1. Introduction
The rate distortion function (RDF) of a source provides the minimum rate at which data can be encoded in order to be able to recover them with a mean squared error (MSE) per dimension not larger than a given distortion.
In this paper, we present a low-complexity coding strategy to encode (compress) finite-length data blocks of Gaussian
N-dimensional vector sources. Moreover, we show that for large enough data blocks of a Gaussian asymptotically wide sense stationary (AWSS) vector source, the rate of our coding strategy tends to the RDF of the source. The definition of AWSS vector process can be found in ([
1] (Definition 7.1)). This definition was first introduced for the scalar case N = 1 (see ([
2] (Section 6)) or [
3]), and it is based on the Gray concept of asymptotically equivalent sequences of matrices [
4].
A low-complexity coding strategy can be found in [
5] for finite-length data blocks of Gaussian wide sense stationary (WSS) sources and in [
6] for finite-length data blocks of Gaussian AWSS autoregressive (AR) sources. Both precedents deal with scalar processes. The low-complexity coding strategy presented in this paper generalizes the aforementioned strategies to Gaussian AWSS vector sources.
Our coding strategy is based on the block discrete Fourier transform (DFT), and therefore, it turns out to be a low-complexity coding strategy when the fast Fourier transform (FFT) algorithm is used. Specifically, the computational complexity of our coding strategy is , where n is the length of the data blocks. Besides being a low-complexity strategy, it does not require the knowledge of the correlation matrix of such data blocks.
We show that this coding strategy is appropriate to encode the most relevant Gaussian vector sources, namely, WSS, moving average (MA), autoregressive (AR), and ARMA vector sources. Observe that our coding strategy is then appropriate to encode Gaussian vector sources found in the literature, such as the corrupted WSS vector sources considered in [
7,
8] for the quadratic Gaussian CEO problem.
The paper is organized as follows. In
Section 2, we obtain several new mathematical results on the block DFT, and we present an upper bound for the RDF of a complex Gaussian vector. In
Section 3, using the results given in
Section 2, we present a new coding strategy based on the block DFT to encode finite-length data blocks of Gaussian vector sources. In
Section 4, we show that for large enough data blocks of a Gaussian AWSS vector source, the rate of our coding strategy tends to the RDF of the source. In
Section 5, we show that our coding strategy is appropriate to encode WSS, MA, AR, and ARMA vector sources. In
Section 6, conclusions and numerical examples are presented.
2. Preliminaries
2.1. Notation
In this paper
,
,
, and
are the set of positive integers, the set of integers, the set of real numbers, and the set of complex numbers, respectively. The symbol ⊤ denotes transpose and the symbol ∗ denotes conjugate transpose.
and
are the spectral and the Frobenius norm, respectively.
denotes the smallest integer higher than or equal to
x.
E stands for expectation, ⊗ is the Kronecker product, and
,
, denote the eigenvalues of an
Hermitian matrix
A arranged in decreasing order.
is the set of real
n-dimensional (column) vectors,
denotes the set of
complex matrices,
is the
zero matrix,
denotes the
identity matrix, and
is the
Fourier unitary matrix, i.e.,
where
is the imaginary unit.
If for all , then denotes the block diagonal matrix with blocks given by , where is the Kronecker delta.
and denote the real part and the imaginary part of a complex number, respectively. If , then and are the real matrices given by and with and , respectively.
If
, then
denotes the real
-dimensional vector given by
If
for all
, then
is the
-dimensional vector given by
Finally, if is a (complex) random N-dimensional vector for all , denotes the corresponding (complex) random N-dimensional vector process.
2.2. New Mathematical Results on the Block DFT
We first give a simple result on the block DFT of real vectors.
Lemma 1. Let . Consider for all . Suppose that is the block DFT of , i.e., Then the two following assertions are equivalent:
- 1.
.
- 2.
for all and .
We now give three new mathematical results on the block DFT of random vectors that are used in
Section 3.
Theorem 1. Consider . Let be a random N-dimensional vector for all . Suppose that is given by Equation (1). If , thenand Theorem 2. Let and be as in Theorem 1. Suppose that is real. If , then Lemma 2. Let and be as in Theorem 1. If , then
- 1.
.
- 2.
.
- 3.
.
2.3. Upper Bound for the RDF of a Complex Gaussian Vector
In [
9], Kolmogorov gave a formula for the RDF of a real zero-mean Gaussian
N-dimensional vector
with positive definite correlation matrix
, namely,
where
denotes trace and
is a real number satisfying
If
, an optimal coding strategy to achieve
is to encode
separately, where
with
U being a real orthogonal eigenvector matrix of
(see ([
6] (Corollary 1))). Observe that in order to obtain
U, we need to know the correlation matrix
. This coding strategy also requires an optimal coding method for real Gaussian random variables. Moreover, as
, if
, then from Equation (
4) we obtain
We recall that
can be thought of as the minimum rate (measured in nats) at which
can be encoded (compressed) in order to be able to recover it with an MSE per dimension not larger than
D, that is:
where
denotes the estimation of
.
The following result gives an upper bound for the RDF of a complex zero-mean Gaussian N-dimensional vector (i.e., a real zero-mean Gaussian -dimensional vector).
Lemma 3. Consider . Let z be a complex zero-mean Gaussian N-dimensional vector. If is a positive definite matrix, then Proof. We divide the proof into three steps:
Step 1: We prove that
is a positive definite matrix. We have
and
Consider
, and suppose that
. We only need to show that
. As
is a positive definite matrix and
we obtain
, or equivalently
.
Step 2: We show that
. We have
, where
and
. Applying ([
10] (Corollary 1)), we obtain
Step 3: We now prove Equation (
6). From Equation (
5), we conclude that
□
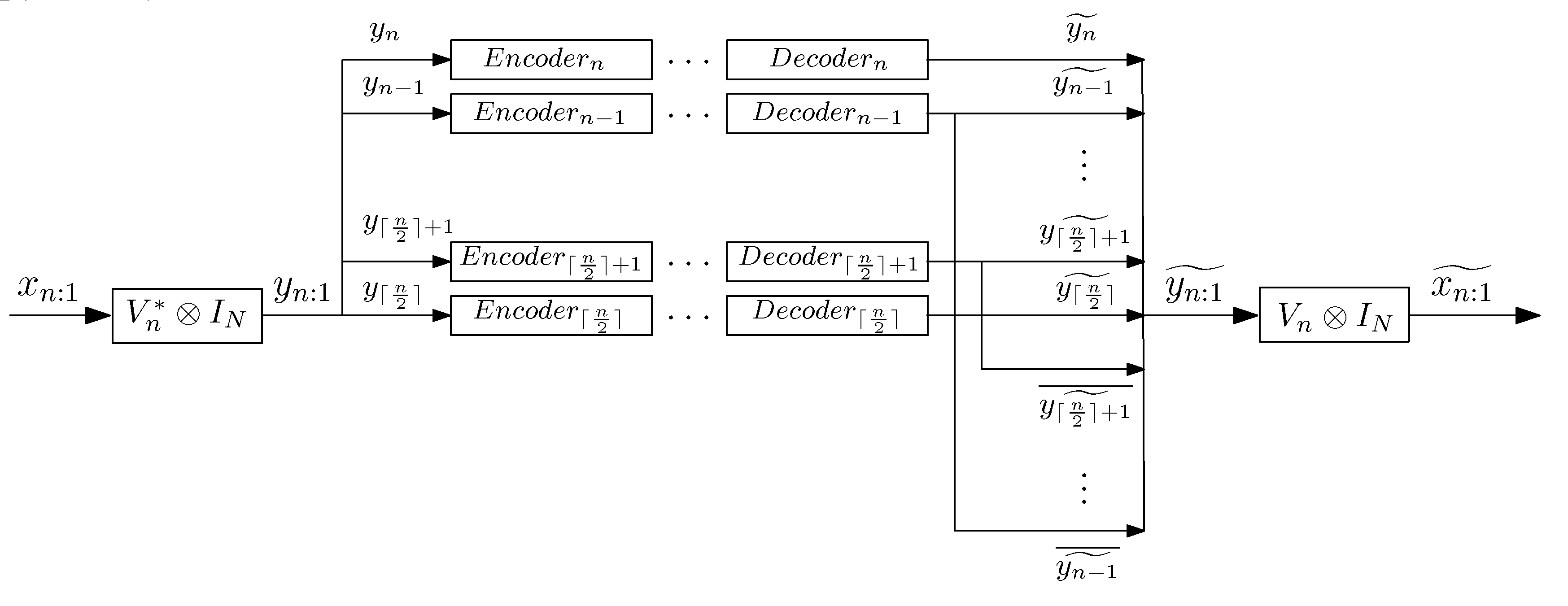
3. Low-Complexity Coding Strategy for Gaussian Vector Sources
In this section (see Theorem 3), we present our coding strategy for Gaussian vector sources. To encode a finite-length data block
of a Gaussian
N-dimensional vector source
, we compute the block DFT of
(
) and we encode
separately with
for all
(see
Figure 1).
We denote by
the rate of our strategy. Theorem 3 also provides an upper bound of
. This upper bound is used in
Section 4 to prove that our coding strategy is asymptotically optimal whenever the Gaussian vector source is AWSS.
In Theorem 3 denotes the matrix , where .
Theorem 3. Consider . Let be a random N-dimensional vector for all . Suppose that is a real zero-mean Gaussian vector with a positive definite correlation matrix (or equivalently, ). Let be the random vector given by Equation (1). If , thenwhere Proof. We divide the proof into three steps:
Step 1: We show that
. From Lemma 1,
for all
, and
with
. We encode
separately (i.e., if
n is even, we encode
separately, and if
n is odd, we encode
separately) with
and
Let
with
where
for all
, and
for all
. Applying Lemma 1 yields
. As
is unitary and
is unitarily invariant, we have
Step 2: We prove that
. From Equations (
3) and (
5), we obtain
and applying Theorem 2 and Equation (
5) yields
Step 3: We show Equation (
8).
As
is a positive definite matrix (or equivalently,
is Hermitian and
for all
),
is Hermitian. Hence,
is Hermitian for all
, and therefore,
is also Hermitian. Consequently,
is Hermitian, and applying Equations (
3) and (
11), we have that
is a positive definite matrix.
Let be an eigenvalue decomposition (EVD) of , where U is unitary. Thus, and .
Since is Hermitian and is a positive definite matrix, is also a positive definite matrix.
From Equation (
5), we have
and applying the arithmetic mean-geometric mean inequality yields
□
In Equation (
12),
is written in terms of
.
can be written in terms of
and
by using Lemma 2 and Equations (
9) and (
10).
As our coding strategy requires the computation of the block DFT, its computational complexity is whenever the FFT algorithm is used. We recall that the computational complexity of the optimal coding strategy for is since it requires the computation of , where is a real orthogonal eigenvector matrix of . Observe that such eigenvector matrix also needs to be computed, which further increases the complexity. Hence, the main advantage of our coding strategy is that it notably reduces the computational complexity of coding . Moreover, our coding strategy does not require the knowledge of . It only requires the knowledge of , with .
It should be mentioned that Equation (
7) provides two upper bounds for the RDF of finite-length data blocks of a real zero-mean Gaussian
N-dimensional vector source
. The greatest upper bound in Equation (
7) was given in [
11] for the case in which the random vector source
is WSS, and therefore, the correlation matrix of the Gaussian vector,
, is a block Toeplitz matrix. Such upper bound was first presented by Pearl in [
12] for the case in which the source is WSS and
. However, neither [
11] nor [
12] propose a coding strategy for
.
4. Optimality of the Proposed Coding Strategy for Gaussian AWSS Vector Sources
In this section (see Theorem 4), we show that our coding strategy is asymptotically optimal, i.e., we show that for large enough data blocks of a Gaussian AWSS vector source
, the rate of our coding strategy, presented in
Section 3, tends to the RDF of the source.
We begin by introducing some notation. If
is a continuous and
-periodic matrix-valued function of a real variable, we denote by
the
block Toeplitz matrix with
blocks given by
where
is the sequence of Fourier coefficients of
X:
If
and
are
matrices for all
, we write
when the sequences
and
are asymptotically equivalent (see ([
13] (p. 5673))), that is,
and
are bounded and
The original definition of asymptotically equivalent sequences of matrices was given by Gray (see ([
2] (Section 2.3)) or [
4]) for
.
We now review the definition of the AWSS vector process given in ([
1] (Definition 7.1)). This definition was first introduced for the scalar case N = 1 (see ([
2] (Section 6)) or [
3]).
Definition 1. Let , and suppose that it is continuous and -periodic. A random N-dimensional vector process is said to be AWSS with asymptotic power spectral density (APSD) X if it has constant mean (i.e., for all and .
We recall that the RDF of is defined as .
Theorem 4. Let be a real zero-mean Gaussian AWSS N-dimensional vector process with APSD X. Suppose that . If , then Proof. We divide the proof into two steps:
Step 1: We show that
. From Equation (
12), ([
1] (Theorem 6.6)), and ([
14] (Proposition 2)) yields
Step 2: We prove that
. Applying Equations (
7) and (
8), we obtain
To finish the proof, we only need to show that
Let
be the
block circulant matrix with
blocks defined in ([
13] (p. 5674)), i.e.,
Consequently, as the Frobenius norm is unitarily invariant, we have
Since
, Equation (
16) and ([
1] (Lemma 6.1)) yields Equation (
15). □
Observe that the integral formula in Equation (
13) provides the value of the RDF of the Gaussian AWSS vector source whenever
. An integral formula of such an RDF for any
can be found in ([
15] (Theorem 1)). It should be mentioned that ([
15] (Theorem 1)) generalized the integral formulas previously given in the literature for the RDF of certain Gaussian AWSS sources, namely, WSS scalar sources [
9], AR AWSS scalar sources [
16], and AR AWSS vector sources of finite order [
17].
5. Relevant AWSS Vector Sources
WSS, MA, AR, and ARMA vector processes are frequently used to model multivariate time series (see, e.g., [
18]) that arise in any domain that involves temporal measurements. In this section, we show that our coding strategy is appropriate to encode the aforementioned vector sources whenever they are Gaussian and AWSS.
It should be mentioned that Gaussian AWSS MA vector (VMA) processes, Gaussian AWSS AR vector (VAR) processes, and Gaussian AWSS ARMA vector (VARMA) processes are frequently called Gaussian stationary VMA processes, Gaussian stationary VAR processes, and Gaussian stationary VARMA processes, respectively (see, e.g., [
18]). However, they are asymptotically stationary but not stationary, because their corresponding correlation matrices are not block Toeplitz.
5.1. WSS Vector Sources
In this subsection (see Theorem 5), we give conditions under which our coding strategy is asymptotically optimal for WSS vector sources.
We first recall the well-known concept of WSS vector process.
Definition 2. Let , and suppose that it is continuous and -periodic. A random N-dimensional vector process is said to be WSS (or weakly stationary) with PSD X if it has constant mean and .
Theorem 5. Let be a real zero-mean Gaussian WSS N-dimensional vector process with PSD X. Suppose that (or equivalently, for all ). If , then Proof. Applying ([
1] (Lemma 3.3)) and ([
1] (Theorem 4.3)) yields
. Theorem 5 now follows from ([
14] (Proposition 3)) and Theorem 4. □
Theorem 5 was presented in [
5] for the case
(i.e., just for WSS sources but not for vector WSS sources).
5.2. VMA Sources
In this subsection (see Theorem 6), we give conditions under which our coding strategy is asymptotically optimal for VMA sources.
We start by reviewing the concept of VMA process.
Definition 3. A real zero-mean random N-dimensional vector process is said to be MA ifwhere , , are real matrices, is a real zero-mean random N-dimensional vector process, and for all with Λ being a real positive definite matrix. If there exists such that for all , then is called a VMA(q) process. Theorem 6. Let be as in Definition 3. Assume that , with and for all , is the sequence of Fourier coefficients of a function , which is continuous and -periodic. Suppose that is stable (that is, is bounded). If is Gaussian and , then Moreover, for all .
Proof. We divide the proof into three steps:
Step 1: We show that
for all
. From ([
15] (Equation (A3))) we have that
. Consequently,
Step 2: We prove the first equality in Equation (
17). Applying ([
15] (Theorem 2)), we obtain that
is AWSS. From Theorem 4, we only need to show that
. We have
Step 3: We show that
for all
. Applying Equation (
12) yields
□
5.3. VAR AWSS Sources
In this subsection (see Theorem 7), we give conditions under which our coding strategy is asymptotically optimal for VAR sources.
We first recall the concept of VAR process.
Definition 4. A real zero-mean random N-dimensional vector process is said to be AR ifwhere , , are real matrices, is a real zero-mean random N-dimensional vector process, and for all with Λ being a real positive definite matrix. If there exists such that for all , then is called a VAR(p) process. Theorem 7. Let be as in Definition 4. Assume that , with and for all , is the sequence of Fourier coefficients of a function , which is continuous and -periodic. Suppose that is stable and for all . If is Gaussian and , then Moreover, for all .
Proof. We divide the proof into three steps:
Step 1: We show that
for all
. From ([
19] (Equation (
19))), we have that
. Consequently,
Step 2: We prove the first equality in Equation (
18). Applying ([
15] (Theorem 3)), we obtain that
is AWSS. From Theorem 4, we only need to show that
. Applying ([
1] (Theorem 4.3)) yields
Step 3: We show that
for all
. This can be directly obtained from Equation (
12). □
Theorem 7 was presented in [
6] for the case of
(i.e., just for AR sources but not for VAR sources).
5.4. VARMA AWSS Sources
In this subsection (see Theorem 8), we give conditions under which our coding strategy is asymptotically optimal for VARMA sources.
We start by reviewing the concept of VARMA process.
Definition 5. A real zero-mean random N-dimensional vector process is said to be ARMA ifwhere and , , are real matrices, is a real zero-mean random N-dimensional vector process, and for all with Λ being a real positive definite matrix. If there exists such that for all and for all , then is called a VARMA(p,q) process (or a VARMA process of (finite) order (p,q)). Theorem 8. Let be as in Definition 5. Assume that , with and for all , is the sequence of Fourier coefficients of a function which is continuous and -periodic. Suppose that , with and for all , is the sequence of Fourier coefficients of a function which is continuous and -periodic. Assume that and are stable, and for all . If is Gaussian and , then Moreover, for all .
Proof. We divide the proof into three steps:
Step 1: We show that
for all
. From ([
15] (Appendix D)) and ([
1] (Lemma 4.2)), we have that
. Consequently,
Step 2: We prove the first equality in Equation (
19). Applying ([
15] (Theorem 3)), we obtain that
is AWSS. From Theorem 4, we only need to show that
. Applying ([
1] (Theorem 4.3)) yields
Step 3: We show that
for all
. This can be directly obtained from Equation (
12). □
6. Numerical Examples
We first consider four AWSS vector processes, namely, we consider the zero-mean WSS vector process in ([
20] (Section 4)), the VMA(1) process in ([
18] (Example 2.1)), the VAR(1) process in ([
18] (Example 2.3)), and the VARMA(1,1) process in ([
18] (Example 3.2)). In ([
20] (Section 4)),
and the Fourier coefficients of its PSD
X are
and
with
. In ([
18] (Example 2.1)),
,
is given by
for all
, and
In ([
18] (Example 2.3)),
,
for all
, and
and
are given by Equations (
20) and (
21), respectively. In ([
18] (Example 3.2)),
,
for all , and for all .
Figure 2,
Figure 3,
Figure 4 and
Figure 5 show
and
with
and
for the four vector processes considered, by assuming that they are Gaussian. The figures bear evidence of the fact that the rate of our coding strategy tends to the RDF of the source.
We finish with a numerical example to explore how our method performs in the presence of a perturbation. Specifically, we consider a perturbed version of the WSS vector process in ([
20] (Section 4)) (
Figure 6). The correlation matrices of the perturbed process are
7. Conclusions
The computational complexity of coding finite-length data blocks of Gaussian N-dimensional vector sources can be reduced by using the low-complexity coding strategy presented here instead of the optimal coding strategy. Specifically, the computational complexity is reduced from to , where n is the length of the data blocks. Moreover, our coding strategy is asymptotically optimal (i.e., the rate of our coding strategy tends to the RDF of the source) whenever the Gaussian vector source is AWSS and the considered data blocks are large enough. Besides being a low-complexity strategy, it does not require the knowledge of the correlation matrix of such data blocks. Furthermore, our coding strategy is appropriate to encode the most relevant Gaussian vector sources, namely, WSS, MA, AR, and ARMA vector sources.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}