1. Introduction
Ordering plays a fundamental role in mathematics, science, engineering, finance, etc. The most well known and commonly used one is the trichotomy order, in which we compare real values. In the applications of wireless communications, when there is perfect channel state information at the transmitter (CSIT), it is known that for some Gaussian multiuser (MU) channels the capacity results can be attained due to the capability of ordering the quality of channels among different users. For example, capacity regions/secrecy capacity of degraded broadcast channels (BC) and wiretap channels (WTC) (even for multiple-antenna cases) [
1], and also the sum capacity of low-interference regime [
2] and capacity regions for some cases of IC such as strong IC [
3,
4,
5] and very strong IC [
4] are derived. When fading effects of wireless channels are taken into account, if there is perfect CSIT, some of the above capacity results still hold with an additional operation of taking an average over the capacity (region) with respect to fading channels. For example, in [
6], the ergodic secrecy capacity of Gaussian WTC is derived; in [
7], the ergodic capacity regions are derived for ergodic very strong and uniformly strong (each realization of the fading process is a strong interference channel) of the Gaussian IC. Notably, the orders in the above scenarios are all trichotomy orders.
Due to several practical limitations, for example, the finite bandwidth of feedback channels, a delay caused by channel estimation, etc., the transmitter may not be able to track channel realizations precisely instantaneously if they vary rapidly. Thus, for fast fading channels, it is more practical to consider the case with only partial CSIT of the legitimate channel, where statistical CSIT is one of the most commonly considered one [
8,
9]. However, when there is only statistical CSIT (In this paper, statistical CSIT and no CSIT will be used interchangeably.), there are only few known capacity results, such as the layered BC [
10], the binary fading interference channel [
11], the one-sided layered IC [
12], Gaussian WTC [
13,
14], and layered WTC [
14], etc. This is because, when the transmitter has imperfect CSIT, e.g., only the statistics of the channels, the comparison of channels cannot be attained directly by trichotomy law due to the random characteristic of the fading channels. Then the optimal strategy for the transmission, including the design of the codebook, channel input distribution, resource allocation, etc., can not be easily done. In particular, those channel orders commonly used in information theory include degraded, less noisy, and more capable [
9] in BC and WTC or the strong and very strong in IC [
9] depends on the knowledge of CSIT. Note that by these information theoretic orders, we can highly simplify the functional optimization with respect to the channel input distribution and/or channel prefixing.
To consider an MU-channel in which the transmitters only know the distributions of the channels but not the realizations, we may ask the following questions: is it possible to compare the channel qualities just according to their distributions? If yes, how to do it? How to derive the capacity region under such comparison of channel qualities? In this work we resort to partly solve these problems by classifying the random channels into stochastically orderable and its complement. In particular, an MU channel with orderable random channels means that there exists an equivalent channel in which we can reorder the channel realizations among different transmitter-receiver pairs in the desired manner. More specifically, we resort to finding a subset of all fading channel tuples, namely, , which should possess the following properties:
It allows the existence of a corresponding set in which the channels follow a certain order, e.g., trichotomy order.
It encompasses a constructive way (or easy) to find a transformation .
Capacity results are attainable.
Taking the BC as an example, an orderable two-user BC means that under the same noise distributions at the two receivers, in the equivalent BC, one channel strength is always stronger or weaker than the other for all fading states. The main tool we use for this channel classification and ordering is stochastic orders [
15] from probability theory, combined with the same marginal property [
16] from information theory. The stochastic orders have been widely used in the last several decades in diverse areas of probability and statistics such as reliability theory, queueing theory, and operations research, etc., see [
15] and references therein. Different stochastic orders such as the usual stochastic order, the convex order, and the increasing convex order can help us to identify the location, dispersion, or both location and dispersion of random variables, respectively. Smartly choosing a proper stochastic order to compare the channels with statistical CSIT allows us to form an equivalent channel in which realizations of channel gains are ordered in a desired manner. Then we are able to derive the capacity regions of the equivalent MU channel, which is simpler than directly considering the original channel. Note that in [
17] the authors also consider stochastic orders for fading channels. However, there is no such alignment concept by constructing an equivalent channel in [
17] and hence the relation between the same marginal property and stochastic orders is completely not investigated there. In contrast, they discuss the stochastic dominance between fading channels by Shannon transform order. Stochastic orders are also used in stochastic geometry to analyze the performance of a random network [
18]. Similarly, the inter-relation between the information theoretic channel orders and probabilistic orders are not addressed in [
18].
The main issues discussed by this overview paper are summarized as follows.
We classify fading MU channels such that we can characterize the capacity results of some memoryless Gaussian MU channels under statistical CSIT. To achieve it, we combine the concept of usual stochastic order and also the same marginal property, i.e., an intrinsic property of some MU channels. Intuitively, by doing so we can align the realizations of the fading channel gains between different users in an identical trichotomy order over time in an equivalent channel.
We then apply the proposed scheme to characterize the capacity regions of Gaussian IC and BC, which is novel in the literature.
We further extend the framework to channels with multiple antennas. Applicable scenarios for channel enhancement scheme under statistical CSIT, which is originally for channels with perfect CSIT, are also discussed.
Several examples with practical channel distributions are illustrated to show the usage scenarios of the developed framework.
Notation: Upper case normal/bold letters denote random variables/random vectors (or matrices), which will be defined when they are first mentioned; lower case bold letters denote vectors. The statistical expectation is denoted by . The mutual information between two random variables X and Y is denoted by . The complementary cumulative density function (CCDF) is denoted by , where is the CDF of X. In addition, we denote the probability mass function (PMF) by p and the probability density function (PDF) by f. denotes that the random variable X follows the distribution F. Markov chain relation between X, Y, and Z is described by . denotes the uniform distribution between a and b. The indicator function is denoted by . The supports of a function f and a random variable X are respectively denoted by supp and supp. The logarithms used in the paper are all of base 2. We denote . We denote the equality in distribution by .
The remainder of the paper is organized as follows. In
Section 2, we introduce the background knowledge and preliminaries. In
Section 3, we formulate a problem and propose a framework to solve it. In
Section 4 we apply the tools developed in
Section 3 to fast fading Gaussian interference channels and broadcast channels with statistical CSIT. In
Section 5 we consider channels with multiple antennas. In
Section 6, an application of Laplace transform order on solving a power allocation problem is reviewed. Finally,
Section 7 concludes the paper.
2. Preliminaries
In this section, some important properties and definitions for deriving the main results of this work will be introduced, including the same marginal properties, degradedness, and the usual stochastic orders.
2.1. Same Marginal Property
The same marginal property plays a crucial role in the proposed channel classification to obtain the capacity results. This is because it provides us the degree of freedom to construct an equivalent channel in the sense that the marginal distributions are the same as the original one, but not the joint distribution. By such a relaxation of considering an equivalent channel, we are able to reorder all channel gains under some conditions.
Two versions of the same marginal property are introduced as follows:
Theorem 1 (Same Marginal Property for One-Transmitter (Theorem 13.9 in [19])). The capacity region of a multiuser channel with one transmitter and two non-cooperative receivers depends only on the conditional marginal distributions and and not on the jointly conditional distribution .
Theorem 2 (Same Marginal Property for Two-Transmitter (Theorem 16.6 in [19])). The capacity region of a multiuser channel with two-transmitter and two non-cooperative receivers depends only on the conditional marginal distributions and and not on the jointly conditional distribution .
Remark 1. By the union bound, the error probability of a channel with multiple-receiver can be upper bounded by the sum of individual error probability. Therefore, the overall error probability approaches zero if the individual error probabilities approach zero, respectively. This fact results in the consequence that only the marginal transition probabilities affect the capacity result, but not the joint one.
Remark 2. Note that since the capacity region of a multiple access channel is determined by , the technique of reordering random fading channels developed in this paper can be useful to simplify the proof for the GMAC with statistical CSIT.
For channels with a single transmitter and multiple receivers, e.g., BC or WTC, we can get Theorem 1 from Theorem 2 by removing or .
2.2. Information Theoretical Orders for Memoryless Channels and Stochastic Orders
The main task in this paper is on ordering channels. Here we introduce several important definitions describing the relation of reception qualities among different receivers from an information theoretic to the probabilistic point of view.
Definition 1. A channel with two non-cooperative receivers and one transmitter is physically degraded if the transition distribution satisfies , i.e., X, , and form a Markov chain . The channel is stochastically degraded if its conditional marginal distribution is the same as that of a physically degraded channel, i.e.,Denote the fading channel gains in AWGN channels from the transmitter to the first and second receivers by and , respectively. Define a set of tuples of random channels and also a set . Recall that
means (
1) is true. In the following, we call a stochastically degraded channel simply a degraded channel due to the same marginal property. Note that discussions on the relation between degradedness and other information theoretic channel orders can be referred to [
19,
20,
21].
Definition 2. A discrete memoryless-IC is said to have very strong interference iffor all . Define the set . After information theoretic orders, we introduce some important definitions of stochastic orders, which are the underlying tools in this paper.
Definition 3 ([
15]).
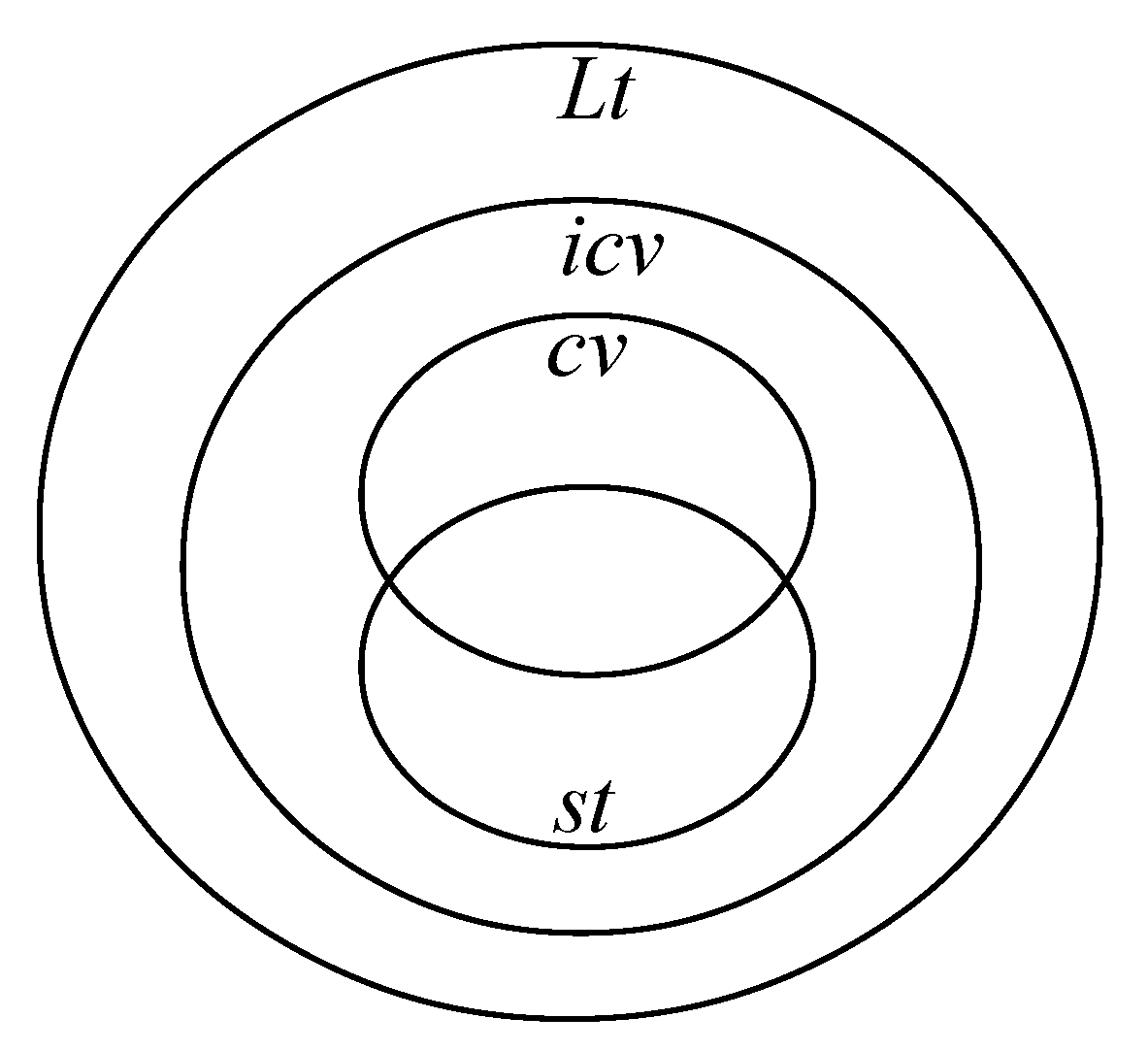
For given random variables X and Y, the usual stochastic order (st), the convex order (cx), the concave order (cv), the increasing convex order (icx), the increasing concave order (icv), and the Laplace transform order (Lt) are respectively defined as follows: Note that the stochastic orders in Definition 3 can be further represented by the following relations, which are more easily evaluated.
Theorem 3 ([
15]).
For random variables X and Y, if and only if for all x, and if and only iffor all t. Moreover, if and only if (
4)
is valid for all t and . Similarly, if and only iffor all t. Finally, if and only if (
5)
is valid for all t and . if an only if Note that when
X and
Y are nonnegative, the condition
can be further expressed as
[
22].
Compared with the original expectation, the integral form of the CCDFs, which unifies the expression of the considered stochastic orders as functions of the CCDFs only, highly simplifies the following derivations. The relation between the aforementioned stochastic orders can be seen from the Venn diagram in
Figure 1. By Definition 3, the constraint to be fulfilled by the Laplace transform order is the least restrict, so pairs of random variables belong to the concave order, increasing concave order, or the usual stochastic order, must also belong to the Laplace transform order. Note that the intersection between the concave order and the usual stochastic order happens only when the distributions of the two random variables are identical, which can be easily seen from the constraint
due to the concave order. In the following sections, we will develop our results mainly based on the usual stochastic order and also the Laplace transform order. Due to the indirect relation to wireless channels, we do not discuss stochastic orders such as convex/concave and increasing convex/concave orders here. Some few discussions can be referred to [
14].
5. Extension to Multiple Antenna Cases
In this section we consider multiple-antenna at both channel input and output. We assume all nodes are equipped with the same number of antennas
. In the following we discuss cases with only one transmitter, e.g., GBC, GWTC, etc. The results can be easily extended to cases with multiple transmitters. Again the signals at receivers 1 and 2 can be respectively expressed as
where
and
,
and
with entries varying over each code symbol. For the (fading) multiple-antenna cases, the description of the channels is by (random) matrices. How to order random matrices or which part of the matrices to be ordered is critical to be clarified. In the following we provide two methods to deal with this problem, including the aforementioned coupling scheme and the channel enhancement scheme.
5.1. Alignment by Usual Stochastic Order
From random matrix theory we know that the probability of a random matrix to be full rank approaches 1. In addition to the assumption of full channel state information at the receiver (CSIR), we can construct an alternative channel which is full rank and does not change the capacity [
1] by normalizing (22) and (23) equivalently as
where
and
,
,
. For full CSIT and full CSIR cases, to make the Markov chain
valid, i.e., to obtain a (stochastically) degraded wiretap channel, the constraint
is sufficient (The reason that it is not necessary is, we may be able to use the channel enhancement scheme to obtain a degraded channel with
). In the considered scenario we have full CSIR but only statistical CSIT. So we aim to construct an equivalent degraded channel by showing
according to the coupling. In the following we will find the relation of the degradedness and the stochastic order among the eigenvalues of
and
. Note that in [
15] the usual stochastic order in a vector (but not matrix) version is considered, where in the expression of
, the inequality is element-wise, i.e.,
, for
. However, we can not directly apply the multivariate usual stochastic order to our scenario. This is because that it will not guarantee the positive definiteness of
, which is required for the degradedness. Instead, it is sufficient to check the stochastic order of the eigenvalues of
, namely,
, to attain the existence of
and
in an equivalent channel, such that
after using coupling.
We first transform into a form that we can simply connect it to the eigenvalues with the aid of the following lemmas.
Lemma 1 ([
38]).
Let and Hermitian, and and Hermitian. if and only if the eigenvalues of all satisfy . We then use the following Lemma to connect the eigenvalues of to those of and .
Lemma 2 ([
39]).
If and are positive semidefinite Hermitian matrices, then Then from Lemmas 1 and 2 we can derive the following theorem.
Theorem 6. A sufficient condition to have a degraded multiple-antenna channel is Remark 9. To have a degraded channel, (
27)
is a strict condition to satisfy. The reasons are (1) the condition may not be necessary for the existence of a degraded channel. More specifically, for the full CSIT case, for arbitrary covariance matrices and , Ref. [1] proves that such channel can be transformed into a degraded one by the channel enhancement technique; (2) the usual stochastic ordering is sufficient but may not necessary, which can be seen from the SISOSE case [14]. Remark 10. Note that the fast fading channel with only statistical CSIT can be verified as a degraded one, if, there exists and such that for each channel realization, where and are the covariance matrices of the equivalent noises at receivers 1 and 2. Then by Proposition 1 in [40] we know that solving the optimal input covariance matrix for a GWTC is a convex problem. For full CSIT cases we can use convex optimization tools to solve it numerically or some partial analytical results can be seen in [40,41], etc. In the following, we show a sufficient condition for channels with additional assumptions to have a degraded channel. Note that due to the additional assumptions, we can derive a less stringent sufficient condition than that in Theorem 6.
Theorem 7. Let and be the singular value decompositions of and , respectively. Assume that is independent to and , and is independent to and . Also assume that and have the same distribution. If , then there exists an equivalently degraded channel.
Proof. To proceed, we form a new 1st user’s channel as
. We can check that the PDF of
is the same as that of
by the following
where (a) is due to the following. To calculate the distributions of
and
, only the joint distributions
and
are needed. With the assumptions that
and
are independent to
and
, we can further have
and
. Since
and
have the same PDF, i.e.,
, we know that
. (b) is by Definition of
. By (
28) and the same marginal property, we know that this new channel with
being the new 1st user’s channel has the same ergodic secrecy capacity as that with
. Then following the same steps in Theorem 6, we can complete the proof. ☐
Remark 11. Channel matrices with i.i.d. Gaussian entries are valid for the requirement in Theorem 7, i.e., is independent to and . In particular, we can apply the LQ decomposition (LQD) on those channel matrices to get the right singular vector and which are the matrices of the LQD and are independent of the matrix [42]. In addition, the random matrix follows the isotropic distribution (i.d.) with PDF [43]where Γ
is the gamma function and δ is the delta function. In the following, we consider another condition on channel matrices with a special structure. We can prove that if the channels can be decomposed into i.d. unitary matrices, the channel is equivalent to a degraded one.
Theorem 8. Let , . If and are i.d. and , then is equivalent to a degraded channel.
Proof. We can form an equivalent channel as
where
and
. After applying the eigenvalue decomposition, the covariance matrices of
and
can be expressed as
and
, respectively, with
, by the monotonicity theorem (Theorem 8.4.9 in [
44]). Now let
which is independent of
and
. We can form another equivalent channel at Eve as
where in (a)
and in (b)
, which has the same distribution as that of
. From the above it is clear that
is stochastically degraded of
. Since
is i.d., we know
and
have the same distribution. In addition, since
and
are i.d., we have
. By same marginal property, we know that the equivalent channel
has the same capacity as the original one. Thus, we conclude that the original channel is equivalent to a degraded one with the same secrecy capacity. ☐
Remark 12. The constraint in Theorem 8 may be relaxed to by the deterministic channel enhancement, which will be shown in the next sub-section.
5.2. Alignment by Channel Enhancement
In this section, we discuss how to apply the channel enhancement argument [
30], which is originally designed for channels with full CSIT, to the considered model where there is only statistical CSIT and the channels are fast faded.
The channel enhancement technique, invented in [
30], is a critical technique to prove that Gaussian input is optimal for MIMO Gaussian BC. Later [
1] applies this technique to wiretap channels. However, there are major differences on the use of channel enhancement. In MIMO GBC, every sub-channel from the transmitter to each receiver is enhanced by reducing the corresponding noise covariance. In GWTC, however, only those Bob’s sub-channels weaker than those of Eve are enhanced to be the same as Eve’s. Therefore, an equivalently degraded WTC can be formed. For more detailed discussions please see [
1]. Note that in both [
1,
30], perfect CSIT are required.
For fading channels which are not isotropically distributed, we use the following example to show that it is still possible to use channel enhancement to attain the capacity region/secrecy capacity.
Example 2: For the received signals
assume that the fading channel
has realizations
, where
is the unitary group with degree
n. Then it can be easily seen that we can apply the channel enhancement to the pair of channel realizations
to achieve the capacity region/secrecy capacity. A simple way to see it is that the receivers know
and multiplying
and
by unitary
does not change the capacity.
Following similar steps in Example 2, we can easily see that if the channels are respectively modeled as and , channel enhancement can still work.
6. Other Stochastic Orders
In this section, we show an application of the Laplace transform order introduced in Definition 3 on solving the resource allocation problem for channels with multiple antennas to attain the capacity result. We consider the wiretap channel as an example. Note that the secrecy capacity of a multiple-antenna Gaussian WTC is a difference of two concave functions with respect to the channel input covariance matrix. Under perfect CSIT assumption, in [
45] the authors proved that the maximum secrecy capacity coincides with the saddle point of a min-max problem, which is by considering a Sato-type outer bound setting, i.e., Bob additionally knows what Eve knows, in addition to an additional parameter, i.e., a correlation matrix between the noises at Bob and Eve. Based on the min-max description, [
40] then developed an algorithm to numerically solve this problem. An analytical solution is still unknown. In contrast, with statistical CSIT, optimal input distribution is open in general. In the following, we will review the result [
13] that under i.i.d. Rayleigh fading, the Laplace transform order combined with completely monotone can help us to prove that uniform power allocation is optimal for multiple-input single-output singe-antenna at eavesdropper GWTC with statistical CSIT of both the legitimate and eavesdropper’s channels.
First of all, we want to find the optimal input covariance matrix
by solving:
After the derivation in [
13] we can transform (32) into the following power allocation problem
where we denote
by
a, which belongs to
since we only need to consider the case where
. From Section V in [
46], the optimal power allocation
satisfies
. Then for any
where
and
. Here we introduce some results from the stochastic ordering theory [
15] to proceed.
Definition 5 ([
15]).
A function is completely monotone if for all and its derivative exists and . Lemma 3 ([
15]).
Let and be two nonnegative random variables. If then , where the first derivative of a differentiable function f on is completely monotone, provided that the expectations exist. To solve (33), we let
,
, and
to invoke Lemma 3. It can be easily verified that
(x), defined as the first derivative of
, is completely monotone by checking Definition 5. More specifically, the
n-th derivative of
meets
when
, since
. Now from Lemma 3 and Definition 3, we know that to prove (33) is equivalent to proving
or
From [
47], we know that
To show that the above is nonnegative, we resort to the majorization theory. Note that
is a Schur-concave function [
39] in
,
, and by Definition of majorization [
39],
where
means that
is majorized by
. Thus, from [
39], we know that the RHS of (35) is nonnegative,
. Then (33) is valid, and
is optimal. Note that
is also the optimal input covariance matrix
since the optimal beamformer
can be selected as
.


{kind=link}
{kind=link}
{kind=link}
{kind=link}



