Factoid Question Answering with Distant Supervision


Abstract
:1. Introduction
- Content. The distribution of synthetic questions is inconsistent with that of the real-world questions. For example, users may seldom ask common sense questions, or questions whose answers could be inferred easily from entity names, such as gender of Madame Curie, or English name of Benjamin Franklin, while we observe that a certain proportion of triples record such information for the completeness of KB.
- Style. The sentence structures of the generated questions are monotonous. If trained on these data, the model will be very sensitive to various expressions of questions.
- We propose automatically generating large-scale training data for factoid QA via distant supervision. QA of specific domains or new languages, where training data is limited, like medical factoid QA and Vietnamese factoid QA, could benefit a lot from the generated data.
- The generated questions are further adapted to accord with the real-world ones in both content and expression styles by utilizing QA corpus, for example the community QA data. The distant paraphrase approach increases the diversity of query expressions and could improve the generalization of the QA model.
- Experiments are carried out on a real-world QA dataset to validate the proposed approach. Results show that the model can achieve an accuracy of 49.34% without labeled data, and significant improvements are observed when the training data is insufficient. Additionally, the proposal improves the state-of-the-art result on the WebQA dataset [5] from 73.50% to 76.55%. We release our data and codes at [18,19] for reproduction and further research.
2. Related Work
2.1. Document Based Question Answering
2.2. Question Generation for Question Answering
2.3. Distant Supervision
2.4. Transfer Learning
3. Approach
3.1. Task Definition
3.2. Training Data Generation via Distant Supervision and Domain Adaptation
3.2.1. Training Data Generation via Distant Supervision
3.2.2. Domain Adaptation
- : the total number of retrieved questions.
- : the number of retrieved questions containing the subject.
- : the number of retrieved questions containing the predicate.
- : the number of retrieved questions whose answers contain the object, i.e., the answer of the synthetic question.
3.3. QA Model
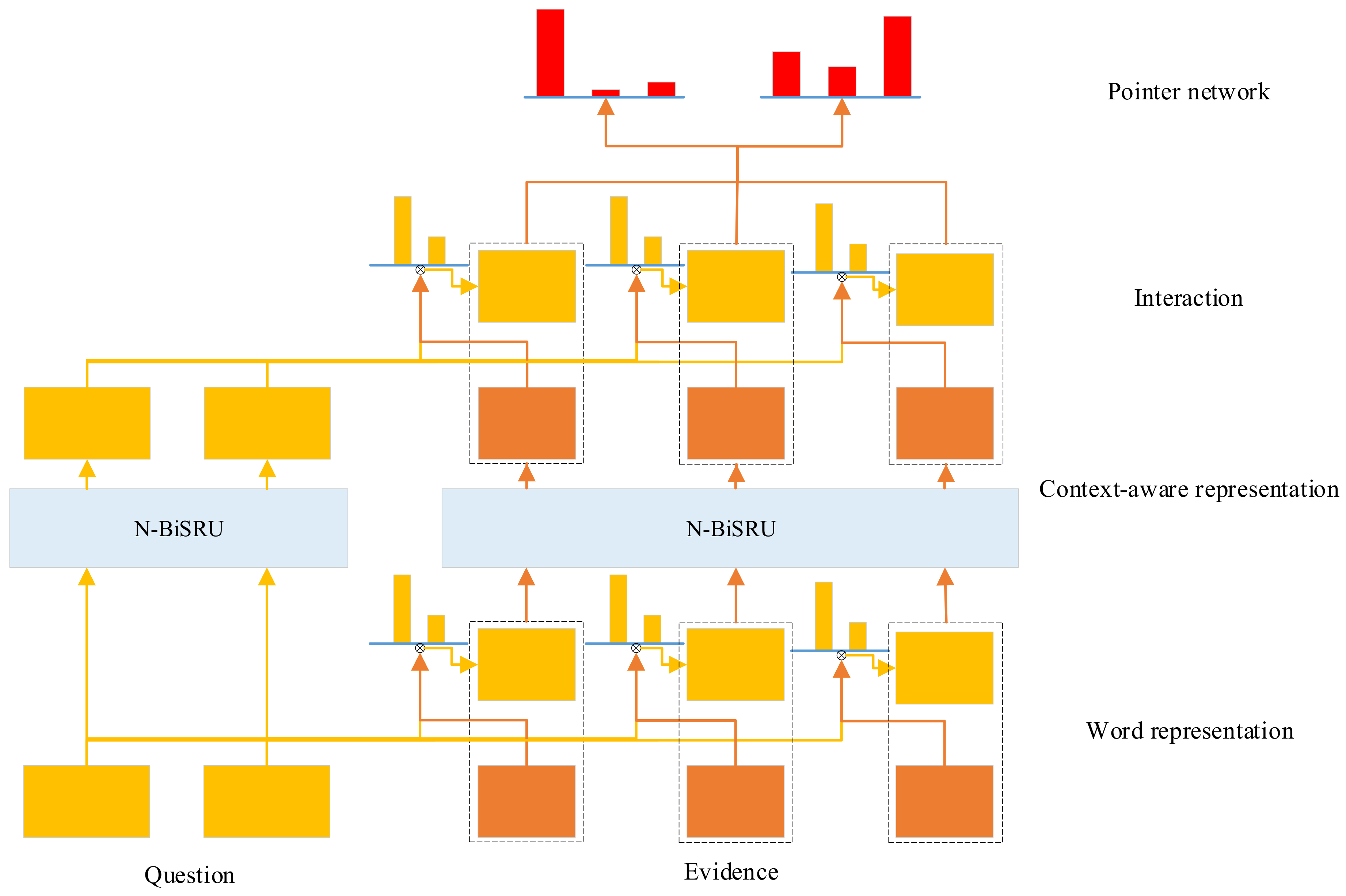
3.3.1. Word Representation Layer
3.3.2. Context Aware Representation Layer
3.3.3. Interaction Layer
3.3.4. Pointer Network Layer
3.4. Training
4. Experiments
4.1. Dataset
4.2. Experiment Settings
4.3. Experimental Results and Analysis
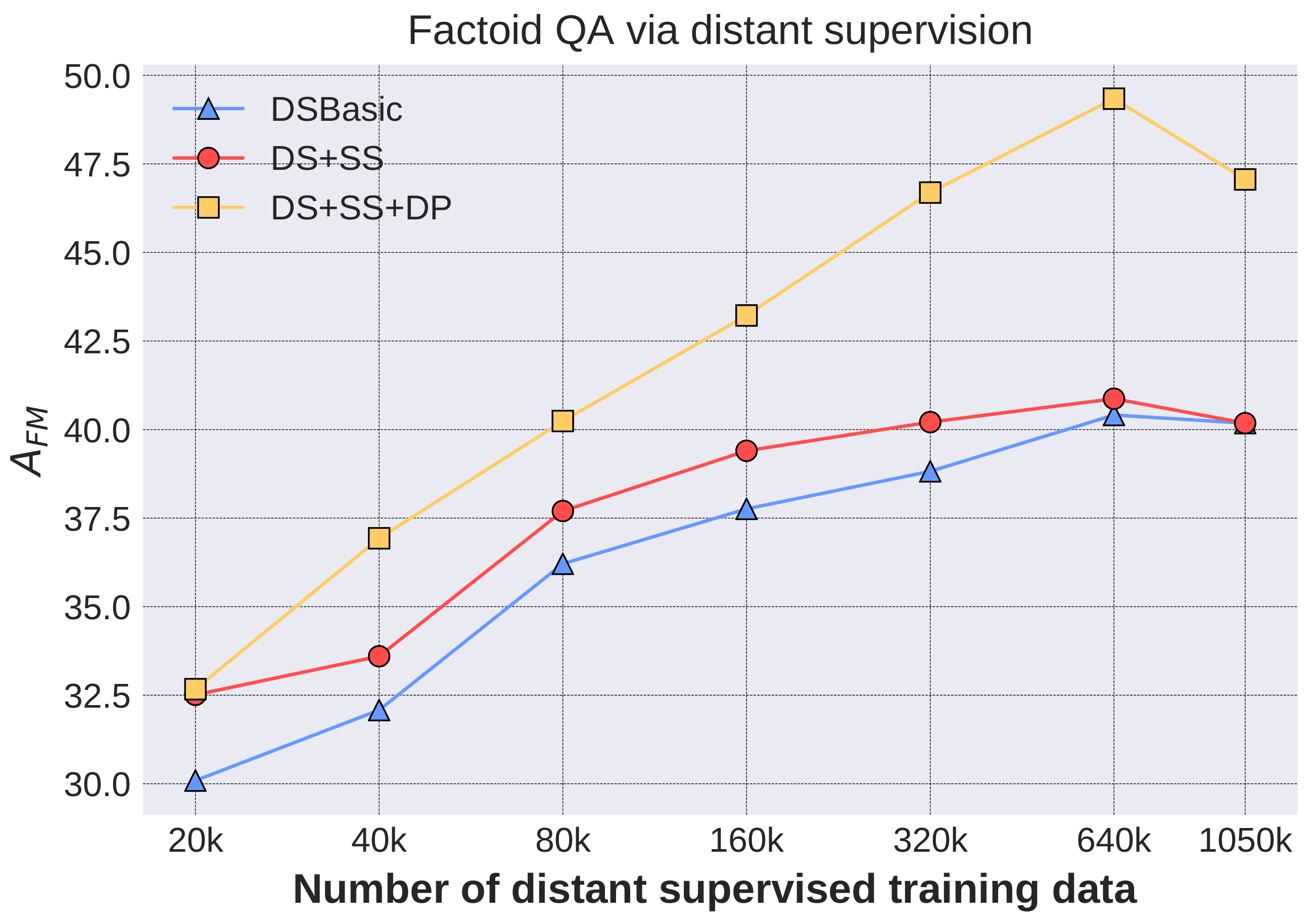
4.3.1. Factoid QA with Only Distantly Supervised Training Data
- DSBasic (Distant Supervision Basic): all the training samples generated by distant supervision are equally treated, and QA pairs are randomly selected.
- DS+SS (Distant supervision with sample selection): the generated samples are weighted by the probability , and QA pairs with the top are selected. In the experiments, synthetic questions with probability 0 are included when is larger than the number of generated questions with non-zero probability.
- DS+SS+DP (DS+SS with disant paraphrase): questions with the top are selected, where is the number of paraphrased questions. Then, QA pairs with paraphrased questions are added.
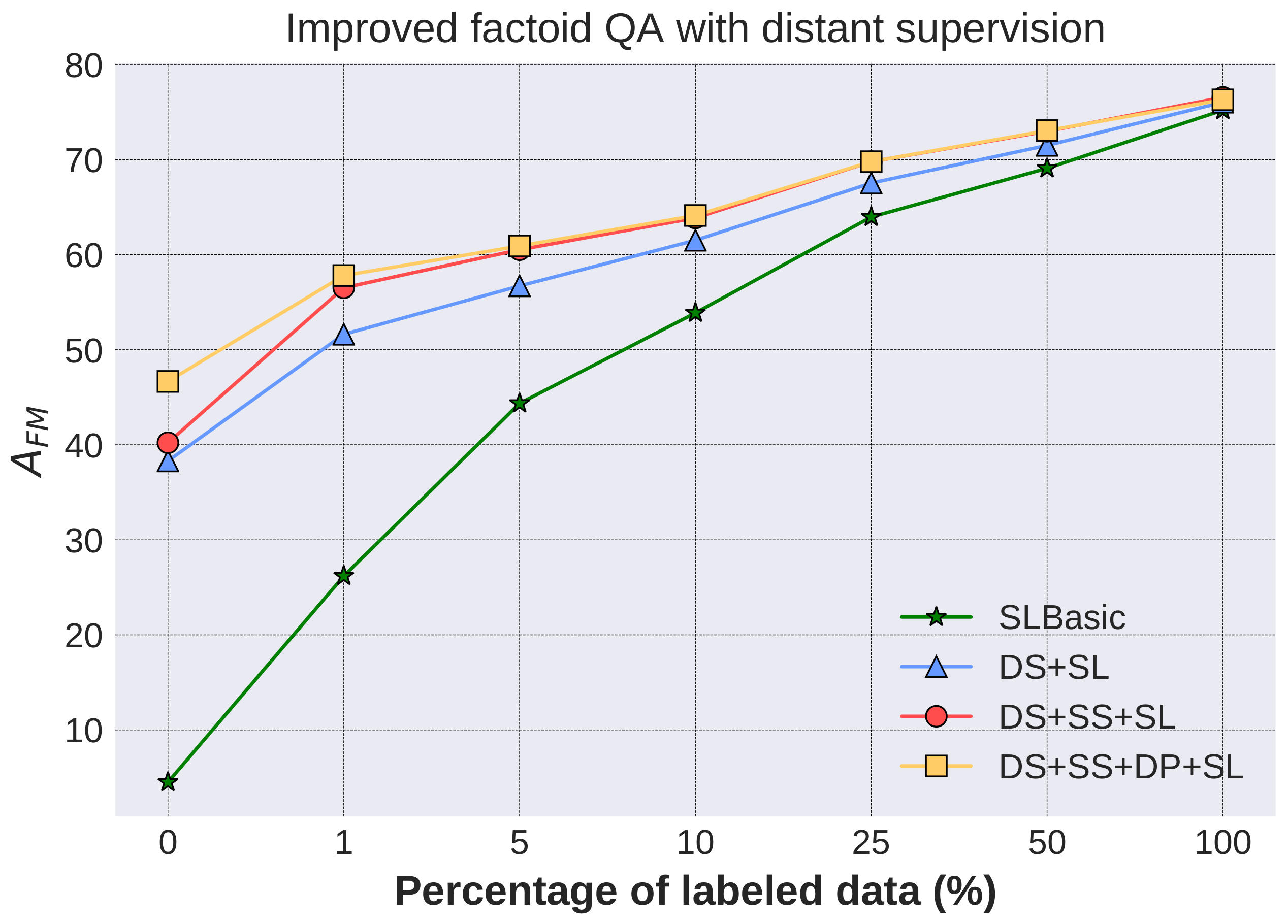
4.3.2. Improved Factoid QA with Distant Supervision
- SLBasic (Supervised Learning Basic): as the baseline, the QA model is trained solely on the labeled data.
- DS+SL: the QA model is pre-trained on 320 k QA pairs generated via distant supervision (DSBasic) and then trained on the labeled data of the same size as SLBasic.
- DS+SS+SL: the QA model is pre-trained on 320 k QA pairs generated via distant supervision (DS+SS) and then trained on the labeled data of the same size as SLBasic.
- DS+SS+DP+SL: the QA model is pre-trained on 320 k QA pairs generated via distant supervision (DS+SS+DP) and then trained on the labeled data of the same size as SLBasic.
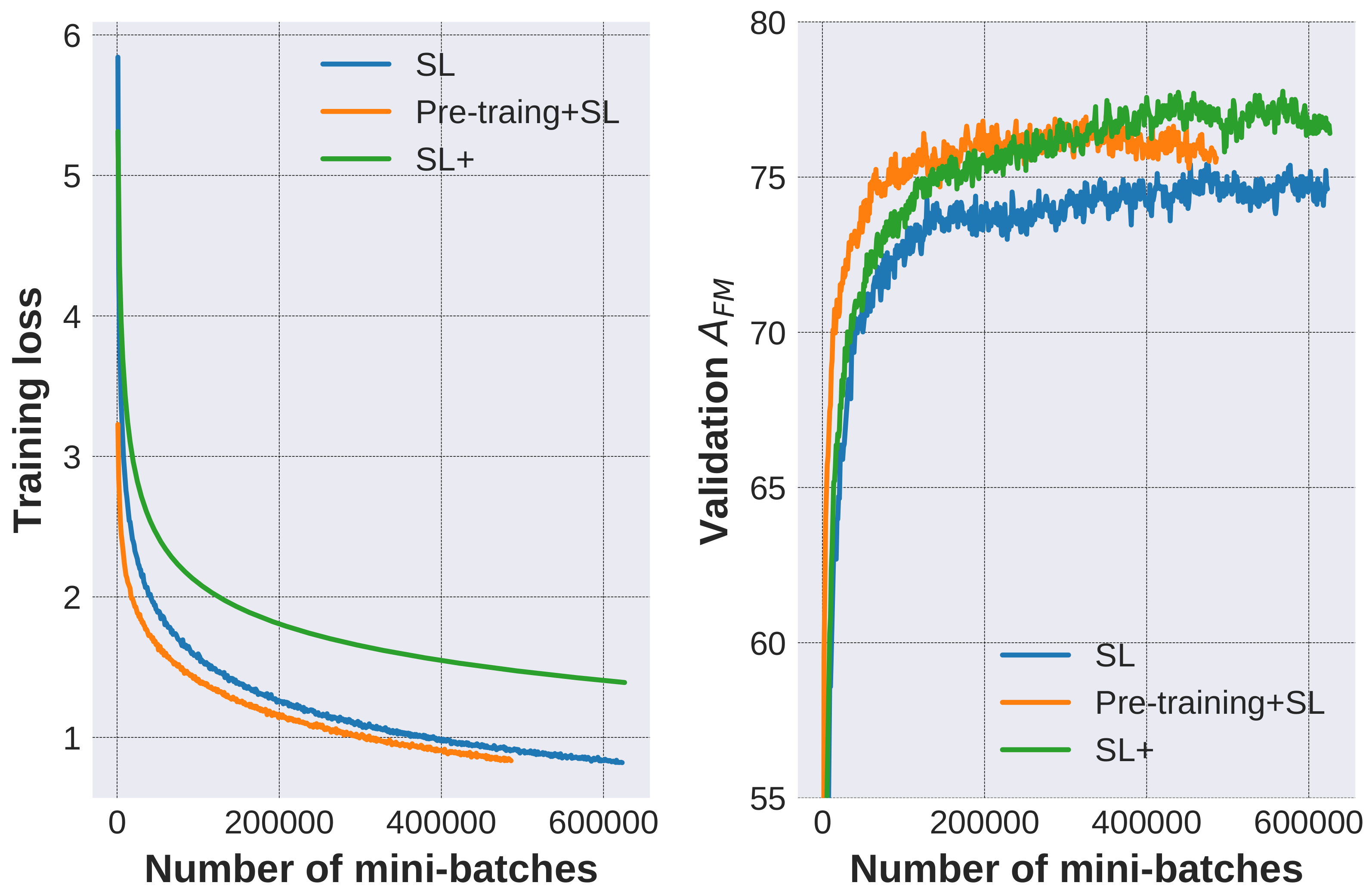
- Supervised learning (SL): The model is solely trained on annotated QA pairs.
- Pre-training+ SL: The model is pre-trained on 320 k generated QA pairs (generated via DS+SS configuration) and then trained on the annotated data.
- SL+: The model is simultaneously trained on both the generated data and annotated data. Specifically, the model is iteratively trained on a mini-batch of generated data and another mini-batch of annotated data. Note that the training loss and mini-batch number are calculated and counted on the annotated data.
- Sequence-labeling methods [5]: the question is first encoded into a vector utilizing single-time attention. Then, question-aware representations of evidence words are learned with bi-directional LSTMs. Finally, a softmax or CRF layer is used to predict the labels. The sequence-labeling methods are capable of generating zero, one or multiple answers for a question and a given document, thus precision (P), recall (R) and F1 scores are used in the evaluation.
- Methods with interaction attention and pointer net: BiDAF [22], R-NET [12] and our baseline all adopt interaction attention and pointer net. These models all contain word–word interactions between the question and the evidence, which are supposed to better perform question aware reading comprehension [23]. BiDAF contains both context to query and query to context attention. Self-attention and several gates are adopted in R-NET considering that only parts of the document contribute to the answer extraction. Our baseline method contains question to document interaction in two layers. Character-level encoding and the binary feature f are used in word representation of these three models.
- Methods with interaction attention and pointer net + DS: models are the same as those of the previous configuration. The only difference is that 320 k generated QA pairs (under DS+SS configuration) are added to the annotated data.
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| QA | Question Answering |
| KB | Knowledge Base |
| NLP | Natural Language Processing |
| LSTM | Long Short-Term Memory |
| TF-IDF | Term Frequency–Inverse Document Frequency |
| RNN | Recurrent Neural Network |
| SRU | Simple Recurrent Unit |
| CRF | Conditional Random Field |
| BiDAF | Bi-Directional Attention Flow |
| DS | Distant Supervision |
References
- Berant, J.; Chou, A.; Frostig, R.; Liang, P. Semantic Parsing on Freebase from Question-Answer Pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1533–1544. [Google Scholar]
- Bordes, A.; Usunier, N.; Chopra, S.; Weston, J. Large-scale Simple Question Answering with Memory Networks. arXiv, 2015; arXiv:1506.02075. [Google Scholar]
- Sun, H.; Ma, H.; He, X.; Yih, W.t.; Su, Y.; Yan, X. Table Cell Search for Question Answering. In Proceedings of the 25th International Conference on World Wide Web, Republic and Canton of Geneva, Switzerland, 11–15 April 2016; pp. 771–782. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. arXiv, 2016; arXiv:1606.05250. [Google Scholar]
- Li, P.; Li, W.; He, Z.; Wang, X.; Cao, Y.; Zhou, J.; Xu, W. Dataset and Neural Recurrent Sequence Labeling Model for Open-Domain Factoid Question Answering. arXiv, 2016; arXiv:1607.06275. [Google Scholar]
- Trischler, A.; Wang, T.; Yuan, X.; Harris, J.; Sordoni, A.; Bachman, P.; Suleman, K. NewsQA: A Machine Comprehension Dataset. arXiv, 2017; arXiv:1611.09830. [Google Scholar]
- Ferrucci, D.A. Introduction to ’This is Watson’. IBM J. Res. Dev. 2012, 56, 1:1–1:15. [Google Scholar] [CrossRef]
- Bao, J.; Duan, N.; Zhou, M.; Zhao, T. Knowledge-Based Question Answering as Machine Translation. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 967–976. [Google Scholar]
- He, S.; Liu, K.; Zhang, Y.; Xu, L.; Zhao, J. Question Answering over Linked Data Using First-order Logic. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1092–1103. [Google Scholar]
- Hermann, K.M.; Kočiský, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching Machines to Read and Comprehend. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 1, pp. 1693–1701. [Google Scholar]
- McCann, B.; Bradbury, J.; Xiong, C.; Socher, R. Learned in Translation: Contextualized Word Vectors. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 6297–6308. [Google Scholar]
- Wang, W.; Yang, N.; Wei, F.; Chang, B.; Zhou, M. Gated Self-Matching Networks for Reading Comprehension and Question Answering. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 189–198. [Google Scholar]
- Jia, R.; Liang, P. Adversarial Examples for Evaluating Reading Comprehension Systems. arXiv, 2017; arXiv:1707.07328. [Google Scholar]
- Du, X.; Shao, J.; Cardie, C. Learning to Ask: Neural Question Generation for Reading Comprehension. arXiv, 2017; arXiv:1705.00106. [Google Scholar]
- Duan, N.; Tang, D.; Chen, P.; Zhou, M. Question Generation for Question Answering. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 866–874. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A Free Collaborative Knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In Proceedings of the 6th International The Semantic Web and 2nd Asian Conference on Asian Semantic Web Conference, Busan, Korea, 11–15 November 2007; pp. 722–735. [Google Scholar]
- Zhang, H. zhhongzhi/factoid_QA_with_distant_spervision: Codes for Our Paper Factoid Question Answering With Distant Supervision. 2018. Available online: https://github.com/zhhongzhi/factoid_QA_with_distant_spervision (accessed on 5 June 2018).
- Zhang, H. Data_for_factoid_QA_with_distant_spervision. 2018. Available online: https://drive.google.com/drive/folders/1EI47PfmeZRfpAUdNq2EI7um_sxlV8prv?usp=sharing (accessed on 5 June 2018).
- He, W.; Liu, K.; Lyu, Y.; Zhao, S.; Xiao, X.; Liu, Y.; Wang, Y.; Wu, H.; She, Q.; Liu, X.; et al. DuReader: A Chinese Machine Reading Comprehension Dataset from Real-world Applications. arXiv, 2017; arXiv:1711.05073. [Google Scholar]
- Nguyen, T.; Rosenberg, M.; Song, X.; Gao, J.; Tiwary, S.; Majumder, R.; Deng, L. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. arXiv, 2016; arXiv:1611.09268. [Google Scholar]
- Seo, M.J.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional Attention Flow for Machine Comprehension. arXiv, 2016; arXiv:1611.01603. [Google Scholar]
- Wang, S.; Jiang, J. Machine Comprehension Using Match-LSTM and Answer Pointer; ICLR 2017; ICLR: Toulon, France, 2017. [Google Scholar]
- Cui, Y.; Chen, Z.; Wei, S.; Wang, S.; Liu, T.; Hu, G. Attention-over-Attention Neural Networks for Reading Comprehension. arXiv, 2016; arXiv:1607.04423. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer Networks. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; pp. 2692–2700. [Google Scholar]
- Hewlett, D.; Jones, L.; Lacoste, A.; Gur, I. Accurate Supervised and Semi-Supervised Machine Reading for Long Documents. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 2011–2020. [Google Scholar]
- Labutov, I.; Basu, S.; Vanderwende, L. Deep Questions without Deep Understanding. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 27–31 July 2015; pp. 889–898. [Google Scholar]
- Chali, Y.; Hasan, S.A. Towards Topic-to-question Generation. Comput. Linguist. 2015, 41, 1–20. [Google Scholar] [CrossRef]
- Song, L.; Zhao, L. Domain-specific Question Generation from a Knowledge Base. arXiv, 2016; arXiv:1610.03807. [Google Scholar]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Suntec, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; Weld, D.S. Knowledge-Based Weak Supervision for Information Extraction of Overlapping Relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Oregon, Poland, 19–24 June 2011; pp. 541–550. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 19–21 September 2015; pp. 1753–1762. [Google Scholar]
- Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; Sun, M. Neural Relation Extraction with Selective Attention over Instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2124–2133. [Google Scholar]
- Levy, O.; Seo, M.; Choi, E.; Zettlemoyer, L. Zero-Shot Relation Extraction via Reading Comprehension. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), Vancouver, Canada, 3–4 August 2017; pp. 333–342. [Google Scholar]
- Purver, M.; Battersby, S. Experimenting with Distant Supervision for Emotion Classification. Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012, 482–491.
- Plank, B.; Hovy, D.; McDonald, R.; Søgaard, A. Adapting taggers to Twitter with not-so-distant supervision. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 1783–1792. [Google Scholar]
- Tabassum, J.; Ritter, A.; Xu, W. TweeTime : A Minimally Supervised Method for Recognizing and Normalizing Time Expressions in Twitter. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing; Austin, Texas, 2–4 November 2016; pp. 307–318. [Google Scholar]
- Zeng, Y.; Feng, Y.; Ma, R.; Wang, Z.; Yan, R.; Shi, C.; Zhao, D. Scale Up Event Extraction Learning via Automatic Training Data Generation. arXiv, 2017; arXiv:1712.03665. [Google Scholar]
- Joshi, M.; Choi, E.; Weld, D.; Zettlemoyer, L. TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 30 July–4 August 2017; pp. 1601–1611. [Google Scholar]
- Dhingra, B.; Mazaitis, K.; Cohen, W.W. Quasar: Datasets for Question Answering by Search and Reading. arXiv, 2017; arXiv:1707.03904. [Google Scholar]
- Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Reading Wikipedia to Answer Open-Domain Questions. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, Canada, 31 July–2 Aufust 2017, 1870–1879.
- Clark, C.; Gardner, M. Simple and Effective Multi-Paragraph Reading Comprehension. arXiv, 2017; arXiv:1710.10723. [Google Scholar]
- Wang, S.; Yu, M.; Guo, X.; Wang, Z.; Klinger, T.; Zhang, W.; Chang, S.; Tesauro, G.; Zhou, B.; Jiang, J. R$3$: Reinforced Reader-Ranker for Open-Domain Question Answering. arXiv, 2017; arXiv:1709.00023. [Google Scholar]
- Kingma, D.P.; Mohamed, S.; Jimenez Rezende, D.; Welling, M. Semi-supervised Learning with Deep Generative Models. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 3581–3589. [Google Scholar]
- Odena, A. Semi-Supervised Learning with Generative Adversarial Networks. arXiv, 2016; arXiv:1606.01583. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vision 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21, October 2013; pp. 1631–1642. [Google Scholar]
- Nallapati, R.; Zhou, B.; dos Santos, C.; Gulcehre, C.; Xiang, B. Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 280–290. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv, 2018; arXiv:1802.05365. [Google Scholar]
- Wiese, G.; Weissenborn, D.; Neves, M. Neural Domain Adaptation for Biomedical Question Answering. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), Vancouver, Canada, 3–4 August 2017; pp. 281–289. [Google Scholar]
- Chung, Y.; Lee, H.; Glass, J.R. Supervised and Unsupervised Transfer Learning for Question Answering. arXiv, 2017; arXiv:1711.05345. [Google Scholar]
- Min, S.; Seo, M.; Hajishirzi, H. Question Answering through Transfer Learning from Large Fine-grained Supervision Data. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, Canada, 31 July–2 August 2017; pp. 510–517. [Google Scholar]
- Yang, Z.; Hu, J.; Salakhutdinov, R.; Cohen, W. Semi-Supervised QA with Generative Domain-Adaptive Nets. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, Canada, 31 July–2 August 2017; pp. 1040–1050. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing, 2nd ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Wang, S.; Yu, M.; Jiang, J.; Zhang, W.; Guo, X.; Chang, S.; Wang, Z.; Klinger, T.; Tesauro, G.; Campbell, M. Evidence Aggregation for Answer Re-Ranking in Open-Domain Question Answering. arXiv, 2017; arXiv:1711.05116. [Google Scholar]
- Galbraith, B.; Pratap, B.; Shank, D. Talla at SemEval-2017 Task 3: Identifying Similar Questions Through Paraphrase Detection. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, Canada, 3–4 August 2017; pp. 375–379. [Google Scholar]
- Filice, S.; Da San Martino, G.; Moschitti, A. KeLP at SemEval-2017 Task 3: Learning Pairwise Patterns in Community Question Answering. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, Canada, 3–4 August 2017; pp. 326–333. [Google Scholar]
- Lei, T.; Zhang, Y. Training RNNs as Fast as CNNs. arXiv, 2017; arXiv:1709.02755. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Triple | Subject | Albert Einstein |
| Predict | Birth place | |
| Object | Ulm, Kingdom of Württemberg, German Empire | |
| Question | Birth place of Albert Einstein? | |
| Answer | Ulm, Kingdom of Württemberg, German Empire | |
| Evidence | Albert Einstein was born in Ulm, the Kingdom of Württemberg in the German Empire, on 14 March 1879. | |
| Tag | Num. | Synthetic Question | Mined Paraphrase of the Question | Error Cate. |
|---|---|---|---|---|
| Correct | 61 | Author of Pride and Prejudice? | Who wrote the book Pride and Prejudice? | - |
| Spouse of Barack Obama? | Who is Barack Obama’s wife? | |||
| Error | 39 | Nation of Odyssey? | Which ancient country did Odyssey and Ilias belong to? | MQI |
| Athletics items of YangWei? | What sport did YangWei and Li Xiaopeng play? | MQI | ||
| Composer of Sambo auspicious? | Who writes the lyrics and composes for Sambo auspicious? | MQI, FoS | ||
| Region of Xi’an? | Which province is Xi’an in? | NEM, FoS | ||
| Author of Pride and Prejudice? | Briefly introduce the writer of Pride and Prejudice. | NEM, DQ | ||
| Producer of Black Humor? | Who composes for Black Humor? | FoS | ||
| Country of Three Meals a Day? | On which website could I watch Three Meals a Day? | FoS | ||
| Abbreviation of LuXian No.2 High School? | LuXian No.2 and LuZhou No.2, which is better? | DQ | ||
| Original singer of DjKunsonRMX? | Who sings DjKunsonRMX better, Guanjie Xu or Baiqiang Chen? | DQ |
| Parameter | Parameter Value |
|---|---|
| Dim. of character embedding | 64 |
| Dim. of word embedding | 64 |
| Num. of characters in a word | 3 |
| Dim. of hidden SRU layer | 100 |
| Num. of stacked SRU layers | 9 |
| Dropout rate of embedding | 0.5 |
| Dropout rate of SRU output | 0.15 |
| Learning rate | 0.001 |
| Method | Question | Evidence | Answer Generated | Score |
|---|---|---|---|---|
| DS+SS | Born place of Archimedes? | … | Sicily | 0.71 |
| Where is the born place of Archimedes? | In 287 BC, Archimedes was born in Sicily (now Italy Siracusa) | Archimedes was born in Sicily | 0.36 | |
| Where was Archimedes born? | Archimedes | 0.59 | ||
| DS+SS+DP | Born place of Archimedes? | Sicily | 0.59 | |
| Where is the born place of Archimedes? | Sicily | 0.50 | ||
| Where was Archimedes born? | … | Sicily | 0.46 |
| Configuration | Labeling Rate (%) | |
|---|---|---|
| SL | 50 | 69.08 |
| Pre-training + SL | 50 | 72.98 |
| SL+ | 50 | 72.02 |
| SL | 100 | 75.20 |
| Pre-training + SL | 100 | 76.55 |
| SL+ | 100 | 77.25 |
| Model Class | Method | Labeling Rate (%) | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|---|
| Sequence-labeling | Seq-labeling with Softmax [5] | 100 | 63.58 | 73.63 | 68.24 |
| Seq-labeling with CRF [5] | 100 | 67.53 | 80.63 | 73.50 | |
| Interaction attention and pointer net | BiDAF [22] | 100 | 74.54 | 74.54 | 74.54 |
| R-NET [12] | 100 | 75.36 | 75.36 | 75.36 | |
| Our baseline | 100 | 75.20 | 75.20 | 75.20 | |
| Interaction attention and pointer net + DS | BiDAF [22] + DS | 100 | 75.66 | 75.66 | 75.66 |
| R-NET [12] + DS | 100 | 76.22 | 76.22 | 76.22 | |
| Our baseline + DS | 100 | 76.55 | 76.55 | 76.55 | |
| Interaction attention and pointer net | BiDAF [22] | 50 | 70.27 | 70.27 | 70.27 |
| R-NET [12] | 50 | 70.23 | 70.23 | 70.23 | |
| Our baseline | 50 | 69.08 | 69.08 | 69.08 | |
| Interaction attention and pointer net + DS | BiDAF [22] + DS | 50 | 72.52 | 72.52 | 72.52 |
| R-NET [12] + DS | 50 | 72.45 | 72.45 | 72.45 | |
| Our baseline + DS | 50 | 72.98 | 72.98 | 72.98 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Liang, X.; Xu, G.; Fu, K.; Li, F.; Huang, T. Factoid Question Answering with Distant Supervision. Entropy 2018, 20, 439. https://doi.org/10.3390/e20060439
Zhang H, Liang X, Xu G, Fu K, Li F, Huang T. Factoid Question Answering with Distant Supervision. Entropy. 2018; 20(6):439. https://doi.org/10.3390/e20060439
Chicago/Turabian StyleZhang, Hongzhi, Xiao Liang, Guangluan Xu, Kun Fu, Feng Li, and Tinglei Huang. 2018. "Factoid Question Answering with Distant Supervision" Entropy 20, no. 6: 439. https://doi.org/10.3390/e20060439
APA StyleZhang, H., Liang, X., Xu, G., Fu, K., Li, F., & Huang, T. (2018). Factoid Question Answering with Distant Supervision. Entropy, 20(6), 439. https://doi.org/10.3390/e20060439