An Analysis of Entropy-Based Eye Movement Events Detection


Abstract
1. Introduction
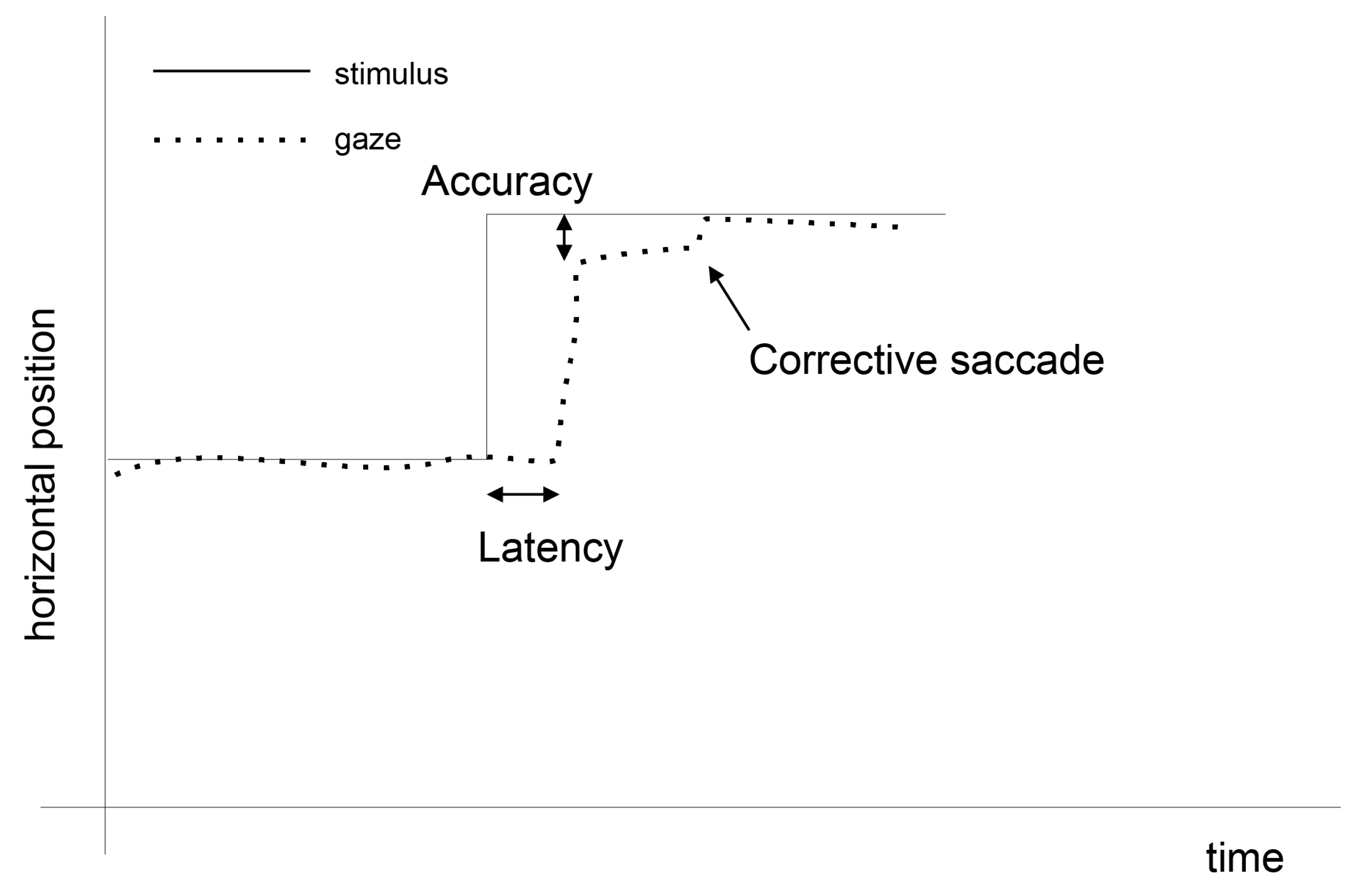
1.1. Eye Movement Processing
1.2. Approximate Entropy Applied for Biological Signals
1.3. Contribution
- Application of approximate entropy for building a general description of eye movement dynamics;
- Introducing a multilevel entropy map representing an eye movement characteristic obtained between successive stimulus appearances;
- Introducing a method utilizing the approximate entropy map, which may prove useful in determining saccade periods in eye movement.
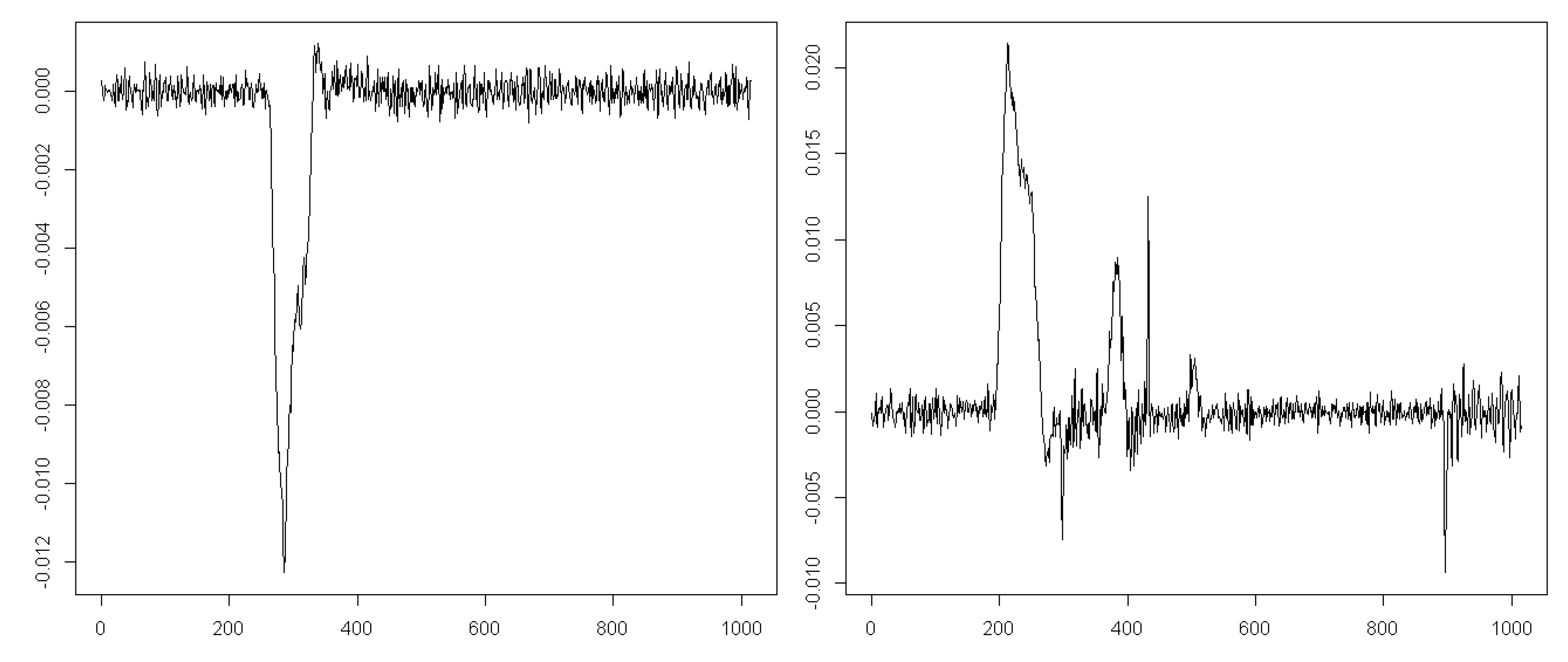
2. Materials and Methods
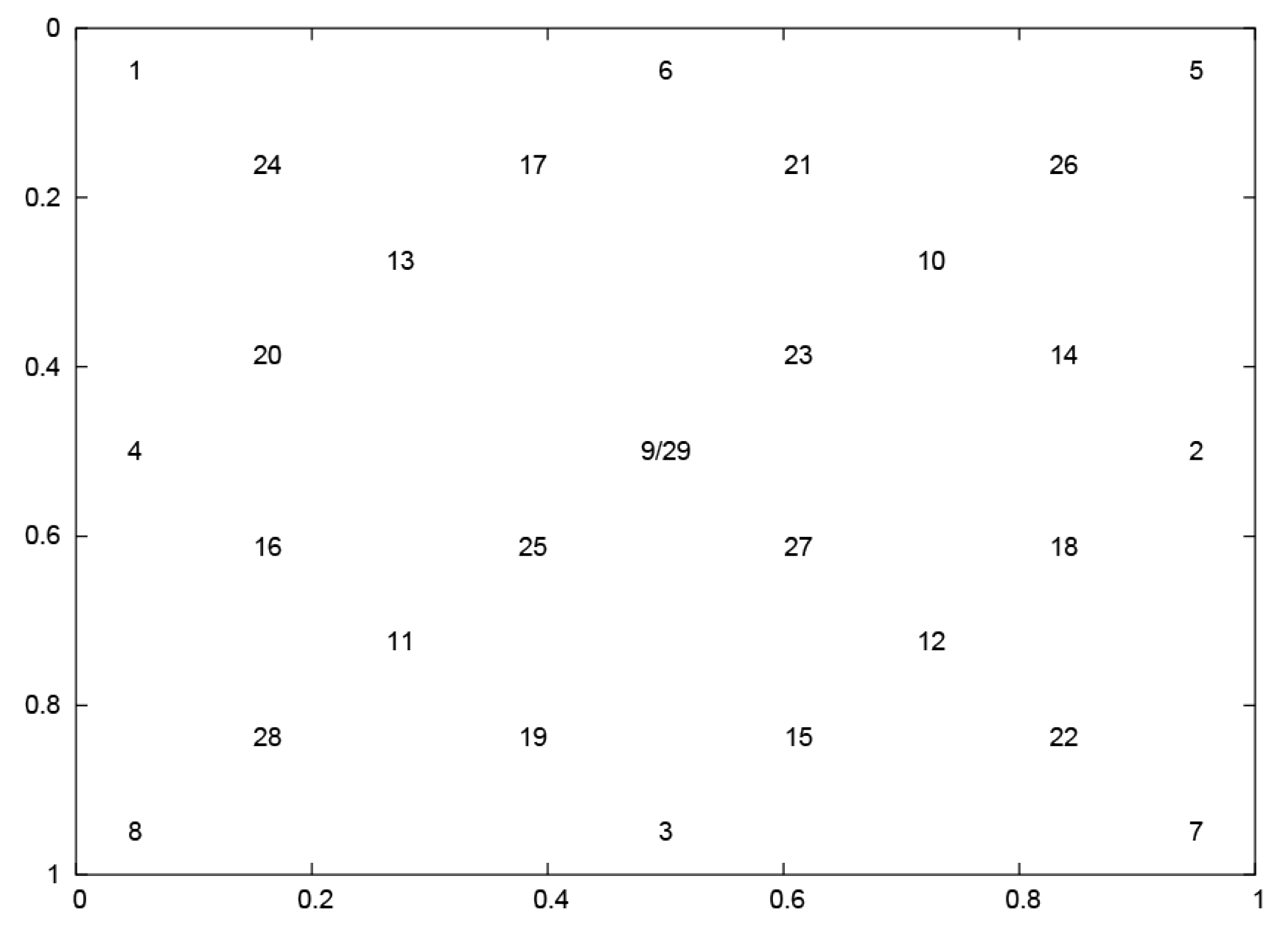
2.1. Description of the Experiment
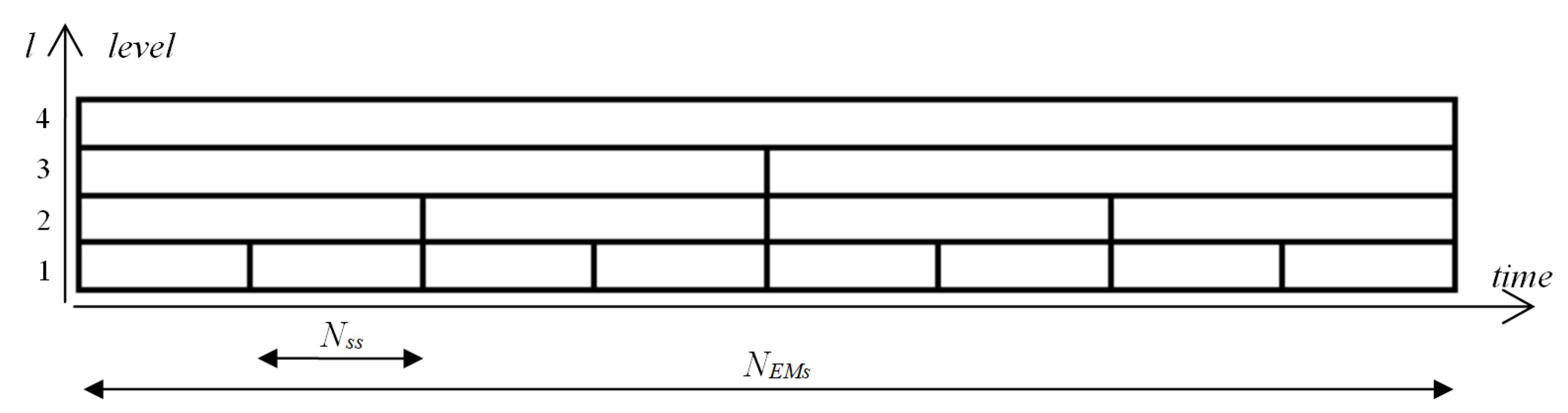
2.2. The Method
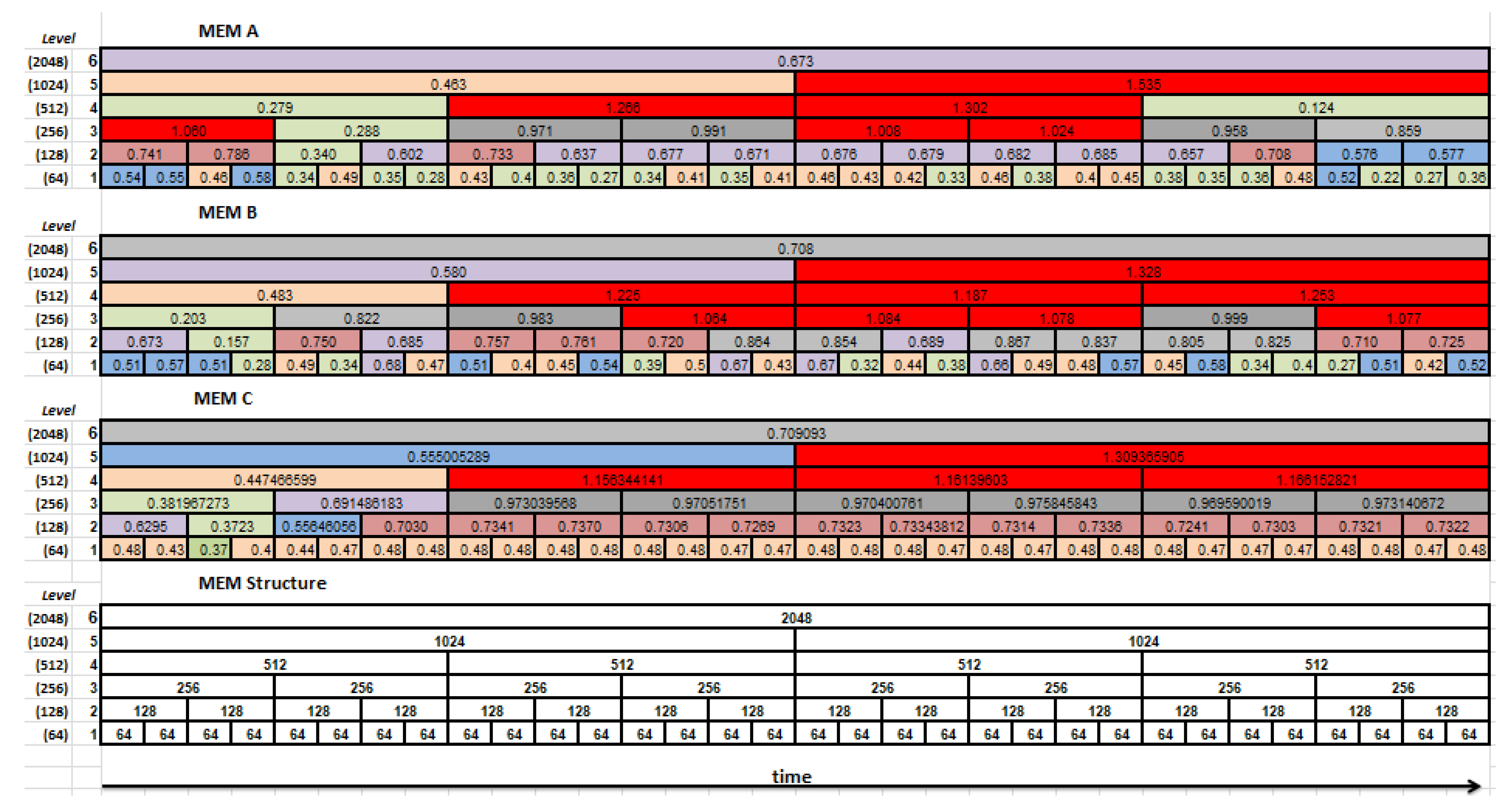
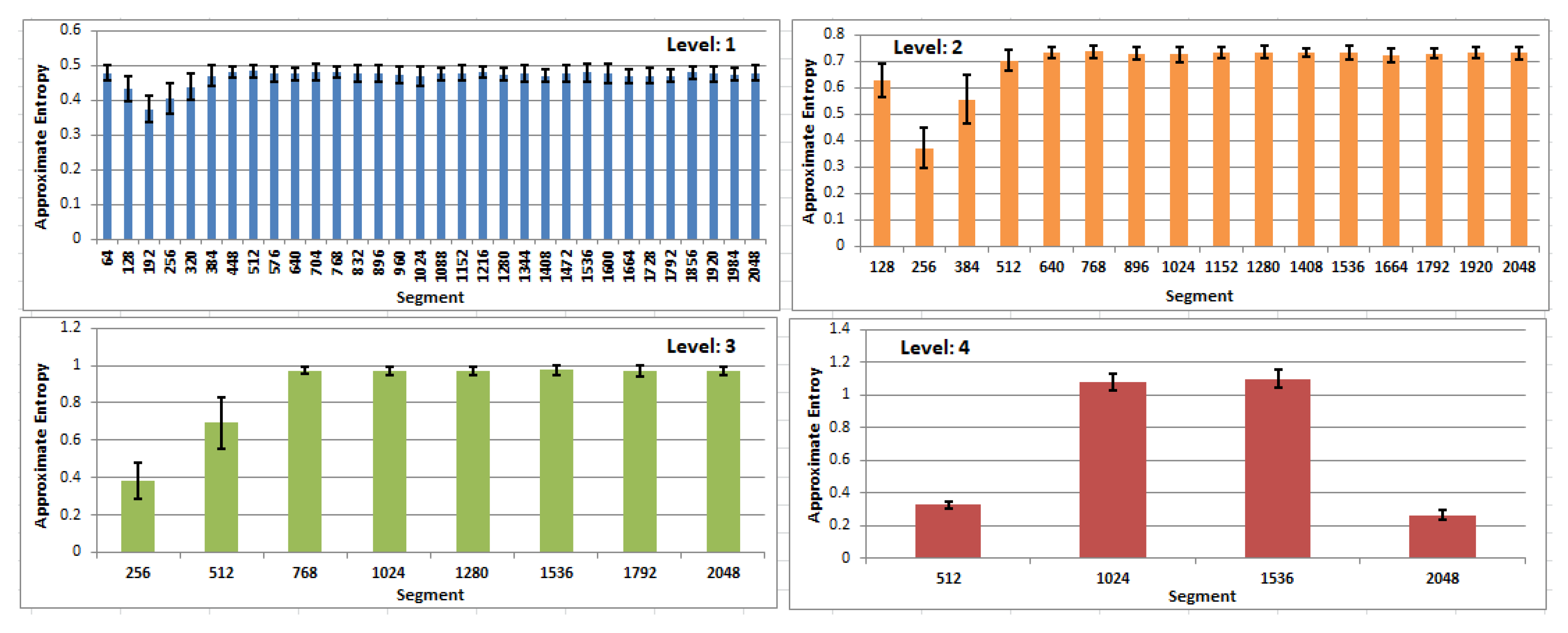
3. Results
- Green was used when the entropy was lower than 0.4;
- Brown was dedicated to entropy values between 0.4 and 0.5;
- was highlighted by blue;
- by light violet;
- by light burgundy;
- and by light and dark gray, respectively;
- Values greater than 1 by red.
- 64, the majority of differences were not significant;
- 128, all differences concerning the first four segments (1–128, 129–256, 257–384, 384–512) turned out to be significant, on the contrary to the group of remaining segments;
- 256, it was similar to set128, where only for the first two segments were significant differences yielded;
- 512, differences were significant only when the first segment was considered;
- 1024, significant differences were disclosed.
Eye-Movement Events Detection
- Set64, set128, set256, and set512 consisted of only one feature;
- Set64_128, set128_256 and set256_512 consisted of two features;
- Set64_128_256 and set128_256_512 consisted of three features;
- Set64_128_256_512 consisted of four features.
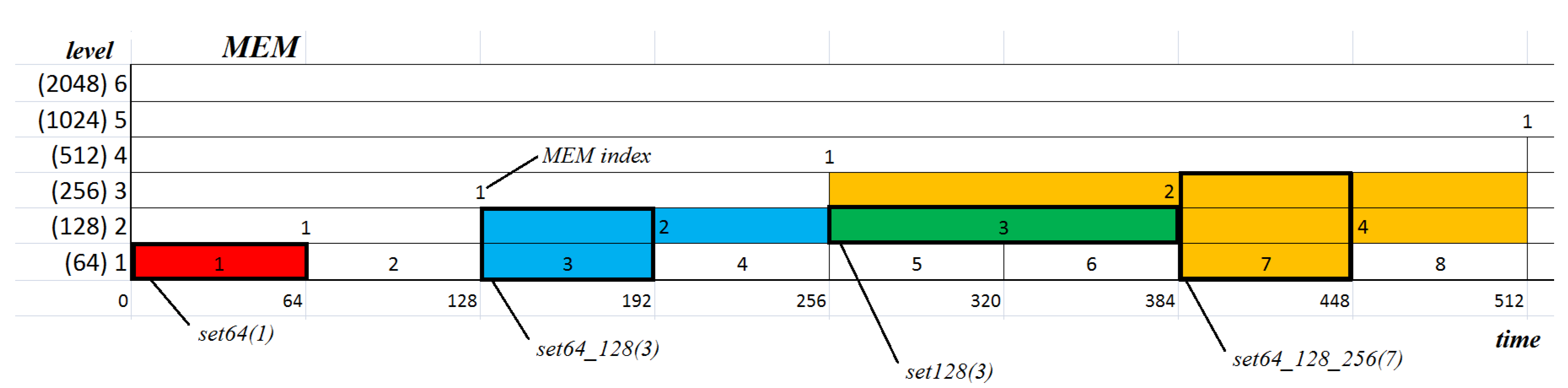
- The dataset denoted by set64 is based on:Only one level of MEM denoted by 64, where the size of segment equals 64, the number of segments equals , a single element of the dataset is a scalar value—e.g., the 1st element is (red box in Figure 8);
- The dataset denoted by set128 is based on:Only one level of MEM denoted by 128, where the size of segment equals 128, the number of segments equals , a single element of the dataset is a scalar value—e.g., the 3rd element is (green box in Figure 8);
- The dataset denoted by set64_128 is based on:Two levels of MEM denoted by 64 and 128, where the size of segment equals , the number of segments equals , and a single element is a two-dimensional vector of features—e.g., the 3rd element is (blue box in Figure 8), and the 4th element is ;
- The dataset denoted by set64_128_256 is based on:Three levels of MEM denoted by 64, 128, and 256, where the size of segment equals , the number of segments equals , and a single element is a three-dimensional vector of features—e.g., the 3rd element is or the 7th element is (yellow box in Figure 8).
- 32 for datasets denoted by set64, set64_128, set64_128_256, set64_128_256_512;
- 16 for set128, set128_256, set128_256_512;
- 8 for set256, set256_512;
- 4 for set512.
4. Discussion
4.1. The Multilevel Entropy Map
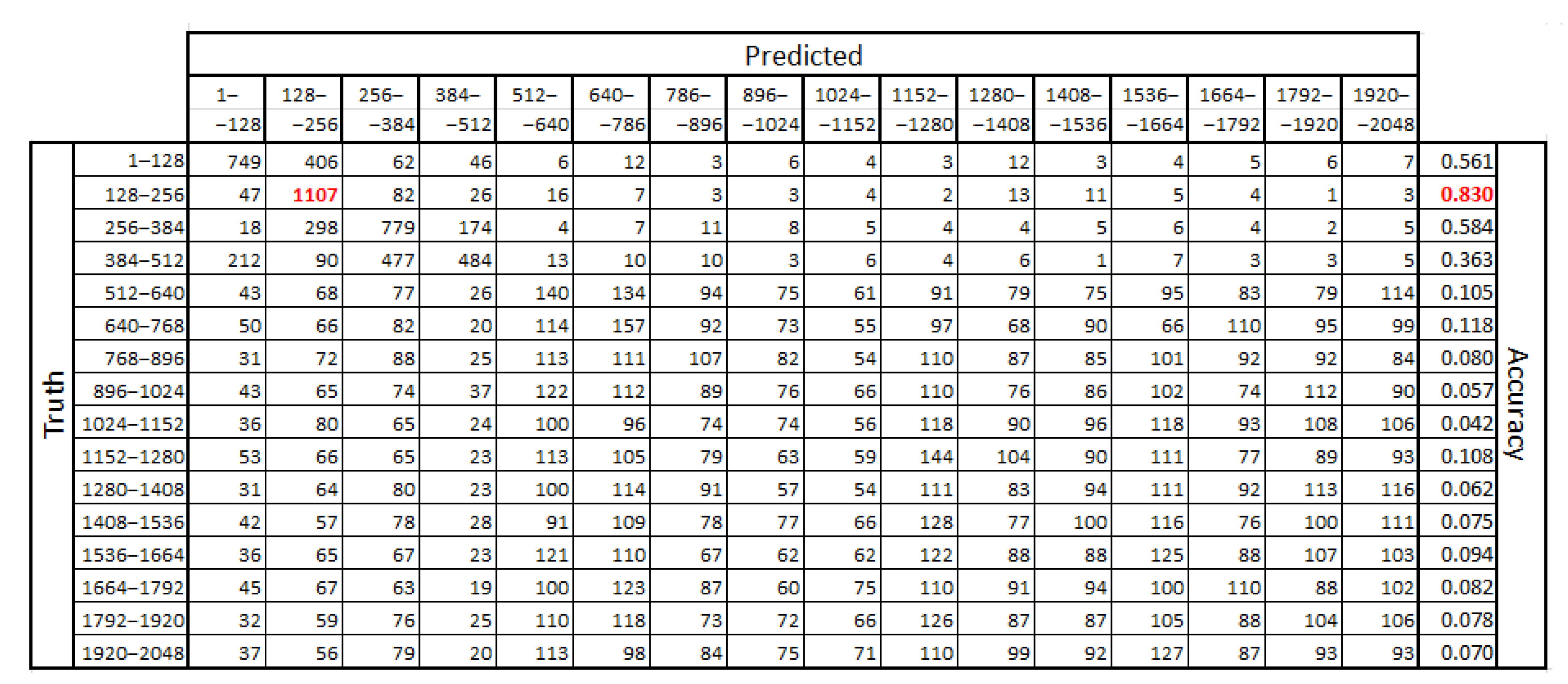
4.2. Eye Movement Events Detection
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| Abbreviation | Description | Value |
| Number of point positions | 29 | |
| Number of participants | 24 | |
| Number of sessions per participant | 2 | |
| Number of participant sessions | 46 | |
| Number of eye movement series | 1334 | |
| Number of eye movement recordings | 2048 | |
| Number of samples in the smallest segment of eye movement recordings | 64 |
References
- Poole, A.; Ball, L.J. Eye tracking in HCI and usability research. In Encyclopedia of Human Computer Interaction; IGI Global: Hershey, PA, USA, 2006; pp. 211–219. [Google Scholar]
- Harezlak, K.; Rzeszutek, J.; Kasprowski, P. The Eye Tracking Methods in User Interfaces Assessment. In Intelligent Decision Technologies, Proceedings of the 7th KES International Conference on Intelligent Decision Technologies (KES-IDT 2015), Sorrento, Italy, 21–23 June 2017; Springer: Cham, Switzerland, 2015; pp. 325–335. [Google Scholar]
- Foster, T.E.; Ardoin, S.P.; Binder, K.S. Underlying changes in repeated reading: An eye movement study. Sch. Psychol. Rev. 2013, 42, 140. [Google Scholar]
- Hyona, J.; Lorch, R.F.; Kaakinen, J.K. Individual differences in reading to summarize expository text: Evidence from eye fixation patterns. J. Educ. Psychol. 2002, 94, 44–55. [Google Scholar] [CrossRef]
- Jarodzka, H.; Scheiter, K.; Gerjets, P.; Van Gog, T. In the eyes of the beholder: How experts and novices interpret dynamic stimuli. Learn. Instr. 2010, 20, 146–154. [Google Scholar] [CrossRef]
- Harezlak, K.; Kasprowski, P.; Kasprowska, S. Eye Movement Traits in Differentiating Experts and Laymen. In Man-Machine Interactions 5. ICMMI 2017; Springer: Cham, Switzerland, 2017; pp. 82–91. [Google Scholar]
- Harezlak, K.; Kasprowski, P. Application of eye tracking in medicine: A survey, research issues and challenges. Comput. Med. Imaging Graph. 2018, 65, 176–190. [Google Scholar] [CrossRef] [PubMed]
- Mele, M.L.; Federici, S. Gaze and eye-tracking solutions for psychological research. Cogn. Process. 2012, 13, 261–265. [Google Scholar] [CrossRef] [PubMed]
- Palinko, O.; Kun, A.L.; Shyrokov, A.; Heeman, P. Estimating cognitive load using remote eye tracking in a driving simulator. In Proceedings of the 2010 Symposium on Eye-Tracking Research & Applications, Austin, TX, USA, 22–24 March 2010; pp. 141–144. [Google Scholar]
- Holmqvist, K.; Nyström, M.; Andersson, R.; Dewhurst, R.; Jarodzka, H.; Van de Weijer, J. Eye Tracking: A Comprehensive Guide to Methods and Measures; OUP Oxford: Oxford, UK, 2011. [Google Scholar]
- Otero-Millan, J.; Troncoso, X.G.; Macknik, S.L.; Serrano-Pedraza, I.; Martinez-Conde, S. Saccades and microsaccades during visual fixation, exploration, and search: Foundations for a common saccadic generator. J. Vis. 2008, 8, 21. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Conde, S.; Otero-Millan, J.; Macknik, S.L. The impact of microsaccades on vision: Towards a unified theory of saccadic function. Nat. Rev. Neurosci. 2013, 14, 83–96. [Google Scholar] [CrossRef]
- Darrien, J.H.; Herd, K.; Starling, L.J.; Rosenberg, J.R.; Morrison, J.D. An analysis of the dependence of saccadic latency on target position and target characteristics in human subjects. BMC Neurosci. 2001, 2, 1–8. [Google Scholar] [CrossRef]
- Zemblys, R.; Niehorster, D.C.; Komogortsev, O.; Holmqvist, K. Using machine learning to detect events in eye-tracking data. Behav. Res. Methods 2018, 50, 160–181. [Google Scholar] [CrossRef]
- Salvucci, D.D.; Goldberg, J.H. Identifying Fixations and Saccades in Eye-tracking Protocols. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications (ETRA ’00), Palm Beach Gardens, FL, USA, 6–8 November 2000; ACM: New York, NY, USA, 2000; pp. 71–78. [Google Scholar]
- Nyström, M.; Holmqvist, K. An adaptive algorithm for fixation, saccade, and glissade detection in eyetracking data. Behav. Res. Methods 2010, 42, 188–204. [Google Scholar] [CrossRef]
- Mould, M.S.; Foster, D.H.; Amano, K.; Oakley, J.P. A simple nonparametric method for classifying eye fixations. Vis. Res. 2012, 57, 18–25. [Google Scholar] [CrossRef] [PubMed]
- Larsson, L.; Nyström, M.; Stridh, M. Detection of Saccades and Postsaccadic Oscillations in the Presence of Smooth Pursuit. IEEE Trans. Biomed. Eng. 2013, 60, 2484–2493. [Google Scholar] [CrossRef] [PubMed]
- Larsson, L.; Nyström, M.; Andersson, R.; Stridh, M. Detection of fixations and smooth pursuit movements in high-speed eye-tracking data. Biomed. Signal Process. Control 2015, 18, 145–152. [Google Scholar] [CrossRef]
- Hessels, R.S.; Niehorster, D.C.; Kemner, C.; Hooge, I.T.C. Noise-robust fixation detection in eye movement data: Identification by two-means clustering (I2MC). Behav. Res. Methods 2017, 49, 1802–1823. [Google Scholar] [CrossRef] [PubMed]
- Astefanoaei, C.; Creanga, D.; Pretegiani, E.; Optican, L.; Rufa, A. Dynamical Complexity Analysis of Saccadic Eye Movements In Two Different Psychological Conditions. Roman. Rep. Phys. 2014, 66, 1038–1055. [Google Scholar]
- Murata, A.; Matsuura, T. Nonlinear Dynamical Analysis of Eye Movement Characteristics Using Attractor Plot and First Lyapunov Exponent. In Human-Computer Interaction: Interaction Technologies; Kurosu, M., Ed.; Springer: Cham, Switzerland, 2015; pp. 78–85. [Google Scholar]
- Harezlak, K. Eye movement dynamics during imposed fixations. Inf. Sci. 2017, 384, 249–262. [Google Scholar] [CrossRef]
- Harezlak, K.; Kasprowski, P. Chaotic Nature of Eye Movement Signal. In Intelligent Decision Technologies 2017; Czarnowski, I., Howlett, R.J., Jain, L.C., Eds.; Springer: Cham, Switzerland, 2018; pp. 120–129. [Google Scholar]
- Rosenstein, M.T.; Collins, J.J.; De Luca, C.J. A Practical Method for Calculating Largest Lyapunov Exponents from Small Data Sets. Phys. D Nonlinear Phenom. 1993, 65, 117–134. [Google Scholar] [CrossRef]
- Harezlak, K.; Kasprowski, P. Searching for Chaos Evidence in Eye Movement Signals. Entropy 2018, 20, 32. [Google Scholar] [CrossRef]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef]
- Engoren, M. Approximate entropy of respiratory rate and tidal volume during weaning from mechanical ventilation. Crit. Care Med. 1998, 26, 715–726. [Google Scholar] [CrossRef]
- Bruhn, J.; Röpcke, H.; Hoeft, A. Approximate entropy as an electroencephalographic measure of anesthetic drug effect during desflurane anesthesia. Anesthesiol. J. Am. Soc. Anesthesiol. 2000, 92, 715–726. [Google Scholar] [CrossRef]
- Vukkadala, S.; Vijayalakshmi, S.; Vijayapriya, S. Automated detection of epileptic EEG using approximate entropy in elman networks. Int. J. Recent Trends Eng. 2009, 1, 307. [Google Scholar]
- Karmakar, C.K.; Khandoker, A.H.; Begg, R.K.; Palaniswami, M.; Taylor, S. Understanding Ageing Effects by Approximate Entropy Analysis of gait variability. Conf. Proc. IEEE Eng. Med. Biol. Soc. 2007, 2007, 1965–1968. [Google Scholar] [CrossRef] [PubMed]
- Castiglioni, P.; Rienzo, M.D. How the threshold “r” influences approximate entropy analysis of heart-rate variability. In Proceedings of the 2008 Computers in Cardiology, Bologna, Italy, 14–17 September 2008; pp. 561–564. [Google Scholar] [CrossRef]
- Li, X.; Jiang, Y.; Hong, J.; Dong, Y.; Yao, L. Estimation of cognitive workload by approximate entropy of EEG. J. Mech. Med. Biol. 2016, 16, 1650077. [Google Scholar] [CrossRef]
- Jazz-Novo. Ober Consulting. 2018. Available online: http://www.ober-consulting.com/9/lang/1/ (accessed on 20 December 2018).
- Pincus, S.M.; Huang, W.M. Approximate entropy: Statistical properties and applications. Commun. Stat. Theory Methods 1992, 21, 3061–3077. [Google Scholar] [CrossRef]
- Pincus, S. Approximate entropy (ApEn) as a complexity measure. Chaos Interdiscip. J. Nonlinear Sci. 1995, 5, 110–117. [Google Scholar] [CrossRef]
- Yentes, J.; Hunt, N.; Schmid, K.; Kaipust, J.; McGrath, D.; Stergiou, N. The appropriate use of approximate entropy and sample entropy with short data sets. Ann. Biomed. Eng. 2013, 41, 349–365. [Google Scholar] [CrossRef]
- Borchers, H.W. Package ‘Pracma’. 2018. Available online: https://cran.r-project.org/web/packages/pracma/pracma.pdf (accessed on 20 December 2018).
- Kasprowski, P.; Harezlak, K. Using Dissimilarity Matrix for Eye Movement Biometrics with a Jumping Point Experiment. In Intelligent Decision Technologies 2016: Proceedings of the 8th KES International Conference on Intelligent Decision Technologies (KES-IDT 2016)—Part II, Tenerife, Spain 15–17 June 2016; Czarnowski, I., Caballero, A.M., Howlett, R.J., Jain, L.C., Eds.; Springer: Cham, Switzerland, 2016; pp. 83–93. [Google Scholar]
- Kennel, M.B.; Brown, R.; Abarbanel, H.D.I. Determining embedding dimension for phase-space reconstruction using a geometrical construction. Phys. Rev. A 1992, 45, 3403–3411. [Google Scholar] [CrossRef]
- Cao, Z.; Lin, C.T. Inherent fuzzy entropy for the improvement of EEG complexity evaluation. IEEE Trans. Fuzzy Syst. 2018, 26, 1032–1035. [Google Scholar] [CrossRef]
- Azami, H.; Fernández, A.; Escudero, J. Refined multiscale fuzzy entropy based on standard deviation for biomedical signal analysis. Med. Biol. Eng. Comput. 2017, 55, 2037–2052. [Google Scholar] [CrossRef]
- Liu, C.; Li, K.; Zhao, L.; Liu, F.; Zheng, D.; Liu, C.; Liu, S. Analysis of heart rate variability using fuzzy measure entropy. Comput. Biol. Med. 2013, 43, 100–108. [Google Scholar] [CrossRef] [PubMed]
- Liang, Z.; Wang, Y.; Sun, X.; Li, D.; Voss, L.J.; Sleigh, J.W.; Hagihira, S.; Li, X. EEG entropy measures in anesthesia. Front. Comput. Neurosci. 2015, 9, 16. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set | k3 | k7 | k15 | k31 | k63 | k127 | k255 |
|---|---|---|---|---|---|---|---|
| set64 | 0.034 | 0.034 | 0.034 | 0.033 | 0.035 | 0.033 | 0.037 |
| set128 | 0.085 | 0.092 | 0.098 | 0.103 | 0.103 | 0.102 | 0.102 |
| set256 | 0.206 | 0.217 | 0.226 | 0.231 | 0.229 | 0.229 | 0.233 |
| set512 | 0.4201 | 0.437 | 0.444 | 0.458 | 0.453 | 0.456 | 0.466 |
| set64_128 | 0.047 | 0.052 | 0.055 | 0.059 | 0.059 | 0.061 | 0.059 |
| set128_256 | 0.138 | 0.148 | 0.153 | 0.157 | 0.157 | 0.159 | 0.161 |
| set256_512 | 0.275 | 0.303 | 0.308 | 0.309 | 0.307 | 0.311 | 0.307 |
| set64_128_256 | 0.072 | 0.079 | 0.084 | 0.087 | 0.087 | 0.087 | 0.087 |
| set128_256_512 | 0.177 | 0.196 | 0.200 | 0.206 | 0.204 | 0.207 | 0.207 |
| set64_128_256_512 | 0.090 | 0.102 | 0.106 | 0.109 | 0.112 | 0.111 | 0.107 |
| Set | segment | k3 | k7 | k15 | k31 | k63 | k127 | k255 |
|---|---|---|---|---|---|---|---|---|
| set64 | 128–192 | 0.053 | 0.071 | 0.079 | 0.076 | 0.086 | 0.121 | 0.186 |
| set128 | 128–256 | 0.599 | 0.682 | 0.723 | 0.742 | 0.716 | 0.705 | 0.720 |
| set256 | 1–256 | 0.618 | 0.677 | 0.730 | 0.749 | 0.718 | 0.703 | 0.721 |
| set512 | 1–512 | 0.802 | 0.852 | 0.876 | 0.900 | 0.915 | 0.935 | 0.936 |
| set64_128 | 192–256 | 0.202 | 0.258 | 0.317 | 0.361 | 0.392 | 0.439 | 0.462 |
| set128_256 | 128–256 | 0.527 | 0.606 | 0.643 | 0.679 | 0.672 | 0.675 | 0.705 |
| set256_512 | 1–256 | 0.670 | 0.7423 | 0.774 | 0.792 | 0.819 | 0.840 | 0.858 |
| set64_128_256 | 128–192 | 0.283 | 0.324 | 0.349 | 0.355 | 0.373 | 0.401 | 0.430 |
| set128_256_512 | 128–256 | 0.564 | 0.6664 | 0.699 | 0.739 | 0.775 | 0.809 | 0.830 |
| set64_128_256_512 | 128–192 | 0.310 | 0.343 | 0.387 | 0.402 | 0.442 | 0.471 | 0.499 |
| Segment | k3 | k7 | k15 | k31 | k63 | k127 | k255 |
|---|---|---|---|---|---|---|---|
| 1–256 | 0.618 | 0.677 | 0.730 | 0.749 | 0.718 | 0.703 | 0.721 |
| 257–512 | 0.188 | 0.171 | 0.197 | 0.202 | 0.232 | 0.268 | 0.2945 |
| 513–768 | 0.156 | 0.164 | 0.158 | 0.174 | 0.202 | 0.178 | 0.185 |
| 769–1024 | 0.139 | 0.144 | 0.136 | 0.136 | 0.123 | 0.127 | 0.130 |
| 1025–1280 | 0.151 | 0.151 | 0.157 | 0.163 | 0.148 | 0.119 | 0.097 |
| 1291–1536 | 0.150 | 0.144 | 0.148 | 0.118 | 0.127 | 0.150 | 0.166 |
| 1537–1792 | 0.137 | 0.149 | 0.133 | 0.1567 | 0.160 | 0.169 | 0.122 |
| 1793–2048 | 0.147 | 0.171 | 0.142 | 0.146 | 0.118 | 0.096 | 0.140 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Harezlak, K.; Augustyn, D.R.; Kasprowski, P. An Analysis of Entropy-Based Eye Movement Events Detection. Entropy 2019, 21, 107. https://doi.org/10.3390/e21020107
Harezlak K, Augustyn DR, Kasprowski P. An Analysis of Entropy-Based Eye Movement Events Detection. Entropy. 2019; 21(2):107. https://doi.org/10.3390/e21020107
Chicago/Turabian StyleHarezlak, Katarzyna, Dariusz R. Augustyn, and Pawel Kasprowski. 2019. "An Analysis of Entropy-Based Eye Movement Events Detection" Entropy 21, no. 2: 107. https://doi.org/10.3390/e21020107
APA StyleHarezlak, K., Augustyn, D. R., & Kasprowski, P. (2019). An Analysis of Entropy-Based Eye Movement Events Detection. Entropy, 21(2), 107. https://doi.org/10.3390/e21020107