Abstract
Parameter estimation is one of the key technologies for system identification. The Bayesian parameter estimation algorithms are very important for identifying stochastic systems. In this paper, a random finite set based algorithm is proposed to overcome the disadvantages of the existing Bayesian parameter estimation algorithms. It can estimate the unknown parameters of the stochastic system which consists of a varying number of constituent elements by using the measurements disturbed by false detections, missed detections and noises. The models used for parameter estimation are constructed by using random finite set. Based on the proposed system model and measurement model, the key principles and formula derivation of the proposed algorithm are detailed. Then, the implementation of the algorithm is presented by using sequential Monte Carlo based Probability Hypothesis Density (PHD) filter and simulated tempering based importance sampling. Finally, the experiments of systematic errors estimation of multiple sensors are provided to prove the main advantages of the proposed algorithm. The sensitivity analysis is carried out to further study the mechanism of the algorithm. The experimental results verify the superiority of the proposed algorithm.
1. Introduction
In modern society, mathematical models are playing increasingly important roles in engineering systems when used for simulating, predicting, managing, and deciding [1]. Since system identification is essential for modeling, it is the potential and vital technology to meet the challenges of model based scientific research. System identification has been applied to many areas, including industrial systems, agricultural systems, biological systems, medical systems and economic systems, and even social systems [2,3,4,5].
Generally speaking, the existing system identification algorithms can be classified into non-parametric model identification algorithms and parametric model identification algorithms [6]. Parametric models are more powerful, because they can represent the studied system with fewer parameters and have more statistical power. The parametric model identification algorithms usually assume some model structure and estimate the associated parameters by reducing the error criterion function of the model and practical system. Therefore, parameter estimation is the core component of these algorithms.
1.1. Parameter Estimation
Parameter estimation refers to identifying, estimating and calibrating continuous or discrete model parameters [7]. The parameters to be estimated could be the time-invariant physical quantities, or the coefficients and other constants in a functional relationship that describe the practical physical system [8]. They can be represented by scalars, vectors, or matrixes. In this paper, we use an n elements vector to represent the unknown model parameters.
The stochastic system is the system whose input, output and interference have random factors, or the system itself has some uncertainty. Only by parameter estimation can we get the model parameters for the stochastic system. Parameter estimation of the stochastic system is the basis of state filtering, stochastic control, fault diagnosis, forecasting and many other fields [9]. This paper deals with the identification problem of stochastic systems whose model structures are known and parameters to be identified. In this case, the identification of stochastic system minimizes the estimating of unknown parameters associated with the known models by using prior information and observations from the practical system.
The Sequential Monte Carlo (SMC) method is a powerful tool to perform optimal state and parameter estimating by using the nonlinear and non-Gaussian state space models. Since SMC based parameter estimation algorithms employ the non-parametric statistic inference based on Bayesian inference theory, and have no assumptions of the distribution and linearity of the studied system, they are widely used for parameter estimation [10,11,12,13,14].
According to [11], the SMC based parameter estimation algorithms can be broadly formulated into Maximum Likelihood (ML) formulation and Bayesian formulation. ML formulation is mainly related to finding a point estimate of the unknown parameter which is the most likely to be associated with the observations. The ML estimate of the parameters is the parameters that minimize the negative logarithm of the likelihood function based on the received measurements. The estimation process is shown as the following equation:
where is the estimated parameter vector, is the sequence of measurements, and is the unknown parameter vector to be estimated.
ML method is only applicable to the estimation problem where a joint probability density function (PDF) can be assigned to the measurements [15]. In addition, ML estimate needs to use the gradient based search methods such as a damped Gauss–Newton method to actually compute estimated parameters [16].
In the Bayesian formulation, the unknown parameters are regarded as an unobserved random variable or vector. The Bayesian parameter estimation gives a posterior PDF of the unknown parameters, conditioned on measurements and prior distribution. Thus, the parameter estimation problem refers to obtaining the posterior PDF of by using the available measurements. According to Bayes’ theory, the posterior distribution can be obtained by Equation (2), where is the prior distribution.
The first advantage of the Bayesian parameter estimation algorithm over the traditional algorithms is the conceptualization of the estimation result. In the traditional algorithms, there is a specific but unknown model that needs to be identified. In the Bayesian algorithm, the model is a random variable rather than deterministic. The estimation result is a probability distribution for the model parameters named as posterior distribution. With the probability distribution, we can answer many probabilistic questions about the model. Such questions are impossible in the traditional algorithms, because the identified model they provided is not a random variable.
The second advantage of the Bayesian parameter estimation algorithm over the traditional algorithms is the incorporation with prior information represented mathematically as a prior distribution for the model. The Bayesian parameter estimation algorithm naturally incorporates prior information about the estimation result, ranging from hard additional constraints to experience based intuition. Once measurements are collected, they are combined with the prior distribution using Bayesian inference to produce the desired posterior distribution of the unknown parameters.
Both ML and Bayesian parameter estimation can be implemented off-line or on-line. In an off-line parameter estimation algorithm, we infer the unknown parameters by iterating over a fixed measurement dataset. In an on-line method, the unknown parameters are sequentially estimated as the measurements become available. The role of SMC for both off-line and on-line parameter estimation is discussed in [10,17]. If we assume that the states of the studied system are unknown, there is a need to deal with the relationship between states and parameters. Marginalization and data augmentation are two different strategies for dealing with this kind of parameter estimation problem. Marginalization means integrating out the states from the problem and viewing the unknown parameters as the only unknown variable of interest. Usually, marginalization is implemented in an off-line manner. Data augmentation estimates the unknown parameters together with the states [11,18]. In other words, the data augmentation performs parameter estimation by extending the state with the unknown parameters and transforming the problem into an optimal filtering problem. Usually, data augmentation is implemented in an on-line manner.
1.2. Nomenclature
An introduction of some concepts used in this paper is provided in the following. More detailed information can be found in the provided references.
1.2.1. Random Finite set (RFS)
In the middle 1970s, G. Matheron systematically described the random set theory [19]. The random finite set (RFS) approach introduced by Mahler is an advanced theory that unifies much of information fusion under a single Bayesian paradigm [20,21]. The RFS is defined as a random variable that draws its instantiations from the hyperspace of all finite subsets Y (the null set ∅ included) of some underlying space . Here, we assume that is a Euclidean vector space and that, therefore, consists of all finite sets of the form or where is an arbitrary positive integer and are arbitrary vectors in .
1.2.2. Finite Set Statistics (FISST)
Here, we adopt FISST which provides the mathematical representation and manipulation of RFS. FISST is a set of tools for filtering and estimating problems involving RFS [22]. FISST enables the RFS based Bayesian inference by providing some mathematical tools. Fundamentally, it approaches the modeling of multi-object tracking by introducing sets that contain a random number of single-object states, each of which is a random vector. It allows the dynamics of each object (member of the object set) to vary according to some motion model while the number of objects (members in the set) is allowed to vary according to some point process model.
1.2.3. Probability Hypothesis Density (PHD)
The difficulty of RFS based Bayesian inference is its computational complexity. To make the RFS based estimation possible, Mahler proposed the PHD (probability hypothesis density) filter [21,23,24]. The PHD of the posterior probability PDF is a density function defined on the single object state as follows:
Here, we use the abbreviation . In point theory, is defined as the intensity density. is not a probability density, but it represents the density of expected number of points at . If represents a region in the single object state space , the integral represents the expected number of targets in the state space . More information about PHD can be found in [22].
1.2.4. Simulated Tempering
Simulated tempering is a stochastic optimization method that is used for improving the probability of an optimization routine converging to a global optima in highly multimodal objectives [25]. It adopts the properties of thermodynamical systems and deals with two important problems with Markov Chain Monte Carlo (MCMC) methods: one is improving exploration of multimodal distributions, and the other one is allowing estimation of the normalizing constant of the target distribution. Simulated tempering augments the Markov chain state with a discrete index variable controlling the inverse temperature of the system [26].
The objective function that we want to minimize is defined by the energy function of the system and the variables being optimized with the state . An increasing schedule of K inverse temperatures is chosen with . The variables on which the target distribution P is defined are augmented with a discrete index variable . A joint density on the target variable and temperature index k is then defined as
where C is a constant, and is a set of prior weights associated with each inverse temperature value, and which can be used to help shape the marginal distribution on the temperature index k. The energy function is defined as the negative logarithm of the unnormalized target density i.e., . Function defines a corresponding energy function for a base distribution Q with normalized density .
If , the conditional distribution on the target variables corresponds to the base distribution Q and . If , it will correspond to the target distribution P and . We can therefore use the components of sampled chain states for which to estimate the variables of interest which is related to the target distribution P. In simulated tempering, a Markov chain with invariant distribution corresponding to (4) is constructed by alternating updates of the target variables given the current value of temperature index k, with updates of the temperature index k given the current value of the target variables . More information about simulated tempering can be found in [27].
1.3. Motivation and Advantages of the Proposed Parameter Estimation Algorithm
In this paper, we choose to use the Bayesian formulation represented by Equation (2). The unknown parameters are regarded as a random vector and associated with a suitable prior information modeled by the prior distribution. The posterior PDF of the parameters is to be characterized by using the given measurements. The proposed parameter estimation algorithm can be regarded as the Monte Carlo batch techniques [28], and it is perfect for estimating parameters of stochastic dynamic systems. The proposed parameter estimation algorithm is an off-line Bayesian parameter estimation algorithm, and it is an updated version of the marginalization based algorithms.
The conventional Bayesian parameter estimation algorithms depend on the vector based representation of data including states and measurements. The vector based representation makes these algorithms have three essential disadvantages. The first one is that they must assume that the studied system is a single permanently active system and the model is presumed. They cannot be used for estimating the dynamic system that switches on and off randomly. The transition from one mode to another is impossible. The second disadvantage is that they are based on the assumption that the detection is perfect which means no clutters and no missed detections, and they also need the number and sort order of measurements to be previously designated. The third disadvantage is that they are not appropriate for estimating the systems with varying state dimensions caused by the varying number of constituent elements contained in the studied system.
The limits of the commonly used random vector based Bayesian estimation algorithms are analyzed in [29]. We can find that the root of their disadvantages is that they must ensure the dimension and elements’ order in each vector to be equal and fixed. They also need necessary operations outside of the Bayesian recursion to ensure the consistency of the vectors used for calculation. The determination of newly observed measurements and missed measurements is through vector augmentation and truncation which are very computationally intensive and irreversible. In this paper, we propose to employ the RFS theory to overcome these disadvantages of the standard vector based Bayesian parameter estimation algorithms.
An RFS has a broader application prospect than a random vector, because an RFS has a random number of constituent vectors and it allows these constituent vectors themselves to be random, distinct and unordered [30]. In practice, the number of measurements is not fixed and the ordering of measurements is irrelevant, so the measurements are better to be modeled as an RFS. RFS based data representation generalizes the system model and measurement model for parameter estimation, because it takes into account a more realistic situation where the varying number of objects, detection uncertainty, clutters, missed detections and data association uncertainty are all taken into consideration.
Unlike the traditional parameter estimation algorithms and the vector based Bayesian parameter estimation algorithms, the proposed Bayesian parameter estimation algorithm employs RFS based modeling, and has the following advantages:
- It can estimate the parameters by using the imperfect detections including noises, clutters, data association uncertainty and missed detections. Thus, it enables the measurement model used for parameter estimation to be more universal and consistent with the practical system.
- It can estimate the parameters for the stochastic systems which consist of a varying number of constituent components or objects. It can take the object birth, object death and spawned objects of the studied system into consideration.
- The proposed algorithm can also accurately estimate the states of the studied system and the number of objects contained in the studied system while estimating the unknown parameters. The estimation of states and object number depends on the estimated parameters.
The rest of the paper is structured as follows. We present the RFS based modeling for both measurement model and system model in Section 2. A detailed description of the PHD based Bayesian inference and the SMC based implementation are given in Section 3. The proposed RFS based parameter estimation algorithm is detailed in Section 4. After describing the proposed algorithm, in Section 5, we take a particular problem of estimating systematic errors of multiple sensors as an example to verify this algorithm. In order to better promote academic exchanges, we provide the source codes for the experiments in the supplementary materials part. Finally, the conclusion is provided in Section 6.
2. RFS Based Modeling
The RFS based parameter estimation algorithm uses two kinds of models to describe the real world: one is the Markov transition density based system model; the other one is the measurement likelihood based measurement model. System model is used to model the state transition of the studied system, and the measurement model is used to model the practical measurement system. Here, we focus on estimating the static parameter vector which features in the state space models that represent system dynamics and measurement system using observations from the practical system. The RFS based representation of measurements and states is the foundation of RFS based algorithm. In this section, we give the RFS based problem formulation and the RFS based models used in the proposed parameter estimation algorithm.
2.1. Problem Formulation
Suppose at time step , the studied system consists of objects. Their states can, respectively, be represented by the vectors , and each state vector is obtained from the state space . In practice, the number and the individual states in of system’s constituent elements are both time varying and random. In this paper, the system state at k is described by an RFS . The state evolution of the RFS based system model can be described by the Markov system state process conditioned on the static parameters . The state evolution is characterized by a prior density and a multiple objects transition density .
The measurement process is imperfect in the sense that there exists detection uncertainty. The measurement devices usually create false detections. If observation datasets are available at time , and there are elements in the observation dataset at time k, and the observations take a values in the measurement space . Then, the observations can be modeled by an RFS . Here, we assume that the measurement process is conditionally independent from the system’s state evolution, and can be fully described by the likelihood which is conditioned on .
We assign a prior distribution to the unknown parameter vector , and estimate it on the parameter vector space according to Bayesian theory. The parameter estimation problem in this paper mainly refers to estimating the posterior PDF ; here, is the measurement set sequence gathered up to time index K. If the prior density is given, according to Equation (2), the estimation result in the Bayesian approach is given by:
The computation of is quite difficult, because it refers to performing estimation on the joint space of the unknown system states history and the unknown parameter vector . To solve this problem, we choose to consider a broader problem instead of solving the problem directly. The parameter estimation problem can be regarded as a subproblem of the chosen problem where the main task is to obtain the following posterior PDF:
where is the posterior PDF of the system states conditioned on and all the given observation datasets.
2.2. RFS Based Measurement Model
For the given predicted system state , the random measurement set collected by the sensor can be represented by , where is the object detection set and it has the form ; is the detection set for state ; and is the set of Poisson clutters.
Any given object in the studied system can generate either a single measurement or no measurement at all. Consequently, can be modeled as . Here, is the sensor-noise model associated with ith state ; and is the discrete random subset of the baseline measurement space . Detection uncertainty is modeled as a Bernoulli RFS as follows:
where is the probability that a single object whose state is gives a single observation, and is the probability that the sensor generates no measurement at all.
The fact that the clutter process is Poisson means that the clutters can be represented by the set , where M is a random nonnegative integer with probability distribution ; are independent, and identically distributed random measurement vectors with density .
For the state set , the PDF of receiving the measurement set is described by the true likelihood function , which describes the sensor measurement for the studied system and characterizes the missed detections, clutters, and object generated observations. As described in [29], the true likelihood function can be calculated as follows:
where and ; the summation is taken over all associated hypothesis . In time, the clutter process is Poisson distributed, and the mean value is . In space, the clutter process is distributed according to an arbitrary density , and is the probability that a set of clutters will be generated. is the likelihood function of a single sensor.
2.3. RFS Based System Model
Some systems may consist of multiple objects, and the number of these objects can be constantly varying, just as the objects appear and disappear from the system. Existing objects can give rise to new objects through spawning. Objects can likewise leave the system, as when disappearing, or they can be damaged or destroyed. All of these instances of multiple object dynamics should be explicitly modeled. If multiple objects contained in the studied system are related to birth, death, spawning, merging, and so on, the standard vector based estimation algorithms are inapplicable, because they fail to accurately estimate the number of objects in the studied system.
We model the time evolution of the system which consists of multiple objects by employing RFS. We take the object birth, death, spawn, and motion into consideration. The system Markov density characterizes the time evolution of the system states. Here, we give the true system Markov density function for the proposed system model, where and . The RFS based representation of system’ states has the following mathematical form
where is the set of predicted system states, is a set of states of persisting objects that are continuing to exist in the system, represents the state set of spawned elements, represents the state set of spontaneous objects. has the form , and is the set of predicted states evolved from . has the form , and is the set of spawned states by the object whose previous state is .
As detailed in [29], the RFS based system model is identical in mathematical form to the RFS based measurement model. The corresponding true Markov density is
where is a Markov transition density, which corresponds to a single object system model . It is the likelihood that a single object will have state vector at time step k if it had state vector at time step . denotes the probability of object’s surviving into time step k. is the probabilistic distribution of spawning a set of new objects at time step k. The summation is taken over all association hypotheses .
The related definitions in Equation (13) are as follows:
Here, is the expected number of spontaneously generated new objects and is their physical distribution. In addition, is the expected number of new objects spawned by an object whose previous state is , and is their physical distribution.
3. PHD Filter
3.1. PHD Based Bayesian Equations
The Bayesian estimator sequentially determines the posterior PDF of the system states at each time step k, where denotes the gathered measurement set sequence up to time step k. The posterior PDF is calculated through the prediction and the correction recursion sequentially. On the assumption that the posterior PDF at time is already known, if the set of measurements which is related to time k has been given, the prediction step and corrected step can be described as in [22]:
The PHD filter is an approximation of the Bayesian estimator described by Equations (17) and (18) [31]. Rather than propagating the FISST PDF , we can only propagate PHD , defined by Equation (3).
The prediction equation of the PHD filter can be represented as follows [21]:
where represents the PHD related to the object birth RFS between step and k. Once the observation dataset for time k is available, the correction equation of the PHD filter can be represented as follows [21]:
where is the PHD related to the clutter RFS at step k. Here, the clutters are characterized by the Poisson RFS. The PHD of the Poisson RFS is ; here, denotes the mean number at step k, and denotes the spatial distribution of clutters in the measurement space.
3.2. SMC based Implementation
Beginning with Sidenbladh [32] and Zajic [33], many researchers have studied how to implement the PHD filter by using the SMC method. By using sequential importance sampling to each terms of Equation (19), the particle approximation of Equation (19) can be obtained. After choosing the importance densities and for spontaneous birth and persisting objects, Equation (19) can be rewritten as
Therefore, we can get the particle approximation of as follows
where
For the correction step of the PHD filter, the predicted PHD can be represented by after prediction step, where . Applying the correction Equation (20), we can get the following particle approximation
where
By updating the weights of the particles in term of Equation (26), the correction step maps the predicted particle system into the corrected particle system .
4. RFS based Parameter Estimation Algorithm
The system states conditioned on , are estimated by using the Bayesian theory. The main task is to obtain an estimate of PDF for each possible value of by running a PHD filter implemented by SMC. By this way, we can evaluate the measurement likelihood , and then we can indirectly obtain a practical solution for .
4.1. Formula Derivation
By employing PHD to approximate Equation (6), we can estimate which depends on RFS based modeling. According to the relationship between the PHD and the RFS based PDF detailed in [22], Equation (6) can be rewritten as the following equation
The advantage of Equation (27) is that the posterior PHD is defined on the standard vector based state space , so the calculation of the RFS based posterior PDF is quite easy.
The observed data likelihood of the accumulated sequence of observation dataset which features in Equations (5) and (27) can be calculated by using the following equation:
Now, the problem is how to calculate the measurement likelihood using the results of PHD filter. The equations and SMC based implementation of the PHD filter for recursively estimating have been introduced in Section 3.1 and Section 3.2. The measurement likelihood , which is defined as in [21], can be calculated as follows
From Equations (28) and (29), we can find the tight relationship between the parameter estimation problem and the state estimation problem. The key challenge is how to deal with the unknown system states. The PHD filter implemented by the SMC method is used to solve this problem. Thus, can be obtained by using PHD filer, and can be calculated as follows:
where is a proportionality constant.
As described in Section 3.2, we can use the weighted particle system to represent the posterior PHD . To estimate the posterior , we should firstly obtain the approximation of given by Equation (30) by running the PHD filter. According to Equation (22), the predicted PHD is approximated by the following particles
Substituting Equation (31) into Equation (30), we can obtain the following result:
Therefore, according to Equation (28), can be calculated as follows:
4.2. Simulated Tempering Based Importance Sampling
We have obtained the estimate of by running the PHD filter, the following step is to compute according to Equation (5). Since the analytic solution for is difficult to compute, we solve Equation (5) by using the simulated tempering based importance sampling method.
Since we are interested in the values of the unknown parameters, we can compute them as the posterior mean by using the following equation:
To avoid doing integral calculus, we propose to approximate Equation (34) via importance sampling. Here, we assume the sample size is M, we draw a sample from the importance density . Thus, the integral in Equation (34) can be approximated by the following equation:
The sample weights are defined as:
According to Equation (36), we find that can be omitted, since it cancels out if we normalize the weights. Thus, for convenience, we assume . The determination of sample weight depends on the selection of importance density . A good selection of importance density should be proportional to the posterior PDF and produce sample weights with a small variance.
Since we can only obtain an estimation of after running the SMC based PHD filter, the selection of the importance density is quite important. If the sample size , the approximation Equation (35) will be quite accurate for many importance densities. However, if M is finite, the approximation accuracy will depend greatly on the specific selection of importance density . As shown in Equation (36), the accuracy of importance sampling by using the prior information is not satisfactory for any possible sample size, since the posterior PDF which is proportional to is unknown. We propose a simulated tempering [2] based importance sampling method to obtain a better importance density which is similar to the posterior PDF .
Here, we use S to represent the maximum stages number and , , represent the proposal density for the s-th stage. The main idea of tempering is to sequentially generate a serious of importance densities from which we can sequentially draw samples. The first importance density usually resembles the prior density , and the final importance density is the posterior PDF . The sequential importance density in the sequence should have very small difference. We obtain at the final stage S . A sequence of importance densities that begin with the prior density and increasingly resemble the posterior PDF can be generated by the following equation, for
where with and at the final stage we have . Thus, increases with the growth of s and its upper bound is 1.
During the tempering process, we should sequentially draw samples from importance densities . At the first stage (), we draw the sample from the prior density . At the s-th stage, we use the sample drawn from at the th stage to obtain a sample from . Firstly, we need to compute weights from particles in by using the equation for . Then, we normalize the weights.
Resampling is quite necessary for tempering, because it can help to remove the particles with lower weights from the sample and improve the diversity of the remaining particles. Thus, the second step is resampling. Resampling means selecting M indices with probability .
After resampling, the particles will almost surely have repeated elements, because the weights will be the most possible to be uneven. Here, the MCMC (Markov Chain Monte Carlo) [34] is employed to the sample that have been resampled. MCMC can help to remove the duplicate particles, thus the diversity of the sample will be increased. For each particle of , a new sample particle can be drawn as follows
where represents the importance density for the s-th stage. The decision of accepting or rejecting with certain probability is made by using the Metropolis–Hastings algorithm. If the MCMC move is accepted, . If the move is rejected, . Thus, we can obtain a new sample . The probability of accepting the MCMC move is determined by the following equation
To diversify the sample, the importance density should generate the candidate particles over a fairly large area of the parameter space. We should ensure that is still within the area where the likelihood is high. We can select the importance density by the following method as introduced in [35]:
where denotes a Gaussian distribution; and are respectively the mean and covariance matrix of the weighted particles .
The pseudo-code of the proposed parameter estimation algorithm is shown in Algorithm 1. Here, and are parameters that should be defined by users.
| Algorithm 1: Random Finite Set based Parameter Estimation Algorithm |
 |
5. Experiments
In this section, we verify the correctness and validity of the proposed algorithm by using an example of multiple sensors. Estimating the systematic errors of multiple sensors is important for sensor registration in cooperative networked surveillance [36]. In this example, we estimate the systematic errors of two sensors. The advantages of the proposed algorithm introduced in Section 1.3 are all successfully proved. In order to ensure that those who are interested in the experiments can conduct these experiments smoothly, we also provide the source codes as the supplementary materials.
5.1. Experimental Models
Here, we use the measurements given by R (here ) static sensors to estimate the systematic errors of these sensors. Here, we denote the observation dataset reported by sensor at time k by . To verify the first advantage introduced in Section 1.3, we use the detection probability to characterize the detection uncertainty, and missed detection. The sensor observations are affected by the systematic errors and the measurement noises. The clutters are characterized by using Poisson RFS. We assume that the observations provided by the sensors are the azimuth and range to the objects in the surveillance system. For an observation which is related to the object with state , the measurement likelihood of the r-th sensor is modeled as:
where is the measurement function of the r-th sensor, and its specific form is as follows:
where is the position of the r-th sensor. The unknown parameter vector consists of four parameters as follows:
where , which appears in Equation (41), denotes the systematic error vector for the r-th sensor (), is the azimuth systematic error and is the range systematic error. is the covariance matrix in (41). denotes the detection probability of the r-th sensor.
To verify the second advantage of the proposed algorithm introduced in Section 1.3, the targeted system surveilled by the sensors consists of a varying number of objects. We use the probability of survival to characterize the uncertainty of target existence. The state of each individual object is described by the vector , here denotes the position of the object and denotes the velocity.
The state of each object in the surveillance system evolves according to the Markov transitional density in time, and it is independent of the unknown parameters . Here, we use the following motion model:
where
and ⊗ is the Kroneker product, denotes the time interval of the sensors, and denotes the intensity of process noises.
5.2. Experimental Setup
The typical observation dataset sequence , the real states of the multiple objects and the location of the sensors in the experiment are shown in Figure 1. The number of observation datasets used for estimating parameter is . The number of component objects is varying in the experiment, with for ; for ; for ; and for . The two sensors in the experiment work asynchronously: Sensor 1 provides observation datasets at odd time steps, and Sensor 2 provides observation datasets at even time steps. s is the time interval between k and . The location of two sensors are = (0 km, 0 km) and = (200 km, 100 km). The probability of detection is , the expected numbers of Poisson clutters for two sensors are: , while are uniform distribution over [0 km, 1000 km]. The standard deviation of observation noises is 1 km and . The true systematic errors are , 10 km, , km.
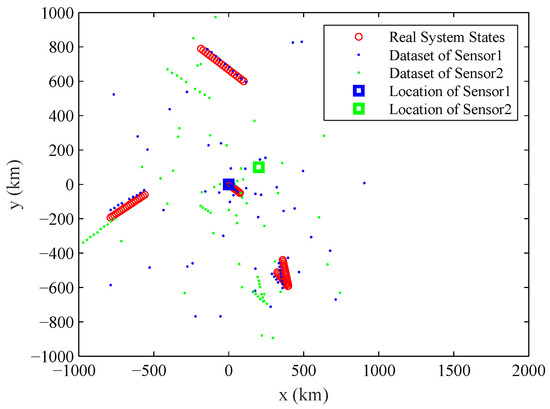
Figure 1.
The location of sensors (marked by square), the real states of the studied system which contains multiple objects and the accumulated observation dataset for two sensors.
The SMC based implementation of PHD filter uses particles per newborn object and persistent object. The probability of object survival is . The expected number of object birth is 0.03. The prior distribution is a uniform distribution over . The sample number in the systematic errors space is . The parameters used in adaptively choosing are: and . We set the maximum number of stages by .
5.3. Experimental Results
The estimated systematic errors for the sensors are given in Figure 2. Figure 2 is the histogram with a distribution fit of the resulted sample . Figure 2a–d marginalizes the posterior PDF approximated by the resulted samples to one dimension and obtain the estimated azimuth systematic error and range systematic error for the sensors. The solid lines in each figure are the kernel density estimate (KDE) of the marginal posterior PDF. The vertical dashed lines in each figure are the true values of the sensors’ systematic errors. Since we have obtained the KDE, we use the maximum a posterior (MAP) method to estimate the sensors’ systematic errors. The estimation results are shown in Table 1.
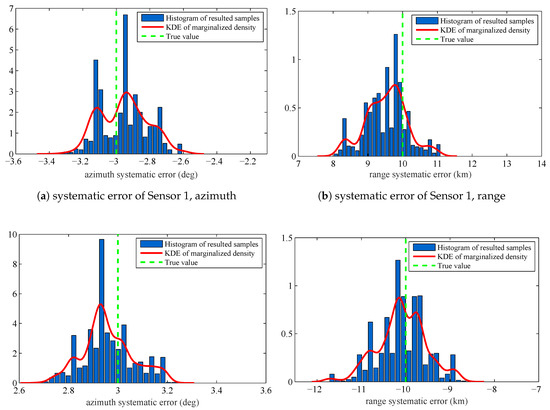
Figure 2.
Histograms with distribution fit of the systematic error sample that are marginalized to : (a) systematic error of Sensor 1, azimuth, ; (b) systematic error of Sensor 1, range, ; (c) systematic error of Sensor 2, azimuth, ; and (d) systematic error of Sensor 2, range.

Table 1.
True and estimated sensors’ systematic errors.
In Figure 2 and Table 1, we can know that the proposed RFS based parameter estimation algorithm can provide the accurate estimated parameters by using the RFS based measurement model and the measurements set that consists of noises, false detections, and missed detections. This is consistent with the first advantage introduced in Section 1.3. Moreover, the proposed algorithm gives the accurate estimated parameters for the stochastic system in which the number of constituent objects (targets) is varying over time. This is consistent with the second advantage introduced in Section 1.3. The obtained experimental results show an outstanding accuracy of the proposed algorithm, although the size of dataset is only 20 scans.
To quantitatively assess the convergence of the algorithm, we adopt the convergence diagnostic named as the estimated potential scale reduction (EPSR). The definition of EPSR is given in [37,38]. The resulted sequence of correction factors and the EPSR at each stage are listed in Table 2. From this table, we can know that the simulated tempering process works effectively. As the stage number increases, the correction factors of each stage increase, and EPSR at each stage decreases, which means that the resulted sample in the simulated tempering process increasingly concentrates in the area of the parameter space characterized by the true likelihood.
Table 2.
Correction factors and EPSR during simulated tempering.
The estimates (the mean of all the particles at each stage) over the simulated tempering stages obtained by running the proposed algorithm are shown in Figure 3. The black solid lines are the true range and azimuth systematic errors of the sensors. The red circles are the sample mean at different tempering stages. From this figure, we can see that, after the fourth stage, the estimation results are very close to the real systematic errors. Since is still less than 1, the estimation process will continue until reaching the maximum stage number .
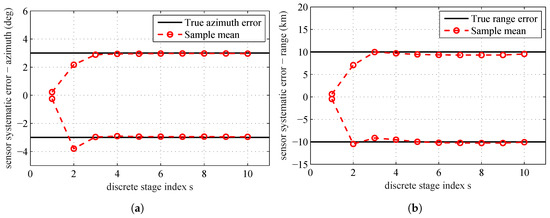
Figure 3.
True sensors’ systematic errors and sample mean for all stages: (a) sensors’ systematic errors–azimuth; and (b) sensors’ systematic errors–range.
The SMC approximation of the posterior PDF of the sensors’ systematic errors according to Equation (35) at the first stage, fifth stage and tenth stage are shown in Figure 4. The true systematic errors for sensors are represented by black circles. In Figure 4, we can see that, as the simulated tempering process evolves, the particles gradually concentrate on the real systematic errors of the sensors.
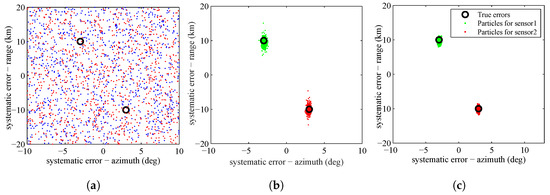
Figure 4.
Particle approximation of the posterior PDF of the systematic errors of the sensors at: (a); (b); and (c).
5.4. System States and Object Number Estimation
As given in Section 1.3, the third advantage of the proposed algorithm is that it can provide the estimate of the system states and the number of targets. Figure 5a gives the real target number contained in the system and the estimated one. Figure 5b gives the real and estimated system states at all the sampling time. From this figure, we can find that the proposed algorithm can accurately estimate the varying number of targets and system states at the final stage by using the estimated systematic errors of sensors.
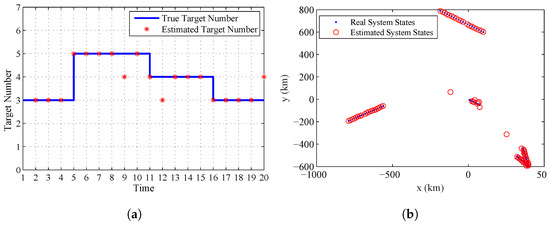
Figure 5.
The estimated target number and system states given by the proposed algorithm: (a) the real and estimated target number; and (b) the real and estimated system states.
5.5. Comparison with Metropolis Hastings Algorithm
There are many probability distributions from which it is impossible to sample directly. The Metropolis Hastings (MH) algorithm is a typical MCMC algorithm that can generate a sequence of random samples from these distributions. Since it is the most widely used method in statistics and in statist physics, we verify the superiority of the proposed algorithm by comparing with MH algorithm. Figure 6 displays the histogram of the resulted samples given by using MH algorithm with the identical experimental setup. From this figure, we can find that the resulted samples given by MH algorithm are more decentralized than the proposed algorithm. The estimated results are shown in Table 3. We can find that the proposed algorithm are more accurate than MH algorithm.
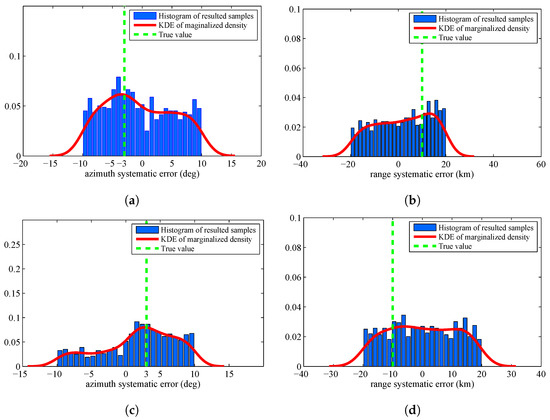
Figure 6.
Histograms with distribution fit of the systematic error sample by using Metropolis Hastings algorithm: (a) systematic error of Sensor 1, azimuth; (b) systematic error of Sensor 1, range; (c) systematic error of Sensor 2, azimuth; and (d) systematic error of Sensor 2, range.
Table 3.
True and estimated sensors’ systematic errors by using two algorithms.
To compare the accuracy of the importance sampling process, we adapt the evaluation criteria named as autocorrelation function (ACF) [39,40]. According to the fundamentals of MCMC, the samples generated by using MCMC are auto-correlated. Compared with the independent samples, the information content of the samples is relatively reduced. The sample based ACF at lag k of a set of samples is defined as follows:
where is the Monte Carlo estimate, and is a sample. From the definition, we can see that, if the ACF dies off to 0 more rapidly, it indicates that the samples are less auto-correlated and more accurate. Figure 7 displays the ACF of the proposed algorithm and MH algorithm. From this figure, we can find that the ACF of the proposed algorithm dies off to 0 more rapidly than the MH algorithm. Thus, the accuracy of the prosed algorithm is much higher.
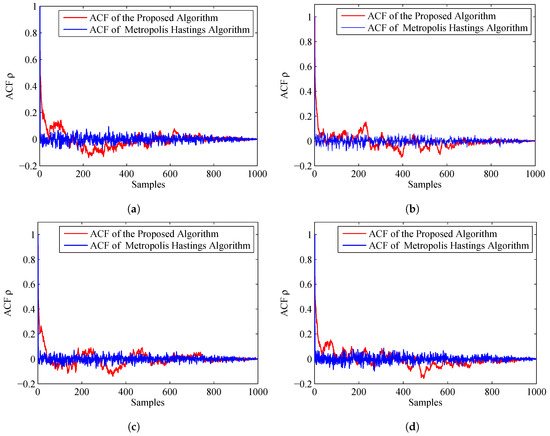
Figure 7.
ACF of the proposed algorithm and MH algorithm: (a) ACF for Sensor 1, azimuth; (b) ACF for Sensor 1, range; (c) ACF for Sensor 2, azimuth; and (d) ACF for Sensor 2, range.
The former experiments assume that the prior is a uniform distribution. To verify the superiority of the proposed algorithm in a more general case, we assume the prior is a Gaussian distribution with mean value and covariance diag . Figure 8 displays the histogram of the resulted samples by using the proposed algorithm. We can find that the resulted KDE densities have deviation by comparing with the former experiment. This is caused by the inaccurate prior distribution. Figure 9 displays the histogram of the resulted samples given by HM algorithm. From this figure, we can find that the resulted samples are still very decentralized and the distribution of samples is heavily depending on the prior distribution.
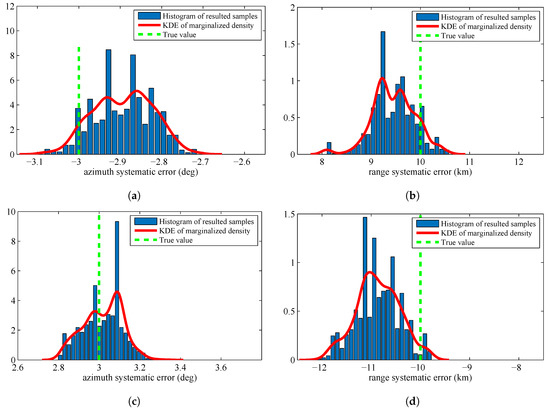
Figure 8.
Histograms with distribution fit of the sample by using the proposed algorithm when the prior is Gaussian distribution: (a) systematic error of Sensor 1, azimuth; (b) systematic error of Sensor 1, range; (c) systematic error of Sensor 2, azimuth; and (d) systematic error of Sensor 2, range.
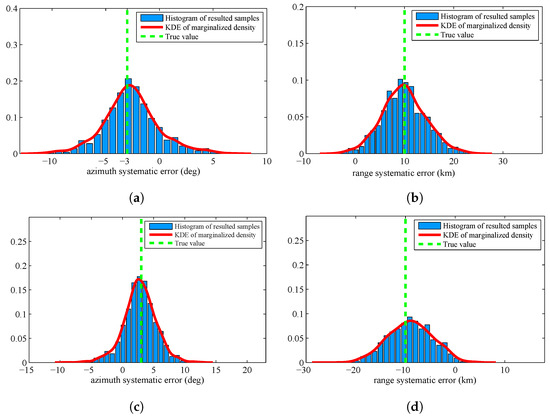
Figure 9.
Histograms with distribution fit of the sample by using MH algorithm when the prior is Gaussian distribution: (a) systematic error of Sensor 1, azimuth; (b) systematic error of Sensor 1, range; (c) systematic error of Sensor 2, azimuth; and (d) systematic error of Sensor 2, range.
The estimated results of the two algorithms are given in Table 4. We can find that the accuracy of the proposed algorithm deteriorates slightly, but it is still better than the results of MH algorithm.
Table 4.
True and estimated sensors’ systematic errors for Gaussian distribution.
The ACF of the two algorithms is given in Figure 10. We can find that the ACF of the proposed algorithm dies off to 0 more slowly than the former experiment, but still more rapidly than the MH algorithm. Thus, the accuracy of the estimated results of the proposed algorithm is a little better than the MH algorithm.
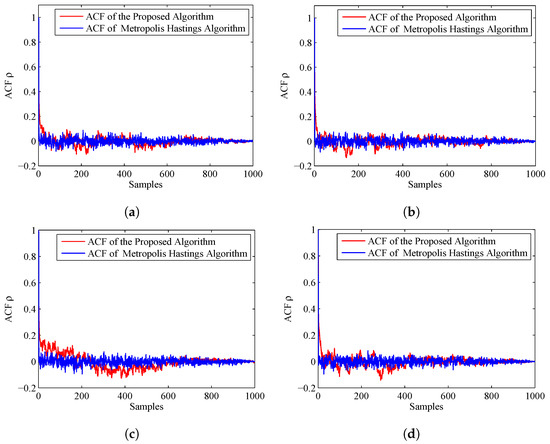
Figure 10.
ACF of the proposed algorithm and MH algorithm when the prior is Gaussian distribution: (a) ACF for Sensor 1, azimuth; (b) ACF for Sensor 1, range; (c) ACF for Sensor 2, azimuth; and (d) ACF for Sensor 2, range.
5.6. Sensitivity Analysis
In this section, we analyze the sensitivity of the proposed algorithm to a number of important parameters, such as the particle number N for PHD filter, the sample number M in parameter space as well as the parameter related to the simulated tempering process.
5.6.1. Particle Number N
The PHD filter can provide the estimation of the likelihood . Hence, the accuracy of the proposed parameter estimation algorithm may depend on the particle number N used by the SMC based PHD filter. The influence of the particle number N on the parameter estimation is presented in Figure 11. The estimated systematic errors at the 10th stage for different particle number N by using MAP are given in Table 5.
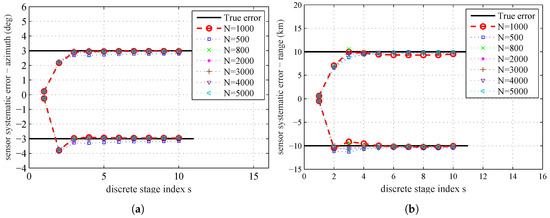
Figure 11.
The sample mean for different particle number N used by PHD filter: (a) sensors’ systematic errors–azimuth; and (b) sensors’ systematic errors–range
Table 5.
Estimated systematic errors at stage s = 10 for different particle number N.
In Figure 11 and Table 5, we can find that the estimation error has a decreasing tendency as N increases. With more particles, PHD filter can give more accurate likelihood , and thus leads to a better coverage of the parameter space. The plot shows that the decreasing tendency in estimation errors by increasing N is not proportional, and when N increases to a certain degree, the improvement of estimation accuracy is very small. The result shows that, if N increases to a certain degree, it will not significantly affect the parameter estimation results. As the accuracy of the estimation results is restricted by the quality of the model and data used in the parameter estimation process, the estimation results without any errors by continuously increasing N is impossible. The computational complexity will also be increased as N increases. Therefore, we should achieve a balance between computational complexity and estimation accuracy.
Figure 12 shows the ACF by using different values of N. For the convenience of analysis, we give the ACF of the first 150 samples. From this figure, we can find that, if N is larger, the corresponding ACF will die off to 0 more rapidly, so the accuracy is higher.
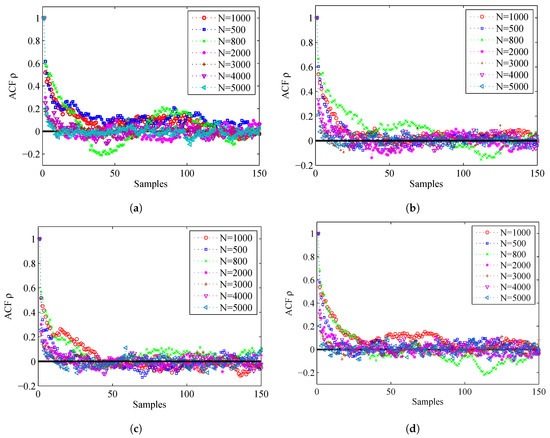
Figure 12.
ACF for different particle number N: (a) ACF for Sensor 1, azimuth; (b) ACF for Sensor 1, range; (c) ACF for Sensor 2, azimuth; and (d) ACF for Sensor 2, range.
Table 6 shows the EPSR at all the stages for different particle number N used by the PHD filter. From this table, we can find that, as the number of stage increases, the EPSR of each stage decreases. This means that as the simulated tempering process progresses, the sample increasingly concentrates in the area of the parameter space characterized by the true likelihood. The increase of the particle number N seams to have no influence on the convergence of the proposed algorithm.
Table 6.
EPSR for different particle number N.
5.6.2. Sample Number M
The sample number M in the parameter space may also have influence on the accuracy of parameter estimation. The influence of the sample number M on the parameter estimation result is summarized in Figure 13. Table 7 is the MAP estimate at the 10th stage for different M. From the plot, we can find that the decreasing tendency in estimation errors by increasing M is quite similar to the result caused by increasing N. If M increases to a certain degree, the improvement of estimation accuracy is very small. There also needs a balance between computational complexity and estimation accuracy.
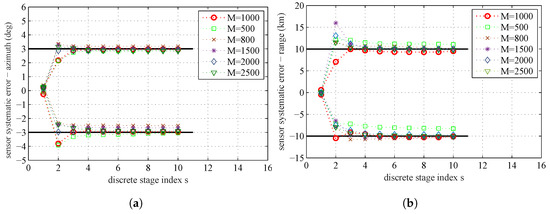
Figure 13.
The sample mean for different sample number M in the parameter space: (a) sensors’ systematic errors–azimuth; and (b) sensors’ systematic errors–range.
Table 7.
Estimated systematic errors at stage for different sample numbers M.
The EPSR of different sample size M is given in Table 8. From this table, we can find that the increase of M will result in the increase of EPSR, which means that the convergence of the proposed algorithm will be increased.
Table 8.
EPSR of different sample size M.
5.6.3. Simulated Tempering Parameter
By setting the maximum stage number to be , the influence of the parameter on the parameter estimation results is presented in Figure 14 and Figure 15. In Figure 14, we can find that a smaller will need more stages and get more accurate estimation result. If is bigger than a certain degree, the number of stages will be very small, and the estimation errors will be bigger. In Figure 15b, we can find that, if a lower value of parameter is used, the MCMC acceptance rate will be increased. In Figure 15a, we can find that, if a lower value of parameter is used, the number of stages S will be increased, because the increments of correction factors become smaller.
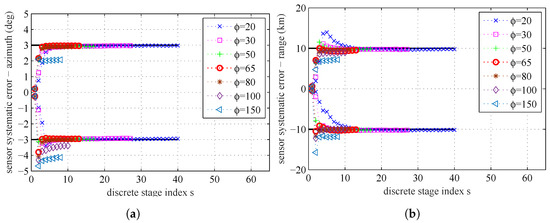
Figure 14.
The sample mean for different : (a) sensors’ systematic errors, azimuth; and (b) sensors’ systematic errors, range.
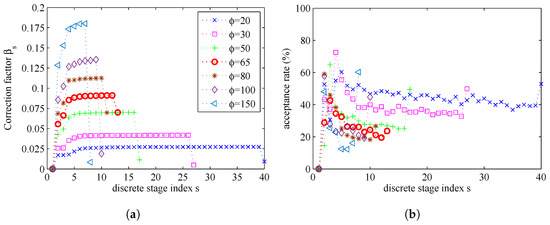
Figure 15.
The relationship between correction factors, acceptance rates and : (a) correction factors; and (b) acceptance rates.
The computational complexity of simulated tempering based importance sampling is determined by the number of stages S and the correction factors . To reduce the computational complexity, we tend to use a small value of S. However, at the same time, if we choose a small S, the sequential intermediate distribution will vary rapidly. There is a balance between the number of stages (related to the computational complexity) and the estimation accuracy.
We give the estimated systematic errors at the final stage for different in Table 9. It seems that, if decreases, the stage number will increase and the estimated results will be more accurate.
Table 9.
Estimated systematic errors at the final stage for different .
6. Conclusions
We have presented the proposed RFS based parameter estimation algorithm to overcome some disadvantages of the vector based Bayesian algorithms. We also detail how to implement this algorithm by using the SMC based PHD filter and simulated tempering based importance sampling. By applying the SMC based PHD filter, the proposed algorithm successfully extends the application of parameter estimation from the single object system to the stochastic system which consists of a varying number of constituent objects. Without any assumptions under ideal conditions, it can fit the dynamic nature of the studied system and the detection uncertainty of the measurement system very well. It can be successfully used for identification of the stochastic systems which consist of a varying number of constituent objects. It can also be used for parameter estimation problem where the observation dataset is affected by false detections, missed detections and noises.
Supplementary Materials
The supplementary files are the source codes for the experiments of this paper. The related experimental results are also given. The files are available online at http://www.mdpi.com/1099-4300/20/8/569/s1.
Author Contributions
P.W. conceived, designed and performed the simulations and wrote the manuscript. Y.P. provided the basic ideas and analyzed the experimental results. G.L. and R.J. reviewed the manuscript.
Funding
The authors are funded by National Natural Science Foundation of China, grant number [No. 61374185].
Acknowledgments
The authors have received patient guidance and great assistance from Professor Kedi Huang. The authors have also obtained the enthusiastic help in English writing from Dongling Liu.
Conflicts of Interest
The authors declare no conflict of interest. The founding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
Abbreviations
| FISST | Finite Set Statistics |
| KDE | Kernel Density Estimate |
| MCMC | Markov Chain Monte Carlo |
| ML | Maximum Likelihood |
| Probability Density Function | |
| PF | Particle Filter |
| PHD | Probability Hypothesis Density |
| RFS | Random Finite Set |
| SMC | Sequential Monte Carlo |
References
- Osman, B.; George, L.B.; Katherine, L.M.; Ernest, P. Model, Reuse, Composition, and Adaptation. In Research Challenges in Modeling and Simulation for Engineering Complex Systems; Fujimoto, R., Bock, C., Chen, W., Page, E., Panchal, J.H., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 87–115. [Google Scholar]
- Gupta, S.; Hainsworth, L.; Hogg, J.; Lee, R.; Faeder, J. Evaluation of Parallel Tempering to Accelerate Bayesian Parameter Estimation in Systems Biology. In Proceedings of the 26th Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, Cambridge, UK, 21–23 March 2018; pp. 690–697. [Google Scholar] [CrossRef]
- Sima, S.; Mort, N.-P. Online Detection and Parameter Estimation with Correlated Data in Wireless Sensor Networks. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Jordehi, A.R. Parameter estimation of solar photovoltaic (PV) cells: A review. Renew. Sustain. Energy Rev. 2016, 61, 354–371. [Google Scholar] [CrossRef]
- Ljung, L.; Oderstrom, S. Theory and Practice of Recursive Identification. IEEE Trans. Autom. Control 1983, 30, 1054–1056. [Google Scholar] [CrossRef]
- Ljung, L. Convergence analysis of parametric identification methods. IEEE Trans. Autom. Control 1978, 23, 770–783. [Google Scholar] [CrossRef]
- Yi, L.H.; Yuan, K.W. Review on model validation and parameter estimation approaches of wind power generators. In Proceedings of the 6th International Conference on Renewable Power Generation (RPG), Wuhan, China, 19–20 October 2017; Volume 13, pp. 2407–2411. [Google Scholar] [CrossRef]
- Ljung, L. Perspectives on system identification. Ann. Rev. Control 2008, 34, 1–12. [Google Scholar] [CrossRef]
- Rushikesh, K. Simultaneous State and Parameter Estimation for Second-Order Nonlinear Systems. In Proceedings of the 2017 IEEE 56th Annual Conference on Decision and Control (CDC), Melbourne, VIC, Australia, 12–15 December 2017; pp. 2164–2169. [Google Scholar] [CrossRef]
- Ding, F.; Chen, T. Hierarchical least squares identification methods for multivariable systems. IEEE Trans. Autom. Control 2005, 50, 242. [Google Scholar] [CrossRef]
- Schon, T.B.; Lindsten, F.; Dahlin, J. Sequential Monte Carlo Methods for System Identification. IFAC PapersOnLine 2015, 775–786. [Google Scholar] [CrossRef]
- Poyiadjis, G.; Doucet, A.; Singh, S.S. Particle approximations of the score and observed information matrix in state space models with application to parameter estimation. Biometrika 2011, 98, 65–80. [Google Scholar] [CrossRef]
- Kantas, N.; Doucet, A.; Singh, S.S.; Maciejowski, J.M. An overview of sequential Monte Carlo methods for parameter estimation in general state-space models. IFAC Proc. Vol. 2009, 42, 774–785. [Google Scholar] [CrossRef]
- Dan, C.; Joaquin, M. Nested particle filters for online parameter estimation in discrete-time state-space Markov models. Bernoulli 2018, 24, 3039–3086. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, X.; Lin, X.; Gu, Y. Maximum likelihood estimation from sign measurements with sensing matrix perturbation. IEEE Trans. Signal Process. 2014, 62, 3741–3753. [Google Scholar] [CrossRef]
- Ljung, L. System Identification, Theory for the User, 2nd ed.; System Sciences Series; Prentice Hall: Upper Saddle River, NJ, USA, 1999; ISBN 0-138-81640-9. [Google Scholar]
- Doucet, A.; Tadic, V.B. Parameter estimation in general state-space models using particle methods (Special section on New trends in statistical information processing). Ann. Ins. Stat. Math. 2003, 55, 409–422. [Google Scholar] [CrossRef]
- Kantas, N.; Doucet, A.; Singh, S.S.; Maciejowski, J.; Chopin, N. On particle methods for parameter estimation in state-space models. Stat. Sci. 2015, 30, 328–351. [Google Scholar] [CrossRef]
- Li, M.; Jing, Z.; Pan, H.; Dong, P. Joint registration and multi-target tracking based on labelled random finite set and expectation maximisation. IET Radar Sonar Navig. 2017, 12, 312–322. [Google Scholar] [CrossRef]
- Xu, J.; Yao, A.L. Random Set Theory. Lecture Notes Econ. Math. Syst. 2011, 647, 1–33. [Google Scholar] [CrossRef]
- Mahler, R.P.S. Multitarget Bayes filtering via first-order multitarget moments. IEEE Trans. Aeros. Electron. Syst. 2004, 39, 1152–1178. [Google Scholar] [CrossRef]
- Mahler, R.P.S. Statistical Multisource-Multitarget Information Fusion; Artech House, Inc.: Norwood, MA, USA, 2007; ISBN 1596930926. [Google Scholar]
- Barbieri, F.; Rifflart, C.; Vo, B.T.; Rajakaruna, S.; Ghosh, A. Intra-Hour Cloud Tracking Based on Probability Hypothesis Density Filtering. IEEE Trans. Sustain. Energy 2018, 9, 340–349. [Google Scholar] [CrossRef]
- Evers, C.; Naylor, P.A. Optimized Self-Localization for SLAM in Dynamic Scenes using Probability Hypothesis Density Filters. IEEE Trans. Signal Proc. 2018, 66, 863–878. [Google Scholar] [CrossRef]
- Enzo, M.; Giorgio, P. Simulated tempering: A new Monte Carlo scheme. Europhys. Lett. 1992, 19, 451–458. [Google Scholar] [CrossRef]
- Marcos, C.; Scotland, L. Weighted particle tempering. Comput. Stat. Data Anal. 2017, 114, 26–37. [Google Scholar] [CrossRef]
- Graham, M.M. Auxiliary Variable Markov Chain Monte Carlo Methods, Ph.D. Dissertation, University of Edinburgh, Edinburgh, Scotland, 2018. [Google Scholar]
- Cappe, O.; Godsill, S.J.; Moulines, E. An Overview of Existing Methods and Recent Advances in Sequential Monte Carlo. Proc. IEEE 2007, 95, 899–924. [Google Scholar] [CrossRef]
- Wang, P.; Li, G.; Ju, R.; Peng, Y. Random Finite Set Based Data Assimilation for Dynamic Data Driven Simulation of Maritime Pirate Activity. Math. Prob. Eng. 2017, 2017. [Google Scholar] [CrossRef]
- Goodman, I.R.; Mahler, R.P.; Nguyen, H.T. Mathematics of Data Fusion; Springer: Berlin/Heidelberg, Germany, 1997; ISBN 9048148871. [Google Scholar]
- Li, C.; Wang, W.; Kirubarajan, T.; Sun, J.; Lei, P. PHD and CPHD Filtering with Unknown Detection Probability. IIEEE Trans. Signal Proc. 2018, 66, 3784–3798. [Google Scholar] [CrossRef]
- Sidenbladh, H. Multi-target particle filtering for the probability hypothesis density. In Proceedings of the Sixth International Conference of IEEE Information Fusion, Queensland, Australia, 8–11 July 2003; pp. 800–806. [Google Scholar] [CrossRef]
- Zajic, T.; Mahler, R. Particle-systems implementation of the PHD multitarget tracking filter. In Proceedings of the SPIE—The International Society for Optical Engineering, Orlando, FL, USA, 25 August 2003; Volume 5096, pp. 291–299. [Google Scholar] [CrossRef]
- Baig, F.; Faiz, M.A.; Khan, Z.M.; Shoaib, M. Utilization of Markov chain Monte Carlo approach for calibration and uncertainty analysis of environmental models. In Proceedings of the 2018 International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 3–4 March 2018. [Google Scholar] [CrossRef]
- Morelande, M.R.; Ristic, B. Radiological Source Detection and Localisation Using Bayesian Techniques. IEEE Trans. Signal Proc. 2009, 57, 4220–4231. [Google Scholar] [CrossRef]
- Fisher, J.W.; Moses, R.L.; Willsky, A.S. Nonparametric belief propagation for self-calibration in sensor networks. IEEE J. Sel. Areas Commun. 2005, 23, 809–819. [Google Scholar] [CrossRef]
- Gonzalez, M.; Martín, J.; Martínez, R.; Mota, M. Non-parametric Bayesian estimation for multitype branching processes through simulation-based methods. Comput. Stat. Data Anal. 2008, 52, 1281–1291. [Google Scholar] [CrossRef]
- Kevin, P.M. Machine Learning A Probabilistic Perspective; The MIT Press: London, UK, 2012; pp. 837–874. ISBN 9780262018029. [Google Scholar]
- Neusser, K. Estimation of the Mean and the Autocorrelation Function; Time Series Econometrics; Springer: Berlin/Heidelberg, Germany, 2016; ISBN 3319328611. [Google Scholar]
- Bykhovsky, D.; Trigano, T. Numerical Generation of Compound Random Processes with an Arbitrary Autocorrelation Function. Fluct. Noise Lett. 2018, 17, 1850001. [Google Scholar] [CrossRef]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).