On the Entropy and Letter Frequencies of Powerfree Words

Abstract
:
1. Introduction
2. Powerfree words and morphisms
3. Characterisations of k-powerfree morphisms
3.1. Characterisations of squarefree morphisms
- (i)
- is squarefree for every squarefree word of length ;
- (ii)
- whenever and is a factor of .
- (i)
- is squarefree for every squarefree word of length ;
- (ii)
- for any, does not have any internal pre-squares.
3.2. Characterisations of cubefree and k-powerfree morphisms
- (i)
- is k-powerfree whenever is k-powerfree and of length ;
- (ii)
- whenever with a factor of ;
- (iii)
- the equality , with and , implies that either or .
4. Entropy of powerfree words
- (i)
- if with , then for all n which implies .
- (ii)
- if with , then and .
4.1. Upper bounds for the entropy
4.2. Lower bounds for the entropy
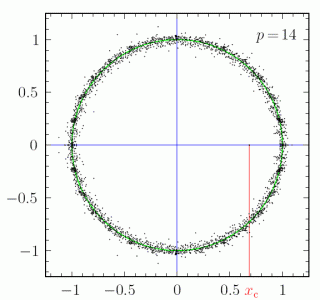
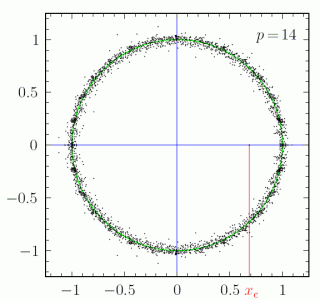
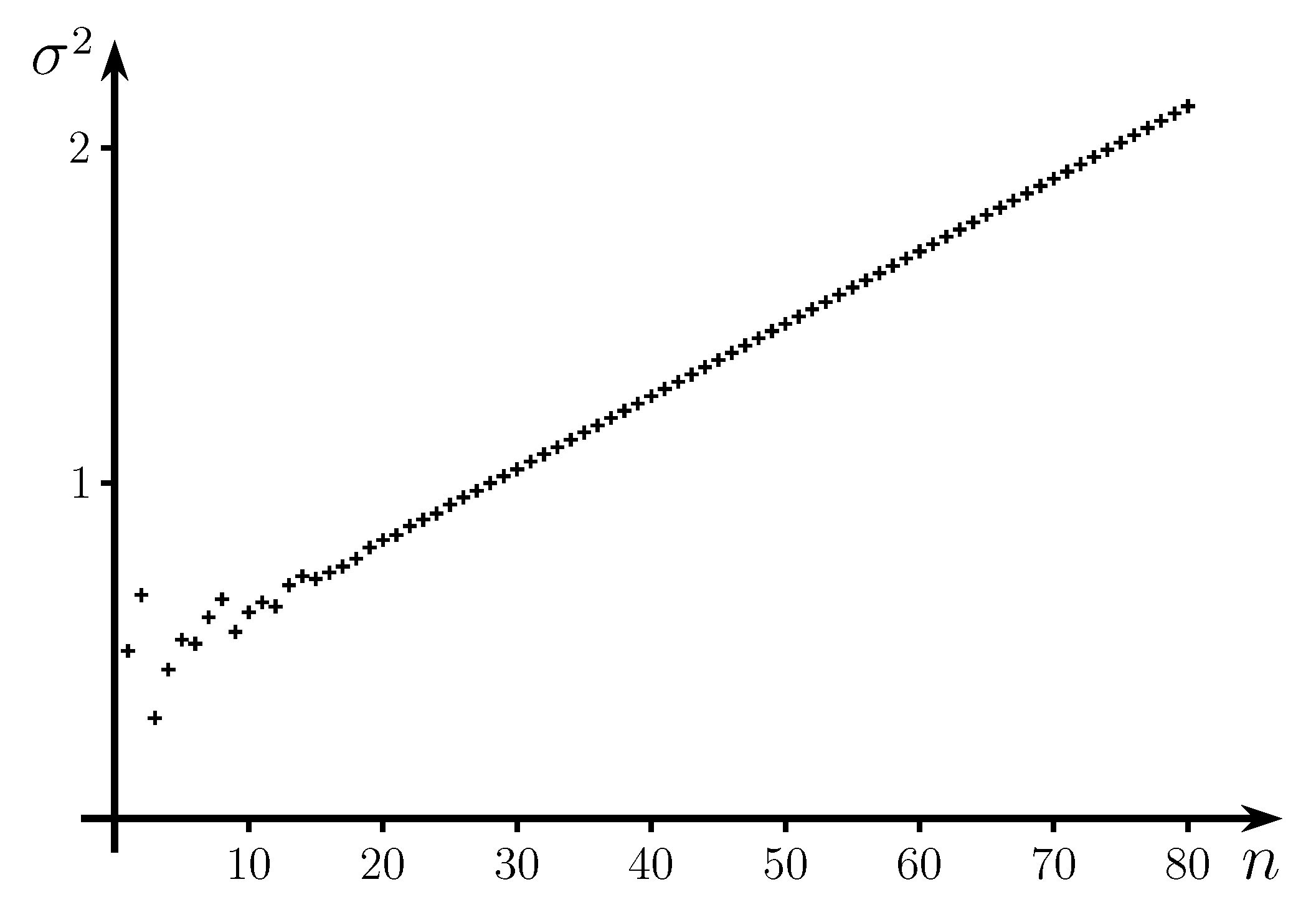
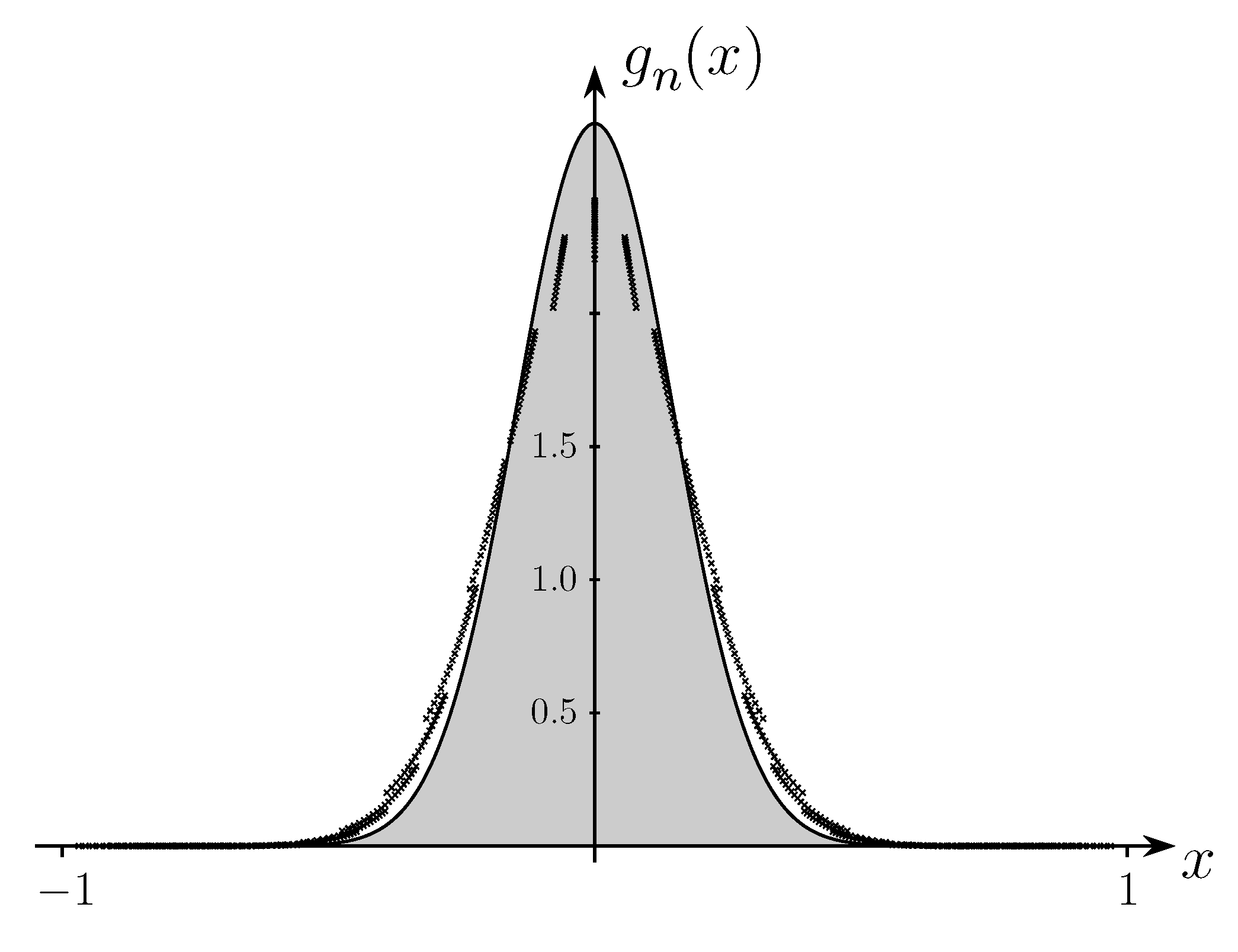
5. Bounds on the entropy of binary cubefree and ternary squarefree words
5.1. Binary cubefree words

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | n | n | n | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 21 | 7754 | 41 | 14565048 | 61 | 27286212876 | |||
| 2 | 4 | 22 | 11320 | 42 | 21229606 | 62 | 39771765144 | |||
| 3 | 6 | 23 | 16502 | 43 | 30943516 | 63 | 57970429078 | |||
| 4 | 10 | 24 | 24054 | 44 | 45102942 | 64 | 84496383550 | |||
| 5 | 16 | 25 | 35058 | 45 | 65741224 | 65 | 123160009324 | |||
| 6 | 24 | 26 | 51144 | 46 | 95822908 | 66 | 179515213688 | |||
| 7 | 36 | 27 | 74540 | 47 | 139669094 | 67 | 261657313212 | |||
| 8 | 56 | 28 | 108664 | 48 | 203577756 | 68 | 381385767316 | |||
| 9 | 80 | 29 | 158372 | 49 | 296731624 | 69 | 555899236430 | |||
| 10 | 118 | 30 | 230800 | 50 | 432509818 | 70 | 810266077890 | |||
| 11 | 174 | 31 | 336480 | 51 | 630416412 | 71 | 1181025420772 | |||
| 12 | 254 | 32 | 490458 | 52 | 918879170 | 72 | 1721435861086 | |||
| 13 | 378 | 33 | 714856 | 53 | 1339338164 | 73 | 2509125828902 | |||
| 14 | 554 | 34 | 1041910 | 54 | 1952190408 | 74 | 3657244826158 | |||
| 15 | 802 | 35 | 1518840 | 55 | 2845468908 | 75 | 5330716904964 | |||
| 16 | 1168 | 36 | 2213868 | 56 | 4147490274 | 76 | 7769931925578 | |||
| 17 | 1716 | 37 | 3226896 | 57 | 6045283704 | 77 | 11325276352154 | |||
| 18 | 2502 | 38 | 4703372 | 58 | 8811472958 | 78 | 16507465616784 | |||
| 19 | 3650 | 39 | 6855388 | 59 | 12843405058 | 79 | 24060906866922 | |||
| 20 | 5324 | 40 | 9992596 | 60 | 18720255398 | 80 | 35070631260904 |
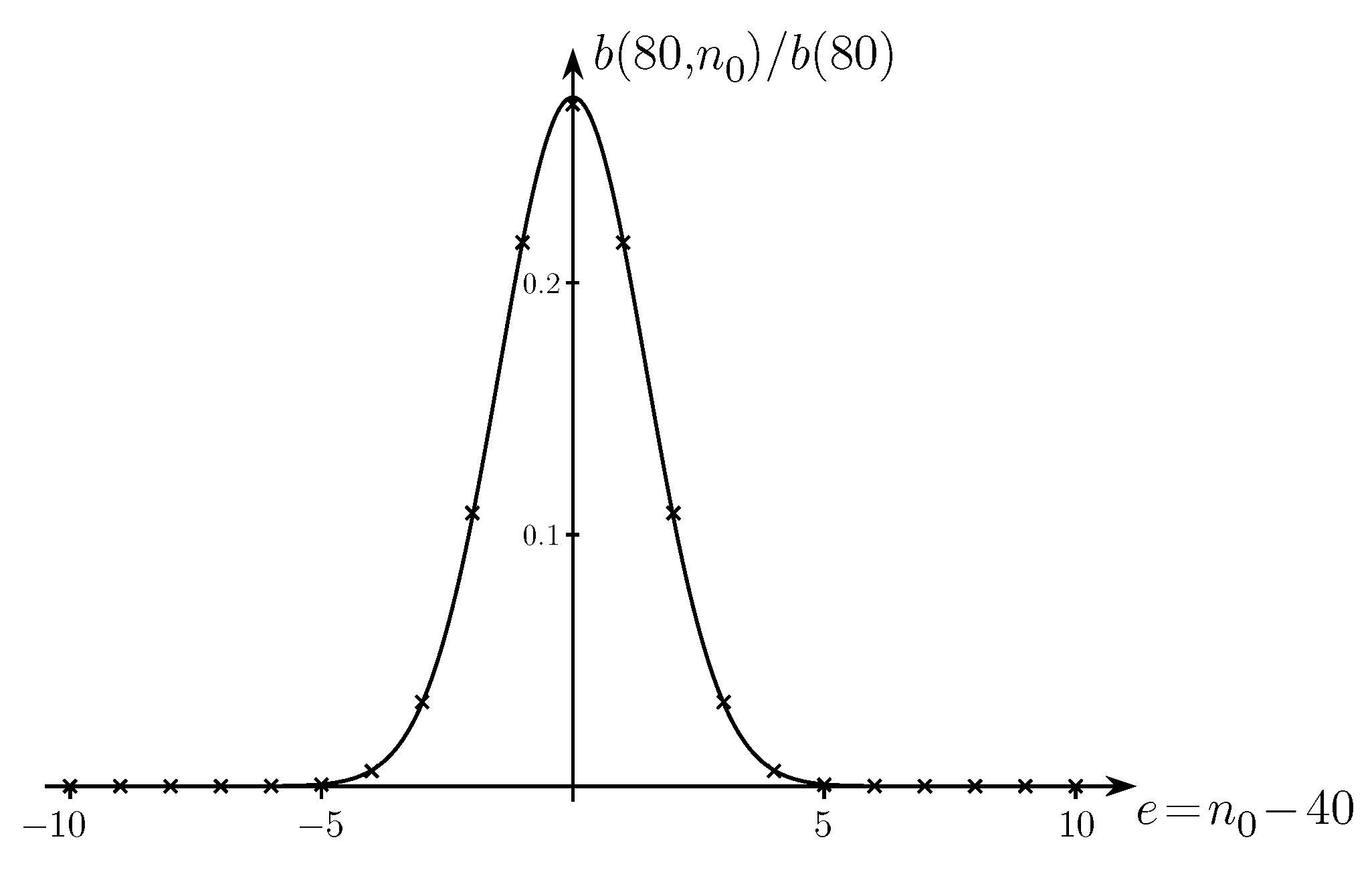
| p | |||
|---|---|---|---|
| 0 | 0 | 1 | 0.693147 |
| 1 | 2 | 2 | 0.481212 |
| 2 | 6 | 5 | 0.427982 |
| 3 | 21 | 13 | 0.394948 |
| 4 | 29 | 17 | 0.385103 |
| 5 | 43 | 25 | 0.380594 |
| 6 | 85 | 57 | 0.378213 |
| 7 | 127 | 99 | 0.377332 |
| 8 | 165 | 127 | 0.377179 |
| 9 | 300 | 254 | 0.376890 |
| 10 | 450 | 395 | 0.376835 |
| 11 | 569 | 513 | 0.376811 |
| 12 | 1098 | 1031 | 0.376790 |
| 13 | 1750 | 1656 | 0.376783 |
| 14 | 2627 | 2540 | 0.376779 |

5.2. Ternary squarefree words
6. Letter frequencies
6.1. Binary cubefree words
| 9502419002570 | |
| 7575510051076 | |
| 3805516412947 | |
| 1172047753336 | |
| 210113470848 | |
| 20038955440 | |
| 866998237 | |
| 12460464 | |
| 26819 | |
| 0 |



6.2. Ternary squarefree words
7. Summary and Outlook
Acknowledgements
References and Notes
- Thue, A. Selected mathematical papers; Nagell, T., Selberg, A., Selberg, S., Thalberg, K., Eds.; Universitetsforlaget: Oslo, 1977. [Google Scholar]
- Morse, H. M. Recurrent geodesics on a surface of negative curvature. Trans. Amer. Math. Soc. 1921, 22(1), 84–100. [Google Scholar] [CrossRef]
- Lothaire, M. Combinatorics on words; Cambridge Mathematical Library; Cambridge University Press: Cambridge, 1997; corrected reprint. [Google Scholar]
- Lothaire, M. Algebraic combinatorics on words; Encyclopedia of Mathematics and its Applications; Cambridge University Press: Cambridge, 2002. [Google Scholar]
- Lothaire, M. Applied combinatorics on words; Encyclopedia of Mathematics and its Applications; Cambridge University Press: Cambridge, 2005. [Google Scholar]
- Zech, T. Wiederholungsfreie folgen. Z. angew. Math. Mech. 1958, 38, 206–209. [Google Scholar] [CrossRef]
- Pleasants, P. A. B. Nonrepetitive sequences. Proc. Cambr. Philos. Soc. 1970, 68, 267–274. [Google Scholar] [CrossRef]
- Bean, D.; Ehrenfeucht, A.; McNulty, G. Avoidable patterns in strings of symbols. Pacific J. Math. 1979, 95, 261–294. [Google Scholar] [CrossRef]
- Crochemore, M. Sharp characterizations of squarefree morphisms. Theoret. Comput. Sci. 1982, 18, 221–226. [Google Scholar] [CrossRef]
- Shelton, R. O. On the structure and extendibility of squarefree words. In Combinatorics on Words; Cummings, J. L., Ed.; Academic Press: Toronto, 1983; pp. 101–118. [Google Scholar]
- Brandenburg, F.-J. Uniformly growing k-th power-free homomorphisms. Theoret. Comput. Sci. 1983, 23, 69–82. [Google Scholar] [CrossRef]
- Brinkhuis, J. Nonrepetitive sequences on three symbols. Quart. J. Math. Oxford Ser. (2) 1983, 34, 145–149. [Google Scholar] [CrossRef]
- Leconte, M. A characterization of power-free morphisms. Theoret. Comput. Sci. 1985, 38(1), 117–122. [Google Scholar] [CrossRef]
- Leconte, M. k-th power-free codes. In Automata on Infinite Words; Nivat, M., Perrin, D., Eds.; Springer: Berlin, 1985; Lecture Notes in Computer Science; Vol. 192, pp. 172–187. [Google Scholar]
- Séébold, P. Overlap-free sequences. In Automata on Infinite Words; Nivat, M., Perrin, D., Eds.; Springer: Berlin, 1985; Lecture Notes in Computer Science; Vol. 192, pp. 207–215. [Google Scholar]
- Kobayashi, Y. Repetition-free words. Theoret. Comput. Sci 1986, 44, 175–197. [Google Scholar] [CrossRef]
- Keräenen, V. On the k-freeness of morphisms on free monoids. Lecture Notes in Computer Science 1987, 247, 180–188. [Google Scholar]
- Baker, K.; McNulty, G.; Taylor, W. Growth problems for avoidable words. Theoret. Comput. Sci. 1989, 69, 319–345. [Google Scholar] [CrossRef]
- Currie, J. Open problems in pattern avoidance. Amer. Math. Monthly 1993, 100, 790–793. [Google Scholar] [CrossRef]
- Kolpakov, R.; Kucherov, G.; Tarannikov, Y. On repetition-free binary words of minimal density. Theoret. Comput. Sci. 1999, 218, 161–175. [Google Scholar] [CrossRef]
- Grimm, U. Improved bounds on the number of ternary square-free words. J. Integer Seq. 2001, 4(2). Article 01.2.7. [Google Scholar]
- Currie, J. There are circular square-free words of length n for n≥18. Electron. J. Combin. 2002, 9, #N10. [Google Scholar]
- Richomme, G.; Wlazinski, F. Some results on k-power-free morphisms. Theoret. Comput. Sci. 2002, 273, 119–142. [Google Scholar] [CrossRef]
- Kucherov, G.; Ochem, P.; Rao, M. How many square occurrences must a binary sequence contain? Electron. J. Combin. 2003, 10, #R12. [Google Scholar]
- Karhumäki, J.; Shallit, J. Polynomial versus exponential growth in repetition-free binary words. J. Combin. Theory Ser. A 2004, 105, 335–347. [Google Scholar] [CrossRef]
- Richard, C.; Grimm, U. On the entropy and letter frequencies of ternary square-free words. Electron. J. Combin. 2004, 11(1), #R14. [Google Scholar]
- Ochem, P.; Reix, T. Upper bound on the number of ternary square-free words. Presented at the Workshop on Words and Automata (WOWA’06); St. Petersburg, 2006. [Google Scholar]
- Richomme, G.; Wlazinski, F. Existence of finite test-sets for k-powerfreeness of uniform morphims. Discrete Applied Math. 2007, 155, 2001–2016. [Google Scholar] [CrossRef]
- Kolpakov, R. Efficient lower bounds on the number of repetition-free words. J. Integer Seq. 2007, 10(3). Article 07.3.2. [Google Scholar]
- Ochem, P. Letter frequency in infinite repetition-free words. Theoret. Comput. Sci. 2007, 380(3), 388–392. [Google Scholar] [CrossRef]
- Chalopin, J.; Ochem, P. Dejean’s conjecture and letter frequency. Electronic Notes in Discrete Mathematics 2007, 501–505. [Google Scholar] [CrossRef]
- Ochem, P. Unequal letter frequencies in ternary square-free words. In Proceedings of 6th International Conference on Words (WORDS 2007), Marseille, 2007.
- Khalyavin, A. The minimal density of a letter in an infinite ternary square-free word is . J. Integer Seq. 2007, 10. Article 07.6.5. [Google Scholar]
- Queffélec, M. Substitution dynamical systems—spectral analysis; Springer-Verlag: Berlin, 1987; Lecture Notes in Mathematics. [Google Scholar]
- Fogg, N. P. Substitutions in dynamics, arithmetics and combinatorics; Berthé, V., Ferenczi, S., Mauduit, C., Siegel, A., Eds.; Springer-Verlag: Berlin, 2002; Lecture Notes in Mathematics. [Google Scholar]
- Allouche, J.-P.; Shallit, J. Automatic sequences; Cambridge University Press: Cambridge, 2003. [Google Scholar]
- Moody, R. V. The mathematics of long-range aperiodic order; Kluwer Academic Publishers Group: Dordrecht, 1997; NATO Advanced Science Institutes Series C: Mathematical and Physical Sciences; Vol. 489. [Google Scholar]
- Keränen, V. On k-repetition free words generated by length uniform morphisms over a binary alphabet. Lecture Notes in Computer Science 1985, 194, 338–347. [Google Scholar]
- Baake, M.; Elser, V.; Grimm, U. The entropy of square-free words. Math. Comput. Modelling 1997, 26, 13–26. [Google Scholar] [CrossRef]
- Walters, P. An introduction to ergodic theory; Springer-Verlag: New York, 1982. [Google Scholar]
- Noonan, J.; Zeilberger, D. The goulden-jackson cluster method: Extensions, applications, and implementations. J. Difference Eq. Appl. 1999, 5, 355–377. [Google Scholar] [CrossRef]
- Berstel, J. Growth of repetition-free words – a review. Theoret. Comput. Sci. 2005, 340(2), 280–290. [Google Scholar] [CrossRef]
- Elser, V. Repeat-free sequences. Lawrence Berkeley Laboratory report 1983, LBL-16632. [Google Scholar]
- Sun, X. New lower-bound on the number of ternary square-free words. J Integer Seq. 2003, 6. Article 03.3.2. [Google Scholar]
- Edlin, A. E. The number of binary cube-free words of length up to 47 and their numerical analysis. J. Differ. Equations Appl. 1999, 5(4-5), 353–354. [Google Scholar] [CrossRef]
- Titchmarsh, E. C. The theory of functions; Oxford University Press: Oxford, 1976. [Google Scholar]
- Ekhad, S.; Zeilberger, D. There are more than 2n/17 n-letter ternary square-free words. J. Integer Seq. 1998, 1. Article 98.1.9. [Google Scholar]
- Baake, M.; Grimm, U.; Joseph, D. Trace maps, invariants, and some of their applications. Int. J. Mod. Phys. B 1993, 7, 1527–1550. [Google Scholar] [CrossRef]
- Tarannikov, Y. The minimal density of a letter in an infinite ternary square-free words is 0.2746…. J. Integer Seq. 2002, 5. Article 02.2.2. [Google Scholar]
© 2008 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Grimm, U.; Heuer, M. On the Entropy and Letter Frequencies of Powerfree Words. Entropy 2008, 10, 590-612. https://doi.org/10.3390/e10040590
Grimm U, Heuer M. On the Entropy and Letter Frequencies of Powerfree Words. Entropy. 2008; 10(4):590-612. https://doi.org/10.3390/e10040590
Chicago/Turabian StyleGrimm, Uwe, and Manuela Heuer. 2008. "On the Entropy and Letter Frequencies of Powerfree Words" Entropy 10, no. 4: 590-612. https://doi.org/10.3390/e10040590
APA StyleGrimm, U., & Heuer, M. (2008). On the Entropy and Letter Frequencies of Powerfree Words. Entropy, 10(4), 590-612. https://doi.org/10.3390/e10040590