

TEE: Real-Time Purchase Prediction Using Time Extended Embeddings for Representing Customer Behavior



Abstract
:1. Introduction
- Is it possible to include information about the time when creating an embedding-based customer representation?
- Does such an extension of the embedding representation better represent the customer, resulting in a better prediction of the customer’s purchase intention?
2. Related Work
3. Use Case and Data Description
4. Methodology
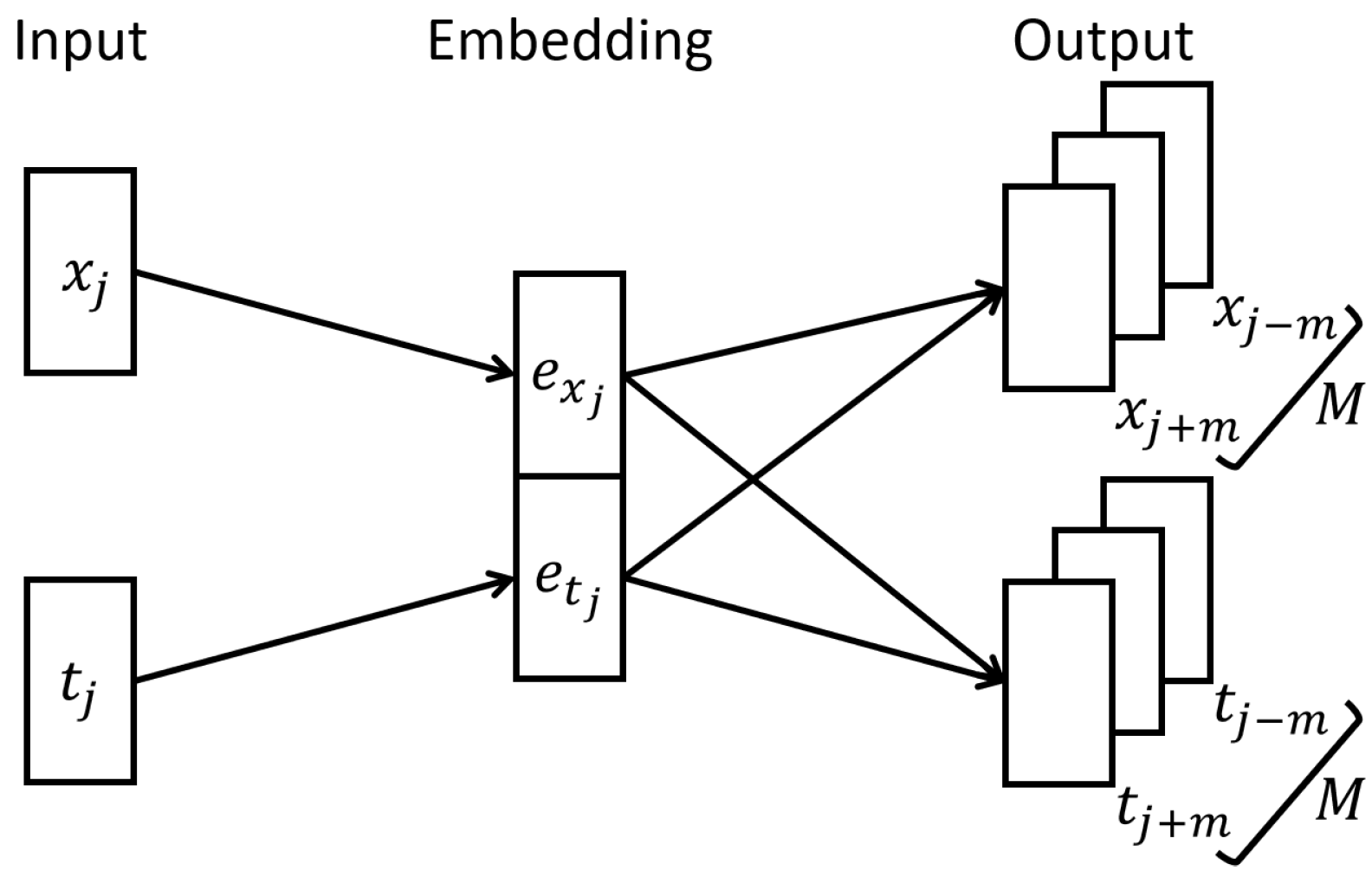
4.1. Time Extended Embeddings
4.2. Time2Vec with Interaction Embedding
5. Experiments
5.1. Data Preprocessing
5.2. Creation of Embedding Training Datasets
5.3. Embedding Training for Customer Representation
5.4. Baseline Customer Representation
5.5. Experiment Evaluation
6. Results and Discussion
6.1. Prediction Evaluation
6.2. Real-Time Evaluation
6.3. Ablation Studies
7. Summary and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rahman, M.S.; Hossain, M.A.; Zaman, M.H.; Mannan, M. E-service quality and trust on customer’s patronage intention: Moderation effect of adoption of advanced technologies. J. Glob. Inf. Manag. (JGIM) 2020, 28, 39–55. [Google Scholar] [CrossRef]
- Statista. Retail E-Commerce Sales Worldwide from 2014 to 2026. 2022. Available online: https://www.statista.com/statistics/379046/worldwide-retail-e-commerce-sales/ (accessed on 3 March 2023).
- Leeflang, P.S.; Verhoef, P.C.; Dahlström, P.; Freundt, T. Challenges and solutions for marketing in a digital era. Eur. Manag. J. 2014, 32, 1–12. [Google Scholar] [CrossRef]
- Hong, T.; Kim, E. Segmenting customers in online stores based on factors that affect the customer’s intention to purchase. Expert Syst. Appl. 2012, 39, 2127–2131. [Google Scholar] [CrossRef]
- Kim, K.J.; Ahn, H. Using a clustering genetic algorithm to support customer segmentation for personalized recommender systems. In Proceedings of the Artificial Intelligence and Simulation, Jeju Island, Repulic of Korea, 4–6 October 2004; Lecture Notes in CoVolumemputer, Science. Kim, T.G., Ed.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3397, pp. 409–415. [Google Scholar]
- Mulhern, F.J. Customer profitability analysis: Measurement, concentration, and research directions. J. Interact. Mark. 1999, 13, 25–40. [Google Scholar] [CrossRef]
- Zeithaml, V.A.; Rust, R.T.; Lemon, K.N. The customer pyramid: Creating and serving profitable customers. Calif. Manag. Rev. 2001, 43, 118–142. [Google Scholar] [CrossRef]
- Kumar, V.; Venkatesan, R.; Reinartz, W. Performance implications of adopting a customer-focused sales campaign. J. Mark. 2008, 72, 50–68. [Google Scholar] [CrossRef]
- Alves Gomes, M.; Meisen, T. Alves Gomes, M.; Meisen, T. A review on customer segmentation methods for personalized customer targeting in e-commerce use cases. In Information Systems and e-Business Management; Springer: Berlin/Heidelberg, Germany, 2023; pp. 1–44. [Google Scholar]
- Lin, W.; Milic-Frayling, N.; Zhou, K.; Ch’ng, E. Predicting Outcomes of Active Sessions Using Multi-Action Motifs. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence, Thessaloniki, Greece, 14–17 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 9–17. [Google Scholar] [CrossRef]
- Martínez, A.; Schmuck, C.; Pereverzyev, S.; Pirker, C.; Haltmeier, M. A machine learning framework for customer purchase prediction in the non-contractual setting. Eur. J. Oper. Res. 2020, 281, 588–596. [Google Scholar] [CrossRef]
- Liu, X.; Lee, D.; Srinivasan, K. Large-scale cross-category analysis of consumer review content on sales conversion leveraging deep learning. J. Mark. Res. 2019, 56, 918–943. [Google Scholar] [CrossRef]
- Behera, R.K.; Gunasekaran, A.; Gupta, S.; Kamboj, S.; Bala, P.K. Personalized digital marketing recommender engine. J. Retail. Consum. Serv. 2020, 53, 101799. [Google Scholar] [CrossRef]
- Esmeli, R.; Bader-El-Den, M.; Abdullahi, H. Towards early purchase intention prediction in online session based retailing systems. Electron. Mark. 2021, 31, 697–715. [Google Scholar] [CrossRef]
- Miller, R.B. Response Time in Man-Computer Conversational Transactions. In Proceedings of the AFIPS ’68 (Fall, Part I), San Francisco, CA, USA, 9–11 December 1968; Association for Computing Machinery: New York, NY, USA, 1968; pp. 267–277. [Google Scholar] [CrossRef]
- Card, S.K.; Robertson, G.G.; Mackinlay, J.D. The Information Visualizer, an Information Workspace. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’91, Orleans, LA, USA, 27 April–2 May 1991; Association for Computing Machinery: New York, NY, USA, 1991; pp. 181–186. [Google Scholar] [CrossRef]
- Alves Gomes, M.; Meyes, R.; Meisen, P.; Meisen, T. Will This Online Shopping Session Succeed? Predicting Customer’s Purchase Intention Using Embeddings. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, CIKM ’22, Atlanta, GA, USA, 17–21 October 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 2873–2882. [Google Scholar] [CrossRef]
- Li, Q.; Gu, M.; Zhou, K.; Sun, X. Multi-classes feature engineering with sliding window for purchase prediction in mobile commerce. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 1048–1054. [Google Scholar]
- Romov, P.; Sokolov, E. RecSys Challenge 2015: Ensemble Learning with Categorical Features. In Proceedings of the 2015 International ACM Recommender Systems Challenge, RecSys ’15 Challenge, Vienna, Austria, 16 September 2015; Association for Computing Machinery: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Sismeiro, C.; Bucklin, R.E. Modeling purchase behavior at an e-commerce web site: A task-completion approach. J. Mark. Res. 2004, 41, 306–323. [Google Scholar] [CrossRef]
- Esmeli, R.; Bader-El-Den, M.; Abdullahi, H. An analyses of the effect of using contextual and loyalty features on early purchase prediction of shoppers in e-commerce domain. J. Bus. Res. 2022, 147, 420–434. [Google Scholar] [CrossRef]
- Chaudhuri, N.; Gupta, G.; Vamsi, V.; Bose, I. On the platform but will they buy? Predicting customers’ purchase behavior using deep learning. Decis. Support Syst. 2021, 149, 113622. [Google Scholar] [CrossRef]
- Esmeli, R.; Bader-El-Den, M.; Abdullahi, H. Using Word2Vec Recommendation for Improved Purchase Prediction. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Mokryn, O.; Bogina, V.; Kuflik, T. Will this session end with a purchase? Inferring current purchase intent of anonymous visitors. Electron. Commer. Res. Appl. 2019, 34, 100836. [Google Scholar] [CrossRef]
- Zeng, M.; Cao, H.; Chen, M.; Li, Y. User behaviour modeling, recommendations, and purchase prediction during shopping festivals. Electron. Mark. 2019, 29, 263–274. [Google Scholar] [CrossRef]
- Baumann, A.; Haupt, J.; Gebert, F.; Lessmann, S. Changing perspectives: Using graph metrics to predict purchase probabilities. Expert Syst. Appl. 2018, 94, 137–148. [Google Scholar] [CrossRef]
- Sheil, H.; Rana, O.; Reilly, R. Predicting purchasing intent: Automatic feature learning using recurrent neural networks. arXiv 2018, arXiv:1807.08207. [Google Scholar]
- Wu, Z.; Tan, B.H.; Duan, R.; Liu, Y.; Mong Goh, R.S. Neural Modeling of Buying Behaviour for E-Commerce from Clicking Patterns. In Proceedings of the 2015 International ACM Recommender Systems Challenge, RecSys ’15 Challenge, Vienna, Austria, 16 September 2015; Association for Computing Machinery: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Park, C.; Kim, D.; Oh, J.; Yu, H. Predicting User Purchase in E-Commerce by Comprehensive Feature Engineering and Decision Boundary Focused Under-Sampling. In Proceedings of the 2015 International ACM Recommender Systems Challenge, RecSys ’15 Challenge, Vienna, Austria, 16 September 2015; Association for Computing Machinery: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Armstrong, G.; Adam, S.; Denize, S.; Kotler, P. Principles of Marketing; Pearson: Richmond, Australia, 2014. [Google Scholar]
- Vasile, F.; Smirnova, E.; Conneau, A. Meta-Prod2Vec: Product Embeddings Using Side-Information for Recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, RecSys ’16, Boston, MA, USA, 15–19 September 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 225–232. [Google Scholar]
- Tercan, H.; Bitter, C.; Bodnar, T.; Meisen, P.; Meisen, T. Evaluating a Session-based Recommender System using Prod2vec in a Commercial Application. In Proceedings of the 23rd International Conference on Enterprise Information Systems, Virtual Event, 26–28 April 2021; SciTePress: Setubal, Portugal, 2021; Volume 1, pp. 610–617. [Google Scholar] [CrossRef]
- Alves Gomes, M.; Tercan, H.; Bodnar, T.; Meisen, P.; Meisen, T. A Filter is Better Than None: Improving Deep Learning-Based Product Recommendation Models by Using a User Preference Filter. In Proceedings of the 2021 IEEE 23rd International Conference on High Performance Computing & Communications, 7th International Conference on Data Science & Systems, 19th International Conference on Smart City, 7th International Conference on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Haikou, China, 20–22 December 2021; pp. 1278–1285. [Google Scholar] [CrossRef]
- Srilakshmi, M.; Chowdhury, G.; Sarkar, S. Two-stage system using item features for next-item recommendation. Intell. Syst. Appl. 2022, 14, 200070. [Google Scholar] [CrossRef]
- Zhou, G.; Mou, N.; Fan, Y.; Pi, Q.; Bian, W.; Zhou, C.; Zhu, X.; Gai, K. Deep Interest Evolution Network for Click-Through Rate Prediction. Proc. AAAI Conf. Artif. Intell. 2019, 33, 5941–5948. [Google Scholar] [CrossRef]
- Li, X.; Wang, C.; Tong, B.; Tan, J.; Zeng, X.; Zhuang, T. Deep Time-Aware Item Evolution Network for Click-Through Rate Prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, 19–23 October 2020; pp. 785–794. [Google Scholar] [CrossRef]
- Huang, G.; Chen, Q.; Deng, C. A New Click-Through Rates Prediction Model Based on Deep&Cross Network. Algorithms 2020, 13, 342. [Google Scholar] [CrossRef]
- Yao, S.; Tan, J.; Chen, X.; Yang, K.; Xiao, R.; Deng, H.; Wan, X. Learning a Product Relevance Model from Click-Through Data in E-Commerce. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 2890–2899. [Google Scholar] [CrossRef]
- Chen, C.; Chen, H.; Zhao, K.; Zhou, J.; He, L.; Deng, H.; Xu, J.; Zheng, B.; Zhang, Y.; Xing, C. EXTR: Click-Through Rate Prediction with Externalities in E-Commerce Sponsored Search. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2732–2740. [Google Scholar] [CrossRef]
- Nalmpantis, C.; Vrakas, D. Signal2vec: Time series embedding representation. In Proceedings of the Engineering Applications of Neural Networks: 20th International Conference, EANN 2019, Xersonisos, Crete, Greece, 24–26 May 2019; pp. 80–90. [Google Scholar]
- Kazemi, S.M.; Goel, R.; Eghbali, S.; Ramanan, J.; Sahota, J.; Thakur, S.; Wu, S.; Smyth, C.; Poupart, P.; Brubaker, M. Time2vec: Learning a vector representation of time. arXiv 2019, arXiv:1907.05321. [Google Scholar]
- Karingula, S.R.; Ramanan, N.; Tahmasbi, R.; Amjadi, M.; Jung, D.; Si, R.; Thimmisetty, C.; Polania, L.F.; Sayer, M.; Taylor, J.; et al. Boosted embeddings for time-series forecasting. In Proceedings of the Machine Learning, Optimization, and Data Science: 7th International Conference, LOD 2021, Grasmere, UK, 4–8 October 2021; Revised Selected Papers, Part II. Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–14. [Google Scholar]
- Uribarri, G.; Mindlin, G.B. Dynamical time series embeddings in recurrent neural networks. Chaos Solitons Fractals 2022, 154, 111612. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 3 March 2023).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. Available online: https://www.researchgate.net/publication/257882504_Distributed_Representations_of_Words_and_Phrases_and_their_Compositionality (accessed on 3 March 2023).
- Van Rossum, G.; Drake, F.L., Jr. Python Reference Manual; Centrum voor Wiskunde en Informatica: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Wes McKinney. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 56–61. [Google Scholar] [CrossRef]
- Buitinck, L.; Louppe, G.; Blondel, M.; Pedregosa, F.; Mueller, A.; Grisel, O.; Niculae, V.; Prettenhofer, P.; Gramfort, A.; Grobler, J.; et al. API design for machine learning software: Experiences from the scikit-learn project. In Proceedings of the ECML PKDD Workshop: Languages for Data Mining and Machine Learning, Prague, Czech Republic, 23–27 September 2013; pp. 108–122. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, NIPS’14, Montreal, QC, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 3104–3112. [Google Scholar]


{kind=link}
| Author | Year | Customer Representation | Prediction Model | Dataset | Real-Time | Unknown |
|---|---|---|---|---|---|---|
| Alves Gomes et al. [17] | 2022 | Pretrained Embedding | DT; RF; GB; MLP; LSTM | yoochoose; OpenCDP; closed | ✓ | ✓ |
| Esmeli et al. [21] | 2022 | Manual Feature Selection | DT; RF; Bagging; MLP | closed | ✓ | ✓ |
| Chaudhuri et al. [22] | 2021 | Manual Feature Selection | DT; RF; SVM; MLP | closed | ✗ | ✗ |
| Esmeli et al. [14] | 2021 | Manual Feature Selection | NB; DT; RF; Bagging; KNN | yoochoose | ✓ | ✓ |
| Esmeli et al. [23] | 2020 | Manual Feature Selection | DT; RF; Bagging | RetailRocket | ✓ | ✓ |
| Martinzes et al. [11] | 2020 | Manual Feature Selection | Lasso Regression; GB; Extrem Learning Machine | closed | ✗ | ✗ |
| Lin et al. [10] | 2019 | Encoding | LR; LSTM | yoochoose; closed | ✓ | ✓ |
| Mokryn et al. [24] | 2019 | Manual Feature Selection | LR; GB, Bagging; NBTree | yoochoose; Zalando | ✗ | ✓ |
| Zeng et al. [25] | 2019 | Manual Feature Selection | LR | closed | ✗ | ✗ |
| Baumann et al. [26] | 2018 | Graph | LR; RF; GB | closed | ✗ | ✗ |
| Sheil et al. [27] | 2018 | Manual Feature Selection and Embedding | GB; LSTM | yoochoose; RetailRocket | ✗ | ✗ |
| Wu et al. [28] | 2015 | Manual Feature Selection | GB; MLP; LSTM | yoochoose | ✗ | ✓ |
| Li et al. [18] | 2015 | Manual Feature Selection | GB with LR | closed | ✗ | ✗ |
| Park et al. [29] | 2015 | Manual Feature Selection | GB | yoochoose | ✗ | ✗ |
| Romov et al. [19] | 2015 | Manual Feature Selection | GB | yoochoose | ✗ | ✗ |
| Notation | Description |
|---|---|
| Set of all possible customer interactions X with interaction . | |
| Set of all interaction times T with interaction time . | |
| A interaction tuple of a customer interaction and its time . | |
| Set of all customer interaction sequences S with sequence of length , . | |
| Context windows of customer interactions. | |
| Context of interaction and time | |
| D-dimensional embedding representation with is the -dimensional embedding representation of the interaction and is the -dimensional embedding representation of the interaction time with . | |
| Embedding function E that uses the trained embedding and maps . |
| Yoochoose | OpenCDP | Closed | |
|---|---|---|---|
| number of events | 24,628,059 | 348,906,538 | 19,740,317 |
| number of sessions | 4,431,931 | 40,103,535 | 2,528,265 |
| number of purchase sessions | 377,376 | 5,297,561 | 99,787 |
| number of no-purchase sessions | 4,054,555 | 34,805,974 | 2,428,478 |
| avg. session length | 5.557 | 8.700 | 7.808 |
| avg. purchase session length | 8.117 | 9.109 | 17.859 |
| avg. no-purchase session length | 5.318 | 8.638 | 7.395 |
| number of unique interactions | 48,012 | 582,082 | 72,759 |
| Baseline | TEE | TEE-CBOW | T2V | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | Split | F1 | AUC | F1 | AUC | F1 | AUC | F1 | AUC |
| yoochoose | 20_percent | 0.744 | 0.829 | 0.881 | 0.951 | 0.862 | 0.944 | 0.749 | 0.816 |
| yoochoose | last_month | 0.680 | 0.778 | 0.843 | 0.922 | 0.851 | 0.927 | 0.708 | 0.757 |
| openCDP | 20_percent | 0.892 | 0.940 | 0.920 | 0.967 | 0.919 | 0.965 | 0.888 | 0.939 |
| openCDP | last_month | 0.908 | 0.948 | 0.930 | 0.965 | 0.925 | 0.963 | 0.908 | 0.946 |
| closed | 20_percent | 0.890 | 0.940 | 0.901 | 0.952 | 0.898 | 0.950 | 0.878 | 0.925 |
| closed | last_month | 0.868 | 0.922 | 0.875 | 0.931 | 0.869 | 0.930 | 0.864 | 0.913 |
| Approach | |||||||
|---|---|---|---|---|---|---|---|
| Baseline | 0.000105 | 0.000224 | 0.001247 | 0.01096 | 0.104631 | 1.021248 | 10.138481 |
| TEE | 0.000221 | 0.000793 | 0.006358 | 0.061467 | 0.610966 | 6.140321 | 60.725083 |
| TEE (mod) | 0.000165 | 0.000614 | 0.004784 | 0.04617 | 0.452097 | 4.499582 | 40.025441 |
| TEE (only mh) | 0.000225 | 0.000377 | 0.002568 | 0.024000 | 0.235588 | 2.355886 | 20.172445 |
| T2V | 0.000169 | 0.000973 | 0.008587 | 0.082118 | 0.807454 | 7.858372 | 80.076782 |
| LSTM | 0.000578 | 0.000962 | 0.002571 | 0.013913 | 0.139333 | 1.506161 | 13.329544 |
| TEE Full | w/o dy | w/o dw | w/o hd | w/o mh | Only mh | |
|---|---|---|---|---|---|---|
| F1 | 0.881 | 0.867 | 0.869 | 0.870 | 0.825 | 0.860 |
| AUC | 0.951 | 0.944 | 0.944 | 0.947 | 0.911 | 0.944 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alves Gomes, M.; Wönkhaus, M.; Meisen, P.; Meisen, T. TEE: Real-Time Purchase Prediction Using Time Extended Embeddings for Representing Customer Behavior. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 1404-1418. https://doi.org/10.3390/jtaer18030070
Alves Gomes M, Wönkhaus M, Meisen P, Meisen T. TEE: Real-Time Purchase Prediction Using Time Extended Embeddings for Representing Customer Behavior. Journal of Theoretical and Applied Electronic Commerce Research. 2023; 18(3):1404-1418. https://doi.org/10.3390/jtaer18030070
Chicago/Turabian StyleAlves Gomes, Miguel, Mark Wönkhaus, Philipp Meisen, and Tobias Meisen. 2023. "TEE: Real-Time Purchase Prediction Using Time Extended Embeddings for Representing Customer Behavior" Journal of Theoretical and Applied Electronic Commerce Research 18, no. 3: 1404-1418. https://doi.org/10.3390/jtaer18030070
APA StyleAlves Gomes, M., Wönkhaus, M., Meisen, P., & Meisen, T. (2023). TEE: Real-Time Purchase Prediction Using Time Extended Embeddings for Representing Customer Behavior. Journal of Theoretical and Applied Electronic Commerce Research, 18(3), 1404-1418. https://doi.org/10.3390/jtaer18030070