1. Introduction
Information inequalities play a crucial role in the proofs for almost all source and channel coding converse theorems. Roughly speaking, these inequalities govern the impossibility in information theory. Among information inequalities discovered to date, the most well-known are the Shannon-type inequalities, including the non-negativity of (conditional) entropies and (conditional) mutual information. In [
2], a non-Shannon information inequality (that cannot be deduced from any set of Shannon-type inequalities) involving more than three random variables was discovered. Since then, many additional information inequalities have been discovered [
4].
Apart from their application in proving converse coding theorems, information inequalities (either linear or non-linear) were shown to have a very close relation with inequalities involving the cardinality of a group and its subgroups [
3]. Specifically, an information inequality is valid if and only if its group-theoretic counterpart (obtained by mechanical substitution of symbols) is also valid. For example, the non-negativity of mutual information is equivalent to the group inequality
, where
and
are subgroups of the group
G.
Information inequalities are also the most common tool (perhaps even unique), for the characterization of entropy functions (see Definition 1 below). In fact, entropy functions and information inequalities are two sides of the same coin. A complete characterization for entropy functions requires complete knowledge of the set of all information inequalities.
The set of entropy functions involving
n random variables,
, and its closure
are of extreme importance not only because of their relation to information inequalities [
6], but also for determination of the set of feasible multicast rates in communication networks employing network coding [
5,
7]. Furthermore, determination of
would resolve the implication problem of conditional independence (determination of every other conditional independence relation implied by a given set of conditional independence relationships). A simple and explicit characterization of
, and
will indeed be very useful. Unfortunately, except in the case when
, such a characterization is still missing [
1,
2,
4].
Recently, it was shown by Matúš that there are countably infinite many information inequalities [
1]. This result, summarized below in
Section 2, implies that
is not polyhedral. The main result of this paper is
non-linear inequalities, which we derive from Matúš’ series in
Section 3. To the best of our knowledge this is the first example of a non-trivial non-linear information inequality. We use the non-linear inequality to deduce that the closure of the set of all entropy functions is not polyhedral – a fact previously proved in [
1] using the infinite sequence of linear inequalities. Finally, in
Section 4, we compare the series of linear inequalities and the proposed nonlinear inequality on a projection of
.
2. Background
Let the index set induce a real dimensional Euclidean space with coordinates indexed by the set of all subsets of N. Specifically, if , then its coordinates are denoted . Consequently, points can be regarded as functions . The focus of this paper is the subset of corresponding to (almost) entropic functions.
Definition 1 (Entropic function) A function is entropic if and there exists discrete random variables such that the joint entropy of is for all . Furthermore, g is almost entropic if it is the limit of a sequence of entropic functions.
Let
be the set of all entropic functions. Its closure
(i.e., the set of all almost entropic functions) is well-known to be a closed, convex cone [
6]. An important recent result with significant implications for
is the series of linear information inequalities obtained by Matúš [
1] (restated below in Theorem 1). Using this series,
was proved to be non-polyhedral for
. This means
cannot be defined by an intersection of any finite set of linear information inequalities.
Following [
1], we will use the following notational conventions. Specific subsets of
N will be denoted by concatenation of elements, e.g. 123 will be written for
. For any
and sets
, define
Furthermore, for singletons , write as shorthand for .
Theorem 1 (Matúš) Let the set of positive integers, and be the entropy function of discrete random variables .
ThenFurthermore, assuming that ,
the inequality reduces to To the best of our knowledge, this is the only result indicating the existence of infinitely many linear information inequalities. Reductions to
with
recovers the Zhang-Yeung inequality [
2] and
obtains an inequality of [
4].
3. Main Results
3.1. Non-linear information inequalities
The series of information inequalities given in Theorem 1 are all “quadratic” in the parameter
,
or equivalently
where in the first series of inequalities (
1)
and in the second series of inequalities (
2)
Proposition 1 Suppose satisfies (3) for all positive integers s and (or equivalently, ).
Then,
, and
. Furthermore, equality holds if and only if .
Proof: Direct verification. ☐
In the following, we will derive non-linear information inequalities from the sequence of linear inequalities (
3).
Theorem 2 Suppose that and .
Let Then g
satisfies (3) for all nonnegative integers s if and only if and Proof: To simplify notation,
and
will simply be denoted as
and c. We will first prove the only-if part. Assume that g satisfies (
3) for all nonnegative integers
s. When
,
. By Proposition 1,
. It remains to prove that (
6) holds.
Suppose first that . If the quadratic has no distinct real roots in s, then clearly and the theorem holds. On the other hand, if has distinct real roots, implying , then is negative and is at its minimum when which is greater than by assumption.
Since
for all non-negative integer
s, the “distance” between the two roots can be at most
. In other words,
or equivalently,
.
If on the other hand that
, then the assumption
and Proposition 1 implies that
. As such, the quadratic inequality
and (
6) clearly holds. Hence, the only-if part of the theorem is proved.
Now, we will prove the if-part. If
, then (
6) and the assumption
implies that
. The theorem then holds as
by assumption. Now suppose
and
. Using a similar argument as before, (
6) implies that either
has no real roots or the two real roots are within the closed interval
. Since
, for all nonnegative integer
s, we have
, or equivalently,
and hence the theorem is proved. ☐
Theorem 2 showed that Matúš series of linear inequalities is equivalent to the single non-linear inequality (
6) under the condition that that
and
.
Clearly,
holds for all entropic g because of the nonnegativity of conditional mutual information. Therefore, imposing these two conditions does not very much weaken (
6). If on the other hand that
does not hold, then Matúš series of inequalities are implied by that
. In that case, Matúš’ inequalities will not be of interest. Therefore, our proposed nonlinear inequality essentially is not much weaker than Matúš’ ones.
While (
6) is interesting in its own right, it is not so easy to work with. In the following, we shall consider a weaker form.
Corollary 1 (Quadratic information inequality) Suppose that g
satisfies (3) for all nonnegative integers s. If ,
then Consequently, if g
is almost entropic and then Proof: Since , the corollary then follows directly from Theorem 2. ☐
Despite the fact that the above “quadratic" information inequality is a consequence of a series of linear inequalities, to the best of our knowledge, it is indeed the first non-trivial non-linear information inequality.
3.2. Implications of Corollary 1
In Proposition 1, we showed that Matúš’ inequalities imply that if
, then
. The same result can also be proved by using the quadratic information inequality in (
7).
Implication 1 For any such thatthen implies .
Proof: If
, then
. Hence, if
, then (
8) will be violated leading to a contradiction. ☐
In [
1], it was proved that the cone
is not polyhedral for
. Ignoring the technical details, the idea of the proof is very simple. First, a sequence of entropic functions
was constructed such that (1) the sequence converges to
, and (2) it has a one-side tangent
which is defined as
. Clearly, if
is polyhedral, then there exists
such that
is contained in
. It was then shown that for any
, the function
is not in
because it violates (
3) for sufficiently large
s. Therefore,
is not polyhedral, or equivalently, there are infinitely many information inequalities.
In fact, we can also show that
also violates the quadratic information inequality obtained in Corollary 1 for any positive
ϵ. As such, (
7) is sufficient to prove that
is not polyhedral for
and hence the following implication.
Implication 2 The quadratic inequality (7) is strong enough to imply that is not polyhedral. Some nonlinear information inequalities are direct consequences of basic linear information inequalities (e.g.,
). Such inequalities are trivial in that they are obtained directly as nonlinear transformations of known linear inequalities. Our proposed quadratic inequality (
7) is non-trivial, as proved in the following.
Implication 3 The quadratic inequality (7) is a non-linear inequality that cannot be implied by any finite number of linear information inequalities. Specifically, for any given finite set of valid linear information inequalities, there exists such that g
does not satisfy (7) but satisfies all the given linear inequalities. Proof: Suppose we are given a finite set of valid linear information inequalities. Then the set of satisfying all these linear inequalities is polyhedral. In other words, the set is obtained by taking intersection of a finite number of half-spaces. For simplicity, such a polyhedron will be denoted by Ψ.
We will once again use the sequence of entropic functions
constructed in [
1]. Clearly,
for all
t since
. Again, as Ψ is polyhedral,
for sufficiently small
. In other words,
satisfies all the given linear inequalities. However, as explained earlier,
violates the quadratic inequality (
7) and hence the theorem follows. ☐
4. Characterizing by projection
Although the set of almost entropic functions is a closed and convex cone, finding a complete characterization is an extremely difficult task. Therefore, instead of tackling the hard problem directly, it is sensible to consider a relatively simpler problem – the characterization of a “projection" of . This projection problem is easier because the dimension of a projection can be much smaller, making it easier to be visualized and to be described. Furthermore, its low dimensionality may also facilitate the use of numerical techniques to find an approximation for the projection.
In this section, we consider a particular projection and will show how inequalities obtained in the previous section be expressed by equivalent ones on the proposed projection. As such, we can have a better idea how the projection looks like. First, we will define our proposed projection Υ.
Define
, or equivalently,
Lemma 1 Υ is a closed and convex set.
Proof: Since the set is a closed and convex one, its cross-section (and its affine transform) Υ is also closed and convex. ☐
Since Υ is obtained by projecting onto a two-dimensional Euclidean space, any inequality satisfied by all points in Υ induces a corresponding information inequality. Specifically, we have the following proposition.
Proposition 2 Suppose that there exists such thatThenif and only ifSimilarly, (
11)
holds for all and if and only if (
12)
holds for all and .
Proof: First, we will prove that (
11) implies (
12). For any
. If
, then by Proposition 1,
and (
12) follows from (
10). Otherwise,
and (
12) follows from (
9).
Conversely, for any
, by definition, there exists
such that (1)
and (2)
and
. The inequality (
11) then follows from (
12) and that
(hence,
).
Finally, the constrained counterpart follows from that if and only if . ☐
By Proposition 2, there is a mechanical way to rewrite inequalities for
as ones for Υ, and vice versa. Therefore, we will abuse notations by calling that (
11) and (
12) equivalent. In the following, we will rewrite inequalities obtained in previous sections by using Proposition 2.
Proposition 3 (Matúš’ inequalities) When s is a positive integer, the inequality (3) is equivalent to Proof: A direct consequence of Proposition 2 and that
☐
By optimizing the choice of s, we can obtain a stronger piecewise linear inequality which can be rewritten as follows.
Theorem 3 (Piecewise linear inequality) The piecewise linear inequalityis equivalent to thatwhere .
Proof: A direct consequence of Propositions 2 and 3. ☐
As we shall see in the following lemma, can be explicitly characterized.
Lemma 2 andfor any ,
where is the smallest positive integer such that .
Proof: Let
. First,
. Therefore,
. Also, it is straightforward to prove that
for any fixed , is a decreasing function of s and hence .
for , is a strictly concave function of s for and is at its maximum when . As a result, where and .
Clearly, for any positive integer
,
Furthermore, if
, we have
and
and hence,
By solving a system of linear equations, we can show that
if and only if
. Therefore,
Together with the fact that
for
, the lemma follows. ☐
Proposition 4 (Quadratic inequality) The quadratic inequality (7) (subject to that )
is equivalent tosubject to that .
Proof: By using Proposition 2 and (
14), it is straightforward to rewrite (
7) as (
18). ☐
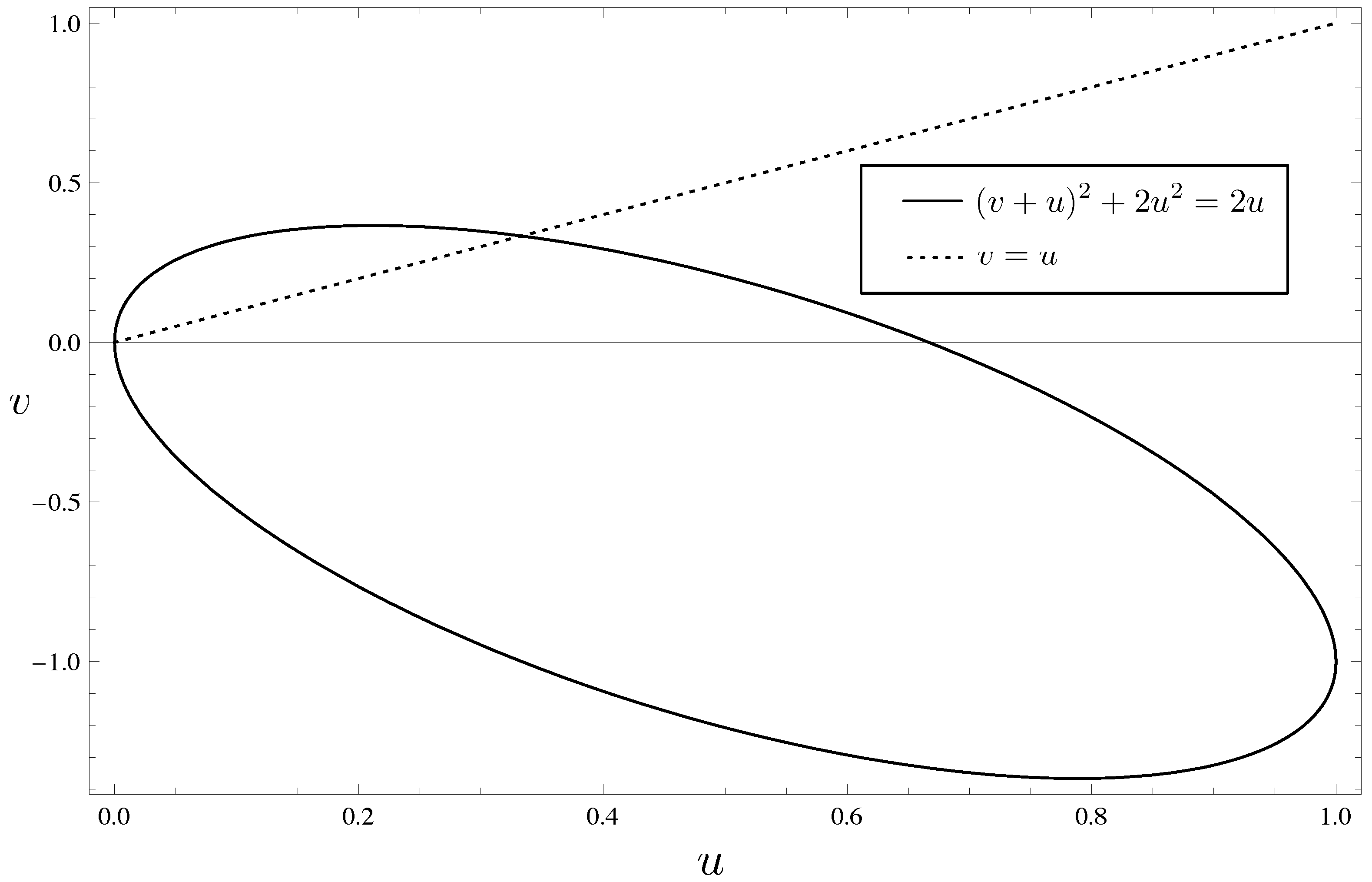
To illustrate (
18), we plot the curves
and
in
Figure 1. From the proposition, if
(i.e., the point
is below the dotted line), then
implies that
is inside the ellipse.
Proposition 4 gives a nonlinear information inequality on Υ subject to a condition that . In the following theorem, we relax the inequality so as to remove the condition.
Figure 1.
Quadratic inequality (
18).
Figure 1.
Quadratic inequality (
18).
Theorem 4 (Non-linear inequality) LetFor any ,
.
Consequently, by Proposition 2, Proof: By Proposition 4, if
such that
, then
As a result,
or equivalently,
On the other hand, if
, then
and hence
. The theorem then follows from Proposition 2. ☐
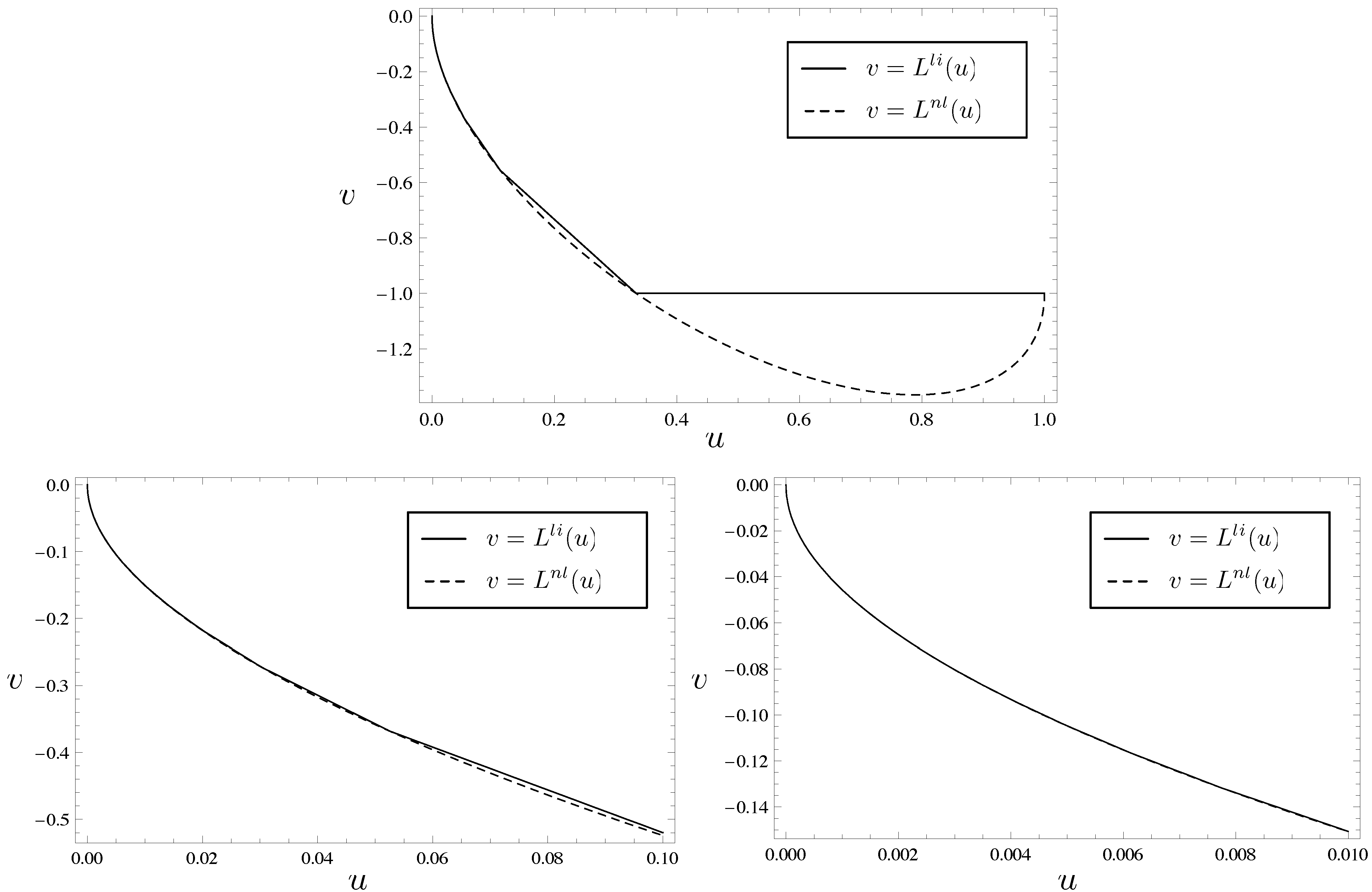
In the next proposition, we will show that the piecewise linear inequality and the proposed nonlinear inequality coincides for countably infinite number of u.
Proposition 5 For any , we have . Furthermore, equality holds if for some nonnegative integer s.
Proof: By definition,
and the proposition holds in this case. Assume now that
. We first show that
when
for some nonnegative integer
s. Suppose that
, then
. On the other hand, if
where
s is a positive integer, then it is straightforward to prove that
Figure 2.
Piecewise linear inequality and nonlinear inequality.
Figure 2.
Piecewise linear inequality and nonlinear inequality.
By differentiating with respect to u, we can prove that is convex over . For each nonnegative integer s, is linear over the interval and when or . Hence, over the interval by the convexity of . As s can be arbitrarily large, for and the theorem then follows. ☐
5. Conclusion
In this paper, we constructed several piecewise linear and quadratic information inequalities from a series of information inequalities proved in [
1]. Our proposed nonlinear inequality (
6) was shown to be equivalent to the whole set of Matúš’ linear inequalities. Hence, we can replace all Matúš’ inequalities with our proposed ones.
However, the inequality is not smooth and may not be easy to work with. Therefore, we relax these nonlinear inequalities to quadratic ones. These quadratic inequalities are strong enough to show that the set of almost entropic functions is not polyhedral.
It is certain that the proposed quadratic inequalities we obtained in (
16) and (
19) are a consequence of Matúš’ linear inequalities. Yet, the non-linear inequality has a much simpler form. By comparing the inequalites on projections of
, our figures suggested that these nonlinear inequalities are indeed fairly good approximations to the corresponding piecewise linear inequalities. Furthermore, they are of particular interest for several reasons.
First, all these inequalities are non-trivial and cannot be deduced from any finite number of linear information inequalities. To the best of our knowledge, they are the first non-trivial nonlinear information inequalities. Second, in some cases, it will be relatively easier to work with a single nonlinear inequality, rather than an infinite number of linear inequalities. For example, in order to compute some bounds on a capacity region (say, in a network coding problem), a characterization of may be needed as input to a computing system. Surely, is unknown and hence an outer bound of will be used instead. If one replace the countably infinite number of linear inequalities with a single nonlinear inequality, it may greatly simplify the computing problem. Third, these nonlinear inequalities prompt us to ask new fundamental questions - are nonlinear information inequalities more fundamental than linear information inequalities? Would it be possible that the set be completely characterized by a finite number of nonlinear inequalities? If so, what will they look like?
As a final remark, Matúš’ inequalities, and also all the non-linear inequalities we obtained, are “tighter” than the Shannon inequalities only in the region where . When , the two inequalities are direct consequences of non-negativity of conditional mutual information. This phenomenon seems to suggest that entropic functions are much more difficult to characterize in the region . An explanation for this phenomenon is still lacking.

{kind=link}
{kind=link}

