
Mathematical Formulation of Learning and Its Computational Complexity for Transformers’ Layers


Abstract
:1. Introduction
2. Key Contributions of This Work
- •
- A description of the equations implemented in BP, PEPITA and MEMPEPITA for all transformer layers;
- •
- A mathematical derivation of the weights’ and activations’ gradient with respect to the loss function;
- •
- Quantitative complexity analysis in terms of multiply and accumulate (MACCs) and floating point operations (FLOPs) of each layer for the forward pass, backward pass and weight updates.
3. Related Works
3.1. Automatic Differentiation
3.2. Alternatives to Backpropagation
3.3. Forward Learning
3.3.1. PEPITA
| Algorithm 1: PEPITA |
| Given: Features(x) and label( ) Standard Pass for do end for Modulated pass for do Weight update end for |
3.3.2. MEMPEPITA
| Algorithm 2: MEMPEPITA |
| Given: Features(x) and label( ) Standard Pass for do end for Modulated + 2nd Standard pass for do Standard Pass Modulated pass Weight update end for |
4. Notation and Conventions
5. Complexity Analysis
5.1. Embedding Layer
5.1.1. Forward Pass
5.1.2. Weight Update (Only PEPITA and MEMPEPITA)
5.2. Position Embeddings
5.3. Multihead Attention
5.3.1. Forward Pass
5.3.2. Backward Pass and Weight Update
5.4. Feed-Forward Network
5.4.1. Forward Pass
5.4.2. Backward Pass
5.4.3. Weight Update
5.5. Add and Norm
5.5.1. Forward Pass
5.5.2. Backward Pass and Weight Update
5.6. Softmax Layer
5.6.1. Forward Pass
5.6.2. Backward Pass and Weight Update
5.7. Error Projection (Only PEPITA and MEMPEPITA)
6. Exemplary Application
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Mielke, S.J.; Alyafeai, Z.; Salesky, E.; Raffel, C.; Dey, M.; Gallé, M.; Raja, A.; Si, C.; Lee, W.Y.; Sagot, B.; et al. Between words and characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP. arXiv 2021, arXiv:2112.10508. [Google Scholar]
- Maslej, N.; Fattorini, L.; Brynjolfsson, E.; Etchemendy, J.; Ligett, K.; Lyons, T.; Manyika, J.; Ngo, H.; Niebles, J.C.; Parli, V.; et al. The AI Index 2023 Annual Report; Technical report; AI Index Steering Committee, Institute for Human-Centered AI, Stanford University: Stanford, CA, USA, 2023. [Google Scholar]
- Hinton, G. The Forward-Forward Algorithm: Some Preliminary Investigations. arXiv 2022, arXiv:2212.13345. [Google Scholar]
- Dellaferrera, G.; Kreiman, G. Error-driven Input Modulation: Solving the Credit Assignment Problem without a Backward Pass. arXiv 2022, arXiv:2201.11665. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Baydin, A.G.; Pearlmutter, B.A.; Radul, A.A.; Siskind, J.M. Automatic Differentiation in Machine Learning: A Survey. J. Mach. Learn. Res. 2017, 18, 5595–5637. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Pre-Training Transformers as Energy-Based Cloze Models. In Proceedings of the EMNLP, Online, 16–20 November 2020. [Google Scholar]
- Crick, F. The recent excitement about neural networks. Nature 1989, 337, 129–132. [Google Scholar] [CrossRef]
- Lillicrap, T.; Santoro, A.; Marris, L.; Akerman, C.; Hinton, G. Backpropagation and the brain. Nat. Rev. Neurosci. 2020, 21, 335–346. [Google Scholar] [CrossRef]
- Burbank, K.S.; Kreiman, G. Depression-Biased Reverse Plasticity Rule Is Required for Stable Learning at Top-Down Connections. PLoS Comput. Biol. 2012, 8, e1002393. [Google Scholar] [CrossRef] [PubMed]
- Liao, Q.; Leibo, J.Z.; Poggio, T. How Important is Weight Symmetry in Backpropagation? arXiv 2016, arXiv:1510.05067. [Google Scholar] [CrossRef]
- Baldi, P.; Sadowski, P. A theory of local learning, the learning channel, and the optimality of backpropagation. Neural Netw. 2016, 83, 51–74. [Google Scholar] [CrossRef] [PubMed]
- Jaderberg, M.; Czarnecki, W.M.; Osindero, S.; Vinyals, O.; Graves, A.; Silver, D.; Kavukcuoglu, K. Decoupled Neural Interfaces using Synthetic Gradients. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1627–1635. [Google Scholar]
- Czarnecki, W.M.; Świrszcz, G.; Jaderberg, M.; Osindero, S.; Vinyals, O.; Kavukcuoglu, K. Understanding Synthetic Gradients and Decoupled Neural Interfaces. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 904–912. [Google Scholar]
- Xiao, W.; Chen, H.; Liao, Q.; Poggio, T. Biologically-plausible learning algorithms can scale to large datasets. arXiv 2018, arXiv:1811.03567. [Google Scholar]
- Lillicrap, T.; Cownden, D.; Tweed, D.; Akerman, C. Random synaptic feedback weights support error backpropagation for deep learning. Nat. Commun. 2016, 7, 13276. [Google Scholar] [CrossRef] [PubMed]
- Nøkland, A. Direct Feedback Alignment Provides Learning in Deep Neural Networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, Barcelona, Spain, 5–10 December 2016; pp. 1045–1053. [Google Scholar]
- Akrout, M.; Wilson, C.; Humphreys, P.; Lillicrap, T.; Tweed, D.B. Deep Learning without Weight Transport. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: New York, NY, USA, 2019; Volume 32. [Google Scholar]
- Frenkel, C.; Lefebvre, M.; Bol, D. Learning Without Feedback: Fixed Random Learning Signals Allow for Feedforward Training of Deep Neural Networks. Front. Neurosci. 2021, 15, 629892. [Google Scholar] [CrossRef] [PubMed]
- Xie, X.; Seung, H. Equivalence of Backpropagation and Contrastive Hebbian Learning in a Layered Network. Neural Comput. 2003, 15, 441–454. [Google Scholar] [CrossRef] [PubMed]
- Scellier, B.; Bengio, Y. Equilibrium Propagation: Bridging the Gap between Energy-Based Models and Backpropagation. Front. Comput. Neurosci. 2017, 11, 24. [Google Scholar] [CrossRef]
- Clark, D.; Abbott, L.; Chung, S. Credit Assignment Through Broadcasting a Global Error Vector. In Proceedings of the Advances in Neural Information Processing Systems 34—35th Conference on Neural Information Processing Systems, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 10053–10066. [Google Scholar]
- Pau, D.P.; Aymone, F.M. Suitability of Forward-Forward and PEPITA Learning to MLCommons-Tiny benchmarks. In Proceedings of the 2023 IEEE International Conference on Omni-layer Intelligent Systems (COINS), Berlin, Germany, 23–25 July 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Banbury, C.; Reddi, V.J.; Torelli, P.; Holleman, J.; Jeffries, N.; Kiraly, C.; Montino, P.; Kanter, D.; Ahmed, S.; Pau, D.; et al. MLCommons Tiny Benchmark. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, Virtual, 6–14 December 2021. [Google Scholar]
- Srinivasan, R.F.; Mignacco, F.; Sorbaro, M.; Refinetti, M.; Cooper, A.; Kreiman, G.; Dellaferrera, G. Forward Learning with Top-Down Feedback: Empirical and Analytical Characterization. arXiv 2023, arXiv:2302.05440. [Google Scholar]
- Justus, D.; Brennan, J.; Bonner, S.; McGough, A.S. Predicting the Computational Cost of Deep Learning Models. arXiv 2018, arXiv:1811.11880. [Google Scholar]
- Zargar, B.; Ponci, F.; Monti, A. Evaluation of Computational Complexity for Distribution Systems State Estimation. IEEE Trans. Instrum. Meas. 2023, 72, 9001512. [Google Scholar] [CrossRef]
- Muhammad, N.; Bibi, N.; Jahangir, A.; Mahmood, Z. Image denoising with norm weighted fusion estimators. Form. Pattern Anal. Appl. 2018, 21, 1013–1022. [Google Scholar] [CrossRef]
- Getzner, J.; Charpentier, B.; Günnemann, S. Accuracy is not the only Metric that matters: Estimating the Energy Consumption of Deep Learning Models. arXiv 2023, arXiv:2304.00897. [Google Scholar]
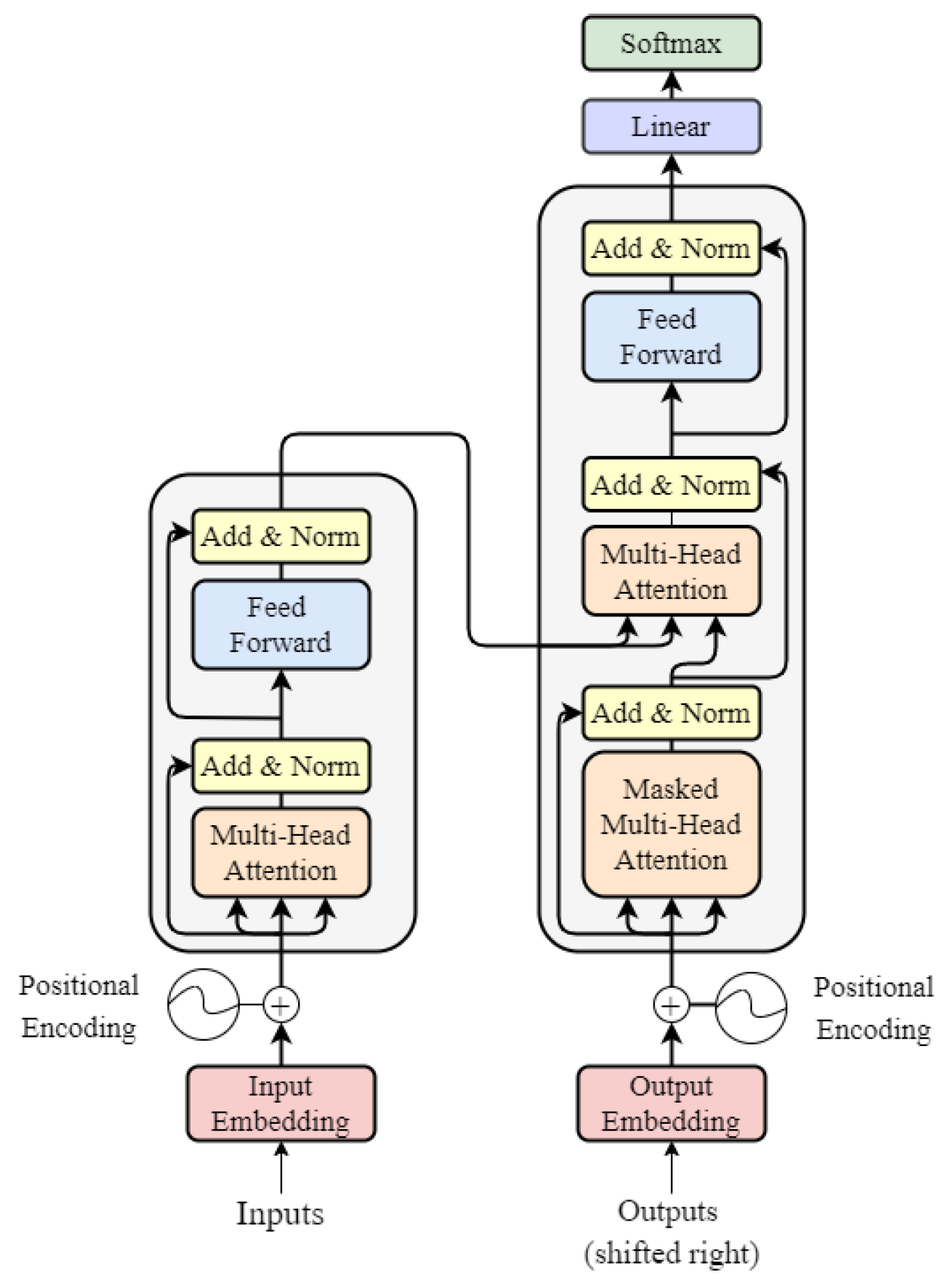
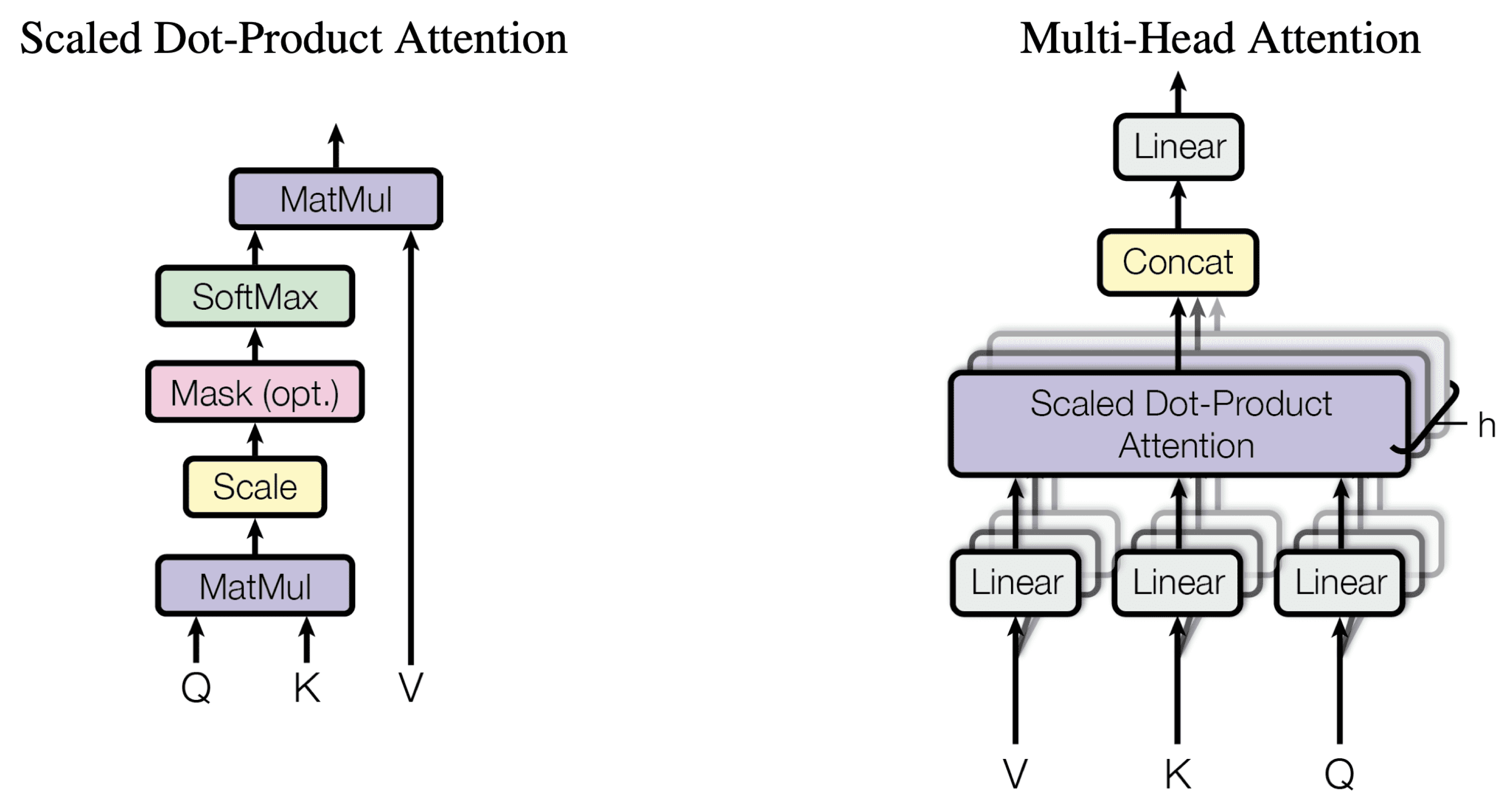

{kind=link}
{kind=link}
| Name | Description |
|---|---|
| Number of word/tokens in the corpus | |
| Dimension of embeddings | |
| Dimension of the single attention head | |
| Dimension of the first layer in the feed forward network | |
| Number of encoder layers | |
| Number of decoder layers | |
| Maximum number of tokens in the context |
| Learning Methods | BP | PEP | MPE |
|---|---|---|---|
| Forward pass | 1 | 2 | 3 |
| Backward pass | 1 | 0 | 0 |
| Weight update | 1 | 1 | 1 |
| Error projection | 0 | 1 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pau, D.P.; Aymone, F.M. Mathematical Formulation of Learning and Its Computational Complexity for Transformers’ Layers. Eng 2024, 5, 34-50. https://doi.org/10.3390/eng5010003
Pau DP, Aymone FM. Mathematical Formulation of Learning and Its Computational Complexity for Transformers’ Layers. Eng. 2024; 5(1):34-50. https://doi.org/10.3390/eng5010003
Chicago/Turabian StylePau, Danilo Pietro, and Fabrizio Maria Aymone. 2024. "Mathematical Formulation of Learning and Its Computational Complexity for Transformers’ Layers" Eng 5, no. 1: 34-50. https://doi.org/10.3390/eng5010003
APA StylePau, D. P., & Aymone, F. M. (2024). Mathematical Formulation of Learning and Its Computational Complexity for Transformers’ Layers. Eng, 5(1), 34-50. https://doi.org/10.3390/eng5010003