Point Divergence Gain and Multidimensional Data Sequences Analysis



Abstract
:1. Introduction
2. Basic Properties of Point Divergence Gain and Derived Quantities
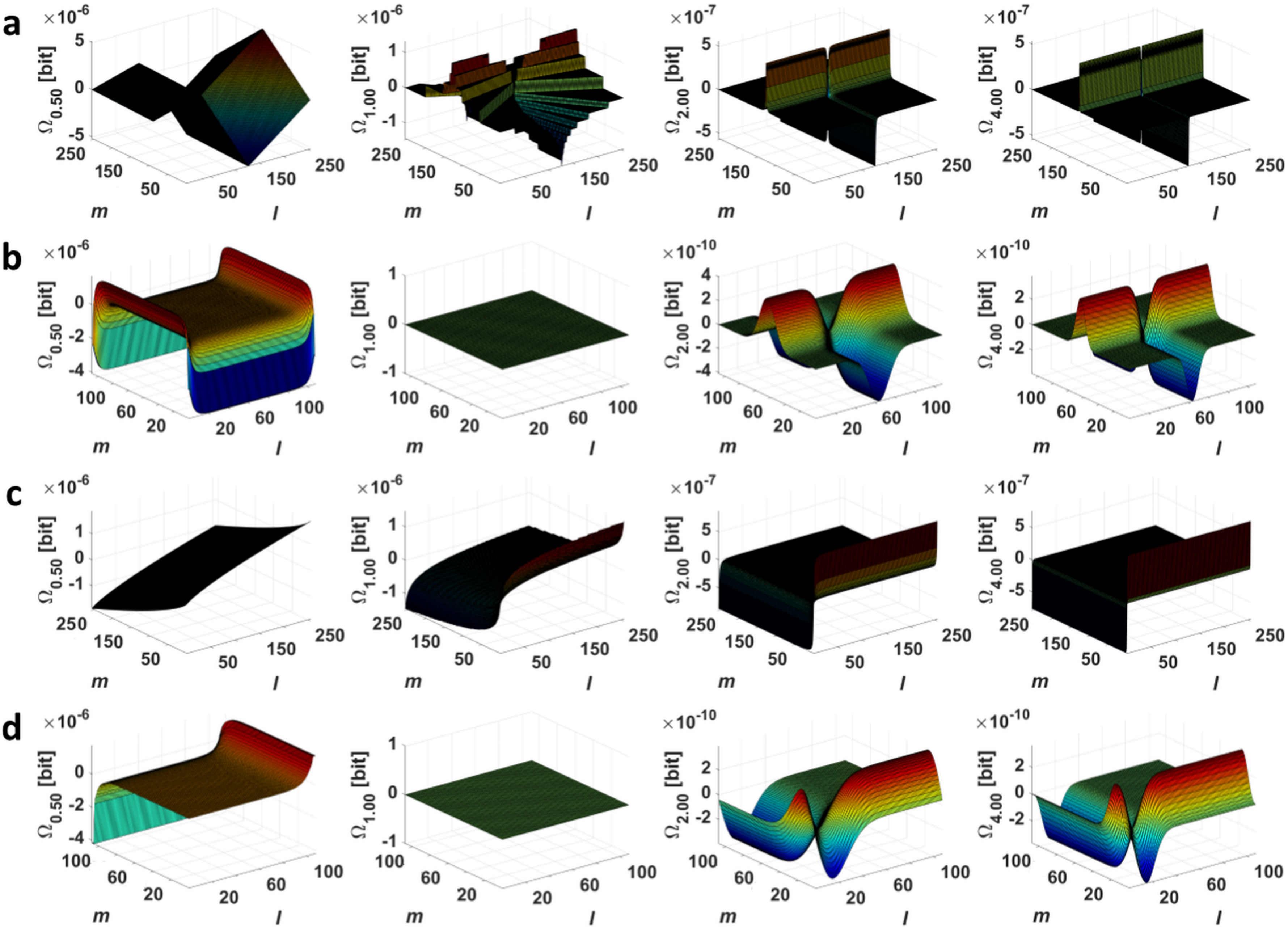
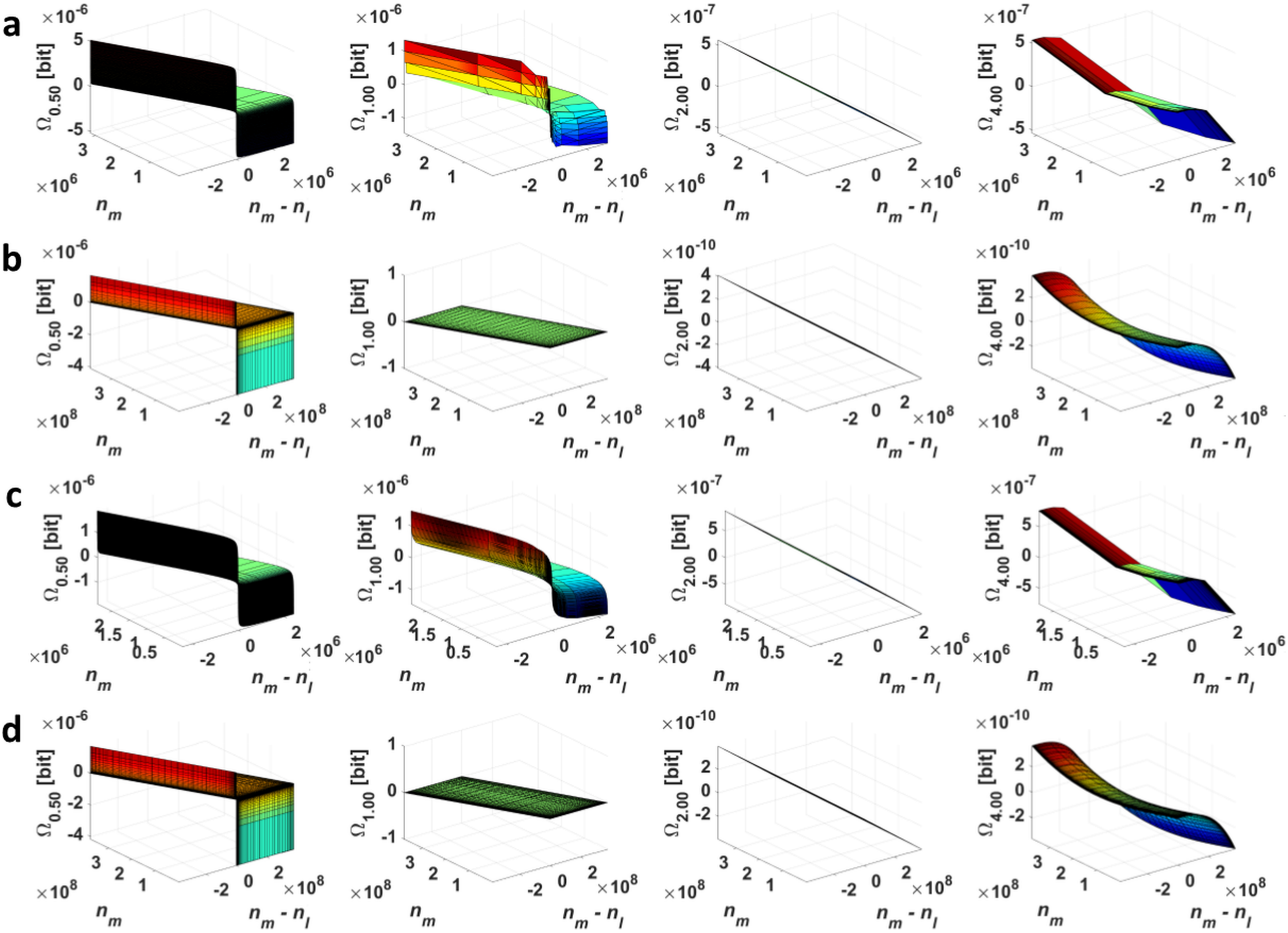
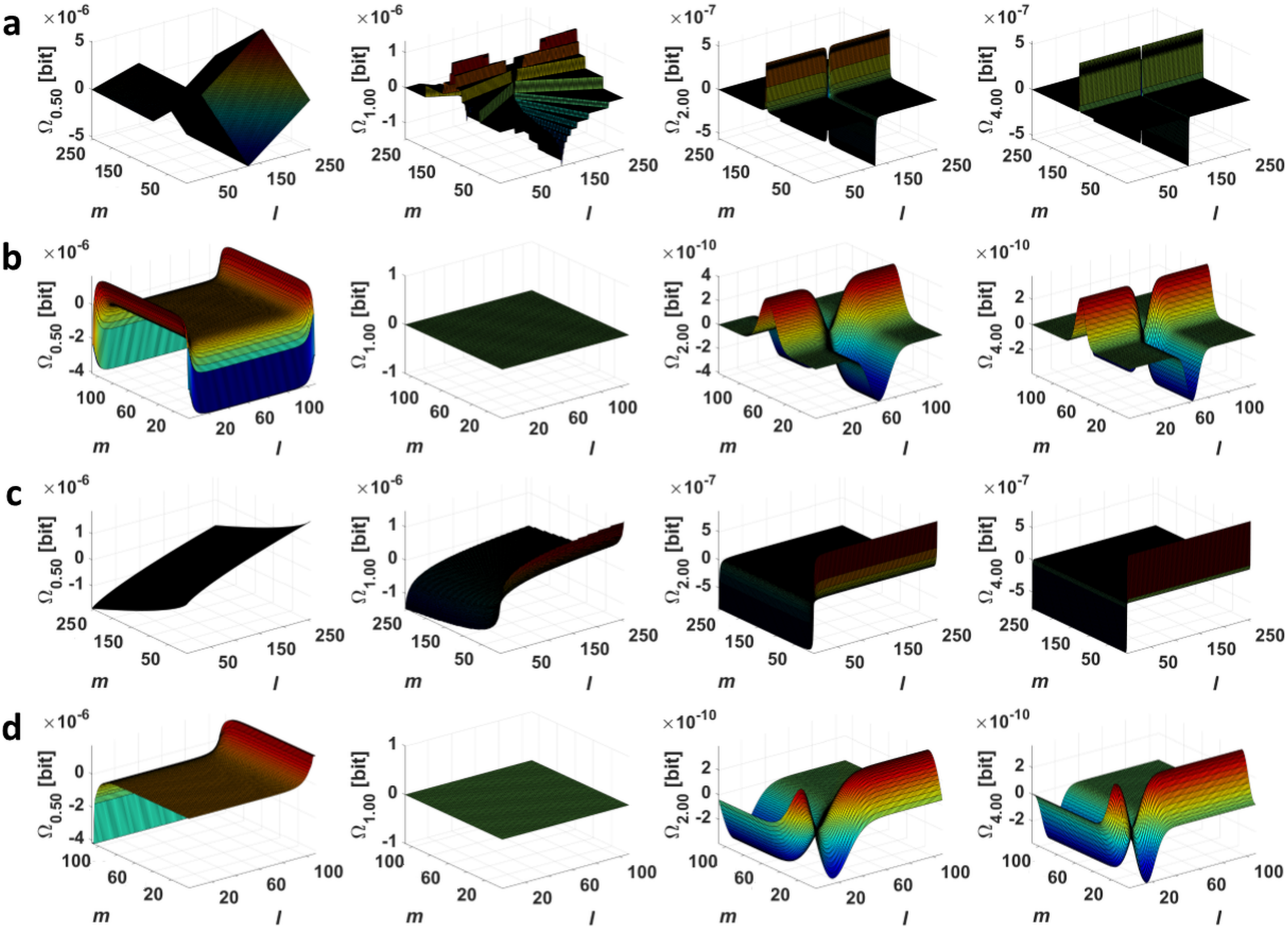
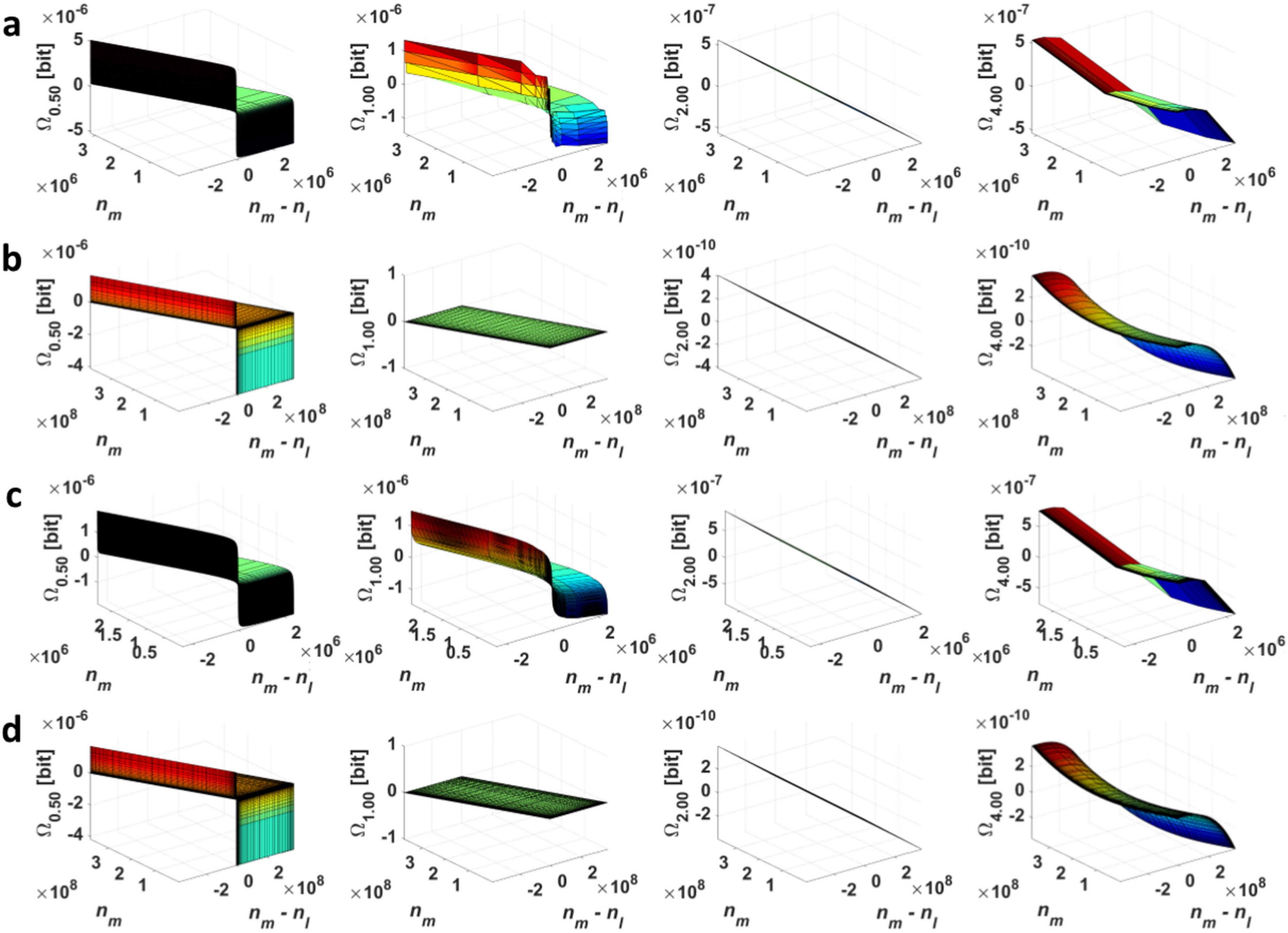
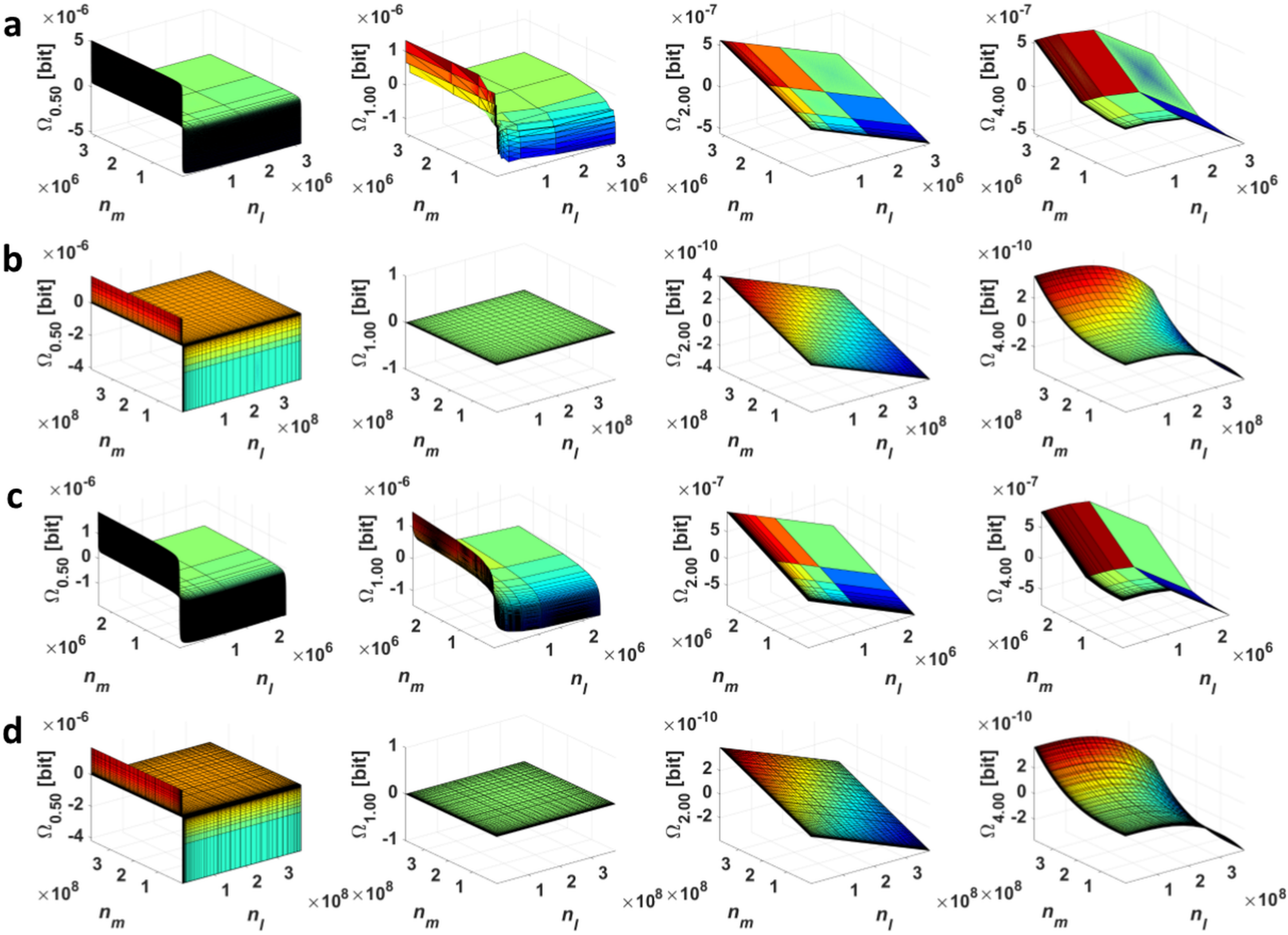
2.1. Point Divergence Gain
| Algorithm 1: Calculation of a point divergence gain matrix () for typical histograms. |
 |
- If , then .
- If , then .
2.2. Point Divergence Gain Entropy and Point Divergence Gain Entropy Density
| Algorithm 2: Calculation of a point information gain matrix () and values and for two consecutive images of a time-spatial series. |
 |
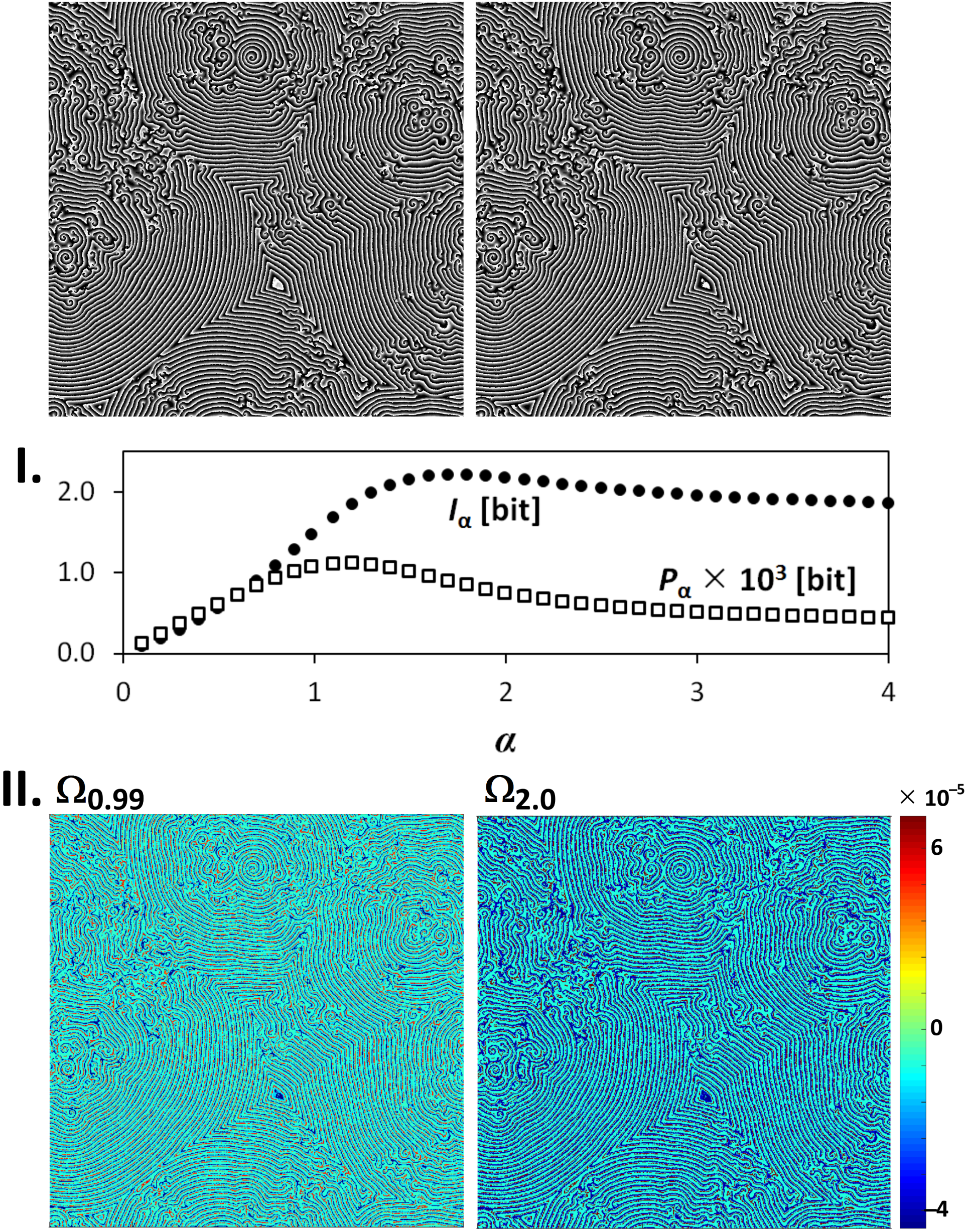
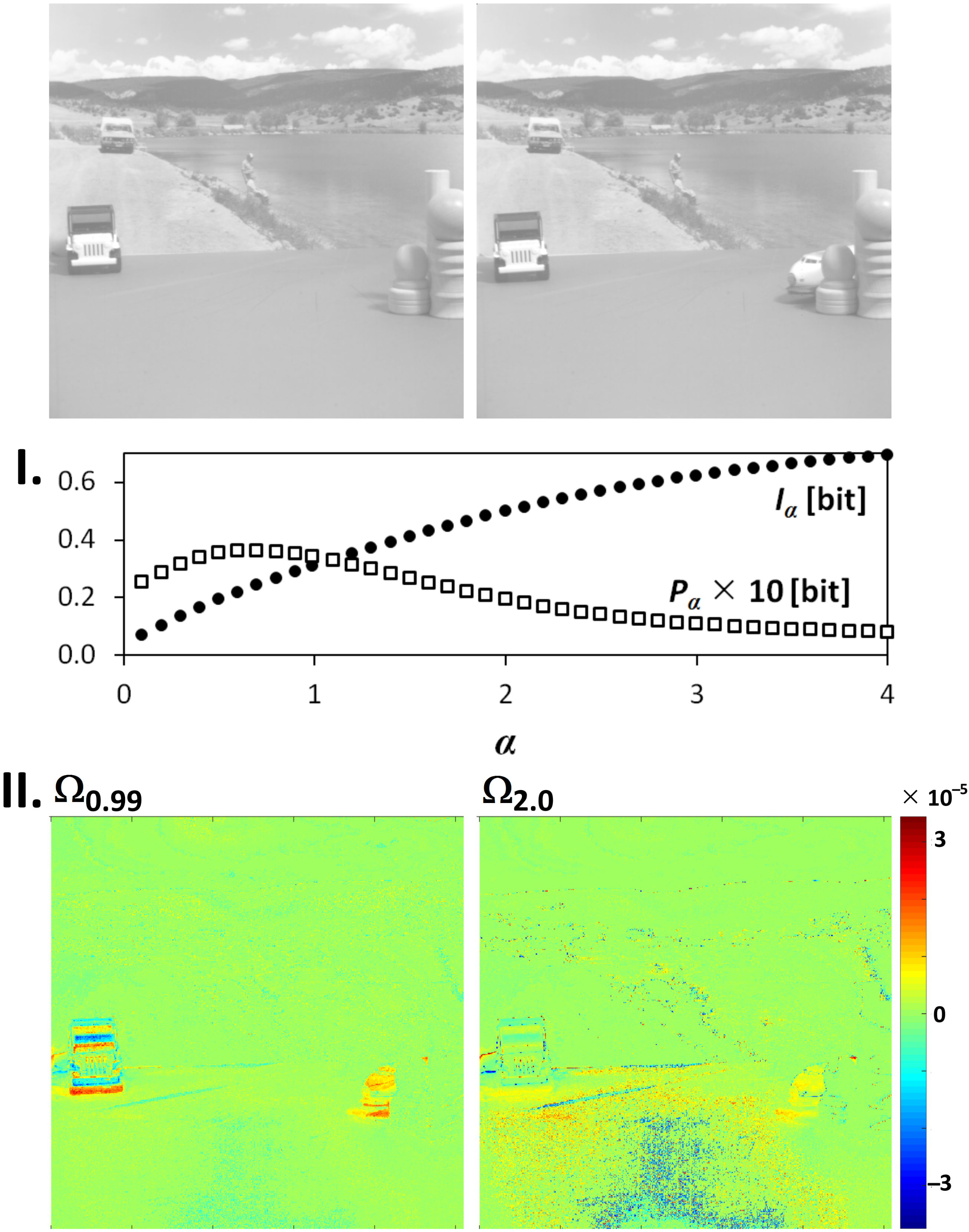
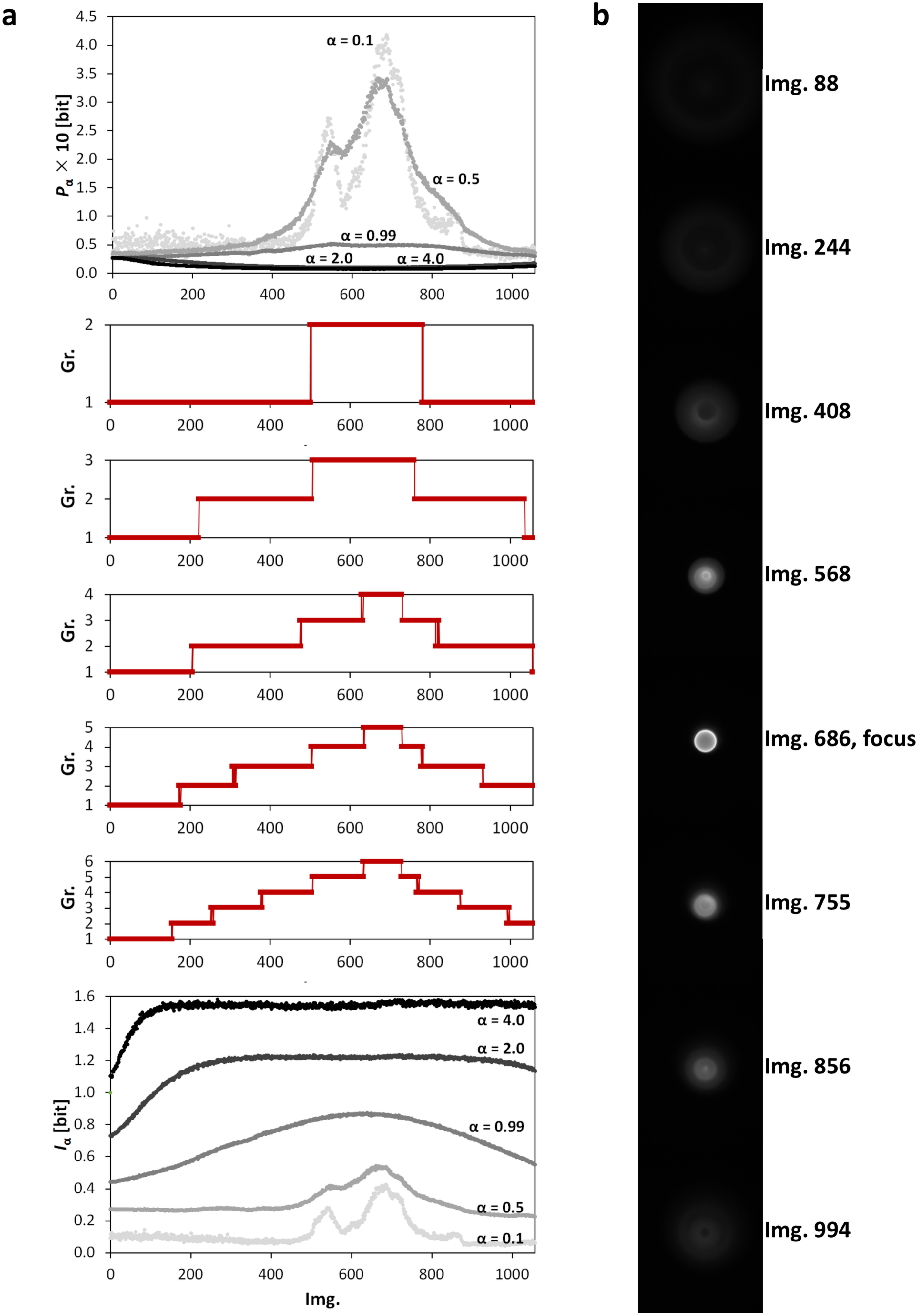
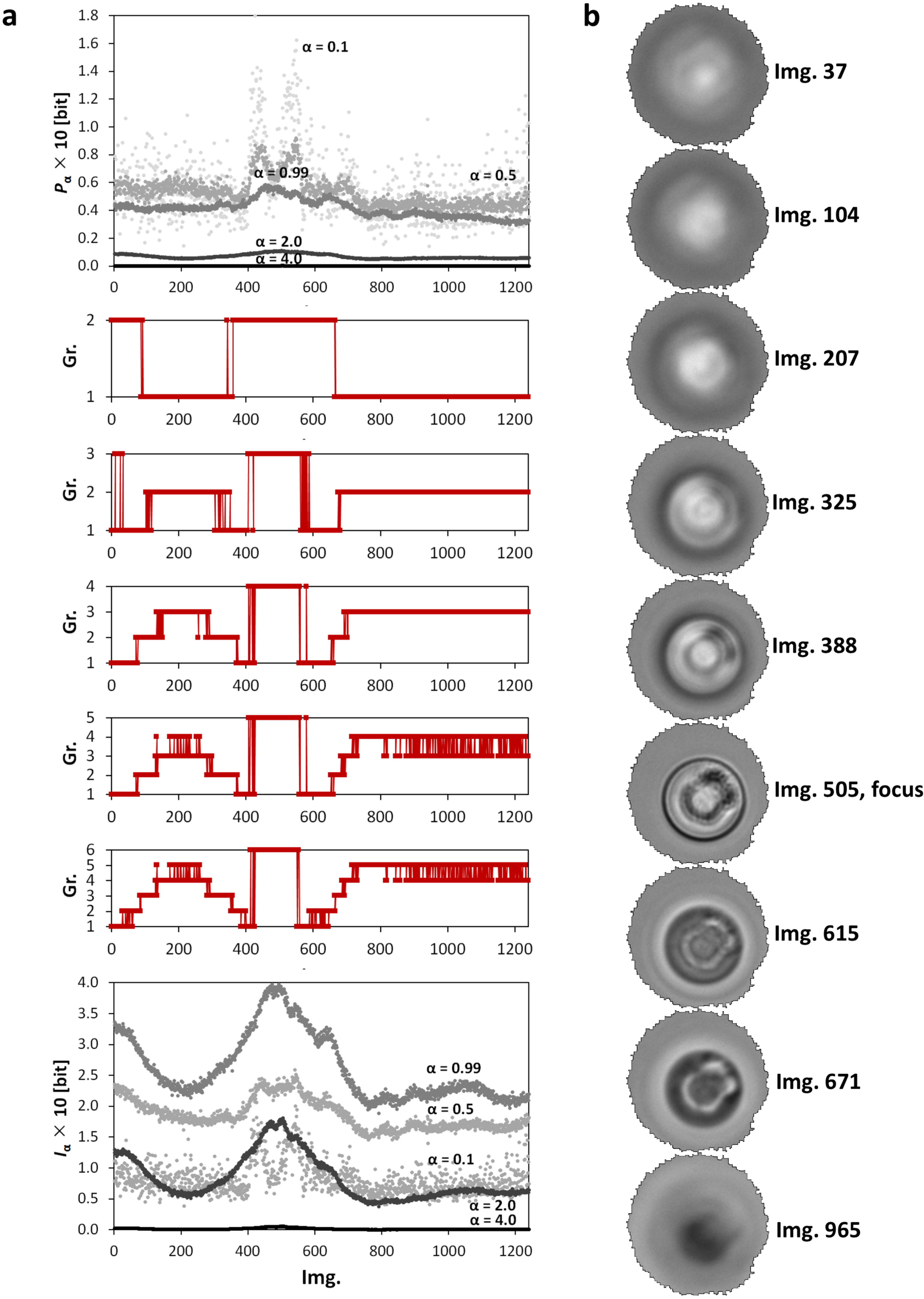
3. Application of Point Divergence Gain and Its Entropies in Image Processing
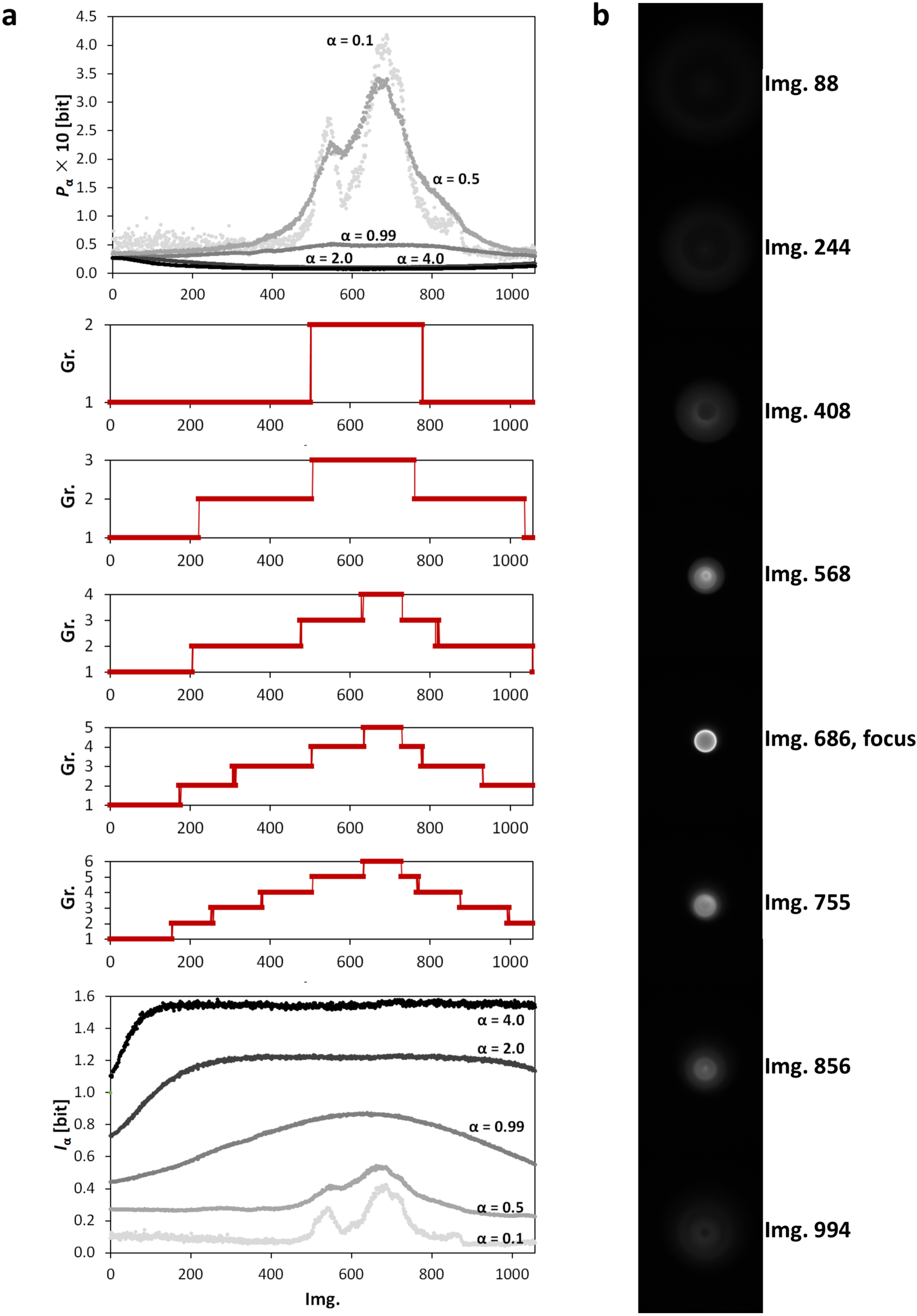
3.1. Image Origin and Specification
3.2. Image Filtering and Segmentation
3.3. Clustering of Image Sets
4. Materials and Methods
4.1. Processing of Typical Histograms
- Lévy distribution:
- Cauchy distribution:
- Gauss distribution:
- Rayleigh distribution:
4.2. Image Processing and Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Rychtáriková, R. Clustering of multi-image sets using Rényi information entropy. In Bioinformatics and Biomedical Engineering (IWBBIO 2016); Lecture Notes in Computer Science Series; Ortuño, F., Rojas, I., Eds.; Springer: Cham, Switzerland, 2016; pp. 527–536. [Google Scholar]
- Rychtáriková, R.; Korbel, J.; Macháček, P.; Císař, P.; Urban, J.; Štys, D. Point information gain and multidimensional data analysis. Entropy 2016, 18, 372. [Google Scholar] [CrossRef]
- Jizba, P.; Kleinert, H.; Shefaat, M. Rényi’s information transfer between financial time series. Phys. A Stat. Mech. Appl. 2012, 391, 2971–2989. [Google Scholar] [CrossRef]
- Jizba, P.; Korbel, J. Multifractal diffusion entropy analysis: Optimal bin width of probability histograms. Phys. A Stat. Mech. Appl. 2014, 413, 438–458. [Google Scholar] [CrossRef]
- Jizba, P.; Korbel, J. Modeling Financial Time Series: Multifractal Cascades and Rényi Entropy. In ISCS 2013: Interdisciplinary Symposium on Complex Systems; Emergence, Complexity and Computation Series; Sanayei, A., Zelinka, I., Rössler, O., Eds.; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Rychtáriková, R.; Náhlík, T.; Smaha, R.; Urban, J.; Štys, D., Jr.; Císař, P.; Štys, D. Multifractality in imaging: Application of information entropy for observation of inner dynamics inside of an unlabeled living cell in bright-field microscopy. In ISCS14: Interdisciplinary Symposium on Complex Systems; Sanayei, A., Zelinka, I., Rössler, O.E., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 261–267. [Google Scholar]
- Rychtáriková, R.; Náhlík, T.; Shi, K.; Malakhova, D.; Macháček, P.; Smaha, R.; Urban, J.; Štys, D. Super-resolved 3-D imaging of live cells’ organelles from bright-field photon transmission micrographs. Ultramicroscopy 2017, 179, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Chevalier, C.; Bect, J.; Ginsbourger, D.; Vazquez, E.; Picheny, V.; Richet, Y. Fast parallel kriging-based stepwise uncertainty reduction with application to the identification of an excursion set. Technometrics 2014, 56, 455–465. [Google Scholar] [CrossRef] [Green Version]
- Eidsvik, J.; Mukerji, T.; Bhattacharjya, D. Value of Information in the Earth Sciences: Integrating Spatial Modeling and Decision Analysis; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Helle, K.B.; Pebesma, E. Optimising sampling designs for the maximum coverage problem of plume detection. Spat. Stat. 2015, 13, 21–44. [Google Scholar] [CrossRef]
- Jizba, P.; Arimitsu, T. The world according to Rényi: Thermodynamics of multifractal systems. Ann. Phys. 2004, 312, 17–59. [Google Scholar] [CrossRef]
- Rényi, A. On measures of entropy and information. In Proceedings of the Fourth Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 20 June–30 July 1961; Volume 1, pp. 547–561. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Csiszár, I. I-divergence geometry of probability distributions and minimization problems. Ann. Probab. 1975, 3, 146–158. [Google Scholar] [CrossRef]
- Harremoes, P. Interpretations of Rényi entropies and divergences. Phys. A Stat. Mech. Appl. 2006, 365, 5–62. [Google Scholar] [CrossRef]
- Van Erven, T.; Harremoes, P. Rényi divergence and Kullback-Leibler divergence. J. Latex Class Files 2007, 6, 1–24. [Google Scholar] [CrossRef]
- Van Erven, T.; Harremoes, P. Rényi divergence and majorization. In Proceedings of the IEEE International Symposium on Information Theory, Austin, TX, USA, 13–18 June 2010; pp. 1335–1339. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. ACM SIGMOBILE Mob. Comput. Commun. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Volume 1: Textures. Available online: http://sipi.usc.edu/database/database.php?volume=textures&image=61#top (accessed on 31 January 2018).
- Štys, D.; Jizba, P.; Zhyrova, A.; Rychtáriková, R.; Štys, K.M.; Náhlík, T. Multi-state stochastic hotchpotch model gives rise to the observed mesoscopic behaviour in the non-stirred Belousov-Zhabotinky reaction. arXiv, 2016; arXiv:1602.03055. Available online: https://arxiv.org/abs/1602.03055(accessed on 31 January 2018).
- Štys, D.; Náhlík, T.; Zhyrova, A.; Rychtáriková, R.; Papáček, Š.; Císař, P. Model of the Belousov-Zhabotinsky reaction. In Proceedings of the International Conference on High Performance Computing in Science and Engineering, Soláň, Czech Republic, 25–28 May 2015; Kozubek, T., Blaheta, R., Šístek, J., Eds.; Springer: Cham, Switzerland, 2016; pp. 171–185. [Google Scholar]
- Štys, D.; Štys, K.M.; Zhyrova, A.; Rychtáriková, R. Optimal noise in the hodgepodge machine simulation of the Belousov-Zhabotinsky reaction. arXiv, 2016; arXiv:1606.04363. Available online: https://arxiv.org/abs/1606.04363(accessed on 31 January 2018).
- Štys, D.; Náhlík, T.; Macháček, P.; Rychtáriková, R.; Saberioon, M. Least Information Loss (LIL) conversion of digital images and lessons learned for scientific image inspection. In Proceedings of the International Conference on Bioinformatics and Biomedical Engineering, Granada, Spain, 20–22 April 2016; Ortuño, F., Rojas, I., Eds.; Springer: Cham, Switzerland, 2016; pp. 527–536. [Google Scholar]
- Braat, J.J.M.; Dirksen, P.; van Haver, S.; Janssen, A.J.E.M. Extended Nijboer-Zernike (ENZ) Analysis & Aberration Retrieval. Available online: http://www.nijboerzernike.nl (accessed on 12 December 2017).
- Rychtáriková, R.; Steiner, G.; Kramer, G.; Fischer, M.B.; Štys, D. New insights into information provided by light microscopy: Application to fluorescently labelled tissue section. arXiv, 2017; arXiv:1709.03894. Available online: https://arxiv.org/abs/1709.03894(accessed on 31 January 2018).
- Jolliffe, I.T. Principal Component Analysis, 2nd ed.; Springer Series in Statistics; Springer: New York, NY, USA, 2002. [Google Scholar]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the 18th ACM-SIAM, Philadelphia, PA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
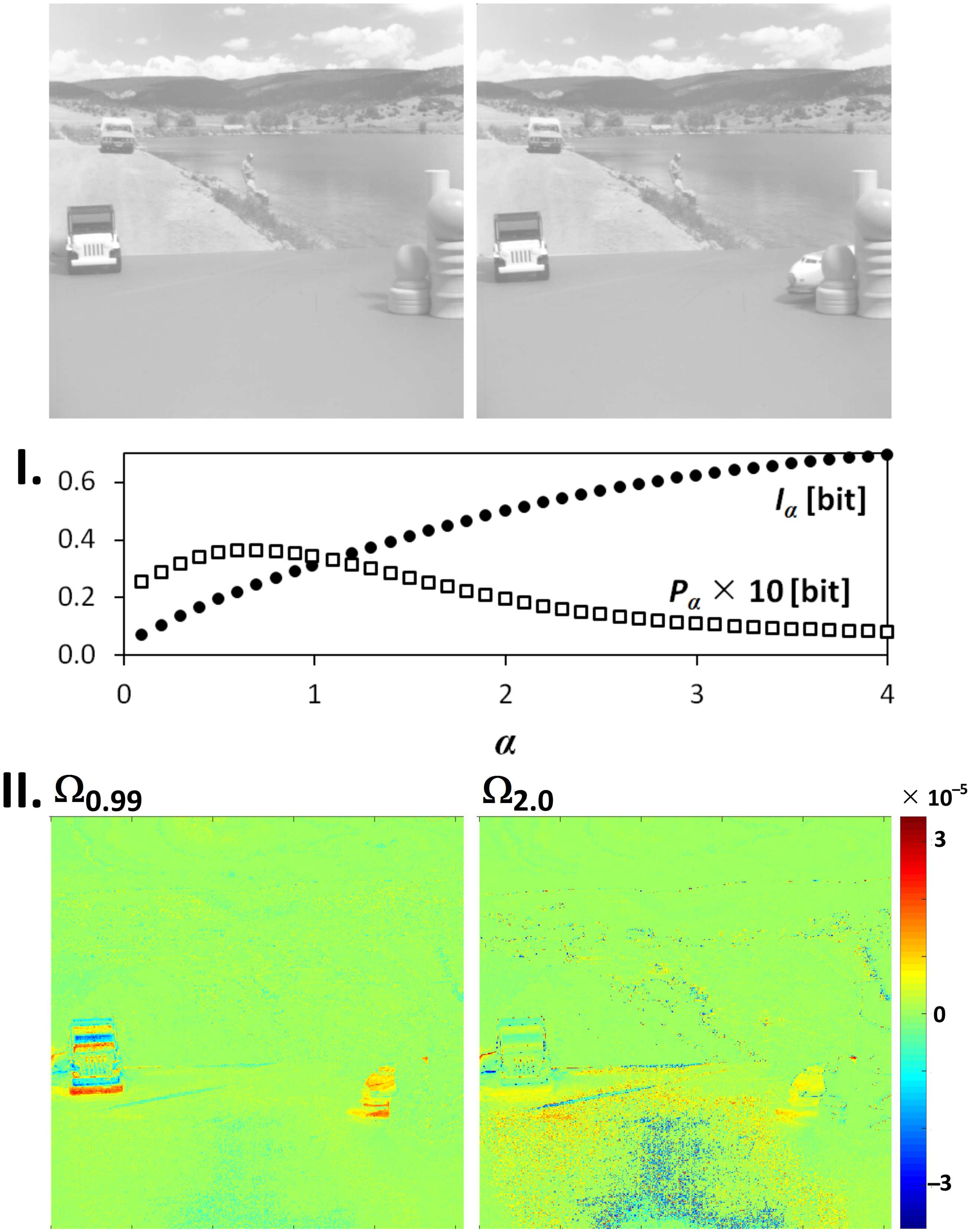{kind=link}
{kind=link}
{kind=link}
| Series | Source | Bit-Depth | Number of Img. | Resolution | Origin |
|---|---|---|---|---|---|
| Toy Vehicle | [19] | 8-bit | 10 | 512 × 512 | camera |
| Walter Cronkite | [19] | 8-bit | 16 | 256 × 256 | camera |
| Simulated BZ | [20,21,22] | 8-bit | 10,521 | 1001 × 1001 | computer-based |
| Ring-fluorescence | 12-bit | 1058 | 548 × 720 | experimental | |
| Ring-diffraction | 8-bit | 1242 | 252 × 280 | experimental |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rychtáriková, R.; Korbel, J.; Macháček, P.; Štys, D. Point Divergence Gain and Multidimensional Data Sequences Analysis. Entropy 2018, 20, 106. https://doi.org/10.3390/e20020106
Rychtáriková R, Korbel J, Macháček P, Štys D. Point Divergence Gain and Multidimensional Data Sequences Analysis. Entropy. 2018; 20(2):106. https://doi.org/10.3390/e20020106
Chicago/Turabian StyleRychtáriková, Renata, Jan Korbel, Petr Macháček, and Dalibor Štys. 2018. "Point Divergence Gain and Multidimensional Data Sequences Analysis" Entropy 20, no. 2: 106. https://doi.org/10.3390/e20020106
APA StyleRychtáriková, R., Korbel, J., Macháček, P., & Štys, D. (2018). Point Divergence Gain and Multidimensional Data Sequences Analysis. Entropy, 20(2), 106. https://doi.org/10.3390/e20020106