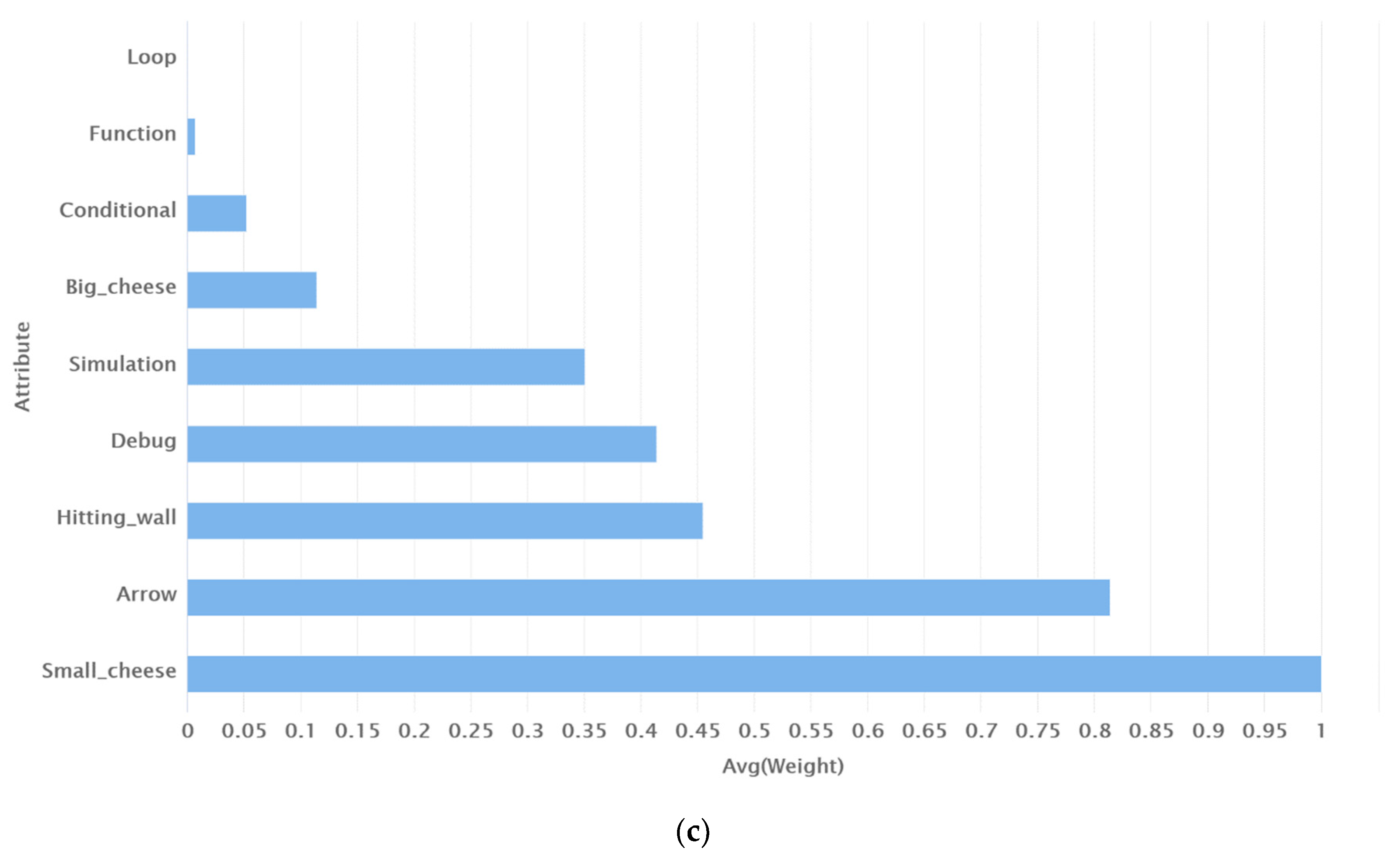
4.5. Performance of Models in Terms of Handling Data Biases and the Interpretability of Predictions
5. Discussion and Conclusions
Limitations and Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vincent-Lancrin, S.; Van der Vlies, R. Trustworthy Artificial Intelligence (AI) in Education: Promises and Challenges; OECD: Paris, France, 2020. [Google Scholar]
- Conati, C.; Lallé, S. 8. Student Modeling in Open-Ended Learning Environments. In Handbook of Artificial Intelligence in Education; Edward Elgar Publishing: Cheltenham, UK, 2023; pp. 170–183. [Google Scholar]
- Abyaa, A.; Khalidi Idrissi, M.; Bennani, S. Learner Modelling: Systematic Review of the Literature from the Last 5 Years. Educ. Technol. Res. Dev. 2019, 67, 1105–1143. [Google Scholar] [CrossRef]
- Azevedo, R.; Wiedbusch, M. Theories of Metacognition and Pedagogy Applied in AIED Systems. In Handbook of Artificial Intelligence in Education; Edward Elgar Publishing: Cheltenham, UK, 2023; pp. 45–67. [Google Scholar]
- Garcez, A.d.A.; Bader, S.; Bowman, H.; Lamb, L.C.; de Penning, L.; Illuminoo, B.; Poon, H.; Zaverucha, C.G. Neural-Symbolic Learning and Reasoning: A Survey and Interpretation. In Neuro-Symbolic Artificial Intelligence: The State of the Art; IOS Press: Amsterdam, The Netherlands, 2022; Volume 342, p. 327. [Google Scholar]
- Lenat, D.B.; Prakash, M.; Shepherd, M. CYC: Using Common Sense Knowledge to Overcome Brittleness and Knowledge Acquisition Bottlenecks. AI Mag. 1985, 6, 65. [Google Scholar]
- Bhanuse, R.; Mal, S. A Systematic Review: Deep Learning Based e-Learning Recommendation System. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 190–197. [Google Scholar]
- Hernández-Blanco, A.; Herrera-Flores, B.; Tomás, D.; Navarro-Colorado, B. A Systematic Review of Deep Learning Approaches to Educational Data Mining. Complexity 2019, 2019, 1306039. [Google Scholar] [CrossRef]
- Hooshyar, D.; Huang, Y.-M.; Yang, Y. GameDKT: Deep Knowledge Tracing in Educational Games. Expert Syst. Appl. 2022, 196, 116670. [Google Scholar] [CrossRef]
- Piech, C.; Bassen, J.; Huang, J.; Ganguli, S.; Sahami, M.; Guibas, L.J.; Sohl-Dickstein, J. Deep Knowledge Tracing. In Proceedings of the Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Algarni, S.; Sheldon, F. Systematic Review of Recommendation Systems for Course Selection. Mach. Learn. Knowl. Extr. 2023, 5, 560–596. [Google Scholar] [CrossRef]
- Nielsen, M.A. Neural Networks and Deep Learning; Determination Press: San Francisco, CA, USA, 2015; Volume 25. [Google Scholar]
- Wiedbusch, M.; Dever, D.; Li, S.; Amon, M.J.; Lajoie, S.; Azevedo, R. Measuring Multidimensional Facets of SRL Engagement with Multimodal Data. In Unobtrusive Observations of Learning in Digital Environments: Examining Behavior, Cognition, Emotion, Metacognition and Social Processes Using Learning Analytics; Springer: Cham, Switzerland, 2023; pp. 141–173. [Google Scholar]
- Hooshyar, D.; Yang, Y. Neural-Symbolic Computing: A Step toward Interpretable AI in Education. Bull. Tech. Comm. Learn. Technol. 2021, 21, 2–6. [Google Scholar]
- Torralba, A.; Efros, A.A. Unbiased Look at Dataset Bias. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1521–1528. [Google Scholar]
- Agrawal, A.; Batra, D.; Parikh, D.; Kembhavi, A. Don’t Just Assume; Look and Answer: Overcoming Priors for Visual Question Answering. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4971–4980. [Google Scholar]
- Gretton, A.; Györfi, L. Consistent Nonparametric Tests of Independence. J. Mach. Learn. Res. 2010, 11, 1391–1423. [Google Scholar]
- Srivastava, M. Addressing Spurious Correlations in Machine Learning Models: A Comprehensive Review. OSF Prepr. 2023. [Google Scholar] [CrossRef]
- Zech, J.R.; Badgeley, M.A.; Liu, M.; Costa, A.B.; Titano, J.J.; Oermann, E.K. Variable Generalization Performance of a Deep Learning Model to Detect Pneumonia in Chest Radiographs: A Cross-Sectional Study. PLoS Med. 2018, 15, e1002683. [Google Scholar] [CrossRef] [PubMed]
- Ye, W.; Zheng, G.; Cao, X.; Ma, Y.; Hu, X.; Zhang, A. Spurious Correlations in Machine Learning: A Survey. arXiv 2024, arXiv:2402.12715. [Google Scholar]
- UNESCO. Beijing Consensus on Artificial Intelligence and Education. In Proceedings of the International Conference on Artificial Intelligence and Education, Planning Education in the AI Era: Lead the Leap, Beijing, China, 16–18 May 2019. [Google Scholar]
- Hooshyar, D. Temporal Learner Modelling through Integration of Neural and Symbolic Architectures. Educ. Inf. Technol. 2024, 29, 1119–1146. [Google Scholar] [CrossRef]
- Conati, C.; Porayska-Pomsta, K.; Mavrikis, M. AI in Education Needs Interpretable Machine Learning: Lessons from Open Learner Modelling. arXiv 2018, arXiv:1807.00154. [Google Scholar]
- Meltzer, J.P.; Tielemans, A. The European Union AI Act: Next Steps and Issues for Building International Cooperation in AI; Brookings Institution: Washington, DC, USA, 2022. [Google Scholar]
- Rosé, C.P.; McLaughlin, E.A.; Liu, R.; Koedinger, K.R. Explanatory Learner Models: Why Machine Learning (Alone) Is Not the Answer. Br. J. Educ. Technol. 2019, 50, 2943–2958. [Google Scholar] [CrossRef]
- Hooshyar, D.; Huang, Y.-M.; Yang, Y. A Three-Layered Student Learning Model for Prediction of Failure Risk in Online Learning. Hum.-Centric Comput. Inf. Sci. 2022, 12, 28. [Google Scholar]
- Saarela, M.; Heilala, V.; Jääskelä, P.; Rantakaulio, A.; Kärkkäinen, T. Explainable Student Agency Analytics. IEEE Access 2021, 9, 137444–137459. [Google Scholar] [CrossRef]
- Alwarthan, S.; Aslam, N.; Khan, I.U. An Explainable Model for Identifying At-Risk Student at Higher Education. IEEE Access 2022, 10, 107649–107668. [Google Scholar] [CrossRef]
- Melo, E.; Silva, I.; Costa, D.G.; Viegas, C.M.D.; Barros, T.M. On the Use of Explainable Artificial Intelligence to Evaluate School Dropout. Educ. Sci. 2022, 12, 845. [Google Scholar] [CrossRef]
- Slack, D.; Hilgard, S.; Jia, E.; Singh, S.; Lakkaraju, H. Fooling Lime and Shap: Adversarial Attacks on Post Hoc Explanation Methods. In Proceedings of the 2020 AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–9 February 2020; pp. 180–186. [Google Scholar]
- Lakkaraju, H.; Bastani, O. “How Do I Fool You?” Manipulating User Trust via Misleading Black Box Explanations. In Proceedings of the 2020 AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–9 February 2020; pp. 79–85. [Google Scholar]
- Hitzler, P.; Sarker, M.K. Neuro-Symbolic Artificial Intelligence: The State of the Art; IOS Press: Amsterdam, The Netherlands, 2022. [Google Scholar]
- Garcez, A.d.A.; Lamb, L.C. Neurosymbolic AI: The 3rd Wave. Artif. Intell. Rev. 2023, 56, 12387–12406. [Google Scholar] [CrossRef]
- Sarker, M.K.; Zhou, L.; Eberhart, A.; Hitzler, P. Neuro-Symbolic Artificial Intelligence. AI Commun. 2021, 34, 197–209. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. An Introduction to Variational Autoencoders. Found. Trends® Mach. Learn. 2019, 12, 307–392. [Google Scholar] [CrossRef]
- Hudon, A.; Phraxayavong, K.; Potvin, S.; Dumais, A. Comparing the Performance of Machine Learning Algorithms in the Automatic Classification of Psychotherapeutic Interactions in Avatar Therapy. Mach. Learn. Knowl. Extr. 2023, 5, 1119–1131. [Google Scholar] [CrossRef]
- Werner, J.; Nowak, D.; Hunger, F.; Johnson, T.; Mark, A.; Gösta, A.; Edelvik, F. Predicting Wind Comfort in an Urban Area: A Comparison of a Regression-with a Classification-CNN for General Wind Rose Statistics. Mach. Learn. Knowl. Extr. 2024, 6, 98–125. [Google Scholar] [CrossRef]
- Mehta, D.; Klarmann, N. Autoencoder-Based Visual Anomaly Localization for Manufacturing Quality Control. Mach. Learn. Knowl. Extr. 2023, 6, 1–17. [Google Scholar] [CrossRef]
- Rodriguez-Bazan, H.; Sidorov, G.; Escamilla-Ambrosio, P.J. Android Malware Classification Based on Fuzzy Hashing Visualization. Mach. Learn. Knowl. Extr. 2023, 5, 1826–1847. [Google Scholar] [CrossRef]
- Samkari, E.; Arif, M.; Alghamdi, M.; Al Ghamdi, M.A. Human Pose Estimation Using Deep Learning: A Systematic Literature Review. Mach. Learn. Knowl. Extr. 2023, 5, 1612–1659. [Google Scholar] [CrossRef]
- Zhou, Q.; Wang, J.; Yu, X.; Wang, S.; Zhang, Y. A Survey of Deep Learning for Alzheimer’s Disease. Mach. Learn. Knowl. Extr. 2023, 5, 611–668. [Google Scholar] [CrossRef]
- Mapundu, M.T.; Kabudula, C.W.; Musenge, E.; Olago, V.; Celik, T. Explainable Stacked Ensemble Deep Learning (SEDL) Framework to Determine Cause of Death from Verbal Autopsies. Mach. Learn. Knowl. Extr. 2023, 5, 1570–1588. [Google Scholar] [CrossRef]
- Nemirovsky-Rotman, S.; Bercovich, E. Explicit Physics-Informed Deep Learning for Computer-Aided Diagnostic Tasks in Medical Imaging. Mach. Learn. Knowl. Extr. 2024, 6, 385–401. [Google Scholar] [CrossRef]
- Bendangnuksung, P.P. Students’ Performance Prediction Using Deep Neural Network. Int. J. Appl. Eng. Res. 2018, 13, 1171–1176. [Google Scholar]
- Wang, L.; Sy, A.; Liu, L.; Piech, C. Deep Knowledge Tracing on Programming Exercises. In Proceedings of the Fourth (2017) ACM Conference on Learning @ Scale, Cambridge, MA, USA, 20–21 April 2017; pp. 201–204. [Google Scholar]
- Kukkar, A.; Mohana, R.; Sharma, A.; Nayyar, A. Prediction of Student Academic Performance Based on Their Emotional Wellbeing and Interaction on Various E-Learning Platforms. Educ. Inf. Technol. 2023, 28, 9655–9684. [Google Scholar] [CrossRef]
- Fei, M.; Yeung, D.-Y. Temporal Models for Predicting Student Dropout in Massive Open Online Courses. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 256–263. [Google Scholar]
- Teruel, M.; Alonso Alemany, L. Co-Embeddings for Student Modeling in Virtual Learning Environments. In Proceedings of the 26th Conference on User Modeling, Adaptation and Personalization, Singapore, 8–11 July 2018; pp. 73–80. [Google Scholar]
- Whitehill, J.; Mohan, K.; Seaton, D.; Rosen, Y.; Tingley, D. Delving Deeper into MOOC Student Dropout Prediction. arXiv 2017, arXiv:1702.06404. [Google Scholar]
- Abhinav, K.; Subramanian, V.; Dubey, A.; Bhat, P.; Venkat, A.D. LeCoRe: A Framework for Modeling Learner’s Preference. In Proceedings of the 11th International Conference on Educational Data Mining, Buffalo, NY, USA, 15–18 July 2018. [Google Scholar]
- Wong, C. Sequence Based Course Recommender for Personalized Curriculum Planning. In Artificial Intelligence in Education. AIED 2018, Proceedings of the AIED 2018, London, UK, 27–30 June 2018; Springer: Cham, Switzerland, 2018; pp. 531–534. [Google Scholar]
- Hooshyar, D.; Yang, Y. ImageLM: Interpretable Image-Based Learner Modelling for Classifying Learners’ Computational Thinking. Expert Syst. Appl. 2024, 238, 122283. [Google Scholar] [CrossRef]
- Taghipour, K.; Ng, H.T. A Neural Approach to Automated Essay Scoring. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1882–1891. [Google Scholar]
- Zhao, S.; Zhang, Y.; Xiong, X.; Botelho, A.; Heffernan, N. A Memory-Augmented Neural Model for Automated Grading. In Proceedings of the Fourth (2017) ACM Conference on Learning @ Scale, Cambridge, MA, USA, 20–21 April 2017; pp. 189–192. [Google Scholar]
- Mao, Y. Deep Learning vs. Bayesian Knowledge Tracing: Student Models for Interventions. J. Educ. Data Min. 2018, 10, 28–54. [Google Scholar]
- Tang, S.; Peterson, J.C.; Pardos, Z.A. Deep Neural Networks and How They Apply to Sequential Education Data. In Proceedings of the Third (2016) ACM Conference on Learning @ Scale, Edinburgh, UK, 25–26 April 2016; pp. 321–324. [Google Scholar]
- Sharada, N.; Shashi, M.; Xiong, X. Modeling Student Knowledge Retention Using Deep Learning and Random Forests. J. Eng. Appl. Sci. 2018, 13, 1347–1353. [Google Scholar]
- Alam, M.M.; Mohiuddin, K.; Das, A.K.; Islam, M.K.; Kaonain, M.S.; Ali, M.H. A Reduced Feature Based Neural Network Approach to Classify the Category of Students. In Proceedings of the 2nd International Conference on Innovation in Artificial Intelligence, Shanghai, China, 9–12 March 2018; pp. 28–32. [Google Scholar]
- Kim, B.-H.; Vizitei, E.; Ganapathi, V. GritNet: Student Performance Prediction with Deep Learning. arXiv 2018, arXiv:1804.07405. [Google Scholar]
- Wang, W.; Yu, H.; Miao, C. Deep Model for Dropout Prediction in MOOCs. In Proceedings of the 2nd International Conference on Crowd Science and Engineering, Beijing, China, 6–9 July 2017; pp. 26–32. [Google Scholar]
- Tato, A.; Nkambou, R.; Dufresne, A.; Beauchamp, M.H. Convolutional Neural Network for Automatic Detection of Sociomoral Reasoning Level. In Proceedings of the 10th International Conference on Educational Data Mining, Wuhan, China, 25–28 June 2017. [Google Scholar]
- Min, W.; Wiggins, J.B.; Pezzullo, L.G.; Vail, A.K.; Boyer, K.E.; Mott, B.W.; Frankosky, M.H.; Wiebe, E.N.; Lester, J.C. Predicting Dialogue Acts for Intelligent Virtual Agents with Multimodal Student Interaction Data. In Proceedings of the 9th International Conference on Educational Data Mining, Raleigh, NC, USA, 29 June–2 July 2016. [Google Scholar]
- Sharma, A.; Biswas, A.; Gandhi, A.; Patil, S.; Deshmukh, O. LIVELINET: A Multimodal Deep Recurrent Neural Network to Predict Liveliness in Educational Videos. In Proceedings of the 9th International Conference on Educational Data Mining, Raleigh, NC, USA, 29 June–2 July 2016. [Google Scholar]
- Tran, S.N.; Garcez, A.S.d.A. Deep Logic Networks: Inserting and Extracting Knowledge from Deep Belief Networks. IEEE Trans. Neural Netw. Learn. Syst. 2016, 29, 246–258. [Google Scholar] [CrossRef]
- Hu, Z.; Ma, X.; Liu, Z.; Hovy, E.; Xing, E. Harnessing Deep Neural Networks with Logic Rules. arXiv 2016, arXiv:1603.06318. [Google Scholar]
- Serafini, L.; d’Avila Garcez, A.S. Learning and Reasoning with Logic Tensor Networks. In AI*IA 2016 Advances in Artificial Intelligence. AI*IA 2016, Proceedings of the XVth International Conference of the Italian Association for Artificial Intelligence, Genova, Italy, 29 November–1 December 2016; Adorni, G., Cagnoni, S., Gori, M., Maratea, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 334–348. [Google Scholar]
- Yu, D.; Yang, B.; Liu, D.; Wang, H.; Pan, S. A Survey on Neural-Symbolic Learning Systems. Neural Netw. 2023, 166, 105–126. [Google Scholar] [CrossRef] [PubMed]
- Shakya, A.; Rus, V.; Venugopal, D. Student Strategy Prediction Using a Neuro-Symbolic Approach. In Proceedings of the 14th International Conference on Educational Data Mining, Online, 29 June–2 July 2021. [Google Scholar]
- Hooshyar, D.; Lim, H.; Pedaste, M.; Yang, K.; Fathi, M.; Yang, Y. AutoThinking: An Adaptive Computational Thinking Game. In Innovative Technologies and Learning. ICITL 2019, Proceedings of the Second International Conference, ICITL 2019, Tromsø, Norway, 2–5 December 2019; Rønningsbakk, L., Wu, T.T., Sandnes, F., Huang, Y.M., Eds.; Springer: Cham, Switzerland, 2019; pp. 381–391. [Google Scholar]
- Towell, G.G.; Shavlik, J.W. Knowledge-Based Artificial Neural Networks. Artif. Intell. 1994, 70, 119–165. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-Agnostic Interpretability of Machine Learning. arXiv 2016, arXiv:1606.05386. [Google Scholar]
- Azevedo, R.; Dever, D. Metacognition in Multimedia Learning. In Cambridge Handbook of Multimedia; Cambridge University Press: Cambridge, UK, 2022; pp. 132–141. [Google Scholar]
- Greene, J.A.; Azevedo, R. A Macro-Level Analysis of SRL Processes and Their Relations to the Acquisition of a Sophisticated Mental Model of a Complex System. Contemp. Educ. Psychol. 2009, 34, 18–29. [Google Scholar] [CrossRef]
- Pekrun, R. The Control-Value Theory of Achievement Emotions: Assumptions, Corollaries, and Implications for Educational Research and Practice. Educ. Psychol. Rev. 2006, 18, 315–341. [Google Scholar] [CrossRef]
- Winne, P.H.; Azevedo, R. Metacognition. In Cambridge Handbook of the Learning Sciences; Cambridge University Press: Cambridge, UK, 2014; pp. 63–87. [Google Scholar]
- Hooshyar, D. Effects of Technology-enhanced Learning Approaches on Learners with Different Prior Learning Attitudes and Knowledge in Computational Thinking. Comput. Appl. Eng. Educ. 2022, 30, 64–76. [Google Scholar] [CrossRef]
- European Union Agency for Fundamental Rights. Bias in Algorithms—Artificial Intelligence and Discrimination; European Union Agency for Fundamental Rights: Vienna, Austria, 2022. [Google Scholar]
- Blodgett, S.L.; Barocas, S.; Daumé, H., III; Wallach, H. Language (Technology) Is Power: A Critical Survey of “Bias” in Nlp. arXiv 2020, arXiv:2005.14050. [Google Scholar]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on Deep Learning with Class Imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Liusie, A.; Raina, V.; Raina, V.; Gales, M. Analyzing Biases to Spurious Correlations in Text Classification Tasks. In Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing, Online, 20–23 November 2022; pp. 78–84. [Google Scholar]
- Hooshyar, D.; El Mawas, N.; Milrad, M.; Yang, Y. Modeling Learners to Early Predict Their Performance in Educational Computer Games. IEEE Access 2023, 11, 20399–20417. [Google Scholar] [CrossRef]
- Venugopal, D.; Rus, V.; Shakya, A. Neuro-Symbolic Models: A Scalable, Explainable Framework for Strategy Discovery from Big Edu-Data. In Proceedings of the 2nd Learner Data Institute Workshop in Conjunction with the 14th International Educational Data Mining Conference, Online, 29 June–2 July 2021. [Google Scholar]
- Ramezankhani, A.; Pournik, O.; Shahrabi, J.; Azizi, F.; Hadaegh, F.; Khalili, D. The Impact of Oversampling with SMOTE on the Performance of 3 Classifiers in Prediction of Type 2 Diabetes. Med. Decis. Mak. 2016, 36, 137–144. [Google Scholar] [CrossRef]
- Zhou, C.; Ma, X.; Michel, P.; Neubig, G. Examining and Combating Spurious Features under Distribution Shift. In Proceedings of the 38th International Conference on Machine Learning, Online, 18–24 July 2021; pp. 12857–12867. [Google Scholar]
- Hutt, S.; Gardner, M.; Duckworth, A.L.; D’Mello, S.K. Evaluating Fairness and Generalizability in Models Predicting On-Time Graduation from College Applications. In Proceedings of the 12th International Conference on Educational Data Mining, Montreal, QC, Canda, 2–5 July 2019. [Google Scholar]
- Fiok, K.; Farahani, F.V.; Karwowski, W.; Ahram, T. Explainable Artificial Intelligence for Education and Training. J. Def. Model. Simul. 2022, 19, 133–144. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step | Description |
|---|---|
| 1 | Rewrite rules (the symbolic knowledge in propositional logic form) to eliminate disjuncts. |
| 2 | Translate the rule structure into a neural network format. |
| 3 | Incorporate essential features that were not explicitly covered in the mapping. |
| 4 | Introduce hidden units into the architecture of the neural network. |
| 5 | Categorize units within the KBANN based on their respective levels. |
| 6 | Establish connections that are not explicitly defined by translating between all units in adjacent levels. |
| 7 | Introduce perturbations to the network by adding small random numbers to all link weights and biases. |
| 8 | Assign significant weight values to links derived from domain knowledge rules. |
| 9 | Apply backpropagation to refine the network to fit the training data. |
| 10 | Use weights and biases of the learned network to extract rules, explaining the predictions. |
| Features | Label (Final Performance) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Low | High | |||||||||
| Goal Setting | ✓ | ✓ | ✓ | ✓ | ||||||
| Prior Knowledge Activation | ✓ | ✓ | ||||||||
| Planning | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Judgement of Learning | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Time Management | ✓ | ✓ | ✓ | ✓ | ||||||
| Monitoring (Progress Towards Goals) | ✓ | ✓ | ✓ | ✓ | ||||||
| Search for Information | ✓ | ✓ | ✓ | ✓ | ||||||
| Help Seeking | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Frustration | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Time Spent Watching Learning Materials | ✓ | ✓ | ✓ | ✓ | ||||||
| Self-reported Emotion Rating | ✓ | ✓ | ||||||||
| Concentration | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Forum Chat | ✓ | ✓ | ||||||||
| Automatic Logout | ✓ | ✓ | ✓ | |||||||
| Making Inferences | ✓ | ✓ | ✓ | |||||||
| Features | Min | Max | Average | Deviation |
|---|---|---|---|---|
| Arrow | 15 | 180 | 82.05 | 34.65 |
| Big cheese | 0 | 4 | 1.6 | 0.7 |
| Small cheese | 0 | 74 | 63.38 | 17.72 |
| Function | 0 | 4 | 0.6 | 1.2 |
| Debug | 0 | 17 | 0.8 | 2.3 |
| Simulation | 0 | 19 | 2.92 | 4.24 |
| Loop | 0 | 50 | 6.66 | 8.12 |
| Conditional | 0 | 46 | 3 | 6.4 |
| Hitting wall | 0 | 180 | 6.19 | 18.57 |
| Final score | True = 364 | False = 63 | ||
| Rule No. | Propositional Logic Representation | Explanation |
|---|---|---|
| 1 | Final_score: CT_concepts, CT_skills. | Final score or performance in a given task is contingent on achieving mastery in both CT skills and concepts. |
| 2 | CT_concepts: Conditional, Loop. | CT concepts are linked to the features of conditional and loop structures within the training dataset. |
| 3 | CT_skills: Debug, Simulation, Function. | CT skills rely on proficiency in debugging, simulation, and function features. |
| Features | Final Score | |||
|---|---|---|---|---|
| Training Data | SMOTE-Augmented Training Data | Autoencoder-Augmented Training Data | Test Data | |
| Arrow | 0.322 1 | 0.412 | 0.51 | 0.255 |
| Big_cheese | 0.728 | 0.858 | 0.68 | 0.445 |
| Conditional | 0.107 | 0.203 | 0.154 | 0.175 |
| Debug | 0.066 | 0.124 | 0.135 | 0.027 |
| Function | 0.011 | 0.027 | 0.005 | 0.233 |
| Hitting_wall | −0.31 | −0.23 | −0.122 | −0.003 |
| Loop | 0.164 | 0.295 | 0.239 | 0.25 |
| Simulation | 0.194 | 0.343 | 0.189 | 0.284 |
| Small_cheese | 0.887 | 0.942 | 0.807 | 0.632 |
| Models | Source of Learning | Accuracy (%) | Recall (%) | Precision (%) | ||
|---|---|---|---|---|---|---|
| High | Low | High | Low | |||
| Deep NN | Training data | 83.53 | 85.81 | 75.00 | 93.65 | 54.55 |
| Deep NN- SMOTE | Training data + synthetical data | 82.35 | 85.51 | 68.75 | 92.19 | 52.38 |
| Deep NN- Autoencoder | Training data + synthetical data | 83.53 | 86.00 | 68.75 | 92.31 | 55.00 |
| NSAI | Training data + educational knowledge | 84.71 | 86.00 | 81.00 | 95.00 | 57.00 |
| Model | Ground Truth | Prediction | Confidence (Low, High) | Supporting | Contradicting |
|---|---|---|---|---|---|
| Deep NN | Low | High | 0.000, 1.000 | Small_cheese = (value = 70, importance = 0.465) Arrow = (value = 76, importance = 0.204) | Hitting_wall = (value = 9, importance = −0.581) Conditional = (value = 0, importance = −0.162) |
| Low | High | 0.000, 1.000 | Small_cheese = (value = 61, importance = 0.463) Arrow = (value = 91, importance = 0.204) | Hitting_wall = (value = 2, importance = −0.582) Conditional = (value = 2, importance = −0.162) | |
| Low | High | 0.000, 1.000 | Small_cheese = (value = 67, importance = 0.463) Arrow = (value = 100, importance = 0.203) | Hitting_wall = (value = 4, importance = −0.582) Conditional = (value = 0, importance = −0.163) | |
| Deep NN- SMOTE | Low | High | 0.000, 1.000 | Small_cheese = (value = 70, importance = 0.397) Arrow = (value = 76, importance = 0.282) | Hitting_wall = (value = 9, importance = −0.643) Conditional = (value = 0, importance = −0.109) |
| Low | High | 0.000, 1.000 | Small_cheese = (value = 61, importance = 0. 397) Arrow = (value = 91, importance = 0.282) | Hitting_wall = (value = 2, importance = −0. 643) Conditional = (value = 2, importance = −0.109) | |
| Low | High | 0.000, 1.000 | Small_cheese = (value = 67, importance = 0. 397) Arrow = (value = 100, importance = 0.282) | Hitting_wall = (value = 4, importance = −0. 643) Conditional = (value = 0, importance = −0.109) | |
| Deep NN- Autoencoder | Low | High | 0.000, 1.000 | Small_cheese = (value = 61, importance = 0.339) Arrow = (value = 91, importance = 0.290) | Hitting_wall = (value = 2, importance = −0.683) Conditional = (value = 2, importance = −0.094) |
| Low | High | 0.000, 1.000 | Small_cheese = (value = 67, importance = 0.339) Arrow = (value = 100, importance = 0.290) | Hitting_wall = (value = 4, importance = −0.683) Conditional = (value = 0, importance = −0.094) | |
| Low | High | 0.000, 1.000 | Small_cheese = (value = 59, importance = 0.339) Arrow = (value = 86, importance = 0.290) | Hitting_wall = (value = 0, importance = −0.683) Conditional = (value = 0, importance = −0.094) |
| Variables | Rules |
|---|---|
| Final_score: | 4.6377187 < 2.4166102 × (head 2, head 3) + 0.8252018 × (CT_concepts) + 2.0046637 × (CT_skills) + 1.7674259 × (head 1) |
| CT_concepts: | 4.6082096 < 0.2453651 × (Small_cheese) + 3.002934 × (Conditional, Loop) + 0.0472862 × (Debug, Simulation, Function, Big_cheese, Hitting_wall) + −0.07132121 × (Arrow) |
| CT_skills: | 8.519821 < 0.20699154 × (Small_cheese) + 2.3430111 × (Simulation) + 1.0791004 × (Function) + −0.18917799 × (Conditional, Loop) + 2.6324146 × (Debug) + 0.45198494 × (Big_cheese) + −0.0066499244 × (Arrow) + −0.11537525 × (Hitting_wall) |
| head 1: | 2.2751489 < −0.070589505 × (Conditional, Loop, Debug, Arrow) + 0.80795884 × nt(Big_cheese) + 0.2296475 × (Hitting_wall) + −0.43813425 × (Function) + 0.09194418 × (Small_cheese) + 0.0072831404 × (Simulation) |
| head 2: | 2.881811 < −0.43790448 × (Function) + −0.04586086 × (Conditional, Loop, Debug, Simulation, Arrow, Hitting_wall) + 0.8505517 × (Big_cheese) + 0.097365424 × (Small_cheese) |
| head 3: | 2.874901 < −0.017702527 × (Simulation, Hitting_wall) + 0.8470087 × (Big_cheese) + −0.4385394 × (Function) + 0.09731795 × (Small_cheese) + −0.06676157 × (Conditional) + −0.09061724 × (Loop) + −0.051380966 × (Debug) + −0.031886093 × (Arrow) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hooshyar, D.; Azevedo, R.; Yang, Y. Augmenting Deep Neural Networks with Symbolic Educational Knowledge: Towards Trustworthy and Interpretable AI for Education. Mach. Learn. Knowl. Extr. 2024, 6, 593-618. https://doi.org/10.3390/make6010028
Hooshyar D, Azevedo R, Yang Y. Augmenting Deep Neural Networks with Symbolic Educational Knowledge: Towards Trustworthy and Interpretable AI for Education. Machine Learning and Knowledge Extraction. 2024; 6(1):593-618. https://doi.org/10.3390/make6010028
Chicago/Turabian StyleHooshyar, Danial, Roger Azevedo, and Yeongwook Yang. 2024. "Augmenting Deep Neural Networks with Symbolic Educational Knowledge: Towards Trustworthy and Interpretable AI for Education" Machine Learning and Knowledge Extraction 6, no. 1: 593-618. https://doi.org/10.3390/make6010028
APA StyleHooshyar, D., Azevedo, R., & Yang, Y. (2024). Augmenting Deep Neural Networks with Symbolic Educational Knowledge: Towards Trustworthy and Interpretable AI for Education. Machine Learning and Knowledge Extraction, 6(1), 593-618. https://doi.org/10.3390/make6010028