Abstract
By proving a strong converse theorem, we strengthen the weak converse result by Salehkalaibar, Wigger and Wang (2017) concerning hypothesis testing against independence over a two-hop network with communication constraints. Our proof follows by combining two recently-proposed techniques for proving strong converse theorems, namely the strong converse technique via reverse hypercontractivity by Liu, van Handel, and Verdú (2017) and the strong converse technique by Tyagi and Watanabe (2018), in which the authors used a change-of-measure technique and replaced hard Markov constraints with soft information costs. The techniques used in our paper can also be applied to prove strong converse theorems for other multiterminal hypothesis testing against independence problems.
1. Introduction
Motivated by situations where the source sequence is not available directly and can only be obtained through limited communication with the data collector, Ahlswede and Csiszár [1] proposed the problem of hypothesis testing with a communication constraint. In the setting of [1], there is one encoder and one decoder. The encoder has access to one source sequence and transmits a compressed version of it to the decoder at a limited rate. Given the compressed version and the available source sequence (side information), the decoder knows that the pair of sequences is generated i.i.d. from one of the two distributions and needs to determine which distribution the pair of sequences is generated from. The goal in this problem is to study the tradeoff between the compression rate and the exponent of the type-II error probability under the constraint that the type-I error probability is either vanishing or non-vanishing. For the special case of testing against independence, Ahlswede and Csiszár provided an exact characterization of the rate-exponent tradeoff. They also derived the so-called strong converse theorem for the problem. This states that the rate-exponent tradeoff cannot be improved even when one is allowed a non-vanishing type-I error probability. However, the characterization the rate-exponent tradeoff for the general case (even in the absence of a strong converse) remains open till date.
Subsequently, the work of Ahlswede and Csiszár was generalized to the distributed setting by Han in [2] who considered hypothesis testing over a Slepian-Wolf network. In this setting, there are two encoders, each of which observes one source sequence and transmits a compressed version of the source to the decoder. The decoder then performs a hypothesis test given these two compression indices. The goal in this problem is to study the tradeoff between the coding rates and the exponent of type-II error probability, under the constraint that the type-I error probability is either vanishing or non-vanishing. Han derived an inner bound to the rate-exponent region. For the special case of zero-rate communication, Shalaby and Papamarcou [3] applied the blowing-up lemma [4] judiciously to derive the exact rate-exponent region and a strong converse theorem. Further generalizations of the work of Ahlswede and Csiszár can be categorized into two classes: non-interactive models where encoders do not communicate with one another [5,6,7,8] and the interactive models where encoders do communicate [9,10].
We revisit one such interactive model as shown in Figure 1. This problem was considered by Salehkalaibar, Wigger and Wang in [11] and we term the problem as hypothesis testing over a two-hop network. The two-hop model considered here has potential applications in the Internet of Things (IoT) and sensor networks. In these scenarios, direct communication from the transmitter to the receiver might not be possible due to power constraints that result from limited resources such as finite battery power. However, it is conceivable in such a scenario to assume that there are relays—in our setting, there is a single relay—that aid in the communication or other statistical inference tasks (such as hypothesis testing) between the transmitter and receiver.
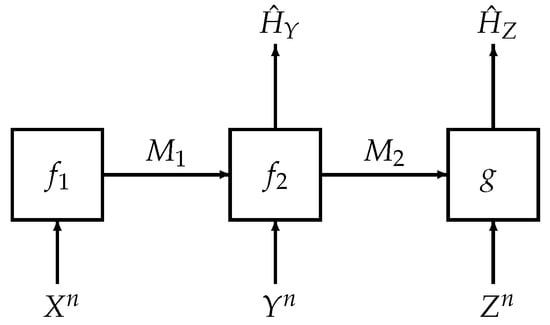
Figure 1.
System model for hypothesis testing over a two-hop network
The main task in this problem is to construct two hypothesis tests between two joint distributions and . One of these two distributions governs the law of where each copy is generated independently either from and . As shown in Figure 1, the first terminal has knowledge of a source sequence and sends an index to the second terminal, which we call the relay; the relay, given side information and compressed index , makes a guess of the hypothesis and sends another index to the third terminal; the third terminal makes another guess of the hypothesis based on and its own side information . The authors in [11] derived an inner bound for the rate-exponent region and showed that the bound is tight for several special cases, including the case of testing against independence in which . However, even in this simpler case of testing against independence, which is our main concern in this paper, the authors in [11] only established a weak converse.
In this paper, we strengthen the result by Salehkalaibar, Wigger and Wang in [11] by deriving a strong converse for the case of testing against independence. Our proof follows by combining two recently proposed strong converse techniques by Liu et al. in [12] and by Tyagi and Watanabe in [13]. In [12], the authors proposed a framework to prove strong converse theorems based on functional inequalities and reverse hypercontractivity of Markov semigroups. In particular, they applied their framework to derive strong converse theorems for a collection of problems including the hypothesis testing with communication constraints problem in [1]. In [13], the authors proposed another framework for strong converse proofs, where they used a change-of-measure technique and replaced hard Markov constraints with soft information costs. They also leveraged variational formulas for various information-theoretic quantities; these formulas were introduced by Oohama in [14,15,16].
Notation
Random variables and their realizations are in upper (e.g., X) and lower case (e.g., x) respectively. All sets are denoted in calligraphic font (e.g., ). We use to denote the complement of . Let be a random vector of length n and its realization. Given any , we use to denote its type (empirical distribution). All logarithms are base e. We use and to denote the set of non-negative real numbers and natural numbers respectively. Given any positive integer , we use to denote . We use to denote the indicator function and use standard asymptotic notation such as . The set of all probability distributions on a finite set is denoted as . Given any two random variables and any realization of x, we use to denote the conditional distribution . Given a distribution and a function , we use to denote . For information-theoretic quantities, we follow [17]. In particular, when the joint distribution of is , we use and interchangeably. Throughout the paper, for ease of notation, we drop the subscript for distributions when there is no confusion. For example, when the joint distribution of is , we use and interchangeably. For any , let denote the binary divergence function, i.e., .
2. Problem Formulation and Existing Results
2.1. Problem Formulation
Fix a joint distribution satisfying the Markov chain , i.e.,
Let , and be induced marginal distributions of . As shown in Figure 1, we consider a two-hop hypothesis testing problem with three terminals. The first terminal, which we term the transmitter, observes a source sequence and sends a compression index to the second terminal, which we term the relay. Given and side information , the relay sends another compression index to the third terminal, which we term the receiver. The main task in this problem is to construct hypothesis tests at both the relay and the receiver to distinguish between
For subsequent analyses, we formally define a code for hypothesis testing over a two-hop network as follows.
Definition 1.
An -code for hypothesis testing over a two-hop network consists of
- Two encoders:
- Two decoders
Given an -code with encoding and decoding functions , we define acceptance regions for the null hypothesis at the relay and the receiver as
respectively. We also define conditional distributions
Thus, for a -code characterized by , the joint distribution of random variables under the null hypothesis is given by
and under the alternative hypothesis is given by
Now, let and be marginal distributions induced by and let and be marginal distributions induced by . Then, we can define the type-I and type-II error probabilities at the relay as
respectively and at the receiver as
respectively. Clearly, , and are functions of n but we suppress these dependencies for brevity.
Given above definitions, the achievable rate-exponent region for the hypothesis testing problem in a two-hop network is defined as follows.
Definition 2.
Given any , a tuple is said to be-achievable if there exists a sequence of -codes such that
The closure of the set of all -achievable rate-exponent tuples is called the-rate-exponent region and is denoted as . Furthermore, define the rate-exponent region as
2.2. Existing Results
In the following, we recall the exact characterization of given by Salehkalaibar, Wigger and Wang ([11] (Corollary 1)). For this purpose, define the following set of joint distributions
Given , define the following set
Finally, let
Theorem 1.
The rate-exponent region for the hypothesis testing over a two-hop network problem satisfies
In the following, inspired by Oohama’s variational characterization of rate regions for multiuser information theory [14,15,16], we provide an alternative characterization of . For this purpose, given any and any , let
be a linear combination of the mutual information terms in (25). Furthermore, define
An alternative characterization of is given by
3. Strong Converse Theorem
3.1. The Case
Theorem 2.
Given any such that and any , for any -code such that , , we have
The proof of Theorem 2 is given in Section 4. Several remarks are in order.
First, using the alternative expression of the rate-exponent region in (30), we conclude that for any such that , we have . This result significantly strengthens the weak converse result in ([11] (Corollary 1)) in which it was shown that .
Second, it appears difficult to establish the strong converse result in Theorem 2 using existing classical techniques including image-size characterizations (a consequence of the blowing-up lemma) [4,6] and the perturbation approach [18]. In Section 4, we combine two recently proposed strong converse techniques by Liu, van Handel, and Verdú [12] and by Tyagi and Watanabe [13]. In particular, we use the strong converse technique based on reverse hypercontractivity in [12] to bound the exponent of the type-II error probability at the receiver and the strong converse technique in [13], which leverages an appropriate change-of-measure technique and replaces hard Markov constraints with soft information costs, to analyze the exponent of type-II error probability at the relay. Finally, inspired by the single-letterization steps in ([19] (Lemma C.2)) and [13], we single-letterize the derived multi-letter bounds from the previous steps to obtain the desired result in Theorem 2.
Third, we briefly comment on the apparent necessity of combining the two techniques in [12,13] instead of applying just one of them to obtain Theorem 2. The first step to apply the technique in [13] is to construct a “truncated source distribution” which is supported on a smaller set (often defined in terms of the decoding region) and is not too far away from the true source distribution in terms of the relative entropy. For our problem, the source satisfies the Markov chain . If we naïvely apply the techniques in [13], the Markovian property would not hold for the truncated source . On the other hand, it appears rather challenging to extend the techniques in [12] to the hypothesis testing over a multi-hop network problem since the techniques therein rely heavily on constructing semi-groups and it is difficult to devise appropriate forms of such semi-groups to be used and analyzed in this multi-hop setting. Therefore, we carefully combine the two techniques in [12,13] to ameliorate the aforementioned problems. In particular, we first use the technique in [13] to construct a truncated source and then let the conditional distribution of given be given by the true conditional source distribution to maintain the Markovian property of the source (see (56)). Subsequently, in the analysis of error exponents, we use the technique in [12] to analyze the exponent of type-II error probability at the receiver to circumvent the need to construct new semi-groups.
Finally, we remark that the techniques (or a subset of the techniques) used to prove Theorem 2 can also be used to establish a strong converse result for other multiterminal hypothesis testing against independence problems, e.g., hypothesis testing over the Gray-Wyner network [7], the interactive hypothesis testing problem [9] and the cascaded hypothesis testing problem [10].
3.2. The Case
In this subsection, we consider the case where the sum of type-I error probabilities at the relay and the receiver is upper bounded by a quantity strictly greater than one. For ease of presentation of our results, let
Given any , define the following set of rate-exponent tuples
Furthermore, define
Given any and , define the following linear combination of the mutual information terms
and let
Then, based on [14,15,16], an alternative characterization of is given by
Analogously to Theorem 2, we obtain the following result.
Theorem 3.
Given any and any , for any -code such that , , we have
The proof of Theorem 3 is similar to that of Theorem 2 and thus omitted for simplicity.
To prove Theorem 3, we need to analyze two special cases (cf. Figure 2) of our system model separately:
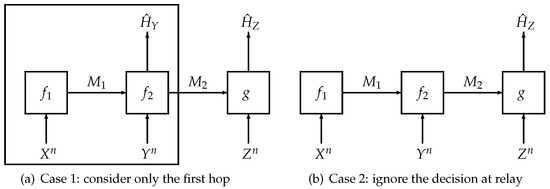
Figure 2.
Illustration of the proof sketch of Theorem 3.
- (i)
- Firstly, we consider the first hop, which involves the transmitter and the relay only. The first hop itself is a hypothesis testing problem with a communication constraint [1]. Using the techniques either in [13] or [12], we can obtain bounds on a linear combination of the rate of the first encoder and the type-II error exponent of the relay, (i.e., for any ) for any type-I error probability at the relay.
- (ii)
- Secondly, we study the second special case in which the relay does not make a decision. Using similar steps to the proof of Theorem 2, we can obtain a lower bound on a linear combination of the rate at the transmitter, the rate at the relay and the type-II exponent at the receiver (i.e., for any ) for any type-I error probability at the receiver.
- (iii)
- Finally, combining the results obtained in the first two steps, we obtain a lower bound on the linear combination of rates and type-II exponents (as shown in Theorem 3). The proof is completed by using standard single-letterization steps and the variational formula in Equation (37).
Using Theorem 3, we obtain the following proposition.
Proposition 1.
For any such that , we have
The converse proof of Proposition 1 follows from Theorem 3 and the alternative characterization of in (37). The achievability proof is inspired by ([6] (Theorem 5)) and is provided in Appendix A. The main idea is that we can time-share between two close-to optimal coding schemes, each of which corresponds to one special case of the current problem as mentioned after Theorem 3.
Recall that in the first remark of Theorem 2, we provide an exact characterization of the rate-exponent region for any such that . The converse proof follows from Theorem 2 and the achievability part was given in ([20] (Corollary 1)). Combining the first remark of Theorem 2 and Proposition 1, we provide an exact characterization of for any such that . We remark the case in which was also excluded in the analysis of the successive refinement of hypothesis testing with communication constraints problem studied by Tian and Chen [6]. In fact, our converse result in Theorem 3 holds for any including the case . However, the achievability result presented in Appendix A holds only when and thus we are unable to characterize when . Because of the need to propose an achievability scheme which uses completely different techniques to handle the case in which , which does not dovetail with the main message and contribution of this paper, we omit this case in this paper.
4. Proof of Theorem 2
4.1. Preliminaries
Before presenting the proof of Theorem 2, in this subsection, we briefly review the two strong converse techniques that we judiciously combine in this work, namely the change-of-measure technique by Tyagi and Watanabe [13] and the hypercontractivity technique by Liu et al. [12].
The critical step in the strong converse technique by Tyagi and Watanabe [13] is to construct a truncated source distribution, which is supported over a small set related to the decoding regions. Furthermore, the constructed truncated distribution should satisfy the following conditions:
- (i)
- The truncated distribution is close to the original source distribution in terms of the KL divergence;
- (ii)
- Under the truncated distribution, the (type-I) error probability is small.
Subsequent steps proceed similarly as the weak converse analysis of the problem and lead to bounds on the rates and (type-II) exponents. We then single-letterize the obtained bounds (using classical techniques in information theory without the memoryless property, e.g., [21]). Finally, we relate the single-letterized results to the the variational characterization [14,16] of the fundamental limit of the problem, which uses the idea of replacing hard Markov constraints with soft information costs.
The advantage of the Tyagi-Watanabe technique lies in its simplicity and similarity to weak converse analyses. In contrast, the disadvantage of the technique is that the structure of the source distribution (e.g., Markovian) is potentially lost in the constructed truncated distribution. As we have illustrated briefly after Theorem 2, this disadvantage prevents us from solely using the Tyagi-Watanabe technique to prove the strong converse theorem for our setting.
On the other hand, the key technique in the strong converse technique by Liu et al. [12] is the use of ideas from reverse hypercontractivity. In particular, one needs to use the variational formula of the KL divergence ([22] (Chapter 12)) and carefully construct Markov semigroups. The operation of applying a Markov semigroup is similar to a soft version of blowing up of decoding sets [4] for the discrete memoryless case. The advantage of the strong converse technique by Liu et al. lies in its wide applicability (beyond discrete settings) and its versatile performance (beyond showing strong converses it can be used to show that the second order terms scale as ). However, the construction of appropriate Markov semigroups is problem-specific, which limits its applicability to other information-theoretic problems in the sense that one has to construct specific semigroups for each problem. Fortunately, in our setting this construction and combination with Tyagi-Watanabe’s technique, is feasible.
4.2. Summary of Proof Steps
In the rest of this section, we present the proof of strong converse theorem for the hypothesis testing over the two-hop network. The proof follows by combining the techniques in [12,13] and is separated into three main steps. First, we construct a truncated source distribution and show that this truncated distribution is not too different from in terms of the relative entropy. Subsequently, we analyze the exponents of type-II error probabilities at the relay and the receiver under the constraint that their type-I error probabilities are non-vanishing. Finally, we single-letterize the constraints on rate and error exponents to obtain desired result in Theorem 2.
To begin with, let us fix an -code with functions such that the type-I error probabilities are bounded above by and respectively, i.e., and . We note from (19) and (20) that and . Since the terms are immaterial in the subsequent analyses, they are omitted for brevity.
4.3. Step 1: Construction of a Truncated Distribution
Paralleling the definitions of acceptance regions in (8) and (9), we define the following acceptance regions at the relay and the receiver as
respectively. Note that the only difference between and lies in whether we consider the compression index or the original source sequence . Recalling the definitions of the type-I error probabilities for the relay denoted by in (14) and for the receiver denoted by in (16), and using (40) and (41), we conclude that
For further analysis, given any , define a conditional acceptance region at the receiver (conditioned on ) as
For ease of notation, given any , we use and (here plays the role of in (44)) interchangeably and define the following set
Thus, we have
For subsequent analyses, let
and define the typical set as
Using the Chernoff bound, we conclude that when n is sufficiently large,
Now, define the following set
Let the truncated distribution be defined as
Note that under our constructed truncated distribution , the Markov chain holds.In other words, the Markovian property of the original source distribution is retained for the truncated distribution , which appears to be necessary to obtain a tight result if one wishes to use weak converse techniques. This is critical for our subsequent analyses.
Finally, note that
4.4. Step 2: Analyses of the Error Exponents of Type-II Error Probabilities
4.4.1. Type-II Error Probability at the Relay
Let and be the outputs of encoders and respectively when the tuple of source sequences is distributed according to defined in (56). Thus, recalling the definitions in (10), (11) and (56), we find that the joint distribution of is given by
Let be induced by . Combining (8) and (56), we conclude that
where (67) follows from the definition of in (40) and the fact that .
Thus, using the data processing inequality for the relative entropy and the definition of in (15), we obtain that
4.4.2. Type-II Error Probability at the Receiver
In this subsection, we analyze the error exponent of the type-II error probability at the receiver. For this purpose, we make use of the method introduced in [12] based on reverse hypercontractivity. We define the following additional notation:
- Give , define
- Given any such that , let
- Give any and , let
- Two operators in ([12] (Equations (25), (26), (29)))
Note that in (84), we use the convenient notation . The two operators in (83) and (84) will be used to lower bound via a variational formula of the relative entropy (cf. ([12] (Section 4))).
Let , , be induced by the joint distribution in (64) and let be induced by the joint distribution in (13). Invoking the variational formula for the relative entropy ([22] (Equation (2.4.67))) and recalling the notation , we have
Given any , similar to ([12] (Equations (18)–(21))), we obtain
Thus, averaging over with distribution on both sides of (88), we have
where (90) follows from the definition of in (17).
Furthermore, given any , we obtain
where (94) follows from ([12] (Lemma 4)) and (95) follows similarly to ([12] (Equations (14)–(17))).
Thus, averaging on both sides of (96) over with distribution and using the definition of the joint distribution in (64), we obtain that
where (100) follows from the definitions of in (45) and in (54).
In the following, we further upper bound . For this purpose, define the following distribution
4.5. Step 3: Analyses of Communication Constraints and Single-Letterization Steps
For any -code, since for , we have that
Furthermore, from the problem setting (see (64)), we have
For subsequent analyses, given any , define
The proof of Theorem 2 is complete by the two following lemmas which provide a single-letterized lower bound for and relate the derived lower bound to . For this purpose, recalling the definition of in (51), we define the following set of joint distributions
Given , define
Recall the definition of in (28). Define
The following lemma presents a single-letterized lower bound for .
Lemma 1.
For any ,
The proof of Lemma 1 is inspired by ([13] (Prop. 2)) and provided in Appendix B.
Combining the results in (114) and Lemma 1, we obtain the desired result and this completes the proof of Theorem 2.
Lemma 2.
Choosing , we have
The proof of Lemma 2 is inspired by ([19] (Lemma C.2)) and provided in Appendix C.
5. Discussion and Future Work
We strengthened the result in ([11] (Corollary 1)) by deriving a strong converse theorem for hypothesis testing against independence over a two-hop network with communication constraints (see Figure 1). In our proof, we combined two recently proposed strong converse techniques [12,13]. The apparent necessity of doing so comes from the Markovian requirement in the source distribution (recall (1)) and is reflected in the construction of a truncated distribution in (56) to ensure the Markovian structure of the source sequences is preserved. Subsequently, due to this constraint, the application the strong converse technique by Tyagi and Watanabe in [13] was only amenable in analyzing the type-II error exponent at the relay. On the other hand, to analyze the type-II error exponent at the receiver, we need to carefully adapt the strong converse technique based on reverse hypercontractivity by Liu, van Handel and Verdú in [12]. Furthermore, to complete the proof, we carefully combine the single-letterization techniques in [12,13].
Another important take-home message is the techniques (or a subset of the techniques) used in this paper can be applied to strengthen the results of other multiterminal hypothesis testing against independence problems. If the source distribution has no Markov structure, it is usually the case that one can directly apply the technique by Tyagi and Watanabe [13] to obtain strong converse theorems. Such examples include [7,8,9]. On the other hand, if the source sequences admit Markovian structure, then it appears necessary to combine techniques in [12,13] to obtain strong converse theorems, just as it was done in this paper.
Finally, we discuss some avenues for future research. In this paper, we only derived the strong converse but not a second-order converse result as was done in ([12] (Section 4.4)) for the problem of hypothesis testing against independence with a communication constraint [1]. Thus, in the future, one may refine the proof in the current paper by deriving second-order converse or exact second-order asymptotics. Furthermore, one may also consider deriving strong converse theorems or simplifying existing strong converse proofs for hypothesis testing problems with both communication and privacy constraints such as that in [23] by using the techniques in the current paper. It is also interesting to explore whether current techniques can be applied to obtain strong converse theorems for hypothesis testing with zero-rate compression problems [3].
Author Contributions
Formal analysis, D.C. and L.Z.; Supervision, V.Y.F.T.; Writing—original draft, D.C. and L.Z.; Writing—review & editing, V.Y.F.T.
Funding
D.C. is supported by the China Scholarship Council with No. 201706090064 and the National Natural Science Foundation of China under Grant 61571122. L.Z. was supported by NUS RSB grants (C-261-000-207-532 and C-261-000-005-001).
Acknowledgments
The authors acknowledge Sadaf Salehkalaibar (University of Tehran) for drawing our attention to ([11] (Corollary 1)) and providing helpful comments and suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Achievability Proof of Proposition 1
Fix any joint distribution . Let be an encoder-decoder pair with rate for the hypothesis testing with communication constraint problem [1] (i.e., no receiver in Figure 1) such that the type-II error probability decays exponentially fast at speed no smaller than and the type-I error probability is vanishing, i.e., , and for any . Furthermore, let be a tuple of encoders and decoders with rates for the problem in Figure 1 such that the type-II error probability at the receiver decays exponentially fast at speed no smaller and type-I error probability at the receiver is vanishing, i.e., , , and for any . Such tuples of encoders and decoders exist as proved in [1,11]. Furthermore, let be the acceptance region associated with at the relay and let be the acceptance region associated with at the receiver.
Now, let us partition the source space into two disjoint sets and such that , and . We construct an -code as follows. Given a source sequence , if , then encoder is used; and if otherwise, the encoder is used. Furthermore, an additional bit indicating whether is also sent to the relay and further forwarded to the receiver by the relay. Given encoded index , if , the relay uses decoder to make the decision; otherwise, if , the relay declares hypothesis to be true. Furthermore, in both cases, the relay transmits an index using encoder . Given the index , if , the receiver declares hypothesis to be true; otherwise, the receiver uses decoder to make the decision.
The performance of the constructed -code is as follows. In terms of rates, we have
The type-I error probability at the relay satisfies that
where (A5) follows when n is sufficiently large and thus can be made arbitrarily close to zero. Furthermore, the type-II error probability at the relay can be upper bounded as follows
Similarly, for n sufficiently large, the error probabilities at the receiver can be upper bounded as follows
and
The achievability proof of Proposition 1 is now complete.
Appendix B. Proof of Lemma 1
Recall the definition of distribution (see (103)). Noting that is the marginal distribution induced by (see (64)), we have that for any
Thus, applying the data processing inequality for the relative entropy, we have that
Using (A18) and following similar steps to the proof of weak converse in ([11] (Equationation (186))), we obtain
Using (A20) and the definition of in (113), we have the following lower bound for
The rest of the proof concerns single-letterizing each term in (A21). For this purpose, for each , we define two auxiliary random variables and and let J be a random variable which is distributed uniformly over the set and is independent of all other random variables.
Using standard single-letterization techniques as in [21], we obtain
and
Furthermore, analogous to ([13] (Prop. 1)), we obtain that
Subsequently, we can single-letterize as follows:
where (A33) follows from the Markov chain implied by the joint distribution of in (64). Furthermore, using similar proof techniques to ([13] (Prop. 1)) and standard single-letterization techniques (e.g., in [4] or [21]), we obtain that
Let , , , and . Using the joint distribution in (64), we conclude that the joint distribution of random variables , denoted by , belongs to the set defined in (115). The proof of Lemma 1 is complete by combining (A21) to (A38) and noting that .
Appendix C. Proof of Lemma 2
Given any , let achieve the minimum in (117). Recall the definition of in (51) and define a new alphabet . We then define a joint distribution by specifying the following (conditional) marginal distributions
Thus, the induced marginal distribution satisfies
Furthermore, let be induced by and define the following distribution
Recall the definition of in (28). The following lemma lower bounds the difference between and and is critical in the proof of Lemma 2.
Lemma A1.
When , we have
The proof of Lemma A1 is deferred to Appendix D.
Now, using the assumption that is a minimizer for in (117), the fact that (see (116)) and the result in (A45), we conclude that when ,
where (A48) follows from the definition of in (29) and the fact that (see (24)).
The proof of Lemma 2 is complete by using (A48) and noting that when ,
Appendix D. Proof of Lemma A1
In subsequent analyses, all distributions indicated by are induced by . We have
Recalling the definitions of in (29) and in (117), we conclude that for any ,
Using the definition of in (116) and recalling that is a minimizer for , we have
We can now upper bound as follows:
where (A56) follows from (A43), and (A59) follows from the result in (A54), the fact that and the definition of in (50). Thus, when , recalling the definition of in (51), we have
Similar to (A59), we obtain
where (A64) follows since (see (115)) implies that and the Markov chains and holds and thus using (A39) to (A40), we have
and
Therefore, we have
Let be the norm between P and Q regarded as vectors. Using Pinsker’s inequality, the result in (105), and the data processing inequality for the relative entropy [17], we obtain
From the support lemma ([21] (Appendix C)), we conclude that the cardinality of U can be upper bounded by a function depending only on , and (these alphabets are all finite). Thus, when , invoking ([4] (Lemma 2.2.7)), we have
Similar to (A79), we have
Combining (A61), (A75), (A80) and (A81), when , using the definition of in (28), we have
The proof of Lemma A1 is now complete.
References
- Ahlswede, R.; Csiszár, I. Hypothesis testing with communication constraints. IEEE Trans. Inf. Theory 1986, 32, 533–542. [Google Scholar] [CrossRef]
- Han, T. Hypothesis testing with multiterminal data compression. IEEE Trans. Inf. Theory 1987, 33, 759–772. [Google Scholar] [CrossRef]
- Shalaby, H.M.; Papamarcou, A. Multiterminal detection with zero-rate data compression. IEEE Trans. Inf. Theory 1992, 38, 254–267. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Han, T.S.; Amari, S. Statistical inference under multiterminal data compression. IEEE Trans. Inf. Theory 1998, 44, 2300–2324. [Google Scholar]
- Tian, C.; Chen, J. Successive refinement for hypothesis testing and lossless one-helper problem. IEEE Trans. Inf. Theory 2008, 54, 4666–4681. [Google Scholar] [CrossRef]
- Wigger, M.; Timo, R. Testing against independence with multiple decision centers. In Proceedings of the IEEE SPCOM, Bengaluru, India, 12–15 June 2016; pp. 1–5. [Google Scholar]
- Zhao, W.; Lai, L. Distributed detection with vector quantizer. IEEE Trans. Signal Inf. Process. Netw. 2016, 2, 105–119. [Google Scholar] [CrossRef]
- Xiang, Y.; Kim, Y.H. Interactive hypothesis testing with communication constraints. In Proceedings of the IEEE 50th Annual Allerton on Communication, Control, and Computing, Monticello, IL, USA, 1–5 October 2012; pp. 1065–1072. [Google Scholar]
- Zhao, W.; Lai, L. Distributed testing with cascaded encoders. IEEE Trans. Inf. Theory 2018, 64, 7339–7348. [Google Scholar] [CrossRef]
- Salehkalaibar, S.; Wigger, M.; Wang, L. Hypothesis Testing Over the Two-Hop Relay Network. IEEE Trans. Inf. Theory 2019, 65, 4411–4433. [Google Scholar] [CrossRef]
- Liu, J.; van Handel, R.; Verdú, S. Beyond the blowing-up lemma: Sharp converses via reverse hypercontractivity. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 943–947. [Google Scholar]
- Tyagi, H.; Watanabe, S. Strong Converse using Change of Measure. IEEE Trans. Inf. Theory 2020, in press. [Google Scholar]
- Oohama, Y. Exponential strong converse for source coding with side information at the decoder. Entropy 2018, 20, 352. [Google Scholar] [CrossRef]
- Oohama, Y. Exponent function for one helper source coding problem at rates outside the rate region. In Proceedings of the 2015 IEEE International Symposium on Information Theory (ISIT), Hong Kong, China, 14–19 June 2015; pp. 1575–1579. [Google Scholar]
- Oohama, Y. Exponential Strong Converse for One Helper Source Coding Problem. Entropy 2019, 21, 567. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Gu, W.; Effros, M. A strong converse for a collection of network source coding problems. In Proceedings of the 2009 IEEE International Symposium on Information Theory, Seoul, Korea, 28 June–3 July 2009; pp. 2316–2320. [Google Scholar] [CrossRef]
- Liu, J.; van Handel, R.; Verdú, S. Beyond the Blowing-Up Lemma: Optimal Second-Order Converses via Reverse Hypercontractivity. Available online: http://web.mit.edu/jingbo/www/preprints/msl-blup.pdf (accessed on 17 April 2019).
- Salehkalaibar, S.; Wigger, M.; Wang, L. Hypothesis testing over cascade channels. In Proceedings of the 2017 IEEE Information Theory Workshop (ITW), Kaohsiung, Taiwan, 6–10 November 2017; pp. 369–373. [Google Scholar] [CrossRef]
- El Gamal, A.; Kim, Y.H. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Raginsky, M.; Sason, I. Concentration of measure inequalities in information theory, communications, and coding. Found. Trends® Commun. Inf. Theory 2013, 10, 1–246. [Google Scholar] [CrossRef]
- Gilani, A.; Amor, S.B.; Salehkalaibar, S.; Tan, V.Y.F. Distributed Hypothesis Testing with Privacy Constraints. Entropy 2019, 21, 478. [Google Scholar] [CrossRef]


© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).