Information Guided Exploration of Scalar Values and Isocontours in Ensemble Datasets


Abstract
1. Introduction
- Using specific information measures, we evaluate the ensemble isocontour uncertainty of all the scalar values in an efficient and effective way.
- For a single scalar value, we propose a conditional entropy based approach to identify the contributions of individual members towards the uncertainty of the ensemble isocontours.
2. Related Work
2.1. Information Theory in Visualization
2.2. Ensemble Data Visualization
3. System Overview
4. Method
4.1. Specific Information Based Scalar Value Exploration
4.1.1. Information Channels
- Input distribution represents the normalized frequency of each scalar value x in the distribution of X.
- Conditional probability distribution expresses how the distribution of each of the scalar values (i.e., x) of the input field X match with the distribution of output field Y.
- Output distribution represents the normalized frequency of each scalar value y in the distribution of Y.
4.1.2. Entropy
4.1.3. Mutual Information
4.1.4. Specific Information
4.1.5. Surprise ()
4.1.6. Predictability()
4.1.7. Relationship with Mutual Information
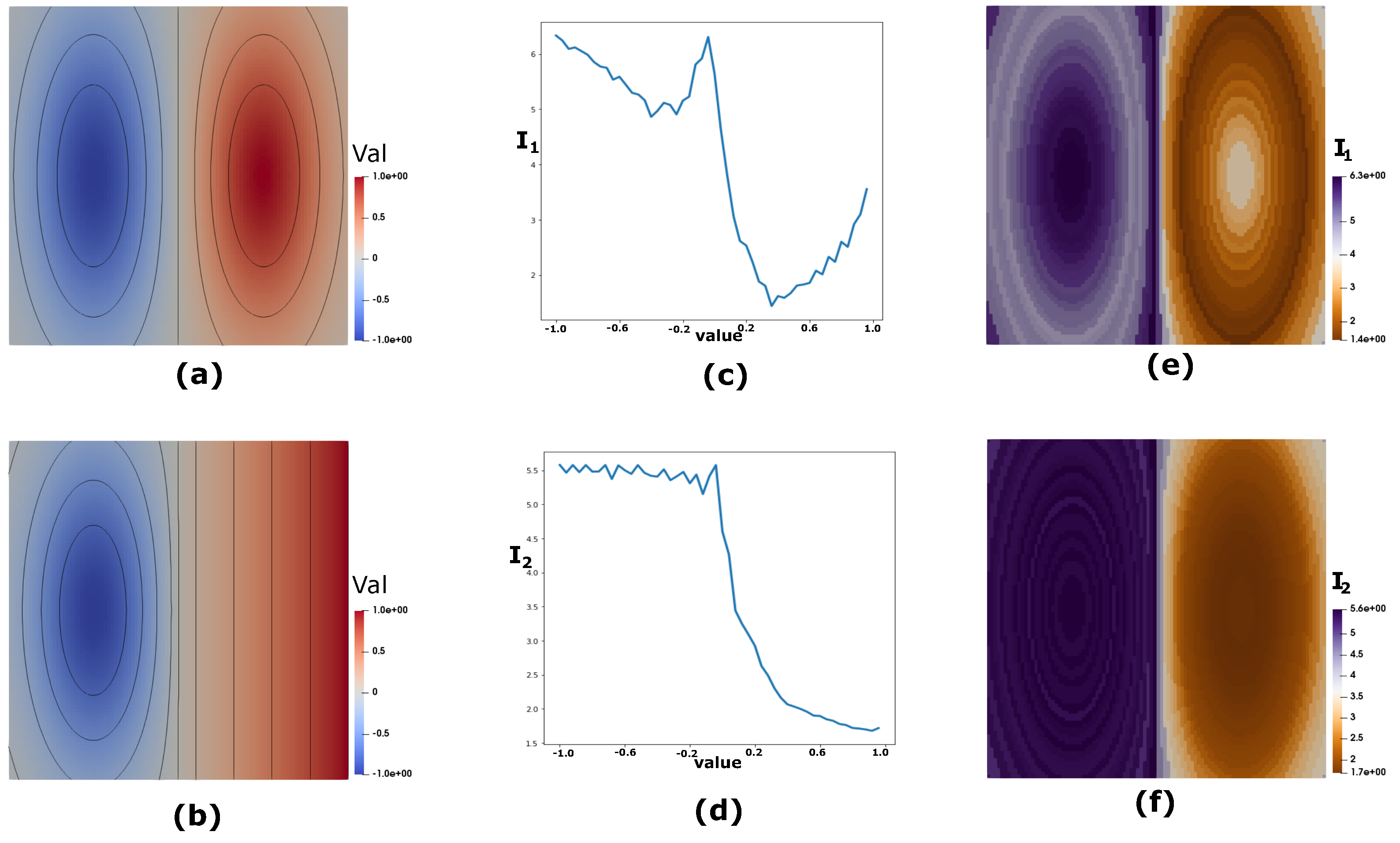
4.1.8. Synthetic Data
4.1.9. Exploration of Scalar Values
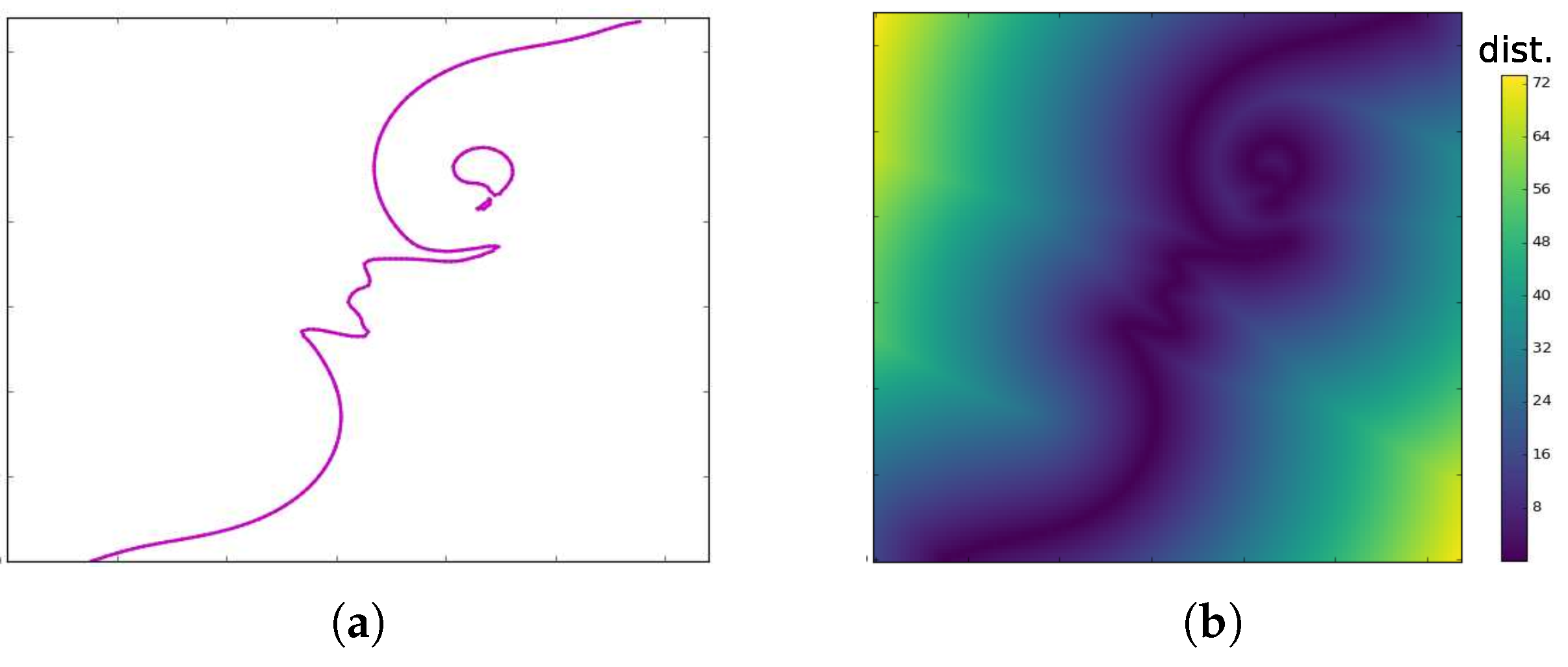
4.2. Conditional Entropy Based Isocontour Exploration
4.2.1. Conditional Entropy
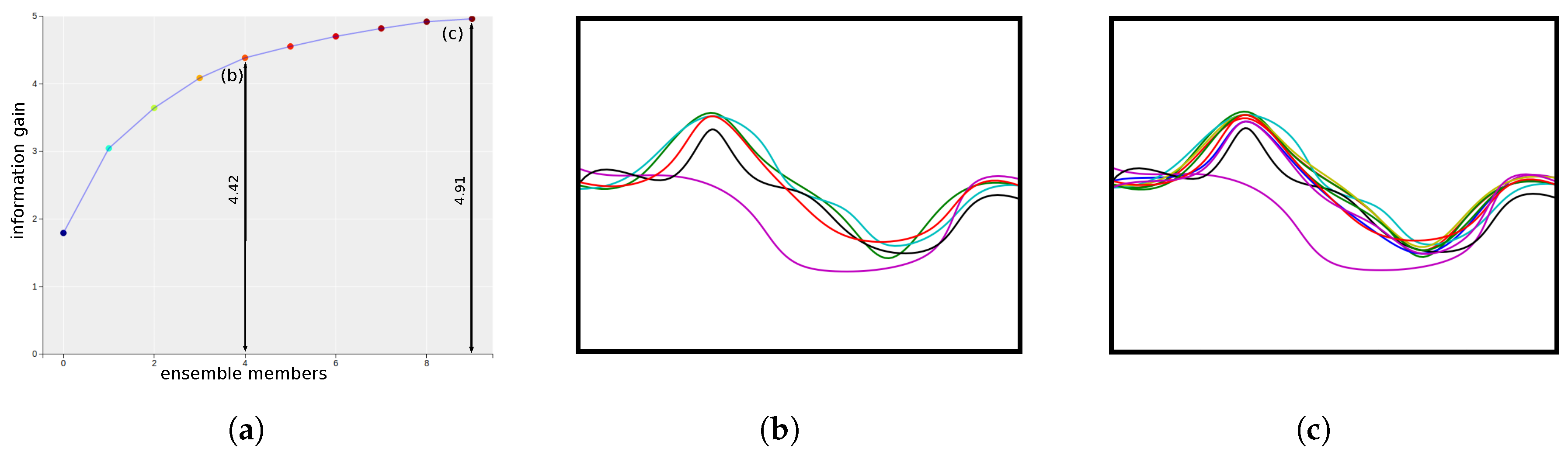
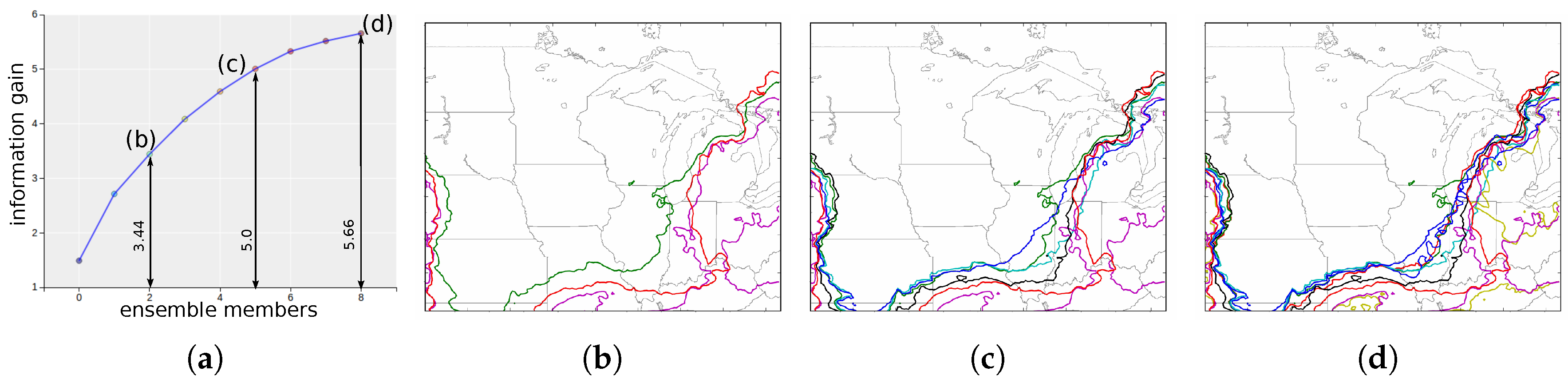
4.2.2. Informative Isocontour Selection
| Algorithm 1 Informative Isocontour Selection Algorithm | ||
| 1: | ||
| 2: | ▹ list of informative contours | |
| 3: | ▹ amount of information gain | |
| 4: | whiledo | ▹ check the info gain of all contours |
| 5: | ||
| 6: | ||
| 7: | for all c in do | |
| 8: | ||
| 9: | ▹ je: joint entropy | |
| 10: | if then | |
| 11: | ||
| 12: | ||
| 13: | ||
| 14: | ||
| 15: | ||
| 16: | ||
5. Results
5.1. Material Density Ensemble
5.2. Great Lakes WRF Ensemble
5.3. Massachusetts Bay Ocean Modeling Ensemble
6. Discussion
7. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bonneau, G.P.; Hege, H.C.; Johnson, C.R.; Oliveira, M.M.; Potter, K.; Rheingans, P.; Schultz, T. Overview and State-of-the-Art of Uncertainty Visualization. In Scientific Visualization: Uncertainty, Multifield, Biomedical, and Scalable Visualization; Hansen, D.C., Chen, M., Johnson, R.C., Kaufman, E.A., Hagen, H., Eds.; Springer: London, UK, 2014; pp. 3–27. [Google Scholar]
- Love, A.L.; Pang, A.; Kao, D.L. Visualizing spatial multivalue data. IEEE Comput. Graph. Appl. 2005, 25, 69–79. [Google Scholar] [CrossRef] [PubMed]
- Pang, A.; Wittenbrink, C.; Lodha, S. Approaches to Uncertainty Visualization; Technical Report; Springer: Santa Cruz, CA, USA, 1996. [Google Scholar]
- Whitaker, R.T.; Mirzargar, M.; Kirby, R.M. Contour boxplots: A method for characterizing uncertainty in feature sets from simulation ensembles. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2713–2722. [Google Scholar] [CrossRef] [PubMed]
- Sanyal, J.; Zhang, S.; Dyer, J.; Mercer, A.; Amburn, P.; Moorhead, R.J. Noodles: A tool for visualization of numerical weather model ensemble uncertainty. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1421–1430. [Google Scholar] [CrossRef] [PubMed]
- Ferstl, F.; Kanzler, M.; Rautenhaus, M.; Westermann, R. Visual Analysis of Spatial Variability and Global Correlations in Ensembles of Iso-Contours. Comput. Graph. Forum (Proc. Eur. Vis.) 2016, 35, 221–230. [Google Scholar] [CrossRef]
- Pöthkow, K.; Weber, B.; Hege, H.C. Probabilistic Marching Cubes. In Proceedings of the 13th Eurographics/IEEE-VGTC Conference on Visualization, Bergen, Norway, 1–3 June 2011; pp. 931–940. [Google Scholar]
- Hintze, J.L.; Nelson, R.D. Violin Plots: A Box Plot-Density Trace Synergism. Am. Stat. 1998, 52, 181–184. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley Series in Telecommunications and Signal Processing, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Chen, M.; Sbert, M.; Shen, H.W.; Viola, I.; Bardera, A.; Feixas, M. Information Theory in Visualization; EG 2016-Tutorials; Sousa, A., Bouatouch, K., Eds.; The Eurographics Association: Lisbon, Portugal, 2016. [Google Scholar]
- Wang, C.; Yu, H.; Ma, K. Importance-Driven Time-Varying Data Visualization. IEEE Trans. Vis. Comput. Graph. 2008, 14, 1547–1554. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Jänicke, H. An Information-theoretic Framework for Visualization. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1206–1215. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Lee, T.Y.; Shen, H.W. An Information-Theoretic Framework for Flow Visualization. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1216–1224. [Google Scholar] [PubMed]
- Pluim, J.P.W.; Maintz, J.B.A.; Viergever, M.A. Mutual-information-based registration of medical images: A survey. IEEE Trans. Med. Imaging 2003, 22, 986–1004. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Paragios, N.; Metaxas, D.N. Shape Registration in Implicit Spaces Using Information Theory and Free Form Deformations. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1303–1318. [Google Scholar] [CrossRef] [PubMed]
- Bruckner, S.; Moller, T. Isosurface Similarity Maps. In Proceedings of the 12th Eurographics/IEEE-VGTC Conference on Visualization, EuroVis’10, Bordeaux, France, 9–11 June 2010; pp. 773–782. [Google Scholar]
- Wei, T.H.; Lee, T.Y.; Shen, H.W. Evaluating Isosurfaces with Level-set-based Information Maps. In Proceedings of the 15th Eurographics Conference on Visualization EuroVis ’13, Leipzig, Germany, 17–21 June 2013; pp. 1–10. [Google Scholar]
- Deweese, M.R.; Meister, M. How to measure the information gained from one symbol. Netw. Comput. Neural Syst. 1999, 10, 325–340. [Google Scholar] [CrossRef]
- Bramon, R.; Boada, I.; Bardera, A.; Rodriguez, J.; Feixas, M.; Puig, J.; Sbert, M. Multimodal Data Fusion Based on Mutual Information. IEEE Trans. Vis. Comput. Graph. 2012, 18, 1574–1587. [Google Scholar] [CrossRef] [PubMed]
- Dutta, S.; Liu, X.; Biswas, A.; Shen, H.W.; Chen, J.P. Pointwise Information Guided Visual Analysis of Time-varying Multi-fields. In Proceedings of the SIGGRAPH ASIA 2017 Symposium on Visualization, Bangkok, Thailand, 27–30 November 2017. [Google Scholar]
- Biswas, A.; Dutta, S.; Shen, H.W.; Woodring, J. An Information-Aware Framework for Exploring Multivariate Data Sets. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2683–2692. [Google Scholar] [CrossRef] [PubMed]
- Brown, G.; Pocock, A.; Zhao, M.J.; Luján, M. Conditional Likelihood Maximisation: A Unifying Framework for Information Theoretic Feature Selection. J. Mach. Learn. Res. 2012, 13, 27–66. [Google Scholar]
- Nguyen, X.V.; Chan, J.; Romano, S.; Bailey, J. Effective Global Approaches for Mutual Information Based Feature Selection. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2014. KDD ’14. pp. 512–521. [Google Scholar]
- Johnson, C.R.; Sanderson, A.R. A Next Step: Visualizing Errors and Uncertainty. IEEE Comput. Graph. Appl. 2003, 23, 6–10. [Google Scholar] [CrossRef]
- Djurcilov, S.; Kim, K.; Lermusiaux, P.; Pang, A. Visualizing Scalar Volumetric Data with Uncertainty. Comput. Graph. 2002, 26, 239–248. [Google Scholar] [CrossRef]
- Potter, K.; Rosen, P.; Johnson, C.R. From quantification to visualization: A taxonomy of uncertainty visualization approaches. In Uncertainty Quantification in Scientific Computing; Springer: Berlin, Heidelberg, 2012; pp. 226–249. [Google Scholar]
- Molteni, F.; Buizza, R.; Palmer, T.; Petroliagis, T. The ECMWF Ensemble Prediction System: Methodology and validation. Q. J. R. Meteorol. Soc. 1996, 122, 73–119. [Google Scholar] [CrossRef]
- Miyoshi, T.; Kondo, K.; Terasaki, K. Big Ensemble Data Assimilation in Numerical Weather Prediction. Computer 2015, 48, 15–21. [Google Scholar] [CrossRef]
- Obermaier, H.; Joy, K. Future challenges for ensemble visualization. Comput. Graph. Appl. IEEE 2014, 34, 8–11. [Google Scholar] [CrossRef]
- Wang, J.; Hazarika, S.; Li, C.; Shen, H.W. Visualization and Visual Analysis of Ensemble Data: A Survey. IEEE Trans. Vis. Comput. Graph. 2018. [Google Scholar] [CrossRef] [PubMed]
- Potter, K.; Wilson, A.; Bremer, P.-T.; Williams, D.; Doutriaux, C.; Pascucci, V.; Johhson, C. Visualization of uncertainty and ensemble data: Exploration of climate modeling and weather forecast data with integrated ViSUS-CDAT systems. J. Phys. Conf. Ser. 2009, 180, 012089. [Google Scholar] [CrossRef]
- Demir, I.; Dick, C.; Westermann, R. Multi-Charts for Comparative 3D Ensemble Visualization. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2694–2703. [Google Scholar] [CrossRef] [PubMed]
- Alabi, O.S.; Wu, X.; Harter, J.M.; Phadke, M.; Pinto, L.; Petersen, H.; Bass, S.; Keifer, M.; Zhong, S.; Healey, C.; Taylor, R.M., II. Comparative Visualization of Ensembles Using Ensemble Surface Slicing; International Society for Optics and Photonics: Burlingame, CA, USA, 2012; Volume 8294. [Google Scholar]
- Hazarika, S.; Dutta, S.; Shen, H.W. Visualizing the variations of ensemble of isosurfaces. In Proceedings of the 2016 IEEE Pacific Visualization Symposium (PacificVis), Taipei, Taiwan, 19–22 April 2016; pp. 209–213. [Google Scholar]
- Pöthkow, K.; Hege, H.C. Positional Uncertainty of Isocontours: Condition Analysis and Probabilistic Measures. IEEE Trans. Vis. Comput. Graph. 2011, 17, 1393–1406. [Google Scholar] [CrossRef] [PubMed]
- Pöthkow, K.; Petz, C.; Hege, H.C. Approximate level-crossing probabilities for interactive visualization of uncertain isocontours. Int. J. Uncertain. Quantif. 2013, 3, 101–117. [Google Scholar] [CrossRef]
- Hazarika, S.; Biswas, A.; Shen, H.W. Uncertainty Visualization Using Copula-Based Analysis in Mixed Distribution Models. IEEE Trans. Vis. Comput. Graph. 2018, 24, 934–943. [Google Scholar] [CrossRef] [PubMed]
- Lermusiaux, P.F.; Chiu, C.S.; Gawarkiewicz, G.G.; Abbot, P.; Robinson, A.R.; Miller, R.N.; Haley, P.J.; Leslie, W.G.; Majumdar, S.J.; Pang, A.; et al. Quantifying Uncertainties in Ocean Predictions; Technical Report, DTIC Document; Harvard Univiversity: Cambridge, MA, USA, 2006. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Jones, M.W.; Baerentzen, J.A.; Sramek, M. 3D Distance Fields: A Survey of Techniques and Applications. IEEE Trans. Vis. Comput. Graph. 2006, 12, 581–599. [Google Scholar] [CrossRef] [PubMed]
- Lu, K.; Shen, H.W. A compact multivariate histogram representation for query-driven visualization. In Proceedings of the 2015 IEEE 5th Symposium on Large Data Analysis and Visualization (LDAV), Chicago, IL, USA, 25–26 October 2015; pp. 49–56. [Google Scholar]
- Micard, D.; Dossmann, Y.; Gostiaux, L. Mixing Efficiency in a Lock Exchange Experiment. In Proceedings of the International Symposium on Stratified Flows, San Diego, CA, USA, 29 August–1 September 2016. [Google Scholar]
- Lermusiaux, P.F. Uncertainty estimation and prediction for interdisciplinary ocean dynamics. J. Comput. Phys. 2006, 217, 176–199. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Dim (Ensembles) | and (secs) | Cond. Entropy (secs) |
|---|---|---|---|
| Material Density | 84.3 | 47.3 | |
| Great Lake | 1.2 | 20.5 | |
| Mass. Bay | 5.1 | 33.2 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hazarika, S.; Biswas, A.; Dutta, S.; Shen, H.-W. Information Guided Exploration of Scalar Values and Isocontours in Ensemble Datasets. Entropy 2018, 20, 540. https://doi.org/10.3390/e20070540
Hazarika S, Biswas A, Dutta S, Shen H-W. Information Guided Exploration of Scalar Values and Isocontours in Ensemble Datasets. Entropy. 2018; 20(7):540. https://doi.org/10.3390/e20070540
Chicago/Turabian StyleHazarika, Subhashis, Ayan Biswas, Soumya Dutta, and Han-Wei Shen. 2018. "Information Guided Exploration of Scalar Values and Isocontours in Ensemble Datasets" Entropy 20, no. 7: 540. https://doi.org/10.3390/e20070540
APA StyleHazarika, S., Biswas, A., Dutta, S., & Shen, H.-W. (2018). Information Guided Exploration of Scalar Values and Isocontours in Ensemble Datasets. Entropy, 20(7), 540. https://doi.org/10.3390/e20070540