1. Introduction
Recent studies deal with the problem of measuring the disparity of a particular probability density function (pdf) from the normal one [
1]. A typical technique to deal with the problem has been exact expressions using information measures over particular distributions. For example, Vidal et al. [
2] measure the sensitivity of the skewness parameter using the
distance between symmetric and asymmetric distributions. Stehlík [
3] proved results on the decomposition of Kullback–Leibler (KL) divergences [
4] in the gamma and normal family for divergence between the Maximum Likelihood Estimator (MLE) of the canonical parameter and the canonical parameter of the regular exponential family [
5]. Contreras-Reyes and Arellano-Valle [
6] considered Jeffrey’s (J) divergence [
7] to compare the multivariate Skew-Normal (SN) from the normal distribution, and Gómez-Villegas et al. [
8] assessed the effect of kurtosis deviations from normality on conditional distributions, such as the multivariate exponential power family. Main et al. [
9] evaluated the local effect of asymmetry deviations from normality using the KL divergence measure of the SN distribution and then compared the local sensitivity with Mardia’s and Malkovich–Afifi’s skewness indexes. They also agree on the use of the SN model to regulate the asymmetry of an empirical distribution because it reflects the deviation in a tractable way. Dette et al. [
10] characterizes the “disparity” between the skew-symmetric models and their symmetric counterparts in terms of the total variation distance, which is later used to construct priors. The paper provides additional insights, to those provided in Vidal et al. [
2], on the interpretation of this distance and also discusses the usage of the KL divergence among several other distances.
Some recent applications of measuring the disparity of a particular pdf from the normal one using negentropy include those by Gao and Zhang [
11] and Wang et al. [
12], where the negentropy method has been successfully applied to seismic wavelet estimation. Pires and Ribeiro [
13] considered the negentropy to measure the distance of non-Gaussian information from the normal one in independent components, with application to Northern Hemispheric winter monthly variability of a high-dimensional quasi-geostrophic atmospheric model. Furthermore, Pires and Hannachi [
14] used a tensorial invariant approximation of the multivariate negentropy in terms of a linear combination of squared coskewness and cokurtosis. Then, the method was applied to global sea surface temperature anomalies, after data anomalies were tested through a non-Gaussian distribution.
In this paper, we develop a procedure, based on KL divergences, to test the significance of the skewness parameter in the Generalized Skew-Normal (GSN) distributions, a flexible class of distributions that includes the SN and normal ones as particular cases. We consider asymptotic expansions of moments and cumulants for the negentropy of two particular cases: the SN and Modified Skew-Normal (MSN) distributions. Given that SN distributions do not accomplish the regularity condition of Fisher Information Matrix (FIM) at
, normality is tested based on the MSN distribution [
15]. This allows one to implement an asymptotic normality test for testing the significance of the skewness parameter. Numerical results are studied by: (a) comparing numerical integration methods with proposed asymptotic expansions; (b) comparing the asymptotic test with the likelihood ratio test and the asymptotic normality test given by Arrué et al. [
15] ; and (c) applying the proposed test to condition factor time series of anchovy (
Engraulis ringens).
This paper is organized as follows: information theoretic measures are described in
Section 2. In
Section 3, we provide an asymptotic expansion in terms of the corresponding cumulants for the GSN, SN and MSN negentropies. We also express the KL and J divergences among each GSN distribution and the normal one in terms of negentropies (as cumulants’ expansion series) to develop the hypothesis test about the significance of the skewness parameter together with a simulation study (
Section 4). A simulation study is given in
Section 5. In
Section 6, the real data of the condition factor time series of anchovies off northern Chile illustrate the usefulness of the developed methodology. The discussion concludes the paper.
2. Shannon Entropy and Related Measures
The Shannon Entropy (SE) of a random variable
Z with pdf
f is given by:
The SE of a localization-scale random variable
does not depend on
and is such that
(see, e.g., [
16]). The SE could serve to define a measure of disparity from normality, the so-called negentropy [
17], which is zero for a Gaussian variable and positive for any distribution. It is defined by:
where
is a normal random variable with the same mean and variance as those of
Z. Equation (
2) expresses the negentropy in terms of the standardized version of
Z, say
, as
; here,
has zero mean and unit variance. Thus, negentropy measures essentially the amount of information that departs from the normal entropy. Furthermore, clearly, the negentropy becomes the KL divergence (see Equation (
3) below) between
and
.
Given that the calculus of negentropy presents a computational challenge, where the integral involves the pdf of
Z [
16,
18], different approximations of negentropy are used, such as cumulants’ expansion series [
17,
19]. Withers and Nadarajah [
19] provided exact and explicit series expansions for the SE and negentropy of a standardized pdf
f on
, in terms of cumulants. Yet, they did not perform numerical studies that allow evaluation and comparison with other procedures in some specific families of distributions.
Other measures related to the SE are KL and J divergences. They measure the degree of divergence between the distributions of two random variables
and
with pdfs
and
, respectively. The KL divergence of the pdf for
from the pdf for
is defined as:
as indicated in the notation, the expectation is defined with respect to the pdf
for
. Since in general
differs from
, the J divergence is considered as a symmetric version of the KL divergence, which is defined by:
3. Generalized Skew-Normal Distributions
An attractive class of Skew-Symmetric (SS) distributions defined in terms of the pdf appears in Azzalini [
20], Azzalini and Capitanio [
21] and Gupta et al. [
22]:
where
represents a skewness/shape parameter,
f and
G are the respective pdf and cumulative distribution function (cdf) of symmetrical continuous distributions and
is an odd function of
z, with
for any fixed value of
. Furthermore, we assume that
for all
z and some value
of
(typically
), so that
, thus recovering symmetry.
The notation
expresses that random variable
Z has a distribution with the pdf given by (
5). If
represents the pdf of the standardized normal distribution, denoted by
, then (
5) becomes a family of skew-symmetric distributions generated by the normal kernel, the GSN family. In this case,
emerges. An important property of the GSN random variable
Z is that all its moments are finite. In particular, it possesses the same even moments of
. For instance,
, and so,
, where
. The most popular GSN distribution is Skew-Normal (SN) [
23], for which
and
is the cdf of the standardized normal distribution. Therefore,
expresses that
Z follows an SN distribution. The location-scale extension of the SS pdf in (
5) follows by applying the Jacobian method to the linear random variable
, where
and
. In this case, we state that
X follows an SS distribution with location parameter
, scale parameter
and shape/skewness parameter
and obtains
. Furthermore, we write
if
,
if
and
; and
if
,
and
.
Two other members of the GSN family that have been studied recently are the Skew-Normal-Cauchy (SNC) distribution [
24,
25], which follows from (
5) by taking
,
and
, and the Modified Skew-Normal (MSN) distribution [
15], for which
,
and
. Nadarajah and Kotz [
24] recall that the SNC distribution appears to attain a higher degree of sharpness than the normal distribution, i.e., disparity exists from the common normal distribution produced by the skewness parameter
. A random variable
Z with the SNC or MSN distribution is denoted, respectively, by
or
and by
or
for their respective location-scale extensions.
We consider the SE for the GSN subclass, i.e., the SE of
. Thus, assuming a normal kernel in (
5), we get the GSN-SE given by:
where
is the SE of
. It is assumed that a specific skewness value
exists so that
and so that
, thus recovering symmetry at
. Therefore, at
,
Z and
have the same distribution and thus the same SE.
Let
and
be the mean and variance of
, respectively, which must constitute functions of the skewness parameter
. Since
and
, we get from (
2) that the negentropy of
Z becomes:
Since at
, we have by symmetry
and
, so the negentropy in this case is null, as expected. Clearly, SE and negentropy depend on the choice of the functions
and
. In this paper, we consider both families of GSN distributions for which
, with
and
, thus following that
and recovering the normality at
. Examples of this type of functions are
and
for some odd function
, with
. In this case, recalling that
, where
,
, and “
” denotes equality in the distribution, we obtain:
thus
and
. That is, the entropy and negentropy of
depend on the skewness parameter
only through its absolute value
.
We have interest in both KL and J divergences for a GSN distribution with respect to the normal distribution. that is, assuming in (
3) and (
4) that
and
. In this case, remembering that
, where
and
, we have
and
, with:
Therefore,
, with:
We also develop asymptotic expansions of the J divergence for the SN and MSN distributions from the normal distribution. To do this, we consider the following preliminary result, the proof of which stems from (
9) and (
10) by using the Taylor expansion of
at
and also because of the facts that (a) all moments of
are finite and (b)
and
contain the same even moments.
Lemma 1. Consider the composite function , , by assuming that both functions and are infinitely differentiable; hence, also is infinitely differentiable at . If , then:where is the k-th derivative of . Moreover, from (11), the expressions (6) and (7) for the SE and negentropy of the GSN distributions have the forms:respectively, where . Notice in Lemma 1 that the coefficient depends on the derivatives of and at , which change for different GSN distributions. Moreover, since the expansion of emerges around by assuming a fixed , the approximations may not be reasonable for some values of .
3.1. Skew-Normal Distribution
If
or
represents an SN random variable, then its pdf is:
Clearly, if
, then (
12) reduces to the
-pdf. The SN random variable
Z can be conveniently represented as a linear combination of half-normal and normal variables through the following stochastic representation [
26]:
where
,
and
U are independent and identically distributed with a unit normal distribution. In particular, since the half-normal random variable
has mean
and variance one, it follows from (
12) that the mean and variance of
,
, are given by:
where
.
In the SN case,
and
, which are both infinitely differentiable functions at
. Consequently, the function
is also infinitely differentiable at
, thus admitting a Taylor expansion about zero. Therefore, since
, where
is the
k-th derivative of
, the expansion (
11) in Lemma 1 of
,
, becomes:
where
and
(see
Appendix A).
In summary, since the even moments of
are also the even moments of
, Equation (
14) can be rewritten as:
Hence, considering also Equation (
13), we can compute for the SN case the results for the KL and J divergences, SE and negentropy given in Lemma 1 using the following Proposition 1.
Proposition 1. Let and . Then:where the coefficients , , are given in the Appendix A. To gain a more complete analysis of the behavior of these series, we need appropriate forms for the calculation of the coefficients
,
(see
Appendix A).
3.2. Modified Skew-Normal Distribution
The pdf for a random variable
Z with MSN distribution, denoted by
, is given by:
where
. Similarly to the SN case, the MSN random variable
,
, has even moments equal to the corresponding even moments of the standardized normal random variable
[
15], i.e.,
(for odd moments
,
, see
Appendix A).
In the MSN case,
and
, both of which are infinitely differentiable at
. Thus, in Lemma 1, we have
, where
is also infinitely differentiable at
. Thus, the series expansion of
,
, can be obtained from (
11) for which we need the derivatives of the composite function
. Another way to obtain these derivatives is to define random variable
and using (
14) with
and
replaced by
and
, respectively. Thus, we obtain the series expansion:
From Lemma 1, the KL and J divergences, SE and negentropy for the MSN case can be computed using the following Proposition 2.
Proposition 2. Let and . Then: In order to compute the quantities given by Proposition 2, we need to calculate the new moments
,
. Since
is a random variable limited to the interval
, all its moments are finite. In particular,
clearly has the same even moments as
Moreover, from the Jacobian method, the pdf of
becomes:
Hence, the
k-th moment of
is:
which must be computed numerically.
3.3. J Divergence between SN and MSN Distributions
In the previous sections, SN and MSN distributions were compared with the normal distribution by means of the J divergence measure. As a byproduct, we were also computing the J divergence between the SN and MSN distributions, both with the same skewness parameter. This allows measuring the distance between these distributions with different
’s. For this, we consider in Equation (
4) that
and
and define the random variables
for
, where
. Let
and
,
. Recall that
and
for all
. Thus, using (
4) and then the Taylor expansion of
around
, Proposition 3 is obtained:
Proposition 3. Let , and . Define the random variables , . Then:where as before: Proposition 3 indicates that J divergence between SN and MSN distributions is decomposed to the divergences of the normal distribution with each of these distributions, which depends only on their odd moments and cumulants.
4. Asymptotic Tests
Let
,
,
, be the pdf of a regular parametric class of distributions, i.e., for which the sample space
does not depend on
, the parametric space
is an open subset of
, and the regularity conditions (i)–(iii) stated in Salicrú et al. [
27] are satisfied. As in Salicrú et al. [
27], we denote the KL divergence between
and
,
, by:
Consider the partition
, where
and
. Let
and consider the null hypothesis
for a known
. Let
and
be the (unrestricted) MLE of
and
, respectively, both based on a random sample of size
n from
X with pdf
. Under these conditions, we have from Part (b) of Theorem 2 presented in Salicrú et al. [
27] that:
where “
” denotes convergence in distribution and
denotes the chi-squared distribution function with
s degrees of freedom. From (
17), the above null hypothesis can be tested by the statistic
, which is asymptotically chi-squared distributed with
degrees of freedom. Specifically, for large values of
n, if we observe
, then
is rejected at level
if
.
4.1. One-Sample Case: Test for Normality
The result in (
17) can be applied for example to construct a normality test from the KL divergence between a regular GSN distribution and the normal distribution. Specifically, consider a random sample
from
and the null hypothesis
under which
; thus, the GSN random variable
X becomes a
random variable. Let
be the MLE of
and
. Therefore, under
, we have:
where
is the MLE of
, which is defined in Equation (
11) of Lemma 1 and depends only on
. As stated in the Introduction, normality is typically obtained from the GSN class at
or equivalently
.
Azzalini [
20], Arellano-Valle and Azzalini [
28] and Azzalini and Capitanio [
23] recall the singularity of SN FIM at
, preventing the asymptotic distribution of the above statistic tests. As suggested by Azzalini [
20], a solution to recover the non-singularity of the information matrix under the symmetry hypothesis comes from the use of the so-called centered parametrization defined in terms of the mean, variance and the skewness parameters of the SN distribution (see also [
28,
29]). Otherwise, the FIM of the MSN model is non-singular at
[
15]. Thus, this model satisfies all the standard regularity conditions of Salicrú et al. [
27], leading to consistence and asymptotic normality of the MLEs under the null hypothesis of normality. Therefore, the MSN model serves to test the null hypothesis of normality using (
18). Hence, the symmetry null hypothesis
is rejected at level
if
, with
.
4.2. Two-Sample Case
Consider two independent samples of sizes
and
from
and
, respectively; where
, and
and
have pdf’s
and
, respectively. Suppose partition
,
, and assume
, so that
,
. Let
be the MLE of
,
, which correspond to the MLE of the full model parameters
under null hypothesis
. Thus, Part (b) of Corollary 1 in Salicrú et al. [
27] establishes that if the null hypothesis
holds and
, with
, then:
Thus, a test of level
for the above homogeneity null hypothesis consists of rejecting
if:
where
is the
-th percentile of the
-distribution.
Contreras-Reyes and Arellano-Valle [
6] considered the result of Kupperman [
30] to develop an asymptotic test of complete homogeneity in terms of the J divergence between two SN distributions. The SN distribution satisfies all the aforementioned regularity conditions when skewness parameter
. Thus, considering this condition, we can also apply (
17) and (
19) to obtain, respectively, asymptotic tests with one or two samples of other hypotheses not covered by Kupperman’s test.
5. Simulations
In this section, we study the behavior of the series expansions of the SE and negentropy for the SN and MSN distributions. In both cases, we compare the SE and negentropies obtained from their series expansions with their corresponding “exact” versions computed from the Quadpack numerical integration method of Piessens et al. [
31]. More precisely, the “exact” expected values
and
are computed using the Quadpack method as in Arellano-Valle et al. [
16], Contreras-Reyes and Arellano-Valle [
6] or Contreras-Reyes [
18]. From the series expansions, the SE and negentropies were carried out for
as in Withers and Nadarajah [
19]. However, they tend to converge for
as in the Gram–Charlier and Edgeworth expansion methods (see, e.g., Hyvärinen et al. [
17] and Stehlík et al. [
1], respectively). All proposed methods are implemented with R software [
32].
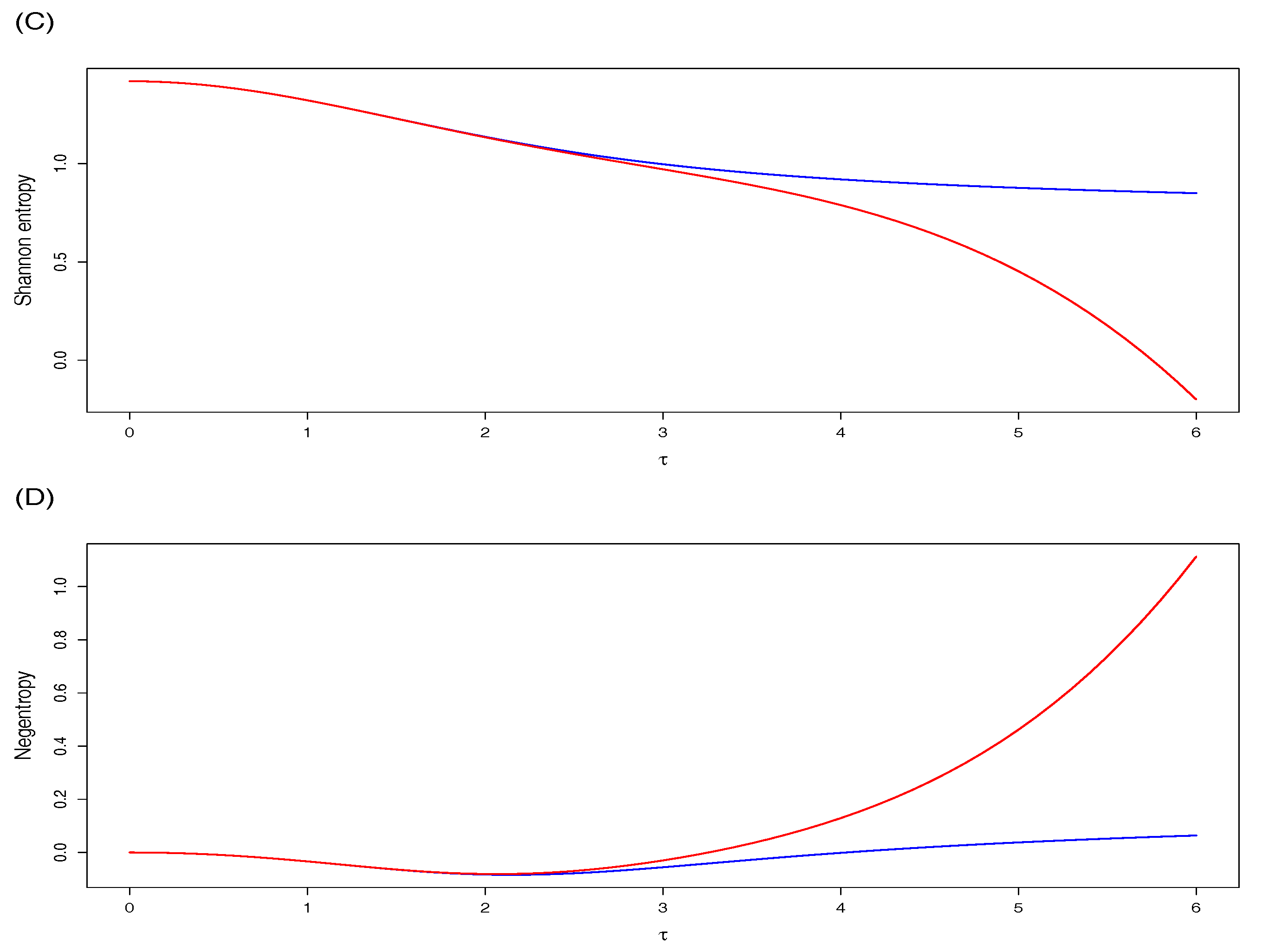
From
Figure 1, we observe that the approximations by series expansions are better in the MSN case (Panels C and D) than in the SN case (Panels A and B). Furthermore, that series expansion approximations are quite exact for small to moderate values of the skewness parameter
; more specifically, for
in the SN case, and
in the MSN case. Additionally, Panels A and C show that the SE decreases as
increases, while Panels B and D indicate that the negentropy increases with
. Finally, as expected in both GSN models, the SE is less than or equal to the SE of the normal model, namely
[
6,
33].
Panel A of
Figure 2 shows, respectively, the behavior of the KL divergences of the SN and MSN distributions from the normal one obtained from the expansions in series given in Equations (
15) and (
16). As in
Figure 1, the KL divergence between the SN and normal distributions increases smoothly for values of
, but rises sharply for
. Meanwhile, the increase in KL divergence between the MSN and normal distributions seems more stable, at least for
. Crucially, for
, the SN model is close to its maximum level of asymmetry, while the MSN model does it for
(see [
15] (Figure 2)).
Table 1 presents the observed power of the asymptotic test of normality obtained from Equation (
18) in
Section 4.1, for different sample sizes and values of the skewness parameter. All these results were obtained from 2000 simulations for a nominal level of 5%. In each simulation, the MLE of
was obtained by maximizing the log-likelihood function:
for shape parameter
and a random sample of size
n from
Z [
15].
Table 1 shows that the proposed test is considerably conservative since the observed rate of incorrect rejections of the normality hypothesis is always lower than the nominal level. The proposed test is also considerably more powerful in large samples (
) and values of the skewness parameter far from zero (
). As expected, the power of the test increases with sample size, particularly for small values of the skewness parameter (close to normality), given that statistic
depends on
n despite
being small (
Figure 2).
Now, we compare the proposed asymptotic test with two additional tests considered by Arrué et al. [
15] for null hypothesis
versus
: the Likelihood Radio Test (LRT) (see
Appendix A) and the asymptotic normality-based test. Since the regularity condition on MSN’s FIM at
is satisfied, the authors proposed a distributional normal theory for testing
, i.e., based on asymptotic normality of MLE given by
, as
, where
is the MLE of
,
and
is the inverse FIM component related to
. For asymptotic normality and LRT, they conclude that
is rejected for large values of
, and for large values of
n, the coverage rate increases when
exists (
is rejected) (see [
15] (Tables 3–5)). Analogously, in Table 6 of Arrué et al. [
15], the coverage rate increase when
exists for large values of
n.
6. Application to Condition Factor Time Series
To apply our results to a real-world problem, we considered the Condition Factor (CF) index [
34], which serves as an important indicator of the fatness condition of fish [
18]. The CF index,
of an individual of length
L is computed in terms of the observed weight
and an estimation
obtained from the morphometric relationships of the expected weight
at length
L. Then, the CF index is interpretable as food deficit (<100%) and abundance (>100%) conditions. The expected length-weight relationship is described through the non-linear relationship:
where
is the theoretical weight at length zero and
is the weight growth rate [
35]. According to (
21),
is computed as
, where
and
are obtained by fitting the non-linear regression induced by (
21) to the length-weight data obtained from a sample of the species under study.
The CF index can be mainly affected by environmental factors such as El Niño (cold events) or La Niña (warm events). These effects are conductors of threshold biological processes due to the limitation of food. For these reasons, Contreras-Reyes [
18] considered a threshold autoregressive model based on the stochastic representation (
12) to model CF time series. That is, by assuming an SN distribution with skewness parameter
for the CF index [
20], the condition
ensures the weak stationarity of the process. Additionally, when
is positive, CF values fall below 100% (food deficit). Otherwise, CF values are greater than 100% (food abundance).
We applied hypothesis testing developed in
Section 4 to monthly CF time series associated with anchovy from Chile’s northern coast during the period 1990–2010, which were classified by length and sex, for length classes 12,...,18 cm and ALL (all length classes). Therefore, the sample size of each classification depends on the availability of the routine biological sampling program (see more details in [
18]). CF were previously standardized, since the shape parameter
is not affected by a linear transformation of the CF [
23].
Table 2 shows the
’s assuming an SN and MSN distribution based on the MLE method of Azzalini [
36] and Arrué et al. [
15], respectively. For MSN, we considered the log-likelihood function of Equation (
20). In both models, negative and positive values of
correspond to asymmetry to the right and left, respectively (see Contreras-Reyes [
18] (Figure 5)). This means that CF of the above-mentioned classes are affected by extreme events. As expected, we find generally that for low values of the empirical skewness index, the shape parameter of both distributions is close to zero.
The values of
obtained from the SN and MSN models are presented in
Table 2. Since that SN model is not regular at
, we used only the MSN model to perform the test of normality and LRT for each sample datum. The results of this analysis appear in
Table 3 and are not analogous for all the length classes in both groups. In fact, for the group of males, the null hypothesis
is not rejected, only in length class 15 (95% confidence level) and in class ALL (90% confidence level). In contrast, for the group of females, the null hypothesis is not rejected for length classes 12, 15, 17 (95% confidence level) and in class ALL (90% confidence level). For both tests, we obtained similar decisions on each time series.
According to Contreras-Reyes [
18], the time series in which the shape parameter is close to zero or when the null hypothesis is not rejected are influenced simultaneously by both normal and extreme events as in the length class ALL, where all the fish population is included for the analysis. For length class 17 in males, for example, the CF is susceptible to some atypical events such as the moderate-strong El Niño event between 1991 and 1992 (high negative empirical skewness and high empirical kurtosis). For length class 13 in both sexes, the CF is susceptible to the strong El Niño event produced between 1997 and 1998.
7. Discussion
We have presented the methodology to compute the Shannon entropy, the negentropy and the Kullback–Leibler and Jeffrey’s divergences for a broad family of asymmetric distributions with the normal kernel called generalized skew-normal distributions. Our method considers asymptotic expansions regarding moments and cumulants for two particular cases: the skew-normal and modified skew-normal distributions. We then measured the degrees of disparity of these distributions from the normal distribution by using exact expressions for the negentropy in terms of moments and cumulants. Additionally, given the regularity conditions accomplished by the modified skew-normal distribution, normality was tested based on the modified skew-normal distribution. This test considered the asymptotic behavior of the Kullback–Leibler divergence, which is determined by the negentropy for normality disparity.
Numerical results showed that the Shannon entropy and negentropy of the modified skew-normal distribution are better approximated than the skew-normal one, at least for a wider range of the shape parameter. For small to moderate values of the asymmetry parameter, where the approximations are appropriate, we find that expansions series converge from the fourth moment/cumulant to greater, as in the Gram–Charlier and Edgeworth expansion methods [
17]. For large values of the skewness parameter, where the expansions are inappropriate, the functions related to negentropy are not well approximated by Taylor expansions around zero, produced by a divergence in the moment and cumulant terms, i.e., the Taylor expansions for the expected values of the functions
and
(SN and MSN case, respectively) if
is too large. When this happens, the normal cdf,
and
(SN and MSN case, respectively), tends to one, since according to the stochastic representation in (
12), for large values of
, the distribution of
converges to the standardized half-normal distribution [
37].
However, the normality test considered in the application used skewness parameters inside the appropriate range. Furthermore, we plan to investigate the negentropy of the modified skew-normal-Cauchy distribution or similar models. In addition, although the approximations are appropriate over the range of variation of the asymmetry admitted by both models, more work should be done in order to improve the asymptotic approximations for a greater range of the skewness parameter values. Besides, this is not an easy task since generally it is difficult to approximate KL divergences involving asymmetric and heavy-tailed distributions [
38].
The statistical application related to condition factor time series of anchovies off northern Chile is given. The results show that the proposed methodology serves to detect non-normal events in these time series, which produces an empirical distribution with high presence of skewness [
18]. The proposed test for normality is therefore useful to detect anomalies in condition factor time series, linked to food deficit (positive shape parameter) or food abundance (negative shape parameter) influenced by environmental conditions.







{kind=link}
{kind=link}
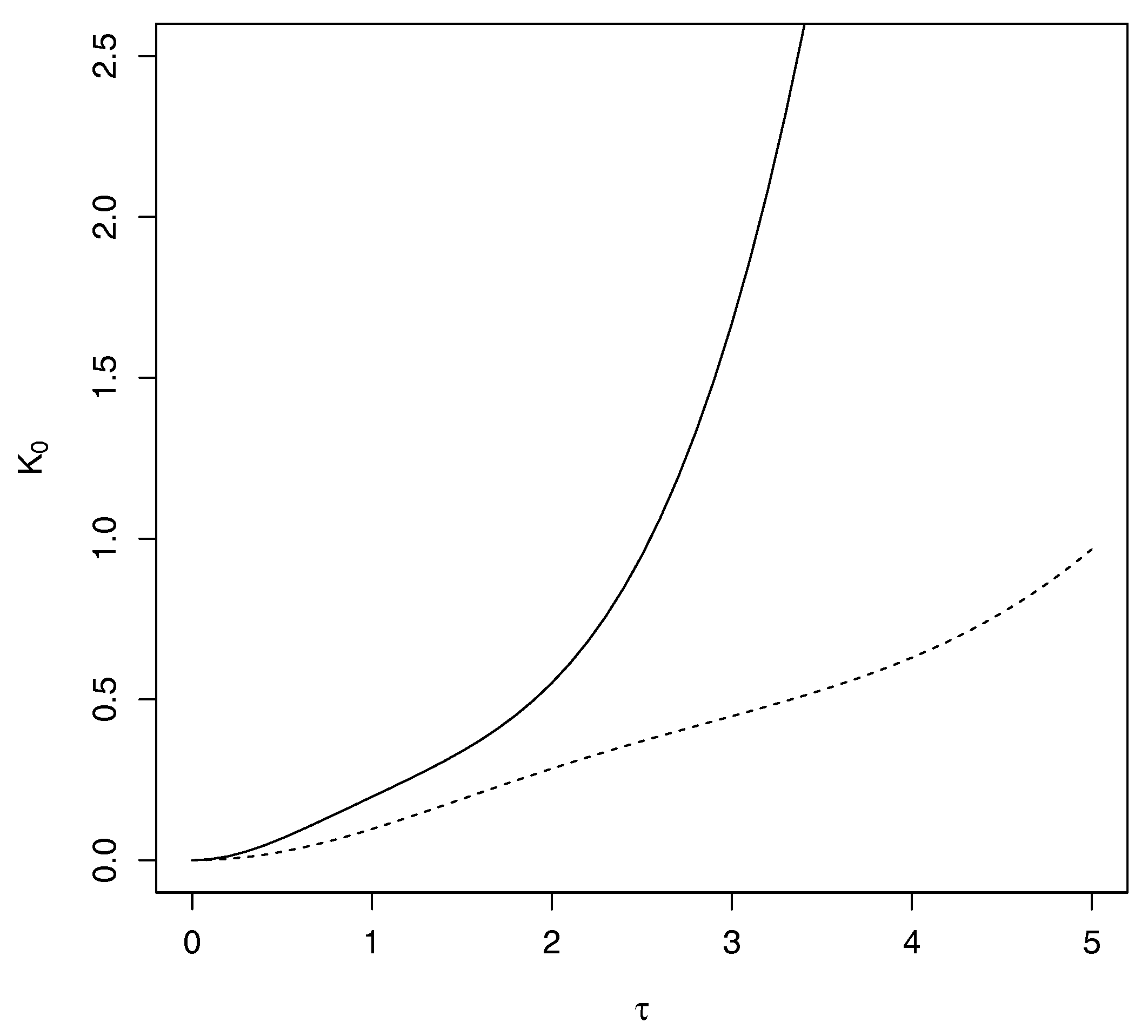{kind=link}