
Exploring the Innovation Diffusion of Big Data Robo-Advisor


Department of Business Administration, Asia University, Taichung 413305, Taiwan
*
Author to whom correspondence should be addressed.
Appl. Syst. Innov. 2022, 5(1), 15; https://doi.org/10.3390/asi5010015
Submission received: 11 December 2021
/
Revised: 1 January 2022
/
Accepted: 20 January 2022
/
Published: 24 January 2022
(This article belongs to the Special Issue Applied Systems on Emerging Technologies and Educational Innovations)
Abstract
:The main objective of this study was to explore the current practical use of an AI robo-advisor algorithmic technique. This study utilizes Roger’s innovation diffusion theory as a basis to explore the application of robo-advisors for forecasting in the stock market by using an abductive reasoning approach. We used literature reviews and semi-structured interviews to interview representatives of fund companies to see if they had adopted AI big data forecasting models to invest in stock selection. This study summarizes the big data stock market forecasts of the literature. According to the summary, the accuracy of the prediction models of these scholars ranged from 52% to 97%, with the prediction results of the models varying significantly. Interviews with 21 representatives of these fund companies revealed that the stock market forecast model of big data robo-advisors have not become a reference basis for fund investment candidates, mainly because of the unstable model prediction rate, and the lack of apparent relative advantages and observability, as well as being too complex. Thus, from the view of innovation diffusion, there is a lack of diffusion for the robo-advisor. Knowledge occurs when an individual is exposed to the existence of innovation, and gains some understanding of how it functions. Thereby, when investors become more familiar with neural network-like stock prediction models, this novel AI stock market forecasting model is expected to become another indicator of technical analysis in the future.
1. Introduction
In recent years, with the rise of artificial intelligence (AI) algorithms, AI algorithms have been used in academia to develop predictive models for the stock market, ranging from early time series and logistic regression to recent decision-making trees. Muncharaz’s stock prediction model (2020) could also be used to speculate the pricing evolution of financial assets. Predictive models can be classified into linear and non-linear models: the former would include time series models, such as autoregressive integrated moving averages, and exponential smooth models, among others, while networks would be classified to the latter [1]. Given that stock returns are not stationary, and present long-term dependence, this second group of models have shown effectiveness in achieving a higher accuracy, and a reduction in errors, compared with linear models [2]. Existing research related to the prediction of stock prices and their trends mainly utilize artificial neuronal networks. Due to substantial advancements in computing power, neural networks based on AI have become mainstream in recent research. Recurrent neural networks (RNN) and convolutional neural networks (CNN) are among the mainstream models used for stock market forecasting, and substantial time and energy have been invested to develop stock market forecasting models with higher accuracy rates. Big data robo-advisors then use these artificial intelligence (AI) algorithm predictive models as the basis for investment decisions [1,2].
For years, market investors have been pursuing a technique that beats the market, such as predicting the future direction of the stock market by studying the relationship between stock prices and volume, or exploring the value of a company, hoping to gain the opportunity to make a profit by understanding the difference between the value of a company and its market price. The existing method of predicting stock market prices can be generally divided into two types: fundamental analysis and technical analysis. Fundamental analysis based on macroeconomic data to study the company’s financial or revenue status as an investment judgment. Technical analysis is based on the theoretical basis of historical repetition, and the correlation between price and quantity shows the behavior of the market by taking advantage of the impact of past trading activities, and by analyzing the patterns and trends shown in the price and volume tables. In recent years, with technological improvements in computing powers, many novel algorithms have also emerged, as a series of stock market forecasting technologies have been developed, including time series or neural networks in hope to accurately predict the trend of stock prices by leveraging machine computing powers. The time series and neural network prediction models are based on historical repetition, and thus categorized as technical analysis [3]. Many factors are known to affect the stock market. Past studies in the financial investment field found that the stock market has the characteristics of a “stochastic random walk”, and thus cannot be predicted easily. According to the efficient market hypothesis by Fama (1965), asset prices reflect all available information. A direct implication is that it is impossible to “beat the market” consistently, on a risk-adjusted basis, since market prices are fully and quickly reflected, and only react to new information [4]. Three types of efficiencies exist depending on the efficiency of the market’s response to information: strong, semi-strong, and weak. These categories of tests refer to the information set used in the statement “prices reflect all available information.” Weak-form tests study the information contained in historical prices. Semi-strong form tests serve to study information (beyond historical prices) which is publicly available, and strong-form tests serve to regard private information. In modern financial markets, stock prices fully reflect earnings surprises on the announcement date, leading to the disappearance of post-earnings announcement drifts [5]. According to the results of the study, with the rise of the Internet, the dissipation of information accelerates, and the asymmetry of information in the form of unexpected news released by companies can no longer bring excess compensation to investors, thereby buttressing the efficiency market hypothesis. In the past, as there were still some trading restrictions in the market, a certain level of inefficiency remained in the market. With microcaps mitigated via NYSE breakpoints and value-weighted returns, capital markets are more efficient than has previously been recognized [6]. The efficient market hypothesis posits that, with weak efficiency, technical analysis would be rendered invalid, and that using technical analysis indicators as stock investment measurement standards would not yield better returns for investors. Therefore, neural networks’ ability to predict stock market trend is in doubt, as the efficient market hypothesis would be invalidated if these big data prediction models can indeed accurately predict the trend of stock prices. In this case, these prediction models will bring disruptive innovation to the investment community.
Recently, most AI stock market forecasting model studies have focused on the construction of algorithmic models to predict stock prices, and the focus of these studies is to improve the accuracy of forecasting. However, these studies lack discussions about the practical application of big data stock market prediction models from the perspective of users (mutual fund companies or professional investors). This study aims to use the empirical results of the past literature and the research method of semi-structured interviews to explore the current use of big data stock market forecasting models by major investment institutions in the market. Based on the innovative diffusion theory proposed by Rogers (2003), this study explores the reasons for the diffusion or non-proliferation of big data stock market forecasting models [7].
2. Literature Review
2.1. Research on Big Data Algorithm in Stock Market Prediction
AI algorithms have been used to develop prediction models for the stock market in many types, such as time series, logistic regression, decision-making trees, and neural networks. Muncharaz (2020) used long short-term recurrent neural network (LSTM) and exponential smooth time series (ETS) ARIMA to predict the S&P 500 stock prices [1]. His research found that the mean absolute error (MAE) of the LSTM model was the lowest, hence resulting in better predictions.
Many factors affect stock prices. When undertaking research on stock price prediction models, many scholars use data mining methods to engage external factors, such as market news, financial information, etc. Theoretically, the more comprehensive the market information available and the more reasonable the utilization of the information, the more likely that better prediction results could be obtained. By taking into consideration the news or information into the prediction models, Schumaker et al. (2012) demonstrated that the prediction accuracy of the model could be improved [8]. Vu et al. (2012) used the decision tree as a prediction model and added variables such as stock price fluctuations. By engaging factors such as consumer sentiment, the accuracy of stock price forecasts has also increased significantly [9]. In recent studies on the prediction models of the stock market, more research is based on neural network-like prediction models, such as Persio and Honchar (2016), Pang et al. (2018), Liu et al. (2020), Ding and Qin (2020), and Cheng et al. (2021) [10,11,12,13,14].
2.2. Innovation Diffusion Theory
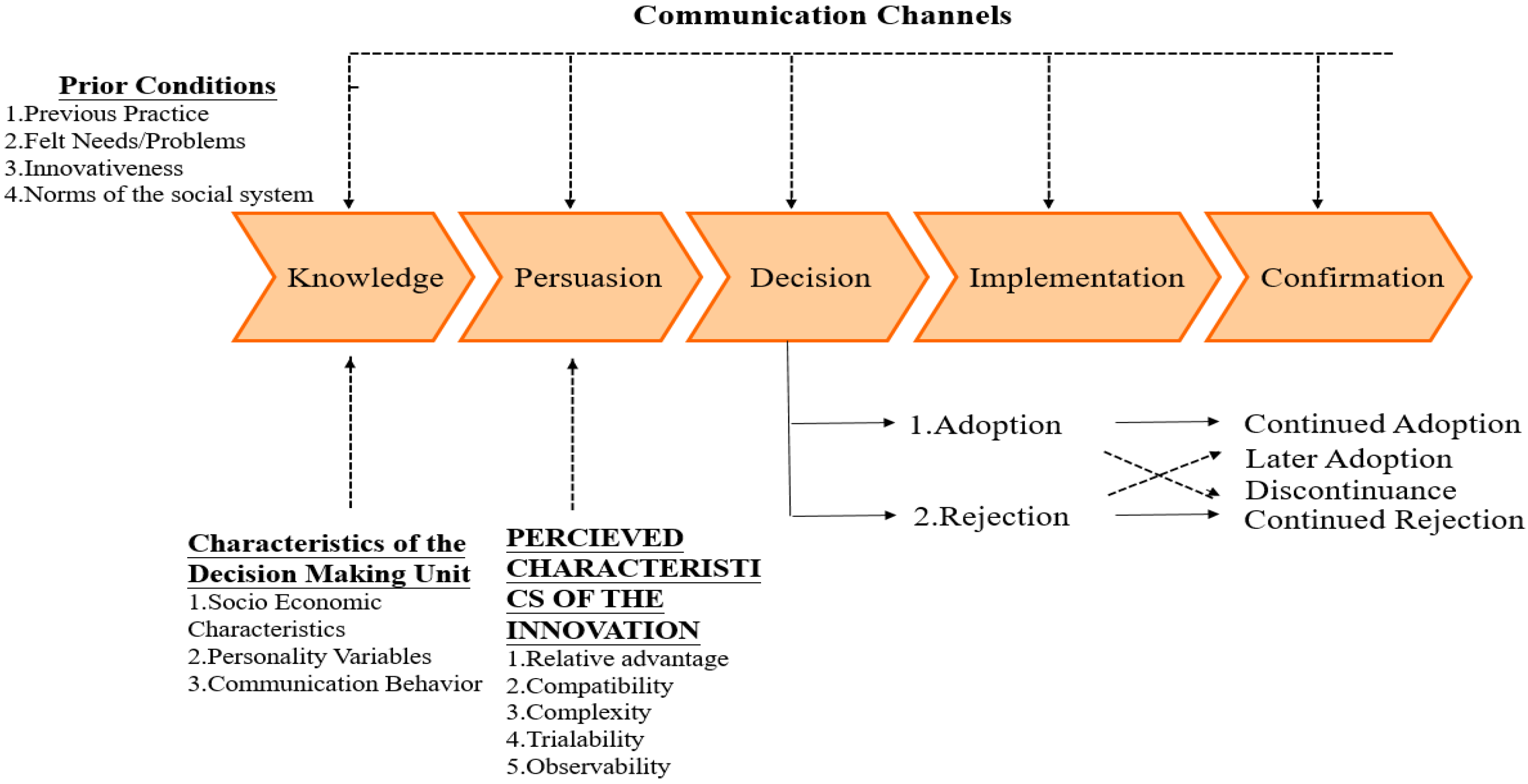
Innovation diffusion theory is a theory that seeks to explain how, why, and at what rate new ideas and technology spread. First put forward by Rogers in 2003, it theorizes and describes the dispersion process of innovation. Taking place within certain social systems, the innovative element uses a certain communication channel, and it takes a period of time. Starting with an incubation and maturing process, the diffusion would involve constituents’ support by their involvement in development, sharing and consensus building. There are four elements of innovation diffusion, including the innovation itself, communication channels, time, and social systems. The communication process is shown in Figure 1 with five stages, including knowledge, persuasion, decision, implementation, and confirmation [7]. The characteristics of innovations, as perceived by individuals, help to explain their different rates of adoption. Relative advantage is the degree to which an innovation as better than the idea it supersedes; the greater the perceived relative advantage of an innovation, the more rapid its rate of adoption is going to be. Compatibility is the degree to which an innovation is perceived as being consistent with the existing values, past experiences, and needs of potential adopters. An idea that is not compatible with the prevalent values and norms of a social system will not be adopted as rapidly as an innovation that is compatible. Complexity is the degree to which an innovation is perceived as difficult to understand and use. In general, new ideas that are simpler to understand will be adopted more rapidly than innovations that require the adopter to develop new skills and understandings. Trialability is the degree to which an innovation may be experimented with on a limited basis. New ideas that can be tried on the installment plan will generally be adopted more quickly than innovations that are not divisible. Observability is the degree to which the results of innovation are visible to others. The easier it is for individuals to see the results of an innovation, the more quickly they are to adopt [7].
Proceeding into the next stage is usually sequential, and time is needed in each stage for the new innovation to be accepted. If one of these steps cannot be satisfied, the process would discontinue, and the innovation cannot be diffused. An individual may also reject an innovation at any time during or after the adoption process. Ram and Sheth (1989) emphasized that the subsequent stages are needed for market users’ acceptance; otherwise, according to Moore (1999), innovative non-proliferation would occur, as shown in Figure 2 [15,16].
Big data robo-advisors are an innovative investment strategy that have recently emerged in the investment field, mainly utilizing big data AI forecasting models such as time series, decision trees, or neural networks to predict market ups and downs. This research will use the innovative diffusion theory, combined with the research results of previous scholars, and semi-structured expert interviews, to explore the diffusion of the new investment prediction model of big data robo-advisors.
3. Methodology
In the study of social sciences, induction and deduction are two different methods of logical reasoning. Deductive-oriented research mainly reviews previous theories and gaps, inconsistencies, or deficiencies in order to propose new concepts or propositions to compensate for these deficiencies. Deductive-oriented theoretical construction mainly relies on the logical thinking of scholars, and does not require continuous matching and adaptation between theory and data. Inductive-oriented research believes that because social phenomena are very complex, and human beings do not understand them well enough, theory should be deeply grounded in social reality, and researchers should actively keep close to reality and systematically collect data and analysis data, including the collection and analysis of previous empirical research results [17,18,19].
For instance, Yakovlev et al. (2021) used data collection (such as information on environmental issues, financial information and the Paris Climate Agreement, etc.) and literature reviews to explore “Changes in Climate Policies and Financial Strategies of Their Implementation in the EU and Russia” [20]. Similarly, Kranina (2021) utilized the same research method to collect relevant environmental issues and literature reviews to explore “China on the way to achieving carbon neutrality” [21]. Their research did not involve the discussion of related theories, but systematically collected data and analyzed the data, supplemented by past empirical results, to draw conclusions or theories. They concluded that this research method was more inductive. Mikhaylov (2021) further expanded upon von Hayek’s theory to explore the application of digital currencies in economic implementation, to conclude that this research method was more deductive [22]. In addition to the logical reasoning method, and the above induction and deduction reasoning, there is also the abduction reasoning, which was introduced by American philosopher Charles Sanders Peirce, and differs from induction reasoning and deduction reasoning. Abduction reasoning starts with an observation or set of observations and then seeks the simplest and most likely conclusion from the observations.
This study adopts an abductive reasoning approach, literature review and semi-structured interviews, and aims to summarize the results of past scholars’ research on AI big data stock market analysis models to understand the predictive effectiveness of these models. Nandi et al. (2020) also use an abductive reasoning approach to explore the impact of block-chain on supply chain performance with the resource-based theory [23]. Data for this research was obtained from a leading business news database and was developed with a guiding framework for identifying block-chain technology that enabled supply chain capabilities by referring to academic papers that focused on supply chain capabilities enabled by various types of ICT resources. Data analysis involved a non-linear path between data, data sources and theory. Content for each sample case was carefully examined and matched with the guiding frameworks independently by three authors. This abductive reasoning approach is a process of reasoning that explains and evaluates real-life phenomena with back-and-forth inference between the theory of existing phenomena and real data [24,25]. This allows researchers to anchor their findings in the initial theory, and then develop and refine the theory as a data collection and analysis process [26,27].
To understand the technological innovation diffusion of AI stock selection models, this study utilizes semi-structured interviews to ask channel representatives of professional investment institutions (such as fund companies) to the current adoption of AI stock selection models to support investment decision-making. However, since stock selection models and operation technologies are considered important trade secrets for fund companies, it is uncommon for external parties to gain knowledge of these aspects. Therefore, this study focused on interviewing business representatives of the main agency fund company of the bank where the author is affiliated, and used semi-structured interviews to verbally identify a prepared list of questions, item-by-item, to collect information.
The abductive reasoning was carried out through the logical theory T, and the observation set O. The explaining set E was observation set O derived from logical theory T. Explaining set E was the interpretation of observation Set O based on Theory T, with its Formula (1) shown below.
T U E = O
This research utilizes a relevant literature review of an AI big data prediction model (observation set O) by innovation diffusion theory (logical theory T) and conducts semi-structural interviews (explaining set E) with professional investment institutions to understand the diffusion of the AI big data prediction model. We conducted a qualitative content analysis following the logic of abduction, as depicted in Figure 3.
4. Discussion
From the previous research, it was found that the prediction effect of neural networks was better than other models [1,2], so this study takes the neural network-like prediction model as the subject of discussion. While earlier studies tended to use mean absolute error (MAE) to show the correctness of predictions of neural network-like models [2], recent studies have used the accuracy ratio as the correctness of predictions, so for the sake of research consistency, we used recent research literature data as a standard. This study summarizes the big data stock market forecasts of scholars such as Persio and Honchar (2016), Pang et al. (2018), Liu et al. (2020), Ding and Qin (2020), and Cheng et al. (2021), as shown in Table 1 [10,11,12,13,14]. According to the summary, the accuracy of the prediction models of these scholars ranged from 52% to 97%, with the prediction results of the models varying significantly.
Investors would like the higher accuracy ratio of the investment forecast model, and the prediction results should be more consistent, otherwise the reliability of the model will be reduced. Table 1 shows the accuracy ratio of the research model of various scholars. In addition to the empirical results of scholars such as Ding and Qin (2020) and Cheng et al. (2021) with higher accuracy rates (above 70%), the accuracy rates from other researchers were less than 70%, and the prediction accuracy rates of the different methods and different markets were inconsistent [13,14]. The results indicate that the accuracy of the stock selection prediction model of recent AI neural networks has indeed improved, but the prediction results are not stable. Therefore, it is impossible to obtain a broad and consistent prediction accuracy rate, which can convince external investors and promote this innovation. The stock price prediction model is used in the actual stock selection operation of the stock market.
Next, semi-structured interviews were conducted with representatives of various asset management companies (such as fund companies) by enquiring whether the mutual funds managed by their companies use neural networks as investment models whilst asking them to provide related supporting sales data. After interviews with the business representatives from 21 fund companies (with a total of 551 funds in portfolios under these managers), only one of the respondents (4.76%) said that he/she was not previously aware of the big data forecasting model. Therefore, from Roger’s proposed communication channels of innovation diffusion theory, this interviewee in the first stage (“knowledge”) did not have a further understanding of this big data prediction model. Twenty respondents (95.24%) said their fund companies did not use the big data forecasting model as a stock selection model. This means that respondents were aware of the big data forecasting model, but it was not used an investment stock selection model for the funds to which they belonged. This also implies that in Roger’s proposed communication channels model, respondents were in the first stage, “knowledge”—they already knew the big data forecasting model. However, for the second stage—“persuasion”—the respondents were not persuaded to use the big data forecasting model as the fund’s investment stock selection model.
Therefore, from the results of Table 2, the prediction model of the big data robo-advisor was not selected by fund companies as the forecast model. From the innovation diffusion theory perspective, this innovative technology had not been diffused.
5. Conclusions
Based on the consolidated relevant big data stock market forecast literature and semi-structured interviews with the business representatives of fund companies, this study found that innovative AI stock selection models have not been widely adopted by fund companies. To further investigate the reasons behind this phenomenon—although the prediction accuracies of AI big data stock selection models, especially the more recently popular neural network prediction models, have improved, the prediction results are neither stable nor accurate enough, and are thus not widely adopted by fund companies.
From Rogers’ (2003) innovation diffusion theory, for an innovative technology to go through the diffusion process to be widely used or fully dispersed, the innovation needs complete the five stages. The initial stage of “knowledge” is when innovative products or technologies have just been proposed; to be accepted by the market and then be commercialized and widely used, the diffusion needs to enter the second stage of “persuasion” (which includes relative advantage, complexity, testability, and observability). Ram and Sheth (1989) believed that, when a new technological innovation is introduced to market with increasing awareness, persuasion is needed to ensure that this technology can be successfully developed [15]. Otherwise, the lack of innovation diffusion (or non-proliferation) would be congruent with Moore (1999)’s research, as shown in Figure 2 [16]. In the context of this research, the AI stock selection model prediction results were not stable, so it failed in the stage of persuasion. There lacks evidence that this prediction technology would perform significantly better than other investment methods, and it is unclear whether more profitability could be yielded compared with current or past investment methods.
Moreover, the AI big data stock selection models focus more on information engineering-based calculation technology, outside of fund managers’ usual knowledge domains, and fund managers have expressed difficulty in adopting them towards decision-making of investment stock selection. Finally, most concepts of the AI big data stock selection models are still in the academic or theoretical discussion stage, and have not been fully commercialized for practical use; thus, they are lacking past investment performance, and therefore observability. In sum, there are high barriers to persuade investors in the market to adopt this innovative technology, thereby preventing the technology from spreading from early adopters to the early majority (as indicated by the chasm shown in Figure 2), resulting in the non-proliferation of innovation.
Regarding the theoretical contributions of this study, the time series and neural network prediction models are based on historical repetition, and hence are categorized as technical analysis methods [3]. As Persio and Honchar (2016), Pang et al. Al. (2018), Liu et al. (2020), Ding and Qin (2020), Cheng et al. (2021), etc., found that the prediction results of neural network-like AI stock selection models are not stable, these findings further support that the use of these innovative calculation techniques cannot bring excess returns to investors. Therefore, the research validated the notion that the recent emergence of artificial neural network-based AI stock selection models cannot break the Fama (1965) efficient-market hypothesis. As the relevant auxiliary market information has been fully and quickly reflected on the stock price, using these data to construct additional technical advancements, such as neural network-like AI stock selection models for stock price forecasts, cannot yield excess gains [10,11,12,13,14].
In practice, this study found that, while neural networks are currently the hottest stock forecasting model of artificial intelligence, there is a gap between academic preference and industry adoption. From Roger’s perspectives, diffusion is a particular type of communication in which the information that is exchanged is concerned with new ideas. The essence of the diffusion process is the information exchange by which one individual communicates a new idea to one or several others. So, knowledge occurs when an individual is exposed to the innovation’s existence and gains some understanding of how it functions [7]. Although the neural network’s stock forecasting model has not been adopted by professional investment institutions as the main stock selection model, investors have become more familiar with neural network-like stock prediction models in a non-linear way to construct the stock prediction model. This novel AI stock-forecasting model is different from the past traditional technical indicators, such as RSI, KD, and MACD, and works in a linear way to construct the stock forecast indicators to make up gap for the past in the technical analysis indicators of non-linear indicators. Therefore, this novel AI stock market forecasting model is expected to become another technical analysis benchmark in the future.
Regarding limitations of this research, although this study endeavored to conduct semi-structured interviews with major asset management companies on related topics, since investment strategies are the companies’ trade secrets, some asset management companies were not willing to be interviewed, hence resulting in limited numbers of interviews conducted. Moreover, because there are many factors affecting stock prices, if the forecast model is developed solely from the stock price itself, the accuracy of the forecast cannot be improved. Therefore, it is recommended to follow Schumaker et al. (2012) and Vu et al. (2012), etc., to consider other possible influencing variables, in addition to the stock price itself [8,9]. Future research could incorporate influencing variables—for example, models such as the Golden stock pricing model with the company’s dividend growth rate, market interest rates, and other variables—to construct further forecasting models.
Author Contributions
Conceptualization, S.-C.T. and C.-H.C.; methodology, C.-H.C.; validation, S.-C.T.; formal analysis, C.-H.C.; investigation, C.-H.C.; resources, C.-H.C.; data curation, C.-H.C.; writing—original draft preparation, C.-H.C.; writing—review and editing, S.-C.T.; visualization, C.-H.C.; supervision, S.-C.T.; project administration, C.-H.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data was collected from the research of scholars, such as Persio and Honchar (2016), Pang et al. (2018), Liu et al. (2020), Ding and Qin (2020), and Cheng et al. (2021), and semi-structured interviews with representatives of various asset management companies.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Muncharaz, J.O. Comparing classic time series models and the LSTM recurrent neural network: An application to S&P 500 stocks. Financ. Mark. Valuat. 2020, 6, 137–148. [Google Scholar]
- Barkoulas, J.T.; Baum, C.F. Long-term dependence in stock returns. Econ. Lett. 1996, 53, 253–259. [Google Scholar] [CrossRef] [Green Version]
- Hou, F.-L.; Li, C.-S. Prediction Model of Multiple Fuzzy Neural Parameter on PSO-RLSE Algorithm in Stock Market Investment Strategy. Taiwan Acad. Manag. J. 2020, 20–21, 23–75. [Google Scholar]
- Fama, E.F. The behavior of stock market prices. J. Bus. 1965, 38, 34–105. [Google Scholar] [CrossRef]
- Martineau, C. Rest in Peace Post-Earnings Announcement Drift. Crit. Financ. Rev. 2021. Forthcoming. [Google Scholar]
- Hou, K.; Xue, C.; Zhang, L. Replicating Anomalies. Rev. Financ. Stud. 2020, 33, 2019–2133. [Google Scholar] [CrossRef]
- Rogers, E.M. Chapter 1 Elements of Diffusion. In Diffusion of Innovations, 5th ed.; The Free Press: New York, NY, USA, 2003; pp. 1–22. [Google Scholar]
- Schumaker, R.P.; Zhang, Y.; Huang, C.N.; Chen, H. Evaluating sentiment in financial news articles. Decis. Support Syst. 2012, 53, 458–464. [Google Scholar] [CrossRef]
- Vu, T.T.; Chang, S.; Quang, T.H.; Collier, N. An Experiment in Integrating Sentiment Features for Tech Stock Prediction in Twitter. Proc. Work. Inf. Extr. Entity Anal. Soc. Media Data 2012, 3, 23–38. [Google Scholar]
- Persio, L.D.; Honchar, O. Artificial Neural Networks architectures for stock price prediction: Comparisons and applications. Int. J. Circuits Syst. Signal Process. 2016, 10, 403–413. [Google Scholar]
- Pang, X.; Zhou, Y.; Wang, P.; Lin, W.; Chang, V. Stock Market Prediction based on Deep Long Short Term Memory Neural Network. In Proceedings of the 3rd International Conference on Complexity, Future Information Systems and Risk, Setubal, Portugal, 20–21 March 2018; pp. 102–108. [Google Scholar]
- Liu, S.; Zhang, X.; Wang, Y.; Feng, G. Recurrent convolutional neural kernel model for stock price movement prediction. PLoS ONE 2020, 15, e0234206. [Google Scholar] [CrossRef] [PubMed]
- Ding, G.; Qin, L. Study on the prediction of stock price based on the associated network model of LSTM. Int. J. Mach. Learn. Cybern. 2020, 11, 1307–1317. [Google Scholar] [CrossRef] [Green Version]
- Cheng, L.-C.; Lin, W.-S.; Lien, Y.-H. A Hybrid Deep Learning Model for Predicting Stock Market Trend Prediction. Int. J. Inf. Manag. Sci. 2021, 32, 121–140. [Google Scholar]
- Ram, S.; Sheth, J.N. Consumer Resistance to Innovation: The Marketing Problem and its Solutions. J. Consum. Mark. 1989, 6, 5–14. [Google Scholar] [CrossRef]
- Moore, G.A.; McKenna, R. Chapter 1 High-Tech Marketing Illusion. In Crossing the Chasm: Marketing and Selling High-Tech Products to Mainstream Customers; HarperCollins Publishers: New York, NY, USA, 1999; pp. 7–19. [Google Scholar]
- Glaser, B.; Strauss, A. The Discovery of Grounded Theory; Aldine: Chicago, IL, USA, 1967. [Google Scholar]
- Dougherty, D. Companion to Organizations (849–867). In Building Grounded Theory: Some Principles and Practices; Baum, J.A.C., Ed.; Blackwell Publishers: Oxford, UK, 2002. [Google Scholar]
- Chen, X.P.; Tsui, A.S.; Farh, J.L.; Cheng, B.S. Empirical Methods for Research in Organization and Management, 3rd ed.; Hwa Tai Publishing: Taipei, Taiwan, 2019. [Google Scholar]
- Yakovlev, I.A.; Kabir, L.S.; Nikulina, S.I. Changes in Climate Policies and Financial Strategies of Their Implementation in the EU and Russia. Financ. J. 2021, 5, 11–28. [Google Scholar] [CrossRef]
- Kranina, E.I. China on the way to achieving carbon neutrality. Financ. J. 2021, 5, 51–61. [Google Scholar] [CrossRef]
- Mikhaylov, A. Development of Friedrich von Hayek’s theory of private money and economic implications for digital currencies. Terra Econ. 2021, 19, 53–62. [Google Scholar] [CrossRef]
- Nandi, M.L.; Nandi, S.; Moya, H.; Kaynak, H. Blockchain technology-enabled supply chain systems and supply chain performance: A resource-based view. Supply Chain. Manag. 2020, 25, 841–862. [Google Scholar] [CrossRef]
- Dunne, D.D.; Dougherty, D. Abductive reasoning: How innovators navigate in the labyrinth of complex product innovation. Organ. Stud. 2016, 37, 131–159. [Google Scholar] [CrossRef]
- Magnani, L. Abduction, Reason and Science: Processes of Discovery and Explanation; Springer Science + Business Media: Berlin, Germany, 2011. [Google Scholar]
- Karatzas, M.; Johnson, M.; Bastl, M. Manufacturer-supplier relationships and service performance in service triads. Int. J. Oper. Prod. Manag. 2017, 37, 950–969. [Google Scholar] [CrossRef] [Green Version]
- Kovacs, G.; Spens, K.M. Abductive reasoning in logistics research. Int. J. Phys. Distrib. Logist. Manag. 2005, 35, 132–144. [Google Scholar] [CrossRef]
Figure 1.
A Model of Five Stages in the Innovation Decision Process. Adapted from Ref. [7].
Figure 1.
A Model of Five Stages in the Innovation Decision Process. Adapted from Ref. [7].

Figure 2.
The Revised Technology Adoption Life Cycle. Adapted from Ref. [16].
Figure 2.
The Revised Technology Adoption Life Cycle. Adapted from Ref. [16].

Figure 3.
Research Methodology.


{kind=link}
{kind=link}
{kind=link}
Table 1.
Summary of Neural Network Prediction Models.
| Author | Research Model | Accuracy |
|---|---|---|
| Persio and Honchar (2016) | MLP | 52.10% |
| CNN | 53.60% | |
| RNN | 52.20% | |
| Pang et al. (2018) | LSTM | 57.00% |
| Liu et al. (2020) | RCNK | 66.26% |
| RCNK-T | 59.44% | |
| RCNK-S | 63.25% | |
| CNK | 65.61% | |
| Ding and Qin (2020) | LSTM | 78.79% |
| DRNN | 97.37% | |
| Cheng et al. (2021) | CNN | 78.00% |
| LSTM | 77.00% | |
| CNN+LSTM | 80.00% |
Table 2.
Results of Interviews Fund Company Representatives.
| The Interviewee Was Not Aware of the Big Data Forecasting Model | The Fund Companies from Which the Representatives Were Interviewed Did Not Use the Big Data Forecasting Model for Stock Selection | The Number of Mutual Funds in the Interviewees’ Fund Company Listed in the Interviewer’s Bank | |
|---|---|---|---|
| Local fund companies | 7 | 101 | |
| Foreign fund companies | 13 | 433 | |
| 1 | 17 | ||
| Total | 1 | 20 | 551 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Tsai, S.-C.; Chen, C.-H. Exploring the Innovation Diffusion of Big Data Robo-Advisor. Appl. Syst. Innov. 2022, 5, 15. https://doi.org/10.3390/asi5010015
AMA Style
Tsai S-C, Chen C-H. Exploring the Innovation Diffusion of Big Data Robo-Advisor. Applied System Innovation. 2022; 5(1):15. https://doi.org/10.3390/asi5010015
Chicago/Turabian StyleTsai, Shuo-Chang, and Chih-Hsien Chen. 2022. "Exploring the Innovation Diffusion of Big Data Robo-Advisor" Applied System Innovation 5, no. 1: 15. https://doi.org/10.3390/asi5010015