

Variational Amplitude Amplification for Solving QUBO Problems


Abstract
:1. Introduction
Layout
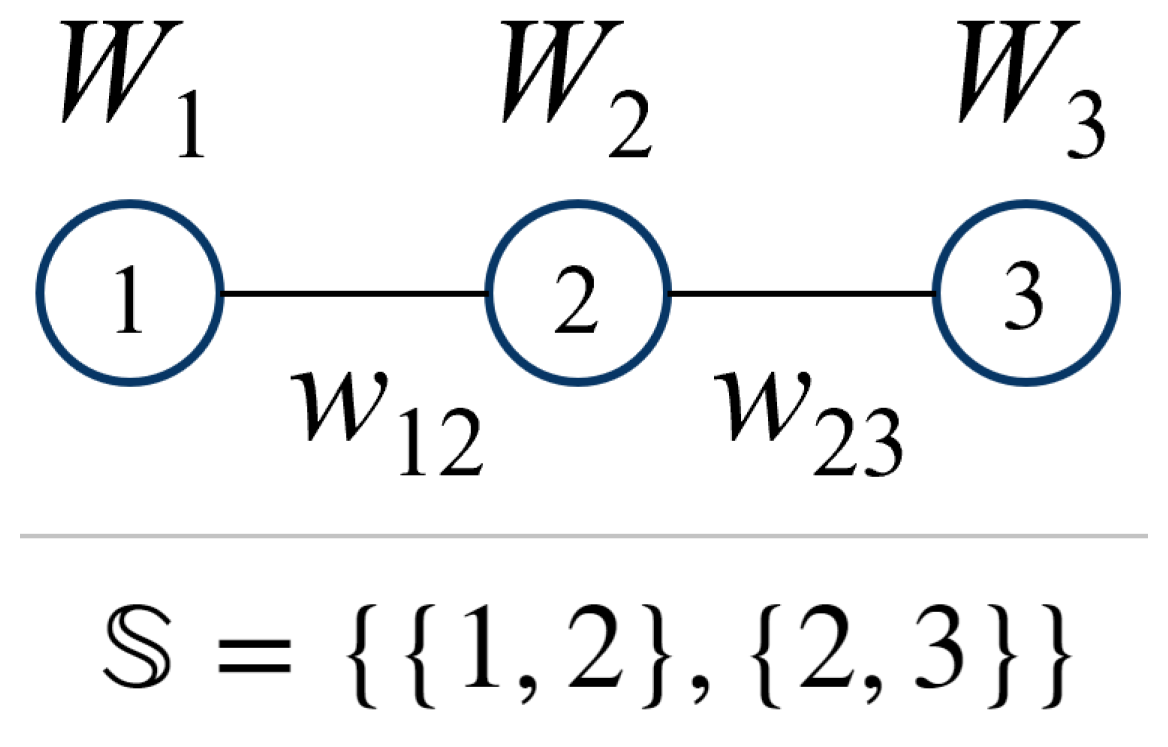
2. QUBO Definitions
Linear QUBO
3. Amplitude Amplification
| Algorithm 1 Amplitude Amplification Algorithm |
|
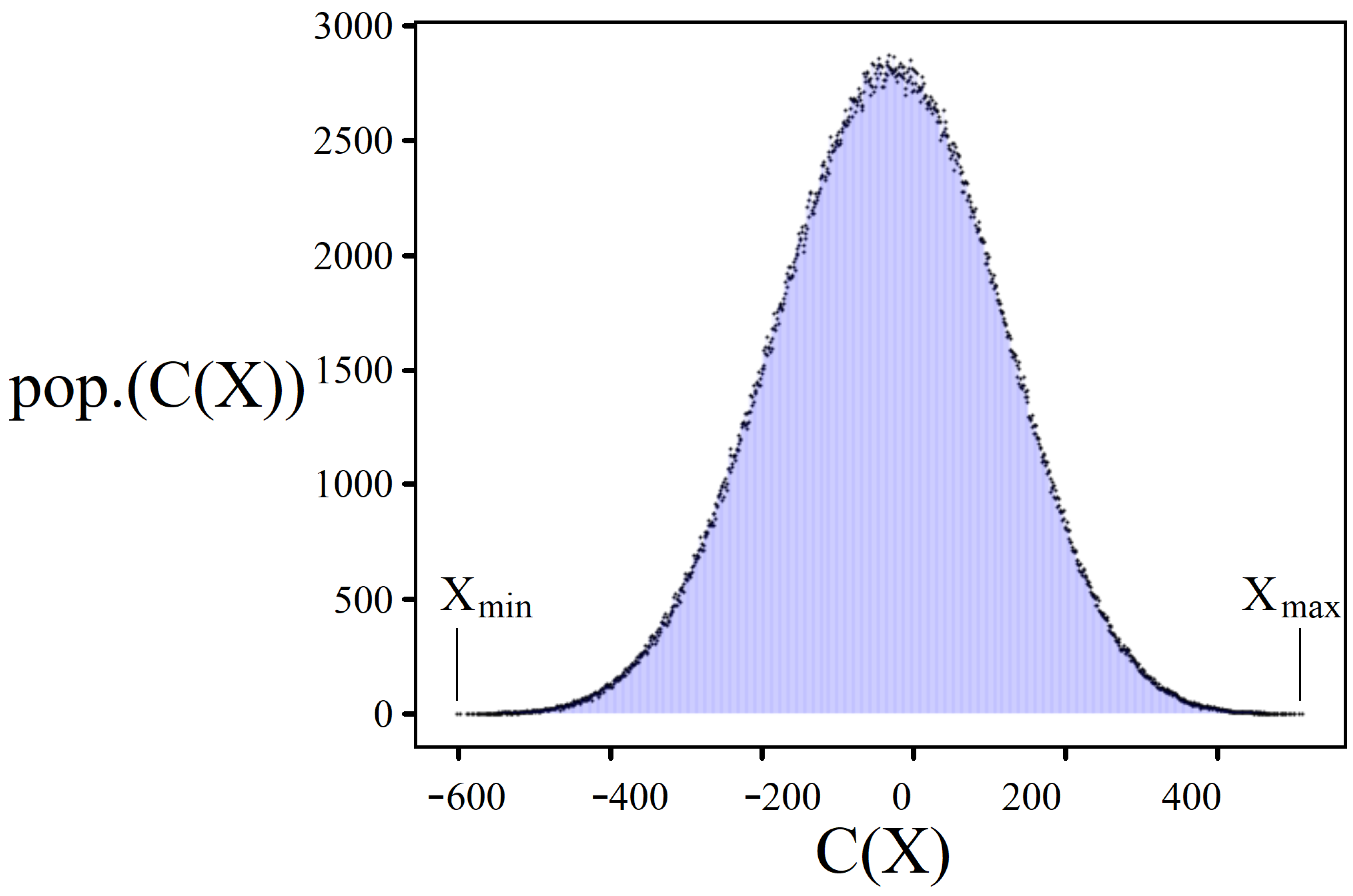
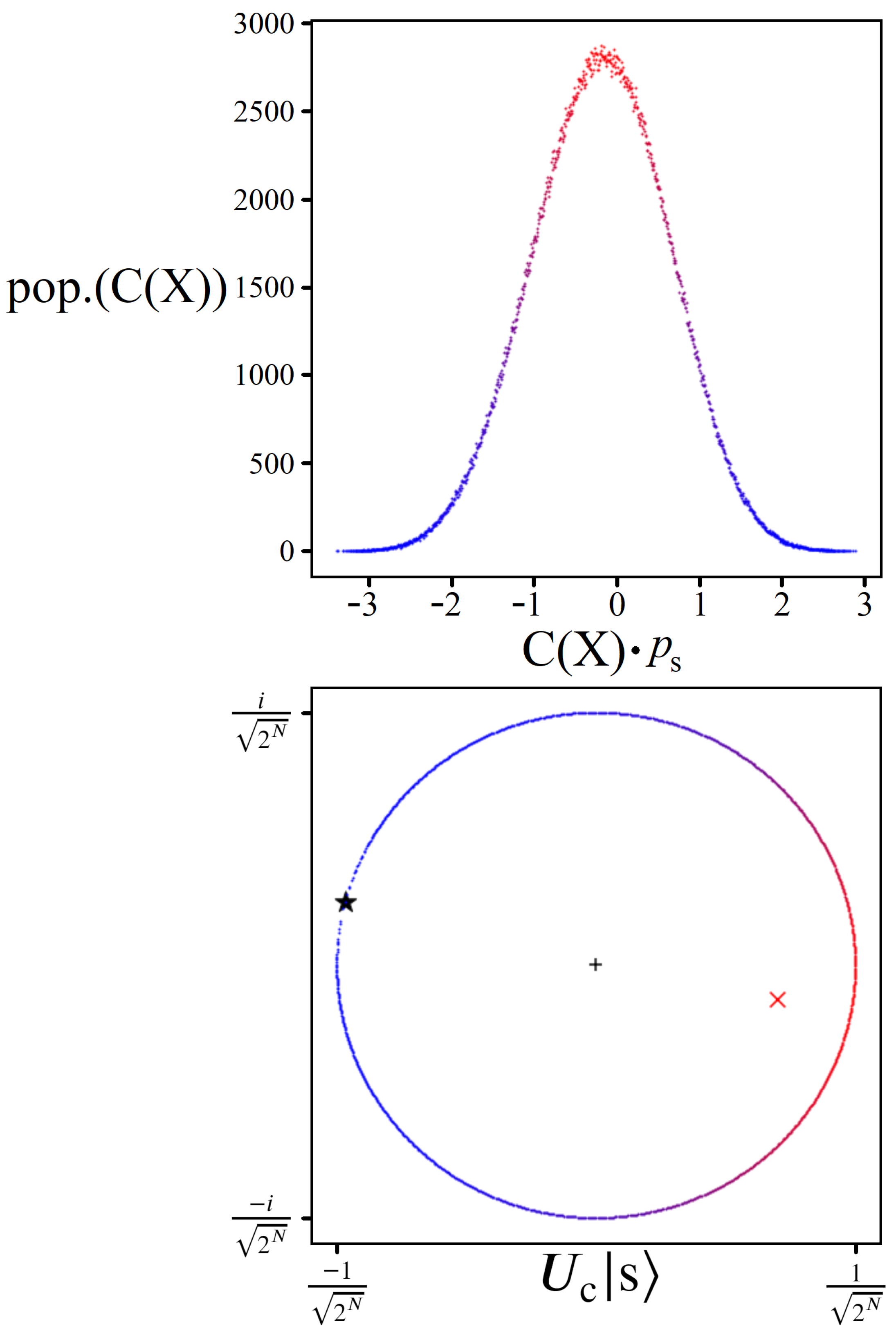
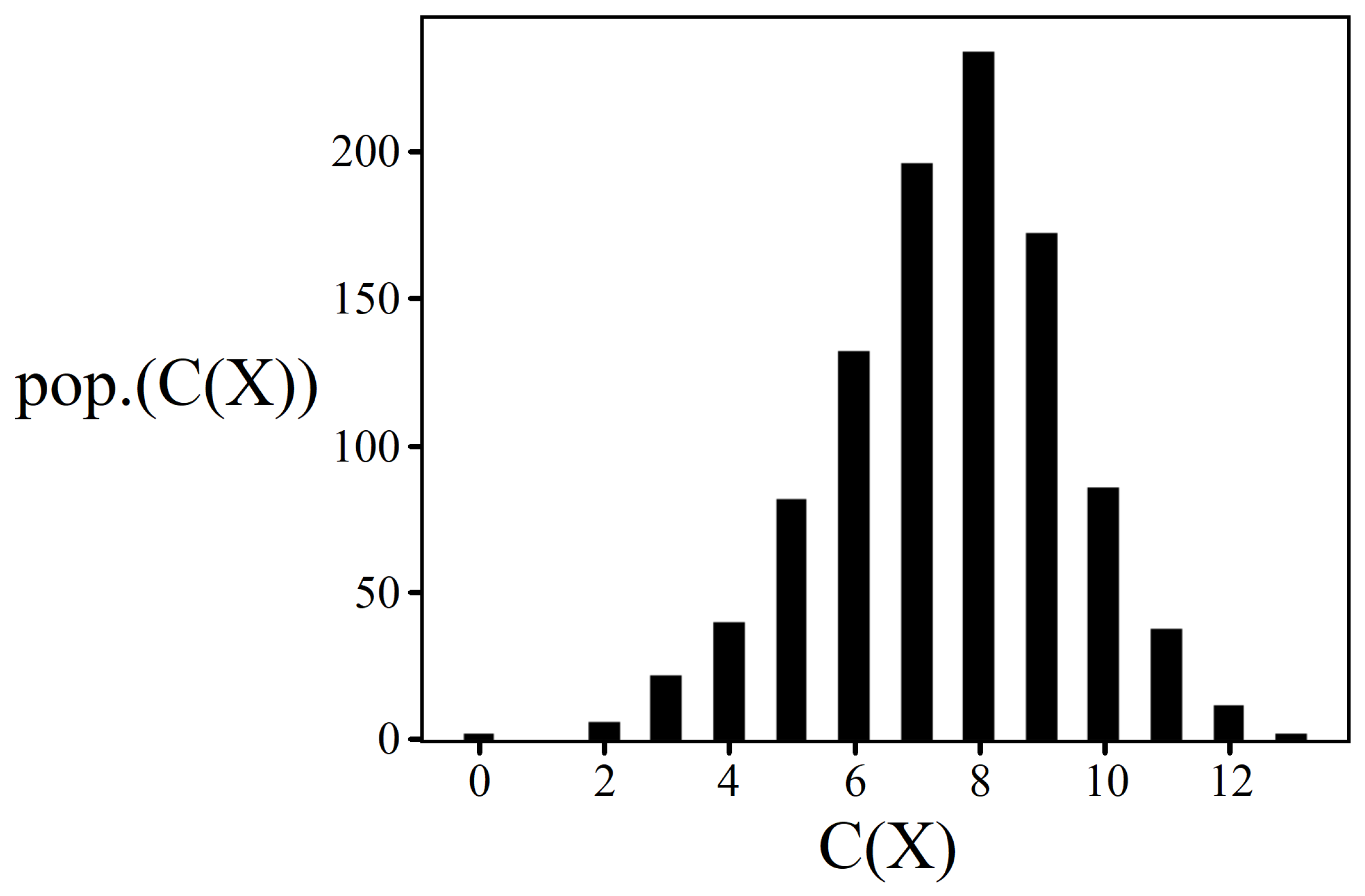
3.1. Solution Space Distribution
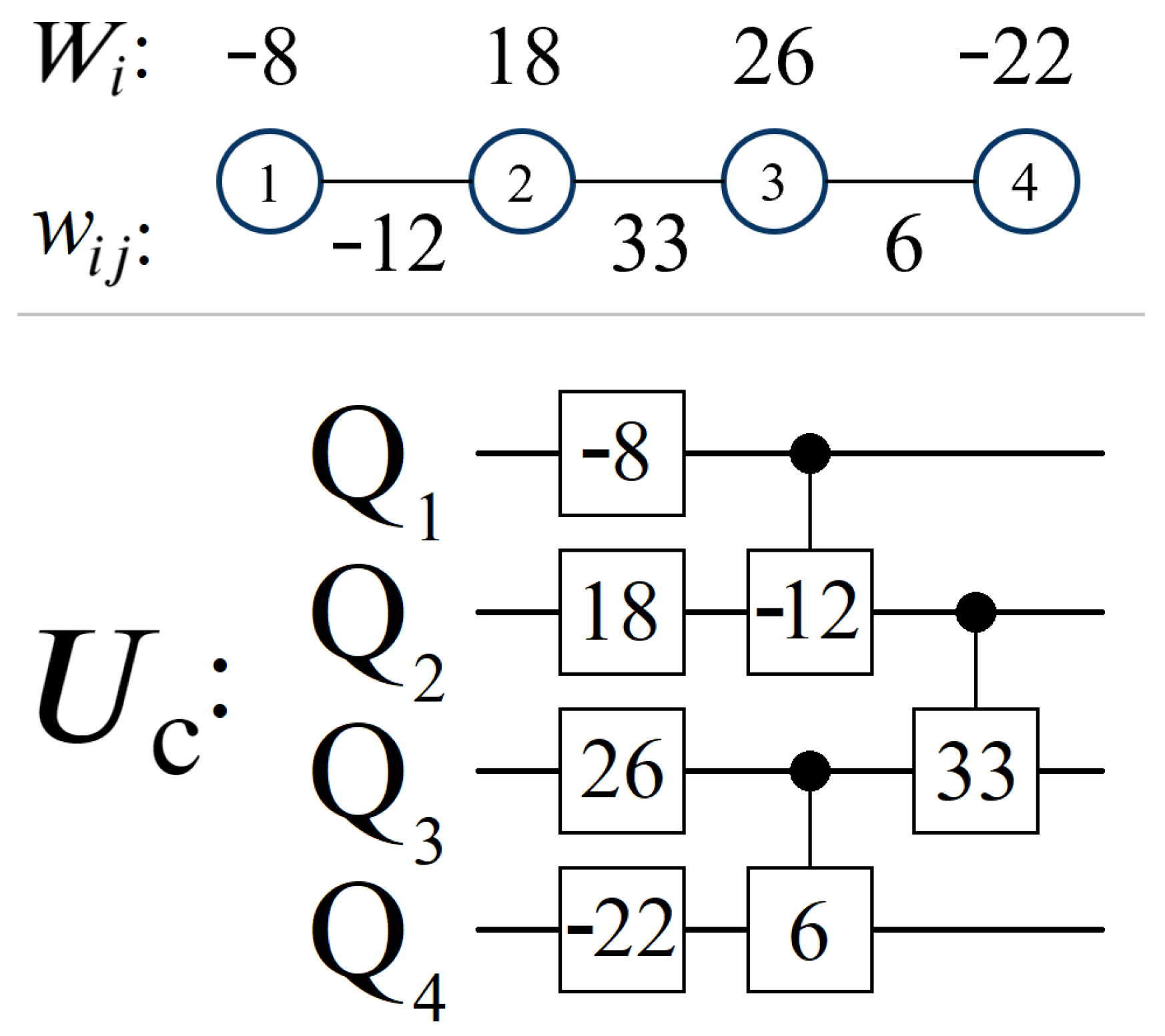
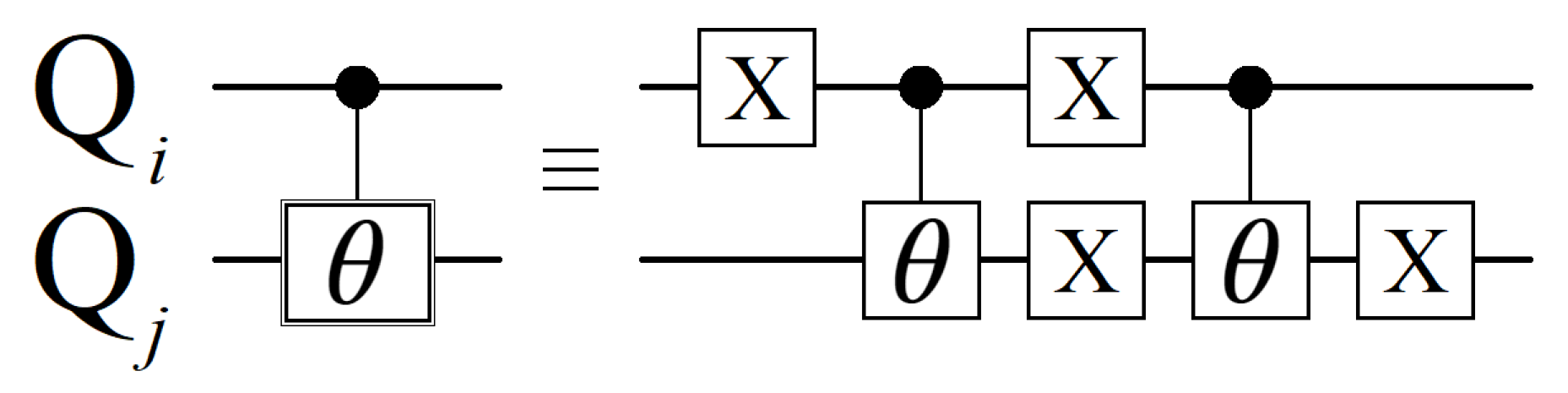
3.2. Cost Oracle
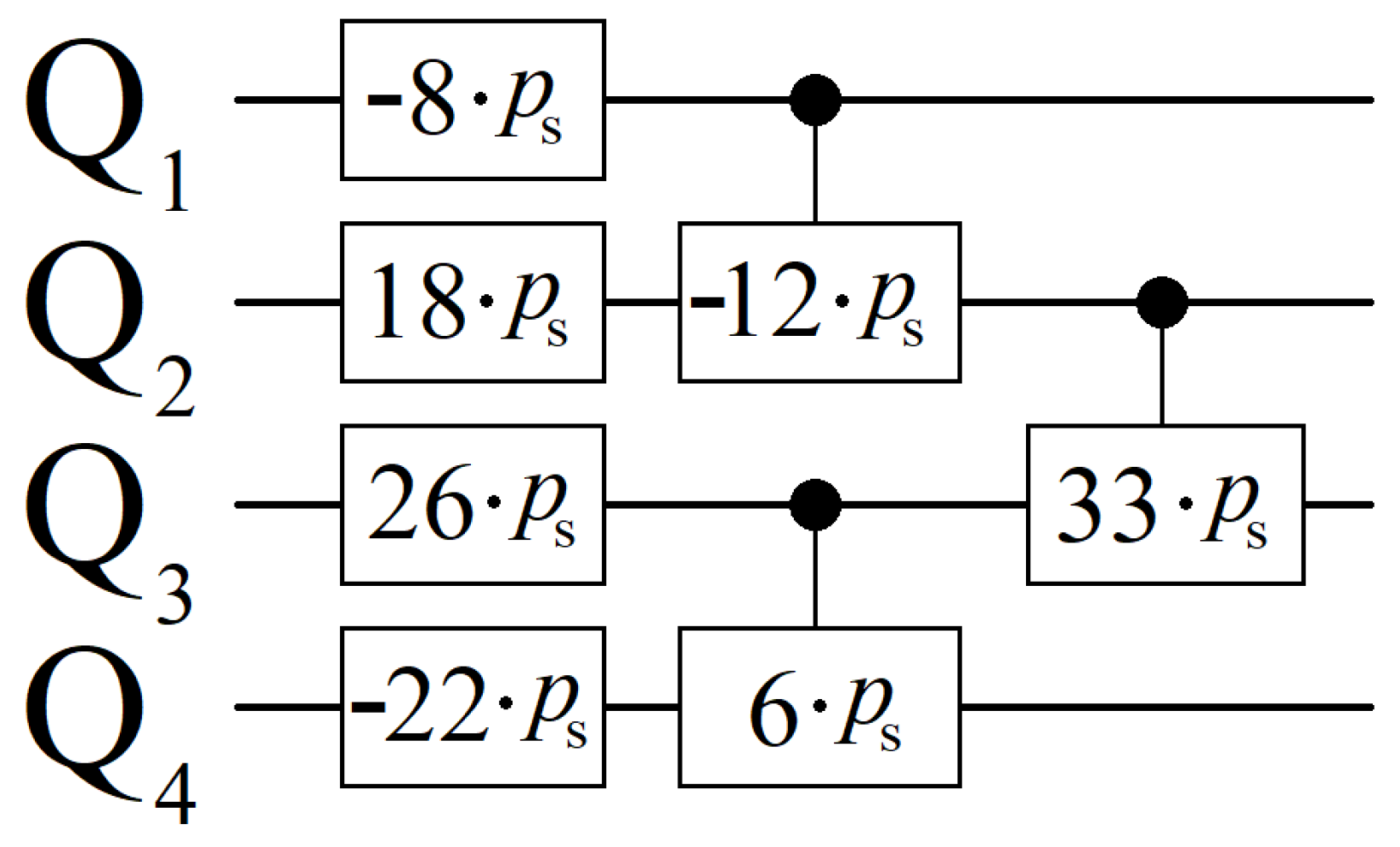
3.3. Scaling Parameter
4. Gaussian Amplitude Amplification
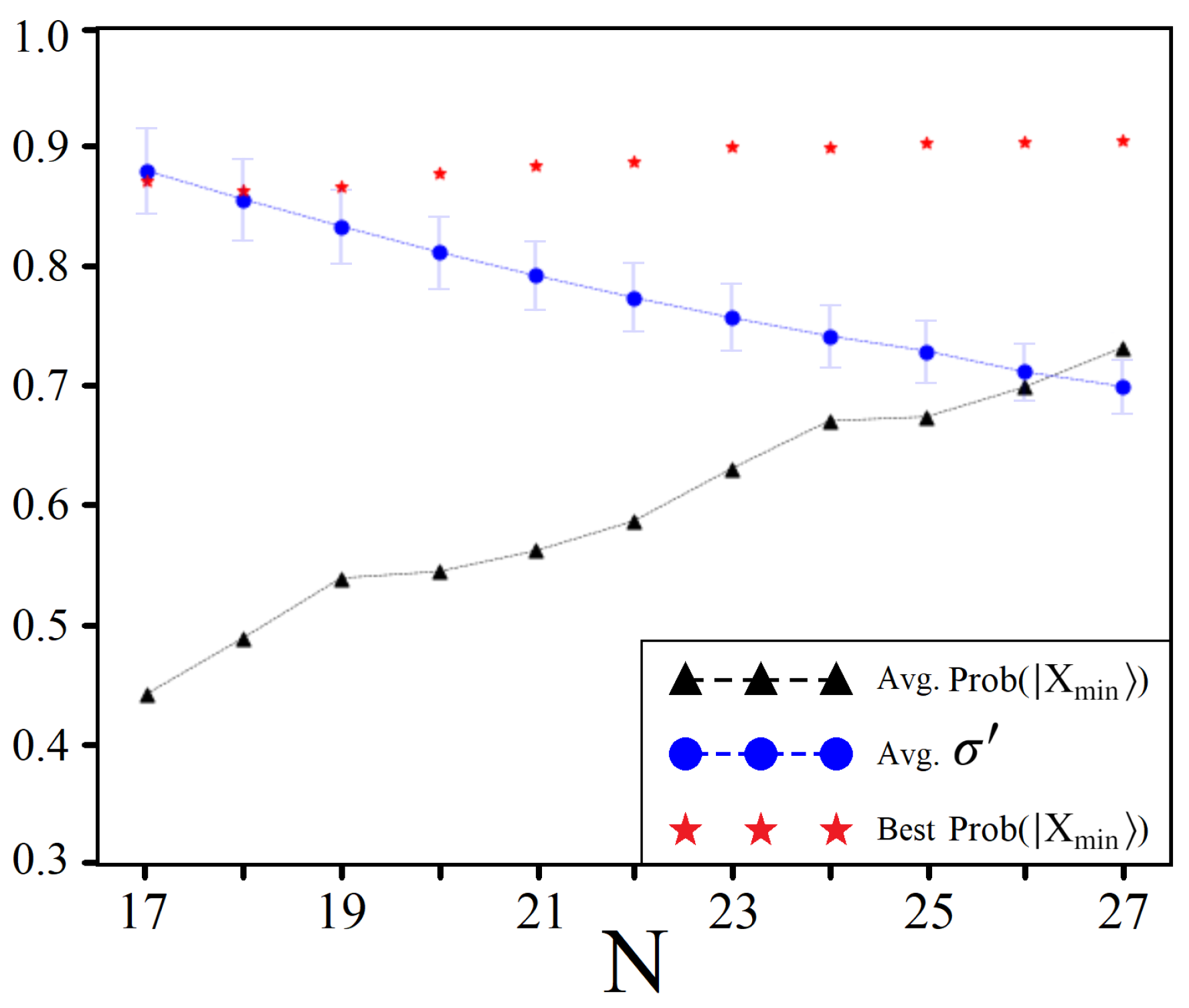
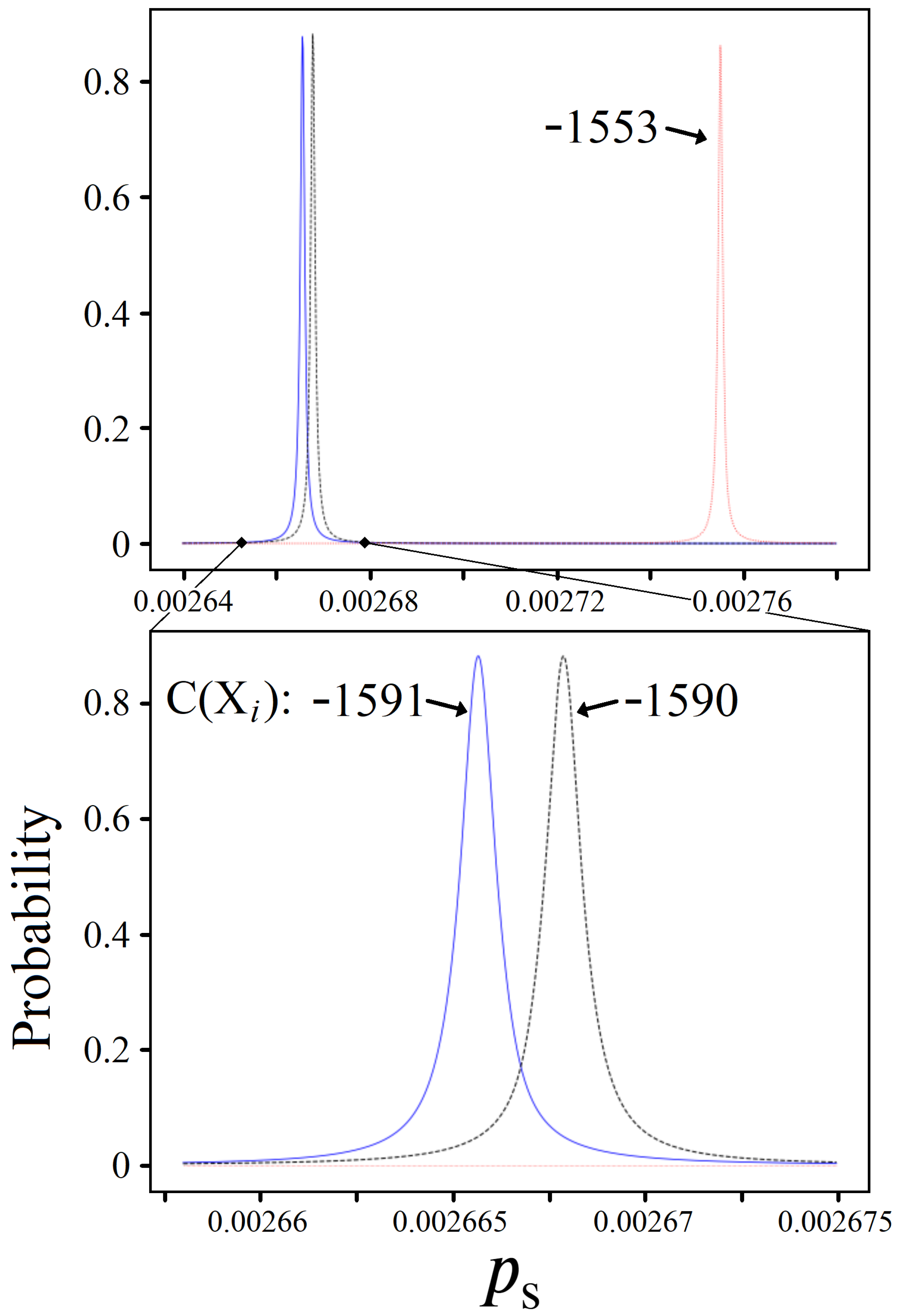
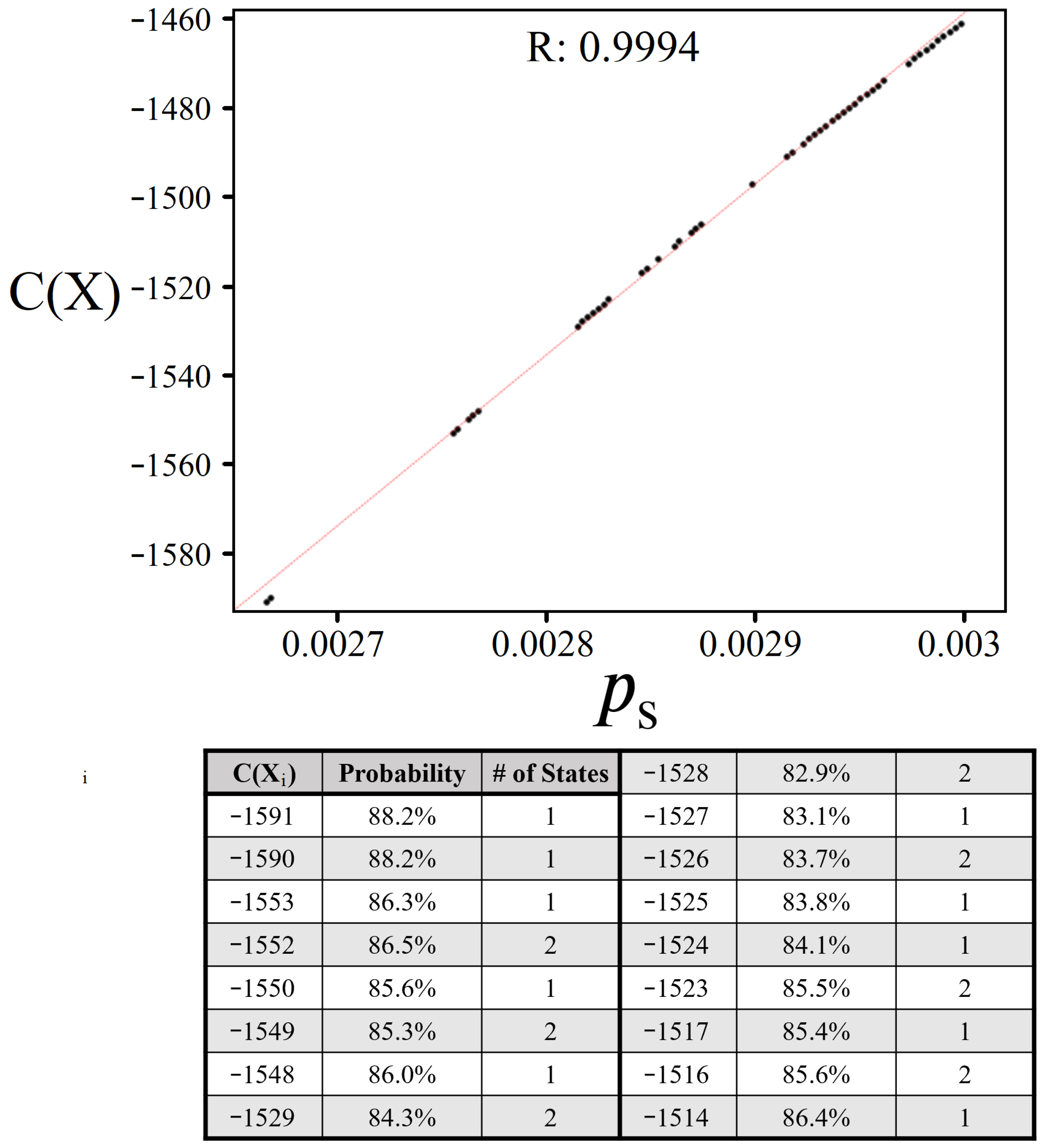
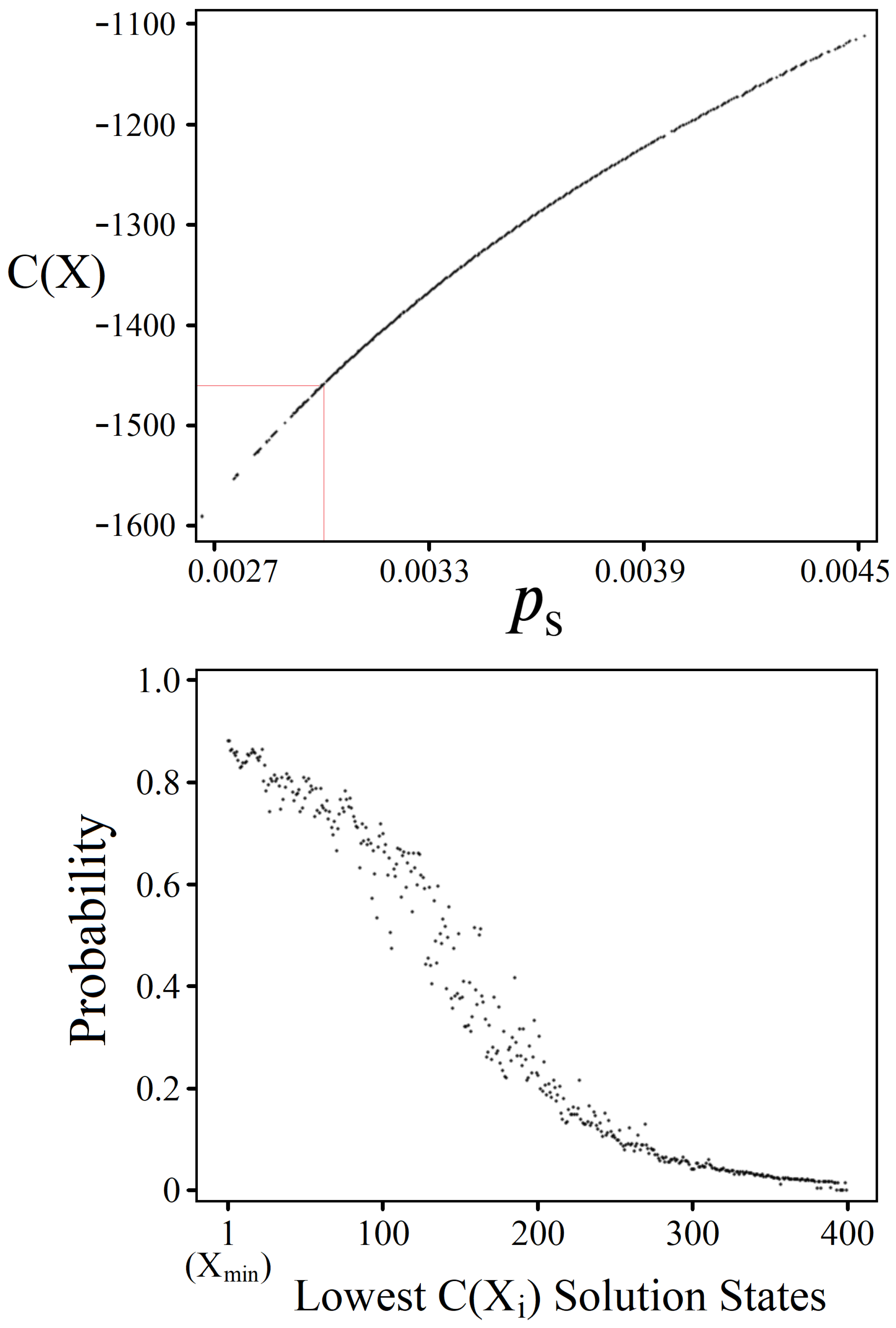
4.1. Achievable Probabilities
4.2. Solution Space Skewness
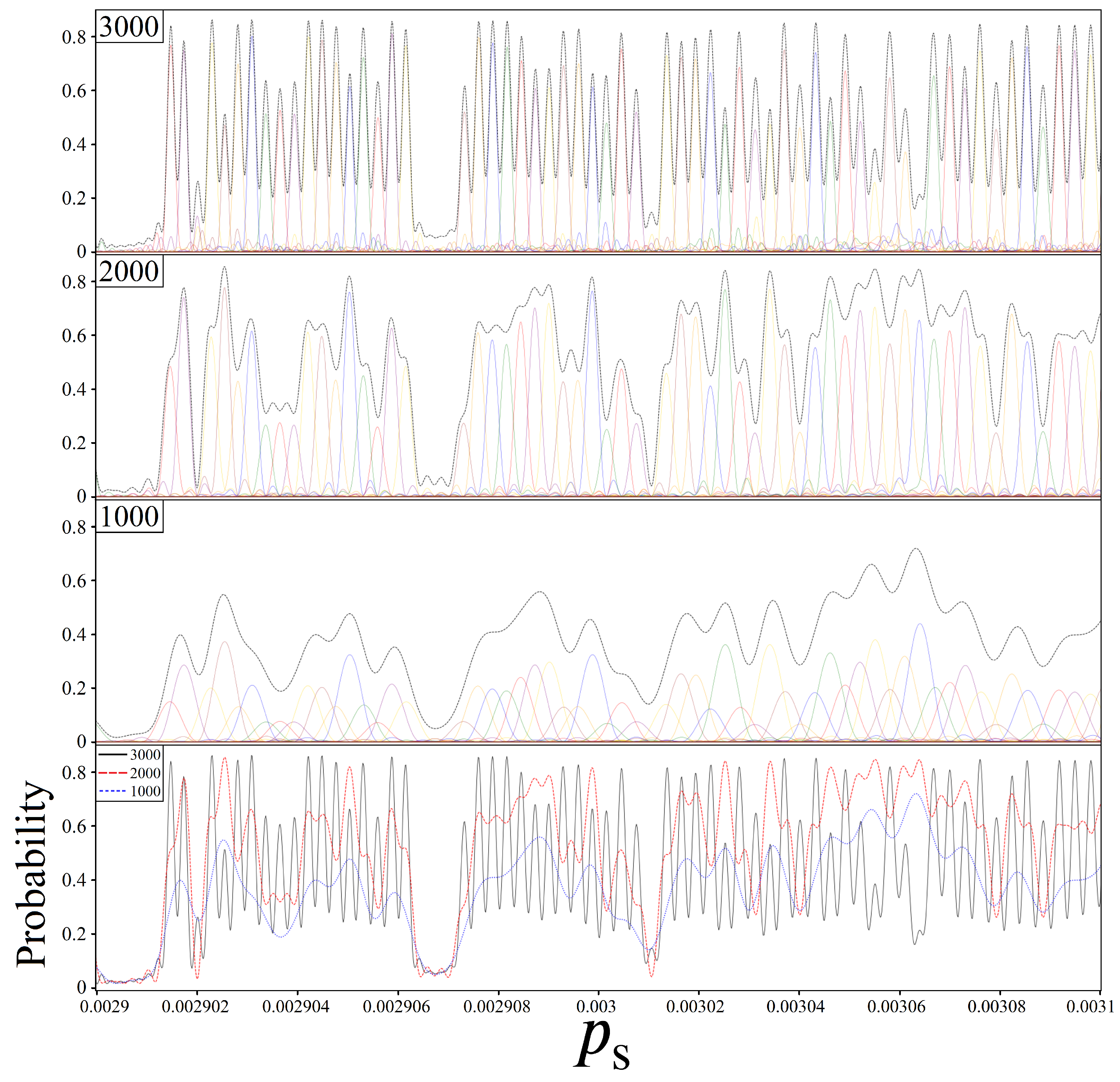
4.3. Sampling for
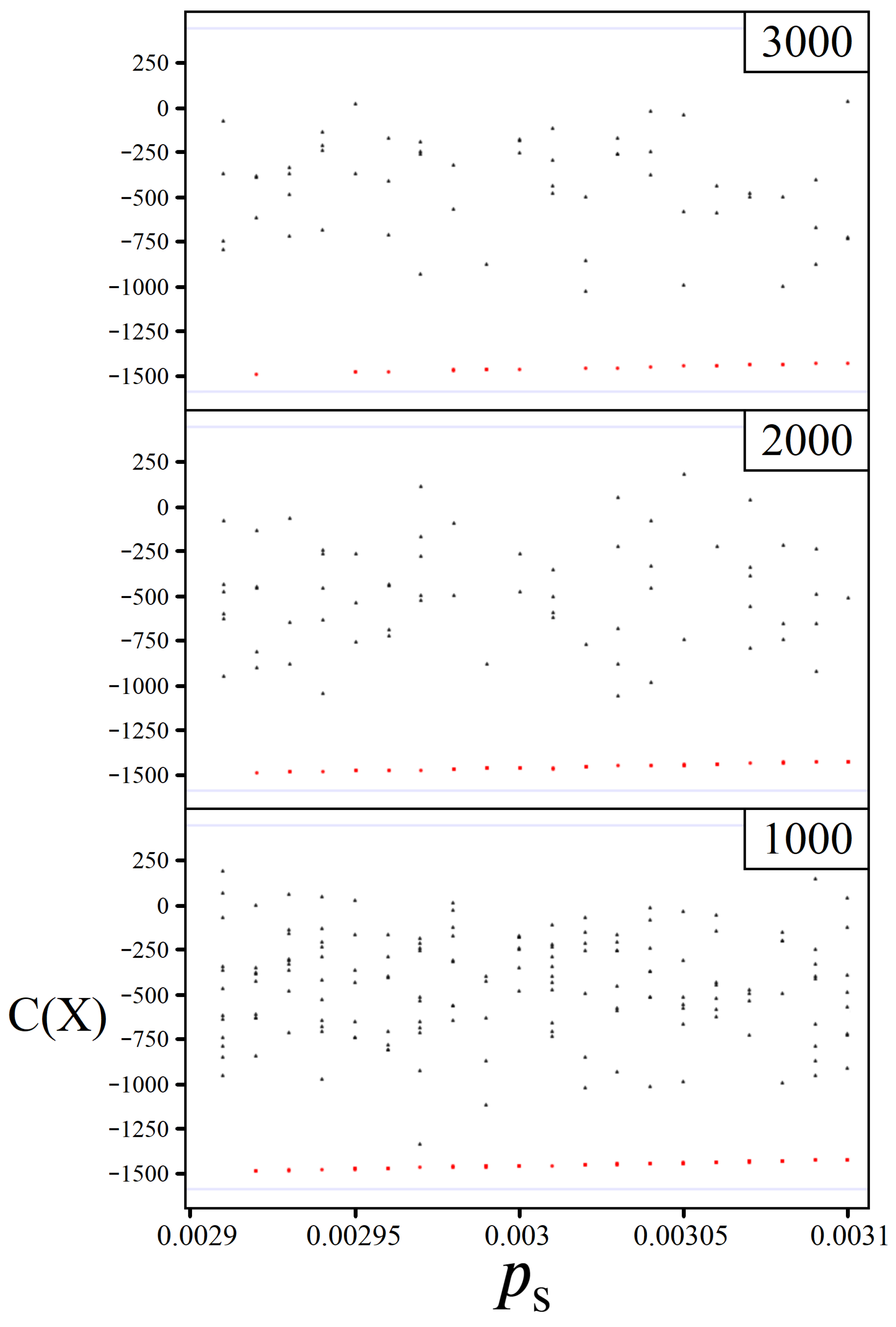
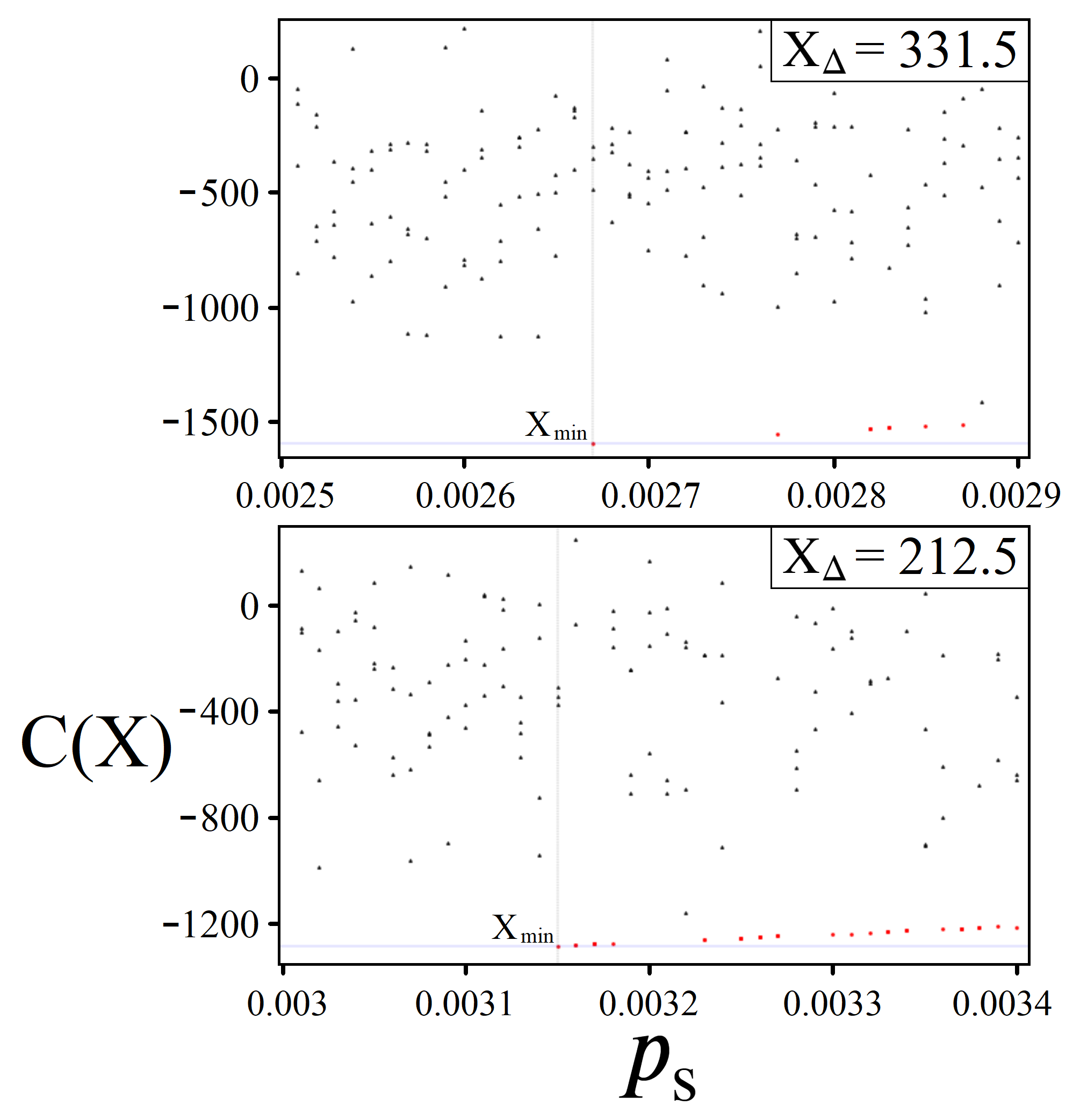
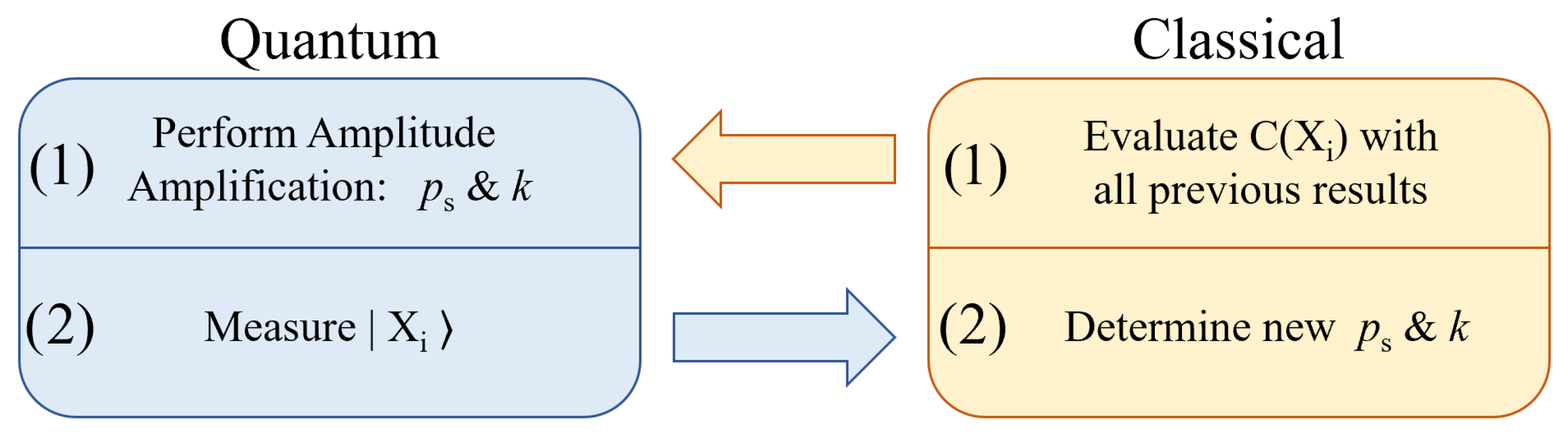
5. Variational Amplitude Amplification
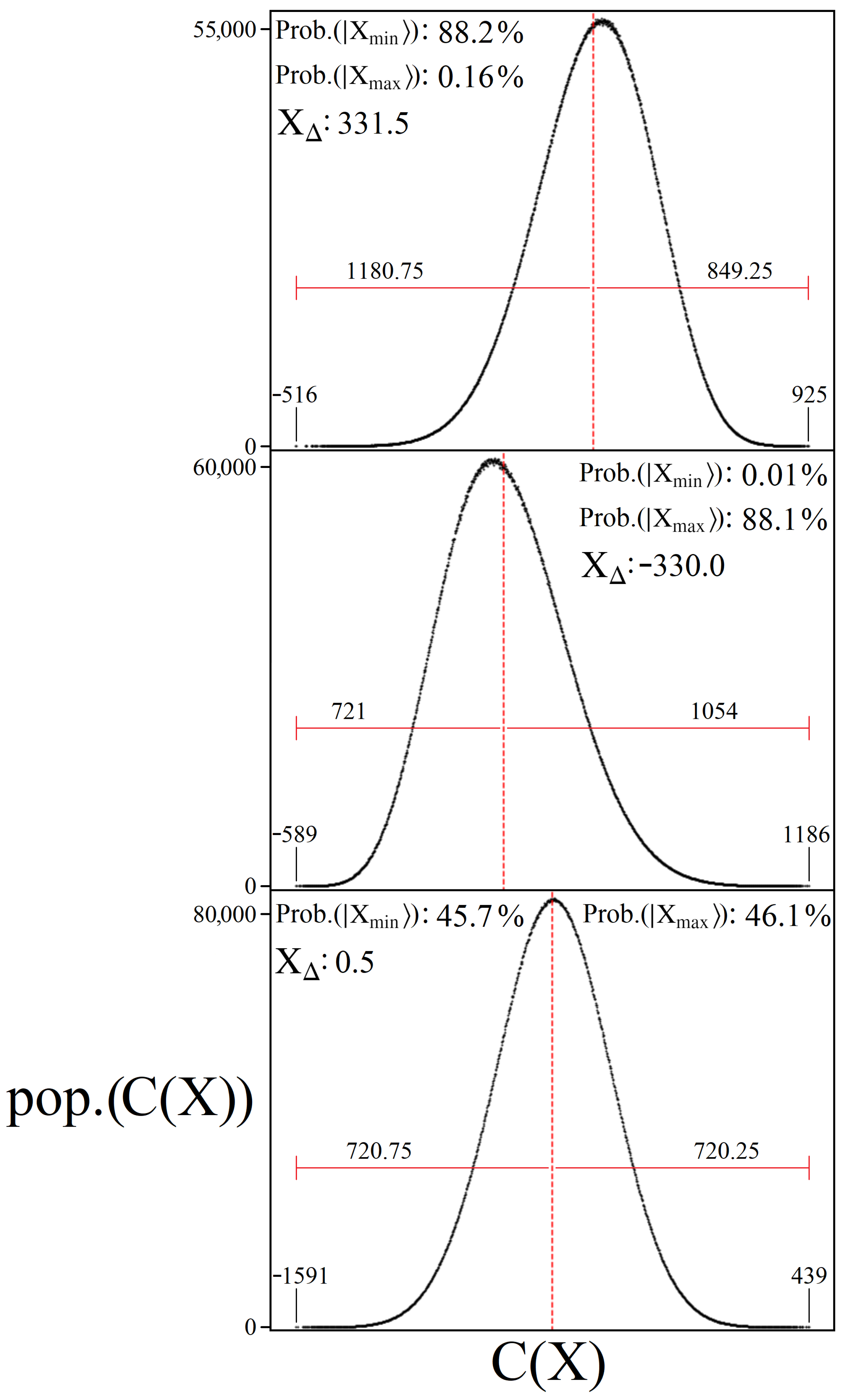
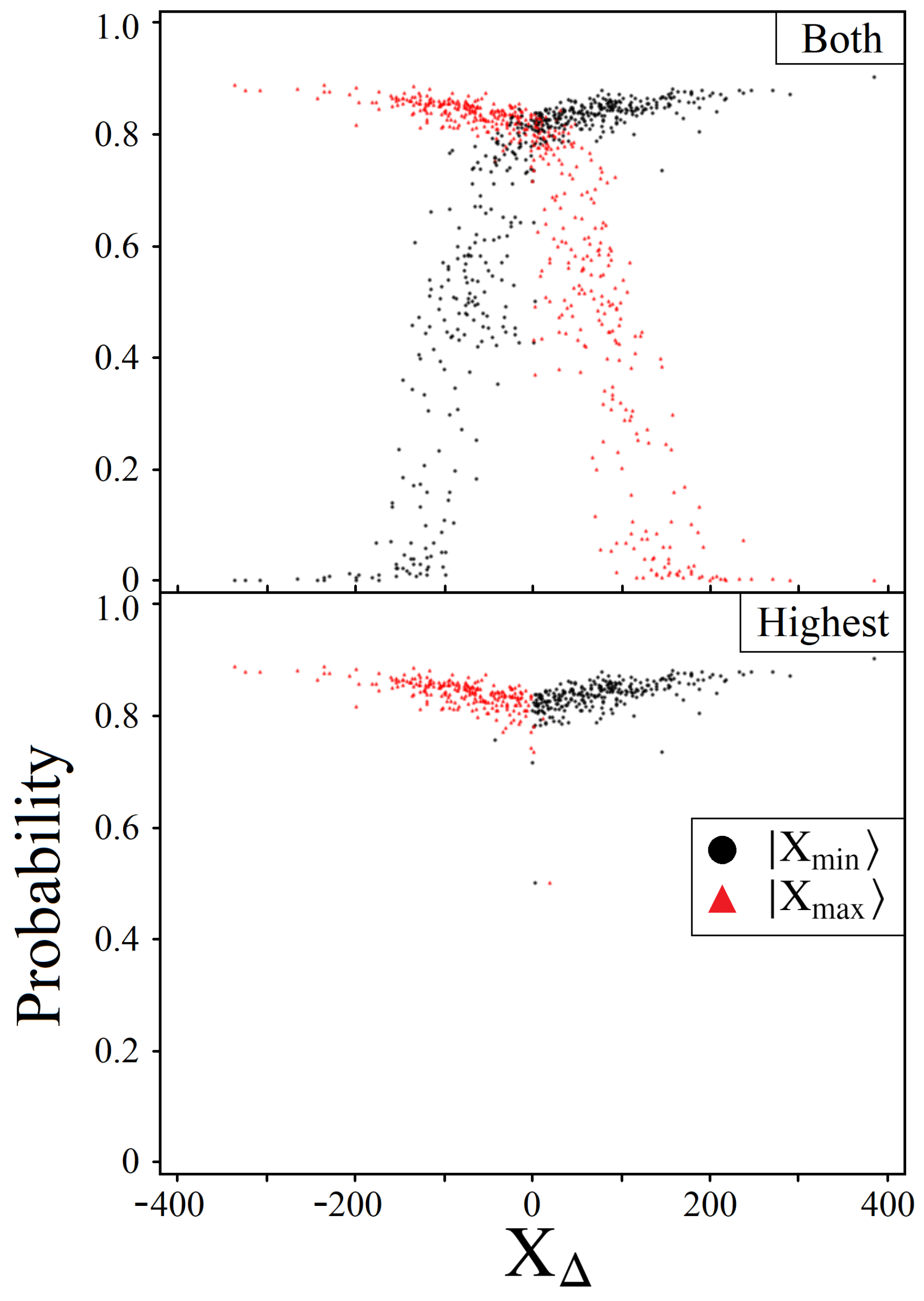
5.1. Boosting Near-Optimal Solutions
5.2. Constant Iterations
5.3. Information through Measurements
5.4. Quantum Verification
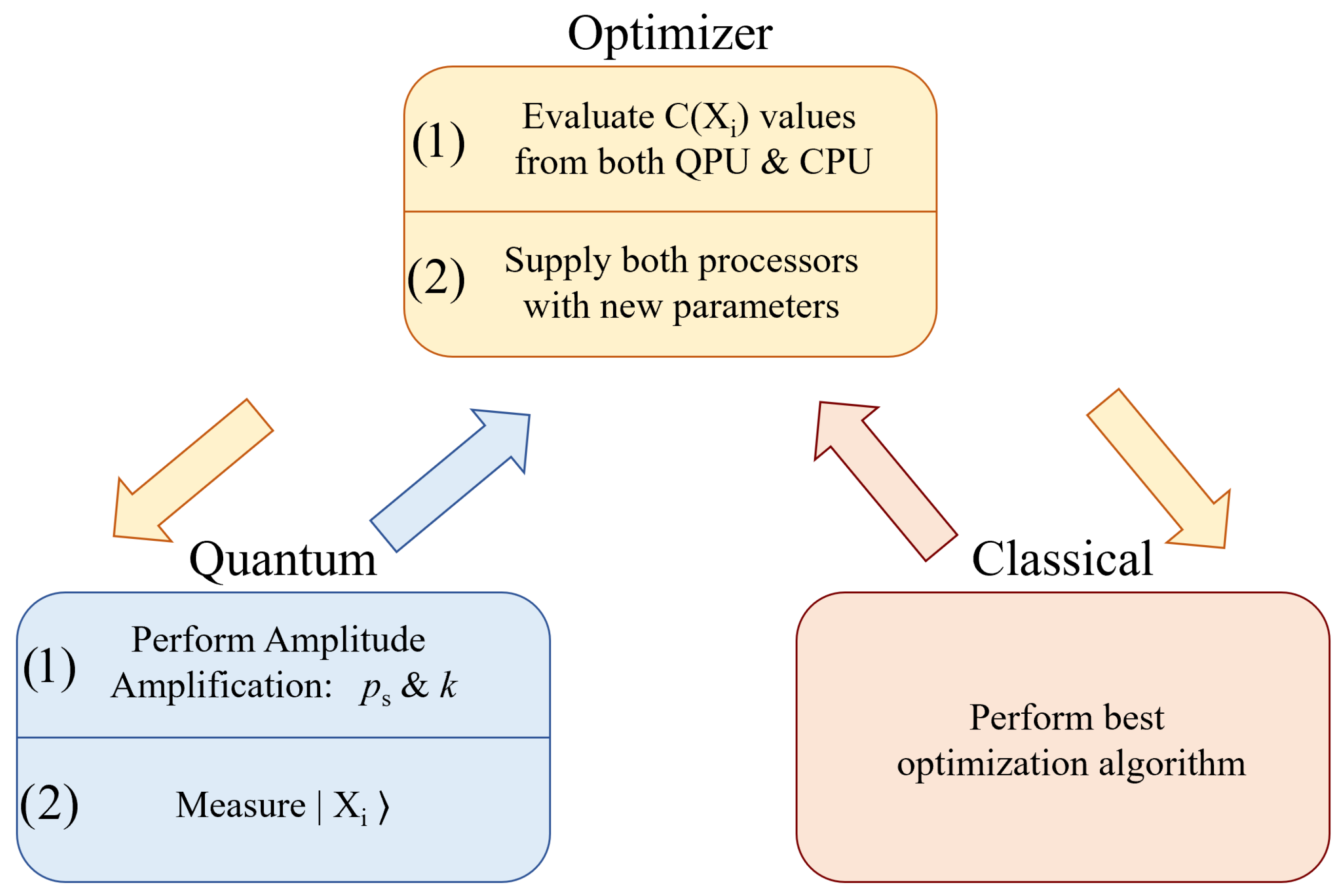
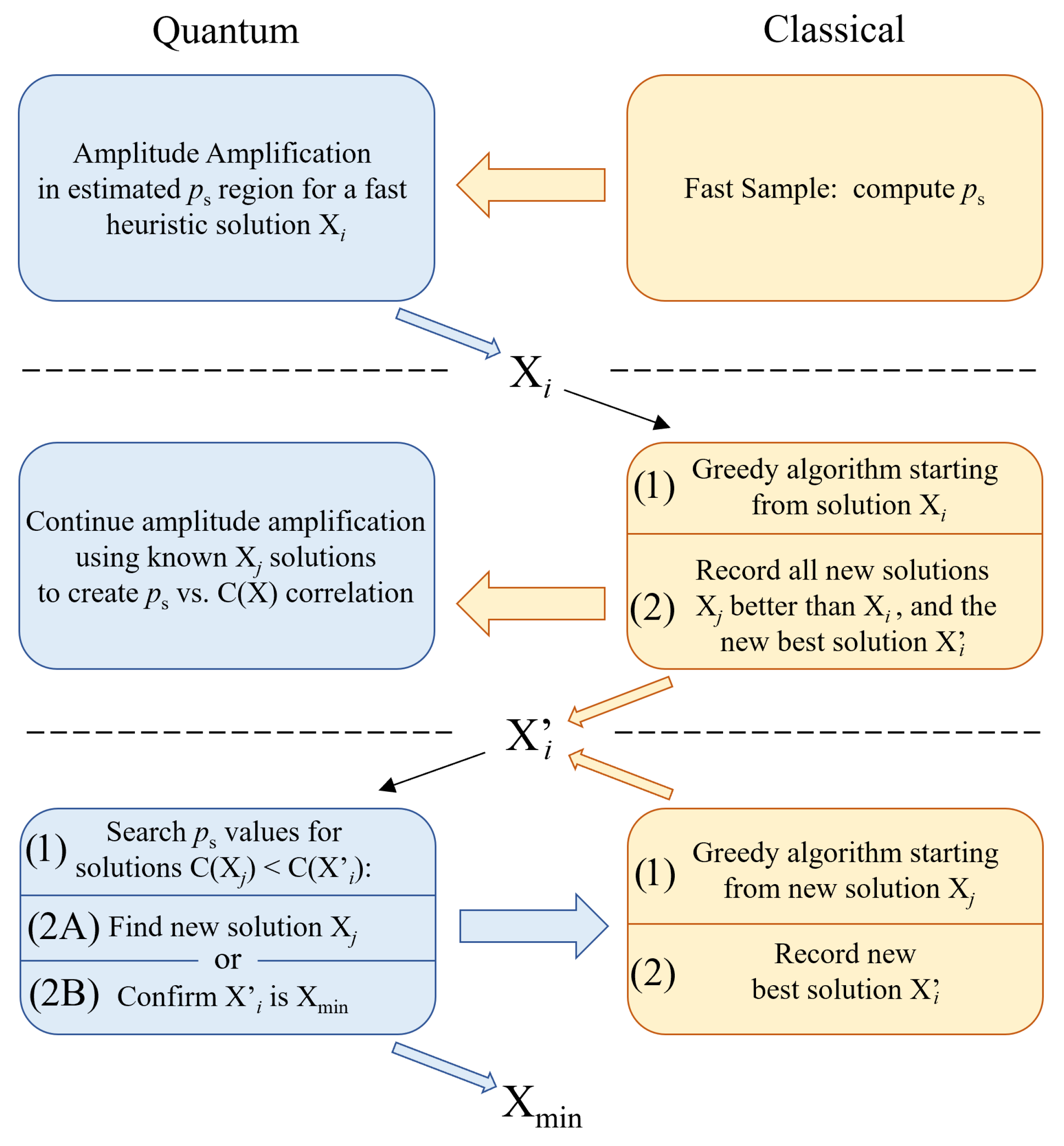
6. Hybrid Solving
Supporting Greedy Algorithms
7. More Oracle Problems
7.1. Weighted and Unweighted Max-Cut
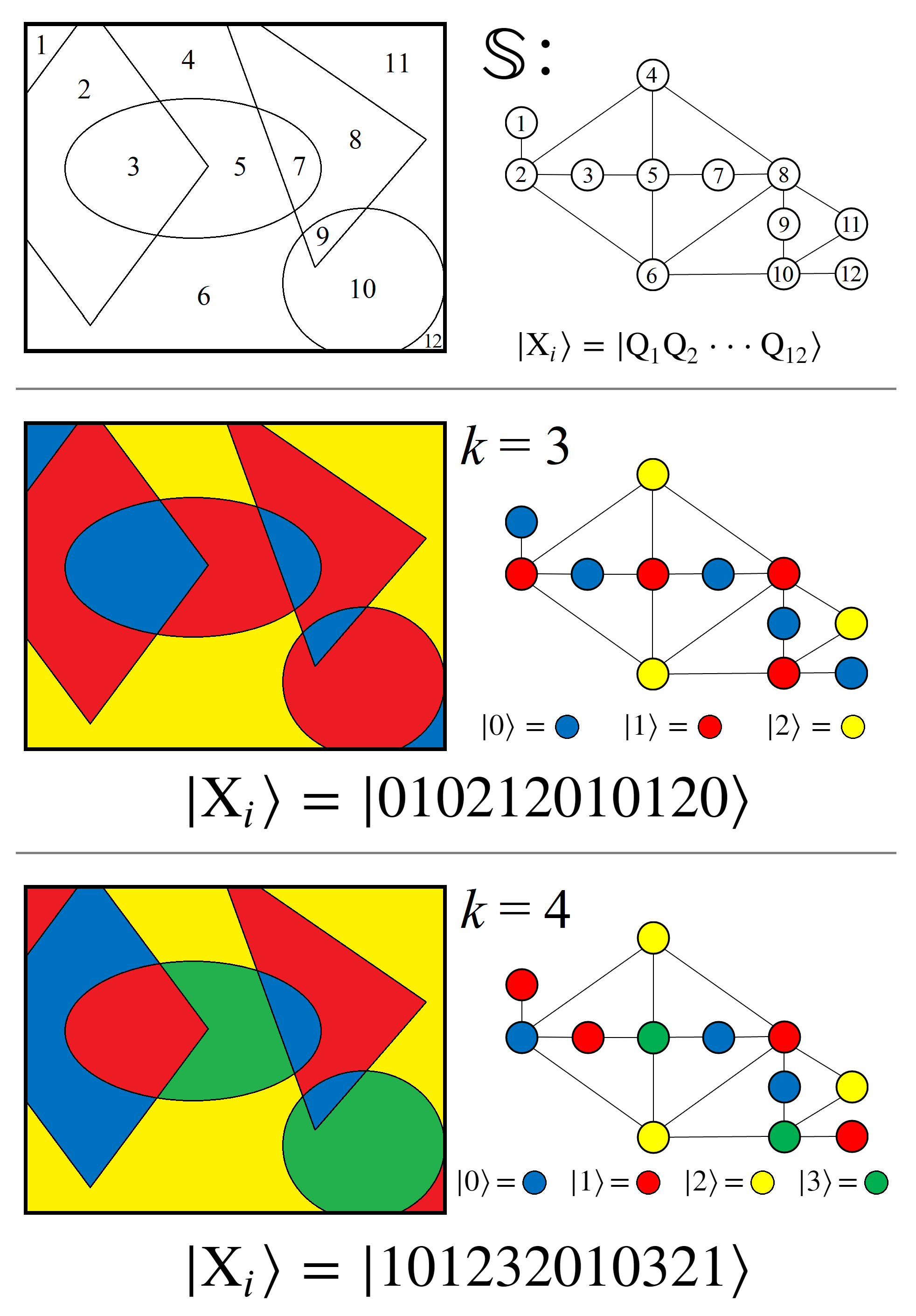
7.2. Graph Coloring
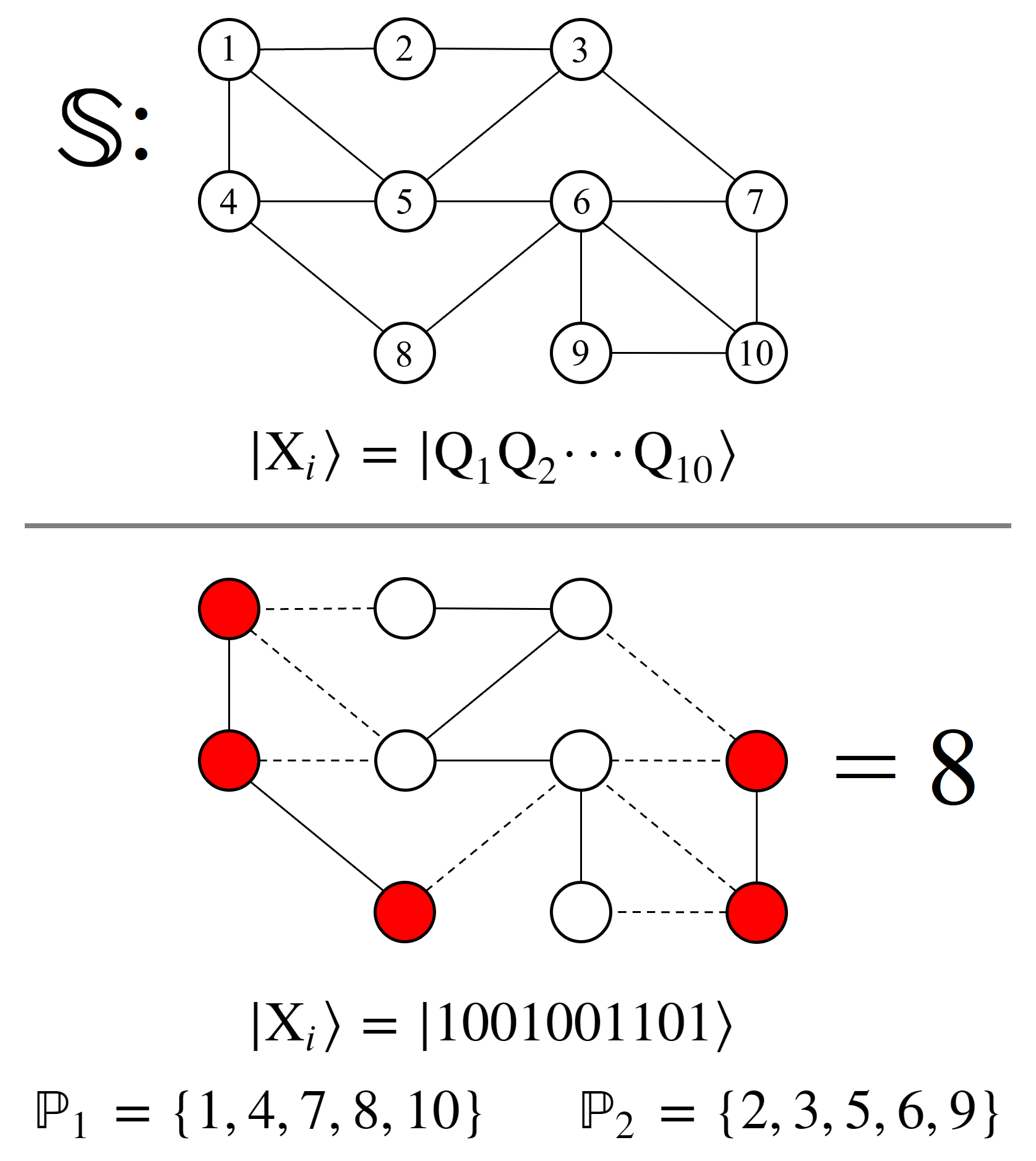
7.3. Subset Sum
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. QUBO Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
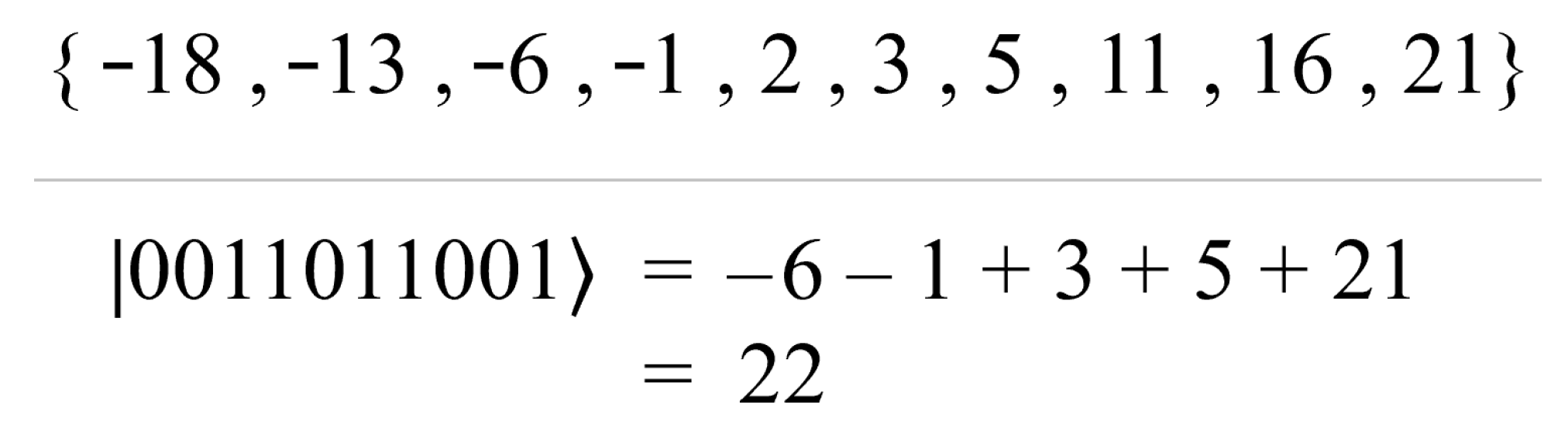{kind=link}
{kind=link}
{kind=link}
| # of QUBOs Studied | |
|---|---|
| 17 | 5000 |
| 18 | 3000 |
| 19 | 2000 |
| 20 | 1500 |
| 21 | 1200 |
| 22 | 1000 |
| 23 | 1000 |
| 24 | 600 |
| 25 | 500 |
| 26 | 400 |
| 27 | 100 |
Appendix B. Linear Regression
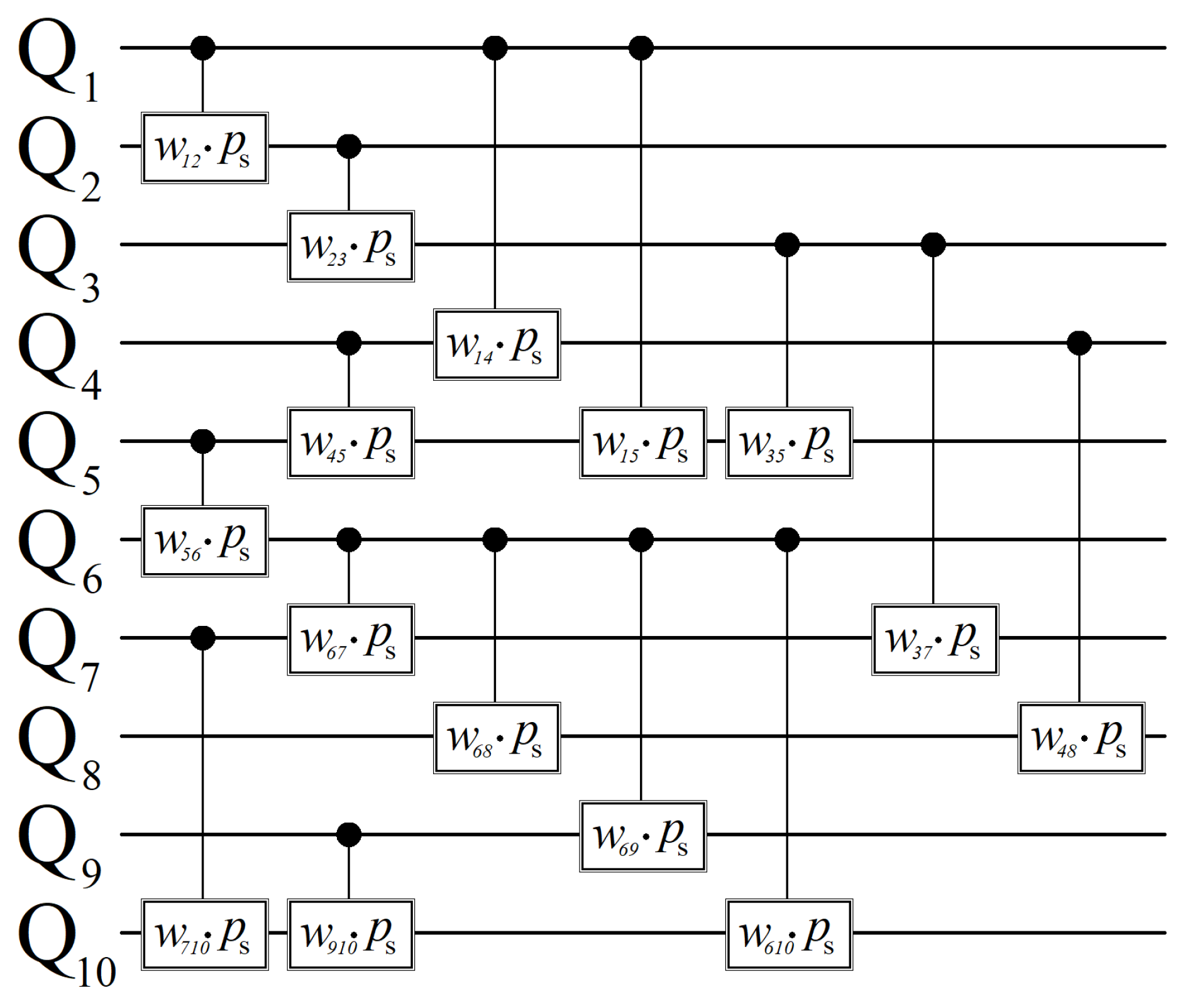
Appendix C. Max-Cut Circuit


References
- Grover, L.K. A fast quantum mechanical algorithm for database search. arXiv 1996, arXiv:9605043. [Google Scholar]
- Boyer, M.; Brassard, G.; Hoyer, P.; Tapp, A. Tight bounds on quantum searching. Fortschritte Phys. 1998, 46, 493–506. [Google Scholar] [CrossRef]
- Bennett, C.H.; Bernstein, E.; Brassard, G.; Vazirani, U. Strengths and weaknesses of quantum computing. SIAM J. Comput. 1997, 26, 1510–1523. [Google Scholar] [CrossRef]
- Farhi, E.; Gutmann, S. Analog analogue of a digital quantum computation. Phys. Rev. A 1998, 57, 2403. [Google Scholar] [CrossRef]
- Brassard, G.; Hoyer, P.; Tapp, A. Quantum counting. In Proceedings of the 25th International Colloquium on Automata, Languages and Programming (ICALP), Aalborg, Denmark, 13–17 July 1998; Volume 1443, pp. 820–831. [Google Scholar]
- Brassard, G.; Hoyer, P.; Mosca, M.; Tapp, A. Quantum amplitude amplification and estimation. Quantum Comput. Quantum Inf. AMS Contemp. Math. 2002, 305, 53–74. [Google Scholar]
- Childs, A.M.; Goldstone, J. Spatial search by quantum walk. Phys. Rev. A 2004, 70, 022314. [Google Scholar] [CrossRef]
- Ambainis, A. Variable time amplitude amplification and a faster quantum algorithm for solving systems of linear equations. arXiv 2010, arXiv:1010.4458. [Google Scholar]
- Singleton, R.L., Jr.; Rogers, M.L.; Ostby, D.L. Grover’s algorithm with diffusion and amplitude steering. arXiv 2021, arXiv:2110.11163. [Google Scholar]
- Farhi, E.; Goldstone, J.; Gutmann, S. A quantum approximate optimization algorithm. arXiv 2014, arXiv:1411.4028. [Google Scholar]
- Hadfield, S.; Wang, Z.; O’Gorman, B.; Rieffel, E.G.; Venturelli, D.; Biswas, R. From the quantum approximate optimization algorithm to a quantum alternating operator ansatz. Algorithms 2019, 12, 34. [Google Scholar] [CrossRef]
- Peruzzo, A.; McClean, J.; Shadbolt, P.; Yung, M.-H.; Zhou, X.-Q.; Love, P.J.; Aspuru-Guzik, A.; O’Brien, J.L. A variational eigenvalue solver on a quantum processor. Nat. Commun. 2014, 5, 4213. [Google Scholar] [CrossRef]
- Date, P.; Patton, R.; Schuman, C.; Potok, T. Efficiently embedding QUBO problems on adiabatic quantum computers. Quantum Inf. Process. 2019, 18, 117. [Google Scholar] [CrossRef]
- Ushijima-Mwesigwa, H.; Negre, C.F.A.; Mniszewski, S.M. Graph partitioning using quantum annealing on the D-Wave system. arXiv 2017, arXiv:1705.03082. [Google Scholar]
- Pastorello, D.; Blanzieri, E. Quantum annealing learning search for solving QUBO problems. Quantum Inf. Process. 2019, 18, 10. [Google Scholar] [CrossRef]
- Cruz-Santos, W.; Venegas-Andraca, S.E.; Lanzagorta, M. A QUBO formulation of minimum multicut problem instances in trees for D-Wave quantum annealers. Sci. Rep. 2019, 9, 17216. [Google Scholar] [CrossRef]
- Gilliam, A.; Woerner, S.; Gonciulea, C. Grover adaptive search for constrained polynomial binary optimization. Quantum 2021, 5, 428. [Google Scholar] [CrossRef]
- Seidel, R.; Becker, C.K.-U.; Bock, S.; Tcholtchev, N.; Gheorge-Pop, I.-D.; Hauswirth, M. Automatic generation of grover quantum oracles for arbitrary data structures. arXiv 2021, arXiv:2110.07545. [Google Scholar] [CrossRef]
- Koch, D.; Cutugno, M.; Karlson, S.; Patel, S.; Wessing, L.; Alsing, P.M. Gaussian amplitude amplification for quantum pathfinding. Entropy 2022, 24, 963. [Google Scholar] [CrossRef] [PubMed]
- Lloyd, S. Quantum search without entanglement. Phys. Rev. A 1999, 61, 010301. [Google Scholar] [CrossRef]
- Viamontes, G.F.; Markov, I.L.; Hayes, J.P. Is quantum search practical? arXiv 2004, arXiv:0405001. [Google Scholar] [CrossRef]
- Regev, O.; Schiff, L. Impossibility of a quantum speed-up with a faulty oracle. arXiv 2012, arXiv:1202.1027. [Google Scholar]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information; Cambridge University Press: Cambridge, UK, 2000; p. 249. [Google Scholar]
- Bang, J.; Yoo, S.; Lim, J.; Ryu, J.; Lee, C.; Lee, J. Quantum heuristic algorithm for traveling salesman problem. J. Korean Phys. Soc. 2012, 61, 1944. [Google Scholar] [CrossRef]
- Satoh, T.; Ohkura, Y.; Meter, R.V. Subdivided phase oracle for NISQ search algorithms. IEEE Trans. Quantum Eng. 2020, 1, 3100815. [Google Scholar] [CrossRef]
- Benchasattabuse, N.; Satoh, T.; Hajdušek, M.; Meter, R.V. Amplitude amplification for optimization via subdivided phase oracle. arXiv 2022, arXiv:2205.00602. [Google Scholar]
- Shyamsundar, P. Non-boolean quantum amplitude amplification and quantum mean estimation. arXiv 2021, arXiv:2102.04975. [Google Scholar]
- Long, G.L.; Zhang, W.L.; Li, Y.S.; Niu, L. Arbitrary phase rotation of the marked state cannot be used for Grover’s quantum search algorithm. Commun. Theor. Phys. 1999, 32, 335. [Google Scholar]
- Long, G.L.; Li, Y.S.; Zhang, W.L.; Niu, L. Phase matching in quantum searching. Phys. Lett. A 1999, 262, 27–34. [Google Scholar] [CrossRef]
- Hoyer, P. Arbitrary phases in quantum amplitude amplification. Phys. Rev. A 2000, 62, 052304. [Google Scholar] [CrossRef]
- Younes, A. Towards more reliable fixed phase quantum search algorithm. Appl. Math. Inf. Sci. 2013, 1, 10. [Google Scholar] [CrossRef]
- Li, T.; Bao, W.; Lin, W.-Q.; Zhang, H.; Fu, X.-Q. Quantum search algorithm based on multi-phase. Chin. Phys. Lett. 2014, 31, 050301. [Google Scholar] [CrossRef]
- Guo, Y.; Shi, W.; Wang, Y.; Hu, J. Q-learning-based adjustable fixed-phase quantum Grover search algorithm. J. Phys. Soc. Jpn. 2017, 86, 024006. [Google Scholar] [CrossRef]
- Song, P.H.; Kim, I. Computational leakage: Grover’s algorithm with imperfections. Eur. Phys. J. D 2000, 23, 299–303. [Google Scholar] [CrossRef]
- Pomeransky, A.A.; Zhirov, O.V.; Shepelyansky, D.L. Phase diagram for the Grover algorithm with static imperfections. Eur. Phys. J. D 2004, 31, 131–135. [Google Scholar] [CrossRef]
- Janmark, J.; Meyer, D.A.; Wong, T.G. Global symmetry is unnecessary for fast quantum search. Phys. Rev. Lett. 2014, 112, 210502. [Google Scholar] [CrossRef]
- Jong, K.D. Learning with genetic algorithms: An overview. Mach. Lang. 1988, 3, 121–139. [Google Scholar] [CrossRef]
- Forrest, S. Genetic algorithms: Principles of natural selection applied to computation. Science 1993, 261, 5123. [Google Scholar] [CrossRef]
- Kochenberger, G.; Hao, J.-K.; Glover, F.; Lewis, M.; Lu, Z.; Wang, H.; Wang, Y. The unconstrained binary quadratic programming problem: A survey. J. Comb. Optim. 2014, 28, 58–81. [Google Scholar] [CrossRef]
- Lucas, A. Ising formulations of many NP problems. Front. Phys. 2014, 12, 2. [Google Scholar] [CrossRef]
- Glover, F.; Kochenberger, G.; Du, Y. A tutorial on formulating and using QUBO models. arXiv 2018, arXiv:1811.11538. [Google Scholar]
- Date, P.; Arthur, D.; Pusey-Nazzaro, L. QUBO formulations for training machine learning models. Sci. Rep. 2021, 11, 10029. [Google Scholar] [CrossRef] [PubMed]
- Herman, D.; Googin, C.; Liu, X.; Galda, A.; Safro, I.; Sun, Y.; Pistoia, M.; Alexeev, Y. A survey of quantum computing for finance. arXiv 2022, arXiv:2201.02773. [Google Scholar]
- Guerreschi, G.G.; Matsuura, A.Y. QAOA for max-cut requires hundreds of qubits for quantum speed-up. Sci. Rep. 2019, 9, 6903. [Google Scholar] [CrossRef]
- Guerreschi, G.G. Solving quadratic unconstrained binary optimization with divide-and-conquer and quantum algorithms. arXiv 2021, arXiv:2101.07813. [Google Scholar]
- Streif, M.; Leib, M. Comparison of QAOA with quantum and simulated annealing. arXiv 2019, arXiv:1901.01903. [Google Scholar]
- Gabor, T.; Rosenfeld, M.L.; Feld, S.; Linnhoff-Popien, C. How to approximate any objective function via quadratic unconstrained binary optimization. arXiv 2022, arXiv:2204.11035. [Google Scholar]
- Pelofske, E.; Bartschi, A.; Eidenbenz, S. Quantum annealing vs. QAOA: 127 qubit higher-order ising problems on NISQ computers. arXiv 2023, arXiv:2301.00520. [Google Scholar]
- Bernoulli, J. Ars Conjectandi; Thurnisiorum: Basileae, Switzerland, 1713. [Google Scholar]
- Laplace, P.S. Mémoire sur les approximations des formules qui sont fonctions de très grands nombres et sur leur application aux probabilités. Mém. Acad. R. Sci. Paris 1810, 10, 353–415. [Google Scholar]
- Gauss, C.F. Theoria Motus Corporum Coelestium in Sectionibus Conicis Solem Ambientium; Friedrich Perthes and I.H. Besser: Hamburg, Germany, 1809. [Google Scholar]
- Srinivas, M.; Patnaik, L.M. Genetic algorithms: A survey. IEEE Comput. 1994, 27, 17–26. [Google Scholar] [CrossRef]
- Parsons, R.J.; Forrest, S.; Burks, C. Genetic algorithms, operators, and DNA fragment assembly. Mach. Learn. 1995, 21, 11–33. [Google Scholar] [CrossRef]
- Finnila, A.B.; Gomez, M.A.; Sebenik, C.; Stenson, C.; Doll, J.D. Quantum annealing: A new method for minimizing multidimensional functions. Chem. Phys. Lett. 1994, 219, 343–348. [Google Scholar] [CrossRef]
- Koshka, Y.; Novotny, M.A. Comparison of D-Wave quantum annealing and classical simulated annealing for local minima determination. IEEE J. Sel. Areas Inf. Theory 2020, 1, 2. [Google Scholar] [CrossRef]
- Wierichs, D.; Gogolin, C.; Kastoryano, M. Avoiding local minima in variational quantum eigensolvers with the natural gradient optimizer. Phys. Rev. Res. 2020, 2, 043246. [Google Scholar] [CrossRef]
- Rivera-Dean, J.; Huembeli, P.; Acin, A.; Bowles, J. Avoiding local minima in variational quantum algorithms with neural networks. arXiv 2021, arXiv:2104.02955. [Google Scholar]
- Sack, S.H.; Serbyn, M. Quantum annealing initialization of the quantum approximate optimization algorithm. Quantum 2021, 5, 491. [Google Scholar] [CrossRef]
- Eisert, J.; Hangleiter, D.; Walk, N.; Roth, I.; Markham, D.; Parekh, R.; Chabaud, U.; Kashefi, E. Quantum certification and benchmarking. Nat. Rev. Phys. 2020, 2, 382–390. [Google Scholar] [CrossRef]
- Willsch, D.; Willsch, M.; Calaza, C.D.G.; Jin, F.; Raedt, H.D.; Svensson, M.; Michielsen, K. Benchmarking advantage and D-Wave 2000Q quantum annealers with exact cover problems. Quantum Inf. Process. 2022, 21, 141. [Google Scholar] [CrossRef]
- Noiri, A.; Takeda, K.; Nakajima, T.; Kobayashi, T.; Sammak, A.; Scappucci, G.; Tarucha, S. Fast universal quantum gate above the fault-tolerance threshold in silicon. Nature 2022, 601, 338–342. [Google Scholar] [CrossRef]
- Zhang, Z.; Schwartz, S.; Wagner, L.; Miller, W. A greedy algorithm for aligning DNA sequences. J. Comp. Biol. 2004, 7, 203–214. [Google Scholar] [CrossRef]
- Lin, L.; Cao, L.; Wang, J.; Zhang, C. The applications of genetic algorithms in stock market data mining optimisation. WIT Trans. Inf. Commun. Technol. 2004, 33. [Google Scholar]
- Korte, B.; Lovasz, L. Mathematical structures underlying greedy algorithms. In Fundamentals of Computation Theory; Springer: Berlin/Heidelberg, Germany, 1981. [Google Scholar]
- Bang-Jensen, J.; Gutin, G.; Yeo, A. When the greedy algorithm fails. Discret. Optim. 2004, 1, 121–127. [Google Scholar] [CrossRef]
- Glover, F.; Gutin, G.; Yeo, A.; Zverovich, A. Construction heuristics for the asymmetric TSP. Eur. J. Oper. Res. 2001, 129, 3. [Google Scholar] [CrossRef]
- Festa, P.; Pardalos, P.M.; Resende, M.G.C.; Ribeiro, C.C. Randomized heuristics for the Max-Cut problem. Optim. Methods Softw. 2002, 17, 6. [Google Scholar] [CrossRef]
- Karp, R. Reducibility among combinatorial problems. In Proceedings of the Symposium on the Complexity of Computer Computations, Yorktown Heights, NY, USA, 20–22 March 1972. [Google Scholar]
- Garey, M.R.; Johnson, D.S.; Stockmeyer, L. Some simplified NP-complete graph problems. Theor. Comput. Sci. 1976, 1, 237–267. [Google Scholar] [CrossRef]
- Wang, Y.; Hu, Z.; Sanders, B.C.; Kais, S. Qudits and high-dimensional quantum computing. Front. Phys. 2020, 10, 8. [Google Scholar] [CrossRef]
- Lanyon, B.P.; Barbieri, M.; Almeida, M.P.; Jennewein, T.; Ralph, T.C.; Resch, K.J.; Pryde, G.J.; O’Brien, J.L.; Gilchrist, A.; White, A.G. Quantum computing using shortcuts through higher dimensions. Nat. Phys. 2009, 5, 134. [Google Scholar] [CrossRef]
- Luo, M.-X.; Wang, X.-J. Universal quantum computation with qudits. Sci. China Phys. Mech. Astron. 2014, 57, 1712–1717. [Google Scholar] [CrossRef]
- Niu, M.Y.; Chuang, I.L.; Shapiro, J.H. Qudit-Basis Universal Quantum Computation Using χ2 Interactions. Phys. Rev. Lett. 2018, 120, 160502. [Google Scholar] [CrossRef]





















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koch, D.; Cutugno, M.; Patel, S.; Wessing, L.; Alsing, P.M. Variational Amplitude Amplification for Solving QUBO Problems. Quantum Rep. 2023, 5, 625-658. https://doi.org/10.3390/quantum5040041
Koch D, Cutugno M, Patel S, Wessing L, Alsing PM. Variational Amplitude Amplification for Solving QUBO Problems. Quantum Reports. 2023; 5(4):625-658. https://doi.org/10.3390/quantum5040041
Chicago/Turabian StyleKoch, Daniel, Massimiliano Cutugno, Saahil Patel, Laura Wessing, and Paul M. Alsing. 2023. "Variational Amplitude Amplification for Solving QUBO Problems" Quantum Reports 5, no. 4: 625-658. https://doi.org/10.3390/quantum5040041