2.1. Distortion-Rate Theory
Clustering can be viewed as projecting a large number of discrete samples from the input space, into a finite set of discrete symbols in the clustered space, where each symbol resembles a cluster. Thus, clustering is a many-to-one mapping from the input space,
, to the clustered space,
, and can be fully characterized by the conditional probability distribution,
. Using this mapping, the distribution of the clustered space is estimated as:
where
is the distribution of the input space.
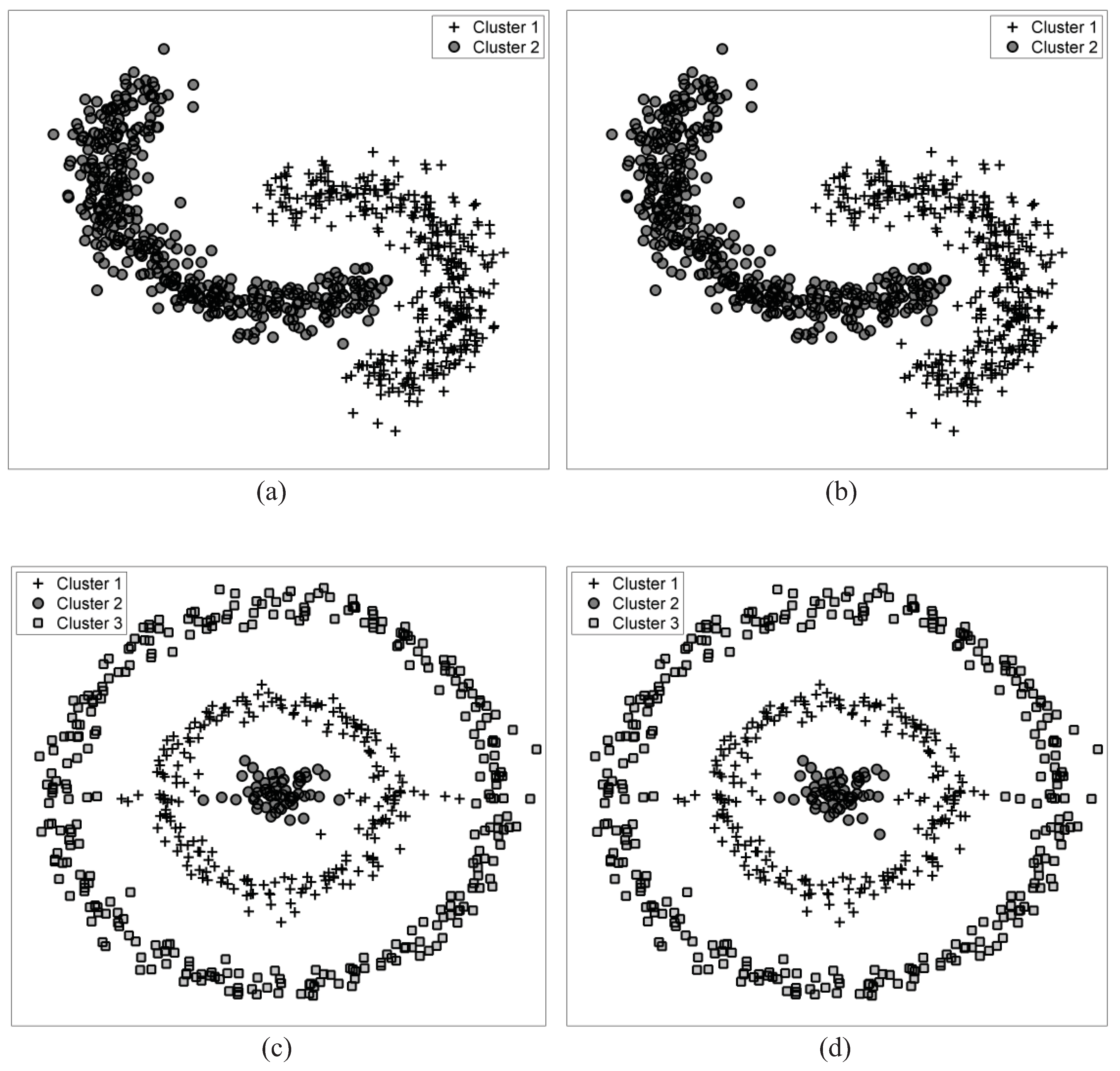
Figure 1 demonstrates a many-to-one mapping, where each symbol,
, for
, represents a cluster of samples from the input space, and
is the number of clusters.
Although clusters have different number of samples, but the average number of samples in each cluster is
, where
is the conditional entropy of the clustered space given the input space and is estimated as:
The number of clusters is
, where
is the entropy of the clustered space. Note that
is upper bounded by
and is equal to the upper bound only when all clusters have an equal number of samples.
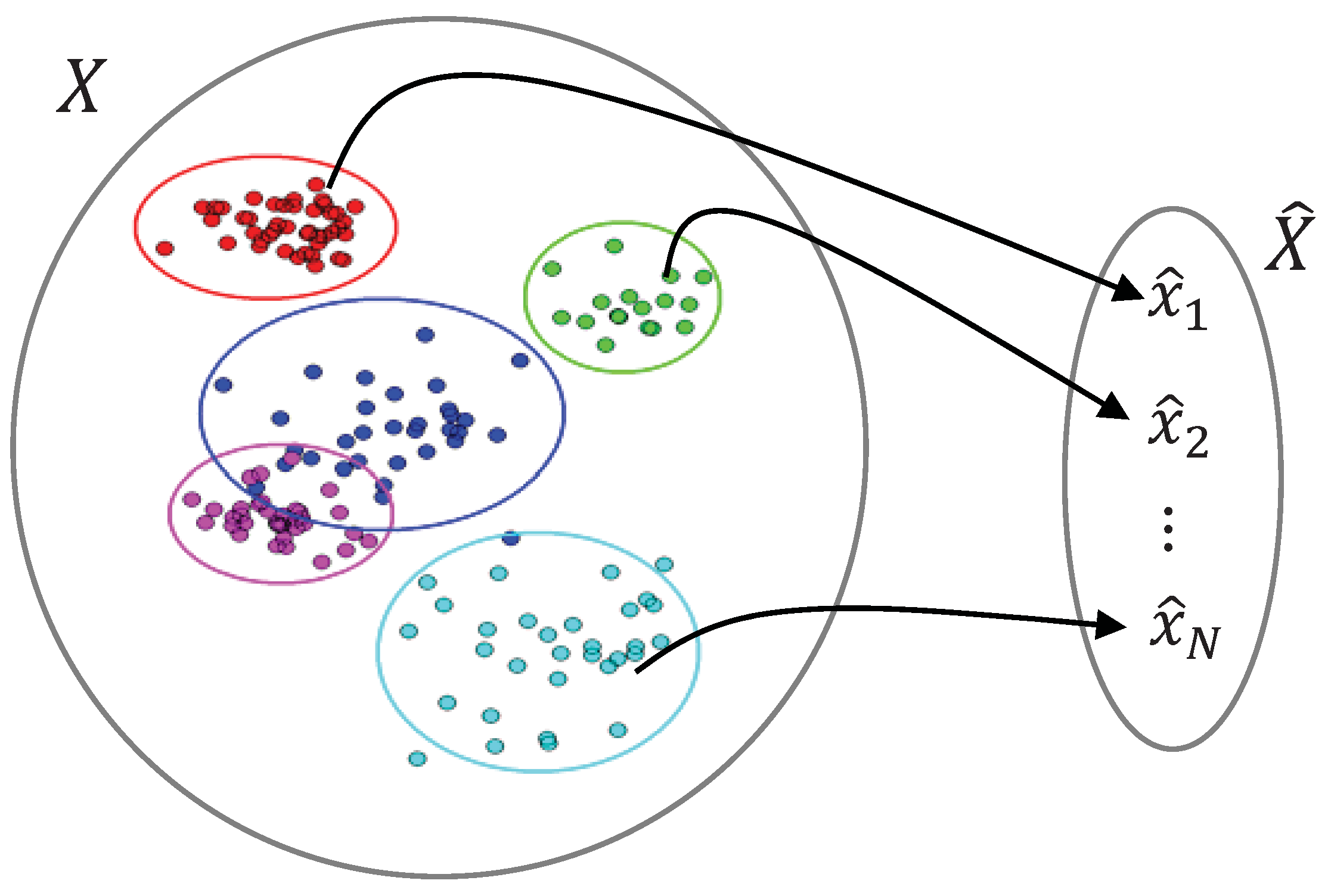
Figure 1.
Demonstration of a many-to-one mapping from the input space, includingsemi-infinite number of discrete samples, to a finite number of symbols, , in the clustered space.
Figure 1.
Demonstration of a many-to-one mapping from the input space, includingsemi-infinite number of discrete samples, to a finite number of symbols, , in the clustered space.
To obtain a lossless many-to-one mapping, the immediate goal is to preserve the information in
in the projected space,
. The loss of information due to mapping is measured by the conditional entropy,
, where
is the amount of information in
. The mutual information between the input and clustered space,
, is estimated as:
Notice how the mutual information is estimated based on only the input distribution,
, and mapping distribution,
. Mutual information gives us the rate by which the clustered space represents the input space. For a lossless mapping,
or
, which in turn means that all the information in the input space is sent to the clustered space. While a higher rate for the clustered space generates less information loss, reducing this rate increases the information loss, therefore introducing a tradeoff between the rate and the information loss. In clustering, the goal is to introduce a lossy many-to-one mapping that reduces the rate by representing the semi-infinite input space with a finite number of clusters, thus introducing information loss such that
.
The immediate goal in clustering is to introduce clusters with the highest similarity or lowest distortion among its samples. Distortion is the expected value of the distance between the input and clustered spaces,
, defined based on the joint distribution,
, as:
Different proximity measures can be defined as distortion, for instance, for the Euclidean distance,
are the center of clusters and
is the cluster variance and
is a uniform distribution, where
is the normalizing term and
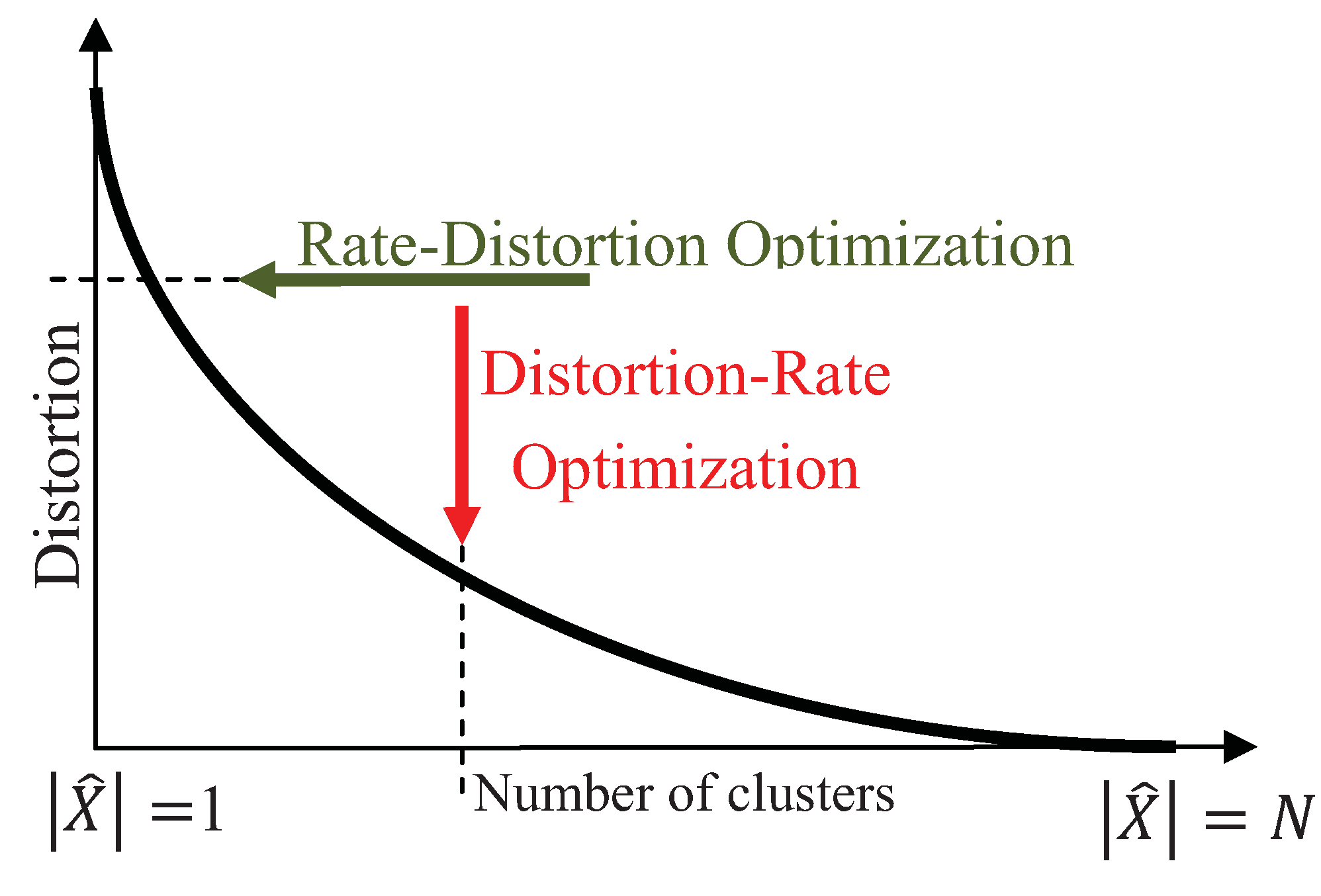
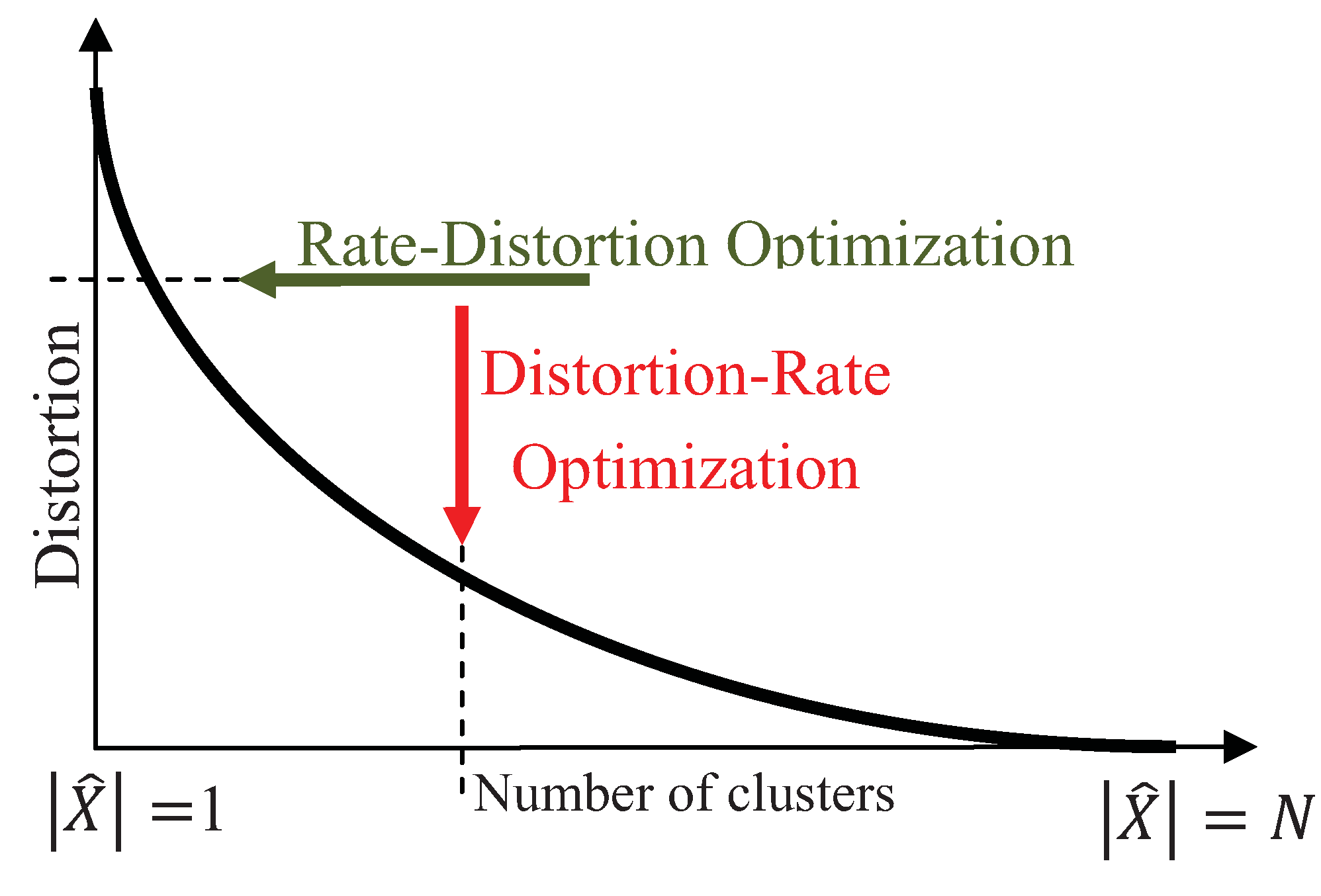
is the indicator function. The tradeoff between the preserved amount of information and the expected distortion is characterized by the Shannon-Kolmogorov rate-distortion function, where the goal is to achieve the minimum rate for a given distortion, illustrated by the horizontal arrow in
Figure 2. The rate-distortion optimization has been extensively used for quantization, where the goal is to achieve the minimum rate for a desired distortion [
17]. Unlike quantization, the goal in clustering is to minimize the distortion for a preferred number of clusters,
, thus, the distortion-rate function is optimized instead:
In
Figure 2, the vertical arrow demonstrates the distortion-rate optimization that achieves the lowest distortion for a desired rate. Note that the number of clusters,
, places an upper bound on the rate, determined by the mutual information. Assuming that decreasing distortion monotonically increases the mutual information, clustering can be interpreted as maximizing the mutual information for a fixed number of clusters,
, where
is the number of clusters.
Figure 2.
Demonstration of the rate-distortion and distortion-rate optimizations by the horizontal and vertical arrows, respectively.
Figure 2.
Demonstration of the rate-distortion and distortion-rate optimizations by the horizontal and vertical arrows, respectively.
2.3. Parzen Window Estimator with Gaussian Kernels
The distribution of samples in cluster
is approximated by the non-parametric Parzen window estimator with Gaussian kernels [
21,
22], in which a Gaussian function is centered on each sample as:
where
is transpose,
is the dimension of
,
is the covariance matrix,
are the samples of cluster
, and the cardinality
is the number of samples in that cluster. Assuming the variances for different dimensions are equal and independent from each other, thus, providing us with a diagonal covariance matrix with constant elements,
, the distribution is simplified as:
where
is a Gaussian function with mean
and variance
. Using the distribution estimator in (9), the quadratic terms in (7) can be further simplified as:
where
and
are the samples from clusters
and
, respectively, and
are clusters from the clustered space. Note that the convolution of two Gaussian functions is also a Gaussian function.
Back to the clustering problem, in which the input space is the individual samples and clustered space is the finite number of clusters, the quadratic mutual information in (7) is restructured in the following discrete form:
The distribution of data,
, is equal to the distribution of all samples considered as one cluster, and is estimated using (9) as:
where
is the total number of samples,
, and
is the number of samples in the
cluster,
. The distribution of the clustered space, on the other hand, is estimated as:
The joint distribution,
, for each of the
clusters of the clustered space is estimated as:
Substituting (12), (13) and (14) in (11) provides us with the following approximation for the discrete quadratic mutual information (proof provided in
Appendix):
For simplification, here we define the between cluster distance among clusters
and
, as
, therefore, (15) can be represented as:
where
is a constant.
2.4. Hierarchical Optimization
The proposed hierarchical algorithm, similar to most hierarchical clustering algorithms, operates in a bottom-up approach. In this approach clusters are merged together until one cluster is obtained, and then the whole process is evaluated to find the best number of clusters that fits the data [
4]. Such clustering algorithms start by assuming each sample as an individual cluster, and therefore require
merging steps. To reduce the number of merging steps, hierarchical algorithms generally exploit an low-complexity initial clustering, such as
k-means clustering, to generate
clusters, far beyond the expected number of clusters in the data, but still much smaller than the number of samples,
[
23,
24]. The initial clustering generates small spherical clusters, while significantly reducing the computational complexity of the hierarchical clustering.
Similarly, in the proposed hierarchical algorithms, clusters are merged; however, the criterion is to maximize the quadratic mutual information. Here we propose two approaches for merging, the agglomerative clustering and the split and merge clustering. In each hierarchy of the agglomerative clustering, two clusters are merged into one cluster to maximize the quadratic mutual information. In each hierarchy of the split and merge clustering, on the other hand, the cluster that has the worst effect on the quadratic mutual information is first eliminated, and then its samples are assigned to the remaining clusters in the clustered space. Following, these two approaches are explained in details.
2.4.1. Agglomerative Clustering
In this approach, we compute the changes in the quadratic mutual information after combining any pair of clusters to find the best two clusters for merging. We pick the pair that generates the largest increase in the quadratic mutual information. Since, at each hierarchy, clusters with the lowest distortion are generated, therefore, this approach can be used for optimizing the distortion-rate function in (5). Assuming that clusters
and
are merged to produce
, the changes in the quadratic mutual information,
, can be estimated as:
where
is the quadratic mutual information at the step
. The closed form equation in (17) provides us with the best pair for merging without literally combining each pair and estimating the quadratic mutual information. Eventually, the maximum
at each hierarchy determines the true number of clusters in the data.
Table 1 introduces the pseudo code for the agglomerative clustering approach.
Table 1.
Pseudo code for the agglomerative clustering.
Table 1.
Pseudo code for the agglomerative clustering.
| 1: Initial Clustering,
|
| 2: for
do |
| 3: Estimate
for all pairs |
| 4: Merge clusters
and , in which |
| 5: end for |
| 6: Determine # of clusters |
2.4.2. Split and Merge Clustering
Unlike the agglomerative clustering, this approach detects one cluster at each hierarchy for elimination. This cluster has the worst effect on the quadratic mutual information, meaning that out of all clusters, this is the cluster to be eliminated such that the mutual information is maximized. Assuming cluster
has the worst effect on the mutual information, the change in the quadratic mutual information,
, can be estimated as:
The samples of the worst cluster are then individually assigned to the remaining clusters of the clustered space based on the minimum Euclidean distance, in which the closest samples are assigned first. This process also proceeds until one cluster remains. Eventually, based on the maximum changes in the quadratic mutual information at different hierarchies,
, the true number of clusters is determined.
Table 2 introduces the pseudo code for the split and merge clustering approach.
Table 2.
Pseudo code for the split and merge clustering.
Table 2.
Pseudo code for the split and merge clustering.
| 1: Initial Clustering,
|
| 2: for
do |
| 3: Estimate
for all pairs |
| 4: Eliminate cluster
, in which |
| 5: for
do |
| 6: Assign sample
to cluster |
| 7: end for |
| 8: end for |
| 9: Determine # of clusters |
Comparing the two proposed hierarchical algorithms, the split and merge clustering has the advantage of being unbiased to the initial clustering, since the eliminated cluster in each hierarchy is entirely re-clustered. However, the computational complexity of the split and merge algorithm is in the order of
and higher than the agglomerative clustering, that is in the order of
. The split and merge clustering also has the advantage of being less sensitive to the variance selection for the Gaussian kernels, since re-clustering is performed based on the minimum Euclidean distance.
Both proposed hierarchical approaches are unsupervised clustering algorithms; therefore require finding the true number of clusters. Determining the number of clusters is challenging, especially when no prior information is given about the data. In the proposed hierarchical clustering, we have access to the changes of the quadratic mutual information from the hierarchies. The true number of clusters is determined when the mutual information is maximized or when a dramatic change in the rate is observed.
Another parameter to be set for the proposed hierarchical clustering is the variance of the Gaussian kernels for the Parzen window estimator. Different variances detect different structures of data. Although there are no theoretical guidelines for choosing this variance, but some statistical methods can be used. For example, an approximation can be obtained for the variance in different dimensions,
where
is the diagonal element of the covariance matrix of thedata [
25]. We can also set the variance proportional to the minimum variance observed in each dimension,
[
26].



{kind=link}
{kind=link}
{kind=link}
{kind=link}