1. Introduction
Monte Carlo methods are one of the essential staples of the basic sciences in the modern age. Although these gained prominence during the early 1940s, thanks to secret research projects carried out in Los Alamos Scientific Laboratory by Ulam and von Neumann [
1,
2], their origins may be traced back to the famous Buffon’s needle problem, posed by Georges-Louis Leclerc, Comte de Buffon, in the 18th century. In the present day, Monte Carlo “experiments” are seen as a broad class of computational algorithms that use repeated random sampling to obtain numerical estimates of a given natural or mathematical process. In order to use these methods efficiently, fully random sequences of numbers are needed. Back in the 1940s, this was a tall order, and various methods to generate random sequences were used (some of them literally using roulettes), until von Neumann pioneered the concept of computer-based random number generators. During the following years, these became the standard tool in Monte Carlo methods and are still generally well-suited for many applications. However, these computer-based methods generate pseudo random numbers [
3], which means that the generated sequence can be determined given an algorithmic program and an initial seed, two ingredients which are hardly random. Thus, in order to achieve a truly unpredictable source of random numbers, we must eliminate these two deterministic aspects. The former is easy to overcome using, for example, a pattern of keystrokes typed on a computer keyboard as a random seed. On the other hand, the algorithmic program could be replaced, for instance, by a classical chaotic system [
4]. Examples of the latter abound in the area of weather prediction and climate sciences.
In recent years, however, the community has been moving towards using the fundamental laws dictating the behaviour of the quantum realm for the generation of sequences of truly random numbers. This seems, at a first glance, to be at odds with the following rather naïve thought: if the natural laws of the microscopic world are considered to be a computer program under which a system evolves from an initial state (a seed), should not its corresponding generated sequence also be predictable? It turns out that Quantum Mechanics, in its current standard view, related to the Copenhagen interpretation, has a special ingredient that makes the random sequence inherently unpredictable for both the generator and the observer. Such a strange behaviour has been eloquently recast over the years in various forms, famously by the quote “spooky action at a distance” due to Einstein, or mathematically by the celebrated work of Bell [
5,
6]. The application of quantum randomness in cryptography has given rise to the concept of device independent randomness certification, which, in a nutshell, corresponds to those processes that violate Bell’s inequalities [
7,
8]. However, there seems to be some confusion in the literature regarding two different properties of a given sequence of random numbers. The first one, rather important as we have argued above, is whether the sequence is truly random, meaning that it is unpredictable. In contrast, the second one is related to the issue of assessing whether or not it is biased. It is crucial to keep in mind that these two properties are independent, as evidenced by the random number generator Quantis [
9], which is based on a quantum system and is able to pass the standard tests of randomness (NIST (National Institute of Standards and Technology) suite) [
10] but has difficulties with other tests [
11].
Due to recent advances in quantum technologies, and since the NIST suite has been examined in other works [
12], together with a critical view on the use of
p-values on which the NIST suite relies [
13], it becomes necessary to consider other criteria for measuring the performance of quantum random number generators. Thus, we focus solely on two recently introduced approaches: the first one is based on algorithmic complexity theory evaluating incompressibility and bias at the same time, since an incompressible sequence is necessarily an unbiased one [
14], while the second one relies on Bayesian model selection. Both methods are based on solid structures which lead to a definition of randomness that is very intuitive and which arises independently of the development of random number generators. We apply them to analyze sequences of random bits generated in our laboratory using quantum systems. We also address the issue about the origin of the biases observed when utilizing these types of devices.
2. Tests of Randomness
A simple criterion for assessing the predictability of a sequence is the presence of patterns in it. For example, for the sequence , we can ask ourselves whether the next number is either 1 or 0. The natural answer is 0 based on the pattern observed in the previous bits. In general, we would like to find any possible regularity that helps us to predict the next bit. Within the framework of algorithmic information theory, it is possible to address this problem by noting that any sequence which exhibits regularity can be compressed using a short algorithm which can produce as output precisely such patterns. Thus, a sequence of this type could be reproduced using fewer bits than the ones contained in its original form. Therefore, whenever a sequence lacks regularity, we refer to it as “algorithmically” random.
We now introduce a remarkable result from algorithmic information theory: the Borel-normality criterion due to Calude [
14], which allows us to asymptotically check whether a sequence is not “algorithmically” random. Assuming we are given a string
of
bits (We will only consider binary sequences, but our results are easily generalizable to other alphabets), the idea of the Borel-normality criterion consists primarily of dividing the original sequence
ℓ into consecutive substrings of length
i and then computing the frequencies of occurrence of each of them. For brevity and later use, let us define
as the set of
substrings that can be formed with
i characters, let
be the sequence obtained after dividing it into substrings, and
. Additionally, let
be the number of times the
j-th substring of length
i appears in
ℓ. For example, when considering substrings of length
, we are looking at the frequencies of the symbols
that conform the original string
ℓ, while for
, we have to consider the frequencies of four substrings, namely
. According to Calude, a necessary condition for a sequence to be maximally random is that the deviations of these frequencies with respect to the expected values in the ideal random case should be bounded as follows [
14,
15]:
This condition must be satisfied for all substrings of lengths from
up to
. Intuitively, this criterion “compresses” the original sequence by reading
i bits at a time and tests whether the substrings appear with a frequency that differs from what would be expected in the random case, thus indicating the presence of some regularity. We emphasize that since Borel-normality is not a sufficient criterion for randomness, it can only be used to assess whether a given sequence is not random. In other words, even if a sequence satisfies Equation (
1) for all substrings and allowed values of
i, the Borel-normality condition cannot guarantee that it is indeed random.
Recently, a Bayesian criterion has been introduced [
16,
17] by some of the authors of the present article to test, from a purely probabilistic point of view, whether a sequence is maximally random as understood within information theory [
18]. The method works by exploiting the Borel-normality compression scheme and then recasting the problem of finding possible biases in the sequence as an inferential one in which Bayesian model selection can be applied. Specifically, for a fixed value of
i, we need to consider all the possible probabilistic models, henceforth denoted as
, that could have generated the sequence
ℓ. Each such model determines a unique probability assignation to the elements of
, which depends on a set of prior parameters
. For these parameters, the Jeffreys’ prior,
, turns out to be a convenient choice of prior parameter distribution, as it entails the “Occam Razor principle” in which more complex models are penalized, as well as being mathematically convenient for the case at hand; some other advantages are pointed out in [
16,
17].
Next, the question of finding all the generative models that can produce a sequence
ℓ is ultimately solved by noticing that all the possible probabilities assignations are in a one-to-one correspondence with all possible partitions of
. Since obtaining the partitions of any set is a straightforward combinatorial task [
19], we are able to determine all the relevant models when searching for possible biases in the generation of
ℓ. For instance, when
, there are two possible models: one in which the two elements of
are equiprobable, corresponding to the partition
of
into one subset—i.e., the same set—and another model with probabilities
,
corresponding to the partition
of
into two subsets. Even though it might seem that the first model is just a particular case of the second one (by letting
), we should keep in mind that the prior distributions are different in both cases,
and
, respectively, thus yielding two different models. Analogously, for
, there is a single unbiased model, which corresponds to the partition of
into one subset (with probabilities
, for
), and 14 additional models associated with the different ways of dividing
into subsets. The latter are related to the number of ways of distinguishing among the elements of
during the assignation of probabilities, and thus any of these models would entail some bias when generating a sequence. Note that, in general, for any value of
i, we will face a similar situation in which a single model can produce an unbiased, and hence maximally random, sequence by means of a uniform distribution, while the rest of them will be some type of categorical distribution.
Once all the models have been identified, the remaining part is the computation of the posterior distribution
, which from an inferential point of view is the most relevant distribution as it gives the probability that the model
has indeed produced the given sequence
ℓ. Note that, since a generative approach was adopted, we have direct access to the distribution
, which can be combined with the parameters’ prior
to obtaining the distribution
. One of the most important results of [
16] is that this marginalization can be accomplished exactly for all the models and any value of
i. Therefore, we can obtain the posterior distribution by a simple application of Bayes’ rule:
with
being the prior distribution in the space of models that can generate sequences of strings of length
i. Therefore, the best model
that describes the dataset
ℓ is quite simply given by
If the best model
turns out to be the unbiased one for all possible lengths
i of the substrings, then we can say that the process that generated that dataset was maximally random. However, it remains to discuss how large the length
i of substrings can be for a given dataset of
n bits. To answer this, we first note that, for any set containing
N elements, the possible number of partitions is given by the
N-th Bell number
[
19]. Thus, for a given
i, all possible partitions of the set
will result in
models to be tested, and, therefore, it is expected for them to be sampled at least once when observing
ℓ. This means that
, which, for sufficiently large
n, yields
, precisely as in the Borel-normality criterion.
Randomness characterization through Bayesian model selection has some clear and natural advantages, as already pointed out in [
16], but, unfortunately, it has an important drawback: the number of all possible models for a given length
i, given by
, grows supra-exponentially with
i: indeed, for
, we have two possible models, for
, we have 15 possible models, for
, we have instead 4140 possible models, while, for
, we have 10,480,142,147 models. Thus, even if we are able to acquire data for the evaluation of these many models, it becomes computationally impractical to estimate the posterior for all of them using Equation (
2). There is an elegant strategy to overcome this difficulty: one can derive bounds similar to those provided by the Borel-normality criterion, by comparing the log-likelihood ratio between the maximally random model and the maximally biased one. This yields the following bound for the frequencies of occurrence [
17]:
where
is the polygamma function of order 1. Note that, unlike Calude’s bound given by Equation (
1), this new Borel-type bound couples all frequencies, and, moreover, results in highly restrictive bounds.
4. Experimental Challenges in Random Number Generation
Suppose now that we have a single-photon source and we want to generate a sequence of bits to be tested against the bounds given by Equation (
1). Let us start by first focusing on the so-called Borel level, the word length
i, which can take a maximum value of
. In
Table 1, we report how
grows with
n, up to a value of
. In order to achieve a Borel level
, we will require a dataset of length
events. Assuming that our single-photon generator and detectors can cope with around a million of events per second, we would then require on the order of 600 years to generate a sequence of that length! It turns out that
is a more realistic value, since it leads to a required dataset
ℓ of size
events, which can be realistically produced in a couple of hours.
The bound on the right-hand-side of Equation (
1) implies that the frequencies of occurrence
for substrings of length
cannot deviate from the ideal random one,
, by more than
, which constitutes an extremely tight tolerance. Hence, in practice, any part of the naïve experimental setup that gives rise to some bias will unfortunately make the dataset
ℓ unable to pass the Calude criterion. The first component that we must be wary about is the BS. A regular BS usually has an error figure in the region of 1%, which is very high with respect to the stringent tolerance
ℓ would need in order fulfill Borel normality. Is it plausible to correct this using a Polarizing Beam Splitter (PBS), instead of the BS, with an active control through feedback of the state of polarization so as to compensate for any bias in the PBS? In what follows, we investigate this question through a simple experiment. The state of polarization of a single photon entering the PBS can be written as
where |
V〉 and |
H〉 refer to the vertical and horizontal polarization components, respectively. We can approach the state in Equation (
5) by transmitting the laser beam trough a half wave plate (HWP) so as to achieve arbitrary rotation of the linear polarization. Assuming a perfect, unbiased BS, we would need an incoming polarization state with
so that the resulting sequence of bits is unbiased. If, on the other hand, the PBS exhibits biases (e.g., due to manufacturing error), we can adjust the orientation of the above-mentioned half wave plate so as to adjust precisely the value of our coefficients
a and
b to compensate for the PBS bias.
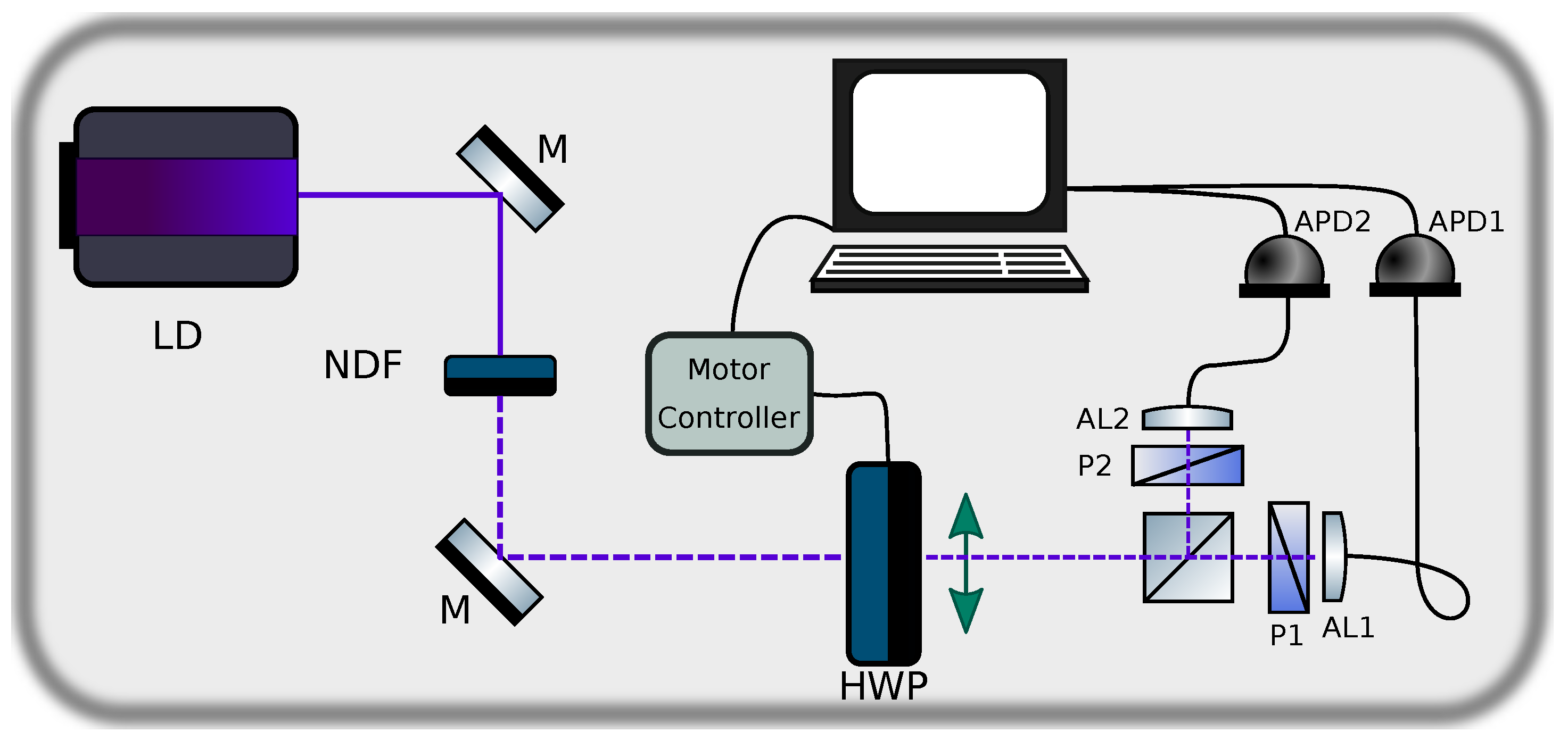
Our experimental setup, shown in
Figure 2, can be regarded as the minimal realistic device for the implementation of a QRNG. The main questions which we wish to address are: (i) how good are the sequences of bits generated by such a device? In addition, (ii) do they pass the Borel-normality criterion?
The input state is prepared using the beam from a laser diode (LD). The beam is transmitted through a set of neutral density filters (NDF) with a combined optical density for attenuation to a level compatible with the maximum recommended count rate of our single photon detectors. The beam is then transmitted through a half wave plate (HWP) mounted on a motorized rotation stage so as to control its orientation angle relative to the PBS axes. The PBS splits the beam into two spatial modes according to the H and V polarizations, each of which is coupled with the help of an aspheric lens (AL1 and AL2) into a multimode fiber leading to an avalanche photodiode (APD1 and APD2). We include a polariser (P1 and P2), with an extinction ratio, defined as the ratio of the maximum to the minimum transmission of a linearly polarized input, of 100,000:1 prior to each of the aspheric lenses (AL1 and AL2) for a reduction of the non-polarized intensity reaching the detectors.
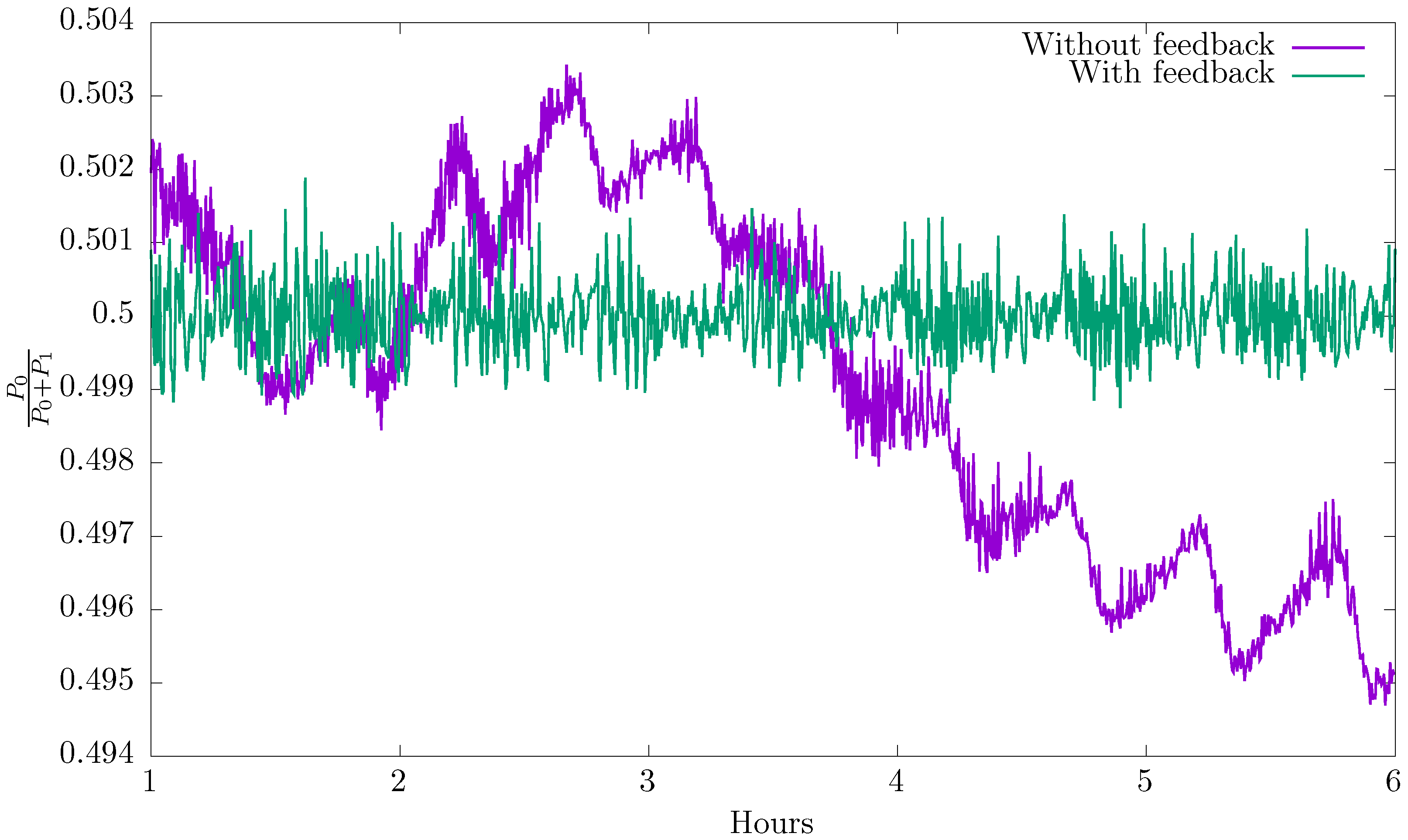
Suppose now that we prepare our system so that the average relative power
of each APD detector
starts ideally at
. In
Figure 3, we show how this average relative power evolves with time (see curve labelled “without feedback”). Note that, even though the system starts in a perfectly balanced state, it rapidly deviates from this condition. The slow change of this curve can be attributed to thermal drift while the oscillatory component with a period of approximately half an hour is related to the air conditioning system in the laboratory. These effects can be effectively compensated by rotating the HWP. After some study of the response function of our experimental setup, a correction every minute with a proportional controller was sufficient to correct for all these effects leading to a steady response (see curve labelled “with feedback”) [
21].
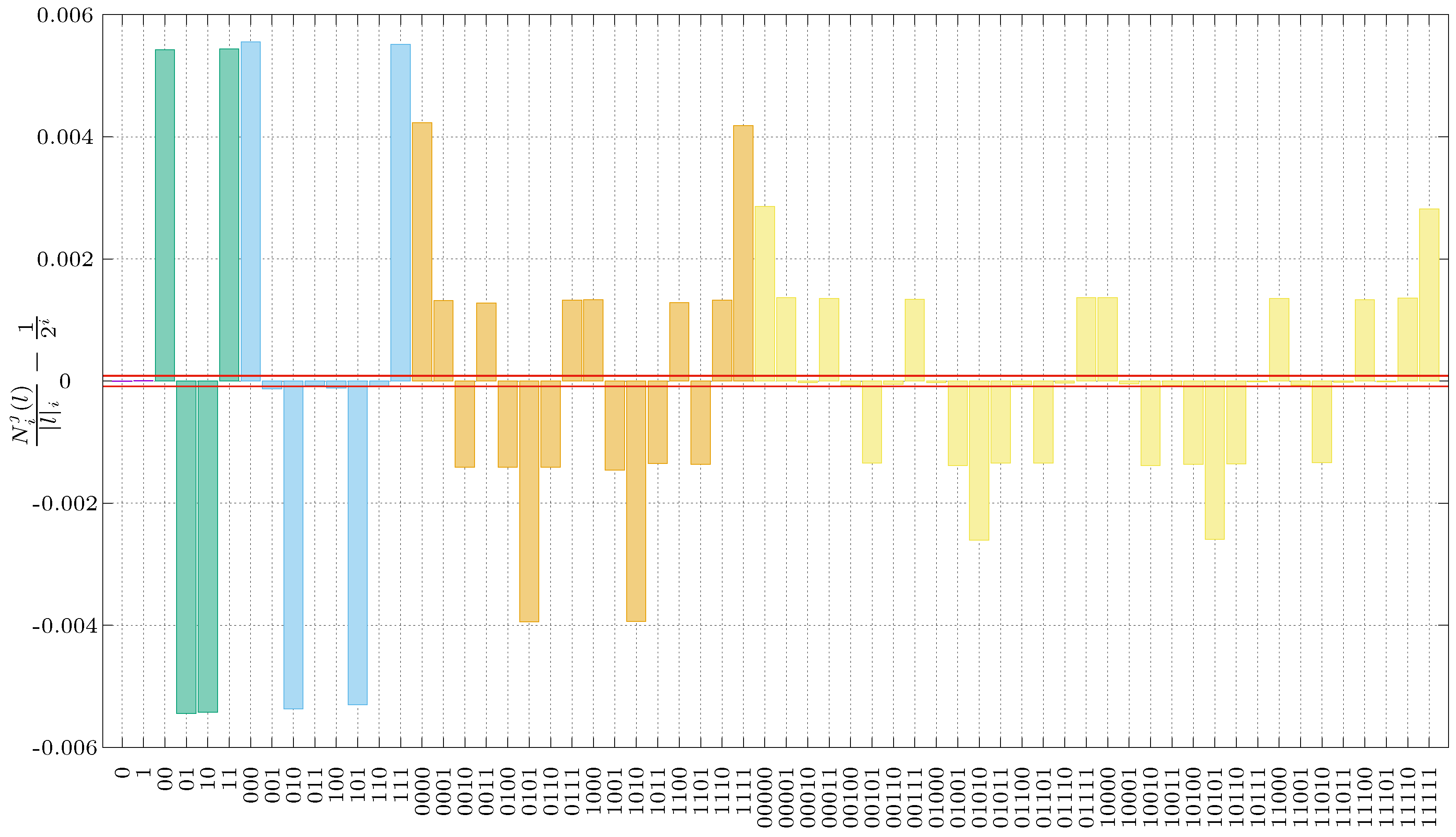
5. First Battery of Results
We have used the experimental setup described in the previous section to generate a sequence of 4,294,967,296 bits, allowing us to test the Borel–Normality criterion up to level
. The results of this analysis are depicted in
Figure 4. In the plot, bars represent the deviations from the ideal value for all the strings at each Borel level. For instance, in the first part of the analysis (purple bars), there are only two bars corresponding to the frequency of occurrences of substrings “1” and “0”. As our initial setup is very fine-tuned and stable, the bars have practically zero height, with value
. The green bars represent the second part of the analysis, or Borel level two, corresponding to frequencies of occurrences of symbols
, and so on. In the same figure, the horizontal lines represent the bound given by the right-hand-side of Equation (
1). Our first battery of results are a clear disappointment: only the first set for substrings of length one clearly passes the test, while, for higher lengths, our QRNG fails miserably to pass Calude’s criterion.
Furthermore, a closer look at the green bars shows that events 00 and 11 appear more frequently than expected, by about , (while events 01 and 10 appear less frequently than expected by the same margin). This effect reveals a correlation between “equal events”, that is, the same digit appearing twice. In terms of our experiment, this means that it is more probable to observe an event in a detector once a previous event has already been recorded. Other parts of our test validate this: for Borel level three, the yellow bars indicate that events with alternate zeroes and ones (010 and 101) appear less frequently than expected, also by about . At Borel levels four and five, the larger deviations appear for events 0101 and 1010, clearly in accordance with the previous results. This indicates that certain parts of our experimental setup are introducing unwanted correlations between bits, which results in the magnitude of some of the deviations to be 50 times larger than expected. Our experimental effort clearly does not suffice for our sequences to pass the Borel–Normality criterion. How is this possible?
7. Random Number Generation Using Time Measurements
We now follow a method introduced in [
3]. Suppose that
is the probability density function of a continuous random random variable
X on an interval
. Let us further assume that its real value
x is represented up to a given precision so that we assign a parity to
x according to the parity of its least significant digit. Next, we divide the interval
into an even number
of bins and introduce
Suppose that
and the precision has been chosen so that
is even for
i even and odd for
i odd. It follows that
with
Approximating the integrals by the left sum rule, we can write that
which implies that, roughly, the probability that the least significant digit is odd can be expressed as
where the bias term can be fine-tuned by increasing either the number of bins or through a smooth density
, or both.
This method can be very easily implemented in the lab as follows. Suppose that the random variable
X is the time difference between two consecutive photon arrivals to the detector. In our case, these times are of the order of 500 ns to 10 µs. A typical sequence of these time differences look like:
We can then look at the parity of the least significant digit and assign, for instance, a 0-bit to even parity and 1-bit to odd parity, thus generating a dataset
ℓ of
n bits. In
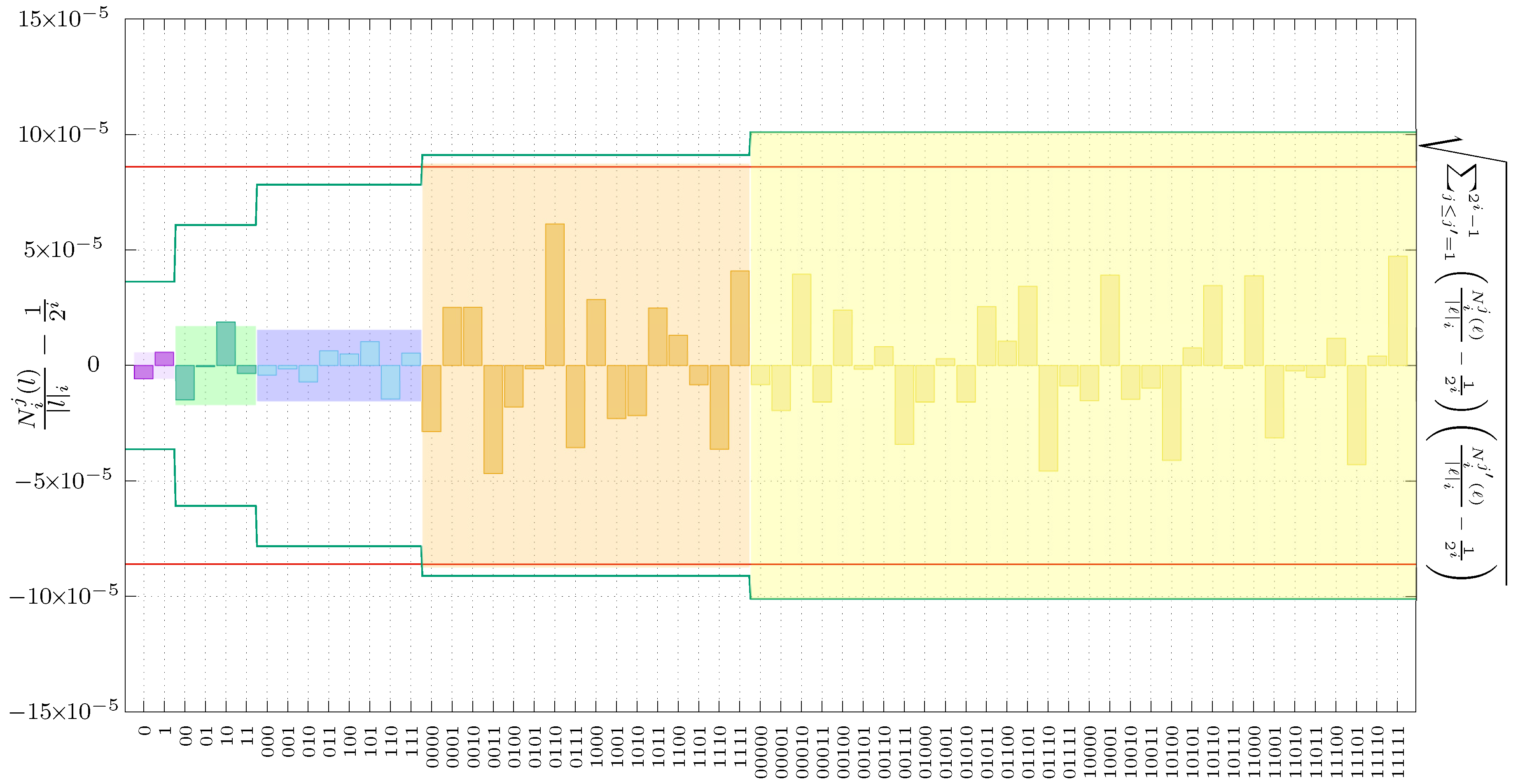
Figure 5, we show the results of testing such a sequence using the Borel-normality bounds and Bayesian bounds, given by Equations (
1) and (
4), respectively, up to Borel level
. The colored bins correspond to the deviations from the ideal value of relative frequencies for all the possible subsequences. These are ordered using its length
(purple bins),
(green bins),
(blue bins),
(orange bins), and
(yellow bins). The solid red line corresponds to the Borel bound,
. In the same graph, the green line is the Bayesian bound given the right-hand-side of Equation (
4) that depends on
i and therefore it is not a constant, as is the case for the Borel bound. Finally, the height of the various background colored boxes correspond to the values given by the left-hand-side expression of the Bayesian bound.
As we can see, this extremely simple QRNG passes the Borel-normality criterion up to
, and nearly passes the Bayesian criterion (passes it for
and slightly exceeds the bound for
). Notice that, while the previous experimental setup required an accurate balance between zeroes and ones, in the present case we already have very small deviations at Borel level
, less than
, showing the convenience of this method. For
(green bins), the deviations are much larger, almost three times the value for
, but nevertheless they pass the test again by a considerable margin. These results show the lack of correlations between consecutive events, which is the main drawback of the previous approach. It is important to note that, in the results at Borel level
, there is a substantial increase in the deviations compared with
. While this increase may indicate the presence of some as yet unidentified correlations, these are of an insufficient magnitude to reach the bounds. On the other hand, this experimental setup fails to pass some of the requirements of the Bayesian scheme. The deviations derived from the Bayesian criterion are shown in
Table 2, and also in
Figure 5. As we can see, all Borel levels pass the Bayesian test, except for the last one, albeit by a small margin.
We can also look at the value of the posterior distribution given by Equation (
2) for the maximally random model. The value of the posterior for the four word lengths is reported in
Table 3. For the first three Borel levels, the posterior distribution of the maximally random model
is very close to one, indicating that, given the dataset, this is the most likely model to have generated such data. For Borel level
, we are only able to analyse those models which are in the vicinity, in parameter space, to the maximally random model. These models correspond to partitioning
into two subsets, resulting in 32,767 models, giving a total of 32,768, including the maximally random one. In this case, it turns out that the most likely model is not the maximally random one. Actually, using the value of the posterior probability, this model is ranked in the position 9240 out of all the explored models, and therefore the sequence of bits fails to pass the Bayesian criterion already at Borel level
. Note that
was not included in
Table 3 because we lack the computational power to address this Borel level.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}