Recommending Queries by Extracting Thematic Experiences from Complex Search Tasks



Abstract
:1. Introduction
- We formally introduce a visual data structure named Relative Chronological Source-tracking Tree (RCST) to capture the temporal, causal, and thematic experiences contained within complex search tasks.
- We seek to provide subtask-oriented query recommendations by leveraging the thematic experiences captured in RCSTs. We introduce a visual based method to identify subtasks from the RCSTs, and a personalized PageRank based method to find key queries from the query networks merged from the subtasks representing the thematic experiences from the crowd of searchers.
- The experimental results show that, compared with the methods extracting subtasks from plain form search logs, the proposed methods can identify subtasks and provide query recommendations with higher quality leveraging RCSTs as rich form search logs.
2. Related Works
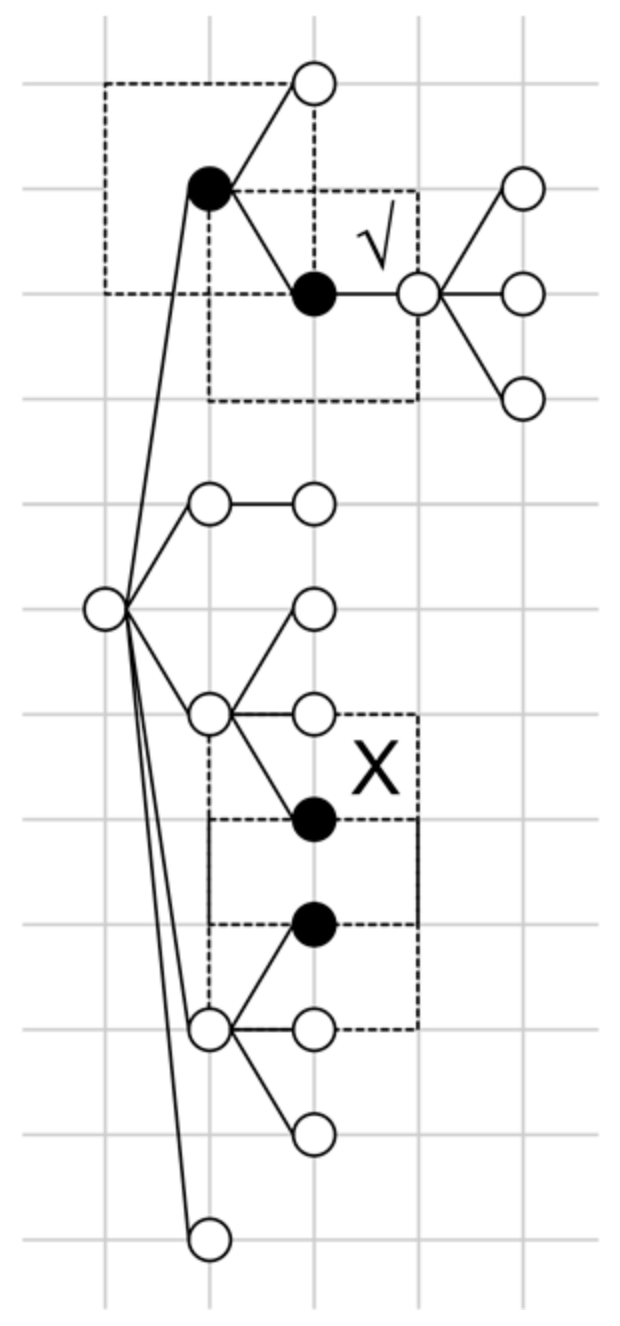
3. The RCST Visual Data Structure of the Search Log
- (1)
- , R(A, B) R(B, A) if R(A, B) or R(B, A) .
- (2)
- , if R(A, B) = R(B, C) = PARENT, then R(A, C) = OTHER.
- (3)
- , if R(A, B) = R(B, C) = BROTHER, then R(A, C) = BROTHER.
4. Recommending Subtask-Oriented Queries Using RCSTs
4.1. Visual-Based Subtask Identification from RCSTs
| Algorithm 1. Subtask Extraction Algorithm for RCST |
| Input: The RCST of a search task, distance d |
| Output: SubtaskSet = {NodeSet1, NodeSet2, …} extracted from the RCST |
|
4.2. Subtask Identification from Node Chains
- (1)
- Exploring different possible search directions. The searcher does not know which search direction to follow, and is trying a series of different possible directions. These possible directions may be related, but do not form a clear structure to fit into a tree structure.
- (2)
- Exploiting a specific topic. The searcher has found a possible search direction, and is digging into that topic.
- (1)
- When a searcher is exploring different possible search directions, each possible direction in the node chain is treated as a separate subtask.
- (2)
- When a searcher is exploiting a specific topic, the whole node chain is considered a single subtask.
∝P (st = Exploitation|ωt = Exploitation) × P (ωt = Exploitation| = Δqt, Dt−1)
∝P (st = Exploration|ωt = Exploration) × P (ωt = Exploration| = Δqt, Dt−1)
4.3. Merging Subtasks into Networks
| Algorithm 2. Subtask Merging Algorithm. |
| Input: Query Q, Subtask set SubtaskSet |
| Output: Network for query Q |
|
4.4. Recommending Queries from the Merged Query Network
4.4.1. Extracting Query Recommendations from Query Networks
4.4.2. Finding Optimized Search Paths for Recommendations
5. Experimental Evaluations
5.1. Evaluations of the Visual-Based Subtask Identification Method
5.1.1. Experimental Setup
- (1)
- DS: the two queries are in different clusters in A but in the same cluster in B.
- (2)
- DD: the two queries are in different clusters both in A and B.
- (3)
- SS: the two queries are in the same cluster both in A and B.
- (4)
- SD: the two queries are in the same cluster in A but in different clusters in B.
- (1)
- Write a report about drugs used in chemotherapy. Introduce common drugs used in chemotherapy, including their pharmacological actions, indications, administrations, and side effects. Introduce treatment strategies and common combinations of chemotherapy regiments. Do not focus only on drugs that beat cancer. Consider also drugs that decrease the toxic effects of other drugs.
- (2)
- Write a report about fine particles (PM2.5) in China. Introduce the concept and sources of PM2.5. Introduce how and why PM2.5 affects human health. Introduce the top affected cities by PM2.5 in China. Analyze the causes of PM2.5 in the top affected cities. Introduce methods as well as the corresponding mechanisms and feasibilities to reduce PM2.5. Analyze both the positive and the negative effects of the introduced methods.
- (3)
- Abstract of S. Shunmuga Krishnan, Ramesh K. Sitaraman. Video Stream Quality Impacts Viewer Behavior: Inferring Causality Using Quasi-Experimental Designs. IEEE/ACM Trans. Netw. 2013 21(6), 2001–2014.
- (4)
- Abstract of Hanqiang Cheng, Yu-Li Liang, Xinyu Xing, Xue Liu, Richard Han, Qin Lv, Shivakant Mishra: Efficient misbehaving user detection in online video chat services. WSDM 2012, 23–32.
- (1)
- Introductions, drugs, drug mechanisms, how to use drugs, indications, side effects, treatments, combinations of drugs, ancillary drugs, miscellaneous.
- (2)
- Introductions, concepts, sources, damages and reasons, PM2.5 in China, most affected cities and reasons, measures against PM2.5, feasibilities.
- (3)
- Web video service, web video charge, video category, user behavior, video quality, web video safety, web video revisit.
- (4)
- Video chat content, online chat misbehavior, online chat algorithms.
5.1.2. Experimental Results
5.2. Evaluations of the Proposed Query Recommendation Method
5.3. Complexity of Algorithms
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Marchionini, G. Exploratory search: From finding to understanding. Commun. ACM 2006, 49, 41–46. [Google Scholar] [CrossRef]
- Hassan, A.; White, R.W. Task tours: Helping users tackle complex search tasks. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management (CIKM 2012), Maui, HI, USA, 29 October–2 November 2012. [Google Scholar]
- Singer, G.; Danilov, D.; Norbisrath, U. Complex search: Aggregation, discovery and synthesis. Proc. Estonian Acad. Sci. 2012, 61, 89–106. [Google Scholar] [CrossRef]
- Yang, Z.; Nyberg, E. Leveraging procedural knowledge for task-oriented search. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2015), Santiago, Chile, 9–13 August 2015. [Google Scholar]
- Cao, H.H.; Jiang, D.X.; Pei, J.; He, Q.; Liao, Z.; Chen, E.H.; Li, H. Context-aware query suggestion by mining click-through and session data. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2008), Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Awadallah, A.H.; White, R.W.; Pantel, P.; Dumais, S.T.; Wang, Y.M. Supporting complex search tasks. In Proceedings of the 23rd ACM International Conference on Information and Knowledge Management (CIKM 2014), Shanghai, China, 3–7 November 2014. [Google Scholar]
- Otsuka, A.; Seki, Y.; Kando, N.; Satoh, T. QAque: Faceted query expansion techniques for exploratory search using community QA resources. In Proceedings of the 21st Annual Conference on World Wide Web (WWW'12), Lyon, France, 16–20 April 2012. [Google Scholar]
- Roitman, H.; Yogev, S.; Tsimerman, Y.; Kim, D.W.; Mesika, Y. Exploratory search over social-medical data. In Proceedings of the 20th ACM Conference on Information and Knowledge Management (CIKM 2011), Glasgow, UK, 24–28 October 2011. [Google Scholar]
- Marie, N.; Gandon, F.; Ribière, M.; Rodio, F. Discovery hub: On-the-fly linked data exploratory search. In Proceedings of the 9th International Conference on Semantic Systems (I-SEMANTICS 2013), Graz, Austria, 4–6 September 2013. [Google Scholar]
- Waitelonis, J.; Sack, H. Towards exploratory video search using linked data. Multimed. Tools Appl. 2012, 59, 645–672. [Google Scholar] [CrossRef]
- Mehrotra, R.; Yilmaz, E. Extracting hierarchies of search tasks & subtasks via a bayesian nonparametric approach. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2017), Tokyo, Shinjuku, Japan, 7–11 August 2017. [Google Scholar]
- Nguyen, P.H.; Xu, K.; Bardill, A.; Salman, B.; Herd, K.; Wong, B.L.W. SenseMap: Supporting browser-based online sensemaking through analytic provenance. In Proceedings of the 11th IEEE Conference on Visual Analytics Science and Technology (VAST 2016), Baltimore, MD, USA, 23–28 October 2016. [Google Scholar]
- Chau, D.H.; Kittur, A.; Hong, J.I.; Faloutsos, C. Apolo: Making sense of large network data by combining rich user interaction and machine learning. In Proceedings of the 29th Annual CHI Conference on Human Factors in Computing Systems (CHI 2011), Vancouver, BC, Canada, 7–12 May 2011. [Google Scholar]
- Gäde, M.; Hall, M.M.; Huurdeman, H.C.; Kamps, J.; Koolen, M.; Skove, M.; Toms, E.; Walsh, D. Report on the first workshop on supporting complex search tasks. ACM SIGIR Forum 2015, 49, 50–56. [Google Scholar] [CrossRef]
- Morris, D.; Morris, M.R.; Venolia, G. SearchBar: A search-centric web history for task resumption and information re-finding. In Proceedings of the 26th Annual CHI Conference on Human Factors in Computing Systems (CHI 2008), Florence, Italy, 5–10 April 2008. [Google Scholar]
- Park, H.; Myaeng, S.H.; Jang, G.; Choi, J.W.; Jo, S.; Roh, H.C. An interactive information seeking interface for exploratory search. In Proceedings of the 10th International Conference on Enterprise Information Systems (ICEIS 2008), Barcelona, Spain, 12–16 June 2008. [Google Scholar]
- Andolina, S.; Klouche, K.; Peltonen, J.; Hoque, M.; Ruotsalo, T.; Cabral, D.; Klami, A.; Głowacka, D.; Floréen, P.; Jacucci, G. IntentStreams: Smart parallel search streams for branching exploratory search. In Proceedings of the 20th ACM International Conference on Intelligent User Interfaces (IUI 2015), Atlanta, GA, USA, 29 March–1 April 2015. [Google Scholar]
- Adeyanju, I.A.; Song, D.; Albakour, M.-D.; Kruschwitz, U.; De Roeck, A.; Fasli, M. Adaptation of the concept hierarchy model with search logs for query recommendation on intranets. In Proceedings of the 35th Annual ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2012), Portland, OR, USA, 12–16 August 2012. [Google Scholar]
- Anagnostopoulos, A.; Becchetti, L.; Castillo, C.; Gionis, A. An optimization framework for query recommendation. In Proceedings of the 3rd ACM International Conference on Web Search and Data Mining (WSDM 2010), New York, NY, USA, 3–6 February 2010. [Google Scholar]
- Zhu, X.F.; Guo, J.F.; Cheng, X.Q.; Lan, Y.Y. More than relevance: High utility query recommendation by mining users’ search behaviors. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management (CIKM 2012), Maui, HI, USA, 29 October–2 November 2012. [Google Scholar]
- Liu, Y.Q.; Miao, J.W.; Zhang, M.; Ma, S.P.; Ru, L.Y. How do users describe their information need: Query recommendation based on snippet click model. Expert Syst. Appl. 2011, 38, 13847–13856. [Google Scholar] [CrossRef]
- Mao, Y.; Shen, H.; Sun, C. A social-knowledge-directed query suggestion approach for exploratory search. In Proceedings of the 3rd International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC 2011), Beijing, China, 10–12 October 2011. [Google Scholar]
- Yuvarani, M.; Iyengar, N.C.S.N.; Kannan, A. Improved concept-based query expansion using Wikipedia. Int. J. Commun. Netw. Distrib. Syst. 2013, 11, 26–41. [Google Scholar] [CrossRef]
- Sarrafzadeh, B.; Vechtomova, O.; Jokic, V. Exploring knowledge graphs for exploratory search. In Proceedings of the 5th Information Interaction in Context Symposium (IIiX 2014), Regensburg, Germany, 26–30 August 2014. [Google Scholar]
- Oliveira, V.; Gomes, G.; Belém, F.; Brandão, W.; Almeida, J.; Ziviani, N.; Gonçalves, M. Automatic query expansion based on tag recommendation. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management (CIKM 2012), Maui, HI, USA, 29 October–2 November 2012. [Google Scholar]
- Yang, G.H.; Tang, Z.W.; Soboroff, I. TREC 2017 dynamic domain track overview. In Proceedings of the Text Retrieval Conference 2017 (TREC 2017), Gaithersburg, MD, USA, 15–17 November 2017. [Google Scholar]
- Grace, H.Y.; Dong, X.C.; Luo, J.Y.; Zhang, S.C. Session search modeling by partially observable Markov decision process. Inf. Retr. J. 2018, 21, 56–80. [Google Scholar]
- Syed, R.; Collins-Thompson, K. Retrieval algorithms optimized for human learning. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2017), Tokyo, Japan, 7–11 August 2017. [Google Scholar]
- Nogueira, R.; Cho, K. Task-oriented query reformulation with reinforcement learning. In Proceedings of the EMNLP 2017, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Guo, J.F.; Zhu, X.F.; Lan, Y.Y.; Cheng, X.Q. Modeling users’ search sessions for high utility query recommendation. Inf. Retr. J. 2017, 20, 4–24. [Google Scholar] [CrossRef]
- Habermas, T.; Bluck, S. Getting a Life: The emergence of the life story in adolescence. Psychol. Bull. 2000, 126, 748–769. [Google Scholar] [CrossRef] [PubMed]
- Walker, J.Q. A node-positioning algorithm for general trees. Softw. Pract. Exp. 1990, 20, 685–705. [Google Scholar] [CrossRef]
- Luo, J.; Zhang, S.; Yang, H. Win-win search: Dual-agent stochastic game in session search. In Proceedings of the 27th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2014), Gold Coast, Queensland, Australia, 6–11 July 2014. [Google Scholar]
- Pelusi, D.; Mascella, R.; Tallini, L.; Nayak, J.; Naik, B.; Abraham, A. Neural network and fuzzy system for the tuning of Gravitational Search Algorithm parameters. Expert Syst. Appl. 2018, 102, 234–244. [Google Scholar] [CrossRef]
- Pelusi, D.; Mascella, R.; Tallini, L. A fuzzy gravitational search algorithm to design optimal IIR filters. Energies 2018, 11, 736. [Google Scholar] [CrossRef]
- Pelusi, D.; Mascella, R.; Tallini, L. Revised gravitational search algorithms based on evolutionary-fuzzy systems. Algorithms 2017, 10, 44. [Google Scholar] [CrossRef]
- Breitinger, C.; Gipp, B.; Langer, S. Research-paper recommender systems: A literature survey. Int. J. Digit. Libr. 2016, 17, 305–338. [Google Scholar]
- Sculley, D. Web-scale k-means clustering. In Proceedings of the 19th International Conference on World Wide Web (WWW 2010), Raleigh, North Carolina, USA, 26–30 April 2010. [Google Scholar]
- Wang, H.; Song, Y.; Chang, M.; He, X.; White, R.W.; Chu, W. Learning to extract cross-session search tasks. In Proceedings of the 22nd International World Wide Web Conference (WWW 2013), Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Li, L.; Deng, H.; Dong, A.; Chang, Y.; Zha, H. Identifying and labeling search tasks via query-based hawkes processes. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2014), New York, NY, USA, 24–27 August 2014. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Informative Search Task | Tentative Search Task | ||||
|---|---|---|---|---|---|---|
| AP | AN | AA | AP | AN | AA | |
| Proposed | 0.508 | 0.794 | 0.651 | 0.553 | 0.589 | 0.571 |
| MF K-Means | 0.371 | 0.786 | 0.576 | 0.536 | 0.563 | 0.550 |
| Bestlink-SVM | 0.366 | 0.772 | 0.569 | 0.533 | 0.552 | 0.543 |
| LDA-Hawkes | 0.360 | 0.764 | 0.562 | 0.524 | 0.542 | 0.533 |
| Task Type | Measures | Proposed | MF K-Means | Bestlink-SVM | LDA-Hawkes |
|---|---|---|---|---|---|
| Informative | Precision | 0.552 | 0.483 | 0.474 | 0.478 |
| Recall | 0.713 | 0.624 | 0.612 | 0.617 | |
| Tentative | Precision | 0.483 | 0.469 | 0.464 | 0.453 |
| Recall | 0.642 | 0.624 | 0.616 | 0.601 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Zhang, Y.; Zhang, B.; Gao, K.; Li, P. Recommending Queries by Extracting Thematic Experiences from Complex Search Tasks. Entropy 2018, 20, 459. https://doi.org/10.3390/e20060459
Zhao Y, Zhang Y, Zhang B, Gao K, Li P. Recommending Queries by Extracting Thematic Experiences from Complex Search Tasks. Entropy. 2018; 20(6):459. https://doi.org/10.3390/e20060459
Chicago/Turabian StyleZhao, Yuli, Yin Zhang, Bin Zhang, Kening Gao, and Pengfei Li. 2018. "Recommending Queries by Extracting Thematic Experiences from Complex Search Tasks" Entropy 20, no. 6: 459. https://doi.org/10.3390/e20060459
APA StyleZhao, Y., Zhang, Y., Zhang, B., Gao, K., & Li, P. (2018). Recommending Queries by Extracting Thematic Experiences from Complex Search Tasks. Entropy, 20(6), 459. https://doi.org/10.3390/e20060459