1. Introduction
The purpose of a learning system is to estimate an unknown true density function (a probability model) that generates the data. Real data associated with, for example, genetic analysis, data mining, image or speech recognition, artificial intelligence, the control of a robot and time series prediction are very complicated and usually are not generated by a simple normal distribution. In Bayesian estimation, we set a learning model that is written in probabilistic form with parameters, and our goal is to estimate the true density function by
a predictive function constructed with the learning model and such data. Therefore, the learning model should be abundant enough to capture the true density function’s structure. Hierarchical learning models, such as the layered neural network, the Boltzmann machine, the reduced rank regression and the normal mixture model, are known to be effective learning models for analyzing such data. These are, however, singular learning models, which cannot be analyzed using the classic theory of regular statistical models, because singular learning models have a singular Fisher metric that is not always approximated by any quadratic form [
1,
2,
3,
4]. Therefore, it is difficult to analyze
their generalization errors, which indicate how precisely the predictive function approximates the true density function.
In recent studies, Watanabe showed using algebraic geometry that the generalization and training errors are subject to a universal law and defined the model selection method “widely applicable information criterion” (WAIC ) as a generalized Akaike information criterion (AIC) [
5,
6,
7,
8,
9]. WAIC can even be applied to singular learning models, whereas AIC cannot. Using the WAIC, we can estimate the generalization errors from the training errors without any knowledge of the true probability density functions. The generalization errors relate to the generalization losses via the entropy of the true distribution. Thus, we can select a suitable model from among several statistical models by this method.
Computing the WAIC requires the values of the learning coefficient and the singular fluctuation, which are both birational invariants. Mathematically, the learning coefficient is the log canonical threshold (Definition 1) of the Kullback function (relative entropy), and the singular fluctuation is known as a statistically generalized log canonical threshold, which is obtained theoretically from the learning coefficient (Equation (
1) in
Section 2). These values can be obtained by Hironaka’s Theorem (
Appendix A). However, it is still difficult to obtain these within learning theory for several reasons, such as degeneration with respect to their Newton polyhedra and non-isolation of their singularities [
10]. Moreover, in algebraic geometry and algebraic analysis, these studies are usually done over an algebraically closed field [
11,
12]; many differences exist for real and complex fields. For example, log canonical thresholds over the complex field are less than one, whereas those over the real field are not necessarily so. We, therefore, cannot apply results over an algebraically closed field to our current situation directly (
Appendix B). One of the bottlenecks in learning theory is to obtain the learning coefficients and the singular fluctuation.
In this paper, we consider the learning coefficient of “Vandermonde matrices-type singularities” in statistical learning theory. The reason why we contribute only to such singularities is that the Vandermonde matrix type is generic and essential in learning theory. These log canonical thresholds give the learning coefficients of normal mixture models, three-layered neural networks and mixtures of binomial distributions, which are widely used as effective learning models (
Section 3.1 and
Section 3.2 and [
13]). Moreover, we prove Theorem 2 (the method for finding a deepest deepest singular point) and Theorem 3 (the method to add variables), which are very beneficial to obtain the log canonical threshold for the homogeneous case. Theorem 2 indicates the best point of singularities that gives the log canonical threshold. Therefore, this theorem is useful for the reduction of the number of blowup processes. Theorem 3 improves our recursive blowup method by simplifying coordinate system changes with added variables. These two theorems enable us to obtain a new bound for the log canonical thresholds of Vandermonde matrix-type singularities in Theorem 5. These bounds are much tighter than those in [
14].
In the past few years, we have obtained the learning coefficients for reduced rank regression [
15], for the three-layered neural network with one input unit and one output unit [
16,
17], and for the normal mixture models with a dimension of one [
18]. The paper [
14] derived bounds on the learning coefficients for the Vandermonde matrix-type singularities and explicit values under some conditions. The learning coefficients for the restricted Boltzmann machine [
19] have also been considered recently. Ref [
20,
21,
22], respectively, obtained these for naive Bayesian networks and for directed tree models with hidden variables. These results give partial answers for the learning coefficients.
The rest of the paper is in three sections.
Section 2 summarizes the framework of Bayesian learning models. In
Section 3, we demonstrate our main theorems and consider the log canonical threshold of Vandermonde matrix-type singularities (Definition 3). We finish with our conclusions in
Section 4.
2. Learning Coefficients and Singular Fluctuations
In this section, we present the theory of learning coefficients and singular fluctuations. Let
be a true probability density function of variables,
, and let
be
n training samples selected from
independently and identically. Consider a learning model that is written in probabilistic form as
, where
is a parameter. The purpose of the learning system is to estimate
from
using
. Let
be an
a priori probability density function on the parameter set,
W, and
be the
a posteriori probability density function:
where:
Let us define for the inverse temperature,
β:
We usually set
.
We then have a predictive density function, , which is the average inference of the Bayesian density function.
We next introduce the Kullback function,
, and the empirical Kullback function,
, for density functions
:
The function,
, always has a non-negative value and satisfies
, if and only if
.
The Bayesian generalization error,
, Bayesian training error,
, Gibbs generalization error,
, and Gibbs training error,
, are defined as follows:
and
The most important of these is the Bayesian generalization error. This error describes how precisely the predictive function approximates the true density function.
Watanabe [
6,
7,
23] proved the following four relations:
Eliminating the expectation of the true probability density function from the above four errors and setting:
we then have:
and
These two equations constitute the WAIC and show that we can estimate the Bayesian and Gibbs generalization errors from the Bayesian and Gibbs training errors without any knowledge of the true probability density functions. Training errors are calculated from training samples, , using a learning model, p. In real applications or experiments, we usually do not know the true distribution, but only the values of the training errors. Our purpose is to estimate the true distribution from the training samples, showing that these relations are effective. We can select a suitable model from among several statistical models by observing these values.
Let
λ denote a learning coefficient and
ν a singular fluctuation, both of which are birational invariants. Mathematically,
λ is equal to the log canonical threshold introduced in Definition 1 and
Appendix B. For regular models,
holds, where
d is the dimension of the parameter space.
The difference between the Bayesian and Gibbs training errors converges to
:
These relations were shown using the resolution of singularities and the Schwarz distribution.
From the learning coefficient,
λ, and its order,
θ, the value,
ν, is obtained theoretically as follows. Let
be an empirical process defined on the manifold obtained by a resolution of singularities, and
denote the sum of local coordinates that attain the minimum
λ and the maximum
θ. We then have:
is a random variable of a Gaussian process with mean zero and variance two. Our purpose in this paper is to obtain
λ.
To assist in achieving this aim, we use the desingularization approach from algebraic geometry (
cf.
Appendix A). It is a new problem in algebraic geometry to obtain the desingularization of the Kullback functions, because the singularities of these functions are very complicated, and as such, most of these have not yet been investigated.
3. Main Theorems and Vandermonde Matrix-Type Singularities
We denote constants, such as , and , by the suffix ∗. Additionally, for simplicity, we use the notation: instead of: because we always have and in this paper.
Define the norm of a matrix, , by . Set .
Definition 1 For a real analytic function, f, in a neighborhood, U, of and a function ψ with a compact support, let be the largest pole of and be its order. If , then we denote and , because the log canonical threshold and its order are independent of ψ.
Definition 2 Fix . Define: if , , and
Definition 3 Fix .
Let , and(the superscript, t, denotes matrix transposition). and are variables in a neighborhood of and , where and are fixed constants.
Let be the ideal generated by the elements of .
We call singularities of Vandermonde matrix-type singularities.
To simplify, we usually assume thatfor andfor . Example 1 If and , then we have: .
This matrix is a Vandermonde matrix.
Example 2 If , , and , then we have: and .
In this paper, we denote:
.
Furthermore, we denote:
and
Theorem 1 ([
18])
Consider a sufficiently small neighborhood, U, ofand variables, , in the set, U. Set: .
Let each: , …, be a different real vector in:That is: Then, is uniquely determined, and by the assumption in Definition 3. Set: for .
Assume that:and . We then have:where: and for . Theorem 2 (Method for finding a deepest singular point) Let , …, be homogeneous functions of with the degree, , of . Furthermore, let ψ be a function, such that and is homogeneous of in a small neighborhood of .
(Proof)
Let
d be the degree of
for
ψ in a neighborhood of
Let us construct the blowup of
,
…,
along the submanifold,
. Let
for
. We have:
and
. Because:
for
, we have:
, and, hence, by Lemma 1 in
Appendix C:
Furthermore, we consider the construction of the blowup of:
,
…,
along the submanifold:
, for which we have
In general, it is not true that:
even if
satisfies:
Example 3 Let , and . Then, we have: if and only if .
In this case, we have
Theorem 3 (Method to add variables) Let , …, be homogeneous functions of of the degree, , in . Set: , …, . If , then we have: (Proof) Set
. Then, we have:
Since
on a small neighborhood of
, there exist positive real numbers,
, such that:
This completes the proof by Lemma 1 in
Appendix C. Q.E.D.
Remark 1
The above theorem shows that we can set nonzero constants as variables to obtain the same log canonical threshold. However, in general, this is not true.
- (1)
Consider the function . We have , whereas .
- (2)
Consider the function . We have , whereas .
The second example shows that the following theorem over the complex field is not true over the real field.
Let be a holomorphic function near zero, and for a hyperplane H, let (or ) denote the restriction of f to (or H). Then, .
Define: ,
Theorem 5 We use the same notation as in Theorem 1. Let:where: ,
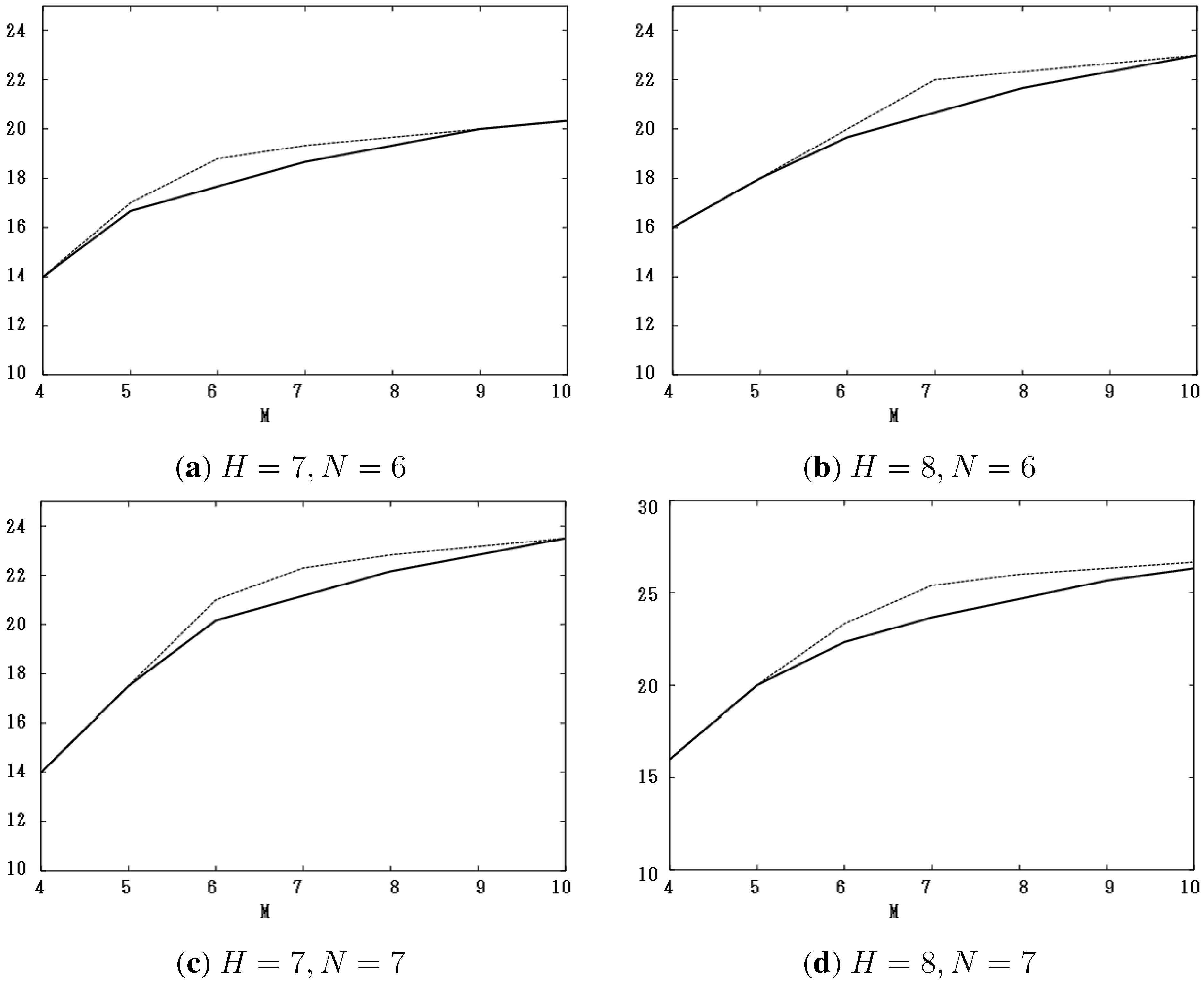
Furthermore, let: where: , and let: Figure 1a–d show the values of new bounds,
, for (a)
, (b)
, (c)
and (d)
with
, respectively. We compare these values with those obtained by the past work in [
14]. In the figures, the horizontal axis is the number,
M, and the vertical one, the value of such bounds. The dashed lines indicate the bounds obtained by the past work. These figures show that new bounds are not greater than old ones.
Figure 1.
The values of new bounds,
, for (
a)
; (
b)
; (
c)
and (
d)
with
, compared with the bounds obtained by the past work in [
14].
Figure 1.
The values of new bounds,
, for (
a)
; (
b)
; (
c)
and (
d)
with
, compared with the bounds obtained by the past work in [
14].
In paper [
24], we had exact values for
:
where:
and we had:
We had other exact values when
H is small on paper [
14]. Both sets of exact values are the bounded values in Theorem 5.
3.1. A Learning Coefficient for a Three-Layered Neural Network
Consider the three-layered neural network with
N input units,
H hidden units and
M output units, which are trained for estimating the true distribution with
r hidden units. Their learning coefficients,
λ, are as follows [
14,
24]:
3.2. A Learning Coefficient for a Normal Mixture Model
Consider normal mixture models with
H peaks and the true distribution with
r peaks. Then, their learning coefficients,
λ, are as follows [
14,
18]:
In particular, we have for
:
where
.

{kind=link}
{kind=link}

