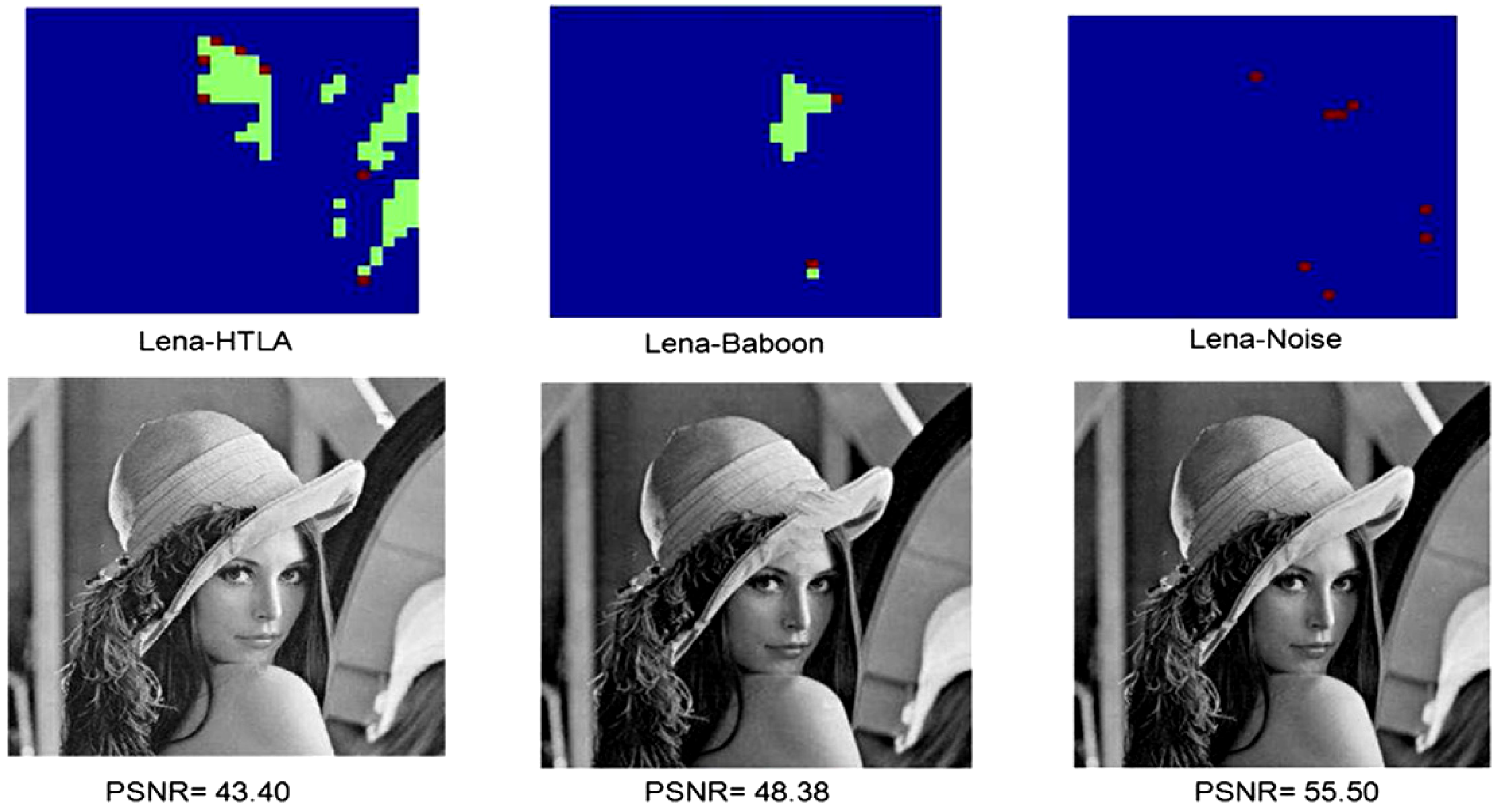
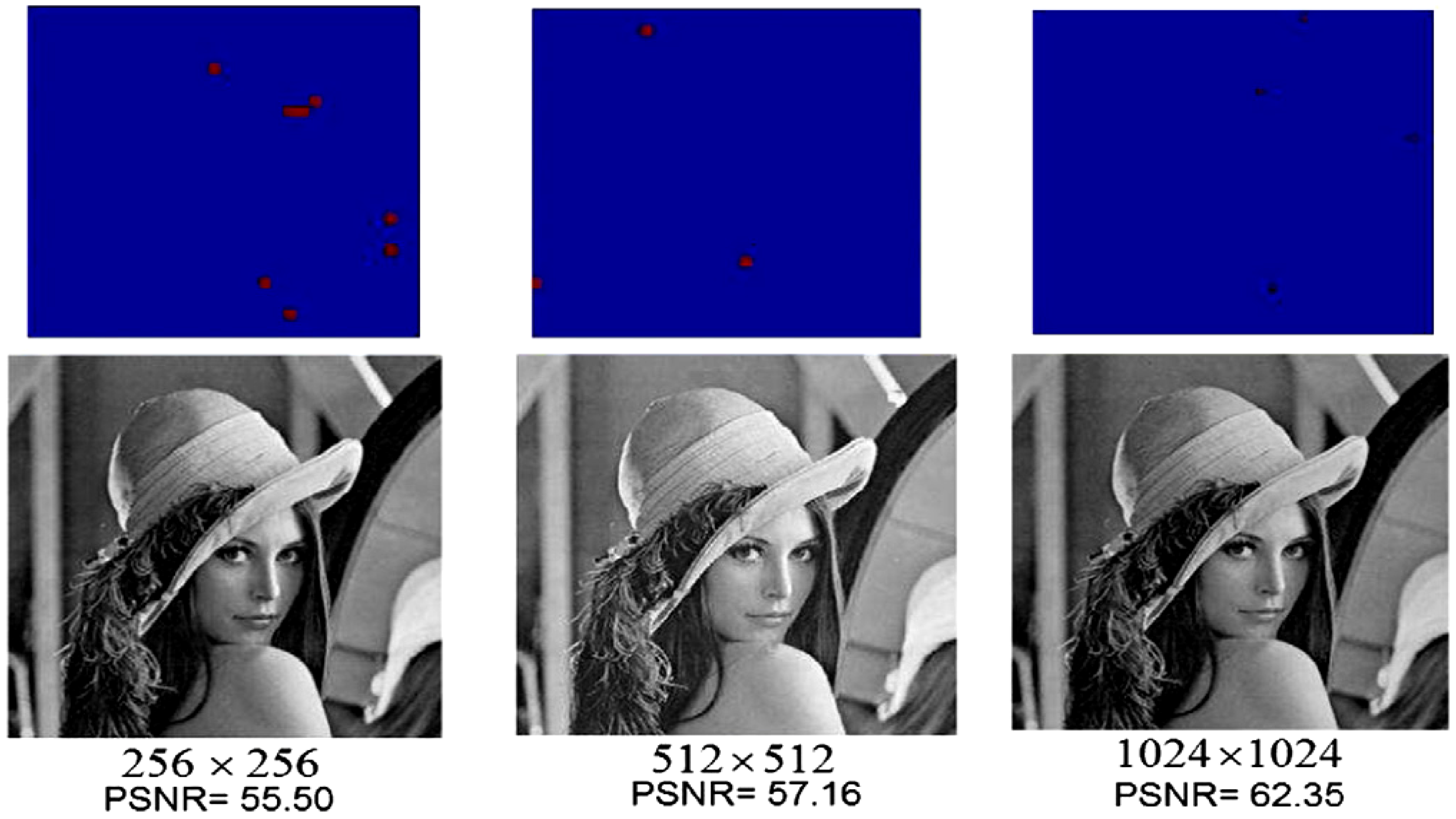
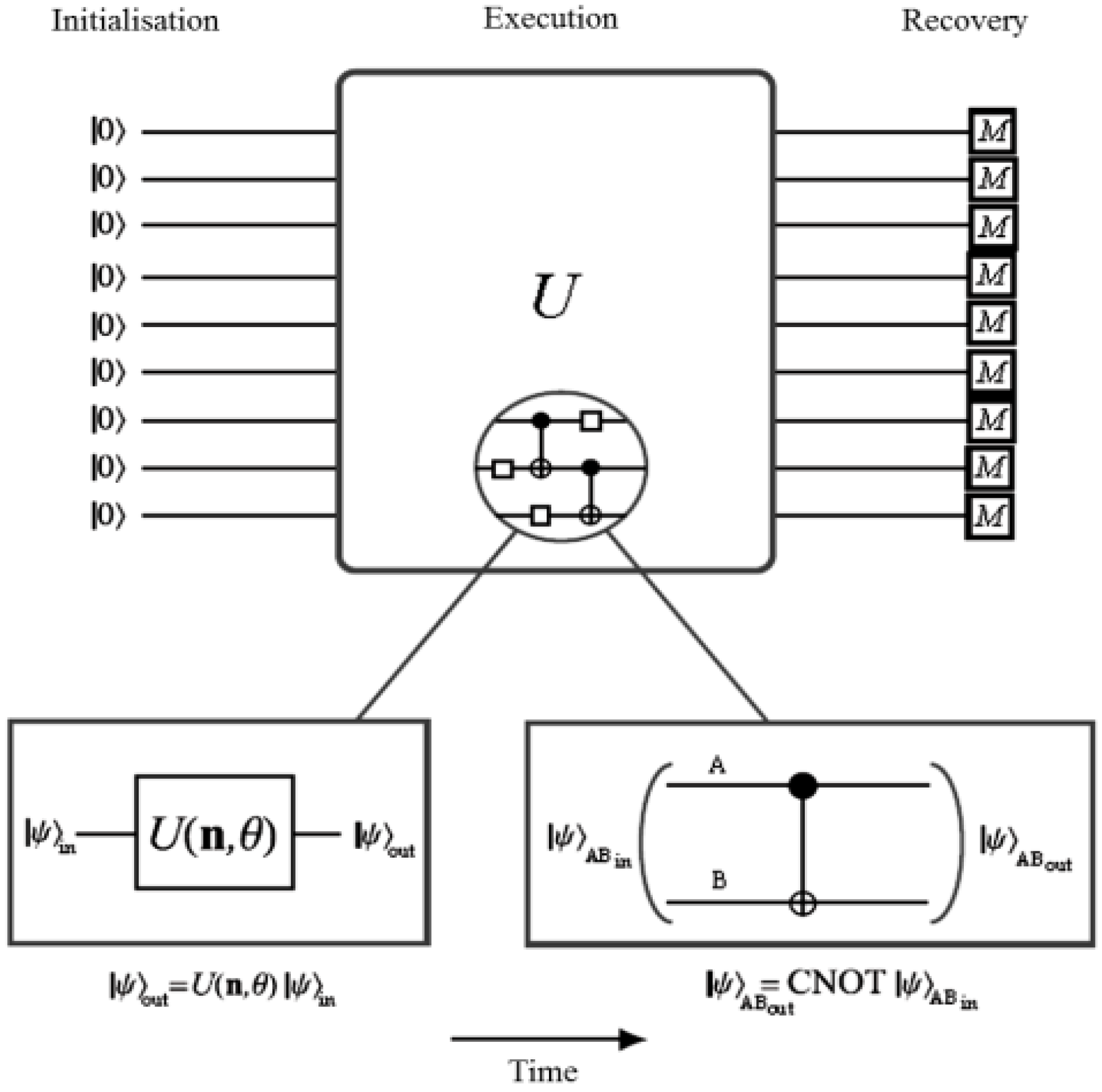
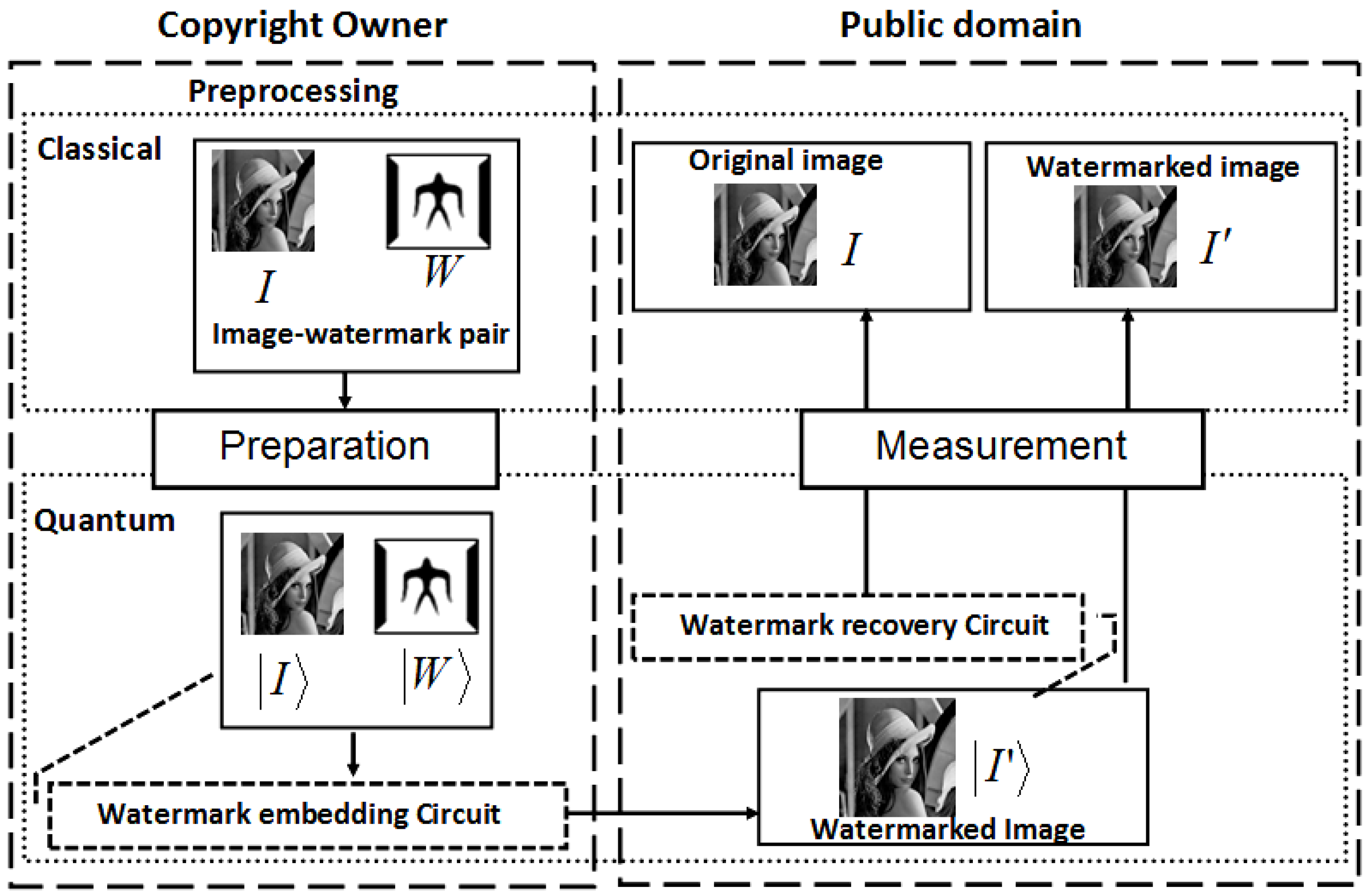
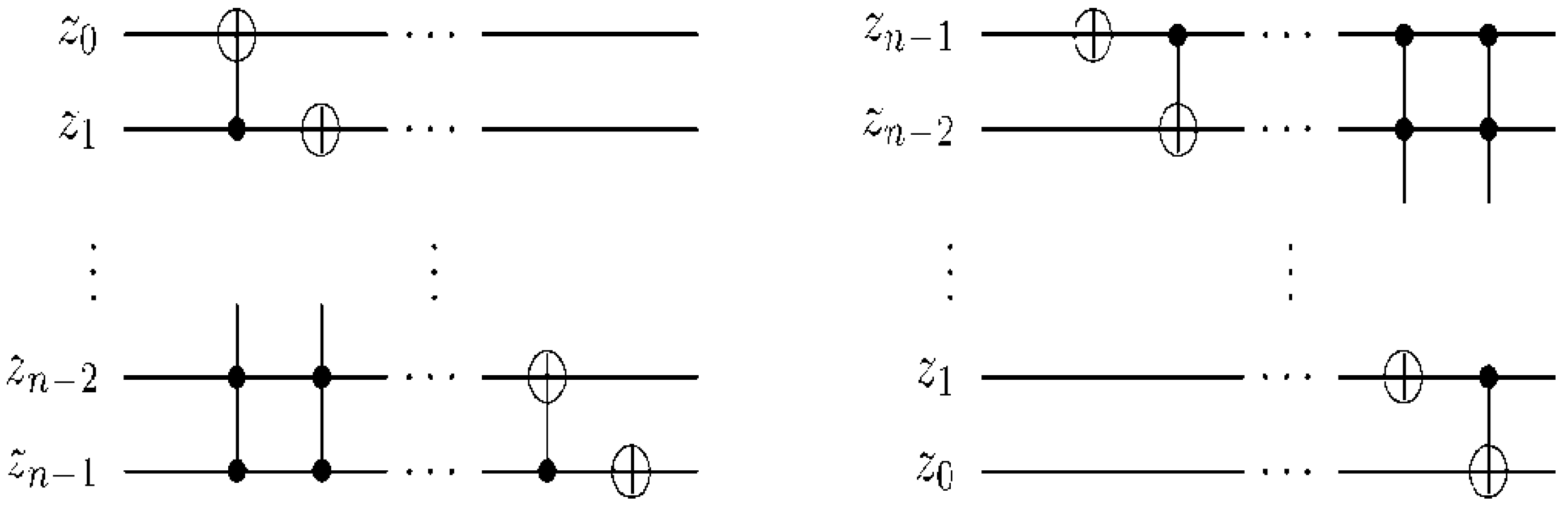Our proposed application to represent and produce quantum movies allows us generalise some of these criteria. Accordingly, we propose to merge the first three requirements to specify the preparation of the system. By this we mean a scalable physical quantum state that has been initialised and is capable of exhibiting all the inherent properties of a quantum mechanical system such as decoherence, entanglement, superposition, etc. The next requirement specifies that, a state so prepared can only be manipulated by a sequence of quantum gates. Intuitively, we refer to this requirement as manipulation of the quantum system. Finally, the last requirement—measurement, allows us to retrieve a classical read out (observation or measurement) of the quantum register which yields a classical-bit string and a collapse of the hitherto quantum state. Throughout the remainder of this section, by measurement we mean non-destructive measurement, whereby the quantum state is recoverable upon the use of appropriate corrections and ancillary information. Our earlier assumptions that the quantum computer is equipped with in-built error correction and that the classical input images (in this case movie frames) are used to prepare their quantum versions; and that the two are exact replicas of one another are also tenable for the proposed quantum movie framework.
The conceit backing our generealisation of Divincenzo’s criteria, and therefore the proposed framework, hinges on the assumption that it is possible to realise standalone components to satisfy each of the aforementioned criteria, and that the components can interact with one another as does the CPU, keyboard, and display (monitor) units of a typical desktop computer.
The framework proposed in this section builds on these various literatures by extending the classical movie applications and terminologies toward a new framework to facilitate movie representation and production on quantum computers.
These classical terminologies and roles are extended to the proposed representation and production of movies on quantum computers. The inherent nature of quantum computers, however, imposes the need for the services of an additional professional whom we shall refer to as the circuitor. His responsibilities complement that of the director, in that, he is saddled with choosing appropriate circuit elements to transform each key frame into a shot (or part thereof), so as to combine with others in order to convey the script to the audience. Alternatively, this role could be added to the director of a quantum movie in addition to his traditionally classical duties.
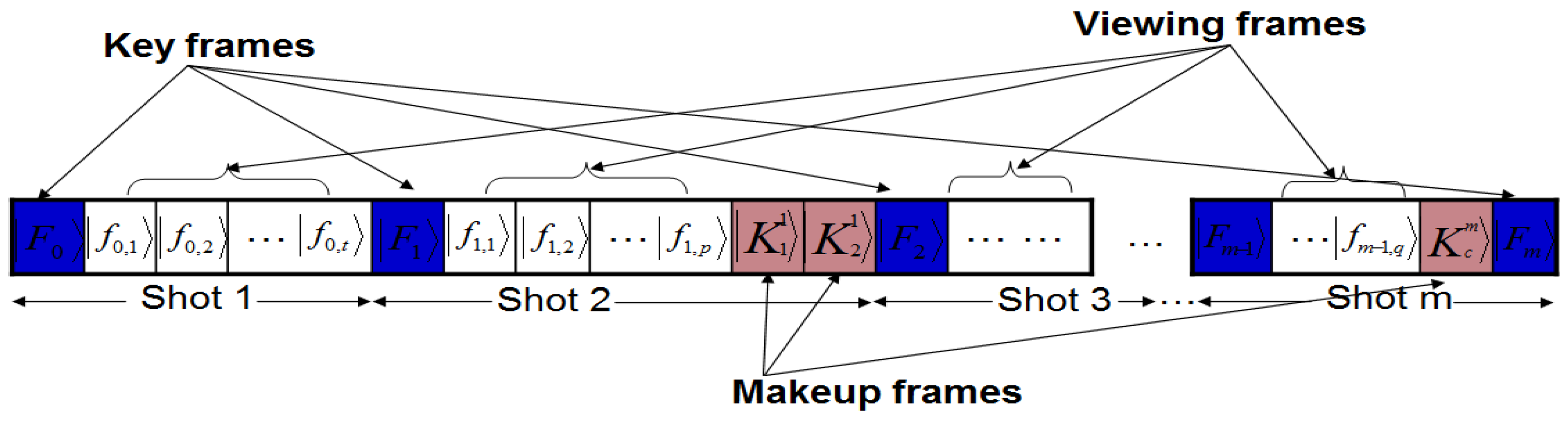
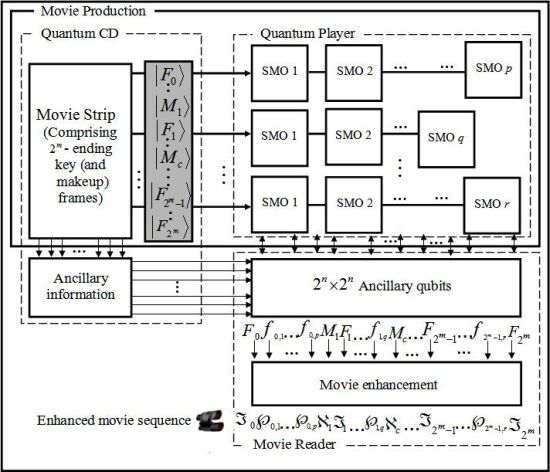
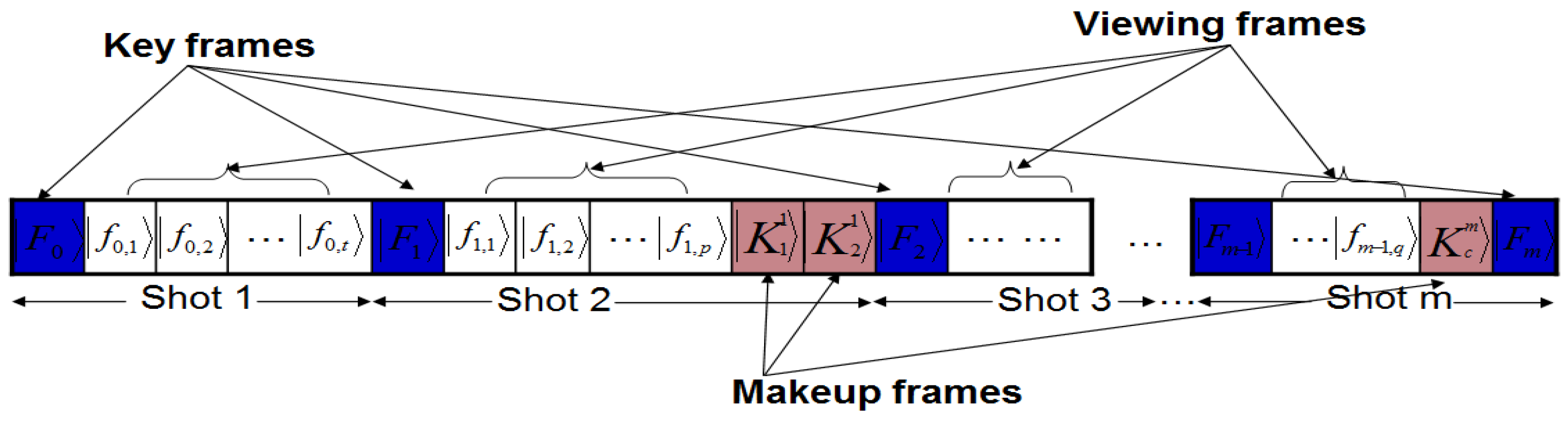
In line with these abstract requirements to represent a movie, we propose a conceptual device or gadget to encompass each of our generalised broad requirements for quantum computing, i.e. preparation, manipulation, and measurement. Accordingly, we propose a compact disc — CD (or cassette) — like device to store the most basic information of the proposed framework, the key frames. Our proposed device, which we shall refer to as the quantum CD, has the additional capability to prepare, initialise, and store as many key frames and their ancillary information as required for the various scenes of the movie. The transformed version of each key frame at every layer of the circuit produces a viewing frame: which is a frame that is marginally different from the frame content at the previous layer. This vastly interconnected circuit network is housed in a single device which we refer to as the quantum player in analogy with the classical CD (VCD, DVD, or VCR) player. The combination of two extreme key frames and the resulting viewing frames to gradually interpolate between them produces a sequence, which conveys a scene from the movie. The last device required to facilitate the representation and production of our quantum movies is the movie reader. As the name suggests, this device measures the contents of the sequence (comprising of the key, makeup, and viewing frames) in order to retrieve their classical readouts. At appropriate frame transition rates, this sequence creates the impression of continuity as in a movie.
The trio of the quantum CD, player, and movie reader, albeit separate, combine together to produce our proposed framework to represent and produce movies on quantum computers.
In addition to these technical advances, the likely challenges to pioneer representing and producing movies on quantum computers are reviewed. This will facilitate the exploitation of the proven speedup of quantum computation by opening the door towards practical implementation of quantum circuits for information representation and processing.
6.3. The Movie Reader
In systems that are based on the quantum computation model, such as the quantum player discussed in the preceding section, computation is performed by actively manipulating the individual register qubits by a network of logical gates. The requirement to control the register is, however, very challenging to realise [
38,
71,
74]. In addition to this, the inherent quantum properties,
i.e. principally, superposition, and entanglement make the circuit model of computation unsuitable for the proposed
movie reader. Measurement-based quantum computation, as noted in
Section 1, is an alternative strategy that relies on effects of measurements on an entangled multi-partite resource state to perform the required computation [
75,
76]. This novel strategy to overcome the perceived shortcomings of the circuit model of quantum computation have been realised experimentally [
39] using single-qubit measurements which are considered “cheap” [
39]. All measurement-based models share the common feature that measurements are not performed solely on the qubits storing the data. The reason is that doing so would destroy the coherence essential to quantum computation.
Instead, ancillary qubits are prepared, and then measurements are used to ‘interact’ the data with the ancilla. By choosing appropriate measurements and initial states of the ancilla carefully, we can ensure that the coherence is preserved [
39]. Even more remarkable is the fact that with suitable choices of ancilla and measurements, it is possible to affect a universal set of quantum gates.
In this section, we introduce a modified or crude version of the standard ancilla-driven quantum computation (ADQC), which was highlighted earlier in this section, as the cornerstone of the proposed movie reader. Our proposed
dependent ancilla-driven movie reader exploits the properties of single-qubit projective measurements and the entanglement-based interaction between the ancilla qubit and the register qubit of the ADQC. The measurements are performed dependent upon satisfying some predefined conditions based on the position of each point in the image, hence, the name dependent ancilla-driven movie reader. An elegant review of the projective measurements can be found in [
74]. Here, we just recall, therefrom, a few notations that are indispensable to discussing our proposed movie reader.
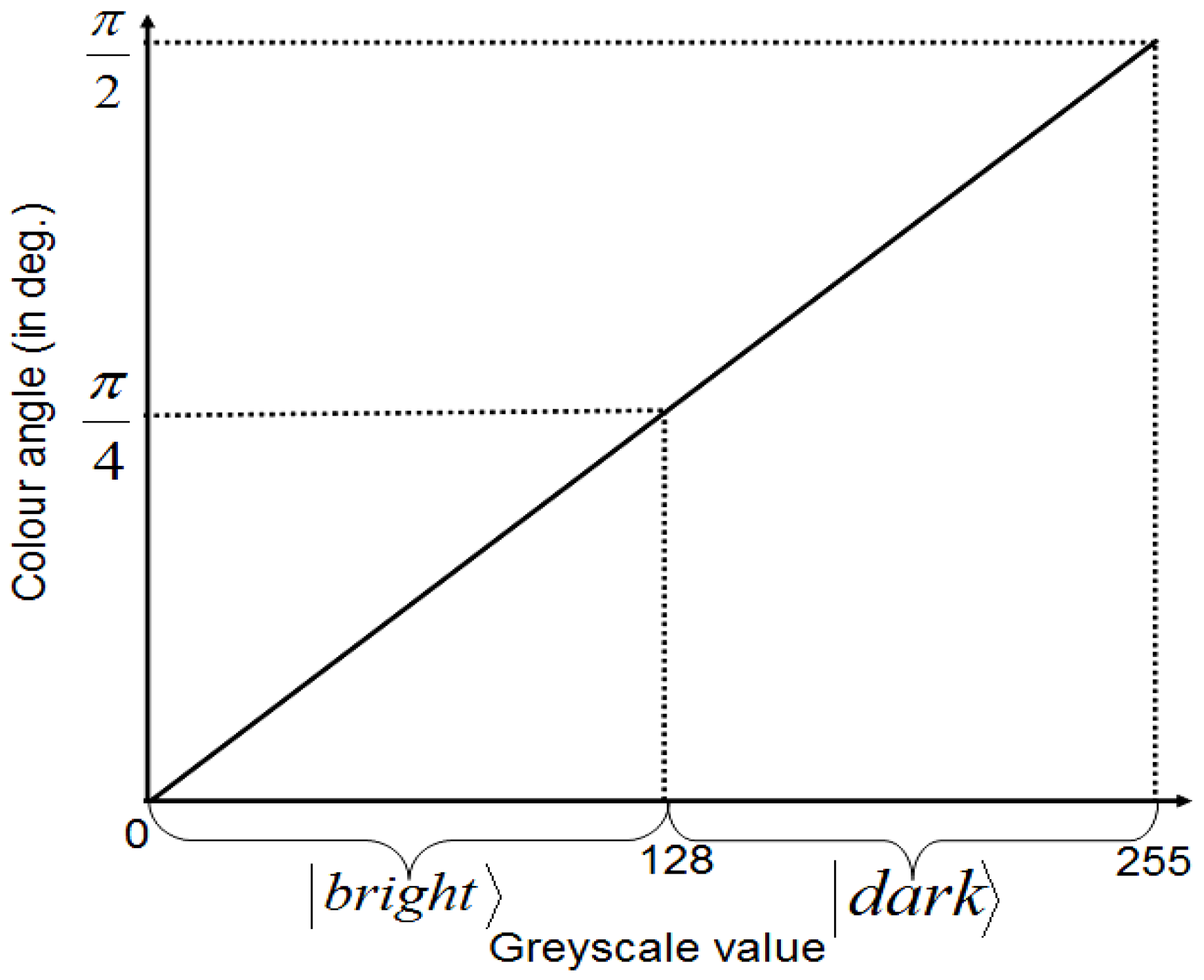
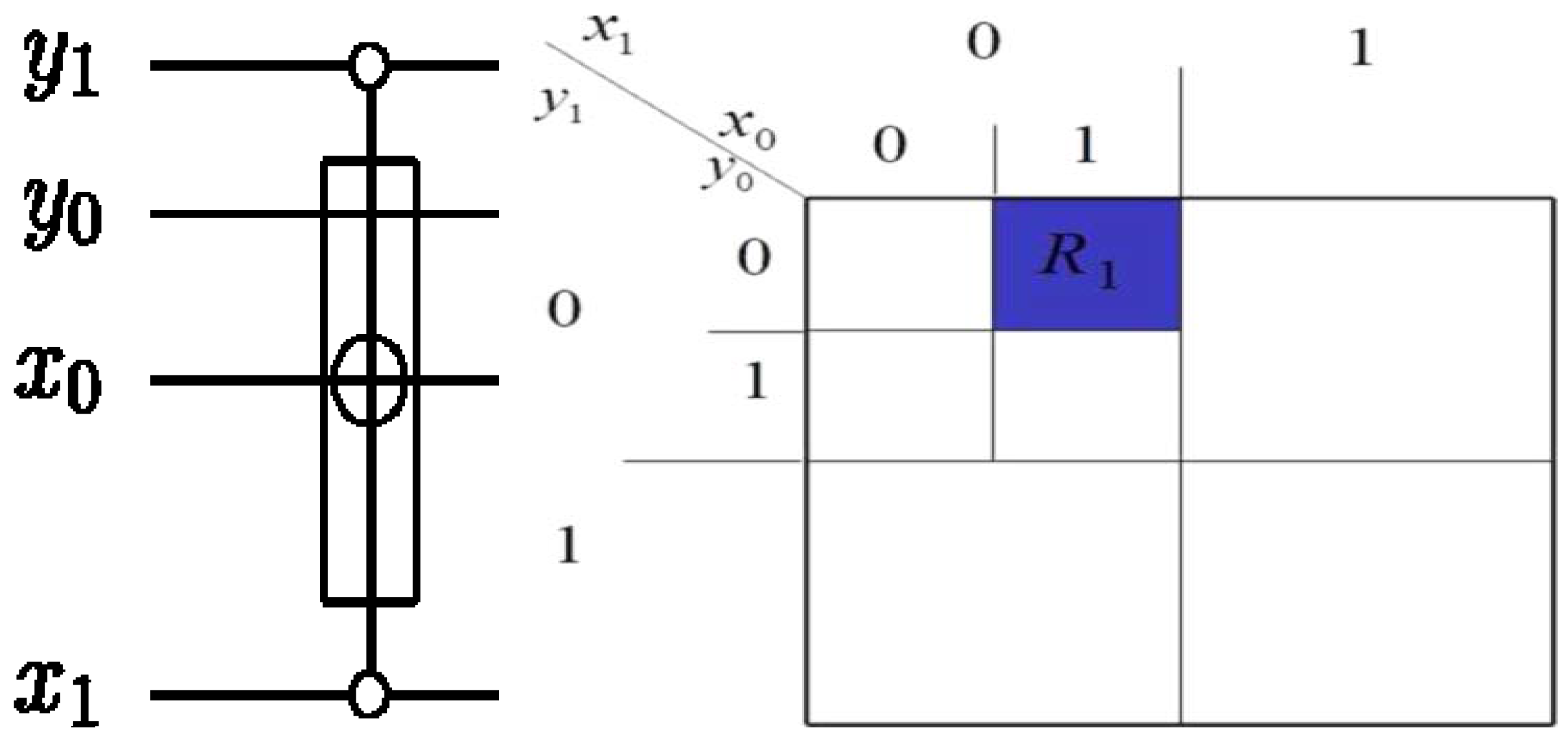
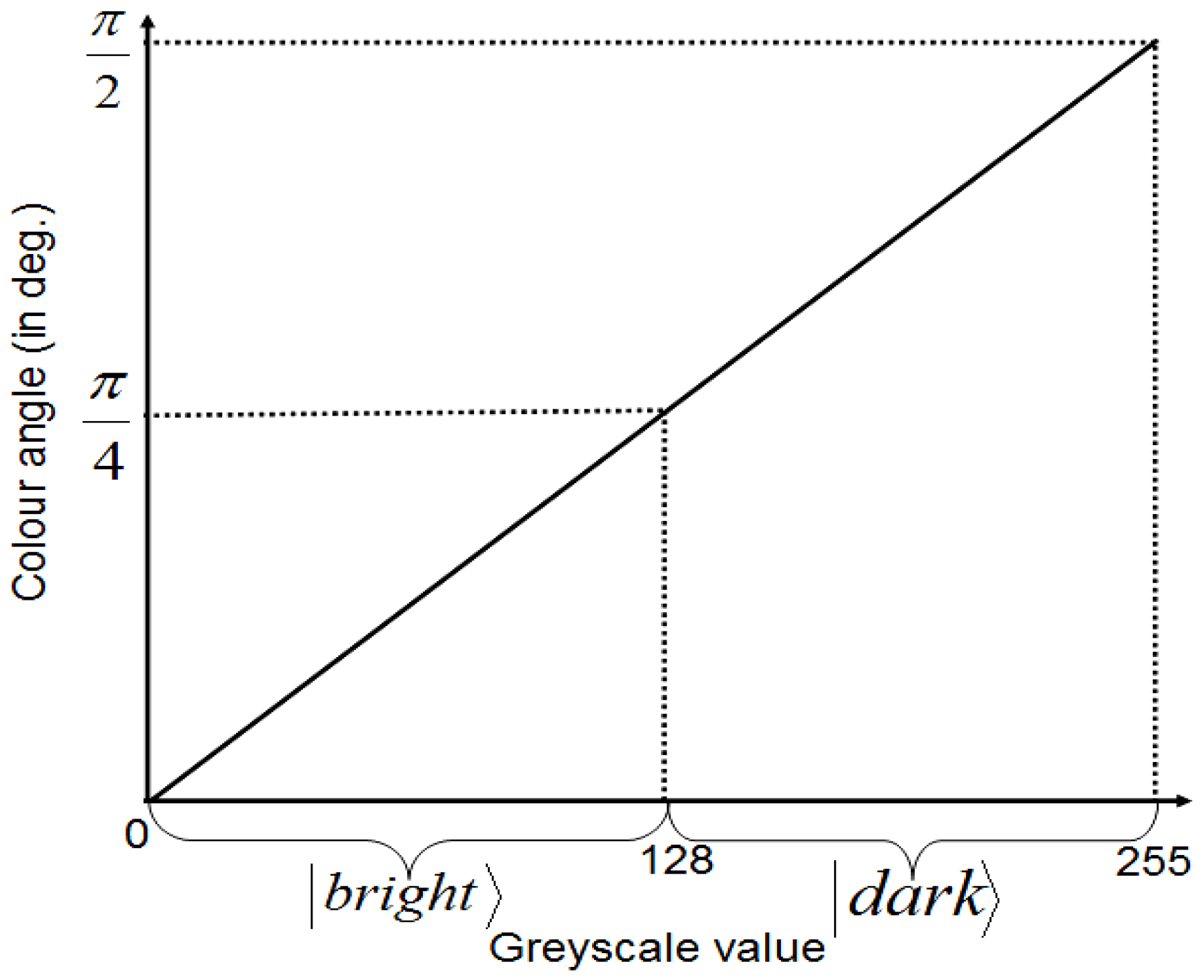
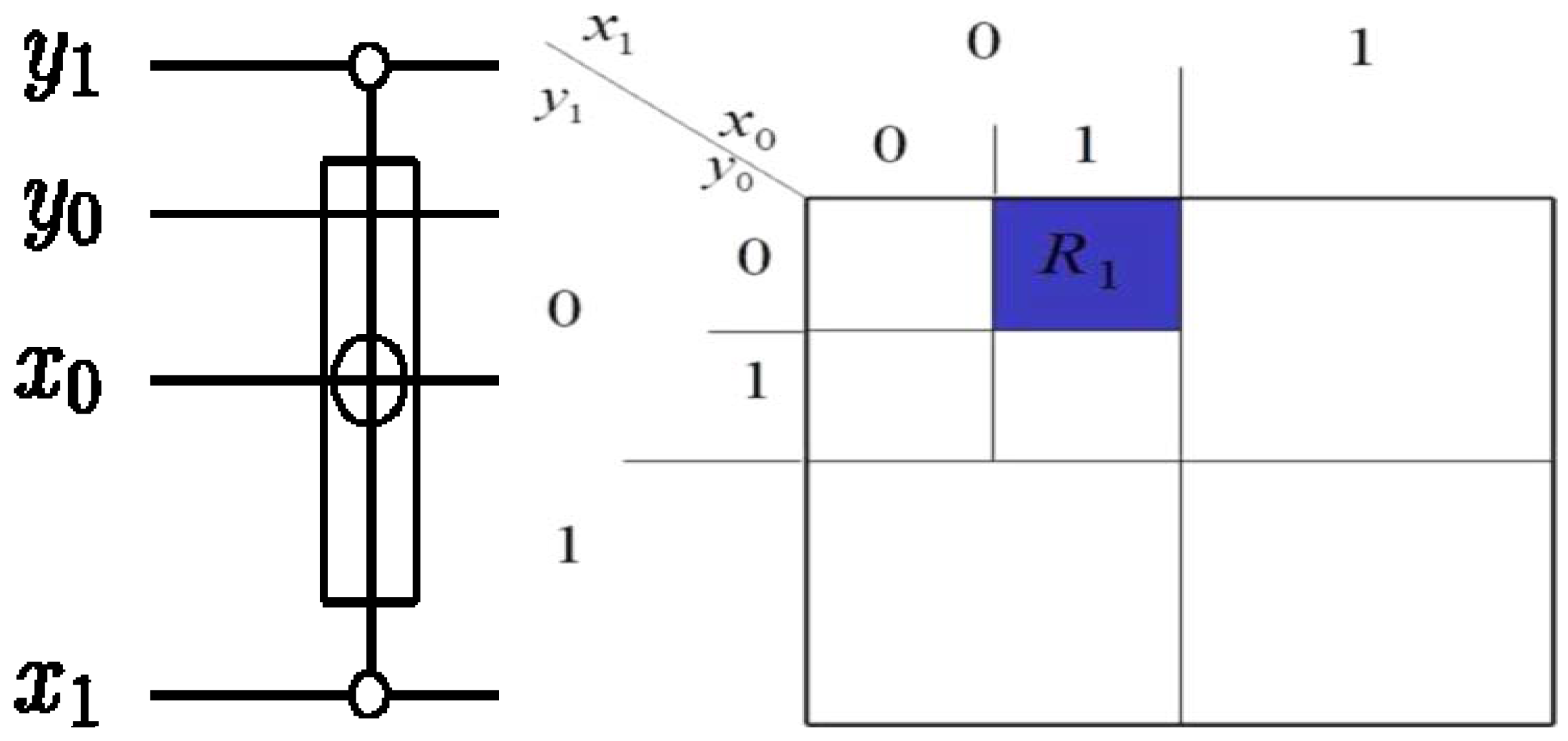
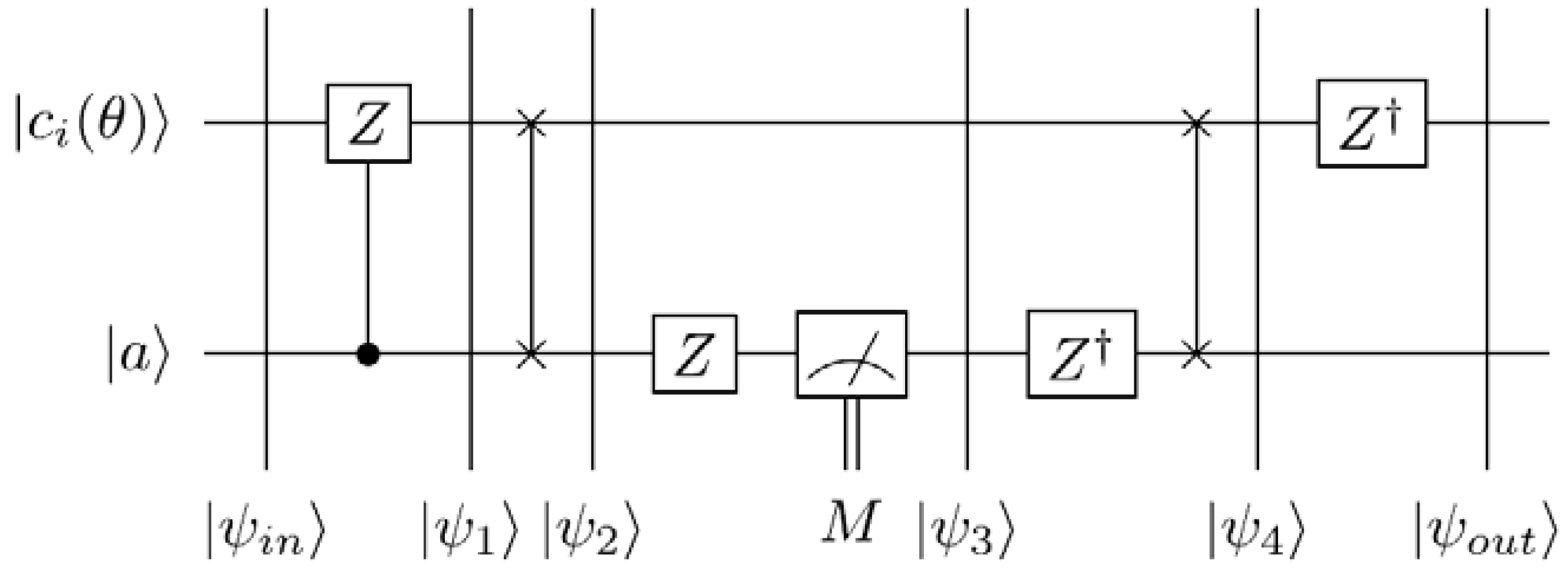
A projective measurement can be specified by orthogonal subspaces of the measured Hilbert space; the measurement projects the state onto one subspace and outputs (the readout) the subspace label. A single-qubit measurement along the computational basis
is equivalent to
Mz and it returns a classical value that is the same as the label of that basis, in this case (0, 1). We will adopt the notations and nomenclature from [
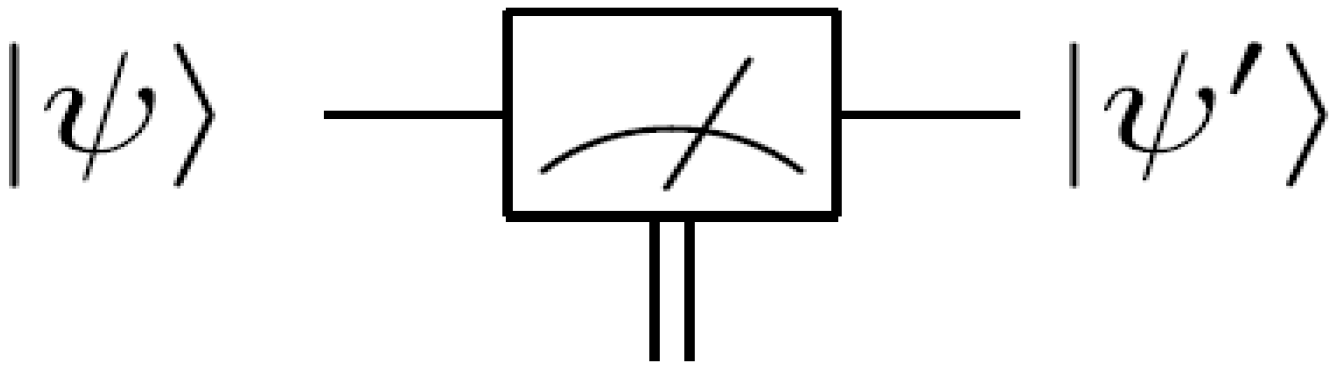
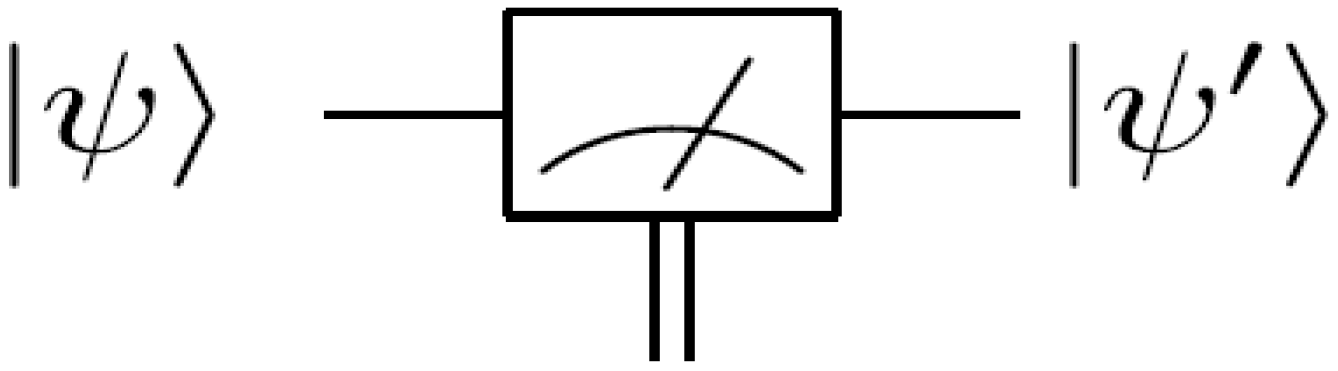
75] for the measurement circuitry of our proposed movie reader. Throughout the rest of this review, a double line coming out of a measurement box represents a classical outcome, and a single line out of the same box represents the post-measurement quantum state being measured as exemplified in
Figure 55 (and some of the circuits earlier in this section). Such a measurement is described by a set of operators
Mr acting on the state of the system. The probability
p of a measurement result
r occurring when state
ψ is measured is
. The state of the system after measurement
is:
Figure 55.
A single qubit measurement gate.
Figure 55.
A single qubit measurement gate.
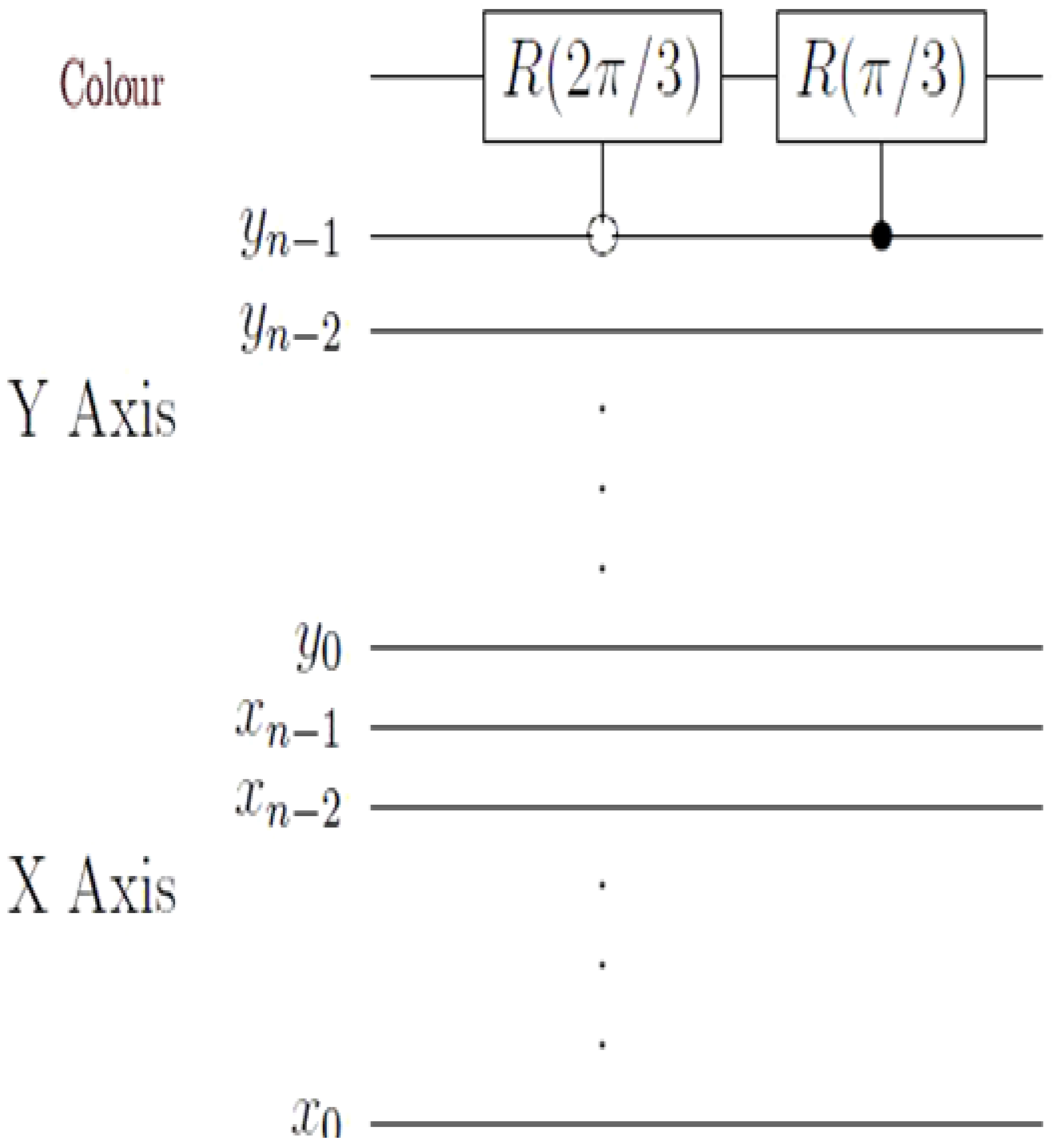
In the ADQC, the ancilla A is prepared and then entangled to a register qubit (in our case the single qubit encoding the colour information) using a fixed entanglement operator E. A universal interaction between the ancilla and register is accomplished using the controlled-Z (CZ) gate and a swap (S) gate and then measured. An ADQC with such an interaction allows the implementation of any computation or universal state preparation [
36]. This is then followed by single qubit corrections on both the ancilla and register qubits.
Figure 56.
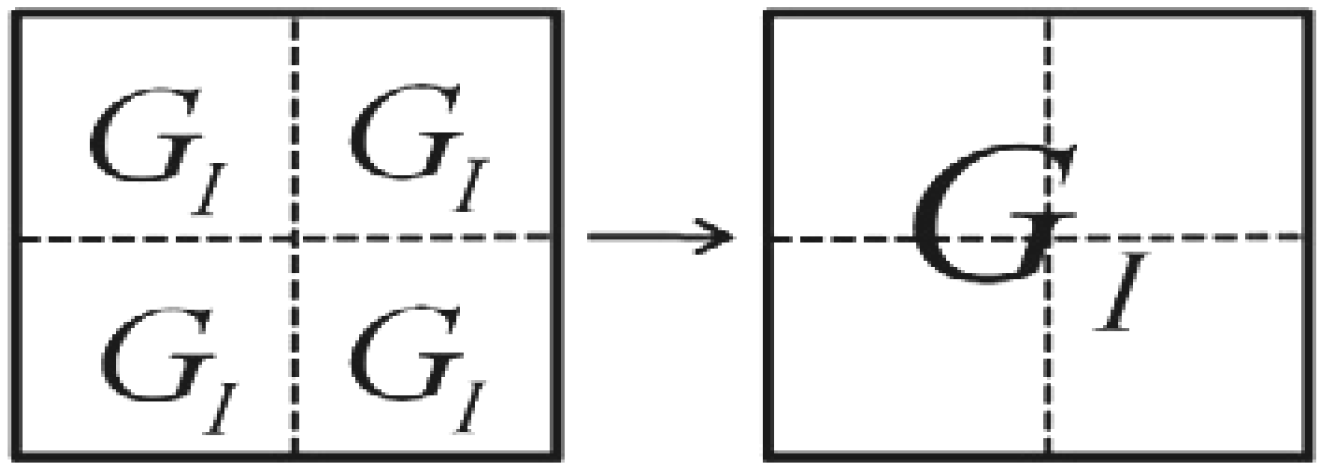
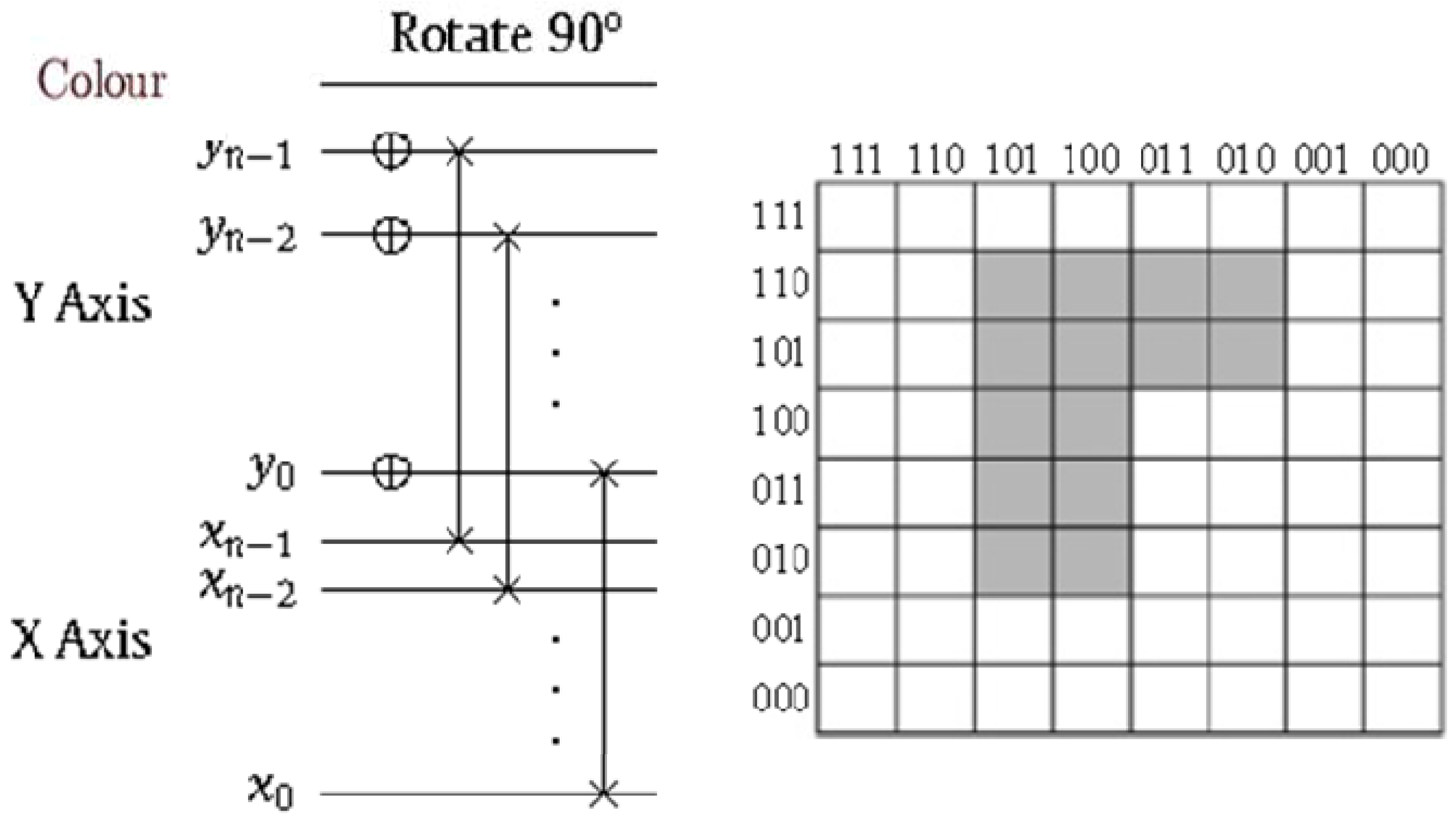
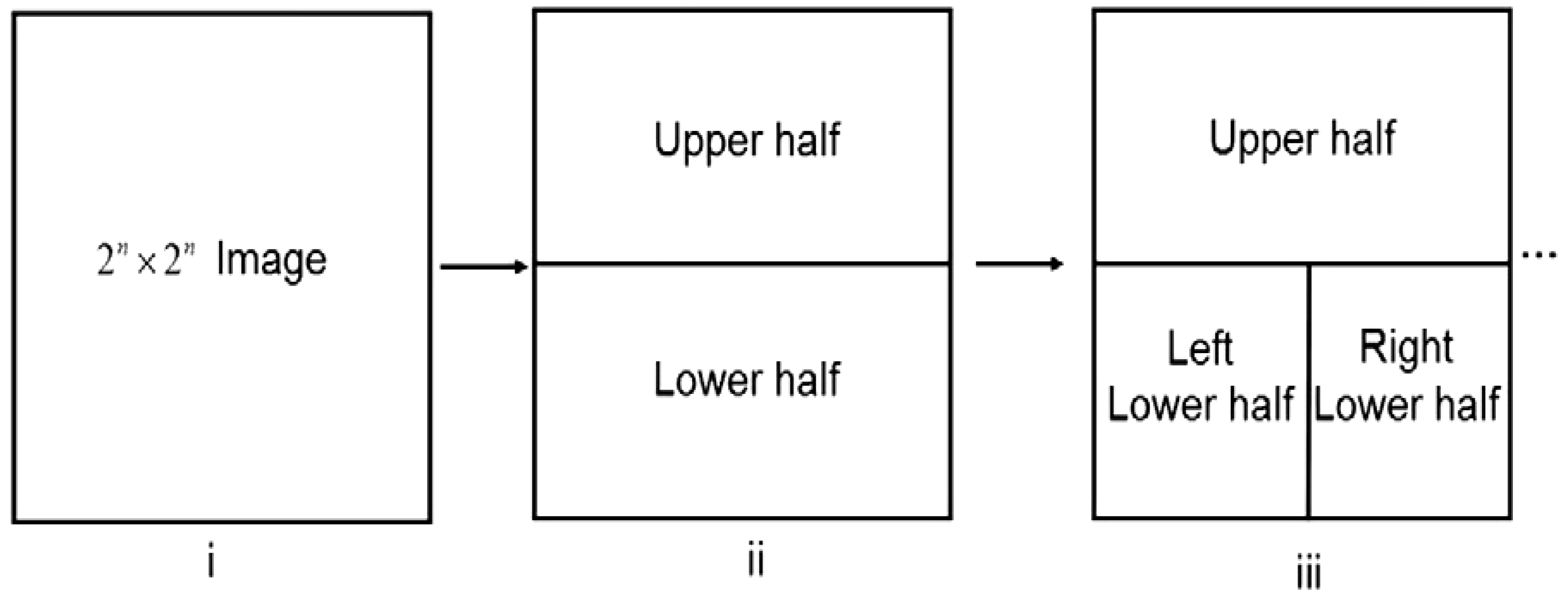
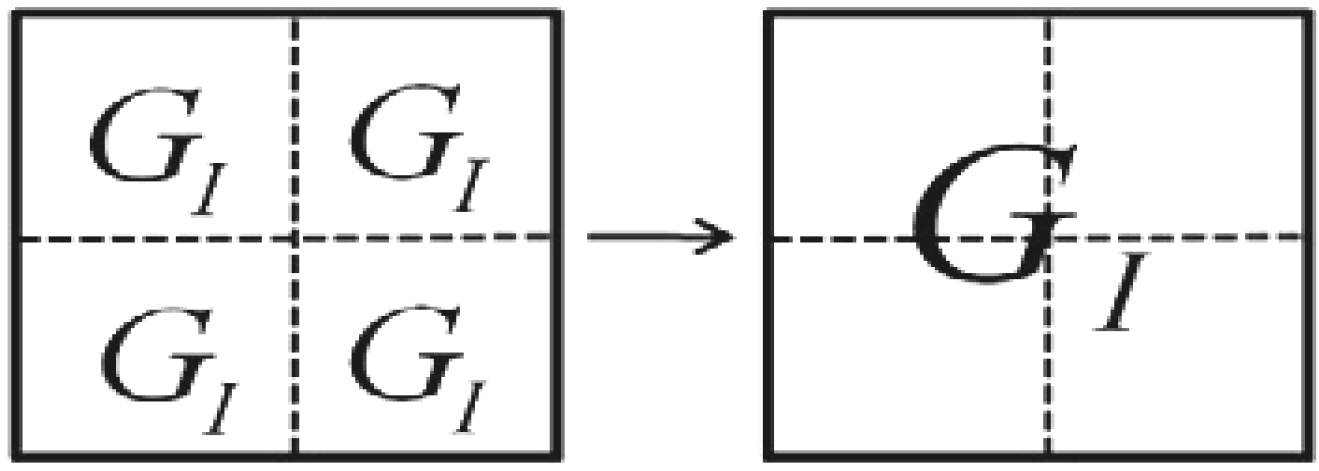
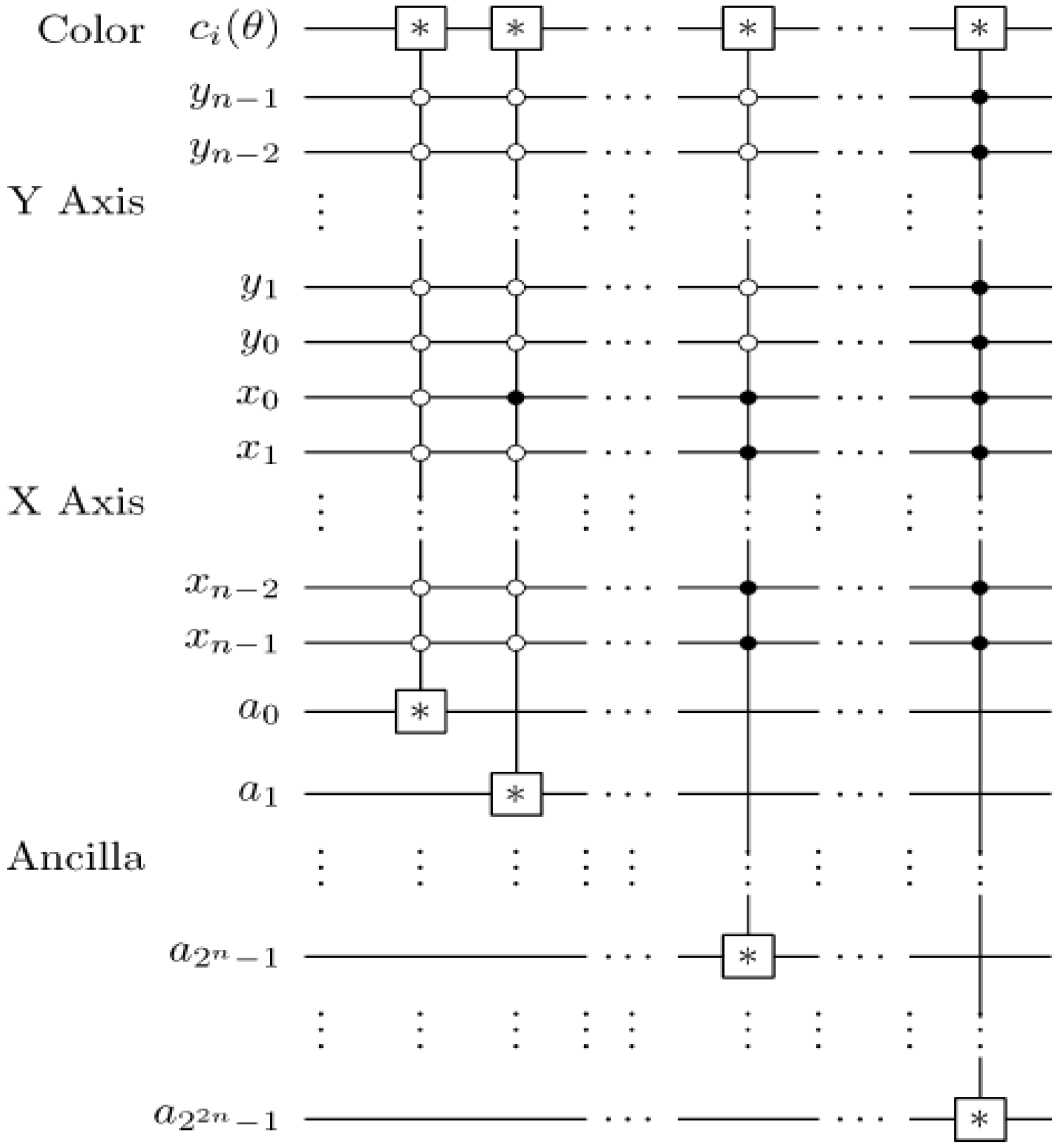
Exploiting the position information |i〉 of the FRQI representation to predetermined the 2D grid location of each pixel in a transformed image GI(|I(θ)〉).
Figure 56.
Exploiting the position information |i〉 of the FRQI representation to predetermined the 2D grid location of each pixel in a transformed image GI(|I(θ)〉).
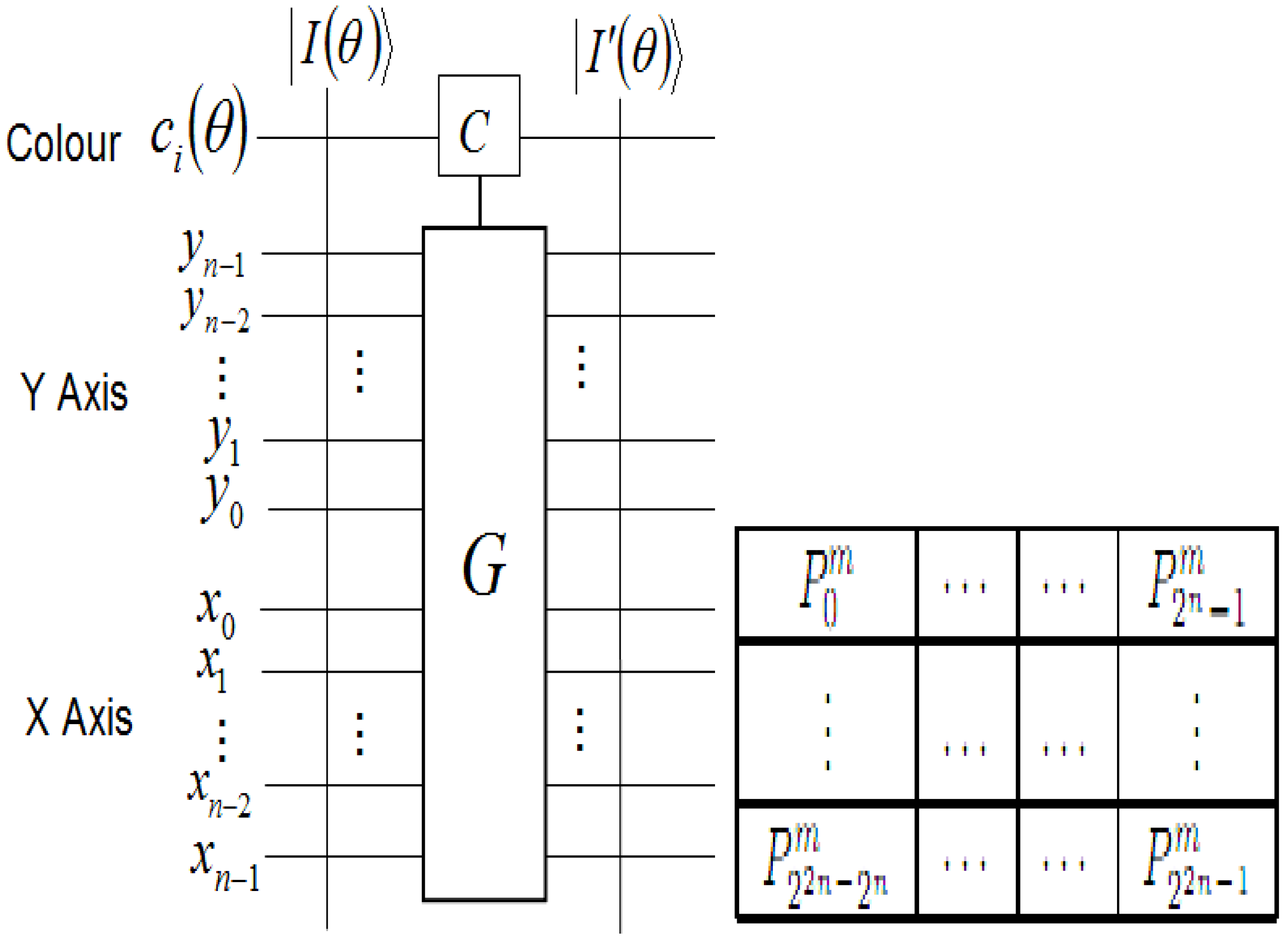
Having introduced these basic rudiments about the projective and ADQC measurements, we are equipped to transfer certain features of each of them to our proposed dependent ancilla-driven movie reader. In so doing, we exploit the fact that the position information about each pixel in an FRQI quantum image after transformation is known beforehand as discussed in earlier sections of this review, and presented in
Figure 56. In other words, we have foreknowledge about the position where each pixel in an FRQI quantum image resides before and after being transformed. This vital knowledge reduces the amount of information required to recover the transformed image to just the information pertaining to the new colour of the pixels. We adopt the under listed simplifications for the purpose of recovering the colour of the
pixel,
.
An interplay is assumed between the quantum CD and the movie reader. This enables the transfer of the ancillary information about the fill of every pixel as stored in the quantum CD to the reader as discussed earlier. Therefore, we simplify the representation for the ancilla states
and
from [
38] as follows:
for the absence and presence of a fill in that pixel, respectively:
A universal interaction between the ancilla
and register (specifically, the colour qubit) is accomplished using the CZ gate and a swap (S) gate and then measured. An ADQC with such an interaction is sufficient for the implementation of any computation or universal state preparation [
38].
This is then followed by single qubit corrections,
and
U on the ancillary information and colour of the pixel, respectively. The measurement to recover the colour of the
pixel
returns a value
ci as defined in Equation (2). Actually, this is the same as retaining the interaction operation E in the ADQC while replacing the measurement and Pauli corrections with a projective measurement as explained in [
19].
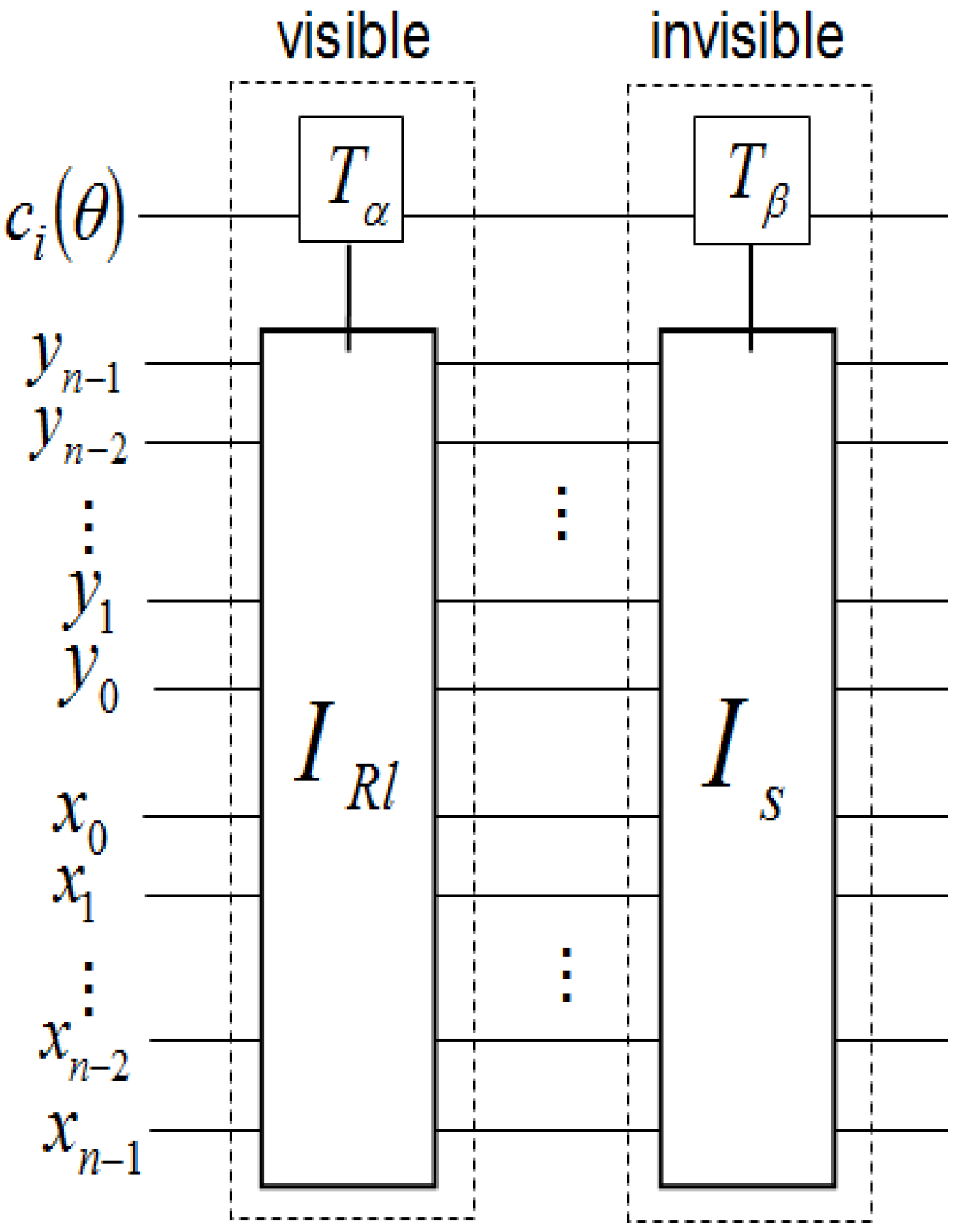
Finally, adopting the 2D grid position information of every point in a transformed key frame (FRQI state) shown in
Figure 56 allows us to determine beforehand the required control-operations needed to recover the transformed key frame,
i.e. the viewing frames. These conditions are summarised in
Figure 57.
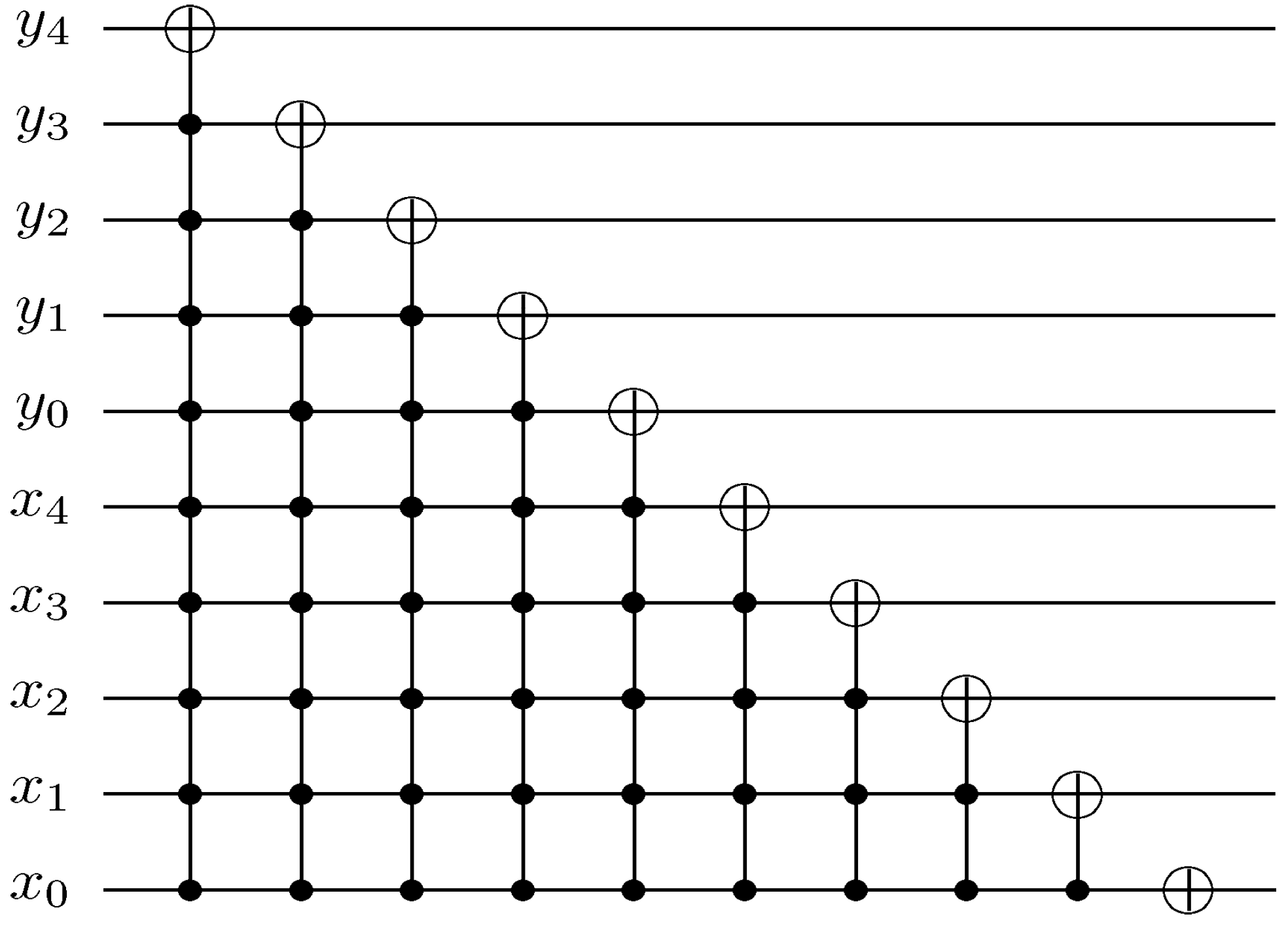
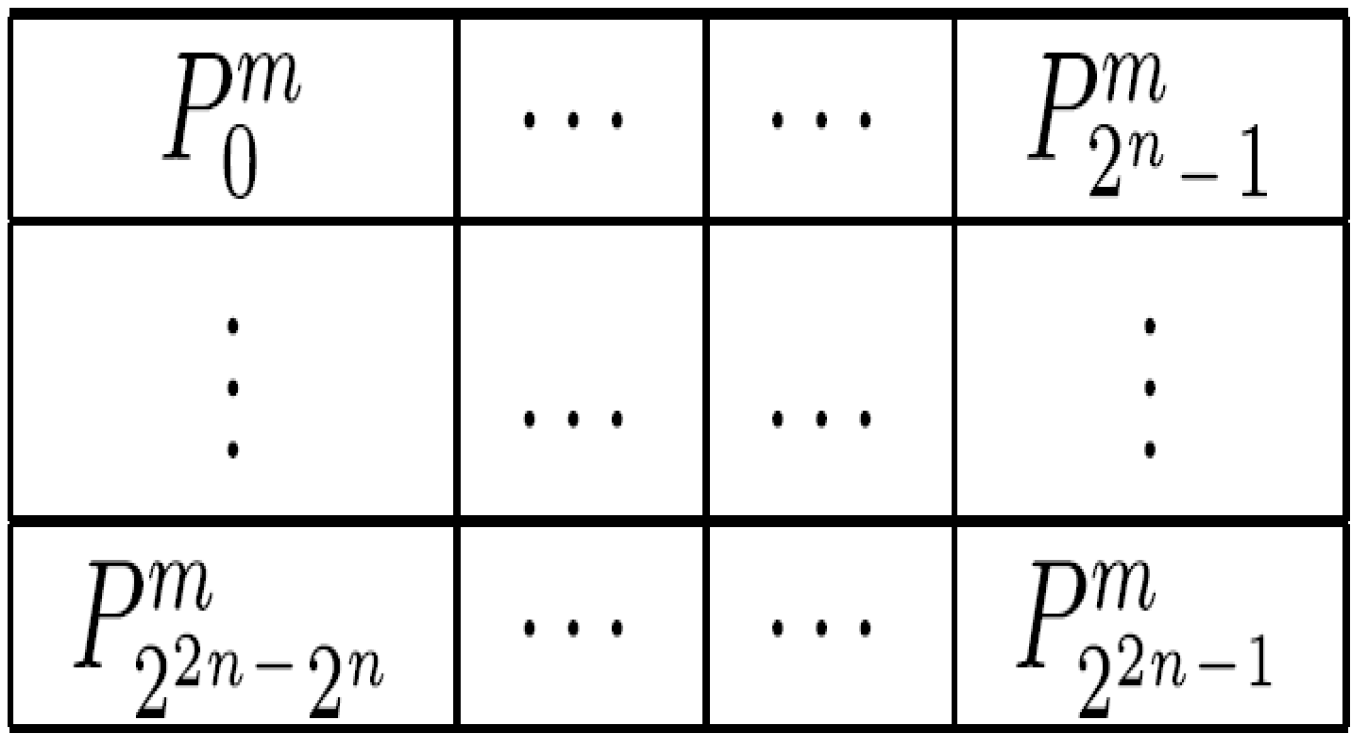
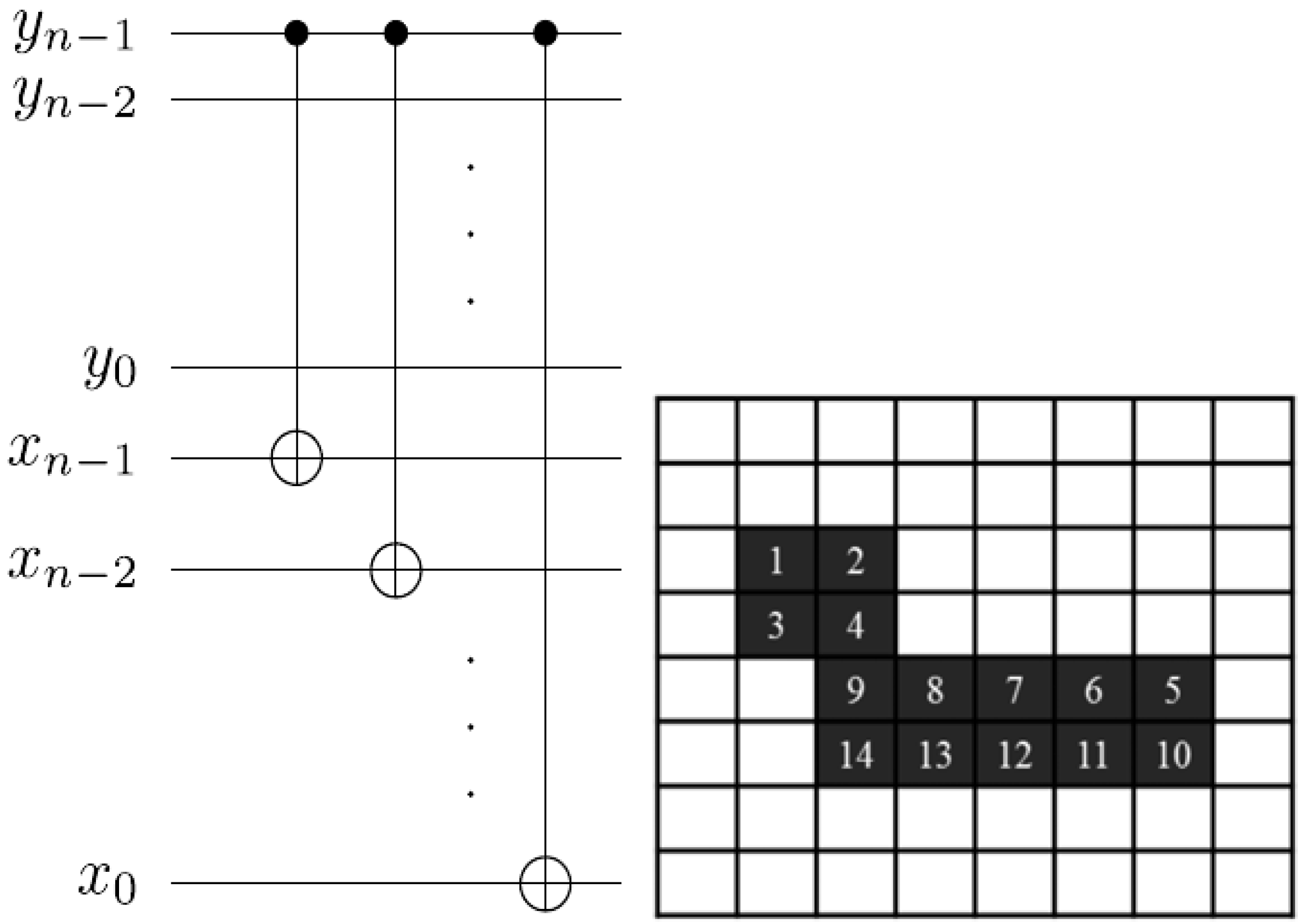
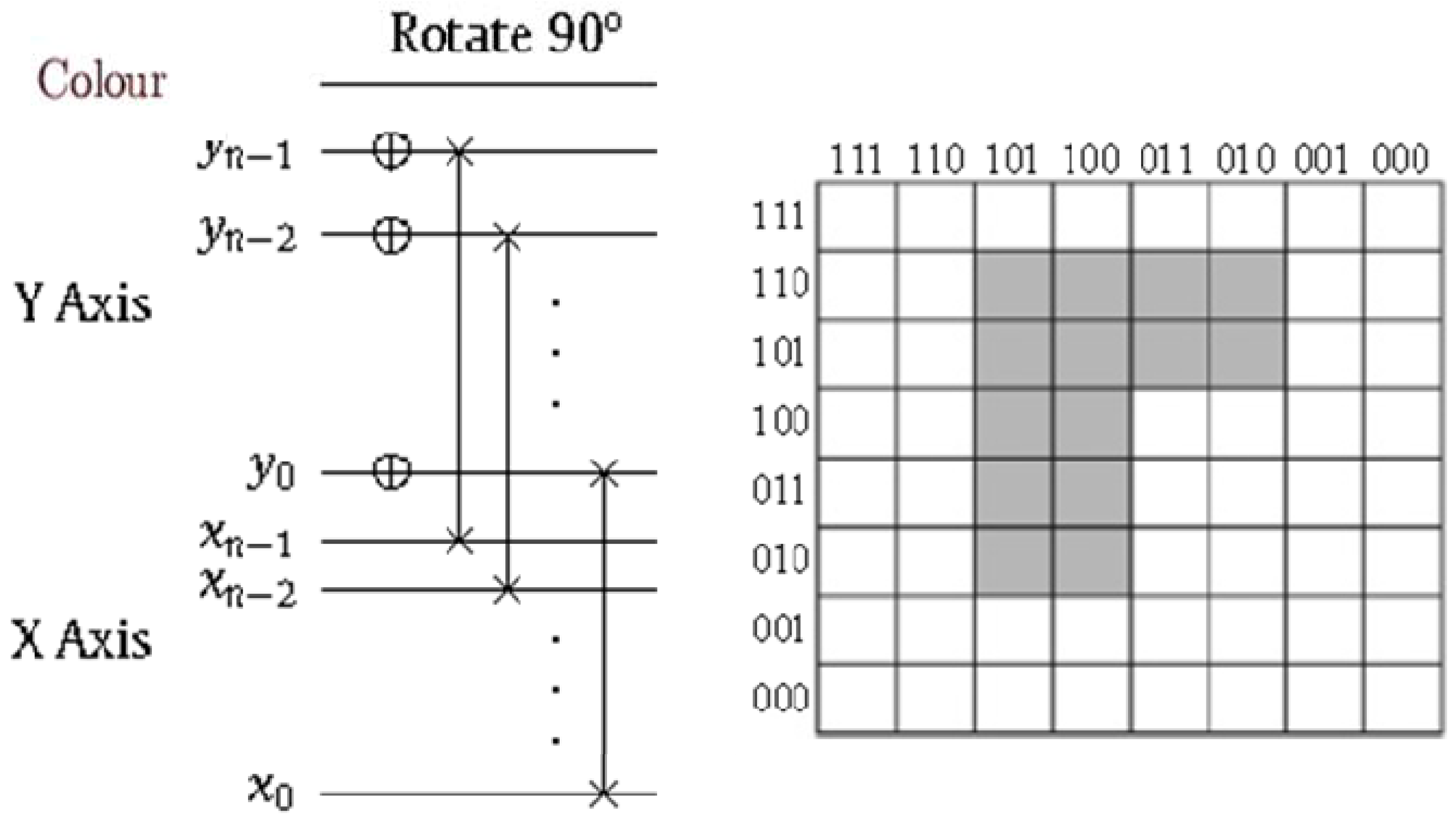
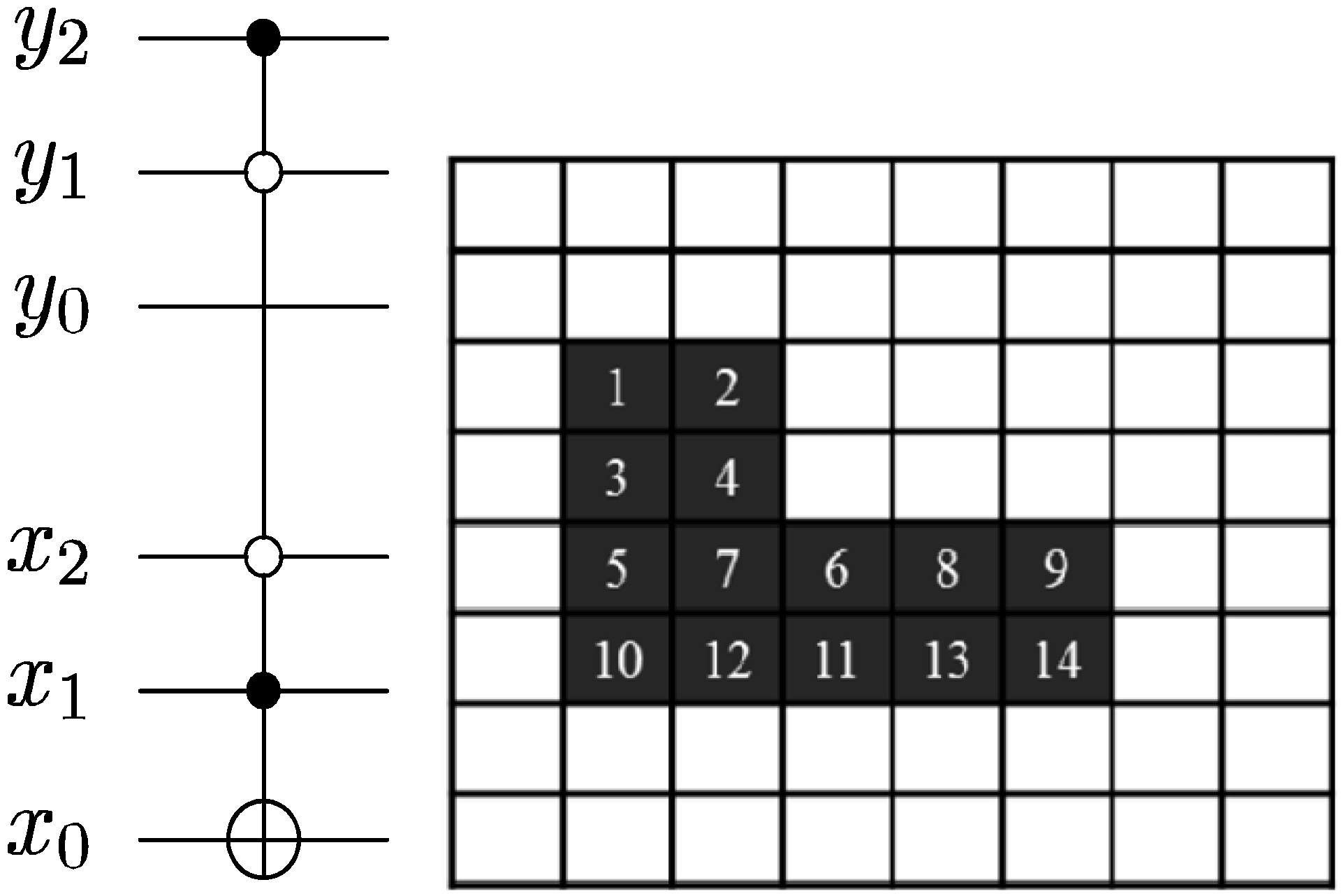
Figure 57.
Control-conditions to recover the readout of the pixels of a 2n×2n FRQI quantum image.
Figure 57.
Control-conditions to recover the readout of the pixels of a 2n×2n FRQI quantum image.
Exploiting this characteristic, a 2
n×2
n FRQI image can be recovered by tracking the changes it undergoes as dictated by movie script using the various elements of the movie circuit. The position information of each pixel as summarised in
Figure 57 serves as the dependency on which the measurement to recover the colour information of each pixel is based. This implies that, each measurement recovers the colour of a specific pixel as specified by this position-specific information. In addition, the measurement is driven by the ancillary information about the colour (specifically, the fill of each pixel) as stored in the quantum CD.
Figure 58.
Predetermined recovery of the position information of an FRQI quantum image. The * between the colour |
c(
θi)〉 and ancilla |
a〉 qubits indicates the dependent ancilla-driven measurement as described in
Figure 59 and Theorem 4.
Figure 58.
Predetermined recovery of the position information of an FRQI quantum image. The * between the colour |
c(
θi)〉 and ancilla |
a〉 qubits indicates the dependent ancilla-driven measurement as described in
Figure 59 and Theorem 4.
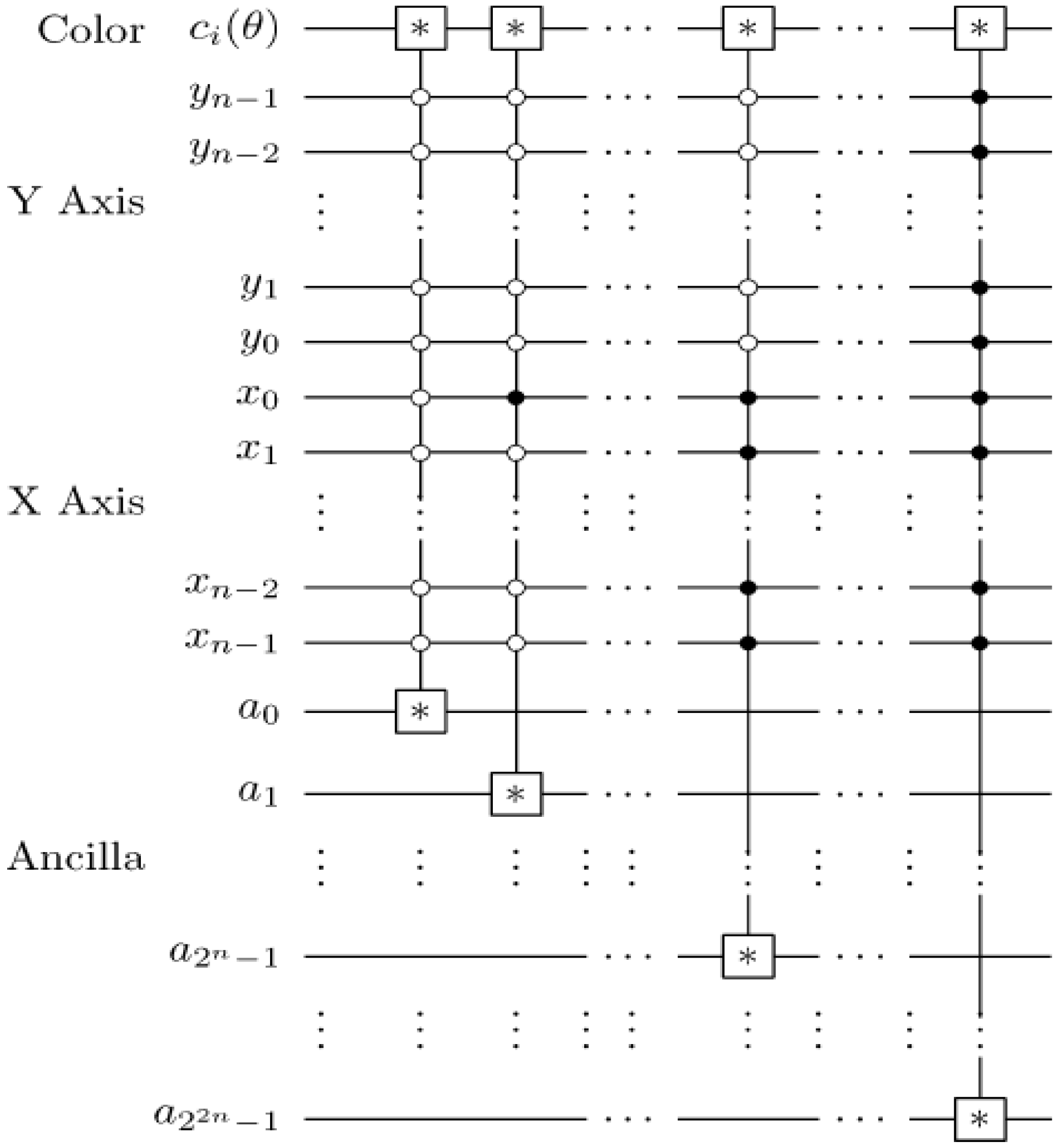
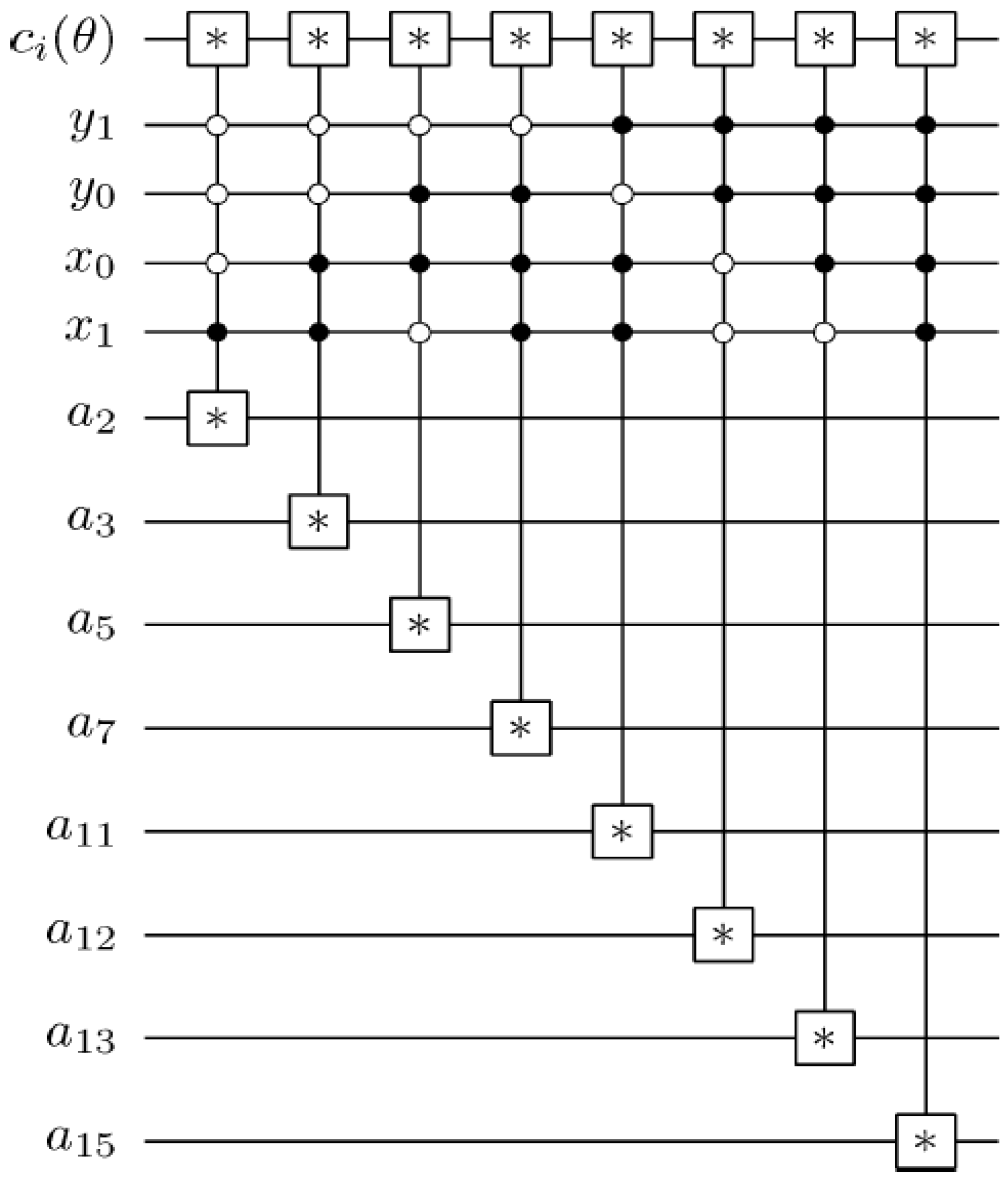
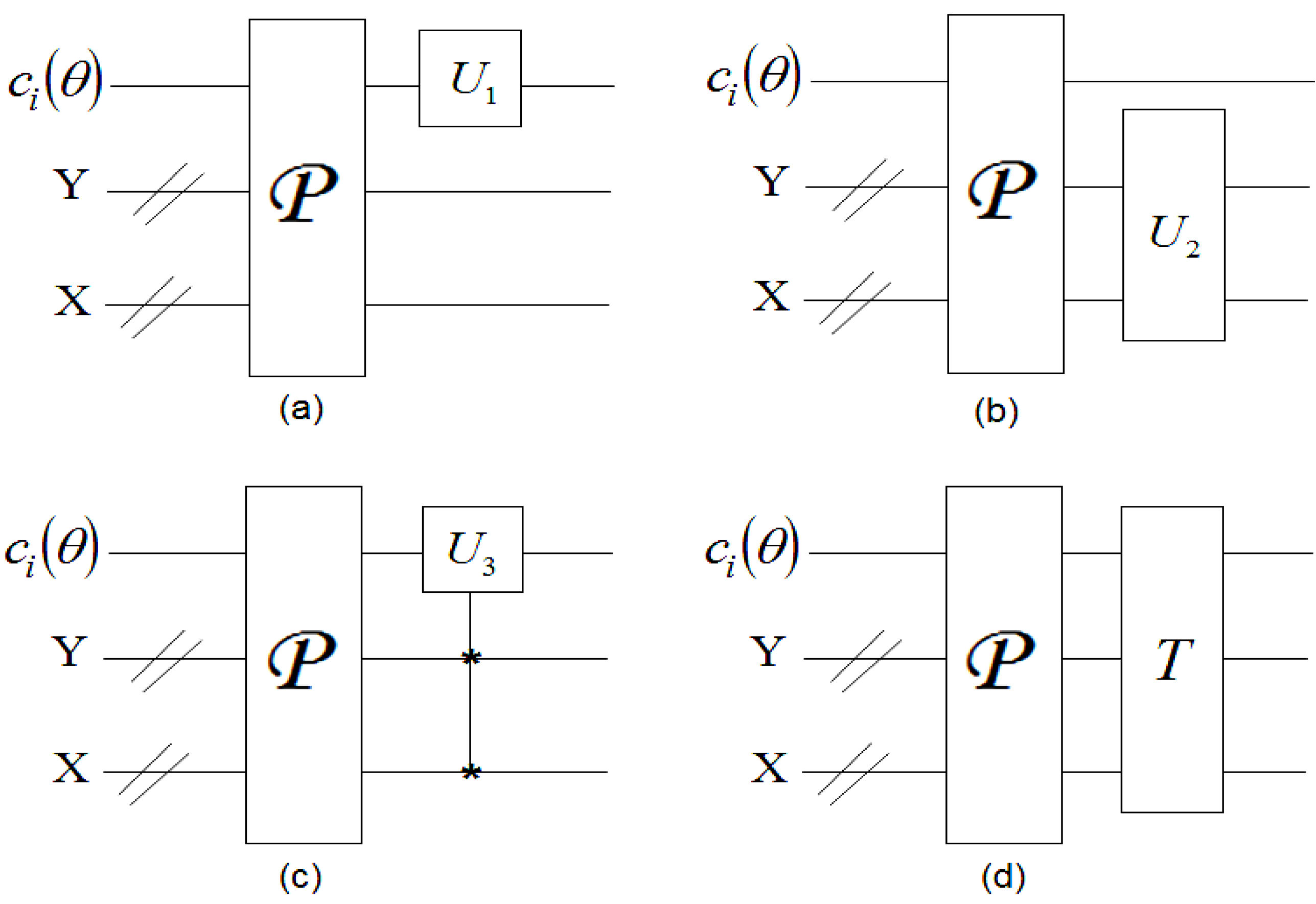
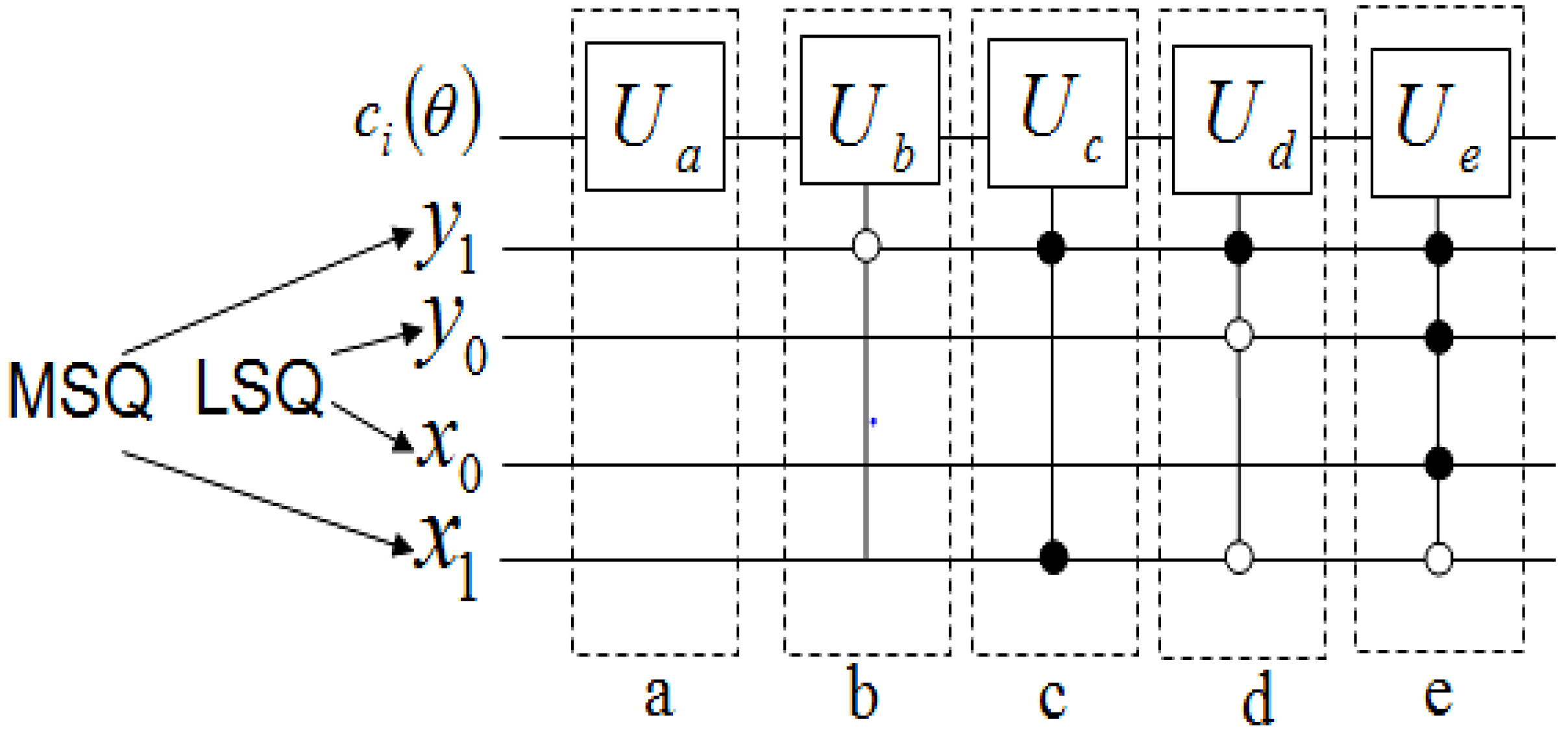
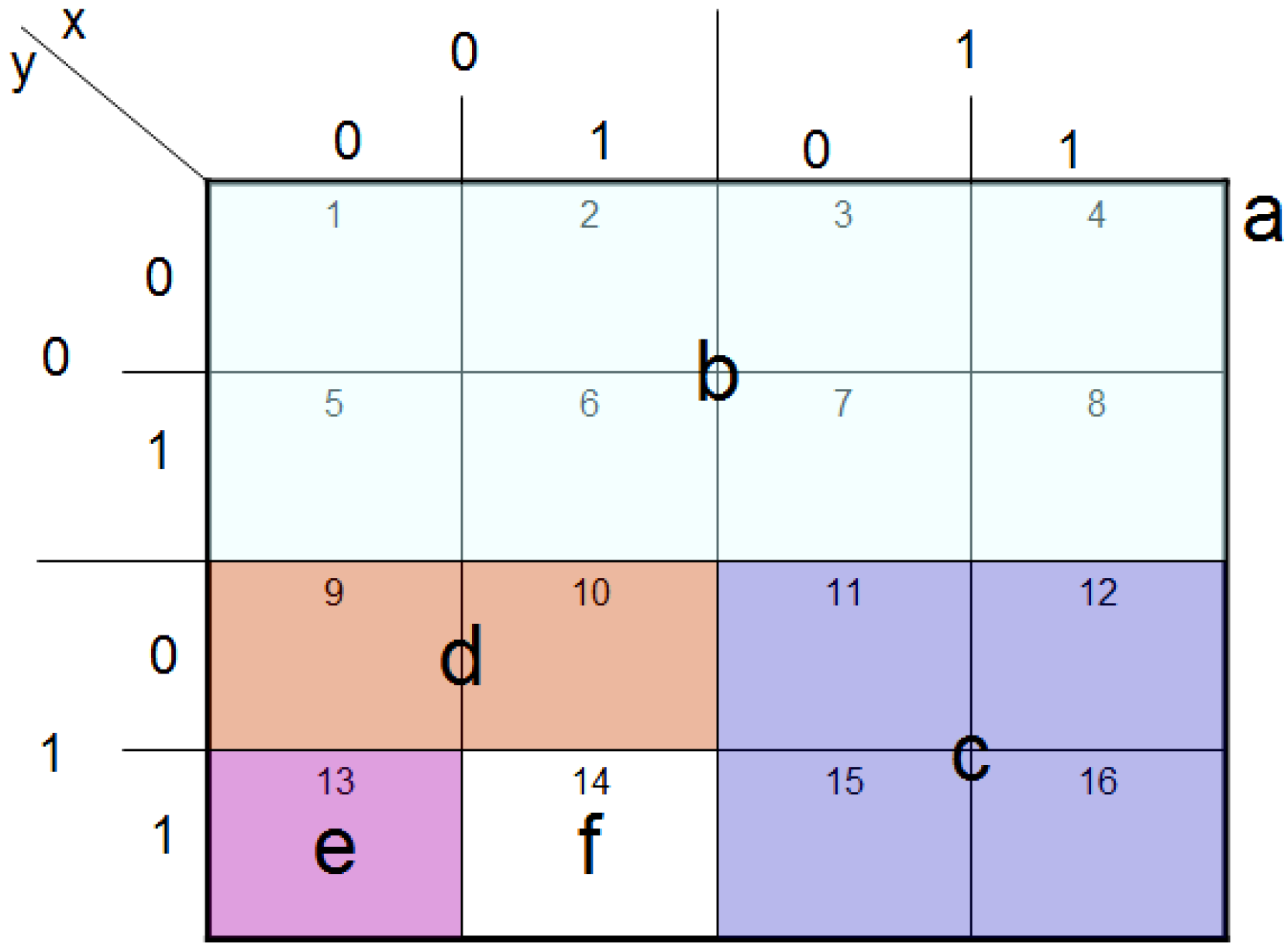
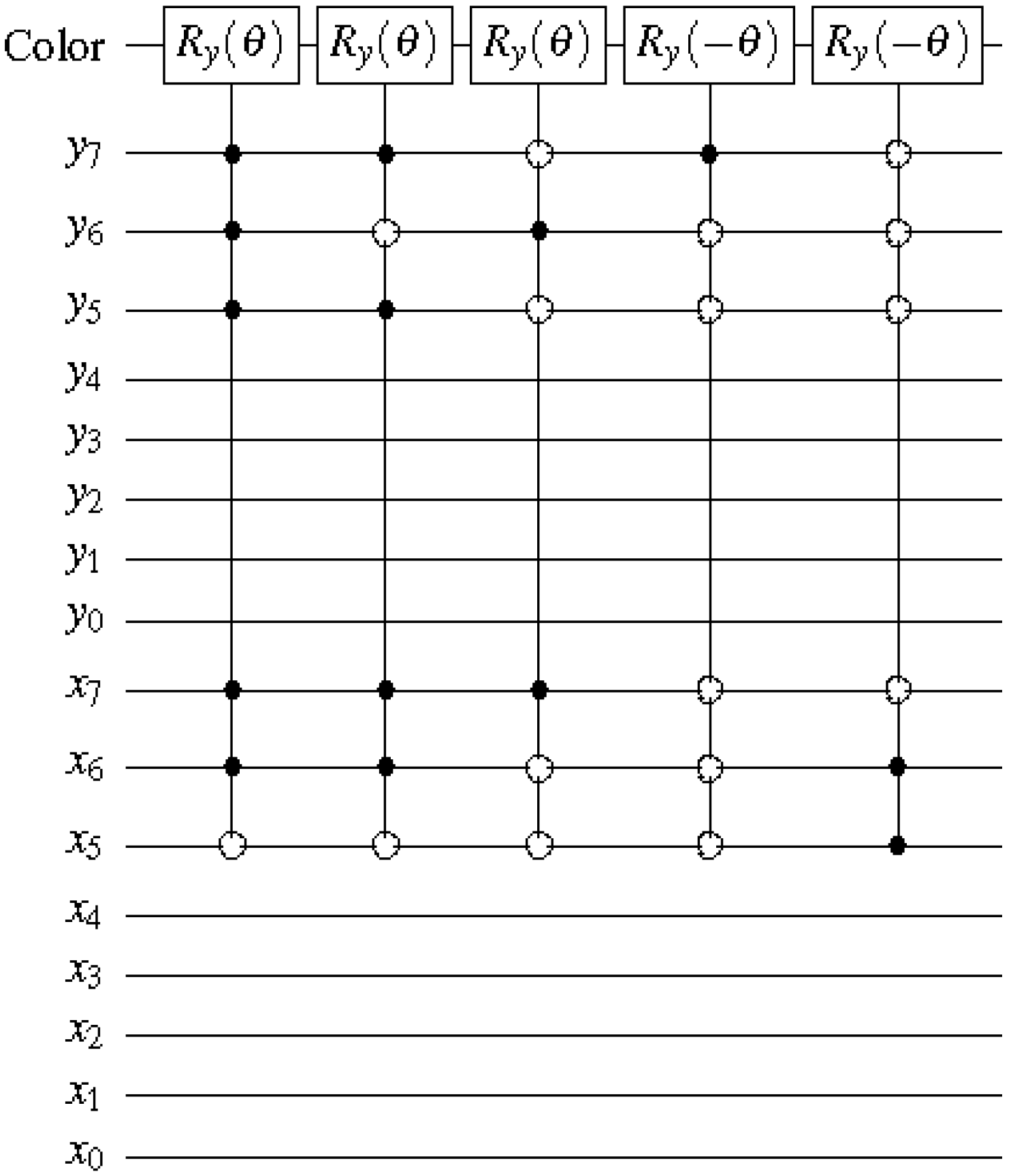
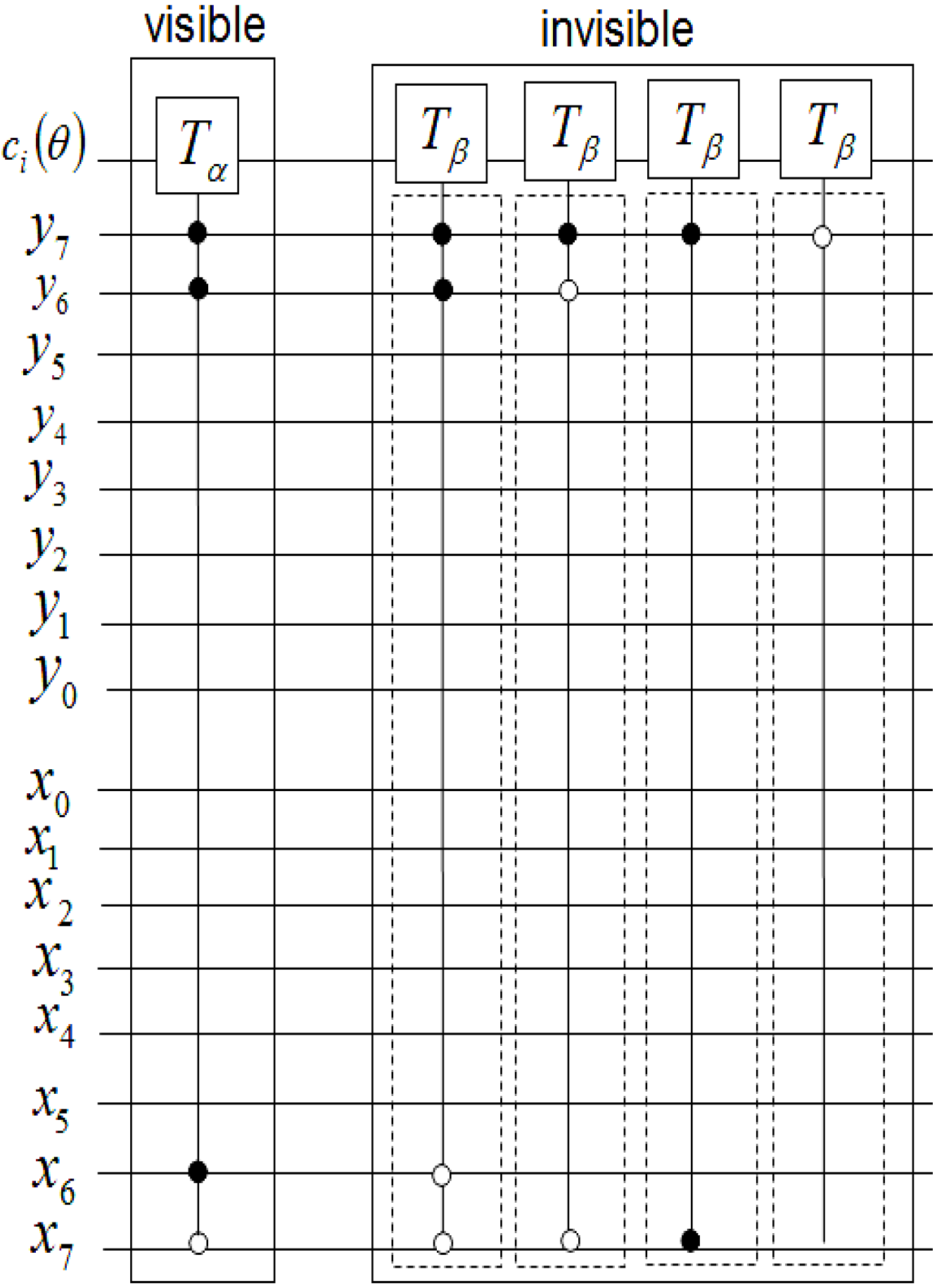
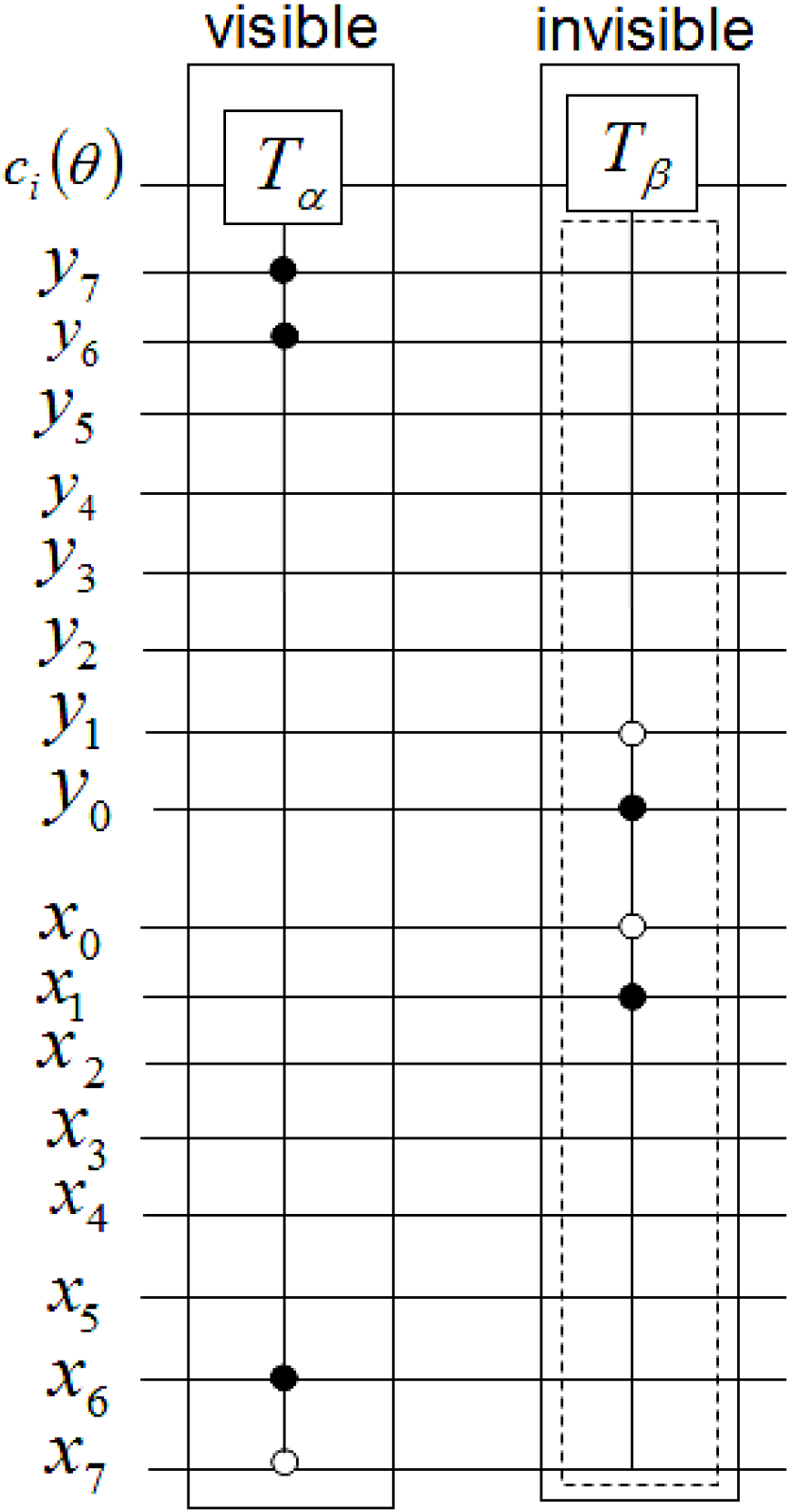
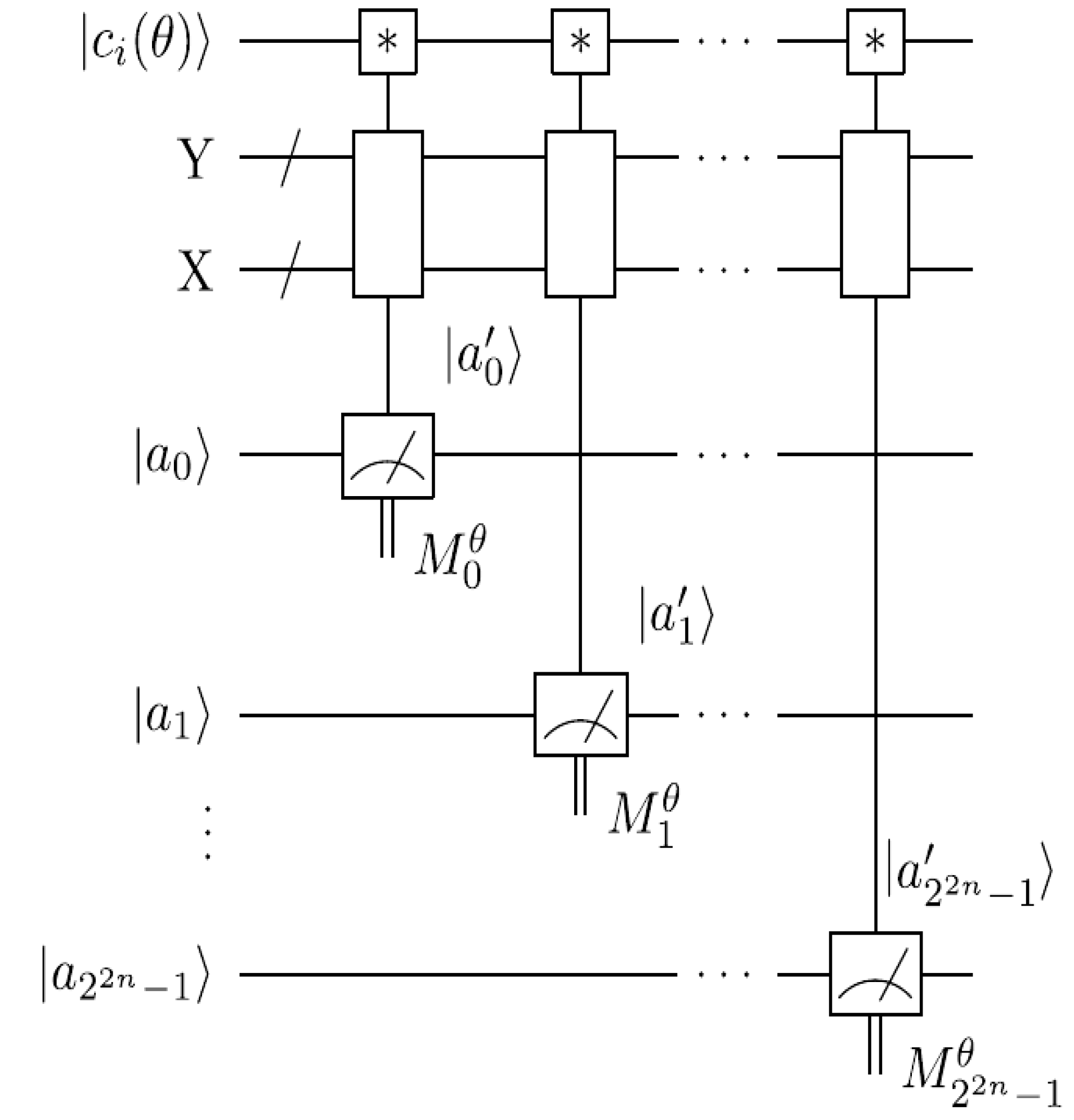
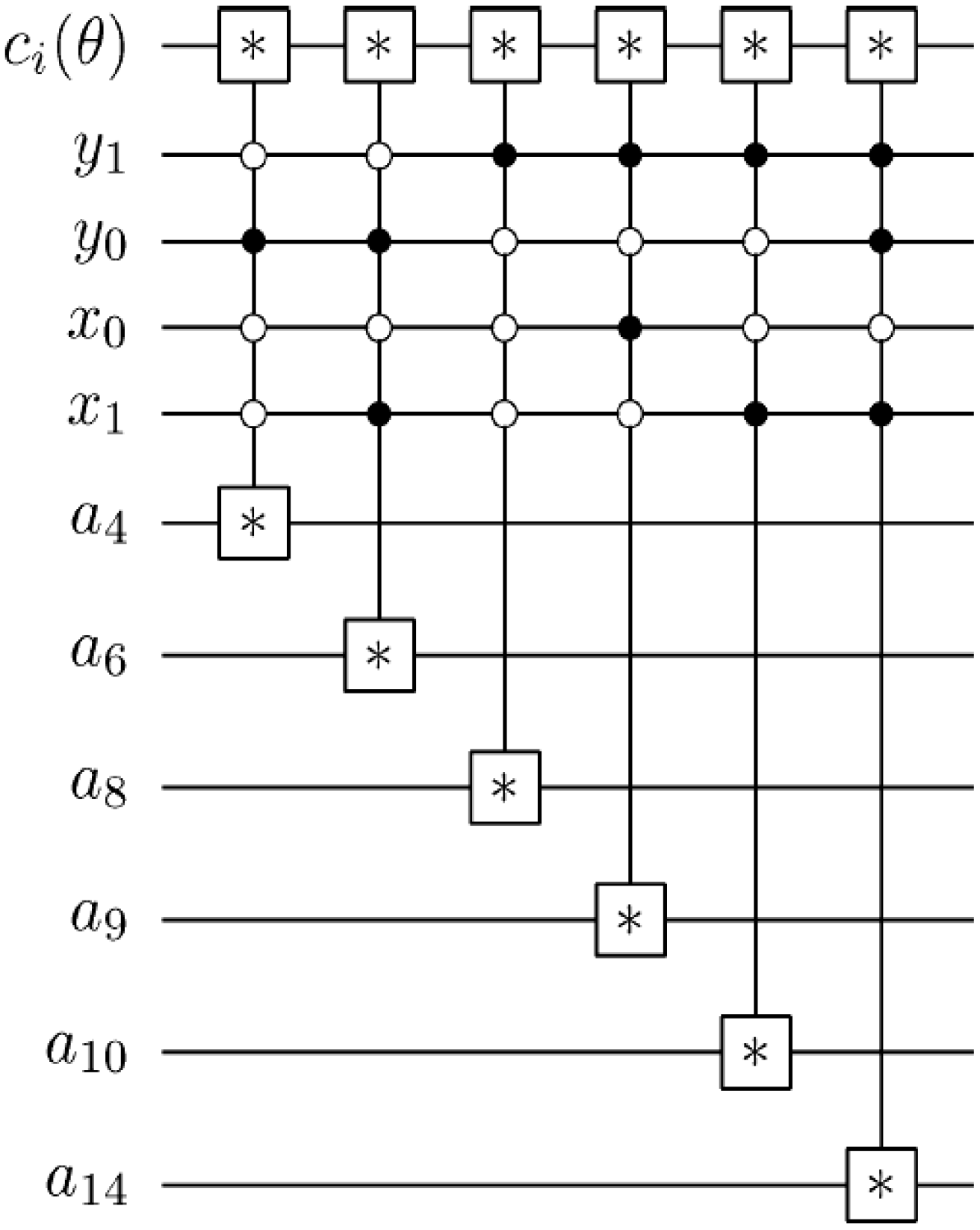
The measurements entail 2
n × 2
n dependent ancilla-driven measurement on each key (makeup or viewing) frame that makes the final movie sequence. The circuit in
Figure 58 shows such a dependent ancilla-driven image reader. In this figure the rectangular boxes on the position information indicate the position dependency, which we will discuss at length in the sequel. In this format each measurement
connecting the colour and ancilla qubits is of the form shown in
Figure 59.
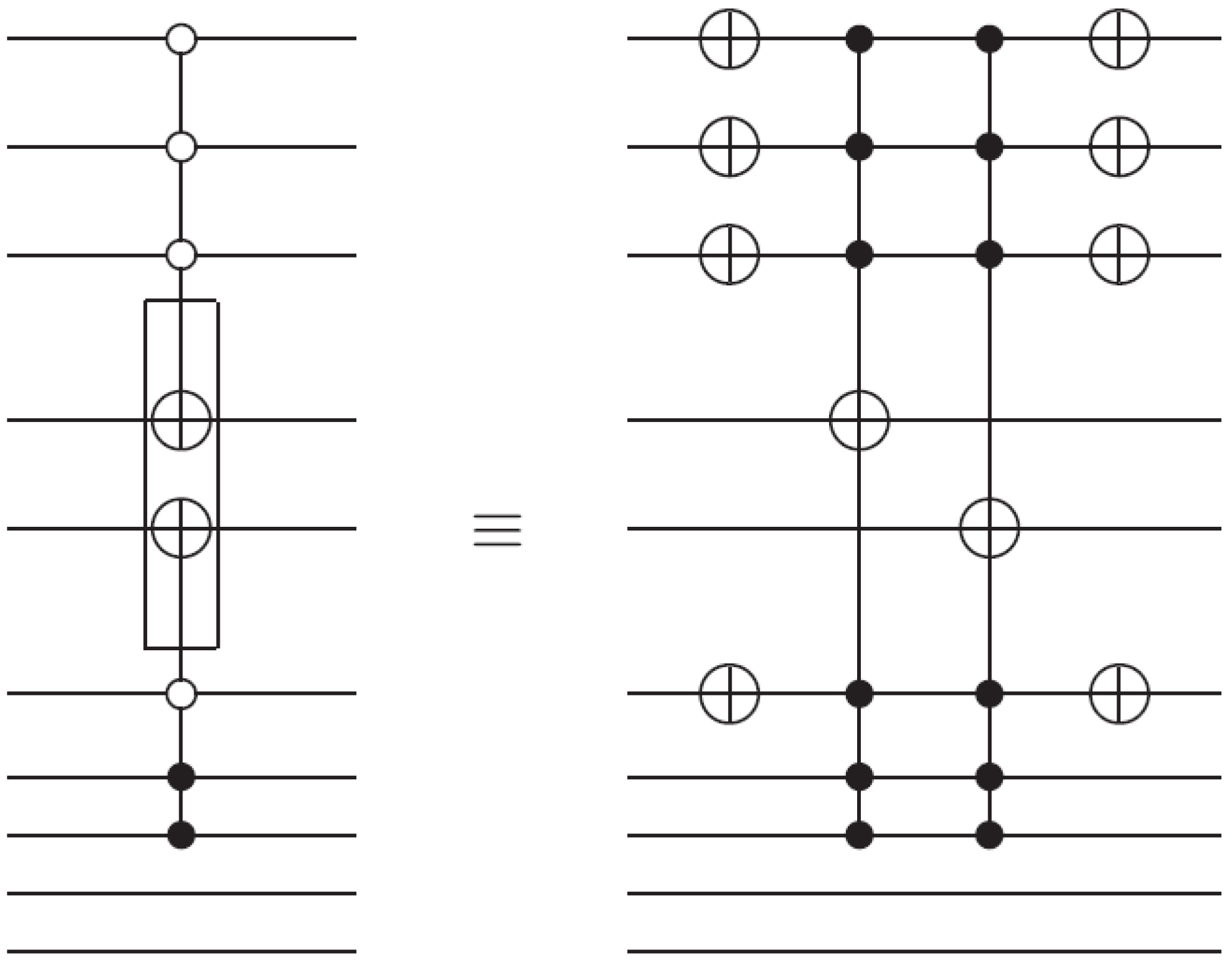
Theorem 4 (Image Reader Theorem) A total of
dependent ancilla-driven measurements
of the colour
each as defined in
Figure 59 are sufficient to recover the readout of the
pixel of a 2
n×2
n FRQI quantum image where
.
Proof: We assume the dependency criteria of the image reader as indicated by the rectangular boxes in
Figure 58 have been satisfied. Therefore, each measurement
on pixel
is performed only once for each readout. In addition to this, ignoring the post-measurement sign of the ancilla qubit, we adopt the elegant proof for similar circuits in [
6] for our proof using
Figure 59. Our objective is to show that the input state
and the initial state of the ancilla qubit
are unaltered by the transformations that yield measurement
, while the classical readout of
is recovered:
where
. Similarly:
where
is the post-measurement state of
as defined in Equation (58):
Since:
we therefore conclude that:
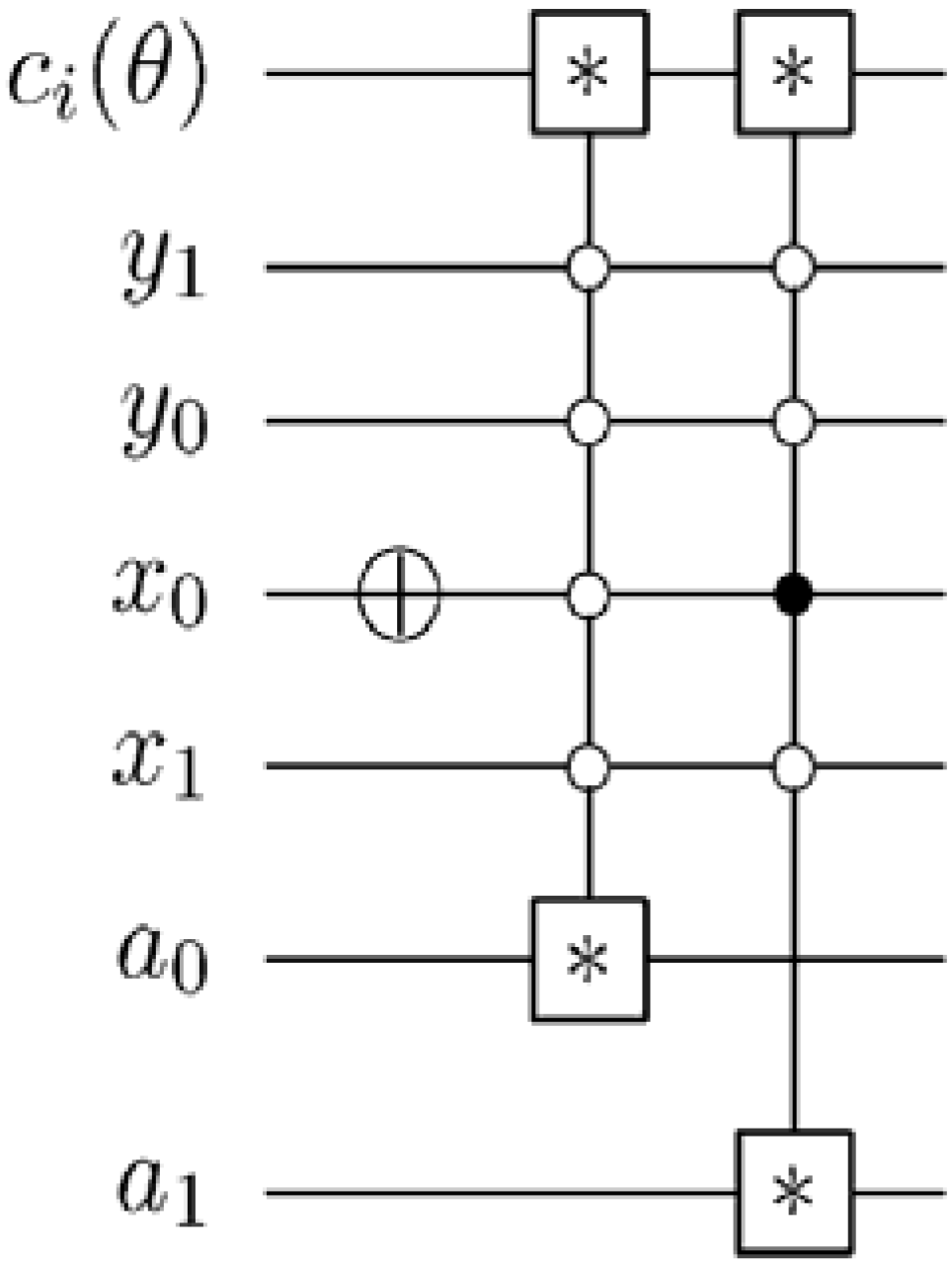
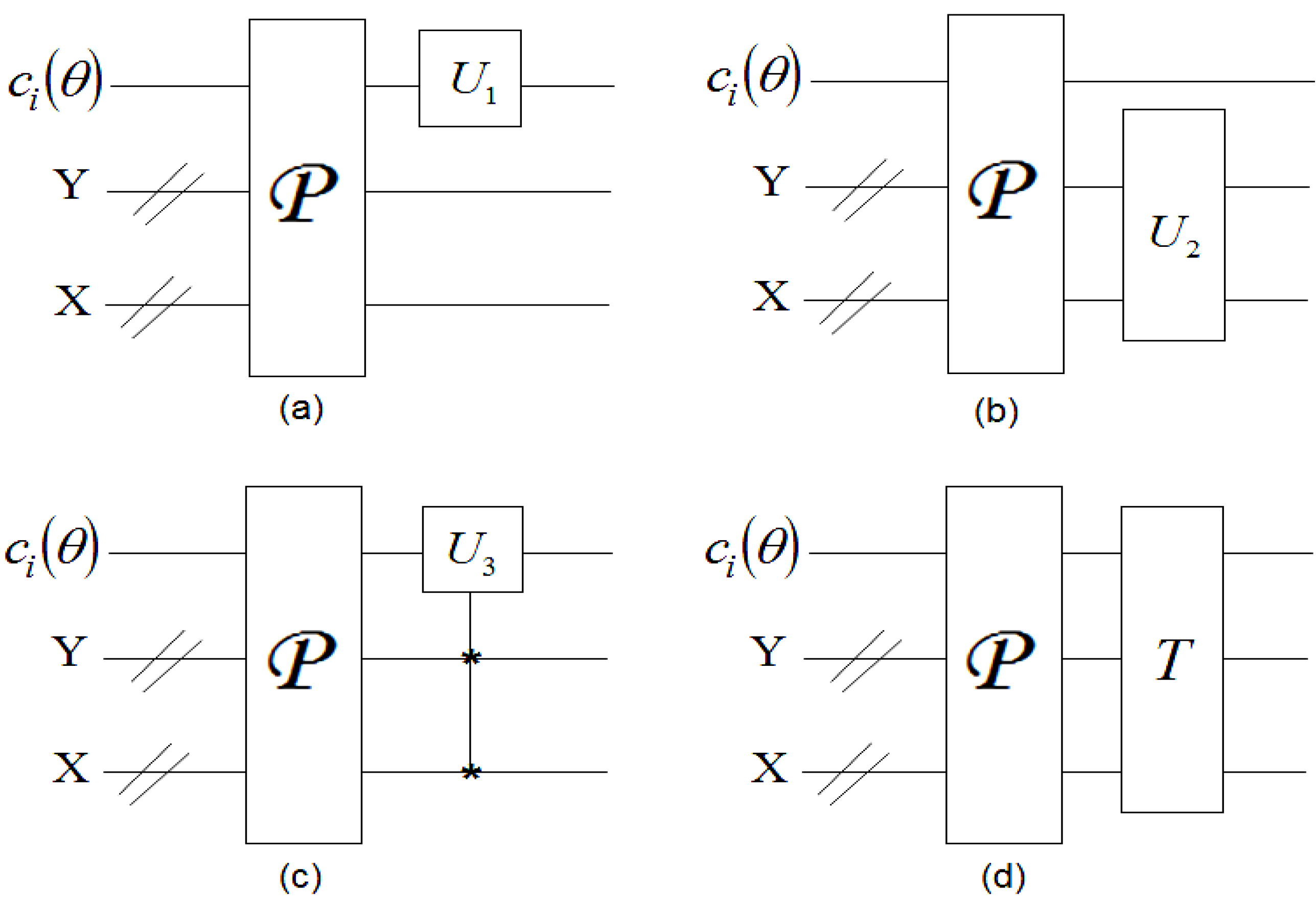
Figure 59.
Circuit to recover the content of the single-qubit colour information of an FRQI quantum image. This circuit represents each of the * between the colour and ancilla qubit in
Figure 58.
Figure 59.
Circuit to recover the content of the single-qubit colour information of an FRQI quantum image. This circuit represents each of the * between the colour and ancilla qubit in
Figure 58.
Simple inspection of our output state
in Equation (60) proves that for a pixel whose ancilla qubit
because using Equation (57) and [
73]
. Similarly, from our explanation of the ancillary information earlier in this section, it is obvious that for a pixel whose ancilla information
, the colour angle
and hence
as defined in Equation (2) becomes
. Therefore,
.
Hence, we conclude that the post-measurement state of our readout:
Our proposed dependent ancilla-driven measurements in
Figure 58 and
Figure 59, and Theorem 3 combines features from the projective and ADQC measurement techniques as reviewed in the earlier parts of this section. As seen in
Figure 58 and the explanation that emanated from it, the measurements are performed depending on whether or not some predetermined conditions are satisfied. These conditions are necessary in order to confine the measurement
to pixel
.
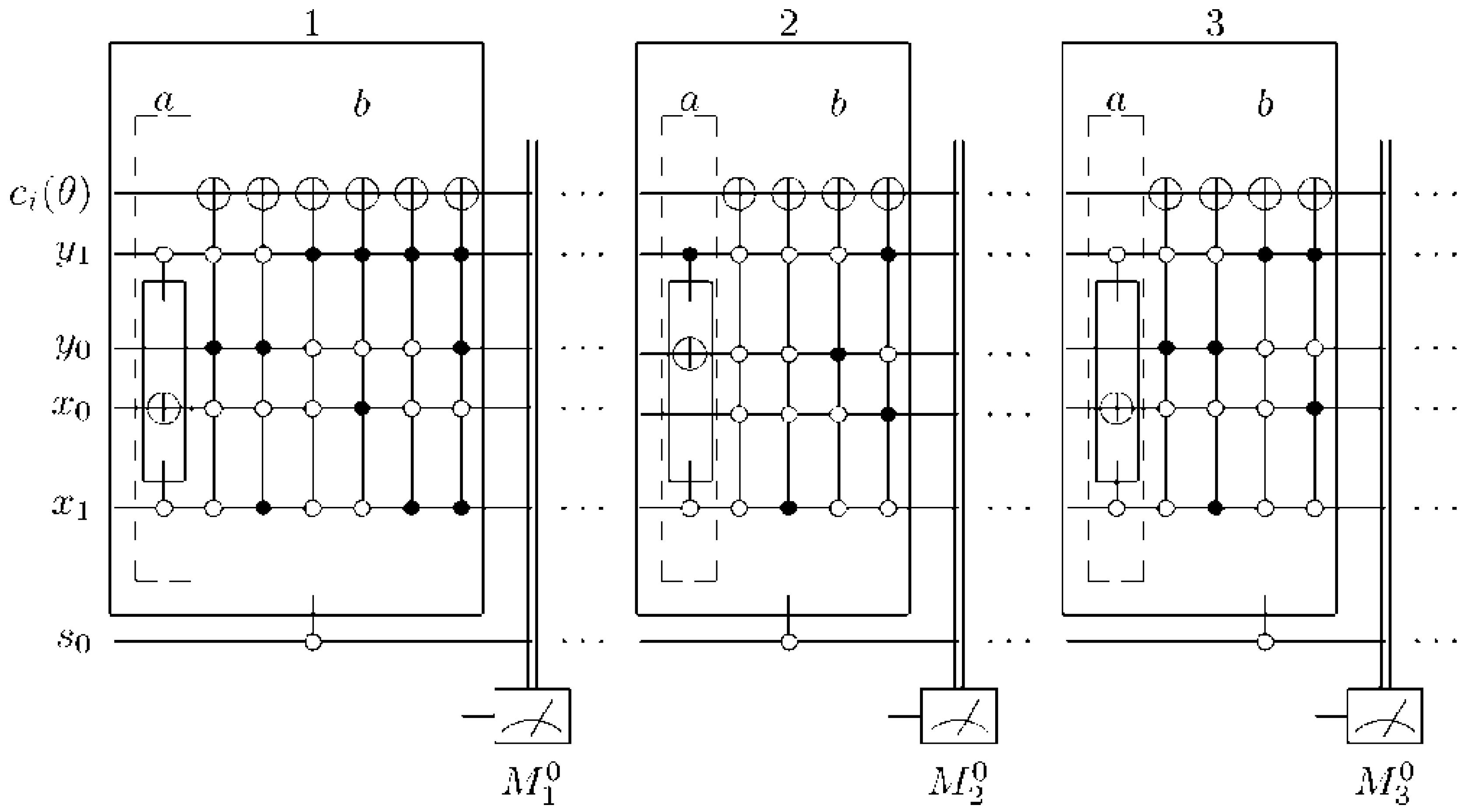
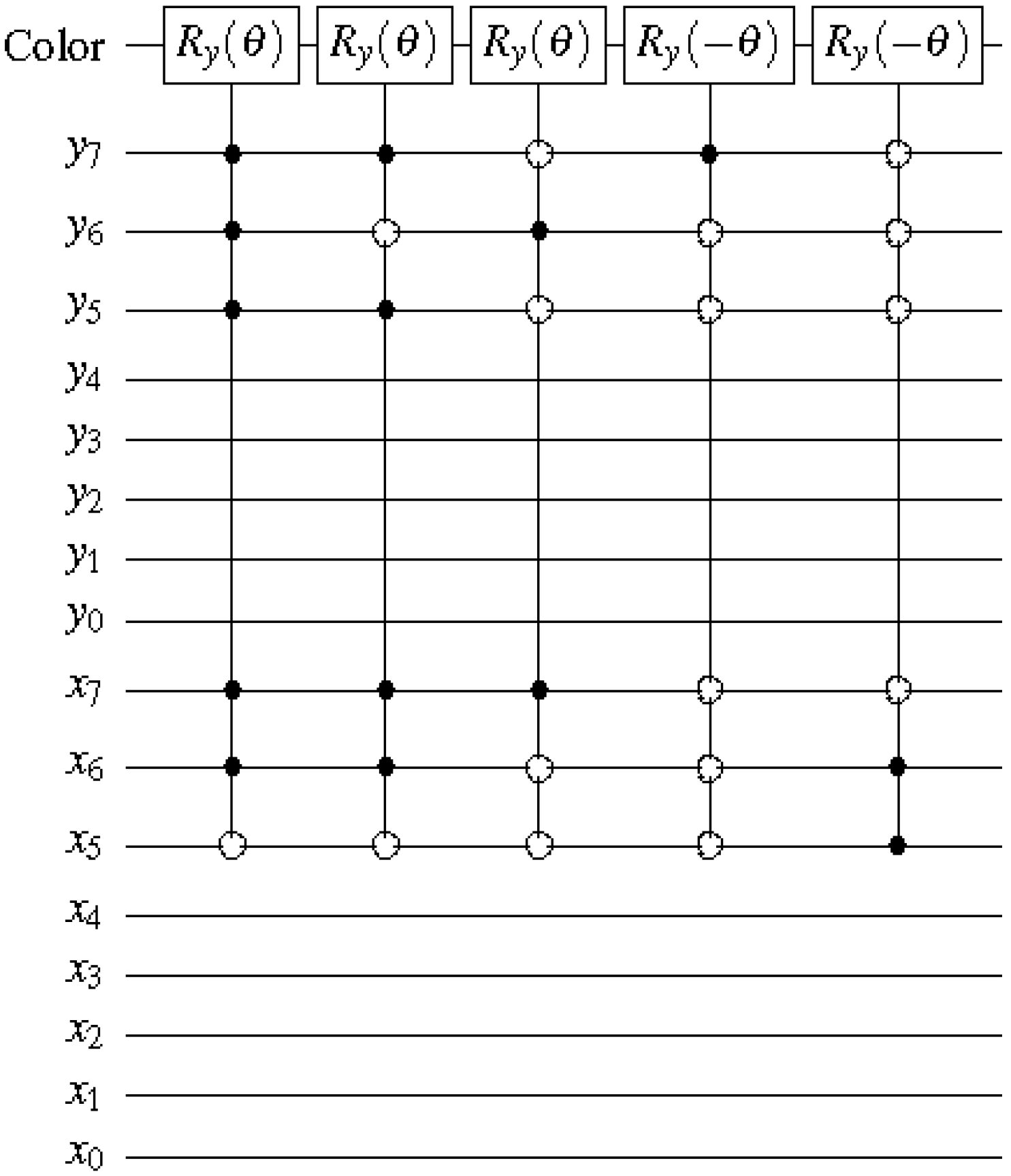
Utilising our foreknowledge about the position of the pixels in an FRQI quantum image before and after its transformation, we could generalise the position dependency portrayed earlier by the rectangular boxes (on the position axis in
Figure 58) to obtain the image reader circuit for a single FRQI quantum image (in our case a key, makeup, or viewing frame) as presented in
Figure 60. These are additional constraints that must be satisfied before the ancillary measurement described in
Figure 58 and Theorem 4 are carried out. Each pair of ∗ connecting the colour and ancilla qubits is a circuit of the form shown in
Figure 59.
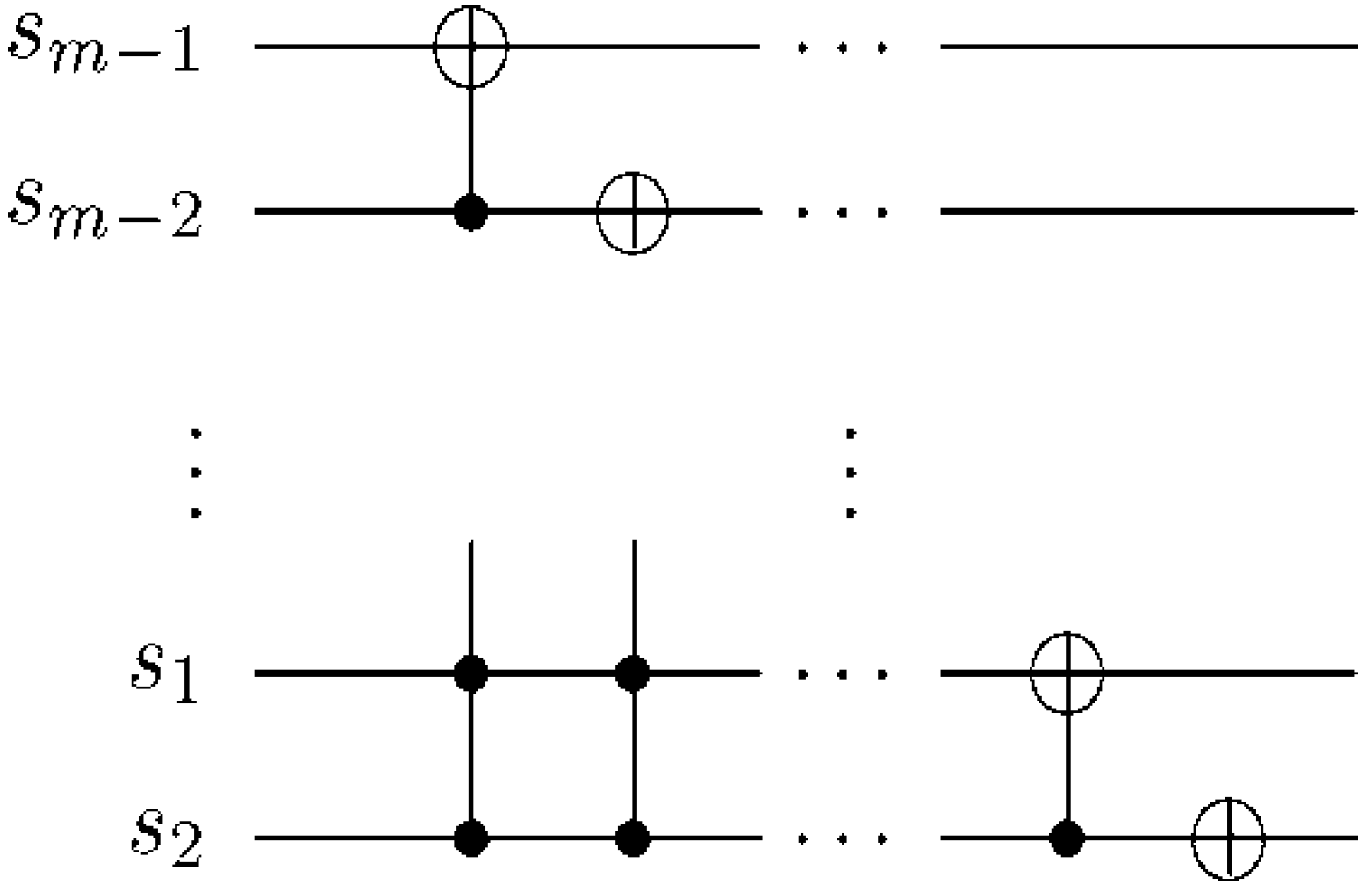
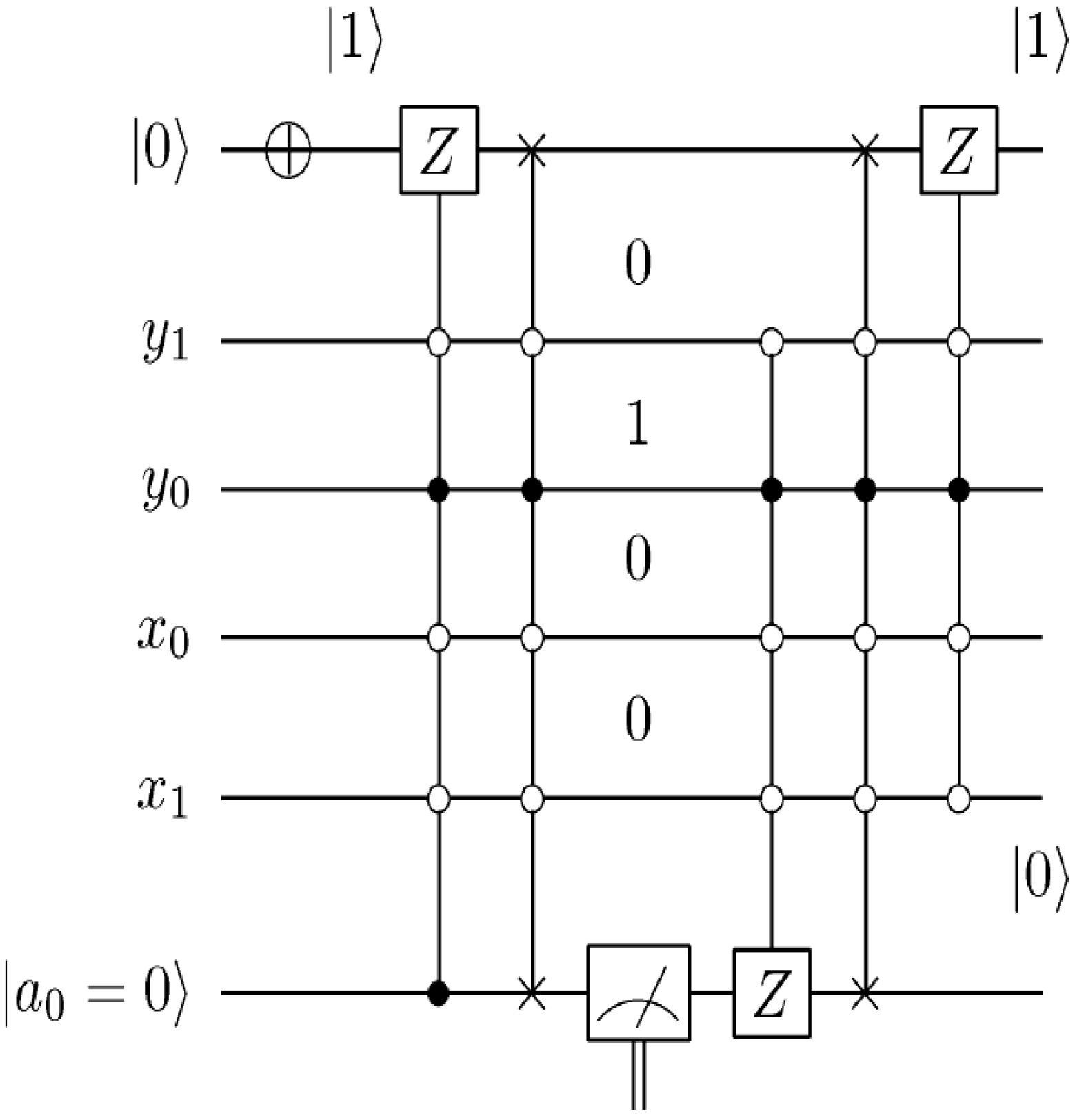
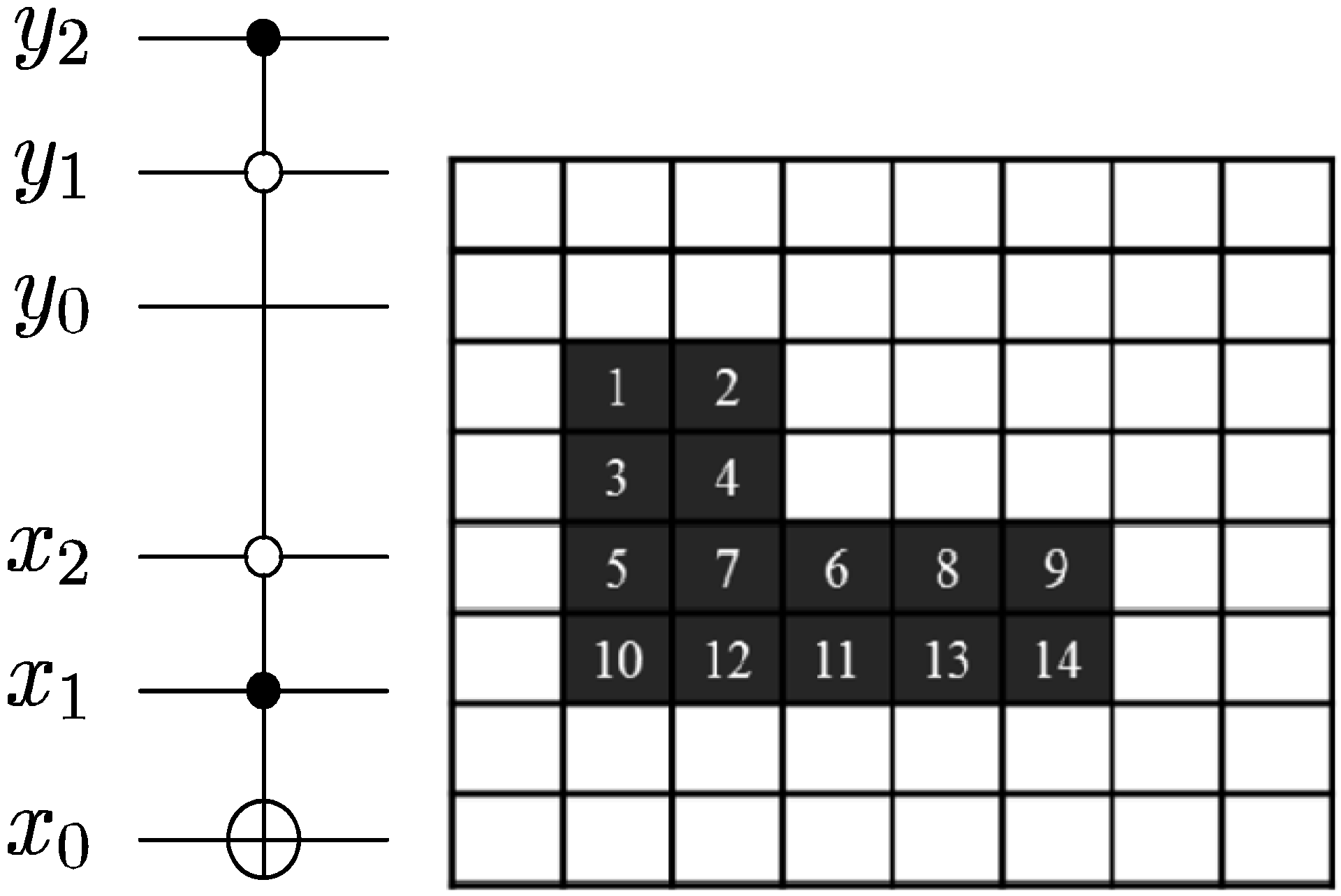
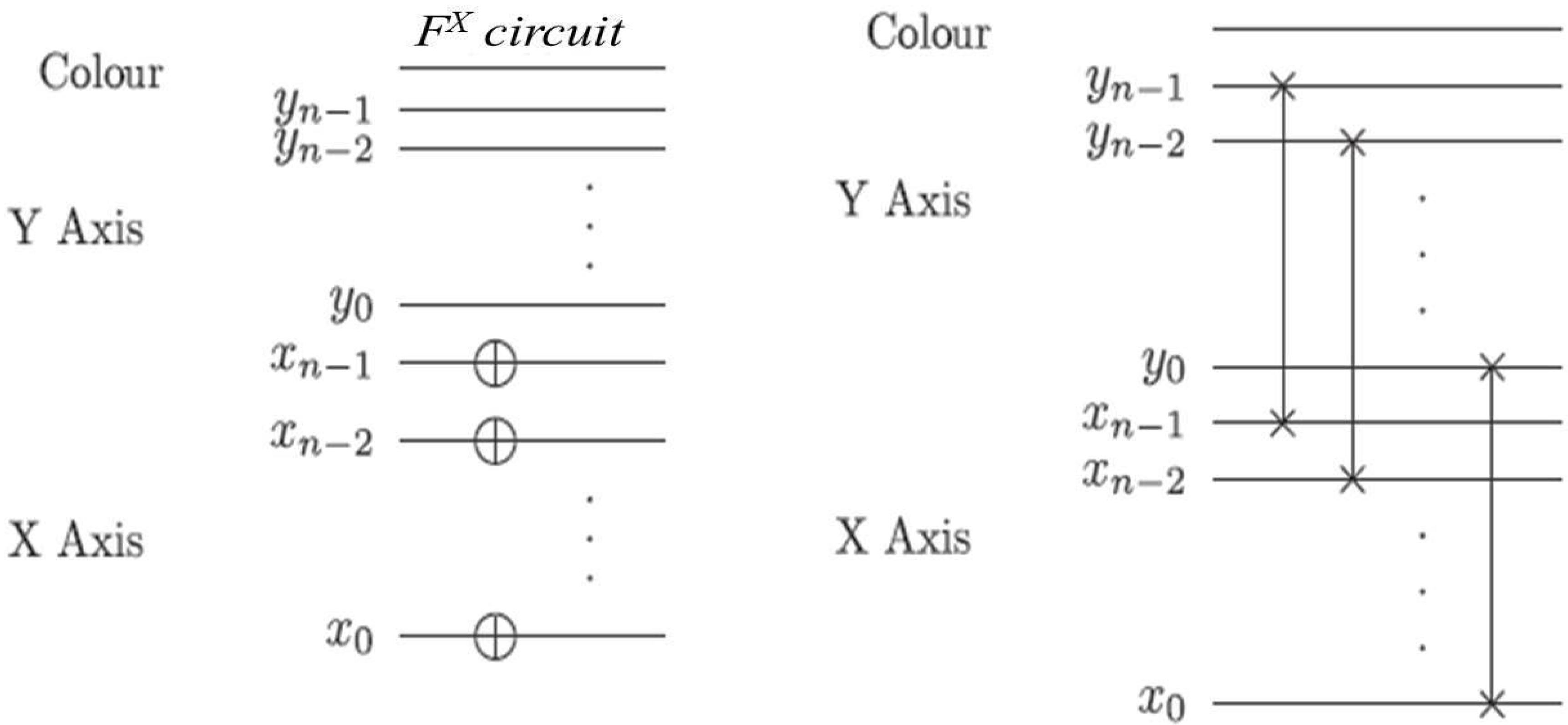
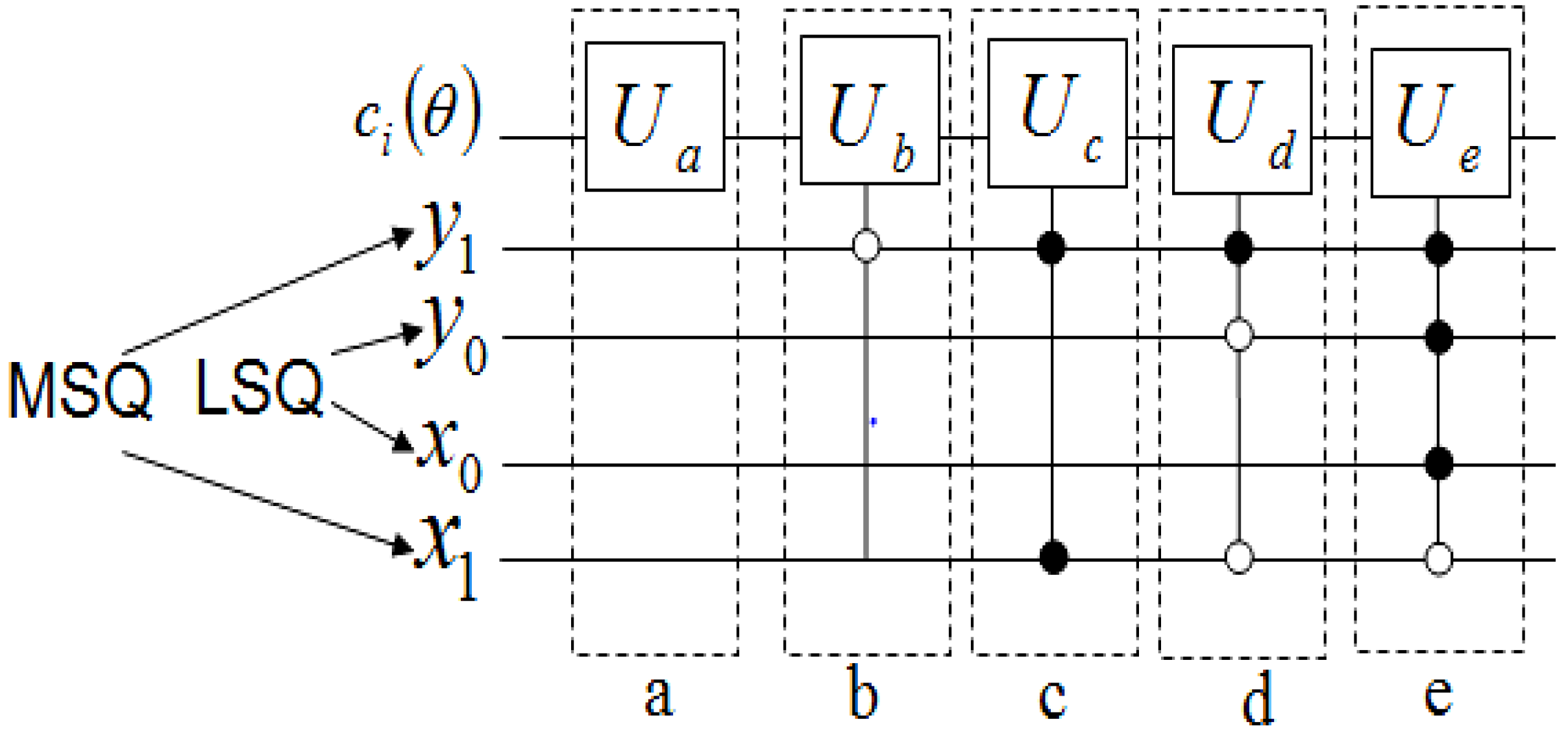
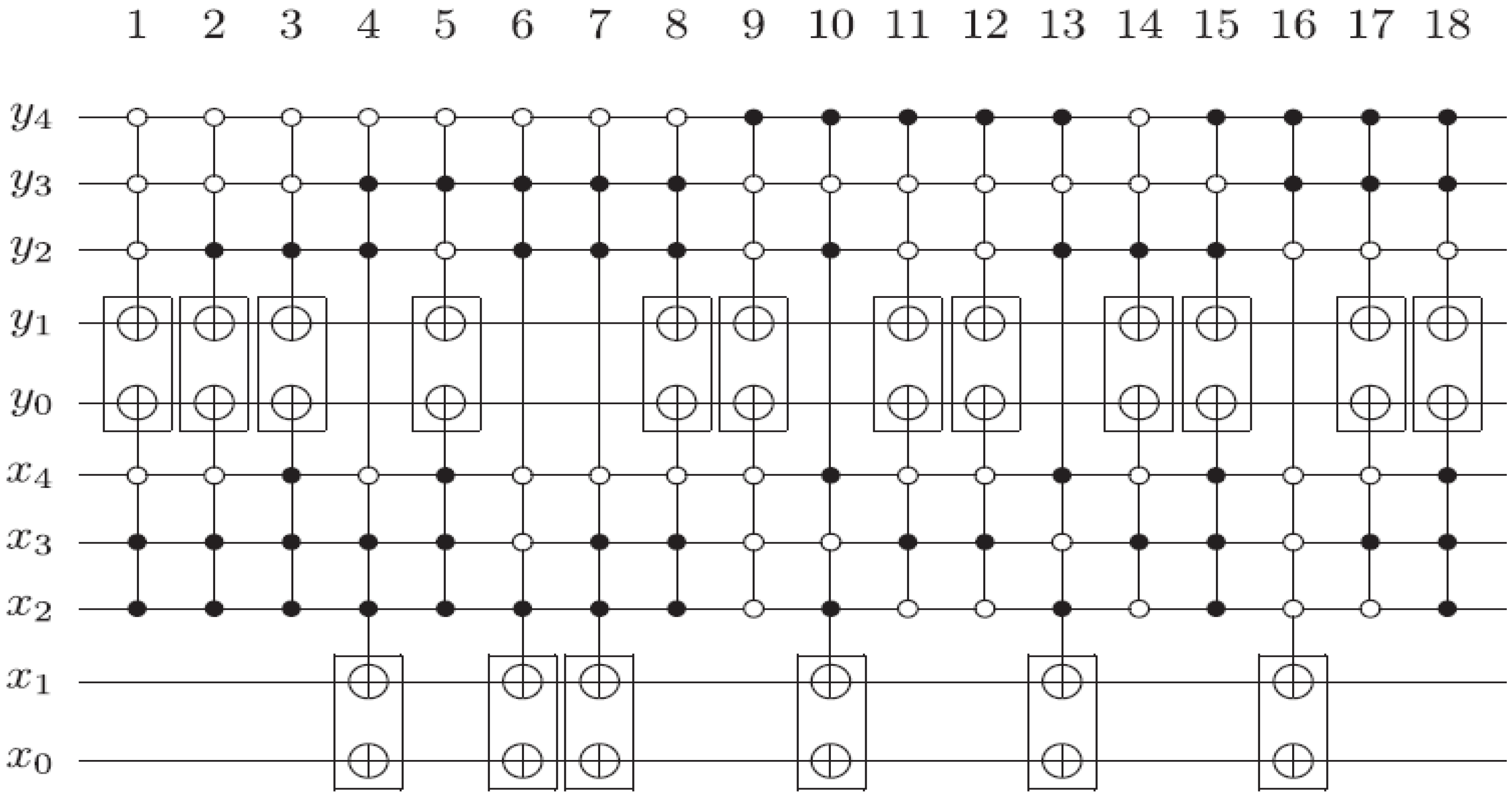
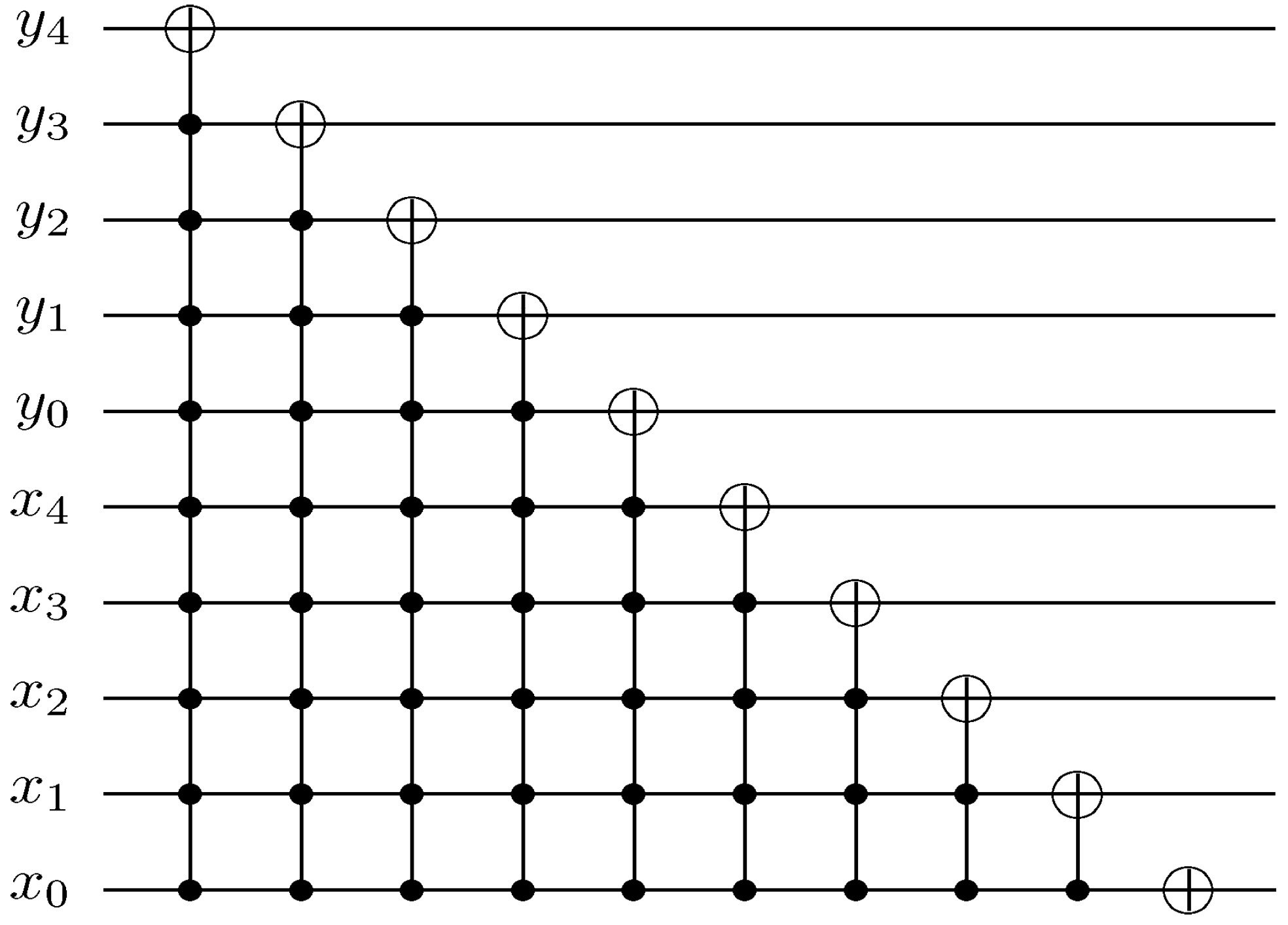
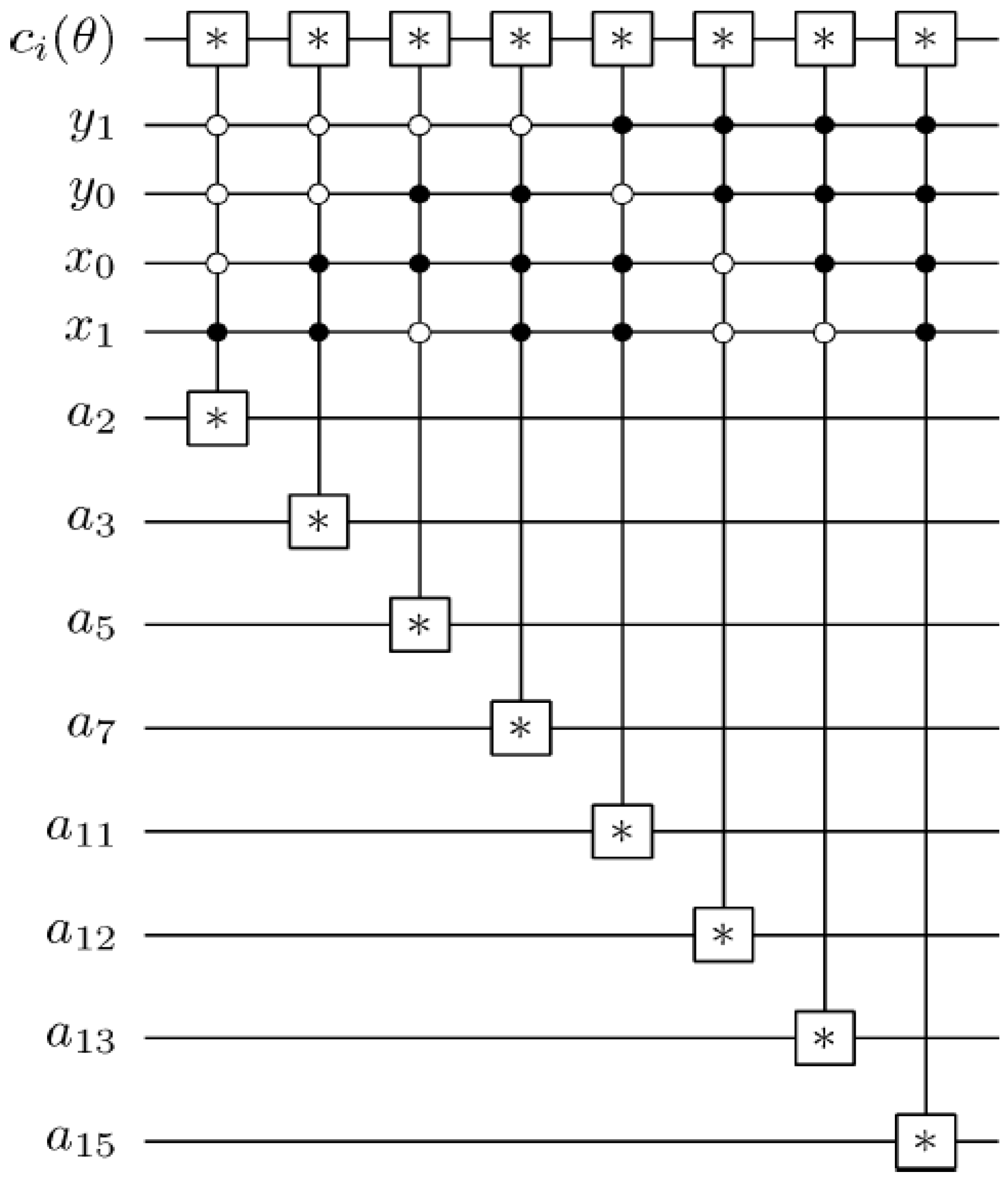
Figure 60.
Reader to recover the content of a 2n×2n FRQI quantum image.
Figure 60.
Reader to recover the content of a 2n×2n FRQI quantum image.
Using this format, the changes in the ancillary information (whether each pixel in the original image, a key frame, has a fill or not) undergoes can be tracked relative to changes in their colours as they evolve based on the transformations by the movie and CTQI operations.
In recovering the contents of a movie, however, multiple such measurements are necessary. Definition 6 formalises our definition of the movie reader.
Definition 6: An
mFRQI quantum movie reader is a system comprising
ancillary qubits each initialised as defined earlier in this section and Equation (58) to track the change in the content of every pixel in each frame (key, makeup, or viewing) that forms part of the movie sequence in Equation (56) based on single-qubit dependent ancilla-driven measurements as described in
Figure 60.
As proposed in this section, any destructive measurement on our movie reader like in the ADQC is made on the ancilla [
38,
75], while the key (makeup and viewing) frame content remains intact for future operations. It is a method for implementing any quantum channel on a quantum register driven by operations on an ancilla using only a fixed entangling operation. Using the ADQC, measurements on each of the frames in the movie sequence
in Equation (58) produce its classical version resulting in a sequence called the viewing sequence,
M given as
At appropriate frame transition rates (classically, 25 frames per second [
65]), its sequence creates the impression of continuity in the movements of the frame content as dictated by the script of the movie.
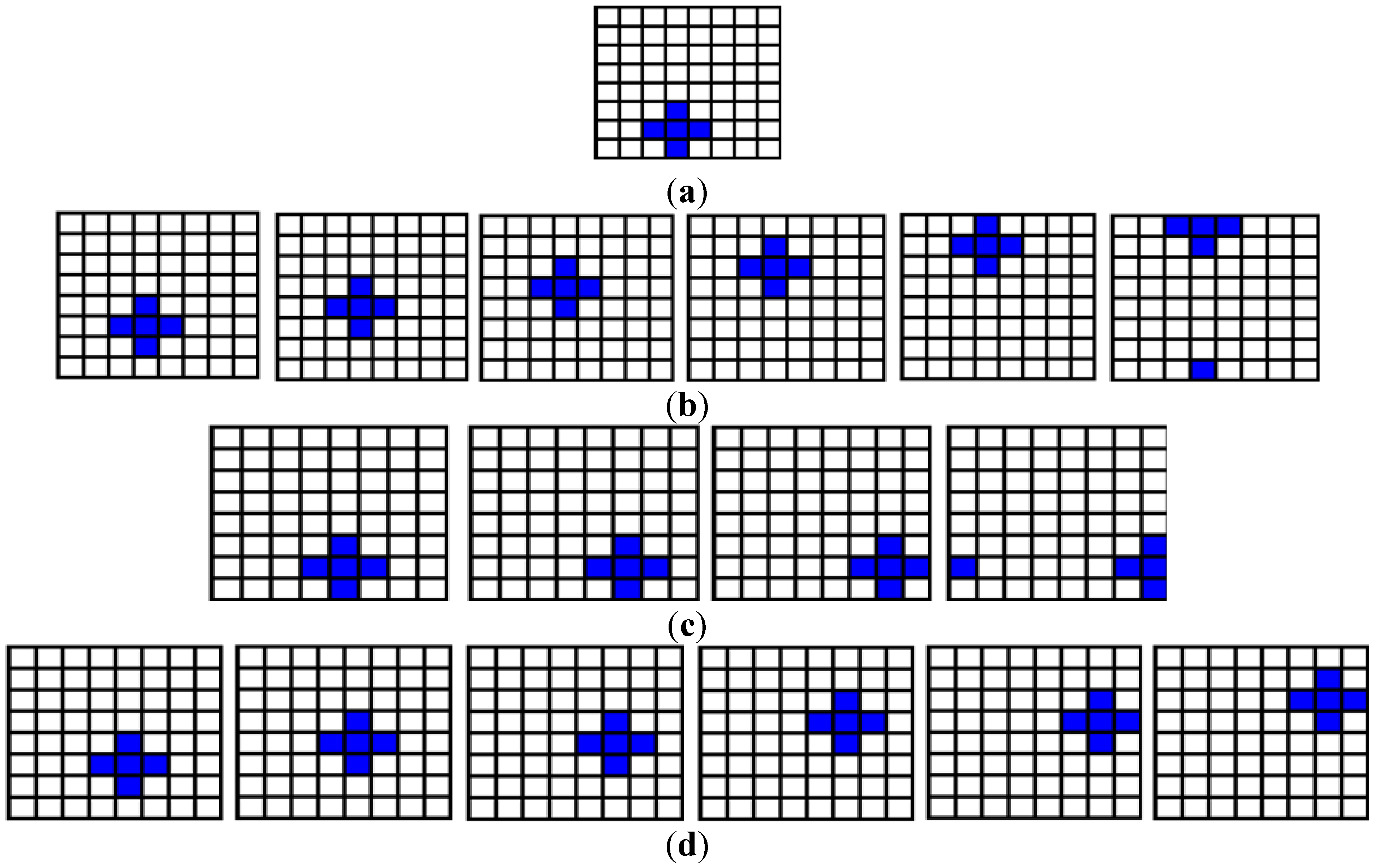
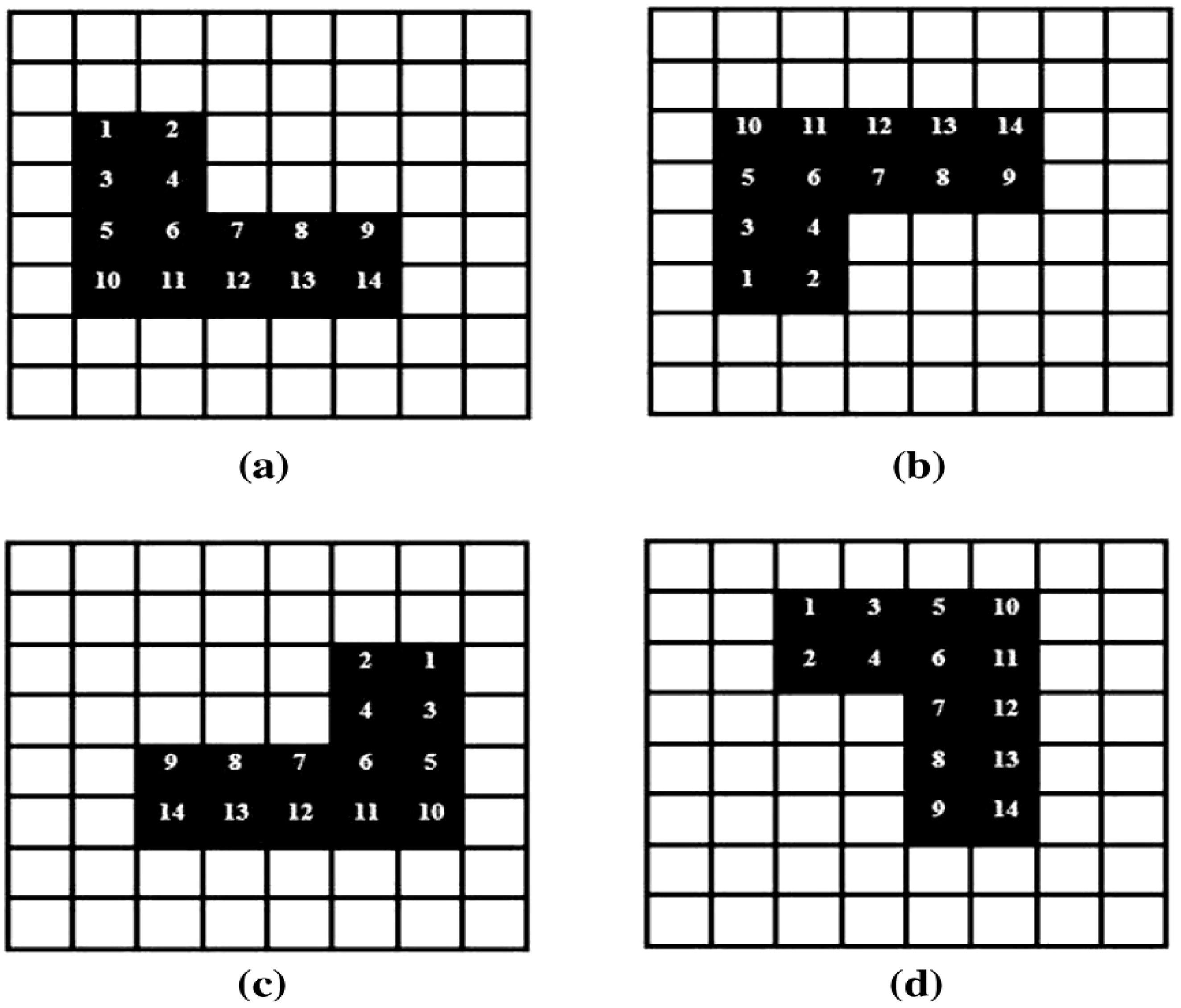
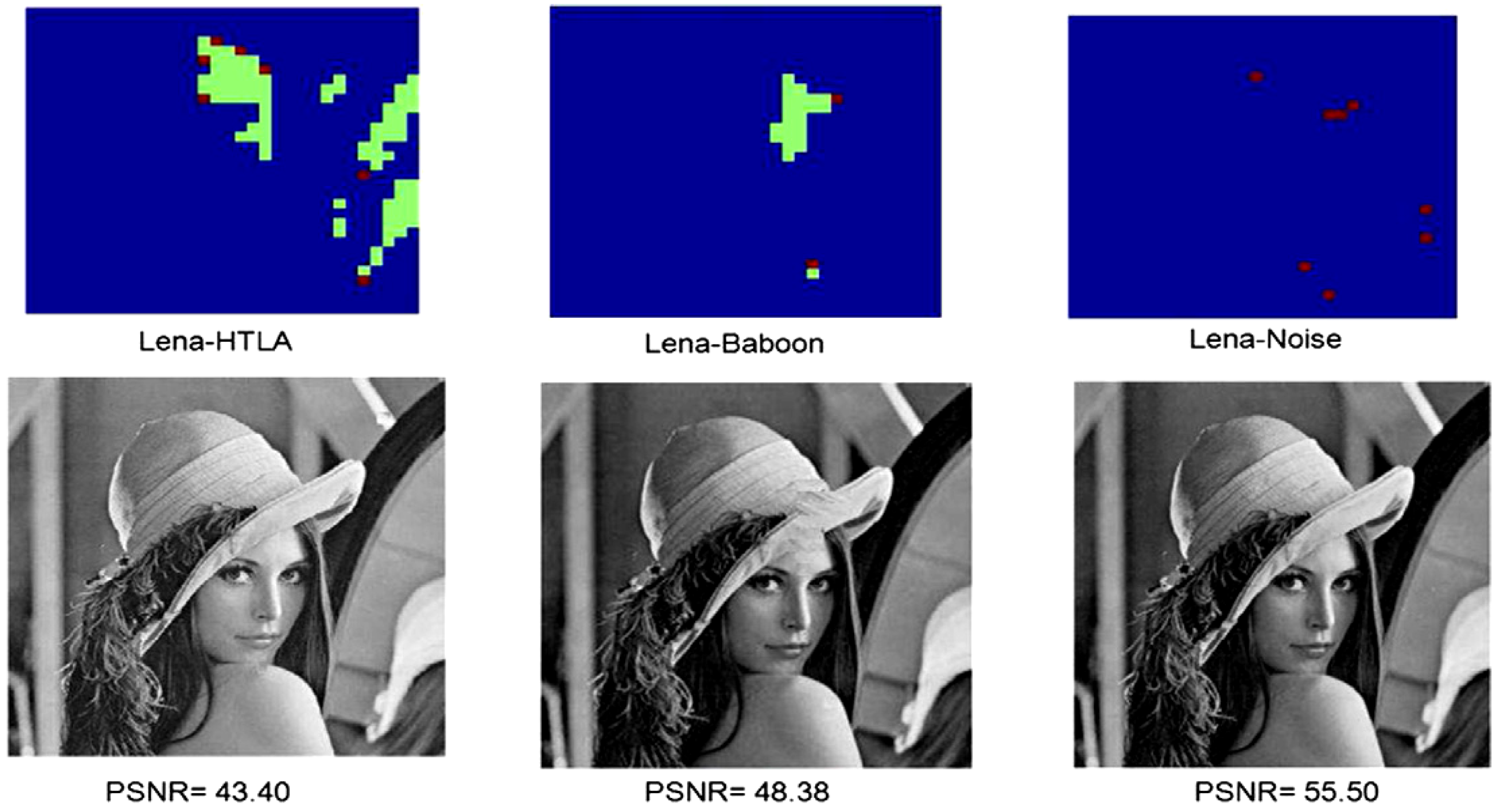
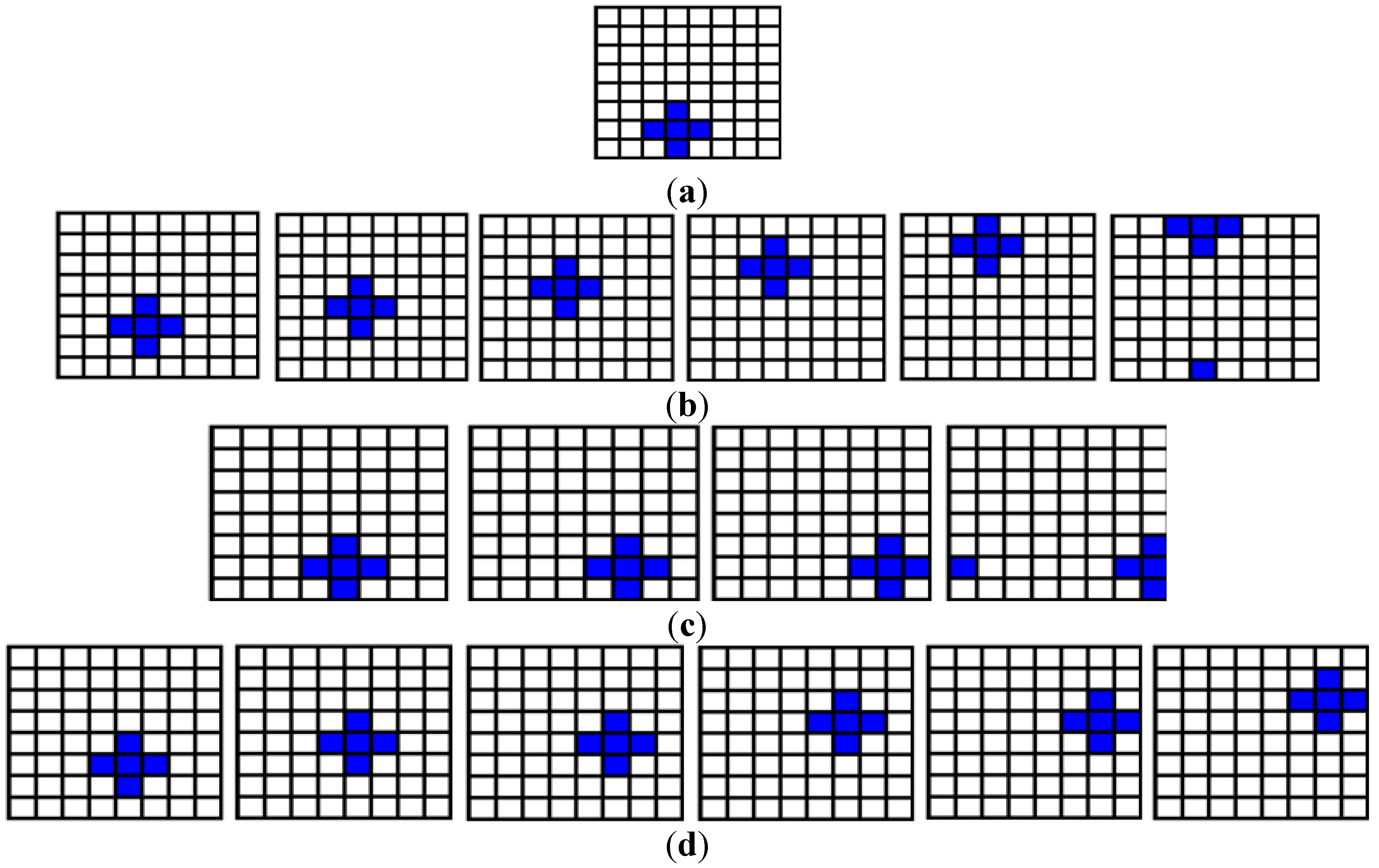
To conclude, we consider the use of our dependent ancilla-driven movie reader to recover the movie sequence for the scene presented in
Figure 49 and discussed earlier in this section. Based on the key frame for this example as presented in
Figure 49(d), the ancillary information consists of 16 ancilla qubits which are prepared as
through
. This information as stored in the quantum CD comprises: the first qubit
, while all the others are prepared in state
as explained in [
19] and earlier parts of this section. The movie reader performs a total of
measurements each of the form described in
Figure 60 in order to obtain the final classical readout of the movie sequence of this scene.
For brevity, we limit the recovery of movie sequence by the movie reader to just the first viewing frame
. The movie reader readout as read by the measurement layer
indicates the new states of the 16 pixels from their original states in the key frame
to those in
as transformed by the SMO and CTQI operations in sub-circuit 1 of
Figure 50 in the form described in
Figure 56. As explained in
subsection 6.2, this sub-circuit comprises two parts labelled (a) and (b) for the SMO and CTQI operations, respectively.
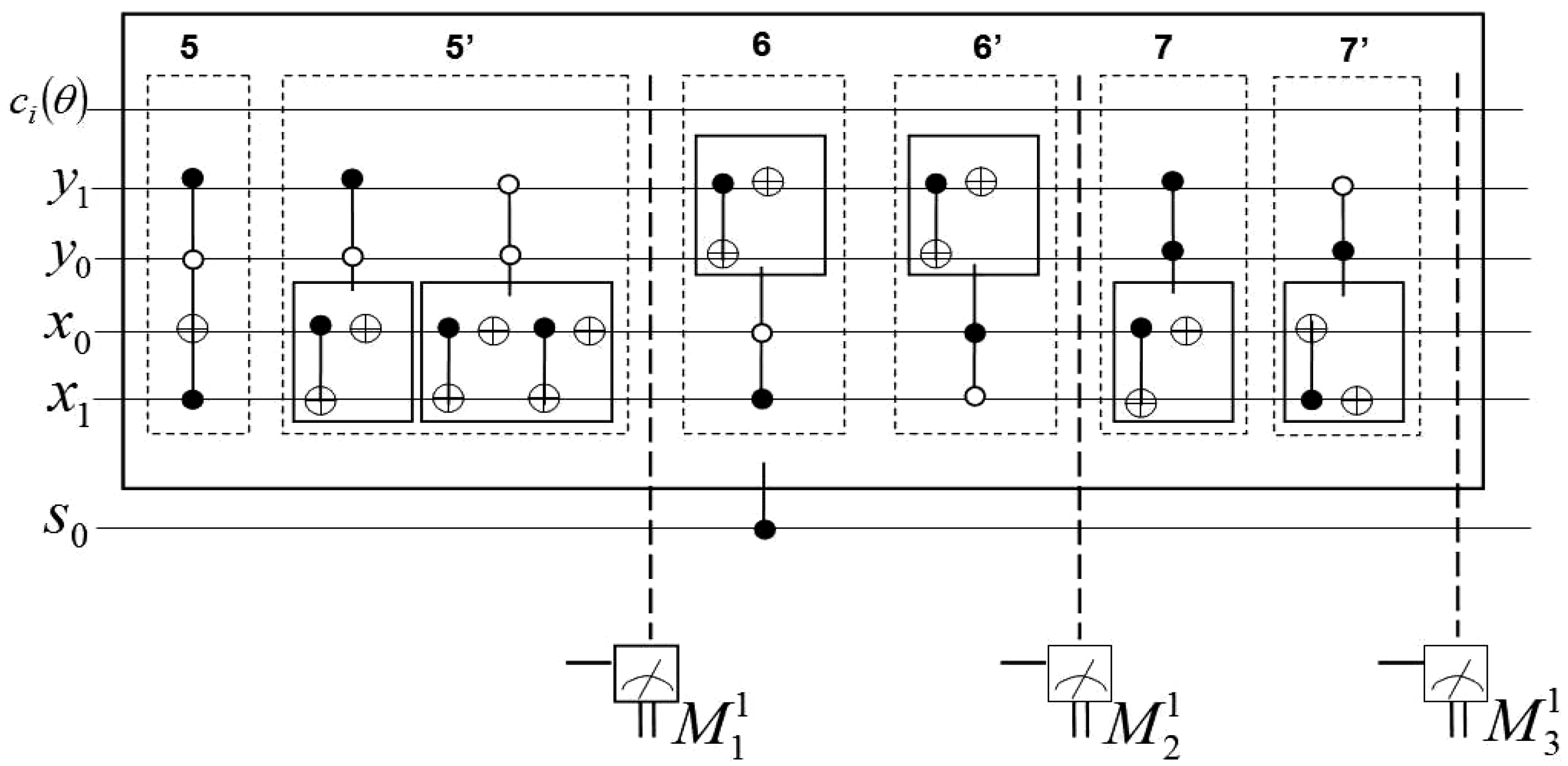
The purpose of measurement
(which is itself a sub-part of the movie reader) is to track the evolution of the key frame
as it undergoes various transformations, which are in turn dictated by the movie script. For clarity, we further divide the measurement
of the movie circuit in
Figure 50 into three groups. The first two groups each focus on new states (of the pixels) obtained by transforming the colour and (or) position content of
. The third group focuses on the pixels of
that were not transformed by the movie circuit,
i.e. pixels that the script requires unchanged between the transitions (evolution) of the content from
to
. These three groups are discussed in the sequel.
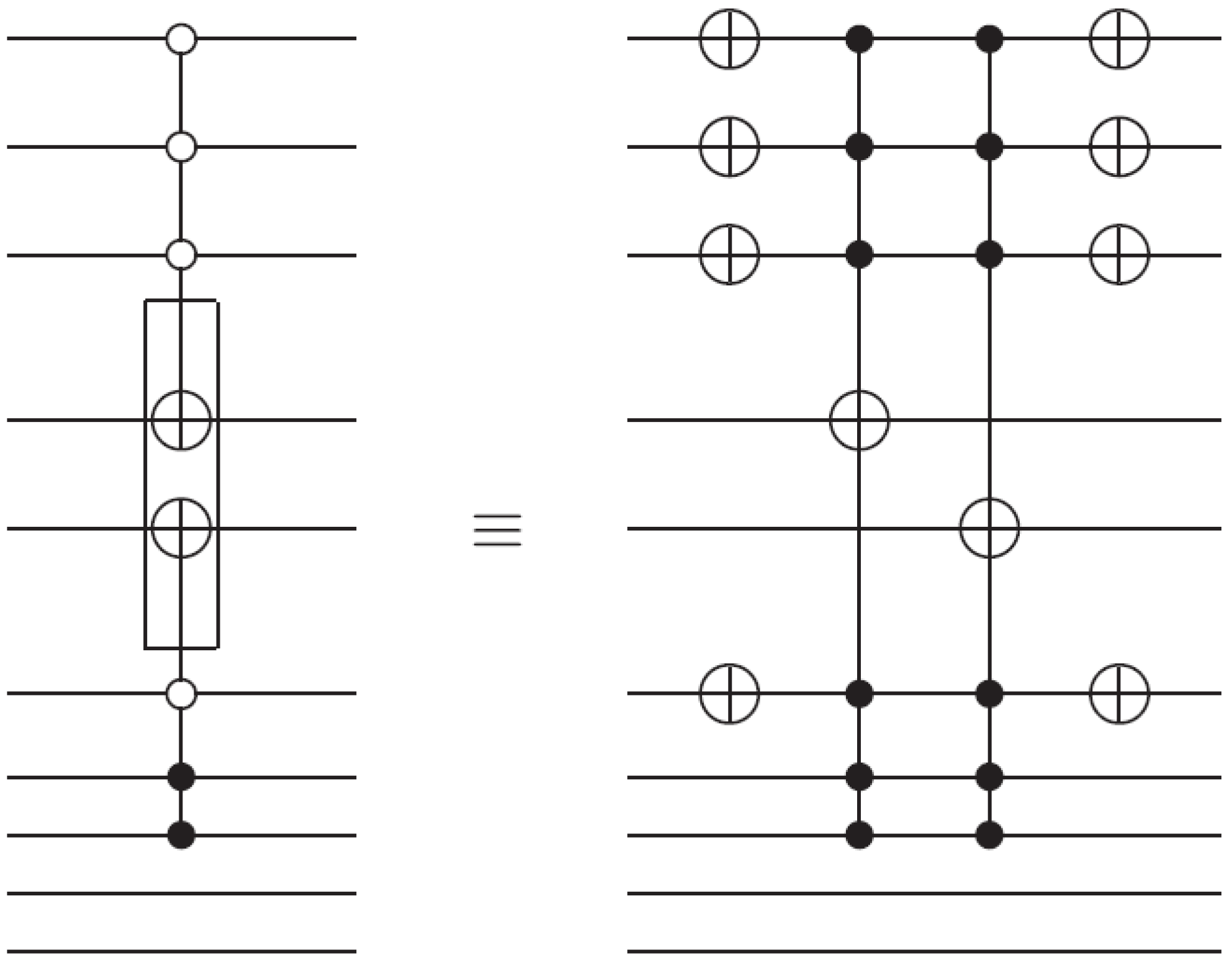
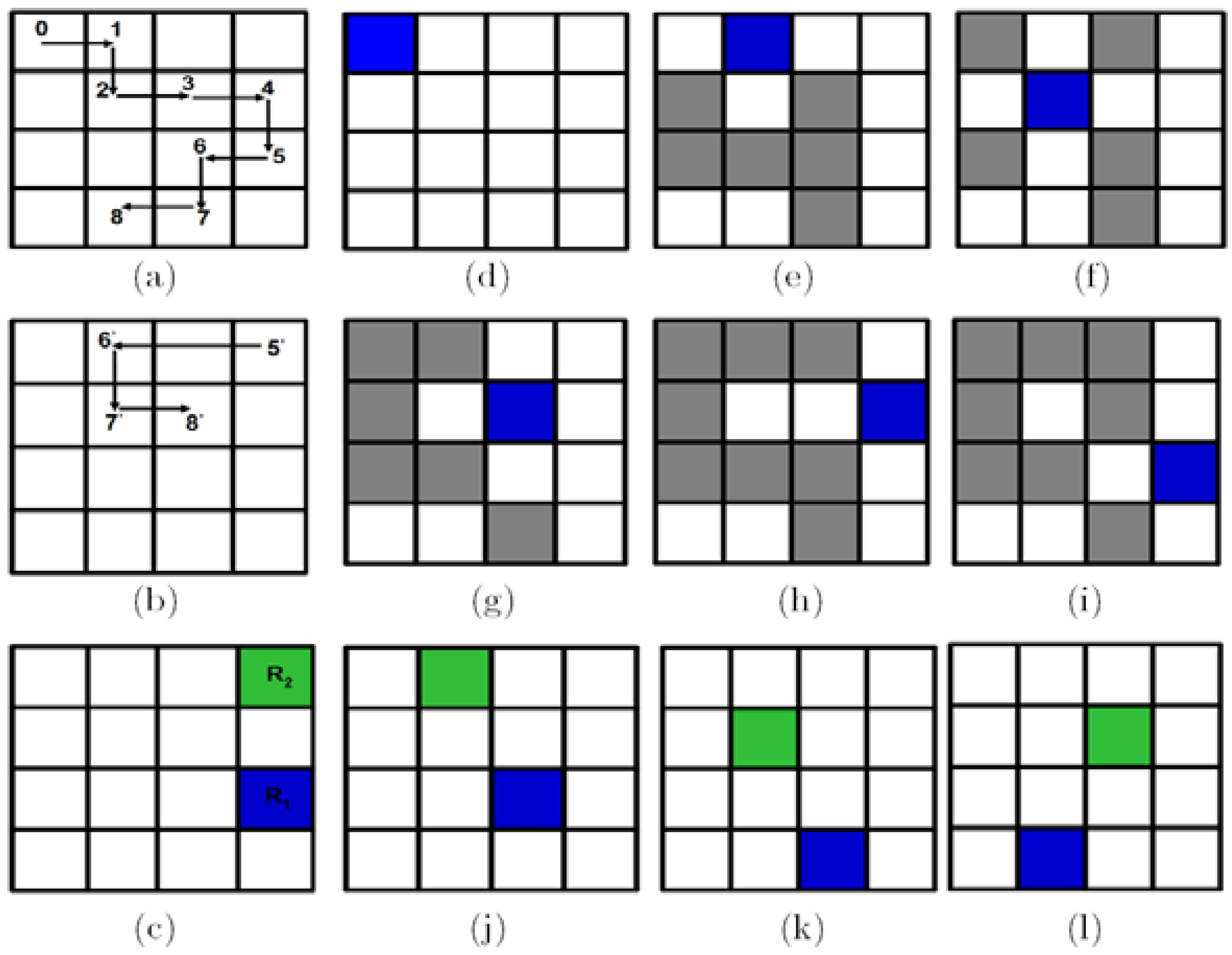
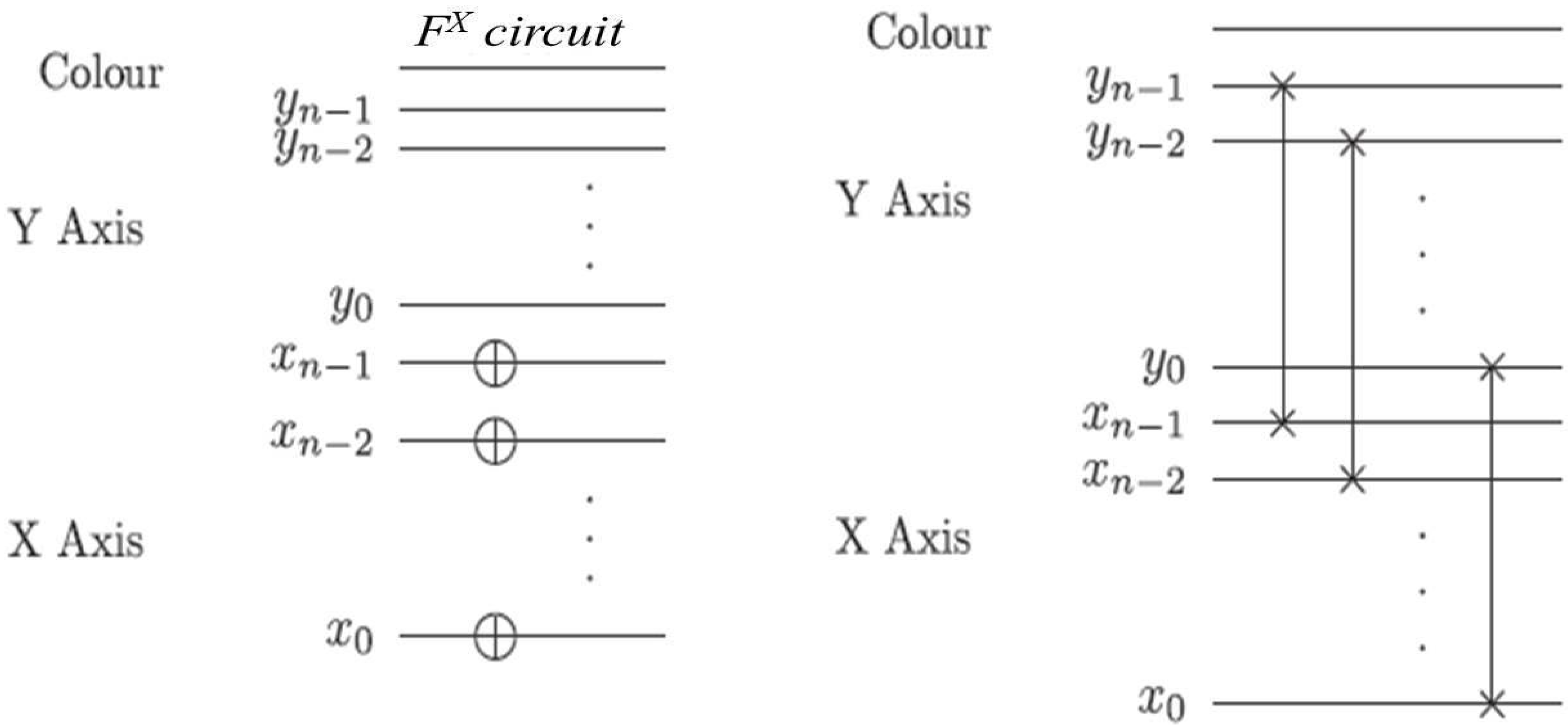
As specified by the movie script, our ROI at pixel
(in
) moves one step forward which is realised by using the
operation as shown in sub-circuit 1(a) of
Figure 50. The effect is a swap in the contents of pixels
and
. Hence, no CTQI operation is involved in this transformation. To recover the new content of these pixels, we must track the transformations in their respective positions.
Tracking the transformations in their respective positions becomes simplified by considering the colour and position information of each pixel as an entangled state [
2,
8] as discussed earlier in section. In this regard, the new readouts 0 and 1 in
for pixel
and
, respectively, are easily visualised. A transformation that changes the position of either or both of these pixels transforms both their colour and position together. The movie reader sub-circuit to recover these two pixels is presented in
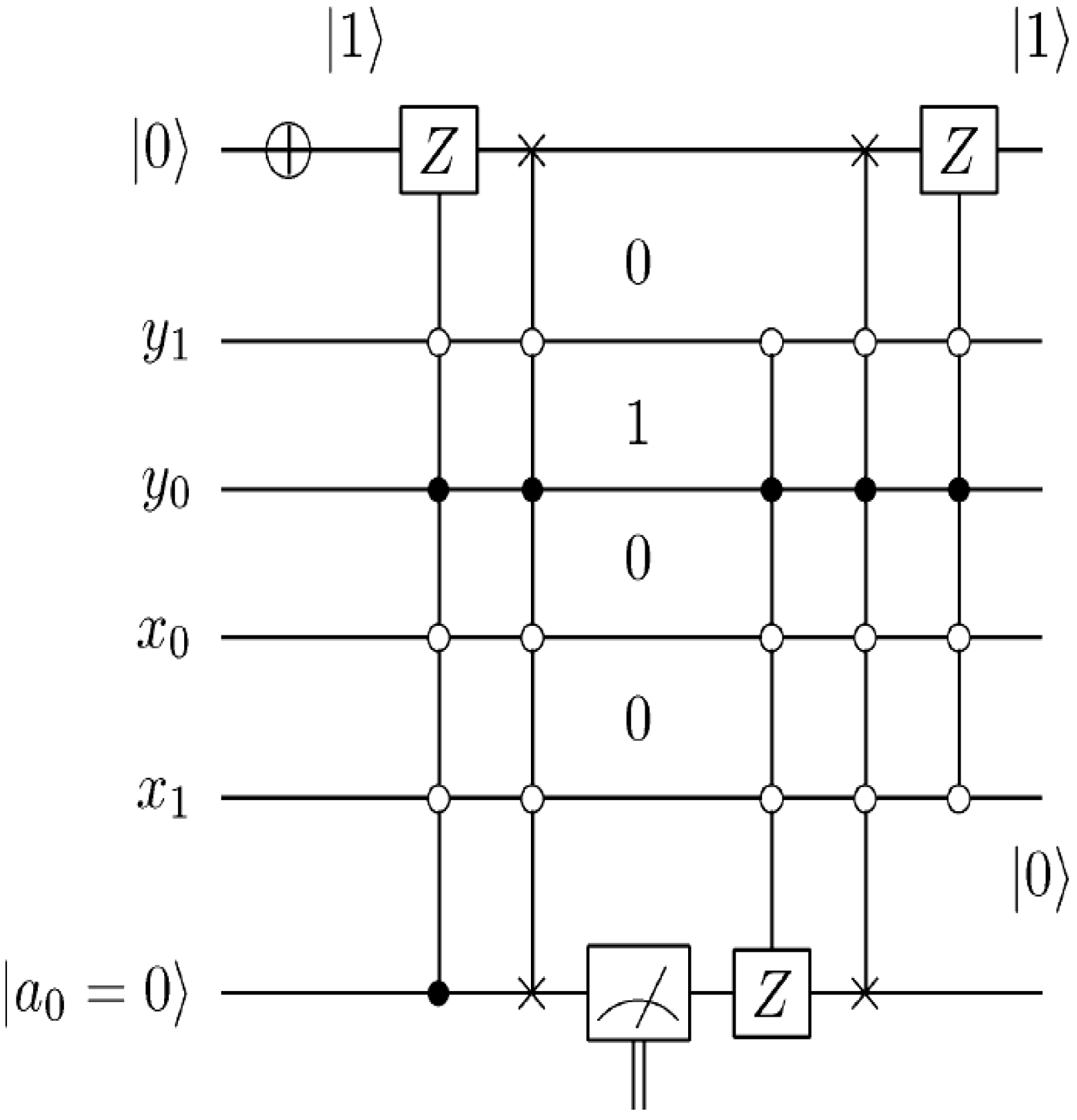
Figure 61.
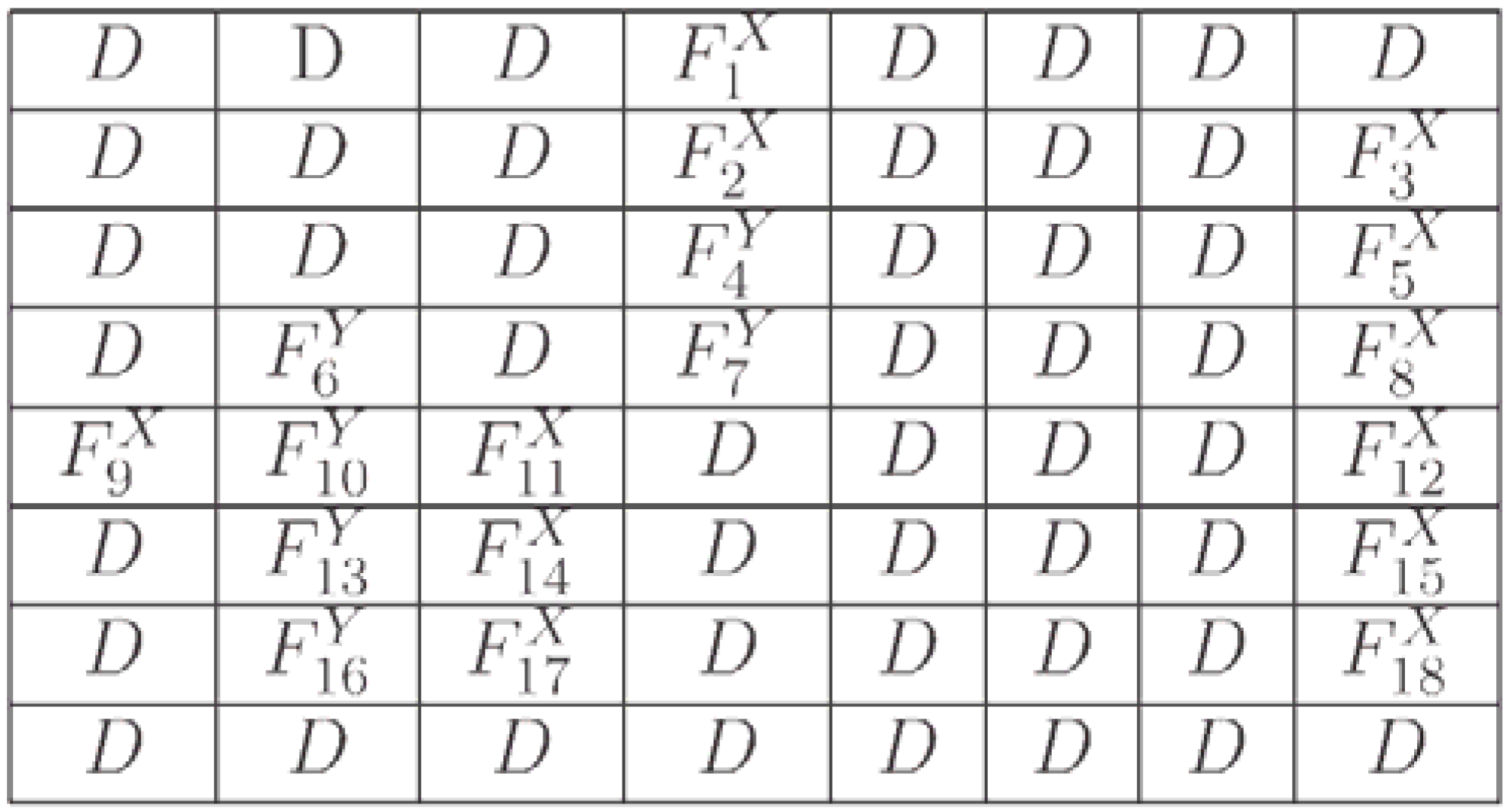
The second group considers pixels for which the effect of the sub-circuit 1 manifests only in changes in the colour content of the key frame. By studying sub-circuit 1, specifically, sub-circuit 1(b), we realise that there are six such pixels namely
,
,
,
,
and
. The position-dependency information of each of these pixels (
Figure 56) is used to track the colour transformations on these pixels. The movie reader sub-circuit in
Figure 62 shows the interaction between the movie reader (specifically, the measurement
) and the quantum player, which facilitates the readout of the new contents of the pixels as transformed by sub-circuit 1(b). For brevity, we have used a single
X gate on
to show the transformation of the contents of all the six pixels (in actual sense, each pixel is transformed separately by such an operation). This (use of a single qubit) is possible because the pixels have the same colour both before (
,
i.e. with
and hence, all their ancilla’s are in state
) and after the transformations in the frames F0 and
, respectively. The operation on the colour qubit transforms the colour from state
to
. Meanwhile, the ∗ connecting the colour and ancilla qubit facilitates the recovery of the new states subject to satisfying the position-dependency on
. The circuit in
Figure 63 demonstrates how such readout is obtained for pixel
while the same procedure suffices to recover the content of the remaining five pixels.
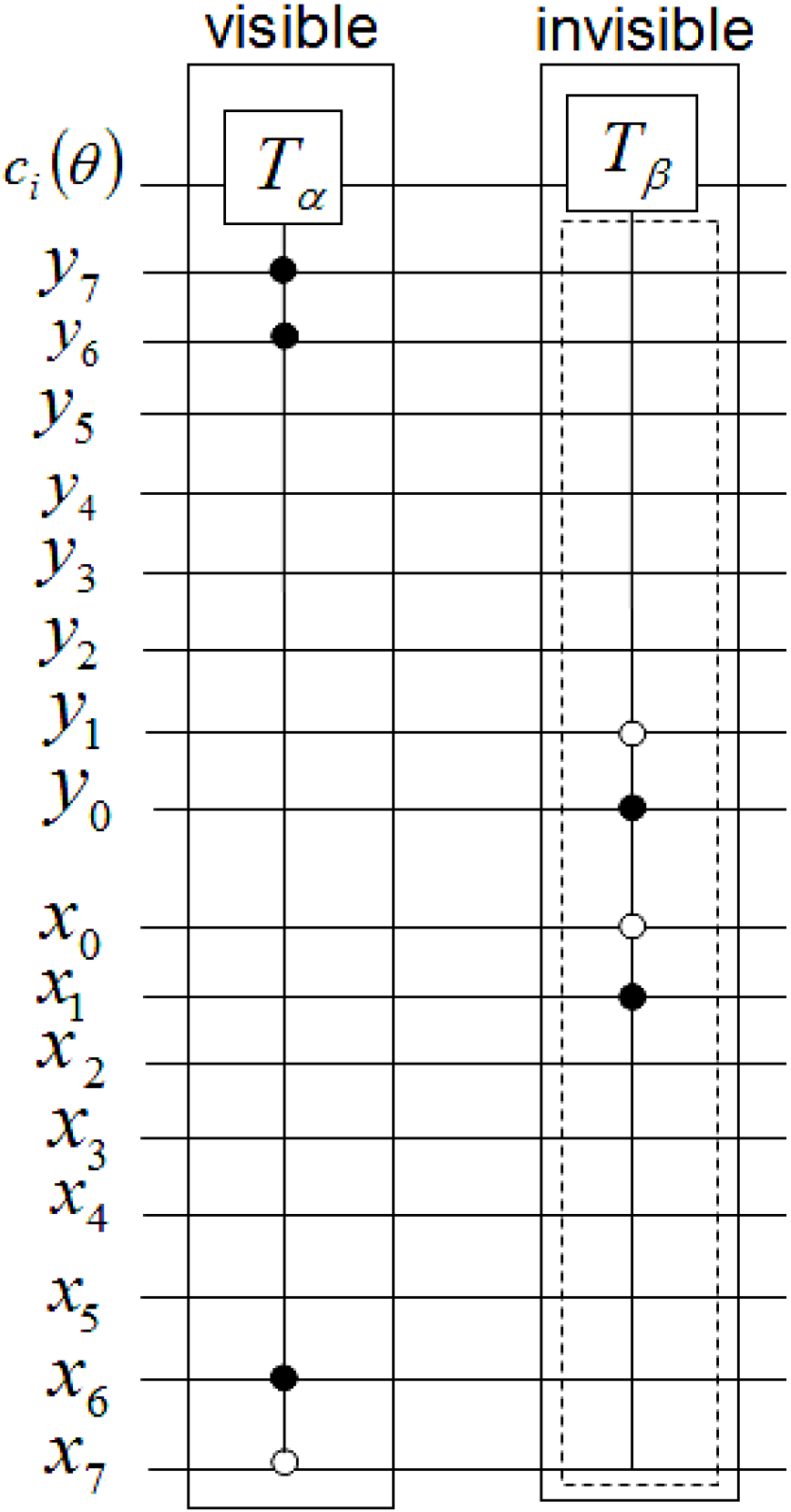
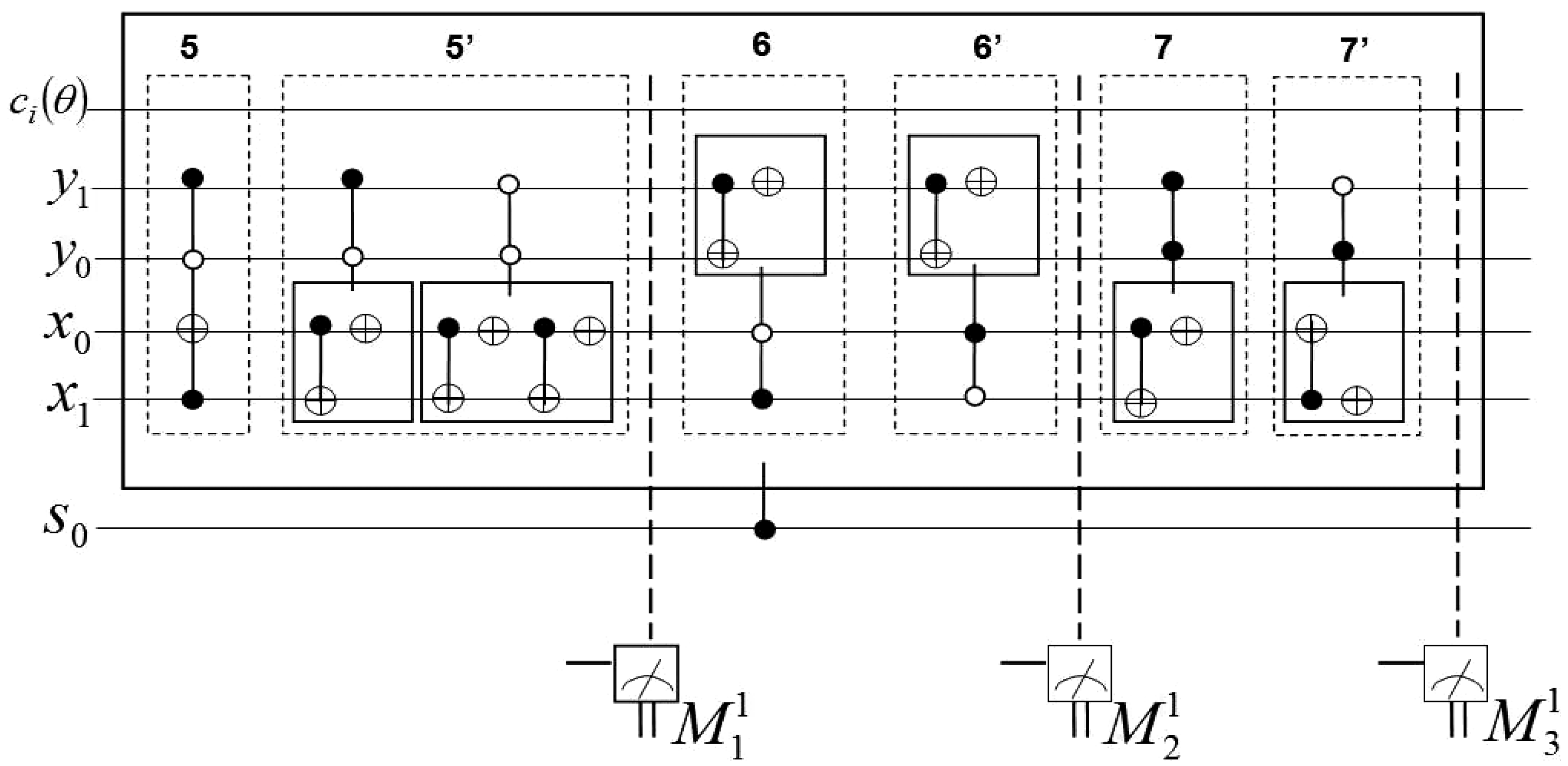
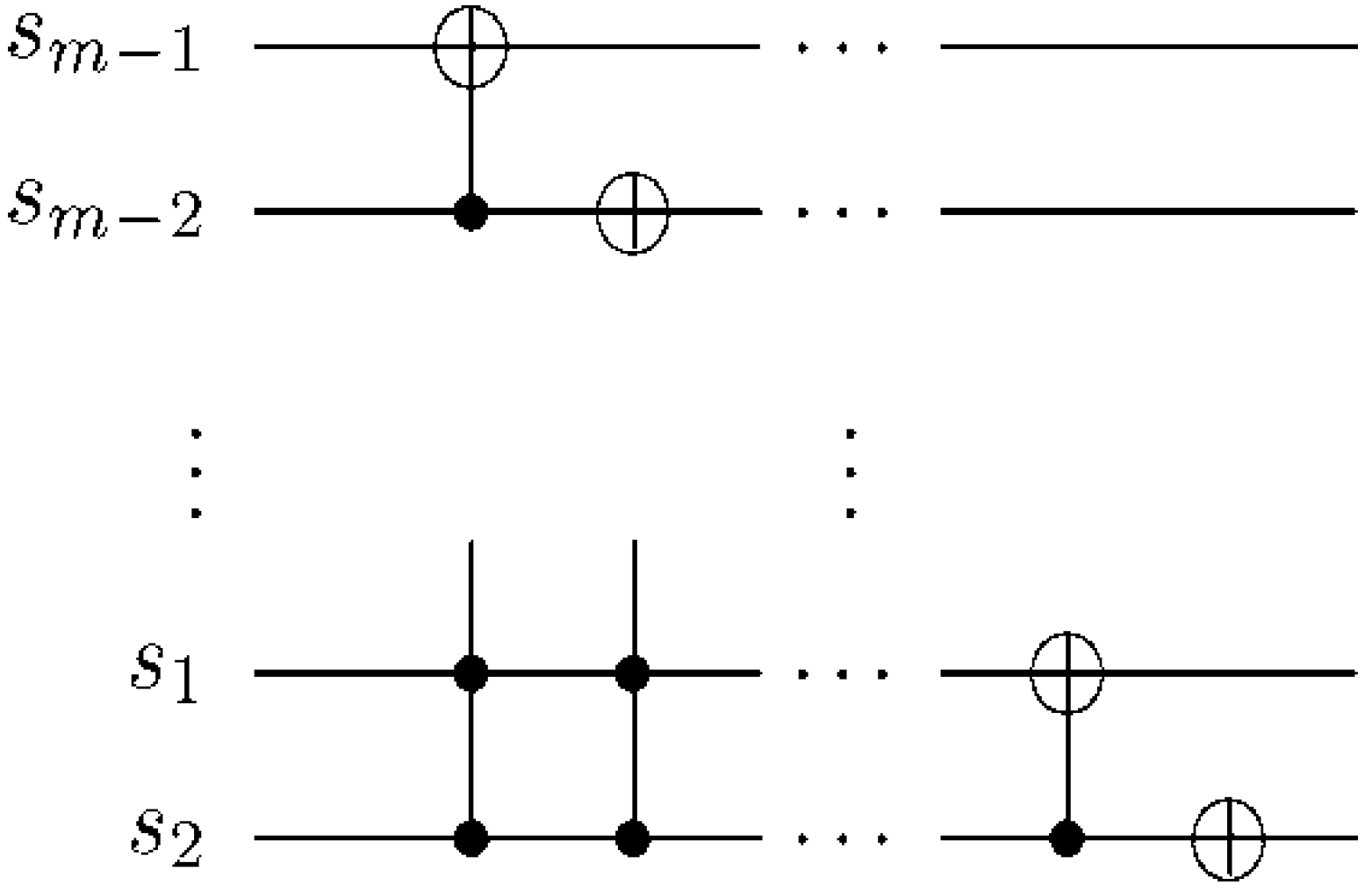
Figure 61.
Movie reader sub-circuit to recover pixel
p0 and
p1 for frame |
f0,1〉 corresponding to
Figure 49e.
Figure 61.
Movie reader sub-circuit to recover pixel
p0 and
p1 for frame |
f0,1〉 corresponding to
Figure 49e.
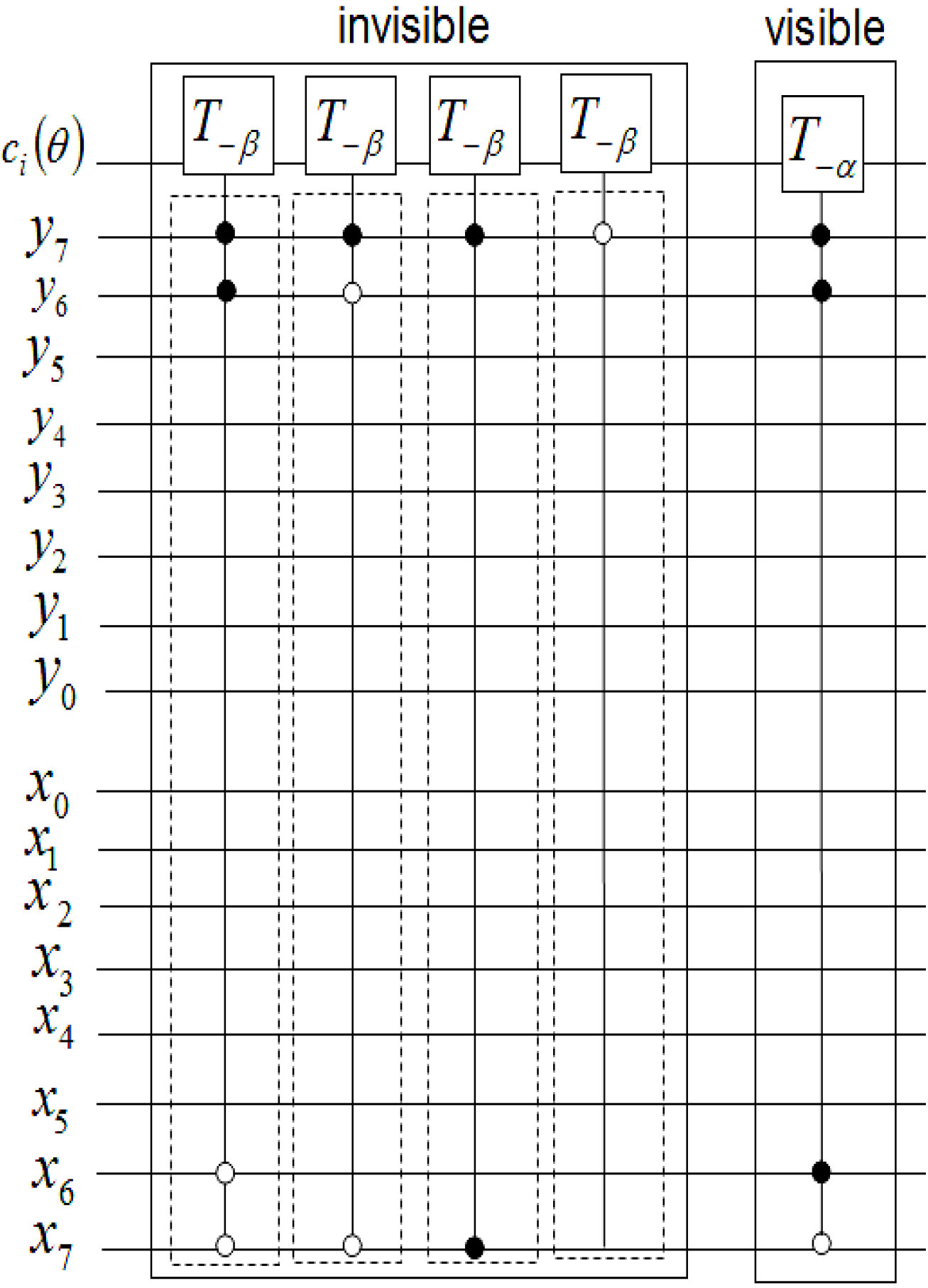
Figure 62.
Movie reader to recover pixels p4, p6, p8, p9, p10 of viewing frame |f0,1〉.
Figure 62.
Movie reader to recover pixels p4, p6, p8, p9, p10 of viewing frame |f0,1〉.
Figure 63.
Readout of the new state of pixel
p4 as transformed by sub-circuit 1 in
Figure 52.
Figure 63.
Readout of the new state of pixel
p4 as transformed by sub-circuit 1 in
Figure 52.
Figure 64.
Movie reader sub-circuit to recover the content of pixels p2, p3, p7, p11, p12, p13 and p15.
Figure 64.
Movie reader sub-circuit to recover the content of pixels p2, p3, p7, p11, p12, p13 and p15.
The last group consists of eight pixels whose colour and position information are not transformed by sub-circuit 1 of the movie circuit in
Figure 50. Hence, the colour and position of these pixels are unchanged in
and
. Combining the simplifications discussed earlier with the position-dependency information in
Figure 56, we obtain a movie reader sub-circuit which is enough to track the changes in the content of these pixels. This sub-circuit is presented in
Figure 64, where each ∗ connecting the colour and ancilla qubits is equivalent to the measurement circuit in
Figure 59. All the eight pixels being measured in this group (using the sub-circuit 1 in
Figure 50 and the measurement circuit in
Figure 64) are characterised by ancillary and colour that are both in state
,
i.e. and
. As presented in Theorem 4, each ∗ connecting the colour and ancilla qubits produces readout 0,
i.e. the label of the measurement on
.
By combining the three movie reader sub-circuits, circuits from these groups, we obtain the larger movie reader sub-circuit to recover the viewing frame
. Extending similar techniques to the measurements
in the movie circuit in
Figure 52, we can recover the content of each of the viewing frames in
Figure 49(e)–(l) of the scene.
6.4. The Cat, the Mouse, and the Lonely Duck: A Quantum Movie
An example that utilises the various tools required to demonstrate the representation and production of quantum movies as it pertains to the operation of the quantum CD and player is presented in this section.
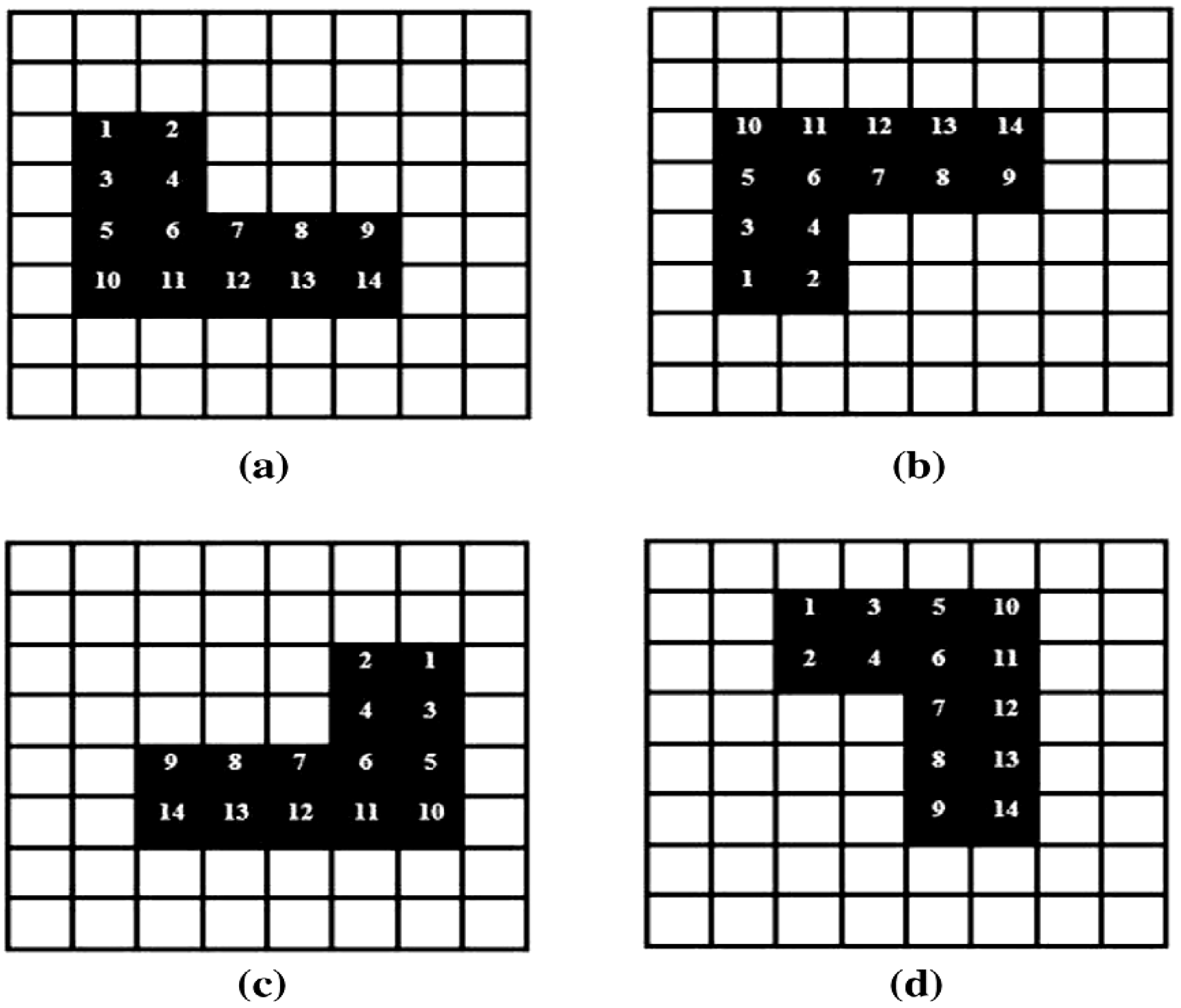
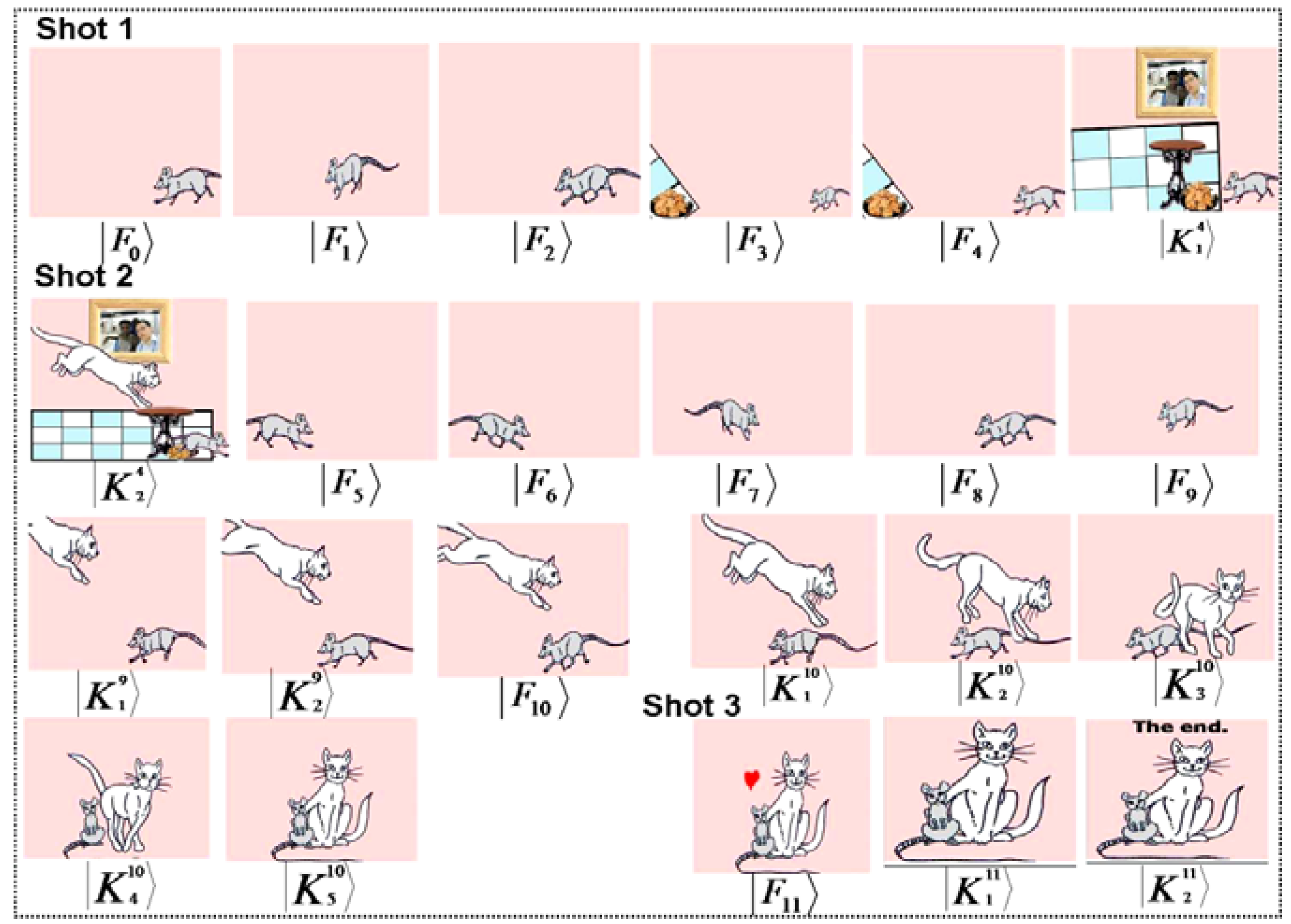
In this example, we assume that the director in liaison with the circuitor have carefully studied the script (usually in writing) and concluded that the key and makeup frames in
Figure 65 and
Figure 66 are adequate to effectively convey the two scenes of the movie which is entitled “The cat, the mouse, and the lonely duck”. The first scene entitled “The lonely duck goes swimming” consists of three shots of varying length and hence varying order and number of key and makeup frames. Similarly, the second scene is made up of 23 key and makeup frames which are divided into the two shots of the scene. Based on the content of this scene, it is appropriately entitled “The cat and mouse chase”.
The two scenes show how divergent contents of a movie can be conveyed using the operations discussed earlier in this section. The scenes involve varying content, movement, pace, and finally, the example illustrates how the frame-to-frame transition operation is used to cover the entire length of the 40-frame movie strip.
Figure 65.
Key and makeup frames for the scene “The lonely duck goes swimming”. See text and [
19] for additional explanation.
Figure 65.
Key and makeup frames for the scene “The lonely duck goes swimming”. See text and [
19] for additional explanation.
Figure 66.
Key and makeup frames for the scene “The cat and mouse chase”. See text and [
19] for additional explanation.
Figure 66.
Key and makeup frames for the scene “The cat and mouse chase”. See text and [
19] for additional explanation.
In the sequel, we present, albeit separately for each scene, an expansive discussion on the circuitry required to metamorphose the movie summary of each scene (i.e. the combination of key and makeup frames in
Figure 65 and
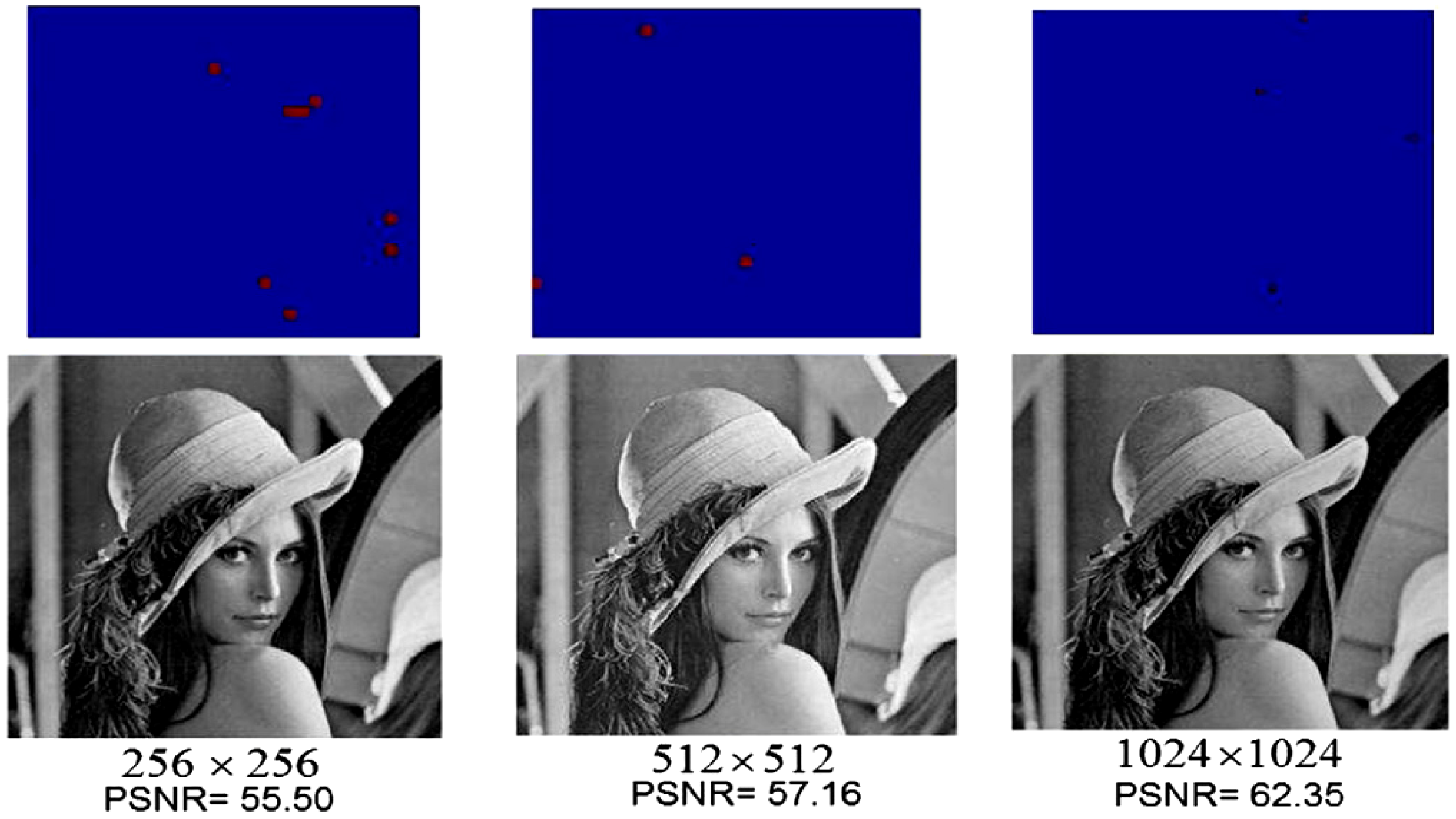
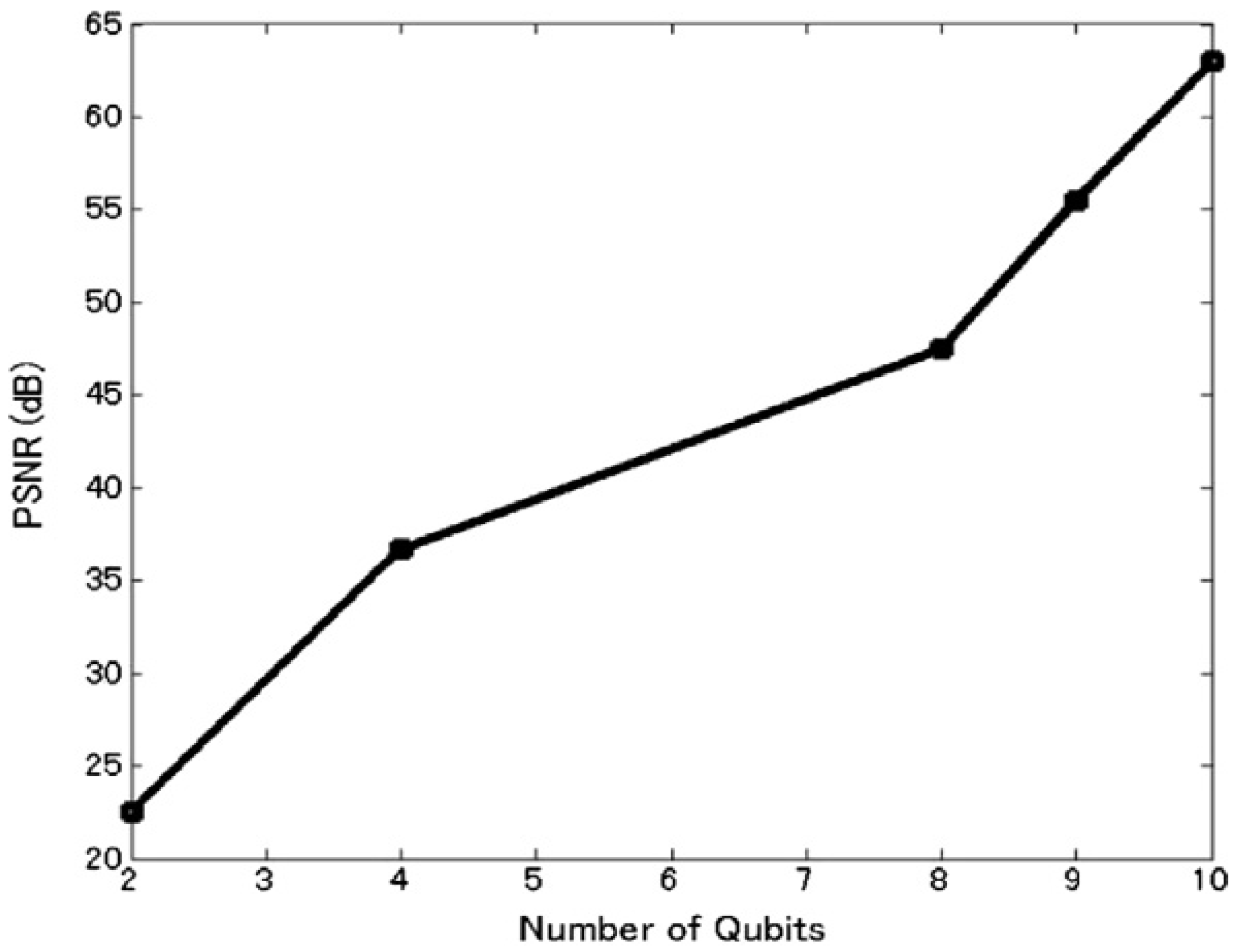
Figure 66) into a more detailed description that conveys the script to the audience. All the frames (makeup, key, and the viewing frames resulting therefrom) are of size 256×256. Hence, eight qubits (four for each position axis) are required to encode the position information, one qubit to encode the colour content, and another six qubits on the strip axis to encode the 40 key and makeup frames that make up the movie summary. Consequently, for brevity, we omit the final movie sub-circuits of the two scenes. The circuit elements of each sub-circuit interpolate the missing content between successive key frames of each scene.
6.4.1. Scene 1: The Lonely Duck Goes Swimming
As suggested by the title, the objective of the scene is to convey the bits and pieces of actions that show the duck right from when it leaves home (makeup frame ), the various dialogues it encounters as it journeys to the stream for a swim (key frame through to key frame ), culminating in transformations on the movie summary to show it swimming. Finally, the scene ends with the duck’s homebound journey at around sunset. Broadly speaking, this scene can be divided into three parts. Consequently, we tailor our discussion on this scene along these three shots. All the movie operations in this scene comprise of SMO and GTQI transformations. These key and makeup frames are assumed to have been prepared and initialised in our movie strip.
From the content of this scene we can realise a total of 402 viewing frames as enumerated in the sequel.
In the first appearance in shot 1, we want to show the duck; its house, from a somewhat wide-angle view; and an impression of when the duck left home. A frame is prepared to convey these requirements. Going by our definitions and delineations between a key and makeup frame in
subsection 6.2, a key frame may not capture all the required information. Consequently, the makeup frame
is prepared to do so. In subsequent frames, appropriate movie operations are applied in order to obtain the expanded description that seamlessly connects the content of the key and makeup frames in the shot. Where necessary, the shift steps are adjusted in order to depict the pace of the particular ROI for each key frame: the duck in
; the dog, ball, and duck in
; the ball and duck in
; the ball in
; and the dog and bird in
. In addition to this, the shift steps are adjusted to overcome the effects of overflow in the new content obtained as discussed in
subsection 6.3, specifically,
Figure 48. In depicting the movements of the various ROI’s in each of the key frames, appropriate control-operations are applied on the position and strip axis in order to constrain the effect of the movie operations to the intended key frame and ROI. A total of 138 viewing frames were realised from the five key frames in this shot. The makeup frames
and
add a bit of realism to the scene by showing us from where and when the duck sets out for the swim and some of the dialogues it encounters on its way. These are crucial to conveying the content of this shot.
The first dialogue depicted in the second shot shows to the audience how the duck spends its time on reaching the stream. The gradual change in background from daylight to sunlight (between , and ) creates an impression about the duration of time it spends there. The key frames and together with the viewing frames obtained from them complete the dialogues in this shot. Meanwhile, the makeup frames , , , and add realism to the content. Altogether, we realise 196 viewing frames by manipulating the key and makeup frames in this shot.
The last shot of this scene consists of (key and makeup) frames with the same background as those in shot 1 but at a different time. The intention is to show the duck on its homebound journey at sunset. The various transformations as discussed in shots 1 and 2 can be used in order to convey the required content. We assume no diversions as the duck heads home and that it does not run into the girl and her dog as in shot 1. From the key frames in this shot we realise the last 32 viewing frames of the scene.
6.4.2. Scene 2: The Cat and Mouse Chase
This scene depicts the dialogues between two traditional foes, a cat and a mouse. Contrary to expectations, however, the characters in this scene are the best of friends. This goes to buttress an earlier assertion that the script, which conveys the various actions and dialogues in the movie, is flexible to changes that convey whichever content is desired. The most important thing is how well the circuitor can study its content, and decide in liaison with the director, the appropriate key and makeup frames that will give an overview of this script.
From this content a more detailed content to efficiently translate the script is then realised. Such a summary for our scene entitled “The cat and mouse chase” that comprises of 23 key and makeup frames is presented in
Figure 66.
The scene starts off with the first shot which comprises of five key frames and a makeup frame from which we would ordinarily realise 112 viewing frames. In order to create the impression of a running mouse, however, the shift steps have to be increased. In the end, using the factors enumerated earlier, we realise 75 viewing frames.
In the second shot, the traditional chase between the cat and the mouse ensues. Using the key frame , the impression of the cat pouncing on the mouse is created.
Sensing the imminent danger, we see the mouse running back towards the safety of its hole. In subsequent key frames
through to
we see the actions of a frightened and confused mouse: first running toward its hole (key frames
,
and
), then turning back toward the cat (key frames
and
). The control-conditions are crucial to effectively convey the different actions of the cat and mouse in key frames
. This key frame and the eight viewing frames we obtain from it when combined with the subsequent makeup frames
,
,
,
, and
convey how the cat and mouse finally meet. Instead of the cat pouncing to eat up the mouse, using key frame
, the cordial relationship between these traditional foes is conveyed to the audience. Finally, by assuming this is the last scene of the movie, makeup frames
and
are used to end the scene as seen in
Figure 66.
From these two scenes, a key advantage of the proposed framework has become manifest. Using only 40 makeup and key frames, a movie comprising 597 frames is realised. Such an astute manipulation of the abstract content of the movie guarantees that the initial cost of producing quantum movies will always be less than the traditional classical versions of the same movie. This is evident because the classical version of our movie “The cat, the mouse, and the lonely duck” would require a 597-frame long strip to realise. This we have accomplished using only 40 key and makeup frames.
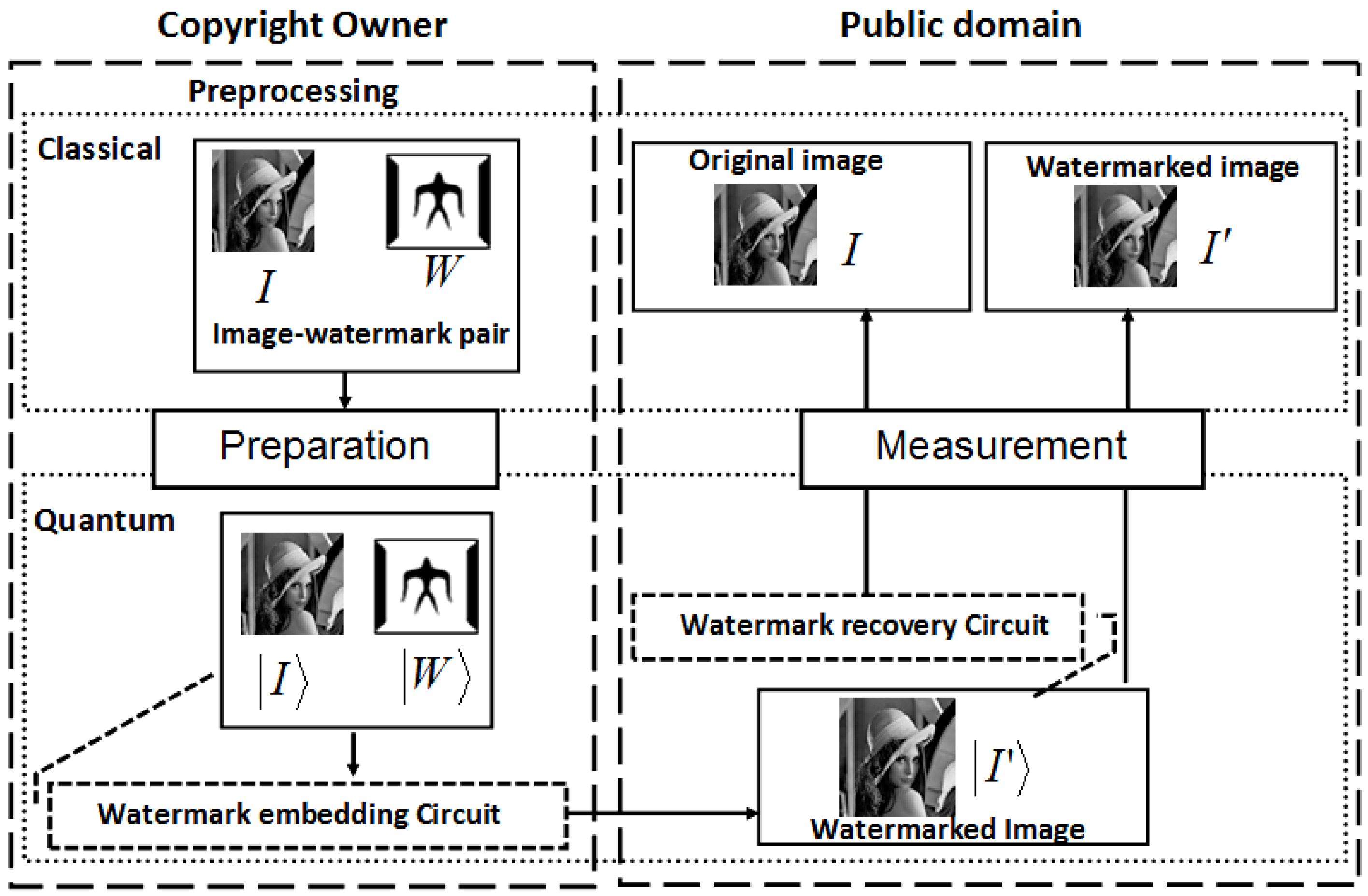
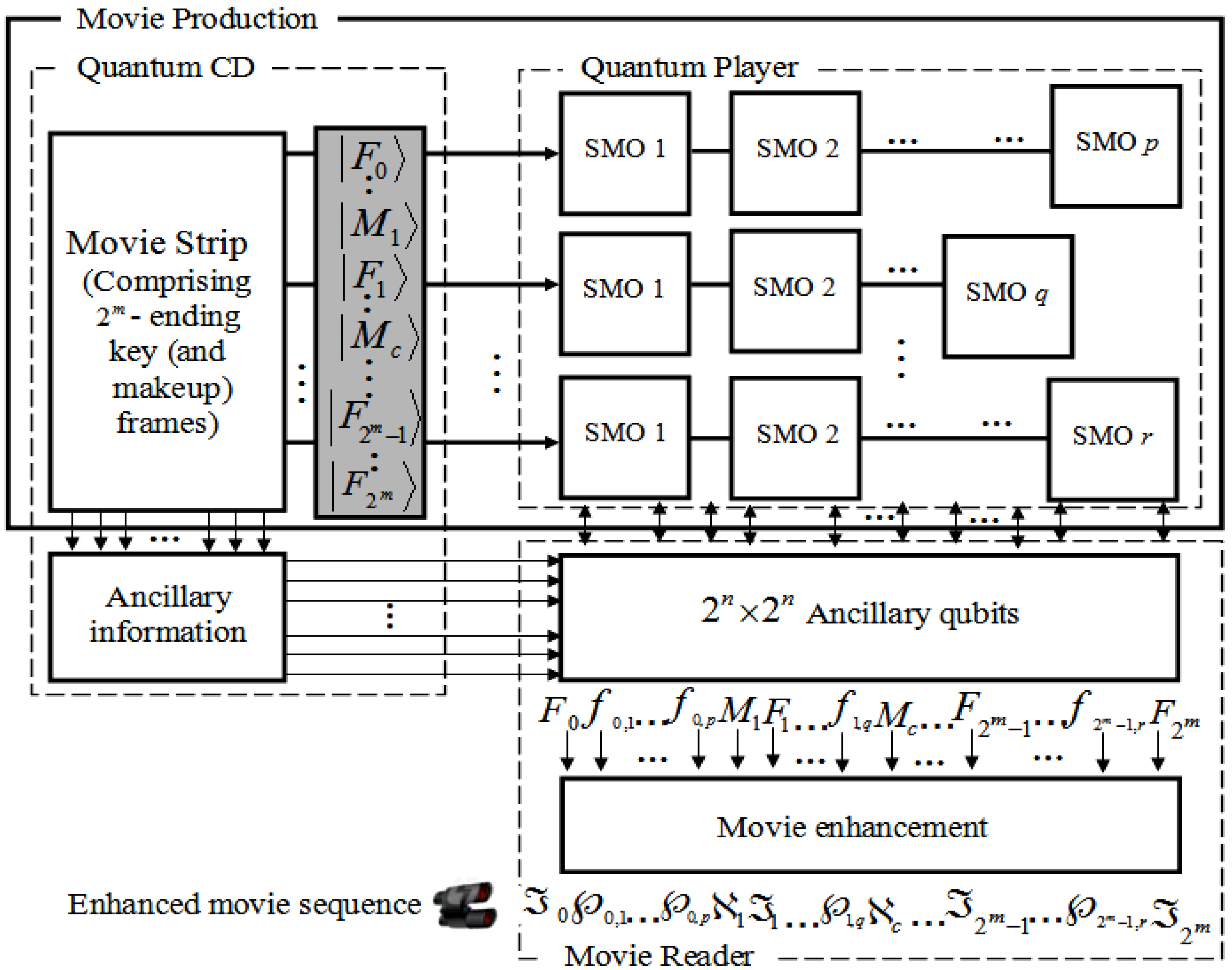
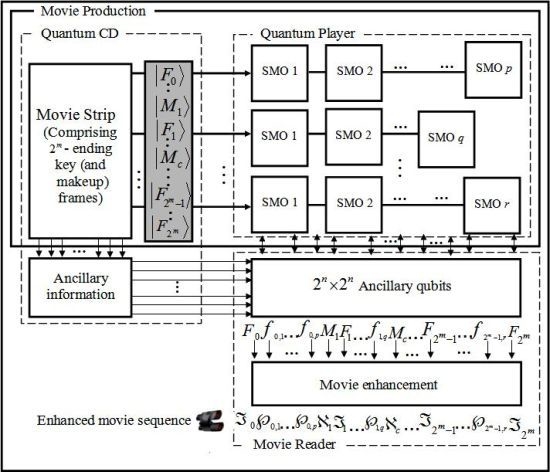
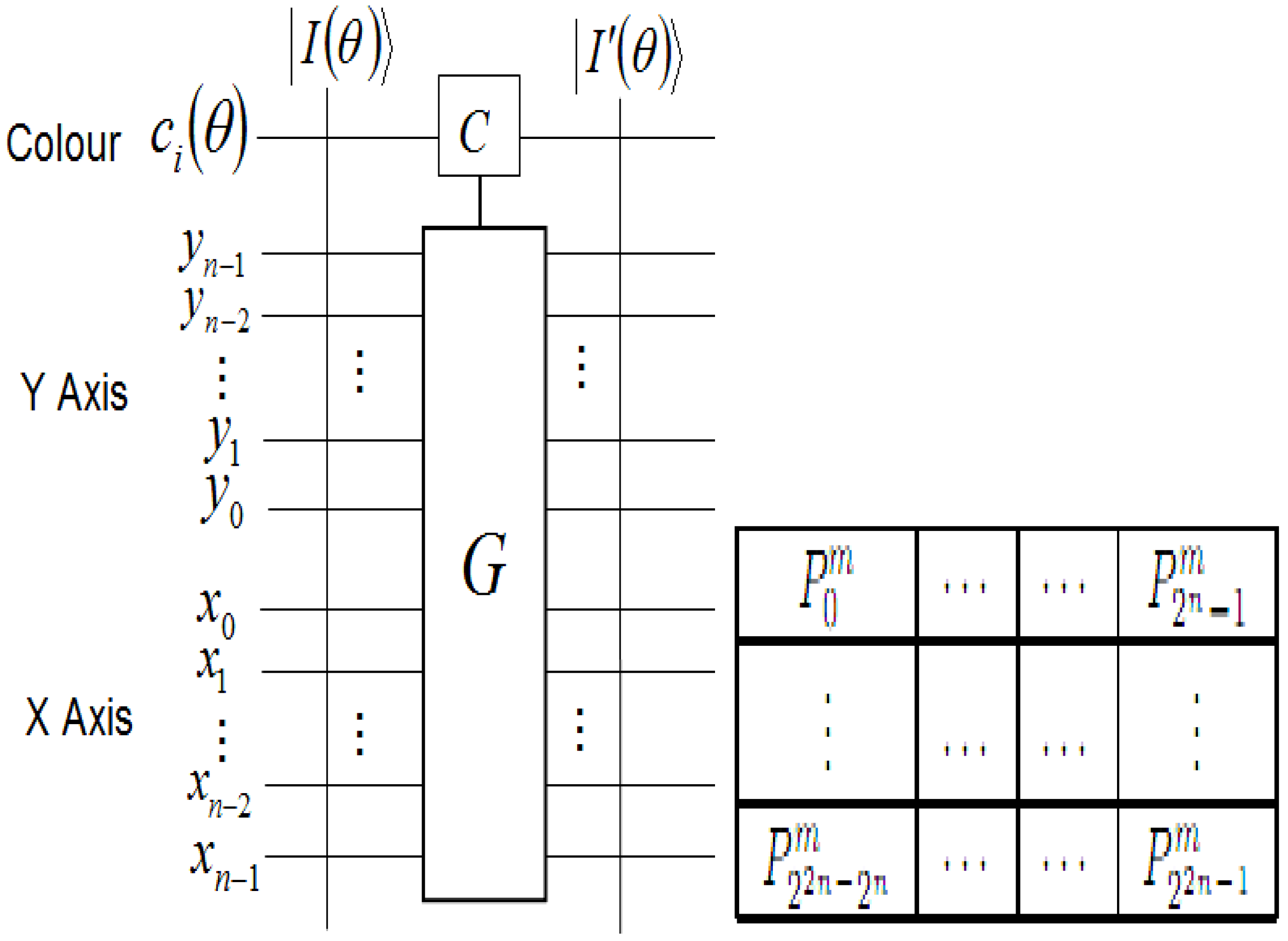
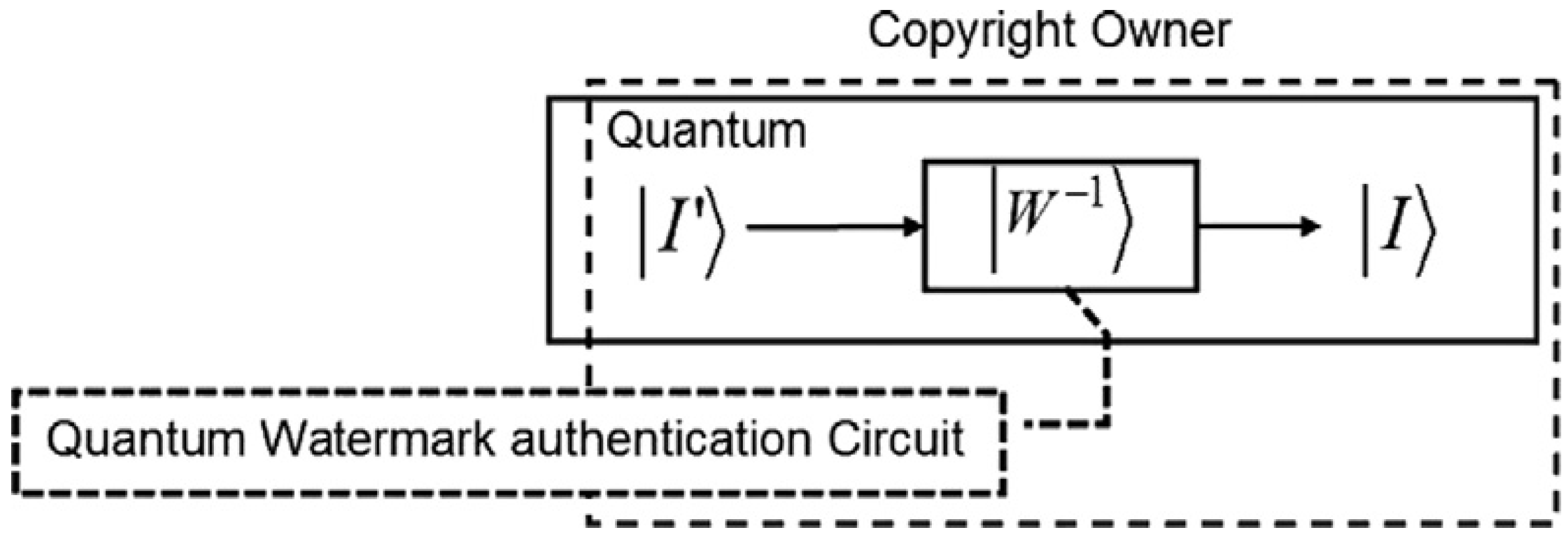
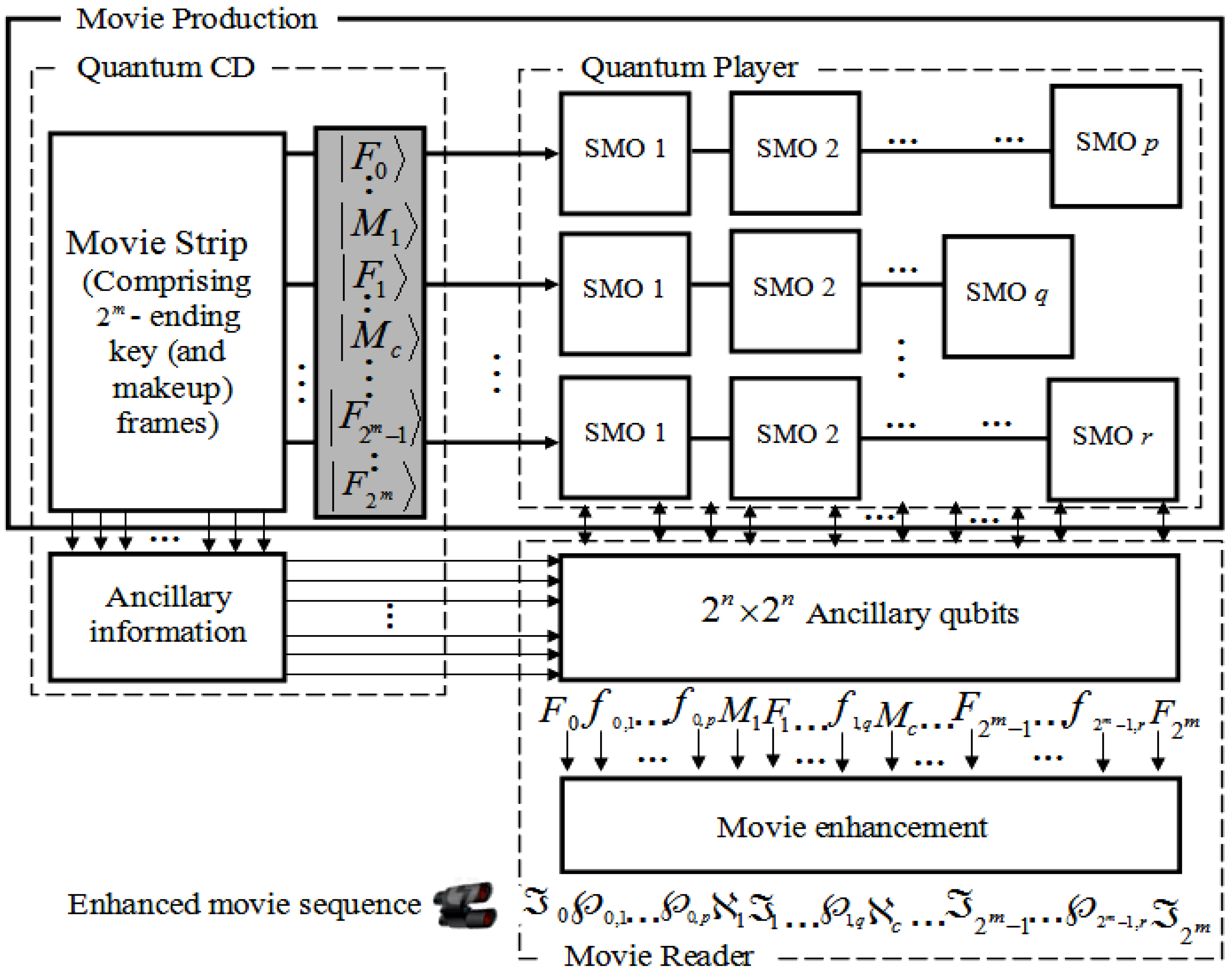
We conclude by presenting the overall framework to represent and produce the quantum movies as shown in
Figure 67. This is achieved by concatenating the three movie components discussed in this section into a single gadget. Based on our proposed framework, the quantum CD and player facilitate the capture of the contents of the key frames and then transform them into viewing frames which together combine to represent the bits and pieces of action required to convey the script to the audience.
The constraints imposed by the quantum-classical interaction of data, more specifically, quantum entanglement and superposition, ensure that the content as produced and manipulated by the quantum CD and player cannot be viewed by the audience. The movie reader is therefore used to “decode” these frame (i.e. key, makeup, and viewing) contents in such a way that the earlier constraints are not unsettled.
It should be emphasised that while the components have been designed as standalones, it is assumed interaction between them is both feasible and mandatory. Notwithstanding the interaction, however, the standalone feature of the three movie components guarantees multiple usage of the data stored and processed by the various components.
The movie enhancement stage of the movie reader is added to show the need to enhance the content of each frame before final display to the audience. This stems from the fact that we have focused our colour processing tasks mainly in terms of the binary states and . This agrees with the intuition in classical image processing.
Numerous classical technologies which can be easily co-opted at this stage of the proposed framework abound [
30]. In addition, the enhancement stage is responsible for tuning the movie sequence to the appropriate frame transition rate (usually 25 frames per second) to be broadcast to the audience. This enhanced content of the movie is given by the sequence:
Figure 67.
Framework for quantum movie representation and manipulation.
Figure 67.
Framework for quantum movie representation and manipulation.

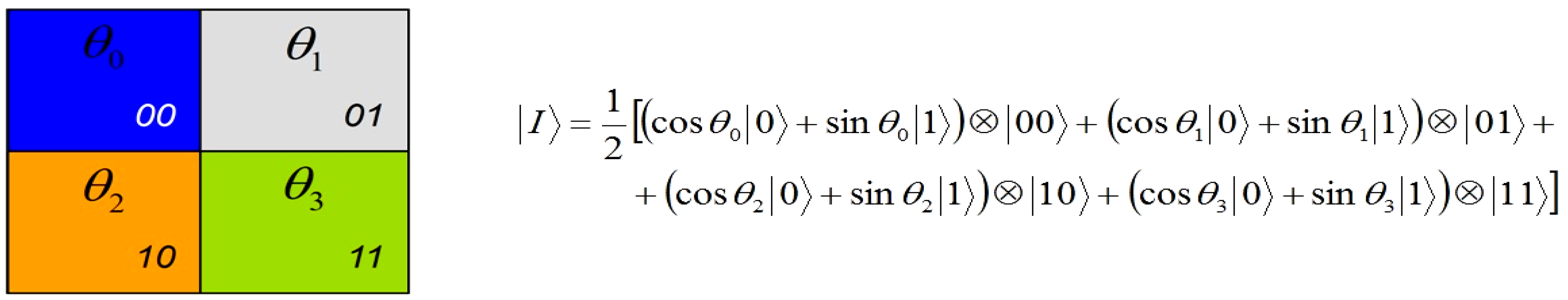

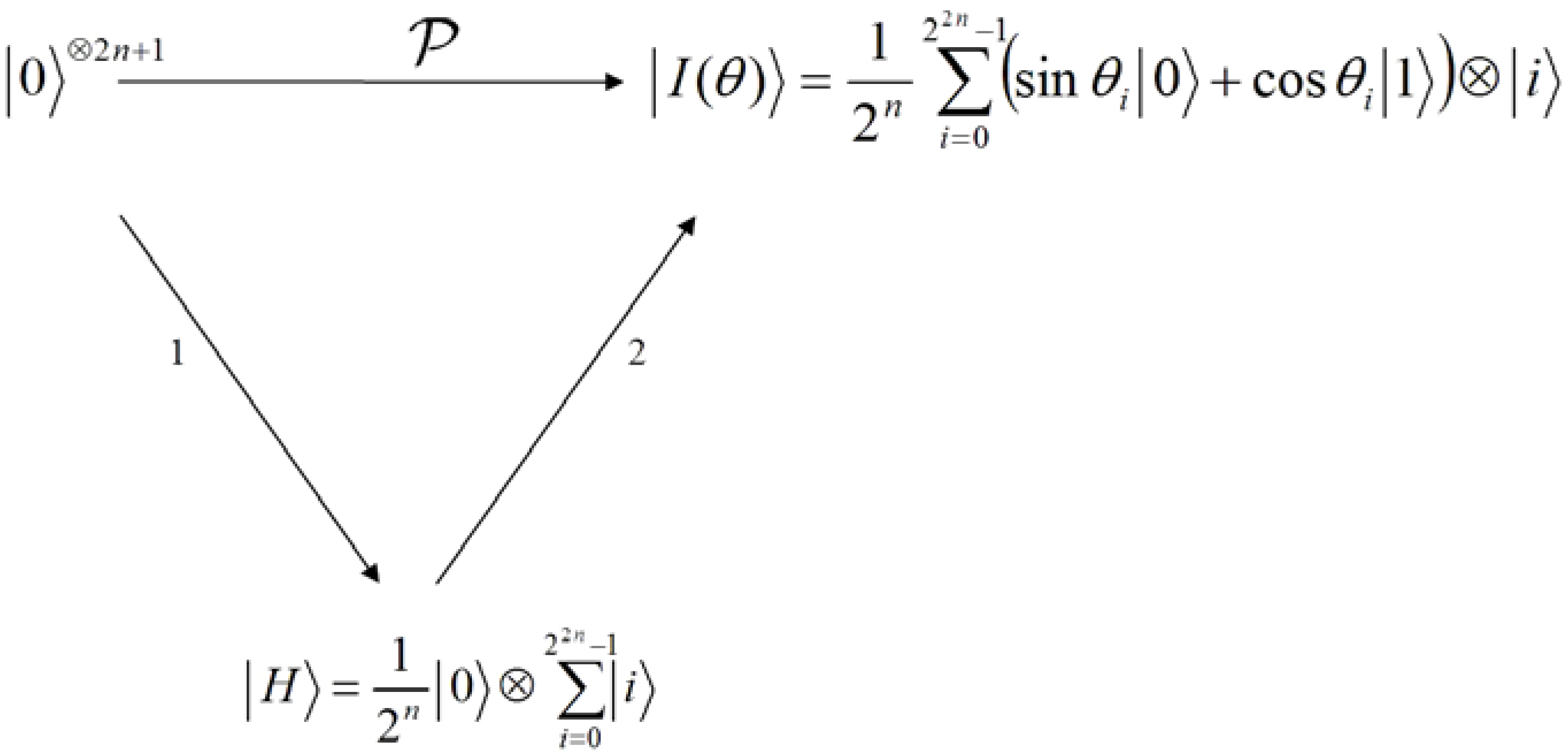





{kind=link}
{kind=link}
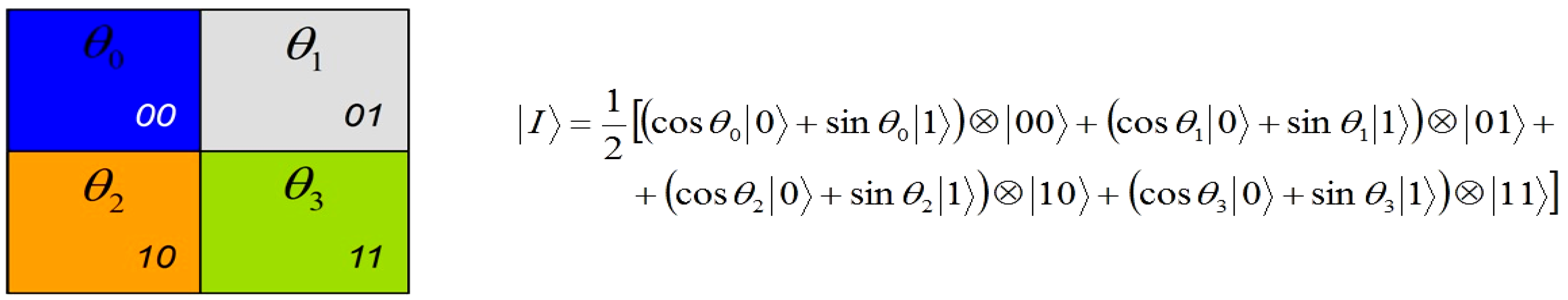{kind=link}
{kind=link}
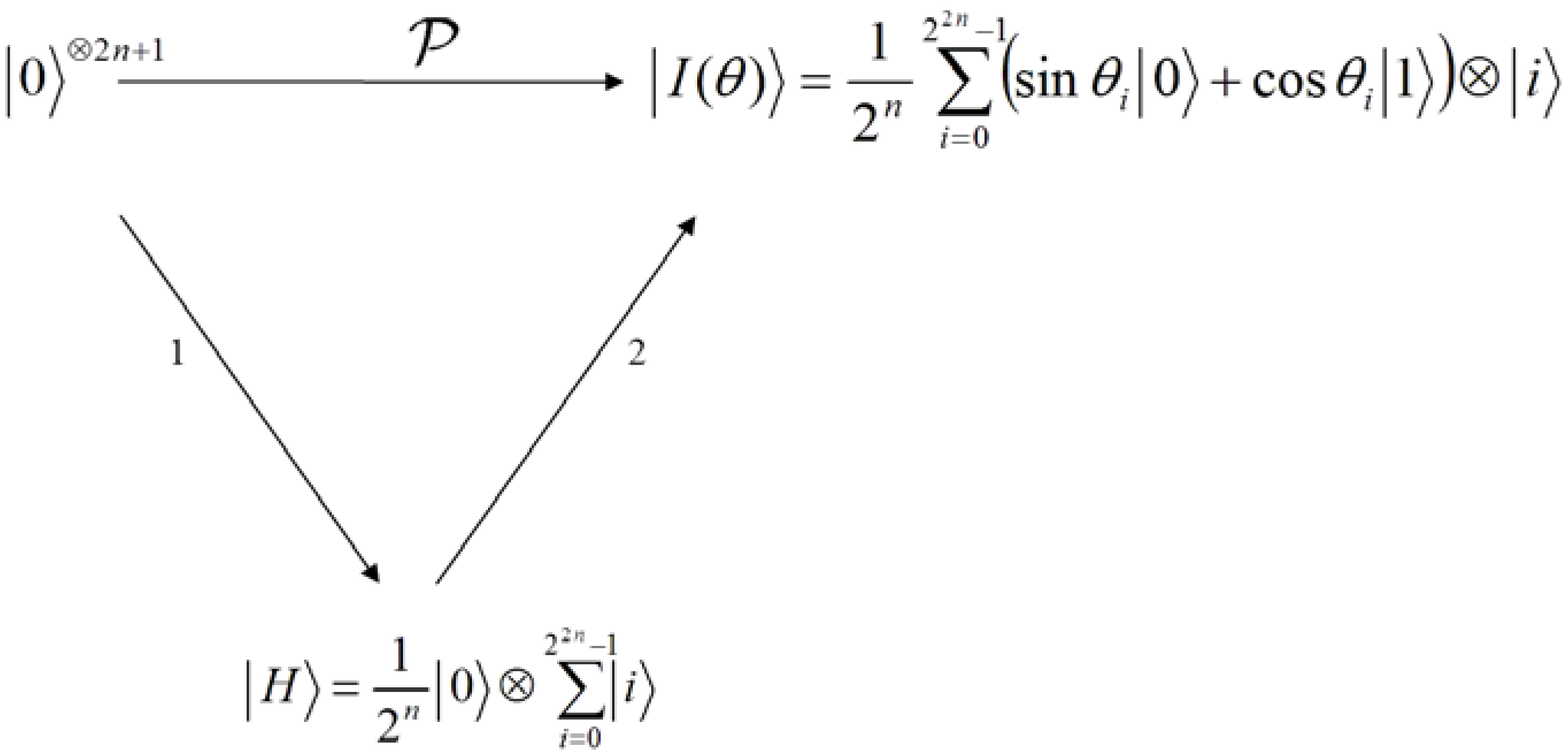{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
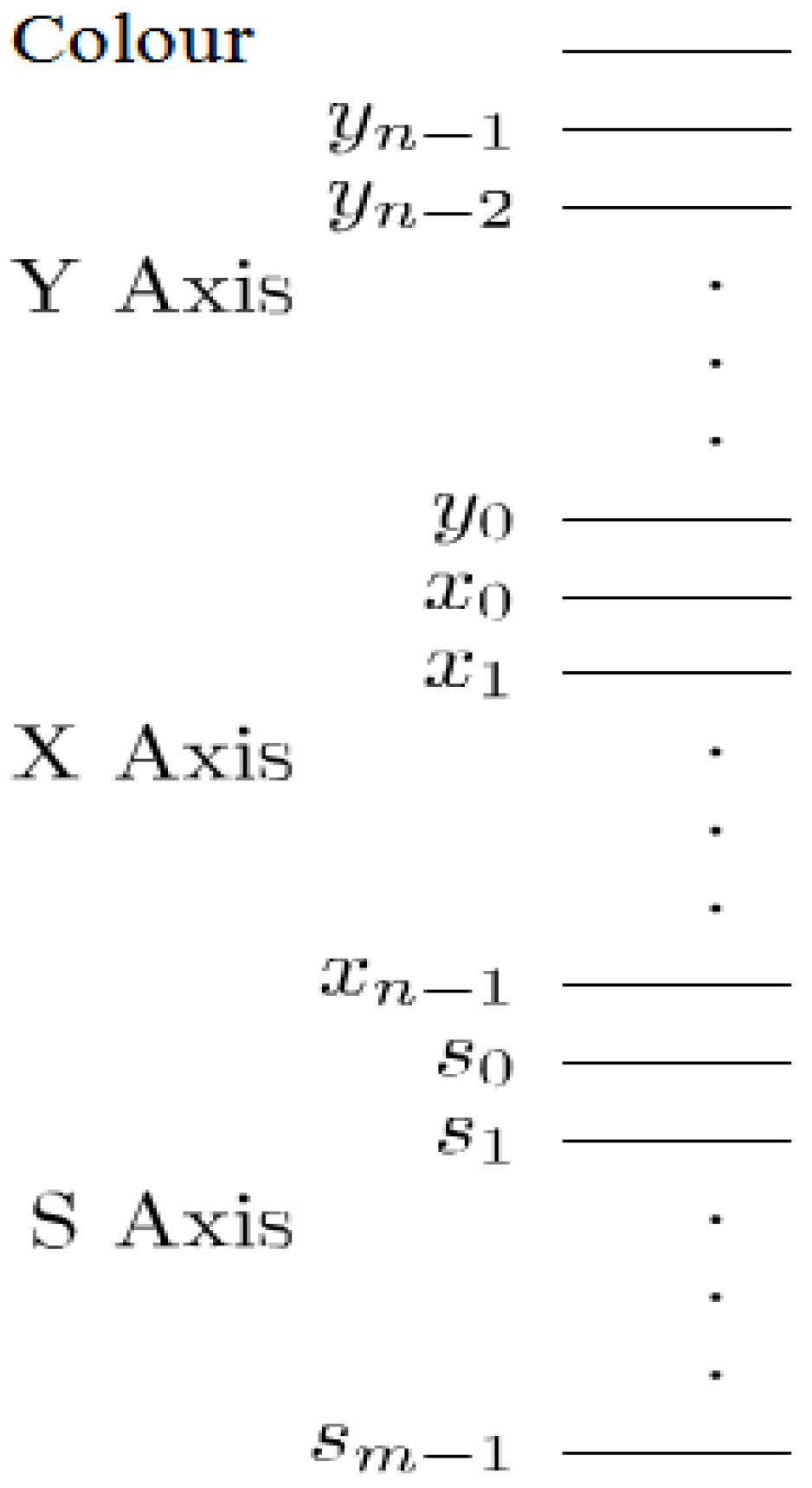{kind=link}
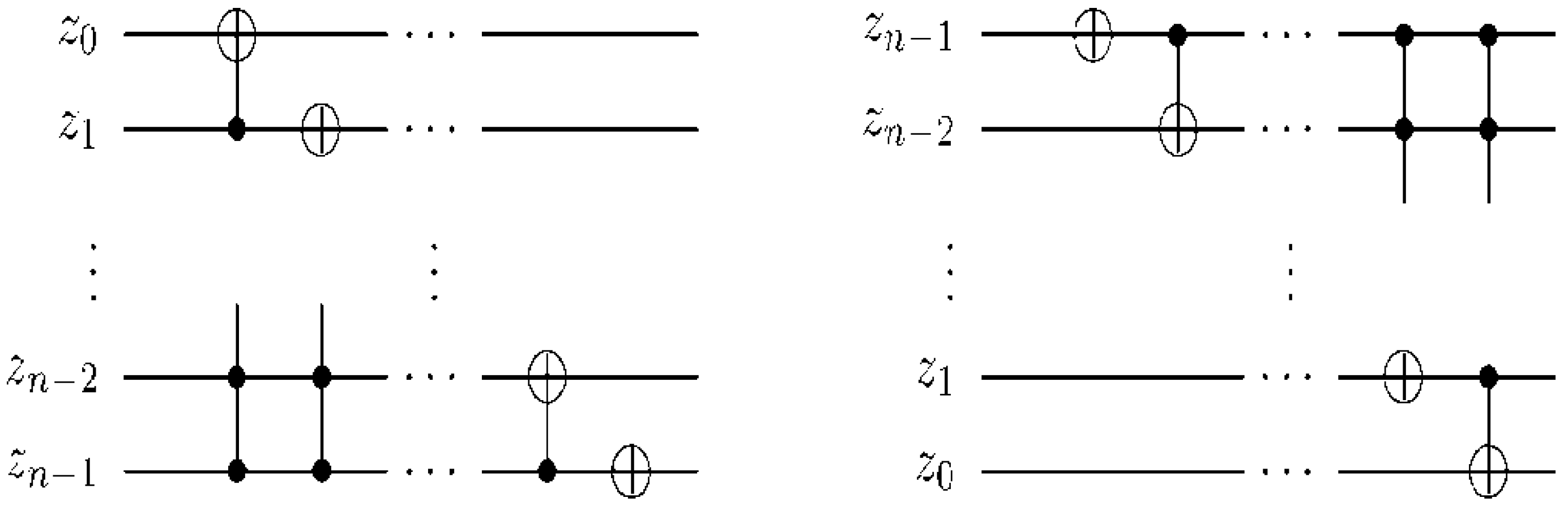{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}