Abstract
The maximum complex correntropy criterion (MCCC) has been extended to complex domain for dealing with complex-valued data in the presence of impulsive noise. Compared with the correntropy based loss, a kernel risk-sensitive loss (KRSL) defined in kernel space has demonstrated a superior performance surface in the complex domain. However, there is no report regarding the recursive KRSL algorithm in the complex domain. Therefore, in this paper we propose a recursive complex KRSL algorithm called the recursive minimum complex kernel risk-sensitive loss (RMCKRSL). In addition, we analyze its stability and obtain the theoretical value of the excess mean square error (EMSE), which are both supported by simulations. Simulation results verify that the proposed RMCKRSL out-performs the MCCC, generalized MCCC (GMCCC), and traditional recursive least squares (RLS).
1. Introduction
As many noises are non-Gaussian distributed in practice, the performance of traditional second-order statistics-based similarity measures may deteriorate dramatically [1,2]. To efficiently handle the non-Gaussian noise, a higher order statistic called correntropy [3,4,5,6] was proposed. The correntropy is a nonlinear and local similarity measure widely used in adaptive filters [7,8,9,10,11,12,13,14,15], and usually employs a Gaussian function as the kernel function thanks to flexible and positive definiteness. However, the Gaussian kernel is not always the best choice [16]. Hence, Chen et al. proposed the generalized maximum correntropy criterion (GMCC) algorithm [16,17] using a generalized Gaussian density function as the kernel. Compared with traditional maximum correntropy criterion (MCC), the GMCC behaves better when the shape parameter is properly selected. In addition, the MCC can be regarded as a special case of GMCC. Considering that the error performance surface of correntropic loss is highly non-convex, Chen et al. proposed another algorithm named the minimum kernel risk-sensitive loss (MKRSL), which is defined in kernel space but also inherits the original form of risk-sensitive loss (RSL) [18,19]. The performance surface of the kernel risk-sensitive loss (KRSL) is more efficient than the MCC, resulting in a faster convergence speed and a higher accuracy. Furthermore, KRSL is also not sensitive to outliers.
Generally, adaptive filter has been mainly focused on the real domain and cannot be used to deal with complex-valued data directly. Recently, the complex domain adaptive filter has drawn more attention. Guimaraes et al. proposed the maximum complex correntropy criterion (MCCC) [20,21] and provided a probabilistic interpretation [20]. MCCC shows an obvious advantage over the least absolute deviation (LAD) [22], complex least mean square (CLMS) [23], and recursive least squares (RLS) algorithms [24]. The stability analysis and the theoretical EMSE of the MCCC have been derived [25]. The MCCC has been extended to the generalized case [26]. The generalized MCCC (GMCCC) algorithm employs a complex generalized Gaussian density as a kernel and offers a desirable performance for handling the complex-valued data. In addition, a gradient-based complex kernel risk-sensitive loss (CKRSL) defined in kernel space has shown a superior performance [27]. Until now, there has been no report about the recursive complex KRSL (CKRSL) algorithm. Therefore, in this paper we first propose a recursive minimum CKRSL (RMCKRSL) algorithm. Then, we analyze the stability and calculate the theoretical value of the EMSE. Simulations show that the RMCKRSL is better than the MCCC, GMCCC, and traditional RLS. Simultaneously, the correctness of the theoretical analysis is also demonstrated by simulations.
The remaining parts of this paper are organized as follows: In Section 2, we provide the loss function of the CKRSL and propose the recursive MCKRSL algorithm. In Section 3 we analyze the stability and obtain the theoretical value of the EMSE for the proposed algorithm. In Section 4, simulations are performed to verify the superior convergence of the RMCKRSL algorithm and the correctness of the theoretical analysis. Finally, in Section 5 we draw a conclusion.
2. Fixed Point Algorithm under Minimizing Complex Kernel Risk-Sensitive Loss
2.1. Complex Kernel Risk-Sensitive Loss
Supposing there are two complex variables and , the complex kernel risk-sensitive loss (CKRSL) is defined as [27]:
where , , and are real variables, is the risk-sensitive parameter, and is the kernel function.
This paper employs a Gaussian kernel which is expressed as:
where is the kernel width.
2.2. Recursive Minimum Complex Kernel Risk-Sensitive Loss (RMCKRSL)
2.2.1. Cost Function
We define the cost function of MCKRSL as:
where
denotes the error at the iteration, represents the expected response at the iteration, denotes the estimated weight vector, is the length of adaptive filter, and is the input vector, and denote the conjugate transpose and transpose, respectively.
2.2.2. Recursive Solution
Using the Wirtinger Calculus [28,29], the gradient of with respect to is derived:
By making , we obtain the optimal solution
where
It is noted that Equation (6) is actually a fixed point solution because and depend on . In practice, and are usually estimated as follows when the samples are finite:
Hence, , and are updated as follows:
Using the matrix inversion lemma [30], we may rewrite in Equation (12) as:
and
After some algebraic manipulations, we may derive the recursive form of as follows:
Finally, Algorithm 1 summarizes the recursive MCKRSL (RMCKRSL) algorithm.
| Algorithm 1: RMCKRSL. |
| Input:, , , 1. Initializations: , , , , 2. While available, do 3. 4. 5. 6. 7. 8. 9. End while |
| 10. |
| Output: Estimated filter weight |
3. Convergence Analysis
3.1. Stability Analysis
Supposing the desired signal is as follows:
we rewrite the error as:
where is the system parameter to be estimated, , represents the noise at discrete time , and .
Furthermore, we rewrite as:
where , , , represents the noise, and the second line is approximately obtained by using the following:
Remark 1.
(1) We can approximate the second line of Equation (20) whenis small enough, where.
(2) According to Equation (20), the RMCKRSL can be approximately viewed as a gradient descend method with variable steps a0/k.
(3) We can estimateby, whereis the number of samples.
By multiplying on both sides of Equation (20), we obtain the following:
where .
Therefore,
where represents the Frobenius norm, is the real part, and denotes the identity matrix.
Then, we can determine that if
the sequence is decreasing and the algorithm will converge.
3.2. Excess Mean Square Error
Let be the excess mean square error (EMSE) and defined as:
To derive the theoretical value of , we adopt some commonly used assumptions [8,27,31]:
(A1) is zero-mean and independently identically distributed (IID); is independent of and also zero-mean;
(A2) is independent of , circular and stationary.
Thus, taking (23) and (25) into consideration, we obtain the following:
Similar to [27], we can obtain the following:
where
Thus,
where , , .
It can be seen from Equation (31), that S(k) is the solution to a first-order difference equation. Thus, we derive that:
where is the homogeneous solution with , and is the particular solution where:
and .
Remark 2.
The theoretical value ofin Equation (32) is reliable only whenis small enough andis large. can be obtained by using the initial value of the EMSE. However, it is not necessary to calculate in general, because when is large. Thus, .
4. Simulation
In this section, two examples are used to illustrate the superior performance of the RMCKRSL i.e., system identification and nonlinear prediction. We obtained the simulation results by averaging 1000 Monte Carlo trials.
4.1. Example 1
We chose the length of the filter as five where the weight vector is generated randomly, where , with and being the real and imaginary parts of , and denoting the Gaussian distribution with and being the mean and variance, respectively. The input signal is also generated randomly, where . An additive complex noise, , with and being the real and imaginary parts, is considered in the simulations.
First, we verify the superiority of the RMCKRSL in the presence of contaminated Gaussian noise [17,19], i.e., , where , with , with represents an outlier (or impulsive disturbances), is the occurrence probability of impulsive disturbances, . To ensure a fair comparison, all the algorithms use the recursive iteration to search the optimal solution. The parameters for different algorithms are chosen experimentally to guarantee the desirable solution. The performances of different algorithms on the basis of weight error power are shown in Figure 1. It is clear that compared with the MCCC, GMCCC and traditional RLS, RMCKRSL has the best filtering performance.
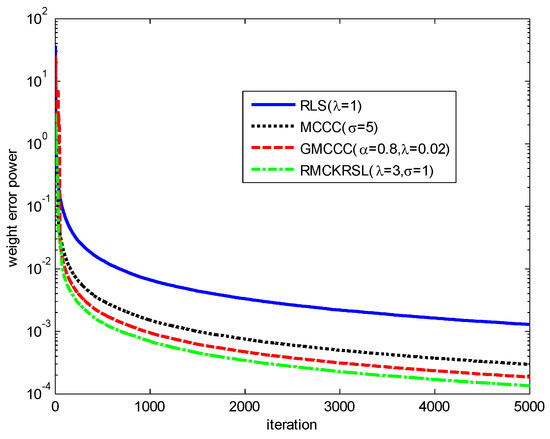
Figure 1.
Learning curves of different algorithms.
Then, the validity of the theoretical EMSEs for MCKRSL is demonstrated. The noise model is also a contaminated Gaussian model, where , , and . Figure 2 compares the values of the theoretical EMSEs and simulated ones under variations of . Obviously there is a good match between the theoretical EMSEs and the simulated ones. In addition, it has been shown that the value of EMSE becomes bigger with the increase of noise variance.

Figure 2.
EMSE as a function of noise variances.
Next, we tested the influence of the outlier on the performance of the RMCKRSL algorithm. The noise model is also a contaminated Gaussian noise, where , , and . Figure 3 compares the performances of different algorithms under different probability of outlier values (), where the sample size is 5000 and the variance of the outlier is . One can observe that the proposed RMCKRSL algorithm is robust to the probability of an outlier and has better performance than the MCCC, GMCCC and RLS. Figure 4 depicts the performances of different algorithms under different variance of outlier () values, where the sample size is also 5000 and the probability of an outlier is . It can be observed that the proposed RMCKRSL algorithm is also robust to the variance of an outlier and has better performance than other algorithms.
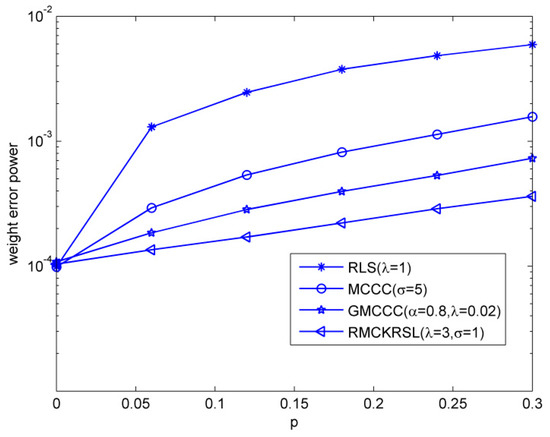
Figure 3.
Influence of the probability of outliers.
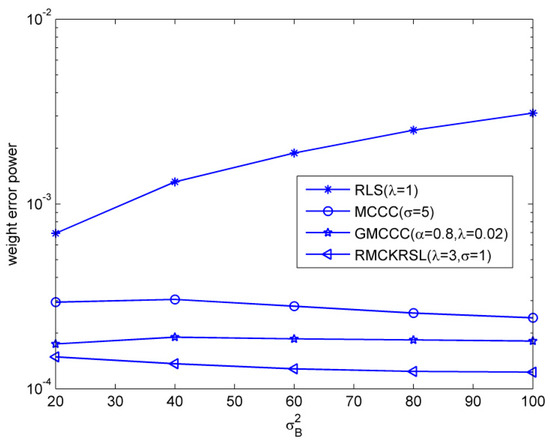
Figure 4.
Influence of the variance of outliers.
Finally, the influences of the kernel width and risk-sensitive parameter on the performance of the RMCKRSL are investigated. The noise model is also a contaminated Gaussian noise, where , , and . Figure 5 and Figure 6 present the performance of the RMCKRSL under a different kernel width and risk-sensitive parameter , respectively. One can see that both the kernel width and risk-sensitive parameter play an important role in the performance of the RMCKRSL. It is challenging to choose the optimal and because it is dependent on the statistical characteristic of the noise, which is unknown in the practical case. Thus, it is suggested that the parameters are chosen by experimentation.
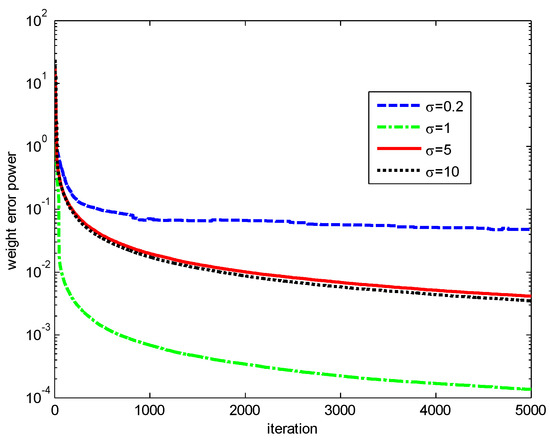
Figure 5.
Influence of the ().
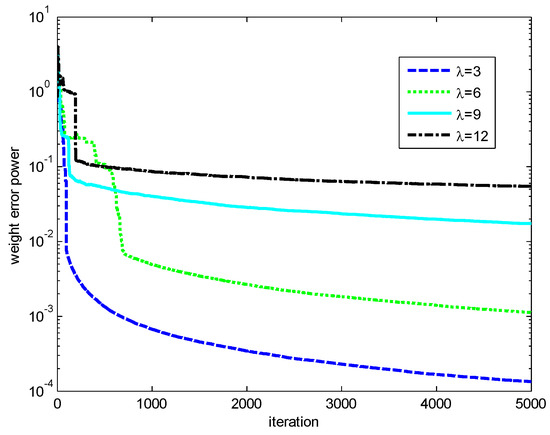
Figure 6.
Influence of the ().
4.2. Example 2
In this example, the superiority of the RMCKRSL is demonstrated by the prediction of a nonlinear system, where , is a Mackey-Glass chaotic time series described as follows [15]:
is the reverse of , and is a complex valued number whose real and imaginary parts are randomly generated and obey a uniform distribution over the interval [0, 1]. is discretized by sampling with an interval of six seconds, and affected by the contaminated Gaussian noise , where , with , with , , . is predicted by x(k) = [s(k − 1) s(k − 2) ⋯ s(k − 6)] and the performance is measured by the mean square error (MSE) with . The convergence curves of different algorithms on the basis of MSE are compared in Figure 7. One may observe that the RMCKRSL has a faster convergence rate and better filter accuracy than other algorithms. In addition, the RLS behaves the worst since the minimum square error criterion is not robust to the impulse noise.
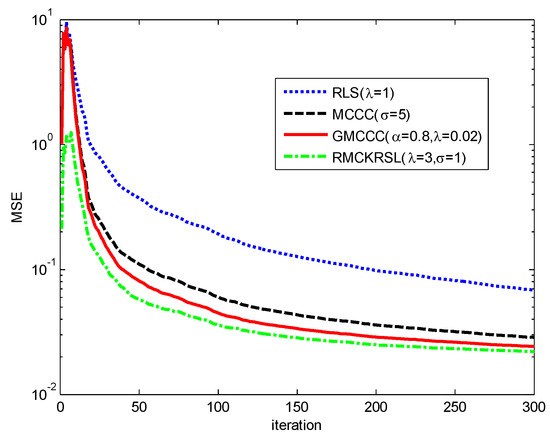
Figure 7.
Convergence curves of different algorithms.
5. Conclusions
As a nonlinear similarity measure defined in kernel space, kernel risk-sensitive loss (KRSL) shows a superior performance in adaptive filter. However, there is no report about the recursive KRSL algorithm. Thus, in this paper we focused on the complex domain adaptive filter and proposed a recursive minimum complex KRSL (RMCKRSL) algorithm. Compared with the MCCC, GMCCC and traditional RLS algorithms, the proposed algorithm offers both a faster convergence rate and higher accuracy. Moreover, we derived the theoretical value of the EMSE, and demonstrated its correctness by simulations.
Author Contributions
Conceptualization, G.Q., D.L. and S.W.; methodology, S.W.; software, D.L.; validation, G.Q.; formal analysis, G.Q.; investigation, G.Q., D.L. and S.W.; resources, G.Q.; data curation, D.L.; writing—original draft preparation, G.Q. and D.L.; writing—review and editing, S.W.; visualization, D.L.; supervision, G.Q., D.L. and S.W.; project administration, G.Q.; funding acquisition, G.Q.
Funding
This research was funded by the China Postdoctoral Science Foundation Funded Project under grant 2017M610583, and Fundamental Research Funds for the Central Universities under grant SWU116013.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Principe, J.C. Information Theoretic Learning: Renyi’s Entropy and Kernel Perspectives; Springer: New York, NY, USA, 2010. [Google Scholar]
- Chen, B.; Zhu, Y.; Hu, J.; Principe, J.C. System Parameter Identification: Information Criteria and Algorithms; Newnes: Oxford, UK, 2013. [Google Scholar]
- Liu, W.; Pokharel, P.P.; Pr´ıncipe, J. Correntropy: A localized similarity measure. In Proceedings of the 2006 IEEE International Joint Conference on Neural Network (IJCNN), Vancouver, BC, Canada, 16–21 July 2006; pp. 4919–4924. [Google Scholar]
- Liu, W.; Pokharel, P.P.; Principe, J.C. Correntropy: Properties and applications in non-Gaussian signal processing. IEEE Trans. Signal Process. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Singh, A.; Principe, J.C. Using correntropy as a cost function in linear adaptive filters. In Proceedings of the 2009 International Joint Conference on Neural Networks (IJCNN), Atlanta, GA, USA, 14–19 June 2009; pp. 2950–2955. [Google Scholar]
- Singh, A.; Principe, J.C. A loss function for classification based on a robust similarity metric. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–6. [Google Scholar]
- Zhao, S.; Chen, B.; Principe, J.C. Kernel adaptive filtering with maximum correntropy criterion. In Proceedings of the 2011 International Joint Conference on Neural Networks (IJCNN), San Jose, CA, USA, 31 July–5 August 2011; pp. 2012–2017. [Google Scholar]
- Chen, B.; Xing, L.; Liang, J.; Zheng, N.; Principe, J.C. Steady-state mean-square error analysis for adaptive filtering under the maximum correntropy criterion. IEEE Signal Process. Lett. 2014, 21, 880–884. [Google Scholar]
- Wu, Z.; Peng, S.; Chen, B.; Zhao, H. Robust Hammerstein adaptive filtering under maximum correntropy criterion. Entropy 2015, 17, 7149–7166. [Google Scholar] [CrossRef]
- Chen, B.; Wang, J.; Zhao, H.; Zheng, N.; Principe, J.C. Convergence of a Fixed-Point Algorithm under Maximum Correntropy Criterion. IEEE Signal Process. Lett. 2015, 22, 1723–1727. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, J.; Qu, H.; Chen, B.; Principe, J.C. Convergence performance analysis of an adaptive kernel width MCC algorithm. AEU-Int. J. Electron. Commun. 2017, 76, 71–76. [Google Scholar] [CrossRef]
- Liu, X.; Chen, B.; Zhao, H.; Qin, J.; Cao, J. Maximum Correntropy Kalman Filter with State Constraints. IEEE Access 2017, 5, 25846–25853. [Google Scholar] [CrossRef]
- Wang, F.; He, Y.; Wang, S.; Chen, B. Maximum total correntropy adaptive filtering against heavy-tailed noises. Signal Process. 2017, 141, 84–95. [Google Scholar] [CrossRef]
- Chen, B.; Liu, X.; Zhao, H.; Principe, J.C. Maximum correntropy Kalman filter. Automatica 2017, 76, 70–77. [Google Scholar] [CrossRef]
- Wang, S.; Dang, L.; Wang, W.; Qian, G.; Tse, C.K. Kernel Adaptive Filters with Feedback Based on Maximum Correntropy. IEEE Access 2018, 6, 10540–10552. [Google Scholar] [CrossRef]
- He, Y.; Wang, F.; Yang, J.; Rong, H.; Chen, B. Kernel adaptive filtering under generalized Maximum Correntropy Criterion. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1738–1745. [Google Scholar]
- Chen, B.; Xing, L.; Zhao, H.; Zheng, N.; Príncipe, J.C. Generalized correntropy for robust adaptive filtering. IEEE Trans. Signal Process. 2016, 64, 3376–3387. [Google Scholar] [CrossRef]
- Chen, B.; Wang, R. Risk-sensitive loss in kernel space for robust adaptive filtering. In Proceedings of the 2015 IEEE International Conference on Digital Signal Processing (DSP), Singapore, 21–24 July 2015; pp. 921–925. [Google Scholar]
- Chen, B.; Xing, L.; Xu, B.; Zhao, H.; Zheng, N.; Príncipe, J.C. Kernel Risk-Sensitive Loss: Definition, Properties and Application to Robust Adaptive Filtering. IEEE Trans. Signal Process. 2017, 65, 2888–2901. [Google Scholar] [CrossRef]
- Guimaraes, J.P.F.; Fontes, A.I.R.; Rego, J.B.A.; Martins, A.M.; Principe, J.C. Complex correntropy: Probabilistic interpretation and application to complex-valued data. IEEE Signal Process. Lett. 2017, 24, 42–45. [Google Scholar] [CrossRef]
- Guimaraes, J.P.F.; Fontes, A.I.R.; Rego, J.B.A.; Martins, A.M.; Principe, J.C. Complex Correntropy Function: Properties, and application to a channel equalization problem. Expert Syst. Appl. 2018, 107, 173–181. [Google Scholar] [CrossRef]
- Alliney, S.; Ruzinsky, S.A. An algorithm for the minimization of mixed l1 and l2 norms with application to Bayesian estimation. IEEE Trans. Signal Process. 1994, 42, 618–627. [Google Scholar] [CrossRef]
- Mandic, D.; Goh, V. Complex Valued Nonlinear Adaptive Filters: Noncircularity, Widely Linear and Neural Models (ser. Adaptive and Cognitive Dynamic Systems: Signal Processing, Learning, Communications and Control); John Wiley & Sons: New York, NY, USA, 2009. [Google Scholar]
- Diniz, P.S.R. Adaptive Filtering: Algorithms and Practical Implementation, 4th ed.; Springer-Verlag: New York, NY, USA, 2013. [Google Scholar]
- Qian, G.; Wang, S.; Wang, L.; Duan, S. Convergence Analysis of a Fixed Point Algorithm under Maximum Complex Correntropy Criterion. IEEE Signal Process. Lett. 2018, 24, 1830–1834. [Google Scholar] [CrossRef]
- Qian, G.; Wang, S. Generalized Complex Correntropy: Application to Adaptive Filtering of Complex Data. IEEE Access 2018, 6, 19113–19120. [Google Scholar] [CrossRef]
- Qian, G.; Wang, S. Complex Kernel Risk-Sensitive Loss: Application to Robust Adaptive Filtering in Complex Domain. IEEE Access 2018, 6, 2169–3536. [Google Scholar] [CrossRef]
- Wirtinger, W. Zur formalen theorie der funktionen von mehr complexen veränderlichen. Math. Ann. 1927, 97, 357–375. [Google Scholar] [CrossRef]
- Bouboulis, P.; Theodoridis, S. Extension of Wirtinger’s calculus to reproducing Kernel Hilbert spaces and the complex kernel LMS. IEEE Trans. Signal Process. 2011, 59, 964–978. [Google Scholar]
- Zhang, X. Matrix Analysis and Application, 2nd ed.; Tsinghua University Press: Beijing, China, 2013. [Google Scholar]
- Picinbono, B. On circularity. IEEE Trans. Signal Process. 1994, 42, 3473–3482. [Google Scholar] [CrossRef]







© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).