A simplified workflow of the current study is presented in
Figure 3. Initially, a design of experiments is created involving different combinations of part geometry, material properties and IR heating cycle data. Then, a finite element model is created and used to simulate the IR curing process. A genetic algorithm is employed to optimize the curing process by creating designs with a high degree of uniform curing and permissible heat build-up. The above procedure is performed until all designs have been evaluated. Factor analysis is performed to identify the significant factors affecting the process while the data generated from the analysis are used to train response surfaces capable of producing the optimal cure cycle. In the rest of
Section 2, each parameter used as input in the FEM solver will be identified along with its range and step. Range defines the variation between the upper and lower limits of each parameter, while step determines how finely the parameter space is sampled. To limit the computational cost, the average number of steps inside each parameter’s design space is 4–6, while parameters that exhibit large ranges, with high variance, or have been shown by the literature to affect the results in a significant manner can have more than 20 steps. Finally, parameters that depend on the use case (e.g., geometry) and display small parameter ranges have 2–3 steps inside the design space.
2.2. Temperature-Related Material Properties
Table 2 provides all the temperature-related material properties with the corresponding range and step in the design space. The volume fraction for aeronautic and automotive applications ranges from 0.3 to 0.6 as lower values result in low mechanical properties and higher values lead to manufacturing errors [
30,
31,
32,
33]. The orthotropic thermal conductivity depends significantly on the direction of the fibers and the fiber volume fraction. Significantly, higher values are observed in the fiber direction, due to the higher thermal conductivity of the reinforcement, while in the other directions, values closer to the resin thermal conductivity are observed [
34,
35,
36]. Unlike thermal conductivity, specific heat capacity is a property dependent on the constitution of the composite, rather than the direction of the reinforcement, with the rule of mixtures providing good estimates [
37,
38]. Thus, using the properties of the constituents [
39,
40] with the rule of mixtures (Equation (1)), the effective specific heat capacity can be calculated, with many researchers providing results corresponding to the region indicated in
Table 2 [
41,
42].
where
is the composite’s effective specific heat,
is the fiber volume fraction,
is the specific heat capacity of the reinforcement and
is the specific heat capacity of the matrix.
Similarly, the density can be calculated from Equation (1) by applying the density of the reinforcement on the term
and the density of the matrix on the term
, with many researchers providing the range presented in
Table 2 [
30,
33,
36,
41,
43].
2.5. Analytical Workflow and Genetic Algorithm Implementation
The analytical workflow of the current multi-parametric study is depicted in
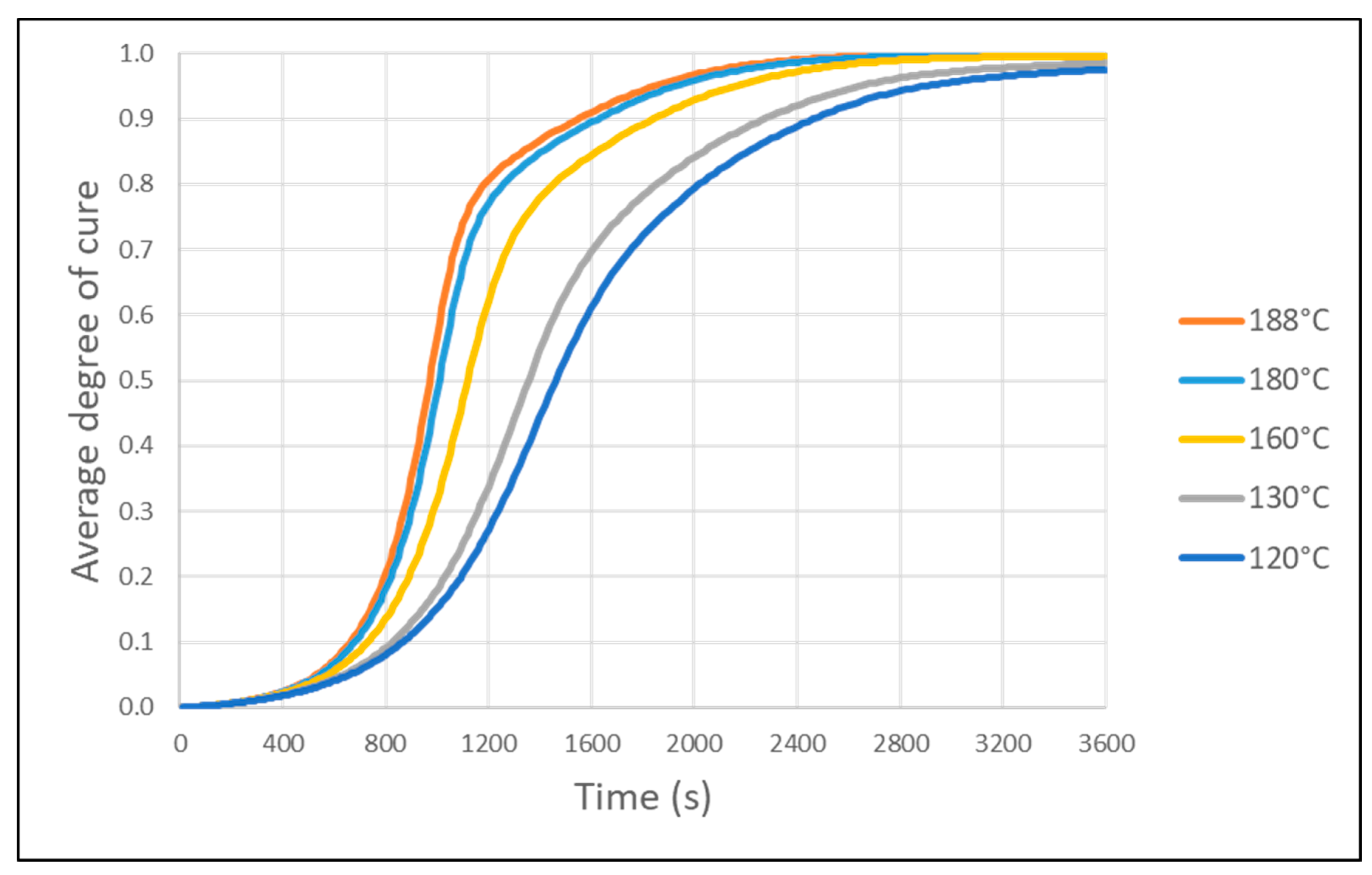
Figure 5. Essentially, geometric data (length in x-direction, length in y-direction, thickness), temperature-related material properties (density, orthotropic thermal conductivity, specific heat, fiber volume fraction), curing-related material properties (pre-exponential factor, activation energy, power m, power n, heat of reaction, initial degree of cure, maximum degree of cure) and radiation data (absorptivity, temperature, time to reach curing temperature, cure duration) are fed into a finite element solver (ANSYS) to simulate the process. Each design’s output involves the average degree of cure of all the elements, the minimum degree of cure on a single element exhibiting the lowest value, the maximum temperature observed during the simulation and total time, which is the sum of the time required to reach the applied temperature, and the curing duration.
The Sobol algorithm is a proven exploration DOE generator, so a sequence of 60 Sobol points is chosen to eliminate subjective bias and allow a good initial sampling of the configuration space [
54,
55,
56]. The above exploration DOEs serve as the starting point for the subsequent optimization process, connected to a multi-objective genetic algorithm (MOGA-II). The parameters of the genetic algorithm are presented in
Table 5. The 60 initial points along with the 15 generations lead to a total of 900 evaluated designs with a computational cost of 70 h. Increasing the number of Sobol points and number of generations leads to unreasonable computational costs, while 900 designs are deemed satisfactory in the context of this analysis.
The objectives are to maximize the average degree of cure and minimize total time. The objective function penalizes violations of constraints (Treat constraints). Based on Tournament selection (Probability of selection) MOGA-II chooses solutions for reproduction. Then, it applies cross-over operators (Probability of directional cross-over, Random generator seed) to pairs of parent solutions to generate offspring solutions. Finally, mutation operators (Probability of mutation, Random generator seed) are applied to the offspring solutions. By enabling elitism, the best solution from the current population is carried over to the next generation without any modification. The combined population of parents and offspring is ranked based on Pareto dominance:
where
are solution vectors and
is the
i-th objective function.
Solutions with the same Pareto rank are sorted based on the crowding distance. Crowding distance measures the density of solutions around each solution in the objective space:
where
is the crowding distance and
and
are solutions adjacent to
in sorted population.
Solutions for the next generation are selected from the combined population based on Pareto dominance and crowding distance.
Finally, the following constraints are added to achieve a complete, uniform cure without excessive heat built up:
Average cure constraint (average degree of cure: minimum value ≥ 0.93): high degree of cure.
minimum cure constraint (minimum degree of cure: minimum value ≥ 0.9): uniform curing.
Maximum temperature constraint (maximum temperature observed during simulation ≤ 210): avoids excess heat generation and resin carbonization.
The data are split into 80% and 20% samples, used for training and validation, respectively. Since the DOE is not fully factorial and activation energy is the dominant factor in the analysis, the 20% validation points are equally spread across the activation energy range. R-squared is chosen as the metric for validation of the response surface methodology (RSM). The first form of response surfaces is based on the kriging interpolation method with data normalization:
where
is the kriging estimate at the unobserved location
,
is the observed value at location
and
are the kriging weights.
The kriging weights and the variance of the estimation error
can be obtained by solving the kriging system of equations:
where
is the covariance between
and
, and
is a Lagrange multiplier used in the minimization of the kriging error to honor the unbiasedness condition.
The Gaussian variogram model is chosen with its formulation being
where
is the variogram value at separation distance
,
is the sill (variance of the process) and
is the range (distance at which the correlation between values is negligible).
The covariance function
is related to the variogram by
The parameters
and
are estimated by maximizing the likelihood function. The log-likelihood function for the kriging model is
where
is the vector of variogram parameters,
is the vector of observed values and
is the covariance matrix.
The second form of response surfaces is based on classical feedforward Neural Networks, with Levenberg–Marquardt back propagation chosen as the training algorithm. Network sizing is automatically handled by the software.
The output
of the
k-th neuron in the output layer is given by
where
is the weight from the
j-th neuron in the hidden layer to the
k-th neuron in the output layer,
is the output of the
j-th neuron in the hidden layer,
is the bias term for the
k-th neuron in the output layer and
is the activation function used in the output layer.
The output of the
j-th neuron in the hidden layer is given by
where
is the weight from the
i-th neuron in the input layer to the
j-th neuron in the hidden layer,
is the input to the
i-th neuron in the input layer,
is the bias term for the
j-th neuron in the hidden layer and
is the activation function used in the hidden layer.
In this study, rectified linear unit (ReLU) is used as the activation function, while the loss function is mean squared error (MSE):
where
is the number of samples or data points,
is the actual or observed value for the
i-th sample and
is the predicted or estimated value for the
i-th sample.
Finally, Multivariate Polynomial Interpolation based on the Singular Value Decomposition (SVD) algorithm with a 3rd-degree polynomial function and variable normalization is chosen for the fitting of the 3rd response surface option. The vector of the coefficient
can be obtained by solving the system of linear equations using Singular Value Decomposition:
where
is the matrix of the input variables and
is the vector containing the values of the target variable corresponding to each data point.
The SVD of matrix
is given by
where
and
are orthogonal matrices and
is a diagonal matrix containing the singular values. The vector of the coefficient
can then be obtained as follows:
The genetic algorithm implementation and the response surface creation are performed in ModeFRONTIER software version 2014 [
57].



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}