1. Introduction
The estimation of a phase shift using interferometric techniques is at the core of metrology and sensing [
1,
2,
3]. Applications range from the definition of the standard of time [
4] to the detection of gravitational waves [
5,
6]. The general problem can be concisely stated as the search for optimal strategies to minimize the phase estimation uncertainty. The noise that limits the achievable phase sensitivity can have a “classical” or a “quantum” nature. Classical noise originates from the coupling of the interferometer with some external source of disturbance, like seismic vibrations, parasitic magnetic fields or from incoherent interactions within the interferometer. Such noise can, in principle, be arbitrarily reduced, e.g., by shielding the interferometer from external noise or by tuning interaction parameters to ensure a fully coherent time evolution. The second source of uncertainty has an irreducible quantum origin [
7,
8]. Quantum noise cannot be fully suppressed, even in the idealized case of the creation and manipulation of pure quantum states. Using classically-correlated probe states, it is possible to reach the so-called shot noise or standard quantum limit, which is the limiting factor for the current generation of interferometers and sensors [
9,
10,
11,
12]. Strategies involving probe states characterized by squeezed quadratures [
13] or entanglement between particles [
14,
15,
16,
17,
18,
19] are able to overcome the shot noise, the ultimate quantum bound being the so-called Heisenberg limit. Quantum noise reduction in phase estimation has been demonstrated in several proof-of-principle experiments with atoms and photons [
20,
21].
There is a vast amount of literature dealing with the parameter estimation problem that has been mostly developed following two different approaches [
22,
23,
24]: frequentist and Bayesian. Both approaches have been investigated in the context of quantum phase estimation [
18,
20,
25,
26,
27,
28,
29,
30,
31] and implemented/tested experimentally [
32,
33,
34,
35,
36]. They build on conceptually different meanings attached to the word “probability” and their respective results provide conceptually different information on the estimated parameters and their uncertainties.
In the limit of a large number of repeated measurements, the sensitivity reached by the frequentist and Bayesian methods generally agree: this fact has very often induced the belief that the two paradigms can be interchangeably used in the phase estimation theory without acknowledging their irreconcilable nature. Overlooking these differences is not only conceptually inconsistent but can even create paradoxes, as, for instance, the existence of ultimate bounds in sensitivity proven in one paradigm that can be violated in the other.
In this manuscript, we directly compare the frequentist and the Bayesian parameter estimation theory. We study different sensitivity bounds obtained in the two frameworks and highlight the conceptual differences between the two. Besides the asymptotic regime of many repeated measurements, we also study bounds that are relevant for small samples. In particular, we show that the Bayesian variance can overcome the frequentist Cramér–Rao bound. The Cramér–Rao bound is a mathematical theorem providing the highest possible sensitivity in a phase estimation problem. The fact that the Bayesian sensitivity can be higher than the Cramér–Rao bound is therefore paradoxical. The paradox is solved by clarifying the conceptual differences between the frequentist and the Bayesian approaches, which therefore cannot be directly compared. Such difference should be considered when discussing theoretical and experimental figures of merit in interferometric phase estimation.
Our results are illustrated with a simple test model [
37,
38]. We consider
N qubits with basis states
and
, initially prepared in a (generalized) GHZ state
, with all particles being either in
or in
. The phase-encoding is a rotation of each qubit in the Bloch sphere
and
, which transforms the
state into
. The phase is estimated by measuring the parity
, where
is the number of particles in the state
[
37,
39,
40,
41]. The parity measurement has two possible results
that are conditioned by the “true value of the phase shift”
with probability
. The probability to observe the sequence of results
in
m independent repetitions of the experiment (with same probe state and phase encoding transformation) is
where
is the number of the observed results
, respectively. Notice that
is the conditional probability for the measurement outcome
, given that the true value of the phase shift is
(which we consider to be unknown in the estimation protocol). Equation (
1) provides the probability that will be used in the following sections for the case
and
.
Section 2 and
Section 3 deal with the case where
has a fixed value and in
Section 4 we discuss precision bounds for a fluctuating phase shift.
2. Frequentist Approach
In the frequentist paradigm, the phase (assumed having a fixed but unknown value ) is estimated via an arbitrarily chosen function of the measurement results, , called the estimator. Typically, is chosen by maximizing the likelihood of the observed data (see below). The estimator, being a function of random outcomes, is itself a random variable. It is characterized by a statistical distribution that has an objective, measurable character. The relative frequency with which the event occurs converges to a probability asymptotically with the number of repeated experimental trials.
2.1. Frequentist Risk Functions
Statistical fluctuations of the data reflect the
statistical uncertainty of the estimation. This is quantified by the variance,
around the mean value
, the sum extending over all possible measurement sequences (for fixed
and
m). An important class is that of
locally unbiased estimators, namely those satisfying
and
(see, for instance, [
42]). An estimator is unbiased if and only if it is locally unbiased at every
.
The quality of the estimator can also be quantified by the mean square error (MSE) [
23]
giving the deviation of
from the true value of the phase shift
. It is related to Equation (
2) by the relation
In the frequentist approach, often the variance is not considered as a proper way to quantify the goodness of an estimator. For instance, an estimator that always gives the same value independently of the measurement outcomes is strongly biased: it has zero variance but a large MSE that does not scale with the number of repeated measurements. Notice that the MSE cannot be accessed from the experimentally available data since the true value
is unknown. In this sense, only the fluctuations of
around its mean value, i.e., the variance
, have experimental relevance. For unbiased estimators, Equations (
2) and (
4) coincide. In general, since the bias term in Equation (
4) is never negative,
and any lower bound on
automatically provides a lower bound on
but not vice versa. In the following section, we therefore limit our attention to bounds on
. The distinction between the two quantities becomes more important in the case of a fluctuating phase shift
, where the bias can affect the corresponding bounds in different ways. We will see this explicitly in
Section 4.
2.2. Frequentist Bounds on Phase Sensitivity
2.2.1. Barankin Bound
The Barankin bound (BB) provides the tightest lower bound to the variance (
2) [
43]. It can be proven to be always (for any
m) saturable, in principle, by a specific local (i.e., dependent of
) estimator and measurement observable. Of course, since the estimator that saturates the BB depends on the true value of the parameter (which is unknown), the bound is of not much use in practice. Nevertheless, the BB plays a central role, from the theoretical point of view, as it provides a hierarchy of weaker bounds which can be used in practice with estimators that are asymptotically unbiased. The BB can be written as [
44]
where
is generally indicated as likelihood ratio and the supremum is taken over
n parameters
, which are arbitrary real numbers, and
, which are arbitrary phase values in the parameter domain. For unbiased estimators, we can replace
for all
i and the BB becomes independent of the estimator:
A derivation of the BB is presented in
Appendix A.
The explicit calculation of
is impractical in most applications due to the number of free variables that must be optimized. However, the BB provides a strict hierarchy of bounds of increasing complexity that can be of great practical importance. Restricting the number of variables in the optimization can provide local lower bounds that are much simpler to determine at the expense of not being saturable in general, namely, for an arbitrary number of measurements. Below, we demonstrate the following hierarchy of bounds:
where
is the Cramér–Rao lower bound (CRLB) [
45,
46] and
is the Hammersley–Chapman–Robbins bound (ChRB) [
47,
48]. We will also introduce a novel extended version of the ChRB, indicated as
.
2.2.2. Cramér–Rao Lower Bound and Maximum Likelihood Estimator
The CRLB is the most common frequentist bound in parameter estimation. It is given by [
45,
46]:
The inequality
is obtained by differentiating
with respect to
and using a Cauchy–Schwarz inequality:
where we have used
and
valid for
m independent measurements, and
is the Fisher information. The equality
is achieved if and only if
with
a parameter independent of
(while it may depend on
). Noticing that
, the CRLB can be straightforwardly generalized to any function
independent of
. In particular, choosing
, we can directly prove that
, which also depends on the bias.
Asymptotically in
m, the saturation of Equation (
8) is obtained for the maximum likelihood estimator (MLE) [
22,
23,
49]. This is the value
that maximizes the likelihood
(as a function of the parameter
) for the observed measurement sequence
,
For a sufficiently large sample size
m (in the central limit), independently of the probability distribution
, the MLE becomes normally distributed [
18,
22,
23,
49]:
with mean given by the true value
and variance equal to the inverse of the Fisher information. The MLE is well defined provided that there is a unique maximum in the considered phase interval. In the case of Equation (
1), this condition is fulfilled provided that one restrict the phase domain to
for instance.
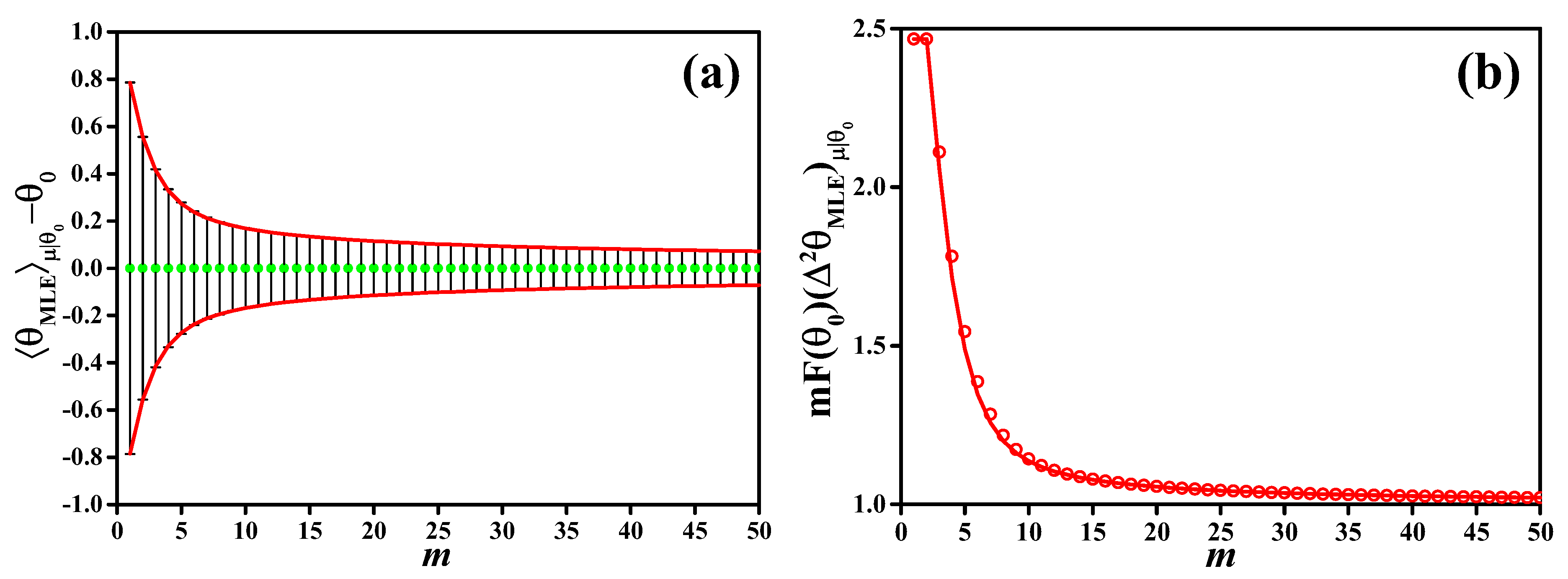
In
Figure 1, we plot the results of a maximum likelihood analysis for the example considered in this manuscript. In this case, the MLE is readily calculated and given by
, and the Fisher information is
, independent of
(we recall that
in our example). In
Figure 1a we plot the bias
(dots) as a function of
m, for
. Error bars are
. Notice that
for every
m. This does not mean that the estimator is locally unbiased: indeed, the derivative
[see panel (b)] is different from 1 for every value of
m. We have
asymptotically in
m. In
Figure 1b, we plot
as a function of the number of independent measurements
m (red dots). This quantity is compared to
(red line). With increasing sample size
m,
corresponding to the CRLB for unbiased estimators.
2.2.3. Hammersley–Chapman–Robbins Bound
The ChRB is obtained from Equation (
5) by taking
,
,
,
, and can be written as [
47,
48]
Clearly, restricting the number of parameters in the optimization in Equation (
5) leads to a less strict bound. We thus have
. For unbiased estimators, we obtain
Furthermore, the supremum over
on the right side of Equation (
14) is always larger or equal to its limit
:
provided that the derivatives on the right-hand side exist. We thus recover the CRLB as a limiting case of the ChRB. The ChRB is always stricter than the CRLB and we obtain the last inequality in the chain (
7). Notice that the CRLB requires the probability distribution
to be differentiable [
24]—a condition that can be dropped for the ChRB and the more general BB. Even if the distribution is regular, the above derivation shows that the ChRB, and more generally the BB, provide tighter error bounds than the CRLB. With increasing
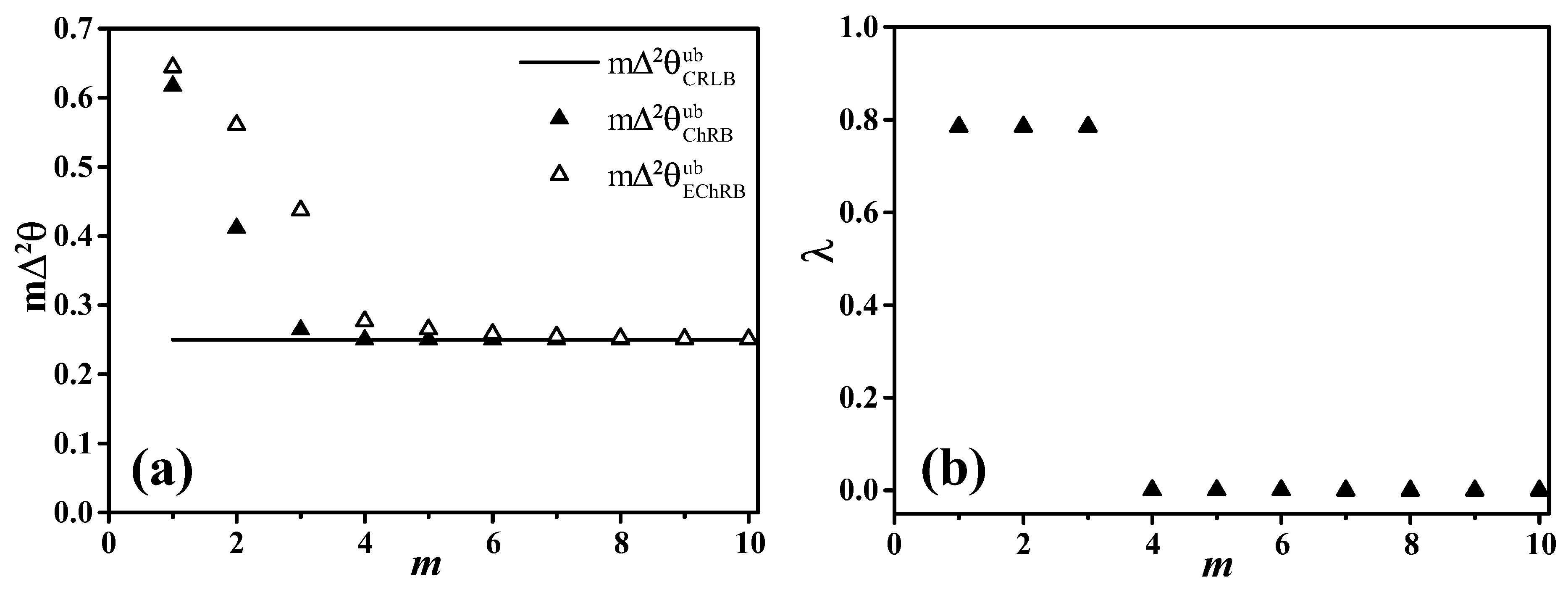
n, the BB becomes tighter and tighter and the CRLB represents the weakest bound in this hierarchy, which can be observed in
Figure 2a. Next, we determine a stricter bound in this hierarchy.
2.2.4. Extended Hammersley–Chapman–Robbins Bound
We obtain the extended Hammersley–Chapman–Robbins bound (EChRB) as a special case of Equation (
5), by taking
,
,
,
,
,
, and
, giving
where the supremum is taken over all possible
and
. Since the ChRB is obtained from Equation (
17) in the specific case
, we have that
. For unbiased estimators, we obtain
In
Figure 2a, we compare the different bounds for unbiased estimators and for the example considered in the manuscript: the CRLB (black line), the ChRB (filled triangles) and the EChRB (empty triangles), satisfying the chain of inequalities (
7). In
Figure 2b, we show the values of
in Equation (
15) for which the supremum is achieved in our case.
3. Bayesian Approach
The Bayesian approach makes use of the Bayes–Laplace theorem, which can be very simply stated and proved. The joint probability of two stochastic variables and is symmetric: , where and are the marginal distributions, obtained by integrating the joint probability over one of the two variables, while and are conditional distributions.
We recall that in a phase inference problem, the set of measurement results
is generated by a fixed and unknown value
according to the likelihood
. In the Bayesian approach to the estimation of
, one introduces a random variable
and uses the Bayes–Laplace theorem to define the conditional probability
The posterior probability
provides a degree of belief, or plausibility, that
(i.e., that
is the true value of the phase), in the light of the measurement data
[
50]. In Equation (
19), the prior distribution
expresses the a priori state of knowledge on
,
is the likelihood that is determined by the quantum mechanical measurement postulate, e.g., as in Equation (
1), and the marginal probability
is obtained through the normalization for the posterior, where
a and
b are boundaries of the phase domain. The posterior probability
describes the current knowledge about the random variable
based on the available information, i.e., the measurement results
.
3.1. Noninformative Prior
In the Bayesian approach, the information on
provided by the posterior probability always depends on the prior distribution
. It is possible to account for the available a priori information on
by choosing a prior distribution accordingly. However, if no a priori information is available, it is not obvious how to choose a “noninformative” prior [
51]. The flat prior
was first introduced by Laplace to express the absence of information on
[
51]. However, this prior would not be flat for other functions of
and, in the complete absence of a priori information, it seems unreasonable that some information is available for different parametrizations of the problem. To see this, recall that a transformation of variables requires that
for any function
. Hence, if
is flat, one obtains that
is, in general, not flat.
Notice that
—called Jeffreys prior [
52,
53]—where
is the Fisher information (
10), remains invariant under re-parametrization. For arbitrary transformations
, the Fisher information obeys the transformation property
. Therefore, if
and we perform the change of variable
, then the transformation property of the Fisher information ensures that
. Notice that, as in our case, the Fisher information
may actually be independent of
. In this case, the invariance property does not imply that Jeffreys prior is flat for arbitrary re-parametrizations
, instead,
.
3.2. Posterior Bounds
From the posterior probability (
19), we can provide an estimate
of
. This can be the maximum a posteriori,
, which coincides with the maximum likelihood Equation (
12) when the prior is flat,
, or the mean of the distribution,
.
With the Bayesian approach, it is possible to provide a confidence interval around the estimator, given an arbitrary measurement sequence
, even with a single measurement. The variance
can be taken as a measure of fluctuation of our degree of belief around
. There is no such concept in the frequentist paradigm. The Bayesian posterior variance
and the frequentist variance
have entirely different operational meanings. Equation (
20) provides a degree of plausibility that
, given the measurement results
. There is no notion of bias in this case. On the other hand, the quantity
measures the statistical fluctuations of
when repeating the sequence of
m measurements infinitely many times.
Ghosh Bound
In the following, we derive a lower bound to Equation (
20) first introduced by Ghosh [
54]. Using
we have
where
depends on the value of the posterior distribution calculated at the boundaries. If
, we have
. Analogously with the derivation of the (frequenstist) CRLB, we exploit the Cauchy–Schwarz inequality,
leading to
, where [
54]
The above bound is a function of the specific measurement sequence
and depends on
that we can identify as a “Fisher information of the posterior distribution”. The Ghosh bound is saturated if and only if
where
does not depend on
while it may depend on
.
3.3. Average Posterior Bounds
While Equation (
20) depends on the specific
, it is natural to consider its average over all possible measurement sequences at fixed
and
m, weighted by the likelihood
:
which we indicate as average Bayesian posterior variance, where
.
We would be tempted to compare the average posterior sensitivity
to the frequentist Cramér–Rao bound
. However, because of the different operational meanings of the frequentist and the Bayesian paradigms, there is no reason for Equation (
24) to fulfill the Cramér–Rao bound: indeed, it does not, as we show below.
Likelihood-Averaged Ghosh Bound
A lower bound to Equation (
24) is obtained by averaging the Ghosh bound Equation (
22) over the likelihood function. We have
, where [
18]
This likelihood-averaged Ghosh bound is independent of
because of the statistical average.
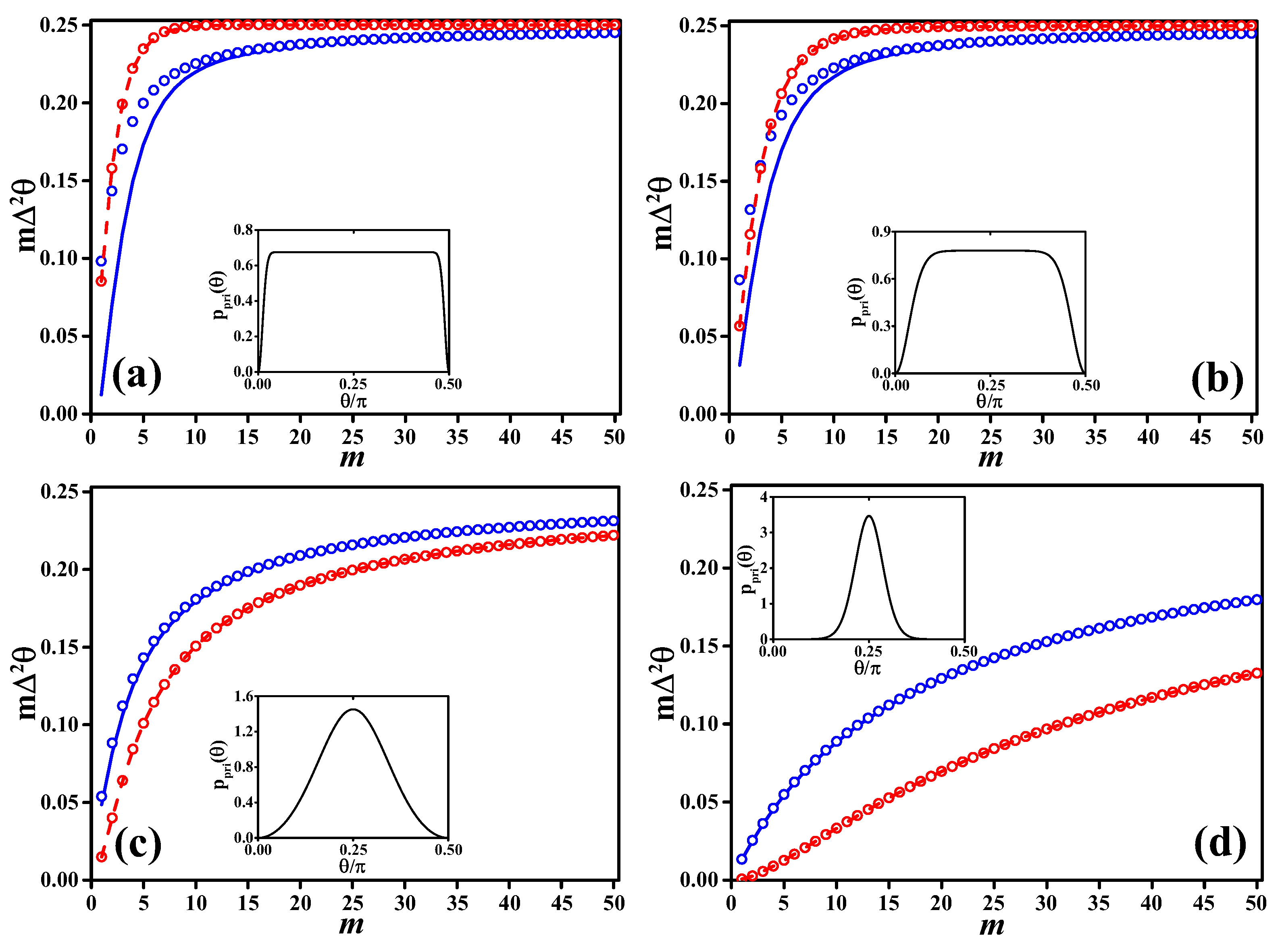
3.4. Numerical Comparison of Bayesian and Frequentist Phase Estimation
In the numerical calculations shown in
Figure 3, we consider a Bayesian estimator given by
with prior distributions
where
is the modified Bessel function of the first kind. This choice of prior distribution can continuously turn from a peaked function to a flat one when changing
, while being differentiable in the full phase interval. The more negative is
, the more
broadens in
. In particular, in the limit
, the prior approaches the flat distribution, which in our case coincides with Jeffreys prior since the Fisher information is independent of
. In the limit
, the prior is given by
. For positive values of
, the larger
, the more peaked is
around
. In particular
for
. Equation (
26) is normalized to one for
. In the inset of the different panels of
Figure 3, we plot
for
[panel (a)],
(b),
(c) and
(d).
In
Figure 3, we plot, as a function of
m, the posterior variance
(blue circles) that, as expected, is always larger than the likelihood-averaged Ghosh bound Equation (
25) (solid blue lines). For comparison, we also plot the frequentist variance
(red dots) around the mean value
of the estimator. This quantity obeys the Cramér–Rao theorem
and the more general chain of inequalities (
7). This is confirmed in the figure where we show
(red line). Notice that, when the prior narrows around
, the variance
decreases, but, at the same time, the estimator becomes more and more biased, i.e.,
decreases as well (note indeed that the red dashed line is proportional to
).
Interestingly, in
Figure 3, we clearly see that the Bayesian posterior variance
and the likelihood-averaged Ghosh bound may stay in some cases below the (frequentist)
[see panels (a) and (b)], even if the prior is almost flat. The discrepancy with the CRLB is remarkable and can be quite large for small values of
m. Still, there is no contradiction since
and
have different operational meanings and interpretations. They both respect their corresponding sensitivity bounds.
Asymptotically in the number of measurements
m, the Ghosh bound as well as its likelihood average converge to the Cramér–Rao bound. Indeed, it is well known that in this limit the posterior probability becomes a Gaussian centered at the true value of the phase shift and with variance given by the inverse of the Fisher information,
a result known as Laplace–Bernstein–von Mises theorem [
18,
23,
55]. By replacing Equation (
27) into Equation (
22), we recover a posterior variance given by
.
4. Bounds for Random Parameters
In this section, we derive bounds of phase sensitivity obtained when is a random variable distributed according to . Operationally, this corresponds to the situation where remains fixed (but unknown) when collecting a single sequence of m measurements . In between measurement sequences, fluctuates according to .
4.1. Frequentist Risk Functions for Random Parameters
Let us first consider the frequentist estimation of a fluctuating parameter
with the estimator
. The mean sensitivity obtained by averaging
, Equation (
3), over
is
where
and
are both random variables and we have used
.
An averaged risk function for the efficiency of the estimator is given by averaging the mean square error (
3) over
, leading to
Analogously to Equation (
4), we can write
In the following, we derive lower bounds for both
and
. Notice that bounds on
hold also for
due to
. Nevertheless, bounds on the average the mean square error are widely used (and are often called Bayesian bounds [
56]) since they can be expressed independently of the bias.
4.2. Bounds on the Mean Square Error
We first consider bounds on
, Equation (
29), for arbitrary estimators.
4.2.1. Van Trees Bound
It is possible to derive a general lower bound on the mean square error (
29) based on the following assumptions:
and are absolutely integrable with respect to and ;
, where .
Multiplying
by
and differentiating with respect to
, we have
Integrating over
in the range of
and considering the above properties, we find
Finally, using the Cauchy–Schwarz inequality, we arrive at
, where
is generally indicated as Van Trees bound [
24,
56,
57]. The equality holds if and only if
where
does not depend on
and
. It is easy to show that
where the first term is the Fisher information
, defined by Equation (
10), averaged over
, and the second term can be interpreted as a Fisher information of the prior [
24]. Asymptotically in the number of measurements
m and for regular distributions
, the first term in Equation (
34) dominates over the second one.
4.2.2. Ziv–Zakai Bound
A further bound on
can be derived by mapping the phase estimation problem to a continuous series of binary hypothesis testing problems. A detailed derivation of the Ziv–Zakai bound [
24,
58,
59] is provided in
Appendix B. The final result reads
, where
and
is the minimum error probability of the binary hypothesis testing problem. This bound has been adopted for quantum phase estimation in Ref. [
26]. To this end, the probability
can be maximized over all possible quantum measurements, which leads to the trace distance [
7]. As the optimal measurement may depend on
and
h, the bound (
35), which involves integration over all values of
and
h, is usually not saturable. We remark that the trace distance also defines a saturable frequentist bound for a different risk function than the variance [
60].
4.3. Bounds on the Average Estimator Variance
We now consider bounds on
, Equation (
28), for arbitrary estimators.
4.3.1. Average CRLB
Taking the average over
of Equation (
7), we obtain a chain of bounds for
. In particular, in its simplest form, we have
, where
is the average CRLB.
4.3.2. Van Trees Bound for the Average Estimator Variance
We can derive a general lower bound for the variance (
28) by following the derivation of the Van Trees bound, which was discussed in
Section 4.2.1. In contrast to the standard Van Trees bound for the mean square error, here the bias enters explicitly. Defining
and assuming the same requirements as in the derivation of the Van Trees bound for the MSE, we arrive at
Finally, a Cauchy–Schwarz inequality gives
, where
with equality if and only if
where
is independent of
and
.
We can compare Equation (
38) with the average CRLB Equation (
37). We find
where in the first step we use Jensen’s inequality, and the second step follows from Equation (
34) which implies
since
.
We thus arrive at
which is valid for generic estimators.
4.4. Bayesian Framework for Random Parameters
The Bayesian posterior variance,
, Equation (
24), averaged over
is
where
is the average probability to observe
taking into account fluctuations of
.
A bound on Equation (
41) can be obtained by averaging Equation (
25) over
, or, equivalently, averaging the Ghosh bound, Equation (
22), over
. We obtain the average Ghosh bound for random parameters
,
, where
The bound holds for any prior
and is saturated if and only if, for every value of
, there exists a
such that Equation (
23) holds.
Bayesian Bounds
In Equation (
41), the prior used to define the posterior
via the Bayes–Laplace theorem is arbitrary. In general, such a prior
is different from the statistical distribution of
, which can be unknown. If
is known, then one can use it as a prior in the Bayesian posterior probability, i.e.,
. In this specific case, we have
, and thus
. In other words, for this specific choice of prior, the physical joint probability
of random variables
and
coincides with the Bayesian
. Equation (
41) thus simplifies to
Notice that this expression is mathematically equivalent to the frequentist average mean square error (
29) if we replace
with
and
with
. This means that precision bounds for Equation (
29), e.g., the Van Trees and Ziv–Zakai bounds can also be applied to Equation (
43). These bounds are indeed often referred to as “Bayesian bounds” (see Ref. [
24]).
We emphasize that the average over the marginal distribution
, which connects Equations (
24) and (
43), has operational meaning if we consider that
is a random variable distributed according to
, and
is used as prior in the Bayes–Laplace theorem to define a posterior distribution. In this case, and under the condition
(for instance if the prior distribution vanishes at the borders of the phase domain), using Jensen’s inequality, we find
which coincides with the Van Trees bound discussed above. We thus find that the averaged Ghosh bound for random parameters (
42) is sharper than the Van Trees bound (
38):
which is also confirmed by the numerical data shown in
Figure 4.
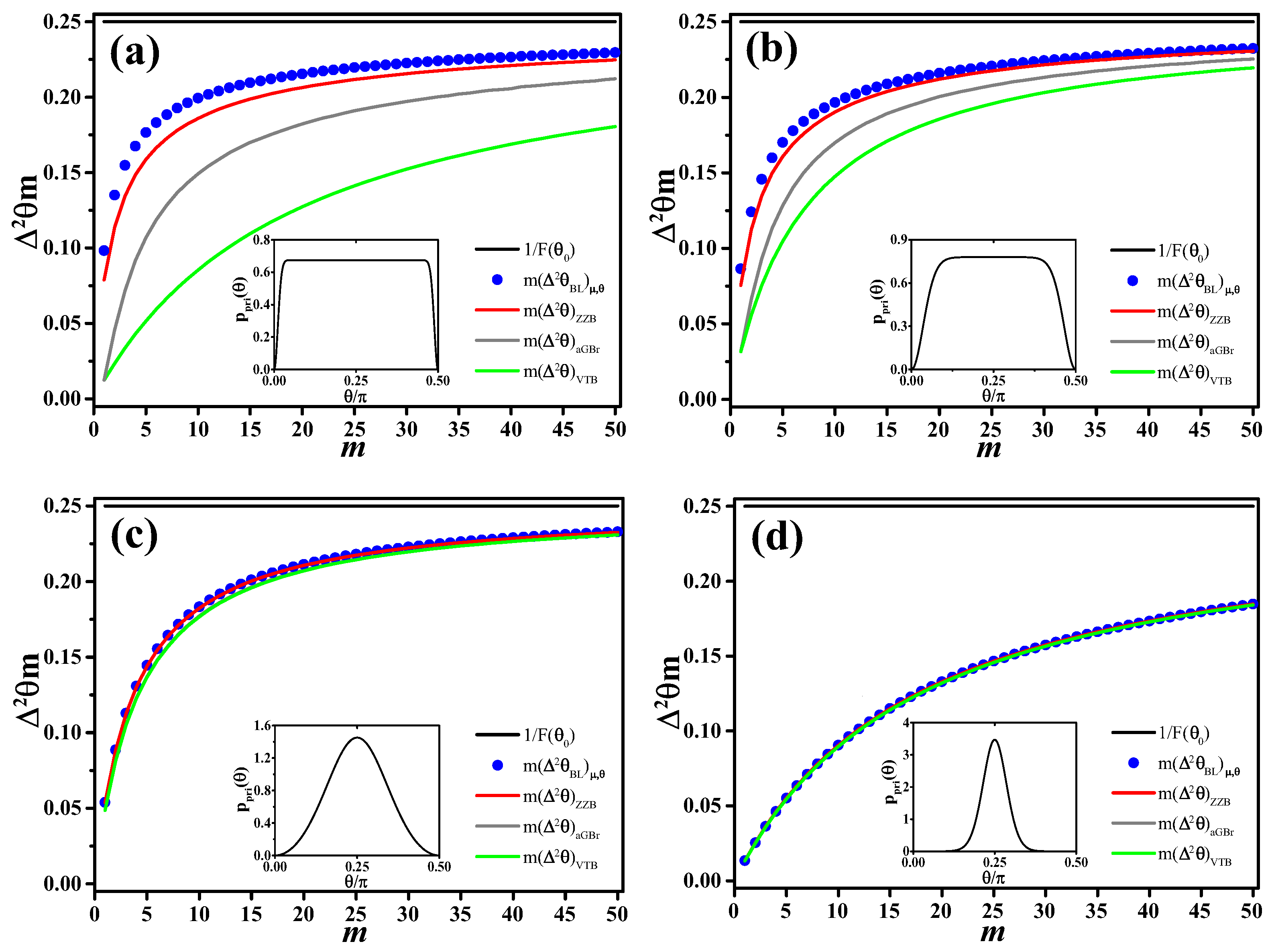
In
Figure 4, we compare
with the various bounds discussed in this section. As
we consider the same prior (
26) used in
Figure 3. We observe that all bounds approach the Van Trees bound with increasing sharpness of the prior distribution. Asymptotically in the number of measurements
m, all bounds converge to the Cramér–Rao bound.
5. Discussion and Conclusions
In this manuscript, we have clarified the differences between frequentist and Bayesian approaches to phase estimation. The two paradigms provide statistical results that have a different conceptual meaning and cannot be compared. We have also reviewed and discussed phase sensitivity bounds in the frequentist and Bayesian frameworks, when the true value of the phase shift
is fixed or fluctuates. These bounds are summarized in
Table 1.
In the frequentist approach, for a fixed , the phase sensitivity is determined from the width of the probability distribution of the estimator. The physical content of the distribution is that, when repeating the estimation protocol, the obtained will fall, with a certain confidence, in an interval around the mean value (e.g., of the times within a interval for a Gaussian distribution) that, for unbiased estimators, coincides with the true value of the phase shift.
In the Bayesian case, the posterior provides a degree of plausibility that the phase shift equals the interferometer phase when the data was obtained. This allows the Bayesian approach to provide statistical information for any number of measurements, even a single one. To be sure, this is not a sign of failure or superiority of one approach with respect to the other one, since the two frameworks manipulate conceptually different quantities. The experimentalist can choose to use one or both approaches, keeping in mind the necessity to clearly state the nature of the statistical significance of the reported results.
The two predictions converge asymptotically in the limit of a large number of measurements. This does not mean that in this limit the significance of the two approaches is interchangeable (it cannot be stated that in the limit of large repetition of the measurements, frequentist ad Bayesian provide the same results). In this respect, it is quite instructive to notice that the Bayesian
confidence may be below that of the Cramér–Rao bound, as shown in
Figure 3. This, at first sight, seems paradoxical, since the CRLB is a theorem about the minimum error achievable in parameter estimation theory. However, the CRLB is a frequentist bound and, again, the paradox is solved taking it into account that the frequentist and the Bayesian approaches provide information about different quantities.
Finally, a different class of estimation problems with different precision bounds is encountered if is itself a random variable. In this case, the frequentist bounds for the mean-square error (Van Trees, Ziv–Zakai) become independent of the bias, while those on the estimator variance are still functions of the bias. The Van Trees and Ziv–Zakai bounds can be applied to the Bayesian paradigm if the average of the posterior variance over the marginal distribution is the relevant risk function. This is only meaningful if the prior that enters the Bayes–Laplace theorem coincides with the actual distribution of the phase shift .
We conclude with a remark regarding the so-called Heisenberg limit, which is a saturable lower bound on the CRLB over arbitrary quantum states with a fixed number of particles. For instance, for a collection of
N two-level systems, the CRLB can be further bounded by
[
18,
20]. This bound is often called the ultimate precision bound since no quantum state is able to achieve a tighter scaling than
N. From the discussions presented in this article, it becomes apparent that Bayesian approaches (as discussed in
Section 3) or precision bounds for random parameters (
Section 4) are expected to lead to entirely different types of ‘ultimate’ lower bounds. Such bounds are interesting within the respective paradigm for which they are derived, but they cannot replace or improve the Heisenberg limit since they address fundamentally different scenarios that cannot be compared in general.
Author Contributions
Y.L., L.P., M.G., W.L. and A.S. conceived the study, performed theoretical calculations and drafted the article. All authors have read and approved the final manuscript.
Acknowledgments
This work was supported by the National Key R & D Program of China (No. 2017YFA0304500 and No. 2017YFA0304203), the National Natural Science Foundation of China (Grant No. 11874247), the 111 plan of China (No. D18001), the Hundred Talent Program of the Shanxi Province (2018), the Program of State Key Laboratory of Quantum Optics and Quantum Optics Devices (No. KF201703), and the QuantEra project Q-Clocks. M.G. acknowledges support by the Alexander von Humboldt Foundation.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Derivation of the Barankin Bound
Let
be an arbitrary estimator for
. Its mean value
coincides with
if and only if the estimator is unbiased (for arbitrary values of
). In the following, we make no assumption about the bias of
and therefore do not replace
by
.
Introducing the likelihood ratio
under the condition
for all
, we obtain with Equation (
A1) that
for an arbitrary family of phase values
picked from the parameter domain. Furthermore, we have
for all
. Multiplying both sides of Equation (
A4) with
and subtracting it from (
A3) yields
Let us now pick a family of
n finite coefficients
. From Equation (
A5), we obtain
The Cauchy–Schwarz inequality now yields
where
is the variance of the estimator
. We thus obtain
for all
n,
, and
. The Barankin bound then follows by taking the supremum over these variables.
Appendix B. Derivation of the Ziv–Zakai Bound
Derivations of the Ziv–Zakai bound can be found in the literature (see, for instance, Refs. [
24,
58,
59]). This Appendix follows these derivations closely and provides additional background, which may be useful for readers less familiar with the field of hypothesis testing.
Let
be a random variable with probability density
. We can formally write
, where
is the probability that
X is larger or equal than
x. We obtain from integration by parts
where we assume that
a is finite [if
the above relation holds when
]. Finally, we can formally extend the above integral up to
∞ since
:
Following Ref. [
59], we now take
and
. We thus have
We express the probability as
Next, we replace
with
in the second integral:
We now take a closer look at the expression within the angular brackets and interpret it in the framework of hypothesis testing. Suppose that we try to discriminate between the two cases (hypothesis 1, denoted ) and (denoted ). We decide between the two hypothesis and on the basis of the measurement result x using the estimator . One possible strategy consists in choosing the hypothesis whose value is closest to the obtained estimator. Hence, if , we assume to be correct and, otherwise, if , we pick .
Let us now determine the probability to make an erroneous decision using this strategy. There are two scenarios that will lead to a mistake. First, our strategy fails whenever
when
. In this case,
is true, but our strategy leads us to choose
. The probability for this to happen, given that
, is
. To obtain the probability error of our strategy, we need to multiply this with the probability with which
assumes the value
, which is given by
. Second, our strategy also fails if
for
. This occurs with the conditional probability
, and
with probability
. The total probability to make a mistake is consequently given by
and we can rewrite Equation (A13) as
The strategy described above depends on the estimator
and may not be optimal. In general, a binary hypothesis testing strategy can be characterized in terms of the separation of the possible values of
x into the two disjoint subsets
and
which are used to choose hypothesis
or
, respectively. That is, if
we pick
and otherwise
. Since one of the two hypotheses must be true, we have
where the error made by such a strategy is given by
This probability is minimized if
for
and, consequently,
for
. This actually identifies an optimal strategy for hypothesis testing, known as the likelihood ratio test: if the likelihood ratio
is larger than the threshold value
we pick
, whereas, if it is smaller, we pick
. With this choice, the error probability is minimal and reads
where we used Equation (A15).
Applied to our case, we obtain
This result represents a lower bound on
for arbitrary choices of
. This includes the case discussed in Equation (A13). Thus, using
in Equation (A14) and inserting back into Equation (
A12), we finally obtain the Ziv–Zakai bound for the mean square error:
This bound can be further sharpened by introducing a valley-filling function [
61], which is not considered here.
References
- Zehnder, L. Ein neuer Interferenzrefraktor. Zeitschrift für Instrumentenkunde 1891, 11, 275. (In German) [Google Scholar]
- Mach, L. Ueber einen Interferenzrefraktor. Zeitschrift für Instrumentenkunde 1892, 12, 89. (In German) [Google Scholar]
- Ramsey, N.F. Molecular Beams; Oxford University Press: London, UK, 1963. [Google Scholar]
- Wynands, R. Atomic Clocks. In Lecture Notes in Physics; Muga, G., Ruschhaupt, A., Campo, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 789. [Google Scholar]
- Barish, B.C.; Weiss, R. LIGO and the Detection of Gravitational Waves. Phys. Today 1999, 52, 44–50. [Google Scholar] [CrossRef]
- Pitkin, M.; Reid, S.; Rowan, S.; Hough, J. Gravitational Wave Detection by Interferometry (Ground and Space). Living Rev. Relativ. 2011, 14, 5. [Google Scholar] [CrossRef] [PubMed]
- Helstrom, C.W. Quantum detection and estimation theory. J. Stat. Phys. 1969, 1, 231. [Google Scholar] [CrossRef]
- Holevo, A.S. Probabilistic and Statistical Aspects of Quantum Theory; North-Holland Publishing Company: Amsterdam, The Netherlands, 1982. [Google Scholar]
- Ludlow, A.D.; Boyd, M.M.; Ye, J.; Peik, E.; Schmidt, P.O. Optical atomic clocks. Rev. Mod. Phys. 2015, 87, 637–701. [Google Scholar] [CrossRef] [Green Version]
- Schnabel, R.; Mavalvala, N.; McClelland, D.E.; Lam, P.K. Quantum metrology for gravitational wave astronomy. Nat. Commun. 2010, 1, 121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aasi, J.; Abadie, J.; Abbott, B.P.; Abbott, R.; Abbott, T.D.; Abernathy, M.R.; Adams, C.; Adams, T.; Addesso, P.; Adhikari, R.X.; et al. Enhanced sensitivity of the LIGO gravitational wave detector by using squeezed states of light. Nat. Photon. 2010, 7, 613–619. [Google Scholar] [CrossRef]
- Cronin, A.D.; Schmiedmayer, J.; Pritchard, D.E. Optics and interferometry with atoms and molecules. Rev. Mod. Phys. 2009, 81, 1051–1129. [Google Scholar] [CrossRef] [Green Version]
- Caves, C.M. Quantum-mechanical noise in an interferometer. Phys. Rev. D 1981, 23, 1693–1708. [Google Scholar] [CrossRef]
- Giovannetti, V.; Lloyd, S.; Maccone, L. Quantum metrology. Phys. Rev. Lett. 2006, 96, 010401. [Google Scholar] [CrossRef] [PubMed]
- Pezzè, L.; Smerzi, A. Entanglement, nonlinear dynamics, and the Heisenberg limit. Phys. Rev. Lett. 2009, 102, 100401. [Google Scholar] [CrossRef] [PubMed]
- Hyllus, P.; Laskowski, W.; Krischek, R.; Schwemmer, C.; Wieczorek, W.; Weinfurter, H.; Pezzè, L.; Smerzi, A. Fisher information and multiparticle entanglement. Phys. Rev. A 2012, 85, 022321. [Google Scholar] [CrossRef]
- Tóth, G. Multipartite entanglement and high-precision metrology. Phys. Rev. A 2012, 85, 022322. [Google Scholar] [CrossRef]
- Pezzè, L.; Smerzi, A. Quantum theory of phase estimation. In Atom Interferometry, Proceedings of the International School of Physics "Enrico Fermi", Italy, 15–20 July 2013; Tino, G.M., Kasevich, M.A., Eds.; IOS Press: Sesto Fiorentino, Italy, 2014; Course 188, 691. [Google Scholar]
- Tóth, G.; Apellaniz, I. Quantum metrology from a quantum information science perspective. J. Phys. A Math. Theor. 2014, 47, 424006. [Google Scholar] [CrossRef] [Green Version]
- Giovannetti, V.; Lloyd, S.; Maccone, L. Advances in quantum metrology. Nat. Photon. 2011, 5, 222–229. [Google Scholar] [CrossRef] [Green Version]
- Pezzè, L.; Smerzi, A.; Oberthaler, M.K.; Schimed, R.; Treutlein, P. Quantum metrology with nonclassical states of atomic ensembles. Rev. Mod. Phys. 2018, in press. [Google Scholar]
- Kay, S.M. Fundamentals of Statistical Signal Processing: Estimation Theory, Volume I; Prentice Hall: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Lehmann, E.L.; Casella, G. Theory of Point Estimation; Springer: Berlin, Germany, 1998. [Google Scholar]
- Van Trees, H.L.; Bell, K.L. Bayesian Bounds for Parameter Estimation and Nonlinear Filtering/Tracking; Wiley: New York, NY, USA, 2007. [Google Scholar]
- Lane, A.S.; Braunstein, S.L.; Caves, C.M. Maximum-likelihood statistics of multiple quantum phase measurements. Phys. Rev. A 1993, 47, 1667. [Google Scholar] [CrossRef] [PubMed]
- Tsang, M. Ziv–Zakai error bounds for quantum parameter estimation. Phys. Rev. Lett. 2012, 108, 230401. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.M.; Tsang, M. Quantum Weiss-Weinstein bounds for quantum metrology. Quantum Sci. Technol. 2016, 1, 015002. [Google Scholar] [CrossRef] [Green Version]
- Hall, M.J.; Wiseman, H.M. Heisenberg-style bounds for arbitrary estimates of shift parameters including prior information. New J. Phys. 2012, 14, 033040. [Google Scholar] [CrossRef]
- Giovannetti, V.; Maccone, L. Sub-Heisenberg estimation strategies are ineffective. Phys. Rev. Lett. 2012, 108, 210404. [Google Scholar] [CrossRef] [PubMed]
- Pezzè, L. Sub-Heisenberg phase uncertainties. Phys. Rev. A 2013, 88, 060101(R). [Google Scholar] [CrossRef]
- Pezzè, L.; Hyllus, P.; Smerzi, A. Phase-sensitivity bounds for two-mode interferometers. Phys. Rev. A 2015, 91, 032103. [Google Scholar] [CrossRef]
- Hradil, Z.; Myška, R.; Peřina, J.; Zawisky, M.; Hasegawa, Y.; Rauch, H. Quantum phase in interferometry. Phys. Rev. Lett. 1996, 76, 4295. [Google Scholar] [CrossRef] [PubMed]
- Pezzè, L.; Smerzi, A.; Khoury, G.; Hodelin, J.F.; Bouwmeester, D. Phase detection at the quantum limit with multiphoton mach-zehnder interferometry. Phys. Rev. Lett. 2007, 99, 223602. [Google Scholar] [CrossRef] [PubMed]
- Kacprowicz, M.; Demkowicz-Dobrzanski, R.; Wasilewski, W.; Banaszek, K.; Walmsley, I.A. Experimental quantum-enhanced estimation of a lossy phase shift. Nat. Photon. 2010, 4, 357. [Google Scholar] [CrossRef]
- Krischek, R.; Schwemmer, C.; Wieczorek, W.; Weinfurter, H.; Hyllus, P.; Pezzè, L.; Smerzi, A. Useful multiparticle entanglement and sub-shot-noise sensitivity in experimental phase estimation. Phys. Rev. Lett. 2011, 107, 080504. [Google Scholar] [CrossRef] [PubMed]
- Xiang, G.Y.; Higgins, B.L.; Berry, D.W.; Wiseman, H.M.; Pryde, G.J. Entanglement-enhanced measurement of a completely unknown optical phase. Nat. Photon. 2011, 5, 43–47. [Google Scholar] [CrossRef]
- Bollinger, J.J.; Itano, W.M.; Wineland, D.J.; Heinzen, D.J. Optimal frequency measurements with maximally correlated states. Phys. Rev. A 1996, 54, R4649–R4652. [Google Scholar] [CrossRef] [PubMed]
- Pezzè, L.; Smerzi, A. Sub shot-noise interferometric phase sensitivity with beryllium ions Schrödinger cat states. Europhys. Lett. 2007, 78, 30004. [Google Scholar] [CrossRef] [Green Version]
- Gerry, C.C.; Mimih, J. The parity operator in quantum optical metrology. Contemp. Phys. 2010, 51, 497. [Google Scholar] [CrossRef]
- Sackett, C.A.; Kielpinski, D.; King, B.E.; Langer, C.; Meyer, V.; Myatt, C.J.; Rowe, M.; Turchette, Q.A.; Itano, W.M.; et al. Experimental entanglement of four particles. Nature 2000, 404, 256–259. [Google Scholar] [CrossRef] [PubMed]
- Monz, T.; Schindler, P.; Barreiro, J.T.; Chwalla, M.; Nigg, D.; Coish, W.; Harlander, M.; Hänsel, W.; Hennrich, M.; Blatt, R. 14-Qubit Entanglement: Creation and Coherence. Phys. Rev. Lett. 2011, 106, 130506. [Google Scholar] [CrossRef] [PubMed]
- Hayashi, M. Asymptotic Theory of Quantum Statistical Inference, Selected Papers; World Scientific Publishing: Singapore, 2005. [Google Scholar]
- Barankin, E.W. Locally best unbiased estimates. Ann. Math. Stat. 1949, 20, 477. [Google Scholar] [CrossRef]
- Mcaulay, R.J.; Hofstetter, E.M. Barankin bounds on parameter estimation. IEEE Trans. Inf. Theory 1971, 17, 669–676. [Google Scholar] [CrossRef]
- Cramér, H. Mathematical Methods of Statistics; Princeton University Press: Princeton, NJ, USA, 1946. [Google Scholar]
- Rao, C.R. Information and the Accuracy Attainable in the Estimation of Statistical Parameters. Bull. Calcutta Math. Soc. 1971, 37, 81–91. [Google Scholar]
- Hammersley, J.M. On estimating restricted parameters. J. R. Stat. Soc. Ser. B 1950, 12, 192. [Google Scholar]
- Chapman, D.G.; Robbins, H. Minimum variance estimation without regularity assumptions. Ann. Math. Stat. 1951, 22, 581. [Google Scholar] [CrossRef]
- Pflanzagl, J.; Hamböker, R. Parametric Statistical Theory; De Gruyter: Berlin, Germany, 1994. [Google Scholar]
- Sivia, D.S.; Skilling, J. Data Analysis: A Bayesian Tutorial; Oxford University Press: London, UK, 2006. [Google Scholar]
- Robert, C.P. The Bayesian Choice: From Decision-Theoretic Foundations to Computational Implementation; Springer: New York, NY, USA, 2007. [Google Scholar]
- Jeffreys, H. An invariant form for the prior probability in estimation problems. Proc. R. Soc. Lond. A 1946, 186, 453. [Google Scholar] [CrossRef]
- Jeffreys, H. Theory of Probability; Oxford University Press: London, UK, 1961. [Google Scholar]
- Ghosh, M. Cramér–Rao bounds for posterior variances. Stat. Probabil. Lett. 1993, 17, 173. [Google Scholar] [CrossRef]
- Cam, L.L. Asymptotic Methods in Statistical Decision Theory; Springer: New York, NY, USA, 1986. [Google Scholar]
- Van Trees, H.L. Detection, Estimation, and Modulation Theory, Part I; Wiley: New York, NY, USA, 1968. [Google Scholar]
- Schutzenberger, M.P. A generalization of the Fréchet-Cramér inequality to the case of Bayes estimation. Bull. Am. Math. Soc. 1957, 63, 142. [Google Scholar]
- Ziv, J.; Zakai, M. Some lower bounds on signal parameter estimation. IEEE Trans. Inform. Theor. 1969, 15, 386–391. [Google Scholar] [CrossRef]
- Bell, K.L.; Steinberg, Y.; Ephraim, Y.; Van Trees, H.L. Extended Ziv–Zakai lower bound for vector parameter estimation. IEEE Trans. Inf. Theor. 1997, 43, 624–637. [Google Scholar] [CrossRef]
- Gessner, M.; Smerzi, A. Statistical speed of quantum states: Generalized quantum Fisher information and Schatten speed. Phys. Rev. A 2018, 97, 022109. [Google Scholar] [CrossRef] [Green Version]
- Bellini, S.; Tartara, G. Bounds on error in signal parameter estimation. IEEE Trans. Commun. 1974, 22, 340–342. [Google Scholar] [CrossRef]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}