1. Introduction
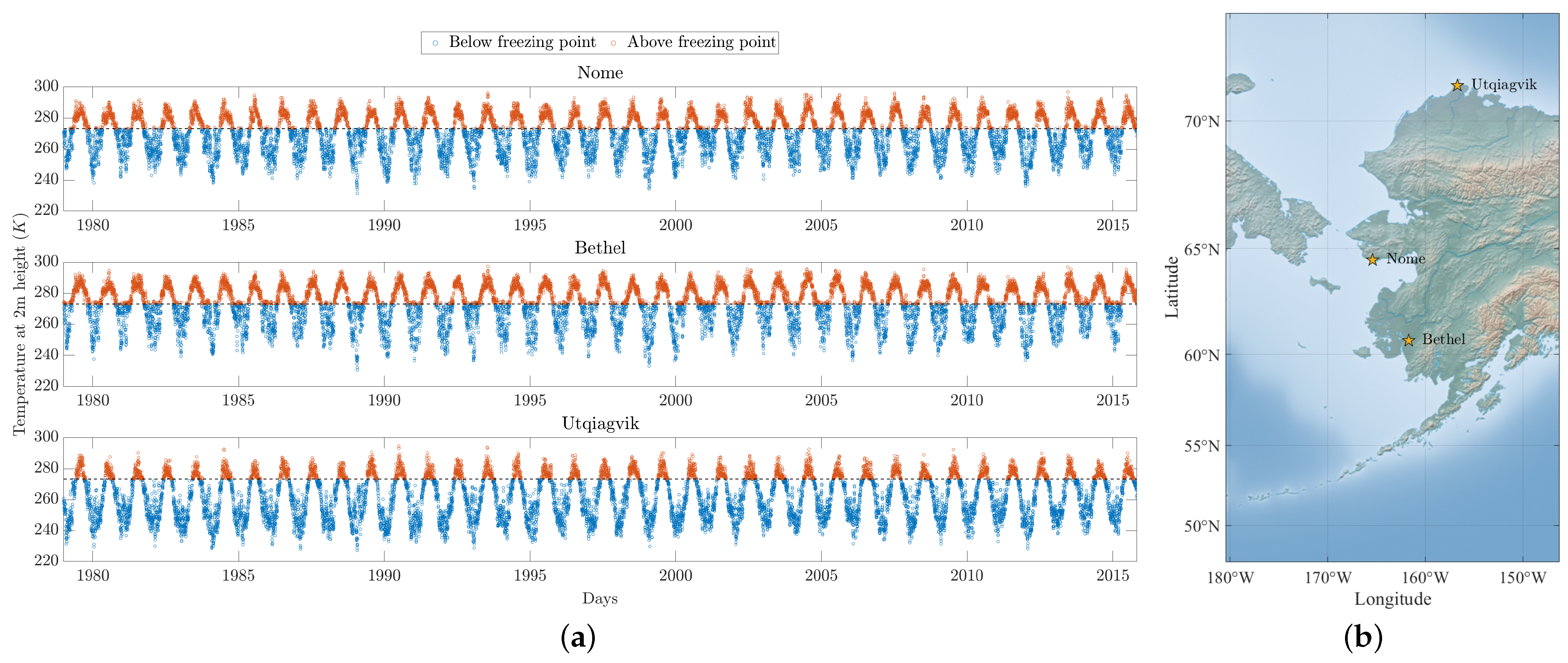
Infrastructure and natural environments in polar areas underlain by permafrost at temperatures near 0
are vulnerable to short- and long-term disturbances. Specifically, the climate-driven changes to the permafrost landscape of the US Arctic provide numerous terrain-related challenges [
1]. For example, the thawing of the permanently frozen ice-bearing regolith can result in the rapid collapse of the soil surface, degradation of roads and railroad embankments, and turn previously solid ground into muddy, waterlogged terrain, unnavigable by vehicle or on foot in summer months.
Permanently frozen ground, or permafrost, covers extended regions of the Earth. In a vertical section, the permafrost, by definition, begins at the bottom of the seasonally freezing and thawing surficial layer, called the active layer, and extends further down. The total thickness of permafrost varies from site to site, from a fraction of a meter in southern parts of the Arctic to over 1000 m in Siberia. For periods of years to tens of years, the permafrost temperatures typically change minimally unless disrupted by surficial changes in forest fires, snow depth, or climate. Most of the annual infrastructure damage and human-perceived problems in permafrost areas, come from the phase change of the water to ice and ice to water within the active layer and/or the melting of the permafrost.
Various drivers are behind thermal changes in permafrost. Long-term (e.g., years and tens of years) changes in boundary conditions can lead to changes in the permafrost thermal regime. For short-term (e.g., weekly, monthly, annual) variations of permafrost and especially the active layer thermal regime, the weather is the most important driver. Therefore, accurate measurement of air temperature can provide insights into thermal effects occurring underground. Such monitoring is especially important in regions of the Arctic where the permafrost temperatures are already close to 0 .
However, in Alaska and elsewhere in the Arctic, accurate local weather forecasts are often available only for cities and larger settlements. In addition, the temperature in these regions can be volatile and fluctuating, rapidly plunging from near 0 to −30 °C or lower. Moreover, traditional weather forecasting in remote Arctic regions is challenging due to the sparse network of ground stations providing real-time observations. The operational climate models that are regularly used for forecasting are physics-based fluid dynamics models aided by historical statistics, and they are guided by observed real-time near surface and atmospheric observations. Due to the lack of surface observations, however, the models are forced to interpolate across vast spaces of terrain. Therefore the forecast at any given point located far from the ground stations is, at best, an interpolated estimate.
Various methods have been proposed in the literature to forecast air temperature. Two main categories can be distinguished: physical models and statistical models. The first category includes numerical weather prediction models [
2,
3]. Although such models rely on physics-based modeling, they constitute large-scale models as they have a relatively large resolution (i.e., their grid spacing is greater than the local scale), require high computational costs, and might not be as accurate under certain meteorological and terrain conditions. Several studies have shown that incorporating post-processing techniques with these models can reduce their forecasting errors [
4,
5]. Diverse correction methods from statistical models, such as model output statistics [
6] and local dynamical analog [
7], to machine learning models, such as support vector regressions (SVRs), convolutional neural networks (CNNs), and gated recurrent units (GRU) [
5,
8], have all been proposed to improve the performance of numerical weather models. Nevertheless, these techniques generally require a large computational capacity as they rely on massive numerical simulations and post-processing approaches to achieve finer-scale end-user forecasts [
9].
In the second category, data-driven techniques have been leveraged in the literature to achieve end-to-end forecasting in primarily non-arctic environments. Such methods include simple statistical time series models, such as the auto-regressive integrated moving average (ARIMA) and its variants [
10,
11], and conventional machine learning techniques, such as SVR, Random Forest (RF), and shallow neural networks [
12,
13,
14]. For instance, the authors of [
10] developed a seasonal ARIMA model through the use of the Box and Jenkins method to predict long-term air temperature in the city of Tetuán, Morocco. Model learning was conducted using the monthly average air temperature data spanning from 1980 to 2022. In [
15], the authors investigated the effect of a combination of weather variables using a shallow neural network to predict the maximum temperature during the winter season of Tehran, Iran. This study employed monthly weather data spanning from 1951 to 2010. In [
16], the authors investigated conventional machine learning techniques for short-term single-horizon air temperature forecasts in Crary City in North Dakota, USA. Specifically, SVR, Regression Tree, Quantile Regression Tree, ARIMA, RF, and Gradient Boosting Regression, were trained and tested on a chronologically split time series temperature dataset of daily and weekly averages spanning from 2000 to 2021. Model performance was assessed using the root mean square error (RMSE), the correlation coefficient, Thiels’ U-statistics, and the mean absolute error (MAE), with RF providing the highest performance. These shallow machine learning techniques, however, have demonstrated limited performance.
In recent years, deep learning techniques have attracted increased attention in a wide range of fields and within this research area as well. Their success can be attributed to the increase in computational power, the availability of large datasets, and the rapid development of newer and more sophisticated architectures. For instance, the authors of [
17], investigated deep learning models for short-term single- and multi-horizon forecasting using data from JFK Airport, New York. Particularly, a long short-term memory (LSTM) model, a combination of CNN and LSTM, as well as multi-layer perceptron, were developed for one- to 10-day ahead forecasting. Model learning was conducted using the past seven days of wind speed, precipitation, snow depth, and mean, maximum, and minimum temperature data spanning from 2009 to 2019. Model performance was assessed using RMSE and the mean absolute percentage error (MAPE). The results highlighted the superiority of the CNN-LSTM model. In [
18], the authors addressed long-term multi-horizon air temperature forecasting using an attention-based network with an encoder–decoder architecture. This model learned the average daily temperature time series of five cities from Spain, India, New Zealand, and Switzerland spanning over 25 years. Model performance was assessed using several metrics, including RMSE, MAPE, and the coefficient of determination (
). The proposed model provided higher performance than different statistical and machine learning models. Despite the improved performances achieved by these deep data-driven models, forecasting air temperature remains a challenging undertaking due to its complex and fluctuating processes.
There is a combination of regularity and stochasticity that governs the temperature of the air, which makes air temperature time series generally highly fluctuating and non-stationary. Yet, the current literature does not consider addressing these inherent issues within data-driven techniques. Instead, they rely primarily on the ability of the machine learning model to accurately predict future patterns in the temperature. In addition, numerous studies evaluate their proposed techniques using temperature data acquired from a single location, overlooking the impact that different geographical and climatic conditions may have on its accuracy.
As a means of addressing these issues, this paper aims to build better operational capability to forecast air temperature at the local scale (1 km) based on limited on-site observations. To enhance the predictions’ accuracy, data-driven techniques can be employed. Specifically, a combination of data processing techniques and advances in deep learning techniques can bypass inherent issues with the input data, reveal their hidden patterns, and improve forecasting accuracy. Moreover, while the proposed technique relies on past air temperature and specific humidity data due to their availability and their established roles as primary indicators of atmospheric dynamics, it offers a pragmatic and computationally economic approach to forecasting the air temperature in areas with sparse observational data.
More specifically, this work makes the following main contributions:
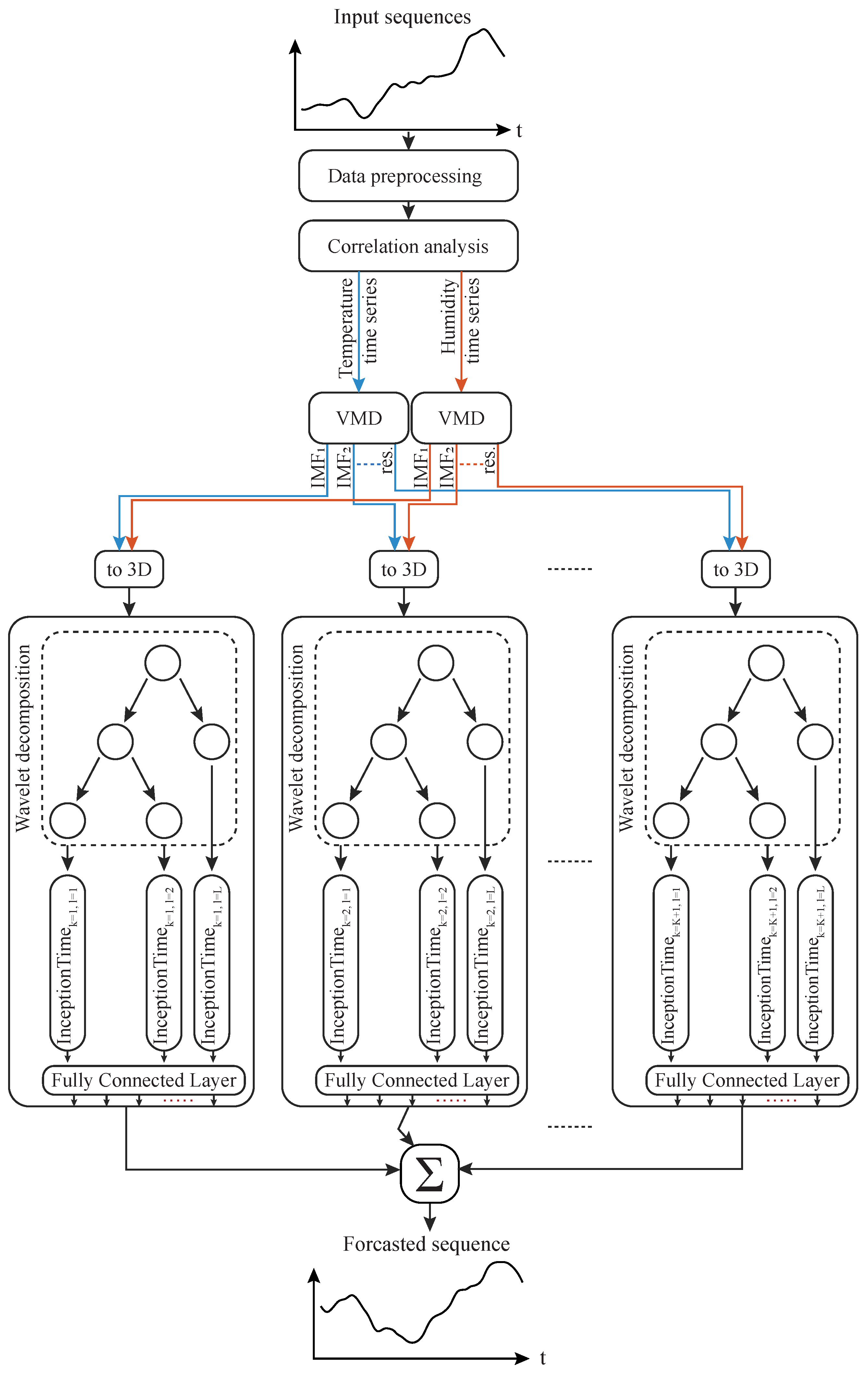
Proposal of VMD-WT-InceptionTime for short-term multi-step air temperature forecasting. This hybrid technique is based on consecutive variational mode decomposition (VMD) and wavelet transform (WT) decompositions aiming to uncover hidden patterns and to reduce the complexity in past temperature and specific humidity sequences. These processed features are fed into a deep convolutional neural network forecasting model (InceptionTime).
Comparison of the performance gains achieved through combined VMD and WT decompositions against using no decomposition or single decomposition techniques. To the best of the authors’ knowledge, the use of VMD and WT has not yet been investigated for the forecasting task at hand.
Examination of the effects of VMD decomposition levels on the performance of the proposed forecasting technique and identification of the optimal level of decomposition.
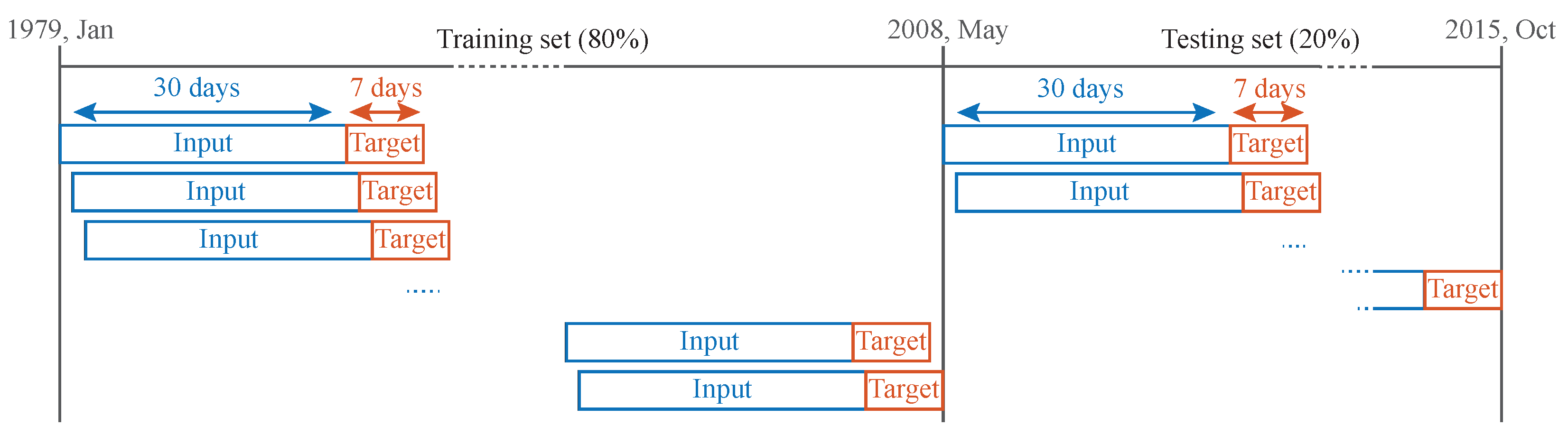
Assessment and validation of the technical experiments using multiple forecasting metrics and daily historical temperature data from three field sites in Alaska spanning 35+ years.
4. Results
4.1. Input Correlation Analysis
In this section, we investigate the correlation between various inputs and the output (i.e., forecasting target). Two types of input features were considered: climate features and time-related features. The first category of features comprises historical data of the temperature, humidity, and precipitation sequences, while the second holds historical data of the corresponding day of the month, the month of the year, the year, and the season. The latter features were extracted from the raw time series.
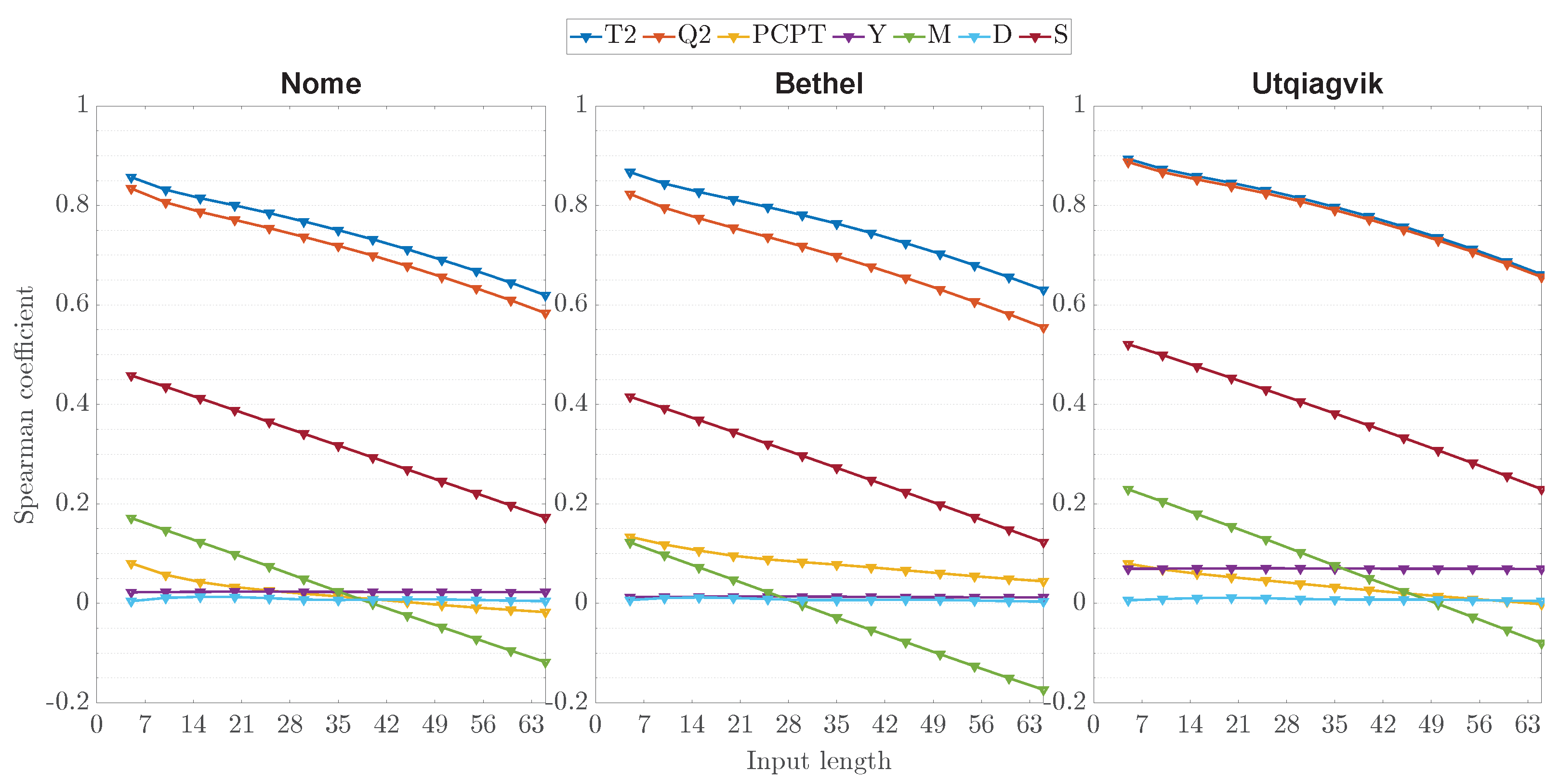
In addition, 10 different input sequence lengths (i.e., L) were considered to analyze the impact of the input lengths on the correlation with the output. We considered lengths ranging from the past five to 60 days with a five-day step.
Figure 4 showcases the results of this study using the Spearman correlation algorithm. First, it is apparent that only the historical temperature and humidity are significantly correlated with the forecasting target sequences. For instance, average Spearman coefficients of
and
were identified for the temperature and humidity input sequences of
days over all three locations. The other input features are either not correlated (e.g., year sequences) or slightly correlated with the targets (e.g., season, precipitation, and day sequences). Thus, it is reasonable to rely solely on the temperature and humidity sequences to forecast the near-future temperature values. Second, a higher correlation is seen with shorter input lengths. This is expected as these sequences can provide windows to the immediate past. With the increasing input lengths, their correlation with the targets decreases in the case of most features except for the month sequences, which seems to slightly increase its reverse correlation. Nevertheless, shorter sequences may not provide enough information to the forecasting model, leading to underperformance, while longer sequences require larger computational loads. Hence, the choice of using input sequences of
elements (i.e., past 30 days) represents a good compromise between both aspects.
4.2. Decomposition Analysis
The notion of entropy serves as an indicator of the randomness and predictability of a system. Higher entropy signifies less order and more randomness. Time series’ regularity and complexity can be quantified by entropy measures such as the approximate entropy or, more recently, the sample entropy [
57]. Although both parameters can reflect the predictability of a time series, the latter provides improved calculations and higher statistical accuracy than the former.
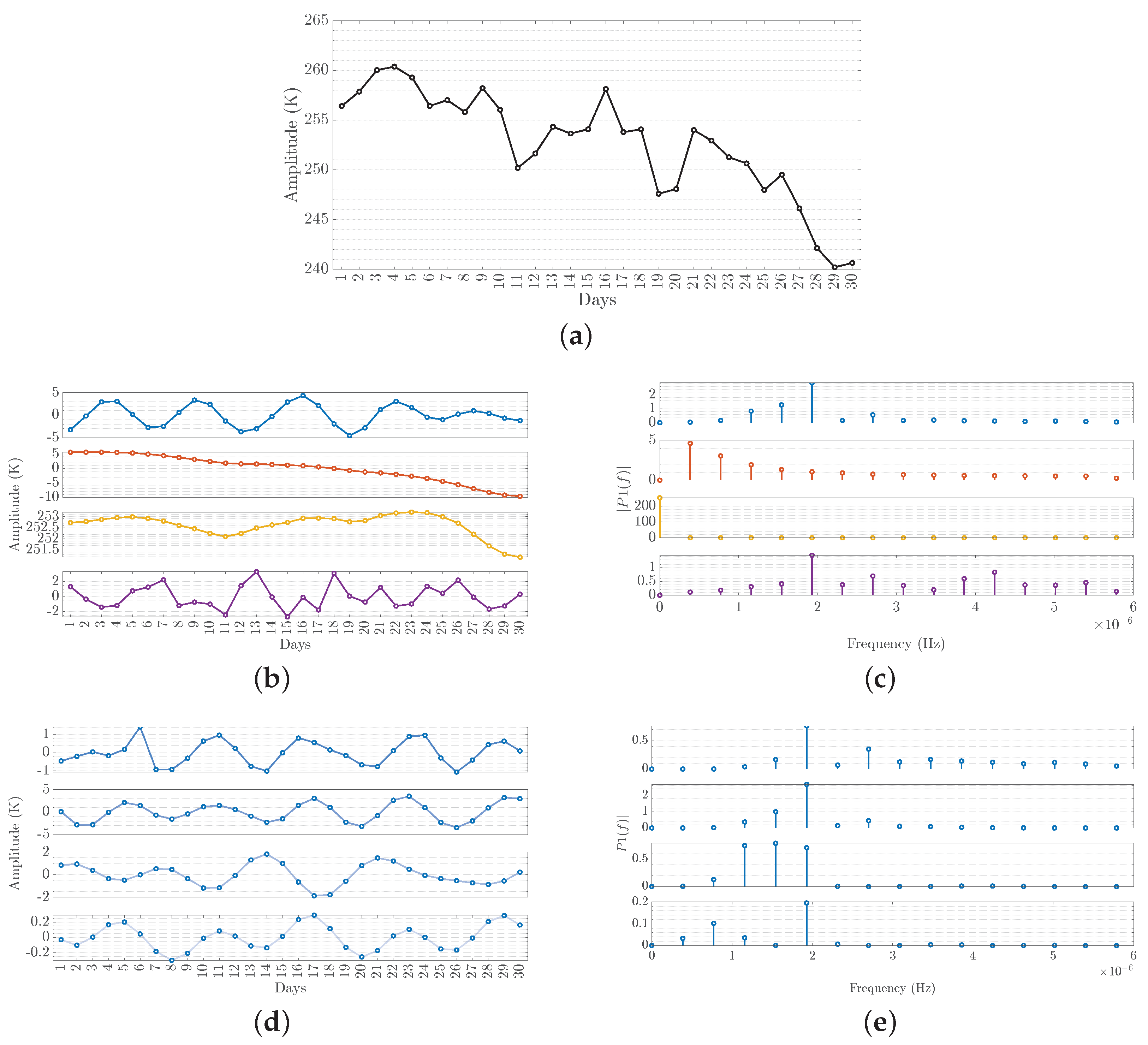
Table 4 presents the average sample entropy for the raw and decomposed T2 and Q2 sequences. Initially, the raw T2 sequences seem to reflect a high degree of complexity. Hence, further preprocessing seems necessary to produce simpler sequences for any subsequent processing. The decomposition using VMD proves capable of decreasing this complexity, where lower entropy values can be achieved with higher decomposition levels for both features. Decomposing every VMD decomposition (and residue) generates detail sequences (i.e., D1–D3) and an approximation sequence (i.e., A4) with lower complexity than those of the original IMFs. Hence, sequential decompositions of both the T2 and Q2 sequences can be useful in decreasing their complexity and ultimately improving the forecasting performance. These observations can be further seen in
Figure 5 that showcases the VMD and WT decompositions of an input temperature sequence seen in
Figure 5a. The raw time series is decomposed into
decompositions, producing three IMFs and a residue.
Figure 5b,c show the VMD resulting sequences of
in their temporal and spectral representations, respectively. The proposed technique incorporates a second decomposition using WT (using the Coif6 wavelet function) that further decomposes each resulting VMD decomposition sequence (i.e., IMFs and residue). Similarly,
Figure 5d,e show the WT resulting sequences of
(i.e., three detail sequences and an approximation sequence) in their temporal and spectral representations, respectively. The residual sequences reflect the overall trend of the temperature time series.
4.3. Performance Benchmark
This section reports performance benchmarks between the proposed hybrid model and various forecasting models. The first benchmark is devised to demonstrate the validity of the proposed technique empowered by both VMD and WT in addressing the forecasting problem, compared with elementary versions of the same technique employing none or a single decomposition technique. The second benchmark is put forward to contextualize the proposed technique within a range of conventional and deep learning models.
Table 5 reports the average performances of the proposed technique and its elementary versions (i.e., with no decomposition and with a single decomposition) for all three field sites.
Table 6 and
Table 7 provide the average performances of the baseline models’ and other deep learning models, respectively, for the three locations. The following observations can be gathered from the reported performances:
First, all the conventional machine learning and statistical forecasting models provide poorer forecasting performances than the historical mean model in terms of all the considered metrics. In particular, all the models clearly struggle to learn the complex fluctuations and trends in the temperature sequences. Nonetheless, the performance of the historical mean is not good enough, as is evident by the similarly low and DA scores achieved in all three locations (i.e., and for Nome, and for Bethel, and and for Utqiagvik). However, the temperature at Utqiagvik seems to be slightly less challenging to forecast by this model as its average errors (i.e., RMSE and MAPE) are slightly better in this location than in the other two. In general, it is evident that the forecasting task is challenging since the patterns of the temperature sequences are evidently highly variable from week to week. This issue can be addressed with the incorporation of signal processing and deeper model architectures.
Indeed, better forecasting performances were achieved in all three field sites when employing a deep learning model (e.g., InceptionTime). In particular, deep learning models generally provided slightly better average performance than that of the historical mean model. In particular, training InceptionTime on undecomposed sequences reached average improvement rates of , , in Nome, , , in Bethel, and , , in Utqiagvik, in terms of RMSE, MAPE, and when compared with the historical mean model. Slightly lower performances were generally found with the other deep learning models. For instance, TST achieved average improvement rates of , , in Nome, , , in Bethel, and , , in Utqiagvik, respectively. However, these models reported lower performances in terms of AD than those achieved using the historical mean. In particular, InceptionTime reported average AD deterioration rates of , , , while TST reported , , , in all three locations, respectively. These results highlight the deep learning models’ inability to forecast the temperature’s trend. Thus, this simple approach of employing temperature sequences directly for deep model learning is ineffective.
Improved performances were obtained when incorporating a decomposition technique in the forecasting approach. Compared with the previous case (i.e., no decomposition), the processing temperature sequences using WT before model learning provided average improvement rates in all metrics of , , , in Nome, , , , in Bethel, and , , , in Utqiagvik, respectively. However, this approach still seems to struggle in forecasting the next week’s trends, as its corresponding average DA score is less than 65% in all the considered field sites. Far greater improvements (compared to the same no decomposition case) were found in terms of all the metrics when incorporating VMD, with , , , in Nome, , , , in Bethel, and , , , in Utqiagvik, respectively. These results prove the adequacy and necessity of decomposing the raw temperature time series first to provide the deep learning model with preprocessed and simpler temperature sequences.
The proposed technique, incorporating both decomposition techniques and the deep learning model, was the most accurate at forecasting the temperature in all three locations. Particularly when compared with the previous case (i.e., VMD only), the hybrid technique reported RMSE and MAPE average increase rates amounting to and in Nome, and in Bethel, and , in Utqiagvik, respectively. Slight improvements were reported in the and metrics, with rates of and in Nome, and in Bethel, and , in Utqiagvik, respectively. The improved performance of the proposed hybrid technique over the VMD-only approach is likely due to the limitations of VMD in considering the temporal dimension of the time series. In particular, VMD decomposes the time series based on the Fourier spectrum, which does not take into account the temporal dimension of different frequencies. Hence, the incorporation of WT can accomplish such analysis on the already simplified input sequences (i.e., resulting IMFs from VMD) and more efficiently extract the inherent multi-resolution patterns, revealing temporal and spectral attributes simultaneously that are directly fed to the forecasting model for improved performance. In addition, similarly to the performances seen with the previous models and techniques, the lowest forecasting errors of the proposed technique among the considered field sites are achieved in Utqiagvik in terms of all the considered metrics. However, the proposed technique still has an average directional error (i.e., DA) lower than , which means that the model can provide forecasts very close to the observed values but seems to struggle slightly in identifying their correct direction (i.e., increasing or decreasing temperature). This can be partly attributed to the training set from all locations having a smaller range of temperature values seen throughout the year, which would mean a smaller range of possible forecast values with higher minute differences between them. It is important to note that the other considered deep learning models were investigated using the decomposed inputs and achieved lower performances than those achieved using InceptionTime.
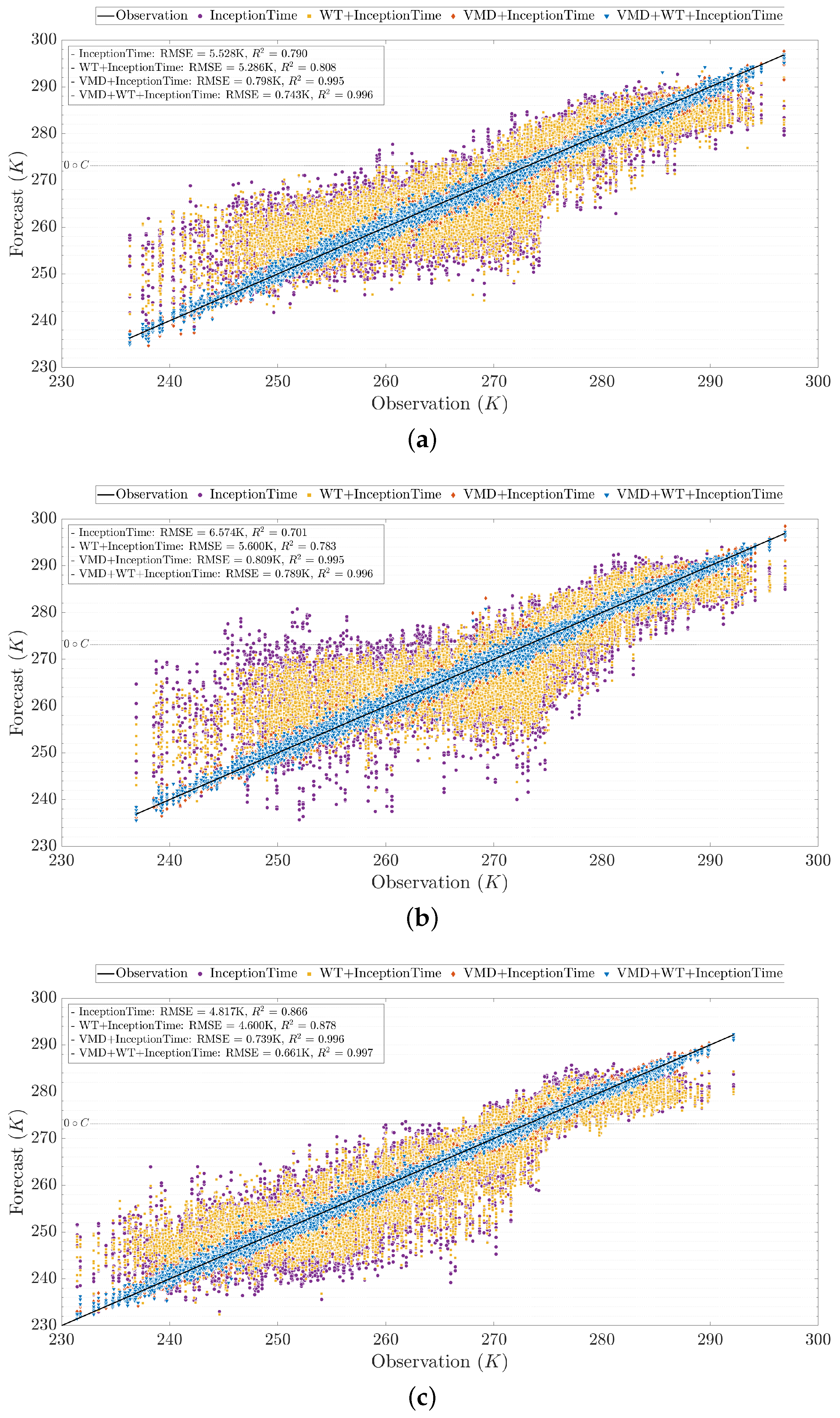
The superiority of the proposed hybrid technique compared to its elementary versions can be further showcased in the scatterplots in
Figure 6, where it can be seen that the points (i.e., predictions) tend to get closer to the black line (i.e., observation) as signal decompositions are incorporated within the deep learning forecasting approach. The forecasts from the proposed technique (i.e., WVD+WT+InceptionTime) are the closest and fit the observed values the most.
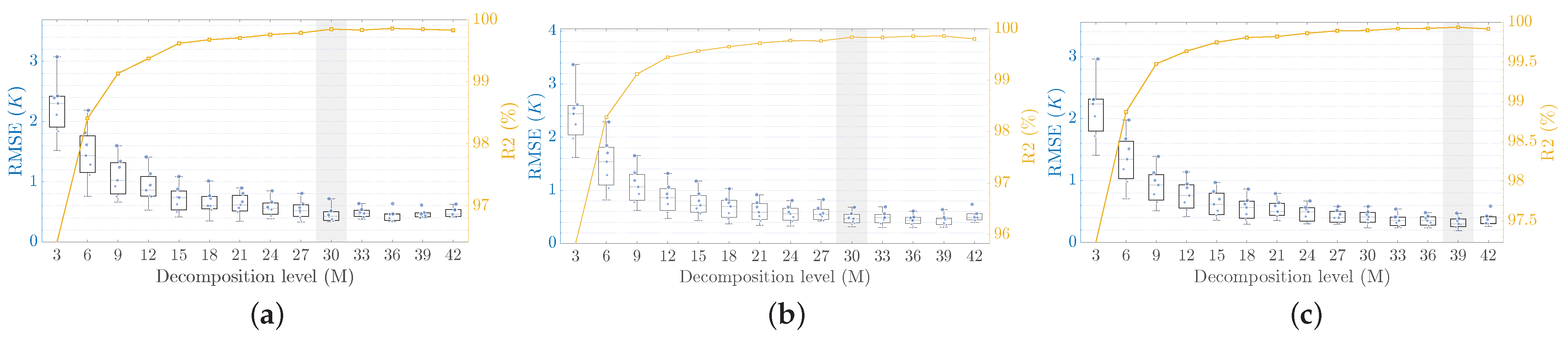
4.4. Impact of VMD Decomposition Level
Figure 7 showcases RMSE and
boxplots computed using the proposed technique under VMD
M values ranging from
to
with three-step increments. We note that only these two metrics are reported in the manuscript because the other two metrics provided a similar pattern.
As can be seen, the VMD decomposition level impacts the forecasting performance of the proposed model. The lowest forecasting performances in all three field sites are found using the lowest decomposition level of . Under this configuration, the proposed model in Nome achieves an average RMSE score of with a maximum value of and a minimum of , while the average score is . For Bethel, the average RMSE score is with a maximum value of and a minimum of , while the average score is . For Utqiagvik, the average RMSE score is with a maximum value of and a minimum of , while the average score is . Nevertheless, the proposed technique with lower M values still provides better average RMSE scores than all the other considered models and approaches. Enhanced performances can be achieved with higher values of M before either stagnating or worsening after a certain value. In particular, the average and the range of the RMSE scores are optimal at around for all Nome and Bethel measurements. For Utqiagvik, further improvements can be achieved with even higher values until . In terms of , the performance follows a similar pattern and stagnates at around the same M values. These improvements can be attributed to providing InceptionTime with less complex and more stationary sequences with highlighted multi-resolution intrinsic patterns.
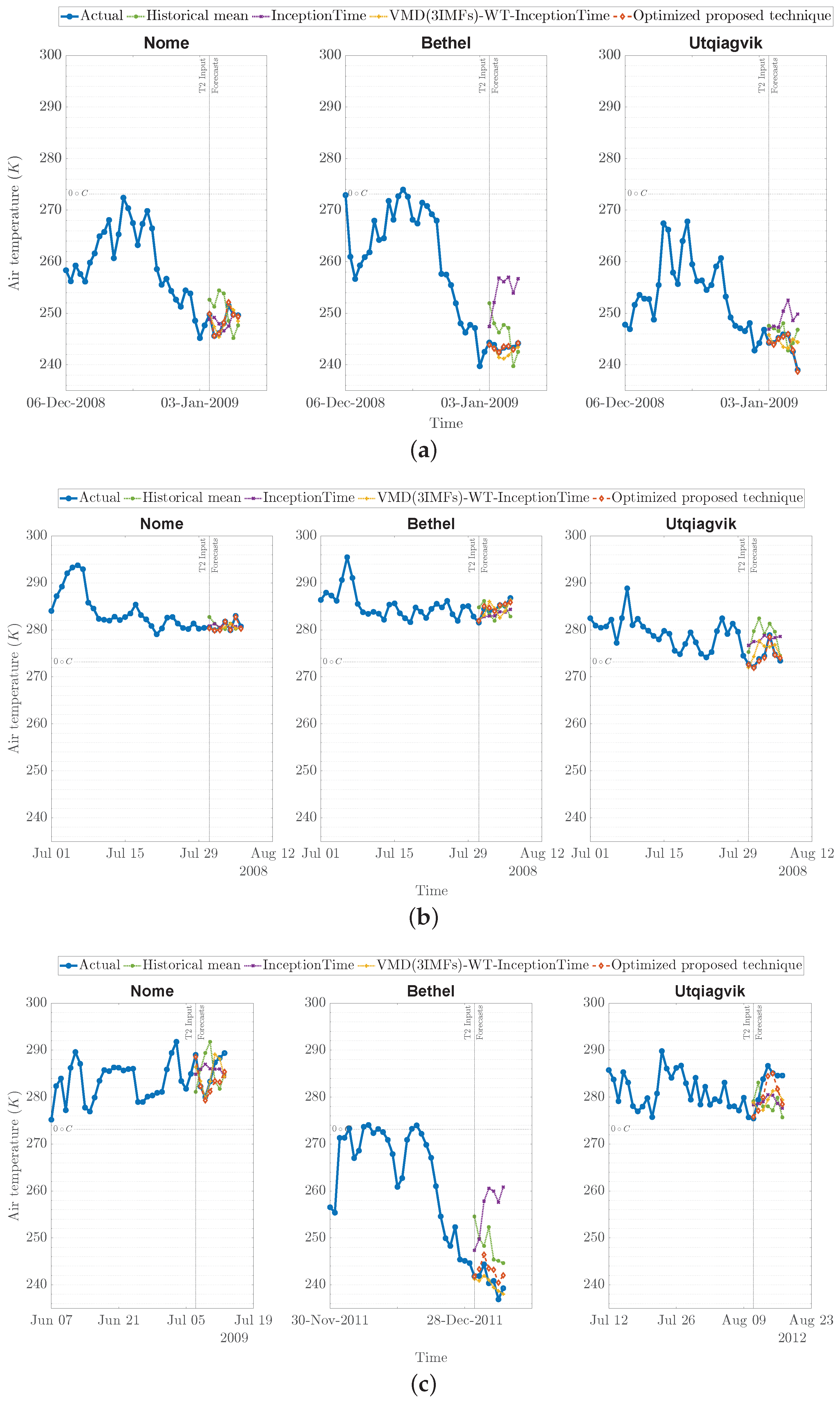
Figure 8 showcases examples of the input temperature sequences and their corresponding forecasts using the historical mean, InceptionTime (i.e., no decomposition), and the proposed technique under
for Nome and Bethel, and
for Utqiagvik, during the transition periods spanning different freezing and thawing periods. Specifically,
Figure 8a,b present randomly selected sequences while
Figure 8c displays the worst performance yielded by the proposed technique under the optimal
M. In these plots, it is apparent that both versions of the proposed technique can follow the general trend of the observed temperature, with more accurate forecasts achieved under the optimal
M for each location. Particularly, the proposed technique under
seems to struggle to forecast abrupt and large changes in the temperature from one day to another. In contrast, the proposed technique under an optimal
M seems to handle these variations more accurately.
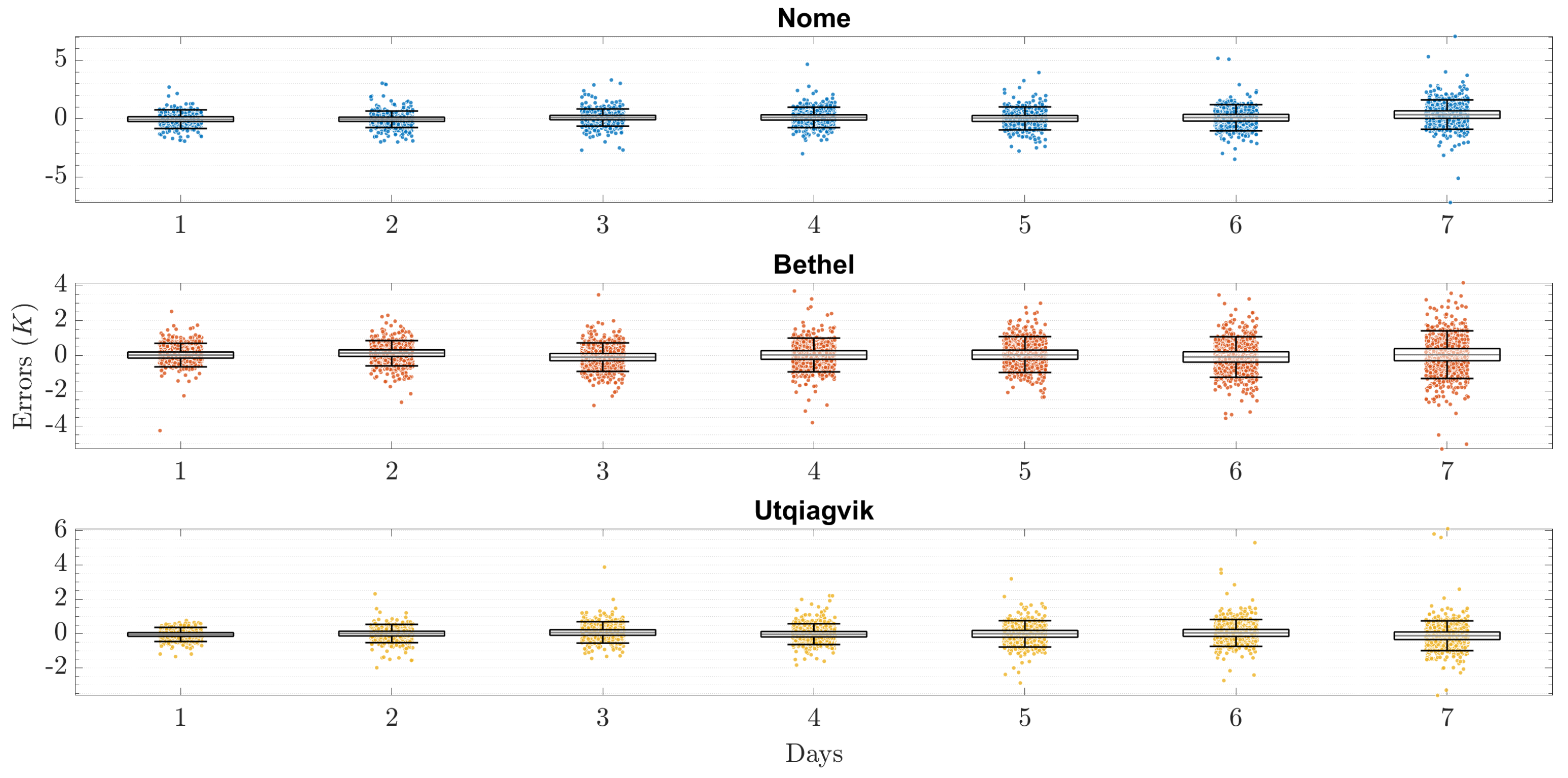
Further insights can be gathered from
Figure 9, which reports a boxplot of per-horizon errors of the proposed technique employed using the optimal
M for each of the three locations. First, it is apparent that the average errors at each horizon are very low. In particular, the optimized proposed technique for Nome produces forecasts over all seven horizons with a maximum error of
, a minimum error of
, and an average error lower than
; for Bethel, a maximum error of
, a minimum error of
, and an average of
; and a maximum error of
, a minimum error of
, and an average of
for Utqiagvik. Nonetheless, slightly higher errors can be seen with higher horizons. This can be attributed to the fact that the forecast uncertainties tend to increase as the horizons get further away in the future.
To better analyze the performance of the optimized proposed technique in handling challenging events, two analyses are conducted and reported. First,
Table 8 and
Table 9 report the horizon-wise top and bottom three errors from the testing set. It seems that the proposed technique’s lowest performances are errors of around
for Nome,
for Bethel, and
for Utqiagvik in the last horizon (i.e., 7th day). In particular, the worst performance of the optimized proposed technique corresponds to an overprediction for both Nome and Bethel and an underprediction for Utqiagvik. In addition, most of these errors are not related to the transition sequences between above- and below-freezing temperatures. Knowing that the average range, minimum, and maximum values in the target temperature sequences are
,
, and
in Nome,
,
, and
in Bethel, and
,
,
in Utqiagvik, most of the worst performances of the proposed technique in all three locations can be attributed to having to produce forecasts of higher variations and wider temperature ranges than the average. Indeed, most of the best performances of the proposed technique correspond to observed temperature sequences of ranges shorter than the average. Nevertheless, the proposed technique under the optimized
M proves adequate and robust at forecasting the temperature at different periods of the year.
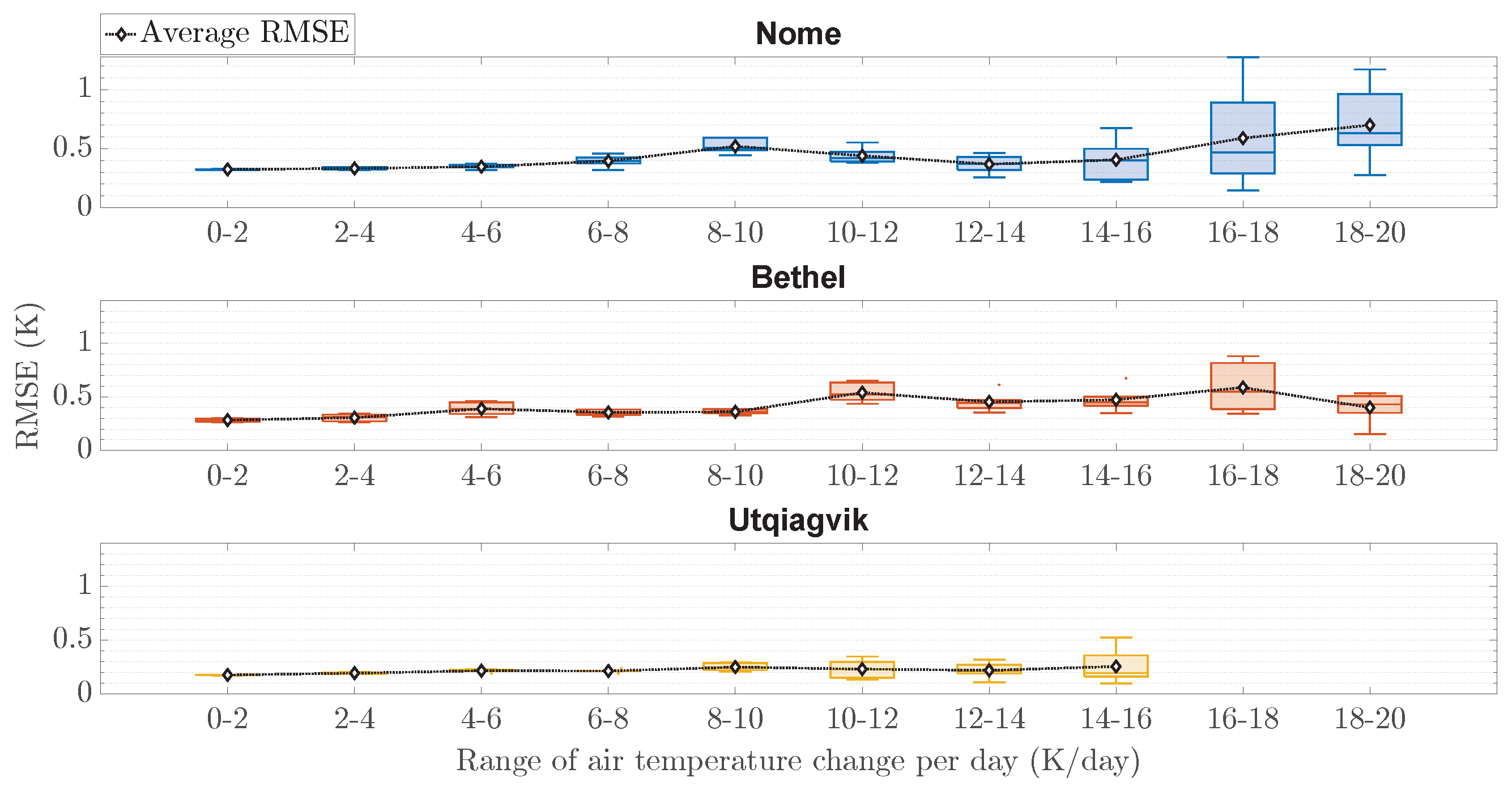
Second,
Figure 10 showcases the RMSE distributions across different ranges of daily temperature spanning the whole testing set. The RMSE values were segmented into bins according to the magnitude of temperature change per day, allowing for an evaluation of the technique’s performance under varying conditions, ranging from low to rapid air temperature changes. Notably, the technique maintains generally low RMSE values across a wide range of daily temperature changes in all locations. Particularly in Bethel and Utqiagvik, the technique showcases consistent RMSE values across all ranges. However, increased RMSE variability can be seen with larger temperature changes in Nome, suggesting a slightly reduced forecast accuracy under extreme conditions. Nonetheless, the proposed technique under the optimized
M proves adequate and robust even during instances of rapid fluctuations due to winter storms or other events.



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}