Ordinal Patterns, Entropy, and EEG


Abstract
:1. Introduction
2. Entropies for Discriminating Complexity
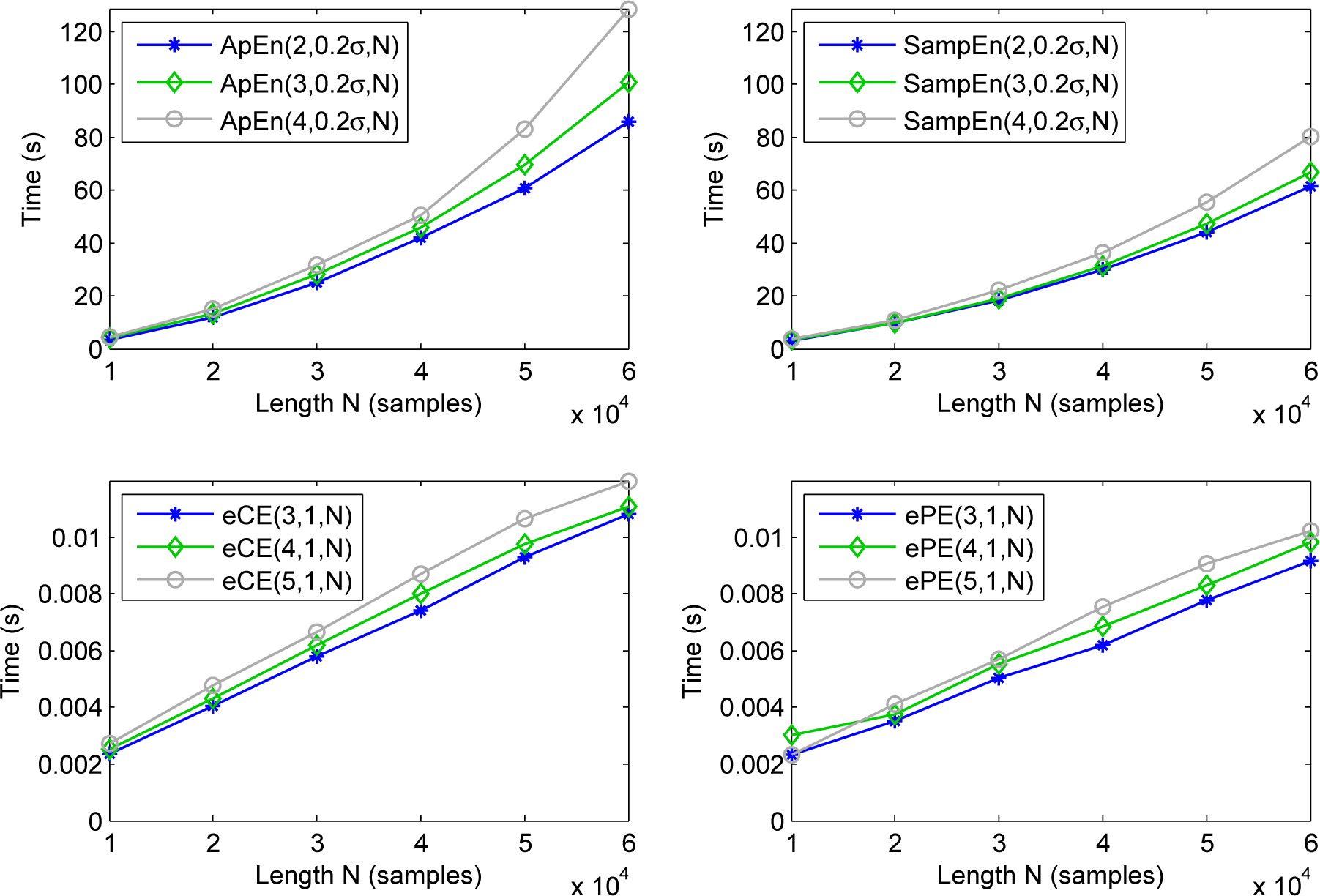
2.1. Approximate Entropy and Sample Entropy
2.2. Ordinal Patterns, Empirical Permutation Entropy and Empirical Conditional Entropy of Ordinal Patterns
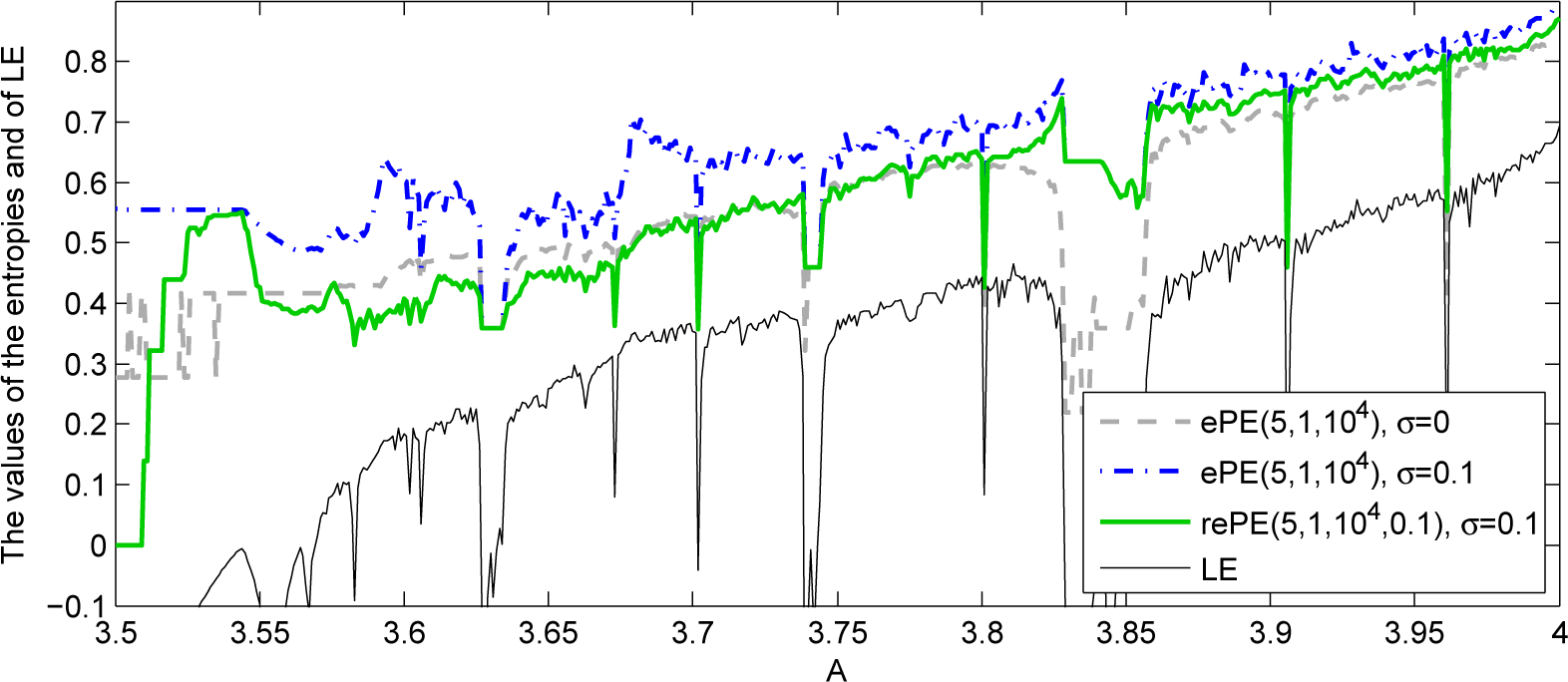
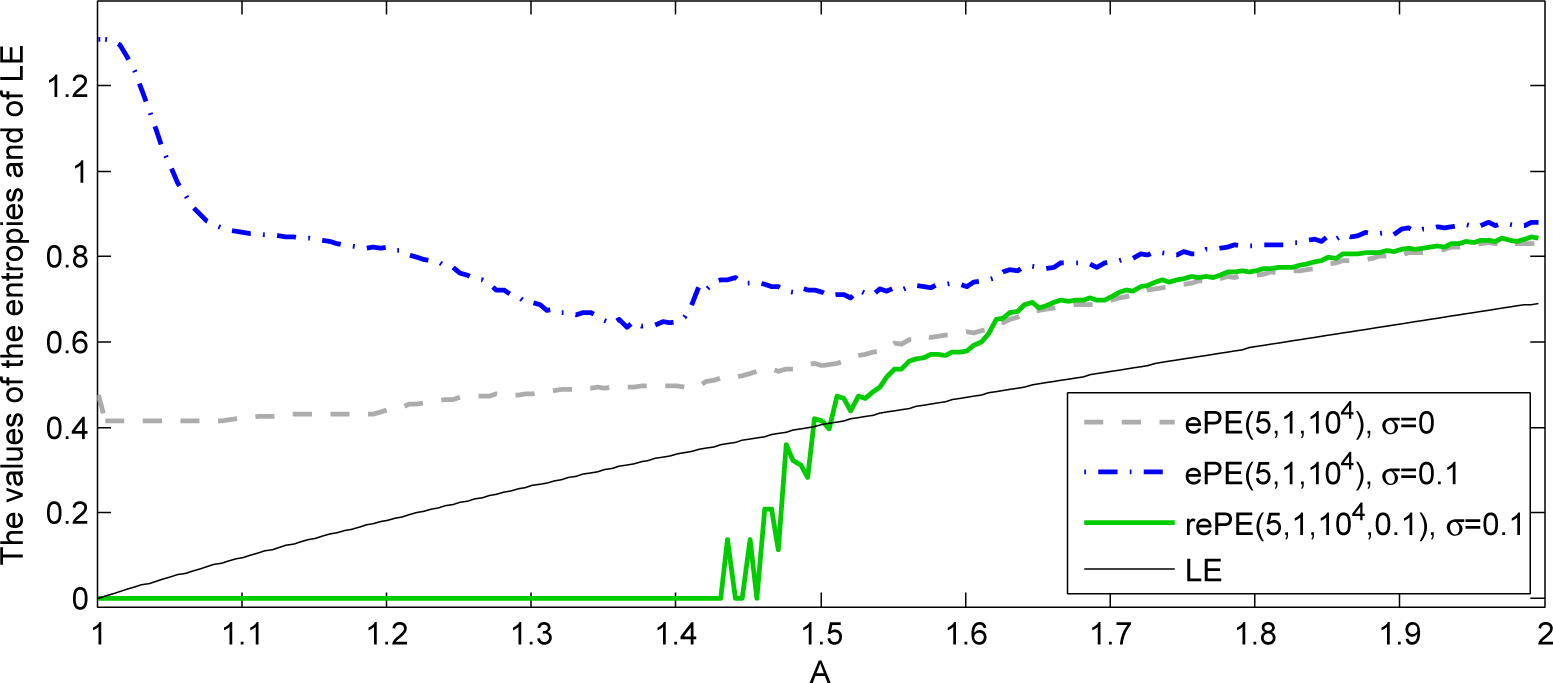
2.3. Robustness of Empirical Permutation Entropy with Respect to Noise
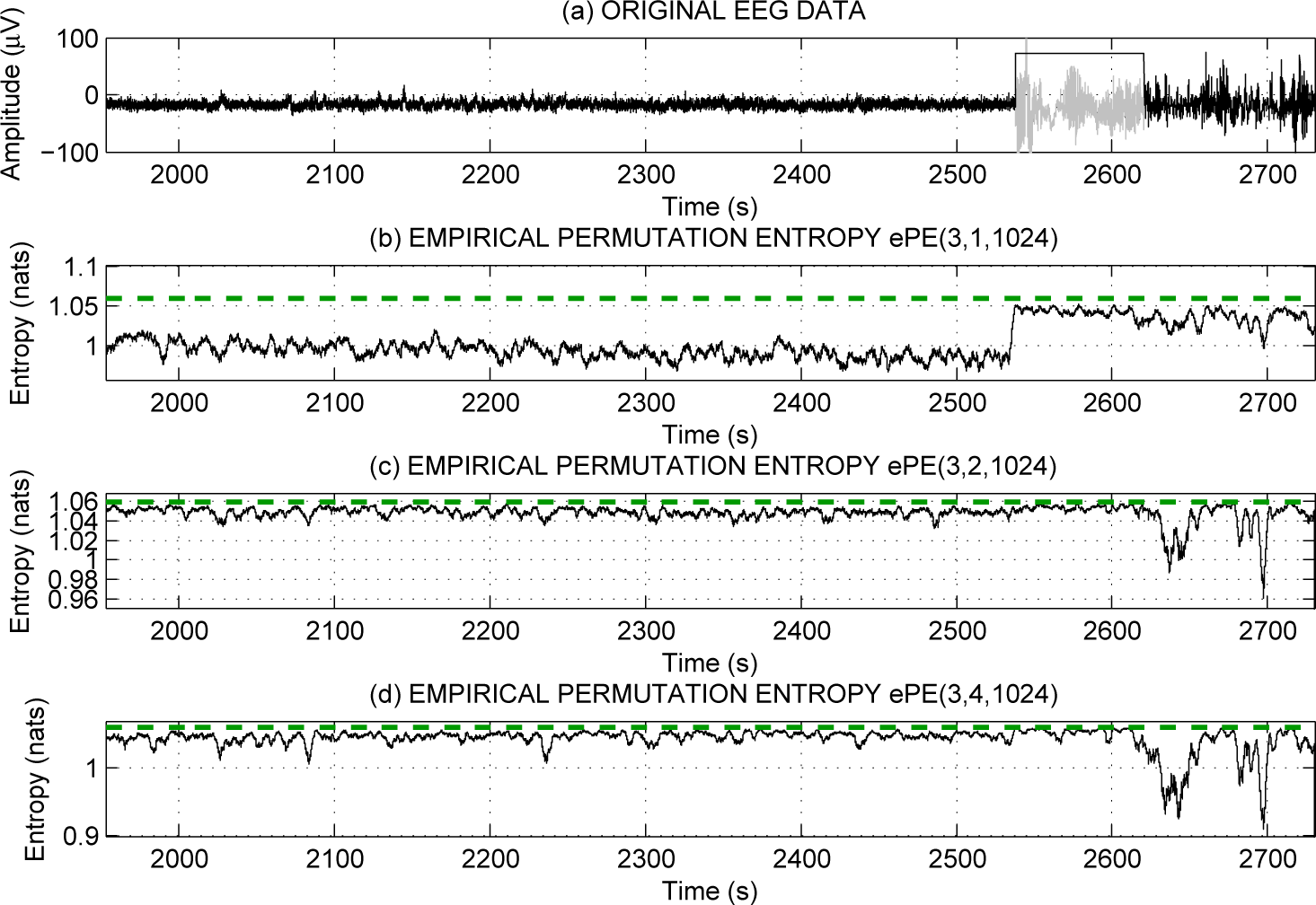
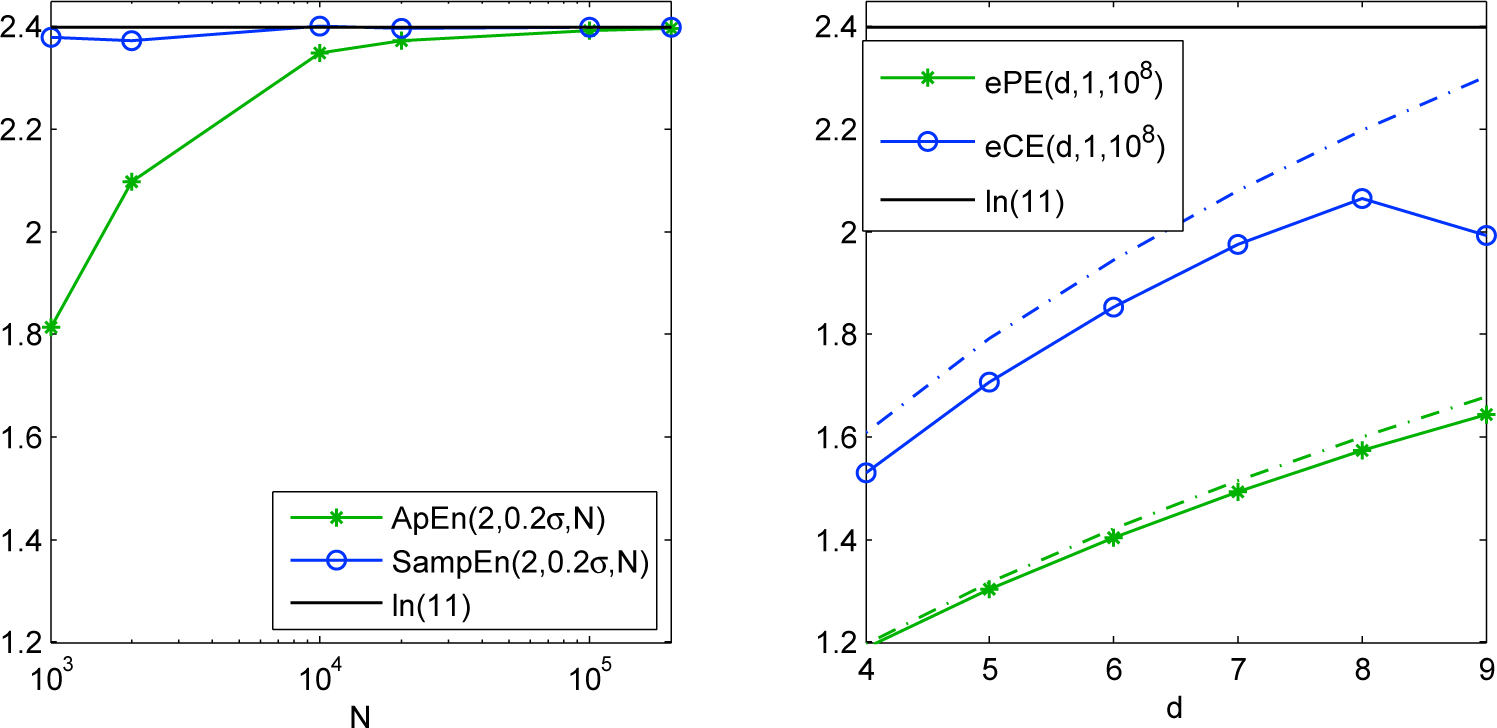
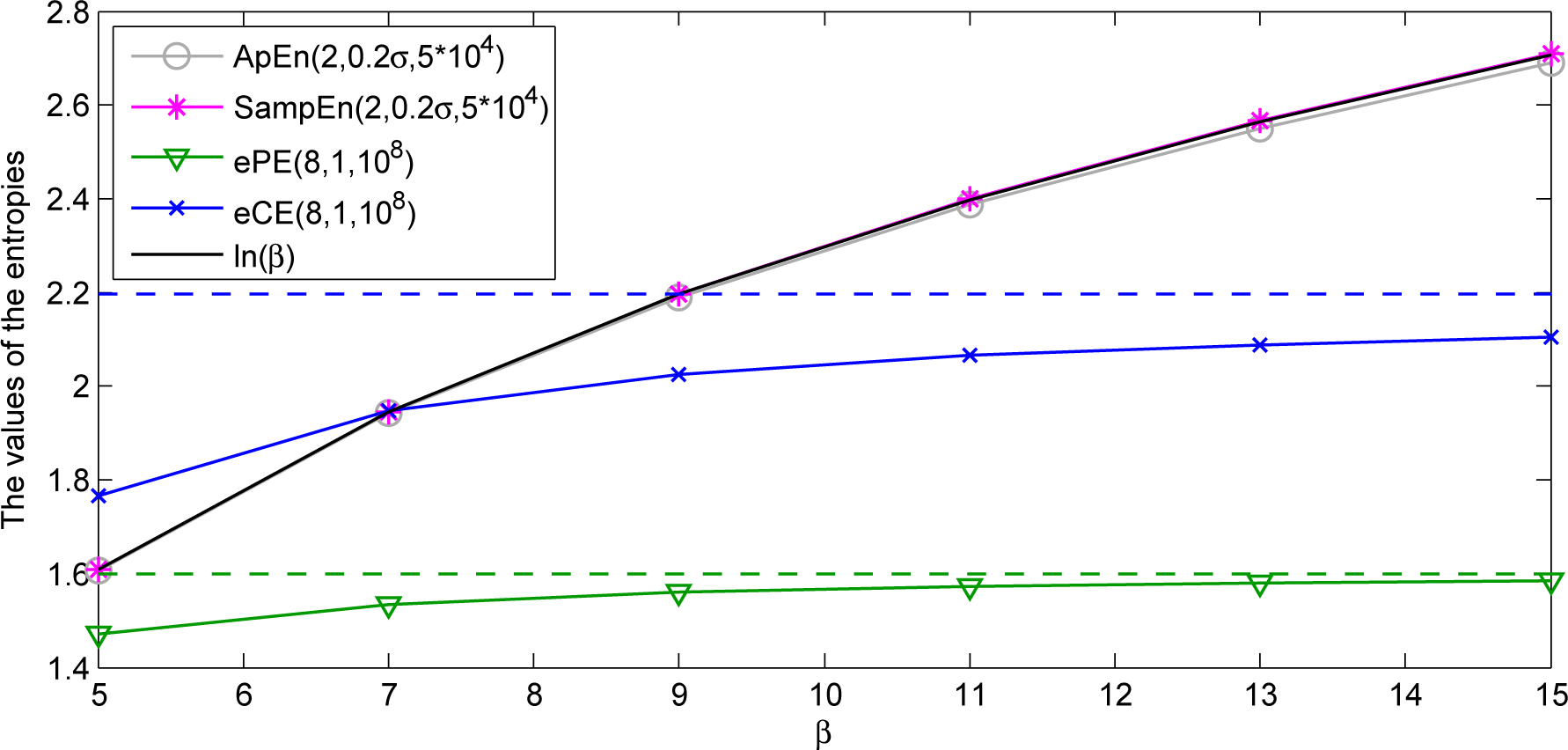
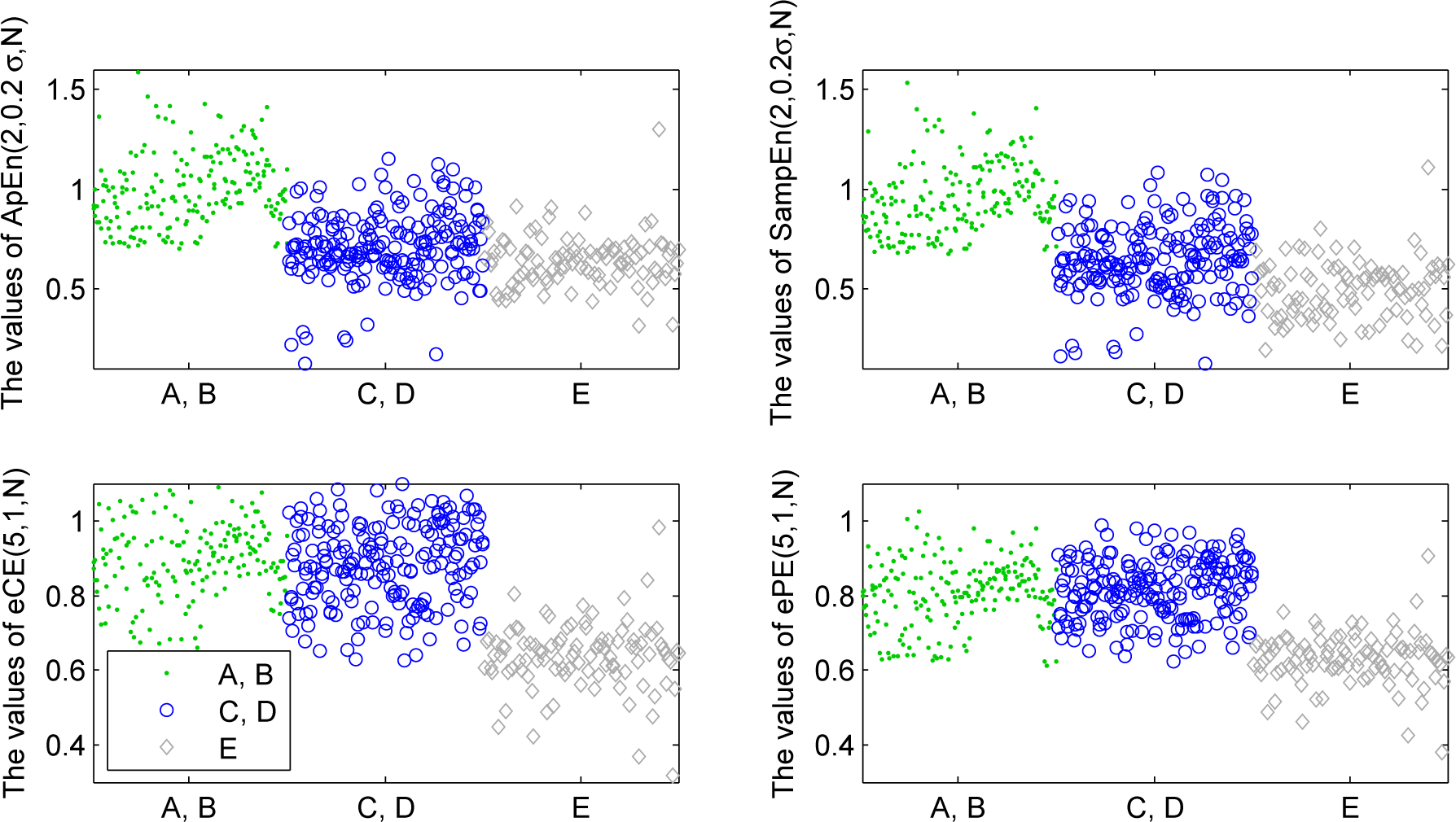
2.4. Examples and Comparisons
- (A) surface EEG recorded from healthy subjects with open eyes,
- (B) surface EEG recorded from healthy subjects with closed eyes,
- (C) intracranial EEG recorded from subjects with epilepsy during a seizure-free period from hippocampal formation of the opposite hemisphere of the brain,
- (D) intracranial EEG recorded from subjects with epilepsy during a seizure-free period from within the epileptogenic zone,
- (E) intracranial EEG recorded from subjects with epilepsy during a seizure period.
- It can be useful to apply approximate entropy, sample entropy, empirical permutation entropy and empirical conditional entropy of ordinal patterns together since they reveal different features of the dynamics underlying a time series.
- It can be useful to apply empirical permutation entropy and empirical conditional entropy of ordinal patterns for different delays τ since they reveal different features of the dynamics underlying a time series.
3. Ordinal-Patterns-Based Segmentation of EEG and Clustering of EEG Segments
3.1. The Idea of Ordinal-Patterns-Based Change-Point Detection
3.2. Change-Point Detection Using the CEofOP Statistic
3.3. Ordinal-Pattern-Distributions Clustering
3.4. An Application of Ordinal-Patterns-Based Segmentation and Ordinal-Pattern-Distributions Clustering to Sleep EEG
- the waking state (W);
- two stages of light sleep (S1, S2);
- two stages of deep sleep (S3, S4);
- rapid eye movement (REM) sleep.
- EEG time series are filtered to the band 1 Hz to 45 Hz (with the Butterworth filter of order 5).
- The ordinal-patterns-based segmentation procedure (described by Algorithm 3 in Appendix A.3) is employed for d = 4, which is the maximal order satisfying 2(d + 1)!(d + 1) < N (see (14)) for N = 3000 corresponding to the epoch length of 30 s.
- OPD clustering (as described in Section 3.3, for d = 4) is applied to the segments of all recordings. The number of clusters 8 is chosen, the transition-state segments (see Algorithm 3) are considered as unclassified. We deliberately choose the number of clusters larger than the number of sleep stages since for different persons EEG may be significantly different (especially in the waking state). Therefore, we analyze the obtained clusters and group them into larger classes:
- class “AWAKE”: three clusters;
- class “LIGHT SLEEP”: three clusters (one of these clusters may be associated with stage S1 and two others with stage S2, but we do not distinguish between S1 and S2 since the amount of the epochs corresponding to S1 is small);
- class “REM”: one cluster.
4. Summary and Conclusions
Acknowledgments
Appendix
A. Algorithms
A.1. Algorithm for Detecting at Most One Change-Point

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
 |
A.2. Algorithm for Detecting Multiple Change-Points
 |
A.3. Algorithm for Ordinal-Patterns-Based Segmentation of Multivariate Time Series
- order d = 4;
- probability of false alarms α = 0.07 (we use a relatively high probability of false alarms since we prefer to split a sleep stage into several segments that can be grouped into one cluster on the next step, rather than to get segments containing several sleep stages);
- minimal length of a valid stationary segment Tsegm = 3000 (i.e., a valid stationary segment should be at least 30 s, which corresponds to the length of an epoch used in manual scoring).
 |
Author Contributions
Conflicts of Interest
References
- Bandt, C.; Pompe, B. Permutation entropy—A natural complexity measure for time series. Phys. Rev. E 2002, 88. [Google Scholar] [CrossRef]
- Li, X.; Ouyang, G.; Richards, D.A. Predictability analysis of absence seizures with permutation entropy. Epilepsy Res. 2007, 77, 70–74. [Google Scholar]
- Cao, Y.; Tung, W.W.; Gao, J.B.; Protopopescu, V.A.; Hively, L.M. Detecting dynamical changes in time series using the permutation entropy. Phys. Rev. E 2004, 70. [Google Scholar] [CrossRef]
- Keller, K.; Lauffer, H. Symbolic analysis of high-dimensional time series. Int. J. Bifurc. Chaos 2003, 13, 2657–2668. [Google Scholar]
- Ouyang, G.; Dang, C.; Richards, D.A.; Li, X. Ordinal pattern based similarity analysis for EEG recordings. Clin. Neurophysiol. 2010, 121, 694–703. [Google Scholar]
- Olofsen, E.; Sleigh, J.W.; Dahan, A. Permutation entropy of the electroencephalogram: A measure of anaesthetic drug effect. Br. J. Anaesth. 2008, 101, 810–821. [Google Scholar]
- Li, D.; Li, X.; Liang, Z.; Voss, L.J.; Sleigh, J.W. Multiscale permutation entropy analysis of EEG recordings during sevoflurane anesthesia. J. Neural Eng. 2010, 7. [Google Scholar] [CrossRef]
- Nicolaou, N.; Georgiou, J. The use of permutation entropy to characterize sleep electroencephalograms. Clin. EEG Neurosci. 2011, 42, 24–28. [Google Scholar]
- Graff, B.; Graff, G.; Kaczkowska, A. Entropy Measures of Heart Rate Variability for Short ECG Datasets in Patients with Congestive Heart Failure. Acta Phys. Polonica B Proc. Suppl. 2012, 5, 153–158. [Google Scholar]
- Parlitz, U.; Berg, S.; Luther, S.; Schirdewan, A.; Kurths, J.; Wessel, N. Classifying cardiac biosignals using ordinal pattern statistics and symbolic dynamics. Comput. Biol. Med. 2012, 42, 319–327. [Google Scholar]
- Frank, B.; Pompe, B.; Schneider, U.; Hoyer, D. Permutation entropy improves fetal behavioural state classification based on heart rate analysis from biomagnetic recordings in near term fetuses. Med. Biol. Eng. Comput. 2006, 44, 179–187. [Google Scholar]
- Bian, C.; Qin, C.; Ma, Q.D.Y.; Shen, Q. Modified permutation-entropy analysis of heartbeat dynamics. Phys. Rev. E 2012, 85. [Google Scholar] [CrossRef]
- Amigó, J.M.; Keller, K. Permutation entropy: One concept, two approaches. Eur. Phys. J. Spec. Top. 2013, 222, 263–273. [Google Scholar]
- Amigó, J.M. Permutation Complexity in Dynamical Systems; Springer-Verlag: Berlin and Heidelberg, Germany, 2010. [Google Scholar]
- Unakafov, A.M.; Keller, K. Conditional entropy of ordinal patterns. Physica D 2013, 269, 94–102. [Google Scholar]
- Acharya, U.R.; Joseph, K.P.; Kannathal, N.; Lim, C.M.; Suri, J.S. Heart rate variability: A review. Med. Biol. Eng. Comput. 2006, 44, 1031–1051. [Google Scholar]
- Bruhn, J.; Röpcke, H.; Hoeft, A. Approximate entropy as an electroencephalographic measure of anesthetic drug effect during desflurane anesthesia. Anesthesiology 2000, 92, 715–726. [Google Scholar]
- Bruhn, J.; Röpcke, H.; Rehberg, B.; Bouillon, T.; Hoeft, A. Electroencephalogram approximate entropy correctly classifies the occurrence of burst suppression pattern as increasing anesthetic drug effect. Anesthesiology 2000, 93, 981–985. [Google Scholar]
- Jordan, D.; Stockmanns, G.; Kochs, E.F.; Pilge, S.; Schneider, G. Electroencephalographic order pattern analysis for the separation of consciousness and unconsciousness: An analysis of approximate entropy, Permutation Entropy, recurrence rate, and phase coupling of order recurrence plots. Anesthesiology 2008, 109, 1014–1022. [Google Scholar]
- Acharya, U.R.; Faust, O.; Kannathal, N.; Chua, T.; Laxminarayan, S. Non-linear analysis of EEG signals at various sleep stages. Comput. Methods Programs Biomed. 2005, 80, 37–45. [Google Scholar]
- Burioka, N.; Miyata, M.; Cornélissen, G.; Halberg, F.; Takeshima, T.; Kaplan, D.T.; Suyama, H.; Endo, M.; Maegaki, Y.; Nomura, T.; et al. Approximate entropy in the electroencephalogram during wake and sleep. Clin. EEG Neurosci. 2005, 36, 21–24. [Google Scholar]
- Kannathal, N.; Choo, M.L.; Acharya, U.R.; Sadasivan, P.K. Entropies for detection of epilepsy in EEG. Comput. Methods Programs Biomed. 2005, 80, 187–194. [Google Scholar]
- Ocak, H. Automatic detection of epileptic seizures in EEG using discrete wavelet transform and approximate entropy. Expert Syst. Appl. 2009, 36, 2027–2036. [Google Scholar]
- Richman, J.S.; Moorman, J.R. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol.-Heart Circ. Physiol. 2000, 278, 2039–2049. [Google Scholar]
- Yentes, J.M.; Hunt, N.; Schmid, K.K.; Kaipust, J.P.; McGrath, D.; Stergiou, N. The Appropriate use of approximate entropy and sample entropy with short data sets. Ann. Biomed. Eng. 2013, 41, 349–365. [Google Scholar]
- Lake, D.E.; Richman, J.S.; Griffin, M.P.; Moorman, J.R. Sample entropy analysis of neonatal heart rate variability. Am. J. Physiol.-Regul. Integr. Comp. Physiol. 2002, 283, R789–R797. [Google Scholar]
- Abásolo, D.; Hornero, R.; Espino, P.; Alvarez, D.; Poza, J. Entropy analysis of the EEG background activity in Alzheimer’s disease patients. Physiol. Meas. 2006, 27. [Google Scholar] [CrossRef]
- Jouny, C.C.; Bergey, G.K. Characterization of early partial seizure onset: Frequency, complexity and entropy. Clin. Neurophysiol. 2012, 123, 658–669. [Google Scholar]
- Chen, W.; Zhuang, J.; Yu, W.; Wang, Z. Measuring complexity using FuzzyEn, ApEn, and SampEn. Med. Eng. Phys. 2009, 31, 61–68. [Google Scholar]
- Sinn, M.; Ghodsi, A.; Keller, K. Detecting change-points in time series by kernel mean matching of ordinal pattern distributions. Proceedings of the 28th Conference on Uncertainty in Artificial Intelligence, Catalina Island, CA, USA, 15–17 August 2012; pp. 786–794.
- Sinn, M.; Keller, K.; Chen, B. Segmentation and classification of time series using ordinal pattern distributions. Eur. Phys. J. Spec. Top. 2013, 222, 587–598. [Google Scholar]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. 1991, 88, 2297–2301. [Google Scholar]
- Grassberger, P.; Procaccia, I. Estimation of the Kolmogorov entropy from a chaotic signal. Phys. Rev. A 1983, 28, 2591–2593. [Google Scholar]
- Eckmann, J.-P.; Ruelle, D. Ergodic theory of chaos and strange attractors. Rev. Mod. Phys. 1985, 57, 617–656. [Google Scholar]
- Walters, P. An Introduction to Ergodic Theory; Springer: New York, NY, USA, 2000. [Google Scholar]
- Broer, H.; Takens, F. Dynamical Systems and Chaos; Springer: New York, NY, USA, 2010. [Google Scholar]
- Unakafova, V.A. Investigating measures of complexity for dynamical systems and for time series. Ph.D. Thesis, draft version, University of Lubeck, Lubeck, Germany, 2015. [Google Scholar]
- Pincus, S.M. Approximate entropy (ApEn) as a complexity measure. Chaos 1995, 5, 110–117. [Google Scholar]
- Keller, K.; Unakafov, A.M.; Unakafova, V.A. On the relation of KS entropy and permutation entropy. Physica D 2012, 241, 1477–1481. [Google Scholar]
- Keller, K.; Emonds, J.; Sinn, M. Time series from the ordinal viewpoint. Stoch. Dyn. 2007, 2, 247–272. [Google Scholar]
- Amigó, J.M.; Zambrano, S.; Sanjuán, M.A.F. Combinatorial detection of determinism in noisy time series. Europhys. Lett. 2008, 83. [Google Scholar] [CrossRef]
- Riedl, M.; Müller, A.; Wessel, N. Practical considerations of permutation entropy. Eur. Phys. J. Spec. Top. 2013, 222, 249–262. [Google Scholar]
- Li, J.; Yan, J.; Liu, X.; Ouyang, G. Using permutation entropy to measure the changes in EEG signals during absence seizures. Entropy 2014, 16, 3049–3061. [Google Scholar]
- The European Epilepsy Database. Available online: http://epilepsy-database.eu/ accessed on 19 September 2014.
- Bandt, C.; Keller, G.; Pompe, B. Entropy of interval maps via permutations. Nonlinearity 2002, 15, 1595–1602. [Google Scholar]
- Choe, H.C. Computational Ergodic Theory; Springer: New York, NY, USA, 2005. [Google Scholar]
- Sprott, J.C. Chaos and Time-Series Analysis; Oxford University Press: Oxford, UK, 2003. [Google Scholar]
- Zanin, M.; Zunino, L.; Rosso, O.A.; Papo, D. Permutation entropy and its main biomedical and econophysics applications: A review. Entropy 2012, 14, 1553–1577. [Google Scholar]
- Morabito, F.C.; Labate, D.; La Foresta, F.; Bramanti, A.; Morabito, G.; Palamara, I. Multivariate multi-scale permutation entropy for complexity analysis of Alzheimer’s disease EEG. Entropy 2012, 14, 1186–1202. [Google Scholar]
- Unakafova, V.A. Fast Permutation Entropy. MATLAB Central File Exchange. Available online: http://www.mathworks.com/matlabcentral/fileexchange/44161-fast-permutation-entropy accessed on 12 August 2014.
- Lee, K. Fast Approximate Entropy. MATLAB Central File Exchange. Available online: http://www.mathworks.com/matlabcentral/fileexchange/32427-fast-approximate-entropy/content/ApEn.m accessed on 12 August 2014.
- Lee, K. Fast Sample Entropy. MATLAB Central File Exchange. Available online: http://www.mathworks.com/matlabcentral/fileexchange/35784-sample-entropy accessed on 12 August 2014.
- Unakafova, V.A.; Keller, K. Efficiently measuring complexity on the basis of real-world data. Entropy 2013, 15, 4392–4415. [Google Scholar]
- Pan, Y.-H.; Wang, Y.-H.; Liang, S.-F.; Lee, K.-T. Fast computation of sample entropy and approximate entropy in biomedicine. Comput. Methods Programs Biomed. 2011, 104, 382–396. [Google Scholar]
- Unakafov, A.M. Ordinal-patterns-based segmentation and discrimination of time series with applications to EEG data. Ph.D. Thesis, draft version, University of Lubeck, Lubeck, Germany, 2015. [Google Scholar]
- Bonn EEG Database. Available online: http://epileptologie-bonn.de accessed on 12 August 2014.
- Andrzejak, R.G.; Lehnertz, K.; Mormann, F.; Rieke, C.; David, P.; Egler, C.E. Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Phys. Rev. E 2001, 64. [Google Scholar] [CrossRef]
- Tzallas, A.T.; Tsipouras, M.G.; Fotiadis, D.I. Epileptic seizure detection in EEGs using time–frequency analysis. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 703–710. [Google Scholar]
- Basseville, M.; Nikiforov, I.V. Detection of Abrupt Changes: Theory and Application; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Richman, J.S.; Lake, D.E.; Moorman, J.R. Sample Entropy. Methods Enzymol. 2004, 384, 172–184. [Google Scholar]
- Carlstein, E.; Muller, H.G.; Siegmund, D. Change-Point Problems; Institute of Mathematical Statistics: Hayward, CA, USA, 1994. [Google Scholar]
- Brodsky, B.E.; Darkhovsky, B.S. Non-Parametric Statistical Diagnosis. Problems and Methods; Kluwer Academic Publishers: Dordrecht, The Netherlands, 2000. [Google Scholar]
- Polansky, A.M. Detecting change-points in Markov chains. Comput. Stat. Data Anal. 2007, 51, 6013–6026. [Google Scholar]
- Kim, A.Y.; Marzban, C.; Percival, D.B.; Stuetzle, W. Using labeled data to evaluate change detectors in a multivariate streaming environment. Signal Process. 2009, 89, 2529–2536. [Google Scholar]
- Brodsky, B.E.; Darkhovsky, B.S.; Kaplan, A.Y.; Shishkin, S.L. A nonparametric method for the segmentation of the EEG. Comput. Methods Programs Biomed. 1999, 60, 93–106. [Google Scholar]
- Han, T.S.; Kobayashi, K. Mathematics of Information and Coding. Transl. from the Japanese by J. Suzuki.; American Mathematical Society: Providence, RI, USA, 2002. [Google Scholar]
- Vostrikova, L.Y. Detecting disorder in multidimensional random processes. Sov. Math. Dokl. 1981, 24, 55–59. [Google Scholar]
- Brandmaier, A.M. Permutation Distribution Clustering and Structural Equation Model Trees. Ph.D. Thesis, University of Saarland, Saarbrucken, Germany, 2012. [Google Scholar]
- Abonyi, J.; Feil, B. Cluster Analysis for Data Mining and System Identification; Springer: Berlin, Germany, 2007. [Google Scholar]
- Silber, M.H.; Ancoli-Israel, S.; Bonnet, M.H.; Chokroverty, S.; Grigg-Damberger, M.M.; Hirshkowitz, M.; Kapen, S.; Keenan, S.A.; Kryger, M.H.; Penzel, T.; et al. The visual scoring of sleep in adults. J. Clin. Sleep Med. 2007, 3, 121–131. [Google Scholar]
- Libenson, M.H. Practical Approach to Electroencephalography; Elsevier Health Sciences: Philadelphia, PA, USA, 2012. [Google Scholar]
- Rechtschaffen, A.; Kales, A. A Manual of Standardized Terminology, Techniques and Scoring System for Sleep Stages of Human Subjects; Public Health Service US Government Printing Office: Washington, DC, USA, 1968. [Google Scholar]
- Kemp, B.; Zwinderman, A.H.; Tuk, B.; Kamphuisen, H.A.C.; Oberyé, J.J.L. Analysis of a sleep-dependent neuronal feedback loop: The slow-wave microcontinuity of the EEG. IEEE-BME 2000, 47, 1185–1194. [Google Scholar]
- Goldberger, A.L.; Amaral, L.A.N.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.-K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar]
- Berthomier, C.; Drouot, X.; Herman-Stoïca, M.; Berthomier, P.; Prado, J.; Bokar-Thire, D.; Benoit, O.; Mattout, J.; d’Ortho, M.-P. Automatic analysis of single-channel sleep EEG: Validation in healthy individuals. Sleep 2007, 30, 1587–1595. [Google Scholar]
- Ronzhina, M.; Janoušek, O.; Kolářová, J.; Nováková, M.; Honzík, P.; Provazník, I. Sleep scoring using artificial neural networks. Sleep Med. Rev. 2012, 16, 251–263. [Google Scholar]














| Quantity | Method of computing | Computational time | Storage use |
|---|---|---|---|
| ApEn | [54] | O(N) | |
| SampEn | [54] | O(N) | |
| ePE | [53] | O(N) | O((d + 1)!(d + 1)) |
| eCE | [37] based on [53] | O(N) | O((d + 1)!(d + 1)) |
| Recording | Amount of sleep-related epochs | Correctly identified epochs |
|---|---|---|
| sc4002 | 1050 | 73.6% |
| sc4012 | 1150 | 73.7% |
| sc4102 | 1050 | 83.8% |
| sc4112 | 750 | 79.2% |
| st7022 | 944 | 61.2% |
| st7052 | 1032 | 81.3% |
| st7121 | 1027 | 80.7% |
| st7132 | 852 | 68.9% |
| Overall | 7855 | 75.4% |
| Results of ordinal-patterns-based discrimination | ||||||
|---|---|---|---|---|---|---|
| Manual score | AWAKE | LIGHT SLEEP | DEEP SLEEP | REM | unclassified | |
| W | 440 | 165 | 0 | 103 | 3 | |
| S1, S2 | 110 | 3234 | 227 | 635 | 19 | |
| S3, S4 | 0 | 404 | 880 | 10 | 5 | |
| REM | 0 | 244 | 0 | 1365 | 0 | |
| Unclassified | 3 | 6 | 1 | 1 | 0 | |
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Keller, K.; Unakafov, A.M.; Unakafova, V.A. Ordinal Patterns, Entropy, and EEG. Entropy 2014, 16, 6212-6239. https://doi.org/10.3390/e16126212
Keller K, Unakafov AM, Unakafova VA. Ordinal Patterns, Entropy, and EEG. Entropy. 2014; 16(12):6212-6239. https://doi.org/10.3390/e16126212
Chicago/Turabian StyleKeller, Karsten, Anton M. Unakafov, and Valentina A. Unakafova. 2014. "Ordinal Patterns, Entropy, and EEG" Entropy 16, no. 12: 6212-6239. https://doi.org/10.3390/e16126212
APA StyleKeller, K., Unakafov, A. M., & Unakafova, V. A. (2014). Ordinal Patterns, Entropy, and EEG. Entropy, 16(12), 6212-6239. https://doi.org/10.3390/e16126212