1. Introduction
Entropy is a single word that refers to a number of very distinct concepts, a fact that has caused much confusion. These concepts cover areas as diverse as statistical mechanics, minimal code lengths, or the multiplicity of available choices in statistical inference. The distinction between the concepts underlying entropy is frequently not made properly. As long as we deal with equilibrium processes or processes with no memory (that can be modeled as i.i.d. sampling processes), formally it does not matter which entropy concept we use: they all lead to the same functional
where
k is a context- and unit-dependent positive constant, and
is the
sample space containing
W distinct states
that occur (or are sampled) with relative frequencies
. In statistical mechanics,
is the set of all accessible microstates; in information theory, it is an alphabet of
W letters that can be coded in a code-alphabet using
b code-letters (typically 0 and 1 for
). Setting
often indicates that
H is used as a measure of
information production. If all we know about a class of messages is the frequency
of letters
i, then
H is a sharp lower bound on the average number of code-letters per letter, needed for coding messages in the original alphabet. In physics,
k is the Boltzmann constant, measuring entropy in units of energy per degree Kelvin. We refer to
H as the Boltzmann–Gibbs–Shannon entropy.
However, this degeneracy of entropy concepts with respect to
H vanishes for processes with memory. For systems or processes away from equilibrium, such as for processes with memory, the different entropy (production) concepts lead to distinct, non-degenerate entropy functionals. “Entropy”, in a way, becomes context-sensitive: the functional form of entropy measures differ from one class of processes to another. The different concepts link structural knowledge about a given system with the functional form of its corresponding entropy measure. We demonstrated this fact for self-reinforcing processes, Pólya urn processes in particular [
1,
2,
3], for driven dissipative systems that can be modeled with slowly driven
sample space reducing (SSR) processes [
4,
5,
6,
7] and for multinomial mixture processes [
1]. Consequently, for non-equilibrium processes, we need to properly distinguish entropies depending on the context they are used for. In Reference [
1], we distinguish three (there is no reason that there could not be more than three) entropy concepts:
The concept of
maximum configuration (MC) predictions defines entropy,
, as the logarithm of the multiplicity of possible equivalent choices and plays a central role in predicting empirical distribution functions of a system. It plays a role in statistical mechanics [
8,
9] but can be extended naturally beyond physics in the context of statistical inference [
10].
The concept of entropy in
information theory [
11,
12,
13] can be identified as the
information production rate (IP) of information sources. The corresponding entropy,
, is an asymptotically sharp lower bound on the loss-free compression that can be achieved in the limit of infinitely long messages.
The necessity of extensive variables (e.g., in thermodynamics) leads us to define an
extensive entropy,
, through an asymptotic
scaling expansion that relates entropy with the phase-space volume growth as the size of a system changes [
14,
15]. (Consistent scaling of extensive variables is a prerequisite for thermodynamics to make sense. We therefore call the corresponding entropy measure “thermodynamic,”
, despite the fact that all of the three mentioned concepts may be required to characterize the full thermodynamics of a non-equilibrium system. However, to avoid confusion, we will use the term
thermodynamic scaling entropy whenever it is necessary to distinguish the notion from Clausius’ thermodynamic entropy,
, for which, for reversible processes,
, holds.)
Here we are interested in the description of driven statistical systems. The interest is to know the most likely probability distribution for finding the system in its possible states. Observables can then be computed. The maximum configuration entropy is a way to compute this probability distribution. In the following, we aim to understand entropies of driven dissipative systems that are relatively simple in the sense that they exhibit stationary distributions. In particular, we are interested in the functional form of their maximum configuration entropy, .
Driven systems are composed from antagonistic processes: a driving process that “loads” or charges the system (e.g., from low energy states to higher states) and a relaxing or discharging process that brings the system towards a “ground state” (equilibrium or sink state). (Both processes by themselves may be non-ergodic. By coupling both processes, the system may—especially when it assumes steady states—regain ergodicity.) The driving process induces a probabilistic “current” that breaks detailed balance. This creates a “preferred direction” in the dynamics of the system.
In previous work [
4,
5], we discussed driven processes in the limit of extremely slow driving rates. We find simple functional expressions for maximum configuration entropies that depend on the probabilities
only. These denote the probability for the system to occupy state
i. The situation for general driving process—which constitutes the essence of this paper—is more involved. To characterize an arbitrary (stochastic) driving process, it is necessary to specify the probability with which the system that is in a given state
i at a given time
t is driven to a “higher” state
j at time
. If we think of states being associated with energy levels, that would mean
. We use
to denote the
probability for the system to be “driven” when it is in state
i. It is clear that entropies for processes that are driven in a specific way will depend on the driving rate that is given by
. As a consequence, the entropy for driven dissipative systems is very different from those that were discussed in the literature of generalized entropies. We will see that the MC entropy of driven dissipative systems is neither of trace form, nor does it depend on one single distribution function only. The latter property means that they violate the first Shannon–Khinchin axiom, see, e.g., [
14]. The adequate entropies of driven systems become measures that jointly describe the relaxation and the driving of the system; they depend on
and the (state-dependent)
.
Despite these complications, we will see that the maximum configuration entropy of driven systems remains a meaningful and useful concept for predicting distribution functions of driven systems. We further show that the maximum entropy principle for driven systems still follows the mantra: maximize an entropy functional + constraints. This functional corresponds (up to a sign) to the information divergence or relative entropy of the driven process. By identifying the constraint terms with cross-entropy, the known formula holds also within the driven context: entropy = cross entropy − divergence.
2. The Sample Space of Driven Dissipative Systems
Imagine a driven system. It is composed of a driving process and a relaxation process. The latter determines the dynamics of the system in the case of no driving—the system relaxes towards an attractor-, sink-, or equilibrium-state. The driving process can be thought of as a potential that keeps the system away from equilibrium. The system dynamics is then described by the details of the driving and relaxation processes. The collection of states
i that a system can take is called the discrete
sample space,
. For simplicity, we also assume discrete time steps. (All of the following can be formulated in continuous variables. A continuous sample space we call
phase space.) The dynamics of a system is characterized by the temporal succession of states:
. If the system is stochastic, the transition probabilities,
, represent the probability that the system will be found in state
j in the next step, given that it is in state
i now. States are characterized by certain properties that allows them to be sorted. In physical systems, such properties could be energy levels,
, that are associated to state
i. A relaxing process is a sequence of states that leads from high to lower energy levels. In other words,
if
, and
if
. This is what we call a
sample space reducing process, a process that reduces its sample space over time [
4,
5]. The current sample space (and its volume) depends on the current state
i the system is in. It is the set of states that can be reached from its current state
i,
. If a system relaxes in a sequence
, then the sequence of sample spaces
is nested. Generally, relaxation processes are sample space reducing processes.
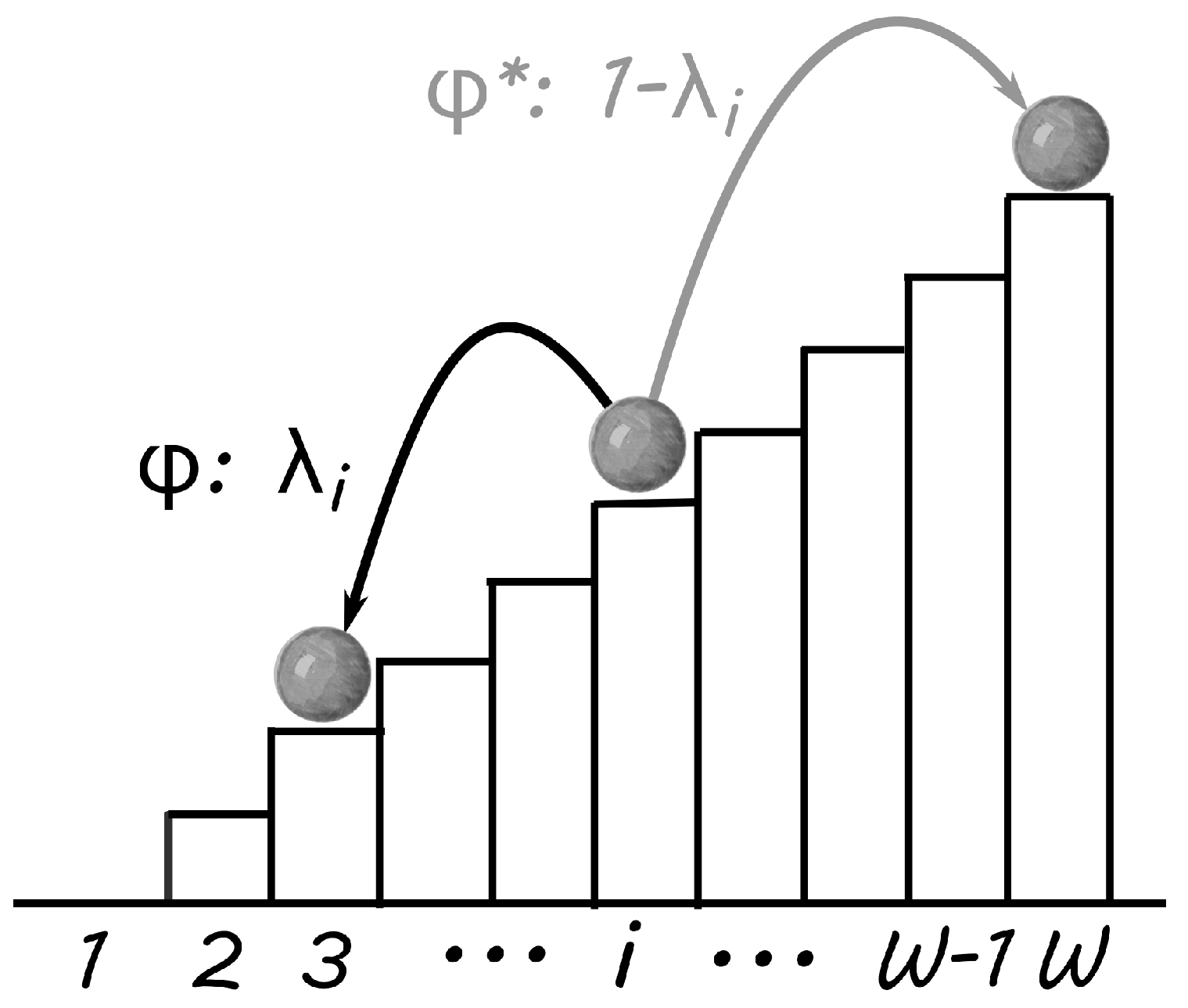
A driving process typically brings a system from “low states” to “higher states”; or it brings low states to any other state. The sample space of the driving process can be the highest state, any state that is higher than the present state, or any state, i.e., the entire sample space,
. In other words, it can (but does not have to) depend on the current state. A driving event is any event that allows the system to change from a low state to a higher state. A schematic view of a driven process is shown in
Figure 1. This particular example consists of a relaxing (SSR) process,
, and a driving process,
, that places the system always in the highest possible state.
2.1. Slowly Driven Sample Space Reducing Processes
Let us briefly recapitulate the properties of sample space reducing processes with a simple example. Given a sample space with
W states,
, imagine that the process samples state
. Then, in the next time step, the process can only sample from
. First assume (without loss of generality [
5]) that all of the states in
are sampled with the same probability. With every sample
, the process is left with a smaller sample space, similar to a ball bouncing down a staircase, which can only sample stairs below its current position (see
Figure 1). Once the process reaches the lowest possible state,
at some point in the process (think of time),
m, then the sample space of the process becomes empty and the process stops at the sink state. The process can only continue if the sample space reducing process is restarted with a driving event that will allow it to sample from larger sample spaces again.
The simplest way to specify the driving process in this example is to allow the process to sample from the entire sample space , once it has arrived at the sink state, . This is done by setting . In this case, the driving process becomes active after the system is completely relaxed. We call that the slow driving limit. Restarting the relaxing sample space reducing process produces an ongoing Markov process, and a stationary visiting distribution function of the states i, . However, detailed balance is explicitly violated in driven processes.
For the slowly driven process, the transition probabilities are given by
where
is the Heaviside function,
is the Kronecker delta, and
is the cumulative distribution of weights (or prior probabilities, which determine how likely the process starts in state
i)
q. Let
be the visiting distribution of states, i.e.,
is the relative frequency of state
i being visited by the driven process, then the equation
holds and
For the choice
(equidistributed prior probabilities), the transition probabilities read
, and we immediately obtain
i.e., Zipf’s law. Remarkably, also for almost any other choice of
, the same result is obtained, meaning that Zipf’s law in the probability of state visits is an attractor of slowly driven systems, regardless of the details of the relaxing process. For details, see [
4,
5,
6]. A physical example is given in [
7], where the kinetic energy of a projectile passing through a box filled with balls—with which it collides elastically—reduces as an sample space reducing process. Zipf’s law is found in the occurrence frequencies of projectiles with specific kinetic energies.
2.2. Driven Sample Space Reducing Processes with Arbitrary Driving
Driven sample space reducing processes on the states
can be characterized as a mixture of the relaxing process
, and a (usually stochastic) driving process,
. As before, let us assume (without loss of generality) that the driving process
samples among all possible states
with probability
. In contrast to the slow driving case, a driving event can now occur at any time, not only after the system reaches its ground state,
. Symbolically, the combination of driving and relaxing processes reads
, where
is the probability that the process follows
(relaxes), and
is the probability for a driving event. In the ground state,
,
, and
behave identically. In the general case,
may depend on the state
i, i.e.,
, and
becomes a state-dependent driving rate. The transition probability from state
j to state
i is
Note that the value of
does not effect the transition probabilities of the process. Technically, we set
. Using
, one finds the exact asymptotic steady state solution:
For the case where all
, we get
, as expected for processes that are dominated by the driving process. For all
(except for
), we recover the slow driving limit of Equation (
3). For the equidistributed prior probabilities,
, the following relation between the state-dependent driving rate,
, and the (stationary) distribution function exists
Here,
x labels the states in a continuous way. For details, see [
7].
3. The Maximum Configuration Entropy of Driven Processes
For stationary systems, the probabilities for state visits can be derived with the use of the maximum entropy principle. We discuss the implications of driving a process for the underlying MC entropy functional. Let count how often a particular state has occurred in N sampling steps (think of a sequence of N samples). is the histogram of the process, and are the relative frequencies.
To find the maximally likely distribution (maximum configuration) of a process, one considers the probability to observe the specific histogram,
k, after
N samples (steps),
. Here
is the multiplicity of the process, i.e., the number of sequences
x that have the histogram
k.
is the probability of sampling one particular sequence with histogram
k, and
parameterizes the process. Taking logarithms on both sides of
, we identify
Here we scaled both sides by a factor,
, that represents the number of degrees of freedom in the system. To arrive at relative frequencies, we use
. Given that
N is sufficiently large,
p approaches the most likely distribution function.
3.1. Slowly Driven Processes
Driving a process slowly means to restart it with a rate that is lower (or of the same order) than the typical relaxation time. In the above context of the sample space reducing process, it is restarted once the process has reached its ground state at
. The computation of the MC entropy, together with its associated distribution functions, for slowly driven systems has been done in [
1,
2]. We include it here for completeness. For simplicity, we present the following derivation in the framework of sequences. They hold more generally for other processes and systems.
Let
be a sequence that records the visits to the states
i.
means that the process is slowly driven and restarts only in state
. To compute the multiplicity,
M, note that we can decompose any sampled SSR sequence
into a concatenation of shorter sequences
such that
. Each
starts directly after a driving event restarted the process, and ends when the process halts at
, where it awaits the next driving event. We call
one “run” of the SSR process. Since every run ends in the ground state
, we can be sure that, for the slowly driven process, we find
: number of runs is equal to the number of times we observe state 1. To determine
M and the probability
G, we represent the sequence
x in a table, where we arrange the runs
in
W columns and
rows, such that the entry in the
rth row and
ith column contains the symbol “∗” if run
r visited state
i, and the symbol “−” otherwise.
Recognizing that each column
i is
entries long and contains
items ∗, it follows that without changing a histogram
k we can rearrange the items ∗ in column
i in
ways.
M therefore is given by the product of binomial factors
In other words,
counts all possible sequences
x with histogram
k. Using Stirling’s approximation, the MC entropy,
, is
Note that for computing the MC entropy of the slowly driven process one only needs to know that the process gets restarted at
. At no point did we need to know the transition probabilities from Equation (
2).
This has an important implication: the entropy of the slowly driven process does not depend on how a process relaxes exactly, it only matters that the process
does relax somehow (replacing the transition probabilities Equation (
2) with other transition probabilities that respect the sample space reducing structure of the processes and restarting at
only changes the expression for the sequence probabilities,
G) and is restarted in state 1.
Using Equation (
2), the probability,
G, for sampling a particular
x can be computed in a similar way. Each visit to any state above the ground state,
, in the sequence
x contributes to the probability of the next visit to a state
with a factor
, independently from the state
j that will be sampled next (only if
do we not obtain such a renormalizing factor, since the process restarts with all possible states
as valid successor states of state 1, with prior probability
.). As a consequence, one obtains
The cross-entropy
is given by
and the maximum entropy functional of the slowly driven staircase process is given by
. Note that
plays the role of a divergence, generalizing the Kullback–Leibler divergence.
To obtain the maximum configuration
or
, we can solve the maximum entropy principle by maximizing
with respect to
p under the constraint
. As a result, one obtains,
, which is exactly the solution that we obtain in Equation (
3).
Note that MC entropy is not of trace form and the driving process “entangles” the ground state with every other state. This entropy violates all but one Shannon–Khinchin axiom. For the uniform distribution , one obtains .
3.2. Arbitrarily Driven Processes
For exploring relaxing systems with arbitrary drivers, again, we have to compute the probability of finding the histogram,
P, by following the generic construction rule for the MC divergence, entropy, and cross entropy (see [
16]). We will see that, for arbitrarily driven processes,
P factorizes again into a well defined multiplicity,
M, and a sequence probability,
G, just as for slowly driven processes.
To find P, we analyze the properties of a sampled sequence x. First note that, by mixing and , we now have to determine at each step, whether the process follows (relaxes) or (is reloaded). To model this stochastically, assume binary experiments, using, e.g., a coin for every sample . If the coin samples with probability , the process relaxes and follows . If the coin samples with probability , the process follows , and a driving event occurs. Let’s call any instance, , a starting point of a run, if (i) , (ii) , or (iii) . We call an instance, , an end point of the run, if (i) , (ii) , or (iii) . Except for and , all starting points directly follow an endpoint, and we can decompose the sequence x into R runs, , as before, such that . Each run, , begins at a starting point , and ends in an endpoint, . Note that , , and . The average length of the sequences is given by .
3.2.1. MC Entropy of Arbitrarily Driven Processes
Let
be the subsequence of
x containing all endpoints of runs
.
is the histogram of
, with
. We can now determine the number
of all sequences of runs
with histograms
k and
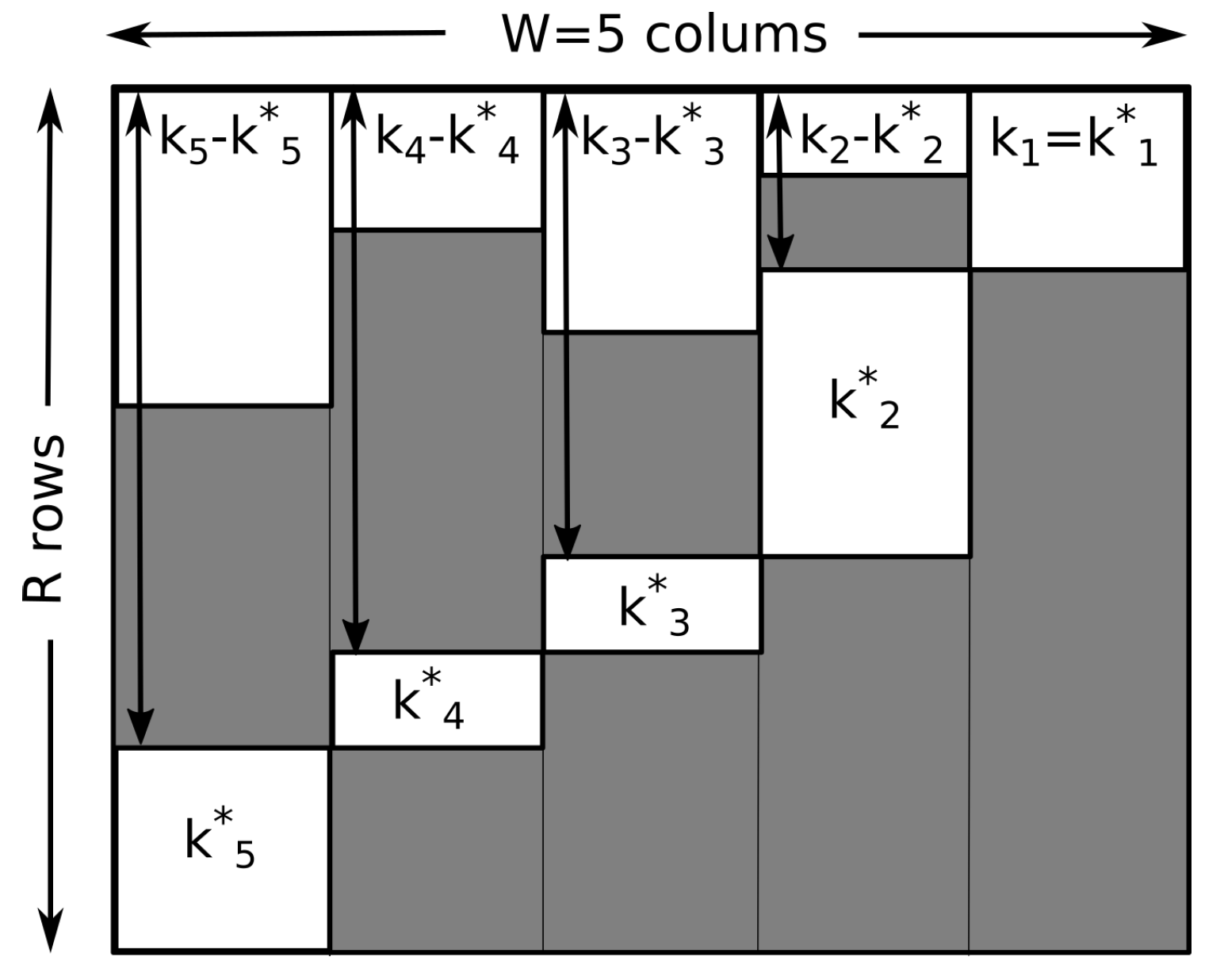
. Similar to the case of slow driving, this can be done by arranging runs in a table of
R rows and
W columns
We mark endpoints with the symbol “•” (one per row), other sequence elements with “∗”, and the rest with “−”. Having fixed
, we can distribute the elements of
in
different ways over
R rows. Given this fact, we can reorder the rows of the table in increasing order of their endpoints
(compare with
Figure 2). Obviously
, since all visits to the ground state are endpoints. We note further that for a state
, we can redistribute
items ∗ over
available positions. We can now simply read off the multiplicity from the ordered table
where the product over the states
j are contributions of binomial factors counting the number of ways
states can be distributed over
possible positions.
The multiplicity, M, does not explicitly depend on how exactly the system is driven. M contains no traces of the driving rates , nor any dependencies on transition probabilities, meaning no dependencies on prior weights, . This independence, however, is paid for with the dependence of M on a second histogram, . M depends only on the combinatorial relations of the relaxing (sample space reducing) process with the driving process. M describes the multiplicity, i.e., the a priori chances of jointly observing k and together. Note that is the empirically observed number of driving events observed in state i, is the empirical number of visits of the process to state i, while is the probability of a driving event to occur when the system is in state i.
The “joint” MC entropy of the arbitrarily driven process,
, is the logarithm of
M times a scaling factor. If we want an entropy per driving event, the factor is
, and we obtain
which depends on the average length of the runs,
. The parameter
corresponds to the
average free relaxation time of the process. Note that we can define the
average driving rate by
, which is nothing but the ratio
, i.e., the average number of driving events per process step. The MC entropy also depends on
and
, the distributions of driving events and state visits, respectively.
is the Shannon entropy of a binary process. From the fact that, by definition,
, we obtain the constraint
3.2.2. Cross-Entropy and Divergence of Arbitrarily Driven Processes
Similarly, we can collect the contributions to the sequence probability,
G. Every time the sequence
x follows the relaxing (or sample space reducing) process, we obtain a factor
, for some
, and a factor
if the sequence reaches an endpoint,
, of a run
. As a consequence, the probability of observing a sequence
x with histograms
k and
is given by
Note that
. The joint probability of observing
and
k together becomes
This shows that the mixing of relaxing and driving processes,
and
, leads to a joint probability that depends on
k and
. Noting that we can define
, the cross entropy construction yields
The MC functional,
, is
.
can be interpreted as the
information divergence or
relative entropy of the process. Maximizing
with respect to
p,
, and
, under the constraints
,
, and
(compare with Equation (
17)), yields the maximum configuration
. The maximization of the MC functional,
with respect to
p,
, and
, is the
maximum entropy principle of a driven processes.
,
, and
are Lagrangian multipliers.
By noting that derivatives of the MC functional Equation (
21) behave differently with respect to
and
, when compared with how they behave with respect to
and
(
), one finds that
, and, using the short hand for
, one obtains the formulas
These allow us to compute the solution for
recursively. The result is exactly the prediction from the eigenvector equation in Equation (
6). This fact shows that, indeed, the maximum entropy principle yields the expected distributions. However, we learn much more here, since by construction,
, is the probability measure of the process. This allows us to study fluctuations of
p and
within a common framework. This framework opens the possibility of extending fluctuation theorems—which are of interest in statistical physics (see, e.g., [
17])—to systems explicitly driven away from equilibrium. We can immediately predict parameters of driven processes, such as the “average free relaxation time” of the process,
.
4. Legendre Structure and Thermodynamic Interpretation
In the standard equilibrium MC principle, one maximizes the functional , with respect to p, , and . and are Lagrange multipliers for the normalization constraint, , and (e.g., in a physics context) the “energy” constraint, , where U represents the “internal energy.” are “energy” states and at the extremal value, is the inverse temperature. One can also see as a parameter of the extremal principle, and think of U as a function of .
The classic MC principle can be obtained from maximizing the functional (in the large N limit), under the constraint, . Asymptotically, one obtains where is the equilibrium cross-entropy. Using the parametrization for the prior probabilities in the variables , one obtains . Maximizing with Lagrange multiplier allows us to absorb the term into the normalization constraint by identifying . Since the distribution q is normalized, is a function of , and one obtains the MC solution, . Here is the normalization constant. Defining , we obtain in the maximum configuration that , with . Moreover, can be interpreted as the Legendre transformation of , where the term transforms the variables into the adjoined variables, . Since asymptotically approaches 1, we obtain and therefore , where is the Helmholtz free energy. Since represents thermodynamic entropy in equilibrium thermodynamics, one might ask whether a similar transformation exists for driven systems.
Let us parametrize the weights
and
as
Note that
need not sum to 1, so
does not need a normalization factor. Moreover, from
, it follows that
. Inserting these definitions in the cross-entropy in Equation (
20), we obtain
with—what we call—the
driving entropyHere
, which, in the given parametrization, is a function of
and
. In the maximum configuration, the terms
and
again are the Legendre transformation from variables
p and
to the adjoined variables,
and
.
is the MC of
and
. By defining now the “thermodynamic entropy,”
, where
, and, analogously, the “thermodynamic driving entropy,”
, one obtains
. Here
, and
is the “internal energy.” Since asymptotically (for large
N) we have
again, it follows that
In contrast to the maximum entropy principle for i.i.d. processes, where the inverse temperature and the normalization term of the distribution function are one-to-one related to the Lagrangian multipliers, this is no longer true for driven systems. The parameters
,
, and
are entangled in
! However, this fact does not—as one might expect—destroy the overall Legendre structure of the statistical theory of driven processes. It has, however, a important consequence: we can no longer expect notions such as the
Helmholtz free energy (which has a clear interpretation for reversible processes) to have the same meaning for driven systems. It is, however, exactly this kind of question that the theory that we outlined in this paper may help us tackle. For example, in a driven system, we have to decide whether we call
the Helmholtz free energy,
F, or if it is
. If we identify
and define the “
driven Helmholtz free energy” as,
, then we obtain
. This means that, for driven systems, it remains possible to switch between thermodynamic potentials using Legendre transformations, e.g., by switching from
U to
. Most importantly, the landscape of thermodynamic potentials is now enriched with two additional terms,
and
, which incorporate the driving process and its interactions with the system,
It is tempting to interpret and as irreversible work and dissipated heat, respectively. However, a clear interpretation of those terms can only be achieved within the concrete context of a given application.
5. Conclusions
We have shown that it is possible to derive a consistent maximum configuration framework for driven dissipative systems that are a combination of a state-dependent driving process and a relaxation process that can always can be modeled as an SSR process. The considered processes must exhibit stationary distributions. The presented framework is a statistical theory that not only allows us to compute visiting distribution functions p from an appropriate entropy functional but also allows us to predict properties, such as its state-dependent driving rates, , or the average relaxation times, . We find that the visiting distributions are in exact agreement with alternatively computable analytical solutions.
Remarkably, the maximum configuration entropy functional that emerges within the context of driven processes decouples completely from the detailed constraints posed by the interactions with the driving system. In this sense, it represents a property that is universally shared by processes within the considered class of driven processes. As a consequence, the maximum configuration mantra: maximize entropy + constraint terms to predict the maximum configuration, remains valid also for driven systems. One only needs to keep in mind that the “reasonable” constraint terms that specify the interactions of the system with the driving process may have a more complicated structure than we are used to from i.i.d. processes. The presented theory further allows us to compute a large number of expectation values that correspond to physically observable macro variables of the system. This includes the possibility of studying fluctuations of the system and the driving process together in the same framework.
The structure of the maximum configuration entropy and the corresponding maximum entropy principle is interesting by itself. By introducing the relative frequencies of the driving process and the average free relaxation time, , as independent quantities, the entropy decouples from the actual driving process and from how the system is linked to it. At the same time, this is only possible when the distributions and p become functionally entangled. effectively quantifies the strength of this entanglement. For slowly driven systems, it is the ground state that is entangled with all other states. For fast driving, all states become “hierarchically” entangled. Remarkably, however complicated this entanglement may be, we still can compute all of the involved distribution functions. As for i.i.d. processes, the maximum configuration asymptotically (for large systems) dominates the system behavior. Therefore, the maximum configuration entropy, at its maximum configuration (determined by the macro state of the driven system), can be given a thermodynamic meaning.
Finally, we discussed the thermodynamic structure of the presented statistical theory. The type of processes we can consistently describe with the presented framework include (kinetic) energy dissipations in elastic collision processes (see [
7]). It is therefore not only conceivable, but in fact highly probable, that for a wide class of driven processes, a consistent thermodynamics can be derived from the statistical theory. Despite the more complicated relations between distribution functions and system parameters, the Legendre structure of equilibrium thermodynamics survives in the statistical theory of the driven processes presented here. The landscape of macro variables (
U,
,
,
, ...) and potentials (
F,
,
, ...) becomes richer, and now includes terms that describe the driving process and how it couples to the relaxing system. Most importantly, however, the underlying statistical theory allows us to analyze all the differential relations between macro variables and potentials that we might consider. These may depend on the parametrization of
q and
. The presented work makes it conceivable that statistical theories can be constructed for situations, where multiple, not just two, driving and relaxing processes are interacting with one another. This results in more complicated functional expressions for MC entropy, cross-entropy, additional macro state variables, and thermodynamic potentials but does not introduce fundamental or conceptual problems.

{kind=link}
{kind=link}

