5.2. Estimation Approach
For Problem 1 involving only two assets (i.e., n = 2) subject to a diversity constraint, the size of the feasible region usually can be calculated directly. However, as n gets larger, the size of the feasible region becomes hard to derive. Here, we adopt a uniform sampling approach to generate a sample set of points in the feasible region of Problem 1, and then use the sample set to estimate the feasible ratio of a diversity constraint, as described below.
This approach first generates an equally spaced hyper-grid in the (n−1)-dimensional subspace . Let the grid spacing be
for some integer m>2, and consequently there are
crossover points in the hyper-grid. For each crossover point () in the (n−1)-dimensional subspace, if , then the point () is included in the sample set where . The total number of points in the sample set is used as an estimate of the size of the feasible region of Problem 1 without any diversity constraint.
In this experiment,
m = 100 is used to generate the equally spaced hyper-grid in the (
n−1)-dimensional subspace
for
n = 2 to 5. For each
n, there are
crossover points in the hyper-grid.
Table 1 shows the number of the crossover points that can be extended to the
n-dimensional space and included into the sample set.
Table 1.
Number of points in the sample set for various n
Table 1.
Number of points in the sample set for various n
| n | 2 | 3 | 4 | 5 |
| # of points in the sample | 101 | 5,151 | 176,845 | 4,596,100 |
Then, functions and
are calculated for every point
in the sample set. Notably, for the Lp-norm constraint, we consider p = 3 and 2, since
and
are commonly used. We also calculate
and
to study the behavior of
as
approaches its limit 1.
The number of points satisfying
in the sample set is used as an estimate for the size of the feasible region of Problem 1 subject to the weight upper-bound constraint in Equation (3). Consequently, the feasible ratio of the diversity constraint
can be calculated by dividing this number by the total number of points in the sample set. Similarly, this can be done for
and
for their respective diversity constraints. In this experiment, we vary the upper bound
from 0 to 1 in step of 0.01.
5.3. Experimental Results
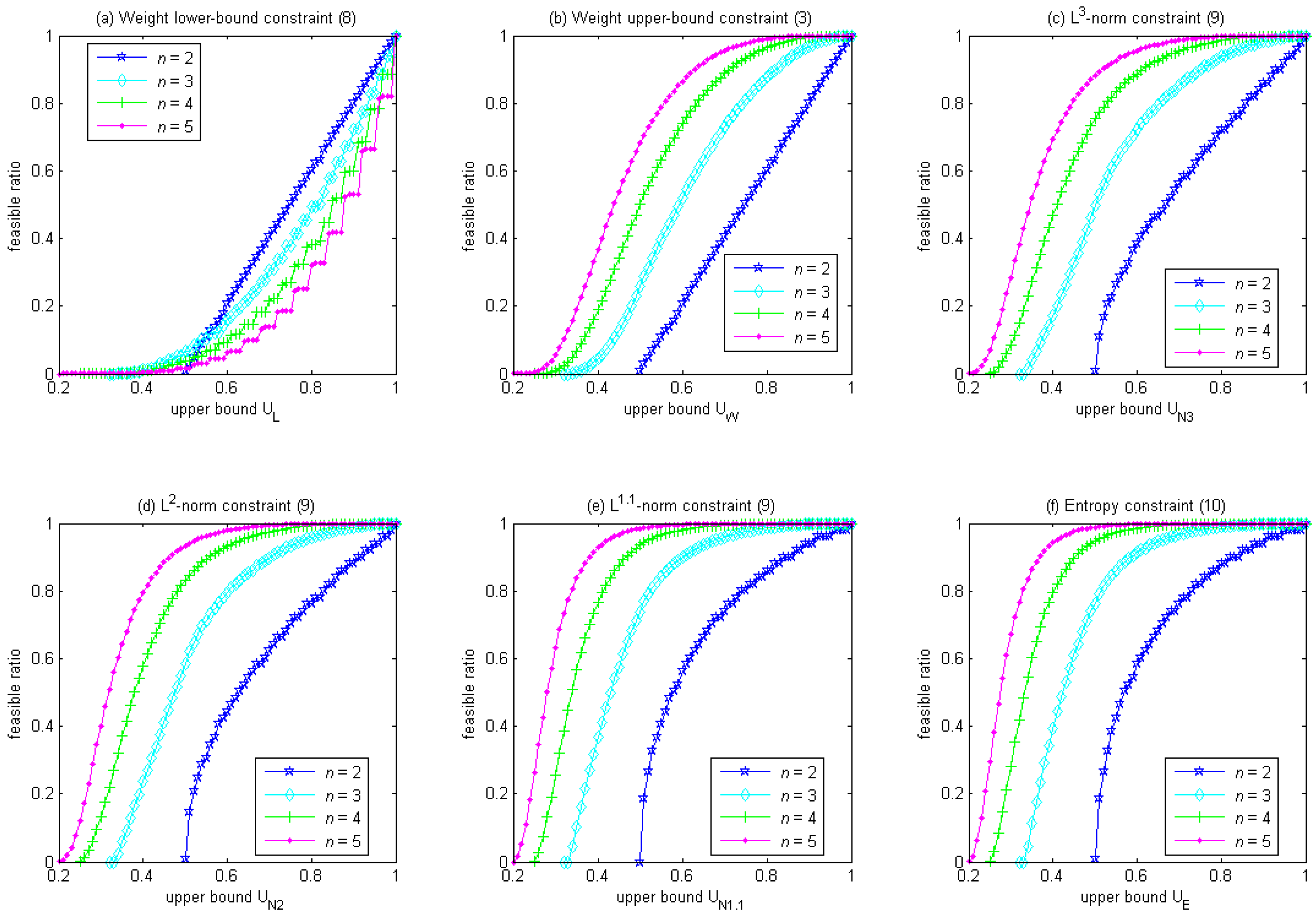
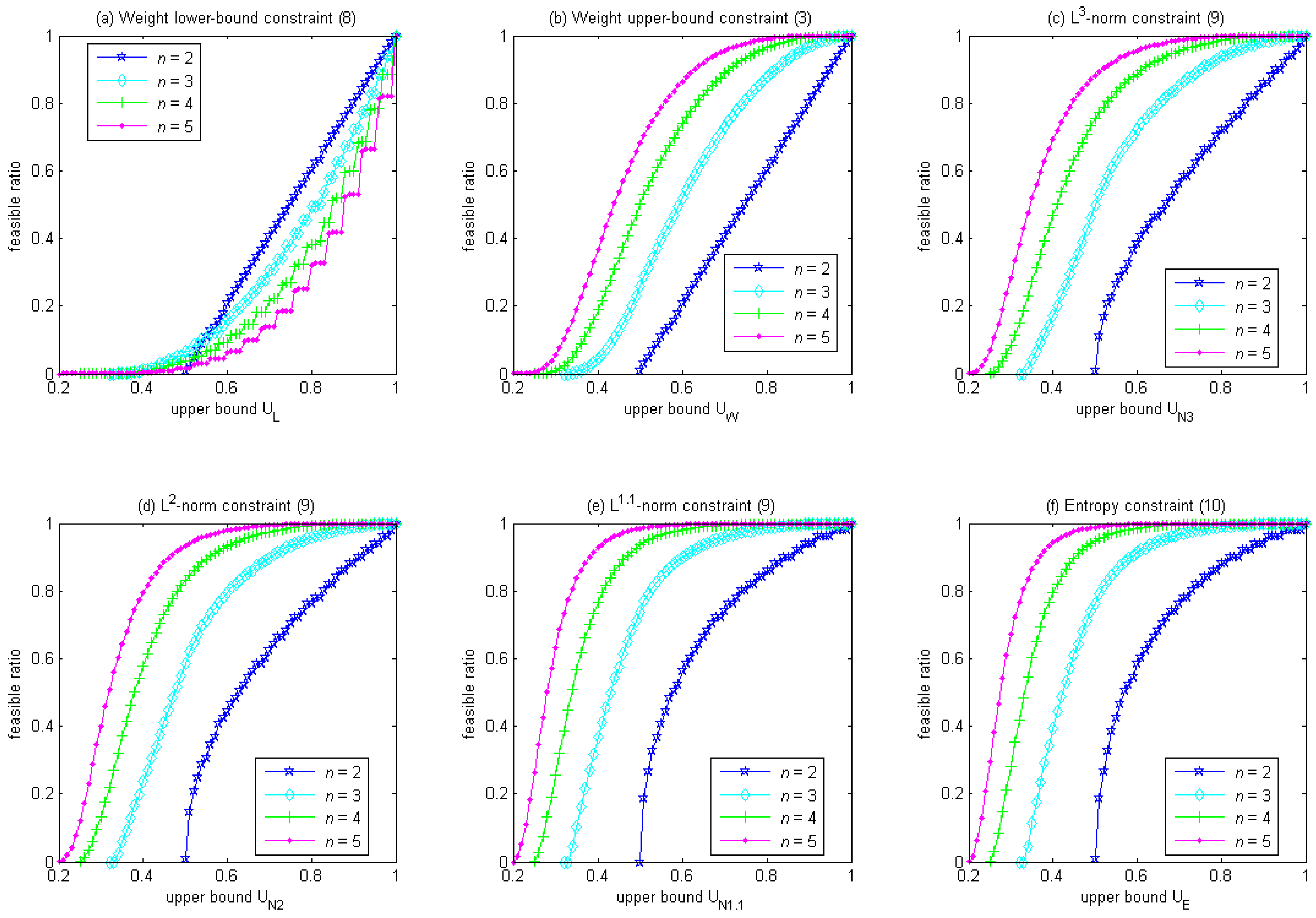
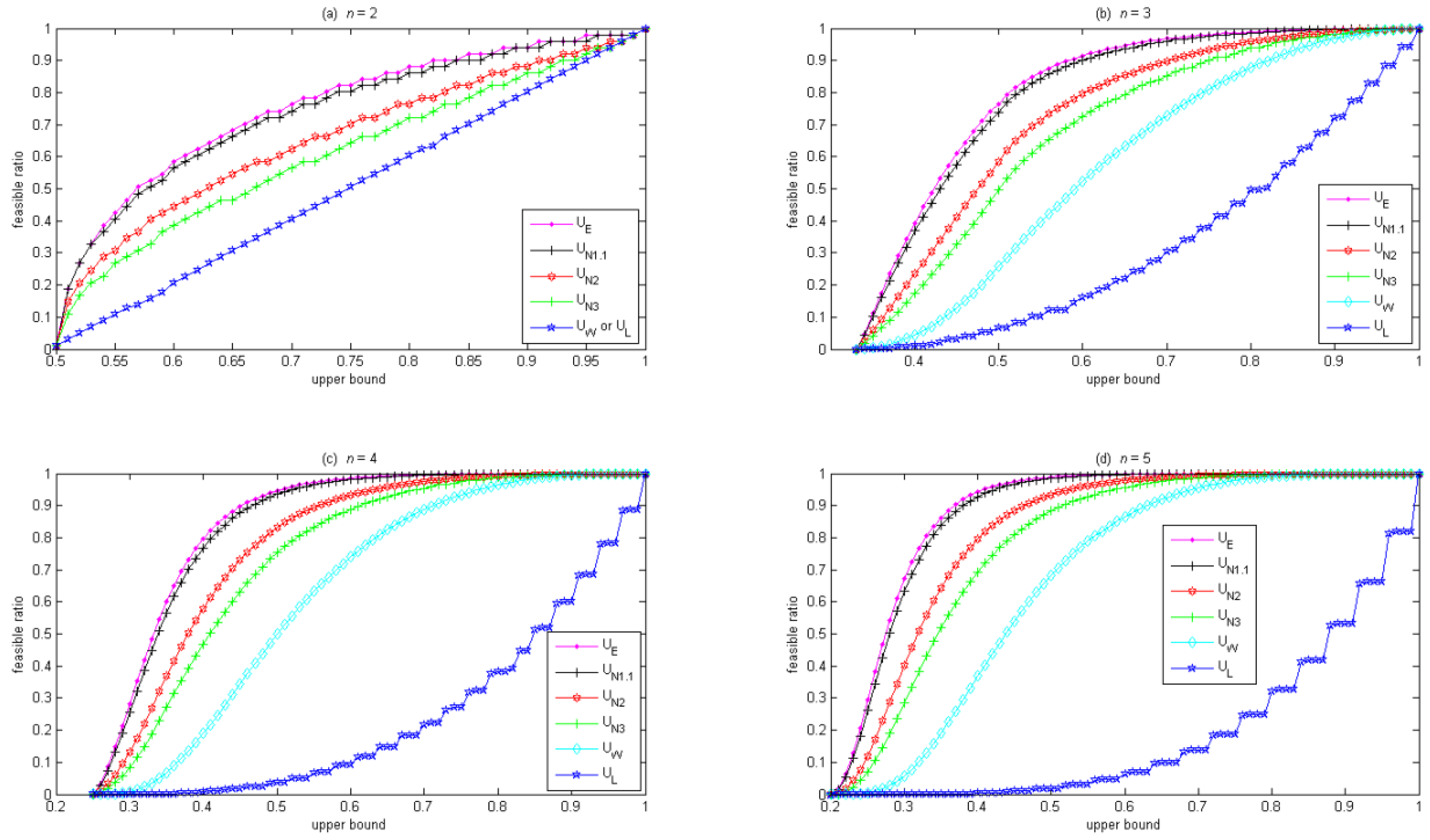
Figure 1 shows that the feasible ratio increases with the upper bound of a diversity constraint in the canonical form. For the weight lower-bound constraint in Equation (8),
Figure 1a shows that, given the same upper bound, larger
n could have a smaller feasible ratio. Also, as the upper bound gradually decreases from 1 to
, the feasible ratio reduces quickly at first but slowly afterward (with the exception at
n = 2, where the feasible ratio reduces at a constant rate). In contrast, for the rest of the diversity constraints,
Figure 1b–f shows that, given the same upper bound, the feasible ratio is always larger for larger
n. Also, as the upper bound gradually decreases from 1 to
, the feasible ratio reduces slowly at first and quickly afterward (with the exception of the weight upper-bound constraint in Equation (3) at
n = 2, where the feasible ratio reduces at a constant rate).
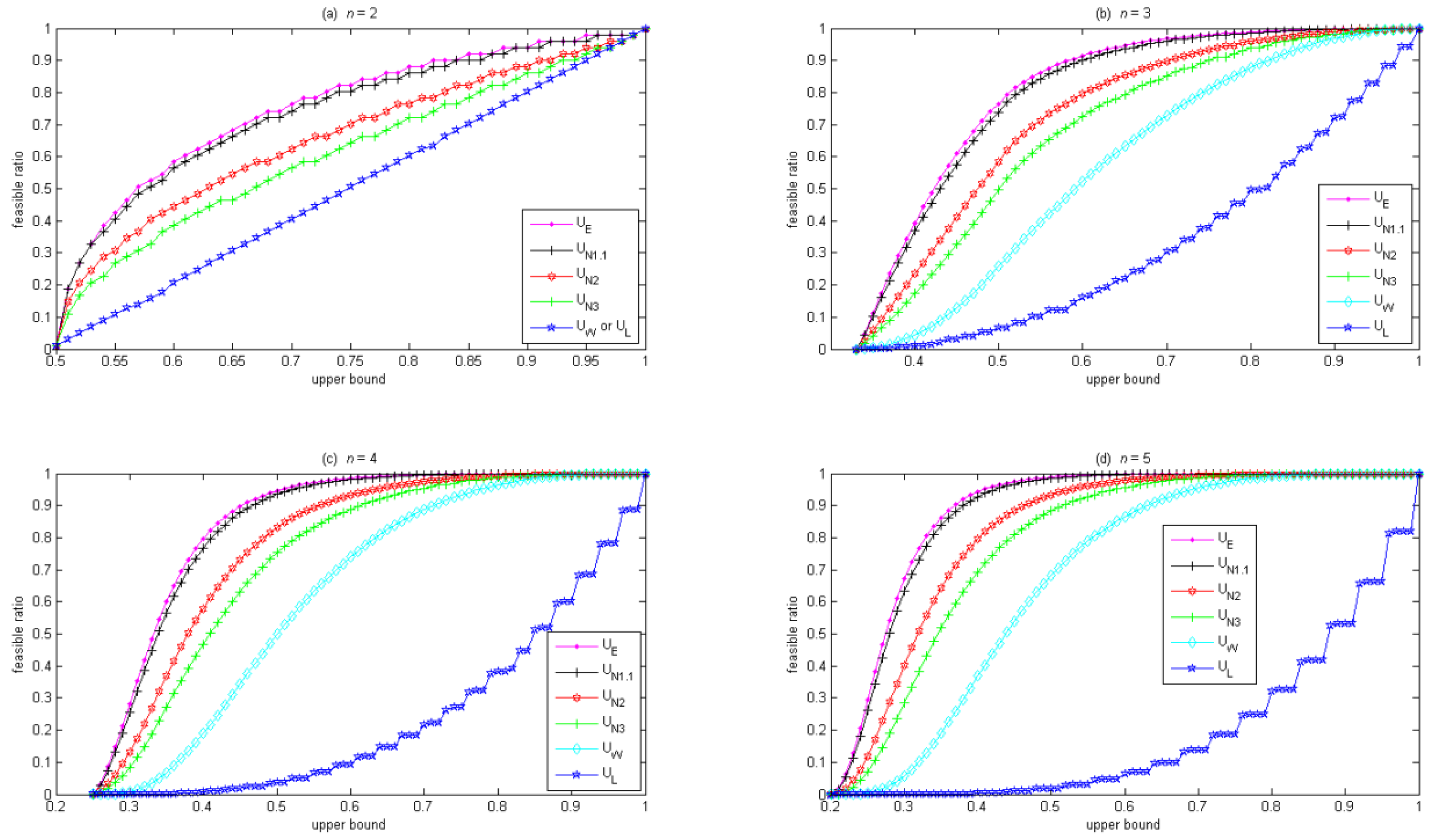
Figure 2 compares how these diversity constraints affect the feasible ratio, where the horizontal axis is the upper bound in these diversity constraints, and the vertical axis is the feasible ratio. Given the same upper bound, the ordering of the feasible ratio is: entropy constraint in Equation (10) ≥
L1.1-norm constraint in Equation (9) ≥
L2-norm constraint in Equation (9) ≥
L3-norm constraint in Equation (9) ≥ weight upper-bound constraint in Equation (3) ≥ weight lower-bound constraint in Equation (8). When the upper bound is 1, the feasible ratio is 1 for all of these diversity constraints. When the upper bound is
, the feasible ratio approaches 0 for all of these diversity constraints since all of these diversity constraints shrink the feasible region to only one solution,
i.e., the equally-weighted portfolio. Notably, when
n = 2, the weight upper-bound constraint in Equation (3) is equivalent to the weight lower-bound constraint in Equation (8), as shown in
Figure 2a. Also note that in
Figure 2, the curve for the
Lp-norm constraint gradually approaches the curve for the entropy constraint as
p decreases from 3 to 1.1. The curves for
L1.01-norm and
L1.001-norm constraints are omitted in
Figure 2 because they closely overlap with the curve for the entropy constraint.
Figure 1.
Feasible ratio vs. upper bound for n = 2 to 5.
Figure 1.
Feasible ratio vs. upper bound for n = 2 to 5.
Figure 2.
Comparison of feasible ratio for various diversity constraints.
Figure 2.
Comparison of feasible ratio for various diversity constraints.
Figure 3.
Distribution of the values of
and
in the feasible region of Problem 1 with n = 3.
Figure 3.
Distribution of the values of
and
in the feasible region of Problem 1 with n = 3.
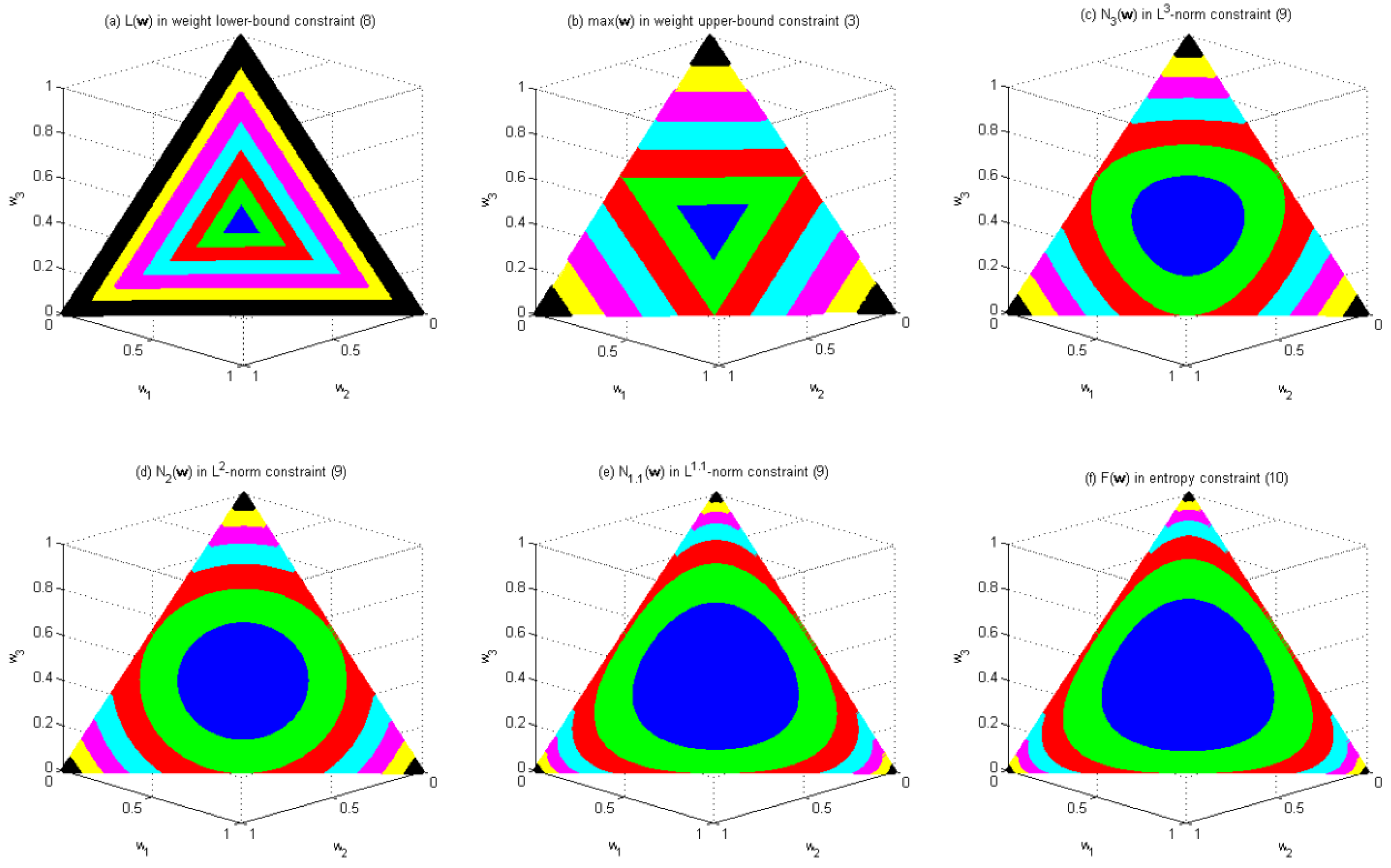
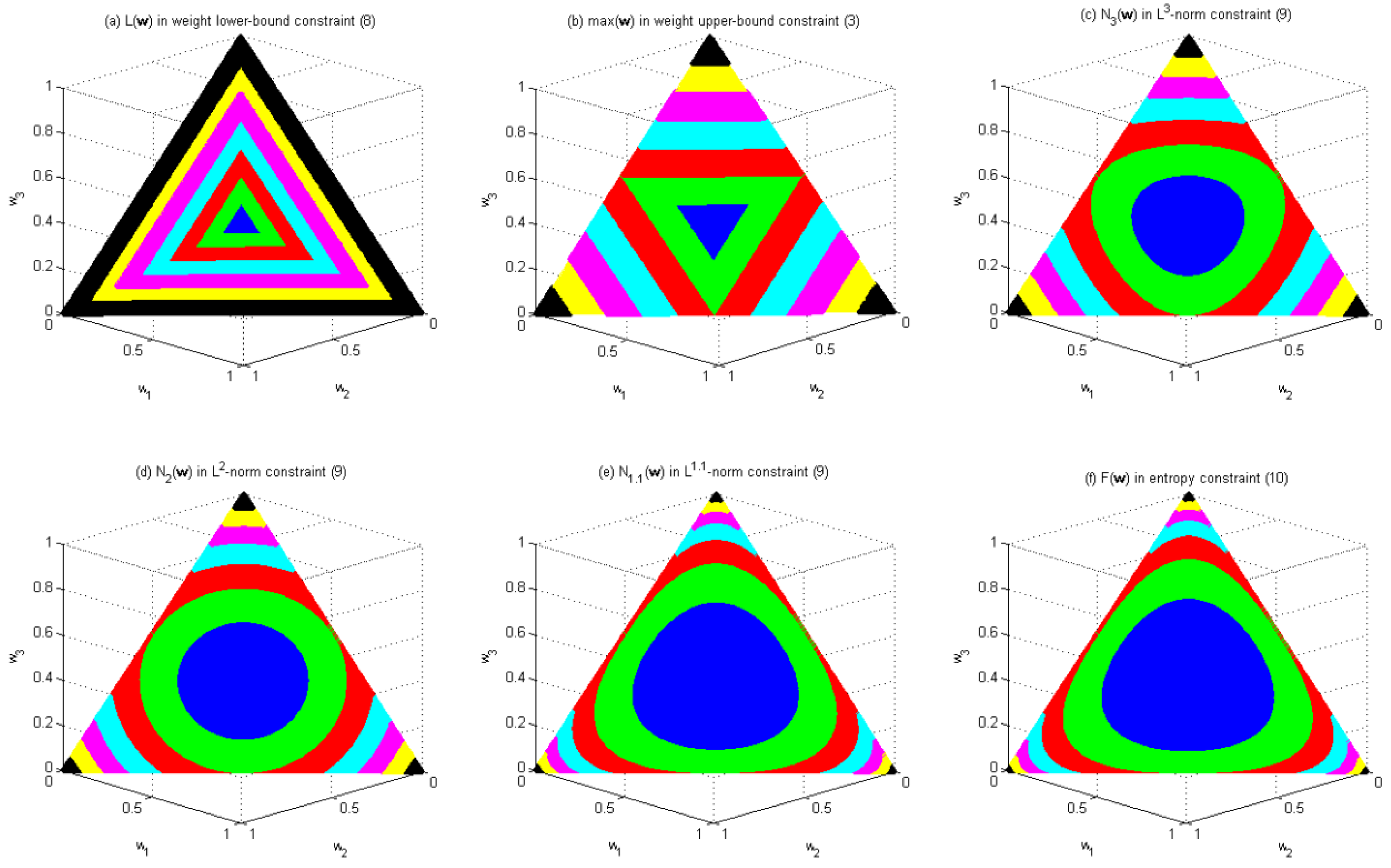
Figure 3 illustrates how these diversity constraints change the shape of the feasible region of Problem 1 with
n = 3. The original feasible region of Problem 1 with
n = 3 is the region enclosed by the largest triangle in each subfigure of
Figure 3.
Figure 3 shows how the values of
and
vary within this feasible region, where different colors are used to indicate the values of these functions. Colors blue, green, red, cyan, magenta, yellow and black represent the intervals (0.3, 0.4], (0.4, 0.5], (0.5, 0.6], (0.6, 0.7], (0.7, 0.8], (0.8, 0.9] and (0.9, 1.0], respectively.
Figure 3a shows that the weigh lower-bound constraint in Equation (8) results in a feasible region similar to the original feasible region, both in terms of shape and orientation. This property has the potential of gradually excluding the solutions along the border of the feasible region as the upper bound of the constraint decreases.
Figure 3b shows that the weigh upper-bound constraint in Equation (3) results in a feasible region similar to the original feasible region in shape but in the opposite orientation. The property has the potential of gradually excluding the solutions near the corners of the feasible region as the upper bound of the constraint decreases.
Figure 3c–e, respectively, shows that the
L3-norm constraint, the
L2-norm constraint and the
L1.1-norm constraint result in a feasible region similar to those in
Figure 3b, except that the shape of the feasible region becomes a squeezed circle for the
L3-norm constraint, a circle for the
L2-norm constraint, and a bloated circle for the
L1.1-norm constraint, instead of a triangle in the weight upper-bound constraint. Thus, they all have the potential of gradually excluding the solutions near the corners of the feasible region as the upper bound of the constraint decreases. Given the same upper bound, they all result in a smaller feasible region than the weight upper-bound constraint does. Furthermore, the feasible region of the
L3-norm constraint is smaller than that of the
L2-norm constraint, which in turn is smaller than that of the
L1.1-norm constraint.
Figure 3f shows that the entropy constraint in Equation (10) results in a feasible region similar to the original feasible region in orientation but different in shape. Similar to
Figure 3a, constraint in Equation (10) has the potential of gradually excluding the solutions along the border of the feasible region as the upper bound of the constraint decreases. Given the same upper bound, constraint in Equation (10) results in a feasible region larger than any of the previous five constraints does. Notably, the feasible region of the
L1.1-norm constraint is similar to that of constraint in Equation (10).





{kind=link}
{kind=link}
{kind=link}