1. Introduction
Entropy, introduced by Shannon [
1,
2], is an information theoretical concept with several appealing properties, and therefore wide applications in information theory, thermodynamics and time series analysis. Based on this classical measure,
transfer entropy (TE) has become a popular information theoretical measure for quantifying the flow of information. This concept, which was coined by Schreiber [
3], was applied to distinguish a possible asymmetric information exchange between the variables of a bivariate system. When based on appropriate non-parametric density estimates, the TE is a flexible non-parametric measure for conditional dependence, coupling structure, or Granger causality in a general sense.
The notion of Granger causality was developed by the pioneering work of Granger [
4] to capture causal interactions in a linear system. In a more general model-free world, the Granger causal effect can be interpreted as the impact of incorporating the history of another variable on the conditional distribution of a future variable in addition to its own history. Recently, various nonparametric measures have been developed to capture such difference between conditional distributions in a more complex, and typically nonlinear system. There is a growing list of such methods, based on, among others, correlation integrals [
5], kernel density estimation [
6], Hellinger distances [
7], copula functions [
8] and empirical likelihood [
9].
In contrast with the above-mentioned methods, TE-based causality tests do not attempt to capture the difference between two conditional distributions explicitly. Instead, with the information theoretical interpretation, the TE offers a natural way to measure directional information transfer and Granger causality. We refer to [
10,
11] for detailed reviews of the relation between Granger causality and directed information theory. However, the direct application of entropy and its variants, though attractive, turns out to be difficult, if not impossible altogether, due to the lack of asymptotic distribution theory for the test statistics. For example, Granger and Lin normalize the entropy to detect serial dependence with critical values obtained from simulations [
12]. Hong and White provide the asymptotic distribution for the Granger–Lin statistic with a specific kernel function [
13]. Barnett and Bossomaier derive a
distribution for the TE at the cost of the model-free property [
14].
On the other hand, to obviate the asymptotic problem, several resampling methods on TE have been developed for providing empirical distributions of the test statistics. Two popular techniques are bootstrapping and surrogate data. Bootstrapping is a random resampling technique proposed by Efron [
15] to estimate the properties of an estimator by measuring those properties from approximating distributions. The “surrogate” approach developed by Theiler et al. [
16] is another randomization method initially employing Fourier transforms to provide a benchmark in detecting nonlinearity in a time series setting. It is worth mentioning that the two methods are different with respect to the statistical properties of the resampled data. For the surrogate method the null hypothesis is maintained, while the bootstrap method does not seek to impose the null hypothesis on the bootstrapped samples. We refer to [
17,
18] for detailed applications of the two methods.
However, not all resampling methods are suitable for entropy-based dependence measures. As Hong and White [
13] put it, a standard bootstrap fails to deliver a consistent entropy-based statistic because it does not preserve the statistical properties of a degenerate
U-statistic [
13]. Similarly, with respect to traditional surrogates based on phase randomization of the Fourier transform, Hinich et al. [
19] criticize the particularly restrictive assumption of linear Gaussian process, and Faes et al. [
20] point out that it cannot preserve the whole statistical structure of the original time series.
As far as we are aware, there are several applications of both methods in entropy-based tests, for example, Su and White [
7] propose a smoothed local bootstrap for entropy-based test for serial dependence, Papana et al. [
21] apply stationary bootstrap in partial TE estimation, Quiroga et al. [
22] use time-shifted surrogates to test the significance of the asymmetry of directional measures of coupling, and Marschinski and Kantz [
23] introduce the effective TE, which relies on random shuffling surrogate in estimation. Kugiumtzis [
24] and Papana et al. [
21] provide some comparisons between bootstrap and surrogate methods for entropy-based tests.
In this paper, we adopt TE as a test statistic for measuring conditional independence (Granger non-causality). Being aware of the fact that the analytical null distribution may not always be accurate or available in an analytically closed form, we resort to resampling techniques for constructing the empirical null distribution. The techniques under consideration include smoothed local bootstrap, stationary bootstrap and time-shifted surrogates, all of which are shown in literature to be applicable to entropy-based test statistics. Using different dependence structures, the size and power performance of all methods are examined in simulations.
The remainder of this paper is organized as follows.
Section 2 first provides the TE-based testing framework and a short introduction to kernel density estimation; then bandwidth selection rules are discussed. After presenting the resampling methods, including the smoothed local bootstrap and time-shifted surrogates for different dependence structure settings.
Section 3 examines the empirical performance of different resampling methods, presenting the size and power of the tests.
Section 4 considers a financial application with the TE-based nonparametric test and
Section 5 summarizes.
3. Simulation Study
In this section, we investigate the performance of the five resampling methods in detecting conditional dependence for several data generating processes. In Equations (9)–(16), we use a single parameter a to control the strength of the conditional dependence. The size assessment is obtained based on testing Granger non-causality from to , and for the power we use the same process but we test for Granger non-causality from to . We set to represent moderate dependence in the size performance investigation and to evaluate the power of the tests. Further, Equation (17) represents a stationary autoregressive process with regime switching, and Equation (18) is included to investigate the power performance in the presence of two-way causal linkages, where the two control parameters are and .
In each experiment, we run 500 simulations for sample sizes . The surrogate and the bootstrap sample size is set to . For fair comparisons between (TS.a) and (TS.b), as well as between (SMB.a) and (SMB.b), we fix the seeds of the random number generator in the resampling functions to eliminate the potential effect of randomness. Besides, we use the empirical standard deviation of as the bootstrapping bandwidth and in the bandwidth equation Equation (7) for the kernel density estimation.
The processes under consideration include a linear vector autoregressive process (VAR) in Equation (9), a nonlinear VAR process in Equation (10), a bivariate ARCH process in Equation (11), a bilinear process in Equation (12), a bivariate AR(2)-GARCH process in Equation (13) where “GARCH” stands for “generalized ARCH”, a bivariate autoregressive-moving average (ARMA)-GARCH process in Equation (14), a bivariate AR(1)-EGARCH process in Equation (15) where “EGARCH” represents “exponential GARCH”, a vector error correction (VECM) process in Equation (16), a threshold AR(1) process in Equation (17), and a two-way VAR process in Equation (18).
It is worth mentioning that the data generating processes in Equations (9)–(12), (17) and (18) are stationary and of finite memory as we assumed earlier. However, it is also important to be aware of the behavior of the proposed non-parametric test for robustness consideration when the two assumptions are not satisfied. The finite memory assumption is violated in Equations (13)–(15) since the GARCH process, being equivalent to an infinite ARCH process, strictly speaking is of infinite Markov order; and the stationarity assumption does not hold in Equation (16) where
and
are cointegrated of order one. Since for the VECM process the two time series
and
are not stationary, we can not directly apply our nonparametric test. In this case, we perform the Engle–Granger approach [
45] first to eliminate the influence of the co-integration, and then perform the nonparametric test on the collected stationary residuals from the linear regression of
and
on a constant and the co-integration term. The procedure is similar to that in [
46].
Linear vector autoregressive process (VAR).
Nonlinear VAR. This process is considered in [
47] to show the failure of linear Granger causality test.
Bilinear process considered in [
48].
Bivariate AR(2)-GARCH process.
Bivariate ARMA-GARCH process.
Bivariate AR(1)-EGARCH process.
VECM process. Note that in this situation both
and
are not stationary.
The empirical rejection rates are summarized in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10. The top panels in each table summarize the empirical rejection rates obtained for the 5% and 10% nominal significance levels for processes (9)–(18) under the null hypothesis, and the bottom panels report the corresponding empirical power under the alternatives. Generally speaking, the size and power are quite satisfactory for almost all combinations of the constant
C, sample size
n and nominal significance level. The performance differences for the various resampling schemes are not substantial.
With respect to the size performance, most of the time we see that the realized rejection rates stay in line with the nominal size. Besides, the bootstrap methods outperform the time-shifted surrogate methods in that their empirical size is slightly closer to the nominal size. Lastly, the size of the tests is not very sensitive to the choice of the constant C apart from the cases for the models given in Equations (13)–(15), where the data generating process has infinite memory.
From the point of view of power, (TS.a) and (SMB.a) seem to outperform their counterparts, yet, the differences are subtle. Along the dimension of the sample size, clearly we see that the empirical power increases in the sample size in most cases. Furthermore, the results are very robust with respect to choices for the constant C in the kernel density estimation bandwidth. For the VAR and nonlinear processes given by Equations (9), (10) and (12) a smaller C seems to give more powerful tests while a larger C is more beneficial for detecting conditional dependence structure in the (G)ARCH processes of Equations 11 and (13)–(15).
Finally,
Table 10 presents the empirical power for the two-way VAR process, where the two variables
and
are inter-tangled with each other. Due to the setting
and
in Equation (18), it is obvious that
is a stronger Granger cause for
than the other way around. As a consequence, the reported rejection rates in
Table 10 are overall higher when testing
than
.
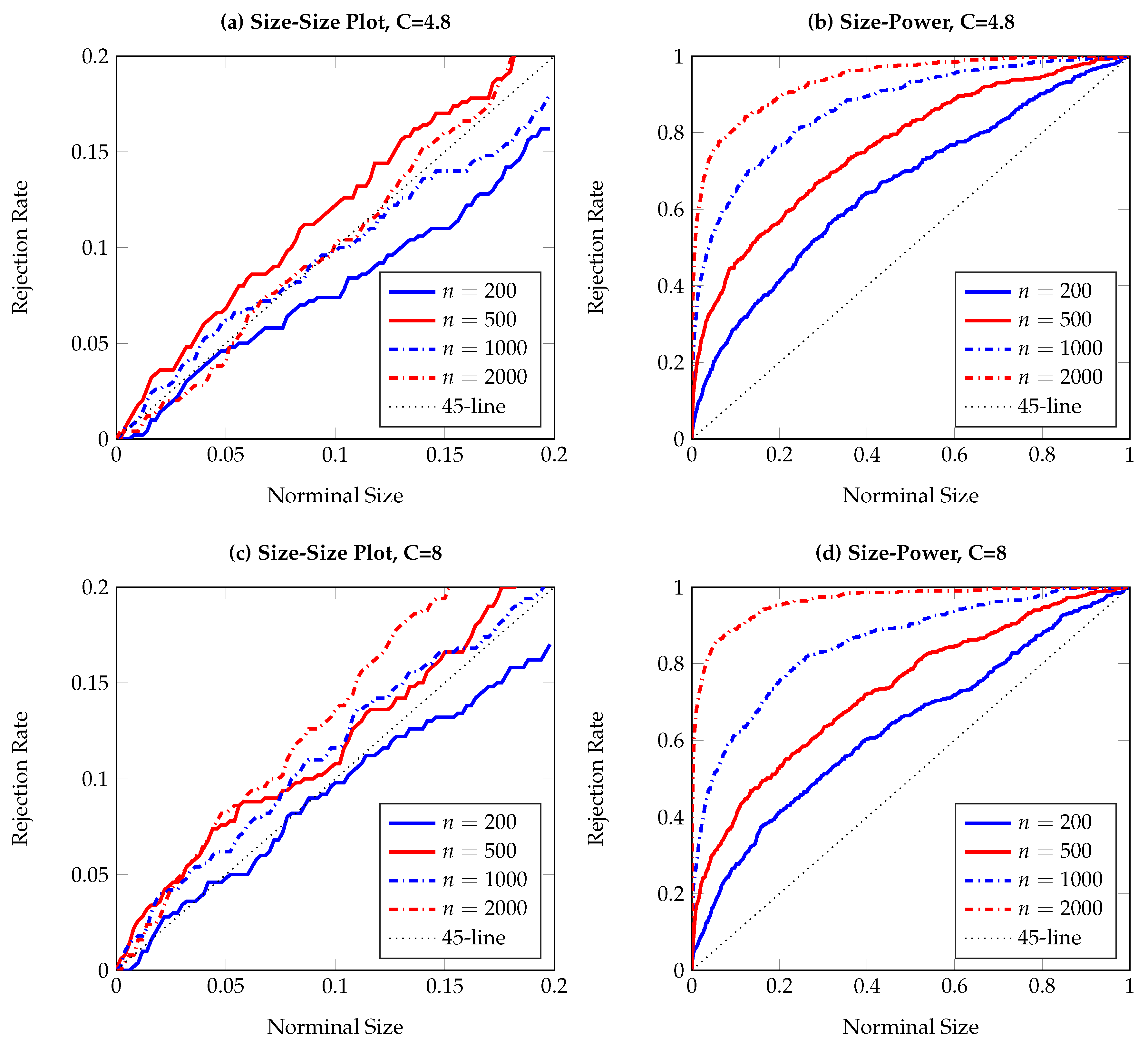
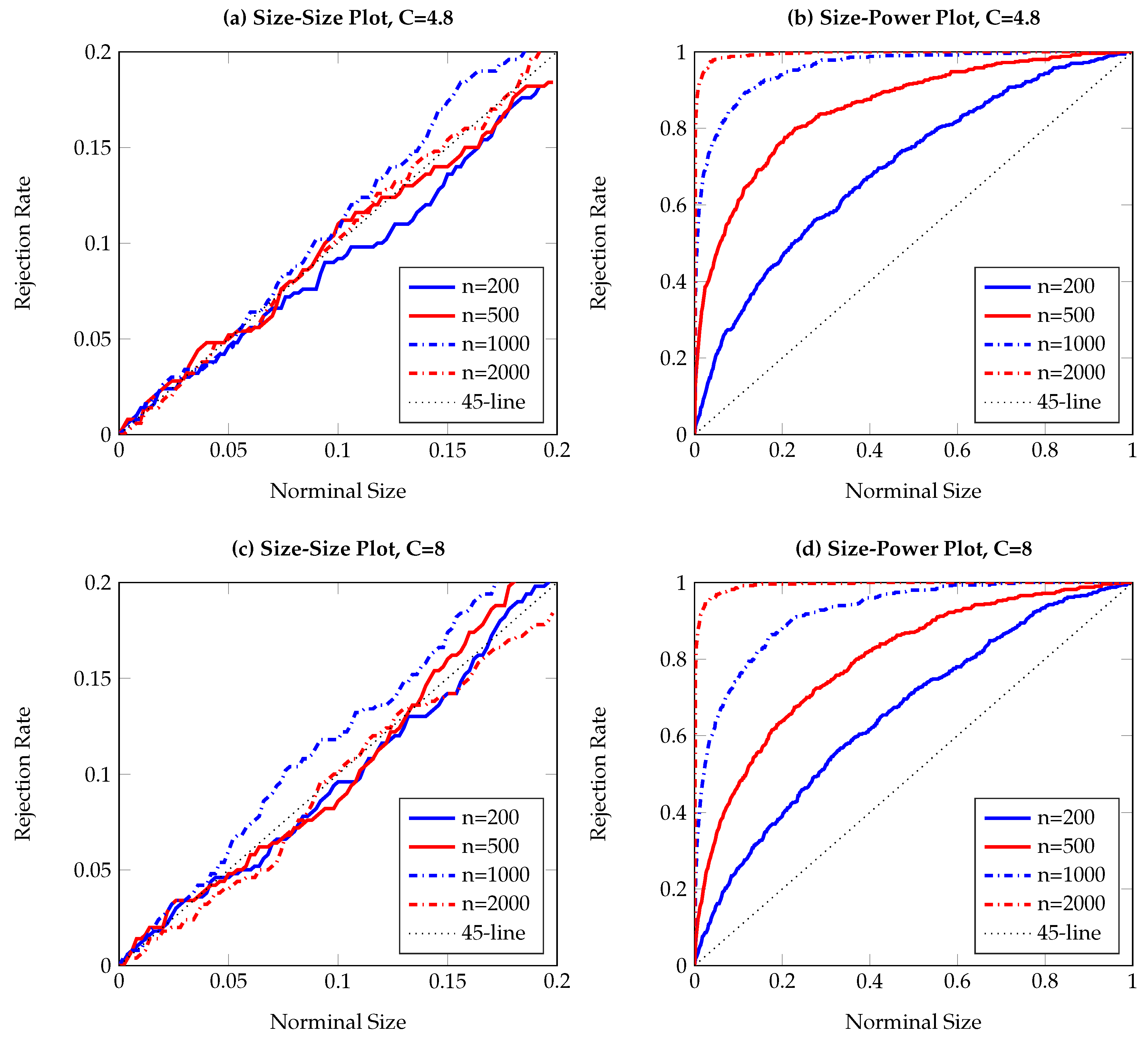
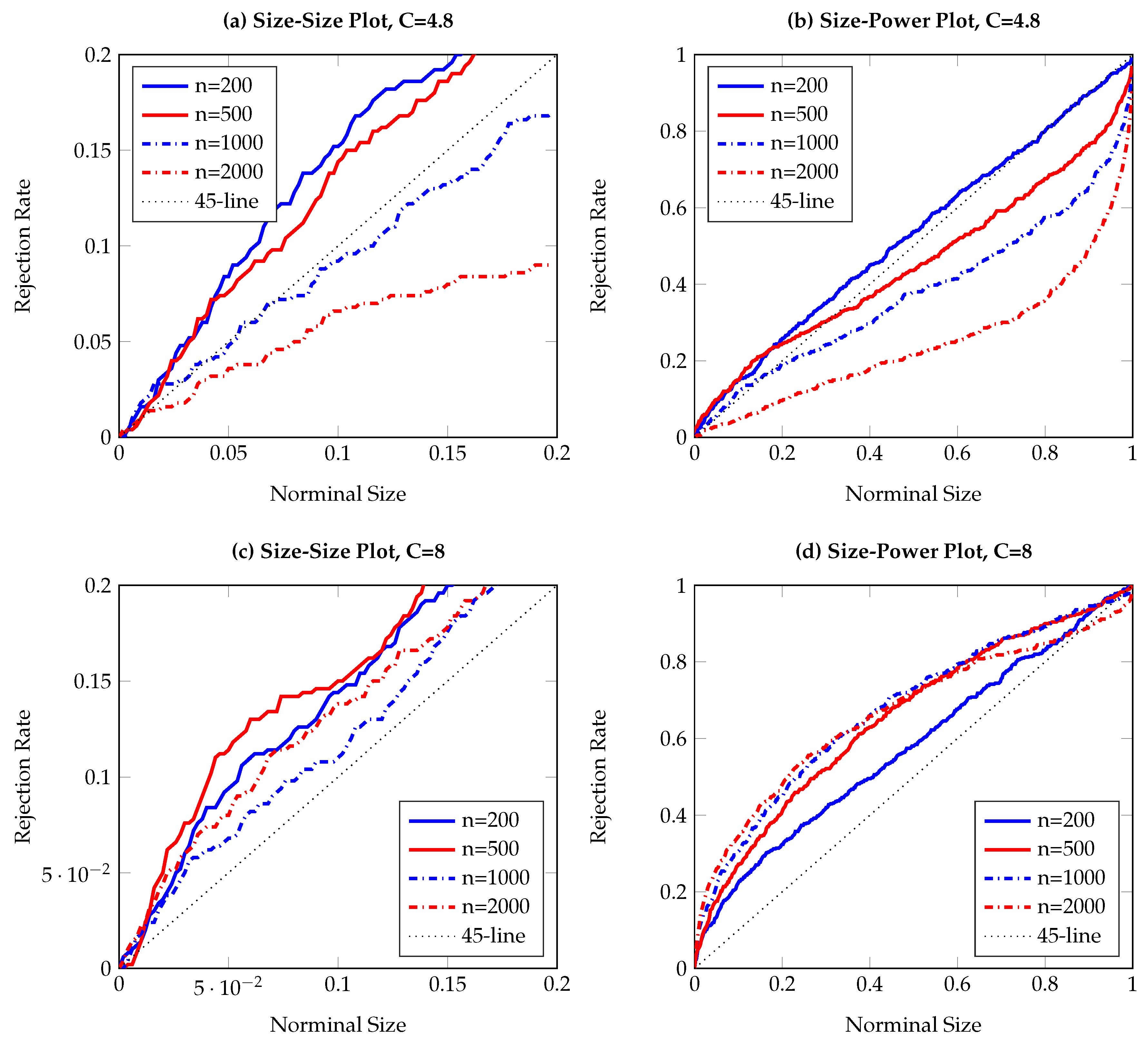
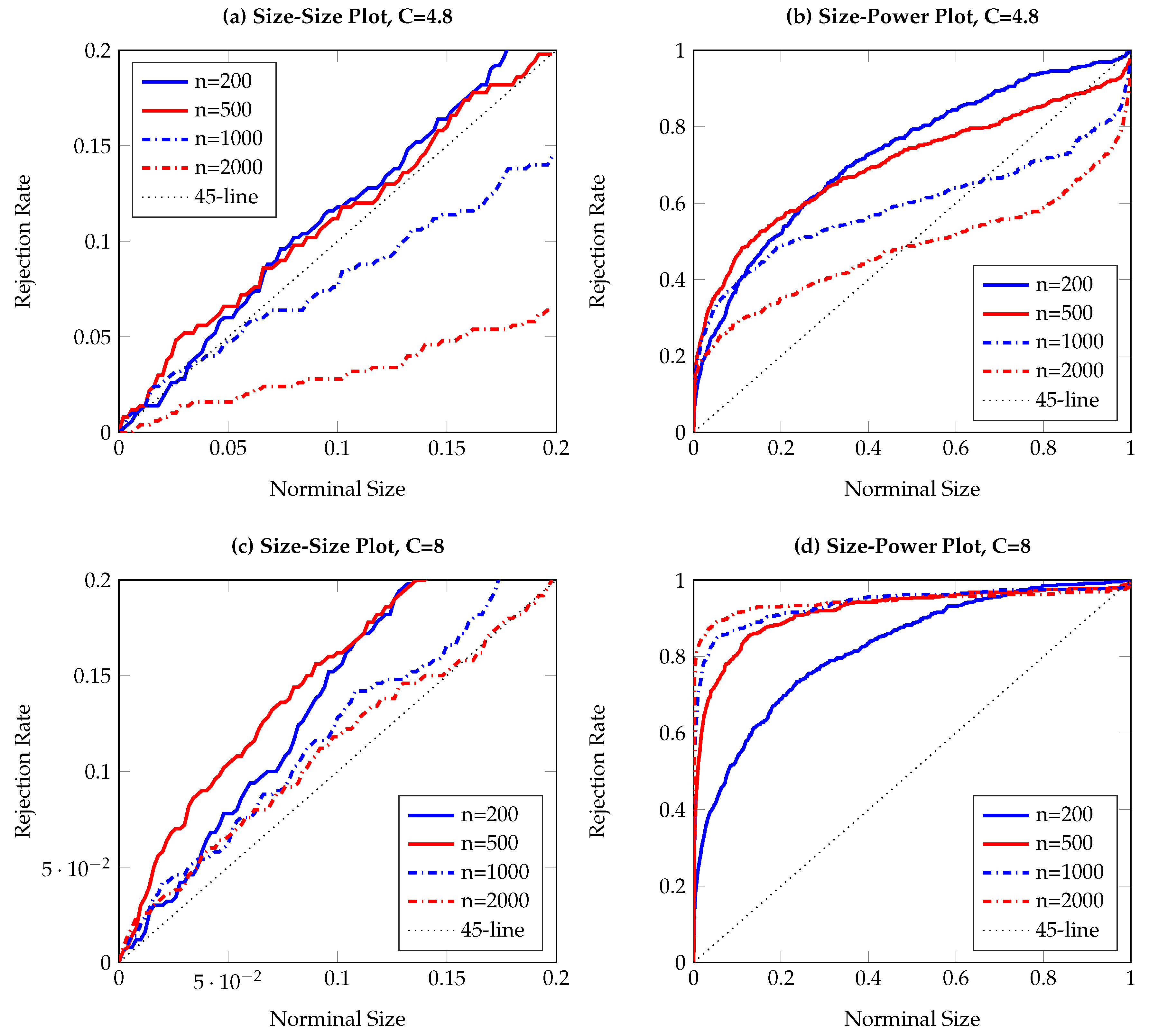
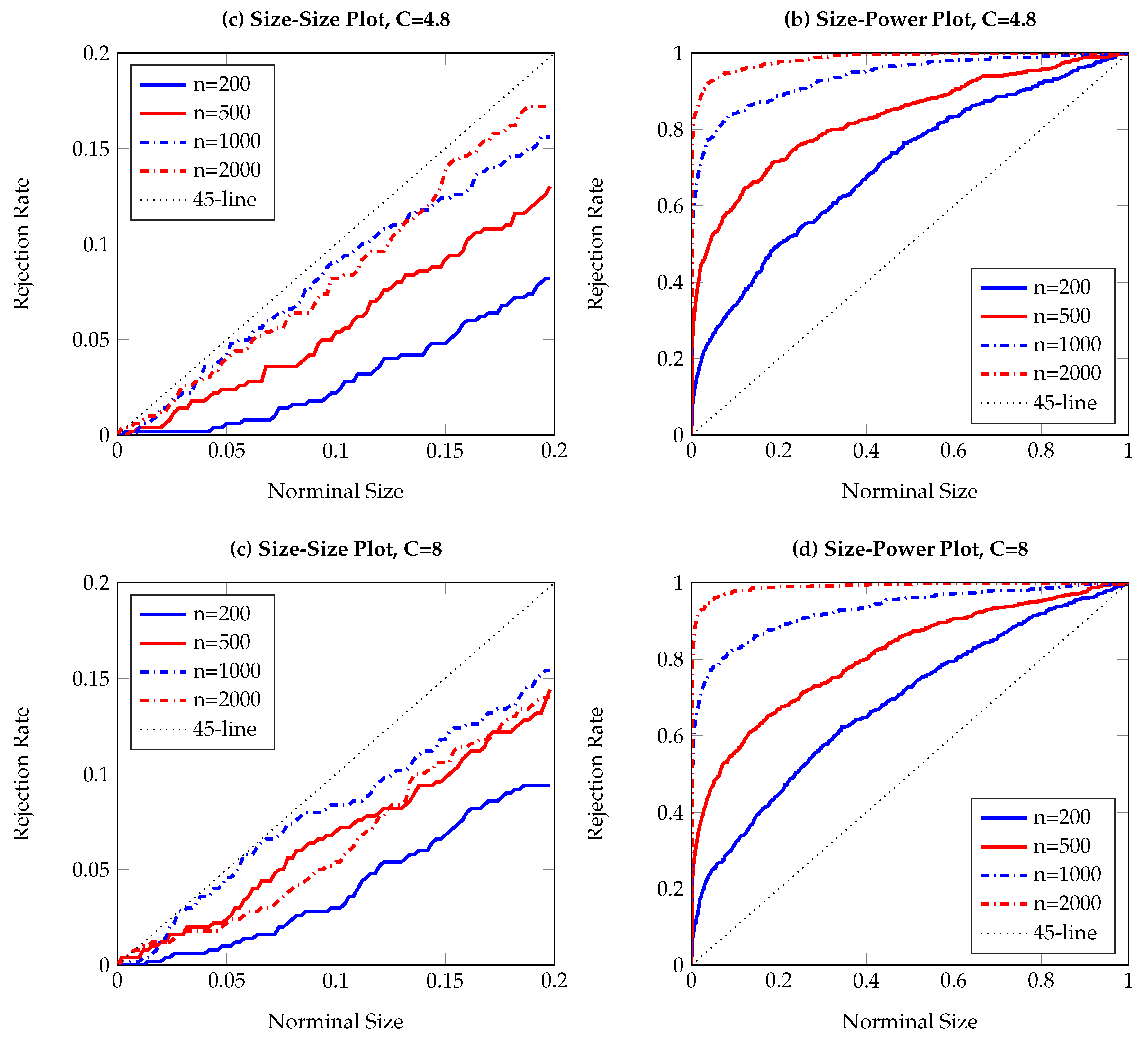
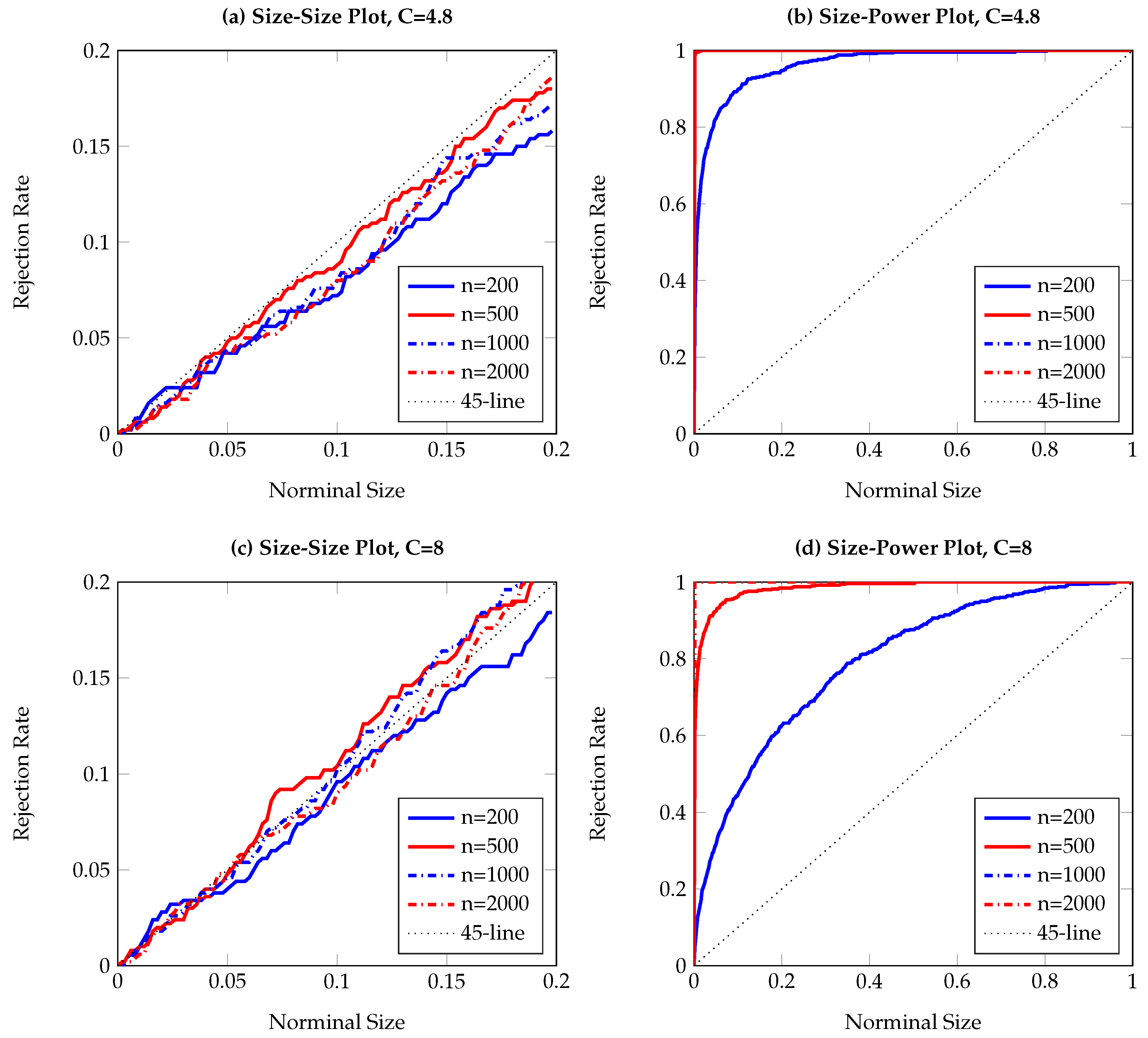
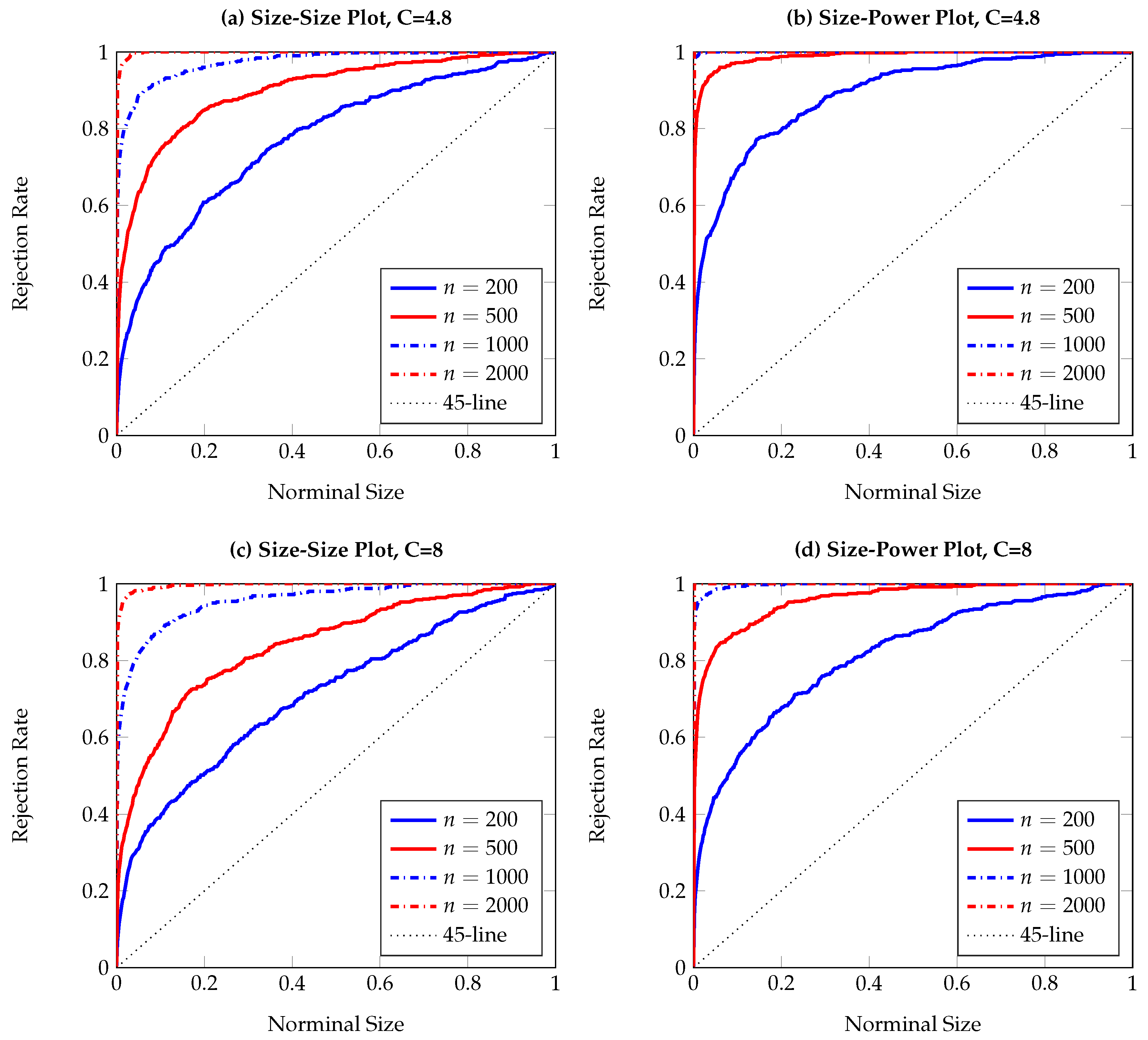
To visualize the simulation results,
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10 report the empirical size and power against the nominal size. Since the performance of the five difference resampling methods is quite similar, we only show the results for (SMB.a) for simplicity. In each figure, the left (right) panels show the realized size (power), and we choose
(
) for the top (bottom) two panels. We can see from the figures that the empirical performance of the TE test are overall satisfactory, apart for those (G)ARCH processes where a small
C may lead to conservative testing size for large sample sizes (see
Figure 3a,
Figure 5a,
Figure 6a and
Figure 7a). The under-rejection problem is caused by the inappropriate choice
, which makes the bandwidth for kernel estimation too small. The influence of an inappropriately small bandwidth can also be seen in
Figure 5b and
Figure 6b, where the test has limited power for the alternative.
4. Application
In this section, we apply the TE-based nonparametric test on detecting financial market interdependence, in terms of both return and volatility. Diebold and Yilmaz [
49] performed a variance decomposition of the covariance matrix of the error terms from a reduced-form VAR model to investigate the spillover effect in the global equity market. More recently, Gamba-Santamaria et al. [
50] extended the framework and considered the time-varying feature in global volatility spillovers. Their research, although providing simple and intuitive methods for measuring directional linkages between global stock markets, may suffer from the limitation of the linear parametric modeling, as discussed above. We revisit the topic of spillovers in the global equity market by the nonparametric method.
For our analysis, we use daily nominal stock market indexes from January 1992 to March 2017, obtained from Datastream, for six developed countries including the US (DJIA), Japan (Nikkei 225), Hong Kong (Hangseng), the UK (FTSE 100), Germany (DAX 30) and France (CAC 40). The target series are weekly return and volatility for each index. The weekly returns are calculated in terms of diffferenced log prices multiplied by 100, from Friday to Friday. Where the price for Friday is not available due to a public holiday, we use the Thursday price instead.
The weekly volatility series are generated following [
49] by making use of the weekly high, low, opening and closing prices, obtained from the underlying daily high, low, opening and closing data. The volatility
for week
t is estimated as
where
is the Monday-Friday high,
is the Monday–Friday low,
is the Monday-Friday open and
is the Monday-Friday close (in natural logarithms multiplied by 100). Futher, after deleting the volatility estimates for the New Year week in 2002, 2008 and 2013 due to the lack of observations for Nikkei 225 index, we have 1313 observations in total for weekly returns volatilities. The descriptive statistics, Ljung Box (LB) test statistics and Augmented Dickey Fuller (ADF) test statistics for both series are summarized in
Table 11. From the ADF test results, it is clear that all time series are stationary for further analysis (we also performed the Johansen cointegration test pair-wisely on the price levels and no cointegration was found for the six market indexes.).
We firstly provide a full-sample analysis of global stock market return and volatility spillovers over the period from January 1992 to March 2017, summarized in
Table 12 and
Table 13. The two tables report the pairwise test statistics for conditional independence between index
X and index
Y, given the constant
C in the bandwidth for kernel estimation is
or 8 and 999 resampling time series. In other words, we test for the absence of the one-week-ahead directional linkage from index
X to
Y by using the five resampling methods described in
Section 2. For example, the first line in the top panel in
Table 12 reports the one-week-ahead influence of DJIA returns upon other indexes by using the first time-shifted surrogates method (TS.a). Given
, DJIA return is shown to be a strong Granger cause for Nikkei, FTSE and CAC at the 1% level, and for DAX at the 5% level.
Based on
Table 12 and
Table 13, we may draw several conclusions. Firstly, the US index and German index are the most important return transmitters and Hong Kong is the largest source for volatility spillover, judged by the numbers of significant linkages. Note that this finding is similar as the result in [
49], where the total return (volatility) spillovers from US (Hong Kong) to others are found to be much higher than from any other country.
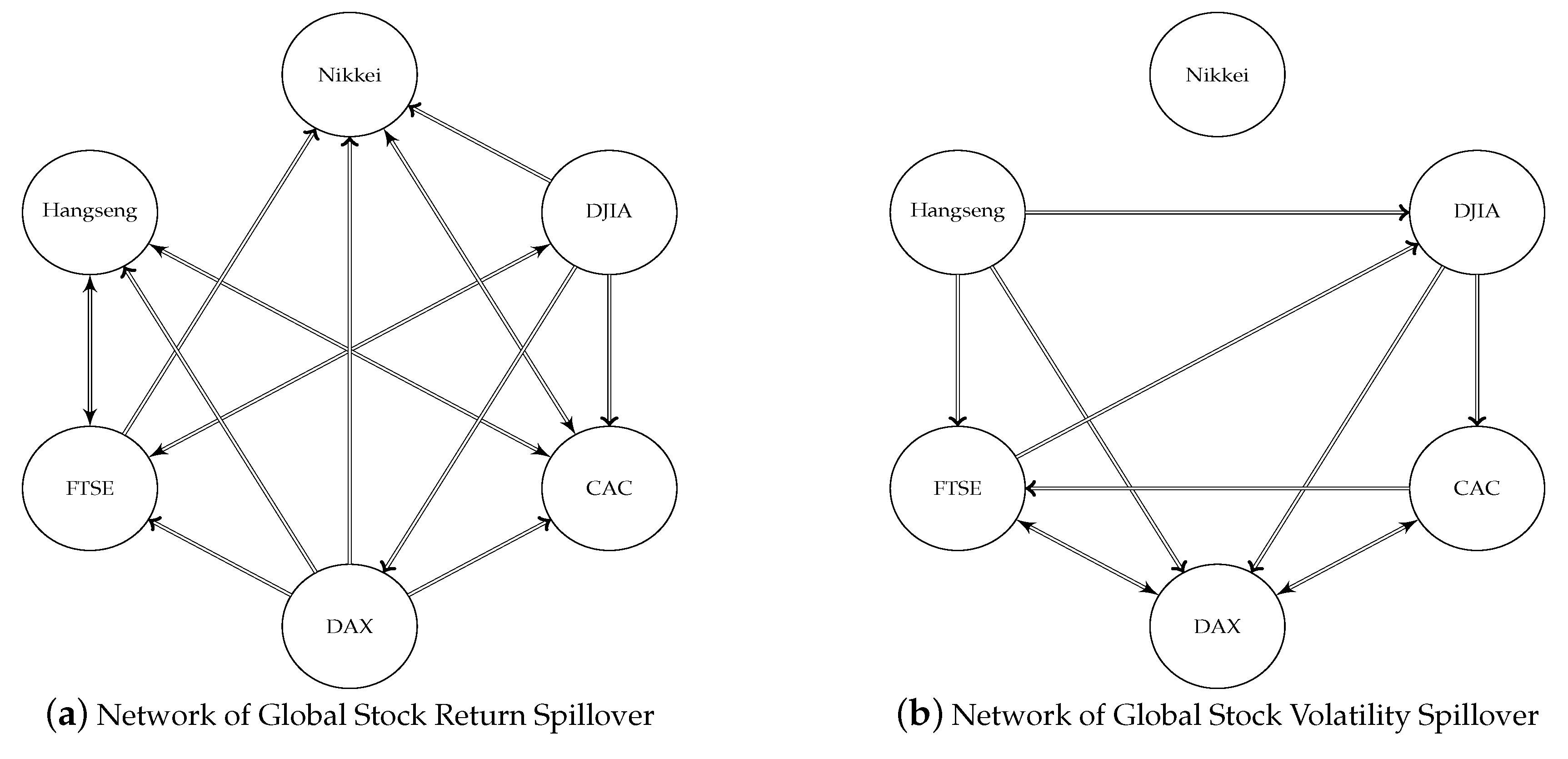
Figure 11 provides a graphical illustration of the global spillover network based on the result of (SMB.a) from
Table 12 and
Table 13. Apart from the main transmitters, we can clearly see that Nikkei and CAC are the main receivers in the global return spillover network, while DAX is the main receiver of global volatility transmission.
Secondly, the result obtained is very robust, no matter which re-sampling method is applied. Although the differences between the five resampling methods are small, (TS.a) is seen to be slightly more powerful than (TS.b) in
Table 12. The three different bootstrap methods are very consistent almost all the time, similarly to what we observed in
Section 3.
However, the summary results in
Table 12 and
Table 13 are static in the sense that they do not take into account possible time-variation. The statistics are measurements for averaged-out directional linkages over the whole period from 1992 to 2017. The conditional dependence structure of the time series, at any point in time, can be very different. Hence, the full-sample analysis is very likely to oversee the cyclical dynamics between each pair of stock indices. To investigate the dynamics in the global stock market, we now move from the full-sample analysis to a rolling-window study. Considering a 200-week rolling window starting from the beginning of the sample and admitting a 5-week forward step for the iterative evaluation of the conditional dependence, we can assess the variation of the spillover in the global equity market over time.
Taking the return series of the DJIA as an illustration, we iteratively exploit the local smoothed bootstrap method for detecting Granger causality from and to the DJIA return in
Figure 12 (all volatility series are extremely skewed, see
Table 11. In a small sample analysis, the test statistics turn out to be sensitive to the clustering outliers, which typically occur during the market turmoil. As a result, the volatility dynamics are more radical and less informative than that of returns). The red line represents the
p-values for the TE-based test on DJIA weekly return as the information transmitter while the blue line shows the
p-values associated with testing on DJIA as a receiver of information spillover on a weekly basis from others. The plots displays an event-dependent pattern, particularly for the recent financial crisis; from early 2009 until the end of 2012, all pairwise tests show the presence of a strong bi-directional linkage. Besides, the DJIA is strongly leading the Nikkei, Hangseng and CAC during the first decade of this century.
Further, we see that the influence from other indices to the DJIA are different, typically responding to economics events. For example, the blue line in the second panel of
Figure 12 plunges below the 5% level twice before the recent financial crisis, meaning that the Hong Kong Hangseng index causes fluctuations in the DJIA during those two periods; first in the late 90’s and again by the end of 2004. The timing of the first fall matches the 1997 Asian currency crisis and the latter one was in fact caused by China’s austerity policy in October 2004.
Finally, the dynamic plots provide additional insights into the sample period that the full sample analysis may omit. The DAX and CAC are found to be less relevant for future fluctuations in the weekly return of the DJIA, according to
Table 12 and
Figure 11. However, one can clearly see that since 2001, the
p-values for DAX→DJIA and CAC→DJIA are consistently below 5% for most of the time, suggesting an increase of the integration of global financial markets.
5. Conclusions
This paper provides guidelines for the practical application of TE in detecting conditional dependence, i.e., Granger causality in a more general sense, between two time series. Although there already is a tremendous literature that tried to apply the TE in this context, the asymptotics of the statistic and the performance of the resampling-based measures are still not understood well. We have considered tests based on five different resampling methods, all of which were shown in the literature to be suitable for entropy-related tests, and investigated the size and power of the associated tests numerically. Two time-shifted surrogates and three smoothed bootstrap methods are tested on simulated data from several processes. The simulation results in this controlled environment suggest that all five measures achieve reasonable rejection rates under the null as well as the alternative hypotheses. Our results are very robust with respect to the density estimation method, including the procedure used for standardizing the location and scale of the data and the choice of the bandwidth parameter, as long as the convergence rate of the kernel estimator of TE is consistent with its first order Taylor expansion.
In the empirical application, we have shown how the proposed resampling techniques can be used on real world data for detecting conditional dependence in the data set. We use global equity data to carry out the detection in pairwise causalities in the return and volatility series among the world leading stock indexes. Our work can be viewed as a nonparametric extension of the spillover measures considered by Diebold and Yilmaz [
49]. In accordance with them, we found evidence that the DJIA and the DAX are the most important return transmitters and Hong Kong is the largest source for volatility spillover. Furthermore, the rolling window-based test for Granger causality in pairwise return series demonstrated that the causal linkages in the global equity market are time-varying rather than static. The overall dependence is more tight during the most recent financial crisis, and the fluctuations of the
p-values are shown to be event dependent.
As for future work, there are several directions for potential extensions. On the theoretical side, it would be practically meaningful to consider causal linkage detection beyond the single period lag and to deal with the infinite order issue in a nonparametric setting. Further nonparametric techniques need to be developed to play a similar role as the information criterion does for order selection of an estimation model in the parametric world. On the empirical side, it will be interesting to further exploit entropy-based statistics in testing conditional dependence when there exists a so-called common factor, i.e., looking at multivariate systems with more than two variables. One potential candidate for this type of test in the partial TE has been coined by Vakorin et al. [
51], but its statistical properties still need to be thoroughly studied yet.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}