Overfitting Reduction of Text Classification Based on AdaBELM

 ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Extreme Learning Machine
2.2. AdaBoost
| Algorithm 1. AdaBoost Algorithm. |
| Input: Training data set D = {(x1,y1),…,(xm, ym)}; Ensemble size T; |
| Output: |
Procedure:
|
3. A Quantitative Measurement for Overfitting
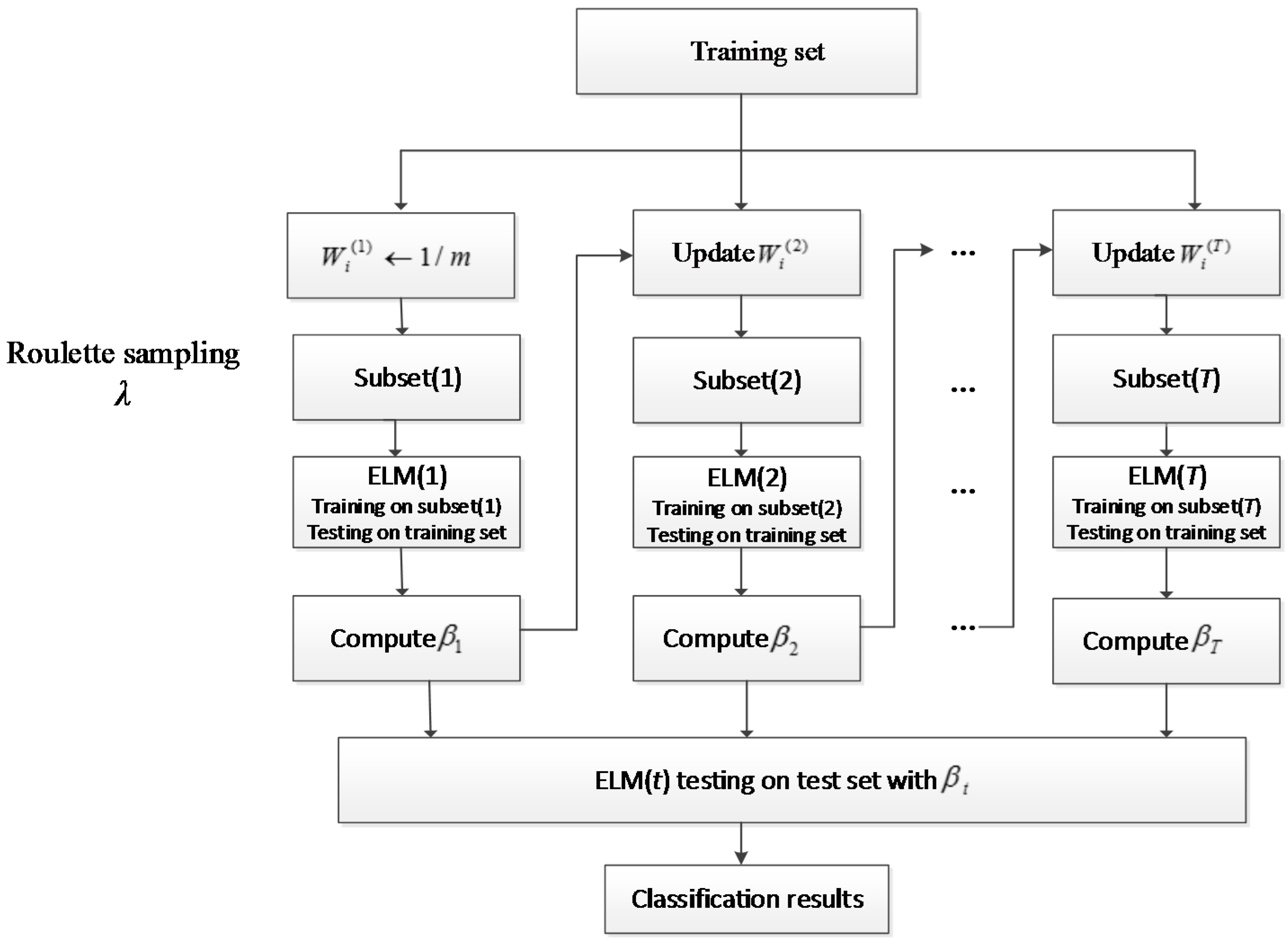
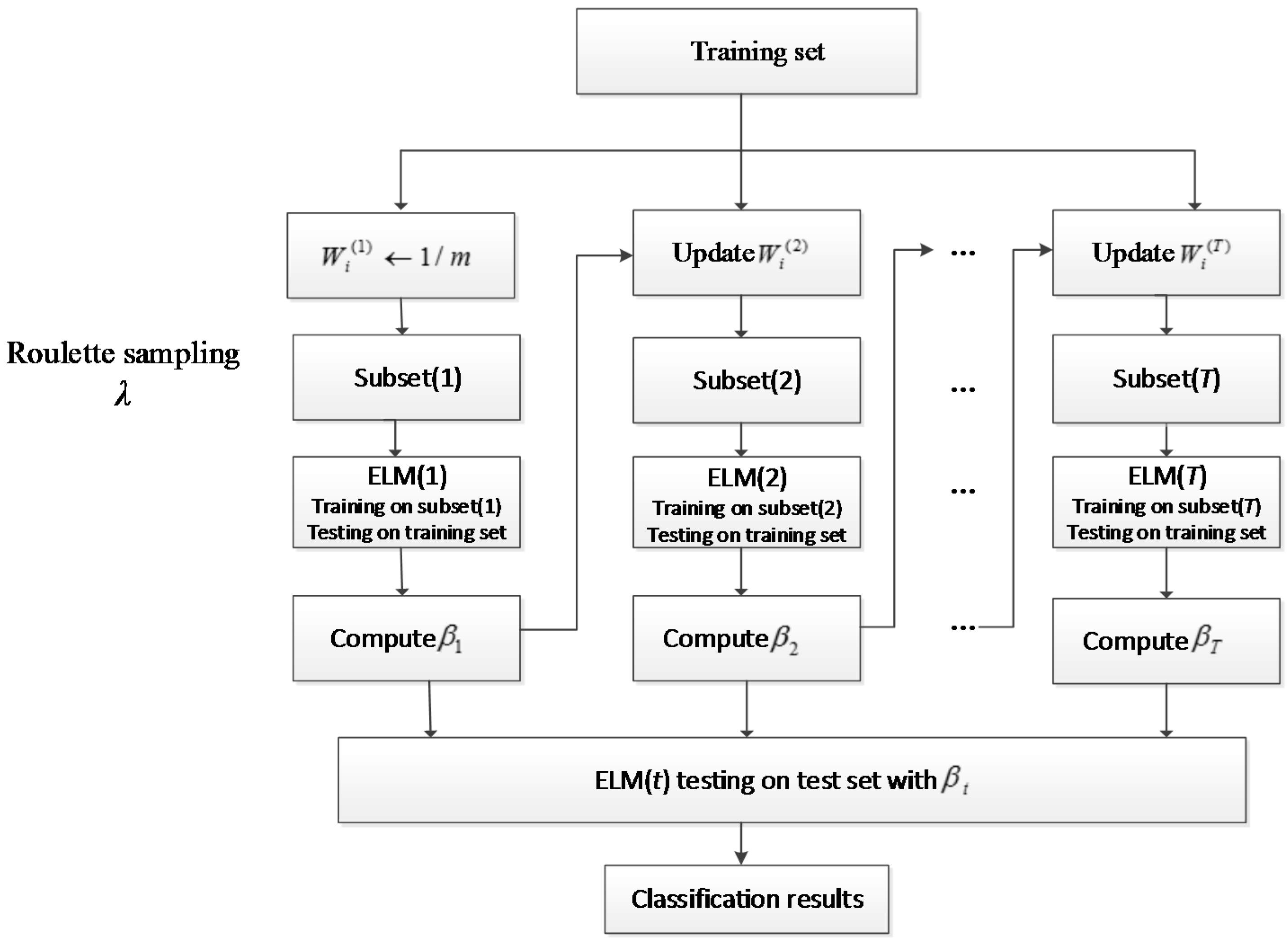
4. AdaBoost ELM Model
| Algorithm 2. AdaBELM Algorithm. |
| Input: Training data set D = {(x1,y1),…,(xm, ym)}; Ensemble size T; |
| Output: |
Procedure:
|
5. Experiments and Discussion
5.1. Datasets
- 20 Newsgroups is a widely used benchmark dataset. It was first collected by Ken Lang and partitioned evenly in 20 different newsgroups [43]; some of the classes are very closely related to one another (e.g., comp.sys.ibm.pc.hardware and comp.sys.mac.hardware) and others are highly unrelated (e.g., misc.forsale and soc.religion.christian). There are three versions, i.e., “20news-19997,” “20news-bydate”, and “20news-18828”; however, we used the “20news-bydate” version. It is recommended by the data provider since the label information has been removed, and the training and testing sets are separated in time, which makes it more realistic.
- Reuters-21578 (Reuters) is a publicly available benchmark text data set, which has been manually pre-classified [37]. The original Reuters data consist of 22 files (a total of 21,578 documents) and contain special tags such as “<TOPICS>” and “<DATE>”, among others. The pre-processing phase on the dataset cuts the files into single texts and strips the document of the special tags. We selected the public available ModApte version from http://www.cad.zju.edu.cn/home/dengcai/Data/TextData.html in our experiment [44]. Compared with 20 Newsgroups, Reuters is more difficult to classify [45]. Each class has a wider variety of documents, and these classes are much more unbalanced. For example, the largest category (“earn”) contains 3713 documents, while some small categories, such as “naphtha”, contains only one document. To determine the robustness of the unbalanced data sets, we used 65 categories, and the number of documents in each category ranges from 2 to 3713.
- BioMed corpora is a BioMed central open-access corpora dataset. From the BioMed corpora, 110,369 articles from January 2012 to June 2012 were downloaded. During the pre-processing phase, small files contain only XML tags (such as <title> and <body>) and those less than 4 KB were removed. Then, the data was divided into different “topics” based on journal names and the top 10 topics (each included in from 1966 to 5022 articles) were selected as the experimental corpora. Stop words and journal-name information were eliminated from the text. Then, each document is represented by a superset of two-tuples as follows:where N is the number of documents in the data set; Mj is the number of term features (unique words or phrases) in the j-th document; di = {<fi1, ni1>, <fi2, ni2>,…, <fiMi, niMi>} refers to the i-th document, and fik and nik represent the k-th term in the i-th document and its frequency, respectively.
5.2. Experimental Results
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Sebastiani, F. Machine Learning in Automated Text Categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Joachims, T. Text Categorization with Support Vector Machines: Learning with Many Relevant Features; Springer: Berlin/Heidelberg, Germany, 1998; pp. 137–142. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Schapire, R.E.; Singer, Y. BoosTexter: A Boosting-based System for Text Categorization. Mach. Learn. 2000, 39, 135–168. [Google Scholar] [CrossRef]
- Laurent, A.; Camelin, N.; Raymond, C. Boosting Bonsai Trees for Efficient Features Combination: Application to Speaker Role Identification. In Proceedings of the 15th Annual Conference of the International Speech Communication Association, Singapore, 12 March 2014; pp. 76–80. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Igelnik, B.; Pao, Y.H. Stochastic Choice of Basis Functions in Adaptive Function Approximation and The Functional-Link Net. IEEE Trans. Neural Netw. 1995, 6, 1320–1329. [Google Scholar] [CrossRef] [PubMed]
- Pao, Y.H.; Takefuji, Y. Functional-link Net Computing: Theory, System Architecture, and Functionalities. Computer 1992, 25, 76–79. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme Learning Machine: A New Learning Scheme of Feedforward Neural Networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; pp. 985–990. [Google Scholar]
- Zhang, L.; Suganthan, P.N. A comprehensive evaluation of random vector functional link networks. Inf. Sci. 2016, 367, 1094–1105. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme Learning Machine: Theory and Applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Extreme Learning Machines: Random Neurons, Random Features, Kernels. Available online: http://www.ntu.edu.sg/home/egbhuang/ (accessed on 16 March 2017).
- Huang, G.B.; Wang, D.H.; Lan, Y. Extreme Learning Machines: A Survey. Int. J. Mach. Learn. Cybern. 2011, 2, 107–122. [Google Scholar] [CrossRef]
- Miche, Y.; Sorjamaa, A.; Bas, P.; Simula, O.; Jutten, C.; Lendasse, A. OP-ELM: Optimally Pruned Extreme Learning Machine. IEEE Trans. Neural Netw. 2010, 21, 158–162. [Google Scholar] [CrossRef] [PubMed]
- Soria-Olivas, E.; Gomez-Sanchis, J.; Martin, J.D.; Vila-Frances, J.; Martinez, M.; Magdalena, J.R.; Serrano, A.J. BELM: Bayesian Extreme Learning Machine. IEEE Trans. Neural Netw. 2011, 22, 505–509. [Google Scholar] [CrossRef] [PubMed]
- Choi, K.; Toh, K.A.; Byun, H. Realtime Training on Mobile Devices for Face Recognition Applications. Pattern Recognit. 2011, 44, 386–400. [Google Scholar] [CrossRef]
- Luo, J.; Vong, C.M.; Wong, P.K. Sparse Bayesian Extreme Learning Machine for Multi-classification. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 836–843. [Google Scholar] [PubMed]
- Neumann, K.; Steil, J.J. Optimizing Extreme Learning Machines via Ridge Regression and Batch Intrinsic Plasticity. Neurocomputing 2013, 102, 23–30. [Google Scholar] [CrossRef]
- Er, M.J.; Shao, Z.; Wang, N. A Fast and Effective Extreme Learning Machine Algorithm Without Tuning. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 770–777. [Google Scholar]
- Yu, Q.; van Heeswijk, M.; Miche, Y.; Nian, R.; He, B.; Séverin, E.; Lendasse, A. Ensemble Delta Test-Extreme Learning Machine (DT-ELM) for Regression. Neurocomputing 2014, 129, 153–158. [Google Scholar] [CrossRef]
- Rong, H.J.; Ong, Y.S.; Tan, A.H.; Zhu, Z. A Fast Pruned-Extreme Learning Machine for Classification Problem. Neurocomputing 2008, 72, 359–366. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; pp. 511–518. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with A New Boosting Algorithm. In Proceedings of the 13th International Conference of machine learning, Bari, Italy, 2 January 1996; pp. 148–156. [Google Scholar]
- Wen, X.; Shao, L.; Xue, Y.; Fang, W. A Rapid Learning Algorithm for Vehicle Classification. Inf. Sci. 2015, 295, 395–406. [Google Scholar] [CrossRef]
- Bauer, E.; Kohavi, R. An Empirical Comparison of Voting Classification Algorithms: Bagging, Boosting, and Variants. Mach. Learn. 1999, 36, 105–139. [Google Scholar] [CrossRef]
- Dietterich, T.G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Gao, W.; Zhou, Z.H. On the Doubt About Margin Explanation of Boosting. Artif. Intell. 2013, 203, 1–18. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Desicion-Theoretic Generalization of On-Line Learning and an Application to Boosting; Springer: Berlin/Heidelberg, Germany, 1995; pp. 23–37. [Google Scholar]
- Grove, A.J.; Schuurmans, D. Boosting in the Limit: Maximizing the Margin of Learned Ensembles. In Proceedings of the 15th National Conference on Artificial Intelligence, Madison, WI, USA, 26–30 July 1998. [Google Scholar]
- Rätsch, G.; Onoda, T.; Müller, K.R. Soft Margins for AdaBoost. Mach. Learn. 2001, 42, 287–320. [Google Scholar] [CrossRef]
- Reyzin, L.; Schapire, R.E. How Boosting the Margin Can Also Boost Classifier Complexity. In Proceedings of the 23rd International Conference on Machine Learning, New York, NY, USA; 2006; pp. 753–760. [Google Scholar]
- Audibert, J.Y.; Munos, R.; Szepesvári, C. Exploration–Exploitation Tradeoff Using Variance Estimates in Multi-Armed Bandits. Theor. Comput. Sci. 2009, 410, 1876–1902. [Google Scholar] [CrossRef]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we Need Hundreds of Classifiers to Solve Real World Classification Problems? J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Zhang, L.; Suganthan, P.N. Oblique Decision Tree Ensemble via Multisurface Proximal Support Vector Machine. IEEE Trans. Cybern. 2015, 45, 2165–2176. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Suganthan, P.N. Random forests with ensemble of feature spaces. Pattern Recognit. 2014, 47, 3429–3437. [Google Scholar] [CrossRef]
- Rao, C.R.; Mitra, S.K. Generalized Inverse of a Matrix and Its Applications. Berkeley Symp. Math. Stat. Probab. 1972, 1, 601–620. [Google Scholar]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 Algorithms in Data Mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Schapire, R.E. The Strength of Weak Learnability. Mach. Learn. 1990, 5, 197–227. [Google Scholar] [CrossRef]
- Deng, W.; Zheng, Q.; Chen, L. Regularized Extreme Learning Machine. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence and Data Mining, Nashville, TN, USA, 30 March–2 April 2009; pp. 389–395. [Google Scholar]
- Zhang, T. Solving Large Scale Linear Prediction Problems Using Stochastic Gradient Descent Algorithms. In Proceedings of the Twenty-First International Conference on Machine Learning, New York, NY, USA, 4–8 July 2004; p. 116. [Google Scholar]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Home Page for 20 Newsgroups Data Set. Available online: http://qwone.com/~jason/20Newsgroups/ (accessed on 17 March 2017).
- Cai, D.; He, X.; Han, J. Document Clustering Using Locality Preserving Indexing. IEEE Trans. Knowl. Data Eng. 2005, 17, 1624–1637. [Google Scholar] [CrossRef]
- Guan, R.; Shi, X.; Marchese, M.; Yang, C.; Liang, Y. Text Clustering with Seeds Affinity Propagation. IEEE Trans. Knowl. Data Eng. 2011, 23, 627–637. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Data Scale | 20% | 40% | 60% | 80% | 100% | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | Training | Testing | Training | Testing | Training | Testing | |
| Gini Tree | 0.00 | 0.53 | 0.00 | 0.47 | 0.00 | 0.45 | 0.00 | 0.45 | 0.00 | 0.43 |
| ELM | 0.00 | 0.64 | 0.00 | 0.66 | 0.00 | 0.50 | 0.00 | 0.57 | 0.00 | 0.58 |
| Random Forests | 0.00 | 0.26 | 0.00 | 0.24 | 0.00 | 0.22 | 0.00 | 0.21 | 0.00 | 0.21 |
| MPSVM-RF | 0.02 | 0.33 | 0.02 | 0.29 | 0.02 | 0.27 | 0.02 | 0.25 | 0.02 | 0.25 |
| LDA-RF | 0.02 | 0.35 | 0.02 | 0.29 | 0.02 | 0.71 | 0.02 | 027 | 0.02 | 0.26 |
| Bonzaiboost | 0.00 | 0.41 | 0.02 | 0.34 | 0.05 | 0.31 | 0.07 | 0.28 | 0.08 | 0.27 |
| Data Scale | 40% | 60% | 80% | 100% |
|---|---|---|---|---|
| Gini Tree | 0.28 | 0.15 | −0.03 | 0.12 |
| ELM | −0.09 | 0.80 | −0.37 | −0.06 |
| Random Forests | 0.13 | 0.07 | 0.06 | 0.02 |
| MPSVM-RF | 0.23 | 0.09 | 0.06 | 0.05 |
| LDA-RF | 0.24 | 0.03 | 0.08 | 0.05 |
| Bonzaiboost | 0.28 | 0.15 | 0.12 | 0.04 |
| Data Sets | Reuters-21578 | 20 Newsgroups | Biomed |
|---|---|---|---|
| No. text | 8293 | 18,846 | 1000 |
| No. classes | 65 | 20 | 10 |
| Max. class size | 3713 | 600 | 100 |
| Min. class size | 2 | 377 | 100 |
| Avg. class size | 127.58 | 942.30 | 100 |
| Number of features | 18,933 | 61,188 | 69,601 |
| Sparsity rate (“0”/all) | 99.77% | 99.73% | 98.85% |
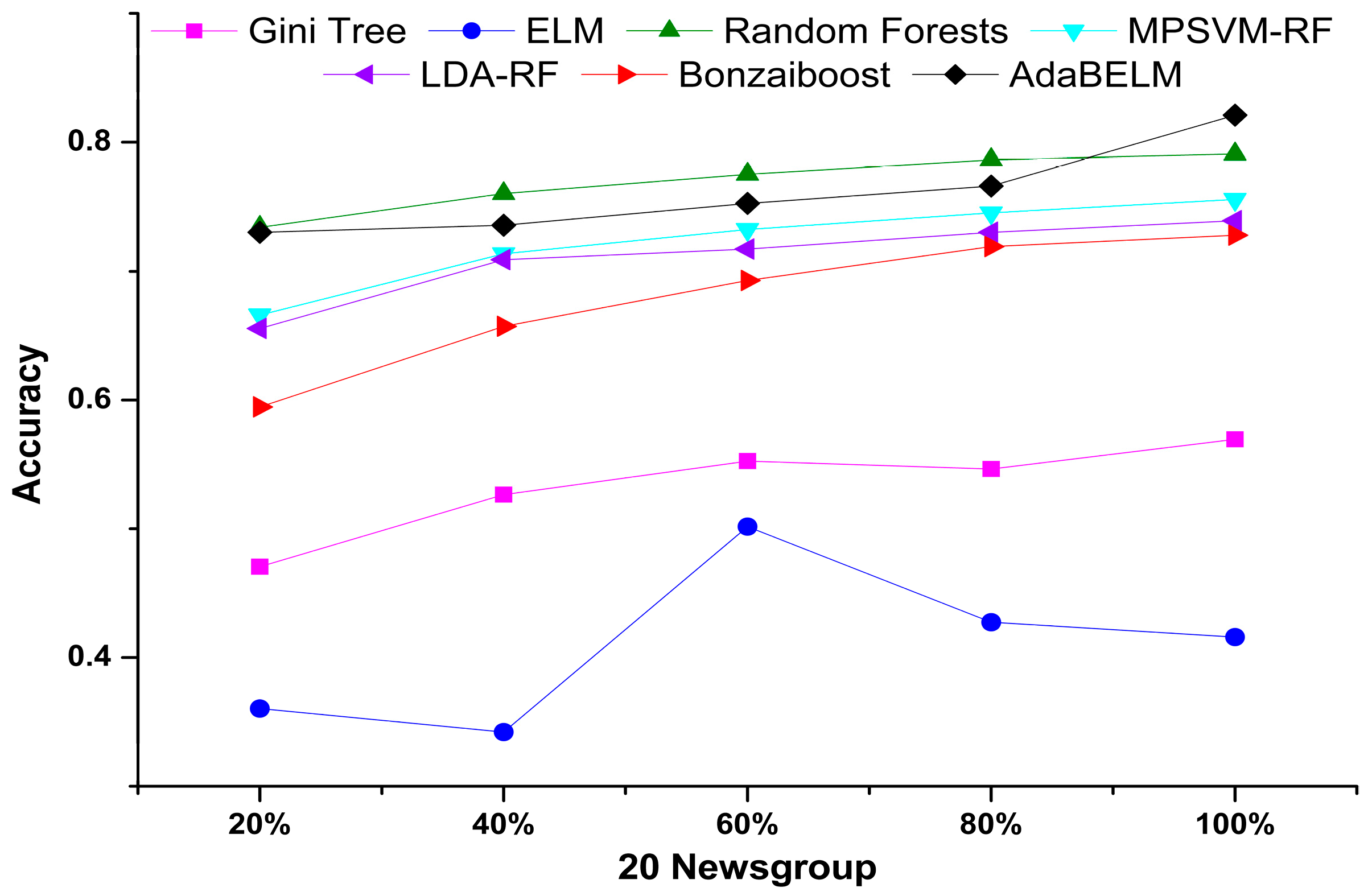
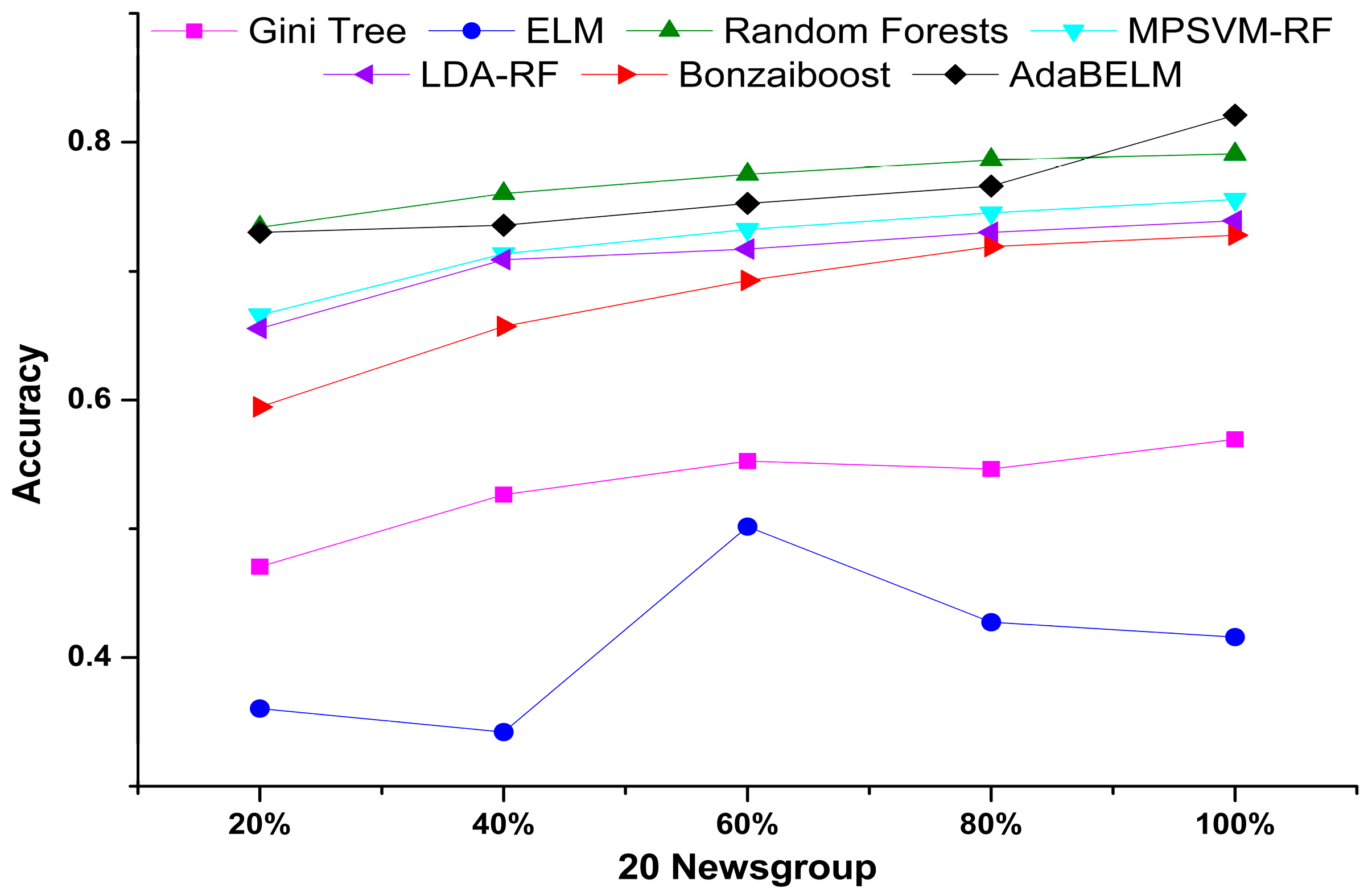
| Data Scale | 20% | 40% | 60% | 80% | 100% | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Training | Testing | Training | Testing | Training | Testing | Training | Testing | Training | Testing | |
| Gini Tree | 0.00 | 0.53 | 0.00 | 0.47 | 0.00 | 0.45 | 0.00 | 0.45 | 0.00 | 0.43 |
| ELM | 0.00 | 0.64 | 0.00 | 0.66 | 0.00 | 0.50 | 0.02 | 0.57 | 0.02 | 0.58 |
| Random Forests | 0.00 | 0.26 | 0.00 | 0.24 | 0.00 | 0.22 | 0.00 | 0.21 | 0.00 | 0.21 |
| MPSVM-RF | 0.02 | 0.33 | 0.02 | 0.29 | 0.02 | 0.27 | 0.02 | 0.25 | 0.02 | 0.25 |
| LDA-RF | 0.02 | 0.35 | 0.02 | 0.29 | 0.02 | 0.71 | 0.02 | 027 | 0.02 | 0.26 |
| Bonzaiboost | 0.00 | 0.41 | 0.02 | 0.34 | 0.05 | 0.31 | 0.07 | 0.28 | 0.08 | 0.27 |
| AdaBELM | 0.00 | 0.27 | 0.00 | 0.26 | 0.00 | 0.25 | 0.00 | 0.23 | 0.00 | 0.18 |
| Data Scale | 40% | 60% | 80% | 100% |
|---|---|---|---|---|
| Gini Tree | 0.28 | 0.15 | −0.03 | 0.12 |
| ELM | −0.09 | 0.80 | −0.37 | −0.06 |
| Random Forests | 0.13 | 0.07 | 0.06 | 0.02 |
| MPSVM-RF | 0.23 | 0.09 | 0.06 | 0.05 |
| LDA-RF | 0.24 | 0.03 | 0.08 | 0.05 |
| Bonzaiboost | 0.28 | 0.15 | 0.12 | 0.04 |
| AdaBELM | 0.03 | 0.08 | 0.06 | 0.27 |
| Data Sets | Reuters-21578 | 20 Newsgroups | Biomed |
|---|---|---|---|
| Gini Tree | 0.81 | 0.57 | 0.71 |
| ELM | 0.84 | 0.42 | 0.61 |
| Random Forests | 0.82 | 0.79 | 0.88 |
| MPSVM-RF | 0.80 | 0.76 | 0.85 |
| LDA-RF | 0.71 | 0.74 | 0.83 |
| Bonzaiboost | 0.86 | 0.73 | 0.86 |
| AdaBELM | 0.88 | 0.82 | 0.88 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, X.; Liang, Y.; Shi, X.; Xu, D.; Wang, X.; Guan, R. Overfitting Reduction of Text Classification Based on AdaBELM. Entropy 2017, 19, 330. https://doi.org/10.3390/e19070330
Feng X, Liang Y, Shi X, Xu D, Wang X, Guan R. Overfitting Reduction of Text Classification Based on AdaBELM. Entropy. 2017; 19(7):330. https://doi.org/10.3390/e19070330
Chicago/Turabian StyleFeng, Xiaoyue, Yanchun Liang, Xiaohu Shi, Dong Xu, Xu Wang, and Renchu Guan. 2017. "Overfitting Reduction of Text Classification Based on AdaBELM" Entropy 19, no. 7: 330. https://doi.org/10.3390/e19070330
APA StyleFeng, X., Liang, Y., Shi, X., Xu, D., Wang, X., & Guan, R. (2017). Overfitting Reduction of Text Classification Based on AdaBELM. Entropy, 19(7), 330. https://doi.org/10.3390/e19070330