2. Robust Parameter Identification: A Brief Summary of the State of the Art
Consider a static system
being
the unknown parameter vector,
the response variable,
the explanatory variables and
the error term. Index
i runs on the number of observations
N that is assumed to be strictly larger than
m. The error term
is assumed to be a normally distributed random variable with zero mean. Denoting with
the set of the available observations, a regression estimator
T is an algorithm associating to
an estimate
of
, namely
. Prediction error estimators
T are designed based on the properties of the regression residuals
where
are the predicted responses
. The most popular prediction error estimators are the Least Squares (LS) and weighted LS estimators defined respectively as
where
is the residual vector
and
a symmetric positive definite (or eventually semidefinite) matrix of weights. Given the symmetric nature of Γ, there is no substantial loss of generality in assuming it to be diagonal, i.e., there exists an orthogonal
matrix Ω such that
diag
, so that the WLS estimator results in
where
. If the weight matrix Γ in the WLS estimator is chosen to be the covariance of the zero mean normally distributed error term
, namely
, the corresponding estimator (some times called the Markov Estimator) coincides with the Maximum Likelihood (ML) estimator defined as
where
is the probability of the data set
given
.
If, moreover, the error terms
are assumed to be independent and identically distributed (i.i.d.) the above ML estimator minimizes the sample version of the entropy associated to
, namely
The properties of the celebrated Maximum Likelihood, Least Squares and Weighted Least Squares estimators are very well known and will not be discussed here. Yet it should be stressed that these methods are also very well known to be highly sensitive to outliers [
1,
2], i.e., to elements of
that do not comply with the model (1). Intuitively the lack of robustness of all ML related methods should not surprise: if
is contaminated by
wrong data (i.e., data that should
not be in
), maximizing the likelihood of
conditioned to
means maximizing the probability that the data set
does contain wrong data.
The issue of designing robust (with respect to outliers) parameter estimators has been explored in many fields of science following often different approaches. In order to motivate and compare the solution proposed in this paper with the state of the art, some of the alternative known approaches are briefly summarized: based on the observation that the ML estimator minimizes the sample version of the entropy associated to the i.i.d. model errors
, in [
3,
4] a minimum entropy (ME) estimator is proposed. The main idea consists in estimating the probability density function of residuals
with a kernel based method (using radial basis functions, by example) and then computing the parameter vector estimate
as the argument minimizing the entropy associated to
. The idea behind this approach is that minimizing the estimated entropy of the residuals will force them to have a minimum dispersion. This approach, although computationally demanding, is indeed appealing and has also been pursued within system identification in [
5].
A different perspective to the problem can be found in the rich statistics literature on the subject. A milestone reference is the book by Peter J. Huber [
2] describing (among the rest) the use of M-estimators (where the M is reminiscent of Maximum Likelihood). M-estimators can be thought of as generalizations of the LS estimator (3) where the square of residuals is replaced by an alternative penalty function
with a unique zero in the origin and such that
, namely
Indeed Laplace or
regression is a special case of equation (
8) corresponding to
, i.e., the absolute value of residuals. Unfortunately,
regression (as LS, i.e.,
regression) turns out to be quite sensitive to outliers [
1] and is computationally complex even for models that are linear in
. M-estimators (as the other parameter estimators) are more easily analysed in the special case that the model (1) is linear in the parameters, namely:
or in vector notation
being
,
,
and
.
With reference to the model (9) and to the M-estimator (8), if
is differentiable, the computation of
can be computed solving a system of
m equations as
Denoting with
ψ the derivative of
ρ with respect to the generic component of
, the above
m equations are usually reported as
where the index
j is omitted for the sake of brevity. Most often the design of M-estimators is performed by selecting the
function in equation (
12) rather than
itself. In this case the corresponding M-estimator is classified as Ψ-type. Robustness to outliers is then sought for by selecting the
function so that it saturates to a constant positive value when its argument (i.e., the residual) is larger than a certain threshold. Eventually the
function can be selected so that it even goes to zero for sufficiently large residuals, in this case
is said to be redescending. Examples of popular redescending
functions include Hampel’s three-part function
for parameters
, Tukey’s biweight
function for some positive
k:
or Andrew’s sine wave (for some positive
ω):
The most popular non redescending design for
is perhaps Huber’s
function for some positive
k:
corresponding to Winsorized Least Squares. Indeed the
function associated to the LS estimator is simply
and the one associated to
regression is
sign
.
A possible measure of the robustness of an estimator is given by the finite sample breakdown point [
1]: assume that an estimator
T associates the estimate
to a given data set
, namely
. Denote with
the set obtained by replacing
c data points in
with arbitrary values and with
(
denotes an arbitrary norm in
) the maximum bias that can be induced in the estimate by such contamination of the data set. The finite sample breakdown point
of
T over
N is defined as
and it measures the least fraction of contamination that can arbitrarily bias the estimate. The asymptotic breakdown point is obtained as the limit of
for
N tending to infinity and it is usually expressed as a percentage. It is well known that in LS regression problems even a single data point can arbitrarily affect the estimate. Denoting with
the LS-estimator, its finite sample breakdown point results in
and its asymptotic breakdown point is
. Unfortunately M-estimators are also reported [
1] to have
asymptotic breakdown point in spite of exhibiting good finite sample performance in practical applications. Some Ψ-type
M-estimators may not be
scale equivariant. Scale equivariance is a property according to which if the data values
should be all scaled by a constant
c, i.e.,
, the corresponding estimate
would scale the same way, i.e.,
. Of course this is a very important property for linear in the parameters models. To ensure proper scaling behavior of
M-estimates that should not be scale equivariant, one can normalize the residuals with an estimate
of the standard deviation of the data. Namely, the normalized Ψ-type
M-estimate equations would take the form:
where the
needs to be estimated as well. Of course this increases the complexity of the overall problem. A possible robust estimate of the standard deviation [
2] can be taken to be
for some positive constant
k being MAD the Median Absolute Deviation defined as:
where med
is the median of the set
. The constant
k can be chosen to achieve consistency with the standard deviation of a known probability distribution: by example, should the
values be distributed normally with standard deviation
σ, the constant
k would need to be approximately equal to
for
to be a consistent estimate of
σ. For a more detailed discussion about estimating the scale of residuals refer to [
2] (Chapter 5).
A common feature to all
M-estimators is the structure described by equation (
8) of the objective function to be minimized: notably, according to this structure, each residual contributes to the objective function independently from the others. Of course residuals are related to each other through the common “generating” model, yet according to the very definition (8) of
M-estimators, the contribution to the objective function of the
i-th residual does not depend on the other residuals. In a very loose sense, one could say that the above presented
M-estimators are somehow “local” in nature as they strive for robustness trying to give a finite (or zero, for redescending
M-estimators) weight to single residuals that exceed a threshold. Each residual contributes to the objective function based on its only value regardless the overall distribution.
An alternative approach is to minimize a “global” measure of the scatter of all residuals. Indeed the novel robust (or resistant) estimators presented in [
1] have a different structure with respect to “local” (in the above sense)
M-estimators: these are the Least Median of Squares (LMS) and Least Trimmed Squares (LTS) estimators. Both estimators appear to have excellent robustness properties: by their very definition they are computed minimizing objective functions that measure the overall distribution of residuals. In particular the LMS (not be confused with the Least Mean Square value) is defined [
1] as:
This estimator is shown [
1] to achieve the maximum breakdown point possible (i.e.,
) although its computation is numerically nontrivial and its performance in terms of asymptotic efficiency is poor. The LMS estimator has also an appealing geometrical interpretation that can be more easily described in the scalar case
, i.e., when
θ is a scalar and the data model is the line
: in this case, the LMS estimate
of
θ corresponds to the center line (
) of the thinnest (measured in the vertical direction, i.e.,
y-axis) stripe containing
of the data points being
the integer part of
. This geometrical interpretation can be extended to the general case of linear in the parameters models as in equation (
9). The LMS estimator can be also interpreted as a special case of a Least Quantile of Squares (LQS) estimator [
1] (pp. 124–125): this is a class of estimators including as a special case also the
or minmax estimator defined as:
A second robust estimator (having the same breakdown point of the LMS) presented and analysed in [
1] is the Least Trimmed Squares (LTS) estimator defined as:
being
the ordered sequence of the squared residuals (first squared, then ordered), namely
where
for all
. Notice that in spite of the similarity with traditional Least Squares, the computation of the LTS estimate is not obvious as the dependance of the ordered sequence of the squared residuals from the parameter vector is by no means trivial. For a (not up-to-date, but still valid) discussion about numerical issues related to the computation of LTS and LMS estimates, see [
1]. Results relative to the complexity and the issues related to the computation of LMS estimates are described in [
6] and [
7].
Other robust estimators used mostly in statistics include
L-estimators,
R-estimators and
S-estimators: the first are computed as linear combinations of order statistics of the residuals. They are mostly used in location (
) problems and are usually simple to compute (example, in location problems,
for proper constants
), although they have been shown [
1] (p. 150) to achieve poor results when compared with alternative robust solutions.
R-estimators are based on ranks of the residuals: such estimators have been studied from the early 1960s and, under certain conditions, have been shown to have the same asymptotic properties of
M-estimators [
1] (p. 150).
S-estimators have been suggested in [
1] and are based on
M-estimates of the scale of the residuals. As reported in [
1] (p. 208),
S-estimates are rather complex to be computed and simulation results suggest that they do not perform better than the LMS.
One of the limits of the LMS estimator is its slow (
) asymptotic convergence rate (notice that LTS is shown to converge at the “usual” rate of
) [
1]. In the attempt to improve convergence of the LMS estimate, it was suggested in [
1] to use a so called “Reweighted” Least Squares (RLS) approach: the basic idea is to use a first robust estimate
of the scale of residuals (by example based on the MAD (21)) to compute binary weights for each residual as:
where
c is an arbitrary threshold (usually equal to
). Weights equal to zero will correspond to data points that will be completely ignored, while weights equal to one will correspond to data points used for the next step of the algorithm. Once that weights
have been computed according to equation (
26), a second estimate of the scale is computed as ([
1] pp. 44–45):
Then a new set of weights
is computed (hence the name “reweighted”) on the basis of the new scale estimate
, namely:
and the final estimate of
is computed as a (Re-) Weighted Least Squares estimate according to:
Accordingly, the final scale estimate is computed as in equation (
27) but with the
weights in place of the
ones.
Numerical simulations reported in [
1] show that the above described Reweighted Least Squares (RLS) solution has very nice finite sample properties, although the hope that this solution could also improve the rate of asymptotic efficiency has been shown to be false in [
8]. Of course many variants to this reweighted schema are possible: by example weights can be computed with a smooth function ([
1] p. 129) rather than a binary one, or they can be computed adaptively [
9], or even based on Pearson residuals [
10] giving rise to a one step robust estimator. The detailed discussion of these (and other) variants to the RLS approach goes beyond the scope of this paper and will be omitted for the sake of brevity.
To conclude this very brief overview of robust estimation methods, it should be noted that besides the statistics research community, other branches of science have been addressing similar problems exploiting different methods. For example, within the machine learning community, popular approaches include Neural Networks based or Support Vector Machine (SVM) estimators [
11]. For pattern recognition and computer vision classification problems, voting algorithms are also widely employed. One of the most popular voting algorithm is the Hugh transform or, more generally, the Radon transform [
12]. This is often used in computer vision applications: it consists in performing a transformation between the image space (pixels) and a parameter space relative to specific curves. In its most common and simple formulation, the Hugh transform is used to detect straight lines in
images: a (simplistic) implementation of the method could be summarized as follows. First a set of candidate pixels
is selected based on a given criteria (by example color, or some other image property). Then, each pixel in
with coordinates
“votes” for sampled parameters
in sets
and
if
for some positive threshold
ε. Once that all pixels in
have been processed, the straight lines in
are determined by selecting the parameter pairs
that have been assigned the highest number of votes. This kind of voting algorithm has the advantage of being computationally simple and relatively fast: this approach is popular in image processing applications where real time performance is essential. Notice that the spirit of voting schemas is to sample the parameter space such that the majority of candidate data points agree on a specific point of the parameter space. The selection of the parameter points is performed “globally” after all candidate data points have expressed their vote. Robustness to outliers is naturally obtained through the voting criteria itself. The Hugh transform method can be extended to identify more complex curves than straight lines. Of course the computation time and the memory requirements of the method increases rapidly with the number of data points to process and with the dimension of the parameter space to be sampled. The computational effort associated with the number of data points is due to the fact that each of them is processed before the estimate can be computed. An alternative algorithm that remedies this problem is RANSAC, i.e., Random Sample Consensus [
13].
The RANSAC is an iterative algorithm based on random sampling of the data: in short, a subset (candidate inlier data set
) of the data points is randomly sampled. In its most simple implementation, the size
of this randomly sampled subset is fixed and is one of the design parameters of the algorithm. The elements in
are then fitted to the model through standard methods as, by example, Least Squares. The rest of the data points (not used for estimating the model parameter vector) is tested against the model: data points with residuals below a given threshold, hence that have reached a
consensus with the candidate parameter vector of the model, are added to the candidate inlier set
. If the size of
built in this manner is sufficiently large (namely larger than a design parameter threshold
), all the data in this set are fitted to the model giving rise to the RANSAC estimate of the parameter vector. Otherwise the whole procedure is repeated for a maximum number of times
. An estimate of how large
should be can be obtained on the basis of an estimate of the percentage of outliers, of the size
of the randomly sampled subset and of the desired probability that the dimension of
after testing all the data is at least
(refer to [
13] for details).
Another approach for robust parameter estimation has been developed in the last 15 years within the information and entropy econometrics research community [
14]: exploiting (in essence) Laplaces principle of insufficient reason and the information theoretic definition of entropy, a method known as Generalized Maximum Entropy (GME) has been developed [
15] for the parameter identification problem. With reference to linear in the parameters models as in equation (
10), contrary to all the other discussed approaches, the GME method aims at estimating both the parameter vector
and the error term
. From a technical point of view, this goal is pursued by re-parametrizing the model in equation (
10) so that
and
are expressed as expected values. A basic scenario is the following: assuming
and
for all
, the linearly spaced support vectors
and
are defined on the sets
and
for some
l. By example, if
one would have
Such support vectors are then used to define block-diagonal matrices
Z and
V
such that
where
and
are the (discrete) probability density functions (on supports
and
) of
and
respectively. Having introduced such discrete probability density functions, the values of
and
are estimated based on the principal of maximum entropy as
subject to the consistency (10)
and normalization constraints
having denoted with
the
k-th component of vector
. Solving equation (
35) subject to constraints (36), (37) and (38) is in general by no means trivial and needs to be accomplished numerically. On the other hand, the entropy function in equation (
35) to be maximized is strictly concave on the interior of the constraints (37) and (38) implying that a unique solution to the constrained optimization problem exists if the intersection between the constraints is non-empty. Of course the GME estimate
of
will be given by
The GME method is extremely interesting for its many noteworthy properties. In particular the method also converges when the model matrix
G in equations (10) or (35) is singular and there is no need for specific assumptions on the distribution of the error term
. Notice, for example, that in the extreme case where
and
, the Least Squares or Weighted Least Squares estimators would be ill-defined whereas the GME method would lead to uniform probability density functions
and
implying
(if the support vectors
and
are symmetrical with respect to zero as in equations (30–31)). Of course this desirable behavior is possible thanks to the prior information on
and
(unnecessary within LS and related approaches) that is embedded in the definition of the support vectors
and
.
It should be noticed that the GME method is widely used in econometrics research (see [
16] for a recent application in this field), but still poorly exploited in other application domains that could greatly benefit from it (consider, for example, system identification and control engineering where robustness is a must [
17,
18]). Notice that the GME approach guarantees high robustness with respect to singular regression models, but in its standard formulation described above it does not offer specific benefits with respect to the presence of outliers.
5. Numerical Results
As a first toy example to investigate the properties of the proposed cost function
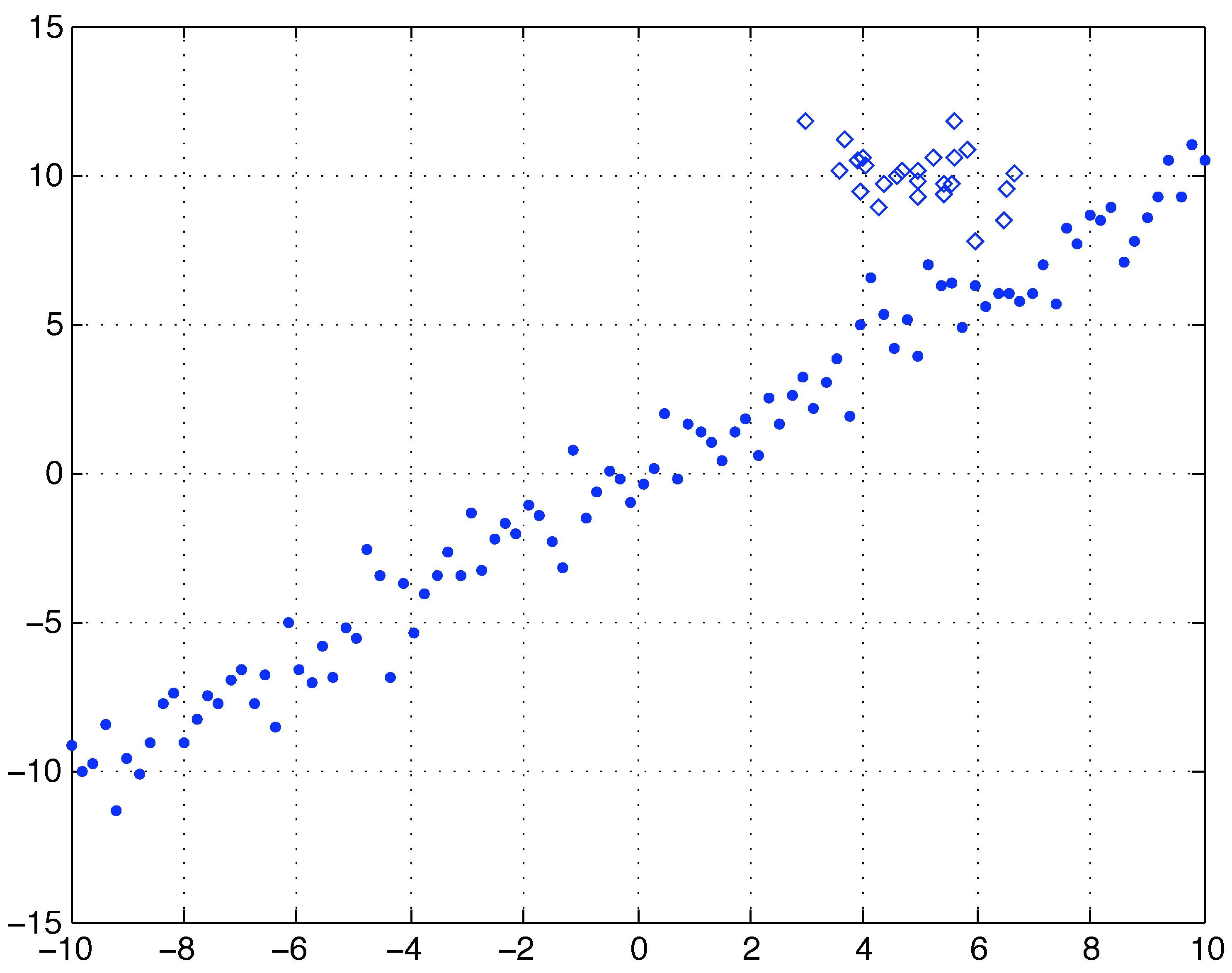
H as compared to the Least Squares (LS) and Least Median of Squares alternatives, consider the data set depicted in
Figure (1): there are 100 points depicted as dots having
coordinates equally spaced in the range
. The
coordinates are computed as
being
ϵ a Gaussian random noise of zero mean and unit variance. Moreover there are other 25 data points depicted with a diamond shape: these have
coordinates normally distributed with mean 5 and unit variance, while their
coordinates are normally distributed with mean 10 and unit variance. The total data set is made of the these 2 subsets, namely it contains 125 points that can be thought of as 100 values satisfying a linear model
(with some noise), plus 25 outliers.
The reference model for the above described data set is
being
and
known while
is the unknown scalar to be estimated. Given the presence of the outliers, the LS estimate is expected to be biased with respect to the “real” value 1. Indeed its value results in
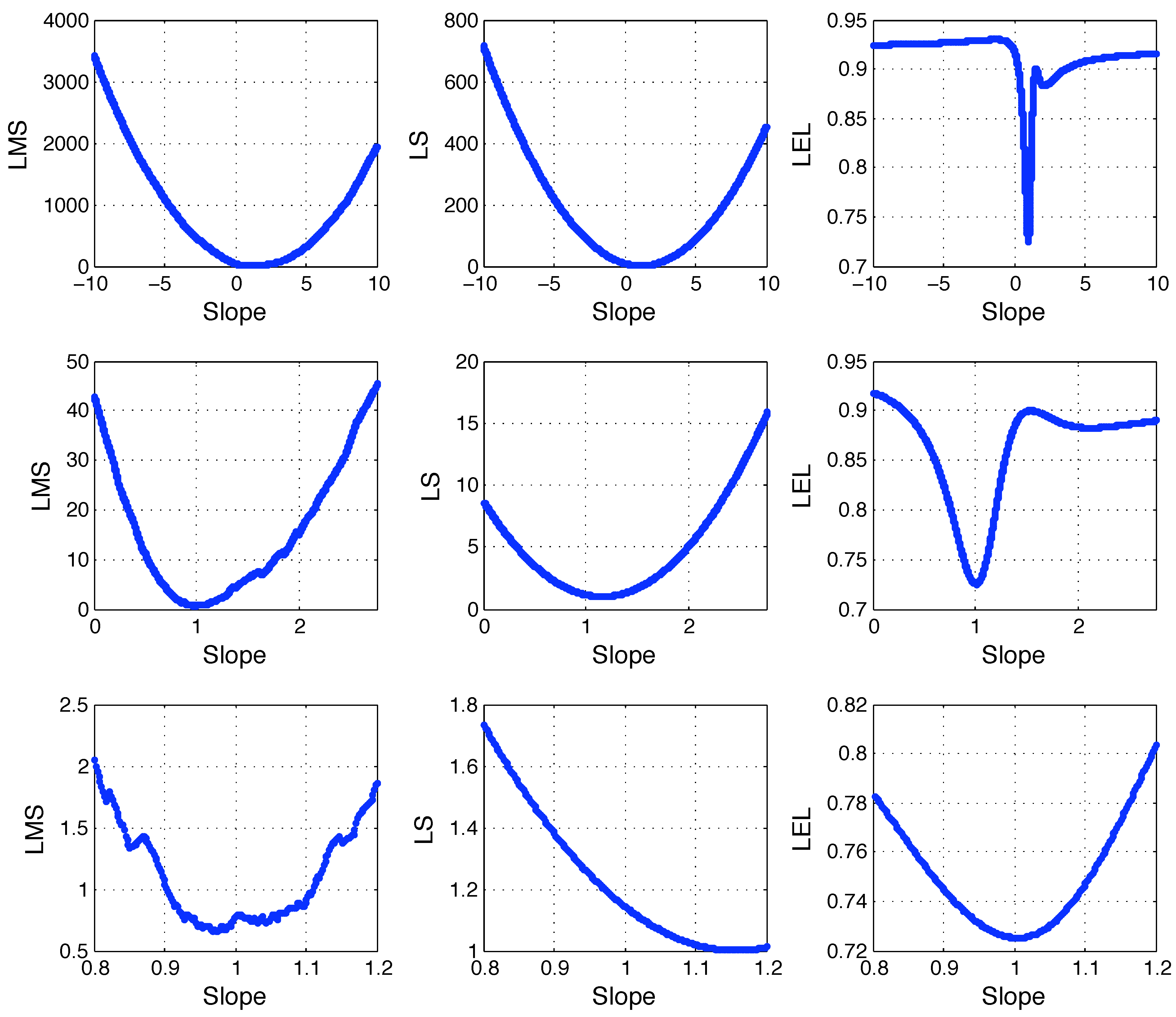
Given that the unknown parameter is a scalar, the LS, LMS and LEL cost functions can be easily plotted as functions of
θ. The LMS, LS (normalized) and LEL cost functions are computed as
Figure 1.
Linearly distributed data with zero mean unit variance noise (100 round dots) plus 25 outliers normally distributed around the point . Refer to the text for details.
Figure 1.
Linearly distributed data with zero mean unit variance noise (100 round dots) plus 25 outliers normally distributed around the point . Refer to the text for details.
where
is the sample median over the set in argument and
. The LS cost
in equation (55) is normalized such that
whereas the LEL cost function
in (56) is the
H function of equation (42) except for checking if
is null or not (unnecessary in practice). These cost functions are sampled in the range
with
equally spaced values of the slope
θ: the resulting plots are depicted in
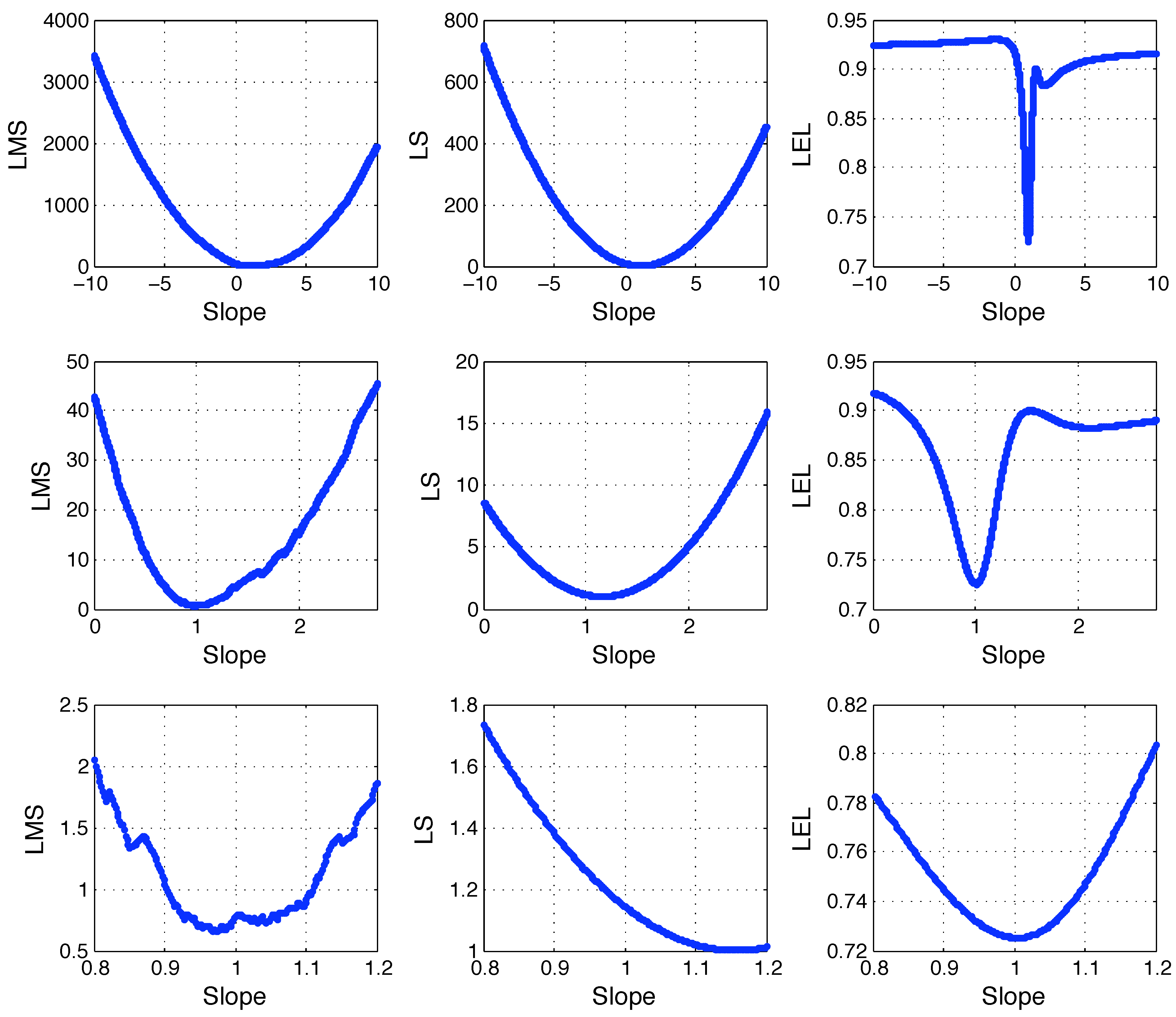
Figure (2) at different zoom levels. As expected, the LS cost has a (unique) minimum in
. The LMS cost has a discontinuous and rather erratic behavior making it difficult to accurately determine where its minima are. The LEL cost function has a regular plot (the function is actually smooth in this case) and it appears to have a sharp local minimum in
. Notice that the LEL function has also a local minimum close to
confirming the local nature of the proposed estimator. To explore the behavior of the proposed approach on a multidimensional problem, consider the following model:
or, in vector notation,
Figure 2.
LMS, LS and LEL costs as function of the line slope. Refer to the text for details.
Figure 2.
LMS, LS and LEL costs as function of the line slope. Refer to the text for details.
where
and
are known, but
is not. Assume that a data set
is available and that
is a vector of zero mean, normally distributed noise (eventually with known covariance). The following numerical experiment (Case 1) is performed: the “real” value of the parameter vector
is randomly generated (each component is the rounded value of a uniformly distributed number in the range
) yielding
. The values of
and
are chosen to be
and
and the noise term
is normally distributed (i.i.d.) with zero mean and variance equal to 10. The independent variable
is generated as a uniform ramp of
values in the range
, whereas
is computed according to equation (
58). Given these numerical values, the LS estimate of
may be computed as
resulting in
. The corresponding LEL estimate (Case 1) is computed according to its definition (46). In particular the minimization of the
H function is performed 4 times starting from 4 different initialization values computed as in equations (50–51) with
. The minimization routine is the
FMINSEARCH multidimensional unconstrained nonlinear minimization (Nelder-Mead) of Matlab (Version 7.8.0.347 (R2009a)). The results of these minimizations are summarized in
Table 1: the first column refers to the values of
used to initialize the minimization routine. The second column refers to the local minimum that was found and the third column refers to the value of
H in such local minimum. Notice that the top element of the first column (case 1A) is
. Also notice that cases 1C and 1D lead to the same local minimum and that the least value of
H is obtained in case 1A. Nevertheless in all four cases the value of
H is relatively high (recall that
) and the differences among the four cases (in particular 1A, 1C and 1D) are extremely small, i.e., poorly significant. The plot of the
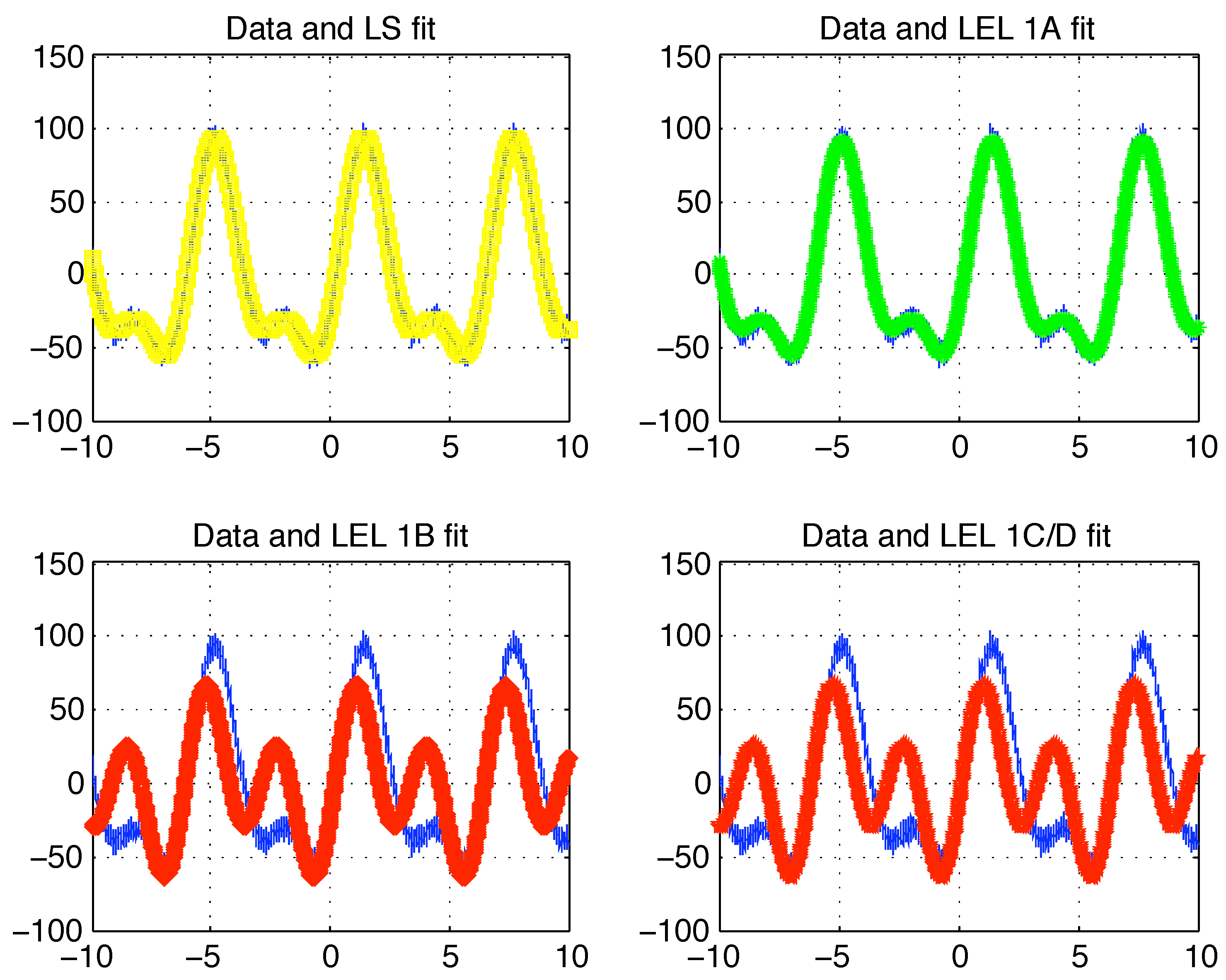
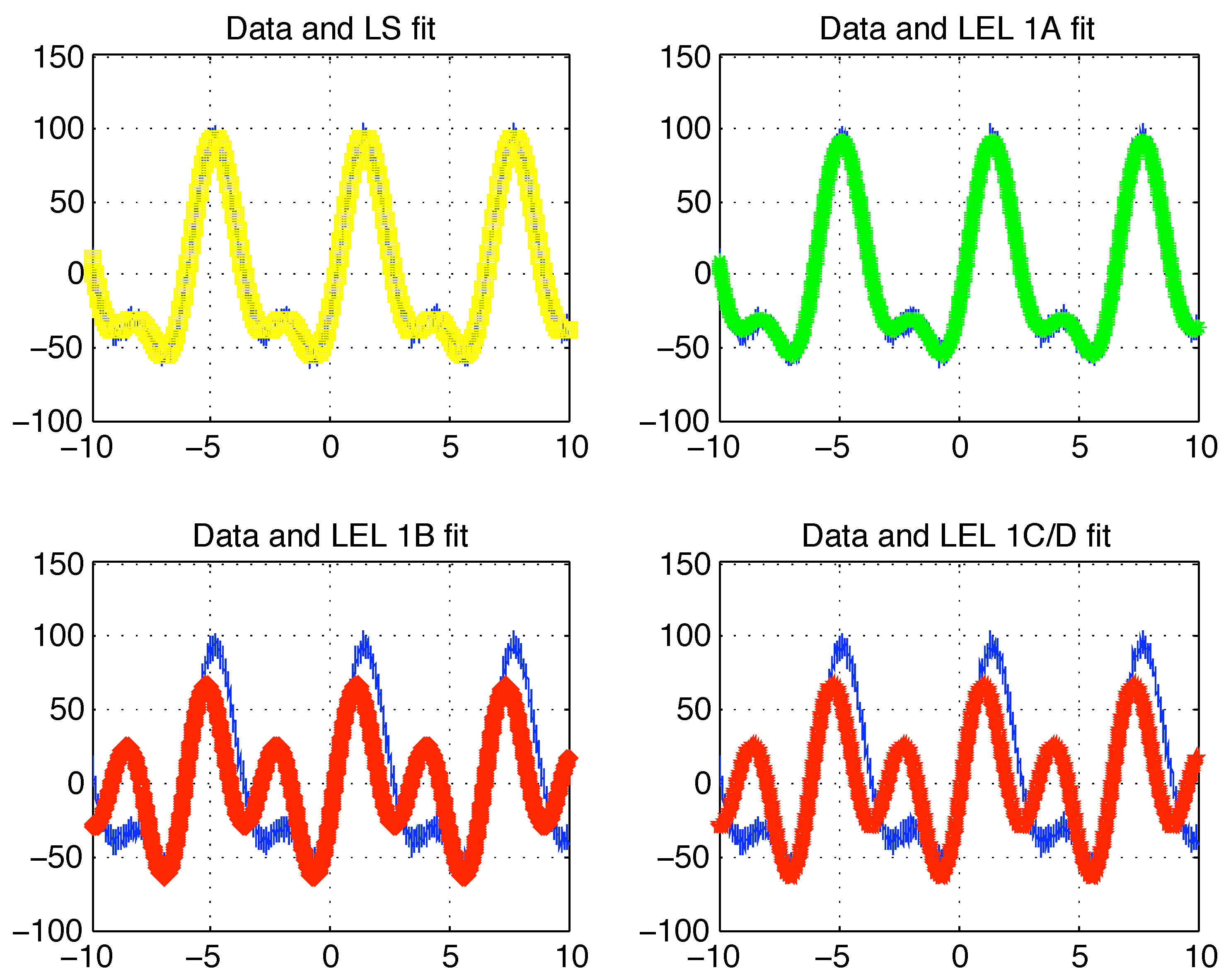
data together with the LS and LEL fits (1A, 1B, 1C/D) are reported in
Figure (3).
Table 1.
LEL estimates: Case 1 (refer to text for details).
Table 1.
LEL estimates: Case 1 (refer to text for details).
| initial θ | final θ | final H | Case |
| | 0.9199 | 1A |
| | 0.9287 | 1B |
| | 0.9219 | 1C |
| | 0.9219 | 1D |
Figure 3.
Case 1 data with LS and LEL fit. Refer to the text for details.
Figure 3.
Case 1 data with LS and LEL fit. Refer to the text for details.
The LEL-1A estimate is very close to the LS one (that is very close to the real parameter vector
) and in
Figure (3) the fitted data
and
appear to be almost perfectly overlapping with the original data
(first row in
Figure (3)). To the contrary, the fitting behavior of the other two LEL estimates is clearly less accurate. A quantitative criteria to determine unambiguously which of the four (LS, LEL-1A, LEL-1B, LEL-1C/D) estimates is the “best” can be the value of the median of the fitting errors. More precisely, the median of the absolute fitting errors or of the squared fitting errors. These values are reported in
Table 2.
Table 2.
Median of fitting errors: Case 1 (refer to text for details).
Table 2.
Median of fitting errors: Case 1 (refer to text for details).
| Estimate | | | Case |
| | | LS |
| | | 1A |
| | | 1B |
| | 3083 | 1C/D |
The results summarized in
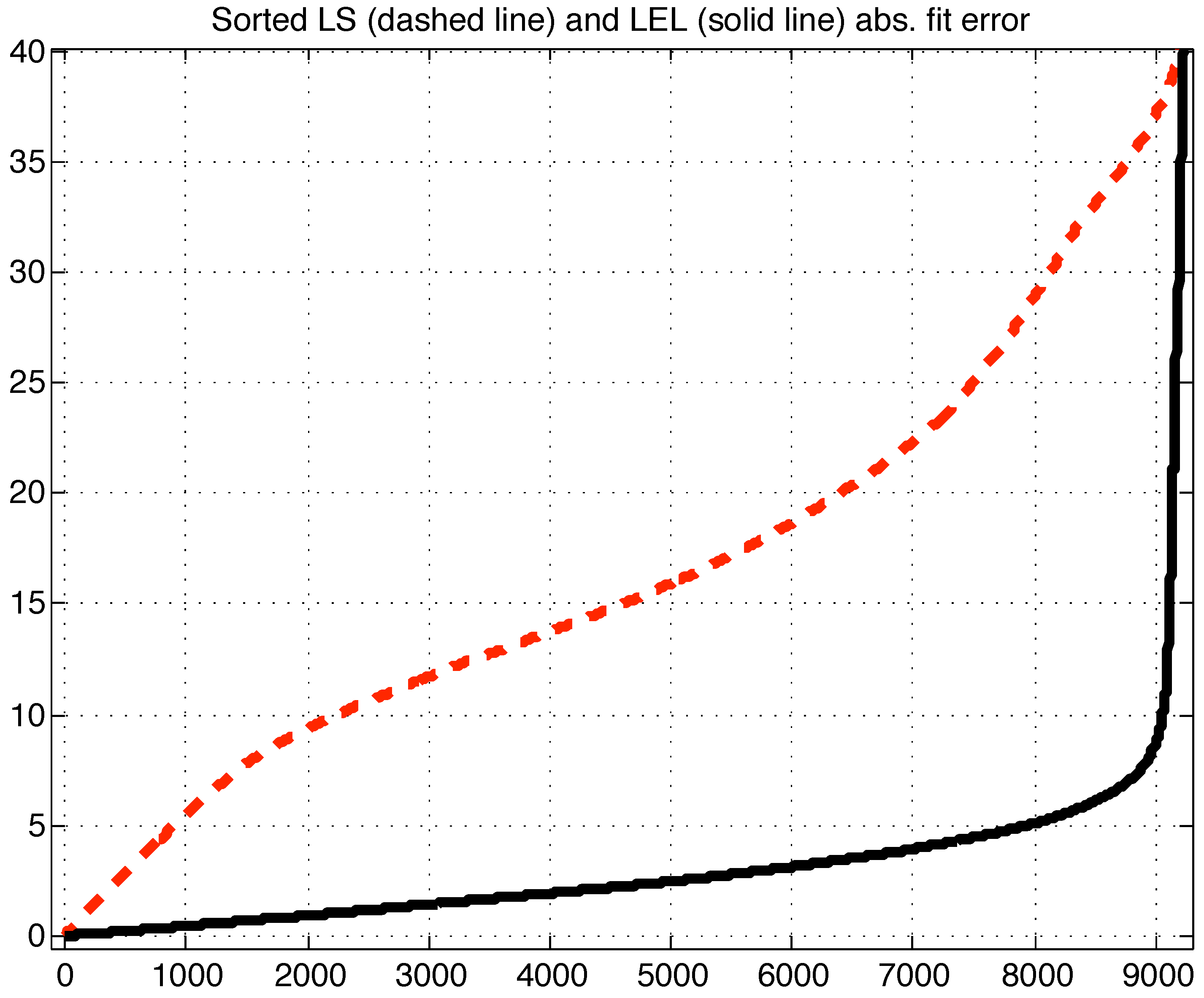
Table 2 suggest that the LS estimate, in this case, should be preferred to the LEL one. To cross check this result, it may be useful to graphically inspect the plot of the sorted absolute values of the fitting errors as depicted in
Figure (5).
These results should not be surprising as in the given setting (no outliers and additive zero mean normally distributed noise) the LS is guaranteed to be the optimal estimator. Yet things change considerably if the data set
is corrupted so that some of the data (a minority) will not satisfy the above hypothesis. Assume, for example, that a fraction of the available
values (say
) are multiplied by a random gain in the range
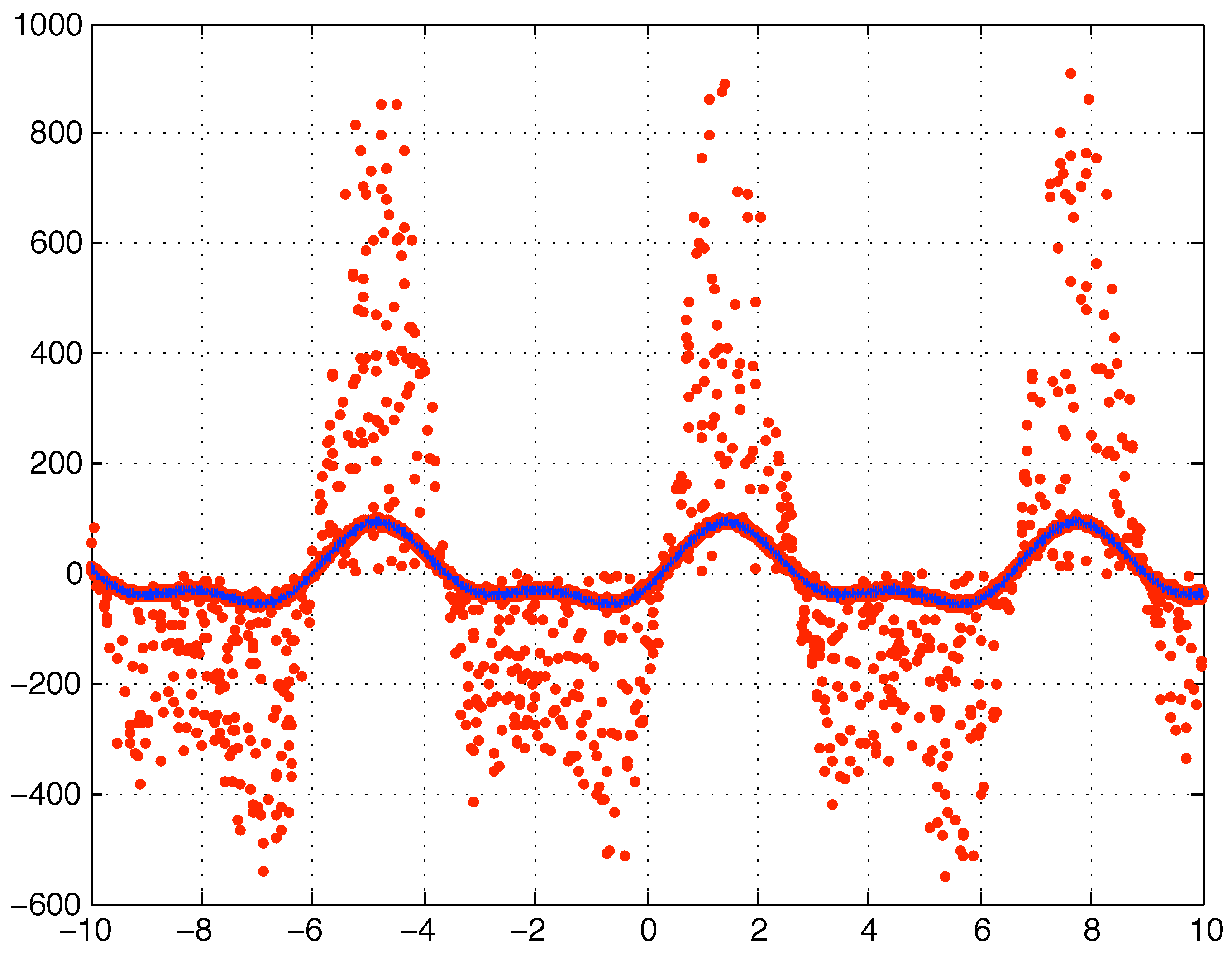
(due to some data recording or communication problem, it does not really matter here). In particular this kind of corruption (Case 2) is generated taking exactly the same
vector of Case 1 and multiplying
randomly selected components of
(i.e., 1000 randomly selected
y values) each by a different random number uniformly distributed in the range
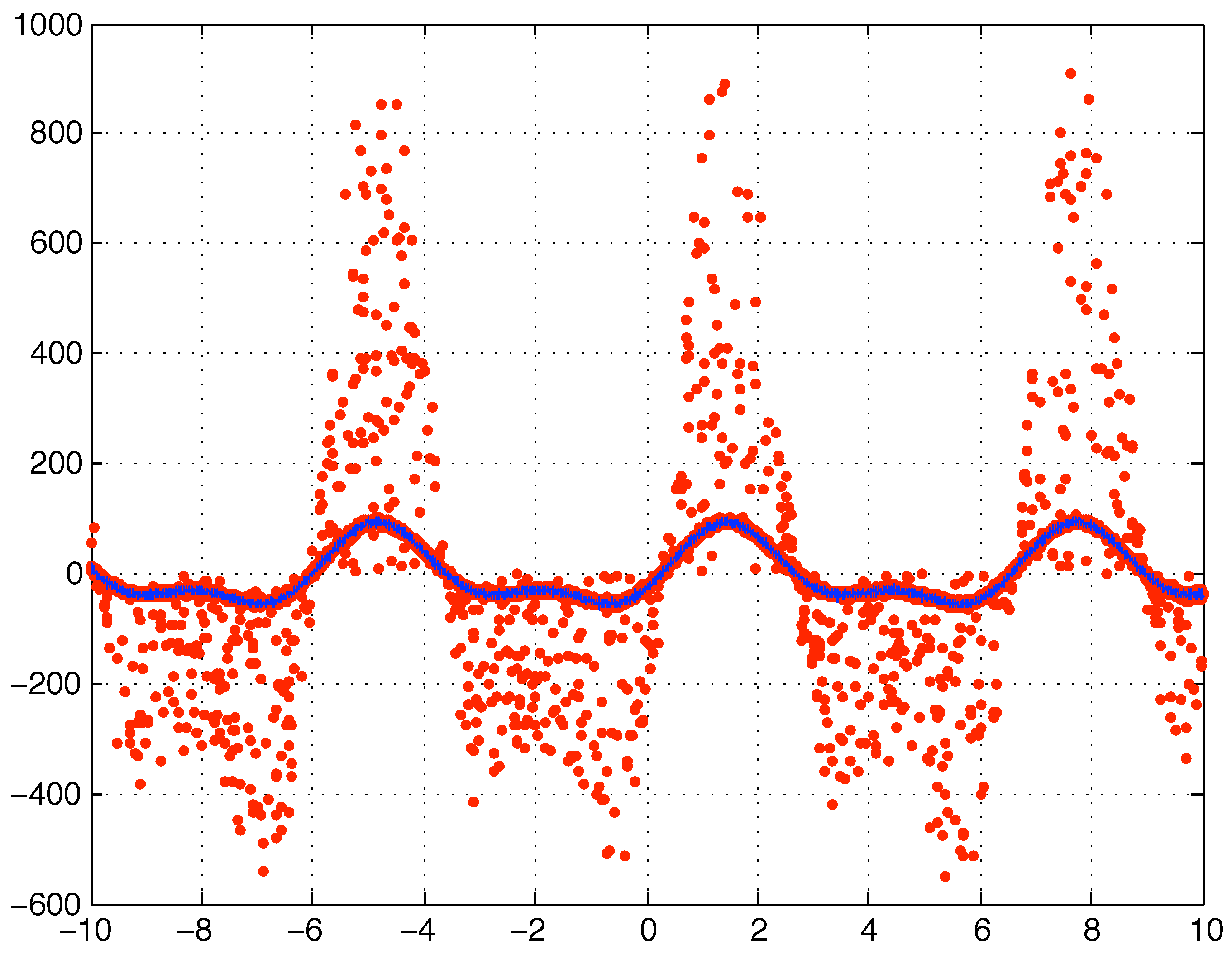
. The resulting data is plotted in
Figure (4).
The LS estimate of based on this corrupted data (Case 2) results in that appears to be significantly distant from the real value (and from the Case 1 LS estimate). The LEL estimate is computed exactly as described for Case 1, but using the new (Case 2) LS estimate as initialization value .
The results are summarized in
Table 3. Notice that the minimization routine always converges to the same value that appears to be very close to the real one. Moreover, the least value of
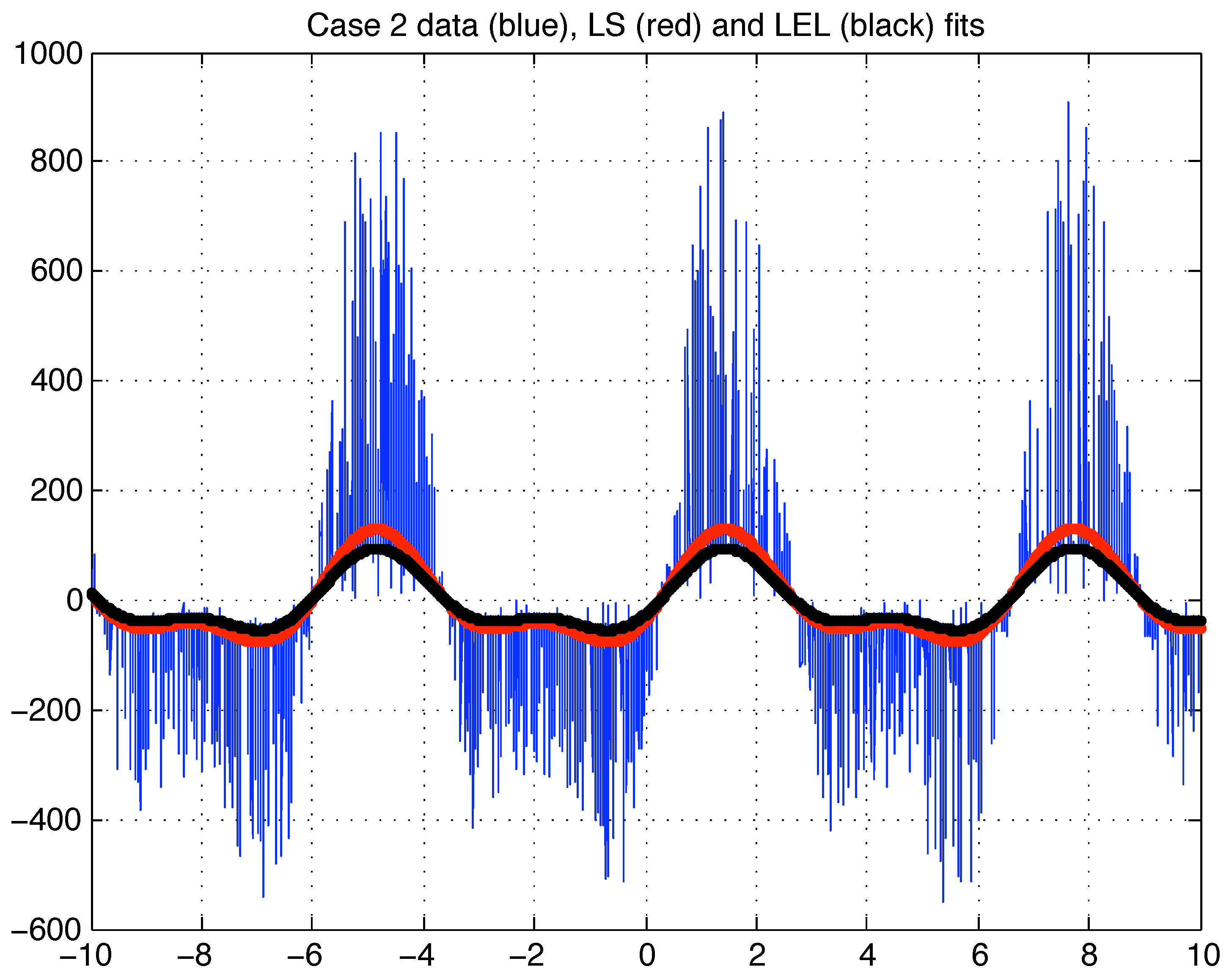
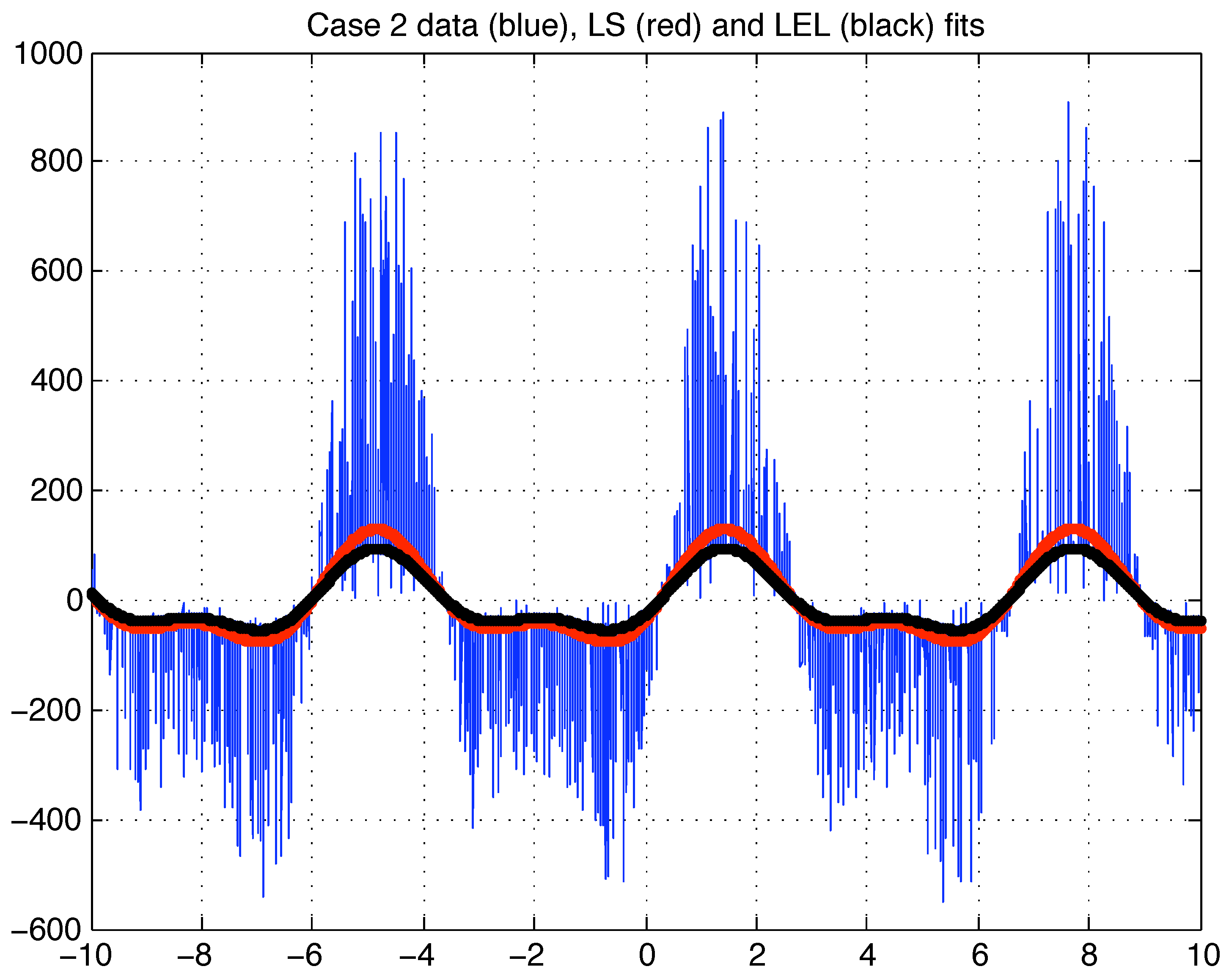
H is significantly smaller than in Case 1 suggesting that the distribution of the relative squared residuals has a smaller dispersion than in Case 1. The plots of the LS fit, the LEL fit and the case 2 data is depicted in
Figure (6).
Figure 4.
Case 2 corrupted data (red dots) and original data (solid blue line).
Figure 4.
Case 2 corrupted data (red dots) and original data (solid blue line).
Figure 5.
Case 1 sorted LS and LEL fitting errors in absolute value.
Figure 5.
Case 1 sorted LS and LEL fitting errors in absolute value.
Figure 6.
Case 2 data (blue), LS fit (red) and LEL fit (black).
Figure 6.
Case 2 data (blue), LS fit (red) and LEL fit (black).
Table 3.
LEL estimates: Case 2 (refer to text for details).
Table 3.
LEL estimates: Case 2 (refer to text for details).
| initial θ | final θ | final H | Case |
| | 0.6455 | 2A |
| | 0.6455 | 2B |
| | 0.6455 | 2C |
| | 0.6455 | 2D |
As for Case 1, based on the only plots of the fitted data, it is not obvious which model is performing better. Yet in terms of the median of the absolute values of the residuals (
Table 4), the LEL estimate is certainly to be preferred. Indeed the plot of the sorted absolute residuals in
Figure (7) and
Figure (8) reveals that the great majority (about
) of the data is significantly closer to the LEL fit rather than the LS fit.
The Case 2 experiment has been repeated 100 times with different values of , namely each time its components were rounded values of uniformly distributed numbers in the range . In each of the 100 iterations all the random variables used were different realizations. Each of the 100 iterations gave similar results to the ones described, i.e., a LEL estimate was computed that had lower median of absolute residuals with respect to the LS estimate and was closer to the real parameter vector. As for computational effort, the minimization of the H function was performed with the FMINSEARCH multidimensional unconstrained nonlinear minimization (Nelder-Mead) of Matlab (Version 7.8.0.347 (R2009a)). The Matlab code was not optimized. The computer platform was an Apple Laptop with a 2.16 GHz Intel Core 2 Duo processor, 2 GB RAM, running the MAC OS X Version 10.5.8 operating system. The CPU time required for minimizing the H function resulted to be on average [s] where the error was computed as the sample standard deviation of all the iterations. Recalling that the number of data points was always this result is rather interesting as it suggests that the proposed method can be eventually employed for on line applications, at least for models of comparable size.
Figure 7.
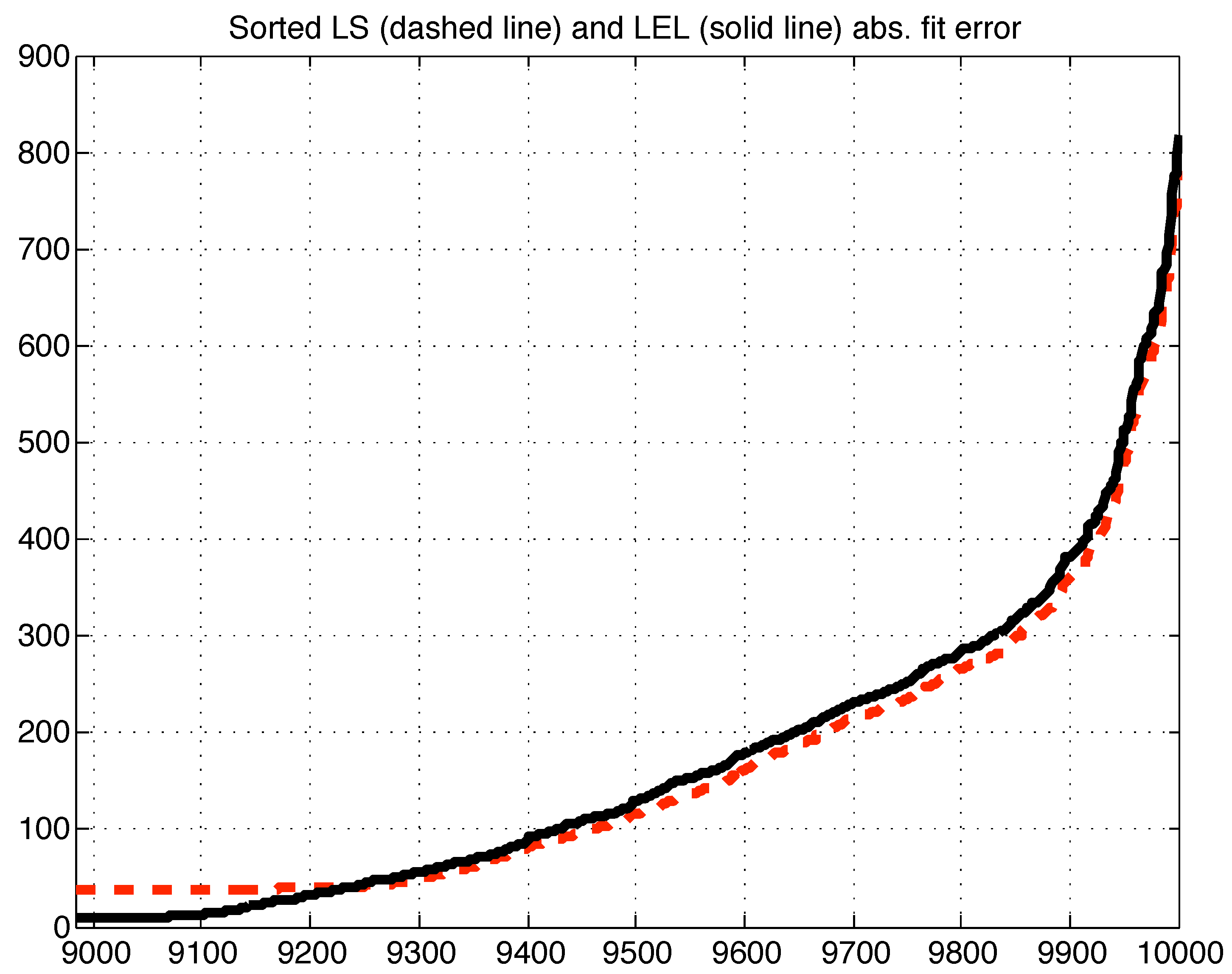
First 9000 sorted LS (dashed line) and LEL (solid line) absolute fitting errors (i.e., residuals).
Figure 7.
First 9000 sorted LS (dashed line) and LEL (solid line) absolute fitting errors (i.e., residuals).
Table 4.
Median of fitting errors: Case 2.
Table 4.
Median of fitting errors: Case 2.
| Estimate | | Case |
| | LS |
| | 2A/B/C/D |
As a final numerical experiment to evaluate the performance of the proposed method in comparison to the LMS technique, consider the following model:
being
,
and
. The
and
values are given by the Hawkins - Bradu - Kass data set [
1] (Chapter 3, section 3) available in electronic format (together with all the other data sets used in [
1]) from the University of Cologne Statistical Resources
http://www.uni-koeln.de/themen/statistik/index.e.html (follow the links DATA and then Cologne Data Sets). The first 10 values of this artificially generated data set correspond to bad leverage points, i.e. outliers that can significantly affect the LS estimate (refer to [
1] for more details). Points 11, 12, 13 and 14 are outliers in
, namely they lay far from the bulk of the rest of the data in
space, but their
y values agree with the model. A LEL estimate of
is computed by minimizing the corresponding
H function from three different initialization values computed as in equations (50–51) using the Least Squares estimate
as a
. The three so computed LEL estimates are labelled as A, B and C. Their values are listed in
Table 5.
Figure 8.
Last 1000 sorted LS (dashed line) and LEL (solid line) absolute fitting errors (i.e., residuals).
Figure 8.
Last 1000 sorted LS (dashed line) and LEL (solid line) absolute fitting errors (i.e., residuals).
Table 5.
Hawkins–Bradu–Kass data set analysis.
Table 5.
Hawkins–Bradu–Kass data set analysis.
| Estimate | | H value |
| | |
| | |
| | |
The A and B estimates coincide and correspond to the least value of
H among the three. Hence the best (local) LEL estimate of
is to be considered
. Nevertheless, interestingly this estimate
does not correspond to the least value of the median of squares cost. The
estimate performs better in terms of the median of squares cost criteria. For a graphical interpretation of these results, refer to
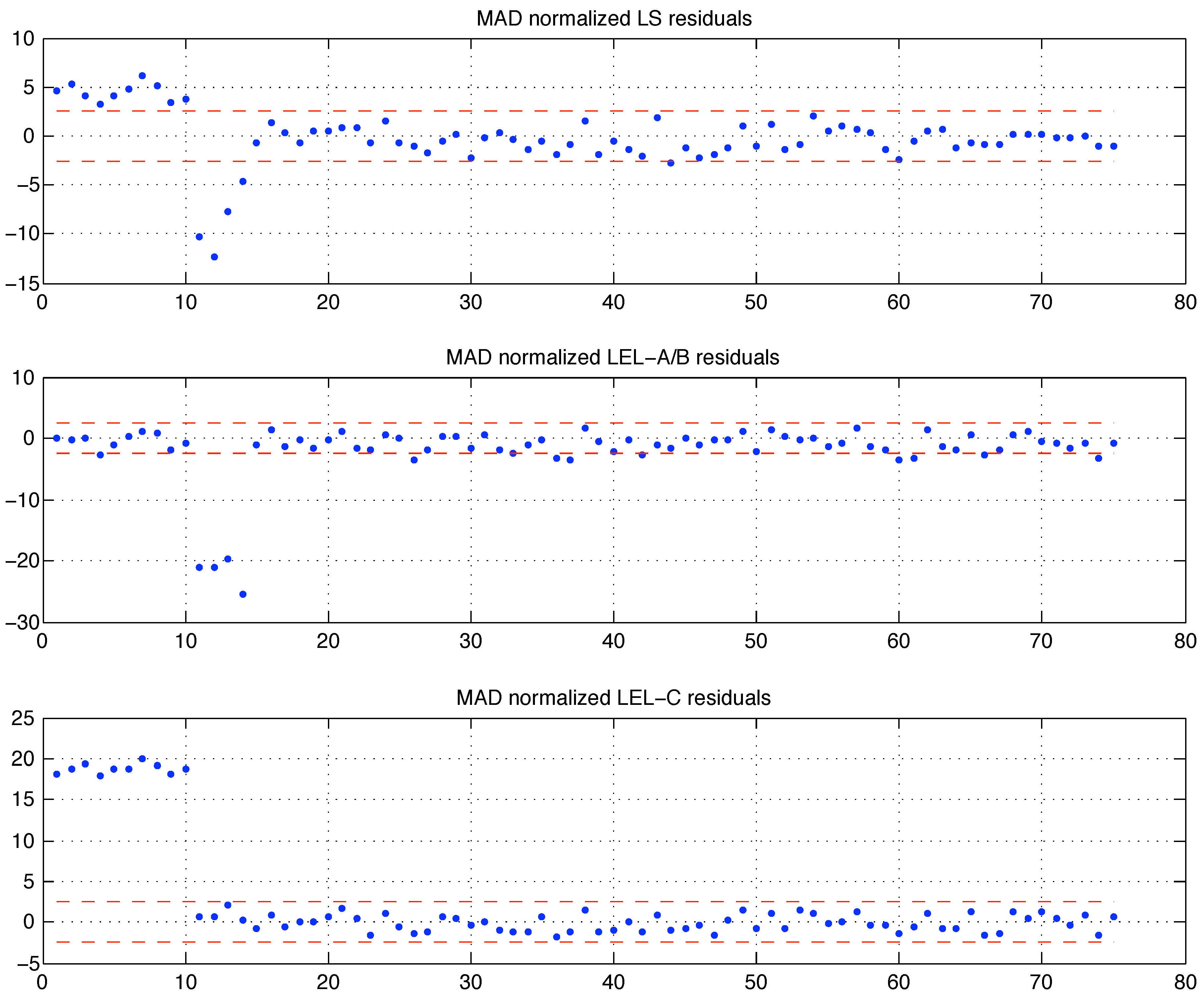
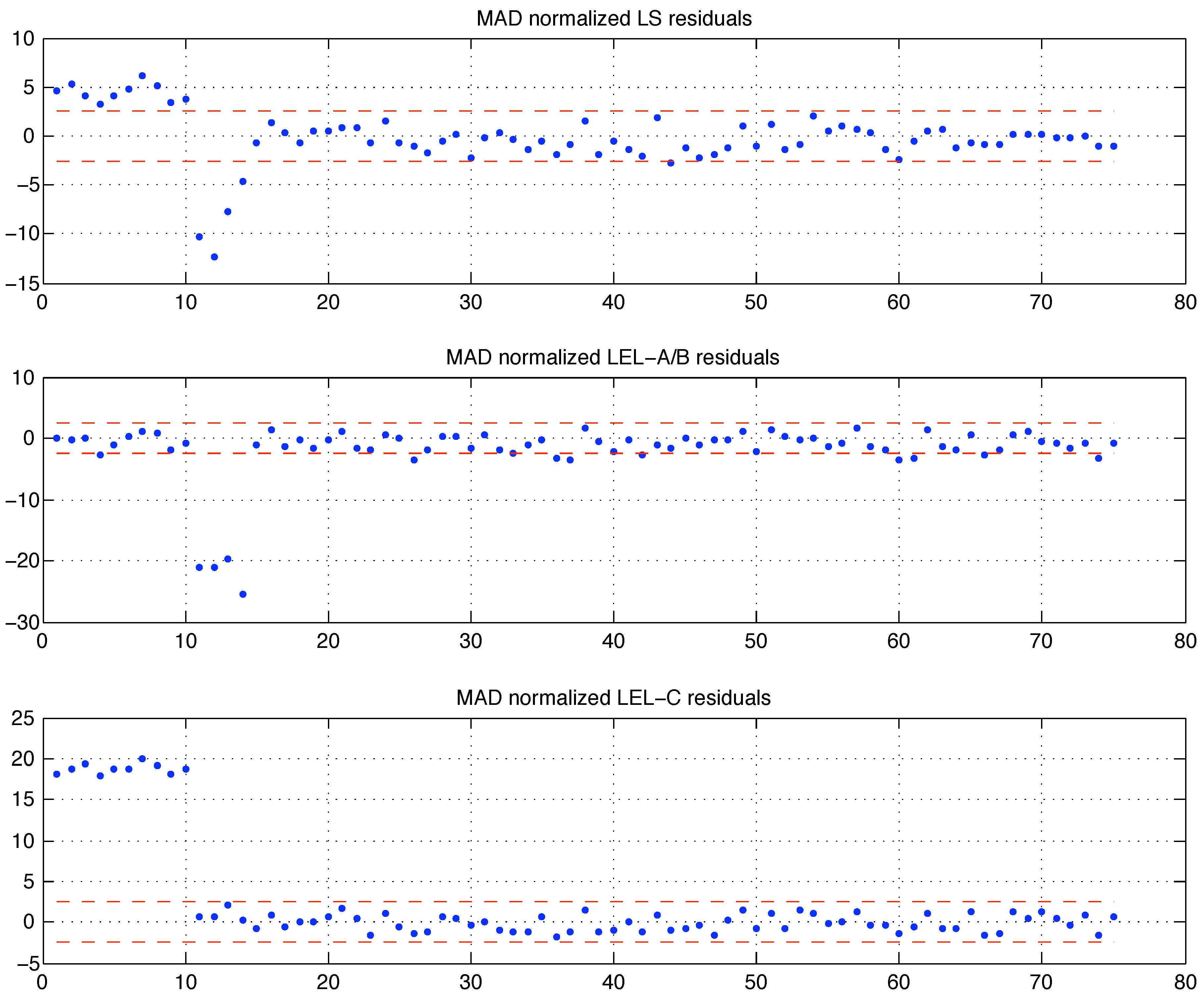
Figure (9) where the residuals, scaled by their median absolute deviation MAD (21) scale estimate, are depicted. Comparing the bottom plot in
Figure (9) with the equivalent plot for the LMS estimate in [
1] (p. 95), one can arguably conclude that the
estimate is (very) close to the LMS one. This shows that the LEL and LMS criteria differ and should not be considered equivalent, although in spirit both are defined so that the residual scatter is somehow minimized. The Hawkins–Bradu–Kass example also shows that the LEL estimate can be affected by the presence of bad leverage points (outliers): notice that the central plot in
Figure (9) reveals how the (best) LEL estimate (A/B) accommodates the 10 bad leverage points within the fit and excludes the four
-space outliers 11, 12, 13 and 14. Although from the LEL criteria perspective one could also argue that the first 10 points are not outliers (or bad leverage points), whereas the following 4 are. Indeed the very definition of outlying data should be given according to a fitting criteria. The interpretation of similar results without an a priori agreement on the definition of outlier will always be debatable.
Figure 9.
LS and LEL residuals of the Hawkins - Bradu - Kass data set fitting. The dashed lines indicate the values.
Figure 9.
LS and LEL residuals of the Hawkins - Bradu - Kass data set fitting. The dashed lines indicate the values.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}