2.2.1. The Case
In this paragraph, we first introduce informally how it is possible to derive a large system approximation of the mutual information corresponding to the case where the covariance matrix of the transmitted signal is . In order to simplify the notations, we denote by I.
Background on the behaviour of the eigenvalue distribution of Let
be a
complex Gaussian random matrix representing the channel matrix of a MIMO system (we indicate that
is a
matrix by denoting
by
), and consider its associated Gram matrix defined by
. Under certain assumptions on the probability distribution of
(see the examples below), it appears that the empirical eigenvalue distribution
of
defined as
tends to have a deterministic behaviour when the dimensions
r and
t converge to
in such a way that
, where
. In order to shorten the notations,
stands in the following for
r and
t converge to
in such a way that
. This is equivalent to saying that it exists deterministic probability measures
(which depend on the dimensions
r and
t) for which
almost surely when
for each well chosen test function
φ. Sometimes, the measures
also converge towards a probability distribution
, which does not depend on the values of
but only on
. In this case, the eigenvalue distribution converges towards
, which is called the limit eigenvalue distribution
. In order to illustrate the above phenomenon, we consider the simplest situation in which the entries of
are independent identically distributed (i.i.d.) zero mean random variables of variance
, and where
. In this case, the measure
is absolutely continuous, and its density
is given by:
The corresponding distribution is called the Marčenko–Pastur distribution, and was introduced for the first time in [
18].
In order to simplify the notations, we no longer mention the dimensions
r and
t in the following, and denote
by
respectively. In order to establish that
has a deterministic behaviour when
, it is well known that it is sufficient to establish that (
3) holds for
for each
(see e.g., [
19,
20]). In order to reformulate (
3) for
, we introduce the Stieltjes transform
of a positive measure
ν carried by
, which is the function defined for each
as:
Equation (
3) for
for each
is thus equivalent to:
for each
because
and
In order to prove (
5), a possible approach is to establish that
has the same asymptotic behaviour as a deterministic quantity which appears to coincide with the value at point
of the Stieltjes transform of a certain probability measure
μ carried by
. For this, it is useful to introduce the resolvent of matrix
defined as the
matrix valued function
defined for each
by:
It is important to notice that
Under suitable hypotheses on
, the random entries of
turn out to have the same behaviour as the entries of a deterministic
matrix
, which, in particular, implies that
The entries of matrix
can be expressed in closed form in terms of the (unique) positive solutions
of a nonlinear system of
equations depending on
,
, and the statistical properties of
. This nonlinear system of equations is called in [
21] the canonical equations associated to the random matrix model
. The number of unknowns
depends on
and the statistics of
. Then, it is shown that function
coincides with the Stieltjes transform of a certain probability measure
μ, which, in turn, establishes that (
5) holds for each
. It is also useful to notice that the entries of matrix
defined as
have the same behaviour as the entries of a
deterministic matrix
. These entries can be evaluated in terms of the solutions of the above-mentioned canonical equations.
We also mention that it is often possible to evaluate the accuracy of the approximations. In the context of a number of complex Gaussian random matrix models, it holds that
Large system approximation of I We finally consider the problem of approximating
. We first note that
and thus coincides with a functional of the eigenvalues of
. It can therefore be approximated by a deterministic term that can very often be expressed in an explicit way. In order to explain this, we use the following well-known identity:
As
can be approximated by
, it can be shown that
But, in the context of the various usual MIMO models, it turns out that
where
and
represent the solutions of the nonlinear system of
equations governing the entries of
and where
g is a well chosen function that is expressed in closed form. Taking the mathematical expectation of (
12), and using that the error between
and
is a
term for each
(see Equation (
10)), it can be shown that
or equivalently
where the large system approximation
of
I is defined by:
As
I and
scale linearly with
t when
t increases, Ref (
14) implies that the relative error between
I and its large system approximation is a
term, and thus decreases rather fast towards 0 when
t increases. This explains partially why large system approximation of mutual information are very accurate even for moderate number of transmit and receive antennas.
Examples In order to illustrate these results, we provide the expressions of
and
in the context of useful random matrix models. We first consider the case where
can be written as:
where the entries of
are complex Gaussian i.i.d. random variables with zero mean and variance 1 and where
and
are
and
deterministic positive matrices such that
Then, it can be shown that the nonlinear system of equations:
has a unique pair of positive solutions denoted
. Matrices
and
introduced above are given by:
The two canonical equations defining
can therefore be written as:
The corresponding large system approximation
of
I is given by:
so that function
g defined by Equation (
13) is given by
. It is useful to justify the above expression of
because the proof below extends in the context of other models. For this, it is necessary to establish that Equation (
13) holds for the above function
g. It can be shown that the right-hand side of (
23) converges towards 0 when
. Therefore, it remains to check that the derivative w.r.t.
of the right-hand side of (
23) coincides with
. We introduce the following function
of three variables:
which is obtained by replacing
with the fixed parameters
into the expression of the right-hand side of (
23). A very important property of function
V is:
In fact, it is straightforward that
and vanishes because
satisfies the canonical Equation (
22). We obtain similarly that (
26) holds because
is the solution of the canonical Equation (
21). In sum, it appears that (
25,
26) are equivalent to the canonical Equations
19 and
20.
The derivative w.r.t.
of the right-hand side of (
23) is given by:
and thus coincides with
by (
25,
26). Using (
21,
22) as well as the expressions (
19,
20) of
and
, this is easily seen to be equal to
; indeed,
Hence, both sides of (
13) have the same derivative w.r.t.
. Moreover, both sides converge towards 0 when
, thus Equation (
13) is verified for
. This, together with (
12), establishes that (
23) holds.
We now consider the case where channel
is given as:
where matrices
are mutually independent complex Gaussian random matrices with i.i.d. entries of mean 0 and variance 1 and where
and
are
and
deterministic positive matrices such that
for
. It is important to notice that the parameter
L is independent of
r and
t, and thus does not scale with the number of antennas. As shown in [
7,
12], model (
27) is useful in the context of multipath channels with independent paths. Matrices
and
are given by:
where the
are the unique positive solutions of the system of
equations:
for
. The large system approximation of
I is this time given by [
7,
12]:
and thus corresponds to Equation (
14) when
. (
33) is proved in the same way as (
23) by introducing the function of
variables
obtained by replacing into the right-hand side of (
33) functions
,
by fixed vectors
κ and
, and by observing that the canonical Equations (
31,
32) are equivalent to:
We now consider a third random matrix model modeling bi-correlated Rician channels. We assume that
can be written as:
where the entries of
are complex Gaussian i.i.d. random variables with zero mean and variance 1 and where
and
are
and
deterministic positive matrices such that
Matrix
is a deterministic
matrix satisfying:
This time, matrices
and
are given by:
where
satisfy the same canonical Equations (
21,
22) as in the case of the Rayleigh bi-correlated MIMO channels,
i.e.,
It can be shown as previously that the corresponding large system approximation
of
I is now given by [
11,
22]:
and corresponds to Equation (
14) when
is equal to:
A slightly more general non-zero mean MIMO model is:
where ∘ represents the Schur–Hadamard product, where
represents a
matrix such that
and
, and where
and
are deterministic unitary
and
matrices.
and
have the same properties as in the context of model (
36). This MIMO channel model was introduced in [
23], studied in the large system regime in the zero mean case in [
10] and in the non-zero mean case in [
24] and, using the replica method, more recently in [
9,
16] in the context of the MIMO multi-access channel. As we are essentially interested by the functionals of the eigenvalues of
, it is possible to assume without restrictions that
and
are reduced to
and
respectively. In this case, matrices
and
are given by:
where
and
are two diagonal
and
matrices whose elements are the positive solutions of the equations:
for
, and
, where
and
. The large system approximation
is now given by:
and corresponds to Equation (
14) for a suitable function
. We finally consider the model representing the MIMO multiple access channel addressed in [
13].
is now a
matrix given by:
where the various matrices
satisfy the same conditions as in the context of model (
27).
and
are the
and
matrices given respectively by:
where matrices
are defined by:
and where the
are the unique positive solutions of the system of
equations:
for each
. The large system approximation
is equal to:
and thus correspond to Equation (
14) when
.
Note that this model can be obtained from model (
27), which provides a unified view. If we consider
and
then
gets the same expression as Equation (
51); the large system approximation (
57) is then easily obtained from (
33).
2.2.2. The General Case
In order to address the general case
, it is sufficient to exchange random matrix model
by random matrix model
, and to evaluate the large system approximation
of the corresponding average mutual information
. This is straightforward if the right multiplication of
by
leads to a random matrix model for which the large system approximations are easy to evaluate. This turns out to be the case in the context of models (
15,
27 and
36) and also in the context of model (
51) if
matrix
is block diagonal,
i.e.,
, a condition that fortunately holds in the multiuser precoding schemes presented in [
13]. For these models,
and
belong to the same class of random matrix model and it is then sufficient to replace:
for model (
15), matrix
by
,
for model (
27), matrices
by
,
for model (
36), matrices
and
by
and
respectively,
for model (
51), matrices
by
(where
)
in the various equations defining the large system approximations of
I (note that the various matrices
are multiplied from both sides by
as they are covariance matrices;
e.g., the matrix
is the transmit covariance matrix of channel
, therefore the transmit covariance matrix of the channel
is
). In the context of model (
45) the right multiplication by
unfortunately modifies the structure of the model. Using the replica trick [
9] nevertheless derived a large system approximation
of
(see also [
16] in the case of the corresponding multi-user MIMO channel). It is however not clear that the optimization of
completely fits with the unified presentation of the present paper. Therefore, we will not elaborate on the model (
45) in the following.
In the context of models (
15,
27 and
36), matrices
and
as well as solutions of the canonical equations
still depend on
, but also on the covariance matrix
. As the dependence versus
does not play any role in the following, we now denote
,
,
δ and
by
,
,
and
respectively. It is easily seen that for the above 3 models the large system approximation of
can be written as:
where
is a certain
positive matrix valued function given in closed form, and
is a function also given in closed form. As previously, it is useful to introduce the function
defined by:
and which corresponds to the expression (
58) of
but in which
is replaced by the fixed parameter
. In others words,
can be written as:
In the context of models (
15,
27 and
36), it holds that
for each pair
. As previously, these relations follow directly from the canonical equations verified by the components of
and
. It is important to notice that the boundedness assumptions (
28,
38) imply that
represents a valid large system approximation of
provided that the mean and the covariance matrices associated to model
satisfy such assumptions. For this, it is sufficient to assume that matrix
satisfies:
In particular, property
holds if matrix
satisfies (
63). As explained below, this induces some technical difficulties to justify the relevance of the approach consisting in replacing the optimization of
by the optimization of
.
We finally mention that in the context of model (
51), if
is block-diagonal, it holds that
for certain matrix valued functions
. In [
13], it is proposed to optimize (
64) w.r.t. matrices
under the constraints
for each
. As the formulation of this problem slightly differs from the optimization of
in models (
15,
27 and
36), we will not discuss this issue in the next sections. However, the results presented below can easily be adapted to the context of model (
51).

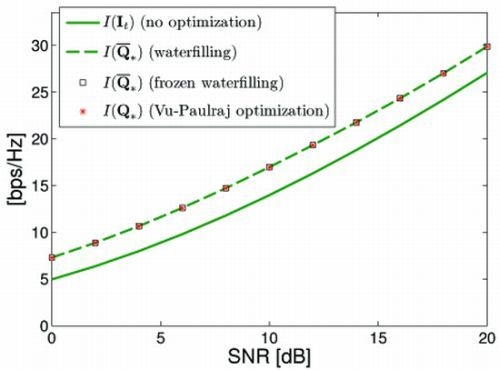

{kind=link}
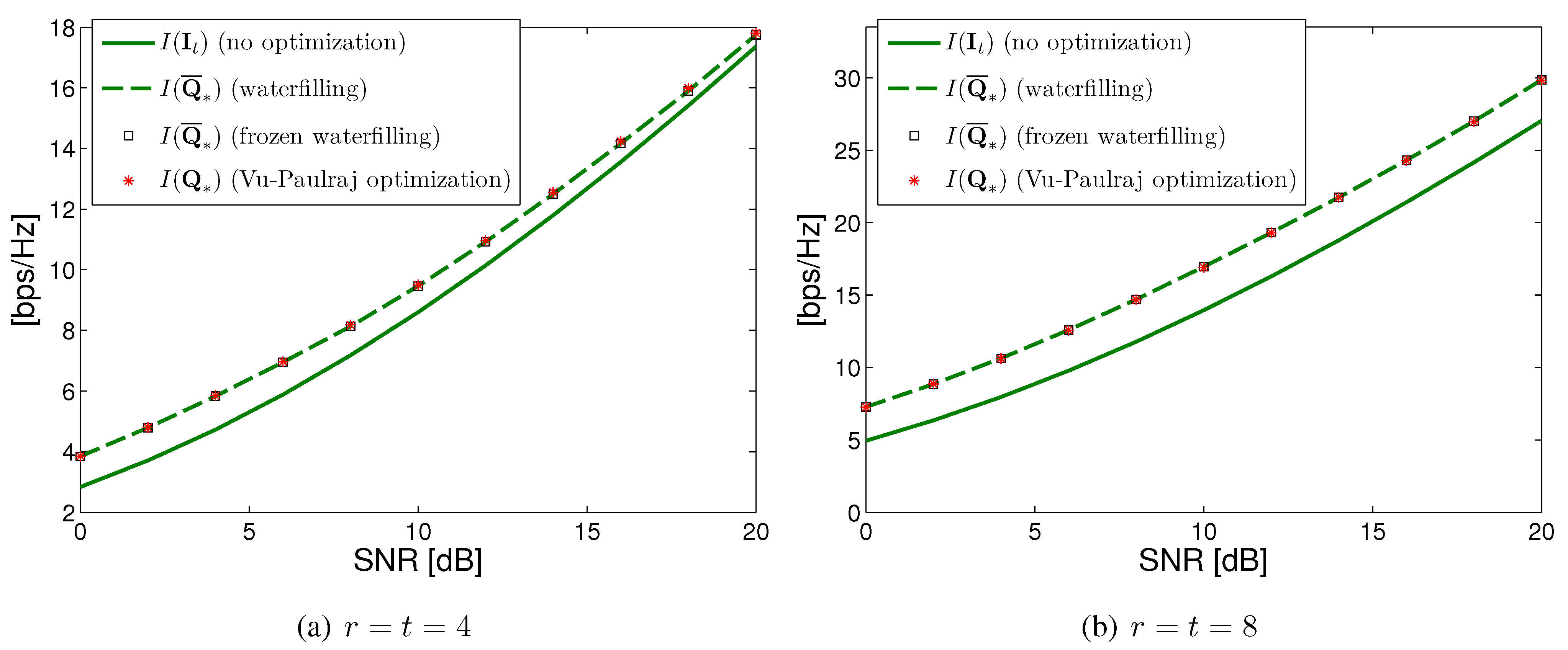{kind=link}
