



Can Artificial Neural Networks Be Used to Predict Bitcoin Data?


Abstract
:1. Introduction
2. Problem Formulation
- How can a platform for running and testing trading systems be implemented?
- How do trading systems, using a standard multilayer perceptron (MLP) ANN, perform on the bitcoin market?
- (a)
- What training data should be used (input and target output)?
- (b)
- Is this trading system more profitable than classical trading systems on the bitcoin market?
3. Trading the Financial Instruments
4. Automatic Trading
5. Fees
6. Backtesting
7. Artificial Neural Networks
7.1. Computational Intelligence
… the study of adaptive mechanisms to enable or facilitate intelligent behavior in complex and changing environments. These mechanisms include those AI paradigms that exhibit an ability to learn or adapt to new situations, to generalize, abstract, discover and associate
7.2. Artificial Neural Networks
8. The Actor Model
Actors and Agents
- Autonomy: agents operate without the direct intervention of humans orothers, and have some kind of control over their actions and internal state;
- Social ability: agents interact with other agents (and possibly humans) via some kind of agent-communication language [15];
- Reactivity: agents perceive their environment (which may be the physical world, a user via a graphical user interface, a collection of other agents, the Internet, or perhaps all of these combined) and respond in a timely fashion to changes that occur in it;
- Pro-activeness: agents do not simply act in response to their environment. They are able to exhibit goal-directed behavior by taking initiative.
- Actors need to get a message to be able to do any computation, while agents can react to an environment or take the initiative.
- Actors need the address of another actor in order to communicate (send messages). The notion of agent does not have this restriction.
9. Design and Development of the System
The Data Collector
10. Artificial Neural Networks for Trading Systems
10.1. Technical Indicators
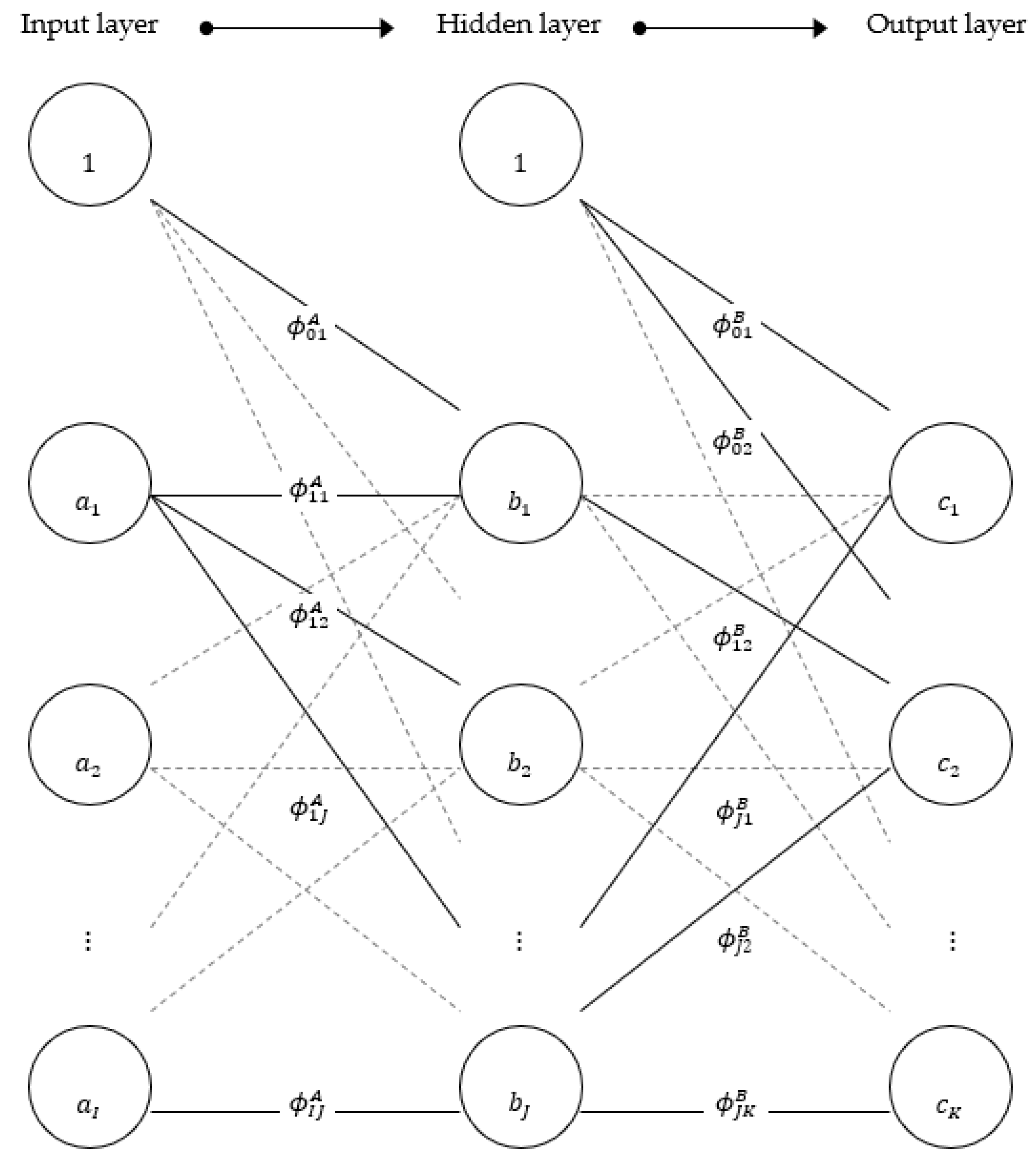
10.2. Architecture
10.3. Training
10.4. Prediction of Trading Variables
10.5. ANN Output
- Two percent or more price increase, [2, ∞].
- Zero to two percent price increase, (0, 2).
- Zero to minus two percent price decrease, [−2, 0].
- Two percent or more price decrease, (−∞, −2).
- 1 if the price change is positive, more than 2%;
- 0 if the price change is less than 2% and positive;
- −1 if the price change is negative, more than 2%.
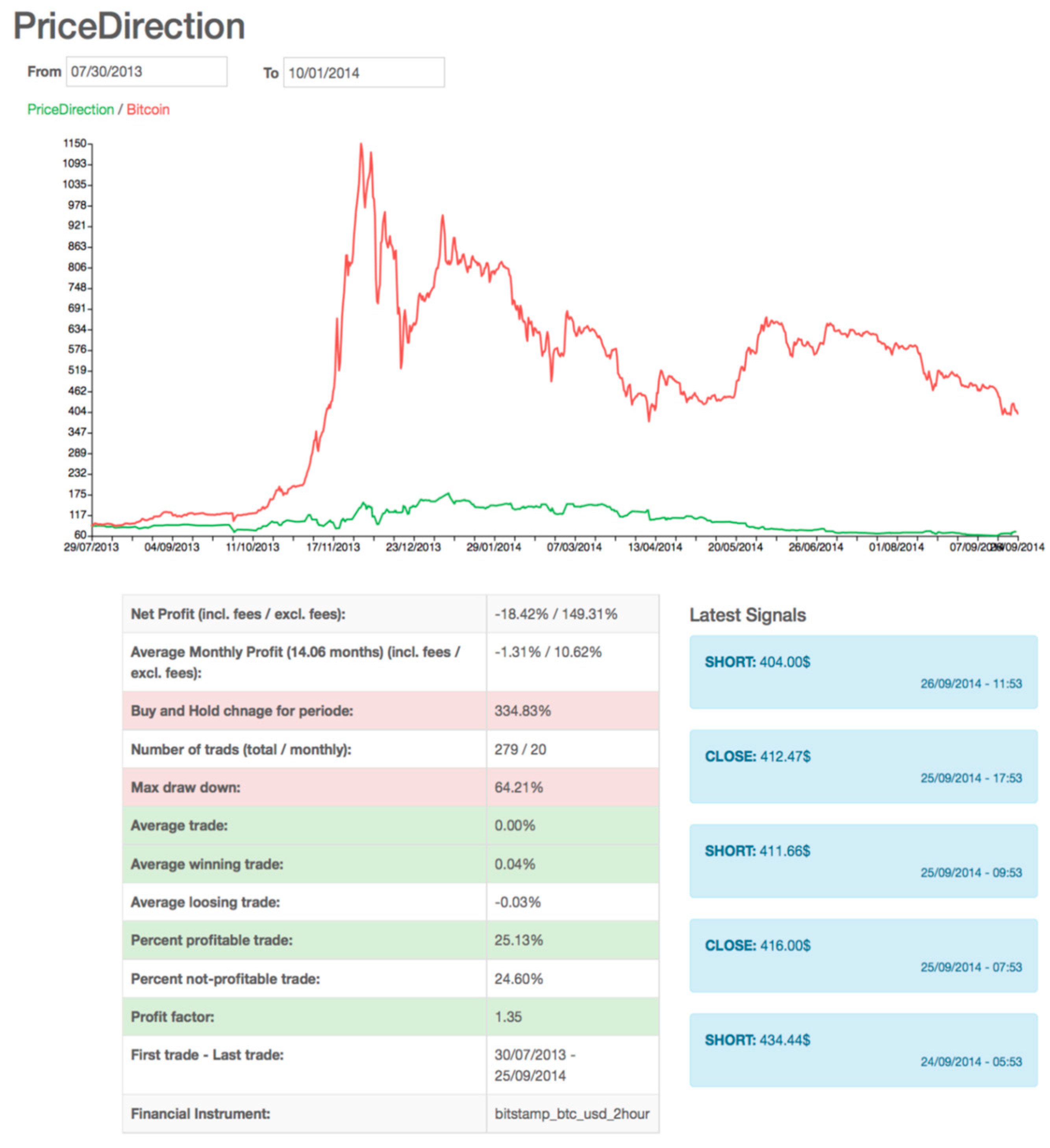
11. Experiments and Results
Testing on the Bitcoin Market
12. Conclusions and Further Work
Further Work
Author Contributions
Funding
Conflicts of Interest
References
- Bianchi, D.; Born, A.; Di Benedetto, M.D.; Di Gennaro, S. Active Attitude Control of Ground Vehicles with Partially Unknown Model. IFAC PapersOnLine 2020, 53, 14420–14425. Available online: www.sciencedirect.com (accessed on 15 June 2023). [CrossRef]
- Box, G.; Jenkins, G. Time Series Analysis: Forecasting and Control; Holden-Day: Oakland, CA, USA, 1970. [Google Scholar]
- Bøvre, J.O.; Viervoll, P.K.; Kristensen, T. An Artificial Walk Down Wall Street: Can Intra-Day Stock Returns Be Predicted Using Artificial Neural Networks? In Proceedings of Eight International Conference on Perspectives in Business Informatics Research (BIR2009); Kristiansand Academic Press: Kristiansand, Sweden, 2009; ISBN 978-91-633-5509-7. [Google Scholar]
- Clinger, W.D. Foundations of Actor Semantics. 1981. Available online: http://dspace.mit.edu/handle/1721.1/6935 (accessed on 15 June 2023).
- NASDAQ. Nasdaq. February 2014. Available online: http://www.nasdaq.com/ (accessed on 15 June 2023).
- XE. August 2014. Available online: http://www.xe.com (accessed on 15 June 2023).
- Bitstamp. August 2014. Available online: http://www.bitstamp.com/ (accessed on 15 June 2023).
- Hewitt, C. Actor Model of Computation: Scalable Robust Information Systems. 2013. Available online: https://docs.google.com/open?id=0Bykigp0x1j92M0p6b0ZWWE9SS3Frb3loV3NKX2sxdw (accessed on 15 June 2023).
- Hewitt, C. What Is Computation? Actor Model versus Turing’s Model. In Understanding and Exploring Nature as Computation; World Scientific: Singapore, 2012. [Google Scholar]
- Engelbrecht, A.P. Computational Intelligence: An Introduction; John Wiley and Sons: Hoboken, UK, 2007; ISBN 0470035617. [Google Scholar]
- Gul, A.A.; Wooyoung, K. A unifying model for parallel and distributed computing. J. Syst. Archit. 1999, 45, 1263–1277. Available online: http://www.sciencedirect.com/science/artickle/pii/S1383762198000678 (accessed on 15 June 2023).
- Chen, S.H.; Wang, P.P. Computational Intelligence in Economics and Finance; Springer: Berlin/Heidelberg, Germany, 2004; ISBN 978-3-642-07902-3. [Google Scholar]
- Grøtte, O. Original Norwegian Title: Aksjekjøp og Datatrading: Metode, Psykologi, Risiko og Strategier. English Title: Stock Purchases and Daytrading: Methodology, Psychology, Risk and Strategies; Hegnar Media: Oslo, Norway, 2006; ISBN 9788271460310. [Google Scholar]
- Kristensen, T. Original Norwegian Title: Nevrale Nettverk, Fuzzy Logikk og Genetiske Algoritmer. English Title: Neural Networks, Fuzzy Logic and Genetic Algorithms; Cappelen Akademic Publisher: Oslo, Norway, 1997; ISBN 82-456-0203-5. [Google Scholar]
- Wooldridge, M.; Jennings, N.R. Intelligent Agents: Theory and practice. Knowl. Eng. Rev. 1995, 10, 115–152. [Google Scholar] [CrossRef]
- Tomasini, E.; Jaekle, U. Trading Systems: A New Approach to System Development and Portfolio Optimization; Harriman House Series; Harriman House: Harriman House, UK, 2009; ISBN 9780857191496. [Google Scholar]
- Vanstone, B.; Finnie, G. An empirical methodology for developing stockmarket traiding systems using artificial neural networks. Expert Syst. Appl. 2009, 36 Pt 2, 6668–6680. Available online: http://www.scienencedirect.com/science/article/pii/SO957417408005836 (accessed on 15 June 2023). [CrossRef]
- Heaton Research Inc. Encog Machine Learning Framework. September 2014. Available online: http://www.heatonresearch.com/encog (accessed on 15 June 2023).
- Karmani, R.K.; Shali, A.; Agha, G. Actor Frameworks for the JVM Platform: A Comparative Analysis. In Proceedings of the 7th International Conference on Principles and Practice of Programming in Java, Calgary, AB, Canada, 27 August 2009; pp. 11–20. [Google Scholar]
- ypesafe Inc. Akka. February 2014. Available online: http://ww.akka.io (accessed on 15 June 2023).
- Mcadam, P.; McNelis, P. Forecasting Inflation with Thick Models and Neural Networks; Economic Modeling; Elsevier: Amsterdam, The Netherlands, 2005; Volume 22, pp. 848–867. [Google Scholar]
- Mills, T.C.; Markellos, R.N. Nonlinear Times Series in Financial Economics; Encyclopedia of Complexity and Systems Science; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Nourani, E.; Rahmani, A.; Mand Navin, A.H. Forcasting stock prices using a hybride Artificial Bee Colony based neural network. In Proceedings of the 2012 International Conference on Innovation Management and Technology Research, Malacca, Malaysia, 21–22 May 2012; pp. 486–490. Available online: http:////ieexplore.ieee.org&lpdocs/epic03/wrapper.htm?arnumber=6236444 (accessed on 15 June 2023).
- Rumelhart, D.E.; McClelland, J.L. Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Shoham, Y. Agent-oriented programming. Artif. Intell. 1993, 60, 51–92. [Google Scholar] [CrossRef]
- Zhai, Y.; Hsu, A.; Halgmuge, S. Combining news and technical indicators in daily stock price trends prediction. In Proceedings of the 4th International Symposium on Neural Networks: Advances in Neural Networks, Part III, ISNN 07, Nanjing, China, 3–7 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1087–1096, ISBN 978-3-540-72394-3. [Google Scholar]



{kind=link}
{kind=link}
| Indicator Name | Formula |
|---|---|
| Stochastic %K (%K) | |
| Stochastic %D (%D) | |
| Stochastic slow %D (slow %D) | |
| Momentum (MO) | |
| Rate of Change (ROC) | |
| Willlama’s %R (%R) | |
| Accumulation/Distribution Oscillator (ADO) | |
| Disparity Index (DI) | |
| Price Oscillator (PO) | |
| Volume Oscillator (VO) | |
| Aroon Oscillator (AO) | |
| Relative Strength Index (RSI) | |
| Moving Average Convergence/Divergence (MACD) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kristensen, T.S.; Sognefest, A.H. Can Artificial Neural Networks Be Used to Predict Bitcoin Data? Automation 2023, 4, 232-245. https://doi.org/10.3390/automation4030014
Kristensen TS, Sognefest AH. Can Artificial Neural Networks Be Used to Predict Bitcoin Data? Automation. 2023; 4(3):232-245. https://doi.org/10.3390/automation4030014
Chicago/Turabian StyleKristensen, Terje Solsvik, and Asgeir H. Sognefest. 2023. "Can Artificial Neural Networks Be Used to Predict Bitcoin Data?" Automation 4, no. 3: 232-245. https://doi.org/10.3390/automation4030014