A Class of Association Measures for Categorical Variables Based on Weighted Minkowski Distance

Department of Mathematical Sciences, University of Arkansas, Fayetteville, AR 72701, USA
Entropy 2019, 21(10), 990; https://doi.org/10.3390/e21100990
Submission received: 16 August 2019
/
Revised: 28 September 2019
/
Accepted: 10 October 2019
/
Published: 11 October 2019
(This article belongs to the Section Information Theory, Probability and Statistics)
Abstract
:Measuring and testing association between categorical variables is one of the long-standing problems in multivariate statistics. In this paper, I define a broad class of association measures for categorical variables based on weighted Minkowski distance. The proposed framework subsumes some important measures including Cramér’s V, distance covariance, total variation distance and a slightly modified mean variance index. In addition, I establish the strong consistency of the defined measures for testing independence in two-way contingency tables, and derive the scaled forms of unweighted measures.
1. Introduction
Measuring and testing the association between categorical variables from observed data is one of the long-standing problems in multivariate statistics. The observed frequencies of two categorical variables are often displayed in a two-way contingency table, and a multinomial distribution can be used to model the cell counts. To be specific, let X and Y be two categorical random variables with finite sampling spaces and (, where stands for the cardinality of a set), and a simple random sample of size N can be summarized in a table with count in cell . Let , , and be the joint and marginal probabilities of X and Y, i.e., , then the statistical independence between X and Y can be defined as for any , i.e., all joint probabilities equal the product of their marginal probabilities. Pearson’s chi-squared statistic,
where , , and , has been widely used to test independence in two-way contingency tables. Under independence and sufficient sample size, approximately follows a chi-squared distribution with . However, for insufficient sample size (e.g., , where ), the chi-squared test tends to be conservative. Zhang (2019) suggested a random permutation test based on the test statistic
which is derived from the squared distance covariance, a measure of the dependence between two random vectors of any type (discrete or continuous) [1,2]. The statistic is closely related to Pearson’s chi-squared statistic, both measuring the squared distance between and , . In the numerical study of Zhang (2019), the distance covariance test was evaluated in terms of the statistical power and type I error rate under various settings (see Figures 1–3 in [1]). It is found that for relatively large sample sizes, the distance covariance test performs similarly well as Pearson’s chi-squared test. However, for relatively small sample sizes, the distance covariance test is substantially more powerful and it controls the type I error rate at the nominal level. For small sample, Pearson’s chi-squared test exhibits substantial conservativeness, in the sense that the type I error rate is much lower than the nominal level and it fails to reject many false hypotheses. For instance, in a simulation setting with 20 by 20 table and only 50 samples, the statistical power and type I error rate are both close to zero by Pearson’s chi-squared test, indicating an extreme conservativeness.
Although the distance covariance test has better empirical performance than Pearson’s chi-squared test, especially for small sample size, its theoretical properties have not been investigated. In addition, Zhang (2019) only studied two alternative measures, including distance covariance and projection correlation, but there are many other association measures in the literature remaining unexplored. To name a few, Goodman and Kruskal (1954) introduced two association measures for categorical variables, namely the concentration coefficient and the coefficient [3]. Cui et al. (2015) developed a generic association measure based on a mean-variance index [4]. Theil (1970) proposed measuring the association between two categorical variables by the uncertainty coefficient [5]. McCane and Albert (2008) introduced the symbolic covariance, which expresses the covariance between categorical variables in terms of symbolic expressions [6]. In addition, Reshef et al. (2011) proposed a pairwise dependence measure called maximal information coefficient (MIC) based on the grid that maximizes the mutual information gained from the data [7].
The purpose of this paper is to extend my previous work [1] to a broad class of association measures using a general weighted Minkowski distance, and numerically evaluate some selected measures from the proposed class. The proposed class unifies many existing measures including coefficient, Cramér’s V, distance covariance, total variation distance and a slightly modified mean variance index. Furthermore, the strong consistency of the independence tests based on these measures was established, and the scaled forms of unweighted measures were derived. The proposed class provides a rich set of alternatives to the prevailing chi-squared statistic, and it has many potential applications. For instance, it can be applied to the correlation-based modeling, such as correlation-based deep learning [8]. As enlightened by a reviewer, the proposed method may also be applied to the pseudorandom number generator tests, and may improve some existing chi-squared based tests including the poker test and gap test [9].
The remainder of this paper is structured as follows: In Section 2, I introduce the defined class of association measures, and study some important special cases. The scaled forms of unweighted measures are also derived. Section 3 compares the performance of selected measures using simulated data. Section 4 discusses some extensions including the application to ordinal data and conditional independence test for three-way tables.
2. Methods
2.1. A Class of Association Measures for Categorical Variables
As the strength of association between two categorical variables can be reflected by the distance between and , here I define a class of measures based on the weighted Minkowski distance
where , , and only depends on the marginal distributions of X and Y. For , the defined distance violates the triangle inequality therefore it is not a metric. However, is allowed, and I denote by the maximum norm. It can be proved that for a given weight . Throughout this paper, I denote by the unweighted measures, i.e., . The defined class is quite broad and I begin with some important special cases.
Firstly, most of the chi-squared-type measures belong to the defined class. For instance, the coefficient for tables, i.e., ,
is a special case of , where . Extensions of to tables including Cramér’s V and Tschuprow’s T [10,11],
are also special cases of , where for Cramér’s V, and for Tschuprow’s T.
Distance covariance for categorical variables also belongs to the defined class. Distance covariance is a measure of statistical dependence between two random vectors X and Y. It is a special case of Hilbert-Schmidt independence criterion (HSIC) [12]. Let , and be three independent copies of , the distance covariance between X and Y is defined as the square root of
where represents distance between vectors, e.g., Euclidean distance. An alternative definition of distance covariance is given in Sejdinovic et al. (2013) [12], which only uses two independent copies of . A proof of the equivalency between the two definitions is provided in Appendix A.1. One property of distance covariance is that if and only if X and Y are statistically independent, indicating its potential of measuring nonlinear dependence. Zhang (2019) studied the distance covariance for categorical variables under multinomial model. Define if and 1 otherwise, one can show that
and it is easy to see that . A detailed proof of Equation (3) is provided in Appendix A.2.
Another special case is total variation distance, which is defined as the largest difference between two probability measures [13]. Let and be the measures under independence and dependence respectively, the total variation distance between and can be used to measure the dependence between variables X and Y
In the case of discrete sampling spaces, let and , then we have
therefore , where .
In addition, I pointed out that the mean variance index (MV) recently developed by Cui et al. [4] also belongs to our defined class, subject to some slight modifications. The MV between two variables X and Y is defined as , where stands for conditional distribution function. It can be proved that if and only if X and Y are independent. The MV measure is originally developed for continuous variables. To make it suitable for categorical variables while maintaining the main theoretical property, I slightly modified the definition of MV. First, I replaced the conditional c.d.f. with conditional p.m.f. . Second, as the MV measure is generally asymmetric, i.e., , I considered a symmetric version of the index, . With the two modifications, one can prove the following result (a detailed proof is provided in Appendix A.3)
therefore , where . As , we also have .
Similar as the MV index, the symmetric version of some other directional association measures (e.g., the concentration coefficient [3]), are also the special cases of .
2.2. Sample Estimate and Independence Test
Given a simple random sample of size N, one can estimate using sample quantities
where , and represent the maximum likelihood estimates of joint and marginal probabilities, respectively, i.e., , , and . The following theorem establishes the strong consistency of the independence test based on (a detailed proof is provided in Appendix A.4):
Theorem 1.
Assume that the estimated weights are bounded above by a constant , i.e., , then for any and , we have under independence. The inequality also holds for maximum norm .
It is noteworthy that the asymptotic null distribution of is impratical to derive. The theorem above provides a simple way to compute the upper bound of p-value, however, the bound is generally not tight, thus the p-value could be largely overestimated. Here, I suggest a simple permutation procedure to evaluate the significance. One can randomly shuffle the observations of X (or equivalently, the observations of Y) for M times, and compute the test statistic for each permuted dataset. The permutation p-value can be computed as the proportion of ’s that exceed the actually observed one. I used the permutation p-value to evaluate statistical significant in our simulation studies.
2.3. Scaled Forms of Unweighted Measures
Motivated by the classic correlation coefficient, I define the following scaled form for unweighted measure :
where , if and otherwise.
The term can be written as
and as examples, the explicit expressions for , , and are given below
It can be seen that is same as the distance correlation between X and Y [1], therefore , where if and only if X and Y are independent. In fact, for any , if for , it can be proved that , where if and only if X and Y are independent, and if and only if X and Y have perfect association, i.e., and for any , there exists a unique , such that .
For , by Cauchy-Schwarz inequality,
therefore . However, in general, does not imply that X and Y are perfectly associated. I gave an example in Table 1, where but X and Y are not perfectly associated.
3. Numerical Study
Two simulation studies were conducted to compare the performance of some selected measures from our defined class. In both simulations, I set and varied the sample size from 25 to 500, so that the simulated contingency tables were relatively large and sparse (average count is between and 5).
In the first simulation study, I considered the independence test based on different unweighted measures, including , , and , under the following multinomial settings:
- Setting 1: for 10 randomly selected cells and for the remaining 90 cells
- Setting 2: for 10 randomly selected cells and for the remaining 90 cells
- Setting 3: for one randomly selected cell and for the remaining 99 cells
- Setting 4: for one randomly selected cell and for the remaining 99 cells
For each test, the p-values were computed based on 2000 random permutations. Figure 1 summarizes the empirical statistical power of the four tests under significance level 0.05. It could be seen that, in settings 1 and 2, the measure (Euclidean distance) performed consistently better than the other three (comparable to ). The maximum norm performs the worst in these two settings. In settings 3 and 4, where a single cell accounts for most deviation from independence, the maximum norm performs the best, while the measure (Manhattan distance) gives the lowest power. Figure 2 summarizes the type I error rate, where it can be seen that all the four tests control the type I error rates at the nominal level of 0.05.
In the second simulation study, I focused on as it subsumes many popular measures. In particular, I compared three different weight functions, including (distance covariance), (Pearson’s chi-squared), and (modified mean variance index). Figure 3 shows the empirical statistical power of the three measures under settings 1 and 2, where it can be seen that the unweighted compares favorably to the weighted ones.
Based on the simulation studies, I recommend to the unweighted measures with a moderate choice of r, for instance, for large sparse tables, because they could give satisfactory and stable statistical power in general scenarios. The maximum norm is not recommended, unless one is very confident that there exist a very small number of cells that account for most deviation from independence.
4. Discussion
In this work, I proposed a rich class of dependence measures for categorical variables based on weighted Minkowski distance. The defined class unifies a number of existing measures including Cramér’s V, distance covariance, total variation distance and a slightly modified mean variance index. I provided the scaled forms of unweighted measures, which range from 0 (independence) to 1 (perfect association). Further, I established the strong consistency of the defined measures and suggested a simple permutation test for evaluating significance. Although I have used nominal and univariate categorical variables for illustrations, the proposed framework can be extended to other data types and problems:
First, the proposed measures can be used to detect ordinal association by assigning proper weights. Similar as Pearson’s correlation coefficient, one may assign larger weights to more extreme categories of X and Y. To be specific, let be the predefined distance between categories and , and be the distance between y and , and one could apply the following weight function
which assigns larger weights to cells in the corners but smaller weights to cells in the center of the table.
Second, my framework can be generalized to random vectors and multi-way tables. In the case of three-way table , one can define the following Minkowski distance between and
which can be used to test the joint independence between and Z, or equivalently, to test the homogeneity of the joint distribution of at different levels of Z. A similar permutation procedure can be applied to evaluate the statistical significance. One can also define the distance between and to test the mutual independence of
Furthermore, the framework can be extended to conditional independence test in three-way tables [14], by defining distance between conditional joint probabilities and the product of conditional marginal probabilities
Author Contributions
Q.Z. conceived of the presented idea, developed the theory, performed the computations and wrote the manuscript.
Funding
This research received no external funding.
Acknowledgments
The author would like to thank the editor and two reviewers for their thoughtful comments and efforts towards improving the manuscript.
Conflicts of Interest
The author declares no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MIC | maximum information coefficient |
| HSIC | Hilbert-Schmidt independence criterion |
| MV | mean variance index |
| c.d.f. | cumulative distribution function |
| p.m.f. | probability mass function |
Appendix A. Technical Details
Appendix A.1. Equivalency between Two Definitions of Distance Covariance
- Definition by Szekely et al. (2007):
- Definition by Sejdinovic et al. (2013):
The first two terms are the same, and the equivalency between the two definitions can be showed as follows:
Appendix A.2. Derivation of Equation (3)
Following Zhang (2019), I rewrite categorical variables X and Y as two random vectors of dimensions and , and , where stands for the indicator function. Let equal 0 if and 1 otherwise. Let , , be three independent copies of . By Equation (2), the squared distance covariance can be also expressed as
Under multinomial sampling scheme, it is straightforward to show that
Summarizing the results above, I have
Appendix A.3. Derivation of the Modified Mean Variance Index
The symmetric mean variance index is defined as
I first derived the explicit formula for :
Similarly, it can seen that , therefore
Appendix A.4. Proof of Theorem 1
Because , I only need prove the strong consistency for . For categorical variable X, let be the probability mass function, N be the sample size, and be the sample estimate, Biau and Gyorfi (2005) [15] proved the following result
Lemma A1.
For any , .
As , I have
Under independence, I have . By Lemma A1, the first term satisfies that
The third term can be bounded as follows:
By Lemma A1, I have
and summarizing the results above, I have
References
- Zhang, Q. Independence test for large sparse contingency tables based on distance correlation. Stat. Probab. Lett. 2019, 148, 17–22. [Google Scholar] [CrossRef]
- Szekely, G.; Rizzo, M.; Bakirov, N. Measuring and testing dependence by correlation of distances. Ann. Stat. 2007, 35, 2769–2794. [Google Scholar] [CrossRef]
- Goodman, L.; Kruskal, W. Measures of association for cross classifications, part I. J. Am. Stat. Assoc. 1954, 49, 732–764. [Google Scholar]
- Cui, H.; Li, R.; Zhong, W. Model-Free Feature Screening for Ultrahigh Dimensional Discriminant Analysis. J. Am. Stat. Assoc. 2015, 110, 630–641. [Google Scholar] [CrossRef] [PubMed]
- Theil, H. On the estimation of relationships involving qualitative variables. Am. J. Sociol. 1970, 76, 103–154. [Google Scholar] [CrossRef]
- McCane, B.; Albert, M. Distance functions for categorical and mixed variables. Pattern Recognit. Lett. 2008, 29, 986–993. [Google Scholar] [CrossRef] [Green Version]
- Reshef, D.; Reshef, Y.; Finucane, H.; Grossman, S.; McVean, P.; Turnbaugh, E.; Lander, M.; Mitzenmacher, M.; Sabeti, P. Detecting novel associations in large data sets. Science 2011, 334, 1518–1524. [Google Scholar] [CrossRef]
- Moews, B.; Herrmann, M.; Ibikunle, G. Lagged correlation-based deep learning for directional trend change prediction in financial time series. arXiv 2018, arXiv:1811.11287. [Google Scholar] [CrossRef]
- Knuth, D. The Art of Computer Programming, 3rd ed.; Addison-Wesley: Boston, MA, USA, 1997. [Google Scholar]
- Cramér, H. Mathematical Methods of Statistics; Princeton Press: Princeton, NJ, USA, 1946. [Google Scholar]
- Tschuprow, A. Principles of the Mathematical Theory of Correlation. Bull. Am. Math. Soc. 1939, 46, 389. [Google Scholar]
- Sejdinovic, D.; Sriperumbudur, B.; Gretton, A.; Fukumizu, K. Equivalence of distance-based and RKHS-based statistics in hypothesis testing. Ann. Stat. 2013, 41, 2263–2291. [Google Scholar] [CrossRef]
- Sriperumbudur, B.; Fukumizu, K.; Gretton, A.; Scholkopf, B.; Lanckriet, G. On the empirical estimation of integral probability metric. Electron. J. Stat. 2012, 6, 1550–1599. [Google Scholar] [CrossRef]
- Zhang, Q.; Tinker, J. Testing conditional independence and homogeneity in large sparse three-way tables using conditional distance covariance. Stat 2019, 8, 1–9. [Google Scholar] [CrossRef]
- Biau, G.; Gyorfi, L. On the asymptotic properties of a nonparametric l1-test statistic of homogeneity. IEEE Trans. Inf. Theory 2005, 51, 3965–3973. [Google Scholar] [CrossRef]
Figure 1.
Empirical statistical power of four different measures including (blue), (red), (black) and (green), under settings 1–4. In each setting, sample sizes are , and all results were based on 1000 replications.
Figure 1.
Empirical statistical power of four different measures including (blue), (red), (black) and (green), under settings 1–4. In each setting, sample sizes are , and all results were based on 1000 replications.

Figure 2.
Empirical Type I error rate of four different measures including (blue), (red), (black) and (green), under settings 1–4. In each setting, sample sizes are , and all results were based on 1000 replications.
Figure 2.
Empirical Type I error rate of four different measures including (blue), (red), (black) and (green), under settings 1–4. In each setting, sample sizes are , and all results were based on 1000 replications.
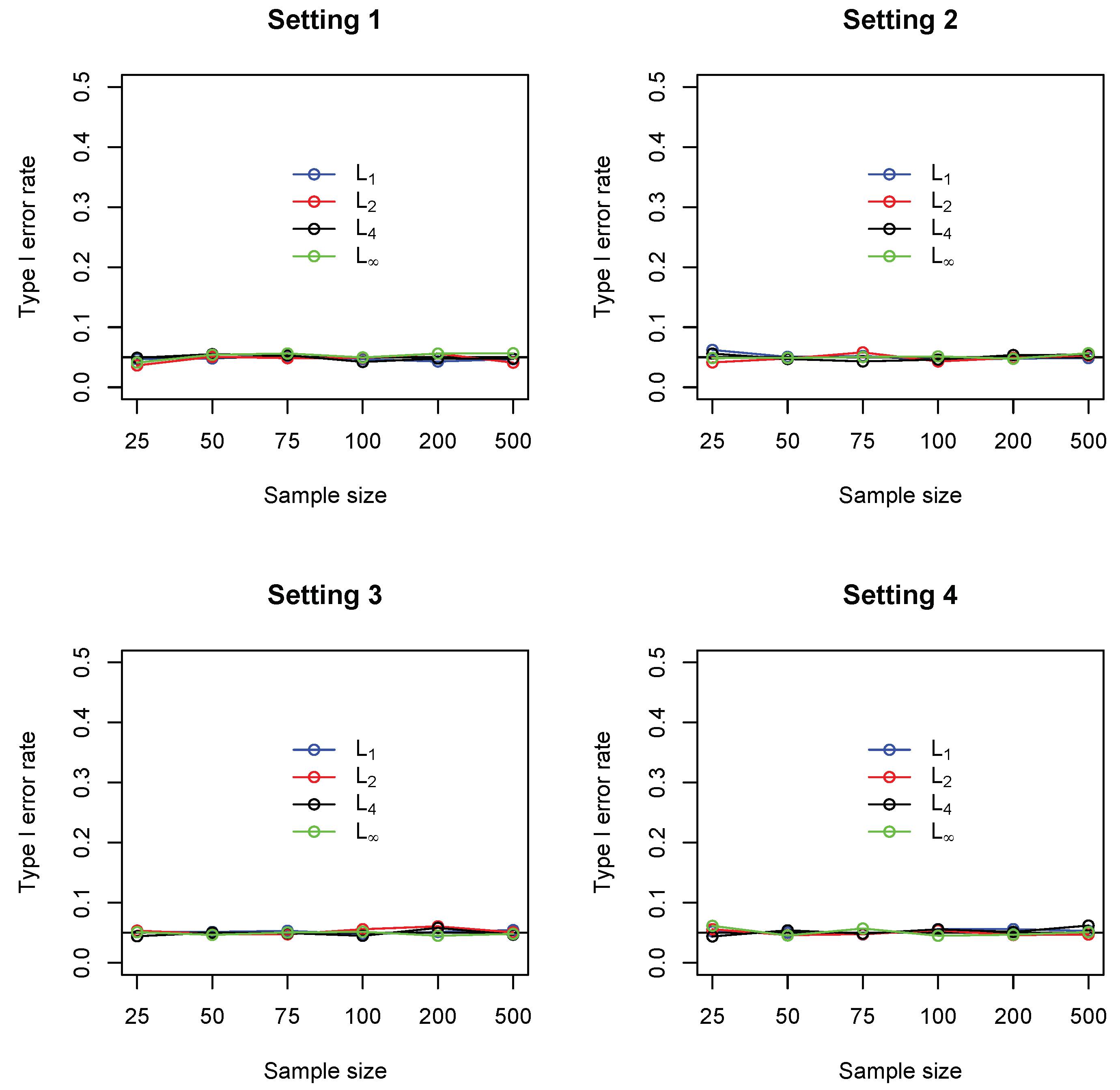
Figure 3.
Empirical statistical power of three measures including (distance covariance), (chi-squared), and (symmetric mean variance index), under settings 1 and 2. In each setting, sample sizes are , and all results were based on 1000 replications.
Figure 3.
Empirical statistical power of three measures including (distance covariance), (chi-squared), and (symmetric mean variance index), under settings 1 and 2. In each setting, sample sizes are , and all results were based on 1000 replications.


{kind=link}
{kind=link}
{kind=link}
Table 1.
An example that X and Y are not perfectly associated, but .
| Y = 1 | Y = 2 | Y = 3 | |
|---|---|---|---|
| X = 1 | 1/2 | 0 | 0 |
| X = 2 | 0 | 1/8 | 1/8 |
| X = 3 | 0 | 1/8 | 1/8 |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, Q. A Class of Association Measures for Categorical Variables Based on Weighted Minkowski Distance. Entropy 2019, 21, 990. https://doi.org/10.3390/e21100990
AMA Style
Zhang Q. A Class of Association Measures for Categorical Variables Based on Weighted Minkowski Distance. Entropy. 2019; 21(10):990. https://doi.org/10.3390/e21100990
Chicago/Turabian StyleZhang, Qingyang. 2019. "A Class of Association Measures for Categorical Variables Based on Weighted Minkowski Distance" Entropy 21, no. 10: 990. https://doi.org/10.3390/e21100990
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.