1. Introduction
In learning Bayesian networks, one of the main concerns is structure learning. Many criteria to detect the network structure have been proposed such as the minimum description length (MDL) [
1], the Bayesian information criterion (BIC) [
2], the Akaike information criterion (AIC) [
3], and the marginal likelihood [
4]. Most of these criteria assume statistical regularity, which means that the network has identifiability on the parameter and then the nodes are observable.
The nodes of the network are not always observable in practical situations; there will be some underlying factors, which are difficult to observe and do not appear in the given data. In such cases, the criteria for the structure learning must be designed by taking account of the existence of the hidden nodes. However, the statistical regularity does not hold when the network contains hidden nodes [
5,
6].
The probabilistic models fall into two types: Regular and singular. If the parameter and the probability function expressed by the parameter have one-to-one mapping, the model has statistical regularity and is referred to as regular. Otherwise, there are singularities in the parameter space and the model is referred to as singular. Due to the singularities, the Fisher information matrix is not positive definite, which means that the conventional analysis based on the Laplace approximation or the asymptotic normality does not work in the singular models. Many probabilistic models such as mixture models, hidden Markov models, and neural networks are singular. To cope with the problem of the singularities, an analysis method based on algebraic geometry has been proposed [
7], and asymptotic properties of the generalization performance and of the marginal likelihood have been investigated in mixture models [
8], hidden Markov models [
9], neural networks [
7,
10], etc.
It is known that the Bayesian network with hidden nodes is singular since the parametrization will change compared with the network without hidden nodes. Even in the simple structure such as the naive Bayesian network, the parameter space has singularities [
5,
11]. A method to select the optimal structure from some candidate networks has been proposed by using the algebraic geometrical method [
5]. For general singular models, new criteria are developed; a widely applicable information criterion (WAIC) is based on the asymptotic form of the generalization error and a widely applicable Bayesian information criterion (WBIC) is derived from the asymptotic form of the marginal likelihood. BIC is also extended to the singular models [
12].
The structure learning of the Bayesian network with hidden nodes is a very widely studied problem. Observable constraints from the Bayesian network with hidden nodes is considered in [
13]. A model based on observable conditional independence constraints is proposed by [
14]. For causal discovery, the related fast causal inference (FCI) algorithm has been developed, e.g., [
15]. In the present paper, we consider a two-step method; the first step obtains the optimal structure with observable nodes and the second step detects the hidden nodes in each partial graph.
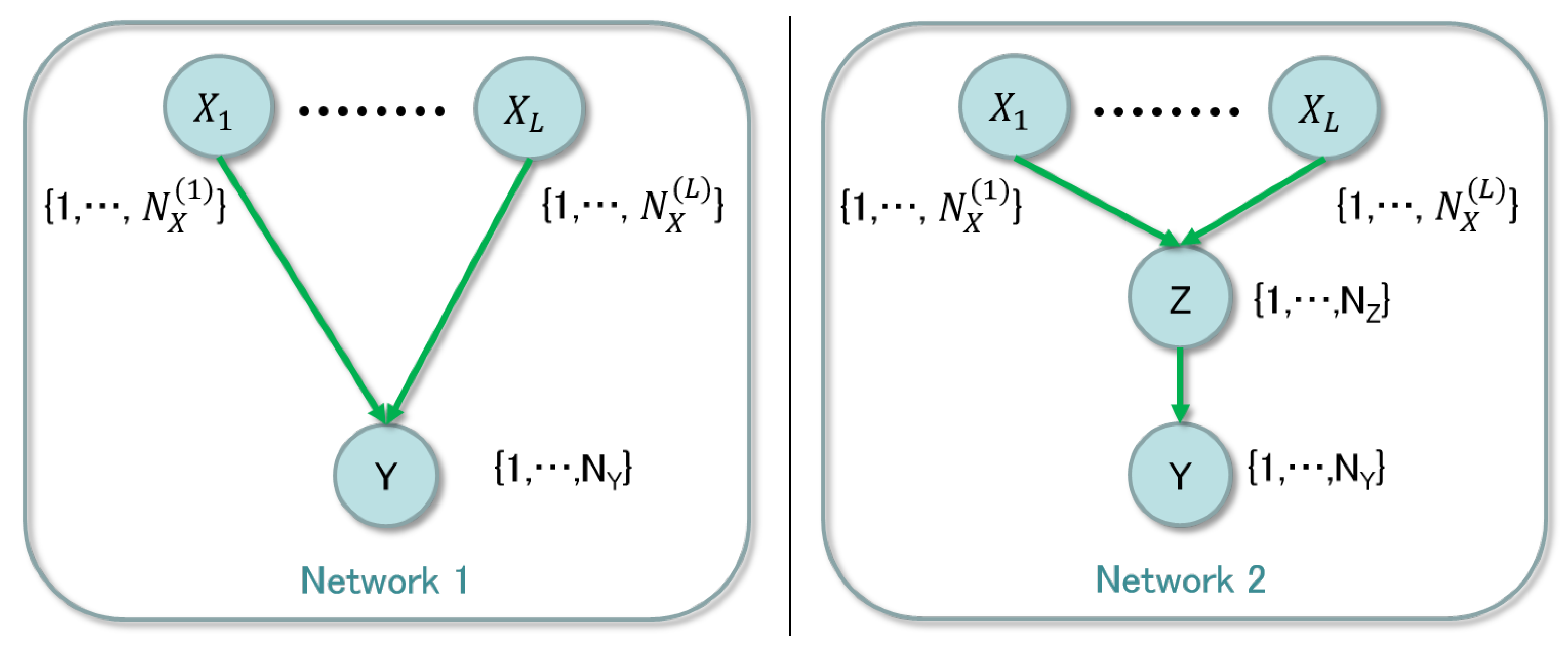
Figure 1 shows the hidden-node detection. The left side of the figure describes the optimal structure with observable nodes only, based on some method of the structure learning. Then, as the second step, we focus on the connections between the observable nodes shown in the right side of the figure. In this example, the parent node
has the domain
and the child node
has the one
. If the value of the child node is determined by only three factors, the middle node
Z, which has the domain
, simplifies the conditional probability tables (CPTs). It has been known that the smaller dimension the parameter of the network is, the more accurate the parameter learning is. So, it is practically useful to find the simplest expression of the CPTs.
The issue comes down to detection of a hidden node between observable nodes. We compare two network structures, which are shown in
Figure 2.
The left and the right panels are networks without and with the hidden node, respectively, where
with the domain
and
are observable and
is hidden. Since the evidence data on
X and
Y are given and there is no information on
Z, we need to consider whether the hidden node exists and its range
. We propose a method to examine whether the middle hidden node should exist or not using Bayesian clustering. In order to obtain the simplest structure, there is a way to use the regularization technique [
16], while it is not straightforward to prove the selected structure is theoretically optimal. Our method is justified based on a property of the entropy term in the asymptotic form of the marginal likelihood, which plays an essential role in the clustering. The result of clustering shows necessary labels to express the relation between the observable nodes
X and
Y. Counting the number of the used labels, we can determine the existence of the hidden node. Note that we do not consider whole possible structures of the network to reduce the computational complexity; in the present paper, we try to optimize the network from the limited structures, where for example there is no multiple inserted hidden nodes or connections between hidden nodes.
The remainder of this paper is organized as follows.
Section 2 presents a formal definition of the network.
Section 3 summarizes Bayesian clustering.
Section 4 proposes the method to select the structure based on Bayesian clustering and derives its asymptotic behavior.
Section 5 shows results of the numerical experiments validating the behavior. Finally, we present a discussion and our conclusions in
Section 6 and
Section 7, respectively.
2. Model Settings
In this section, the network structure and its parameterization are formalized. The naive structure has been applied to classification and clustering tasks and its mathematical properties are studied [
5] since it is expressed as a mixture model. As mentioned in the previous section, we consider the hidden node with both parent and child observable nodes. One of the simplest networks is shown in the right panel of
Figure 2. Let the probabilities of
,
Z, and
Y be defined by
for
,
,
, and
. Since they are probabilities, we assume that
It is easy to find that
is the element of the CPT for
Z and
is that for
Y. Let
w be the parameter consisting of
, where the dimension is
We also define the probabilities of the network shown in the left panel of
Figure 2;
The parameter
u consisting of
and
has the dimension
If the relation between
X and
Y can be simplified, the degree of freedom
is not necessary and is reduced to
such as the case shown in
Figure 1. This is similar to the dimension reduction of data with sandglass type neural networks or the non-negative matrix factorization, which have a smaller number of nodes in the middle layers than the one in the input and output layers. The relation between the necessary dimension of the parameter and the probability of the output is not always trivial [
17]. The present paper focuses on the sufficient case in terms of the dimension reduction, where
rewritten as
Recall that
X and
Y are observable and
Z is hidden, where
and
are given and
is unknown. When the minimum
is detected from the given evidence pairs of
X and
Y, and is satisfied Equation (
11), the network structure with the hidden node expresses the pairs with smaller dimension of the parameter. We use Bayesian clustering technique to detect the minimum
.
3. Bayesian Clustering
In this section, let us formally introduce Bayesian clustering. Let the evidence be described by
and there are
n pairs, which are denoted by
. Recall that
. The corresponding value of the hidden node is
and the set of
n data is denoted by
. We can estimate
based on the probability
. In Bayesian clustering, it is defined by
where
is a prior distribution and
is the hyperparameter.
In the network with the hidden node,
If the prior distribution is expressed as the Dirichlet distribution for
,
, and
, the numerator
is analytically computable. Based on the relation
, the Markov Chain Monte Carlo (MCMC) method provides the sampling of
from
. This is a common method to estimate hidden variables in machine learning; the underlying topics are estimated based on the Gibbs sampler in topic models such as the latent Dirichlet allocation [
18].
4. Hidden Node Detection
In this section, the algorithm to detect the hidden node is introduced and its asymptotic property reducing the number of the used labels is revealed.
4.1. The Proposed Algorithm
When the size of the middle node is large such as
there is no reason to have the node
Z; the middle node should reduce the degree of freedom from
X. If only
satisfies Equation (
11), the middle node is not necessary. Note that
shows that there is no edge between
X and
Y, which is already excluded in structure learning.
Example 1. When , and , only satisfies Equation (11), which shows that there is no hidden node between X and Y. The present paper proposes the following algorithm to determine the existence of Z;
Algorithm 2. Assume that there is for given and , that is Equation (11) is satisfied. Apply the Bayesian clustering method to the given evidence and estimate based on the MCMC sampling. Let the number of used labels be denoted by . If the following inequality holds, the hidden node reduces the parameter, 4.2. Asymptotic Properties of the Algorithm
The MCMC method in Bayesian clustering is based on the probability
as shown in
Section 3. Since the proposed method depends on this clustering method, let us consider the properties of
. The negative logarithm of the probability is expressed as follows:
where
,
, and
are given as
respectively, and the prior distribution
consists of the Dirichlet distributions;
The function and are the Kronecker delta and the gamma function, respectively. The hyperparameter consists of , , and . The sampling result of is dominantly taken from the area, which makes large. Then, we investigate which minimizes for given .
Theorem 3. When the number of the given data n is sufficiently large, is written aswhere is the number of such that . The proof will be shown in
Appendix A. The first term
is the dominant factor, and its coefficient
S is maximized in the clustering. This coefficient determines
, which is the number of used labels in the clustering result.
Assume that the true structure with the hidden node has the minimal expression, where the range of Z is , and that the estimated size is larger than the true one; . We can easily confirm that Bayesian clustering chooses the minimum structure as follows. The three terms in the coefficient S correspond to the negative entropy functions of the parameter , , and , respectively. Then, the minimum obviously makes the coefficient S maximized since the number of elements of parameter should be minimized for the small entropy. When the hidden node has the redundant state, which means that two values of Z have completely same output distribution of Y, the second term of S is larger than the case of non-redundant situation . Based on the assumption that the true structure is minimal, the estimation therefore gets the minimum structure, .
According to this property, the number of used label asymptotically goes to . The proposed algorithm compares the essential number of the values of Z and will be a criterion to select the proper structure when n is large. This property exists only in Bayesian clustering so far; the eliminating effect of the redundant labels has not been found in other method of the clustering such as the maximum-likelihood clustering based on the expectation-maximization algorithm.
5. Numerical Experiments
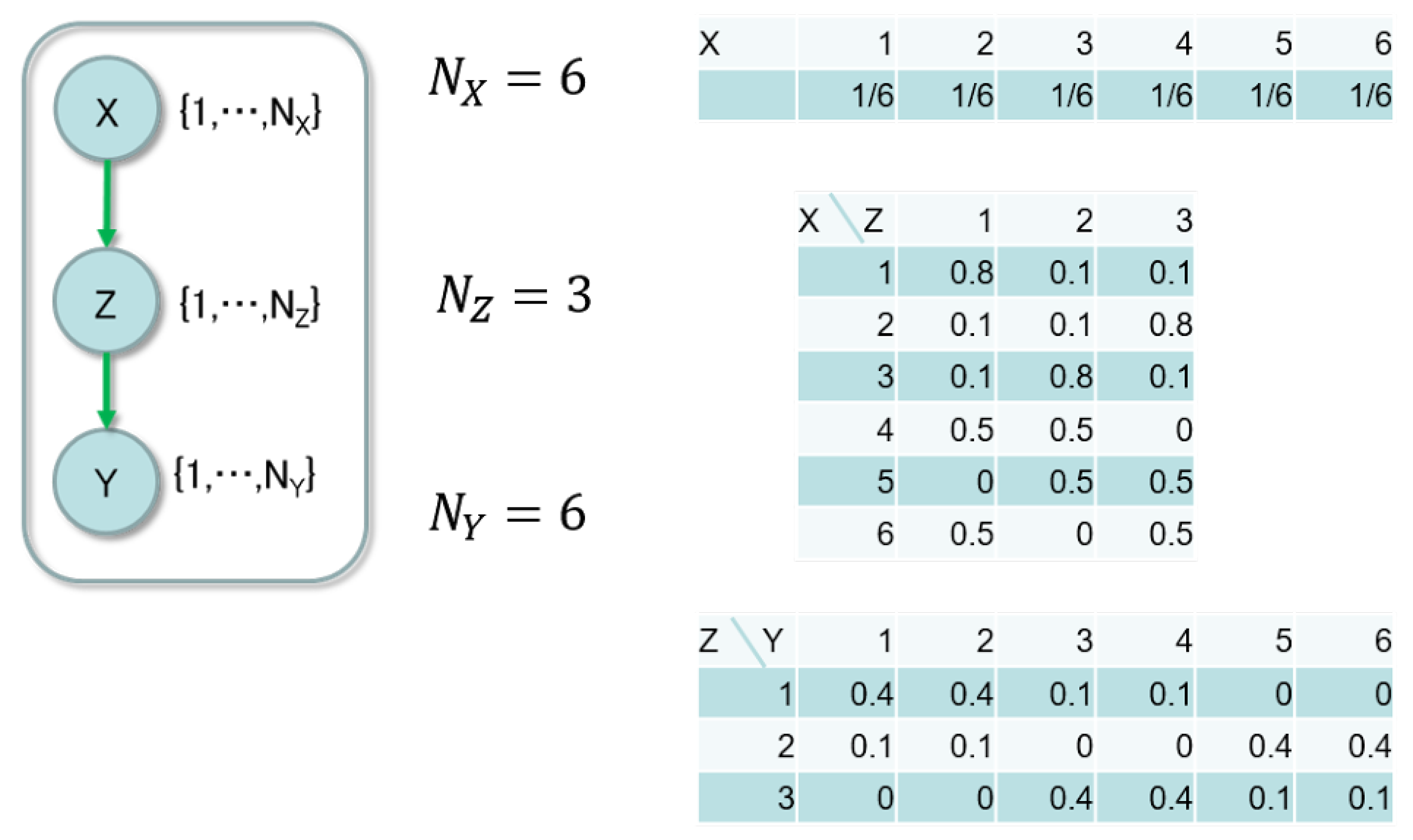
In this section, we validate the asymptotic property in numerical experiments. We set the data-generating model shown in
Figure 3 and prepared ten evidence data sets.
There was a single parent node
. The sizes of the nodes were
,
and
. The CPTs are described on the right-side of the figure, where the true parameter consists of these probabilities. There were 2000 pairs of
in each data set. Since the following condition is satisfied,
the structure of the data-generating model with the hidden node had smaller dimension of the parameter than the one without a hidden node.
We applied Bayesian clustering to each data set, where the model had the size of the hidden node . According to the asymptotic property in Theorem 3, the MCMC method should take label assignment from the area, where the number of the used labels was reduced to three. The estimated model size was determined by the assignment, which minimized the function . Since the sampling of the MCMC method depended on the initial assignment, we conducted ten trials for each data set and regarded the estimated size as the minimum one. The number of iterations in the MCMC method was 1000.
Table 1 shows the results of the experiments.
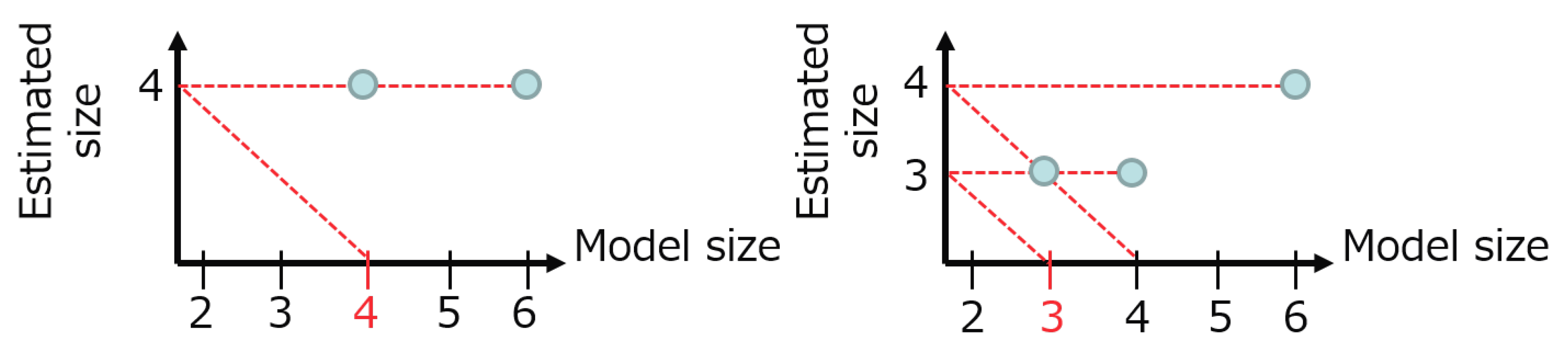
In all data sets, the size of the hidden node Z is reduced and the correct size is estimated in more than half sets, we confirmed the effect eliminating the redundant labels. Since the result of the MCMC method depends on the given data, the minimum size is not always found; the estimated size is four in some data sets instead of three. Even in such case, however, we could estimate the correct size after setting the initial size of the model as . Repeating this procedure, we will be able to avoid the local optimal size and find the global one.
Figure 4 shows this estimation procedure in the practical cases. The initial model size starts from six. The left panel is the case, where the proper size is directly found and the estimated size does not change at size four. The right panel is the case, where the estimated size is first four and then the next result is three, which is the fixed point.
To investigate the properties of the estimated size, we tried some different numbers of pairs
and a skewed distribution of the parent node (
Figure 5), and nearly uniform distribution of the child node (
Figure 6).
Table 2 shows the results of
.
Since these CPTs of
are a straightforward case to distinguish the role of the hidden node, the smaller number of the pairs does not adversely affect the estimation.
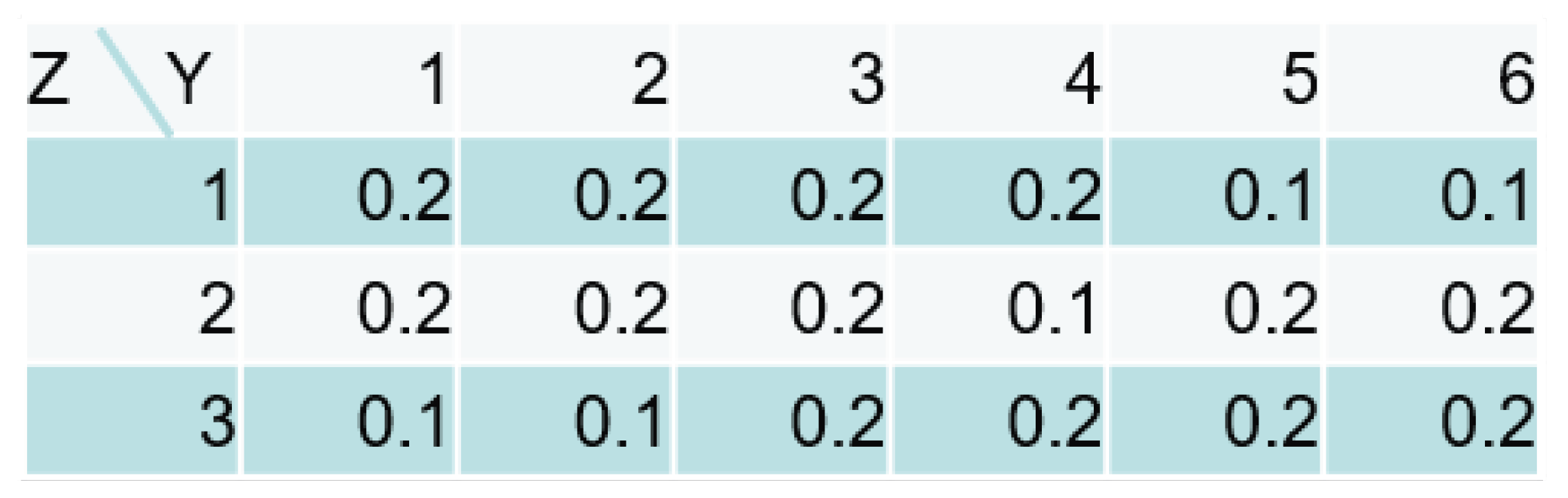
Table 3 shows the results of the different CPTs in the parent and the child nodes.
The number of pairs was . Due to the CPT of Z, the skewed distribution of the parent node still keeps the sufficient variation of Z to estimate the size , which provides the same accuracy as the uniform distribution. On the other hand, the nearly uniform distribution of the child node makes the estimation difficult because each value of Z has the similar output distribution. The Dirichlet prior of Z has a strong effect to eliminate the redundancy, which means the estimated sizes tend to be smaller than the true one.
6. Discussion
In this section, we discuss the difference between the proposed method and other conventional criteria for the model selection. In the proposed method, the label assignment
is obtained from the MCMC method, which takes the samples according to
. The probability
is the marginal likelihood on the complete data
; recall the definition,
This looks similar to the criteria based on the marginal likelihood such as BDu(e) [
19,
20] and its asymptotic form such as BIC [
2], MDL [
1]. Since it is assumed that the network has the statistical regularity or the nodes are all observable, many criteria do not work on the network with hidden nodes.
WBIC is proposed for the singular models. The main difference is that it is based on the marginal likelihood of the incomplete data
;
Due to the marginalization over
, it requires the calculation of values for all candidate structures. For example, assume that we have candidate structures
denoted by
,
, and
, respectively. In WBIC, we calculate all values and select the optimal structure;
On the other hand, in the proposed method, we calculate the label assignment with the structure and obtain , which shows the necessity of the node Z.
Another difference from the conventional criteria is the dominant order of the objective function, which determines the optimal structure. As shown in Corollary 6.1 of [
6], the negative logarithm of the marginal likelihood of the incomplete data has the following asymptotic form;
where the coefficient
is the empirical entropy of the observation
and
depends on the data-generating distribution, the model, and the prior distribution. This form means that the optimal model is selected by
order term with the coefficient
, while it is selected by
n order term with the coefficient
S of Theorem 3 in the proposed method. Since the largest terms are
n order in both
and
, the proposed method will have stronger effect to distinguish the difference of the structures.
The asymptotic accuracy of Bayesian clustering has been studied [
21], which considers the error function between the true distribution of the label assignment and the estimated one measured by the Kullback-Leibler divergence:
where
is the expectation over all evidence data and
The true network is denoted by . The proposed method minimizes this error function, which means that the label assignment is optimized in the sense of the density estimation. Even though the optimized function is not directly for the model selection, due to the asymptotic property of the Bayes clustering simplifying the label use, the proposed method is computationally efficient to determine the existence of the hidden node and the result asymptotically has coincident.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}