Entropy Measures for Stochastic Processes with Applications in Functional Anomaly Detection

Abstract
:1. Introduction
2. Entropy of a Stochastic Process
Estimating Entropy in a Reproducing Kernel Hilbert Space
| Algorithm 1: Estimation of from a sample of random paths. |
 |
3. Minimum Entropy for Anomaly Detection
3.1. Parametric Approach
3.2. Non-Parametric Approach
4. Experimental Section
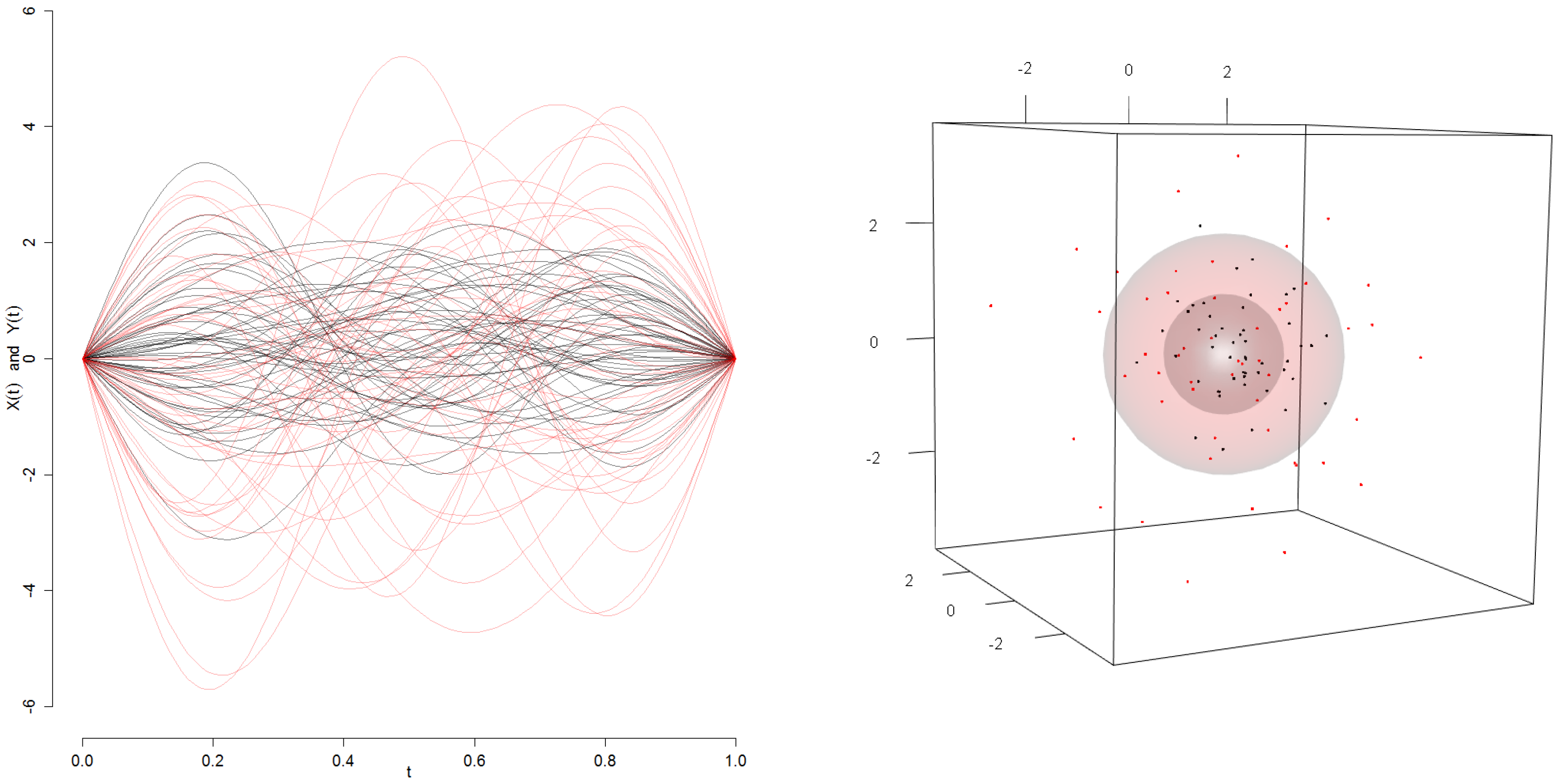
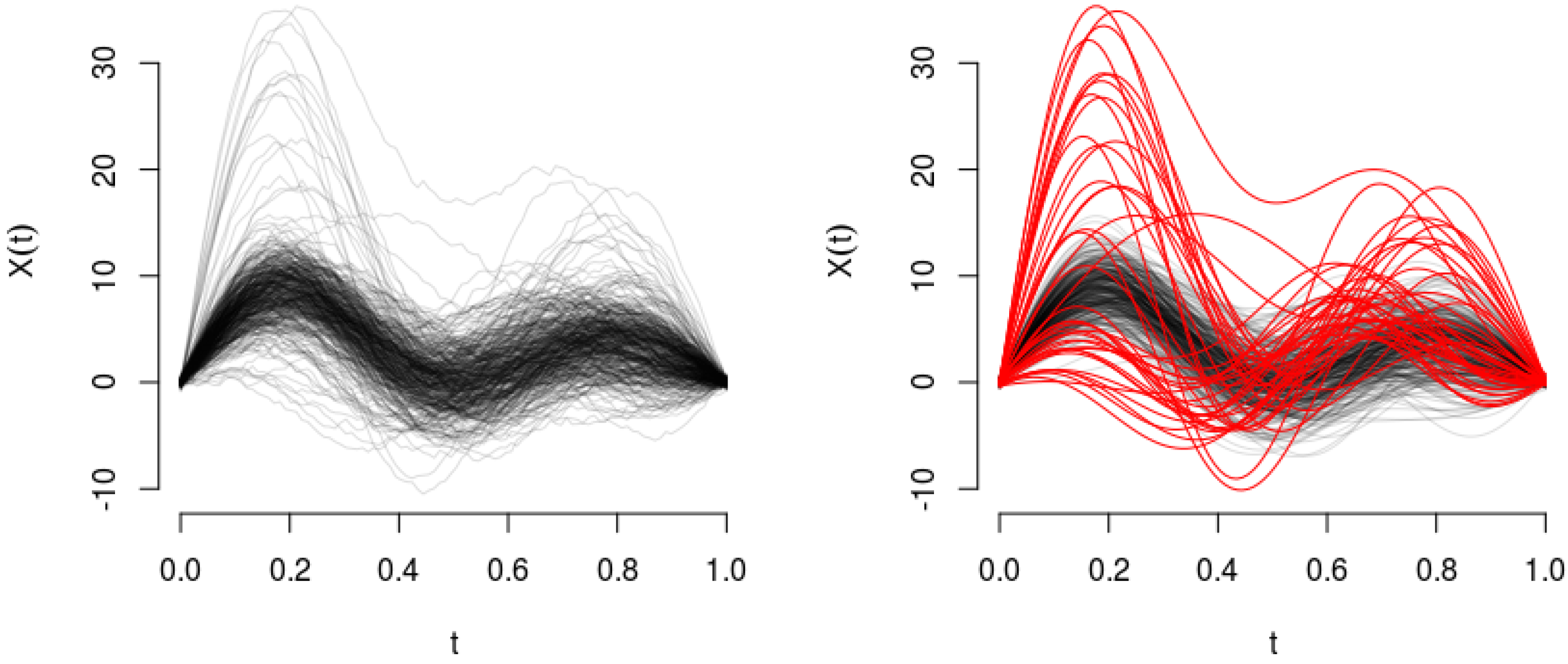
4.1. Simulation Analysis
- (A)
- Magnitude outliers: where is a normally-distributed multivariate r.v. with parameters and .
- (B)
- Shape outliers: where is a normally-distributed multivariate r.v. with parameters and .
- (C)
- A combination considering outliers from Scenario A and outliers from Scenario B.
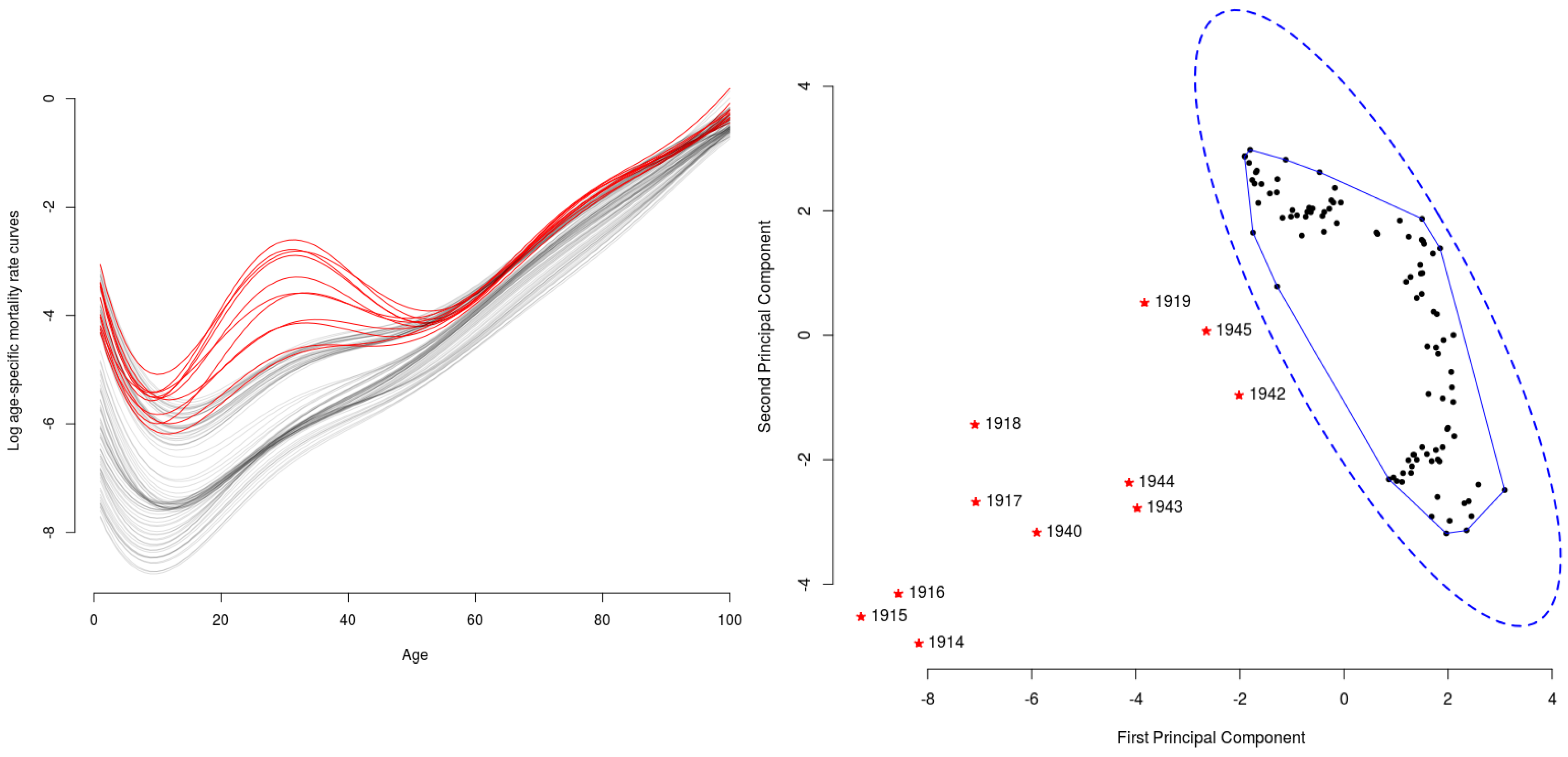
4.2. Outliers in the Context of Mortality-Rate Curve Analysis
5. Discussion
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| RML | Robust Maximum Likelihood. |
| MES and HDS | Minimum Entropy and High Density Sets, respectively. |
| PA and NPA | Parametric and Non-Parametric approaches. |
| MBD, HMD, RTD, FSD | Modified Band, H-Mode, Random Tukey and Functional Spatial Depths. |
Appendix A
References
- Rényi, A. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics; University of California Press: Berkeley, CA, USA, 1961; pp. 547–561. [Google Scholar]
- Bosq, D. Linear Processes in Function Spaces: Theory and Applications; Springer Science & Business Media: New York, NY, USA, 2012. [Google Scholar]
- Ramsay, J.O. Functional Data Analysis; Wiley: New York, NY, USA, 2006. [Google Scholar]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis: Theory and Practice; Springer: New York, NY, USA, 2006. [Google Scholar]
- Berlinet, A.; Thomas-Agnan, C. Reproducing Kernel Hilbert Spaces in Probability and Statistics; Springer: New York, NY, USA, 2011. [Google Scholar]
- Kimeldorf, G.; Wahba, G. Some results on Tchebycheffian spline functions. J. Math. Anal. Appl. 1971, 33, 82–94. [Google Scholar] [CrossRef]
- Cucker, F.; Smale, S. On the mathematical foundations of learning. Bull. Am. Math. Soc. 2002, 39, 1–49. [Google Scholar] [CrossRef]
- Munñoz, A.; González, J. Representing functional data using support vector machines. Pattern Recognit. Lett. 2010, 31, 511–516. [Google Scholar]
- Zhu, H.; Williams, C.; Rohwer, R.; Morciniec, M. Gaussian Regression and Optimal Finite Dimensional Linear Models; Aston University: Birmingham, UK, 1997. [Google Scholar]
- López-Pintado, S.; Romo, J. On the concept of depth for functional data. J. Am. Stat. Assoc. 2009, 104, 718–734. [Google Scholar] [CrossRef]
- Cuevas, A.; Febrero, M.; Fraiman, R. Robust estimation and classification for functional data via projection-based depth notions. Comput. Stat. 2007, 22, 481–496. [Google Scholar] [CrossRef]
- Sguera, C.; Galeano, P.; Lillo, R. Spatial depth-based classification for functional data. Test 2014, 23, 725–750. [Google Scholar] [CrossRef]
- Cuesta-Albertos, J.A.; Nieto-Reyes, A. The random Tukey depth. Comput. Stat. Data Anal. 2008, 52, 4979–4988. [Google Scholar] [CrossRef]
- Hero, A. Geometric entropy minimization (GEM) for anomaly detection and localization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 585–592. [Google Scholar]
- Xie, T.; Narabadi, N.; Hero, A.O. Robust training on approximated minimal-entropy set. arXiv, 2016; arXiv:1610.06806. [Google Scholar]
- Hyndman, R.J. Computing and graphing highest density regions. Am. Stat. 1996, 50, 120–126. [Google Scholar]
- Maronna, R.; Martin, R.; Yohai, V. Robust Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Beirlant, J.; Dudewicz, E.; Györfi, L.; Van der Meulen, E. Nonparametric entropy estimation: An overview. Int. J. Math. Stat. Sci. 1997, 6, 17–39. [Google Scholar]
- Cano, J.; Moguerza, J.M.; Psarakis, S.; Yannacopoulos, A.N. Using statistical shape theory for the monitoring of nonlinear profiles. Applied Stochastic Models in Business and Industry. Appl. Stoch. Models Bus. Ind. 2015, 31, 160–177. [Google Scholar] [CrossRef]
- Febrero-Bande, M.; De la Fuente, M.O. Statistical computing in functional data analysis: The R package fda.usc. J. Stat. Softw. 2012, 51, 1–28. [Google Scholar] [CrossRef]
- Hyndman, R.J. Demography Package; R Foundation for Statistical Computing: Vienna, Austria, 2017. [Google Scholar]
- Muñoz, A.; Moguerza, J.M. Estimation of high-density regions using one-class neighbor machines. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 476–480. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Method | Metric | Scenario A | Scenario B | Scenario C | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 10% | 5% | 1% | 10% | 5% | 1% | 10% | 5% | 1% | ||
| MBD | TPR | 74.867 | 71.010 | 55.300 | 48.275 | 39.395 | 13.475 | 67.787 | 58.365 | 36.300 |
| (4.699) | (7.712) | (20.852) | (5.914) | (9.013) | (16.180) | (5.351) | (7.772) | (18.341) | ||
| TNR | 97.207 | 98.474 | 99.548 | 94.252 | 96.810 | 99.126 | 96.420 | 97.808 | 99.356 | |
| (0.522) | (0.406) | (0.210) | (0.657) | (0.474) | (0.163) | (0.594) | (0.409) | (0.185) | ||
| aROC | 96.662 | 97.375 | 97.735 | 89.393 | 91.693 | 93.244 | 95.272 | 95.444 | 95.354 | |
| (1.245) | (1.517) | (3.059) | (2.033) | (2.388) | (4.425) | (1.399) | (1.831) | (4.370) | ||
| HMD | TPR | 92.665 | 91.545 | 88.675 | 66.532 | 62.780 | 47.475 | 79.992 | 76.765 | 66.025 |
| (3.295) | (5.173) | (14.793) | (6.084) | (8.809) | (21.206) | (4.562) | (7.039) | (18.004) | ||
| TNR | 99.185 | 99.555 | 99.885 | 96.281 | 98.041 | 99.469 | 97.776 | 98.777 | 99.656 | |
| (0.366) | (0.272) | (0.149) | (0.676) | (0.463) | (0.214) | (0.506) | (0.370) | (0.181) | ||
| aROC | 99.200 | 99.256 | 99.346 | 94.980 | 96.153 | 96.969 | 97.676 | 97.924 | 97.842 | |
| (0.851) | (1.105) | (2.391) | (1.583) | (1.812) | (3.473) | (1.089) | (1.401) | (3.542) | ||
| RTD | TPR | 83.555 | 83.045 | 76.400 | 50.972 | 43.940 | 22.700 | 71.975 | 65.225 | 49.700 |
| (4.743) | (0.694) | (18.931) | (9.409) | (1.279) | (2.1334) | (7.178) | (9.716) | (1.834) | ||
| TNR | 98.174 | 99.104 | 99.762 | 94.544 | 97.049 | 99.218 | 96.889 | 98.165 | 99.491 | |
| (0.526) | (0.365) | (0.191) | (1.045) | (0.674) | (0.215) | (0.798) | (0.511) | (0.184) | ||
| aROC | 98.187 | 98.605 | 98.962 | 90.426 | 92.510 | 94.154 | 96.156 | 96.345 | 96.242 | |
| (1.094) | (1.347) | (2.538) | (2.817) | (2.967) | (4.574) | (1.580) | (1.977) | (4.085) | ||
| FSD | TPR | 81.472 | 83.215 | 81.925 | 50.275 | 46.550 | 27.400 | 74.775 | 69.485 | 53.775 |
| (3.978) | (5.947) | (16.671) | (5.238) | (8.018) | (19.547) | (4.601) | (6.859) | (16.707) | ||
| TNR | 97.941 | 99.116 | 99.817 | 94.475 | 97.186 | 99.267 | 97.197 | 98.396 | 99.533 | |
| (0.442) | (0.313) | (0.168) | (0.582) | (0.421) | (0.197) | (0.511) | (0.361) | (0.168) | ||
| aROC | 97.934 | 98.738 | 99.163 | 90.059 | 93.279 | 95.485 | 96.777 | 97.148 | 97.125 | |
| (1.030) | (1.232) | (2.490) | (1.794) | (2.061) | (3.723) | (1.158) | (1.477) | (3.682) | ||
| Entropy-PA | TPR | 94.150 | 93.215 | 91.725 | 80.740 | 77.390 | 66.925 | 87.550 | 84.935 | 77.650 |
| (3.078) | (4.817) | (12.591) | (6.250) | (8.550) | (20.330) | (4.632) | (6.604) | (17.015) | ||
| TNR | 99.350 | 99.649 | 99.916 | 97.860 | 98.810 | 99.664 | 98.616 | 99.207 | 99.774 | |
| (0.342) | (0.253) | (0.127) | (0.694) | (0.450) | (0.205) | (0.514) | (0.347) | (0.171) | ||
| aROC | 99.351 | 99.353 | 99.374 | 97.549 | 97.987 | 98.301 | 98.677 | 98.752 | 98.641 | |
| (0.788) | (1.078) | (2.474) | (1.364) | (1.495) | (2.785) | (0.944) | (1.208) | (3.081) | ||
| Entropy-NPA | TPR | 92.725 | 91.505 | 89.050 | 74.215 | 77.145 | 71.250 | 87.225 | 85.805 | 79.775 |
| (3.325) | (5.228) | (14.630) | (6.237) | (7.904) | (19.970) | (4.217) | (6.198) | (16.788) | ||
| TNR | 99.191 | 99.552 | 99.889 | 97.135 | 98.792 | 99.709 | 98.586 | 99.252 | 99.795 | |
| (0.369) | (0.275) | (0.147) | (0.693) | (0.416) | (0.201) | (0.468) | (0.326) | (0.169) | ||
| aROC | 99.243 | 99.266 | 99.293 | 97.240 | 98.253 | 98.685 | 98.782 | 98.880 | 98.861 | |
| (0.815) | (1.097) | (2.528) | (1.130) | (1.250) | (2.550) | (0.856) | (1.145) | (2.880) | ||
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martos, G.; Hernández, N.; Muñoz, A.; Moguerza, J.M. Entropy Measures for Stochastic Processes with Applications in Functional Anomaly Detection. Entropy 2018, 20, 33. https://doi.org/10.3390/e20010033
Martos G, Hernández N, Muñoz A, Moguerza JM. Entropy Measures for Stochastic Processes with Applications in Functional Anomaly Detection. Entropy. 2018; 20(1):33. https://doi.org/10.3390/e20010033
Chicago/Turabian StyleMartos, Gabriel, Nicolás Hernández, Alberto Muñoz, and Javier M. Moguerza. 2018. "Entropy Measures for Stochastic Processes with Applications in Functional Anomaly Detection" Entropy 20, no. 1: 33. https://doi.org/10.3390/e20010033
APA StyleMartos, G., Hernández, N., Muñoz, A., & Moguerza, J. M. (2018). Entropy Measures for Stochastic Processes with Applications in Functional Anomaly Detection. Entropy, 20(1), 33. https://doi.org/10.3390/e20010033