1. Introduction
We shall begin with the definitions and fix some notations. Several results in the literature that we will use later are also gathered in this section. Probability measures on in this paper are always assumed to be absolutely continuous with respect to the Lebesgue measure. Thus, we say that a probability measure μ has the continuous density f, which means , and the measure μ is sometimes identified with its density f. Throughout this paper, if we simply write an integral symbol without specifying any domain, which means is the integral over the whole space on .
Definition 1. For a probability measure μ on with the density f, the entropy of μ (or f) is defined byand, if the density f is smooth, then we define the Fisher information of μ (or f) asFor an -valued random variable X, if X is distributed according to the probability measure μ, then we define the entropy and the Fisher information of X by and , respectively. In a one-dimensional case, the gradient
in (
2) is usually called
the score function of
X (or
μ) and denoted by
(or
). For a differentiable function
ξ with bounded derivative, the score function behaves that
which is known as
Stein’s identity.
Let X be an -valued random variable distributed according to the probability measure μ, and Z be an n-dimensional standard (with mean vector and identity covariance matrix ) Gaussian random variable independent of X. Then, for , the independent sum is called the Gaussian perturbation of X.
We denote by
the probability measure corresponding to the Gaussian perturbation
, and
stands for the density of
. It is fundamental that the density function
satisfies
the heat equation:
where
is the Laplacian operator.
The remarkable relationship between the entropy and the Fisher information can be established by the Gaussian perturbation as follows (see, for instance, [
1] or [
2]), which is known as
the de Bruijn identity.
Lemma 1. Let X be an -valued random variable distributed according to the probability measure μ. Then, for the Gaussian perturbation, it holds thatNamely, using the density of the Gaussian perturbed measure , we can write Definition 2. Let μ and ν be probability measures on with (μ is absolutely continuous with respect to ν). We denote the probability density functions of μ and ν by f and g, respectively. Then, as the ways of indicating the difference between two measures, we shall introduce the following quantities: the relative entropy of μ with respect to ν, of f with respect to g, is defined by Although it does not appear to have received widespread attention, it is natural to define the relative Fisher information of μ with respect to ν, of f with respect to g as (see, for instance, [3])where the relative density is assumed to be sufficiently smooth such that the above expressions make sense. The relative entropy and the relative Fisher information take non-negative values and 0 if and only if for almost all . Similar to Definition 1, for random variables X and Y with the distributions μ and ν, the relative entropy and the relative Fisher information of X with respect to Y are defined as and , respectively.
In view of the de Bruijn identity, one might expect that there is a similar connection between the relative entropy and the relative Fisher information. Indeed, Vérdu in [
4] investigated the derivative in
τ of
for two Gaussian perturbations, and derived the following identity of the de Bruijn type via minimum mean-square error (MMSE) in estimation theory.
Lemma 2. Let X and Y be -valued random variables distributed according to the probability measure μ and ν, respectively. Then, for the Gaussian perturbations, it holds thatthat is,where and are the corresponding measures of the Gaussian perturbations. An alternative proof of this identity by direct calculation with integrations by part has been given in [
5]. It should be noted here that the reference measure does move by the same heat equation in the formula of Lemma 1.
Other derivative formulas of the relative entropy have been investigated in [
6,
7,
8], which are closely related to the theory of optimal transport and functional inequalities of informations. It is common in these fields that the reference measure is unchanged with the equilibrium measure. Here, we shall recall such a derivative formula and will list some useful related results.
Let
V be a
map on
and consider the probability measure
κ by
where
, the normalization constant. Such a probability measure
κ is called
the equilibrium (or
Gibbs)
measure for the potential function V.
Given a probability measure
, we consider the diffusion flow of probability measures
associated with the gradient
, that is, the density
of the measure
(
) is defined as the solution to the partial differential equation:
which is called
the Fokker–Planck equation. It is easily found that the long-time asymptotically stationary measure for Fokker–Planck Equation (
12) is given by the above equilibrium (Gibbs) measure.
Setting the equilibrium measure as the reference, we can understand the relationship between the relative entropy and the relative Fisher information via the Fokker–Planck equation as follows (see, for instance, [
8]):
Proposition 1. Let be a diffusion flow of the probability measure associated with the gradient , and let κ be the equilibrium measure for the potential function V. Then, it holds the differential formula: Definition 3. A function V on is called strictly K-convex if there exists a positive constant such that .
In the case where the potential function
V has the above convexity, we can obtain the inequality between the relative entropy and the relative Fisher information with respect to the equilibrium measure for the potential
V, which is known as
the logarithmic Sobolev inequality (see, for instance, [
7,
9,
10]).
Theorem 1. Let κ be the equilibrium measure for the potential function V. If the potential function V is strictly K-convex, then it follows that, for any probability measure , Combining Proposition 1 and Theorem 1, we can obtain the following convergence of the diffusion flow to the equilibrium:
Proposition 2. Let be the diffusion flow of probability measures by the Fokker–Planck equation associated with the strictly K-convex potential V, and κ be the equilibrium for the potential V. Then, it follows thatwhich implies that converges exponentially fast, as , to the equilibrium κ in the relative entropy. Namely, The diffusion flow by the quadratic potential
is called
the Ornstein–Uhlenbeck flow, and the corresponding Fockker–Planck equation is reduced to
In this case, we can obtain the explicit solution
, and it follows that the equilibrium measure becomes the standard Gaussian.
Furthermore, it is known that the solution to Equation (
17) can be represented in terms of random variables as follows: let
X be a random variable on
having the initial density
, and
Z be an
n-dimensional standard Gaussian random variable independent of
X. Then, the density function of the independent sum
gives the solution
to partial differential Equation (
17). Since the Ornstein–Uhlenbeck flow has Gaussian equilibrium, it has been widely used as the technical tool for the proof of Gross’s logarithmic Sobolev inequality [
9] and Talagrand inequality [
11].
Here, we shall mention one more useful result concerned with the convergence of the relative entropy, which is called
the Csiszár–Kullback–Pinsker inequality (see, for instance, [
12] or [
13]).
Lemma 3. The convergence in the relative entropy is stronger than in -norm, that is, it holds for probability densities that The problem of finding the time derivative of the relative entropy between two densities under the same continuity equation has been investigated in [
14,
15]. In this paper, we will treat the Focker–Planck equation with strictly convex potential as our continuity equation, which is because the first natural extension of the heat equation and the similar dissipation formula in Lemma 2 of Vérdu can be derived by the fundamental method, the integration by parts like in [
5].
The time integration of our formula will give an integral representation of the relative entropy. Applying this representation to the Ornstein–Uhlenbeck flows, we can give an extension of the formula for entropy gap.
2. Dissipation of the Relative Entropy
We will calculate the time derivative of the relative entropy for the case where the objective and the reference measures are evolved by the Fokker–Planck equation with the same strictly convex potential. We shall begin with describing our situation of calculation precisely.
• Situation A:
Let and be Lebesgue absolutely continuous probability measures on with , and let and () be the diffusion flows by the Fokker–Planck equation with the strictly K-convex potential function V starting from and , respectively. Here, the growth rate of the potential function V is assumed to be at most polynomial.
We assume that, for , the measures and have finite Fisher information and , and are absolutely continuous with respect to the Lebesgue measure, the densities and of which are sufficiently smooth and rapidly decreasing at infinity. Furthermore, it is naturally required that .
Here, we shall impose the following assumption on the relative densities, which does not cause any loss of generality but for simplicity of the proof.
• Assumption on the relative densities D:
Let be the equilibrium measure of the potential function V, where the potential function V is normalized (shifted) so that . The Fokker–Planck equation will not be made of any effect by this normalization (shift) because it depends only on the gradient .
We may assume that the relative densities
and
are bounded away from zero and infinity for sufficiently large
t. Namely, there exist uniform constants
and
for sufficiently large
t such that
and
Hence, the relative density
is also bounded away from zero and infinity for sufficiently large
t, that is, there exist uniform constants
such that
for sufficiently large
t.
Remark 1. The above technical assumptions on the relative densities are due to the non-linear approximation argument given by Otto and Villani in [8] and the following fact: in our situation, it follows that the density of the diffusion flow of probability measure by the Fokker–Planck equation converges to the equilibrium in -norm as by combining Proposition 2 with Lemma 3—so does . Proposition 3. Let and be the flows of the probability measures on by the Fokker–Planck equation as in Situation A with the assumptions on the relative densities D. Then, it holds that, for , Proof. We expand the derivative of the relative entropy as
Since we know that
and
converge to the equilibrium
in
, and that the time derivatives
and
are converging to 0 as
, and the densities
,
and
,
are uniformly bounded for
t. Furthermore, by our assumptions on the relative density,
is bounded away from zero and infinity. Hence, we are allowed to exchange integration and
t-differentiation, which is justified by a routine argument with the bounded convergence theorem (see, for instance, [
2] and also [
8]).
Then, the first term on the right-hand side of (
24) is calculated with the Fokker–Planck equation as follows:
The integral (I) in (
25) is clearly 0. By applying integration by parts, the integral (II) can be written by
Here, it should be noted that
will vanish at infinity by the following observation: if we factorize it as
then, as
has finite Fisher information
,
has finite
-norm in
and must be bounded at infinity. Furthermore,
will vanish at infinity by the limit formula,
.
The integral (III) in (
25) becomes
by the following observations: since
is rapidly decreasing at infinity and the growth rate of the potential function
V is at most polynomial by our assumption, we have
The limit
is the same as above. Thus,
will vanish at infinity.
Substituting (
26) and (
28) into (
25), we can obtain
Next, we shall see the second term on the right-hand side of (
24), which can be reformulated by the Fokker–Planck equation as follows:
The integral (IV) in (
31) can be reformulated by applying integration by parts as follows:
where we can see that
vanishes at infinity by the following observation: factorize it as
and then the boundedness of
is by our assumptions on the relative density and that of
comes from the finiteness of Fisher information
.
Applying integration by parts again, the integral (V) in (
31) becomes
Because the growth rate of the function
V is at most polynomial and
is rapidly decreasing at infinity, thus
will vanish at infinity.
The integral (VI) in (
31) can be reformulated as
where we can find that
vanishes at infinity by factorizing
with the assumption of
and the boundedness of
.
The last integral (VII) in (
31) becomes
where
will vanish with the following factorization by the same reasons as above:
In reformulation of the integrals (VI) and (VII), we have, of course, used integration by parts.
Substituting the equations from (
32) to (
37) into (
31), we can have
Finally, combining (
30) and (
39), we obtain that
☐
Remark 2. The assumption of dropping surface terms on integrations by parts, that is, vanishing at infinity in the proof of Proposition 3, is rather common in various physics, which has been also repeatedly employed in a series of works by Plastino et al., for instance, in [16,17]. Next, we will see the convergence of the relative entropy for the pair of time evolutes by the same Fokker–Planck equations.
Proposition 4. Under Situation A with Assumption D, the relative entropy converges exponentially fast to 0 as .
Proof. We first expand the relative entropy
as
where
is the potential function of the Fokker–Planck equation. Then, we obtain
Since the first term on the right-hand side of (
42) is the relative entropy
, we concentrate our attention on the second term.
We put the set
as
, and then we have
Thus, for sufficiently large
t, it can be evaluated as follows:
where in the last inequality is by virtue of the assumption on the relative densities. Consequently, we can have the estimation that
with the positive constant
.
As we have mentioned in Lemma 3 that the relative entropy controls the
-norm, we have
Thus, we obtain that, for sufficiently large
t,
Taking the limit
, it follows that
exponentially fast because
and
converge to 0 in exponentially fast with rate
. ☐
By the dissipation formula in Proposition 3, together with the above convergence, we can obtain the following integral representation of relative entropy.
Theorem 2. Let and be the flows of probability densities on by the Fokker–Planck equation under situation A with the assumptions on relative densities D. Then, we have the integral representation of the relative entropy If we choose particularly the equilibrium as the initial measure of the reference , then it is stationary such that . Hence, as the direct consequence of the above theorem, we have the following integral formula:
3. An Application to the Entropy Gap
In this section, we shall apply the formula of the time integration in Theorem 2 to the Ornstein–Uhlenbeck flows, which gives an extension of the formula of the entropy gap. For simplicity, we will consider the one-dimensional case in this section.
Among random variables with unit variance, the Gaussian has the largest entropy. Let
X be a standardized (mean 0 and variance 1) random variable, and let
Z be a standard Gaussian random variable. Then, the quantity
is called
the entropy gap or
the non-Gaussianity, which coincides, of course, with the relative entropy
. It is known (see, for instance, [
18]) that this entropy gap can be written as the integration of the Fisher information. Namely,
where
is the time evolute at
t of the random variable
X by the Ornstein–Uhlenbeck semigroup in (
17). It is easy to find that our formula (
48) of Theorem 2 covers (
50) as one of the special cases.
In the formula (
48) of Theorem 2, even for the case of the quadratic potential
, we can choose the initial reference measure
more freely other than the standard Gaussian as we will illustrate below. Let
X be a centered random variable of variance
(not a unit in general) and
G be a centered Gaussian of the same variance
. Then, applying the integral formula with the potential function
, the relative entropy
, which is equal to the entropy gap
, can be written by the integration
where
and
are the time evolutes by the Ornstein–Uhlenbeck semigroup of
X and
G, respectively.
By formula (
18),
and
can be given as
where
Z is a standard Gaussian random variable independent of
X and
G.
Since the time evolute
becomes a Gaussian random variable of variance
, the score function of which is given by
and it is easy to find that the time evolute
has the same variance as of
,
.
We denote by
the probability distribution of
, and let
and
be the score functions of the random variables
and
, respectively. Then, by direct calculation, we obtain that
which corresponds to the special case of the Stein’s identity in (
3).
With the above observations, we can reformulate the relative Fisher information
as follows:
where we have used formula (
54) and the fact that
in the last equality. Now, the following formula can be obtained as a direct consequence of Theorem 2.
Proposition 5. Let X be a centered random variable of finite variance , and let G be a centered Gaussian variable of the same variance . For , we denote by the evolute of by the Ornstein–Uhlenbeck semigroup, that is,where Z stands for the standard Gaussian random variable independent of X. Then, it follows that Remark 3. The Ornstein–Uhlenbeck model can be regarded as the time-dependent dilation of Gaussian perturbation. Thus, we can rewrite formula (57) in terms of Gaussian pertabation. Since the Fisher information behaves for dilation of a random variable as , we obtainChanging the variables by , the integral on the right-hand side of (56) becomesHence, we obtainthat is,which is the known integral representation for the entropy of a random variable X by the Fisher information of Gaussian perturbation derived by Barron in Section 2 in [2]. 4. Some Numerical Examples
In this section, we will give numerical examples for the case of the Ornstein–Uhlenbeck flows, which are given by the potential
, and, hence, have the standard Gaussian equilibrium. As we mentioned in (
18), the densities of the flows at time
t can be calculated analytically by convolution of the scaled initial measures.
Example 1.
In the first numerical example, we take the uniform distribution on the interval
as the initial objective measure. Namely, the density
is given by
which has the mean 0 and the variance
. We set the centered Gaussian of variance
as the initial reference measure. Namely,
, where the function
φ is defined by
Here, we can calculate the densities
and
of the Ornstein–Uhlenbeck flows at time
t analytically as follows: we rescale the time parameter
t as
and put
Then,
and
are given by
and
respectively. Now, we shall illustrate the convergence of
and the upper bound of the right-hand side in (
47) numerically by graphs. We claim that the constant
can be assumed to be 1 because, in our assumptions (
20), (
21), and (
22), the relative densities converge uniformly to 1. The convergence of
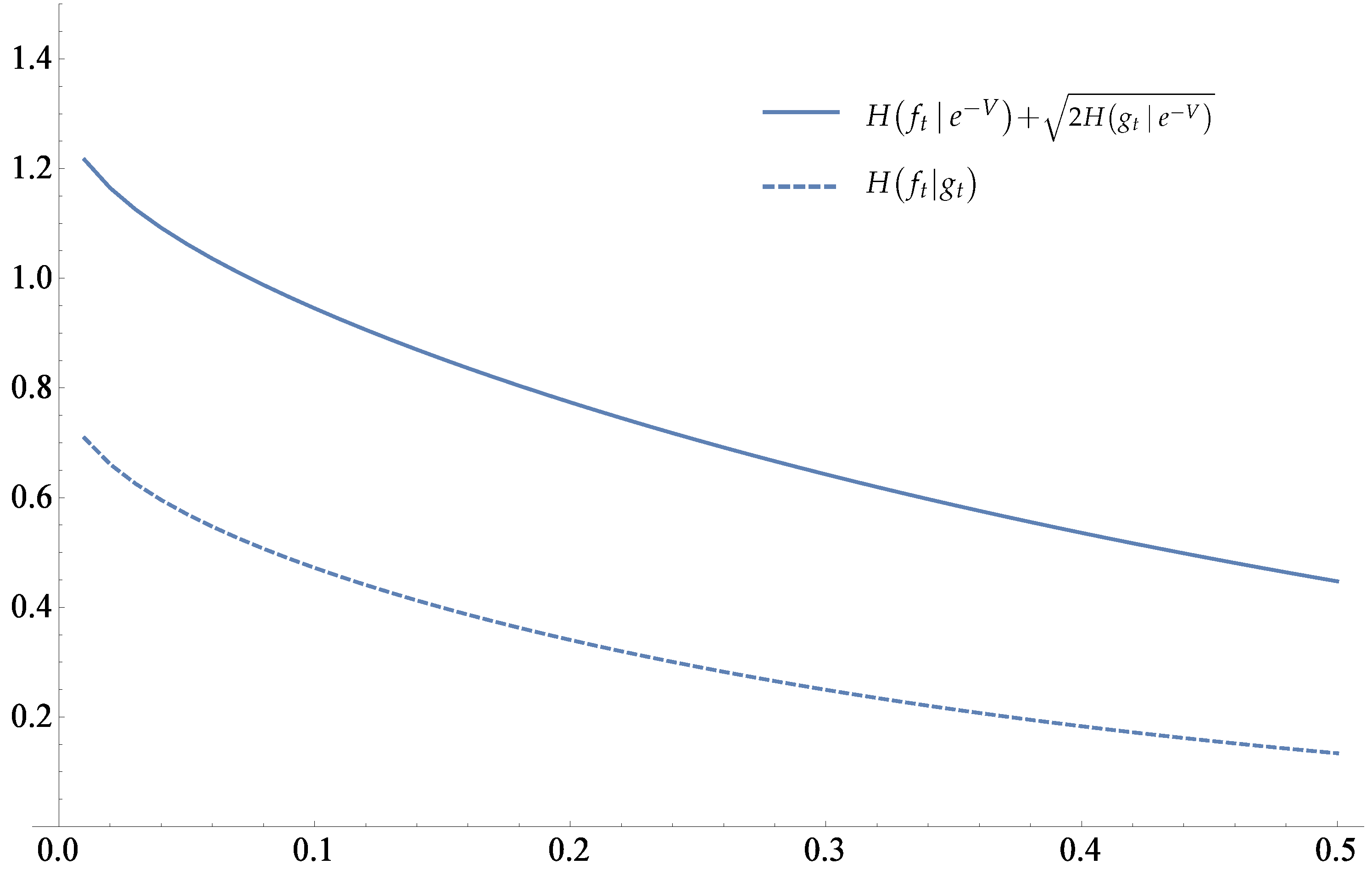
is illustrated in
Figure 1.
In
Figure 2, the dashed curve indicates the convergence of
in
Figure 1.
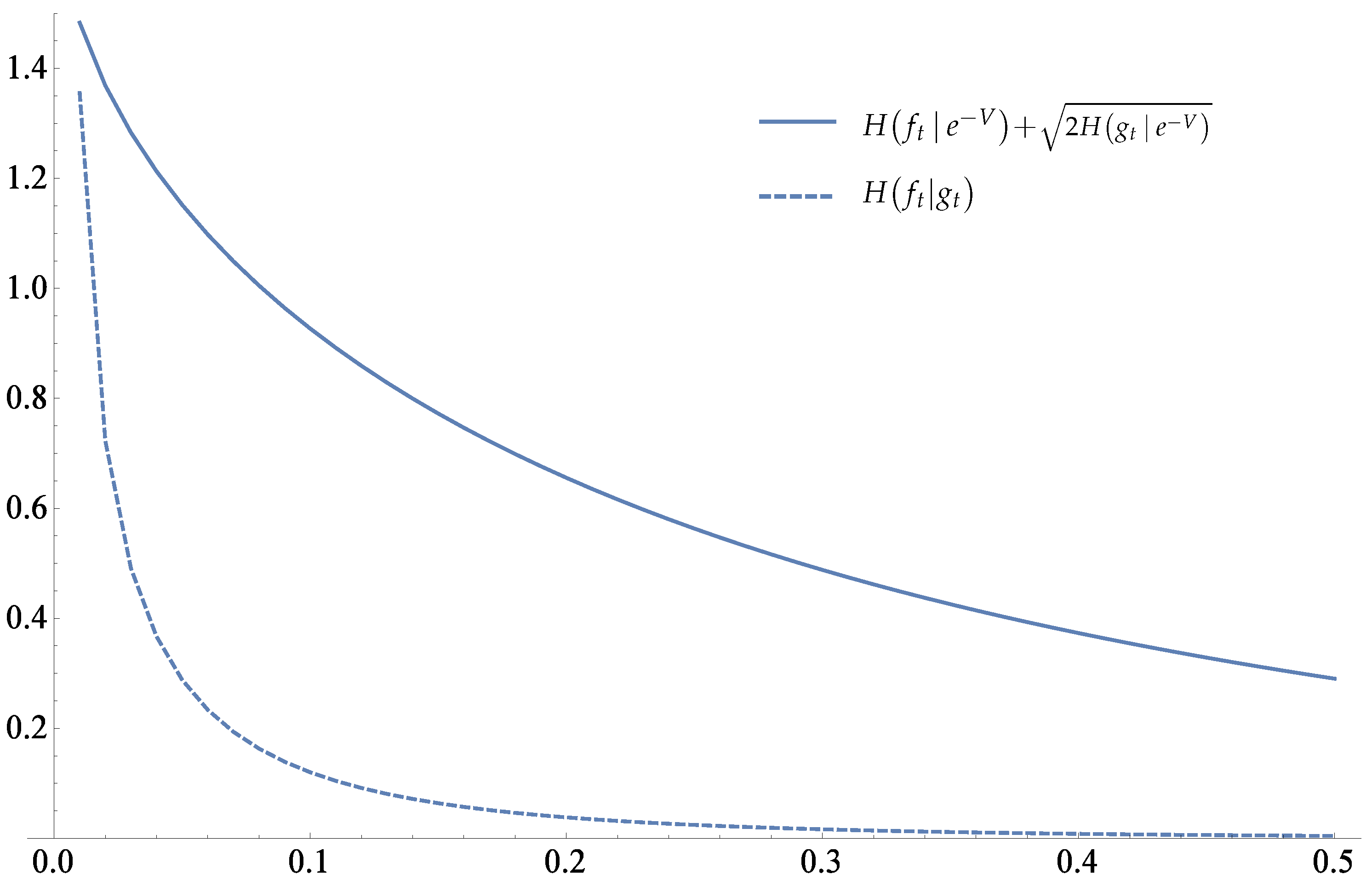
Example 2.
In the second example, we put the initial reference measure as
, that is, we take the centered Gaussian of variance 3 as the initial reference measure, but
is unchanged. In
Figure 3, the convergence of
is illustrated.
In
Figure 4, the dashed curve indicates the convergence of
in
Figure 3.
Example 3.
In the third numerical example, the initial objective and the initial reference measures are given as the uniform distributions on the intervals
and
, respectively. Namely, we set the densities as
and
. We illustrate the convergence of
in
Figure 5.
In
Figure 6, the dashed curve indicates the convergence of
in
Figure 5.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





