
SenseTrust: A Sentiment Based Trust Model in Social Network


Abstract
1. Introduction
1.1. Trust
1.2. Related Works
1.2.1. Trust Models Based on Network Topology
- Members whose levels of output are greater have higher levels of trust.
- If a person’s relation is more oriented to individuals with higher output levels, they are endowed with higher levels of trust.
- While centralization of individuals (those who are in a network center) has a positive impact on their levels of trust, the average levels of trust in all members decease as the entire network centralizes.
- Calculating a user’s skill in a specific subject: calculating the quality of reviews of users’ contents relying on reputation of those who had rated them or authors’ reputation.
- Determining level of dependence between users on thematic categories through calculating average ratings and users’ reviews in thematic categories, and also calculating level of trust via level of dependence in users to a subject and other skills concerning that subject.
1.2.2. Trust Models Based on Interaction
- Categorizing users’ activities in terms of information shared such as reviews, comments posted, ratings, etc. through measures such as number/sequence of reviews, number/sequence of rates, and average of number/length of comments posted, and so on.
- Categorizing binary interactions for different possible interactions/relations that may occur between two individuals; for example, between author and rater, author and author, and rater and rater.
- Popularity trust which refers to acceptance of a member in a community and shows a member’s trust from other members’ perspective.
- Participation trust that points to members’ participation in a community and reflects their trust in a community.
- Conversational trust that specifies length and/or sequence of relations between two members. Longer relations or those with longer sequences indicate more trust between two individuals.
- Publication trust which refers to publication of information received from a person in a network by another one. Publication of more information received from one person in a network by another individual shows their trust in that person’s information and implicitly reflects their trust in producers of that information.
1.2.3. Hybrid Trust Models
- Explicit social trust, which can be established based on conscious social relations. Whenever two users interact with each other, they exchange their lists of friends with each other and store them as graphs of friends. Trust is also created based on a friendship graph in which individuals assign highest level of trust with a value of one to each other through direct relationships.
- Implicit trust, which is created based on sequence and length of relationships between two users. For this purpose, two criteria can be used: Familiarity and similarity of nodes. Familiarity refers to duration of interactions/relations between two nodes and similarity is degree of compliance of two nodes in a familiarity circle.
2. Methodology
2.1. Sentiment and Trust Correlation: A Simple Test
- Yes: 97 users
- I do not know: 3 users
- No: 0 users
2.2. Reliability and Validity
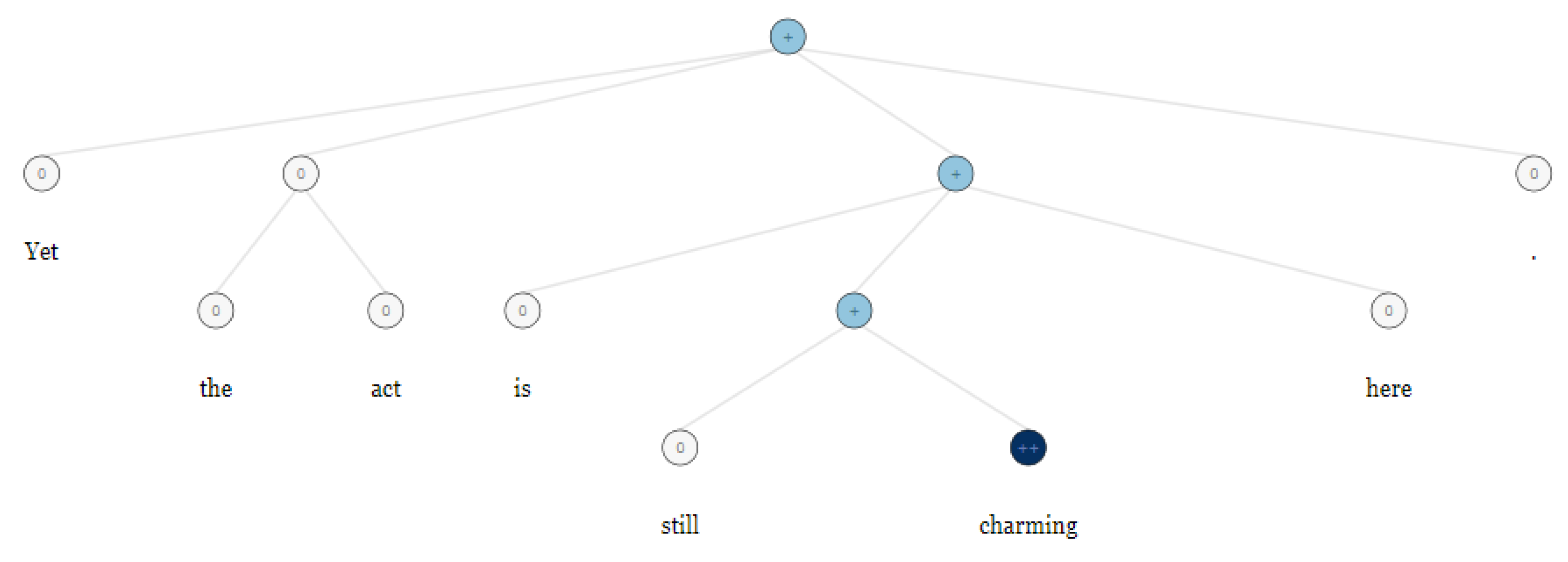
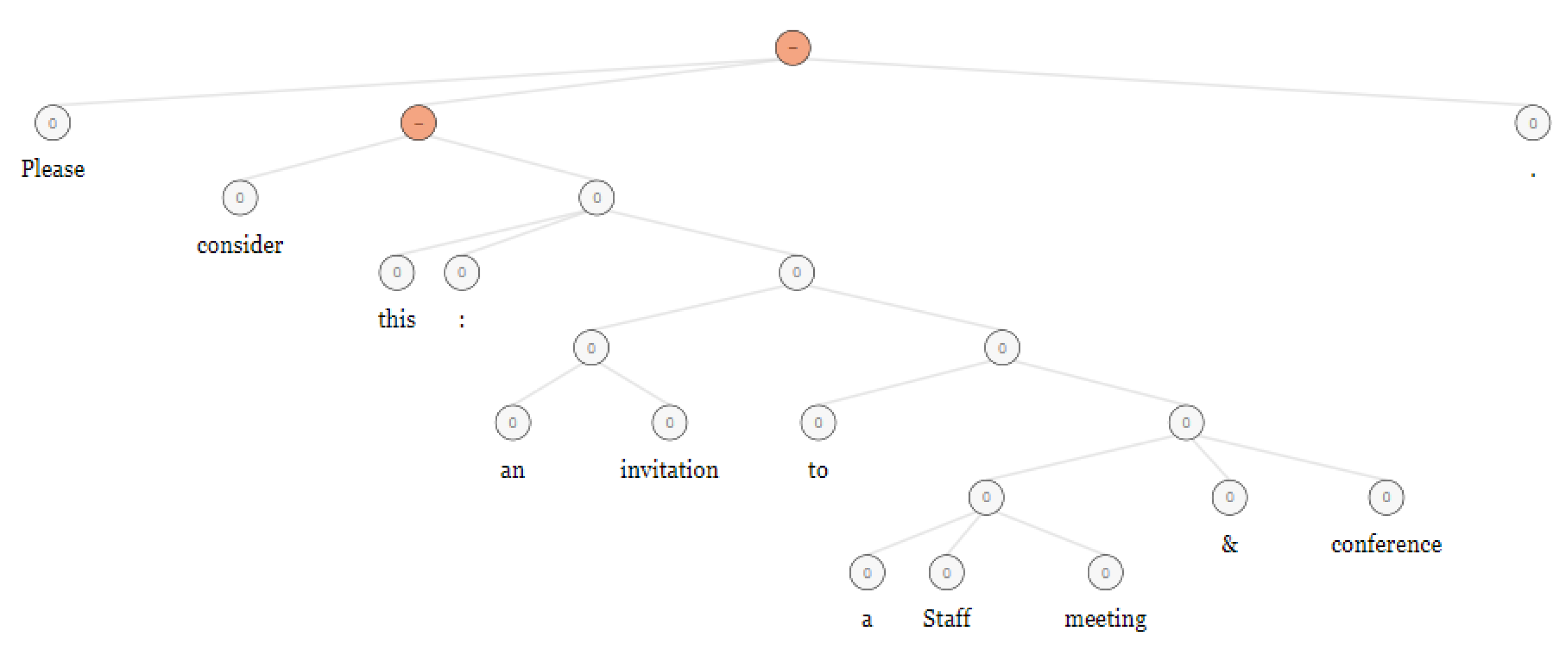
2.3. Sentiment Analysis
2.4. Train RNTN for Trust Sentiment
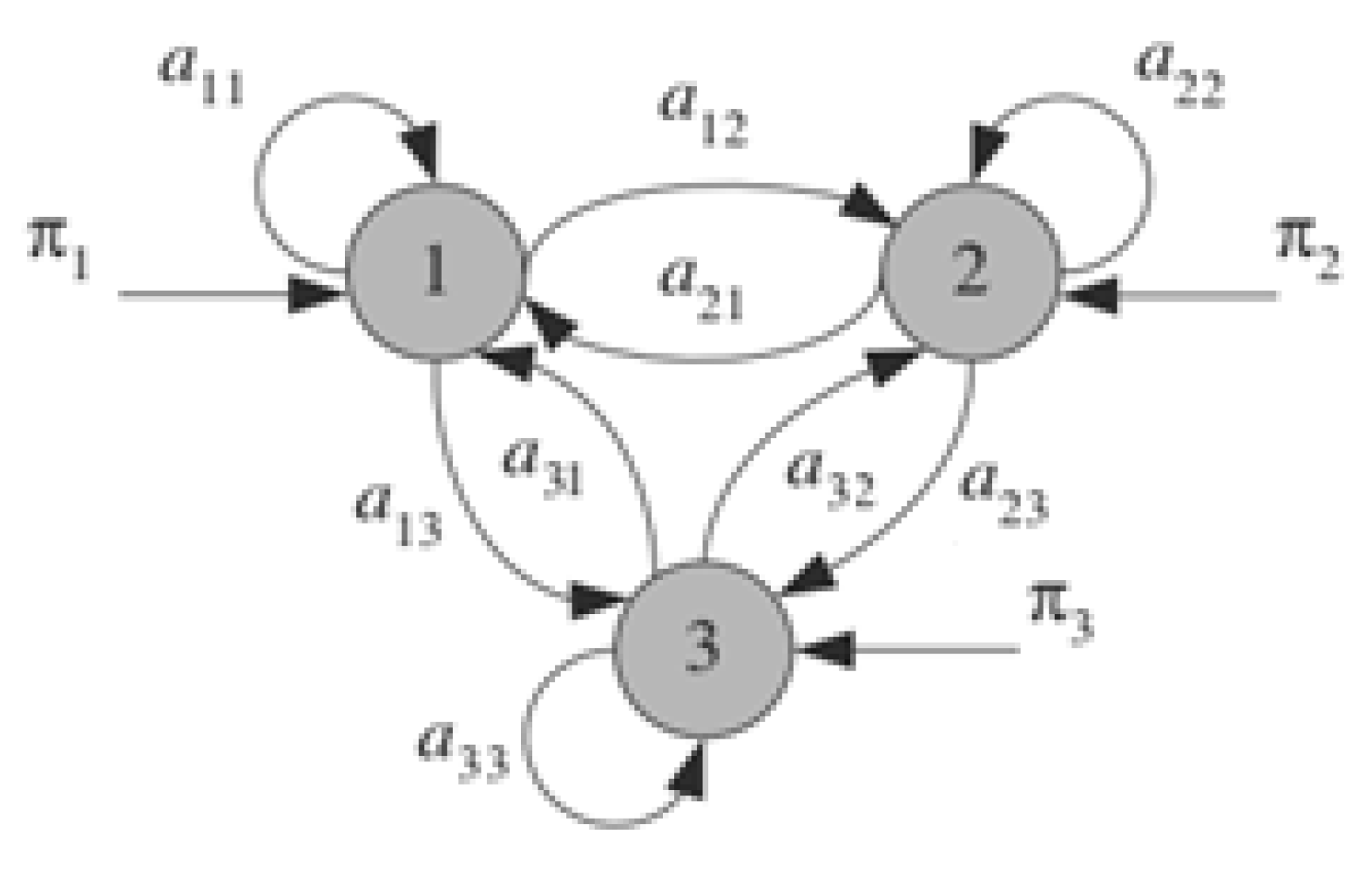
2.5. Hidden Markov Model
- A set of states.
- Sequence of observations.
- State transition probabilities
- A sequence of observation likelihoods, also called emission probabilities.
- Initial state probabilities
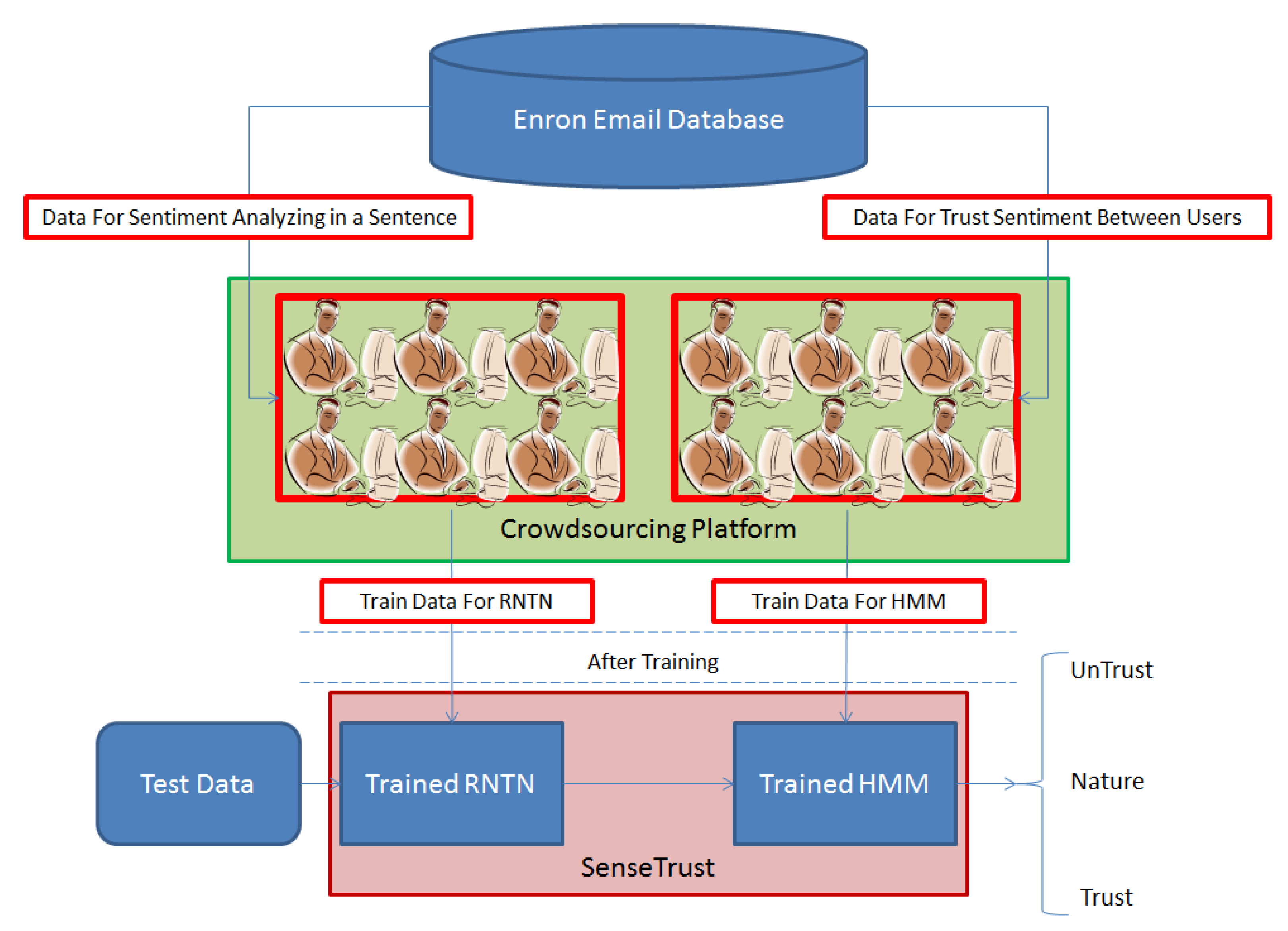
2.6. SenseTrust Schema
- Textual content exchanged has a high volume of exchanges between social network users in the form of texts.
- To perform sentiment analysis on each statement, the outputs of researchers at Stanford University entitled as RNTN is used to discover the hidden sentiments.
- To analyze trust among social network users, based on sentiments discovered in the statements exchanged, Hidden Markov Model (HMM) is utilized.
- Both RNTN and HMM are trained with emails extracted from Enron Corporation undergoing crowdsourcing and labeling.
- To estimate trust among social network users:
- ○
- Statements exchanged among users are imported into the SenseTrust model.
- ○
- They are trained by RNTN and levels of sentiments in statements are discovered through sentiment analysis.
- ○
- Sequences of the values of hidden sentiments in statements are conveyed to the trained HMM to determine the level of trust among users.
- ○
- The SenseTrust output is trust among social network users with three levels of interpretation (Untrusted, Nature, Trusted).
- The SenseTrust model can estimate trust among users of most conventional social networking sites including Twitter, Facebook, etc. based on textual exchanges.
3. Experimental Results
4. Discussion
5. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Websites List
References
- Bawa, S.; Singh, S. A privacy, trust and policy based authorization framework for services in distributed environ-ments. Int. J. Comput. Sci. 2007, 1, 85–92. [Google Scholar]
- Nepal, S.; Paris, C.; Sherchan, W. A Survay of Trust in Social Networks. ACM Comput. Surv. 2013, 45, 1–33. [Google Scholar]
- Rotter, J.B. A new scale for the measurement of interpersonal trust. J. Personal. 1967, 651–665. [Google Scholar] [CrossRef]
- Reay, I.; Dick, S.; Miller, J.; Beatty, P. Consumer trust in e-commerce web sites: A meta-study. ACM Comput. Sur-Veys (CSUR) 2011, 43, 1–46. [Google Scholar]
- Dumouchel, P. Trust as an action. Eur. J. Sociol. 2005, 46, 417–428. [Google Scholar] [CrossRef]
- Sitkin, S.B.; Burt, R.S.; Camerer, C.; Roussea, D.M. Not so different after all: A cross-discipline view of trus. Acad. Manag. Rev. 1998, 23, 393–404. [Google Scholar]
- Takahashi, N.; Peterson, G.; Molm, L.D. Risk and trust in social exchange: An experimental test of a classical propo-sition. Am. J. Sociol. 2000, 105, 1396–1427. [Google Scholar]
- Kollock, P. The emergence of exchange structures: An experimental study of uncertainty, commitment, and trust. Am. J. Sociol. 1994, 100, 313–345. [Google Scholar] [CrossRef]
- Weigert, A.; Lewis, J.D. Trust as a social reality. Soc. Forces 1985, 63, 967–985. [Google Scholar]
- Marsh, S.P. Formalising Trust as A Computational Concept. Ph.D. Thesis, University of Stirling, Scotlan, UK, 1994. [Google Scholar]
- Mui, L. Computational Models of Trust and Reputation: Agents, Evolutionary Games, and Social Networks. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2002. [Google Scholar]
- Kutvonen, L.; Koutrouli, E.; Ruohomaa, S. Reputation management survey. In Proceedings of the Second International Conference on Availability, Reliability and Security (ARES’07), Vienna, Austria, 10–13 April 2007. [Google Scholar]
- Hailes, S.; Abdul-Rahman, A. Supporting trust in virtual communities. In Proceedings of the 33rd Annual Hawaii International Con-ference on System Sciences, Maui, HI, USA, 7 January 2000. [Google Scholar]
- Yu, B.; Venkatraman, M.; Singh, M.P. Community-based service location. Commun. ACM 2001, 44, 49–54. [Google Scholar]
- Chen, S.; Nepal, S.; Levy, D.; Zic, J.; Yao, J. Truststore: Making amazon s3 trustworthy with services composition. In Proceedings of the 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing, Melbourne, VIC, Australia, 17–20 May 2010. [Google Scholar]
- Nepal, S.; Hwang, H.; Zic, J.; Moreland, D. A snapshot of trusted personal devices applicable to transaction processing. Pers. Ubiquitous Comput. 2010, 14, 347–361. [Google Scholar]
- Perrig, A.; van Doorn, L.; Khosla, P.; Seshadri, A. SWATT: Software-based attestation for embedded devices. In Proceedings of the IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 12 May 2004. [Google Scholar]
- Li, J.; Chen, L. Revocation of direct anonymous attestation. In Trusted Systems; Springer: Berlin/Heidelberg, Germany, 2001; pp. 128–147. [Google Scholar]
- Williamson, O.E. Calculativeness, trust, and economic organization. J. Law Econ. 1993, 36, 453–486. [Google Scholar] [CrossRef]
- James, S.C. Foundations of Social Theory; Belknap Press of Harvard University Press: Cambridge, MA, USA, 1990. [Google Scholar]
- Stassen, W. Your news in 140 characters: Exploring the role of social media in journalism. Glob. Media J. Afr. Ed. 2010, 4, 116–131. [Google Scholar] [CrossRef][Green Version]
- Bock, G.W.; Kuan, H.H. The collective reality of trust: An investigation of social relations and networks on trust in multi-channel retailers. In Proceedings of the ECIS 2005, Regensburg, Germany, 26–28 May 2005. [Google Scholar]
- Holmes, J.G. Trust and the appraisal process in close relationships. Adv. Pers. Relatsh. 1991, 2, 57–104. [Google Scholar]
- Taylor, R.K. Marketing strategies: Gaining a competitive advantage through the use of emotion. Compet. Re-View Int. Bus. J. Inc. J. Glob. Compet. 2000, 10, 146–152. [Google Scholar] [CrossRef]
- Coleman, J.S. Social capital in the creation of human capital. Am. J. Sociol. 1988, 94, S95–S120. [Google Scholar] [CrossRef]
- Granovetter, M.S. The strength of weak ties. Am. J. Sociol. 1973, 78, 1360–1380. [Google Scholar] [CrossRef]
- Komiak, S.X.; Benbasat, I. Understanding customer trust in agent-mediated electronic commerce, web-mediated electronic commerce, and traditional commerce. Inf. Technol. Manag. 2004, 5, 181–207. [Google Scholar] [CrossRef]
- Möllering, G. The nature of trust: From Georg Simmel to a theory of expectation, interpretation and suspension. Sociology 2001, 35, 403–420. [Google Scholar] [CrossRef]
- Miles, R.E.; Creed, W.D. Organizational forms and managerial philosophies-a descriptive and analytical review. Res. Organ. Behav. Annu. Ser. Anal. Essays Crit. Rev. 1995, 17, 333–372. [Google Scholar]
- Rubin, A.D.; Cranor, F.; Waldman, M. Publius: A robust, tamper-evident, censorship-resistant, web publishing sys-tem. In Proceedings of the 9th USENIX Security Symposium, Denver, CO, USA, 14–17 August 2000. [Google Scholar]
- Lenzini, G.; Uusitalo, I.; Toivonen, S. Context-aware trust evaluation functions for dynamic reconfigurablein. In Proceedings of the Workshop on Models of Trust for the Web (MTW’06), Scotland, UK, 22 May 2006. [Google Scholar]
- Bhargava, B.; Lilien, L.; Rosenthal, A.; Winslett, M.; Sloman, M.; Dillon, T.S.; Chang, E.; Hussain, F.K.; Nejdl, W.; Staab, S. The pudding of trust: Managing the dynamic nature. IEEE Intell. Syst. 2004, 19, 74–88. [Google Scholar]
- Christianson, B.; Harbison, W.S. Why isn’t trust transitive? In Security Protocols; Springer: Berlin/Heidelberg, Germany, 1997; pp. 171–176. [Google Scholar]
- Singh, M.P.; Sycara, K.; Yu, B. Developing trust in large-scale peer-to-peer systems. In Proceedings of the 1st IEEE Symposium on Mul-ti-Agent Security and Survivability, Drexel, PA, USA, 31–31 August 2004; pp. 1–10. [Google Scholar]
- Sabater, J. Trust and Reputation for Agent Societies. Ph.D. Thesis, Autonomous University of Barcelona, Barcelona, Spain, 2005. [Google Scholar]
- Yu, B.; Singh, M.P. A social mechanism of reputation management in electronic communities. In Cooperative Information Agents IV-The Future of Information Agents in Cyberspace; Springer: Berlin/Heidelberg, Germany, 2000; pp. 154–165. [Google Scholar]
- Sherchan, W.; Bouguettaya, A.; Nepal, S. A behaviour-based trust model for service web. In Proceedings of the IEEE International Conference on Service-Oriented Computing and Applications (SOCA’10), Perth, WA, Australia, 13–15 December 2010. [Google Scholar]
- Buskens, V. The social structure of trust. Soc. Netw. 1998, 20, 265–289. [Google Scholar] [CrossRef]
- Parsia, B.; Hendler, J.; Golbeck, J. Trust networks on the semantic web. In Cooperative Information Agents VII; Springer: Berlin/Heidelberg, Germany, 2003; pp. 238–249. [Google Scholar]
- Golbeck, J.A. Computing and Applying Trust in Web-Based Social Networks. Ph.D. Thesis, University of Maryland, College Park, MD, USA, 2005. [Google Scholar]
- Golbeck, J.A. Trust and Nuanced Profile Similarity in Online Social Networks. ACM Trans. Web (TWEB) 2009, 3, 1–33. [Google Scholar] [CrossRef]
- Shahriari, H.R.; Mohammadhassanzadeh, H. Using User Similarity to Infer Trust Values in Social Networks Re-gardless of Direct Ratings. In Proceedings of the 9th International ISC Conference on Information Security and Cryptology, Tabriz, Iran, 13–14 September 2012; pp. 171–187. [Google Scholar]
- Chen, H.; Wu, Z.; Zhang, Y. A social network-based trust model for the semantic web. In Autonomic and Trusted Computing; Springer: Berlin/Heidelberg, Germany, 2006; pp. 183–192. [Google Scholar]
- Ziegler, C.N.; Lausen, G. Spreading activation models for trust propagation. In Proceedings of the IEEE International Conference on e-Technology, e-Commerce and e-Service, Taipei, Taiwan, 28–31 March 2004. [Google Scholar]
- Hang, W.C.; Singh, M.P. Trust Based Recommendation Based on Graph Similarities. 2010. Available online: http://www.csc.ncsu.edu/faculty/mpsingh/papers/mas/aamas-trust-10-graph.pdf (accessed on 13 September 2012).
- Hu, Y.; O’keefe, W.C.; Zuo, T. Trust computing for social networking. In Proceedings of the 6th International Conference on Infor-mation Technology: New Generations, Las Vegas, NV, USA, 27–29 April 2009. [Google Scholar]
- Liu, L.; Webb, L.; Caverlee, S. Socialtrust: Tamper-resilient trust establishment in online communities. In Proceedings of the 8th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL’08), Pittsburgh PA, USA, 16–20 June 2008; ACM Press: New York, NY, USA, 2008. [Google Scholar]
- Kuter, U.; Golbeck, J.A. Sunny: A new algorithm for trust inference in social networks using probabilistic confidence models. Adv. Artif. 2007, 7, 1377–1382. [Google Scholar]
- Kim, Y.A.; Le, M.-T.; Lauw, H.W.; Lin, E.-P.; Liu, H.; Sricastava, J. Building a web of trust without explicit trust ratings. In Proceedings of the 24th IEEE International Conference on Data Engi-neering Workshop, Cancun, Mexico, 7–12 April 2008. [Google Scholar]
- Tang, M.; Ghunaim, H.C.; Maheswaran, A. Towards a gravity-based trust model for social networking sys-tems. In Proceedings of the International Conference on Distributed Computing Systems Workshops, Toronto, ON, Canada, 22–29 June 2007. [Google Scholar]
- Lim, E.P.; Lauw, H.W.; Le, M.T.; Sun, A.; Srivastava, J.; Kim, Y.; Liu, H. Predicting trusts among users of online communities: An epinions case study. In Proceedings of the 9th ACM conference on Electronic commerce, Chicago, IL, USA, 8–12 July 2008. [Google Scholar]
- Sherchan, W.; Paris, C.; Nepal, S. STrust: A trust model for social networks. In Proceedings of the 10th IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom’11), Changsha, China, 16–18 November 2011. [Google Scholar]
- Escriva, S.; Goldberg, R.; Hayvanovych, M.K.; Magdon-Ismail, M.; Szymanski, M.; Wallace, B.K.; Williams, W.A.; Adali, G. Measuring behavioral trust in social networks. In Proceedings of the IEEE International Conference on Intel-ligence and Security Informatics (ISI’10), Vancouver, BC, Canada, 23–26 May 2010. [Google Scholar]
- Legendre, F.; Anastasiades, C.; Trifunovic, S. Social trust in opportunistic networks. In Proceedings of the INFOCOM IEEE Conference on Computer Communications Workshops, San Diego, CA, USA, 15–19 March 2010. [Google Scholar]
- Petkevič, V. Media Sentiment Analysis for Measuring Perceived Trust in Government. Soc. Commun. Trust Interact. 2018, 50, 23–45. [Google Scholar]
- Shaozhong, Z.; Zhong, H. Mining Users Trust from E-Commerce Reviews Based on Sentiment Similarity Analysis. IEEE Access 2019, 7, 13523–13535. [Google Scholar]
- Alahmadi, D.; Zeng, X.-J. Improving Recommendation Using Trust and Sentiment Inference from OSNs. Int. J. Knowl. Eng. 2015, 1, 9–17. [Google Scholar] [CrossRef][Green Version]
- Socher, R.; Huval, B.; Manning, C.D.; Ng, A.Y. Semantic Compositionality through Recursive Matrix-Vector Spaces. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.Y.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the Conference on Em-pirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013. [Google Scholar]
- Lee, L.; Pang, B. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar]
- Tishby, N.; Lee, L.; Pereira, F. Distributional Clustering of English Words. 1994. Available online: https://arxiv.org/abs/cmp-lg/9408011 (accessed on 24 July 2021).
- Lee, L.; Vaithyanathan, S.; Pang, B. Sentiment Classification using Machine Learning Techniques. Int. J. Sci. Res. (IJSR) 2016, 5, 819–821. [Google Scholar]
- Lee, L.; Pang, B. Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts. 2004. Available online: https://arxiv.org/abs/cs/0409058 (accessed on 1 July 2021).
- Lee, L.; Pang, B. Seeing Stars: Exploiting Class Relationships for Sentiment Categorization with Respect to Rating Scales. 2005. Available online: https://arxiv.org/abs/cs/0506075 (accessed on 1 July 2021).
- Socher, R.; Pennington, J.; Huang, E.H.; Ng, A.Y.; Manning, C.D. Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions. In Proceedings of the Conference on Empir-ical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011. [Google Scholar]
- Alpaydin, E. Introductio to Machine Learning; The MIT Press: Cambridge, MA, USA; London, UK, 2010; Chapter 15. [Google Scholar]
- Baum, L.E. An inequality and associated maximization technique in statistical estimation for probabilistic functions of Markov processes. In Proceedings of the Inequalities III: Proceedings of the 3rd Symposium on Inequalities, Los Angeles, CA USA, 1–9 September 1969. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. 1977, 39, 1–21. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing, 2nd ed.; Prentice Hall: Hoboken, NJ, USA, 2009. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sender | Receiver | Email ID | Subject | Body |
|---|---|---|---|---|
| joseph.alamo@enron.com | susan.mara@enron.com | 20011102165120 | Re: A.98-07-003—Comments of AReM and WPTF on the Assigned Commissioner’s Ruling Regarding Direct Access | A.98-07-003—Response to SDG&E to the Assigned Commissioner’s Ruling Regarding Comments on Certain Direct Access Issues Attached for your information are the comments filed today by the Alliance for Retail Energy Markets and the Western Power Trading Forum with regard to the ACR concerning retroactive direct access suspension. |
| joseph.alamo@enron.com | susan.mara@enron.com | 20010919125209 | Staff Meeting & Conference call on 20 September 2001 | Please consider this an invitation to a Staff meeting and conference call. |
| susan.mara@enron.com | joseph.alamo@enron.com | 20010509023200 | AGENDA for Workshop on Assuring Adequate Capacity | Please see the attached memo and agenda for the Workshop on Assuring Adequate Capacity in Competitive Markets. |
| Sentiment Levels | ||||||
|---|---|---|---|---|---|---|
| Very Negative | Negative | Nature | Positive | Very Positive | ||
| Trust Levels | Untrusted | 9 | 43 | 13 | 0 | 0 |
| Nature | 0 | 3 | 93 | 4 | 0 | |
| Trusted | 0 | 0 | 11 | 86 | 38 | |
| Real Trust Level (by Experts) | |||
|---|---|---|---|
| Total Tests | Condition Negative | Condition Positive | |
| Proposed Models’ Predicted Trust Level | Predicted Positive | False Positive (FP) | True Positive (TP) |
| Predicted Negative | True Negative (TN) | False Negative (FN) | |
| Name | Formula |
|---|---|
| Precision | |
| Recall | |
| F-Measure | |
| Accuracy | |
| Specificity |
| Chats Labeled by Experts | ||||
|---|---|---|---|---|
| Trusted | Nature | Untrusted | ||
| Chats Labeled by SenseTrust | Untrusted | 25 | 4 | 0 |
| Nature | 5 | 23 | 4 | |
| Trusted | 0 | 3 | 26 | |
| Trust Level | Precision | Recall | F-Measure | Accuracy | Specificity |
|---|---|---|---|---|---|
| UnTrusted | 0.86 | 0.83 | 0.84 | 0.89 | 0.92 |
| Nature | 0.71 | 0.76 | 0.73 | 0.82 | 0.85 |
| Trusted | 0.89 | 0.86 | 0.87 | 0.91 | 0.94 |
| Average | 0.82 | 0.81 | 0.81 | 0.87 | 0.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammadi, A.; Hashemi Golpayegani, S.A. SenseTrust: A Sentiment Based Trust Model in Social Network. J. Theor. Appl. Electron. Commer. Res. 2021, 16, 2031-2050. https://doi.org/10.3390/jtaer16060114
Mohammadi A, Hashemi Golpayegani SA. SenseTrust: A Sentiment Based Trust Model in Social Network. Journal of Theoretical and Applied Electronic Commerce Research. 2021; 16(6):2031-2050. https://doi.org/10.3390/jtaer16060114
Chicago/Turabian StyleMohammadi, Alireza, and Seyyed Alireza Hashemi Golpayegani. 2021. "SenseTrust: A Sentiment Based Trust Model in Social Network" Journal of Theoretical and Applied Electronic Commerce Research 16, no. 6: 2031-2050. https://doi.org/10.3390/jtaer16060114
APA StyleMohammadi, A., & Hashemi Golpayegani, S. A. (2021). SenseTrust: A Sentiment Based Trust Model in Social Network. Journal of Theoretical and Applied Electronic Commerce Research, 16(6), 2031-2050. https://doi.org/10.3390/jtaer16060114