Abstract
To characterize the irregularity of the spectrum of a signal, spectral entropy and its variants are widely adopted measures. However, spectral entropy is invariant under the permutation of the power spectrum estimations on a predefined grid. This erases the inherent order structure in the spectrum. To disentangle the order structure and extract meaningful information from raw digital signal, a novel analysis method is necessary. In this paper, we tried to unfold this order structure by defining descriptors mapping real- and vector-valued power spectrum estimation of a signal into a scalar value. The proposed descriptors showed its potential in diverse problems. Significant differences were observed from brain signals and surface electromyography of different pathological/physiological states. Drastic change accompanied by the alteration of the underlying process of signals enables it as a candidate feature for seizure detection and endpoint detection in speech signal. Since the order structure in the spectrum of physiological signal carries previously ignored information, which cannot be properly extracted by existing techniques, this paper takes one step forward along this direction by proposing computationally efficient descriptors with guaranteed information gain. To the best of our knowledge, this is the first work revealing the effectiveness of the order structure in the spectrum in physiological signal processing.
1. Introduction
Many real-world signals including physiological signals are irregular in some aspects. They are neither purely periodic nor can they be expressed by an analytic formula. The inherent irregularities imply the uncertainty during the evolution of the underlying process from which the signals are observed. The uncertainty enables information transfer but also limits the predictability of those signals. The unpredictability of signal in time domain makes researchers have to toil in frequency domain. Fourier transform (FT) bridges signals in original space (time domain) with their representations in dual space (frequency domain) by decomposing a signal satisfying some weak constraints into infinitely many periodic components, which has numerous applications in signal processing.
For most of the real-world applications, finite samples drawn (usually evenly spaced) from a continuous random process cannot give us full information about the process’ evolution but only a discrete depiction. FT was adapted into discrete Fourier transform (DFT) for such scenarios [1]. Moreover, line spectrum wherein the total energy of the signal distributes on only few frequency components is rarely encountered among physiological signals due to the inherent irregularities therein.
To characterize the irregularity of digital signals in frequency domain, spectral entropy is introduced analogous to the Shannon entropy in information theory [2]. The estimations on the frequency grid are firstly divided by the total power, and then, a list of proxies in the form of probabilities whose sum is 1 is obtained. Then, the Shannon entropy formula, which is the negative sum of probability-weighted log probabilities, map those proxies into a quantity representing the irregularity of energy distribution on frequency domain. Under this perspective, a flat spectrum has maximal spectral entropy, and the spectrum of a single frequency signal has minimal spectral entropy, which is zero. Spectral entropy has been applied in diverse areas, including endpoint detection in speech segmentation [3] and spectrum sensing in cognitive radio [4]. Moreover, it has also served as the base of a famous inductive bias, maximum entropy [5], which is widely adopted for spectrum estimation of some kinds of physiological signals like electroencephalogram (EEG).
Although spectral entropy is well-defined and can be computed efficiently by Fast Fourier Transform (FFT), it is difficult to relate spectral entropy with other interpretable properties of interest of original signal, especially when taking no account of the overwhelming endorsement from its counterpart (information entropy), which is the foundational concept in information theory which quantifies the uncertainty. Furthermore, it is apparent that the spectral entropy ignored the order information since the power estimations are arranged on the frequency grid with intrinsic partial order structure. Any permutations of these values on the grid yields a same spectral entropy, but obviously, the representations of those signals in time domain can look very different.
The motivation to incorporate the order information carried by the power spectrum is guided by the following belief. The normal operations of any system (biological/electromechanical, etc.) are impossible without the proper processing of information through some physical/chemical process. It could be the signaling between different modules within the system or the communications between the system as a whole and the external environment. Information transfers happening in those scenarios are accomplished with the help of carrier signals of particular forms with nontrivial structures in their spectra. Moreover, only limited frequency precision of the control and recognition of those signals is practical for real systems. Therefore, it is unreasonable for well-designed artificial systems or natural systems that have gone through long-term evolution to arrange the internal signals responsible for different functions close with each other in frequency domain within a certain time window. Otherwise, the efficient transfer of information could be degraded, and frequency divided multiplex [4] in modern communication systems can be considered as a living example of this belief.
Therefore, if we use power estimations on the frequency grid as proxies of the intensities of activities corresponding to those frequencies, it seems reasonable to infer that the energy distributed on neighboring rather than remote frequency grids is more likely caused by the very same function. The alpha band activities (8–13 Hz) which can be interrupted by visual perception tasks in human’s EEG is one of the examples. To sum up, we want to develop a metric to characterize the aforementioned structural irregularities of the power spectra, that is, how the frequency components of different intensities in a spectrum close to each other instead of what is captured in spectral entropy, which is how the intensities of frequency components are distributed no matter their locations in frequency domain. It was supposed to assign a larger value to a signal wherein the frequency components having similar intensities are distributed far apart from, rather than close to, each other. In addition, the similarities of intensities can be reflected (partially and heuristically) by the relative order of power estimates on discrete frequency grid. That is why the order information in the spectrum can shed new light on the structure aspects of signal and how the order information is incorporated into our analysis.
In this paper, we explore the effectiveness of the order information carried by the power spectra of signals. Given the motivation illustrated above, in Section 2 we provide details about our method. In Section 3 we present several use cases to justify the effectiveness of our preliminary approach and, more importantly, the promising potential to find some new research niche in the field of physiological signal processing. Finally, discussion about the limitations of our work and future directions are followed in Section 4.
2. Materials and Methods
Given an equally spaced, real-valued digital signal , we assume the length of is an even number , for simplicity. Then DFT is applied to and a complex-valued vector of dimension is obtained as follows:
Due to the conjugate symmetry of , we take the square of the modulus of the first half of and get . Thanks to the Parseval identity, the 1-norm of equals to the energy of up to factor 1/2. Although has a dimension of energy instead of power, the constant factor having a dimension of time does not change the relative ordinal relations between its components. So we just use as the estimations of power on normalized frequency range , whereby the component of is the estimation of signal’s power on grid point .
Now, let us assume again that every two components of are different from each other, so we can rank these components without any ambiguity in ascending/descending order.
These grid points have an intrinsic partial order structure from low frequency range to high frequency range, so we get eigen-triple for these grid points:
The first row indicates the grid points by their location on frequency range. The second row contains the corresponding power estimations. The third row contains the relative order of corresponding power estimation among all estimations, denoted by . Since no duplicated values in are assumed, will traverse number set .
The first two rows of are just a kind of representation of traditional power spectrum. Novelty lies in taking the order information, carried in the third row, into consideration.
It should be noted that the first and the third row together have defined a permutation over the natural number set , with its complete detail determined by implicitly. Remember that spectral entropy is defined in a permutation-invariant way. Such an invariance must be broken down so as to disentangle the order information. Therefore, this permutation per se returns the long-overdue ladder to understand structural irregularities of signals under a new perspective.
The sketch of our method is illustrated in Figure 1. Using the measurements in time domain (Figure 1a), the power estimations on normalized frequency grid with resolution determined by half the length of original signal are obtained (Figure 1b). By ranking these estimations in descending order, we arrange against . As shown in Figure 1c, the first stem indicates the location on the frequency grid of the largest power component and so on. From (b) to (c), we are actually performing a nonlinear stretching while the order information of the spectrum is preserved and calibrated. Then a distance matrix (in Figure 1d) is induced for every point pair. Here in (c) we define .
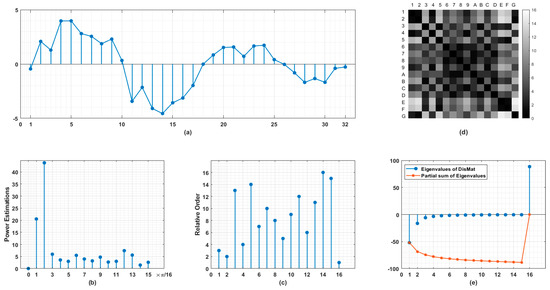
Figure 1.
Schematic diagram of proposed method. (a) Original signal represented as equally spaced time series. (b) Power estimations on normalized frequency range , the number of points in (b) is just half of those in (a). (c) Relative orders of frequency components. The values on horizontal axis indicate the ranking of frequency components in descending order. The values on vertical axis indicate the location of corresponding frequency component in normalized range . (d) Distance matrix (DisMat) of frequency components arranged in (c) whereby A-G represent 10–16th points. (e) Eigenvalues of DisMat and their partial sums. Note that DisMat’s trace identically equals to 0.
So is real-symmetric with trace identically equals to 0. The structural aspects of are reflected in its eigenvalues (Figure 1e). Due to the sophisticated relationships between its entries, it is unwise to reshape such a high dimensional object with far lower degrees of freedom into a long vector for pattern recognition. In addition to the eigenvalues, a descriptor, named as Circular Difference Descriptor (), accounting for the total variation of the locations on frequency grids of frequency components having adjacent intensities is defined as follows, to a large extent, in a heuristic manner:
The first term makes Circular Difference veritable and endows translational invariance instead of permutational invariance.
Another heuristic descriptor is defined slightly different from , named as Correspondence Difference Descriptor (). It equals to the 1-norm of the difference of and , aiming to characterize the difference between and the perfectly ordered case where ,
Results from the Monte-Carlo simulation (shown in Figure 2) imply that the empirical distributions of and among all permutations could well be Gaussian. Although theoretical distributions of and must have bounded supports for finite , they fit a bell-shaped curve very well, which in theory has unbounded support.
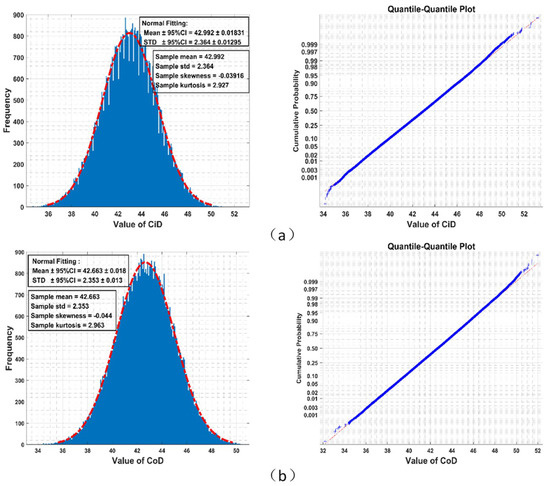
Figure 2.
Given , 640,000 times random generations of permutation over letters yields an empirical distribution of Circular Difference Descriptor () fitting normal distribution well (red dot dash line) in the left panel (STD: standard deviation, CI: confidence interval). The right panel is the quantile-quantile plot of this empirical distribution (blue cross) with theoretical value of normal distribution (red dot dash line). (a) Circular Difference Descriptor (); (b) Correspondence Difference Descriptor ().
Since permutational invariance of spectral entropy is broken herein, and actually encode the signal in different ways but both with guaranteed information gain with respect to spectral entropy. To be specific, given without , the corresponding and are fixed, but the distribution of can form widely differed spectra. We take flat spectrum in and line spectrum in as examples:
The corresponding spectral entropy values vary from infinitesimal (in ) to maximum possible (in ). On the contrary, given , any permutation on it yields an exactly same spectral entropy, as mentioned before, but the corresponding and will absolutely transverse all possible values.
The relationship between spectral entropy and the proposed descriptors is illustrated in Figure 3. The set A denotes full space of signals’ spectra whereby for each no duplicate value exists for its sub-components , which is an assumption made by us for simplicity and with only minimal loss of generality. Signals in the set B have the same spectral entropy, denoted by . The following conditions need to be satisfied for signals in C:
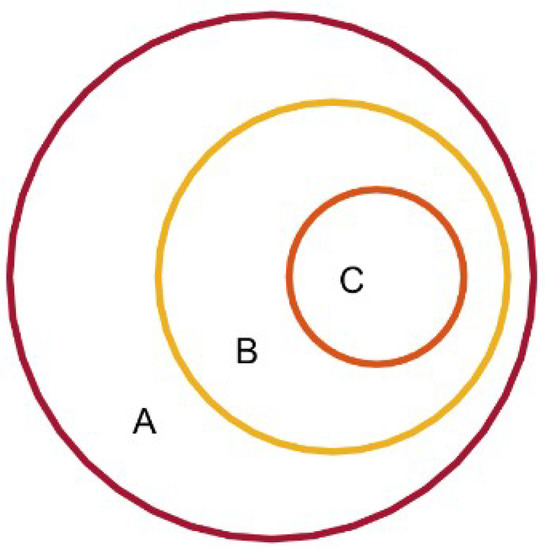
Figure 3.
The relationship between spectral entropy and the order information.
Spectral entropy operator is denoted by , and denotes the rank vector of . For example, if we have , then we will have .
Since all members in C are with a same rank vector, we can obtain many different counterparts of C which share this spectral entropy value with it by a certain permutation on the arrangement of . Since there are different permutations other than the identical permutation, the following relationship is obtained:
Until now, we get a coverage of B by disjoint subsets. Members in the same subset share a specific spectral entropy value, a same rank vector, and cannot be transformed to be identical to each other by simply rearranging their sub-components.
Given only the value of spectral entropy () without rank vector, we can localize the signal in A to B. Given , the location will be more accurate (to one of many Cs in B). From this perspective, we can distinguish signals which have completely different order structures with the same spectral entropy.
If no a priori about the signals’ spectra is available, then the equiprobable distribution of is substantially and implicitly pre-assumed. Then under such circumstance, the so-called Kullback–Liebler Divergence (KLD) which is a widely used method to measure the difference between two probability distributions is adopted to illustrate the advantage when using the proposed descriptors. KLD between the proposed descriptors and spectral entropy as different coding schemes having probability distribution and are always nonnegative [6], no matter the direction (KLD is lack of symmetry). KLD between two distributions and is defined as follows:
Such a property is welcomed since it guarantees the nonnegative information gain when using both spectral entropy and the proposed descriptors instead of only one of them. In other words, the representation will be more informative with a combination of our proposed descriptors and spectral entropy.
As for the distance matrix with its entries representing the distance or similarity between point and , distance measures other than the absolute difference can be applied on and to form different distance matrices. Given any distance measure, a topology is induced on this finite set , based on the coarse-grained, discrete-valued rankings among them, and certainly, more order information is unrevealed yet. For example, is just the circular difference of the first sub-diagonal line of , captures only a portion of full information.
To sum up, by ranking power estimations of signal on a discrete frequency grid, an interesting picture of order structure carried by signal’s spectrum is obtained.
3. Results
In this section we provide several use cases to show the effectiveness of order information carried by signal’s power spectrum in physiological signal processing.
3.1. Surface Electromyography (sEMG)
It was found the proposed descriptors may be able to distinguish sEMG signals collected under different actions. A publicly available dataset containing sEMG recordings from three females and two males acting six different actions is involved in the analysis [7]. Wilcoxon rank sum test and Kruskal–Wallis test with Bonferroni’s correction are used to compare the medians of each class. A representative example is given in Figure 4 with statistical significance achieved between the medians among most of comparisons. As for full comparison, Supplementary Information contains all comparisons for remaining subjects.
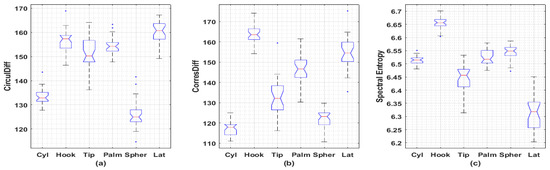
Figure 4.
Boxplots of irregularity metrics obtained from sEMG signals collected from 6 different actions. (a) Circular Difference Descriptor; (b) Correspondence Difference Descriptor; (c) Spectral Entropy. Totally, there are 5 subjects (3 females and 2 males) involved in this dataset. Each subject repeated 30 times for each action with 2 channels’ EMG signals recorded. Each recording is of length 6 s under sampling frequency 500 Hz (3000 data points). Only the latest 2048 data points for each recording are used to generate these metrics. Female 3, channel 2 is used here with remaining boxplots left in the Supplementary Information. Significant differences (p < 0.001) between sample medians are observed among inter-subset Wilcoxon rank sum tests, except for Hook-vs-Tip (p = 0.0017), Hook-vs-Palm (p = 0.0378), Hook-vs-Tip (p = 0.0042), Tip-vs-Palm (p = 0.0138) in CirculDiff’s comparisons and Cyl-vs-Palm (p = 0.2340), Palm-vs-Spher (p = 0.0117) in Spectral Entropy’s comparisons. Significant differences (p < 0.01) between sample medians are observed among Kruskal–Wallis test with Bonferroni’s correction, except for Spher-vs-Cyl (p = 1.000), Tip-vs-Palm (p = 1.000), Hook-vs-Tip (p = 0.467), Hook-vs-Palm (p = 1.000), Palm-vs-Lat (p = 0.134), Hook-vs-Lat (p = 1.000) in CirculDiff’s comparisons; Spher-vs-Cyl (p = 1.000), Spher-vs-Tip (p = 0.288), Tip-vs-Palm (p = 0.171), Palm-vs-Lat (p = 1.000), Hook-vs-Lat (p = 0.704) in CorresDiff’s comparisons; Lat-vs-Tip (p = 0.294), Tip-vs-Cyl (p = 0.044), Cyl-vs-Palm (p = 1.000), Cyl-vs-Spher (p = 0.240), Palm-vs-Spher (p = 1.000), Spher-vs-Hook (p = 0.016) in Spectral Entropy’s comparisons. (Cyl: Cylindrical, for holding cylindrical tools; Hook: for supporting a heavy load; Tip: for holding small tools; Palm: Palmar, for grasping with palm facing the object; Spher: Spherical, for holding spherical tools; Lat: Lateral: for holding thin, flat objects; CirculDiff: Circular Difference Descriptor; CorresDiff: Correspondence Difference Descriptor).
3.2. Electroencephalogram (EEG)
It was also found that the proposed descriptors may be able to distinguish brain signals under different pathological states. A publicly available dataset, Bonn Seizure Dataset, which is widely used as materials for brain signal related pattern recognition and machine learning tasks is employed [8]. In this dataset, 5 subsets contain 100 recordings each with identical length, sampling frequency and other conditions, collected under different pathological states. Rank sum test used in 3.1 is performed. Significant (p < 0.001) differences between the medians of the values of proposed descriptors corresponding to these 5 subsets were observed in most of the cases, with boxplots given in Figure 5.
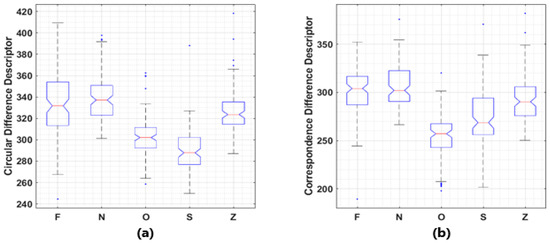
Figure 5.
Boxplots of the value distributions of two descriptors. (a) Circular Difference Descriptor; (b) Correspondence Difference Descriptor. Bonn seizure dataset consists EEG recordings collected from 5 healthy volunteers with eyes open (Z) or closed (O) and 5 patients during ictal period (S), inter-ictal period in epileptogenic zone (F), or hippocampal formation of the opposite hemisphere (N). Another classification criterion is healthy EEG (OZ), inter-ictal period activities (FN), and ictal period activities (S). Significant differences (p < 0.001) between sample medians are observed among inter-subset Wilcoxon rank sum tests, except for F-vs-N (p = 0.238) and F-vs-Z (p = 0.002) in Correspondence Difference Descriptor’s comparisons, F-vs-N (for p = 0.158) in Circular Difference Descriptor’s comparisons.
3.3. Speech Signal
When is fixed and performing the operator defined in (3) and (4) on moving window mounted on a long signal, we are able to unfold the structural irregularities of signal in a finer time resolution, and thus, change point detection is possible.
In Figure 6 we provide an example of endpoint detection in human speech signals. It can be seen that the start points and stop points of syllables are accompanied by the steep increase/decrease of descriptors’ values. In this example, we also found that the descriptors defined in (3) and (4), which are purely based on order information, as opposed to spectral entropy, which has nothing to do with order information, could become noise vulnerable in some problems. This is due to the amplitudes of are barely removed after transforming into . Consider such a case where a large portion of only accounts for a negligible portion of total energy, then, their relative order can vary drastically because of possible noise and so can the descriptors’ values. However, it seems unreasonable to deem the structure of signal must have changed accordingly.
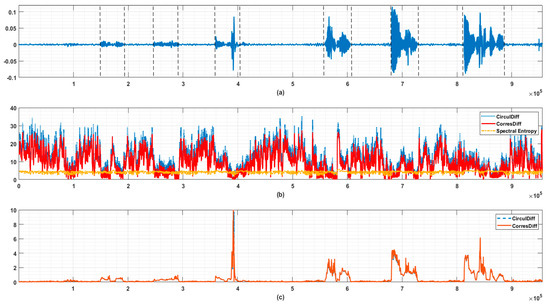
Figure 6.
Use case of endpoint detection in speech signal. (a) Original speech signal. The starts and end points of syllables are indicated by dashed lines. (b) Circular Difference Descriptor, Correspondence Difference Descriptor, and Spectral Entropy of signal (a). The window length is 1024, and step length is 128 here. The energy threshold is set to be 0.9 here. It is obvious that the proposed descriptors are more sensitive to the appearance of syllables (reduced irregularity implies possible formant caused) than spectral entropy. (c) Monitoring value taking local energy into consideration (let the standard deviation of last 1024 points be here). The values on y-axis are calculated by (CirculDiff: Circular Difference Descriptor; CorresDiff: Correspondence Difference Descriptor).
Therefore, a simple thresholding segmentation trick of total variance, similar to what is usually adopted in principal component analysis is used in this case. The descriptors are calculated based on the first components whereby is defined as follows:
The is a tunable parameter selecting L largest frequency components accounting for just above a preset portion of total energy. This trick improves the robustness against wide-band weak noise but removes some welcomed properties. Possible modifications of naive descriptors proposed here will be discussed later.
3.4. Amplitude-Integrated EEG (aEEG)
Another example validates the effectiveness of the proposed method by revealing the temporal evolution of physiological process is founded in the analysis of aEEG [9]. aEEG is a kind of condensed sketch of long-term EEG recording. It was believed to be able to reflect long term trends of brain activities in a horizon suitable for visual inspection and evaluation. It has been widely used for seizure detection in neonates, brain disorder evaluation, etc.
In Figure 7 a segment of EEG drawn from CHB-MIT dataset [10] is transformed into aEEG first and then similar analysis used in Section 3.3 is adopted. Ictal period is indicated by colored bar.
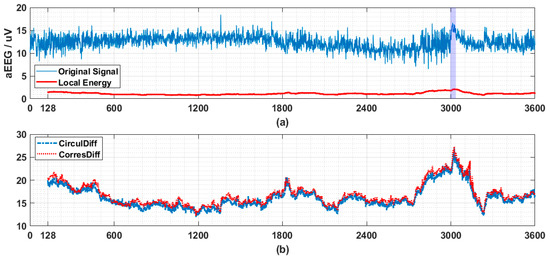
Figure 7.
The application of proposed descriptors on seizure detection. (a) Amplitude-integrated EEG (aEEG) tracing contains a seizure event (indicated by purple bar from 2996th to 3036th s) with its local energy (here standard deviation of last 128 points, referred as is used). The original multichannel EEG signals (23 channels with sampling frequency being 256 Hz) are drawn from patient 1, record 3 from CHB-MIT dataset and consist of a one hour recording. The channel 7 (C3-P3) is transformed by recommended pipeline into aEEG. Every second’s data points (256 data points) are compressed into 2 data points (upper bound and lower bound each). So totally 3600 × 2 data points are obtained. Here we use only upper bound, and similar results have also been observed for lower bound data. (b) Circular Difference Descriptor and Correspondence Difference Descriptor monitoring (calculated based on last 128 data points in (a)). The step length is fixed to be 1 here, which means that after obtaining every new point, the values of two descriptors will be updated to provide the finest and most sensitive anomaly monitoring. The values on y-axis are calculated by . Drastic change accompanied by the onset of seizure (a high value first and then a steep decresing) is observed in both of the descriptors (CirculDiff: Circular Difference Descriptor; CorresDiff: Correspondence Difference Descriptor).
4. Discussion
Order structure of signal’s spectrum is revealed by simply ranking the power estimations. Several use cases justify that taking that order structure into consideration could contribute valuable information to the processing of physiological signals. The possible applications include serving as candidate features for pattern recognition among signals, change point detection in process tracking for anomaly detection and many more.
The permutation of length N defined by rankings of power estimations on frequency grid has huge capacity (). Although in practice it is not necessarily that these different ordinal patterns are equiprobable, the proved information gain under such an assumption is still hoped to be found in practice. An established metric, permutation entropy is based on ranking consecutive measurements in time domain and doing statistics among a sufficient number of segments [11]. The length of such segments must be small otherwise the density estimation will be impractical for time series of reasonable length. Our method delves into the order structure of signal’s representation in dual space (frequency domain) instead of original space (time domain). Every point in the dual space is bridged to all points in the time domain through FT, so no one-to-one correspondence exists between original measurements and mapped points in the proposed method. This is also an important distinction.
The proposed descriptors in their original forms could be noise vulnerable, but they can be modified using techniques include but not limit what is used here. In practice, we observed high correlation between and , and one could outperform another at times. In addition, the pairwise distances in the distance matrix in Figure 1d can be induced in a way other than that used here. Anyway, more fruitful and distinguishable features can be extracted along this way from such a representation with large capacity.
As for future research, we have several proposals.
The first is to establish relationships between the order information given by a recorded digital signal of length 2N and that of its sub-signals, obtained by (nonuniformly) down-sampling these 2N points. Uniformly down-sampling is equivalent to folding the power spectrum. Situations will be more sophisticated under nonuniform cases (include but not limit to evolving/truncating case where the length of signal is ever-increasing), but usually a more flat spectrum with lower frequency resolution is produced. The original signal with its sub-signals together could provide an informative and hierarchical object of study.
The second is to develop distance measures other than the absolute difference of ranks used here. By incorporating both the discrete-valued ranks and the continuous-valued power estimations, parameters more robust to broad band noise could be anticipated. Furthermore, could ‘ranking’ of power spectrum of a continuous function (signal) be possible in some sense?
The third is about the topology induced from the distance matrix. The distance matrix in Figure 1d or the distance defined by possible modified measures, as mentioned above, whereby block structures frequently occur, provides full neighborhood information of N points on frequency grid. Given such information, could we find some relations with the eigenvalues of DisMat (with possible modification mentioned in the second point) with some properties of interest of original signal? Despite that, we can also calculate so-called persistent homology—a dominant methodology usually referred as synonym of topological data analysis (TDA)—of these N points by computing a series of simplicial complexes with their topological invariants [12] and get topological description of signal’s power spectrum. That means the order information in spectrum enables a nontrivial embedding method of data points with temporal structure. Such an embedding method is different from the famous delay-embedding [13], which is an operation performed in signal’s original space rather than dual space. Delay-embedding could be vulnerable to short and noisy process. A messy point cloud could provide nothing except for ‘topological noises’. However, by ranking power spectrum, the data points are arranged in an organized way, and the application of TDA can be free from such pitfalls encountered in delay-embedding.
In conclusion, order structures of physiological signals’ power spectra are almost neglected in existing methods, but they are not meaningless. On the contrary, such structures could provide a unique perspective to understand the intrinsic properties of physiological processes.
Supplementary Materials
Full intra-subject comparison of two descriptors across six different actions are available online at https://www.mdpi.com/1099-4300/21/11/1057/s1.
Author Contributions
X.Y., Z.M. and W.C. designed the research. Z.M. developed the analytic tool to unfold the order structure of a spectrum. X.Y., Z.M., and C.C. analyzed the data, prepared the figures and interpreted the results. X.Y., Z.M., C.C., and W.C. drafted the manuscript.
Funding
This work is supported by National Key R&D Program of China (No. 2017YFE0112000), Shanghai Municipal Science and Technology Major Project (No. 2017SHZDZX01), and China Postdoctoral Science Foundation (No.2018T110346 and No.2018M632019).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cooley, J.; Lewis, P.; Welch, P. The finite Fourier transform. IEEE Trans. Audio Electroacoust. 1969, 17, 77–85. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Wu, B.-F.; Wang, K.-C. Robust endpoint detection algorithm based on the adaptive band-partitioning spectral entropy in adverse environments. IEEE Trans. Speech Audio Process. 2005, 13, 762–775. [Google Scholar]
- Zhang, Y.; Zhang, Q.; Melodia, T. A frequency-domain entropy-based detector for robust spectrum sensing in cognitive radio networks. IEEE Commun. Lett. 2010, 14, 533–535. [Google Scholar] [CrossRef]
- Smith, C.R.; Grandy, W.T. Maximum-Entropy and Bayesian Methods in Inverse Problems; Springer: Dordrecht, The Netherlands, 1985. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Sapsanis, C.; Georgoulas, G.; Tzes, A.; Lymberopoulos, D. Improving EMG based classification of basic hand movements using EMD. In Proceedings of the 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Osaka, Japan, 3–7 July 2013. [Google Scholar]
- Andrzejak, R.G.; Lehnertz, K.; Mormann, F.; Rieke, C.; David, P.; Elger, C.E. Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Phys. Rev. E 2001, 64. [Google Scholar] [CrossRef]
- Mastrangelo, M.; Fiocchi, I.; Fontana, P.; Gorgone, G.; Lista, G.; Belcastro, V. Acute neonatal encephalopathy and seizures recurrence: A combined aEEG/EEG study. Seizure 2013, 22, 703–707. [Google Scholar] [CrossRef] [PubMed]
- Shoeb, A.; Guttag, J. Application of Machine Learning to Epileptic Seizure Onset Detection. In Proceedings of the 27th International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 975–982. [Google Scholar]
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88. [Google Scholar] [CrossRef] [PubMed]
- Rote, G.; Vegter, G. Computational Topology: An Introduction. In Effective Computational Geometry for Curves and Surfaces; Boissonnat, J.-D., Teillaud, M., Eds.; Springer: Berlin Heidelberg, Germany, 2006; pp. 277–312. [Google Scholar]
- Takens, F. Detecting strange attractors in turbulence. In Dynamical Systems and Turbulence; Rand, D., Young, L.-S., Eds.; Springer: Berlin Heidelberg, Germany, 1981; pp. 366–381. [Google Scholar]







© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).