1. Introduction
With the rapid rise of various wireless technologies, wireless transmissions have been widely developed in various fields such as mobile communications and satellite communication systems [
1,
2]. However, the signal might be distorted due to the diffraction, refraction, reflection or deviation from obstacles such as buildings, mountains and so on, resulting in transmission delays and other adverse effects. In the wireless communication transmission channels, the selective fading will lead to delays, which is also known as multi-path effects. In fact, the multi-path channel is always sparse [
3,
4,
5], which means that most of the channel impulse response (CIR) coefficients are small while only a few of them are large in magnitude [
6]. Since the CIR is sparse, many channel estimation algorithms have been presented to utilize this characteristic to improve the communication quality [
2,
7]. It is known that the adaptive filtering (AF) algorithm can be used for implementing channel estimation. Thus, various AF algorithms have been reported and used for channel estimation. Among these AF algorithms, the most typical algorithm is the least mean square (LMS) which is invented by B. Widrow. The LMS algorithm has been extensively investigated in channel estimation and noise cancellation owing to its simple implementation, high stability and fast convergence speed [
4,
8]. However, its performance is not satisfactory for sparse channel estimation with a low signal to noise ratio (SNR).
Recently, the compressive sampling (CS) concept has been introduced into AF algorithms to handle the sparse signals [
9,
10]. After that, Y. Chen et al. put forward to the zero attracting LMS (ZA-LMS) and reweighting ZA-LMS (RZA-LMS) algorithms [
11]. ZA-LMS and RZA-LMS algorithms are implemented by integrating
-norm and reweighting
-norm into the LMS’s cost function, respectively. These two algorithms achieve lower steady-error and faster convergence speed than that of the basic LMS algorithm for handling sparse signals owing to the constructed zero attractors. Moreover,
-norm and
-norm have also been employed and introduced into the LMS’s cost function to improve the performance of the ZA- and RZA-LMS algorithms in the sparse signal processing area [
12,
13,
14,
15,
16]. All of those norm-constrained LMS algorithms can effectively exploit sparse characteristics of the in-nature sparse channels. However, they have a common drawback, i.e., their sensitivity to the input signal scaling (ISS) and noise interferences. In order to reduce the effects of the ISS, several improved AF algorithms have been presented by using high order error criteria or mixed error norms such as least mean fourth (LMF), least mean squares-fourth (LMS/F) and so on [
17,
18,
19,
20]. Similarly, their related sparse forms have also been developed based on the above mentioned norm penalties [
17,
21,
22,
23,
24,
25,
26,
27]. However, those AF algorithms and their related sparse forms are not good enough for dealing with the sparse channel under non-Gaussian or mixed noise environments.
In recent years, information theoretic quantities were used for implementing cost function in adaptive systems. The effective entropy-based AF algorithms include the maximum correntropy criterion (MCC) and the minimum error entropy (MEE) [
28,
29,
30,
31,
32]. In [
28], it is shown that the MEE is more complex than the MCC algorithm in the computational overhead. Therefore, the MCC algorithm has been extensively developed in non-Gaussian environments [
29,
31,
32]. Furthermore, the MCC has low complexity which is nearly the same as that of the LMS-like algorithms. However, the performance of the MCC algorithm may be degraded for sparse signal processing. In order to enhance the MCC algorithm for handling sparse signal and sparse system identification,
-norm and reweighting
-norm constraints have been exerted on the channel coefficient vector and integrated into the MCC’s cost function. Similar to the ZA-LMS and RZA-LMS algorithms, the zero attracting MCC (ZA-MCC) and reweighting ZA-MCC (RZA-MCC) algorithms [
33] were obtained within the zero attracting framework. Then, the normalized MCC (NMCC) algorithm was also presented [
34,
35] by referring to the normalized least mean square (NLMS) algorithm. Recently, W. Ma proposed a correntropy-induced metric (CIM) penalized MCC algorithm in [
33], and Y. Li presented a soft parameter function (SPF) constrained MCC algorithm [
34]. The CIM and SPF are also one kind of
-norm approximation to form sparse MCC algorithms, and the SPF-MCC is given in the appendix. As for these improved MCC algorithms, the
-norm, CIM and SPF penalties are incorporated into the MCC’s cost function to devise desired zero attractors. In the ZA-MCC algorithm, the zero attractor gives uniform penalty on all the channel coefficients, while the
-norm approximation MCC algorithms will increase the complexity.
In this paper, a group-constrained maximum correntropy criterion (GC-MCC) algorithm based on the CS concept and zero attracting (ZA) techniques is proposed in order to fully exploit the sparseness characteristics of the multi-path channels. The GC-MCC algorithm is derived by incorporating a non-uniform norm into the MCC’s cost function and the non-uniform norm is split into two groups according to the mean of the magnitudes of the channel coefficients. For the large channel coefficients group, the -norm penalty is used, while the -norm penalty is implemented for the small channel group. Then, a reweighting technique is utilized in the GC-MCC algorithm to develop the reweighted GC-MCC (RGC-MCC) algorithm. The performance of the GC- and RGC-MCC algorithms is evaluated and discussed for estimating mix-noised sparse channels. The GC- and RGC-MCC algorithms achieve superior performance in both steady-error and convergence for sparse channel estimations with different sparsity levels. Simulation results show that the GC- and RGC-MCC algorithms can effectively enhance the sparse channel estimation by using the proposed group constraints and can provide smaller steady-state errors and faster convergence for application in a mixed noise environment.
The structure of this paper is summarized as follows. In
Section 2, the MCC and its related sparse algorithms are briefly reviewed.
Section 3 introduces the GC-MCC and RGC-MCC algorithms, and mathematically derives them. In
Section 4, simulations that show the effectiveness of the proposed GC-MCC and RCG-MCC algorithms are presented. Finally, our work is summarized in
Section 5.
2. Review of the MCC and Its Related Sparse Algorithms
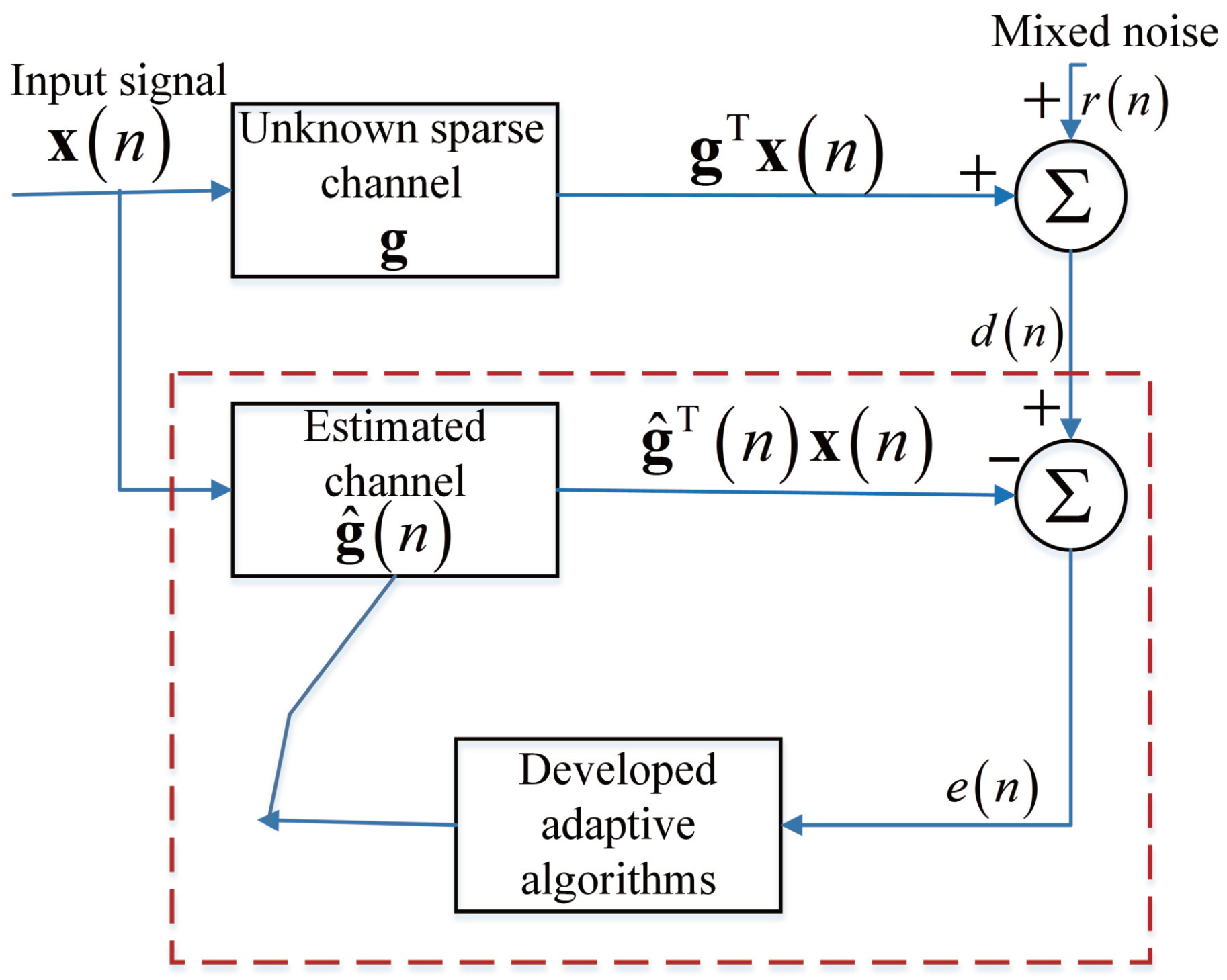
We consider a typical channel estimation system based on the MCC algorithm, which is given in
Figure 1.
is the input training signal with a length of
M, which is surveyed to an unknown sparse channel whose vector form is
. As a sparse channel, most of the channel coefficients in the unknown sparse channel
are zeros or near-zeros. Herein, we use
K to represent the number of nonzero coefficients in the unknown sparse channel
. Then, the desired signal can be written as
where
is a mixed Gaussian noise which is independent of the input training signal
. Moreover, the instantaneous estimation error at
n-th iteration is defined as
where
denotes the estimated channel vector. The MCC-based channel estimation is to obtain the minimization of the iterative instantaneous estimation error
, and hence, we can estimate the unknown sparse channel
.
The MCC algorithm is using the localized similarity to solve the following problem
where
, and
is a trade off parameter. Additionally,
represents the Euclidean norm [
36], and
, where
is the step-size of the MCC algorithm. Based on Equation (
3), we can write MCC’s cost function as
where
is the multiplier parameter. By utilizing the Lagrange multiplier method (LMM), we can obtain the partial derivatives of
and
in Equations (
5) and (
6)
Substituting (
7) into (
5), the updating equation with the vector formed of the MCC algorithm is
It can be seen that the recursion of the MCC algorithm is similar to the LMS algorithm, except the exponential term. Similarly, the MCC algorithm does not utilize the intrinsic sparsity property of the sparse channels. Motivated by the ZA-LMS and RZA-LMS algorithms, sparse MCC algorithms have been presented and they are named as zero attracting MCC (ZA-MCC) and reweighting ZA-MCC (RZA-MCC) [
33]. For the ZA-MCC algorithm, it is implemented by integrating a
-norm into MCC’s cost function, and solving [
33]
where
is the
-norm, and a regularization parameter
is used for controlling its ability. Based on the LMM, the ZA-MCC’s cost function is [
33]
where
is the multiplier parameter of the ZA-MCC algorithm. By using LMM, the updating Equation of the ZA-MCC algorithm is [
33]
where
is a zero attracting ability controlling parameter that is used for giving a tradeoff between the estimation error and
-norm constraint, and
is the step-size of the ZA-MCC algorithm. However, we noticed that the zero attraction term
uniformly attracts all the channel coefficients to zero. Therefore, its performance might be degraded when it deals with less sparse channels. Then, a reweighting factor is introduced into the zero attraction term
, resulting in a RZA-MCC algorithm whose updating equation is [
33]
where
,
and
are the reweighting controlling factor, zero attraction controlling parameter and the RZA-MCC’s step-size, respectively. It can be seen from the upgrading equation that
acts as the zero attractor which exerts different zero attraction to the channel coefficients that depends on their magnitudes.
3. The Proposed Group-Constrained Sparse MCC Algorithms
From the above discussion, we found that the zero attractor
is realized by incorporating the
-norm penalty in the MCC’s cost function, and it can speed up the convergence and reduce the channel estimation error. Moreover, the
-norm-constrained MCC algorithm can further improve the performance since the
-norm can count the number of the non-zero channel coefficients. However, the complexity is significantly increased due to the calculation of the
-norm approximation and its constraint. In order to fully exploit the sparsity property of the multi-path channel, we propose a group-constrained MCC algorithm by exerting the
-norm penalty on the group of large channel coefficients and forcing the
-norm penalty on the group of small channel coefficients. Herein, a non-uniform norm is used to split the non-uniform penalized algorithms into a large group and a small group, and the non-uniform norm is defined as [
37,
38]
which is a
-norm when
and it is a
-norm when
p is infinitely close to 1
Herein, the uniform-norm given in Equation (
13) is a variable norm which is controlled by the parameter
p. When
p is very close to zero, the proposed norm in Equation (
13) can be regarded as a
-norm. As for
1, the norm in Equation (
13) is the
-norm. Then, the constructed non-uniform norm in Equation (
13) is introduced into the MCC’s cost function to devise our proposed GC-MCC algorithm, and GC-MCC is to solve
where
is a kind of
, which uses a different value of
p for each channel coefficient at
M-th position in the sparse channels, here with the introduction of
, and
is a regularization parameter. Then, the cost function of the GC-MCC algorithm is
In Equation (
17),
is a multiplier. Based on the LMM, the gradients of
with respect to
and
are
and
Then, we can get
and
where
is the
i-th element of matrix
. From Equations (
20) and (
21), we can obtain
Substituting
into Equation (
20), the updated equation of the proposed GC-MCC algorithm is
where
is a step-size for GC-MCC algorithm. It can be seen from Equation (
23), the matrix
can assign different
to each channel coefficients. To better exert the
to the channel coefficients, the channel coefficients are classified according to their magnitudes. From the measurement and the previous investigations of the sparse channels [
2,
6,
7,
10,
11,
12,
13,
14,
15,
16,
21,
22,
23,
24,
26,
27], we found that few channel coefficients are active non-zero ones, while most of the channel coefficients are inactive zero or near-zero ones. Thus, we propose a threshold to categorize the channel coefficients into two groups. Herein, a classify criterion which is used as the threshold is proposed based on the absolute value expectation of
and it is defined as
Then, we categorize the channel coefficients into two groups in terms of the criterion in (
24). When the channel coefficients
, the channel coefficients belong to the “large” group, while
, the channel coefficients are located in the “small” group. In fact, a threshold is proposed to split the variable norm into the “large” group and the “small” group, where the threshold is implemented using the mean of the estimated channel coefficients. If the channel coefficients are greater than this threshold, they are the “large” group. Otherwise, the channel coefficients belong to the “small” group when the channel coefficients are smaller than this threshold. For the “large” group,
-norm penalty is used to count the number of active channel coefficients, and
-norm penalty is adopted to uniformly attract inactive coefficients to zero for the “small” group. To effectively integrate these two groups into (
23), we define [
37]
Therefore,
is set to be 0 when
, while
will be 1 for
. Finally, the updated equation of the GC-MCC is
In Equation (
26),
is far less than 1, so it can be ignored. Thus, the updating recursion of the GC-MCC algorithm is rewritten as
The last term
is the proposed zero attraction term which exerts different zero attracting on the two grouped channel coefficients. We can see that both the
-norm and
-norm constraints are implemented on the channel coefficients in the GC-MCC algorithm, which is different from the ZA-MCC and
-MCC algorithms. For the GC-MCC channel estimation, our proposed zero attractor can distinguish the value of coefficients and categorize the channel coefficients into two groups. The proposed GC-MCC algorithm can achieve small steady-state error and fast convergence due to the term
.
To further enhance the performance of our proposed GC-MCC algorithm, a reweighting factor is introduced into the GC-MCC’s update equation to implement the RGC-MCC algorithm, which is similar to the RZA-LMS algorithm. Thus, the RGC-MCC’s updating equation is
where
is the zero attraction controlling parameter,
is the reweighting controlling parameter and
is a step-size of the RGC-MCC algorithm.
With the help of
, our proposed RGC-MCC algorithm can assign well different values
to channel coefficients according to the magnitudes of the channel coefficients. Moreover, we can properly select the value of
to obtain a better channel estimation performance. In fact, the proposed GC-MCC and RZA-GC-MCC algorithms are the extension of the ZA-MCC and RZA-MCC algorithms. However, the proposed GC-MCC and RGC-MCC are different with the proposed ZA-MCC, RZA-MCC and
-norm penalized MCC algorithms. Our contributions are summarized herein. The GC-MCC algorithm is realized by incorporating a variable norm in Equation (
13) into the cost function of the traditional MCC algorithm, where the variable norm is controlled by the parameter
p. To distinguish the large channel coefficients and the small channel coefficients, a mean of the estimated channel coefficients shown in Equation (
24) is proposed to provide a threshold. Then, the variable norm is split into two groups by comparing the channel coefficients with the threshold. As a result, a large group is given when
, while a small group is created when
. For the channel coefficients in the large group, we use a
-norm to count the number of the non-zero channel coefficients. As for the channel coefficients in the small group,
-norm penalty is used for attracting the zero or near-zero channel coefficients to zero quickly. It is found that a norm penalty matrix with values in its diagonal is proposed in Equation (
25) to implement the
and
in the GC-MCC algorithm, which is also different with the conventional
- and
- norm constraints. Then, we use a reweighting factor to enhance the zero attracting ability in the GC-MCC algorithm to generate the RGC-MCC algorithm. Both the GC-MCC and RGC-MCC algorithms are developed to exploit well the inherent sparseness properties of the multi-path channels due to the expected zero-attraction terms in their iterations. The channel estimation behaviors will be discussed over sparse channels in mixed Gaussian noise environments in the next section.
4. Computational Simulations and Discussion of Results
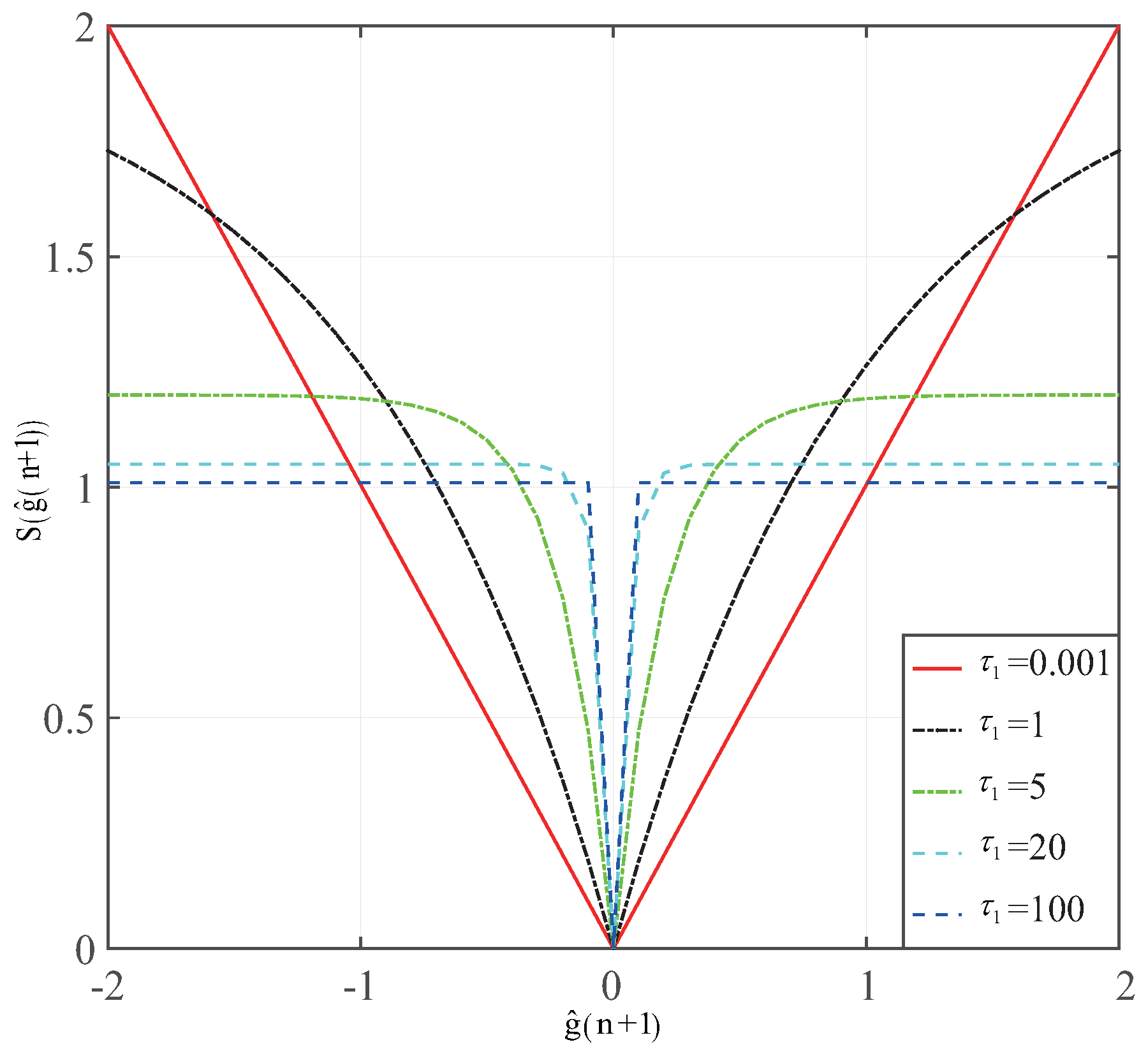
In this section, we will construct several experiments to verify the GC- and RGC-MCC’s channel estimation performance. The steady-state channel estimation error and the convergence are considered to give an evaluation of the proposed GC- and RGC-MCC algorithms. The results are also compared with the MCC, NMCC, ZA-, RZA- and SPF-MCC algorithms. From the discussion, we know that the CIM and SPF are
-norm approximations. Thus, we first set up an experiment to discuss the zero attraction ability of the CIM, SPF and
-norm approximation. The zero attraction ability of these
-norm approximations is shown in
Figure 2. The related parameters in these
-norm approximations are
,
and
. It can be seen that the zero attraction ability of the SPF is close to the
-norm for larger
, while the zero attraction ability of the CIM approximates to
-norm when
is small. From these results, we found that the SPF can give an accurate approximation and can provide a better zero attraction when
and
. For
and
, the zero attraction ability of SPF is weak. However, it can give an adaption for a wider range of sparse channel estimation applications. It can be concluded that the zero attraction ability of the zero attractor produced by SPF is superior. Thus, we will choose SPF-MCC to give a comparison with our proposed GC-MCC and RGC-MCC algorithms in terms of the steady-state error and convergence.
All of the experiments are constructed under a mix-Gaussian noise environment, and the mixed noise model has been used in the previous study and is a better description of the real wireless communication environment. The mixed noise model is given by [
34,
36]
where
represent the Gaussian distribution, and parameters
,
and
are the means, variances and mixing parameter, respectively. In all the experiments, we set
. The estimated performance of our proposed GC-MCC and RGC-MCC algorithms is given by mean square deviation (MSD), which is defined as
For all the simulations, 300 Monte Carlo runs are performed for obtaining each point in all mentioned algorithms. Herein, the total length of the unknown channel is
and the number of the non-zero channel coefficients is
K. The signal-to-noise ratio (SNR) is 30 dB. Those non-zero channel coefficients are randomly distributed within the length of the channel. Since the regularization parameters have an important effect on the performance of the proposed GC-MCC and RGC-MCC algorithms, the effects of regularization parameters
,
and
are investigated and given in
Figure 3,
Figure 4 and
Figure 5.
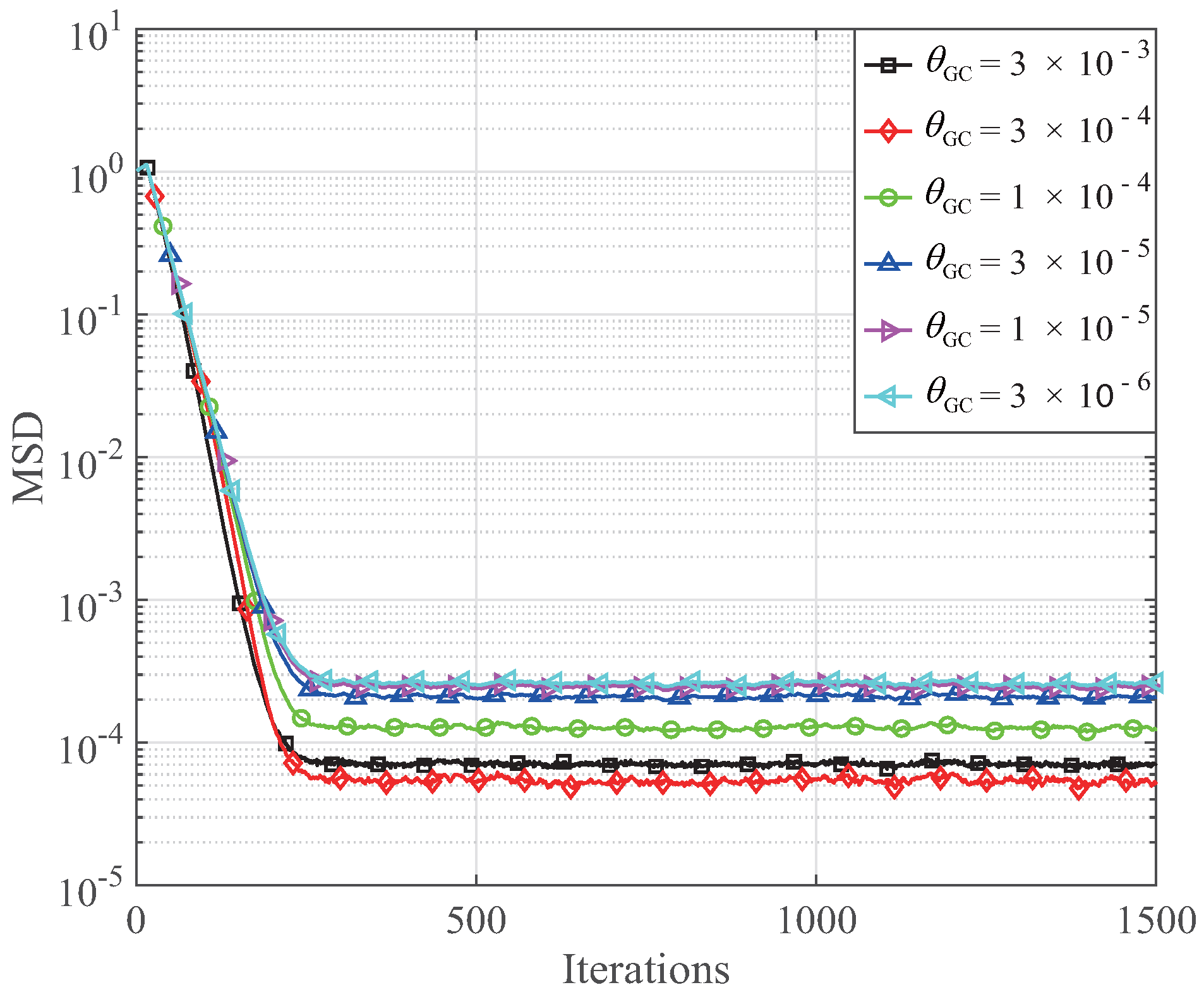
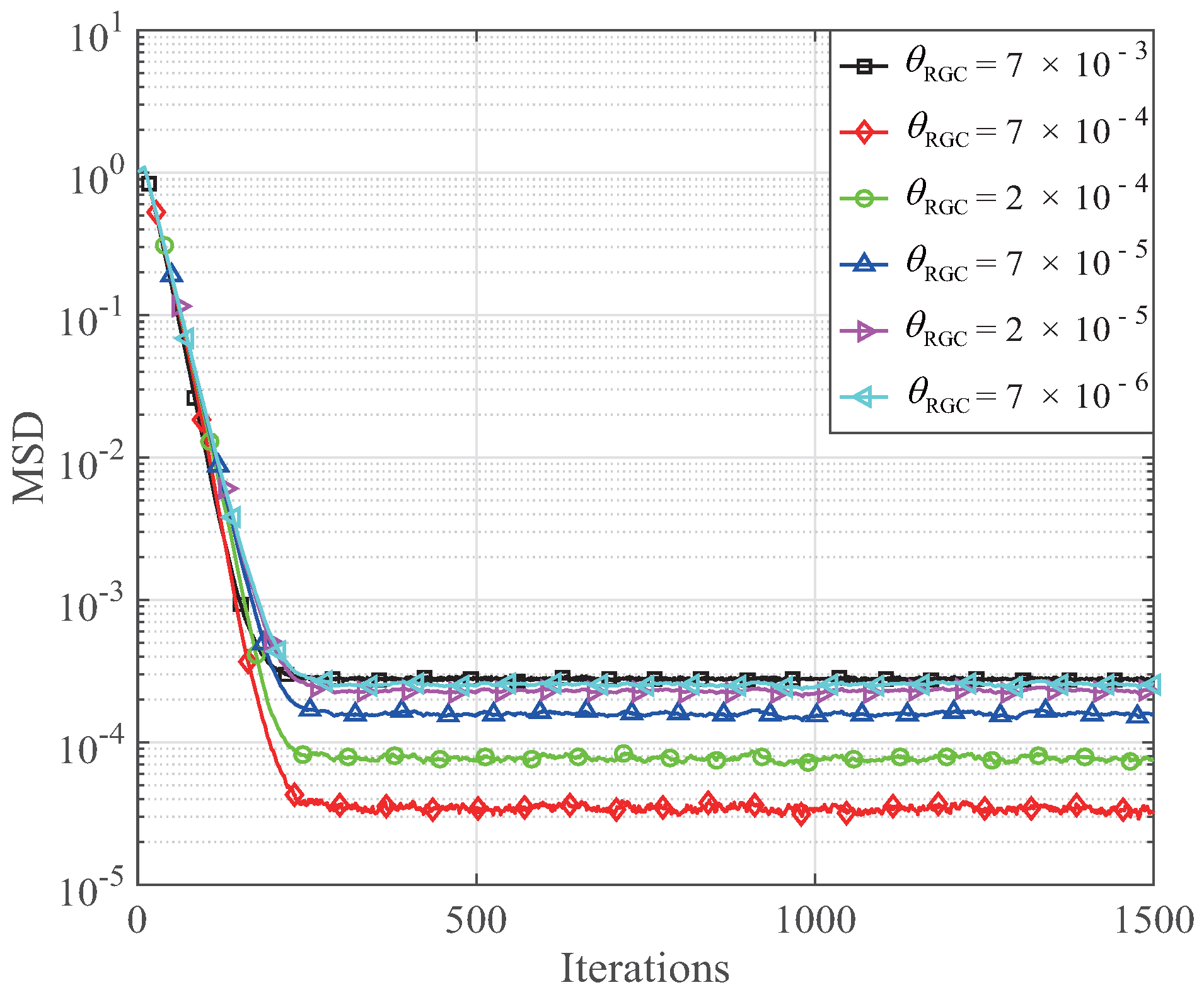
In this experiment, the step size of the GC-MCC and RGC-MCC is 0.026,
and
K = 1. The influence of
on the MSDs of the GC-MCC algorithm is shown in
Figure 3, while the influence of
on the MSDs of the RGC-MCC algorithm is shown in
Figure 4. From
Figure 3 and
Figure 4, the steady-state error with respect to the MSDs of the GC-MCC is reduced with the decrease of the
ranging from
to
. Then, the steady-state error of the GC-MCC algorithm becomes worse when the
continues to reduce. When
, the GC-MCC algorithm achieves the smallest steady-state MSD. As for the RGC-MCC algorithm, the MSD is reduced when
ranges from
to
. Then, the MSD of the RGC-MCC algorithm is increased with a continuous decrement of
. The RGC-MCC algorithm achieves the smallest steady-state MSD for
. Therefore, we take
and
into consideration to ensure the best channel estimation performance of the proposed GC-MCC and RGC-MCC algorithms. Next, the effect of the
that includes
and
on the proposed GC-MCC and RGC-MCC algorithms is given in
Figure 5. It can be seen that the MSD of the RGC-MCC is worse than the GC-MCC when the step size is less than 0.013, while the RGC-MCC is better than the GC-MCC when
. It is noted that the steady-state errors of the GC-MCC and RGC-MCC algorithms become worse as the parameter
increases. Therefore, we should carefully choose the step size and the zero attraction controlling parameters to achieve a good estimation performance for handling sparse channel estimations. The effects of the reweighting controlling parameter are given in
Figure 6. It can be seen that the reweighting controlling parameter mainly affects the small channel coefficients when
increases from 4 to 25. It means that the reweighted zero attractor mainly exerts effects on the magnitudes which are comparable to
, while little shrinkage is penalized on the channel coefficients that are far greater than
. In the RGC-MCC algorithm, the reweighting controlling parameter exerts strong zero attracting on the small group to provide a fast convergence.
As we know, adaptive filters have been extensively investigated and applied for channel estimation, and have been used in real time systems. Moreover, adaptive filters algorithms have been further developed for sparse channel estimations. Similar to the previous investigations [
2,
6,
7,
10,
11,
12,
13,
14,
15,
16,
21,
22,
23,
24,
26,
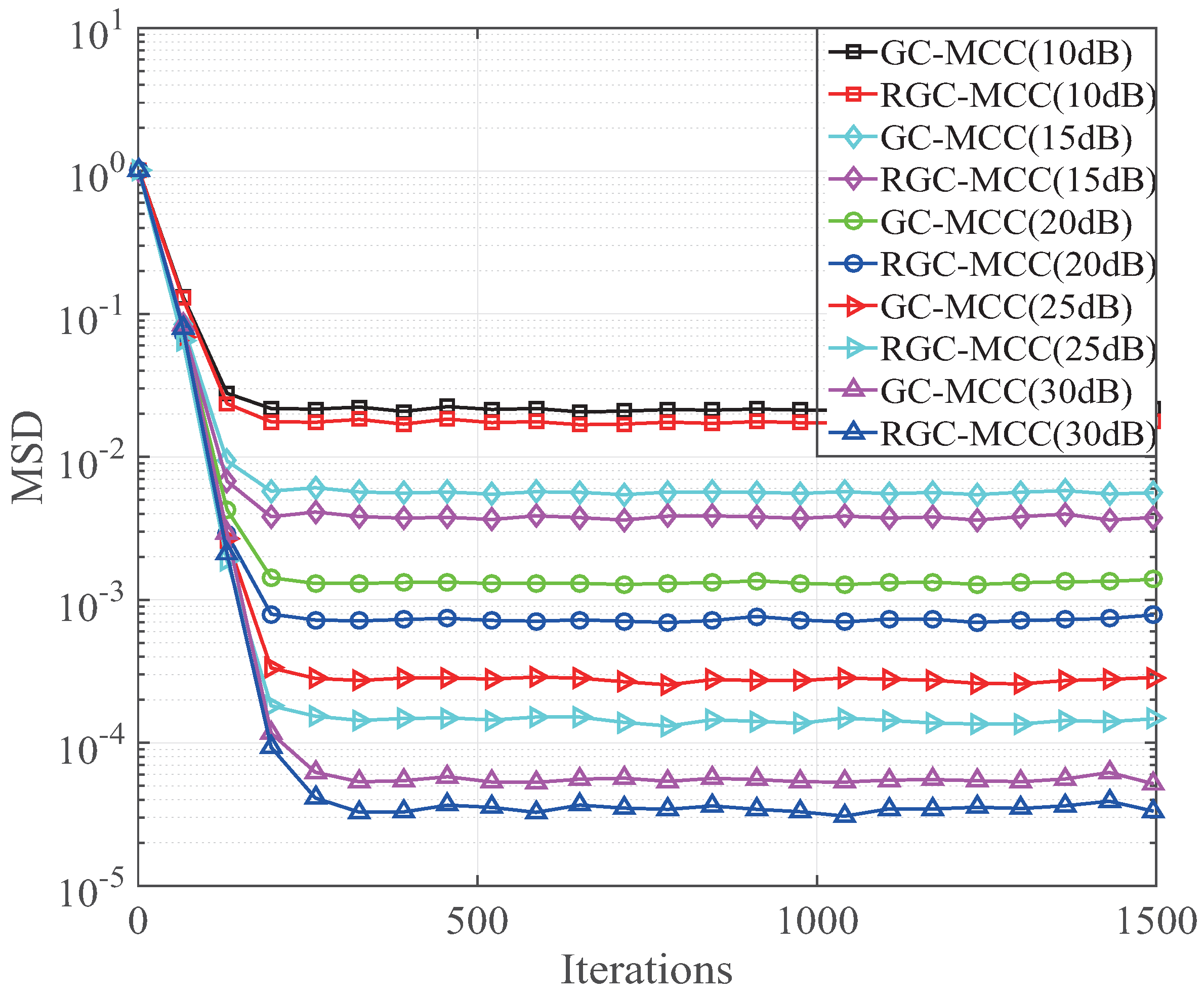
27], the proposed GC-MCC and RGC-MCC algorithms are investigated and their performance is compared with the SPF-MCC algorithm. In the following experiment, the proposed GC-MCC and RGC-MCC algorithms are investigated in different SNR environments. In this experiment, the step size of the GC-MCC and RGC-MCC algorithms is 0.026, and
and
. The MSD performance at different SNRs is shown in
Figure 7. It can be seen that the performance of the proposed GC-MCC and RGC-MCC algorithms is improved with the increment of SNR. It is worth noting that the performance of the RGC-MCC is always better than that of the GC-MCC at the same SNR. This is because the reweighting factor provides a selective zero attracting in the RGC-MCC algorithm.
Next, the convergence of the GC-MCC and RGC-MCC algorithms is studied and it is compared with the MCC, NMCC, ZA-MCC, RZA-MCC and SPF-MCC algorithms at SNR = 30 dB. The corresponding simulation parameters for the mentioned algorithms are
,
,
,
,
,
,
,
,
,
,
,
,
,
and
. Herein,
is the step size of the NMCC algorithm. The convergence of the proposed GC-MCC and RGC-MCC algorithms is given in
Figure 8. It can be seen that the convergence of the proposed GC-MCC and RGC-MCC algorithms is better than that of the MCC, NMCC, ZA-MCC, RZA-MCC and SPF-MCC algorithms at the same MSD level. Moreover, our RGC-MCC has the fastest convergence speed rate.
Next, the channel estimation performance of our presented GC-MCC and RGC-MCC algorithms is analyzed under a different sparsity level
K that is also the number of the non-zero channel coefficients of the sparse channel. Firstly, only one non-zero channel coefficient is randomly distributed within the unknown sparse channel. This means that the sparsity level is
. In this experiment, the related parameters are the following
,
,
,
,
,
,
,
,
,
,
and
. The MSD performance of the GC-MCC and RGC-MCC algorithms is demonstrated in
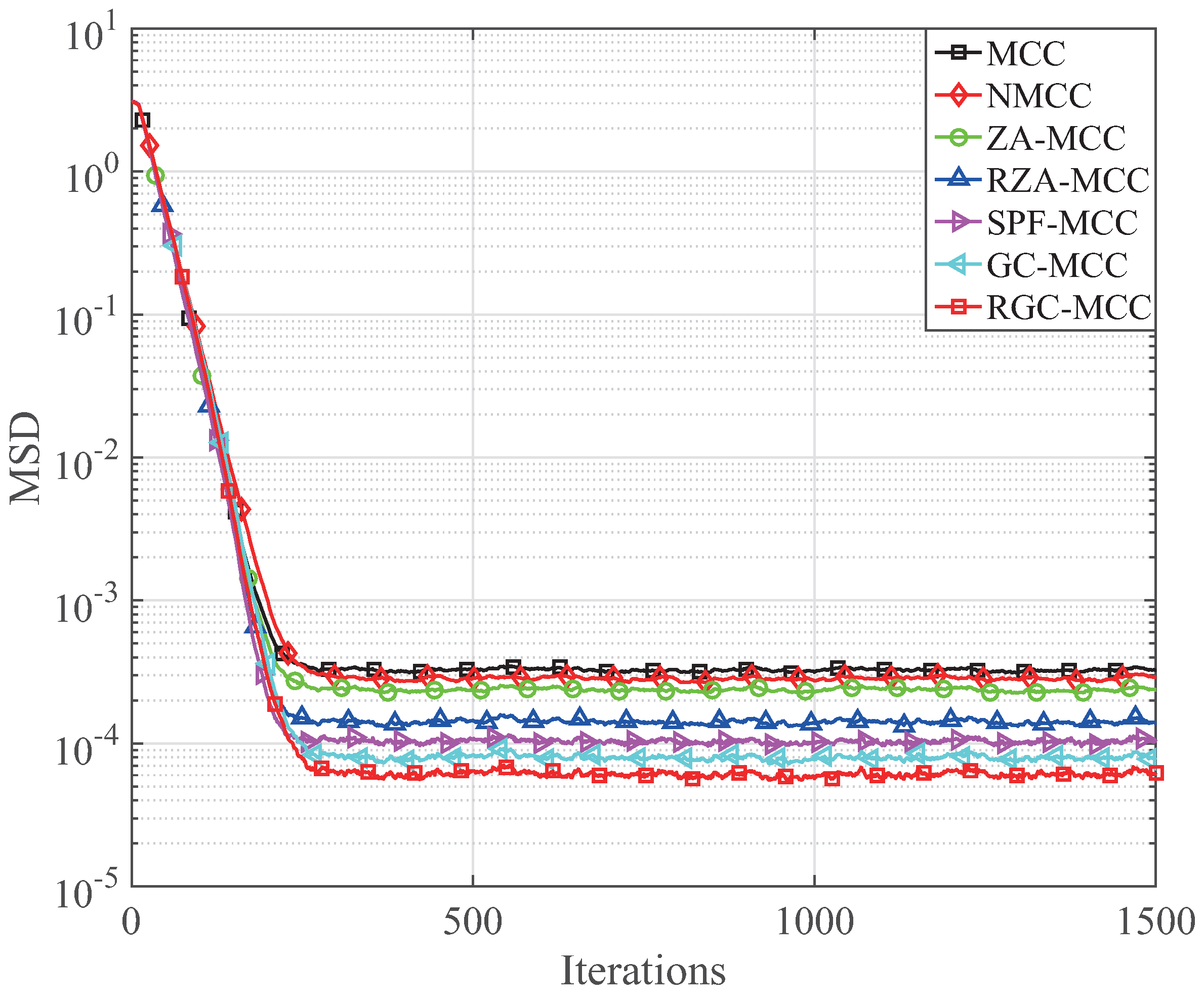
Figure 9 for
. It can be seen in
Figure 9 that the steady-state MSD of our presented GC-MCC and RGC-MCC algorithms is lower than that of the mentioned MCC algorithms with the same convergence speed. The channel estimations with respect to the MSD for
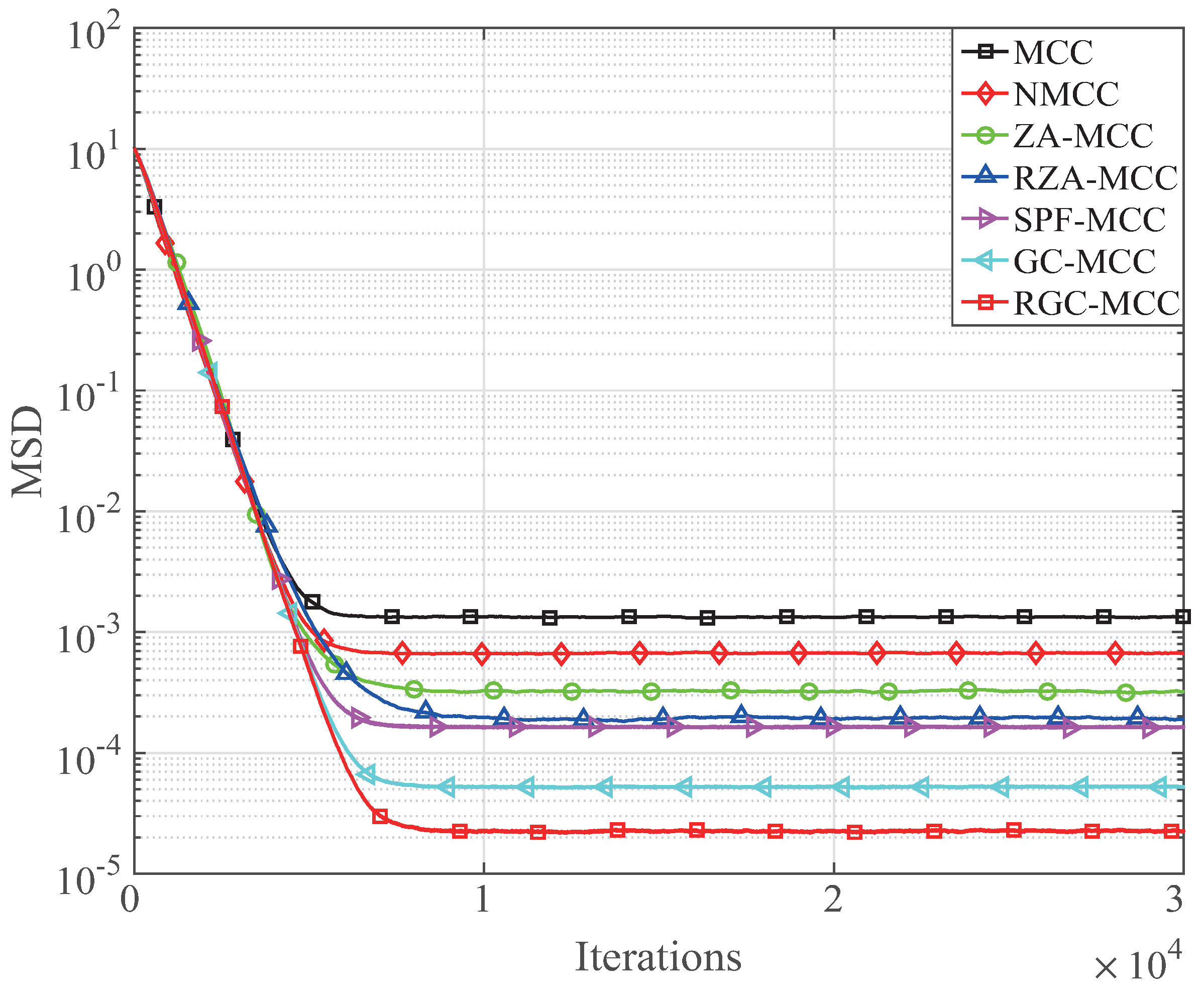
and
are given in
Figure 10 and
Figure 11, respectively. When the sparsity level increases from
to
, the MSD floor is increased in comparison with
because the sparseness is reduced. However, it is worth noting that our proposed GC-MCC and RGC-MCC algorithms still outperform the existing MCC and its sparse forms. In addition, the RGC-MCC always achieves the lowest MSD for different
K.
Then, a realistic IEEE 802.15.4a channel model, which can be downloaded from [
39], that works in CM1 mode is employed to discuss the effectiveness of the proposed GC-MCC and RGC-MCC algorithms. The simulation parameters are
,
,
,
,
,
,
,
,
,
,
and
. The simulation result is given in
Figure 12. It is found that the proposed GC-MCC and RGC-MCC algorithms achieve better performance with respect to the MSD, which means that the proposed GC-MCC and RGC-MCC algorithms have small MSDs.
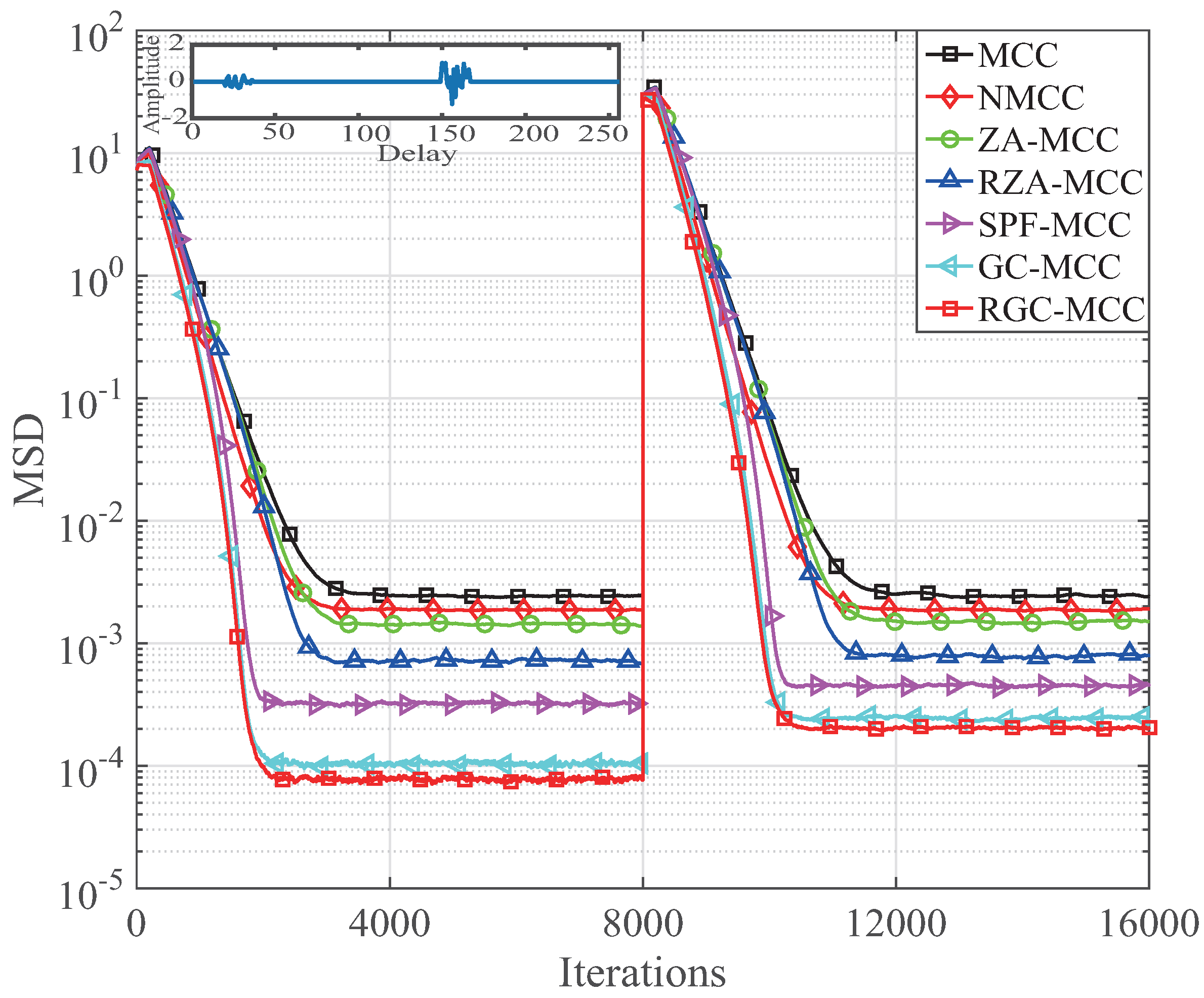
At last, our GC-MCC and RGC-MCC algorithms are used for estimating an echo channel to further discuss their channel estimation performance. The sparseness measurement of the echo channel is defined as
. In this experiment,
and
are used for discussing the estimation performance for the first 8000 iterations and after 8000 iterations, respectively. For the echo channel, its total length is 256 and there are 16 non-zero coefficients in the total echo channel. The simulation parameters are
,
,
,
,
,
,
,
,
,
,
,
and
. The estimation behavior of the proposed GC-MCC and RGC-MCC algorithms for the echo channel is depicted in
Figure 13. From
Figure 13, we found that our GC-MCC and RGC-MCC algorithms outperform the MCC, NMCC and spare MCC algorithms with respect to both the steady-state MSD and convergence. Although the sparsity reduces from
to
, our GC-MCC and RGC-MCC algorithms are still superior to the other MCC algorithms, which means that our GC-MCC and RGC-MCC algorithms have little effect on the sparsity under the mixture-noised sparse channel.
Based on the parameter analysis and performance investigation of our proposed GC-MCC and RGC-MCC algorithms, we can summarize that the proposed RGC-MCC algorithm can provide the fastest convergence speed rate in comparison with all the mentioned algorithms when they converge to the same steady-state MSD level. Also, the proposed RGC-MCC algorithm provides the lowest steady-state MSD when all the MCC algorithms have the same convergence speed rate. In addition, the proposed GC- and PGC-MCC algorithms outperform the MCC, NMCC and the related sparse MCC algorithms. This is because the proposed GC- and RGC-MCC algorithms exert the -norm penalty on the large group to seek the non-zero channel coefficients quickly; then, they provide -norm constraint on the small group to attract the zero or near-zero channel coefficients to zero quickly. Thus, both the GC- and RGC-MCC can provide a faster convergence and a lower steady-state MSD. However, both the GC- and RGC-MCC increase the computational complexity by calculating the group matrix. Additionally, the complexity of the RGC-MCC algorithm also comes from the computation of the reweighting factor. However, the complexity of the GC-MCC and RGC-MCC algorithms is comparable with the previously reported sparse MCC algorithms. According to the early published articles, we believe that the proposed GC-MCC and RGC-MCC algorithms can be used in a real system.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













