A Statistical Method for Estimating Activity Uncertainty Parameters to Improve Project Forecasting

Abstract
:1. Introduction
2. Managing Projects
2.1. Entropy in Project Management
“With the aid of the entropy one can estimate the amount of managerial effort required to overcome the uncertainty of a particular project.”
- Step 1. Identifying sources of project uncertainty,
- Step 2. Quantifying project uncertainty,
- Step 3. Using the uncertainty metrics for improving decision-making.
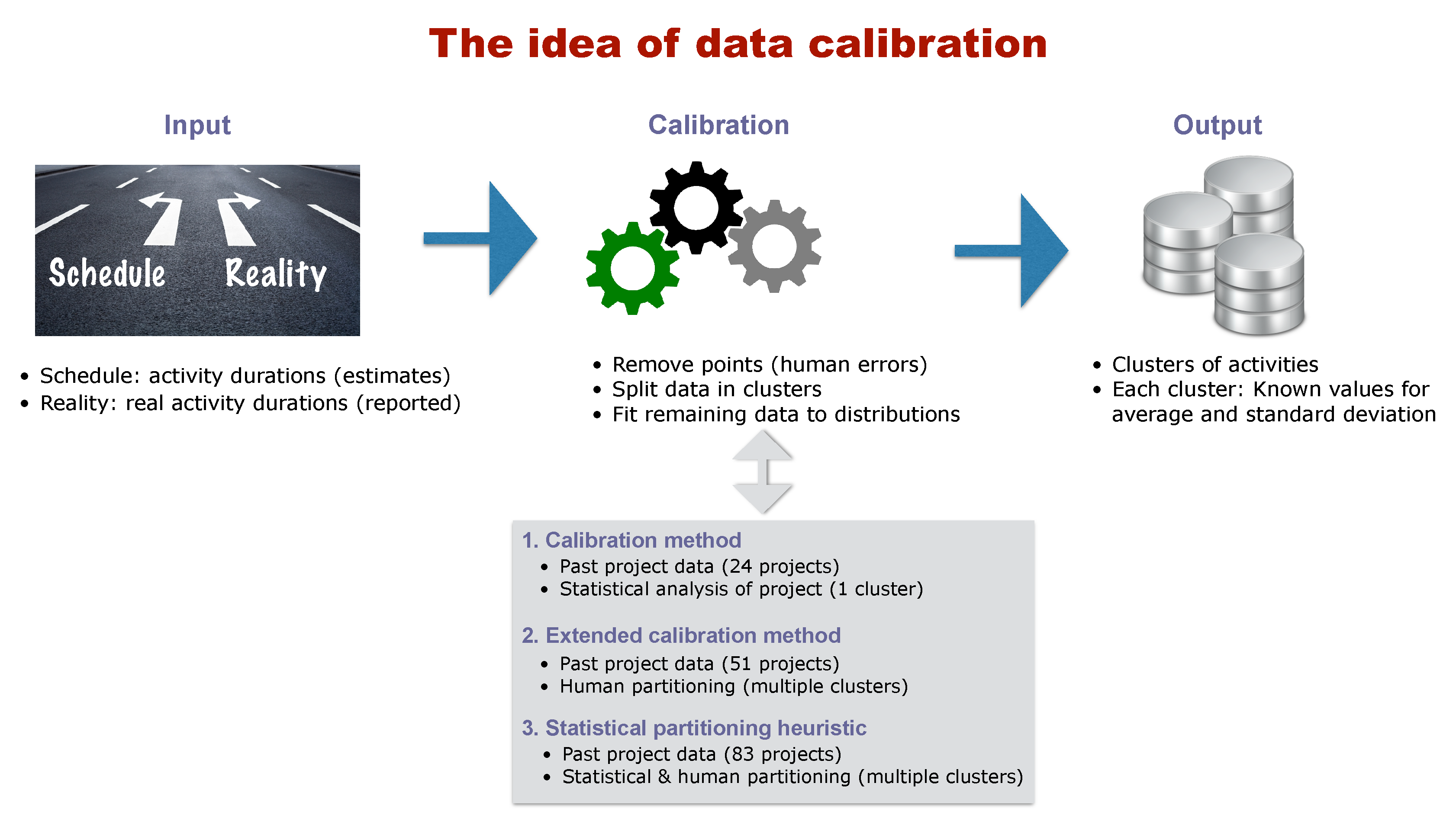
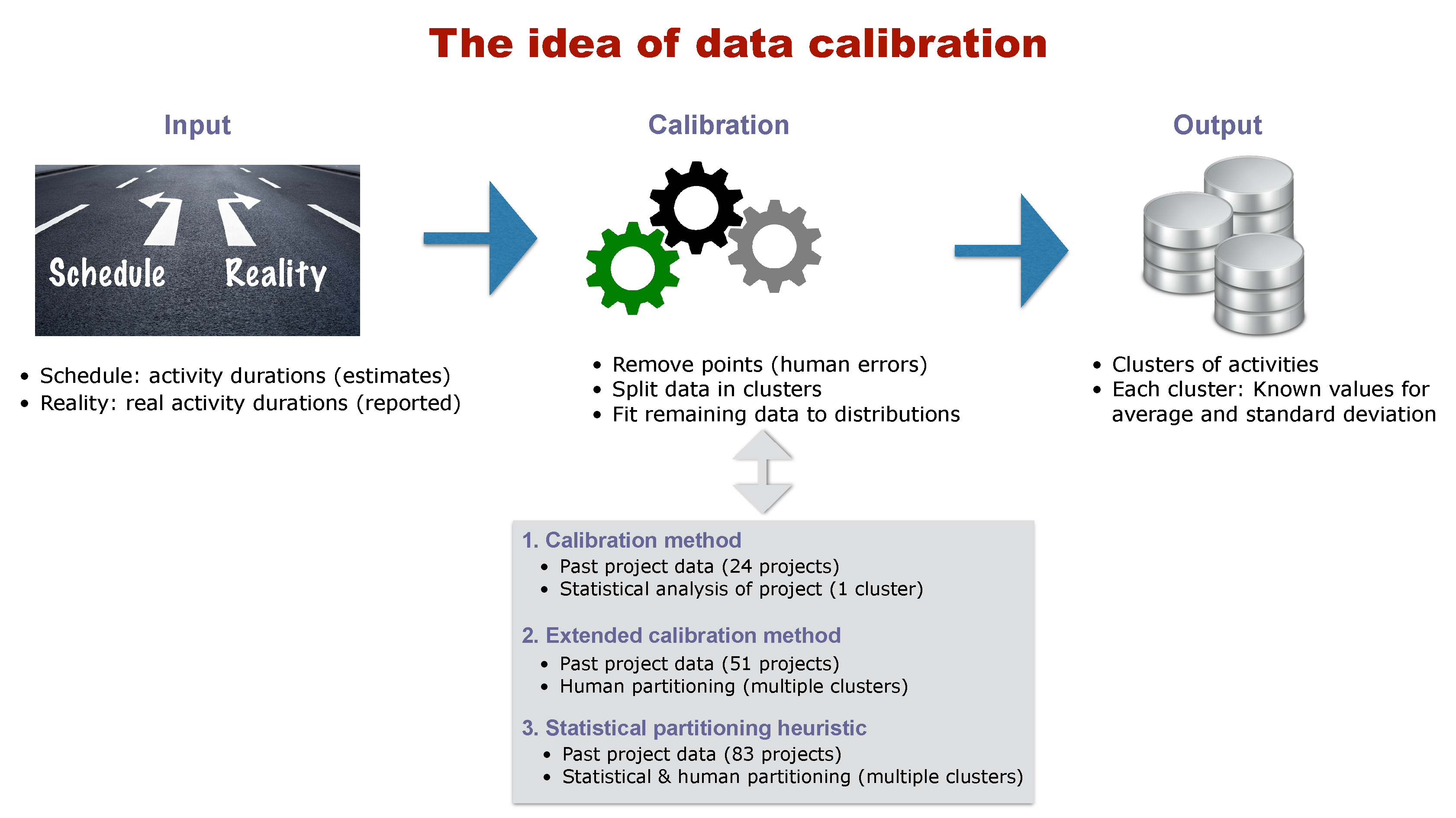
2.2. Calibrating Data
- Input: The input data should exist of a set of empirical projects that are finished and for which the outcome is known. More specifically, the empirical project data should consist of a set of planned activity durations (estimates made during the schedule construction) and a set of known real activity durations (that are collected after the project is finished).
- Calibration: The calibration phase makes use of the input data (planned and real activity durations) and performs a sequence of hypothesis tests to split the set of activities into clusters (partitions) with similar characteristics. Throughout these hypothesis tests, it is assumed that the activity durations follow a predefined probability distribution, but a calibration method differs from an ordinary statistical test since it recognizes that the reported values in the empirical data might contain some biases. More precisely, the data might be biased due to the presence of the Parkinson effect (activities that finish early are reported to be on time (hidden earliness)) as well as rounding errors (real activity durations are rounded up or down when reported). In order to overcome these potential biases, the calibration method starts with a sequence of hypothesis tests (for which the null hypothesis is that all activity durations follow the predefined distribution), and, if the hypothesis cannot be accepted, a portion of the activities of the project has to be removed from the set to correct for the previously mentioned biases. This approach continues until the remaining set of project activities follows the predefined distribution (i.e., the test is accepted), and then the value for the average and variance of this distribution can be accurately estimated.
- Output: The ultimate goal of the data calibration phase is to define one or multiple clusters of activities with similar and known values for the parameters for the predefined probability distribution (i.e., average durations and standard deviation). These values can be used to better predict the project outcome, and since the activity uncertainty is then no longer set as randomly chosen values (as is often the case in simulation studies) but based on realistic values, it should enable the project manager to better predict the project outcome and reduce the project uncertainty more efficiently. Hence, calibration methods aim at better estimating the activity and project uncertainty based on real project data, by taking human input biases into account, and by recognizing that not all activities should have the same values but can be clustered in smaller groups with similar values within each group, but different values between groups.
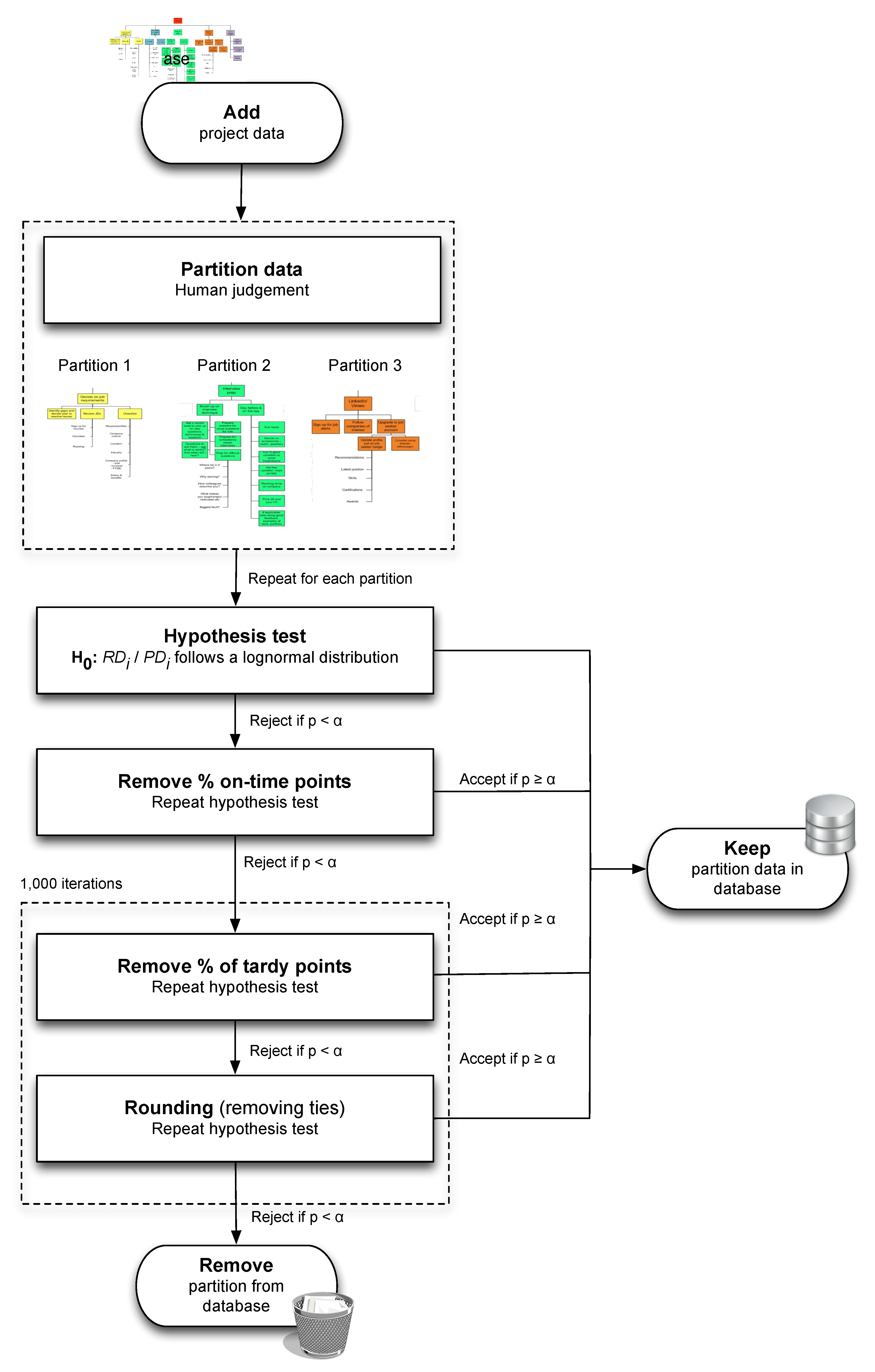
3. Calibration Procedures
3.1. Summary of Procedure
3.2. Limitations
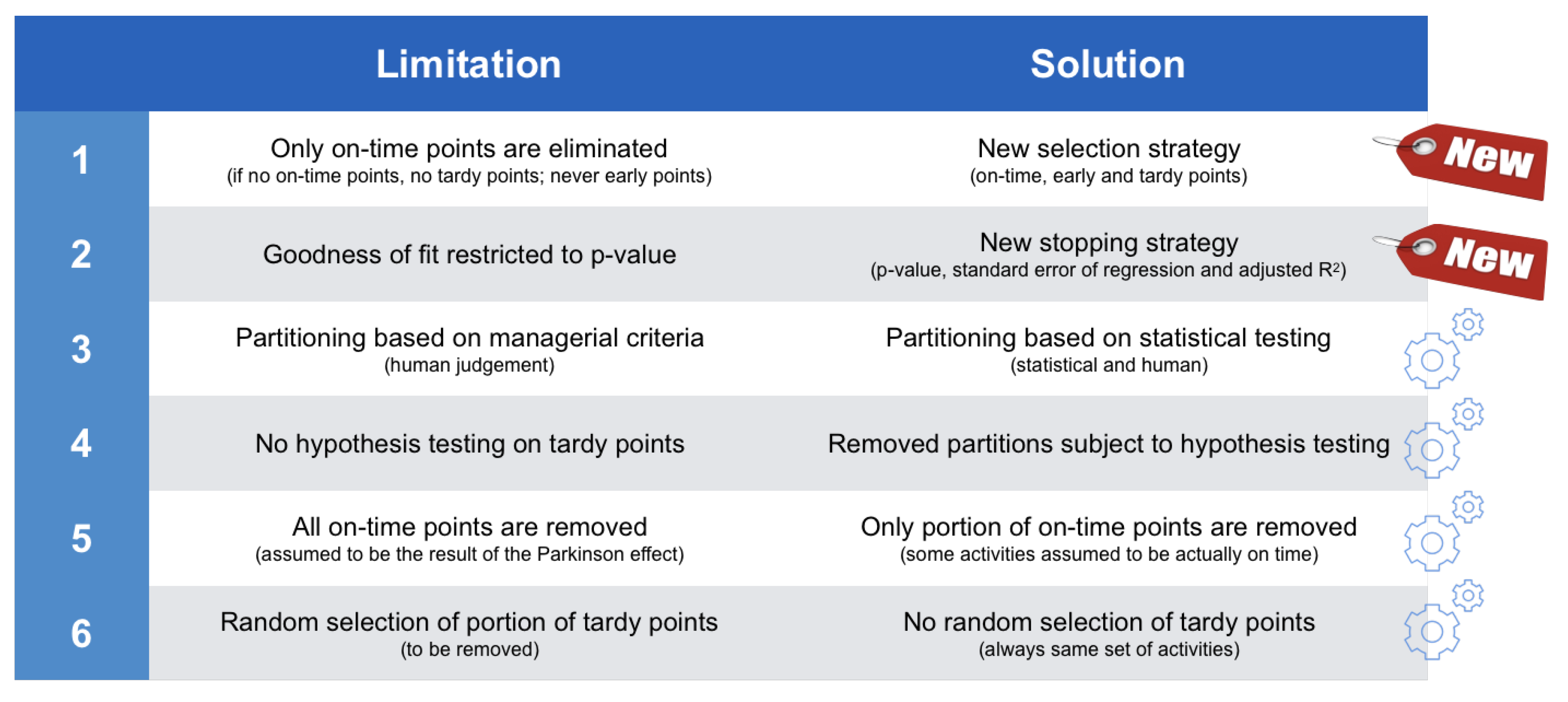
- Limitation 1. Only on-time activities can be eliminated in S2. Moreover, if there are no on-time activities in the project, any further analysis is impossible (the proportion x in S3 would per definition also be zero so that no tardy points can be removed either) and no (better) fit can be obtained. Note that early activities are never eliminated from the project in the calibration procedures.
- Limitation 2. The p-value is the only measure that is applied to assess the goodness-of-fit, whereas other measures exist that could also be utilized to this end and thus prove useful to calibrate data.
- Limitation 3. Partitioning can only be done based on managerial criteria (using the three criteria, i.e., PD, WP and RP) and is thus influenced by human judgement.
- Limitation 4. The lognormality hypothesis is not tested for the tardy activities that are removed in S3. This should be done, since these activities do not follow the pure Parkinson distribution like the eliminated on-time activities in S2 do.
- Limitation 5. S2 only allows the elimination of all on-time activities, whereas removing only a fraction of them could be more optimal (i.e., better fit to the PDLC).
- Limitation 6. Although 1000 iterations are performed, the tardy points that are to be removed in S3 are still chosen randomly within every iteration. Deviations in results, however minor, can thus still occur.
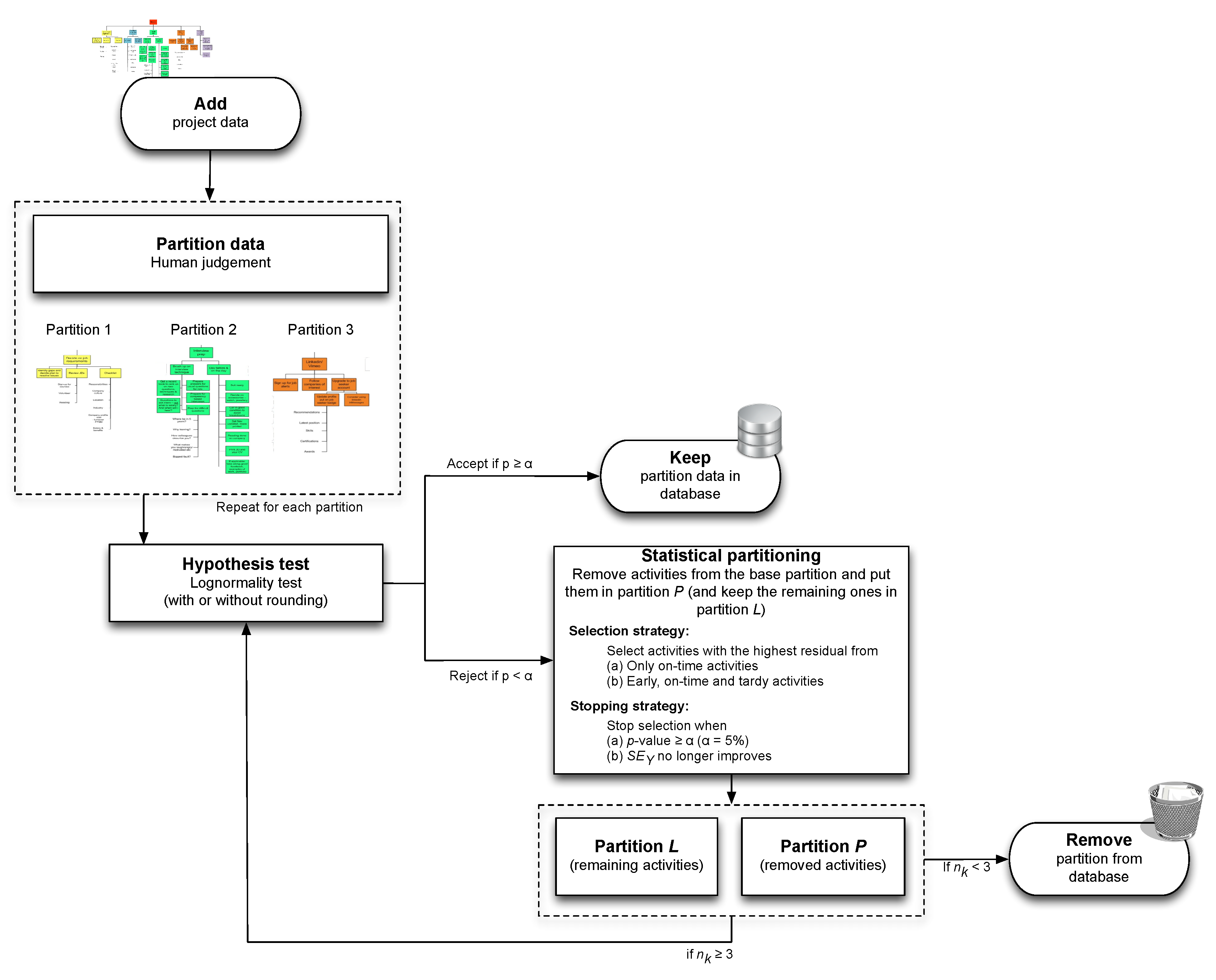
4. Partitioning Heuristic
4.1. Human Partitioning
4.2. Hypothesis Test
4.3. Statistical Partitioning
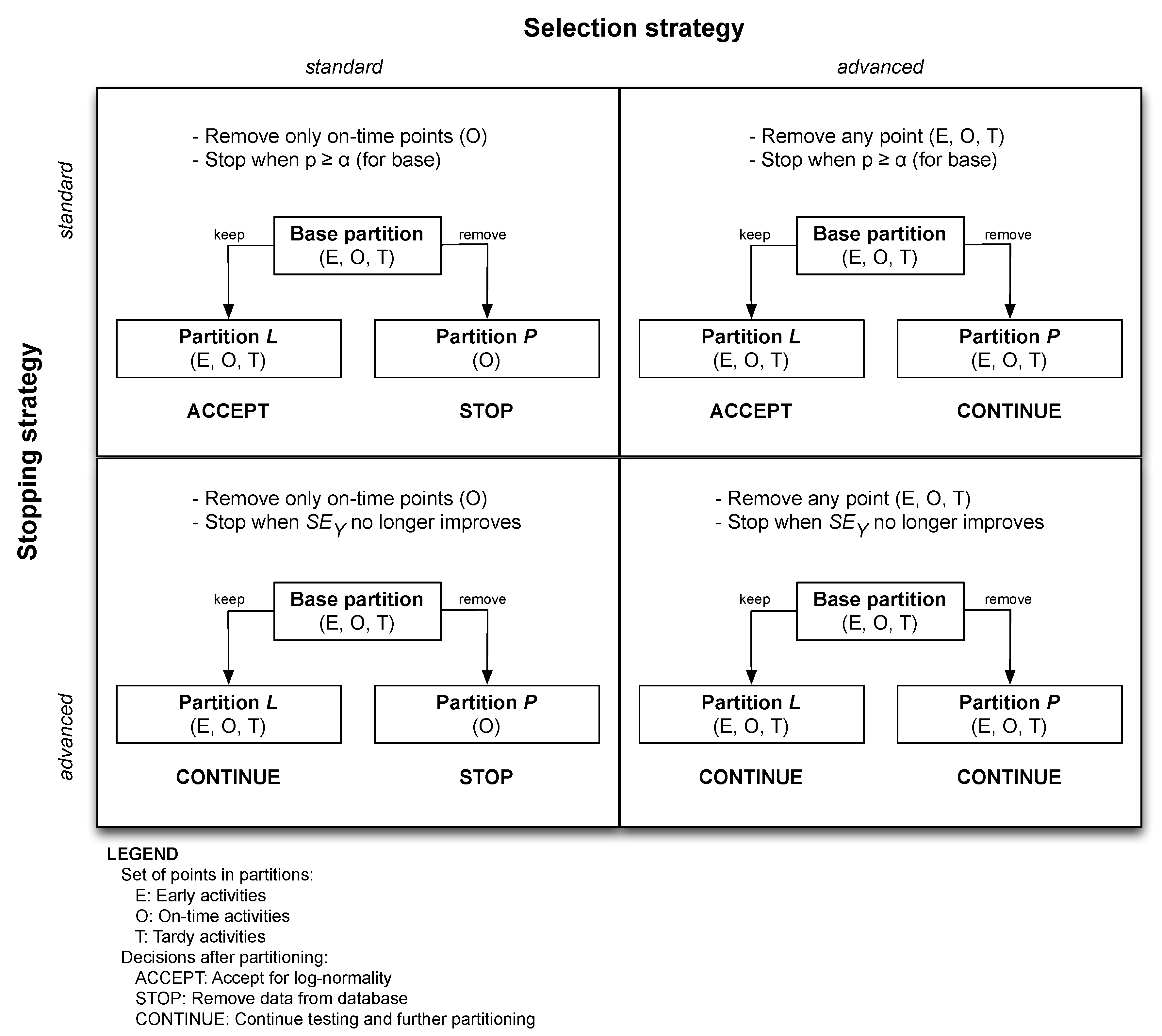
4.3.1. Selection Strategy
4.3.2. Stopping Strategy
4.3.3. Solutions
- Solution 1. The calibration procedures only removed on-time (S2) and tardy (S3) activities from the project. This is no longer true in the statistical partitioning heuristic. The advanced selection strategy states that all activities are selectable for removal, thus also the early and tardy ones. Early activities could never be eliminated from the project in the calibration procedures.
- Solution 4. The calibration procedures never apply the lognormality hypothesis to the removed tardy activities (S3). However, such a test should be performed, since these tardy activities do not follow the pure Parkinson distribution like the eliminated on-time activities in S2 do. Hence, there is no reason why these tardy points should automatically be removed from the database, and, therefore, they are subject to a new hypothesis test in the statistical partitioning heuristic.
- Solution 6. Thanks to the use of the criterion, 1000 iterations are no longer necessary (S3). Instead, the statistical partitioning heuristic always selects the exact same set of activities for elimination, since it now relies on the calculations. Since calculations of residuals are invariable, the created partitions would be exactly the same for every simulation run.
- Solution 2. The p-value is no longer the one and only measure that is applied to assess the goodness-of-fit. Instead, the advanced stopping strategy relies on two other measures— and —that can also be utilized to assess the goodness-of-fit.
- Solution 5. The Parkinson treatment of data points (S2) only allows the elimination of all on-time activities, whereas removing only a fraction of them could be more optimal, i.e., leading to a better fit to the PDLC.
- Solution 3. The extended version of the calibration procedure added project data partitioning as a promising feature to accept lognormality, but this new feature could only be performed based on managerial criteria influenced by human judgement. The statistical partitioning heuristic has followed the same logic, but transformed it into a statistical, rather than managerial, partitioning approach. Statistical partitioning is not subject to human (mis-)judgement and not victim to human biases but does not exclude the option of human partitioning as an initialisation step (S0). In the computational experiments of Section 5, it will be shown that human and statistical partitioning lead to a higher acceptance rate of project data.
5. Computational Results
- The hypothesis test (S1) can be performed with (1) or without (0) rounding (S4), and will further be abbreviated as rounding = 0 or 1.
- The selection strategy can be set to standard (0) or advanced (1), and will be abbreviated as selection = 0 or 1.
- The stopping strategy can also be set to be standard (0) or advanced (1), abbreviated as mboxemphstopping = 0 or 1.
5.1. Without Managerial Partitioning
5.2. With Managerial Partitioning
5.3. Limitations
- The statistical partitioning heuristic—as the name itself indicates—is still a heuristic and therefore produces good but not (always) optimal results. Indeed, removing the activities with the biggest residuals as long as the of the considered base partition (put in partition L) decreases is a plausible and logical approach. However, it is not optimal for multiple reasons. First, it is no certainty that the biggest residual always designates the best activity to eliminate (i.e., which produces the biggest decrease of ). Second, it is not assessed what the future impact (i.e., over multiple partitioning steps) of this removal would be on the remaining activities in partition L (e.g., maybe it would be more optimal to remove two other high-residual activities instead of that with the biggest residual, but the algorithm does not analyse this). In addition, third, when removing an activity from partition L, it becomes part of another partition (i.e., partition P), but we do not check the influence of this operation on partition P (for all we know, it could deteriorate the there). In addition, then there still is the issue of being susceptible to lapse into a local optimum, which we now—also heuristically—addressed by considering as a secondary optimization criterion. The ultimate goal would be to develop an algorithm that divides the activities of a project into partitions that all pass the lognormality test (with possible exception of some clear outliers), and moreover, show an average over all partitions that is as low as possible (or a p-value that is as high as possible). The advanced algorithm could, for example, contain a fine-tuning stage in which activities can be shifted from one partition to another in order to further improve the overall or p. Furthermore, a limit could be set for the minimal allowed partition size, to make the partitions themselves more meaningful and comparison with partitions from similar future projects more workable. We have now set the minimum size of each partition arbitrarily to 3.
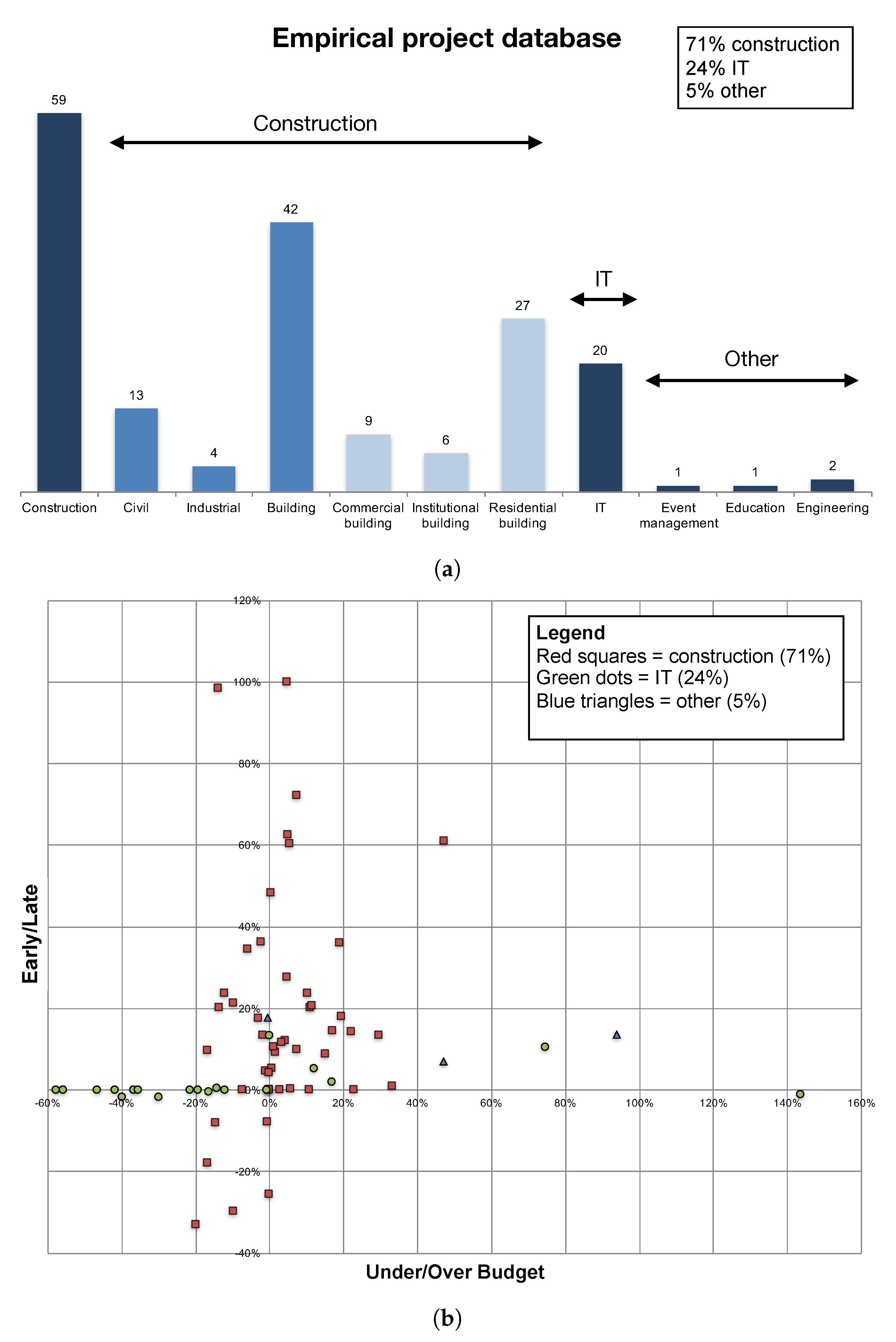
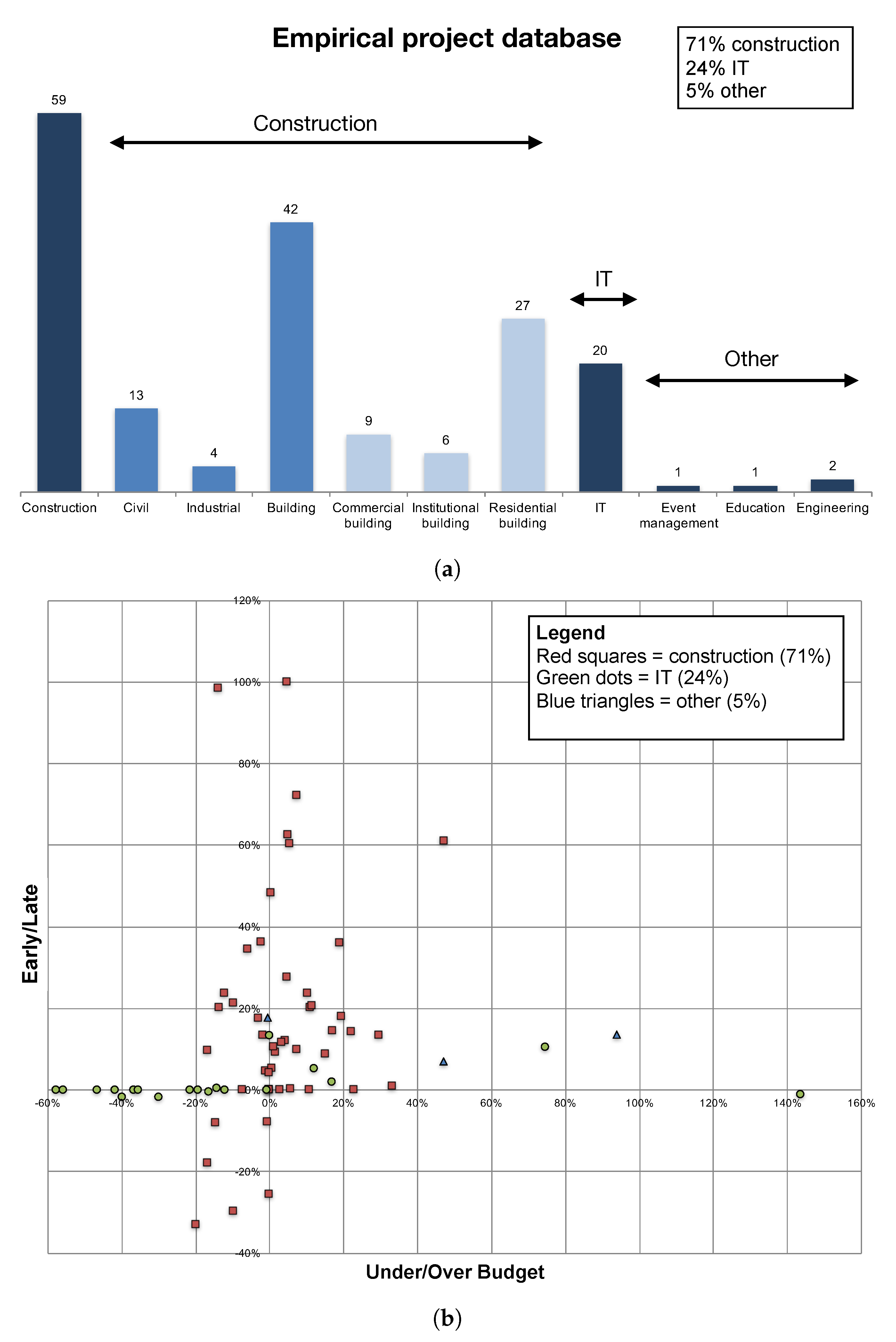
- The employed project database is large for an empirical data set, but still rather limited in comparison to simulation studies using artificial project data. Therefore, the database should ever be further expanded, so that future empirical studies based on it can keep increasing their validity and generalizability.
- Currently, we only considered the initial partitioning according to one managerial criterion at a time. This could be extended to the application of multiple consecutive criteria. For example, the PD criterion could be performed after the project has already been partitioned according to RP. In that way, we get even more specific partitions that should exhibit activities that are more strongly related. Furthermore, the extra managerial partitioning could be applied together with or instead of the statistical partitioning (i.e., if ).
- Furthermore, the managerial partitioning criteria should not stay limited to PD, WP and RP. These are perhaps some of the most obvious and logical criteria, but there can still be others that might show even greater distinctive power for dividing a project into adequate partitions. These extra managerial partitioning criteria could be harvested from more empirical research, for example, into the drivers of project success. If those drivers could be reliably identified for a particular kind of project, they could also provide a good basis for grouping similar activities that thus show similar risks (and should therefore belong to the same partition).
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Uyttewaal, E. Dynamic Scheduling With Microsoft Office Project 2003: The Book by and for Professionals; International Institute for Learning, Inc.: New York, NY, USA, 2005. [Google Scholar]
- Vanhoucke, M. Project Management with Dynamic Scheduling: Baseline Scheduling, Risk Analysis and Project Control; Springer: New York, NY, USA, 2012; Volume XVIII. [Google Scholar]
- Vanhoucke, M. Integrated Project Management and Control: First Comes the Theory, Then the Practice; Management for Professionals; Springer: New York, NY, USA, 2014. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Vanhoucke, M. Using activity sensitivity and network topology information to monitor project time performance. Omega Int. J. Manag. Sci. 2010, 38, 359–370. [Google Scholar] [CrossRef]
- Vanhoucke, M. On the dynamic use of project performance and schedule risk information during project tracking. Omega Int. J. Manag. Sci. 2011, 39, 416–426. [Google Scholar] [CrossRef]
- Martens, A.; Vanhoucke, M. The impact of applying effort to reduce activity variability on the project time and cost performance. Eur. J. Oper. Res. 2019. to appear. [Google Scholar] [CrossRef]
- Bushuyev, S.D.; Sochnev, S.V. Entropy measurement as a project control tool. Int. J. Proj. Manag. 1999, 17, 343–350. [Google Scholar] [CrossRef]
- Chenarani, A.; Druzhinin, E. A quantitative measure for evaluating project uncertainty under variation and risk effects. Eng. Technol. Appl. Sci. Res. 2017, 7, 2083–2088. [Google Scholar]
- Tseng, C.C.; Ko, P.W. Measuring schedule uncertainty for a stochastic resource-constrained project using scenario-based approach with utility-entropy decision model. J. Ind. Prod. Eng. 2016, 33, 558–567. [Google Scholar] [CrossRef]
- Cosgrove, W.J. Entropy as a measure of uncertainty for PERT network completion time distributions and critical path probabilities. Calif. J. Oper. Manag. 2010, 8, 20–26. [Google Scholar]
- Asllani, A.; Ettkin, L. An entropy-based approach for measuring project uncertainty. Acad. Inf. Manag. Sci. J. 2007, 10, 31–45. [Google Scholar]
- Williams, T. A classified bibliography of recent research relating to project risk management. Eur. J. Oper. Res. 1995, 85, 18–38. [Google Scholar] [CrossRef]
- Willems, L.; Vanhoucke, M. Classification of articles and journals on project control and Earned Value Management. Int. J. Proj. Manag. 2015, 33, 1610–1634. [Google Scholar] [CrossRef]
- Trietsch, D.; Mazmanyan, L.; Govergyan, L.; Baker, K.R. Modeling activity times by the Parkinson distribution with a lognormal core: Theory and validation. Eur. J. Oper. Res. 2012, 216, 386–396. [Google Scholar] [CrossRef]
- Malcolm, D.; Roseboom, J.; Clark, C.; Fazar, W. Application of a technique for a research and development program evaluation. Oper. Res. 1959, 646–669. [Google Scholar] [CrossRef]
- AbouRizk, S.; Halpin, D.; Wilson, J. Fitting beta distributions based on sample data. J. Constr. Eng. Manag. 1994, 120, 288–305. [Google Scholar] [CrossRef]
- Williams, T. Criticality in stochastic networks. J. Oper. Res. Soc. 1992, 43, 353–357. [Google Scholar] [CrossRef]
- Colin, J.; Vanhoucke, M. Empirical perspective on activity durations for project management simulation studies. J. Constr. Eng. Manag. 2015, 142, 04015047. [Google Scholar] [CrossRef]
- Vanhoucke, M.; Batselier, J. Fitting activity distributions using human partitioning and statistical calibration. Comput. Ind. Eng. 2019, 129, 126–135. [Google Scholar] [CrossRef]
- Batselier, J.; Vanhoucke, M. Construction and evaluation framework for a real-life project database. Int. J. Proj. Manag. 2015, 33, 697–710. [Google Scholar] [CrossRef]
- Blom, G. Statistical Estimates and Transformed Beta-Variables; John Wiley & Sons: Hoboken, NJ, USA, 1958. [Google Scholar]
- Looney, S.W.; Gulledge, T.R., Jr. Use of the correlation coefficient with normal probability plots. Am. Stat. 1985, 39, 75–79. [Google Scholar]
- Batselier, J.; Vanhoucke, M. Empirical Evaluation of Earned Value Management Forecasting Accuracy for Time and Cost. J. Constr. Eng. Manag. 2015, 141, 1–13. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Partitioning Setting | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| (––) | |||||||||
| (0-0-0) | (1-0-0) | (0-0-1) | (1-0-1) | (0-1-0) | (1-1-0) | (0-1-1) | (1-1-1) | ||
| (a) | # partitions (total) | 83 | 83 | 83 | 83 | 195 | 145 | 249 | 215 |
| # partitions (avg/p) | - | - | - | - | 2.3 | 1.7 | 3.0 | 2.6 | |
| # partitions (max) | - | - | - | - | 5 | 3 | 6 | 5 | |
| 1 partition [%] | - | - | - | - | 13 | 36 | 4 | 6 | |
| 2 partitions [%] | - | - | - | - | 51 | 53 | 25 | 42 | |
| 3 partitions [%] | - | - | - | - | 25 | 11 | 47 | 40 | |
| 4 partitions [%] | - | - | - | - | 10 | 0 | 17 | 11 | |
| 5 partitions [%] | - | - | - | - | 1 | 0 | 6 | 1 | |
| 6 partitions [%] | - | - | - | - | 0 | 0 | 1 | 0 | |
| (b) | # partitioning steps | 2566 | 2177 | 2771 | 2634 | 1361 | 365 | 1705 | 771 |
| /project | 31 | 26 | 33 | 32 | 16 | 4 | 21 | 9 | |
| (c) | % act / partition L | 62 | 73 | 54 | 59 | - | - | - | - |
| % act / partition P | 38 | 27 | 46 | 41 | - | - | - | - | |
| (d) | avg. | 0.271 | 0.229 | 0.250 | 0.212 | 0.257 | 0.191 | 0.264 | 0.139 |
| avg. p | 0.075 | 0.193 | 0.280 | 0.479 | 0.219 | 0.362 | 0.461 | 0.731 | |
| accepted partitions [%] | 61 | 72 | 61 | 72 | 90 | 95 | 86 | 94 | |
| Partitioning Setting | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| (––) | |||||||||
| (1-0-1) | (1-1-1) | ||||||||
| PD (x4) | PD (x5) | WP | RP | PD (x4) | PD (x5) | WP | RP | ||
| (a) | # projects | 83 | 83 | 53 | 21 | 83 | 83 | 53 | 21 |
| avg. # activities | 61 | 61 | 72 | 42 | 61 | 61 | 72 | 42 | |
| tot. # activities | 5068 | 5068 | 3796 | 887 | 5068 | 5068 | 3796 | 887 | |
| () | # partitions (human) | 232 | 213 | 426 | 65 | 232 | 213 | 426 | 65 |
| # partitions (avg/p) | 2.8 | 2.6 | 8.0 | 3.1 | 2.8 | 2.6 | 8.0 | 3.1 | |
| # partitions (max) | 4 | 4 | 26 * | 6 | 4 | 4 | 26 * | 6 | |
| 1 partition [%] | 4 | 6 | 36 | 0 | 4 | 6 | 36 | 0 | |
| 2 partitions [%] | 32 | 40 | 45 | 24 | 32 | 40 | 45 | 24 | |
| 3 partitions [%] | 45 | 46 | 8 | 52 | 45 | 46 | 8 | 52 | |
| 4 partitions [%] | 19 | 8 | 7 | 19 | 19 | 8 | 7 | 19 | |
| 5 partitions [%] | 0 | 0 | 2 | 0 | 0 | 0 | 2 | 0 | |
| 6 partitions [%] | 0 | 0 | 2 | 5 | 0 | 0 | 2 | 5 | |
| () | # subpartitions (statistical) | - | - | - | - | 423 | 399 | 631 | 117 |
| # subpartitions (avg/p) | - | - | - | - | 5.1 | 4.8 | 11.9 | 5.6 | |
| # subpartitions (max) | - | - | - | - | 4 | 4 | 5 | 4 | |
| 1 subpartition [%] | - | - | - | - | 40 | 37 | 59 | 34 | |
| 2 subpartitions [%] | - | - | - | - | 40 | 41 | 35 | 54 | |
| 3 subpartitions [%] | - | - | - | - | 18 | 19 | 4 | 11 | |
| 4 subpartitions [%] | - | - | - | - | 2 | 3 | 1 | 1 | |
| 5 subpartitions [%] | - | - | - | - | 0 | 0 | 1 | 0 | |
| (c) | tot. # partitioning steps | 2150 | 2246 | 835 | 348 | 689 | 751 | 555 | 182 |
| /project | 26 | 27 | 16 | 17 | 8 | 9 | 10 | 9 | |
| (d) | % act. partition L | 79 | 78 | 90 | 77 | - | - | - | - |
| % act. partition P | 21 | 22 | 10 | 23 | - | - | - | - | |
| (f) | avg. | 0.161 | 0.171 | 0.196 | 0.101 | 0.108 | 0.130 | 0.146 | 0.088 |
| avg. p | 0.614 | 0.589 | 0.658 | 0.741 | 0.774 | 0.756 | 0.783 | 0.811 | |
| accepted (sub)partitions [%] | 88 | 85 | 92 | 95 | 97 | 94 | 97 | 97 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vanhoucke, M.; Batselier, J. A Statistical Method for Estimating Activity Uncertainty Parameters to Improve Project Forecasting. Entropy 2019, 21, 952. https://doi.org/10.3390/e21100952
Vanhoucke M, Batselier J. A Statistical Method for Estimating Activity Uncertainty Parameters to Improve Project Forecasting. Entropy. 2019; 21(10):952. https://doi.org/10.3390/e21100952
Chicago/Turabian StyleVanhoucke, Mario, and Jordy Batselier. 2019. "A Statistical Method for Estimating Activity Uncertainty Parameters to Improve Project Forecasting" Entropy 21, no. 10: 952. https://doi.org/10.3390/e21100952
APA StyleVanhoucke, M., & Batselier, J. (2019). A Statistical Method for Estimating Activity Uncertainty Parameters to Improve Project Forecasting. Entropy, 21(10), 952. https://doi.org/10.3390/e21100952