
Measuring the Complexity of Continuous Distributions



Abstract
:1. Introduction
2. Information Theory
2.1. Discrete Entropy
2.2. Asymptotic Equipartition Property for Discrete Random Variables
2.3. Properties of Discrete Entropy
- Entropy is always non-negative,
- with equality iff are i.i.d.
- with equality iff X is distributed uniformly over X.
- is concave.
2.4. Differential Entropy
2.5. Asymptotic Equipartition Property of Continuous Random Variables
2.6. Properties of Differential Entropy
- depends on the coordinates. For different choices of coordinate systems for a given probability distribution , the corresponding differential entropies might be distinct.
- [16]. The of a Dirac delta probability distribution, is considered the lowest bound, which corresponds to .
- Information measures such as relative entropy and mutual information are consistent, either in the discrete or continuous domain [22].
2.7. Differences between Discrete and Continuous Entropies
3. Discrete Complexity Measures
3.1. Emergence
3.2. Multiple Scales
3.3. Self-Organization
3.4. Complexity
4. Continuous Complexity Measures
4.1. Differential Emergence
4.2. Multiple Scales
- If we know a priori the true , we calculate , and is the cardinality within the interval of Equation (15). In this sense, a large value will denote the cardinality of a “ghost” sample [16]. (It is ghost, in the concrete sense that it does not exist. Its only purpose is to provide a bound for the maximum entropy accordingly to some large alphabet size.)
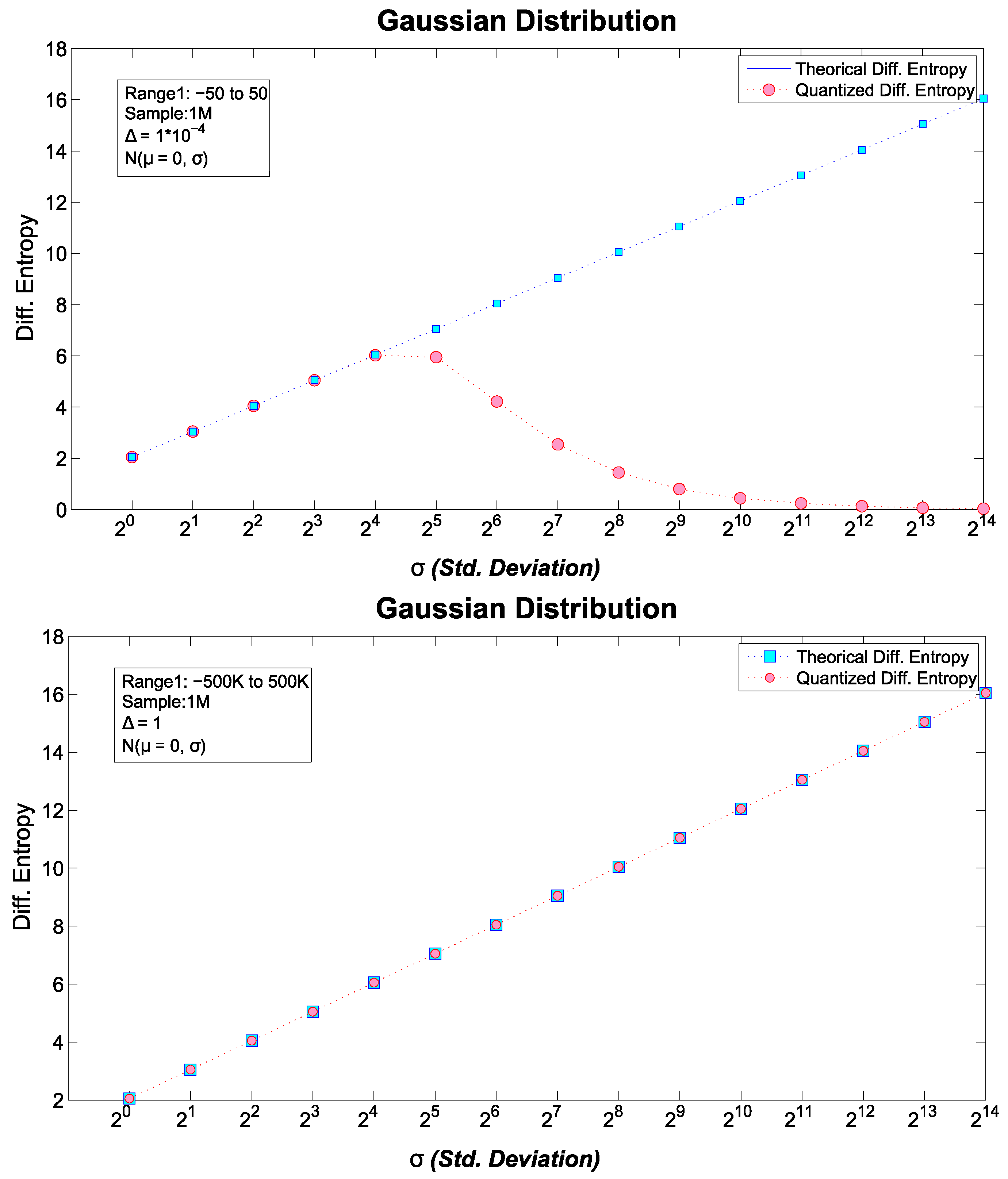
- If we do not know the true , or we are interested rather in where a sample of finite size is involved, we calculate b’ assuch that, the non-negative function is defined asFor instance, in the quantized version of the standard normal distribution (), only values within satisfy this constraint despite the domain of Equation (15). In particular, if we employ rather than , we compress the value as it will be shown in the next section. On the other hand, for a uniform distribution or a Power-Law (such that ), the whole range of points satisfies this constraint.
5. Probability Density Functions
5.1. Uniform Distribution
5.2. Normal Distribution
5.3. Power-Law Distribution
6. Results
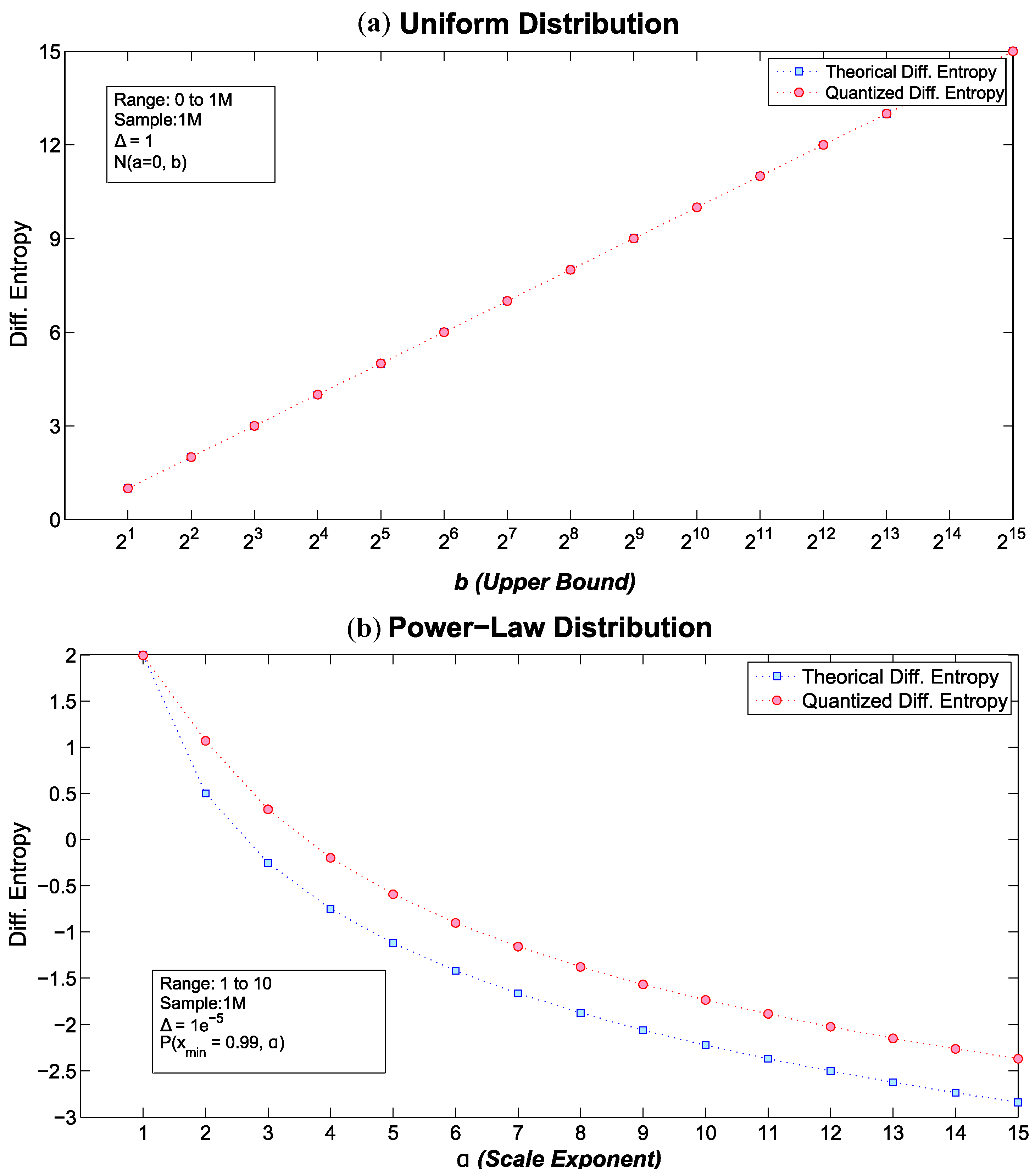
6.1. Theoretical vs. Quantized Differential Entropies
6.1.1. Uniform Distribution
6.1.2. Normal Distribution
6.1.3. Power-Law Distribution
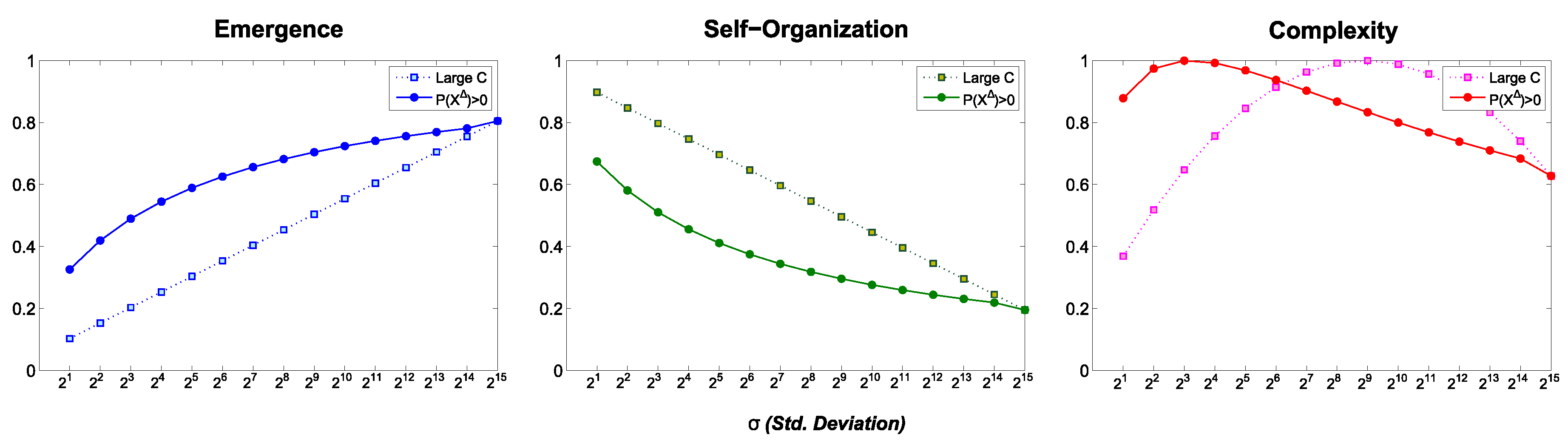
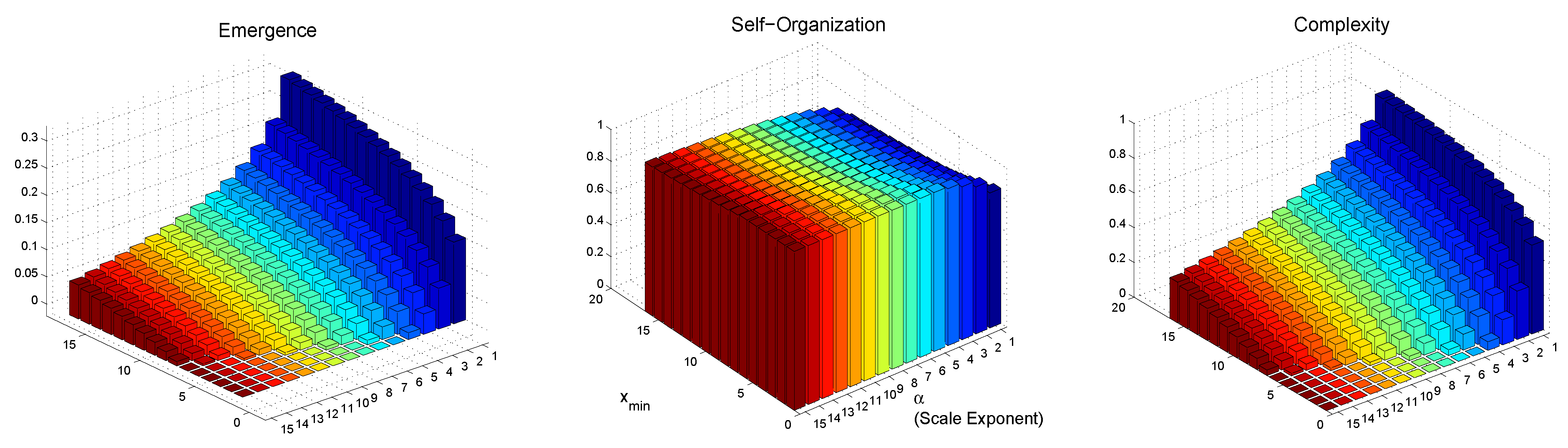
6.2. Differential Complexity: , , and
6.2.1. Normal Distribution
- is employed for .
- A constant with a large value () is used for the analytical formula of .
6.2.2. Power-Law Distribution
6.3. Real World Phenomena and Their Complexity
- Numbers of occurrences of words in the novel Moby Dick by Hermann Melville.
- Numbers of citations to scientific papers published in 1981, from the time of publication until June 1997.
- Numbers of hits on websites by users of America Online Internet services during a single day.
- Number of received calls to A.T.&T. U.S. long-distance telephone services on a single day.
- Earthquake magnitudes occurred in California between 1910 and 1992.
- Distribution of the diameter of moon craters.
- Peak gamma-ray intensity of solar flares between 1980 and 1989.
- War intensity between 1816–1980, where intensity is a formula related to the number of deaths and warring nations populations.
- Frequency of family names accordance with U.S. 1990 census.
- Population per city in the U.S. in agreement with U.S. 2000 census.
7. Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gershenson, C. (Ed.) Complexity: 5 Questions; Automatic Peess/VIP: Copenhagen, Denmark, 2008.
- Prokopenko, M.; Boschetti, F.; Ryan, A. An Information-Theoretic Primer on Complexity, Self-Organisation and Emergence. Complexity 2009, 15, 11–28. [Google Scholar] [CrossRef]
- Gershenson, C.; Fernández, N. Complexity and Information: Measuring Emergence, Self-organization, and Homeostasis at Multiple Scales. Complexity 2012, 18, 29–44. [Google Scholar] [CrossRef]
- Fernández, N.; Maldonado, C.; Gershenson, C. Information Measures of Complexity, Emergence, Self-organization, Homeostasis, and Autopoiesis. In Guided Self-Organization: Inception; Prokopenko, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2014; Volume 9, pp. 19–51. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef]
- Gershenson, C.; Heylighen, F. When Can We Call a System Self-Organizing? In Advances in Artificial Life; Banzhaf, W., Ziegler, J., Christaller, T., Dittrich, P., Kim, J.T., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 606–614. [Google Scholar]
- Langton, C.G. Computation at the Edge of Chaos: Phase Transitions and Emergent Computation. Physica D 1990, 42, 12–37. [Google Scholar] [CrossRef]
- Kauffman, S.A. The Origins of Order; Oxford University Press: Oxford, UK, 1993. [Google Scholar]
- Lopez-Ruiz, R.; Mancini, H.L.; Calbet, X. A statistical measure of complexity. Phys. Lett. A 1995, 209, 321–326. [Google Scholar] [CrossRef]
- Zubillaga, D.; Cruz, G.; Aguilar, L.D.; Zapotécatl, J.; Fernández, N.; Aguilar, J.; Rosenblueth, D.A.; Gershenson, C. Measuring the Complexity of Self-organizing Traffic Lights. Entropy 2014, 16, 2384–2407. [Google Scholar] [CrossRef]
- Amoretti, M.; Gershenson, C. Measuring the complexity of adaptive peer-to-peer systems. Peer-to-Peer Netw. Appl. 2015, 1–16. [Google Scholar] [CrossRef]
- Febres, G.; Jaffe, K.; Gershenson, C. Complexity measurement of natural and artificial languages. Complexity 2015, 20, 25–48. [Google Scholar] [CrossRef]
- Santamaría-Bonfil, G.; Reyes-Ballesteros, A.; Gershenson, C. Wind speed forecasting for wind farms: A method based on support vector regression. Renew. Energy 2016, 85, 790–809. [Google Scholar] [CrossRef]
- Fernández, N.; Villate, C.; Terán, O.; Aguilar, J.; Gershenson, C. Complexity of Lakes in a Latitudinal Gradient. Ecol. Complex. 2016. submitted. [Google Scholar]
- Cover, T.; Thomas, J. Elements of Information Theory; John Wiley Sons: Hoboken, NJ, USA, 2005; pp. 1–748. [Google Scholar]
- Michalowicz, J.; Nichols, J.; Bucholtz, F. Handbook of Differential Entropy; CRC Press: Boca Raton, FL, USA, 2013; pp. 19–43. [Google Scholar]
- Haken, H.; Portugali, J. Information Adaptation: The Interplay Between Shannon Information and Semantic Information in Cognition; Springer: Berlin/Heideberg, Germany, 2015. [Google Scholar]
- Heylighen, F.; Joslyn, C. Cybernetics and Second-Order Cybernetics. In Encyclopedia of Physical Science & Technology, 3rd ed.; Meyers, R.A., Ed.; Academic Press: New York, NY, USA, 2003; Volume 4, pp. 155–169. [Google Scholar]
- Ashby, W.R. An Introduction to Cybernetics; Chapman & Hall: London, UK, 1956. [Google Scholar]
- Michalowicz, J.V.; Nichols, J.M.; Bucholtz, F. Calculation of differential entropy for a mixed Gaussian distribution. Entropy 2008, 10, 200–206. [Google Scholar] [CrossRef]
- Calmet, J.; Calmet, X. Differential Entropy on Statistical Spaces. 2005; arXiv:cond-mat/0505397. [Google Scholar]
- Yeung, R. Information Theory and Network Coding, 1st ed.; Springer: Berlin/Heideberg, Germany, 2008; pp. 229–256. [Google Scholar]
- Bedau, M.A.; Humphreys, P. (Eds.) Emergence: Contemporary Readings in Philosophy and Science; MIT Press: Cambridge, MA, USA, 2008.
- Anderson, P.W. More is Different. Science 1972, 177, 393–396. [Google Scholar] [CrossRef] [PubMed]
- Shalizi, C.R. Causal Architecture, Complexity and Self-Organization in Time Series and Cellular Automata. Ph.D. thesis, University of Wisconsin, Madison, WI, USA, 2001. [Google Scholar]
- Singh, V. Entropy Theory and its Application in Environmental and Water Engineering; John Wiley Sons: Chichester, UK, 2013; pp. 1–136. [Google Scholar]
- Gershenson, C. The Implications of Interactions for Science and Philosophy. Found. Sci. 2012, 18, 781–790. [Google Scholar] [CrossRef]
- Sharma, K.; Sharma, S. Power Law and Tsallis Entropy: Network Traffic and Applications. In Chaos, Nonlinearity, Complexity; Springer: Berlin/Heidelberg, Germany, 2006; Volume 178, pp. 162–178. [Google Scholar]
- Dover, Y. A short account of a connection of Power-Laws to the information entropy. Physica A 2004, 334, 591–599. [Google Scholar] [CrossRef]
- Bashkirov, A.; Vityazev, A. Information entropy and Power-Law distributions for chaotic systems. Physica A 2000, 277, 136–145. [Google Scholar] [CrossRef]
- Ahsanullah, M.; Kibria, B.; Shakil, M. Normal and Student’s t-Distributions and Their Applications. In Atlantis Studies in Probability and Statistics; Atlantis Press: Paris, France, 2014. [Google Scholar]
- Box, G.; Jenkins, G.; Reinsel, G. Time Series Analysis: Forecasting and Control, 4th ed.; John Wiley Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Mitzenmacher, M. A Brief History of Generative Models for Power Law and Lognormal Distributions. 2009; arXiv:arXiv:cond-mat/0402594v3. [Google Scholar]
- Mitzenmacher, M. A brief history of generative models for Power-Law and lognormal distributions. Internet Math. 2001, 1, 226–251. [Google Scholar] [CrossRef]
- Clauset, A.; Shalizi, C.R.; Newman, M.E.J. Power-Law Distributions in Empirical Data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Frigg, R.; Werndl, C. Entropy: A Guide for the Perplexed. In Probabilities in Physics; Beisbart, C., Hartmann, S., Eds.; Oxford University Press: Oxford, UK, 2011; pp. 115–142. [Google Scholar]
- Virkar, Y.; Clauset, A. Power-law distributions in binned empirical data. Ann. Appl. Stat. 2014, 8, 89–119. [Google Scholar] [CrossRef]
- Yapage, N. Some Information measures of Power-law Distributions Some Information measures of Power-law Distributions. In Proccedings of the 1st Ruhuna International Science and Technology Conference, Matara, Sri Lanka, 22–23 January 2014.
- Newman, M. Power laws, Pareto distributions and Zipf’s law. Contemp. Phys. 2005, 46, 323–351. [Google Scholar] [CrossRef]
- Landsberg, P. Self-Organization, Entropy and Order. In On Self-Organization; Mishra, R.K., Maaß, D., Zwierlein, E., Eds.; Springer: Berlin/Heidelberg, Germany, 1994; Volume 61, pp. 157–184. [Google Scholar]
- Gershenson, C.; Lenaerts, T. Evolution of Complexity. Artif. Life 2008, 14, 241–243. [Google Scholar] [CrossRef] [PubMed]
- Cocho, G.; Flores, J.; Gershenson, C.; Pineda, C.; Sánchez, S. Rank Diversity of Languages: Generic Behavior in Computational Linguistics. PLoS ONE 2015, 10. [Google Scholar] [CrossRef]
- Gershenson, C. Requisite Variety, Autopoiesis, and Self-organization. Kybernetes 2015, 44, 866–873. [Google Scholar]
- Newman, M.E.J. The structure and function of complex networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef]
- Newman, M.; Barabási, A.L.; Watts, D.J. (Eds.) The Structure and Dynamics of Networks; Princeton University Press: Princeton, NJ, USA, 2006.
- Boccaletti, S.; Latora, V.; Moreno, Y.; Chavez, M.; Hwang, D.U. Complex networks: Structure and dynamics. Phys. Rep. 2006, 424, 175–308. [Google Scholar] [CrossRef]
- Gershenson, C.; Prokopenko, M. Complex Networks. Artif. Life 2011, 17, 259–261. [Google Scholar] [CrossRef] [PubMed]
- Motter, A.E. Networkcontrology. Chaos 2015, 25, 097621. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distribution | Differential Entropy | |
|---|---|---|
| Uniform | ||
| Normal | ||
| Power-law |
| σ | |||
|---|---|---|---|
| 78 | 6.28 | 0.16 | |
| 154 | 7.26 | 0.14 | |
| 308 | 8.27 | 0.12 | |
| 616 | 9.27 | 0.11 | |
| 1232 | 10.27 | 0.10 | |
| 2464 | 11.27 | 0.09 | |
| 4924 | 12.27 | 0.08 | |
| 9844 | 13.27 | 0.075 | |
| 19,680 | 14.26 | 0.0701 | |
| 39,340 | 15.26 | 0.0655 | |
| 78,644 | 16.26 | 0.0615 | |
| 157,212 | 17.26 | 0.058 | |
| 314,278 | 18.26 | 0.055 | |
| 628,258 | 19.26 | 0.0520 | |
| 1,000,000 | 19.93 | 0.050 |
| Phenomenon | α (Scale Exponent) | ||||||
|---|---|---|---|---|---|---|---|
| 1 | Frequency of use of words | 1 | 2.2 | 1.57 | 0.078 | 0.92 | 0.29 |
| 2 | Number of citations to papers | 100 | 3.04 | 7.1 | 0.36 | 0.64 | 0.91 |
| 3 | Number of hits on web sites | 1 | 2.4 | 1.23 | 0.06 | 0.94 | 0.23 |
| 4 | Telephone calls received | 10 | 2.22 | 4.85 | 0.24 | 0.76 | 0.74 |
| 5 | Magnitude of earthquakes | 3.8 | 3.04 | 2.38 | 0.12 | 0.88 | 0.42 |
| 6 | Diameter of moon craters | 0.01 | 3.14 | 0 | 1 | 0 | |
| 7 | Intensity of solar flares | 200 | 1.83 | 10.11 | 0.51 | 0.49 | 0.99 |
| 8 | Intensity of wars | 3 | 1.80 | 4.15 | 0.21 | 0.79 | 0.66 |
| 9 | Frequency of family names | 10000 | 1.94 | 15.44 | 0.78 | 0.22 | 0.7 |
| 10 | Population of U.S. cities | 40000 | 2.30 | 16.67 | 0.83 | 0.17 | 0.55 |
| Category | Very High | High | Fair | Low | Very Low |
|---|---|---|---|---|---|
| Range | |||||
| Color | Blue | Green | Yellow | Orange | Red |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santamaría-Bonfil, G.; Fernández, N.; Gershenson, C. Measuring the Complexity of Continuous Distributions. Entropy 2016, 18, 72. https://doi.org/10.3390/e18030072
Santamaría-Bonfil G, Fernández N, Gershenson C. Measuring the Complexity of Continuous Distributions. Entropy. 2016; 18(3):72. https://doi.org/10.3390/e18030072
Chicago/Turabian StyleSantamaría-Bonfil, Guillermo, Nelson Fernández, and Carlos Gershenson. 2016. "Measuring the Complexity of Continuous Distributions" Entropy 18, no. 3: 72. https://doi.org/10.3390/e18030072
APA StyleSantamaría-Bonfil, G., Fernández, N., & Gershenson, C. (2016). Measuring the Complexity of Continuous Distributions. Entropy, 18(3), 72. https://doi.org/10.3390/e18030072