1. Introduction
The rapid and accurate estimate of the probability density function (pdf) for a random variable is important in many different fields and areas of research [
1,
2,
3,
4,
5,
6]. For example, accurate high throughput pdf estimation is sought in bioinformatics screening applications and in high frequency trading to evaluate profit/loss risks. In the era of big data, data analytics and machine learning, it has never been more important to strive for automated high-quality pdf estimation. Of course, there are numerous other traditional areas of low throughput applications where pdf estimation is also of great importance, such as damage detection in engineering [
7], isotope analysis in archaeology [
8], econometric data analysis in economics [
9], and particle discrimination in high energy physics [
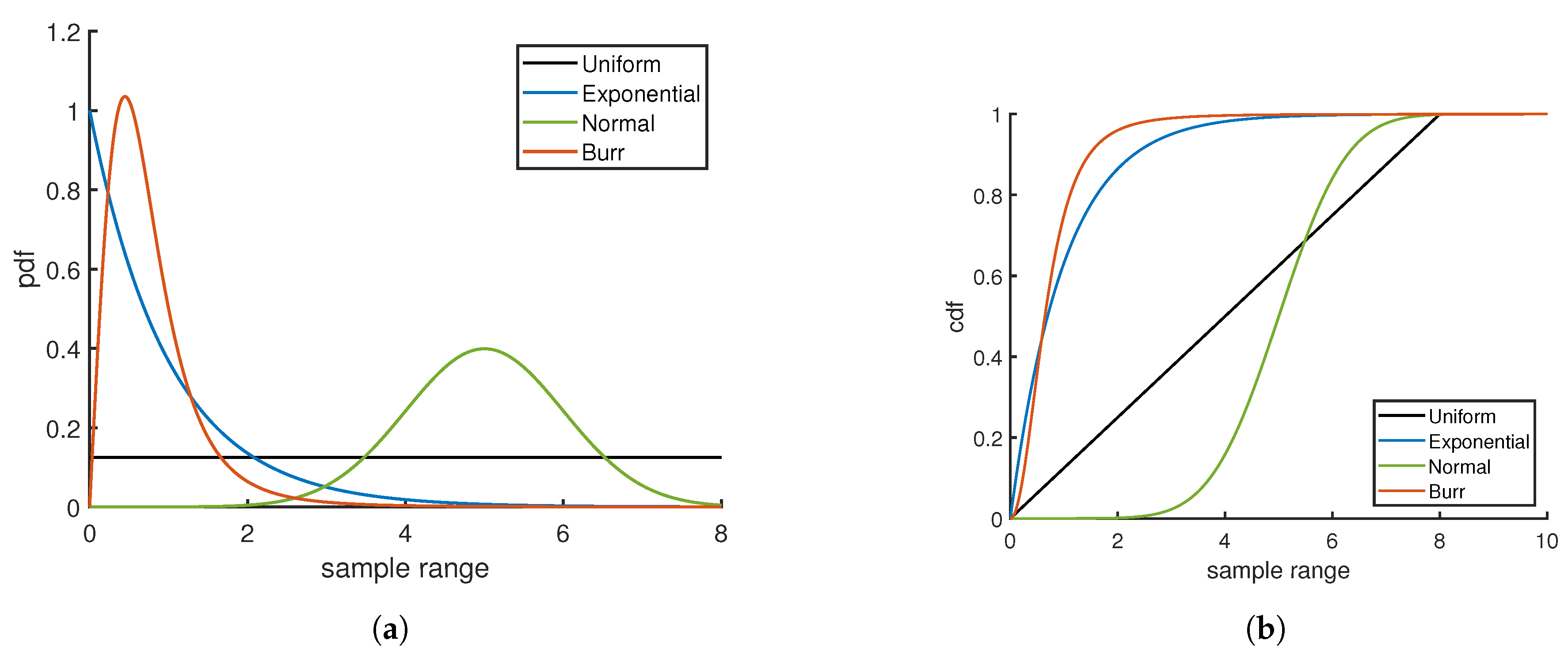
10]. The wide range of applications for pdf estimation exemplifies its ubiquitous importance in data analysis. However, a continuing objective regarding pdf estimation is to establish a robust distribution free method to make estimates rapidly while quantifying error in an estimate. To this end, it is necessary to develop universal measures to quantify error and uncertainties to enable comparisons across distribution classes. To illustrate the need for universality, the pdf and cumulative distribution function (cdf) for four distinctly different distributions are shown in
Figure 1a,b. Comparing the four cases of pdf and cdf over the same sample range, it is apparent that the data are distributed very differently.
The process of estimating the pdf for a given sample of data is an inverse problem. Due to fluctuations in a sample of random data, many pdf estimates will be able to model the data sample well. If additional smoothness criteria are imposed, many proposed pdf estimates can be filtered out. Nevertheless, a pdf estimate will carry intrinsic uncertainty along with it. The development of a scoring function to measure uncertainty in a pdf estimate without knowing the form of the true pdf is indispensable in high throughput applications where human domain expertise cannot be applied to inspect every proposed solution for validity. Moreover, it is desirable to remove subjective bias from human (or artificial intelligence) intervention. Automation can be achieved by employing a scoring function that measures over-fitting and under-fitting quantitatively based solely on mathematical properties. The ultimate limit is set by statistical resolution, which depends on sample size.
Solving the inverse problem becomes a matter of optimizing a scoring function, which breaks down into two parts—first, developing a suitable measure that resists under- and over-fitting to the sampled data, which is the focus of this paper. Second, developing an efficient algorithm to optimize the score while adaptively constructing a non-parametric pdf. The second part will be accomplished by an algorithm involving a non-parametric maximum entropy method (NMEM) that was recently developed by JF and DJ [
11] and implemented as the “PDFestimator.” Similar to a traditional parametric maximum entropy method (MEM), NMEM employs Lagrange multipliers as coefficients to orthogonal functions within a generalized Fourier series. The non-parametric aspect of the process derives from employing a data driven scoring function to select an appropriate number of orthogonal functions, as their Lagrange multipliers are optimized to accurately represent the complexity of the data sample that ultimately determines the features of the pdf. The resolution of features that can be uncovered without over-fitting naturally depends on the sample size.
Some important results in statistics [
12] that are critical to obtain universality in a scoring function are summarized here. For a univariate continuous random variable,
X, the cdf is given by
, which is a monotonically increasing function of
x and, irrespective of the domain, the range of
is on the interval
. A new random variable,
R, that spans the interval
is obtained through the mapping
. The cdf for the random variable
R can be determined as follows,
Since the pdf for the random variable R is given as it follows that R has a uniform pdf on the interval . Furthermore, due to the monotonically increasing property of it follows that a sort ordered set of N random numbers maps to the transformed set of random numbers in a 1 to 1 fashion, where k is a labeling index that runs from 1 to N. In particular, for an index , it is the case that . The 1 to 1 mapping that takes has important implications for assessing the quality of a pdf estimate. The universal nature of this approach is that, for a given sample of random data and no a priori knowledge of the underlying functional form of the true pdf, an evaluation can be made of the transformed data.
Given a high-quality pdf estimate from an estimation method,
, the corresponding estimated cdf,
, will exhibit sampled uniform random data (SURD). Conversely, for a given sample from the true pdf, a poor trial estimate,
, will yield transformed random variables that deviate from SURD. The objective of this work is to consider a variety of measures that can be used as a scoring function to quantify the uncertainty in how close the estimate
is to the true pdf based on how closely the sort order statistics of
matches with the sort order statistics of SURD. The powerful concept of using sort order statistics to quantify the quality of density estimates [
13] will be leveraged to construct universal scoring functions that are sample size invariant.
The strategy employed in the NMEM is to iteratively perturb a trial cdf and evaluate it with a scoring function. By means of a random search using adaptive perturbations, the trial cdf with the best score is tracked until the score reaches a threshold where optimization terminates. At this point, the trial cdf is within an acceptable tolerance to the true cdf and constitutes the pdf estimate. Different outcomes are possible since the method is based on a random fitness-selection process to solve an inverse problem. The role of the scoring function in the NMEM includes defining the objective target for optimizing the Lagrange multipliers, providing stopping criteria for adding orthogonal functions in the generalized Fourier series expansion and marking a point of diminishing returns where further optimizing the Lagrange multipliers results in over-fitting to the data. Simply put, the scoring function provides a means to quantify the quality of the NMEM density estimate. Optimizing the scoring function in NMEM differs from traditional MEM approaches that minimize error in estimates based on moments of the sampled data. Note that the universality of the scoring function eliminates problems with heavy tailed distributions that have divergent moments. Nevertheless, Lagrange multipliers are determined based on solving a well defined extremum problem in both cases.
Before tackling how to evaluate the efficacy of scoring functions, a brief description is given here on how the quality of a pdf estimate can be assessed without knowing the true pdf. Visualizing a quantile-quantile plot (QQ-plot) is a common approach in determining if two random samples come from the same pdf. Given a set of
N sort ordered random variables
that are monotonically increasing, along with a cdf estimate, the corresponding empirical quantiles are determined by the mapping
as described above. It is not necessary to have a second data set to compare. As described previously [
11], the empirical quantile can be plotted on the y-axis versus the theoretical average quantile for the true pdf plotted on the x-axis. From single order statistics (SOS) the expectation value of
is given by
for
, which gives the mean quantile.
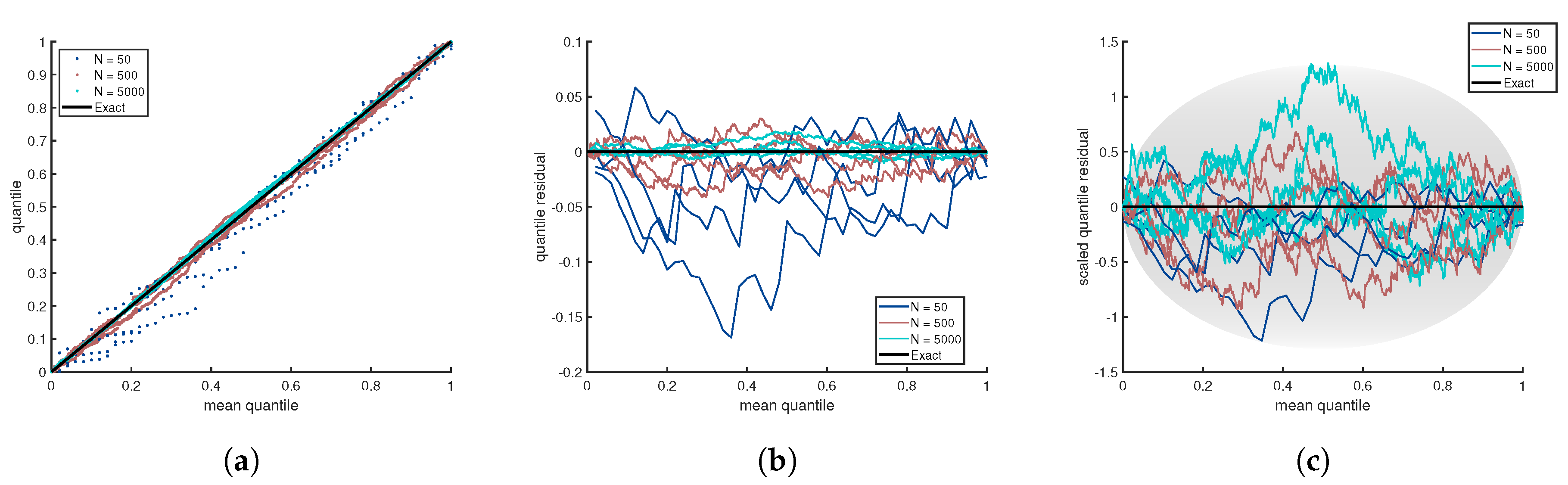
Figure 2a illustrates the QQ plot for the distributions shown in
Figure 1. The benefit of the QQ plot is that it is a universal measure. Unfortunately, for large sample sizes, the plot is no longer informative because all curves approach a perfect straight line as random fluctuations decrease with increasing sample size. A quantile residual (QR) allows deviations from the mean quantile to be readily visualized when one sample size is considered. However, as illustrated in
Figure 2b, the residuals in a QR-plot decrease as sample size increases. Hence, the quantile residual is not sample size invariant.
The QR-plot is scaled [
11] in such a way as to make the scaled quantile residual (SQR) sample size invariant. From SOS, the standard deviation for the empirical quantile to deviate from the mean quantile is well-known to be
where
k is the sort order index. Interestingly, all fluctuations regardless of the value for the mean quantile scale with sample size as
. Sample size invariance is achieved by defining SQR as
and, when plotted against
, one obtains a SQR-plot.
Figure 2c shows an SQR-plot for three different sample sizes for each of the four distributions considered in
Figure 1. It is convenient to define contour lines using the formula
, where the scale factor,
, can be adjusted to control how frequently points on the SQR plot will fall within a given contour. In particular, 99% of the time the SQR points will fall within the boundaries of the oval when bounded by
. Scale factors of
,
,
and
lead to 90%, 95%, 99% and 99.9% of SQR points falling within the oval based on numerical simulation. Interestingly, the scale factors of
,
,
and
respectively correspond to the
z-values of a Gaussian distribution at the 90%, 95%, 99% and 99.9% confidence levels.
The SQR-plot provides a distribution free visualization tool to assess the quality of a cdf estimate in three ways. First, when the SQR falls appreciably within the oval that encloses 99% of the residual, it is not possible to reject the null hypothesis. Second, when the SQR exhibits non-random patterns, this is an indication of systematic error introduced by the estimator method. Finally, when the SQR has suppressed random fluctuations such that it is close to 0 for an extended interval, this indicates that the pdf estimate is over-fitting to the sample data. In general, over-fitting is hard to quantify [
14]. As the graphical abstract shows, it is possible to plot the SQR against the original random variable
x instead of the mean quantile. Doing this deforms the oval or "lemon drop" shape of the SQR-plot but it directly shows where problems in the estimate are locally occurring in relation to the pdf estimate. The aim of this paper is to quantify these salient features of an SQR-plot using a scoring function.
This work was motivated by the concern that different scoring functions will likely perform differently in terms of speed and accuracy in NMEM. The scoring function that was initially considered was constructed from the natural logarithm of the product of probabilities for each transformed random variable, given by
. This log-likelihood scoring function provides one way to measure the quality of a proposed cdf. Interestingly, the log-likelihood scoring function has a mathematical structure similar to the commonly employed Anderson-Darling (AD) test [
15,
16]. As such, the current study considers several alternative scoring functions that use SQR and compares how sensitive they are in quantifying the quality of a pdf estimate. Other types of information measures that use cumulative relative entropy [
17] or residual cumulative Kullback–Leibler information [
18,
19] are possible. However, these alternatives are outside the scope of this study, which focuses on leveraging SQR properties. The scoring function must exhibit distribution free and sample size invariant properties so that it can be applied to any sample of random data of a continuous variable and also to sub-partitions of the data when employed in the PDFestimator. It is worth noting that all the scoring functions presented in this paper exhibit desirable properties with similar or greater efficacy than the AD scoring function and all are useful for assessing the quality of density estimates.
In the remainder of this paper, a numerical study is presented to explore different types of measures for SQR quality. The initial emphasis is on constructing sensitive quality measures that are universal and sample size invariant. These scoring functions based on SQR properties can be applied to quantifying the accuracy (or ‘’goodness of fit”) of a pdf estimate created by any methodology, without knowledge of the true pdf. The SQR is readily calculated from the cdf which is obtained by integrating the pdf. To determine which scoring function best distinguishes between good and poor cdf estimates, the concept of decoy SURD is introduced. Once decoys are generated, Receiver Operator Characteristics (ROC) are employed to identify the most discriminating scoring function [
17]. In addition to ROC evaluation, performance of the PDFestimator for different plugged in scoring functions is evaluated. This benchmark is important because the scoring function is expected to affect the rate of convergence toward a satisfactory pdf estimate using the NMEM approach. After discussing the significance of the results, several conclusions are drawn from an extensive body of experiments.
3. Discussion
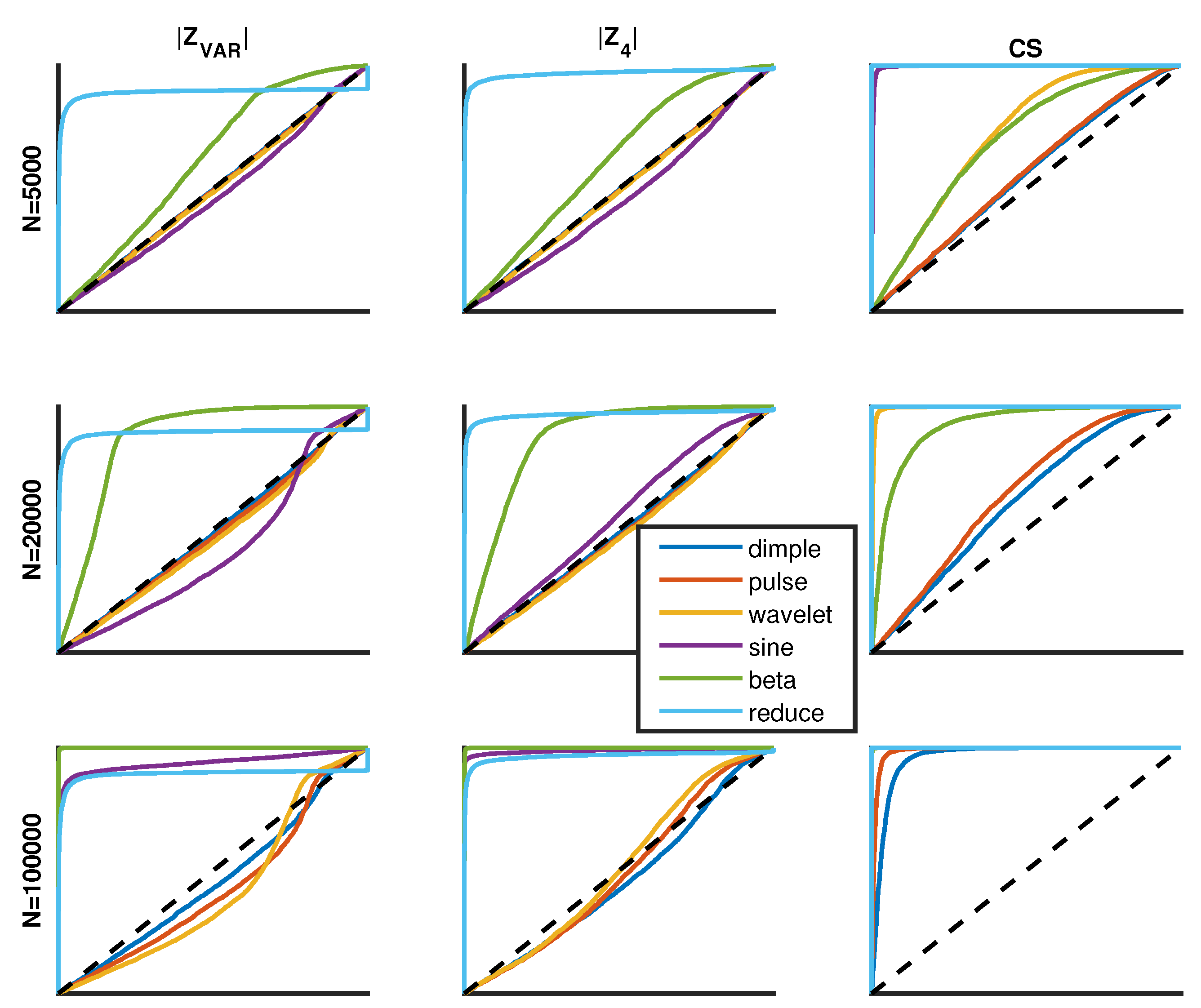
Each of the five scoring methods have been evaluated when utilized within the PDFestimator and applied to the same distribution test set in terms of scalability, sensitivity, failure rate and KL-divergence. Each of the proposed measures have strengths and weaknesses in different areas. The
measure produces the most accurate scaling and the lowest KL-divergence. The
measure shows the greatest sensitivity for detecting small deviations from SURD. The
method, although not a clear winner in any particular area, is notably well-performing in all tests. These results suggest a possible trade-off between a lower KL-divergence versus longer computational time with the
scoring method. However, the slight benefit of a lower KL-divergence is arguably not worth the computational cost, particularly when also considering the higher failure rate. In contrast, the significantly low failure rate and fast performance times are strong arguments in favor of
as the preferred scoring method. However, this result is only true when the score of a sensitive measure is minimized, while the threshold to terminate is based on a less sensitive measure (see
Section 4.7 in methods for details).
Qualitative analysis is used to elucidate why
minimization is the best overall performer. The pdf and SQR for hundreds of different estimates were compared visually and robust trends were observed between the
and
methods.
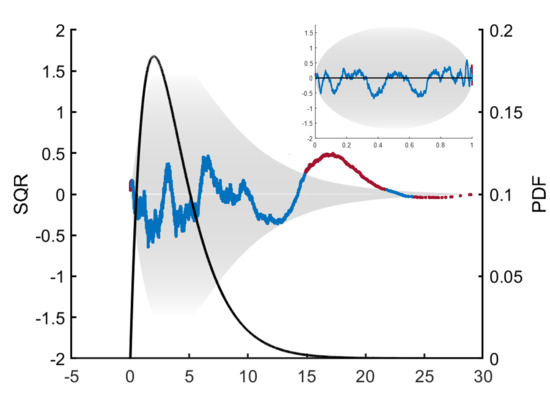
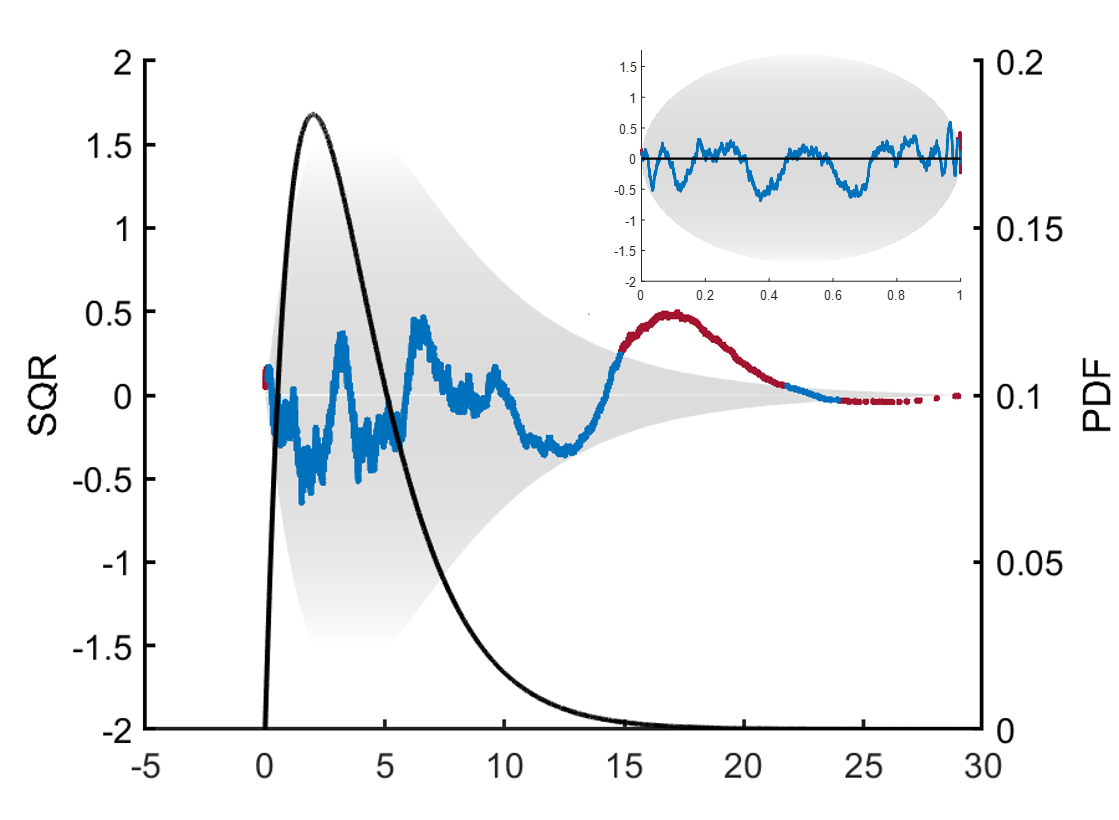
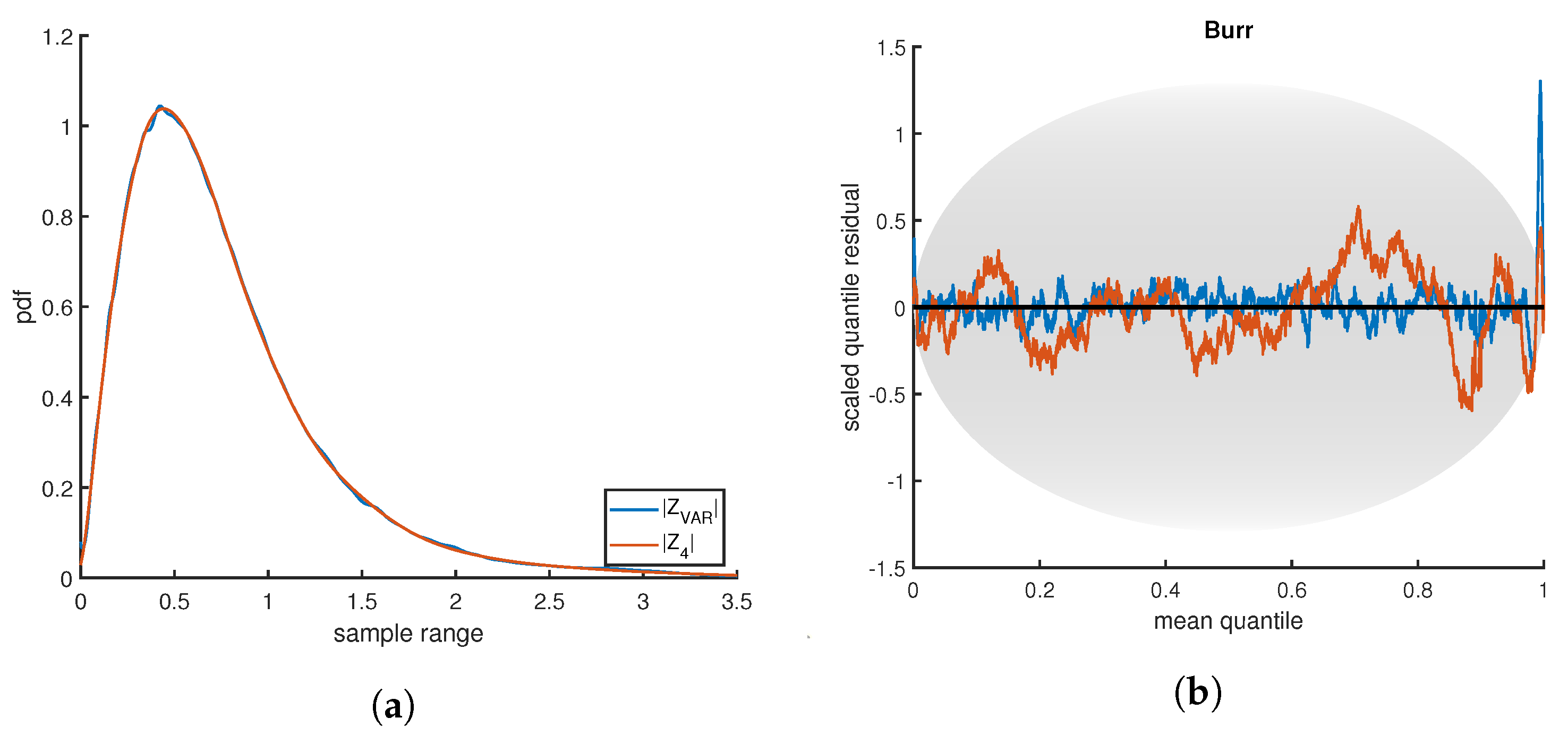
Figure 13a is a representative example, showing the density estimates for the Burr distribution at 100,000 samples. Although both estimates were terminated at the same quality level, the smooth curve found for
would be subjectively judged superior. However, there is nothing inherently or measurably incorrect about the small wiggles in the
estimate. Note that no smoothness conditions are enforced in the PDFestimator.
The SQR-plot, shown in
Figure 13b, is especially insightful in evaluating the differences in this example. The Burr distribution is deceptively difficult to estimate accurately due to a heavy tail on the right. Both
and
fall mostly within the expected range, except for the sharp peak to the right corresponding to the long tail. Although the peak is more pronounced for
, the more relevant point in this example is the shape of the entire SQR-plot. SQR for
contains scaled residuals close to zero, behavior virtually never observed in true SURD. Hence, this corresponds to over-fitting. This contrast in the SQR-plot between
and
is generally true with the following explanation.
The
scoring method uses the same threshold scoring as
, but simultaneously seeks to minimize the variance from average, thus highly penalizing outliers to the expected z-score. The
method, by contrast, tends to over-fit some areas of the distribution of high density, attempting to compensate for areas of relatively low density where it deviates significantly. This often results in longer run times, many unnecessary Lagrange multipliers, less smooth estimates and unrealistic SQR-plots, as the NMEM algorithm attempts to improve inappropriately. For example, in the test shown in
Figure 13, the number of Lagrange multipliers required for the
estimate was 141, whereas
required only 19. Therefore, it is easy to see why
took much longer to complete. This phenomenon is a general trend but it is exacerbated in cases where there are large sample sizes on distributions that have a combination of sharp peaks and heavy tails.
A surprising null result of this work is that the measure, custom designed to have the greatest overall sensitivity and selectivity, failed to be the best overall performer in practice when invoked in the PDFestimator. Although more investigation is required, all comparative results taken together suggest that the scoring function is the most sensitive but is over-designed for the capability of the random search optimization method currently employed in the PDFestimator. In the progression of improvements on pdf estimation, the results from the initial PDFestimator suggested that a more sensitive scoring function would improve performance. With that aim, more sensitive scoring functions have been determined and performance of the PDFestimator substantially improved. However, it appears the opposite is now true, requiring a shift in attention to optimize the optimizer, with access to a battery of available scoring functions. In preparation, another work (ZM, JF, DJ) optimizes the overall scheme by dividing the data into smaller blocks, which gives much greater speed and higher accuracy, while taking advantage of parallelization.
4. Methods
MATLAB 2019a (MathWorks, Natick, MA, USA) and the density estimation program “PDFestimator” were used to generate all the data presented in this work. The PDFestimator is a C++ program that JF and DJ developed as previously reported [
11], which has the original Java program in supporting material. Upgrades on the PDFestimator are continuously being made on the BioMolecular Physics Group (BMPG) GitHub website, Available online:
https://github.com/BioMolecularPhysicsGroup-UNCC/PDF-Estimator, where the source code is freely available, including a MATLAB interface to the C++ program. An older C++ version is also available in R,
https://cran.r-project.org/web/packages/PDFEstimator/index.html. The version on the public GitHub website is the most recent stable version that has been well tested.
4.1. Generating SURD and Scoring Function Evaluation
MATLAB was employed in numerical simulations to generate SURD. For a sample size N, the sort ordered sequence of numbers was used to evaluate each scoring function being considered. The same realization of SURD was assigned multiple scores to facilitate subsequent cross correlations.
4.2. Method for Partitioning Data
As previously explained in detail [
11], sample sizes of N > 1025 were partitioned in the PDFestimator to achieve rapid calculations. The lowest and highest random number in the set
define the boundaries of each partition. The random number closest to the median was also included. Partitions have an odd number of random numbers due to the recursive process of adding one additional random number between the previously selected random numbers in the current partition. Partition sizes follow the pattern of
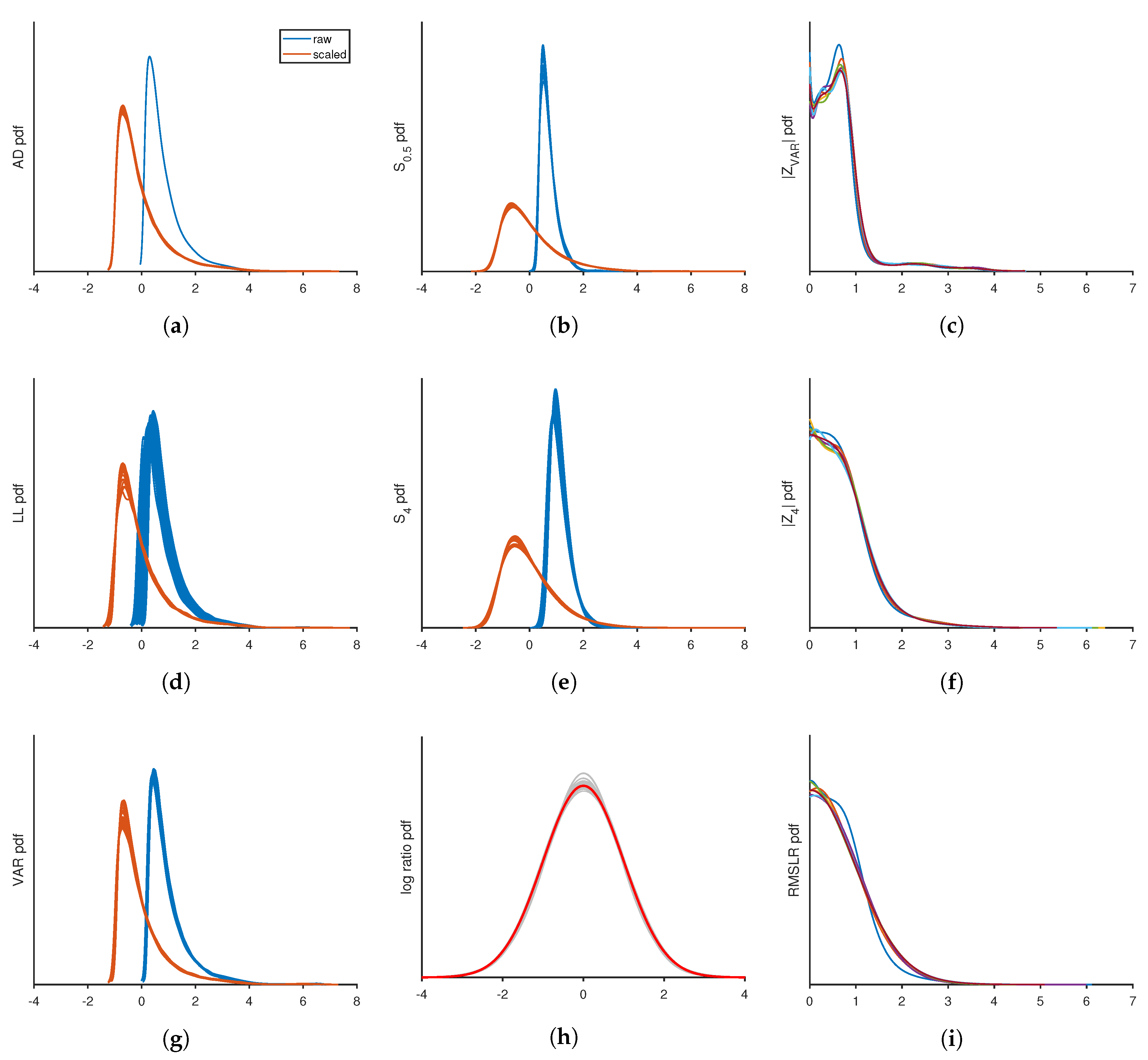
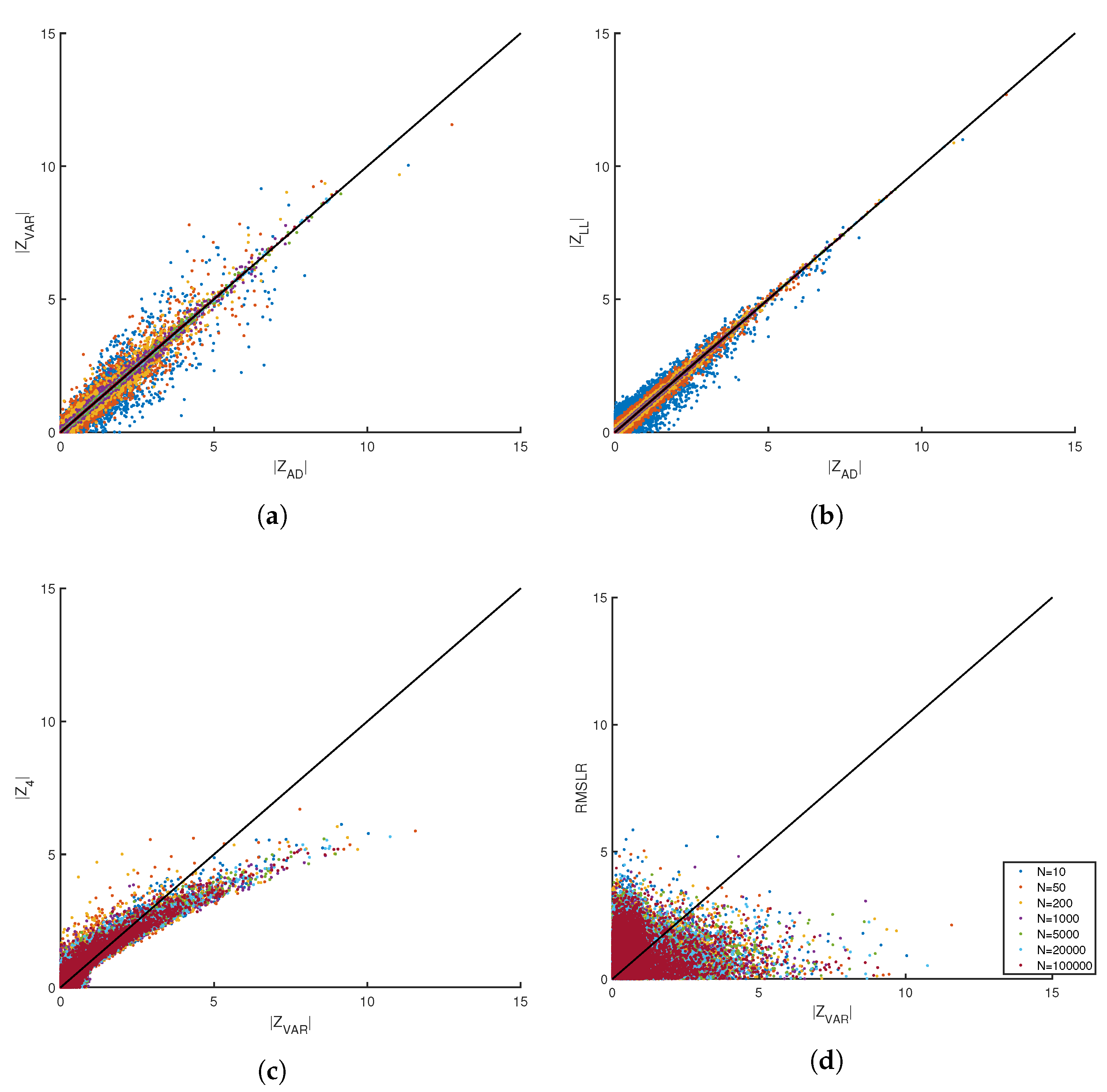
. A desired property of scoring functions is that they should maintain size invariance for all partitions. Scores for each measure were tracked for all partitions of size 1026 and greater, including the full data set, which is the last partition. For example, with N = 100,000 the scores for partitions of size Np = 1025, 2049, 4097, 8193, 16,385, 32,769, 65,537, 100,000 were calculated. Scores from different partitions were cross correlated in scatter plots.
4.3. Finite Size Corrections
For each partition of size
, including the last partition of size
N, the scores were transformed to obtain data collapse. For all practical purposes finite size corrections were successfully achieved by shifting the average of a score to zero and normalizing the data by the standard deviation of the raw score. That is to say, the score,
for
samples in the p-th partition, was a random variable. This score was transformed to a Z-value through the procedure
. Operationally, tens of thousands of random sequences of SURD were generated for each scoring function type to empirically estimate
and
. Note that
and
were obtained using basic fitting tools in the MATLAB graphics interface, and these are reported in
Table 1.
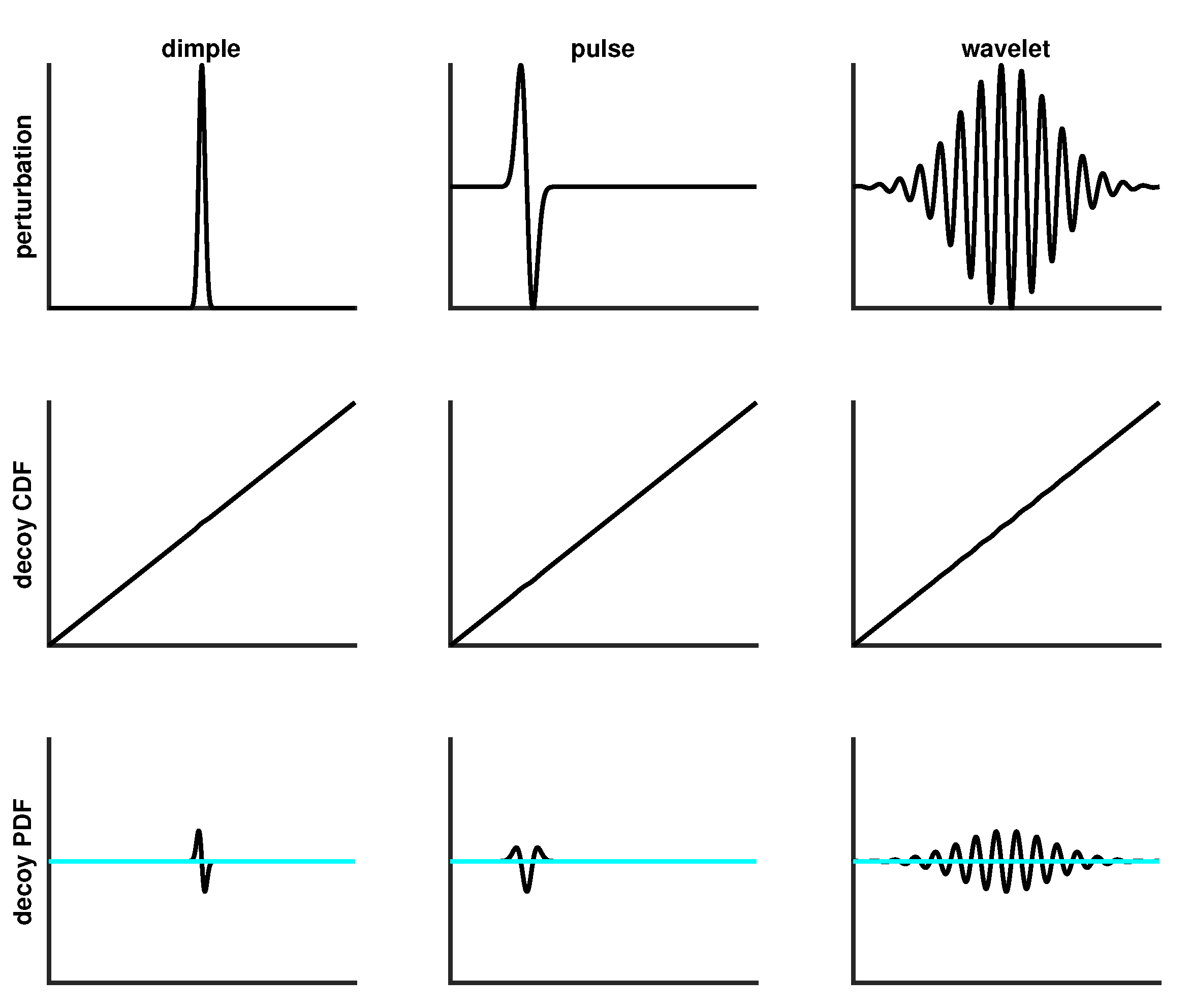
4.4. Decoy Generation
For each decoy the sort ordered sequence of numbers defining SURD was transformed into decoy-SURD, denoted as dSURD. This was accomplished by creating a model decoy cdf, . A new set of sort ordered random numbers was created by the 1 to 1 mapping , yielding a dSURD realization per SURD realization. Different decoys were generated based on different types of perturbations, which must meet certain criteria. Let represent a perturbation to SURD, such that
For the perturbation to be valid, the pdf given by
must satisfy
, which implies
. The boundary conditions
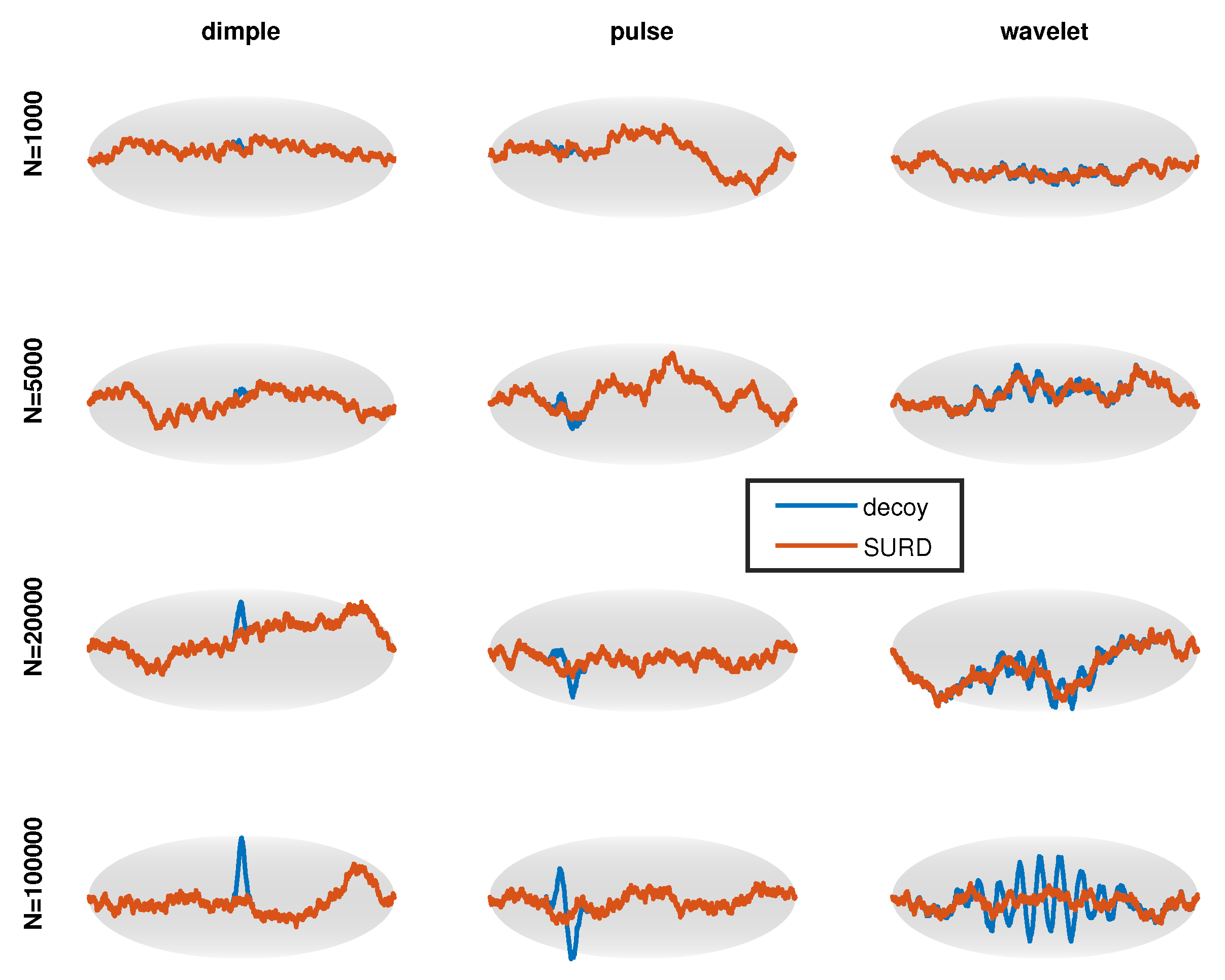
must also be imposed. With these conditions satisfied, decoys of a wide variety could be generated. Four types of decoys were created using this approach, listed in the first 4 rows of
Table 3. In this approach, the amplitude of the perturbation is a parameter. A decoy that is marginally difficult to detect at sample size of
has
. It will be challenging to discriminate between SURD and dSURD for
, and markedly distinguishable when
.
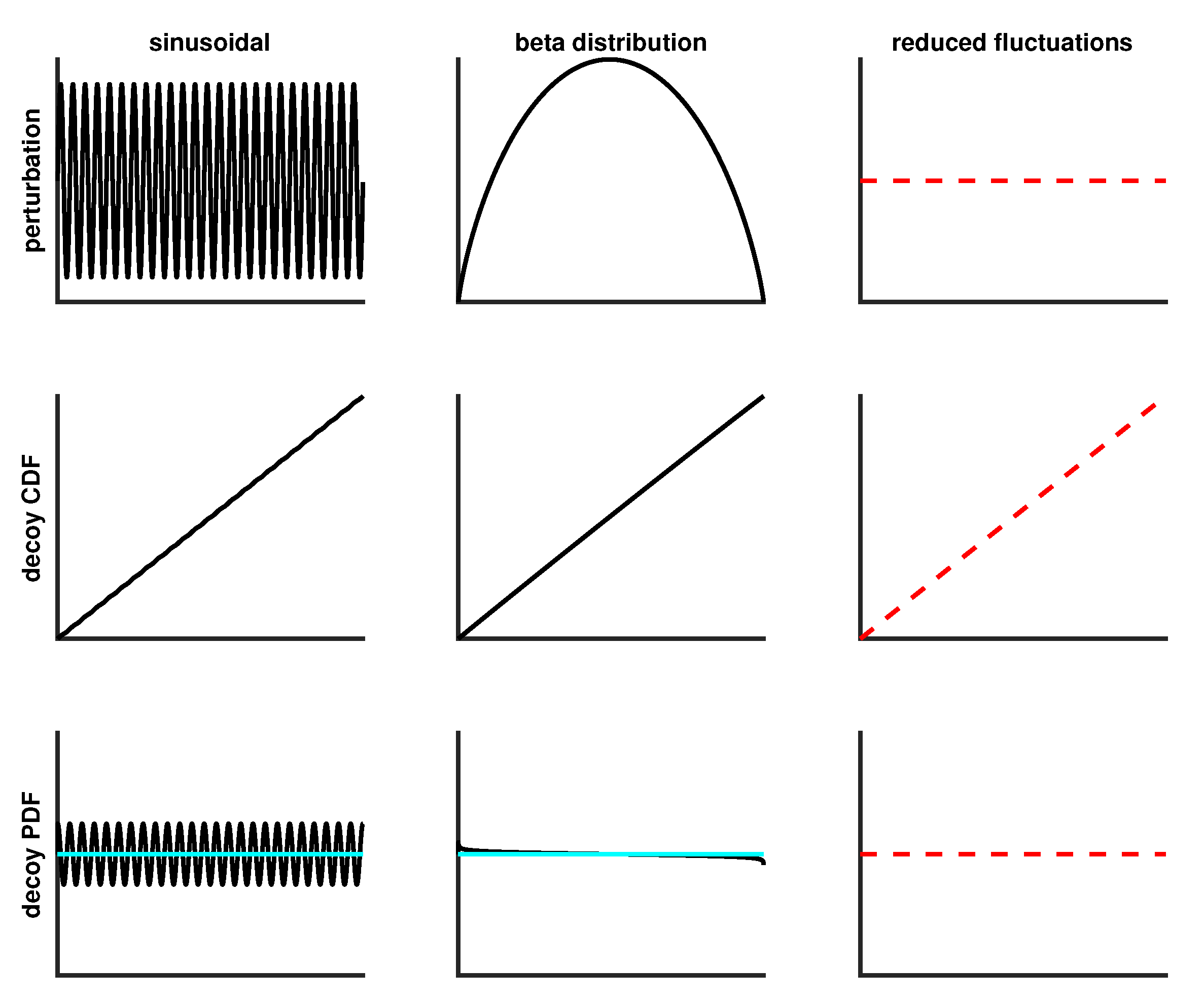
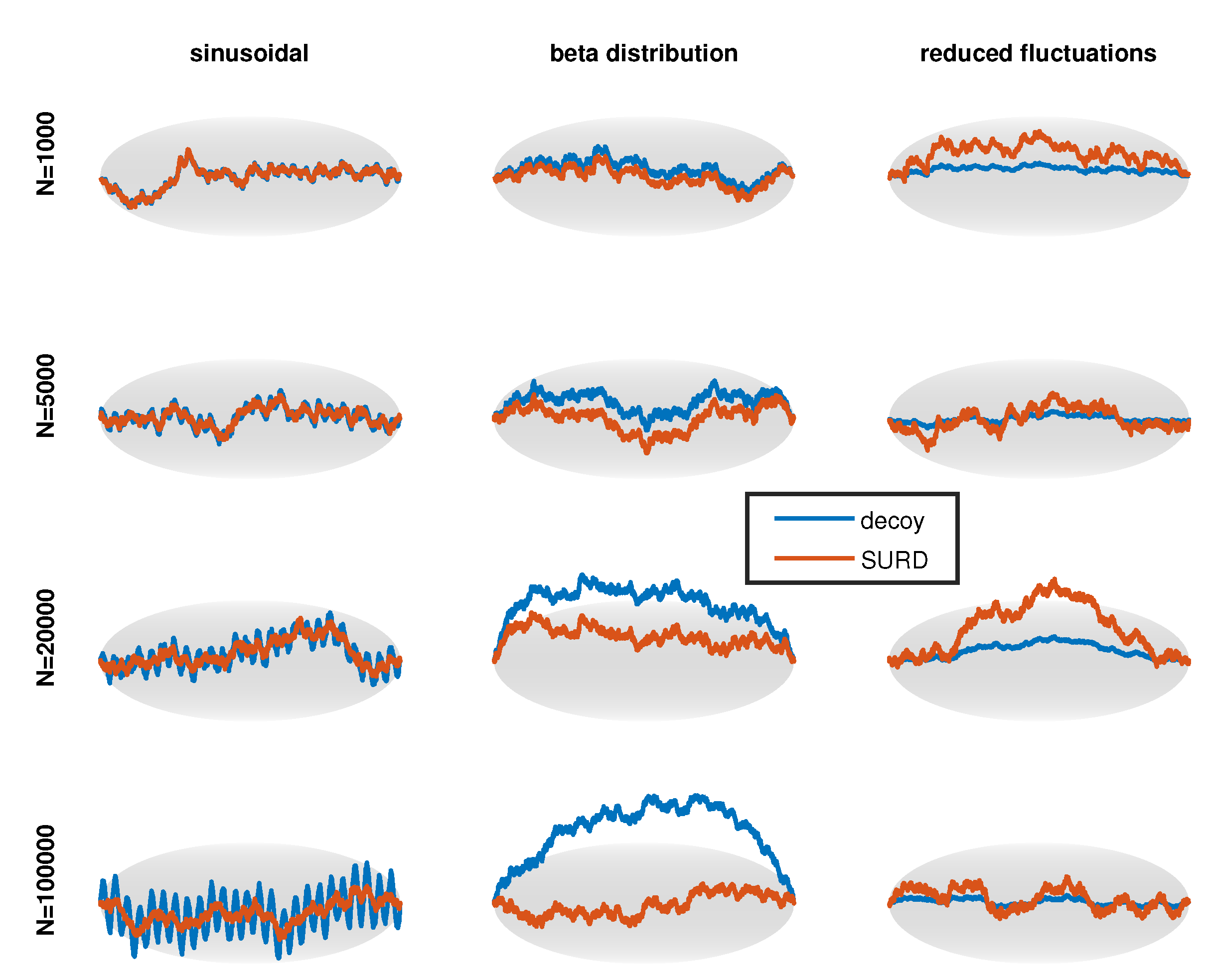
Two additional types of decoys were also generated. First, is set to a beta distribution cdf, denoted as . Therefore, the perturbation is given as . The and parameters were adjusted to tune detection difficulty, by systematically searching for pairs of and on a high resolution square grid to find when was at a level that was consistent with the targeted sample size, . Second, a decoy can be defined by uniformly reducing fluctuations according to where . When the decoy was the same as SURD, but as the decoy retained no fluctuations. In this sense, this decoy type mimics extreme over-fitting, where p controls how much of the fluctuations are reduced.
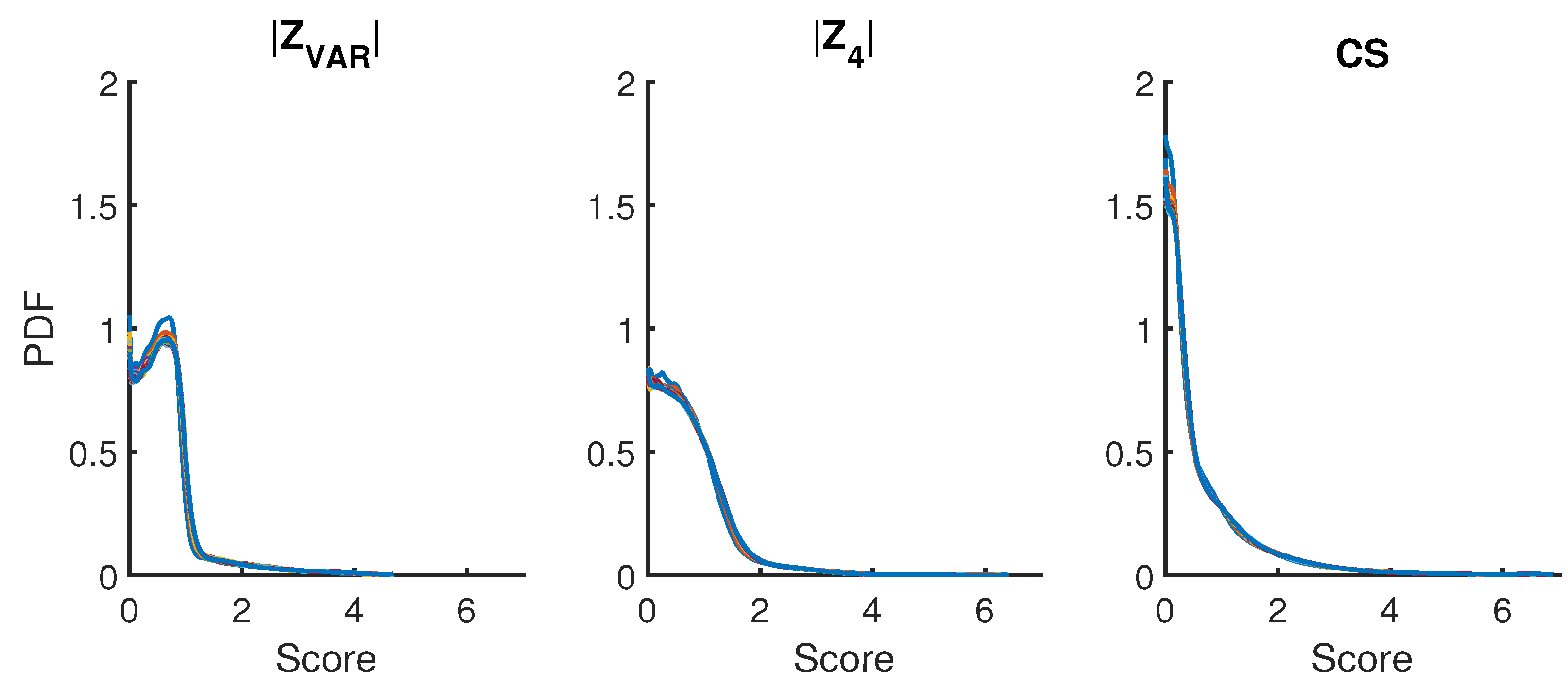
4.5. ROC Curves
All ROC curves were generated according to the definition that the fraction of true positives (FTP) were plotted on the y-axis versus the fraction of false positives (FFP) plotted on the x-axis [
22]. Note that alternative definitions for ROC are possible. To calculate FTP and FFP, a threshold score must be specified. If a score is below this threshold, the sort ordered sequence of numbers is predicted to be SURD. Conversely, if a score exceeds the threshold, the prediction is not SURD. As such, there are four possible outcomes. First, true SURD can be predicted as SURD or not, respectively, corresponding to a true positive (TP) or a false negative (FN). Second, dSURD can be predicted as SURD or not, respectively corresponding to a false positive (FP) or true negative (TN). All possible outcomes are tallied, such that FTP = TP/(TP + FN) and FFP = FP/(FP + TN). For a given threshold value, this calculation determines one point on the ROC curve. By considering a continuous range of possible thresholds, the entire ROC curve is constructed.
Procedurally, the data used to calculate the fractions of true and false positives that come from numerical simulations in MATLAB comprised 10,000 random SURD and dSURD pairs for sample sizes, 10, 50, 200, 1000, 5000, 20,000 and 100,000. About 60 different types of decoys were considered with diverse sets of parameters.
4.6. Distribution Test Set
To benchmark the effect of a scoring function on the performance of the PDFestimator, a diverse collection of distributions was selected and these are listed in
Table 4. A MATLAB script was created to utilize built in functions dealing with statistical distributions to generate random samples of specified size. The random samples were subsequently processed by the PDFestimator to estimate the pdf, but for which the exact pdf is known. The set of possible distributions available for analysis cover a range of monomodal distributions that represent many types of features that include sharp peaks, heavy tails and multiple resolution scales. Some mixture models were also included that combine difficult distributions to create a greater challenge.
4.7. PDF Estimation Method
Each alternative scoring function,
was implemented in the PDFestimator and were evaluated separately. Factors confounding comparisons in performance include sample size, distribution type, selection of key factors to evaluate and consistency across multiple trials. To provide a quantitative synopsis of the strengths and weaknesses of the proposed scoring methods, large numbers of trials were conducted on the distribution test set listed in
Table 4. The distribution test set increases atypical failures amongst the estimates because it is necessary to consider extreme scenarios to identify breaking points in each of the scoring methods. Nevertheless, easier distributions, such as Gaussian, uniform and exponential, were included. To wit, good performance of an estimator when applied to challenging cases should not suffer when applied to easier distributions.
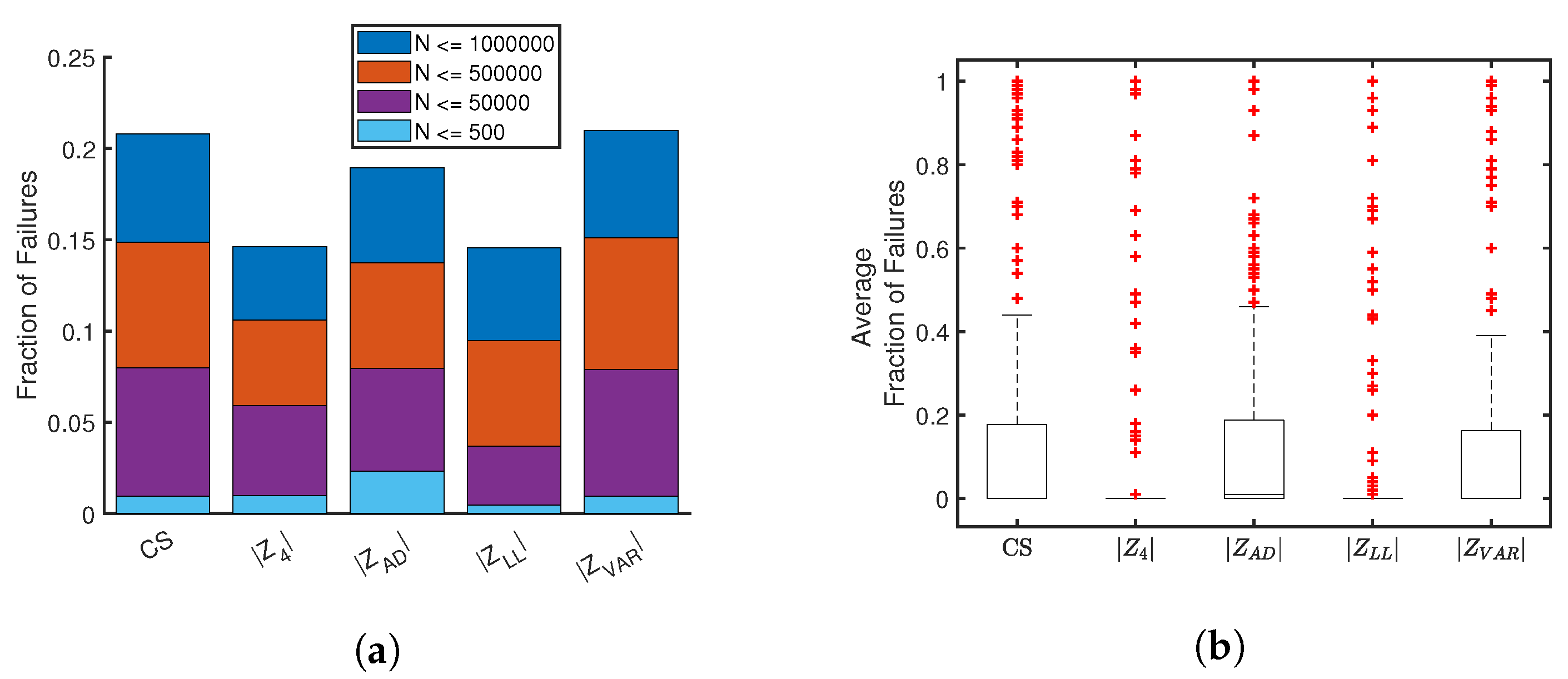
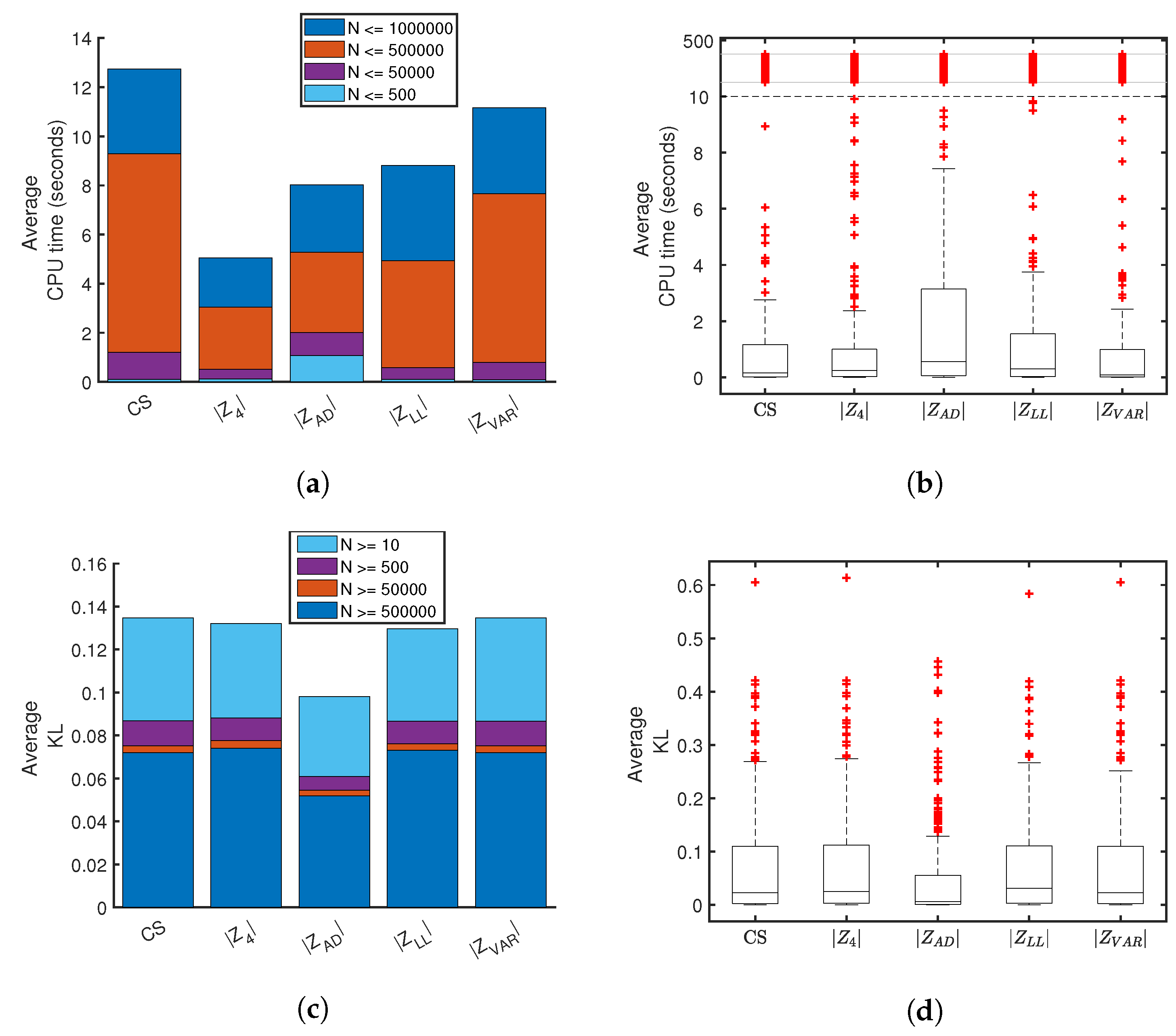
As an inverse problem, density estimation applied to multiple random samples of the same size for any given distribution will generally produce variation amongst the estimates. For small samples, the pdf estimate must resist over-fitting, whereas large sample sizes create computational challenges that must trade between speed and accuracy. To monitor these issues, a large range of sample sizes were tested, each with 100 trials of an independently generated input sample data set. Specifically, 100 random samples were generated for each of the 25 distributions, for each of the following 11 sample sizes with 10, 50, 100, 500, 1000, 5000, 10,000, 50,000, 100,000, 500,000, 1,000,000. This produced a total of 27,500 test cases, each of which were estimated using five scoring methods. Statistics were collected and averaged over each of the 100 random sample sets.
Three key quantities were calculated for a quantitative comparison of the scoring methods—failure rate, computational time and Kullback-Leibler (KL) divergence [
21]. It was found that the KL-divergence distance was not sensitive to the different scoring functions. Alternative information measures [
23,
24] could be considered in future work. Failure rate is expressed as a fraction of failures out of 100 random samples. The KL-divergence measures the difference between the estimate against the known reference distribution. Computational times and KL-divergences were averaged only for successful solutions and thus were not impacted by failures. A failure is automatically determined by the PDFestimator when a score does not reach a minimum threshold.
During an initial testing phase, it was found that the measures
and
for
AD, LL, and VAR all worked successfully, which is not surprising considering the original measure,
, works markedly well. However, for the more sensitive measures,
,
and
, the PDFestimator failed consistently because the score rarely reached its target threshold, at least within a reasonable time. Therefore, a hybrid method was developed that minimizes a sensitive measure as usual, but the
measure was invoked to determine when to terminate. In tests of
for
AD, LL or VAR, these measures were optimized and were simultaneously used as a stopping condition with a threshold of 0.66 corresponding to the 40% level in the cdf, which was the same level used previously [
11]. All these measures have the same pdf and cdf, and thus the same threshold value. This threshold was used for
as a stopping condition when different scoring functions are minimized.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}