Polar Codes for Covert Communications over Asynchronous Discrete Memoryless Channels


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Asynchronous Covert Communication Model and Results
2.1. Notation
2.2. Channel Model
2.3. Main Results
| Algorithm 1 Alice’s encoder |
Require:
|
| Algorithm 2 Bob’s decoder |
Require:
|
3. Preliminaries: Polarization of Sources with Vanishing Entropy Rate
4. Polar Codes for Covert Communication
4.1. Covert Process
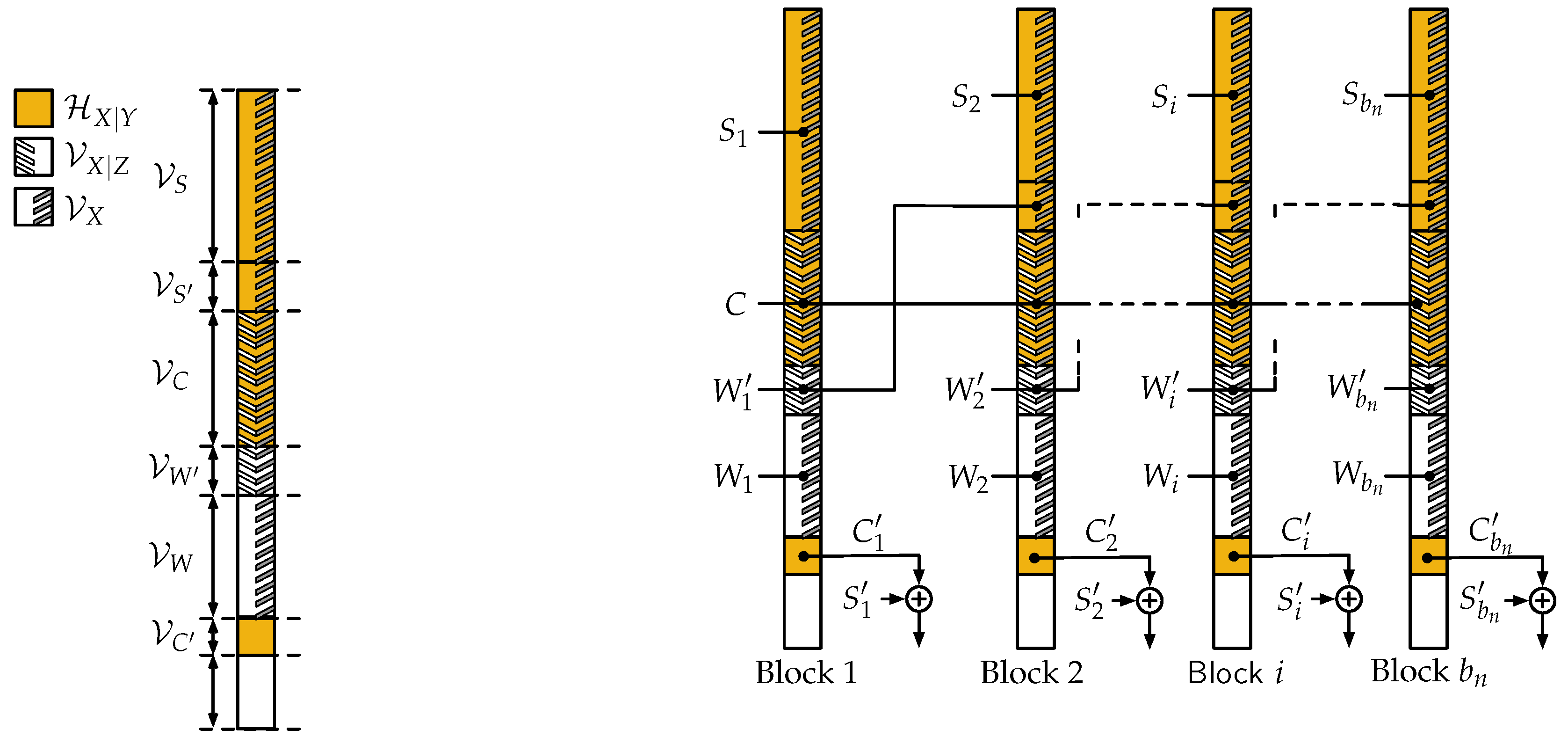
4.2. Encoding and Decoding Algorithms
- Transmitter and receiver use a secret key of bits to determine the position of the codeword window within the transmission window. Note that this secret key is not required in the random coding proof of [6], but is required here to maintain a low complexity at the decoder; fortunately, this change has negligible effect on the scaling of the key.
- The content of each codeword window is obtained through a polar-code based scheme that ensures reliable decoding to the receiver and approximates the process at the adversary’s output, which we describe next.
- , which will contain uniformly distributed bits C representing the code;
- , which will contain non-uniformly distributed bits computed from the other bits;
- , the largest subset of such that , which will contain uniformly distributed messages ;
- , which will contain additional uniformly distributed messages W;
- , any subset of such that , which will use messages transmitted in the previous transmission window as a key;
- , which will contain uniformly distributed secret key symbols S.
4.3. Analysis of Normalized Set Sizes
4.4. Reliability Analysis
4.5. Covertness Analysis
5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bash, B.; Goeckel, D.; Towsley, D. Limits of reliable communication with low probability of detection on AWGN channels. IEEE J. Sel. Areas Commun. 2013, 31, 1921–1930. [Google Scholar] [CrossRef]
- Che, P.H.; Bakshi, M.; Jaggi, S. Reliable deniable communication: Hiding messages in noise. In Proceedings of the IEEE International Symposium on Information Theory, Istanbul, Turkey, 7–12 July 2013; pp. 2945–2949. [Google Scholar]
- Bloch, M.R. Covert communication over noisy channels: A resolvability perspective. IEEE Trans. Inf. Theory 2016, 62, 2334–2354. [Google Scholar] [CrossRef]
- Wang, L.; Wornell, G.W.; Zheng, L. Fundamental limits of communication with low probability of detection. IEEE Trans. Inf. Theory 2016, 62, 3493–3503. [Google Scholar] [CrossRef]
- Bash, B.; Goeckel, D.; Towsley, D. LPD communication when the warden does not know when. In Proceedings of the IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 606–610. [Google Scholar]
- Arumugam, K.S.K.; Bloch, M.R. Keyless asynchronous covert communication. In Proceedings of the IEEE Information Theory Workshop, Cambridge, UK, 11–14 September 2016; pp. 191–195. [Google Scholar]
- Zhang, Q.; Bakshi, M.; Jaggi, S. Computationally efficient deniable communication. In Proceedings of the IEEE International Symposium on Information Theory, Barcelona, Spain, 10–15 July 2016; pp. 2234–2238. [Google Scholar]
- Han, T.; Verdú, S. Approximation theory of output statistics. IEEE Trans. Inf. Theory 1993, 39, 752–772. [Google Scholar] [CrossRef]
- Bloch, M.R.; Hayashi, M.; Thangaraj, A. Error-control coding for physical-layer secrecy. Proc. IEEE 2015, 103, 1725–1746. [Google Scholar] [CrossRef]
- Arikan, E. Channel polarization: A method for constructing capacity-achieving codes for symmetric binary-input memoryless channels. IEEE Trans. Inf. Theory 2009, 55, 3051–3073. [Google Scholar] [CrossRef] [Green Version]
- Chou, R.A.; Bloch, M.R. Polar coding for the broadcast channel with confidential messages: A random binning analogy. IEEE Trans. Inf. Theory 2016, 62, 2410–2429. [Google Scholar] [CrossRef]
- Guruswami, V.; Xia, P. Polar codes: Speed of polarization and polynomial gap to capacity. IEEE Trans. Inf. Theory 2015, 61, 3–16. [Google Scholar]
- Hassani, S.H.; Alishahi, K.; Urbanke, R.L. Finite-length scaling for polar codes. IEEE Trans. Inf. Theory 2014, 60, 5875–5898. [Google Scholar] [CrossRef]
- Mondelli, M.; Hassani, S.H.; Urbanke, R.L. Unified scaling of polar codes: Error exponent, scaling exponent, moderate deviations, and error floors. IEEE Trans. Inf. Theory 2016, 62, 6698–6712. [Google Scholar] [CrossRef]
- Pfister, H.D.; Urbanke, R. Near-optimal finite-length scaling for polar codes over large alphabets. In Proceedings of the IEEE International Symposium on Information Theory, Barcelona, Spain, 10–15 July 2016; pp. 215–219. [Google Scholar]
- Renes, J.; Renner, R. Noisy channel coding via privacy amplification and information reconciliation. IEEE Trans. Inf. Theory 2011, 57, 7377–7385. [Google Scholar] [CrossRef]
- Yassaee, M.; Aref, M.; Gohari, A. Achievability proof via output statistics of random binning. IEEE Trans. Inf. Theory 2014, 60, 6760–6786. [Google Scholar] [CrossRef]
- Mondelli, M.; Hassani, S.H.; Sason, I.; Urbanke, R.L. Achieving marton’s region for broadcast channels using polar codes. IEEE Trans. Inf. Theory 2015, 61, 783–800. [Google Scholar] [CrossRef]
- Arikan, E. Source polarization. In Proceedings of the IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; pp. 899–903. [Google Scholar]
- Chou, R.A.; Bloch, M.R.; Abbe, E. Polar coding for secret-key generation. IEEE Trans. Inf. Theory 2015, 61, 6213–6237. [Google Scholar]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Akademiai Kiado: Budapest, Hungary, 1981. [Google Scholar]
- Bloch, M.R.; Guha, S. Optimal covert communications using pulse-position modulation. In Proceedings of the IEEE International Symposium on Information Theory, Aachen, Germany, 25–30 June 2017; pp. 2835–2839. [Google Scholar]



© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frèche, G.; Bloch, M.R.; Barret, M. Polar Codes for Covert Communications over Asynchronous Discrete Memoryless Channels. Entropy 2018, 20, 3. https://doi.org/10.3390/e20010003
Frèche G, Bloch MR, Barret M. Polar Codes for Covert Communications over Asynchronous Discrete Memoryless Channels. Entropy. 2018; 20(1):3. https://doi.org/10.3390/e20010003
Chicago/Turabian StyleFrèche, Guillaume, Matthieu R. Bloch, and Michel Barret. 2018. "Polar Codes for Covert Communications over Asynchronous Discrete Memoryless Channels" Entropy 20, no. 1: 3. https://doi.org/10.3390/e20010003