Statistical Information and Uncertainty: A Critique of Applications in Experimental Psychology

Abstract
:1. Introduction
- In each psychological application a function of probability is sought that will be additive over independent events. Since independent probabilities multiply, that function has to be logarithmic.
- The transmission of information effects a decrease in a potential (in the physical scientist’s sense of that term). Uncertainty and entropy are potential functions from which information is derivative.
- There are a number of different information functions involved both in the testing of statistical hypotheses and in the various applications of information theory in psychology. The choice between them depends on the question of interest. Uncertainty and entropy are potential functions for one particular information function, specifically the function that measures ‘amount of message’ in a communication channel or work done on a closed physical system, though this same function appears in other contexts as well.
2. Information and Uncertainty

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stimuli (dB) | Responses (dB) | |||||||||
| 68 | 70 | 72 | 74 | 76 | 78 | 80 | 82 | 84 | 86 | |
| 68 | 120 | 37 | 8 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 70 | 33 | 74 | 42 | 15 | 0 | 0 | 0 | 0 | 0 | 0 |
| 72 | 8 | 47 | 76 | 33 | 10 | 2 | 0 | 0 | 0 | 0 |
| 74 | 0 | 8 | 38 | 73 | 48 | 10 | 1 | 0 | 0 | 0 |
| 76 | 0 | 1 | 9 | 43 | 108 | 45 | 9 | 0 | 0 | 0 |
| 78 | 0 | 0 | 1 | 9 | 61 | 77 | 36 | 3 | 1 | 0 |
| 80 | 0 | 0 | 0 | 0 | 7 | 48 | 58 | 29 | 1 | 0 |
| 82 | 0 | 0 | 0 | 0 | 0 | 5 | 38 | 74 | 38 | 1 |
| 84 | 0 | 0 | 0 | 0 | 0 | 1 | 6 | 25 | 115 | 29 |
| 86 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 32 | 123 |
- (i)
- The information defined in Equation 4 is a property of the data matrix X. Since likelihood ratio is the most efficient use of the data possible, there is no possibility of improving on the discrimination afforded by λ as test statistic. Kullback (see p. 22 [23]) expresses this in a fundamental theorem, “There can be no gain of information by statistical processing of data.”
- (ii)
- Information (Equation 4) is defined relative to two hypotheses, H0 and H1. Change those hypotheses, that is, change the question of interest, and the value of the test statistic changes as well. Information is information about something. Data is absolute, but information is relative to the two hypotheses to be distinguished.
2.1. Testing Statistical Hypotheses
2.2. Inverting the Test Procedure
2.3. Channel Capacity in A Communication System
2.4. Uncertainty [29]
2.5. Entropy
2.6. Bayes’ Theorem
- (i)
- One cannot invoke prior probabilities in psychological theory in the same way as information.
- (ii)
- Although the format of significance testing appears to assign an absolute probability to H0, this is illusory. A significance test calculates the probability of the observed data if H0 were true; that probability cannot be transposed into an absolute probability of H0 without reference to an absolute prior. All that a significance test can do is assess the concordance between observation and theory.
- (iii)
- Since ‘probable’ is used in everyday parlance, it is natural to attempt to extrapolate the calculus of probability theory to ‘subjective probabilities’. But these are no different from beliefs of various strengths cf. [35] and beliefs have their own psychology [36, Ch. IX; 37]. There is no a priori reason why beliefs should satisfy any particular calculus.
- (iv)
- The use of ‘information’ in this article is specific to information derived from the analysis of empirical data. ‘Information’, of course, has many other meanings in everyday discourse and those other meanings are excluded from consideration here. Likewise the scope of ‘uncertainty’ is restricted to those potentials with respect to which information can be calculated. Other uses of ‘uncertainty’ in everyday parlance are likewise excluded.
2.7. Interim Summary
- (i)
- applications in which the mathematical assumptions fail to match the details of the experiment;
- (ii)
- applications in which the experiment and the human observer taken together is treated as a purely physical system; and
- (iii)
- applications which use Bayes’ theorem to relate experimental performance to prior stimulus probabilities.
| Information theory | Communication theory | Thermodynamics | Experimental application |
|---|---|---|---|
| Message sent | Stimulus | ||
| Message received | Response | ||
| Data | Transmission frequencies | Performance data | |
| Null hypothesis | Channel open-circuit | Independence | |
| Alternative hypothesis | Channel functioning, but subject to error | Task completed, but with errors | |
| Information statistic | Information transmitted | Work done | Measure of task performance |
| Uncertainty | Entropy | Maximum yield of information |
3. Mathematical Theory not Matched to the Psychological Task
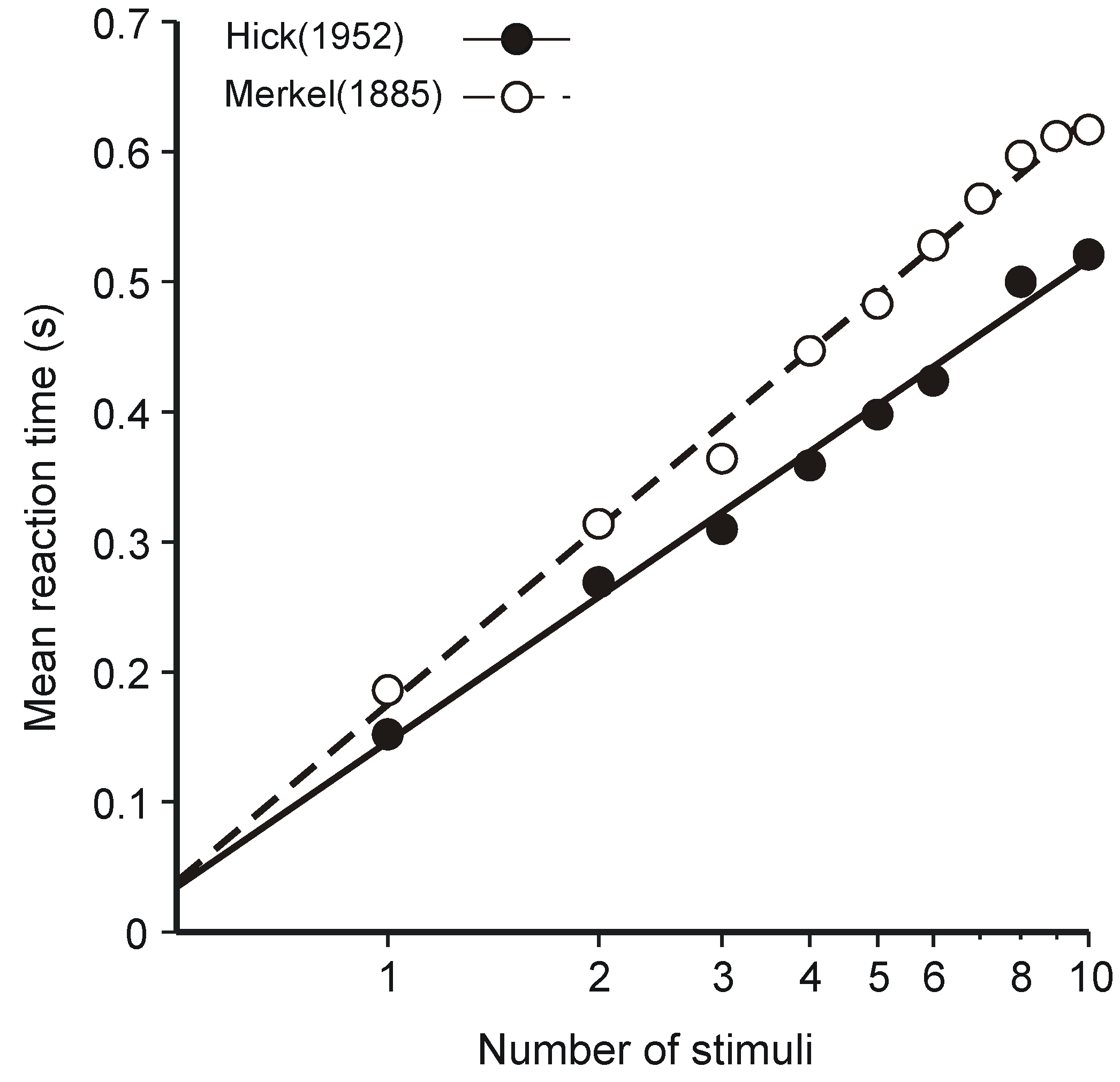
3.1. Hick’s Law
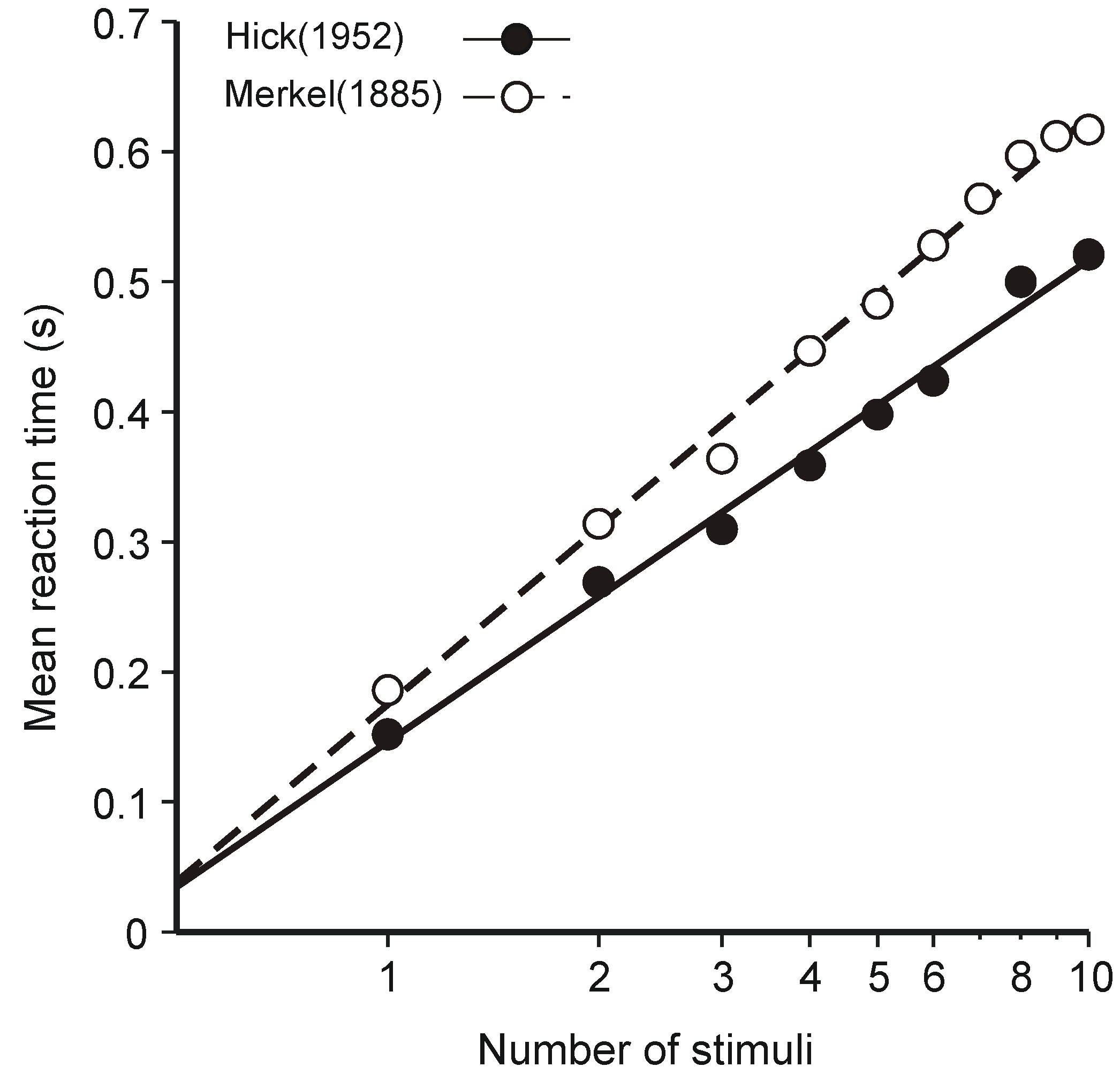
- (i)
- The human operator is functionally a communication system—that assumption is patently true and goes without saying—and
- (ii)
- The (human) communication system is operating at (or near) maximum capacity.
| Subjects | Experimental condition | |||
|---|---|---|---|---|
| No-back | One-back | Two-back | Three-back | |
| Sailors | 100.0 | 99.4 | 86.0 | 55.0 |
| Students | 100.0 | 98.8 | 92.9 | 69.8 |
| Old people | 99.1 | 87.3 | 51.9 | |
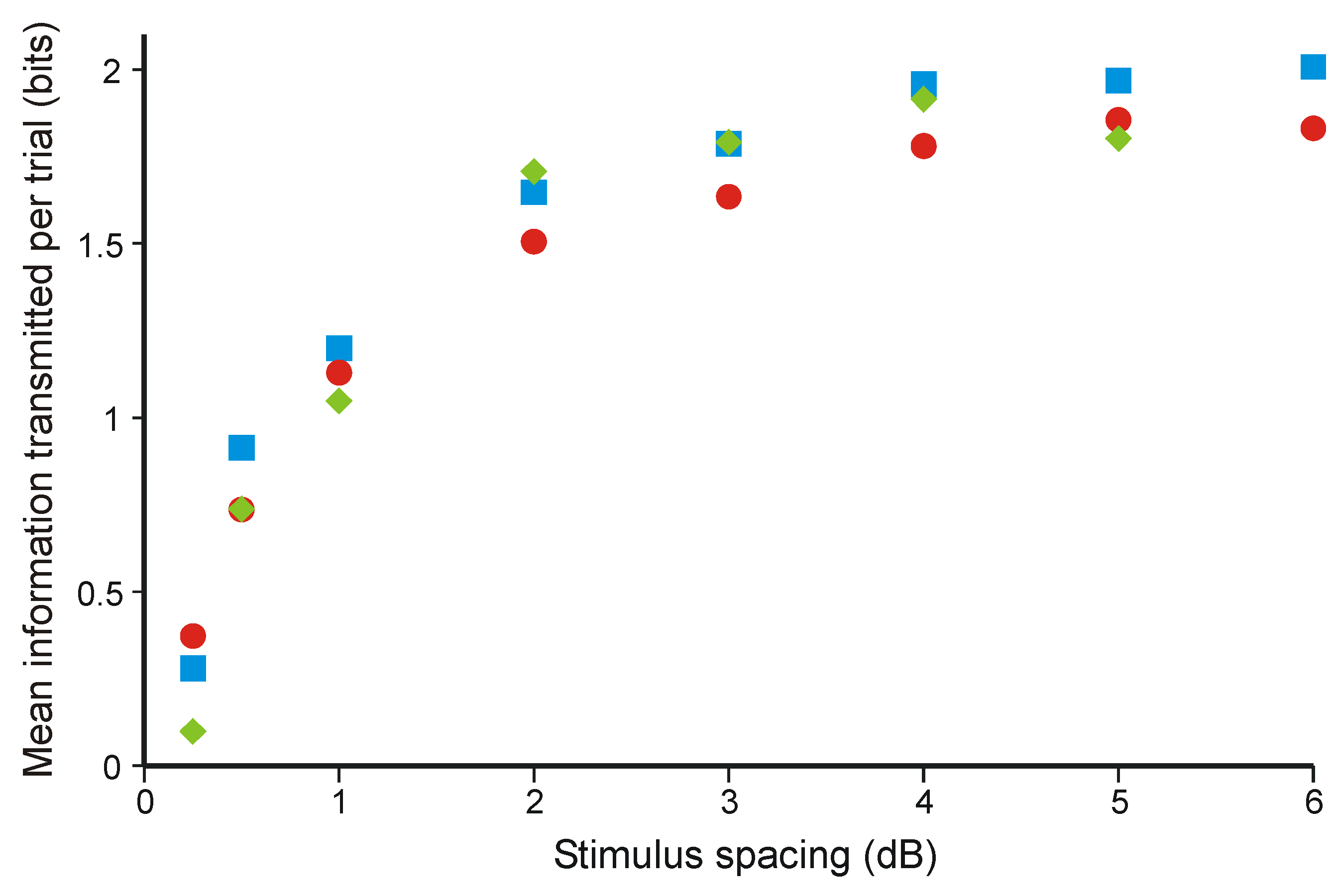
3.2. Information Transmission in Category Judgments
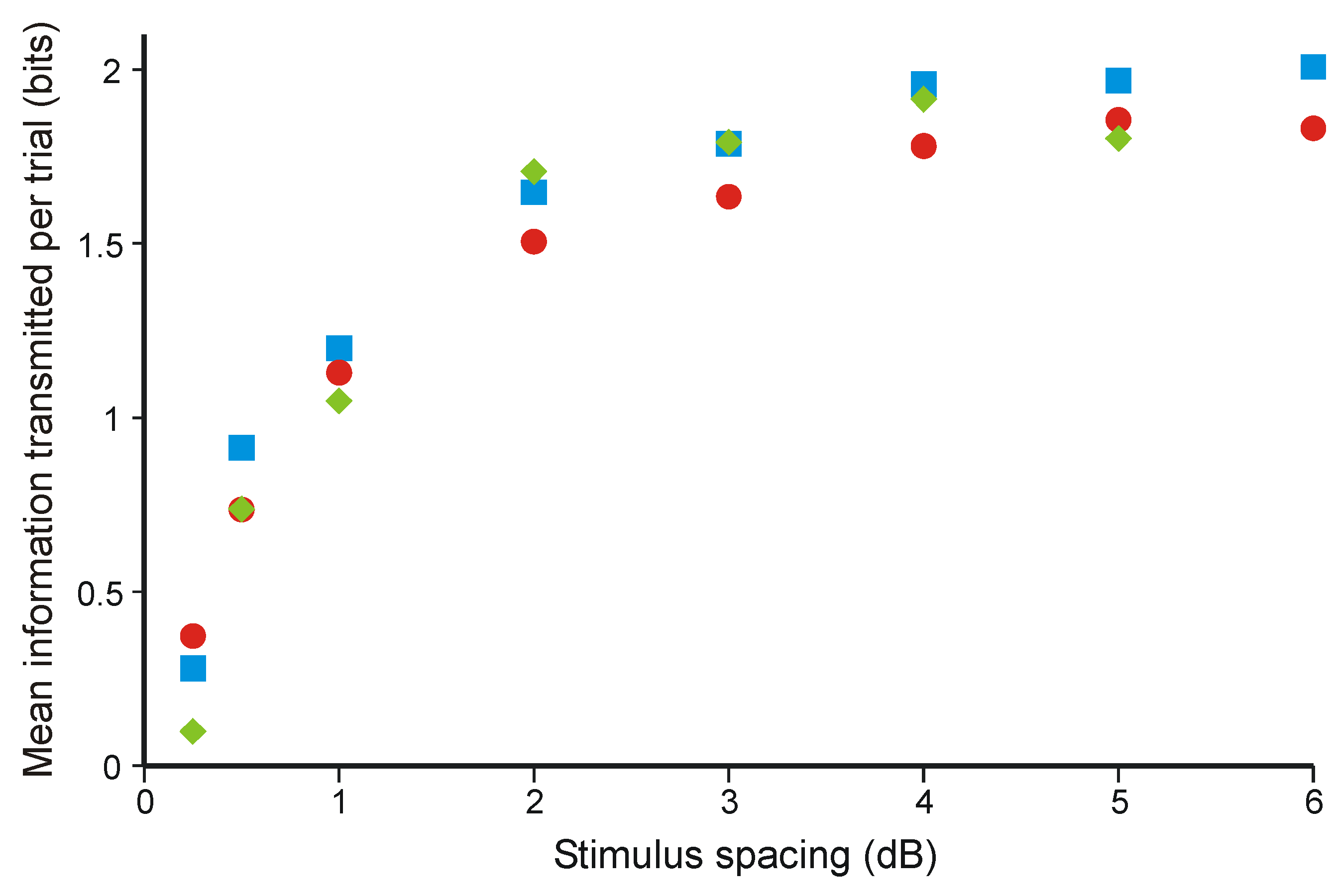
3.3. Optimal Data Selection in Wason’s Selection Task
- H0: P(vowel & odd number) = 0.
- H1: Number (even or odd) independent of letter (vowel or consonant).
- H2: P(vowel & odd number) ≠ 0,
3.4. Gambling
| Gambles | A | B |
|---|---|---|
| $2,500 with p. 0.33 | ||
| Choose between | $2,400 with p. 0.66 | $2,400 with certainty |
| Nothing with p. 0.01 | ||
| No. choices (out of 72) | 13 | 59 |
| Gambles | C | D |
| Choose between | $2,500 with p. 0.33 Nothing with p. 0.67 | $2,400 with p. 0.34 Nothing with p. 0.66 |
| No. choices (out of 72) | 60 | 12 |
| Gambles | E | F |
|---|---|---|
| Choose between | £2,500 with p. 0.33 Nothing with p. 0.01 | £2,400 with p. 0.34 |
3.5. Interim Conclusions
- (1)
- We are concerned with message space rather than with certainty.
- (2)
- The receiver knows the probabilities and joint probabilities of the source.
- (3)
- We deal with infinitely long messages. Somewhere prior to the ultimate receiver or decision maker, a storage permitting infinite delay is allowed.
- (4)
- All categories and all errors are equally important. Numerical data are to be treated as a nominal scale.
4. The Human Observer as a Physical System
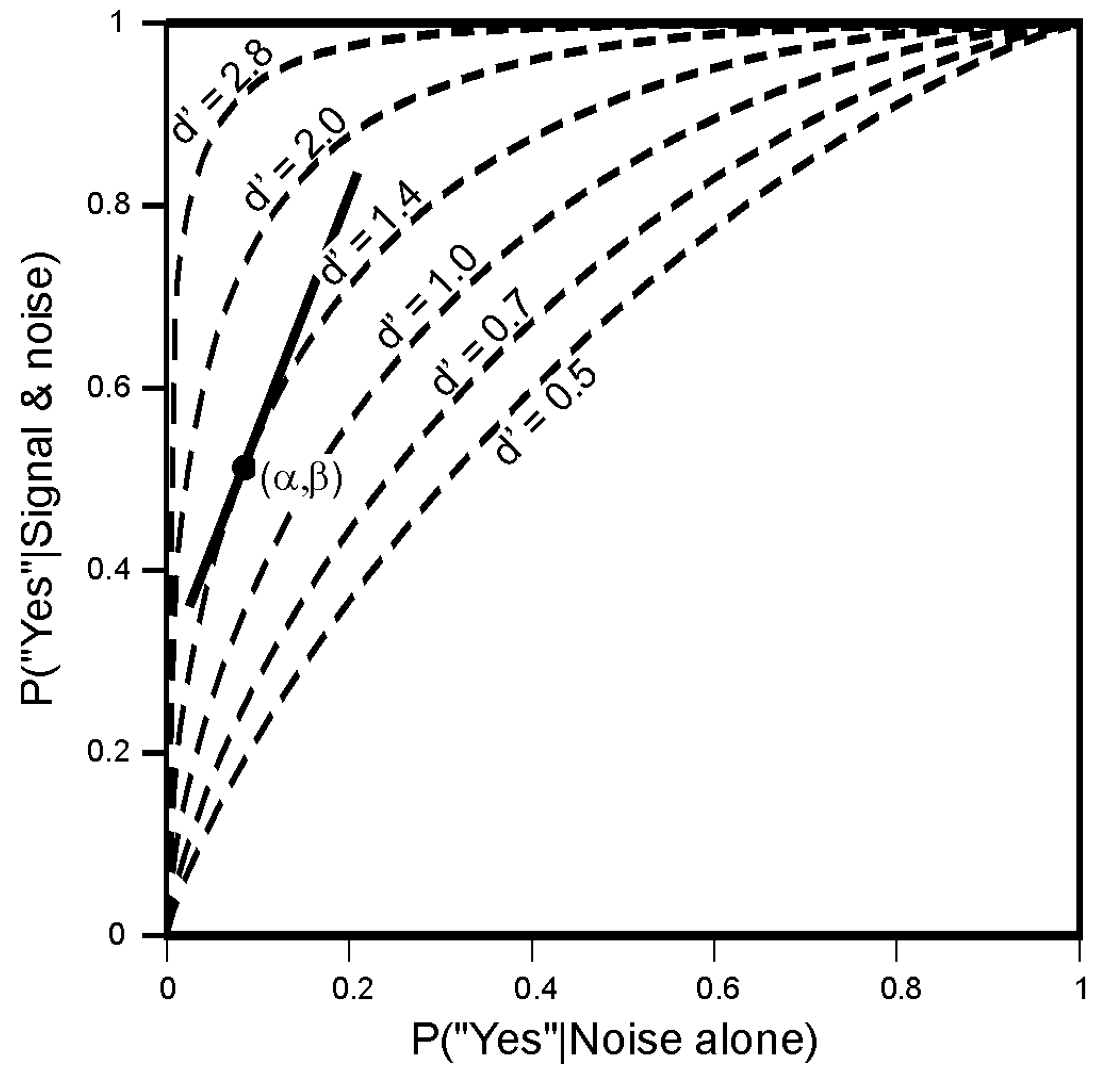
4.1. Signal Detection
4.2. Combining Information from Different Sensory Modalities
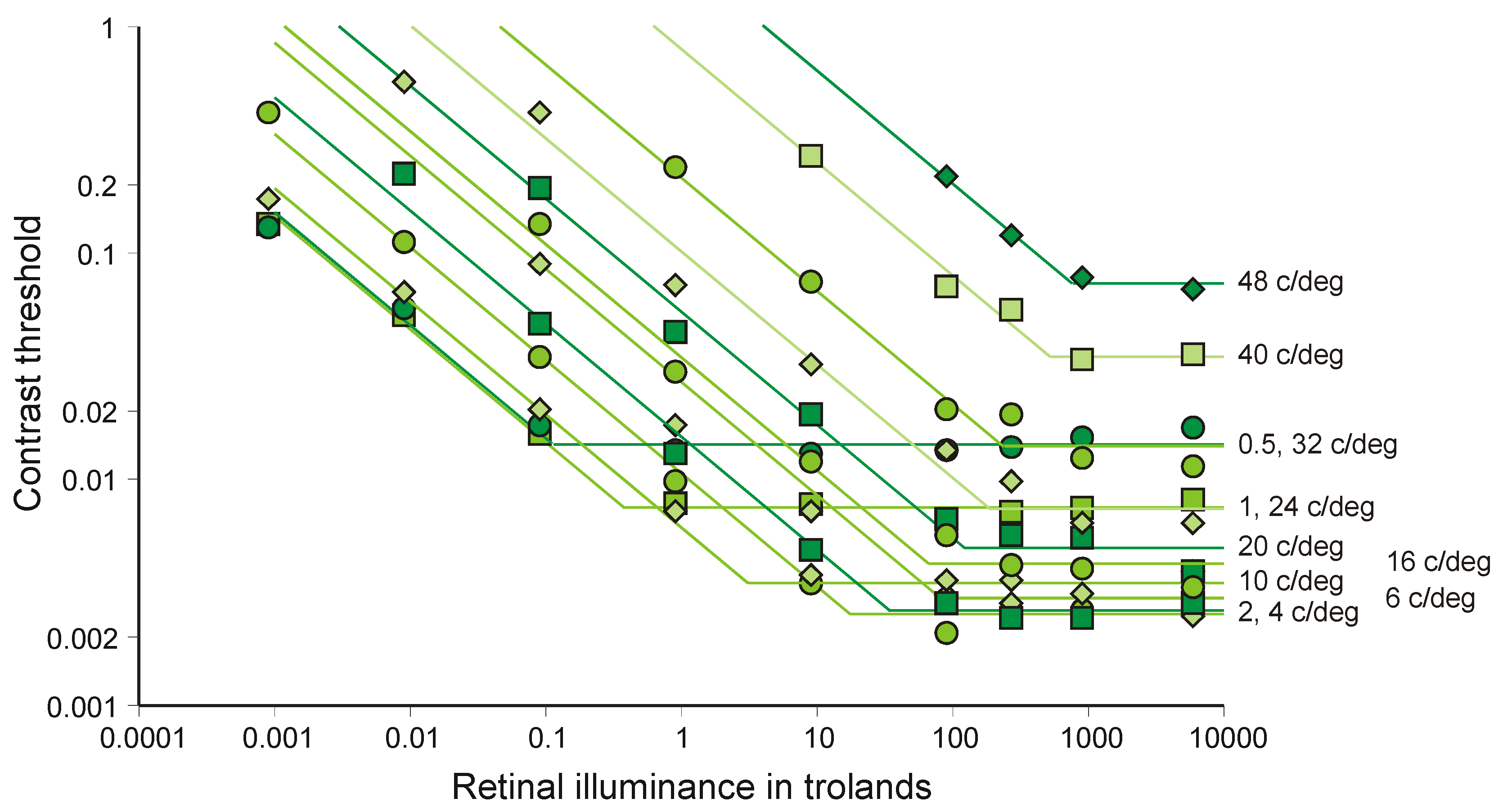
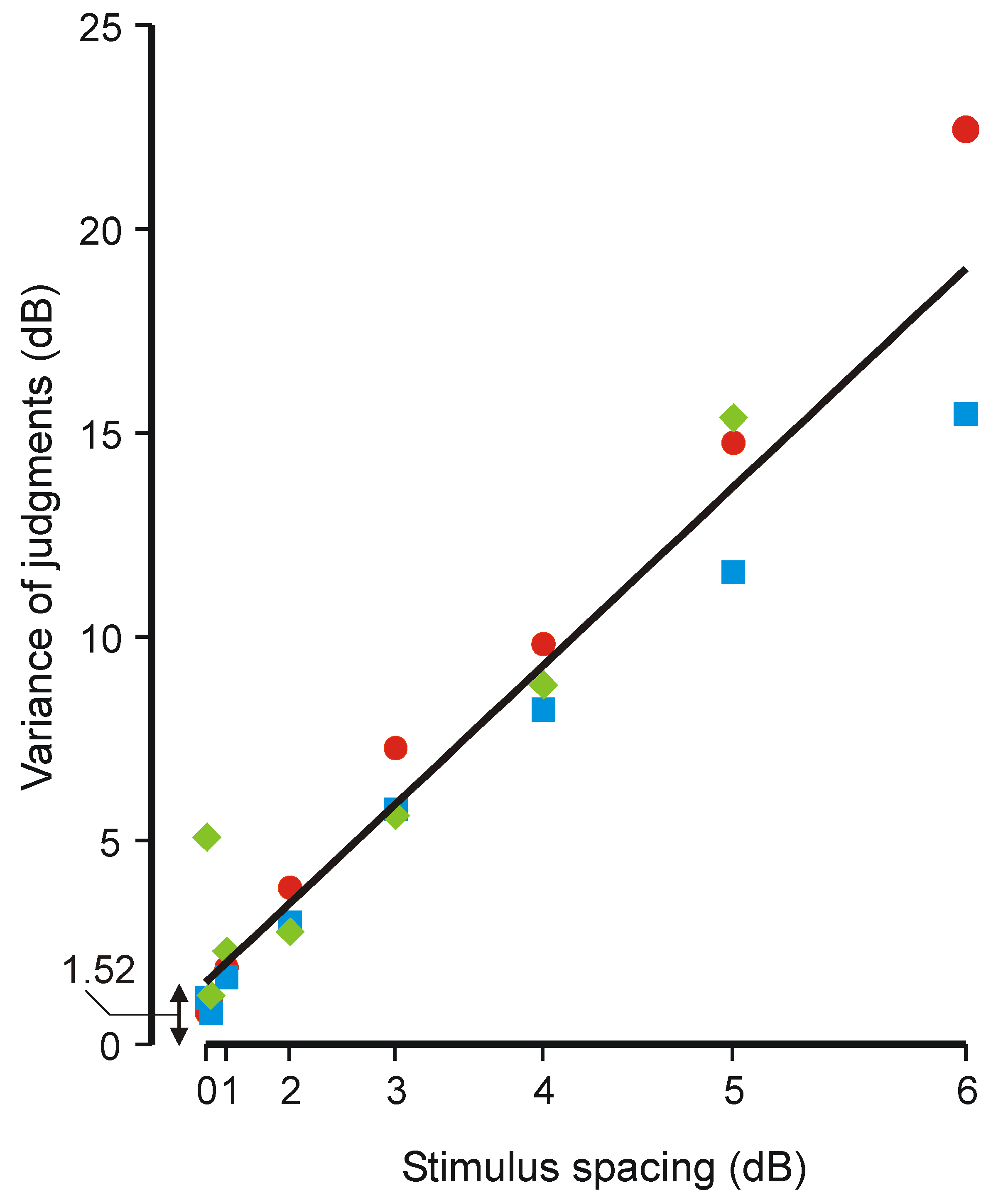
4.3. Weber’s Law
4.4. Parallel Channels in Vision
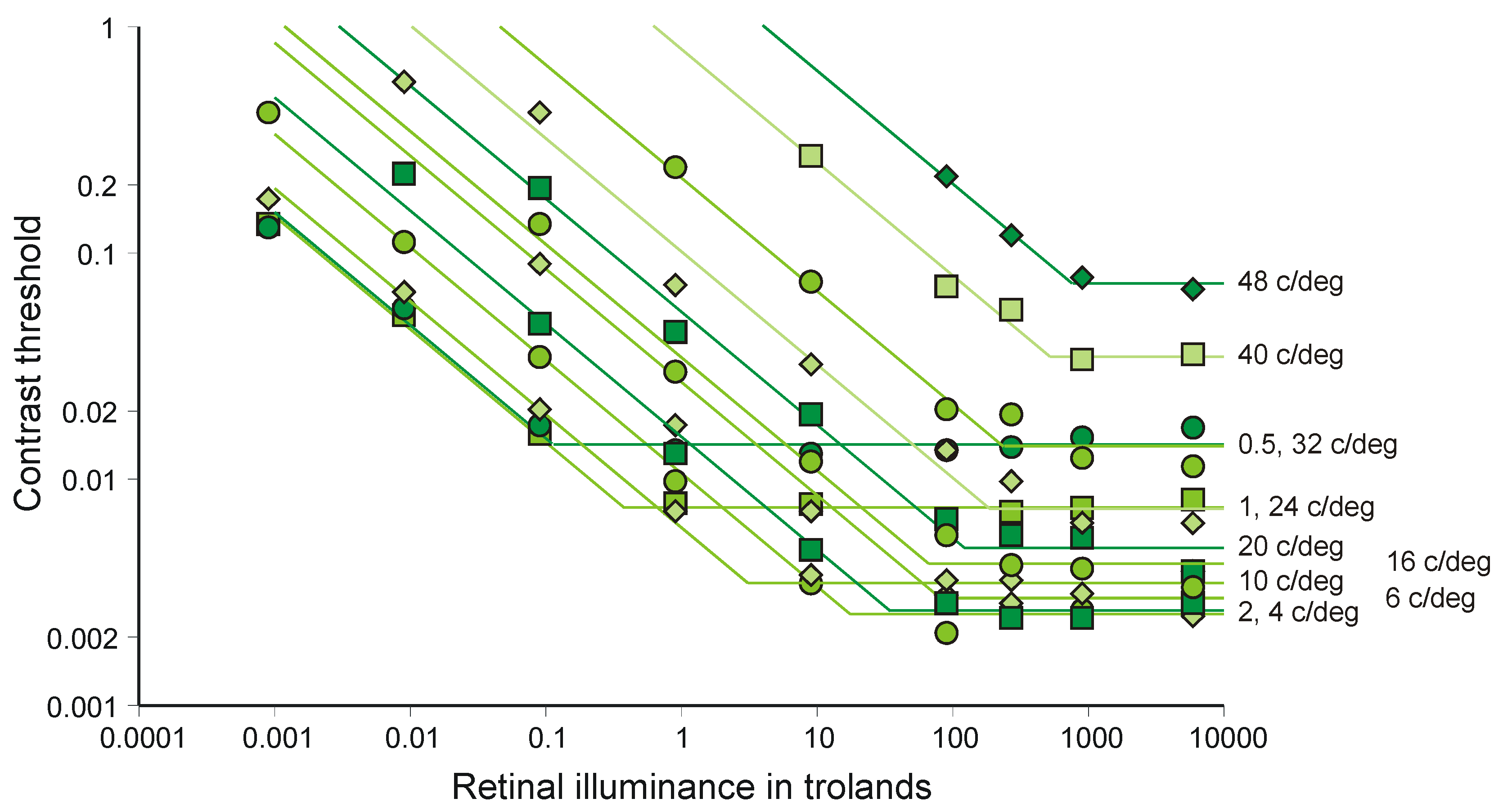
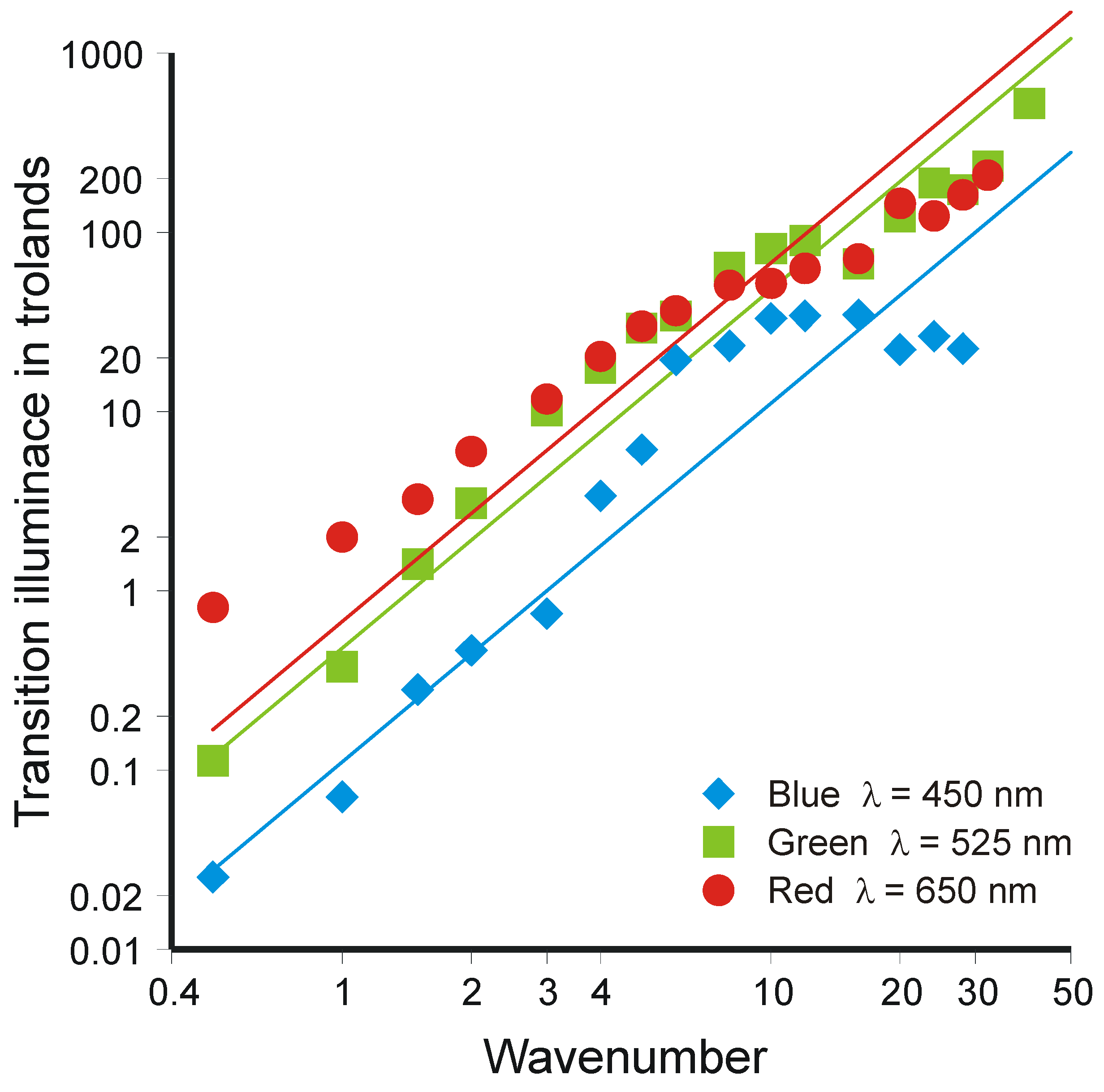
4.5. Accumulation of Information in the Brain
4.6. Interim Conclusions
5. Bayes’ Theorem
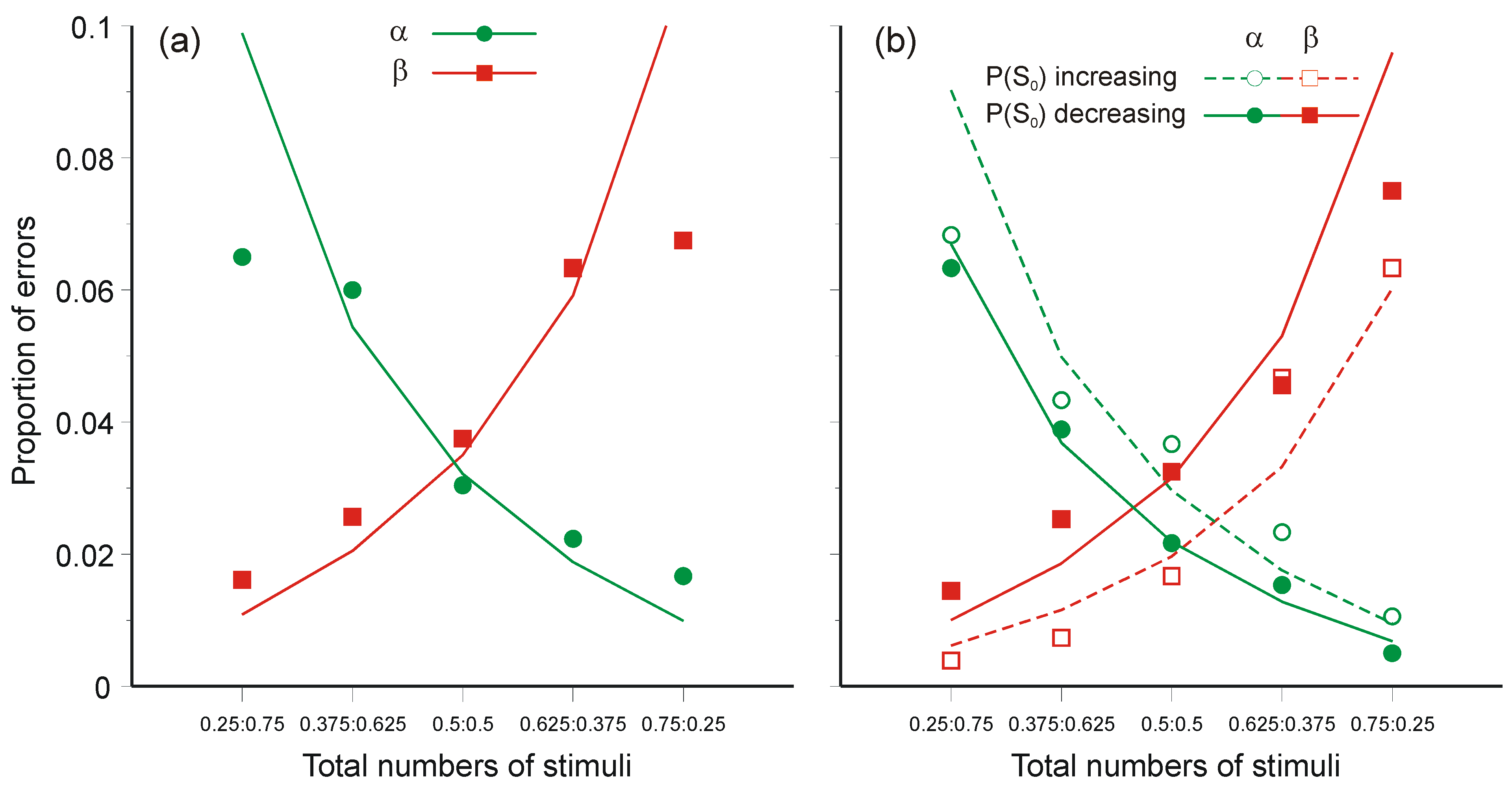
5.1. Two-Choice Reaction Experiments
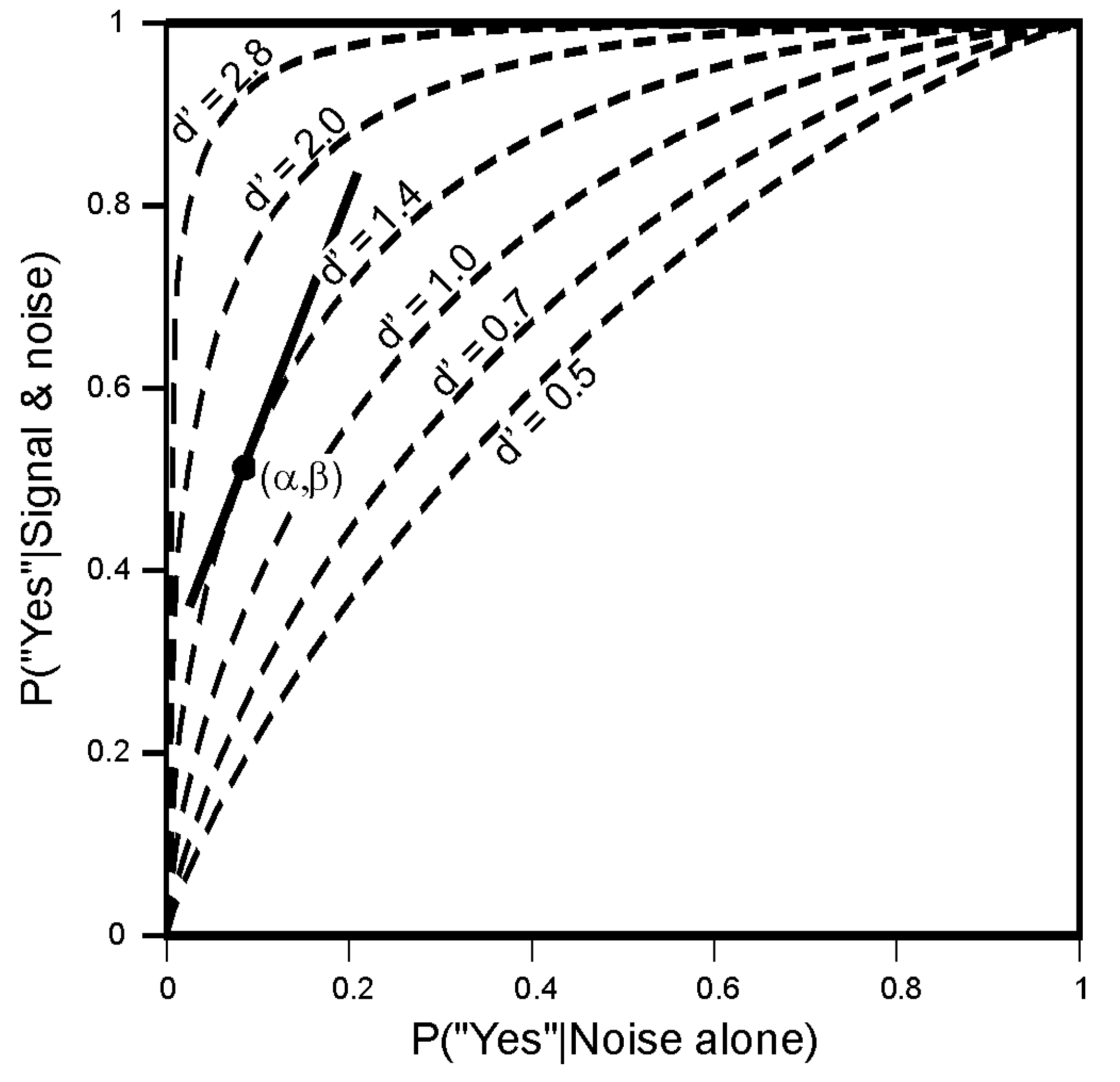
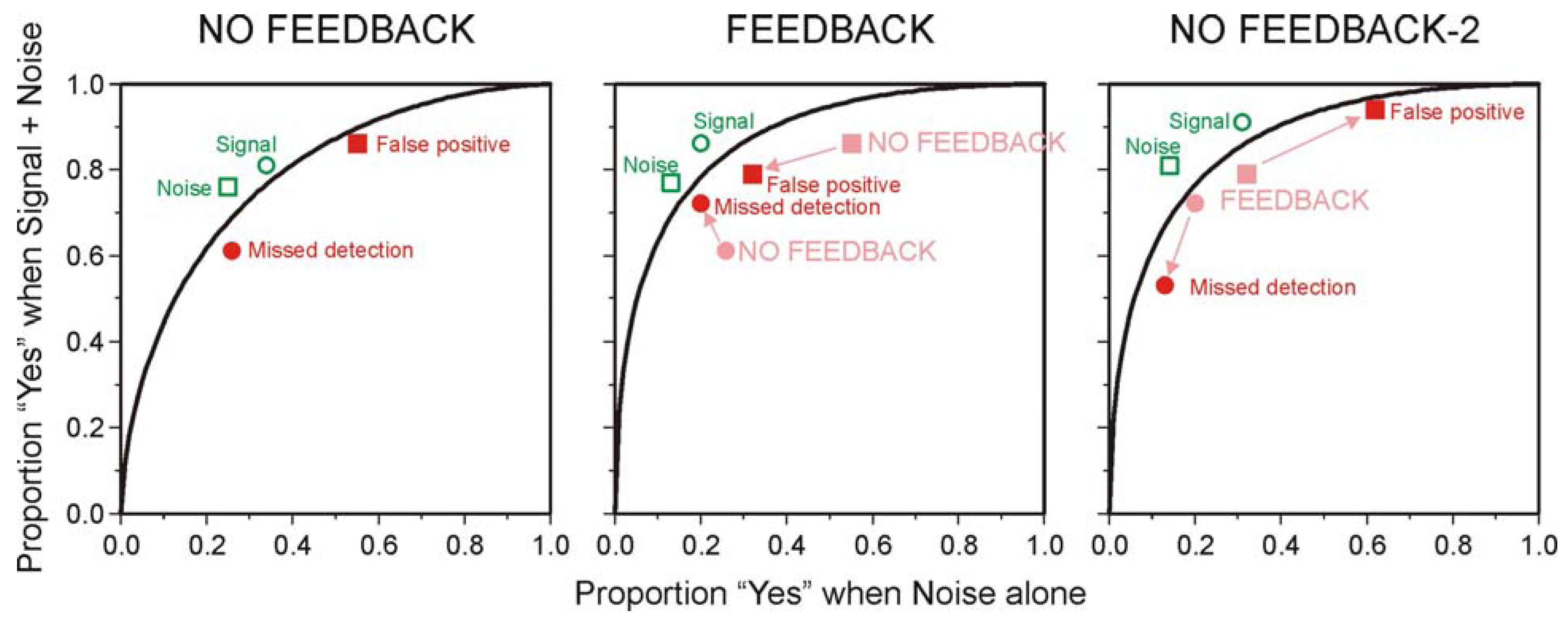
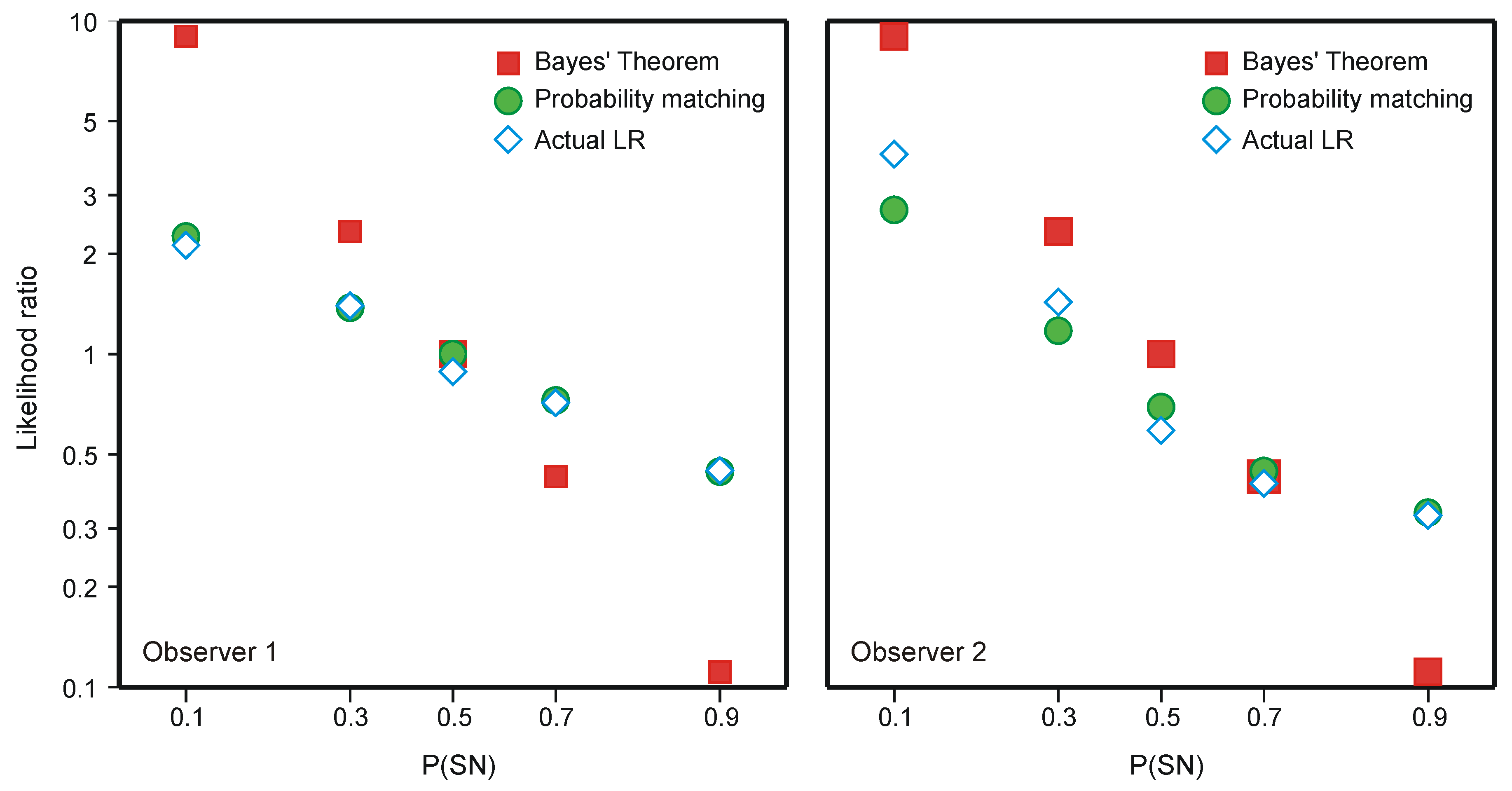
5.2. The Choice of Criterion in Signal Detection Experiments
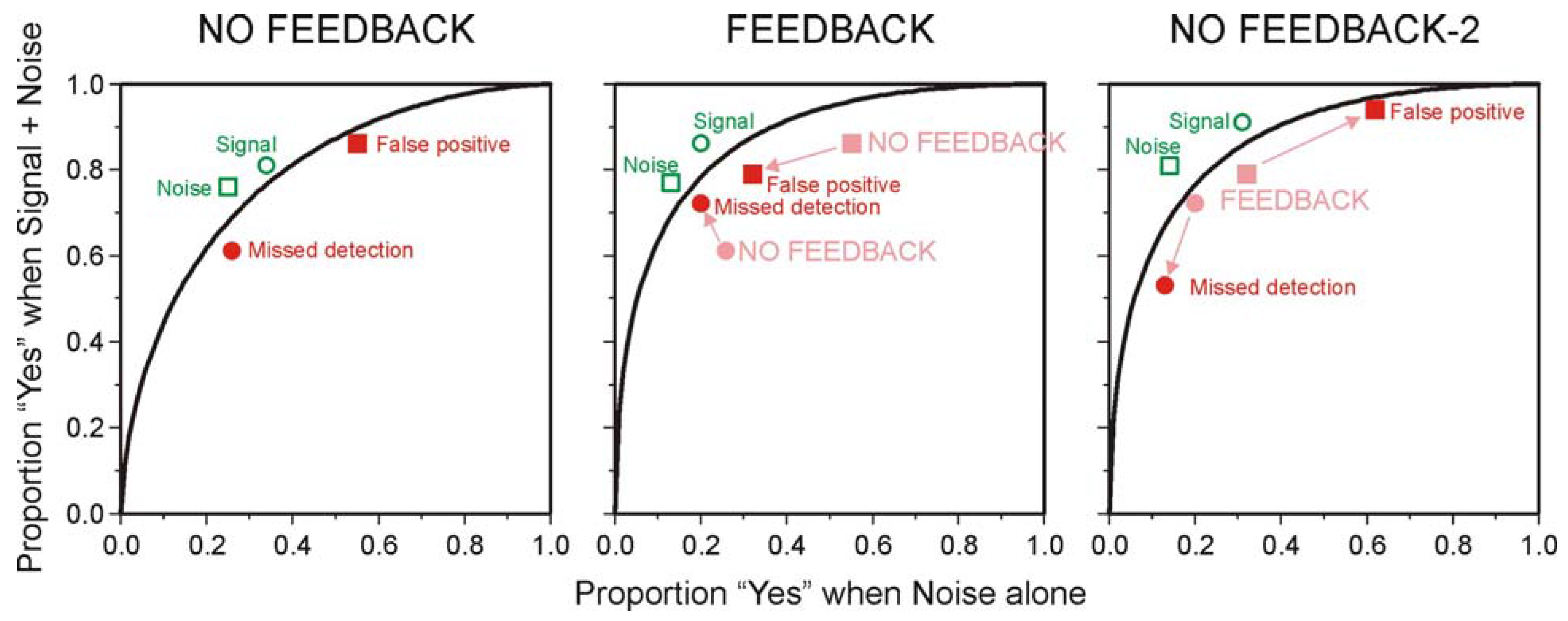
| Probability of 70 dB tone | |||
|---|---|---|---|
| 0.2 | 0.5 | 0.8 | |
| NO FEEDBACK | |||
| False positive | 0.376 | 0.17 | 0.044 |
| Missed detection | 0.038 | 0.11 | 0.28 |
| FEEDBACK | |||
| False positive | 0.048 | 0.09 | 0.062 |
| Missed detection | 0.076 | 0.1 | 0.056 |
| NO FEEDBACK-2 | |||
| False positive | 0.248 | 0.14 | 0.042 |
| Missed detection | 0.026 | 0.075 | 0.152 |
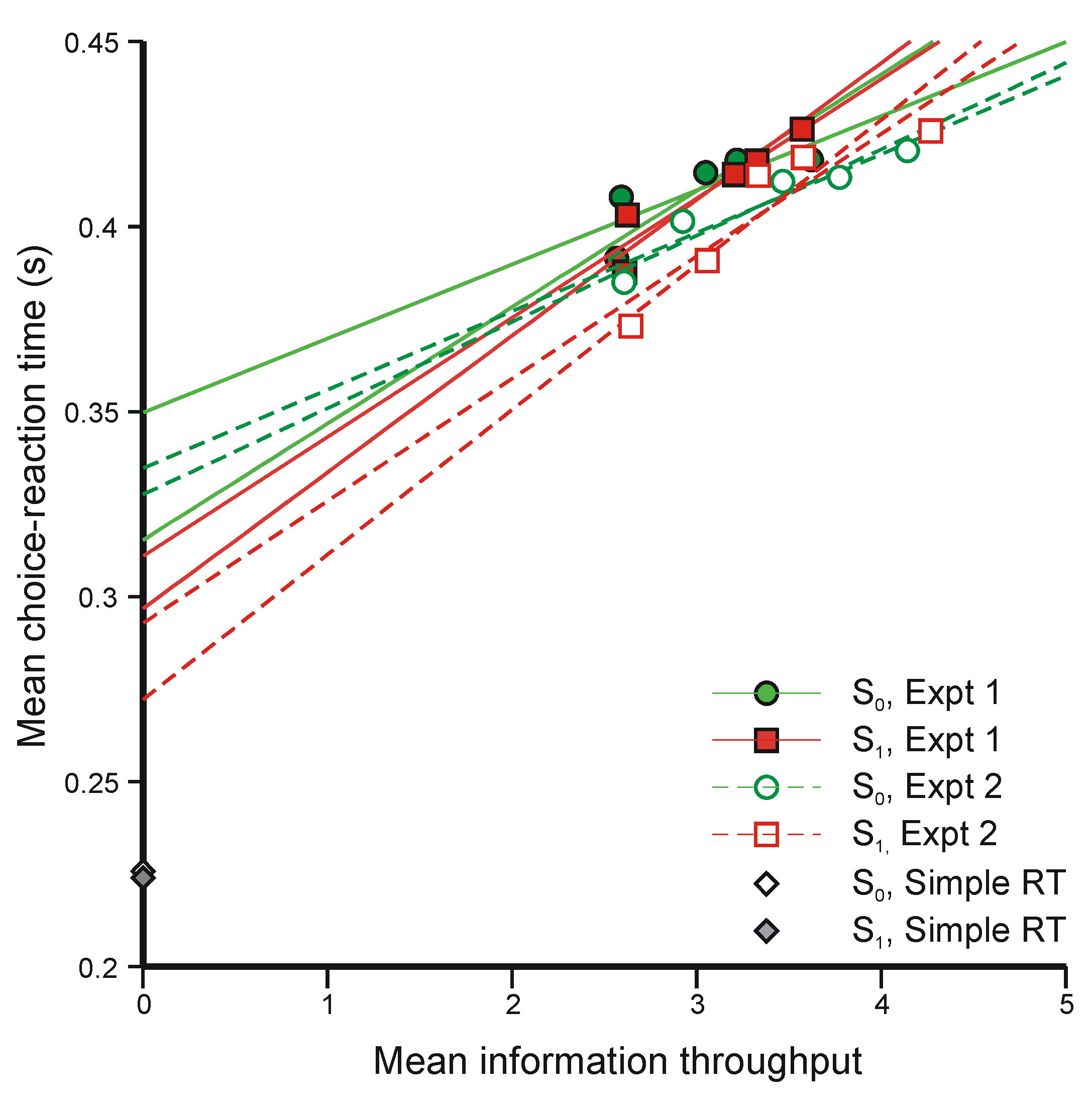
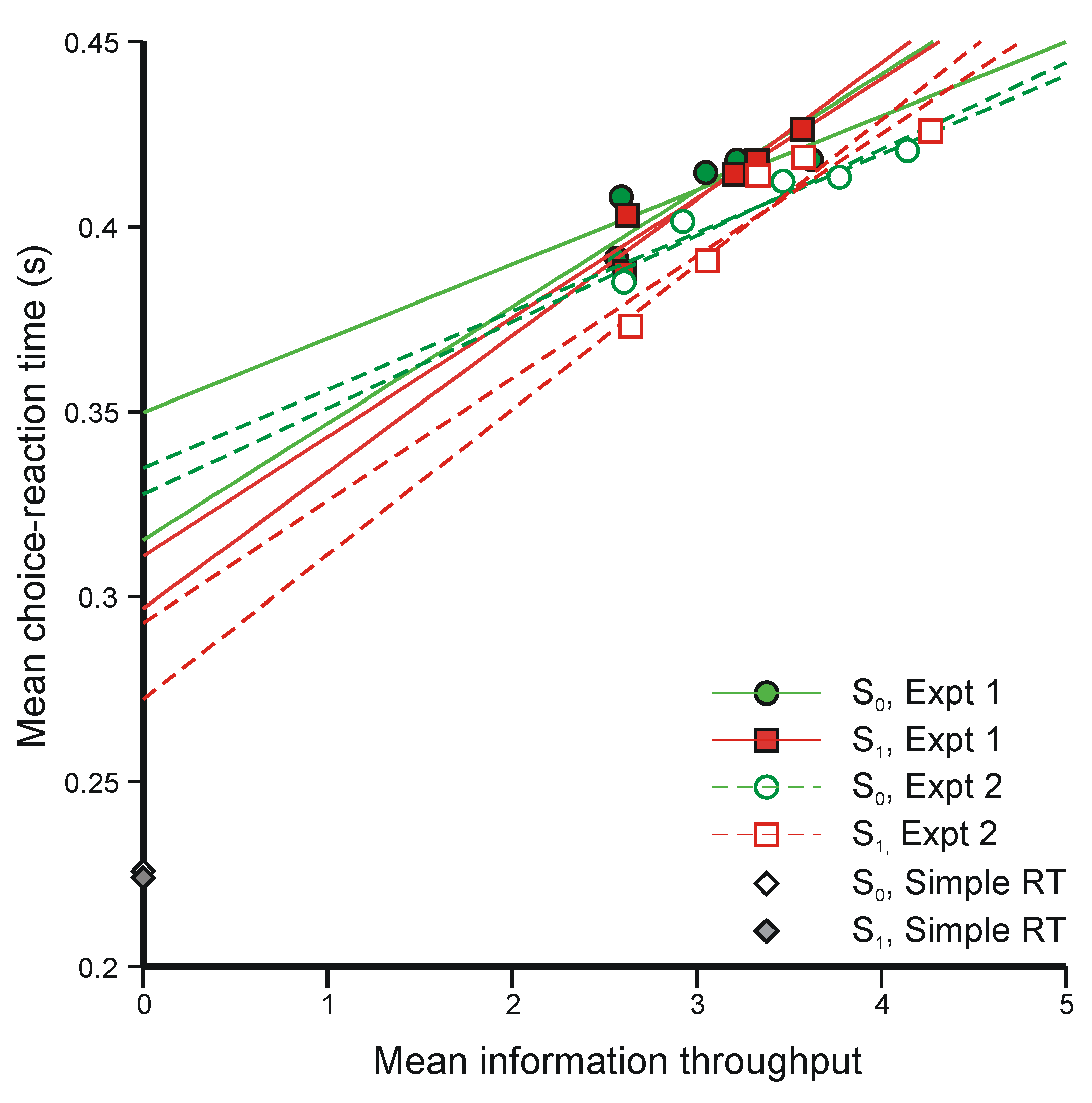
5.3. Two-Choice Reaction Experiments (Again)
{Mean information throughput}/{Mean rate of transmission}
- (i)
- The regression lines in Figure 10 intersect at a positive value of information, whereas Equation 47 requires intersection at zero information. The model would still be tenable if the regression lines intersected at negative values of information, because ‘Mean information throughput’ is estimated from aggregate data. Since it is a non-linear function of that data, information could be lost in the aggregation. But intersection at positive values cannot be accommodated.
- (ii)
- Extrapolation of the regression lines to zero information gives an intercept very much greater than the measured simple reaction time for the same stimuli (about 0.22 s), represented by the diamonds on the ordinate (from Experiment 4 [42]).
5.4. Absolute Identification
5.5. Interim Conclusions

6. Conclusions: The Use of Information Theory in Psychology
- There are some simple interrelationships between the notions of statistical information, statistical hypothesis testing, uncertainty, and entropy that are less well understood than they need to be. In particular, under the influence of Shannon’s mathematical theory of communication, psychologists are wont to suppose that information is an absolute. Not so! Data are absolute, but information is always relative to the two hypotheses to which it relates.
- The derivation of the logarithmic relation (Hick’s Law) from Shannon’s communication theory depends essentially on channel capacity as an effective limit to human performance, and the argument needed to deliver that limit introduces assumptions that do not match other details of the experiment. But the human operator may alternatively be viewed as a purely physical system. information theory is then applicable to the flow of stimulation through that system (‘sensory processing’) and provides a ‘model-independent’ technique for identifying the ‘information-critical’ operations involved. The summary of results on discrimination between two separate stimuli, for example, poses the question: What information is lost in transmission to the discrimination response and how? If that loss of information can be accurately characterized (this is ultimately no more than an analysis of experimental data), the theoretical possibilities are correspondingly constrained.
- In view of the simplicity of Bayes’ theorem, psychologists have been tempted to write simple normative models for the influence of prior probabilities on human performance. Such models do not agree with the data. They also pose the question: How might the optimum combination of information from different sources be realized in nature? If subjects are not informed in advance of the prior probabilities applicable to any given series of stimuli, they certainly cannot carry out calculations based on those prior probabilities, and we have to suppose some internal stochastic process (unspecified) that homes in on the normative ideal. While the analysis of signal-detection performance, of absolute identification, and of choice-reaction times reveals a rich substructure of sequential interactions (the internal stochastic process is fact), and performance appears to fluctuate from trial to trial in a dynamic equilibrium, there is no necessity for that equilibrium to be normative—and in general it is not.
- There are, therefore, three categories of applications of information theory that need to be distinguished. There is
- (a) information as a measure of the amount of message being sent through a communications system, and other applications of the entropy formula which, while not admitting the same psychological interpretion, are nevertheless derived from the same axiomatic foundation;
- (b) information theory as a technique for investigating the behavior of complex systems, analogous to systems analysis of physical systems; and
- (c) information theory as an algorithm for combining information from different sources (prior probabilities, stimulus presentation frequencies), based on Bayes’ theorem.
- Applications falling within Category (a) have long since lost interest, though we are still left with terms—‘encoding’, ‘capacity’—that have been stripped of their meaning. My conclusion from the examples presented above is that Category (c) (probably) does not apply to the human operator; but Category (b) has great, as yet unexploited, potential. Category (b) provides, as it were, a ‘model-free’ technique for the investigation of all kinds of systems without the need to understand the machinery—to model the brain without modeling the neural responses.
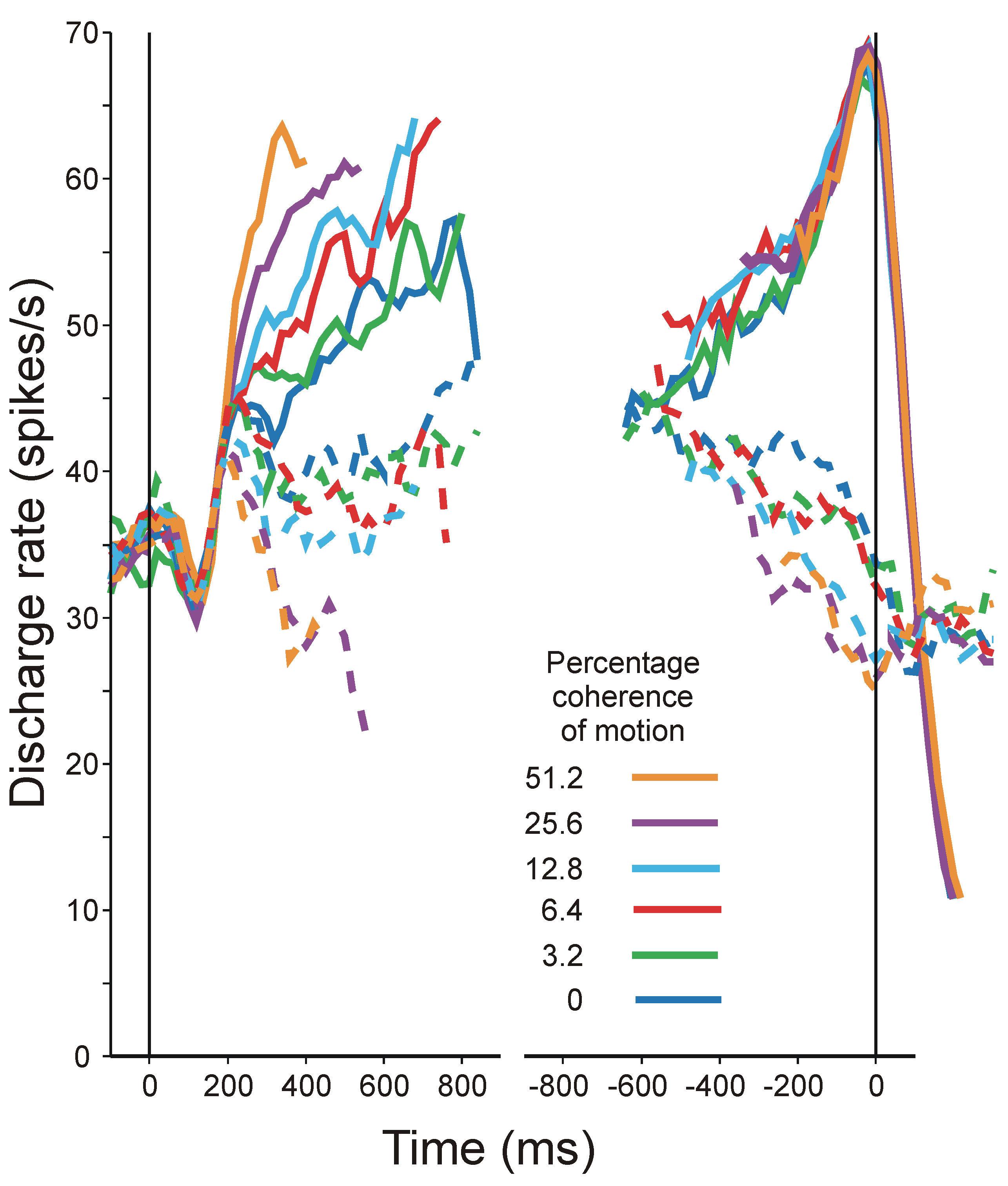
- 5
- The phenomena that most need to be investigated are the sequential interactions that are found in all sorts of experiments in which human subjects respond throughout a long series of discrete trials. Figure 9 displays a simple example. Performance oscillates about an equilibrium and, provided only that aggregate information is a non-linear function of trial-to-trial observation, information is lost in the aggregation. Treating the human subject as a purely physical communication system (Category b again) provides the technique for isolating component interactions and estimating their effects.
Acknowledgements
References and Notes
- Miller, G.A.; Frick, F.C. Statistical behavioristics and sequences of responses. Psychol. Rev. 1949, 56, 311–324. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.E. A mathematical theory of communication. Bell Labs Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Garner, W.R. Uncertainty and Structure as Psychological Concepts; Wiley: New York, NY, USA, 1962. [Google Scholar]
- Cherry, E.C. Information Theory. In Presented at Information Theory Symposium, London, UK, 12–16 September, 1955; Butterworths: London, UK, 1956. [Google Scholar]
- Cherry, E.C. Information Theory. In Presented at Information Theory Symposium, London, UK, 29 August– 2 September, 1960; Butterworths: London, UK, 1961. [Google Scholar]
- Jackson, W. Report of proceedings, symposium on information theory, London, England, September 1950. IEEE Trans. Inf. Theory 1953, PGIT-1, 1–218. [Google Scholar]
- Jackson, W. Communication Theory. In Presented at Applications of Communication Theory Symposium, London, UK, 22–26 September, 1952; Butterworths: London, UK, 1953. [Google Scholar]
- Quastler, H. Essays on the Use of Information Theory in Biology; University of Illinois Press: Urbana, Illinois, USA, 1953. [Google Scholar]
- Quastler, H. Information theory in psychology: problems and methods. In Proceedings of a conference on the estimation of information flow, Monticello, IL, USA, 5–9 July, 1954; and related papers. The Free Press: Glencoe, Illinois, USA, 1955. [Google Scholar]
- Luce, R.D. Whatever happened to information theory? Rev. Gen. Psychol. 2103, 7, 183–188. [Google Scholar] [CrossRef]
- Tanner, W.P., Jr.; Swets, J.A. A decision-making theory of visual detection. Psychol Rev. 1954, 61, 401–409. [Google Scholar] [CrossRef] [PubMed]
- Peterson, W.W.; Birdsall, T.G.; Fox, W.C. The theory of signal detectability. IEEE Trans. Inf. Theory 1954, PGIT-4, 171–212. [Google Scholar] [CrossRef]
- Neyman, J.; Pearson, E.S. On the problem of the most efficient tests of statistical hypotheses. Philos. Trans. R. Soc. Lond. A 1933, 231, 289–337. [Google Scholar] [CrossRef]
- Laming, D. The antecedents of signal-detection theory. A commentary on D.J. Murray, A perspective for viewing the history of psychophysics. Behav. Brain Sci. 1993, 16, 151–152. [Google Scholar] [CrossRef]
- The term ‘ideal observer’ has been used in two different ways. Green and Swets (Ch. 6 [16]) use it to denote a model of the information contained in the physical stimulus, borrowing ideas and mathematics from Peterson, Birdsall and Fox [12]. Peterson, Birdsall and Fox do not themselves use the term in this sense, but do refer to ‘Siegert’s “Ideal observer’s” criteria’, which adds to their analyses of physical stimuli criteria that maximize the expectation of a correct decision. More recently (e.g., [17]), the term has been used to denote the selection of a criterion to maximize the expectation of a correct decision, without necessarily there being a prior model of the physical stimulus. To avoid confusion, I shall not use this term hereafter.
- Green, D.M.; Swets, J.A. Signal Detection Theory and Psychophysics; Wiley: New York, NY, USA, 1966. [Google Scholar]
- Kersten, D.; Mamassian, P.; Yuille, A. Object perception as bayesian inference. Annu. Rev. Psychol. 2104, 55, 271–304. [Google Scholar] [CrossRef] [PubMed]
- Edwards, W.; Lindeman, H.; Savage, L.J. Bayesian statistical inference for psychological research. Psychol. Rev. 1963, 70, 193–242. [Google Scholar] [CrossRef]
- Green, D.M. Psychoacoustics and detection theory. J. Acoust. Soc. Am. 1960, 32, 1189–1213. [Google Scholar] [CrossRef]
- Norwich, K.H. Information, Sensation and Perception; Academic Press: San Diego, CA, USA, 1993. [Google Scholar]
- Braida, L.D.; Durlach, N.I. Intensity perception. II. Resolution in one-interval paradigms. J. Acoust. Soc. Am. 1972, 51, 483–502. [Google Scholar] [CrossRef]
- Laming, D. Statistical information, uncertainty, and Bayes’ theorem: Some applications in experimental psychology. In Symbolic and Quantitative Approaches to Reasoning with Uncertainty (Lecture notes in Artificial Intelligence, Volume 2143); Benferhat, S., Besnard, P., Eds.; Springer-Verlag: Berlin, Germany, 2001; pp. 635–646. [Google Scholar]
- Kullback, S. Information Theory and Statistics; Wiley: New York, NY, USA, 1959. [Google Scholar]
- Wilkes, S.S. The large-sample distribution of the likelihood ratio for testing composite hypotheses. Ann. Math. Stat. 1938, 9, 60–62. [Google Scholar] [CrossRef]
- Wilkes, S.S. The likelihood test of independence in contingency tables. Ann. Math. Stat. 1935, 6, 190–196. [Google Scholar] [CrossRef]
- Swets, J.A.; Tanner, W.P., Jr.; Birdsall, T.G. Decision processes in perception. Psychol. Rev. 1961, 68, 301–340. [Google Scholar] [CrossRef] [PubMed]
- Laming, D. Mathematical Psychology; Academic Press: London, UK, 1973. [Google Scholar]
- Shannon, C.E. Communication in the presence of noise. Pro. Inst. Radio Eng. 1949, 37, 10–21. [Google Scholar] [CrossRef]
- A distinction is needed between uncertainty (Equation 13) in a psychological context and the same formula in a purely physical context. The interpretation of this formula is not the same in all contexts. To preserve this distinction I shall use ‘uncertainty’ in psychological contexts and ‘entropy’ in relation to the second law of thermodynamics (below).
- In fact, by a suitable choice of H0 and H1, uncertainty can itself be cast as a measure of information transmitted. Take H0: Message is one (unspecified) selected from the set {i} with probabilities pi. (∑i pi = 1) Hi: Message is message i. Initially, P(Hi)/P(H0) = pi. When message i is received, this probability ratio becomes 1, the gain in information is –ln pi., and the mean information averaged over the set of messages is Formula 13 (p. 7 [23]). But these hypotheses are not of any practical interest.
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620–630, 108, 171–190. [Google Scholar] [CrossRef]
- Landau, L.D.; Lifshitz, E.M. Statistical Physics; Sykes, J.B., Kearsley, M.J., Eds.; Pergamon Press: Oxford, UK, 1968. [Google Scholar]
- Aczél, J.; Daróczy, Z. On Measures of Information and Their Characterizations; Academic Press: New York, NY, USA, 1975. [Google Scholar]
- Laming, D. Spatial frequency channels. In Vision and Visual Dysfunction; Kulikowski, J.J., Walsh, V., Murray, I.J., Eds.; Macmillan: London, UK, 1991; Volume 5. [Google Scholar]
- Good, I.J. Probability and the weighting of evidence; Griffin: London, UK, 1950. [Google Scholar]
- Krech, D.; Crutchfield, R.S. Theory and Problems of Social Psychology; McGraw-Hill: New York, NY, USA, 1948. [Google Scholar]
- Sherif, M.; Hovland, C.I. Social Judgment; Yale University Press: New Haven, CN, USA, 1961. [Google Scholar]
- Hick, W.E. On the rate of gain of information. Q. J. Exp. Psychol. 1952, 4, 11–26. [Google Scholar] [CrossRef]
- Merkel, J. Die zietlichen Verhältnisse der Willensthätigkeit. Philosophische Studien 1885, 2, 73–127. [Google Scholar]
- Kirchner, W.K. Age differences in short-term retention of rapidly changing information. J. Exp. Psychol. 1958, 55, 352–358. [Google Scholar] [CrossRef] [PubMed]
- Bricker, P.D. Information measurement and reaction time: A review. In Information Theory in Psychology: Problems and Methods, Proceedings of a conference on the estimation of information flow, Monticello, IL, USA, 5–9 July, 1954; and related papers. The Free Press: Glencoe, IL, USA, 1955; pp. 350–359. [Google Scholar]
- Laming, D. Information Theory of Choice-Reaction Times; Academic Press: London, UK, 1968. [Google Scholar]
- Leonard, J.A. Tactual choice reactions: I. Q. J. Exp. Psychol. 1959, 11, 76–83. [Google Scholar] [CrossRef]
- Christie, L.S.; Luce, R.D. Decision structure and time relations in simple choice behavior. Bull. Math. Biophys. 1956, 18, 89–111. [Google Scholar] [CrossRef]
- Laming, D. A new interpretation of the relation between choice-reaction time and the number of equiprobable alternatives. Br. J. Math. Stat. Psychol. 1966, 19, 139–149. [Google Scholar] [CrossRef] [PubMed]
- Townsend, J.T.; Ashby, F.G. The Stochastic Modeling of Elementary Psychological Processes; Cambridge University Press: Cambridge, UK, 1983. [Google Scholar]
- Hake, H.W.; Garner, W.R. The effect of presenting various numbers of discrete steps on scale reading accuracy. J. Exp. Psychol. 1951, 42, 358–66. [Google Scholar] [CrossRef] [PubMed]
- Chapanis, A.; Halsey, R.M. Absolute judgments of spectrum colors. J. Psychol. 1956, 42, 99–103. [Google Scholar] [CrossRef]
- Eriksen, C.W.; Hake, H.W. Multidimensional stimulus differences and, accuracy of discrimination. J. Exp. Psychol. 1955, 50, 153–160. [Google Scholar] [CrossRef] [PubMed]
- Muller, P.F., Jr.; Sidorsky, R.C.; Slivinske, A.J.; Alluisi, E.A.; Fitts, P.M. The symbolic coding of information on cathode ray tubes and similar displays. USAF WADC Technical Report 1955, No. 55–37. [Google Scholar]
- Johnson-Laird, P.N.; Wason, P.C. A theoretical analysis of insight into a reasoning task. Cogn. Psychol. 1970, 1, 134–148. [Google Scholar] [CrossRef]
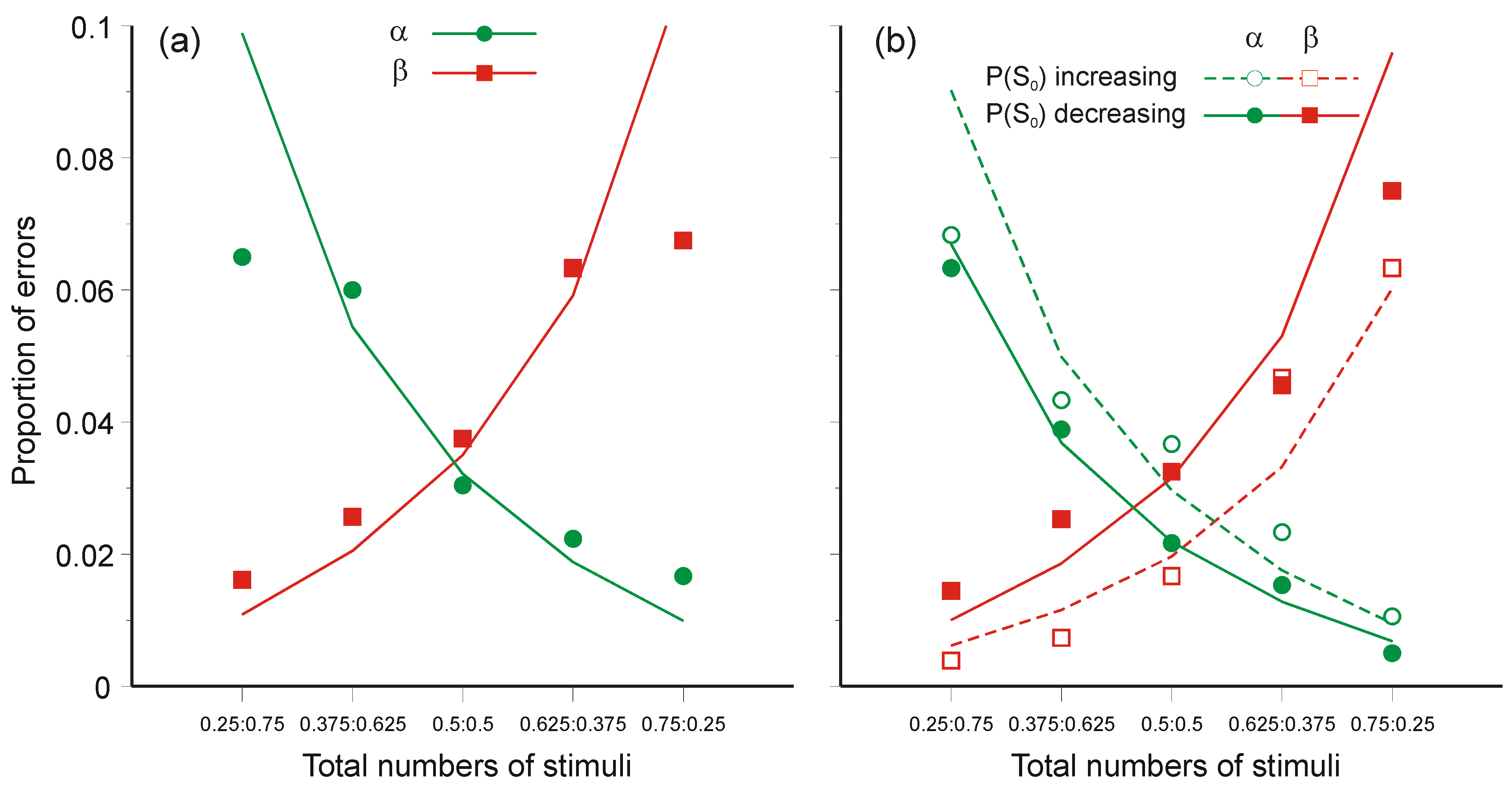
- Oaksford, M.; Chater, N. A rational analysis of the selection task as optimal data selection. Psychol. Rev. 1994, 101, 608–631. [Google Scholar] [CrossRef]
- Oaksford, M.; Chater, N. Optimal data selection: Revision, review and re-evaluation. Psychon. Bull. Rev. 2003, 10, 289–318. [Google Scholar] [CrossRef] [PubMed]
- Oaksford, M.; Chater, N. Bayesian rationality: The Probabilistic Approach to Reasoning; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Oaksford, M.; Chater, N.; Grainger, B. Probabilistic effects in data selection. Thinking and Reasoning 1999, 5, 193–243. [Google Scholar] [CrossRef]
- Oberauer, K.; Wilhelm, O.; Dias, R.R. Bayesian rationality for the Wason selection task? A test of optimal data selection theory. Thinking and Reasoning 1999, 5, 115–144. [Google Scholar] [CrossRef]
- the comparison between this H0 and Oaksford and Chater’s particular H1 generates the so-called ‘ravens paradox’ [58,59], in which the observation of a pink flamingo (anything that is neither black nor a raven) is asserted, erroneously, to confirm the hypothesis that all ravens are black. Observations of black ravens (of course) and of non-black non-ravens jointly militate against the hypothesis that color and ravenhood are independent in nature. But confirmation requires the further assumption that independence and ‘all ravens are black’ are mutually exhaustive hypotheses, and that is patently false.
- Mackie, J.L. The paradox of confirmation. Br. J. Philos. Sci. 1963, 13, 265–277. [Google Scholar] [CrossRef]
- Oaksford, M.; Chater, N. Rational explanation of the selection task. Psychol. Rev. 1996, 103, 381–391. [Google Scholar] [CrossRef]
- Klauer, K.C. On the normative justification for information gain in Wason’s selection task. Psychol. Rev. 1999, 106, 215–222. [Google Scholar] [CrossRef]
- Birnbaum, M.H. Tests of branch splitting and branch-splitting independence in Allais paradoxes with positive and mixed consequences. Organ. Behav. Hum. Decis. Process 2007, 102, 154–173. [Google Scholar] [CrossRef]
- Birnbaum, M.H.; Birnbaum, H. Causes of Allais common consequence paradoxes: An experimental dissection. J. Math. Psychol. 2004, 48, 87–106. [Google Scholar] [CrossRef]
- Fryback; Goodman; Edwards [64] report two ‘laboratory’ experiments conducted in a Las Vegas casino with patrons of the casino. In these experiments participants typically won or lost ±$30 of their own money.
- Fryback, D.G.; Goodman, B.C.; Edwards, W. Choices among bets by Las Vegas gamblers: Absolute and contextual effects. J. Exp. Psychol. 1973, 98, 271–278. [Google Scholar] [CrossRef]
- Wagenaar, W.A. Paradoxes of Gambling Behavior; Lawrence Erlbaum: Hove, UK, 1988. [Google Scholar]
- Von Neumann, J.; Morgenstern, O. Theory of Games and Economic Behavior; Princeton University Press: Princeton, NJ, USA, 1944. [Google Scholar]
- Allais, M. Le Comportement de l’Homme Rationnel devant le Risque: Critique des Postulats et Axiomes de l’Ecole Americaine. Econometrica 1953, 21, 503–546. [Google Scholar] [CrossRef]
- Kahneman, D.; Tversky, A. Prospect theory: an analysis of decision under risk. Econometrica 1979, 47, 263–291. [Google Scholar] [CrossRef]
- Luce, R.D.; Ng, C.T.; Marley, A.A.J.; Aczél, J. Utility of gambling II: Risk, Paradoxes, and Data. J. Econ. Theory 2008, 36, 165–187. [Google Scholar]
- Luce, R.D.; Ng, C.T.; Marley, A.A.J.; Aczél, J. Utility of gambling I: Entropy-modified linear weighted utility. J. Econ. Theory 2008, 36, 1–33. [Google Scholar]
- In this context Formula 13 does not permit the same kind of psychological interpretation (transmission through an ideal communications system) as previous examples. Instead, the formula is derived from a set of individually testable behavioral axioms.
- The entropy formula arises here on the assumption that the status quo relative to a multiple-outcome {xi} gamble is a function of the probabilities of the gamble only and can be decomposed recursively into two parts, a choice between x1 and x2, and a choice between x1 and x2 jointly and all the other outcomes. This is substantially the same set of constraints as previously (p. 11 above).
- Laming, D. Human Judgment: The Eye of the Beholder; Thomson Learning: London, UK, 2004. [Google Scholar]
- Used here in an everyday, not a technical, sense.
- Laming, D. Understanding human motivation: what makes people tick? Blackwells: Malden, MA, USA, 2004. [Google Scholar]
- Wagenaar, W.A. Subjective randomness and the capacity to generate information. In Attention and performance III, Proceedings of a symposium on attention and performance, Soesterberg,, The Netherlands, August 4-8, 1969; Sanders, A.F., Ed. Acta Psychol. (Amst) 1970, 33, 233–242. [Google Scholar] [CrossRef]
- Cronbach, L.J. On the non-rational application of information measures in psychology. In Information theory in psychology: problems and methods, Proceedings of a conference on the estimation of information flow, Monticello, IL, USA, July 5–9, 1954; and related papers. The Free Press: Glencoe, IL, USA, 1955; pp. 14–30. [Google Scholar]
- Linker, E.; Moore, M.E.; Galanter, E. Taste thresholds, detection models, and disparate results. J. Exp. Psychol. 1964, 67, 59–66. [Google Scholar] [CrossRef] [PubMed]
- Mountcastle, V.B.; Talbot, W.H.; Sakata, H.; Hyvärinen, J. Cortical neuronal mechanisms in flutter-vibration studied in unanesthetized monkeys. Neuronal periodicity and frequency discrimination. J. Neurophysiol. 1969, 32, 452–484. [Google Scholar] [PubMed]
- Nachmias, J.; Steinman, R.M. Brightness and discriminability of light flashes. Vision Res. 1965, 5, 545–557. [Google Scholar] [CrossRef]
- Semb, G. The detectability of the odor of butanol. Percept. Psychophys. 1968, 4, 335–340. [Google Scholar] [CrossRef]
- Viemeister, N.F. Intensity discrimination: Performance in three paradigms. Percept. Psychophys. 1971, 8, 417–419. [Google Scholar] [CrossRef]
- Brown, W. The judgment of difference. Publ. Psychol. 1910, 1, 1–71. [Google Scholar]
- Hanna, T.E.; von Gierke, S.M.; Green, D.M. Detection and intensity discrimination of a sinusoid. J. Acoust. Soc. Am. 1986, 80, 1335–1340. [Google Scholar] [CrossRef] [PubMed]
- Leshowitz, B.; Taub, H.B.; Raab, D.H. Visual detection of signals in the presence of continuous and pulsed backgrounds. Percept. Psychophys. 1968, 4, 207–213. [Google Scholar] [CrossRef]
- Laming, D. Fechner’s Law: Where does the log transform come from? In Fechner Day 2001; Sommerfeld, E., Kompass, R., Lachmann, T., Eds.; Pabst: Lengerich, Germany, 2001; pp. 36–41. [Google Scholar]
- Laming, D. Fechner’s Law: Where does the log transform come from? Seeing and Perceiving 2010, in press. [Google Scholar]
- McBurney, D.H.; Kasschau, R.A.; Bogart, L.M. The effect of adaptation on taste jnds. Percept. Psychophys. 1967, 2, 175–178. [Google Scholar] [CrossRef]
- Stone, H.; Bosley, J.J. Olfactory discrimination and Weber's Law. Percept. Mot. Skills 1965, 20, 657–665. [Google Scholar] [CrossRef] [PubMed]
- Ernst, M.O.; Banks, M.S. Humans integrate visual and haptic information in a statistically optimal fashion. Nature 2002, 415, 429–433. [Google Scholar] [CrossRef] [PubMed]
- Hamer, R.D.; Verrillo, R.T.; Zwislocki, J.J. Vibrotactile masking of Pacinian and non-Pacinian channels. J. Acoust. Soc. Am. 1983, 73, 1293–303. [Google Scholar] [CrossRef] [PubMed]
- Harris, J.D. The effect of sensation-levels on intensive discrimination of noise. Am. J. Psychol. 1950, 63, 409–421. [Google Scholar] [CrossRef] [PubMed]
- Schutz, H.G.; Pilgrim, F.J. Differential sensitivity in gustation. J. Exp. Psychol. 1957, 54, 41–48. [Google Scholar] [CrossRef] [PubMed]
- Stone, H. Determination of odor difference limens for three compounds. J. Exp. Psychol. 1963, 66, 466–473. [Google Scholar] [CrossRef] [PubMed]
- Laming, D. The discrimination of smell and taste compared with other senses. Chem. Ind. 1987, 12–18. [Google Scholar]
- de Vries, H. The quantum character of light and its bearing upon threshold of vision, the differential sensitivity and visual acuity of the eye. Physica. 1943, 10, 553–564. [Google Scholar] [CrossRef]
- Rose, A. The sensitivity performance of the human eye on an absolute scale. J. Opt. Soc. Am. 1948, 38, 196–208. [Google Scholar] [CrossRef] [PubMed]
- van Nes, F.L.; Bouman, M.A. Spatial modulation transfer in the human eye. J. Opt. Soc. Am. 1967, 57, 401–406. [Google Scholar] [CrossRef]
- Fullerton, G.S.; Cattell, J.McK. On the perception of small differences. Publications of the University of Pennsylvania, Philosophical Series, No. 2 1892. [Google Scholar]
- Laming, D. Sensory Analysis; Academic Press: London, UK, 1986. [Google Scholar]
- Laming, D. On the limits of visual perception. In Vision and Visual Dysfunction; Kulikowski, J.J., Walsh, V., Murray, I.J., Eds.; Macmillan: London, UK, 1991; Volume 5. [Google Scholar]
- Graham, C.H.; Kemp, E.H. Brightness discrimination as a function of the duration of the increment in intensity. J. Gen. Physiol. 1938, 21, 635–650. [Google Scholar] [CrossRef] [PubMed]
- Bartlett, N.R. The discrimination of two simultaneously presented brightnesses. J. Exp. Psychol. 1942, 31, 380–392. [Google Scholar] [CrossRef]
- Steinhardt, J. Intensity discrimination in the human eye. I. The relation of ΔI/I to intensity. J. Gen. Physiol. 1936, 20, 185–209. [Google Scholar] [CrossRef] [PubMed]
- Cornsweet, T.N.; Pinsker, H.M. Luminance discrimination of brief flashes under various conditions of adaptation. J. Physiol. 1965, 176, 294–310. [Google Scholar] [CrossRef] [PubMed]
- Rodieck, R.W.; Stone, J. Analysis of receptive fields of cat retinal ganglion cells. J. Neurophysiol. 1965, 28, 833–849. [Google Scholar]
- Ditchburn, R.W. Eye-Movements and Visual Perception; Oxford University Press: Oxford, UK, 1973. [Google Scholar]
- Yarbus, A.L. Eye Movements and Vision; from the 1965 Russian Edition; Haigh, B.T., Ed.; Plenum Press: New York, NY, USA, 1967. [Google Scholar]
- Laming, D. Précis of Sensory Analysis and A reexamination of Sensory Analysis. Behav. Brain Scis. 1988, 11, 275–296; 316–339. [Google Scholar] [CrossRef]
- Barlow, H.B. Optic nerve impulses and Weber's Law. Cold Spring Harb. Symp. Quant. Biol. 1965, 30, 539–546. [Google Scholar] [CrossRef] [PubMed]
- Grossberg, S. The quantized geometry of visual space: The coherent computation of depth, form and lightness. Behav. Brain Sci. 1983, 6, 625–692. [Google Scholar] [CrossRef]
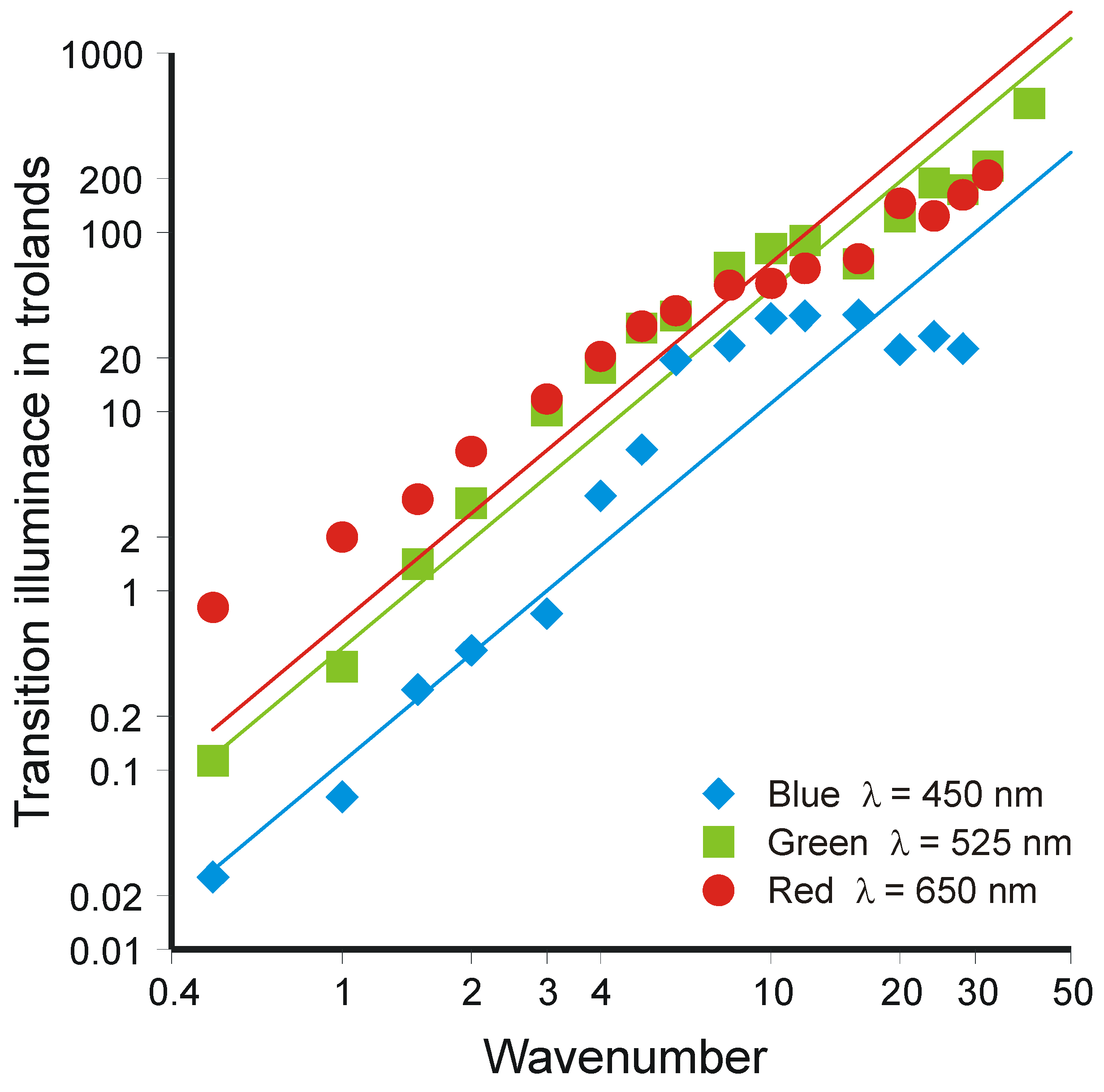
- If this idea be applied to an increment added to a continuous background of luminance L, it neglects entirely the relation of threshold to size of increment, which changes with increase in luminance. If it be applied to a discrimination between separate luminances, where Weber’s Law holds the most accurately, it requires the luminance L+ΔL to be scaled as though it were luminance L.
- van Nes, F.L. Experimental studies in spatiotemporal contrast transfer by the human eye. Ph.D Thesis, University of Utrecht, Utrecht, The Netherlands, 1968. [Google Scholar]
- Laming, D. Contrast sensitivity. In Vision and Visual Dysfunction; Kulikowski, J.J., Walsh, V., Murray, I.J., Eds.; Macmillan: London, UK, 1991; Volume 5. [Google Scholar]
- Legge, G.E. Spatial frequency masking in human vision: Binocular interactions. J. Opt. Soc. Am. 1979, 69, 838–847. [Google Scholar] [CrossRef] [PubMed]
- Campbell, F.W.; Kulikowski, J.J. Orientational selectivity of the human visual system. J. Physiol. 1966, 187, 437–445. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Functional architecture of macaque monkey visual cortex. Proc. R. Soc. Lond B Biol. Sci. 1977, 198, 1–59. [Google Scholar] [CrossRef] [PubMed]
- Watson, A.B. Summation of grating patches indicates many types of detector at one retinal location. Vision Res. 1982, 22, 17–25. [Google Scholar] [CrossRef]
- Campbell, F.W.; Cooper, G.F.; Enroth-Cugell, C. The spatial selectivity of the visual cells of the cat. J. Physiol. 1969, 203, 223–235. [Google Scholar] [CrossRef] [PubMed]
- Maffei, L.; Fiorentini, A. The visual cortex as a spatial frequency analyzer. Vision Res. 1973, 13, 1255–1267. [Google Scholar] [CrossRef]
- Robson, J.G.; Tolhurst, D.J.; Freeman, R.D.; Ohzawa, I. Simple cells in the visual cortex of the cat can be narrowly tuned for spatial frequency. Vis. Neurosci. 1988, 1, 415–419. [Google Scholar] [CrossRef] [PubMed]
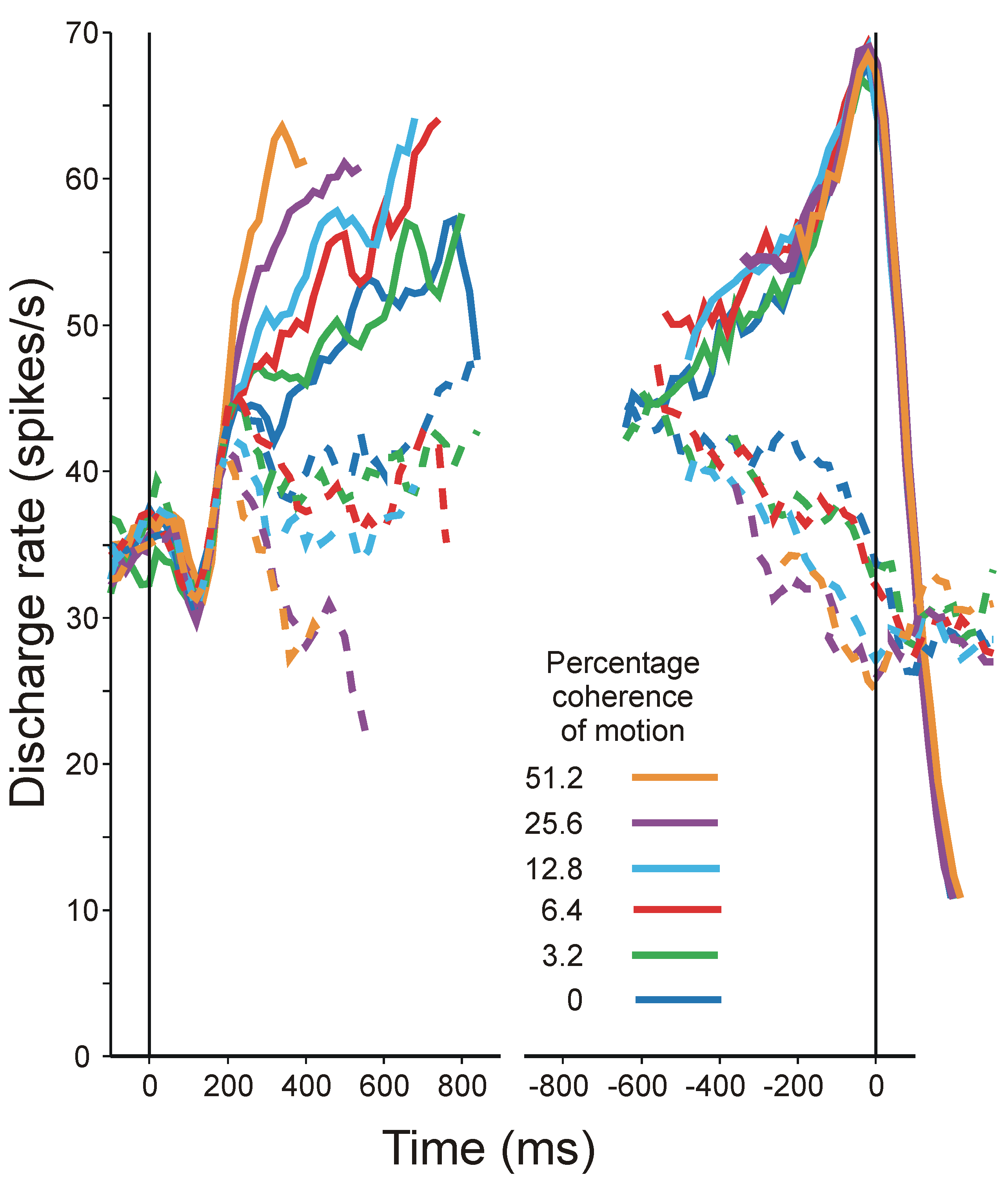
- Roitman, J.D.; Shadlen, M.N. Response of neurons in the lateral intraparietal area during a combined visual discrimination reaction time task. J. Neuros. 2002, 22, 9475–9489. [Google Scholar]
- Shadlen, M.N.; Newsome, W.T. Neural basis of a perceptual decision in the parietal cortex (area LIP) of the rhesus monkey. J. Neurophysiol. 2001, 86, 1916–1936. [Google Scholar] [PubMed]
- Britten, K.H.; Shadlen, M.N.; Newsome, W.T.; Movshon, J.A. Responses of neurons in macaque MT to stochastic motion signals. Vis. Neurosci. 1993, 10, 1157–1169. [Google Scholar] [CrossRef] [PubMed]
- Britten, K.H.; Newsome, W.T. Tuning bandwidths for near-threshold stimuli in area MT. J. Neurophysiol. 1998, 80, 762–770. [Google Scholar] [PubMed]
- Stone, M. Models for choice-reaction time. Psychometrika 1960, 25, 251–260. [Google Scholar] [CrossRef]
- Edwards, W. Subjective probabilities inferred from decisions. Psychol. Rev. 1962, 69, 109–135. [Google Scholar] [CrossRef] [PubMed]
- Wald, A. Sequential Analysis; Wiley: New York, NY, USA, 1947. [Google Scholar]
- Thomas, E.A.C.; Legge, D. Probability matching as a basis for detection and recognition decisions. Psychol. Rev. 1970, 77, 65–72. [Google Scholar] [CrossRef]
- Tanner, W.P., Jr.; Swets, J.A.; Green, D.M. Some general properties of the hearing mechanism. University of Michigan: Electronic Defense Group, Technical Report No. 30. 1956. [Google Scholar]
- Tanner, T.A.; Rauk, J.A.; Atkinson, R.C. Signal recognition as influenced by information feedback. J. Math. Psychol. 1970, 7, 259–274. [Google Scholar] [CrossRef]
- Laming, D. Choice-reaction performance following an error. Acta Psychol. (Amst) 1979, 43, 199–224. [Google Scholar] [CrossRef]
- The unbiased estimate of functional relationship depends on the relative variances attributed to the two sets of variables (Ch. 29, esp. p. 404 [134]). One or the other regression line is correct when one of those variances is zero. Since neither variance can be negative, the unbiased estimate must lies between the two regression lines.
- Kendall, M.G.; Stuart, A. Advanced Theory of Statistics, 4th Edition ed; Griffin: London, UK, 1979. [Google Scholar]
- Torgerson, W.S. Theory and Methods of Scaling; Wiley: New York, NY, USA, 1958. [Google Scholar]
- Laming, D. The Measurement of Sensation; Oxford University Press: Oxford, UK, 1997. [Google Scholar]
- Laming, D. Screening cervical smears. Br. J. Psychol. 1995, 86, 507–516. [Google Scholar] [CrossRef] [PubMed]
- Laming, D. Reconciling Fechner and Stevens? Behav. Brain Sci. 1991, 14, 188–191. [Google Scholar] [CrossRef]
© 2010 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open-access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Laming, D. Statistical Information and Uncertainty: A Critique of Applications in Experimental Psychology. Entropy 2010, 12, 720-771. https://doi.org/10.3390/e12040720
Laming D. Statistical Information and Uncertainty: A Critique of Applications in Experimental Psychology. Entropy. 2010; 12(4):720-771. https://doi.org/10.3390/e12040720
Chicago/Turabian StyleLaming, Donald. 2010. "Statistical Information and Uncertainty: A Critique of Applications in Experimental Psychology" Entropy 12, no. 4: 720-771. https://doi.org/10.3390/e12040720
APA StyleLaming, D. (2010). Statistical Information and Uncertainty: A Critique of Applications in Experimental Psychology. Entropy, 12(4), 720-771. https://doi.org/10.3390/e12040720